A dynamic load balancing strategy for parallel datacube computation
(完整版)LTEMLB负载均衡功能介绍
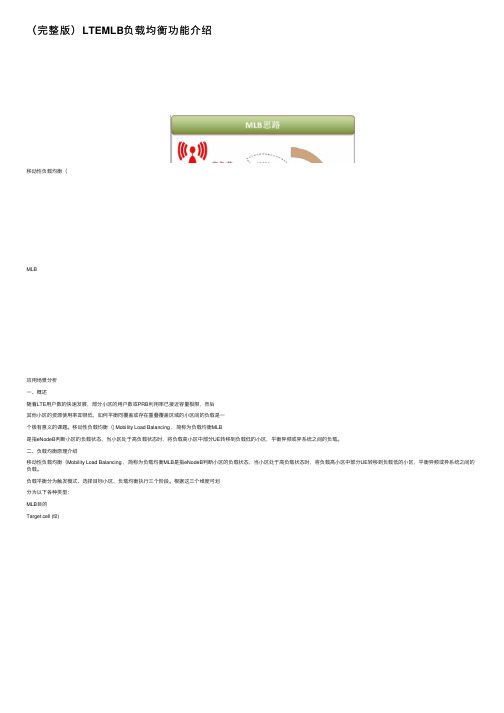
(完整版)LTEMLB负载均衡功能介绍移动性负载均衡(MLB应⽤场景分析⼀、概述随着LTE⽤户数的快速发展,部分⼩区的⽤户数或PRB利⽤率已接近容量极限,然后其他⼩区的资源使⽤率却很低,如何平衡同覆盖或存在重叠覆盖区域的⼩区间的负载是⼀个极有意义的课题。
移动性负载均衡(| Mobility Load Balancing ,简称为负载均衡MLB是指eNodeB判断⼩区的负载状态,当⼩区处于⾼负载状态时,将负载⾼⼩区中部分UE转移到负载低的⼩区,平衡异频或异系统之间的负载。
⼆、负载均衡原理介绍移动性负载均衡(Mobility Load Balancing ,简称为负载均衡MLB是指eNodeB判断⼩区的负载状态,当⼩区处于⾼负载状态时,将负载⾼⼩区中部分UE转移到负载低的⼩区,平衡异频或异系统之间的负载。
负载平衡分为触发模式、选择⽬标⼩区、负载均衡执⾏三个阶段。
根据这三个维度可划分为以下各种类型:MLB⽬的Target cell (f2)2.1触发模式负载均衡根据触发模式可以分为空闲态UE预均衡、同步态⽤户数负载均衡、PRB利⽤率/PRB评估值负载均衡、下⾏数传⽤户数负载均衡等模式,现阶段实现主要负载标准为PRB利⽤率、同步态⽤户数、UE预均衡。
2.1.1基于PRB利⽤率的触发模式启动基于PRB利⽤率的负载均衡后,eNodeB以每秒为周期测量⼩区PRB利⽤率和⼩区同步态⽤户数。
若连续5秒内同时满⾜以下条件,则触发基于PRB利⽤率的负载均衡。
⼩区某类PRB利⽤率》InterFreqMlbThd +LoadOffet⼩区同步态⽤户数》MlbMi nU eNumThd +MlbMi nU eNumOffset对于同⼀⽅向,⼩区PRB利⽤率状态判决的顺序依次为:GBR业务、Non-GBR业务、Total业务。
上下⾏独⽴判决,互不影响。
负载均衡触发类型为判决满⾜负载平衡触发条件的PRB利⽤率类型,负载平衡触发⽅向为判决满⾜负载平衡触发条件的上⾏/下⾏⽅向。
负载均衡的几种策略

负载均衡的几种策略Load balancing is a critical component in ensuring the reliability and scalability of modern IT infrastructures. It involves distributing incoming network traffic across multiple servers to optimize resource utilization and prevent any single server from being overwhelmed. There are several strategies that can be employed to achieve load balancing, each with its own advantages and limitations.负载均衡是确保现代IT基础设施可靠性和可扩展性的关键组成部分。
它涉及将传入的网络流量分布到多台服务器上,以优化资源利用率,防止任何一台服务器被过度压倒。
有几种策略可以用来实现负载均衡,每种策略都有其自身的优点和局限性。
One common strategy for load balancing is round-robin, where incoming requests are distributed evenly across a pool of servers in a cyclical manner. This approach ensures that each server receives an equal share of the workload, preventing any single server from becoming a bottleneck. However, round-robin may not take into account the actual load on each server, leading to inefficient resource allocation.负载均衡的一种常见策略是循环调度,其中传入的请求以循环方式均匀分布到服务器池中。
java英文参考文献

java英⽂参考⽂献java英⽂参考⽂献汇编 导语:Java是⼀门⾯向对象编程语⾔,不仅吸收了C++语⾔的各种优点,还摒弃了C++⾥难以理解的多继承、指针等概念,因此Java语⾔具有功能强⼤和简单易⽤两个特征。
下⾯⼩编为⼤家带来java英⽂参考⽂献,供各位阅读和参考。
java英⽂参考⽂献⼀: [1]Irene Córdoba-Sánchez,Juan de Lara. Ann: A domain-specific language for the effective design and validation of Java annotations[J]. Computer Languages, Systems & Structures,2016,:. [2]Marcelo M. Eler,Andre T. Endo,Vinicius H.S. Durelli. An Empirical Study to Quantify the Characteristics of Java Programs that May Influence Symbolic Execution from a Unit Testing Perspective[J]. The Journal of Systems & Software,2016,:. [3]Kebo Zhang,Hailing Xiong. A new version of code Java for 3D simulation of the CCA model[J]. Computer Physics Communications,2016,:. [4]S. Vidal,A. Bergel,J.A. Díaz-Pace,C. Marcos. Over-exposed classes in Java: An empirical study[J]. Computer Languages, Systems & Structures,2016,:. [5]Zeinab Iranmanesh,Mehran S. Fallah. Specification and Static Enforcement of Scheduler-Independent Noninterference in a Middleweight Java[J]. Computer Languages, Systems & Structures,2016,:. [6]George Gabriel Mendes Dourado,Paulo S Lopes De Souza,Rafael R. Prado,Raphael Negrisoli Batista,Simone R.S. Souza,Julio C. Estrella,Sarita M. Bruschi,Joao Lourenco. A Suite of Java Message-Passing Benchmarks to Support the Validation of Testing Models, Criteria and Tools[J]. Procedia Computer Science,2016,80:. [7]Kebo Zhang,Junsen Zuo,Yifeng Dou,Chao Li,Hailing Xiong. Version 3.0 of code Java for 3D simulation of the CCA model[J]. Computer Physics Communications,2016,:. [8]Simone Hanazumi,Ana C.~V. de Melo. A Formal Approach to Implement Java Exceptions in Cooperative Systems[J]. The Journal of Systems & Software,2016,:. [9]Lorenzo Bettini,Ferruccio Damiani. Xtraitj : Traits for the Java Platform[J]. The Journal of Systems & Software,2016,:. [10]Oscar Vega-Gisbert,Jose E. Roman,Jeffrey M. Squyres. Design and implementation of Java bindings in OpenMPI[J]. Parallel Computing,2016,:. [11]Stefan Bosse. Structural Monitoring with Distributed-Regional and Event-based NN-Decision Tree Learning Using Mobile Multi-Agent Systems and Common Java Script Platforms[J]. Procedia Technology,2016,26:. [12]Pablo Piedrahita-Quintero,Carlos Trujillo,Jorge Garcia-Sucerquia. JDiffraction : A GPGPU-accelerated JAVA library for numerical propagation of scalar wave fields[J]. Computer Physics Communications,2016,:. [13]Abdelhak Mesbah,Jean-Louis Lanet,Mohamed Mezghiche. Reverse engineering a Java Card memory management algorithm[J]. Computers & Security,2017,66:. [14]G. Bacci,M. Bazzicalupo,A. Benedetti,A. Mengoni. StreamingTrim 1.0: a Java software for dynamic trimming of 16S rRNA sequence data from metagenetic studies[J]. Mol Ecol Resour,2014,14(2):. [15]Qing‐Wei Xu,Johannes Griss,Rui Wang,Andrew R. Jones,Henning Hermjakob,Juan Antonio Vizcaíno. jmzTab: A Java interface to the mzTab data standard[J]. Proteomics,2014,14(11):. [16]Rody W. J. Kersten,Bernard E. Gastel,Olha Shkaravska,Manuel Montenegro,Marko C. J. D. Eekelen. ResAna: a resource analysis toolset for (real‐time) JAVA[J]. Concurrency Computat.: Pract. Exper.,2014,26(14):. [17]Stephan E. Korsholm,Hans S?ndergaard,Anders P. Ravn. A real‐time Java tool chain for resource constrained platforms[J]. Concurrency Computat.: Pract. Exper.,2014,26(14):. [18]M. Teresa Higuera‐Toledano,Andy Wellings. Introduction to the Special Issue on Java Technologies for Real‐Time and Embedded Systems: JTRES 2012[J]. Concurrency Computat.: Pract. Exper.,2014,26(14):. [19]Mostafa Mohammadpourfard,Mohammad Ali Doostari,Mohammad Bagher Ghaznavi Ghoushchi,Nafiseh Shakiba. Anew secure Internet voting protocol using Java Card 3 technology and Java information flow concept[J]. Security Comm. Networks,2015,8(2):. [20]Cédric Teyton,Jean‐Rémy Falleri,Marc Palyart,Xavier Blanc. A study of library migrations in Java[J]. J. Softw. Evol. and Proc.,2014,26(11):. [21]Sabela Ramos,Guillermo L. Taboada,Roberto R. Expósito,Juan Touri?o. Nonblocking collectives for scalable Java communications[J]. Concurrency Computat.: Pract. Exper.,2015,27(5):. [22]Dusan Jovanovic,Slobodan Jovanovic. An adaptive e‐learning system for Java programming course, based on Dokeos LE[J]. Comput Appl Eng Educ,2015,23(3):. [23]Yu Lin,Danny Dig. A study and toolkit of CHECK‐THEN‐ACT idioms of Java concurrent collections[J]. Softw. Test. Verif. Reliab.,2015,25(4):. [24]Jonathan Passerat?Palmbach,Claude Mazel,David R. C. Hill. TaskLocalRandom: a statistically sound substitute to pseudorandom number generation in parallel java tasks frameworks[J]. Concurrency Computat.: Pract.Exper.,2015,27(13):. [25]Da Qi,Huaizhong Zhang,Jun Fan,Simon Perkins,Addolorata Pisconti,Deborah M. Simpson,Conrad Bessant,Simon Hubbard,Andrew R. Jones. The mzqLibrary – An open source Java library supporting the HUPO‐PSI quantitative proteomics standard[J]. Proteomics,2015,15(18):. [26]Xiaoyan Zhu,E. James Whitehead,Caitlin Sadowski,Qinbao Song. An analysis of programming language statement frequency in C, C++, and Java source code[J]. Softw. Pract. Exper.,2015,45(11):. [27]Roberto R. Expósito,Guillermo L. Taboada,Sabela Ramos,Juan Touri?o,Ramón Doallo. Low‐latency Java communication devices on RDMA‐enabled networks[J]. Concurrency Computat.: Pract. Exper.,2015,27(17):. [28]V. Serbanescu,K. Azadbakht,F. Boer,C. Nagarajagowda,B. Nobakht. A design pattern for optimizations in data intensive applications using ABS and JAVA 8[J]. Concurrency Computat.: Pract. Exper.,2016,28(2):. [29]E. Tsakalos,J. Christodoulakis,L. Charalambous. The Dose Rate Calculator (DRc) for Luminescence and ESR Dating-a Java Application for Dose Rate and Age Determination[J]. Archaeometry,2016,58(2):. [30]Ronald A. Olsson,Todd Williamson. RJ: a Java package providing JR‐like concurrent programming[J]. Softw. Pract. Exper.,2016,46(5):. java英⽂参考⽂献⼆: [31]Seong‐Won Lee,Soo‐Mook Moon,Seong‐Moo Kim. Flow‐sensitive runtime estimation: an enhanced hot spot detection heuristics for embedded Java just‐in‐time compilers [J]. Softw. Pract. Exper.,2016,46(6):. [32]Davy Landman,Alexander Serebrenik,Eric Bouwers,Jurgen J. Vinju. Empirical analysis of the relationship between CC and SLOC in a large corpus of Java methods and C functions[J]. J. Softw. Evol. and Proc.,2016,28(7):. [33]Renaud Pawlak,Martin Monperrus,Nicolas Petitprez,Carlos Noguera,Lionel Seinturier. SPOON : A library for implementing analyses and transformations of Java source code[J]. Softw. Pract. Exper.,2016,46(9):. [34]Musa Ata?. Open Cezeri Library: A novel java based matrix and computer vision framework[J]. Comput Appl Eng Educ,2016,24(5):. [35]A. Omar Portillo‐Dominguez,Philip Perry,Damien Magoni,Miao Wang,John Murphy. TRINI: an adaptive load balancing strategy based on garbage collection for clustered Java systems[J]. Softw. Pract. Exper.,2016,46(12):. [36]Kim T. Briggs,Baoguo Zhou,Gerhard W. Dueck. Cold object identification in the Java virtual machine[J]. Softw. Pract. Exper.,2017,47(1):. [37]S. Jayaraman,B. Jayaraman,D. Lessa. Compact visualization of Java program execution[J]. Softw. Pract. Exper.,2017,47(2):. [38]Geoffrey Fox. Java Technologies for Real‐Time and Embedded Systems (JTRES2013)[J]. Concurrency Computat.: Pract. Exper.,2017,29(6):. [39]Tórur Biskopst? Str?m,Wolfgang Puffitsch,Martin Schoeberl. Hardware locks for a real‐time Java chip multiprocessor[J]. Concurrency Computat.: Pract. Exper.,2017,29(6):. [40]Serdar Yegulalp. JetBrains' Kotlin JVM language appeals to the Java faithful[J]. ,2016,:. [41]Ortin, Francisco,Conde, Patricia,Fernandez-Lanvin, Daniel,Izquierdo, Raul. The Runtime Performance of invokedynamic: An Evaluation with a Java Library[J]. IEEE Software,2014,31(4):. [42]Johnson, Richard A. JAVA DATABASE CONNECTIVITY USING SQLITE: A TUTORIAL[J]. Allied Academies International Conference. Academy of Information and Management Sciences. Proceedings,2014,18(1):. [43]Trent, Rod. SQL Server Gets PHP Support, Java Support on the Way[J]. SQL Server Pro,2014,:. [44]Foket, C,De Sutter, B,De Bosschere, K. Pushing Java Type Obfuscation to the Limit[J]. IEEE Transactions on Dependable and Secure Computing,2014,11(6):. [45]Parshall, Jon. Rising Sun, Falling Skies: The Disastrous Java Sea Campaign of World War II[J]. United States Naval Institute. Proceedings,2015,141(1):. [46]Brunner, Grant. Java now pollutes your Mac with adware - here's how to uninstall it[J]. ,2015,:. [47]Bell, Jonathan,Melski, Eric,Dattatreya, Mohan,Kaiser, Gail E. Vroom: Faster Build Processes for Java[J]. IEEE Software,2015,32(2):. [48]Chaikalis, T,Chatzigeorgiou, A. Forecasting Java Software Evolution Trends Employing Network Models[J]. IEEE Transactions on Software Engineering,2015,41(6):. [49]Lu, Quan,Liu, Gao,Chen, Jing. Integrating PDF interface into Java application[J]. Library Hi Tech,2014,32(3):. [50]Rashid, Fahmida Y. Oracle fixes critical flaws in Database Server, MySQL, Java[J]. ,2015,:. [51]Rashid, Fahmida Y. Library misuse exposes leading Java platforms to attack[J]. ,2015,:. [52]Rashid, Fahmida Y. Serious bug in widely used Java app library patched[J]. ,2015,:. [53]Odeghero, P,Liu, C,McBurney, PW,McMillan, C. An Eye-Tracking Study of Java Programmers and Application to Source Code Summarization[J]. IEEE Transactions on Software Engineering,2015,41(11):. [54]Greene, Tim. Oracle settles FTC dispute over Java updates[J]. Network World (Online) [55]Rashid, Fahmida Y. FTC ruling against Oracle shows why it's time to dump Java[J]. ,2015,:. [56]Whitwam, Ryan. Google plans to remove Oracle's Java APIs from Android N[J]. ,2015,:. [57]Saher Manaseer,Warif Manasir,Mohammad Alshraideh,Nabil Abu Hashish,Omar Adwan. Automatic Test Data Generation for Java Card Applications Using Genetic Algorithm[J]. Journal of Software Engineering andApplications,2015,8(12):. [58]Paul Venezia. Prepare now for the death of Flash and Java plug-ins[J]. ,2016,:. [59]PW McBurney,C McMillan. Automatic Source Code Summarization of Context for Java Methods[J]. IEEE Transactions on Software Engineering,2016,42(2):. java英⽂参考⽂献三: [61]Serdar Yegulalp,Serdar Yegulalp. Sputnik automates code review for Java projects on GitHub[J].,2016,:. [62]Fahmida Y Rashid,Fahmida Y Rashid. Oracle security includes Java, MySQL, Oracle Database fixes[J]. ,2016,:. [63]H M Chavez,W Shen,R B France,B A Mechling. An Approach to Checking Consistency between UML Class Model and Its Java Implementation[J]. IEEE Transactions on Software Engineering,2016,42(4):. [64]Serdar Yegulalp,Serdar Yegulalp. Unikernel power comes to Java, Node.js, Go, and Python apps[J]. ,2016,:. [65]Yudi Zheng,Stephen Kell,Lubomír Bulej,Haiyang Sun. Comprehensive Multiplatform Dynamic Program Analysis for Java and Android[J]. IEEE Software,2016,33(4):. [66]Fahmida Y Rashid,Fahmida Y Rashid. Oracle's monster security fixes Java, database bugs[J]. ,2016,:. [67]Damian Wolf,Damian Wolf. The top 5 Java 8 features for developers[J]. ,2016,:. [68]Jifeng Xuan,Matias Martinez,Favio DeMarco,Maxime Clément,Sebastian Lamelas Marcote,Thomas Durieux,Daniel LeBerre. Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs[J]. IEEE Transactions on Software Engineering,2017,43(1):. [69]Loo Kang Wee,Hwee Tiang Ning. Vernier caliper and micrometer computer models using Easy Java Simulation and its pedagogical design features-ideas for augmenting learning with real instruments[J]. Physics Education,2014,49(5):. [70]Loo Kang Wee,Tat Leong Lee,Charles Chew,Darren Wong,Samuel Tan. Understanding resonance graphs using Easy Java Simulations (EJS) and why we use EJS[J]. Physics Education,2015,50(2):.【java英⽂参考⽂献汇编】相关⽂章:1.2.3.4.5.6.7.8.。
电机类的参考文献

[1] 国家技术监督局,建设联合发布. 泵站设计规范[M].北京:中国计划出版社,1994:58.[2] 丁毓山. 变电所设计[M]. 辽宁: 辽宁科学技术出版社,1993:48.[3] 熊信银. 发电厂电气部分[M]. 北京: 中国电力出版社,2004:107-117.[4] 傅知兰.电力系统电气设备选择与实用计算[M]. 北京: 中国电力出版社,2004:105.[5] 陈跃.电气工程专业毕业设计指南[M]. 北京: 中国水利水电出版社,2003:84-85.[6] 工厂常用电气设备编写组. 工厂常用电气设备手册上、下册[M]. 北京: 中国电力出版社,1986.[7] 国家技术监督局、建设联合发布. 泵站设计规范[M].北京:中国计划出版社,1994:59.[8] 苏文成. 工厂供电[M]. 北京: 机械工业出版社,1980:149.[9] 贺家李,宋从矩.电力系统继电保护原理[M]. 北京: 中国电力出版社,1991:129-186.[10] 刘介才.工厂供电[M]. 北京: 机械工业出版社,2004:301-304.[11] A. Greewood: “Electrical Transients in Power Systems”[J], Book, Wiley-Inters Cience,Second Edition, New York, 1991.[12] 国家技术监督局,建设联合发布. 10kV及以下变电所设计规范[M]. 北京:中国计划出版社,1994:15.[13] Electricity Association.Electricity industry revive 6[R].London,2002.[1]王兆安,杨君,刘进军,王跃.谐波抑制和无功功率补偿.机械工业出版社[2]肖湘宁等.电能质量分析与控制[M].中国电力出版社,2005.[3]Talor C.W. Industrial and subtransmiss/distribution SVCs. McGraw-Hill,1994[4]Wang P,Jenkins N,Bollen M H J.Experimental investigation of voltage sag mitigation by an advanced static var compensator[J]. IEEE Trans. on Power Delivery 1998, 13(4):1461~1467[5]赵强,张丽.故障电流限制器现状及应用前景.电力建设,2008,(1):44~47[6]王文廷.电网短路电流限制措施的探讨:[硕士学位论文].浙江: 浙江大学,2005[7]袁娟,刘文颖等.西北电网短路电流的限制措施. 电网技术, 2007, 31(10):42~45.[8]Nielsen J G,Newman M,Nielsen H,etal.Control and testingof adynamic voltage restorer(DVR)at medium voltage level[J].IEEETrans on Power Electronics,2004,19(3):806~813[9]YUN Weili, A Dual-Functional Medium Voltage Level DVR to Limit Downstream Fault Currents. IEEE transactions on power electronics ,2007,22(4):1130~1140[10]邸亚静,尹忠东,肖湘宁等.级联多电平电压质量调节装置的研究.电气工程自动化,2009,33(12):80~84[11]Yajing Di, Zhongdong Yin, Xiangning Xiao,Simulation Research On The Multiple Objective Voltage Quality Regulator,The IEEE APPEEC 2009,2009.3[12]Junjie Zhang, Zhongdong Yin, Xiangning Xiao, Yajing Di, Enhancement voltage stability of wind farm access to power grid by novel SVC,The IEEE ICIEC 2009,2009.4[13]杨淑英,杜彬. 基于dq变换的动态电压恢复器综合求导检测算法,电力系统自动化, 2008,32(2):40~44[14]王晨,张晓锋,庄劲武等. 新型混合式限流断路器设计及其可靠性分析. 电力系统自动化,2008,32(12):61~67.[15] 张晓丽,石新春,王毅.多电平变换器拓扑结构和控制方法研究.电源技术应用,2003,6(7):330~334[16]尹忠东,周丽霞,于坤山,2MVA无串联变压器级联多电平动态电压调节器的设计与仿真.电网技术,2006,30(1):80~84[17]石新春,齐涛等. 基于瞬时无功功率理论的SVC设计和实现. 电力电子技术,2006,42(5):12~14[18]马慧,刘静芳.基于瞬时无功功率理论的三相电路谐波、无功和不平衡电流检测.四川电技术,2004(4):4~7[19]刘开培,张俊敏,宣扬.基于重采样理论和均值滤波的三相电路谐波检测方法.中国电机工程学报,2003,23(9):78~82[20]彭春萍,陈允平,孙建军.动态电压恢复器及其检测方法的探讨[J].电力自动化设备,2003,23(1):68-71[21]李建林.载波相移级联H桥型多电平变流器及其在有源电力滤波器中的应用研究.浙江大学博士学位论文.2005[22]杨亚飞,颜湘武,娄尧林,等.一种新的电压骤降特征量检测方法[J].电力系统自动化,2004,28(2):41~44[23]曾琦,带串联补偿故障限流器的仿真和实验研究[硕士学位论文].四川:四川大学,2003[24]S.S.Choi,B.H.Li,and D.M.Vilathgamuwa,"Dynamic voltage restoration with minimum energy injection"IEEE Trans. Power Syst,vol.15,no.1,pp. 51-57,Feb.2000[25]尹忠东.瞬时电压补偿装置的零序电压控制.电力系统自动化,2002.10[26]赵剑峰,蒋平,唐国庆,等.基于电压型逆变器的串联型电能质量补偿器与电力系统相互作用的研究.中国电机工程学报,2001,21(4):75~79[27]王卫勤,刘汉奎,徐殿国,等.电压跟踪型单相电网有源滤波器补偿特性的研究.中国电机工程学报,1999,19(7):72~76[28]谢小荣,姜齐荣.柔性交流输电系统的原理与应用.北京:清华大学出版社,2006[29]赵剑锋.基于电压型逆变器的可连续运行的动态电压恢复器(UDVR)的研究:[博士学位论文].南京:东南大学电气工程学院,2001[30]尤勇.动态电压恢复器的研制:[硕士学位论文].北京:华北电力大学电力系,2004[31]彭力.基于状态空间理论的PWM逆变电源控制技术研究:[博士学位论文].武汉:华中科技大学,2004[32]孙驰,毕增军,魏光辉,一种新颖的三相四桥臂逆变器解藕控制的建模与仿真.中国电机工程学报告,2004,24(1):124~128[33]Michael J, AnalysisR. Modeling and control of three-phase, four-wire sine wave inverter systems [D]. University of Wisconsin-Madison, 1997[34] Elmitwally A, Abdelkader S, Elkateb M, Performanceevaluation of fuzzy controlled three and four wire shunt active power conditioners. IEEE Power Engineering Society winter meeting. vol.3,Singapore:2000,1650~1655[35] Richard Zhang,Pasad V H,Dushan Broyevich,et al., Three-dimensional space vector modulation for four-leg voltage-source converters. IEEE Trans on PE, 2002, 17(3):314~326[36] Ryan M J, Rik W. De Doncker, Lorenz R D. Decoupled control of a four-leg inverter via a new 4 X 4 transformation matrix.IEEE Trans on PE, 2001,16(5): 694~700[37] 王刚.基于DSP和FPGA的七电平级联H桥型变流器的控制研究.华东交通大学硕士学位论文.2006年6月[38] S.Lee,W.Chang,C.Wu.A compact algorithm for three-phase three-wire system reactive power compensation and load balancing,Proc.EMPD’95 1 (1995) 358~363[39] 孙曙光,王景芹,师顺泉.单相电路谐波及无功电流实时检测的研究.电测与仪表[J],2008,1[40] 刘二虎,梁文怡,张文栋.基于FPGA的IIR数字滤波器硬件模块的设计.微计算机信息[J],2008,24[1] 刘振亚.特高压电网[M].北京:中国经济出版社,2005:1~100.[1] 陈珩.电力系统稳态分析[M].北京:中国电力出版社,1995:1~28.[1] V E Wagner,J C Balda,D C Griffith,et al.Effects of harmonics onequipment, Report of the IEEE task force on the effects of harmonics on equipment. IEEE Transactions on Power Delivery,1993,B(2):672~680.[1] Narain G,Hingorani.High Power Electronics and Flexible ACTransmission System.IEEE Power Engineering Review,1988,8(7):3~4.[1] Alexander E Emanuel,John A Orr,David Cyganski,et al.A survey ofharmonic voltages and currents at the customer's bus.IEEE Transactions on Power Delivery,1993,8(1):411~421.[1] G Manchur,C C Erven.Development of a model for predicting flicker fromelectric arc furnaces.IEEE Transactions on Power Delivery,1992,7(1):416~420.[1] 吴竞昌.供电系统谐波[M].北京:中国电力出版社,1998.[1] 肖湘宁.电能质量分析与控制[M].北京:中国电力出版社,2004:1~30.[1] 朱桂萍,王树民.电能质量控制技术综述.电力系统自动化,2002,26(19):28~31.[1] 程浩忠,范宏,翟海保.输电网柔性规划研究综述.电力系统及其自动化学报,2007,19(1):21~27.[1] Georage J,Wakileh.Power systems harmonics,Fundamental,analysis andfilter design.徐政译.电力系统谐波一畸变原理,分析方法和滤波器设计[M].北京:机械工业出版社,2003.[1] 王兆安,杨君,刘进军.谐波抑制和无功功率补偿[M].北京:机械工业出版社,2004:6-8.[1] 林海雪,孙树勤.电力网中的谐波[M].北京:中国电力出版社,1998.[1] 李建林,张仲超.关于谐波及无功电力检测方法的综述.电力系统及其自动化学报,2003,15(4):89~93.[1] 朱桂萍,王树民.电能质量控制技术综述.电力系统自动化,2002,26(19):28~31.[1] 李永东,倚鹏.大功率高性能逆变器技术发展综述.电气传动,2000,6:3~8.[1] 张斌,刘晓川,许之晗.基于变换的电能质量分析方法.电网技术,2001,25(1) :26~29.[1] 王建赜,李威,纪延超,等.电能质量监测算法研究及实现.继电器,2001,29(2):29~31.[1] 文继锋,刘沛.一种电能质量扰动的检测和分类方法.电力系统自动化,2002,26(1):42~44.[1] 孙元章,刘前进.FACTS控制技术综述——模型,目标与策略.电力系统自动化,1999,23(6):1~7.[1] Xia Jiang,Xinghao Fang,Joe H Chow,et al.A Novel Approach for ModelingVoltage-Sourced Converter-Based FACTS Controllers.IEEE Transactions on Power Delivery,2008,23(4):2591~2598.[1] 陈国柱,吕征宇,钱照明.有源电力滤波器的一般原理及应用.中国电机工程学报,2000,20(9):17-21.[1] 刘飞,邹云屏,李辉.C 型混合有源电力滤波器.中国电机工程学报,2005,25(6):75-80.[1] 周柯,罗安,汤赐,等.一种大功率混合注入式有源电力滤波器的工程应用.中国电机工程学报,2007,27(22):80-86.[1] 查晓明,孙建军,陈允平.并联型有源电力滤波器的重复学习Boost变换控制策略.电工技术学报,2005,20(2):57~62.[1] Fukuda S,Yoda T.A novel current-tracking method foractive filters basedon a sinusoidal internal model forPWM inverters.IEEE Transactions on Industry Application,2001,37(5):888~895.[1] Malesani L,Mattavelli P,Buso S.Robust dead-beat current control forPWM rectifiers and active filters.IEEE Transactions on Industry Application,1999,36(5):613~620.[1] 王同勋,薛禹胜,SSCHOI.动态电压恢复器研究综述.电力系统自动化,2007,31(9):101~107.[1] S S Choi,B H Li,D M Vilathgamuwa.Dynamic voltage restoration withminimum energy injection.IEEE Transactions on Power Systems,2000,15(1):51~57.[1] Mahinda Vilathgamuwa D,Ranjith Perera A A D,Choi S S.Voltage sagcompensation with energy optimized dynamic voltage restorer.IEEE Transactions on Power Delivery,2003,18(3):928~936.[1] 袁川,杨洪耕.动态电压恢复器的改进最小能量控制.电力系统自动化,2004,28(21):49~53.[1] 谢旭,胡明亮,梁旭,等.动态电压恢复器的补偿特性与控制目标.电力系统自动化,2002,26(8):41~44.[1] 冯小明,杨仁刚.动态电压恢复器电压补偿策略的研究.电力系统自动化,2004,28(6):68~72.[1] 魏文辉,刘文华,宋强,等.基于逆系统方法有功-无功解耦PWM控制的链式STATCOM动态控制策略研究.中国电机工程学报,2005,25(3):23~28.[1] 耿俊成,刘文华,俞旭峰,等.链式STATCOM的数学模型.中国电机工程学报.2003,23(6):66~70.[1] 魏文辉,宋强,滕乐天,等.基于反故障控制的链式STATCOM动态控制策略的研究.中国电机工程学报,2005,25(4):19~24.[1] 栗春,姜齐荣,王仲鸿.STATCOM电压控制系统性能分析.中国电机工程学报,2000,20(8):46~50.[1] C D Schauder,L Gyugyi,M R Lund,et al.AEP UPFC project installation,commissioning and operation of the ±160 MVA STATCOM (phase I).IEEE Transactions on Power Delivery,1998,13(4):1530~1535.[1] Li Yidan,Wu Bin.A novel DC voltage detection technique in the CHBinverter-based STATCOM.IEEE Trans. on Power Delivery,2008,23(3):1613-1619.[1] Barrena J A,Marroyo L,Vidal M A R,et al.Individual voltage balancingstrategy for PWM cascaded H-Bridge converter based STATCOM.IEEE Trans. on Industry Electronics,2008,55(1):1512-1521.[1] 刘文华,宋强,张东江,等.50MVA静止同步补偿器链节的等价试验.中国电机工程学报,2006,26(12):73~78.[1] 马晓军,姜齐荣,王仲鸿,等.静止同步补偿器的分相不对称控制.中国电机工程学报,2001,21(1):52~56.[1] 栗春,马晓军,姜齐荣,等.用STATCOM改善系统电压调节特性的动模实验.中国电机工程学报,1999,19(9):46~49.[1] Liang Yiqiao,Nwankpa C O.A new type of STATCOM based on cascadingvoltage-source inverters with phase-shifted unipolar SPWM.IEEE Trans.on Industry Applications,1999,35(5):1118-1123.[1] Komurcugil H,Kukrer O.Lyapunov-based control for three phase PWMAC/DC voltage-source converters.IEEE Transactions on Power Electronics,1998,13(9):801-813.[1]Lee D C,Lee G M,Lee K D.DC-bus voltage control of three-phase AC/DCPWM converters using feedback linearization.IEEE Transactions on Industry Applications,2000,36(5):826-833.[1] H Akagi.New trends in active filters for power conditioning.IEEETransactions on Industral Application,1996,32(6):1312~1322.[1] S Moran.A line voltage regulator/conditioner for harmonic sensitive loadisolation.IEEE/IAS Annu Meet,1989:947~951.[1] F Kamran,T G Habetler.Combined deadbeat control of a seriesparallelconverter combination used as a universal powerfilter.IEEE Power Electronics Specialist Conf,1995:196~201.[1] Woodhouse M L,Donoghue M W,Osborne M.Type testing of the GTOvalves for a novel STATCOM convertor.Proc. 2001 IEE AC-DC Power Transmission Conf,London,2001,84~90.[1] 吴耀辉,杨焦贇,魏仁灿.IGBT高频开关电源的故障分析及处理.电力电子技术,2009,43(5):61~62.[1] 陈坚.电力电子学2版[M].北京:高等教育出版社,2004.[1] Steffen Bernet.Recent developments of high power coverters for industryand traction applications.IEEE Transactions on Power Electronics,2000,15(6):1102~1117.[1] 最新功率器件专集[M].西安:西安电力电子技术研究所,2000.[1] 王正元,由宇义珍,宋高升.IGBT技术的发展历史和最新进展.电力电子,2004,2(5):7~12.[1] 张占松,蔡宣三.开关电源的原理与设计[M].北京:电子工业出版社,1998.[1] 刘文华,宋强,滕乐天,等.基于链式逆变器的50MVA STATCOM的直流电压平衡控制.中国电机工程学报,2004,24(4):145~150.[1] 刘钊,刘邦银,段善旭,等.链式静止同步补偿器的直流电容电压平衡控制.中国电机工程学报,2009,29(30):7~12.[1] Woodhouse M L,Donoghue M W,Osbome M M.Type testing of the GTOvalves for a novel STATCOM converter.Seventh International Conference on AC-DC Power Transmission,London,United Kingdom,2001.[1] Baker M H,Gemmell B D,Horwill C,et al.STATCOM helps to guaranteea stable system.Transmission and Distribution Conference and Exposition,Atlanta,USA,2001.[1] Hanson D J,Woodhouse M L,Horwill C,et al.STATCOM:a new era ofreactive compensation.Power Engineering Journal,2002,16(3):151~160.[1] An T,Powell M T,Thanawala H L,et al.Assessment of two differentSTATCOM configurations for FACTS application in power systems.International Conference on Power System Technology,Beijing,China,1998.[1] 解大,张延迟,吴非,等.并联型有源电力滤波器的直流侧电压控制和补偿电流反馈控制.电网技术,2006,30(3):18~21.[1] 耿俊成,刘文华,袁志昌.链式STATCOM电容电压不平衡现象研究(一)仿真和试验.电力系统自动化,2003,27(16):53~86.[1] 耿俊成,刘文华,袁志昌.链式STATCOM电容电压不平衡现象研究(二)数学模型.电力系统自动化,2003,27(17):35~39.[1] A Nagel,S Bernet,P K Steimer,et al.A 24 MVA Inverter using IGCTSeries Connection for Medium Voltage Applications.Reprinted from the Industry Applications Society,IAS,October 2001,Chicago,USA.[1] 查申森,郑建勇,苏麟,等.基于IGBT串联运行的动态均压研究.电力自动化设备,2005,25(5):20~22.[1] 付志红,苏向丰,周雒维.功率器件IGBT串联的移相控制技术.重庆大学学报,2003,26(2):113~116.[1] 金其龙,孙鹞鸿,严苹,等.IGBT串联技术动态均压电路的研究.高电压技术,2009,35(1):176~180.[1] 孙荣丙.IGBT串联技术的研究[硕士学位论文].合肥:合肥工业大学,2009.[1] 郑连清,王青峰.馈能型电子负载的并网控制.电网技术,2008,32(7):40~45.[1] 刘志刚,李宝昌,汪至中.电能反馈型电子负载的设计与实现.铁道学报,2001,23(3):37~41.[1] Emadi A.Modeling of power electronic loads in AC distribution systemsusing the generalized state-space averaging method.IEEE Trans on industrial Electronics,2004,51(5):992~1000.[1] 赵剑锋,潘诗锋,王浔.大功率能量回馈型交流电子负载及其在电力系统动模实验中的应用.电工技术学报,2006,21(12):35~39.[1] 王成智,邹旭东,陈鹏云,等.大功率电力电子负载并网变换器的设计与改进.中国电机工程学报,2009,29(18):1~7.[1] 王成智,邹旭东,许赟,等.采用改进重复控制的大功率电力电子负载.中国电机工程学报,2009,29(12):1~9.[1] 李时杰,李耀华,陈睿.Back-to-Back变流系统中改进前馈控制策略的研究.中国电机工程学报,2006,26(22):74~79.[1] 杨超,龚春英.基于DSP的能量回馈型交流电子负载的研究.通信电源技术,2008,25(2):12~15.[1] 李芬,邹旭东,王成智,等.基于双PWM 变换器的交流电子负载研究.高电压技术,2008,34(5):930~934.[1] Hanson D J.Horwill C,Gemmell B D,et al.A STATCOM-basedrelocatable SVC project in the UK for national grid.Power Engineering SocietyWinter Meeting,2002.IEEE,New York,2000,1:532~537.[1] R Mohan Mathur,Rajiv K Varma.基于晶闸管的柔性交流输电控制装置[M].徐政译.北京:机械工业出版社,2005年,363~401.[1] Horwill C,Totterdell A J,Hanson D J,et al.Commission of a 225 MvarSVC incorporating a ±75Mvar STATCOM AT NGC’s 400kV east claydon substation.Seventh International Conference on AC-DC Power Transmission,London,2001.232~237.[1] 张文亮,邱文亮,来小康.储能技术在电力系统中的应用.电网技术,2008,32(7):1~9.[1] Suzuki I,Shizuki T,Nishiyama K.High power and long life lithium-ionbattery for backup power source.The 25th International Telecommunications Energy Conference,Brazil,2003:317~322.[1] Madawala U K,Thrimawithana D J,Nihal K.An ICPT-supercapacitorhybrid system for surge-free power transfer.IEEE Trans on Industrial Electronics,2007,54(6):3287~3297.[1] Schoenung S M,Burns C.Utility energy storage applications studies.IEEETrans on Energy Conversion,1996,11(3):658~665.[1] Juan Segundo-Ramírez,Aurelio Medina.Modeling of FACTS DevicesBased on SPWM VSCs.IEEE Transactions on Power Delivery,2009,24(4):1815~1823.[1] Sirisukprasert S,Huang A Q,Lai J-S.Modeling,analysis and control ofcascaded-multilevel converter-based STATCOM.IEEE Power Engineering Society General Meeting,2003,4:2568~2574.[1] 刘黎明,康勇,陈坚,等.SSSC建模、控制策略及性能.电工技术学报,2006,21(9):37~43.[1] 郭雷,程代展,冯德兴.控制理论导论[M].北京:科学出版社,2005.[1] 戴忠达.自动控制理论基础[M].北京:清华大学出版社,2001.[1] 刘豹.现代控制理论[M].北京:机械工业出版社,1992.[1] 钟秋海,付梦印.现代控制理论与应用[M].北京:机械工业出版社,1997.[1] T Tayjasanant,W Wang,C Li and W Xu.Interharmonic-flickercurves[J].IEEE Transactions on Power Delivery,2005,20(2):1017~1024.[1] L Peretto and A E Emanuel.A theoretical study of the incandescent filamentlamp performance under voltage flicker.IEEE Transactions on Power Delivery,1997,12(1):279~288.[1] A E Emanuel and L Peretto.The response of fluorescent lamp withmagnetic ballast to voltage distortion.IEEE Transactions on Power Delivery,1997,12(1):289~295.[1] T Keppler,N R Watson,J Arrillaga and S Chen.Theoretical assessmentoflight flicker caused by sub- and interharmonic frequencies.IEEE Transactions on Power Delivery,2003,18(1):329~333.[1] 全国电压电流等级和频率标准化技术委员为,欧盟——亚洲电能质量项目中国合作组电能质量国家标准应用指南[M].北京,中国标准出版社,2009:103~120.[1] Jing Yong,Wilsun Xu,Caixin Sun.Characterizing Voltage FluctuationsCaused by a Pair of Interharmonics.IEEE Transactions on Power Delivery,2008,23(1):319~326.[1] 康劲松,陶生桂,王新祺.大功率IGBT直流特性和动态特性的PSPICE仿真.同济大学学报,2002,30(6):710~714.[1] 田伟,于海生.MATLAB在电力电子仿真中的应用.船电技术,2006,26(5):31~33.[1] 罗伟,张明焱.基于Saber的Buck电路仿真与分析.电力系统及其自动化学报,2007,19(3):122~124.[1] 洪乃刚.电力电子和电力拖动控制系统的MATLAB仿真.北京:机械工业出版社,2006.[1] 文小玲,尹项根.三电平STATCOM的建模和仿真分析.武汉工程大学学报,2008,30(1):87~90.[1] 刘永超,杨振宇,姚军,等.三相四桥臂动态无功补偿器仿真研究.电力自动化设备,2006,26(11):24~27.[1] 单任仲,尹忠东,肖湘宁.电压源型快速动态无功补偿器.中国电机工程学报,2009,1~5.[1] 尹忠东,周丽霞,于坤山.2MVA无串联变压器级联多电平动态电压调节器的设计与仿真. 电网技术,2006,30(1):80~84.[1] 龙英,马玉龙,曾南超,等.RTDS应用于直流控制保护系统的仿真试验.高电压技术,2005,31(8):56~58.[1] 钱珞江,邓红英,陶瑜.灵宝背靠背直流输电工程中的RTDS试验模型.高电压技术,2005,31(12):45~65.[1] 洪潮,饶宏.南方电网直流多落点系统实时仿真研究.中国电机工程学报,2005,25(25):29~35.[1] 朱庆春,丁洪发,张明龙,等.与RTDS互联的TCSC物理模拟装置研制. 电力自动化设备,2005,25(2):50~55.[1] 王学强,黄立滨,崔伟.纵差线路保护装置RTDS实验方案设计.继电器,2003,31(9):26~30.[1] 王婷,王大光,邓超平,林因,张明龙,宋福海.用RTDS建立省级电力系统等值模型的初步研究.福建电力与电工,2005,25(3):1~4.[1] Wei Qiao,Ganesh Kumar Venayagamoorthy,Ronald Garley.MissingSensor Fault Tolerant Control for SSSC FACTS Device With Real-Time Implementation.IEEE Transactions on Power Delivery,2009,24(2):740~750.[1] 姜旭.H桥级联式SSSC主电路拓扑分析及控制策略研究[博士学位论文].北京:华北电力大学,2007.[1] 赵洋.静止同步串联补偿器控制策略及抑制次同步谐振的研究[博士学位论文].北京:华北电力大学,2009.[1] 江建军,刘继光.LabVIEW程序设计教程[M].北京:电子工业出版社,2008.[1] 陈锡辉,张银鸿.LabVIEW 8.20程序设计从入门到精通[M].北京:清华大学出版社,2007.[1] Wang X,Ooi B T.Unity PF current-source rectifier based on dynamictrilogic PWM.IEEE Transaction on Power Electronics,1993,8(3):288~294.[1] 陈首先.网络化的电力电子通用数字平台设计[硕士学位论文].杭州:浙江大学,2008.[1] Andrew bateman,Iain Paterson-stephens.The DSP handbook algorithms,applications and design techniques[M].北京:机械工业出版社,2006.[1] Mark zwolinski.Digital system design with VHDL[M].北京:电子工业出版社,2006,51~164.[1] 鲁挺,赵争鸣,张颖超,等.基于双DSP的电力电子变换器通用控制平台.清华大学学报,2008,48(10):1541~1544.[1] 李建林,王立乔,李彩霞,等.基于现场可编程门阵列的多路PWM波形发生器.中国电机工程学报,2005,25(10):55~59.[1] 范伟健.M57959L/M57962L型IGBT厚膜驱动电路.国外电子元器件,1999,(2):8~9.[1] 蓝宏,胡广艳,张立伟,等.大电流高频IGBT用M57962L驱动能力解决方案研究.电力电子,2006,4:27~30.[1] 华伟.IGBT驱动及短路保护电路M57959L研究.电力电子技术,1998,(1):88~90.[1] 占荣.可编程逻辑器件在逆变器控制中的应用[硕士学位论文].武汉:华中科技大学,2005.[1] 潘松,黄继业.EDA 技术实用教程[M].北京:科学出版社,2002.[1] 杨恒.FPGA/VHDL快速工程实践入门与提高[M].北京:北京航空航天大学出版社,2003.。
电力英语文献---配电网络中较少损耗的实际方法

A realistic approach for reduction of energy losses in low voltage distribution networkabstractThis paper proposes reduction of energy losses in low voltage distribution network using Lab VIEW as simulation tool. It suggests a methodology for balancing load in all three phases by predicting and controlling current unbalance in three phase distribution systems by node reconfiguration solution for typical Indian scenario. A fuzzy logic based load balancing technique along with optimization oriented expert system for implementing the load changing decision is proposed. The input is the total phase current for each of the three phases. The average unbalance per phase is calculated and checked against threshold value. If the average unbalance per phase is below threshold value, the system is balanced. Otherwise, it goes for the fuzzy logic based load balancing. The output from the fuzzy logic based load balancing is the value of load to be changed for each phase. A negative value indicates that the specific phase is less loaded and should receive the load, while a positive value indicates that the specific phase is surplus load and should release that amount of load. The load change configuration is the input to the expert system which suggests optimal shifting of the specific number of load points, i.e., the consumers.1. IntroductionAmong three functional areas of electrical utility namely, generation, transmission and distribution, the distribution sector needs more attention as it is very difficult to standardize due to its complexity. Transmission and distribution losses in India have been consistently on the higher side in the range of 21–23%. Out of these losses, 19% is at distribution level in which 14% is contributed by technical losses. This is due to inadequate investments for system improvement work. To reduce technical losses, the important parameters are inadequate reactive compensation, unbalance of current and voltage drops in the system. There are two main distribution network lines namely, primary distribution lines (33 kV/22 kV/11 kV) and secondary distribution lines (415 V line voltage). Primary distribution lines are feeding HT consumers and are regularized by insisting the consumers to maintain power factor of 0.9 and above and their loads in all three phases is mostly balanced. The energy loss control becomes a critical task in secondary distribution network due to the very complex nature of the network.Distribution Transformer caters to the needs of varying consumers namely Domestic, Commercial, Industrial, Public lighting, Agricultural, etc. Nature of load also varies as single phase load and three phase load. The system is dynamic and ever expanding. It requires fast response to changes in load demand, component failures and supply outages. Successful analysis of load data at the distribution level requiresprocedures different from those typically in use at the transmission system level. Several researchers have proposed methods for node reconfiguration in primary distribution network [1–11]. Two types of switches used in primary distribution systems are normally closed switches (sectionalizing switches) and normally open switches (tie switches). Those two types of switches are designed for both protection and configuration management and by altering the open/ closed status of switches loss reduction and optimization of primary distribution network can be achieved. Siti et al. [12] discussed reconfiguration algorithms in secondary distribution network with load connections done via a switching matrix with triacs and hence costly alternative for developing countries. Much work needs to be done in the secondary distribution network where lack of information is an inherent characteristic. For example in most of the developing countries (India, China, Brazil, etc.) the utilities charge the consumers based on their monthly electric energy consumption. It does not reflect the day behaviour of energy consumption and such data are insufficient for distribution system analysis.Conventionally, to reduce the unbalance current in a feeder the load connections are changed manually after field measurement and software analysis. Although this process can improve the phase current unbalance, this strategy is more time consuming and erroneous. The more scientific process of node reconfiguration of LV network which involves thearrangement of loads or transfer of load from heavily loaded area to the less loaded area is needed. This paper focuses on this objective. In the first stage, the energy meter reading from secondary of Distribution Transformer is downloaded and is applied as input to Lab-VIEW based distribution simulation package to study the effects of daily load patterns of a typical low voltage network (secondary distribution network). The next stage is to develop an intelligent model capable of estimating the load unbalance on a low voltage network in any hour of day and suggesting node reconfiguration to balance the currents in all three phases.Objectives are to:Study the daily load pattern of low voltage network of Distribution Transformer by using Lab VIEW.Study the unbalance of current in all three phases and power factor compensation in individual phases.Develop distribution simulation package.The distribution simulation package contains fuzzy logic based load balancing technique and fuzzy expert system to shift the number of consumers from over loaded phase to under loaded phase.2. Existing systemIn the existing system of distribution network, the energymeters are provided for energy accounting, but there is no means of sensingunbalance currents, voltage unbalance and power factor correction requirement for continuous 24 h in three phases of LT feeder. In other words, instantaneous load curves, voltage curves, energy curves and power factor curves for individual three phases are not available for monitoring, analyzing and controlling the LV network. The individual phase of Distribution Transformer could be monitored only by taking reading whenever required and if there is unequal distribution of load in three phases, the consumer loads are shifted from overloaded phase to under loaded phase of distribution LT feeder by the field staff in charge of the Distribution Transformer. There is no scientific methodology at present.3. Proposed systemIn the proposed system, Lab VIEW is used as software simulation tool [13]. In the existing system of distribution network, the Distribution Transformers are fixed with energy meters in the Secondary of the Distribution Transformer and energy meter readings can be downloaded with Common Meter Reading Instrument (CMRI instrument). The energy meter reading includes VI profile and it can be used for the power measurement.4. Monitoring parametersThe phase voltages and the line currents of all three phases are available every half an hour and the voltage curve and load curve are obtained fromthese values. The active, the reactive and the apparent power are computed from these quantities after the phase angle is determined. The following parameters are plotted:1. Individual phase voltage.2. Individual phase current.3. Individual phase active power.4. Individual phase reactive power.5. Individual phase apparent power.6. Individual phase power factor.With the above concepts, the front panel and block diagram are developed for unbalanced three phase loads by downloading the VI profile from energy meter installed in the Distribution Transformer and simulating the setup using practical values. From the actual values obtained load unbalance is predicted using fuzzy logic and node reconfiguration is suggested using expert system.The Lab VIEW front panel displays the VI profile on a particular date with power and energy measurement as in Table 1. The Lab VIEW reads the VI profile and computes the real power, reactive power, apparent power and energy, kWh.4.1. Prediction of current unbalanceThe maximum current consumption in each phase is IRmax, IYmax, and IBmax. The optimum current (Iopt) is given in the following equation:()3max max max B Y R opt I I I I ++=The difference between opt I and m ax R I is then determined. Similarly thedifference between opt I and max Y I , opt I and max B I is computed. If thedifference is positive then that phase is considered as overloaded and if the difference is negative then that phase is considered to be under loaded. If the difference is within the threshold value, then that load is perfectly balanced.To balance the current in three phases, if the difference between opt I and m ax R I is less than threshold value then that phase is left as such.Otherwise, if the difference is greater than threshold value, some of the consumers are suggested reconfiguration from overloaded phase to under loaded phase using expert system.5. Fuzzy based load balancingA fuzzy logic based load balancing technique is proposed along with combinatorial optimization oriented expert system for implementing the load changing decision. The flowchart of the proposed system is shown in Fig. 1. Here the input is the total phase current for each of the three phases. Typical loads on low voltage networks are stochastic by nature. However it has been ensured that there is similarity in stochastic nature throughout the day as seen from load graph of Distribution Transformer as shown in Fig. 6. It has been verified that if R phase is overloaded followed by Y phase and thenB phase the same load pattern continuesthroughout the day.The average unbalance per phase is calculated as (IRmax _ Iopt) for R phase, (IYmax _ Iopt) for Y phase and (IBmax _ Iopt) for B phase and is checked against a threshold value (allowed unbalance current) of 10 A. If the average unbalance per phase is below 10 A, it can be assumed that the system is more or less balanced and discard any further load balancing. Otherwise, it goes for the fuzzy logic based load balancing. The output from the fuzzy logic based load-balancing step is the load change values for each phase.This load change configuration is the input to the expert system, which tries to optimally suggest shifting of specific number of load points. However, sometimes the expert system may not be able to execute the exact amount of load change as directed by the fuzzy step. This is because the actual load points for any phase might not result in a combination which sums up to the exact change value indicated by the fuzzy controller however optimization is achieved because of balancing attempted during peak hours of the day of the load graph.5.1. Fuzzy controller: input and outputTo design the fuzzy controller, at first the input and output variables are to be designed. For the load balancing purpose, the inputs selected are ‘phase current’ i.e., the individual phase current for each of the three phases and optimum current required and the output as ‘change’, i.e., thechange of load (positive or negative) to be made for each phase. For the input variable, Table 2 and Fig. 2 show the fuzzy nomenclature and the triangular fuzzy membership functions. And for the output variable, Table 3 shows the fuzzy nomenclature and Fig. 3 the corresponding triangular fuzzy membership functions.The IF-THEN fuzzy rule set governing the input and output variable is described in Table 4.5.2. Fuzzy expert systemA fuzzy expert system is an expert system that uses a collection of fuzzy membership functions and rules, instead of Boolean logic, to reason out data. The rules in a fuzzy expert system are usually of a form similar to the following:If x is low and y is high then z = mediumwhere x and y are input variables (names for known data values), z is an output variable (a name for a data value to be computed), low is a membership function (fuzzy subset) defined on x, high is a membership function defined on y, and medium is a membership function defined on z .The antecedent (the rule’s premise) describes to what degree the rule applies, while the conclusion (the rule’s consequent) assigns a membership function to each of one or more output variables. Most tools for working with fuzzy expert systems allow more than one conclusion per rule. The set of rules in a fuzzy expert system is known as the rulebase or knowledge base.The load change configuration is the input to the expert system which tries to optimally shift the specific number of load points. The following are the objectives of the expert system:_ Minimum switching._ Minimum losses._ Satisfying the voltage and current constraints.Fg. 4 shows the block diagram of the expert system. The inputs to the expert system are the value added or subtracted to that particular phase from the fuzzy controller and the current consumption of the individual consumers on that particular phase. The expert system should display which of the consumers are to be shifted from the overloaded phase to under loaded phase and also displays the message NO CHANGE if that phase is balanced.6. Simulation resultsTable 1 shows the display of output of Lab-VIEW based power and energy measurement [14]. It asks for the Distribution Transformer secondary reading, date, tolerance value (threshold value), and fuzzy conditioner of three phases for load balancing. It then displays the date, time, voltage, current, power factor, real power, reactive power, apparent power.Fig. 5 shows the line voltage curve for R, Y and B phases. It alsoindicates the voltage drop during peak hours of the day. The current curve for R, Y and B phases is shown in Fig. 6. It indicates the current unbalance in the existing supply network. The load graph from typical Distribution Transformer for entire day indicates interesting similarity in load patterns of consumers. Hence load balancing attempted during peak load band yielded fruitful result for the entire day.Fig. 7 displays the results of fuzzy logic based load balancing technique. Fuzzy toolkit in Lab VIEW is used for simulation. Mamdani fuzzy inference technique is applied and centroid based defuzzication technique is employed in the load balancing system. The output from the fuzzy controller is the value that is to be subtracted or added to a particular phase. The positive value indicates that the specific phase is overloaded and it should release the amount of load. The negative value indicates that the specific phase is under loaded and it should receive the amount of load. The value less than 10 A indicate that phase is perfectly loaded. Fig. 8 show the expert system output for all three phases. It gives the Service connection number (SC No.) and current consumption of individual consumer. The output of the fuzzy controller is applied as the input to the expert system. If the output of the fuzzy controller is a positive value then the expert system should inform which of the consumers are to be shifted from that phase.From Fig. 8, the R phase is overloaded, so the expert system informs thatthe SC No.’s 56 and 23 should be shifted. The output of the fuzzy controller for the Y phase is less than threshold value 10 A so that phase is perfectly loaded. The output of the fuzzy controller for B phase is a negative value; hence it receives the load from R-phase. There is no shifting of consumer in Y phase and B phase therefore the entries are indicated by zero values. There is no switching arrangement in secondary low voltage distribution network in Indian scenario and hence shifting to be done manually.The suggested approach has been tested practically on 70 nodes (70 consumers) low voltage distribution network and results are as shown in Fig. 9 (before balancing) and Fig. 10 (after balancing). Single phase customers physically reconfigured from overloaded phase into under loaded phase and then test results studied. Unbalancing has been observed for 10 days and then balancing attempted. Balanced network was studied and then results obtained. There is a percentage reduction in Energy loss from 9.695% to 8.82% though there is increase in cumulative kWh from 1058.95 to 1065.9. This Distribution Transformer belongs to urban area of a typical Indian city and has 41 single phase consumers and 29 three-phase consumers and three-phase consumers have balanced loads. In rural areas where number of single phase consumers are predominant and scattered around lengthy distribution lines this balancing technique will be much more beneficial than the tested study indicates.This research is significant to the Indian scenario considering the fact that there are 180,763 Distribution Transformers (www.tneb.in) and 2,07,00,000 consumers and length of secondary distribution network 5,17,604 km in one state, Tamil Nadu alone, 1% saving in energy loss per transformer per day will save few crores of rupees for a month to electrical utility.7. ConclusionIn this paper, the complete online monitoring of low voltage distribution network is done by using Lab VIEW and the fuzzy logic based load balancing technique is presented. With the results obtained from Lab VIEW, currents in individual phases are predicted and unbalance pattern is studied without actually measuring instantaneous values from consumer premise.A fuzzy logic based load balancing is implemented to balance the current in three phases and expert system to reconfigure some of the consumers from over loaded phase to under loaded phase. The input to the fuzzy controller is the individual phase current. The output of the fuzzy controller is the load change value, negative value for load receiving and positive value for load releasing. Expert system performs the optimal interchanging of the load points between the releasing and receiving phases.The proposed phase balancing system using fuzzy logic and expertsystem is effective for reducing the phase unbalance in the low voltage secondary distribution network. The energy losses are reduced and efficiency of the distribution network is improved and has been practically studied in typical Distribution Transformer of electrical utility.图一图2图3 图4图5图6图7图8图9图10。
殷保群教授个人简历范文

以下是为⼤家整理的关于殷保群教授个⼈简历范⽂的⽂章,希望⼤家能够喜欢!殷保群,男,教授,博⼠⽣导师。
中国科学技术⼤学教授。
1962年2⽉⽣,1985年7⽉毕业于四川⼤学数学系基础数学专业,随后考⼊中国科学技术⼤学基础数学研究⽣班,1987年7⽉毕业,并留校任教。
1993年5⽉在中国科学技术⼤学数学系应⽤数学专业获得理学硕⼠学位,1998年12⽉在中国科学技术⼤学⾃动化系模式识别与智能系统专业获得⼯学博⼠学位,现在中国科学技术⼤学⾃动化系任教。
长期从事随机系统、系统优化以及信息络系统理论及其应⽤等⽅⾯的研究⼯作,⽬前感兴趣的主要⽅向为Markov决策过程、络建模与优化、络流量分析、媒体服务系统的接⼊控制以及云计算等。
在国内外主要学术刊物上发表学术论⽂100余篇,其中SCI收录10余篇,EI收录30余篇,出版学术专著1部。
曾于2004年4⽉⾄12⽉在⾹港科技⼤学做访问学者。
第xx届(2006年)何潘清漪优秀论⽂获奖者。
⽬前感兴趣的主要研究⽅向:1、离散事件动态系统; 2、Markov决策过程; 3、排队系统; 4、信息络论⽂著作主要著作殷保群,奚宏⽣,周亚平,排队系统性能分析与Markov控制过程,合肥:中国科学技术⼤学出版社,2004.期刊论⽂Yin, B. Q., Guo, D., Huang, J., Wu, X. M., Modeling and analysis for the P2P-based media delivery network, Mathematical and Computer Modelling (2011), doi:10.1016/j.mcm.2011.10.043. (SCI 收录, JCR II 区) Yin, B. Q., Lu, S., Guo, D., Analysis of Admission Control in P2P-Based Media Delivery Network Based on POMDP, International Journal of Innovative Computing, Information and Control, 2011, 7(7B): 4411-4422. (SCI收录, JCR II 区) Kang, Yu, Yin, Baoqun, Shang, Weike, Xi, Hongsheng, Performance sensitivity analysis and optimization for a class of countable semi-Markov decision processes, Proceedings of the World Congress on Intelligent Control and Automation (WCICA2011), June 21, 2011 - June 25, 2011, Taipei, Taiwan. (EI收录20113614311870) Li, Y. J., Yin, B. Q., Xi, H. S., Finding Optimal Memoryless Policies of POMDPs under the Expected Average Reward Criterion, European Journal of Operational Research, 2011, 211(2011): 556-567. (SCI 收录, JCR II 区) 江琦,奚宏⽣,殷保群,事件驱动的动态服务组合策略在线⾃适应优化,控制理论与应⽤,2011, 28(8): 1049-1055. (EI收录20114214431454) Jiang, Q., Xi, H. S., Yin, B. Q., Adaptive Optimization of Timeout Policy for Dynamic Power Management Based on Semi-Markov Control Processes, IET Control Theory and Applications, 2010, 4(10): 1945-1958. (SCI收录) Tang, L., Xi, H. S., Zhu, J., Yin, B. Q., Modeling and Optimization of M/G/1-Type Queueing Networks: An Efficient Sensitivity Analysis Approach, Mathematical Problems in Engineering, 2010, 2010: 1-20. (SCI收录) Shan Lu, Baoqun Yin, Dong Guo, Admission Control for P2P-Based Media Delivery Network, Proceedings of the 29th Chinese Control Conference, July 29-31, 2010, Beijing, China, 2010: 1494-1499. ( EI收录20105113504286) ⾦辉宇,康宇,殷保群,局部Lipschitz系统的采样控制,Proceedings of the 29th Chinese Control Conference, July 29-31, 2010, Beijing, China, 2010: 992-997. ( EI收录20105113504436) 江琦,奚宏⽣,殷保群,络新媒体服务系统事件驱动的动态服务组合,Proceedings of the 29th Chinese Control Conference, July 29-31, 2010, Beijing, China, 2010: 1121-1125. ( EI收录20105113504230) Dong Guo, Baoqun Yin, Shan Lu, Jing Huang, Jian Yang, A Novel Dynamic Model for Peer-to-Peer File Sharing Systems, ICCMS, 2010 Second International Conference on Computer Modeling and Simulation, 2010, 1: 418-422. ( EI收录20101812900175) Jing Huang, Baoqun Yin, Dong Guo, Shan Lu, Xumin Wu, An Evolution Model for P2P File-Sharing Networks, ICCMS, 2010 Second International Conference on Computer Modeling and Simulation, 2010, 2: 361-365. ( EI收录20101712882202) 巫旭敏,殷保群,黄静,郭东,流媒体服务系统中⼀种基于数据预取的缓存策略,电⼦与信息学报,2010,32(10): 2440-2445. (EI 收录20104513372577) 马军,郑烇,殷保群,基于CDN和P2P的分布式络存储系统,计算机应⽤与软件,2010,27(2):50-52. Bao, B. K., Xi, H. S., Yin, B. Q., Ling, Q., Two Time-Scale Gradient Approximation Algorithm for Adaptive Markov Reward Processes, International Journal of Innovative Computing, Information and Control, 2010, 6(2): 655-666. (SCI收录, JCR II 区) Jiang, Q., Xi, H. S., Yin, B. Q., Dynamic File Grouping for Load Balancing in Streaming Media Clustered Server Systems, International Journal of Control, Automation, and Systems, 2009, 7(4): 630-637. (SCI收录) 江琦,奚宏⽣,殷保群,动态电源管理超时策略与随机型策略的等效关系,计算机辅助设计与图形学学报,2009, 21(11): 1646-1651. (EI 收录20095012535449) 唐波,李衍杰,殷保群,连续时间部分可观Markov决策过程的策略梯度估计,控制理论与应⽤,2009,26(7):805-808. (EI 收录20093712302646) 芦珊,黄静,殷保群,基于POMDP的VOD接⼊控制建模与仿真,中国科学技术⼤学学报,2009,39(9):984-989. 李洪亮,殷保群,郑诠,⼀种基于负载均衡的数据部署算法,计算机仿真,2009,26(4):177-181. 鲍秉坤,殷保群,奚宏⽣,基于性能势的Markov控制过程双时间尺度仿真算法,系统仿真学报,2009,21(13):4114-4119. Jin Huiyu; Yin Baoqun; Ling Qiang; Kang Yu; Sampled-data Observer Design for Nonlinear Autonomous Systems, 2009 Chinese Control and Decision Conference, CCDC 2009, 2009: 1516-1520. ( EI收录20094712469527) ⾦辉宇,殷保群,⾮线性采样系统指数稳定的新条件,控制理论与应⽤,2009,26(8):821-826. (EI 收录20094512429319) Yin, B. Q., Li, Y. J., Zhou, Y. P., Xi, H. S., Performance Optimization of Semi-Markov Decision Processes with Discounted-Cost Criteria. European Journal of Control, 2008, 14(3): 213-222. (SCI收录) Li, Y. J., Yin, B. Q. and Xi, H. S., Partially Observable Markov Decision Processes and Performance Sensitivity Analysis. IEEE Trans. System, Man and cybernetics-Part B., 2008, 38(6): 1645-1651. (SCI收录, JCR II 区) Tang, B., Tan, X. B., Yin, B. Q. , Continuous-time hidden markov models in network simulation, 2008 IEEE International Symposium on Knowledge Acquisition and Modeling Workshop Proceedings, Wuhan, China, DEC 21-22, 2008: 667-670. (EI收录20092812179753) Bao, B. K., Yin, B. Q., Xi, H. S., Infinite-Horizon Policy-Gradient Estimation with Variable Discount Factor for Markov Decision Process. icicic,pp.584,2008 3rd International Conference on Innovative Computing Information and Control, 2008. ( EI收录************) Chenfeng Xu, Jian Yang, Hongsheng Xi, Qi Jiang, Baoqun Yin, Event-related optimization for a class of resource location with admission control, 2008. IJCNN 2008. (IEEE World Congress on Computational Intelligence). IEEE International Joint Conference on Neural Networks, 1-8 June 2008: 1092 – 1097. ( EI收录************)JinHuiyu;KangYu;YinBaoqun; Synchronization of nonlinear systems with stair-step signal, 2008. CCC 2008. 27th Chinese Control Conference,16-18 July 2008: 459 – 463. ( EI收录************)JiangQi;XiHongsheng;YinBaoqun;XuChenfeng;Anevent-drivendynamicload balancing strategy for streaming media clustered server systems, 2008. CCC 2008. 27th Chinese Control Conference, 16-18 July 2008: 678 – 682. ( EI收录************)⾦辉宇,殷保群,唐波,⾮线性采样观测器的误差分析,中国科学技术⼤学学报,2008, 38(10): 1226-1231. 黄静,殷保群,李俊,基于观测的POMDP优化算法及其仿真,信息与控制,2008, 37(3): 346-351. 马军,殷保群,基于POMDP模型的机器⼈⾏动的仿真优化,系统仿真学报,2008, 20(21): 5903-5906. (EI 收录************)江琦,奚宏⽣,殷保群,动态电源管理超时策略⾃适应优化算法,控制与决策,2008, 23(4): 372-377. (EI 收录************)徐陈锋,奚宏⽣,江琦,殷保群,⼀类分层⾮结构化P2P系统的随机切换模型,控制与决策,2008, 23(3): 263-266. (EI 收录************)徐陈锋,奚宏⽣,殷保群,⼀类混合资源定位服务的优化模型,微计算机应⽤,2008,29(9):6-11. 郭东,郑烇,殷保群,王嵩,基于P2P媒体内容分发络中分布式节点的设计与实现,电信科学,2008,24(8): 45-49. Tang, H., Yin, B. Q., Xi, H. S., Error bounds of optimization algorithms for semi-Markov decision processes. International Journal of Systems Science, 2007, 38(9): 725-736. (SCI收录) 徐陈锋,奚宏⽣,江琦,殷保群,⼀类分层⾮结构化P2P系统的随机优化,系统科学与数学,2007, 27(3): 412-421. 蒋兆春,殷保群,李俊,基于耦合技术计算Markov链性能势的仿真算法,系统仿真学报,2007, 19(15): 3398-3401. (EI收录************)庞训磊,殷保群,奚宏⽣,⼀种使⽤TCP/ IP 协议实现⽆线传感器络互连的新型设计,传感技术学报,2007, 20(6): 1386-1390. Niu, L. M., Tan, X. B., Yin, B. Q. , Estimation of system power consumption on mobile computing devices, 2007. International Conference on Computational Intelligence and Security, Harbin, China, DEC 15-19, 2007: 1058-1061. (EI收录************)Jiang,Q.,Xi, H. S., Yin, B. Q., Dynamic file grouping for load balancing in streaming media clustered server systems. Proceedings of the 2007 International Conference on Information Acquisition, ICIA, Jeju City, South Korea, 2007:498-503. (EI收录************)徐陈锋, 奚宏⽣, 江琦, 殷保群,⼀类分层⾮结构化P2P系统的随机优化,第2xx届中国控制会议论⽂集,2007: 693-696. (EI收录************)Jiang,Q.,Xi,H.S.,Yin,B.Q.,OptimizationofSemi-MarkovSwitchingState-spaceControl Processes for Network Communication Systems. 第2xx届中国控制会议论⽂集,2007: 707-711. (EI收录************) Jiang, Q., Xi, H. S., Yin, B. Q., Adaptive Optimization of Time-out Policy for Dynamic Power Management Based on SMCP. Proc. of the 2007 IEEE Multi-conference on Systems and Control, Singapore, 2007: 319-324. (EI收录************)Jin,H. Y., Yin, B. Q., New Consistency Condition for Exponential Stabilization of Smapled-Data Nonlinear Systems. 第2xx届中国控制会议论⽂集,2007: 84-87. (EI收录************)江琦,奚宏⽣,殷保群,⽆线多媒体通信适应带宽配置在线优化算法,软件学报, 2007, 18(6): 1491-1500. (EI收录************)Ou,Q.,Jin,Y.D.,Zhou,T.,Wang,B.H.,Yin,B.Q.,Power-law strength-degree correlation from resource-allocation dynamics on weighted networks, Physical Review E, 2007, 75(2): 021102 (SCI收录) Yin, B. Q., Dai, G. P., Li, Y. J., Xi, H. S., Sensitivity analysis and estimates of the performance for M/G/1 queueing systems, Performance Evaluation, 2007, 64(4): 347-356. (SCI收录) 江琦,奚宏⽣,殷保群,动态电源管理的随机切换模型与在线优化,⾃动化学报,2007, 33(1): 66-71. (EI收录************)Zhang,D.L.,Yin,B.Q.,Xi,H.S.,Astate aggregation approach to singularly perturbed Markov reward processes. International Journal of Intelligent Technology, 2006, 2(4): 230-239. 欧晴,殷保群,奚宏⽣,基于动态平衡流的络赋权,中国科学技术⼤学学报,2006, 36(11): 1196-1201.殷保群,李衍杰,周亚平,奚宏⽣,可数半Markov控制过程折扣代价性能优化,控制与决策,2006, 21(8): 933-936. (EI收录************)江琦,奚宏⽣,殷保群,动态电源管理的随机切换模型与策略优化,计算机辅助设计与图形学学报,2006, 18(5): 680-686. (EI收录***********)代桂平,殷保群,李衍杰,奚宏⽣,半Markov控制过程基于性能势仿真的并⾏优化算法,中国科学技术⼤学学报,2006, 36(2): 183-186. 殷保群,李衍杰,唐昊,代桂平,奚宏⽣,半Markov决策过程折扣模型与平均模型之间的关系,控制理论与应⽤,2006, 23(1): 65-68. (EI收录***********)江琦,奚宏⽣,殷保群,半Markov控制过程在线⾃适应优化算法,第2xx届中国控制会议论⽂集,2006: 1066-1071. (ISTP收录BFQ63) Dai, G. P., Yin, B. Q., Li, Y. J., Xi, H. S., Performance Optimization Algorithms based on potential for Semi-Markov Control Processes. International Journal of Control, 2005, 78(11): 801-812. (SCI收录) Zhang, D. L., Xi, H. S., Yin, B. Q., Simulation-based optimization of singularly perturbed Markov reward processes with states aggregation. Lecture Notes in Computer Science, 2005, 3645: 129-138. (SCI 收录) Tang, H., Xi, H. S., Yin, B. Q., The optimal robust control policy for uncertain semi-Markov control processes. International Journal of System Science, 2005, 36(13): 791-800. (SCI收录) 张虎,殷保群,代桂平,奚宏⽣,G/M/1排队系统的性能灵敏度分析与仿真,系统仿真学报,2005, 17(5): 1084-1086. (EI收录***********)陈波,周亚平,殷保群,奚宏⽣,隐马⽒模型中的标量估计,系统⼯程与电⼦技术,2005, 27(6): 1083-1086. (EI收录***********)代桂平,殷保群,李衍杰,周亚平,奚宏⽣,半Markov控制过程在平均准则下的优化算法,中国科学技术⼤学学报,2005, 35(2): 202-207. 殷保群,李衍杰,奚宏⽣,周亚平,⼀类可数Markov控制过程的平稳策略,控制理论与应⽤,2005, 22(1): 43-46. (EI收录***********)Li,Y.J.,Yin,B.Q.,Xi,H.S.,Thepolicygradientestimationofcontinuous-timeHiddenMarkovDecision Processes. Proc. of IEEE ICIA, Hong Kong, 2005. (EI收录************)Sensitivity analysis and estimates of the performance for M/G/1 queueing systems, To Appear in Performance Evaluation, 2006.Performance optimization algorithms based on potential for semi-Markov control processes. International Journal of Control, Vol.78, No.11, 2005.The optimal robust control policy for uncertain semi-Markov control processes. International Journal of System Science, Vol.36, No.13, 2005.A state aggregation approach to singularly perturbed Markov reward processes. International Journal of Intelligent Technology, Vol.2, No.4, 2005.Simulation optimization algorithms for CTMDP based on randomized stationary policies, Acta Automatics Sinica, Vol. 30, No. 2, 2004.Performance optimization of continuous-time Markov control processes based on performance potentials, International Journal of System Science, Vol.34, No.1, 2003.Optimal Policies for a Continuous Time MCP with Compact Action set, Acta Automatics Sinica, Vol. 29, No. 2, 2003. Relations between Performance Potential and Infinitesimal Realization Factor in Closed Queueing Networks, Appl. Math. J. Chinese Univ. Ser. B, Vol. 17, No. 4, 2002.Sensitivity Analysis of Performance in Queueing Systems with Phase-Type Service Distribution, OR Transactions, Vol.4, No.4, 2000.Sensitivity Formulas of Performance in Two-Server Cyclic Queueing Networks with Phase-Type Distributed Service Times, International Transaction in Operational Research, Vol.6, No.6, 1999.Simulation-based optimization of singularly perturbed Markov reward processes with states aggregation. Lecture Notes in Computer Science, 2005.Markov decision problems with unbounded transition rates under discounted-cost performance criteria. Proceedings of WCICA, Vol.1, Hangzhou, China, 2004.排队系统性能分析与Markov控制过程,合肥:中国科学技术⼤学出版社,2004.可数半Markov控制过程折扣代价性能优化. 控制与决策,Vol.21, No.8, 2006.动态电源管理的随机切换模型与策略优化. 计算机辅助设计与图形学学报,Vol.18, No.5, 2006.半Markov决策过程折扣模型与平均模型之间的关系.控制理论与应⽤,Vol.23, No.1, 2006.⼀类可数Markov控制过程的平稳策略. 控制理论与应⽤,Vol.22, No.1, 2005.G/M/1排队系统的性能灵敏度分析与仿真.系统仿真学报,Vol.17, No.5, 2005.M/G/1排队系统的性能优化与算法,系统仿真学报,Vol.16, No.8, 2004.半Markov过程基于性能势的灵敏度分析和性能优化. 控制理论与应⽤,Vol.21, No.6, 2004.半Markov控制过程在折扣代价准则下的平稳策略. 控制与决策,Vol.19, No.6, 2004.Markov控制过程在紧致⾏动集上的迭代优化算法. 控制与决策,Vol.18, No.3, 2003.闭Jackson络的优化中减少仿真次数的算法研究,系统仿真学报,Vol.15, No.3, 2003.M/G/1排队系统的性能灵敏度估计与仿真,系统仿真学报,Vol.15, No.7, 2003.Markov控制过程基于性能势仿真的并⾏优化,系统仿真学报,Vol.15, No.11, 2003.Markov控制过程基于性能势的平均代价策略. ⾃动化学报,Vol.28, No.6, 2002.⼀类受控闭排队络基于性能势的性⽅程.控制理论与应⽤,Vol.19, No.4, 2002.Markov控制过程基于单个样本轨道的在线优化算法.控制理论与应⽤,Vol.19, No.6, 2002.闭排队络当性能函数与参数相关时的性能灵敏度分析,控制理论与应⽤,Vol.19, No.2, 2002.M/G/1 排队系统的性能灵敏度分析,⾼校应⽤数学学报,Vol.16, No.3, 2001.连续时间Markov决策过程在呼叫接⼊控制中的应⽤,控制与决策,Vol.19, 2001.具有不确定噪声的连续时间⼴义系统确保估计性能的鲁棒Kalman滤波器,控制理论与应⽤,Vol.18, No.5, 2001.状态相关闭排队络中的性能指标灵敏度公式,控制理论与应⽤,Vol.16, No.2, 1999.科研项⽬半Markov控制过程基于性能势的优化理论和并⾏算法,2003.1-2005.12,国家⾃然科学基⾦,60274012隐Markov过程的性能灵敏度分析与优化,2006.1-2008.12,国家⾃然科学基⾦, 60574065部分可观Markov系统的性能优化,2005.1-2006.12,安徽省⾃然科学基⾦, 050420301宽带信息运营⽀撑环境及接⼊系统的研制――⼦课题: 流媒体服务器研究及实现, 2005.1-2006.12, 国家863计划,2005AA103320离散复杂系统的控制与优化研究,2006.9-2008.8,中国科学院⾃动化研究所中国科学技术⼤学智能科学与技术联合实验室⾃主研究课题基⾦络新媒体服务系统的建模及其动⼒学⾏为分析研究,2012.01-2015.12,国家⾃然科学基⾦;⾯向服务任务的快速机器视觉与智能伺服控制,2010.01-2013.12,国家⾃然科学基⾦重点项⽬;新⼀代业务运⾏管控协同⽀撑环境的开发,2008.07-2011.06,国家863计划;多点协作的流媒体服务器集群系统及其性能优化,2006.12-2008.12,国家863计划;获奖情况第xx届何潘清漪优秀论⽂奖联系信息办公室地址:电⼆楼223 实验室地址:电⼆楼227 办公室电话:************。
外文文献阅读笔记

A dynamic replica management strategy in data grid--- Journal of Network and Computer Applications expired, propose, indicate, profitable, boost, claim, present, congestion, deficiency, moderately, metric, turnaround, assume,specify, display, illustrate, issue,outperform over .... about 37%, outperform ....lead todraw one's attentionaccordinglyhave great influence ontake into accountin terms ofplay major role inin comparison with, in comparison toi.e.=(拉丁)id estReplication is a technique used in data grid to improve fault tolerance and to reduce the bandwidth consumption.Managing this huge amount of data in a centralized way is ineffective due to extensive access latency and load on the central server.Data Grids aggregate a collection of distributed resources placed in different parts of the world to enable users to share data and resources.Data replication is an important technique to manage large data in a distributed manner.There are three key issues in all the data replication algorithms which are replica placement, replica management and replica selection.Meanwhile, even though the memory and storage size of new computers are ever increasing, they are still not keeping up with the request of storing large number of data.each node along its path to the requester.Enhanced Dynamic Hierarchical Replication and Weighted SchedulingStrategy in Data Grid--- Journal of Parallel and Distributed Computing duration, manually, appropriate, critical, therefore, hybrid, essential, respectively, candidate, typically, advantage, significantly, thereby, adopt, demonstrate, superiority, scenario, empirically, feasibility, duplicate, insufficient, interpret, beneficial, obviously, whilst, idle, considerably, notably, consequently, apparently,in a wise manneraccording tofrom a size point of viewdepend oncarry outis comprised ofalong withas well asto the best of our knowledgeBest replica placement plays an important role for obtaining maximum benefit from replication as well as reducing storage cost and mean job execution time.Data replication is a key optimization technique for reducing access latency and managing large data by storing data in a wise manner.Effective scheduling in the Grid can reduce the amount of data transferred among nodes by submitting a job to a node where most of the requested data files are available.Effective scheduling of jobs is necessary in such a system to use available resources such as computational, storage and network efficiently.Storing replicas close to the users or grid computation nodes improves response time, fault tolerance and decreases bandwidth consumption.The files of Grid environments that can be changed by Grid users might bring an important problem of maintaining data consistency among the various replicas distributed in different machines.So the sum of them along with the proper weight (w1,w2) for each factor yields the combined cost (CCi,j) of executing job i in site j.A classification of file placement and replication methods on grids--- Future Generation Computer Systems encounter, slightly, simplistic, clairvoyance, deploy, stringent, concerning, properly, appropriately, overhead, motivate, substantial, constantly, monitor, highlight, distinguish, omit, salient, entirely, criteria, conduct, preferably, alleviate, error-prone, conversely,for instanceaccount forhave serious impact ona.k.a.= also known asconsist inaim atin the hands offor .... purposesw.r.t.=with regard toconcentrate onfor the sake ofbe out of the scope of ...striping files in blocksProduction approaches are slightly different than works evaluated in simulation or in controlled conditions....File replication is a common solution to improve the reliability and performance of data transfers.Many file management strategies were proposed but none was adopted in large-scale production infrastructures.Clairvoyant models assume that resource characteristics of interest are entirely known to the file placement algorithm.Cooperation between data placement and job scheduling can improve the overall transfer time and have a significant impact on the application makespan as shown in.We conclude that replication policies should rely on a-priori information about file accesses, such as file type or workflow relation.Dynamic replica placement and selection strategies in data grids----Acomprehensive survey--- Journal of Parallel and Distributed Computing merit, demerit, tedious, namely, whereas, various, literature, facilitate, suitable, comparative, optimum, retrieve, rapid, evacuate, invoke, identical, prohibitive, drawback, periodically,with respect toin particularin generalas the name indicatesfar apartconsist of , consist inData replication techniques are used in data grid to reduce makespan, storage consumption, access latency and network bandwidth.Data replication enhances data availability and thereby increases the system reliability.Managing dynamic architecture of the grid, decision making of replica placement, storage space, cost of replication and selection are some of the issues that impact the performance of the grid.Benefits of data replication strategies include availability, reliability, scalability, adaptability and improved performance.As the name indicates, in dynamic grid, nodes can join and leave the grid anytime.Any replica placement and selection strategy tries to improve one or more of the following parameters: makespan, quality assurance, file missing rate, byte missing rate, communication cost, response time, bandwidth consumption, access latency, load balancing, maintenance cost, job execution time, fault tolerance and strategic replica placement.Identifying Dynamic Replication Strategies for a High-PerformanceData Grid--- Grid Computing 2001 identify, comparative, alternative, preliminary, envision, hierarchical, tier, above-mentioned, interpret, exhibit, defer, methodology, pending, scale, solely, churn outlarge amounts ofpose new problemsdenoted asadapt toconcentrate on doingconduct experimentssend it offin the order of petabytesas of nowDynamic replication can be used to reduce bandwidth consumption and access latency in high performance “data grids” where users require remote access to large files.A data grid connects a collection of geographically distributed computer and storage resources that may be located in different parts of a country or even in different countries, and enables users to share data and other resources.The main aims of using replication are to reduce access latency and bandwidth consumption. Replication can also help in load balancing and can improve reliability by creating multiple copies of the same data.Group-Based Management of Distributed File Caches--- Distributed Computing Systems, 2002 mechanism, exploit, inherent, detrimental, preempt, incur, mask, fetch, likelihood, overlapping, subtle,in spite ofcontend withfar enough in advancetake sth for granted(be) superior toDynamic file grouping is an effective mechanism for exploiting the predictability of file access patterns and improving the caching performance of distributed file systems.With our grouping mechanism we establish relationships by observing file access behavior, without relying on inference from file location or content.We group files to reduce access latency. By fetching groups of files, instead of individual files, we increase cache hit rates when groups contain files that are likely to be accessed together.Further experimentation against the same workloads demonstrated that recency was a better estimator of per-file succession likelihood than frequency counts.Job scheduling and data replication on data grids--- Future Generation Computer Systems throttle, hierarchical, authorized, indicate, dispatch, assign, exhaustive, revenue, aggregate, trade-off, mechanism, kaleidoscopic, approximately, plentiful, inexact, anticipated, mimic, depict, exhaust, demonstrate, superiority, namely, consume,to address this problemdata resides on the nodesa variety ofaim toin contrast tofor the sake ofby means ofplay an important role inhave no distinction betweenin terms ofon the contrarywith respect toand so forthby virtue ofreferring back toA cluster represents an organization unit which is a group of sites that are geographically close.Network bandwidth between sites within a cluster will be larger than across clusters.Scheduling jobs to suitable grid sites is necessary because data movement between different grid sites is time consuming.If a job is scheduled to a site where the required data are present, the job can process data in this site without any transmission delay for getting data from a remote site.RADPA: Reliability-aware Data Placement Algorithm for large-scale network storage systems--- High Performance Computing and Communications, 2009 ever-going, oblivious, exponentially, confront,as a consequencethat is to saysubject to the constraintit doesn't make sense to doMost of the replica data placement algorithms concern about the following two objectives, fairness and adaptability.In large-scale network storage systems, the reliabilities of devices are different relevant to device manufacturers and types.It can fairly distributed data among devices and reorganize near-minimum amount of data to preserve the balanced distribution with the changes of devices.Partitioning Functions for Stateful Data Parallelism in Stream Processing--- The VLDB Journal skewed, desirable, associated, exhibit, superior, accordingly, necessitate, prominent, tractable, exploit, effectively, efficiently, transparent, elastically, amenable, conflicting, concretely, exemplify, depict,a deluge ofin the form of continuous streamslarge volumes ofnecessitate doingas a examplefor instancein this scenarioAccordingly, there is an increasing need to gather and analyze data streams in near real-time to extract insights and detect emerging patterns and outliers.The increased affordability of distributed and parallel computing, thanks to advances in cloud computing and multi-core chip design, has made this problem tractable.However, in the presence of skew in the distribution of the partitioning key, the balance properties cannot be maintained by the consistent hash.MORM: A Multi-objective Optimized Replication Management strategyfor cloud storage cluster--- Journal of Systems Architecture issue, achieve, latency, entail, consumption, article, propose, candidate, conclusively, demonstrate, outperform, nowadays, huge, currently, crucial, significantly, adopt, observe, collectively, previously, holistic, thus, tradeoff, primary, therefore, aforementioned, capture, layout, remainder, formulate, present, enormous, drawback, infrastructure, chunk, nonetheless, moreover, duration, substantially, wherein, overall, collision, shortcoming, affect, further, address, motivate, explicitly, suppose, assume, entire, invariably, compromise, inherently, pursue, handle, denote, utilize, constraint, accordingly, infeasible, violate, respectively, guarantee, satisfaction, indicate, hence, worst-case, synthetic, assess, rarely, throughout, diversity, preference, illustrate, imply, additionally, is an important issuea series ofin terms ofin a distributed mannerin order toby defaultbe referred to astake a holistic view ofconflict witha variety ofis highly in demandgiven the aforementioned issue and trendtake into accountyield close toas followstake into considerationwith respect toa research hot spotcall foraccording todepend upon/onmeet ... requirementfocus onis sensitive tois composed ofconsist offrom the latency minimization perspectivea certain number ofis defined as (follows) / can be expressed as (follows) /can be calculated/computed by / is given by the followingat handcorresponding tohas nothing to do within addition toas depicted in Fig.1et al.The volume of data is measured in terabytes and some time in petabytes in many fields.Data replication allows speeding up data access, reducing access latency and increasing data availability.How many suitable replicas of each data should be created in the cloud to meet a reasonable system requirement is an important issue for further research.Where should these replicas be placed to meet the system task fast execution rate and load balancing requirements is another important issue to be thoroughly investigated.As the system maintenance cost will significantly increase with the number of replicas increasing, keeping too many or fixed replicas are not a good choice.Where should these replicas be placed to meet the system task fast execution rate and load balancing requirements is another important issue to be thoroughly investigated.We build up five objectives for optimization which provides us with the advantage that we can search for solutions that yield close to optimal values for these objectives.The shortcoming of them is that they only consider a restricted set of parameters affecting the replication decision. Further, they only focus on the improvement of the system performance and they do not address the energy efficiency issue in data centers.Data node load variance is the standard deviation of data node load of all data nodes in the cloud storage cluster which can be used to represent the degree of load balancing of the system.The advantage of using simulation is that we can easily vary parameters to understand their individual impact on system performance.Throughout the simulation, we assumed "write-once, read-many" data and did not include the consistency or write and update propagations costs in the study.Distributed replica placement algorithms for correlated data--- The Journal of Supercomputing yield, potential, congestion, prolonged, malicious, overhead, conventional, present, propose, numerous, tackle, pervasive, valid, utilize,develop a .... algorithmsuffer fromin a distributed mannerbe denoted as Mconverge toso on and so forthWith the advances in Internet technologies, applications are all moving toward serving widely distributed users.Replication techniques have been commonly used to minimize the communication latency by bringing the data close to the clients and improve data availability.Thus, data needs to be carefully placed to avoid unnecessary overhead.These correlations have significant impact on data access patterns.For structured data, data correlated due to the structural relations may be frequently accessed together.Assume that data objects can be clustered into different classes due to user accesses, and whenever a client issues an access request, it will only access data in a single class.One challenge for using centralized replica placement algorithms in a widely distributed system is that a server site has to know the (logical) network topology and the resident set of all structured data sets to make replication decisions.We assume that the data objects accessed by most of the transactions follow certain patterns, which will be stable for some time periods.Locality-aware allocation of multi-dimensional correlated files on thecloud platform--- Distributed and Parallel Databases enormous, retrieve, prevailing, commonly, correlated, booming, massive, exploit, crucial, fundamental, heuristic, deterministic, duplication, compromised, brute-force, sacrifice, sophisticated, investigate, abundant, notation, as a matter of factin various wayswith .... taken into considerationplay a vital role init turns out thatin terms ofvice versaa.k.a.= also known asThe effective management of enormous data volumes on the Cloud platform has attracted devoting research efforts.Currently, most prevailing Cloud file systems allocate data following the principles of fault tolerance and availability, while inter-file correlations, i.e. files correlated with each other, are often neglected.There is a trade-off between data locality and the scale of job parallelism.Although distributing data randomly is expected to achieve the best parallelism, however, such a method may lead to degraded user experiences for introducing extra costs on large volume of remote accesses, especially for many applications that are featured with data locality, e.g., context-aware search, subspace oriented aggregation queries, and etc.However, there must be several application-dependent hot subspaces, under which files are frequently being processed.The problem is how to find a compromised partition solution to well serve the file correlations of different feature subspaces as much as possible.If too many files are grouped together, the imbalance cost would raise and degrade the scale of job parallelism;if files are partitioned into too many small groups, data copying traffic across storage nodes would increase.Instead, our solution is to start from a sub-optimal solution and employ some heuristics to derive a near optimal partition with as less cost as possible.By allocating correlated files together, significant I/O savings can be achieved on reducing the huge cost of random data access over the entire distributed storage network.Big Data Analytics framework for Peer-to-Peer Botnet detection usingRandom Forests--- Information Sciences magnitude, accommodate, upsurge, issue, hence, propose, devise, thereby, has struggled toit was revealed thatis expanding exponentiallytake advantage ofin the pastin the realm ofover the last few yearsthere has also been research onin a scalable manneras per the current knowledge of the authorson the contraryin naturereport their work onNetwork traffic monitoring and analysis-related research has struggled to scale for massive amounts of data in real time.In this paper the authors build up on the progress of open source tools like Hadoop, Hive and Mahout to provide a scalable implementation of quasi-real-time intrusion detection system.As per the current knowledge of the authors, the area of network security analytics severely lacks prior research in addressing the issue of Big Data.Improving pattern recognition accuracy of partial discharges by newdata preprocessing methods--- Electric Power Systems Research stochastic, oscillation, literature, utilize, conventional, derive, distinctive, discriminative, artificial, significantly, considerably, furthermore, likewise, Additionally, reasonable, symbolize, eventually, scenario, consequently, appropriate, momentous, conduct, depict, waveshape, deficiency, nonetheless, derived, respectively, suffer from, notably,be taken into considerationby means ofto our best knowledgein accordance withwith respect toas mentionedwith regard tobe equal withlead tofor instancein additionin comparison toThus, analyzing the huge amount of data is not feasible unless data pre-processing is manipulated.As mentioned, PD is completely a random and nonlinear phenomenon. Since ANNs are the best classifiers to model such nonlinear systems, PD patterns can be recognized suitably by ANNs.In other words, when classifier is trained after initial sophistications based on the PRPD patterns extracted from some objects including artificial defects, it can be efficiently used in practical fields to identify the exactly same PD sources by new test data without any iterative process.In pulse shape characterization, some signal processing methods such as Wavelet or Fourier transforms are usually used to extract some features from PD waveshape. These methods are affected by noise and so it is necessary to incorporate some de-noising methods into the pattern recognition process.PD identification is usually performed using PRPD recognition which is not influenced by changing the experimental set up.Partial Discharge Pattern Recognition of Cast Resin CurrentTransformers Using Radial Basis Function Neural Network--- Journal of Electrical Engineering & Technology propose, novel, vital, demonstrate, conduct, significant,This paper proposes a novel pattern recognition approach based on the radial basis function (RBF) neural network for identifying insulation defects of high-voltage electrical apparatus arising from partial discharge (PD).PD measurement and pattern recognition are important tools for improving the reliability of the high-voltage insulation system.。
印度大停电官方调查报告(英文原版)

REPORT OF THE ENQUIRY COMMITTEEONGRID DISTURBANCEIN NORTHERN REGIONON 30th July 2012ANDIN NORTHERN, EASTERN & NORTH-EASTERN REGIONON 31st JUL Y 201216th AUGUST 2012NEW DELHIACKNOWLEDGEMENTThe committee gratefully acknowledges the efforts put in by all assisting members to the enquiry committee namely :a. Shri R. N. Nayak, CMD, POWERGRIDb. Shri S. K. Soonee, CEO, POSOCOc. Shri Balvinder Singh, IPS Retired.The Committee places on record the efforts of Shri K. K. Agrawal, Member (GO&D), CEA for overall coordination in the whole exercise of grid disturbance enquiry.The committee also gratefully acknowledges and places on record its appreciation towards the following members of various sub-groups, for their efforts of in-depth analysis and compilation of grid disturbance analysis:(i) Shri Manjit Singh, Member (Thermal), CEA(ii) Shri P.K. Pahwa, Member Secretary, NRPC,(iii) Dr. Anil Kulkarni, IIT-B, Mumbai,(iv) Shri Ajit Singh, Ex-Addl. Secretary, Cabinet Secretariat(v) Shri R.K. Verma, Chief Engineer I/c (DP&D), CEA(vi) Shri Dinesh Chandra, Chief Engineer (I/C), GM Div., CEA(vii) Shri Ajay Talegaonkar, SE (Operation), NRPC(viii) Shri S. Satyanarayan, SE (Operation), WRPC,(ix) Shri D. K. Srivastava, Director, GM Div., CEAThe committee expresses its appreciation of the cooperation extended by POWERGRID and POSOCO, for making the data available from various Sub-Stations/RLDCs.Last but not the least Committee also acknowledges the efforts of all those persons who gave their valuable support directly or indirectly.CONTENTS Page No.Executive Summary iv-ixChapter 1: Introduction 1-4Chapter 2: Overview of the regional grids 5-7Chapter 3: Analysis of the grid disturbance on 30th July 2012 8-20Chapter 4: Analysis of grid disturbance on 31st July 2012 21-32Chapter 5: Factors contributing to grid disturbances on 30th and 31st July 2012 33-39Chapter 6: Review of islanding schemes 40-44Chapter7: Review of restoration of generation 45-58Chapter 8: Cyber security related aspects 59-62Chapter 9: Recommendations of the Committee 63-70Supplementary V olume:A separate volume containing the relevant DR outputs during the grid disturbances on 30th and 31st July, 2012.GLOSSARY:ABT: Availability Based TariffATC: Available Transfer CapacityAUFLS: Automatic Under Frequency Load SheddingBLU: Boiler Light UpBTPS: Badarpur Thermal Power StationCB: Circuit BreakerCEA: Central Electricity AuthorityCERC: Central Electricity Regulatory CommissionCESC: Calcutta Electric Supply CompanyCTU: Central Transmission UtilityD/C: Double CircuitDMRC: Delhi Metro Rail CorporationDR: Disturbance Recorderdf/dt: Rate of change of frequency with timeEL: Event LoggerER: Eastern RegionFGMO: Free Governor Mode of OperationFSC: Fixed Series CompensationGPS: Gas Power StationGT: Gas TurbineHVDC: High V oltage Direct CurrentMERC: Maharashtra Electricity Regulatory CommissionNAPS: Narora Atomic Power StationNER: North-Eastern RegionNR: Northern RegionPMU: Phasor Measurement UnitPLCC: Power Line Carrier CommunicationPOSOCO: Power System Operation Corporation Ltd.POWERGRID Powergrid Corporation of India LtdPPA: Power Purchase AgreementPSS: Power System StabilizerRAPP: Rajasthan Atomic Power PlantRPC: Regional Power CommitteeRLDC: Regional Load Despatch CentreSCADA: Supervisory Control and Data Acquisition SystemSIL: Surge Impedance LoadingSR: Southern RegionSTOA: Short Term Open AccessSVC: Static VAR CompensatorTTC: Total Transfer CapabilityTCSC: Thyristor Controlled Series CompensationUI: Unscheduled Interchange (under ABT)V AR: Volt Ampere ReactiveWAFMS: Wide Area Frequency Measurement SystemWR: Western RegionEXECUTIVE SUMMARYThere was a major grid disturbance in Northern Region at 02.33 hrs on 30-07-2012. Northern Regional Grid load was about 36,000 MW at the time of disturbance. Subsequently, there was another grid disturbance at 13.00 hrs on 31-07-2012 resulting in collapse of Northern, Eastern and North-Eastern regional grids. The total load of about 48,000 MW was affected in this black out. On both the days, few pockets survived from black out. Ministry of Power constituted an Enquiry Committee, to analyse the causes of these disturbances and to suggest measures to avoid recurrence of such disturbance in future.The Committee analysed the output of Disturbance Recorders (DR), Event loggers (EL), PMUs, W AFMS, SCADA data and reports submitted by various SLDCs , RLDCs /NLDC, POWERGRID and generation utilities to arrive at the sequence of events leading to the blackouts on 30th July, 2012 and 31st July 2012. The Committee also interacted with POWERGRID and POSOCO on various aspects of these grid disturbances. Some teams also made field visits to sub-stations, generating stations, NRLDC, NLDC, UPSLDC and Haryana SLDC.The Committee is of the opinion that no single factor was responsible for grid disturbances on 30th and 31st July 2012. After careful analysis of these grid disturbances, the Committee has identified several factors, which led to the collapse of the power systems on both the days, as given below:Factors that led to the initiation of the Grid Disturbance on 30th July, 2012a. Weak Inter-regional Corridors due to multiple outages: The system was weakened by multiple outages of transmission lines in the WR-NR interface. Effectively, 400 kV Bina-Gwalior-Agra (one circuit) was the only main AC circuit available between WR-NR interface prior to the grid disturbance.b. High Loading on 400 kV Bina-Gwalior-Agra link: The overdrawal by some of the NR utilities, utilizing Unscheduled Interchange (UI), contributed to high loading on this tie line.c. Inadequate response by SLDCs to the instructions of RLDCs to reduce overdrawal by the NR utilities and underdrawal/excess generation by the WR utilities.d. Loss of 400 kV Bina-Gwalior link: Since the interregional interface was very weak, tripping of 400 kV Bina-Gwalior line on zone-3 protection of distance relay caused the NR system to separate from the WR. This happened due to load encroachment (high loading of line resulting in high line current and low bus voltage). However, there was no fault observed in the system.Factors that led to the initiation of the Grid Disturbance on 31st July, 2012(i) Weak Inter-regional Corridors due to multiple outages: The system was weakened by multiple outages of transmission lines in the NR-WR interface and the ER network near the ER-WR interface. On this day also, effectively 400 kV Bina-Gwalior-Agra (one circuit) was the only main circuit available between WR-NR.(ii) High Loading on 400 kV Bina-Gwalior-Agra link: The overdrwal by NR utilities, utilizing Unscheduled Interchange (UI), contributed to high loading on this tie line. Although realpower flow in this line was relatively lower than on 30th July, 2012, the reactive power flow in the line was higher, resulting in lower voltage at Bina end.(iii) Inadequate Response by SLDCs to RLDCs‟ instructions on this day also to reduce overdrawl by the NR utilities and underdrawal by the WR utilities.(iv) Loss of 400 kV Bina-Gwalior link: Similar to the initiation of the disturbance on 30th July, 2012, tripping of 400 kV Bina-Gwalior line on zone-3 protection of distance relay, due to load encroachment, caused the NR system to separate from the WR system. On this day also the DR records do not show occurrence of any fault in the system.Brief Sequence of Events leading to the Grid Collapse on 30th and 31st July 2012(i) On 30th July, 2012, after NR got separated from WR due to tripping of 400 kV Bina-Gwalior line, the NR loads were met through WR-ER-NR route, which caused power swing in the system. Since the center of swing was in the NR-ER interface, the corresponding tie lines tripped, isolating the NR system from the rest of the NEW grid system. The NR grid system collapsed due to under frequency and further power swing within the region.(ii) On 31st July, 2012, after NR got separated from the WR due to tripping of 400 kV Bina-Gwalior line, the NR loads were met through WR-ER-NR route, which caused power swing in the system. On this day the center of swing was in the ER, near ER-WR interface, and, hence, after tripping of lines in the ER itself, a small part of ER (Ranchi and Rourkela), along with WR, got isolated from the rest of the NEW grid. This caused power swing in the NR-ER interface and resulted in further separation of the NR from the ER+NER system. Subsequently, all the three grids collapsed due to multiple tripping attributed to the internal power swings, under frequency and overvoltage at different places.(iii) The WR system, however, survived due to tripping of few generators in this region on high frequency on both the days.(iv)The Southern Region (SR), which was getting power from ER and WR, also survived on 31st July, 2012 with part loads remained fed from the WR and the operation of few defense mechanism, such as AUFLS and HVDC power ramping.(v) On both the days, no evidence of any cyber attack has been found by the Committee.Measures that could have saved the system from collapse:In an emergency system operating condition, such as on 30th and 31st July 2012, even some of the corrective measures out of the list given below might have saved the system from the collapse.(i) Better coordinated planning of outages of state and regional networks, specifically under depleted condition of the inter-regional power transfer corridors.(ii) Mandatory activation of primary frequency response of Governors i.e. the generator‟s automatic response to adjust its output with variation in the frequency.(iii) Under-frequency and df/dt based load shedding relief in the uti lities‟ networks.(iv) Dynamic security assessment and faster state estimation of the system at load despatch centers for better visualization and planning of the corrective actions.(v) Adequate reactive power compensation, specifically Dynamic Compensation.(vi) Better regulation to limit overdrawal/underdrawl under UI mechanism, specifically under insecure operation of the system.(vii) Measures to avoid mal-operation of protective relays, such as the operation of distance protection under the load encroachment on both the days.(viii) Deployment of adequate synchrophasor based Wide Area Monitoring System and System Protection Scheme.Restoration of the systemThe Committee observed that on both the days unduly long time was taken by some of the generating units in starting the units after start up power was made available.Recommendations of the CommitteeDetailed recommendations of the committee are given in the main report, which are summarized below.i) An extensive review and audit of the Protection Systems should be carried out to avoid their undesirable operation.ii) Frequency Control through Generation reserves/Ancillary services should be adopted, as presently employed UI mechanism is sometimes endangering the grid security. The present UI mechanism needs a review in view of its impact on recent disturbances.iii) Primary response from generators and operation of defense mechanisms, like Under Frequency & df/dt based load shedding and Special Protection Schemes, should be ensured in accordance with provisions of the grid code so that grid can be saved in case of contingencies.iv) A review of Total Transfer Capability (TTC) procedure should be carried out , so that it can also be revised under any significant change in system conditions, such as forced outage. This will also allow congestion charges to be applied to relieve the real time congestion.v) Coordinated outage planning of transmission elements need to be carried out so that depletion of transmission system due to simultaneous outages of several transmission elements could be avoided.vi) In order to avoid frequent outages/opening of lines under over voltages and also providing voltage support under steady state and dynamic conditions, installation of adequate static and dynamic reactive power compensators should be planned.vii) Penal provisions of the Electricity Act, 2003 need to be reviewed to ensure better compliance of instructions of Load Desptach Centres and directions of Central Commission.viii) Available assets, providing system security support such as HVDC, TCSC, SVC controls, should be optimally utilized, so that they provide necessary support in case of contingencies.ix) Synchrophasor based W AMS should be widely employed across the network to improve the visibility, real time monitoring, protection and control of the system.x) Load Desptach Centres should be equipped with Dynamic Security Assessment and faster State Estimation tools.xi) There is need to plan islanding schemes to ensure supply to essential services and faster recovery in case of grid disruptions.xii) There is need to grant more autonomy to all the Load Despatch Centres so that they can take and implement decisions relating to operation and security of the gridxiii) To avoid congestion in intra-State transmission system, planning and investment at State level need to be improved.xiv) Proper telemetry and communication should be ensured to Load Despatch Centres from various transmission elements and generating stations. No new transmission element/generation should be commissioned without the requisite telemetry facilities.xv) Start up time of generating stations need to be shortened to facilitate faster recovery incase of grid disruptions.xvi) There is a need to review transmission planning criteria in view of the growing complexity of the system.xvii) System study groups must be strengthened in various power sector organizations.xviii) It was also felt that a separate task force may be formed, involving experts from academics, power utilities and system operators, to carry out a detailed analysis of the present grid conditions and anticipated scenarios which might lead to any such disturbances in future. The committee may identify medium and long term corrective measures as well as technological solutions to improve the health of the grid.CHAPTER-1INTRODUCTION1.1 There was a major grid disturbance at 02.33 hrs on 30-07-2012 in Northern region and again at 13.00 hrs on 31-07-2012 resulting in collapse of Northern, Eastern, North-Eastern regional grids barring a few pockets.1.2 The first disturbance which led to the collapse of Northern Regional Electricity grid occurred at 02.33 hrs on 30th July, 2012, in which all states of Northern Region viz. Uttar Pradesh, Uttarakhand, Rajasthan, Punjab, Haryana, Himachal Pradesh, Jammu & Kashmir, Delhi and Union Territory of Chandigarh were affected. Northern Regional Grid‟s load was about 36,000 MW at the time of disturbance. Small islands which comprised of three units of BTPS with the load of approximately 250 MW in Delhi, NAPS on houseload, Area around Bhinmal (Rajasthan) with approximate load of 100 MW connected with Western Region survived the blackout. Restoration was completed by 16.00 hrs.1.3 The second incident which was more severe than the previous one occurred at 13.00 hours on 31.7.2012, leading to loss of power supply in three regions of the country viz. Northern Region, Eastern Region and North Eastern Region affecting all states of Northern Region and also West Bengal, Bihar, Jharkhand, Odisha, Sikkim in Eastern region and Assam, Arunachal Pradesh, Meghalaya, Manipur, Mizoram, Nagaland and Tripura in North-Eastern region. The total load of about 48,000 MW was affected in this black out. Islands comprising of NAPS, Anta GPS, Dadri GPS and Faridabad in Northern Region, Ib TPS / Sterite, Bokaro steel and CESC survived in Eastern Region. It has been reported that major part of the system could be restored in about 5 hrs, 8hrs and 2 hrs in Northern, Eastern and North-Eastern regions respectively.1.4 To look into the detailed causes of these disturbances and to suggest remedial measures, Ministry of Power vide its OM No. 17/1/2012-OM Dt. 30-07-2012 constituted an Enquiry Committee headed by Chairperson, CEA and CEO, POSOCO and CMD POWERGRID as members. With the second major grid disturbance on 31-07-2012 involving three regions the Ministry of Power vide its OM No. 17/1/2012-OM Dt. 03-08-2012 modified the constitution of the above enquiry committee with following members:(i) Shri A.S. Bakshi, Chairperson, CEA Chairman(ii) Shri A. Velayutham, Member (retd.), MERC Member(iii) Dr. S. C. Srivastava, IIT Kanpur Member(iv) Sh. K. K. Agrawal, Member (GO&D), CEA Member Secretary1.5 In addition, following members assisted the Committee:(i) Shri R. N. Nayak, CMD, POWERGRID(ii) Shri S. K. Soonee, CEO, POSOCO(iii) Shri Balvinder Singh, IPS Retired.1.6 The Terms of Reference of the Committee are as under:a) To analyse the causes and circumstances leading to the grid disturbance affecting power supply in the affected region.b) To suggest remedial measures to avoid recurrence of such disturbance in future.c) To review the restoration of system following the disturbances and suggest measures for improvement in this regard, if anyd) Other relevant issues concerned with safe and secure operation of the Grid.1.7 The Committee has been asked to submit its report by 16th August, 2012. A copy of MoP OM dated 3-8-2012 constituting the above Committee is given at Annexure-1.1.1.8 First meeting of the initially constituted Enquiry Committee was held on 01-08-2012. Second meeting of the Enquiry Committee was held on 03-08-2012 which was attended by the members of the Committee and representatives of NLDC, all RPCs, RLDCs, POSOCO and POWERGRID.1.9 The Committee constituted five sub-groups to facilitate detailed and quick analysis of various aspects of grid disturbances viz.(i) …Analysis of grid collapse on 30th& 31st July 2012 and simulation of the event‟ under Shri A. Velayutham, Ex. Member, MERC and Prof. S.C. Srivastava, IIT, Kanpur assisted by Dr. Anil Kulkarni, IIT, Bombay, Shri Ajay Talegaonkar, SE (Operation), NRPC & Shri S. Satyanarayan, SE (Operation), WRPC,(ii) …Islanding scheme for Railways & Delhi Metro‟ under Shri K.K. Agrawal, Member (GO&D), CEA,(iii) …Analysis of restoration process of thermal plants‟ under Shri Manjit Singh, Member (Thermal), CEA,(iv) …Islanding schemes in Northern Region‟ under Shri P.K. Pahwa, Member Secretary, NRPC,(v) …Cyber Security aspects‟ under Shri Ajit Singh, Ex-Addl. Secretary, Cabinet Secretariat and Shri R.K. Verma, Chief Engineer I/c (DP&D), CEA1.10 In addition, a sub-group comprising Shri Dinesh Chandra, Chief Engineer I/c and ShriD.K. Srivastava, Director, Grid Management Division was formed to compile and prepare the report based on the progress made by the five sub-groups on day-to-day basis.1.11 For secure grid operation after two grid collapses, following steps were taken immediately:a) NLDC reduced the TTC of the Inter-Regional lines and other critical lines limiting to its SIL thereby necessary restrictions imposed on STOA.b) CEA advised utilities that senior and experienced officials should be available in RLDCs, SLDCs, Generating Stations and Sub-Stations for at least one week.c) CEA also advised to all generating stations to be responsive and develop a mechanism for bringing Units at the earliest in case of contingencies.1.12 Enquiry Committee held its third meeting on 11-8-2012. On 12-8-2012, detailed discussions were held with POSOCO and POWERGRID at NLDC, New Delhi to have their view points on the causes of grid collapse. The Committee finalized its findings in its meetings on 14th and 15th August, 2012.1.13 The Committee analysed the output of Disturbance Recorders (DR), Event loggers (EL),PMUs, W AFMS, SCADA data and reports submitted by various SLDCs , RLDCs /NLDC, POWERGRID and generation utilities to arrive at the sequence of events leading to the blackouts on 30th July, 2012 and 31st July 2012. The Committee also interacted with POWERGRID and POSOCO on various aspects of these grid disturbances. Some teams also made field visits to sub-stations, generating stations, NRLDC, NLDC, UPSLDC and Haryana SLDC.CHAPTER-2OVERVIEW OF REGIONAL GRIDS2.1 Power system in the country is divided into five regional grids namely Northern, Western, Southern, Eastern and North Eastern grids. Except for Southern grid, remaining four regional grid operate in synchronism. Southern grid is connected to Eastern and Western grids through asynchronous links.2.2 Northern Regional Grid2.2.1 Northern Region is the largest in geographical area amongst the five regions in the country covering approximately 31% of the area and having largest number of constituents. It has largest sized hydro unit (250 MW at Tehri/ Nathpa Jhakri) in the country. Northern Grid has an installed generating capacity of about 56,058 MW as on 30.06.2012 comprising 34608 MW of thermal and 19830 MW of Hydro generation The Thermal-Hydro (including renewable) mix is of the order of 64:36. The installed capacity of nuclear stations is 1620 MW.2.2.2 Major generating stations including Super Thermal Power Stations of NTPC at Rihand and Singrauli are located in the eastern part of the NR grid. Due to such concentration of generation in the eastern part of the grid and major load centers in the central and western part of the grid there is bulk power transmission from eastern to western part over long distances. To handle this bulk transmission of power, a point to point high voltage DC line viz. HVDC Rihand-Dadri bipole with capacity of 1500 MW exists and operates in parallel with 400 kV AC transmission network besides under lying 220 kV network.2.2.3 During the month of July, 2012 the Peak demand of Northern Region was 41,659 MW against the Demand Met of 38,111 MW indicating a shortage of 3,548 MW (8.5%). The energy requirement of Northern Region was 29,580 MU against availability of 26,250 MU indicating shortage of 3,330 MU (11.3%.).2.3 WESTERN REGIONAL GRIDThe Western Grid has an installed capacity of 66757 MW (as on 30-06-2012) consisting of 49402 MW thermal, 7448 MW hydro, 1,840 MW nuclear and 7909.95 MW from renewable energy sources.2.4 EASTERN REGIONAL GRIDThe Eastern Grid has an installed capacity of 26838 MW (as on 30-06-2012) consisting of22545 MW thermal, 3882 MW hydro and 411 MW from renewable energy sources. The Eastern Regional grid operates in synchronism with Western, Northern and North-Eastern Regional grids.2.5 NORTH-EASTERN REGIONAL GRID2.5.1The North-Eastern Grid has an installed capacity of 2454.94 MW as on 31-03-2012 consisting of 1026.94 MW thermal, 1200 MW hydro and 228.00 MW from renewable energy sources. The North-Eastern Grid operated in synchronism with Northern Grid, Eastern Grid and Western Grid. North Eastern Regional Grid is connected directly only to the Eastern Regional Grid and any export of power to the other Regions has to be wheeled through the Eastern Regional Grid.2.5.2The power transfer from North-Eastern Region to Eastern Region is taking place over Bongaigaon – Malda 400 kV D/C lines and Birpara – Salakati 220 kV D/C lines.2.6 Inter-regional interconnectionsThe interconnections between various regional grids is depicted in Exhibit 2.1Chapter-3Analysis of Grid Disturbance on 30th July, 20123.1 IntroductionOn 30th July, 2012 there was a grid disturbance in the NEW grid at 02:33:11 hrs that led to the separation of the NR grid from the rest of the NEW grid and eventually NR system collapsed. The pre-disturbance conditions, sequence of events and analysis of the disturbance are described below.3.2 Pre-Disturbance ConditionsThe details of the generation-demand and power export/import scenario in the four regions of the NEW grid on 30.07.2012 at 02:00 hrs are given below.A number EHV lines were out prior to the disturbance and the same are listed in the enclosed Annexure- 3.1. The grid frequency, just prior to the disturbance, was 49.68 Hz.3.3 Sequence of Events on 30th July, 2012The committee studied the data provided by various SLDCs , RLDCs /NLDC , POWERGRID and generation utilities to analyse the sequence of events leading to the blackouts in Northern grid on 30th July, 2012. The committee experienced some difficulty in analysing the available information because of the time synchronisation problems at various stations. The committee, however, established the sequence of events based on correlation of the data from various sources like Disturbance Recorders (DRs), Event Loggers (ELs), few Phasor Measurement Units (PMUs) in the NR and WR at different stations and Wide Area Frequency Monitoring System (WAFMS) of IIT Bombay.It may be noted that the NEW grid was operating in an insecure condition due to a large number of line outages particularly near the WR-NR interface. Though an exhaustive list of lines under outage is given at Annexure-3.1, it may be noted that the following lines had tripped within an interval of a few hours prior to the grid disturbance.1. 220 kV Badod(WR)-Modak(NR)2. 220 kV Badod (WR)-Kota (NR)3. 220 kV Gwalior-Mahalgaon ckt 2 (in WR but near WR-NR interface)4. 220 kV Gwalior(PG)-Gwalior(MP)(in WR but near WR-NR interface causing only 220 kV Gwalior-Malanpur as only 220 kV NR-WR interconnection, and 220 kV Bina-Gwalior was no longer in parallel with 400 kV Gwalior-Bina)Following are the sequence of the events, which took place on 30th July, 2012, leading to the Northern Grid blackout:Some of the subsequent events of cascaded tripping are listed in Annexure-3.2, which has led the NR system to practically total blackout except a few pockets, such as Badarpur and NAPS (only household loads), which survived in islanded mode.++ Power Swings: The rotors of synchronous machines inter-connected by AC lines tend to run at the same electrical speed in steady state due to the underlying physics of this system. When this system experiences small disturbances, restorative torques bring back the machines to synchronism (i.e., the same electrical speed). This response is characterized by an oscillatory behaviour since the underlying equations which determine the transient behaviour are like those of a spring-mass system. The oscillations are called “swings” and are seen in practically all parameters including line power flows. The oscillations die down if damping is adequate.For large disturbances (e.g faults, loss of critical transmission links), the behaviour is non-linear and the electrical torques may be unable to bring all the generators to the same electrical speed. If this happens the angular difference between the generators goes on increasing (Transient Instability or Angular Separation). This causes large variations in voltage and power flow in lines.Other equivalent terms are “Loss of Synchronism”, “Out of Step”, “Pole slipping”, although the latter two terms are typically used if only one machine loses synchronism. In a multi-machine system groups of machines may separate.3.4 Analysis of the Disturbance on 30th July 2012I. It is observed that even though the frequency of the NEW grid (49.68 Hz) was near to its nominal value (50 Hz), a number of lines were not available due to either forced outages, planned outages or kept out to control high voltages. This resulted in a depleted transmission network, which, coupled with high demand in the Northern Region, resulted in an insecure state of the system operation.II. From WR-NR interface, 400 kV Gwalior-Agra line was carrying about 1055 MW and 400 kV Zerda-Bhinmal was carrying about 369MW, while 400 kV Gwalior-Bina was carrying about 1450 MW. The loading on 400 kV Gwalior-Agra was high. The Surge Impedance Loading (SIL) of the 400 kV Gwalior-Agra and also Gwalior-Bina lines, which are 765 kV lines charged at 400 kV, is about 691 MW (uncompensated), but its thermal loading limit is much higher (for quad Bersimis conductor).III. NR constituents were instructed by NRLDC to carry out load shedding to relieve the Gwalior-Agra line loading. However, the quantum of load shedding undertaken by the NR constituents seems to be insignificant. WRLDC also issued similar instructions to its constituents for reduction in generation.IV. The 400 kV Agra-Gwalior line is fed from 400 kV Bina-Gwalior line in the WR.V. At 02:33:11:907 hrs, the 400 kV Bina-Gwalior line in WR tripped on Zone 3 protection, which is due to load encroachment (DR records do not show any evidence of fault or swing). Prior to tripping the voltage was 374 kV at Bina end and the line was carrying about 1450 MW approximately as per DR report of POWERGRID for this line.VI. With the tripping of the above line, the supply to NR from 400 kV Agra-Gwalior was lost. 400 kV Zerda-Bhinmal-Bhinmal (220 kV)-Sanchore (220 kV) and Dhaurimanna (220 kV) was the only AC tie link left between WR-NR. Subsequently 220 kV Bhinmal–Sanchore line tripped on power swing, and as per SLDC Rajasthan 220 kV Bhinmal-Dhaurimanna tripped on Zone 1distance protection. This resulted in loss of the WR-NR tie links. A small load at Bhinmal remained connected with WR system through the 400 kV Zerda-Bhinmal line.VII. In some cases the impedance measured by a distance relay at one end of the line may reduce to a point where it is less than the tripping condition for that relay for back-up protection (Zone 3). This may happen even if there is no fault in the nearby transmission system, and may occur when the line carries a very heavy load. This phenomenon of the mal-operation of the distance relays is known as …Load Encroachment‟. Generally, it is an unintended tripping for distance relays since no fault has actually occurred.It may be noted that at the time of disturbance, the 400 kV Bina-Gwalior line experienced a lower voltage and higher load current (resulting in less impedance, seen by the relay, which, possibly, was below the zone-3 reach setting of the relay) caused the relay operation under load encroachment. It was informed by POSOCO that this line had not tripped earlier due to zone-3 operation under load encroachment, although few incidences of such operation of distance relays in Western Region are observed in prior disturbances.VIII. The tripping of the 400 kV Bina-Gwalior line initiated a very large angular deviation between NR system on one side and ER+WR+NER system on the other side. The power from WR to NR was now routed via WR-ER-NR interface, which is a very long path.IX. An illustrative simulation to understand angular separation of the WR and NR regions was carried out. The simulation confirms that the systems may separate under such conditions. The simulation details are given at Annexure-3.3。
nacos默认的负载均衡策略

nacos默认的负载均衡策略Nacos is an open-source service discovery and configuration management platform that provides dynamic service discovery, service health management, and dynamic configuration management capabilities for microservices and cloud-native applications. One of the key features of Nacos is its built-in support for load balancing, which allowsfor efficient distribution of traffic across multiple instances of a service. However, the default load balancing strategy used by Nacos may not always be suitable for every use case, and it is important to understand its limitations and potential drawbacks.The default load balancing strategy employed by Nacosis known as "random" load balancing. As the name suggests, this strategy randomly selects an instance from theavailable pool of instances to handle each incoming request. While this approach is simple and easy to implement, it may not be the most efficient or effective strategy in all scenarios.One of the limitations of the random load balancing strategy is that it does not take into account the actual load or capacity of each instance. This means that a heavily loaded instance may still be selected to handle new requests, leading to potential performance issues and decreased overall system efficiency. In addition, the random selection of instances may result in uneven distribution of traffic, with some instances being underutilized while others are overloaded.Another drawback of the random load balancing strategy is its lack of support for session affinity or sticky sessions. In some cases, it may be desirable to route requests from the same client to the same instance in order to maintain session state or ensure consistent behavior. However, the random load balancing strategy does not provide any mechanism for achieving this, and requests from the same client may be routed to different instances each time.To overcome these limitations, Nacos provides supportfor pluggable load balancing strategies. This means that developers can implement and configure custom load balancing algorithms that better suit their specific requirements. Some of the alternative load balancing strategies that can be used with Nacos include round-robin, weighted round-robin, least connections, and consistent hashing.The round-robin strategy, for example, distributes requests equally among all available instances in a cyclic manner. This ensures that each instance receives an equal share of the traffic and prevents any single instance from being overloaded. The weighted round-robin strategy allows for assigning different weights to instances based on their capacity or performance, enabling more efficientutilization of resources.The least connections strategy selects the instance with the least number of active connections to handle each request. This helps to evenly distribute the load across instances and ensures that heavily loaded instances are not overwhelmed with new requests. On the other hand, theconsistent hashing strategy uses a hashing algorithm to map each request to a specific instance, ensuring that requests from the same client are consistently routed to the same instance.In conclusion, while Nacos provides a default random load balancing strategy, it may not always be the most suitable choice for every use case. Developers should carefully evaluate their specific requirements and consider alternative load balancing strategies provided by Nacos to ensure optimal performance, efficient resource utilization, and consistent behavior. By leveraging the pluggable load balancing capabilities of Nacos, developers can customize the load balancing behavior to meet the unique needs of their applications and infrastructure.。
F5-301B-复习总结

F5 301B 复习总结1.stream profile:1)在所有事件中执行搜索替换字符串的工作2)可以应用在任何standard virtual server,和http profile兼容。
3)当不配置http profile的时候,整个搜索替换过程会在所有的TCP分段上面执行,配置之后只会在HTTP实体进行此过程4)当steam profile和HTTP profile都关联到一个VS的时候,在HTTP response事件中不需要配置response chunking.BIG-IP会自动分片。
when HTTP_REQUEST {# Disable the stream filter for client requestsSTREAM::disable}when HTTP_RESPONSE {# Disable the stream filter for server responsesSTREAM::disable# Enable the stream filter for text responses onlyif {[HTTP::header value Content-Type] contains "text"}{# Replace 'old_text' with 'new_text'STREAM::expression {@old_text@new_text@}# Enable the stream filter for this response onlySTREAM::enable}}5)替换工作是单向进行的,只进行一次替换。
6)当HTTP压缩功能开启的时候将会阻止替换工作的进行,所以要替换字符,必须首先一处Accept-Encoding头部。
2.tcp-cell-optimized 对移动用户进行应用优化(从移动蜂窝网络过来的用户相对较慢),可以增加大量的缓存。
在大学如何平衡学业与活动英语作文

Balancing Academics and ExtracurricularActivities in UniversityUniversity life is a dynamic and vibrant phase filled with opportunities for growth and exploration. From attending lectures, engaging in research, and networking with peers, there is never a dull moment. However, with the abundance of academic pursuits, it's easy to overlook the importance of extracurricular activities. Balancing both academics and activities is crucial for a comprehensive and enriching university experience.Prioritizing academics is essential. After all, the primary objective of university is to acquire knowledge and skills. This requires a significant amount of time and effort, especially when dealing with complex subjects and demanding professors. Attending classes regularly, completing assignments promptly, and preparing for exams are non-negotiable responsibilities. Missing a class or submitting a late assignment can have significant consequences on one's academic performance.However, focusing solely on academics can lead to burnout and a lack of diversity in one's universityexperience. This is where extracurricular activities play a vital role. Engaging in clubs, sports, volunteer work, or any other form of extracurricular activity not only provides a break from the monotony of academics but also fosters personal growth and development.Extracurricular activities help students develop important skills like teamwork, leadership, and communication. They also provide an opportunity to make new friends and expand one's social network. These experiences are invaluable in shaping one's personality and preparing them for the real world.To strike a balance between academics and extracurricular activities, students need to be disciplined and strategic. They should create a schedule that allocates sufficient time for both. For instance, they can plan their weekly routine to include a balance of academic commitments and extracurricular activities. They should also learn to prioritize their tasks effectively, ensuring that urgent and important academic work is completed before engaging in extracurricular activities.Moreover, students should take advantage of the resources available to them. University libraries, mentors, and peer support groups can provide invaluable assistancein managing their workload. They can also seek advice from their professors or mentors on how to balance their academic and extracurricular commitments.In conclusion, balancing academics and extracurricular activities in university is a challenging but rewarding task. It requires discipline, strategy, and the willingness to embrace new opportunities. By allocating sufficient time to both areas and prioritizing their tasks effectively, students can ensure that they have a comprehensive and enriching university experience.**平衡大学学业与活动**大学生活是一个充满机遇、动态和充满活力的阶段,对于个人的成长和探索具有重要意义。
负载均衡load balance的英文缩写

负载均衡load balance的英文缩写Title: Load Balance (LB): The Cornerstone of Efficient Resource ManagementIntroductionIn the realm ofputing and networking, one term that frequently crops up is "Load Balance" or LB for short. This concept plays a pivotal role in optimizing resource utilization, enhancing system performance, and ensuring fault tolerance. In this article, we will delve into the intricacies of load balancing, its significance, and how it contributes to efficient resource management.What is Load Balancing?Load balancing refers to the methodical distribution of network traffic across multiple servers to optimize resource utilization, enhance responsiveness, and avoid overloading any single server. It is an essentialponent of fault-tolerant systems as it ensures that no single point of failure exists.The Importance of Load BalancingThe importance of load balancing can be summed up in three main points:1. Improved Performance: By distributing the workload evenly across multiple servers, each server operates within its optimal capacity, leading to better overall system performance.2. Enhanced Availability: If one server fails or needs maintenance, the load balancer redirects traffic to other available servers, thereby ensuring continuous service availability.3. Scalability: As the demand for services increases, new servers can be added to the system without disrupting existing services. This allows for easy expansion and scalability of the system.How does Load Balancing Work?Load balancing typically involves the use of a software or hardware device called a load balancer. The load balancer acts as a traffic cop, directing client requests to the various backend servers based on certain predefined algorithms and policies. These algorithms may consider factors such as server availability, server load, geographic location, or specific application requirements.Types of Load Balancing AlgorithmsThere are several types of load balancing algorithms, including:1. Round Robin: Each iing request is assigned to the next available server in a rotation.2. Least Connections: New requests are sent to the server with the fewest active connections.3. IP Hash: A hash function is used to determine which server should handle a request based on the client's IP address.4. Weighted Algorithms: Servers are assigned weights based on their processing power or capacity, and requests are distributed accordingly.ConclusionLoad balancing (LB) is a crucial aspect of modernputing and networking infrastructure. Its ability to distribute workloads efficiently, ensure high availability, and facilitate scalability makes it an indispensable tool for managing resources effectively. Understanding the concepts and mechanisms behind load balancing can help organizations make informed decisions about their IT infrastructure and improve the overall user experience.。
ribbon负载均衡原理

ribbon负载均衡原理负载均衡是一种常见的网络架构,它可以很好地管理网络访问量,使客户可以尽可能快速地访问服务或资源。
其中,ribbon负载均衡是一种流行的负载均衡技术,它可以通过多种策略实现负载均衡,并且提供了很多高级特性,如服务发现,客户端负载均衡,路由策略,failover等。
本文将介绍ribbon负载均衡原理及其应用场景。
一、ribbon负载均衡原理ribbon负载均衡是基于客户端的负载均衡,它采用了客户端轮询的策略,将客户端的请求分发到多个服务实例上,以减少服务端的压力,也就是说,客户端请求在客户端提交之前,就已经确定好将被转发到哪个服务实例上去,具体的流程如下:1.户端发送一个请求,ribbon客户端接收请求并查找服务列表(service discovery);2.析服务列表,根据负载均衡策略(Load balancing strategy),获取服务实例;3.户端将请求发送给指定的服务实例,服务实例处理请求,并发送响应给客户端;4.户端接收响应,处理响应,完成请求。
二、ribbon负载均衡的应用场景ribbon负载均衡可以应用于以下几种应用场景:1.布式系统:ribbon的负载均衡能够有效地将客户端的请求转发到整个分布式系统中的不同服务实例上,减轻单个服务实例的负载,提高服务的可用性和可靠性;2.时服务:ribbon的负载均衡也可以应用于实时服务,它可以有效地使得客户端的请求尽可能地快速地返回给客户端,而不用太多等待时间;3.端服务:ribbon的负载均衡也可以用于后端服务,如Web应用,可以将网页流量分发到多台服务器上,以获得更好的性能。
三、总结ribbon的负载均衡是一种流行的负载均衡技术,它采用客户端轮询的方式,将客户端的请求分发到多个服务实例上,以达到负载均衡的目的,可以应用于分布式系统、实时服务和后端服务等多个场景中。
ribbon的负载均衡能够提高系统的性能和可用性,是一种比较流行的负载均衡技术。
高三英语梦想与国家发展战略的协同作用分析单选题40题

高三英语梦想与国家发展战略的协同作用分析单选题40题1. Mary has a dream of becoming a doctor, but she finds it difficult to balance her studies and hobbies. The underlined part means _____.A. keep a good relationshipB. give equal attentionC. make a choiceD. have no problem答案:B。
本题考查短语“balance”的意思。
选项A“keep a good relationship”意为“保持良好关系”;选项C“make a choice”意为“做出选择”;选项D“have no problem”意为“没有问题”,均不符合“balance”在句中“平衡”的意思,选项B“give equal attention”意思是“给予同等关注”,与“balance”的意思相近。
2. Tom dreams of traveling around the world, and he is saving money _____.A. at presentB. in the pastC. in the futureD. just now答案:A。
本题考查时间短语的用法。
选项B“in the past”表示“在过去”,与句子时态不符;选项C“in the future”表示“在未来”,与句子语境不符;选项D“just now”表示“刚才”,通常用于一般过去时。
选项A“at present”意为“目前,现在”,符合句子中“正在存钱”的语境。
3. Lily's dream is to be a singer, but she needs to practice ______ if she wants to succeed.A. a lot ofB. a lotC. lots ofD. many答案:B。
不能帮别人的英语作文

不能帮别人的英语作文Title: The Importance of Balancing Assistance with Personal Growth。
Assisting others is a fundamental aspect of human nature, ingrained in our social fabric and ethical principles. However, there comes a point where the desire to help others can potentially hinder their personal growth and development. Striking a balance between providing assistance and fostering independence is crucial for both the helper and the recipient. In this essay, we will explore the significance of this balance and strategies for achieving it effectively.Firstly, it's essential to acknowledge that offering assistance to others is inherently noble and often necessary, particularly in times of need or crisis. Whether it's lending a helping hand to a friend in distress, supporting a colleague with a challenging task, or volunteering for a charitable cause, acts of kindness andsupport enrich our lives and strengthen social bonds.However, the line between genuine assistance and enabling dependency can sometimes blur. While it's natural to want to alleviate someone else's burdens, excessive help can inadvertently disempower them and impede their growth. This phenomenon is often observed in relationships where one person consistently takes on the role of the caretaker, depriving the other of the opportunity to learn from their experiences and develop problem-solving skills.Moreover, the dynamic of perpetual assistance can create a sense of indebtedness or inadequacy in the recipient, leading to feelings of resentment or dependency. In the long run, this can strain relationships and hinder mutual trust and respect. Therefore, it's essential to approach assistance with mindfulness and consideration for the long-term well-being of both parties involved.One effective strategy for balancing assistance with personal growth is to adopt a collaborative approach that empowers the recipient to take an active role in problem-solving and decision-making. Instead of simply offering solutions or doing tasks on their behalf, encourage them to brainstorm potential solutions, weigh the pros and cons, and make informed choices independently. This approach not only fosters self-reliance but also cultivates a sense of ownership and accountability.Additionally, setting clear boundaries and expectations is crucial in maintaining a healthy balance between assistance and autonomy. Clearly communicate what kind of support you're willing to provide and under what circumstances, while also respecting the recipient's boundaries and autonomy. By establishing mutual understanding and respect, you can avoid overstepping boundaries and foster a relationship based on equality and reciprocity.Furthermore, it's essential to recognize when assistance may no longer be beneficial or sustainable and encourage the recipient to seek alternative sources of support or professional help if necessary. While it's important to offer a helping hand in times of need, it'sequally important to empower individuals to seek solutions independently and build resilience in the face of adversity.In conclusion, while offering assistance to others is a commendable trait, it's essential to strike a balance between support and personal growth. By adopting a collaborative approach, setting clear boundaries, and encouraging independence, we can empower others to overcome challenges, develop essential life skills, and ultimately lead fulfilling lives. Remember, true assistance lies notin doing everything for someone else but in helping them discover their own strength and resilience.。
如何平衡想法与行动的英语作文素材

如何平衡想法与行动的英语作文素材英文回答:Ideas vs. Actions: Achieving a Harmonious Balance.The human experience is characterized by a perpetual interplay between ideas and actions. Ideas, the seeds of innovation and change, ignite within our minds and possess the potential to transform the world around us. Actions, on the other hand, are the concrete manifestations of our ideas, the physical steps we take to bring our aspirations to fruition.Striking a harmonious balance between ideas and actions is crucial for personal growth and societal advancement. An overabundance of ideas without corresponding actions can lead to a state of perpetual stagnation, where dreams remain unfulfilled and potential untapped. Conversely, an excessive focus on actions without adequate ideation can result in impulsive decisions, missed opportunities, andwasted effort.The ideal balance between ideas and actions is a dynamic one that varies depending on the individual and the context. For some, it may require prioritizing the generation of new ideas, while for others, it may involve dedicating more time to executing plans. Regardless of the specific balance, it is essential to cultivate a mindset that fosters both ideation and action.One effective technique for balancing ideas and actions is to practice "structured daydreaming." This involves setting aside dedicated time for brainstorming and generating new ideas without judgment or self-criticism. By allowing our minds to wander freely, we can tap into a wealth of creative potential. Once we have a collection of ideas, we can then prioritize them, identify actionable steps, and develop a plan for implementation.Another key strategy is to break down large goals into smaller, more manageable steps. This helps to reduce feelings of overwhelm and makes the task of taking actionseem less daunting. By focusing on completing one small step at a time, we can gradually make progress towards our ultimate objectives.Furthermore, it is important to cultivate a growth mindset that embraces failure as an opportunity for learning and improvement. When we encounter setbacks or challenges, instead of dwelling on negative emotions, we should view them as valuable lessons that can inform our future decisions and actions.By embracing a balanced approach to ideas and actions, we can unlock our full potential and make meaningful contributions to the world around us. Ideas, when coupled with purposeful actions, become catalysts for positive change and lasting impact.中文回答:如何平衡想法与行动。
平衡工作与兴趣的英语作文

平衡工作与兴趣的英语作文Balancing work and personal interests is a delicate dancethat requires discipline and time management. It's about finding harmony between the responsibilities of a job and the pursuits that fuel our passions.The key to achieving this balance lies in setting priorities. Identifying what is most important in both our professional and personal lives helps us allocate time effectively. For instance, setting aside specific hours for work and reserving others for hobbies or relaxation can create a clear boundary.Time management tools, such as calendars and to-do lists, are invaluable aids in this endeavor. They help us visualize our commitments and ensure that we are not overextendingourselves in either sphere.Another strategy is to integrate our interests into our work. This could mean finding a job that aligns with our passionsor incorporating elements of our hobbies into our daily tasks. Such integration can make work feel less like a chore andmore like an extension of our personal lives.However, it's also crucial to recognize when to step back and recharge. Overworking can lead to burnout, which cannegatively impact both our professional performance and our ability to enjoy our interests. Taking breaks and vacationsis essential for maintaining a healthy work-life balance.Communication is another vital component in this equation. Whether it's discussing workload with a supervisor or setting expectations with family and friends, clear communication helps manage the expectations of others and ensures that our personal time is respected.Lastly, it's important to be flexible and adaptable. Life is unpredictable, and sometimes our best-laid plans need to be adjusted. Being open to change and willing to reassess our priorities can help us navigate the unexpected twists and turns that life throws our way.In conclusion, balancing work and interests is about creating a lifestyle that nurtures both our professional ambitions and our personal fulfillment. It's a dynamic process that requires ongoing attention and adjustment, but the rewards are well worth the effort.。
控制注意力的英语

控制注意力的英语Controlling Attention in EnglishIn the realm of language acquisition, the ability to control one's attention is paramount, especially when it comes to learning a language as widely spoken and diverse as English. The vast array of accents, dialects, and colloquialisms can be daunting to a learner, but with focused attention, mastery becomes more attainable.Firstly, it is essential to identify the specific aspects of English that one wishes to improve. Whether it's the intricacies of grammar, the fluidity of conversational speech, or the nuances of written communication, focusing attentionon these areas can lead to significant progress. For instance, a learner might choose to dedicate a month to mastering the past tenses, followed by a period of intensive listening practice to become accustomed to different English accents.Moreover, controlling attention also involves filteringout distractions. In today's world, where information is abundant and easily accessible, it's easy to get sidetracked. However, by setting specific goals and adhering to a study routine, learners can maintain their focus. Using tools like language learning apps, which are designed to keep users engaged for set periods, can be an effective way to manage attention.Another strategy to control attention is to immerse oneself in the language. This could mean watching English-language films with subtitles, participating in language exchanges, or even traveling to an English-speaking country. Immersion forces the brain to process the language in real-time, enhancing attention and retention.Furthermore, learning to control attention can also mean being mindful of the learning environment. A quiet, comfortable space with minimal interruptions can greatly improve the efficiency of language study. It's alsobeneficial to vary the learning methods to keep the mind engaged and to cater to different learning styles.Lastly, it's important to remember that controlling attention is not just about focusing on English; it's also about being aware of when to take breaks. Cognitive overload can lead to diminished returns, so balancing study with relaxation is crucial.In conclusion, controlling attention in English is a multifaceted endeavor that requires discipline, strategy, and an understanding of one's own learning preferences. By focusing on specific goals, filtering out distractions, immersing in the language, and being mindful of the learning environment, learners can make significant strides in their English language journey.。
怎样平衡必修课和选修课英语作文

怎样平衡必修课和选修课英语作文Balancing Required and Elective CoursesAs a student, it can be challenging to balance required courses with elective courses. Required courses are necessary to fulfill graduation requirements, while elective courses allow students to pursue their interests and passions. Finding the right balance between the two is crucial for a well-rounded education.Firstly, it is important to prioritize required courses. These courses are essential for graduation and often provide a strong foundation in a specific field of study. It is important to carefully plan and schedule required courses to ensure that they are completed in a timely manner. This may involve taking a certain number of required courses each semester and carefully considering prerequisites and course availability.At the same time, elective courses offer valuable opportunities for exploration and personal growth. These courses allow students to delve into subjects that may not be directly related to their major, but are of personal interest. It is important to choose elective courses that align with one'sinterests and goals, as they can provide a welcome break from the rigor of required courses.One strategy for balancing required and elective courses is to carefully plan out one's academic schedule. This may involve consulting with an academic advisor to ensure that all graduation requirements are being met while also allowing for the pursuit of elective courses. Additionally, some students may choose to take elective courses during summer or winter sessions to lighten the load during the regular academic year.Another important consideration is time management. Balancing required and elective courses requires effective time management skills. This may involve setting aside dedicated study time for each course, prioritizing assignments and deadlines, and seeking assistance when needed. By managing one's time effectively, students can successfully navigate the demands of both required and elective courses.In conclusion, balancing required and elective courses is a critical aspect of the college experience. By carefully planning and prioritizing required courses while also pursuing elective courses that align with one's interests, students can achieve a well-rounded education. Effective time management and academic planning are essential for successfullynavigating the demands of both types of courses.在学生阶段,平衡必修课和选修课是一项具有挑战性的任务。
负载均衡技术综述

©2004 Journal of Software 软件学报负载均衡技术综述*殷玮玮1+1(南京大学软件学院,江苏南京210093)Overview of Load Balancing TechnologyYIN Wei-Wei1+1(Department of Software Institute, Nanjing University, Nanjing 210093, China)+ Corresponding author: Phn +86-**-****-****, Fax +86-**-****-****, E-mail: bingyu0046@, Received 2000-00-00; Accepted 2000-00-00Yin WW. Overview of Load Balancing Technology. Journal of Software, 2004,15(1):0000~0000./1000-9825/15/0000.htmAbstract: Load balance technology based on existing network structure, provides a cheap and efficient method for expanding bandwidth of the server and increase the server throughput, strengthens network data processing ability, increases network flexibility and availability. This paper introduces in detail the three aspects: the classification of load balancing, load balancing and load balancing algorithm, then compares the load balancing algorithm commonly used and their advantages and disadvantages, and describes the dynamic load balancing strat egy and three kinds of scheduling methods.Key words: load balancing technology; the load conditions; the static load balancing algorithm; the dynamic load balancing algorithm摘要: 负载均衡技术基于现有网络结构,提供了一种扩展服务器带宽和增加服务器吞吐量的廉价有效的方法,加强了网络数据处理能力,提高了网络的灵活性和可用性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A Dynamic Load Balancing Strategy for Parallel DatacubeComputationSeigo Muto Institute of Industrial Science, University of Tokyo7-22-1 Roppongi, Minato-ku, Tokyo, 106-8558 Japan+81-3-3402-6231 ext. 2357 muto@tkl.iis.u-tokyo.ac.jpMasaru Kitsuregawa Institute of Industrial Science,University of Tokyo7-22-1 Roppongi, Minato-ku, Tokyo, 106-8558 Japan+81-3-3402-6231 ext. 2357 kitsure@tkl.iis.u-tokyo.ac.jpABSTRACTIn recent years, OLAP technologies have become one of the important applications in the database industry. In particular, the datacube operation proposed in [5] receives strong attention among researchers as a fundamental research topic in the OLAP technologies. The datacube operation requires computation of aggregations on all possible combinations of each dimension attribute. As the number of dimensions increases, it becomes very expensive to compute datacubes, because the required computation cost grows exponentially with the increase of dimensions. Parallelization is very important factor for fast datacube computation. However, we cannot obtain sufficient performance gain in the presence of data skew even if the computation is parallelized. In this paper, we present a dynamic load balancing strategy, which enables us to extract the effectiveness of parallizing datacube computation sufficiently. We perform experiments based on simulations and show that our strategy performs well.KeywordsOLAP, datacube, dynamic load balancing, parallel processing. 1. INTRODUCTIONIn recent years, OLAP technologies have become one of the important applications in the database industry. OLAP systems provide multidimensional views for users who attempt to analyze data from various viewpoints for use in decision making. In particular, the datacube operation proposed in [5] receives strong attention among researchers as a fundamental research topic in the OLAP technologies. The datacube operation requires computation of aggregations on all possible combinations of each dimension attribute. As the number of dimensions increases, it becomes very expensive to compute datacubes, because the required computation cost grows exponentially with the increase of dimensions. To overcome this problem, several algorithms for computing datacubes as efficiently as possible have been developed[1][2][3][10][11][15]. They studied the optimization techniques considering overlaps of computations among aggregations, utilization of memory space and efficiency of disk I/O. However, in spite of these optimizations, the target of these techniques is only for uniprocessor systems, while multiprocessor systems are widely used today for database applications. Parallelization is very important factor for fast datacube computation and there are parallel algorithms developed for further performance improvement[6]. Simple parallelization of datacube computation is not so difficult, however, we cannot obtain sufficient performance gain in the presence of data skew. In this paper, we present a dynamic load balancing strategy, which enables us to extract the effectiveness of parallizing datacube computation sufficiently. In this strategy, we detect the load status of each processor and dynamically transfer the data between processors to balance the load during processing. We perform experiments based on simulations and show that our strategy performs well.This paper is organized as follows. In section 2, we introduce the datacube operation and computation algorithms for this operation. In section 3, a parallelization method of datacube computation is described. Section 4 explains load balancing strategies and section 5 presents experimental results. Related work is presented in section 6. Section 7 concludes with future work. 2. DATACUBE COMPUTATION2.1 Datacube Operation[5] generalized the group-by of SQL language in relational databases and proposed the datacube operation, which performs aggregation operations on all possible combinations of each dimension attribute. For example, we assume tuples with 4 attributes named A, B, C and D. The first 3 attributes are assumed to be used for dimensions in a multidimensional space and the last one is assumed to be used as a value to be aggregated, which is usually called a measure value. In this case, we can compute a 3 dimensional datacube in which aggregations are performed using dimension combinations such as ABC, AB, AC, AD, A, B, C and all, which represents a value obtained by aggregating measure values of all tuples. Each view generated by these aggregations is often called cuboid.As mentioned in [5], aggregate functions can be classified into three groups named distributive functions, algebraic functions and holistic functions. The feature of distributive and algebraicfunctions is that we can use a divide and conquer strategy to compute these functions. Functions count , sum , max , min and average can be classified to this group. We assume that aggregate fucntions to be used are always distributive or algebraic because the most of frequently used aggregate functions belong to this group. Because of this property of these fucntions, there are dependencies among cuboids where a cuboid can be computed from another cuboid which is already computed. For example, AB, AC and BC can be computed from ABC. These dependencies are often represented by tree structures introduced in [8] as shown in Figure 1. [5] also mentioned the optimization technique called the smallest parent . Aggregation costs are minimized if we compute a cuboid from the smallest parent cuboid from which the child cuboid can be generated. This optimization technique is incorporated into the most ofalgorithms proposed for processing datacube operations.Figure 1: Dependency Tree2.2 Computation AlgorithmsAlgorithms for computing datacubes can be categorized into two groups called ROLAP and MOLAP from the difference of data format to be handled directly by the systems. The ROLAP systems process tuples as data because the systems are based on relational databases, while the MOLAP systems use array structures that are more suitable for multidimensional data processing although a loading process is needed. Algorithms PipeSort, PipeHash[1][11], Overlap[1][3], PartitionedCube and MemoryCube[10] and BottomUpCube[2] are devised as the ROLAP approach. These algorithms make use of techniques sorting or hashing, which is commonly employed in implementations of normal aggregation operations in relational database systems. PipeSort, Overlap and MemoryCube are sort-based algorithms. The basic idea is to compute as many cuboids sharing the same dimension order as possible simultaneously after sorting tuples, because we can utilize the dependencies among the cuboids. Although BottomUpCube is also a sort-based algorithm, this algorithm does not use the smallest parent and computes cuboids in the opposite direction of dependencies using the results which is previously sorted for computing other cuboids. Different from other methods, PipeHash is an algorithm based on a hashing technique. For the detail of this algorithm, we describe in the next subsection. In [5], a simple algorithm using array structures is described. As the MOLAP approach, [15] developed more sophisticated array-based algorithm for computing datacubes.2.3 PipeHashAmong the algorithms described in the previous subsection, we choose the PipeHash as an algorihtm to be parallelized. In the following, we present the detail description of this algorithm.The PipeHash algorithm proceeds as follows. First we read raw data from disk into main memory, and apply a hash function to dimension attributes of tuples in main memory to insert the tuple into a hash table for the root cuboid. If the tuple with the same dimension attribute values is found in the hash table, the measure attribute value of the input tuple is aggregated into the measure attribute value of the tuple in the hash table. After all tuples are processed, the next child cuboids of the root cuboid are computed. Hash tables of these child cuboids are created and tuples from the hash table of the root cuboids are inserted into these hash tables by being applied a hash function to aggregate the measure attribute value. After these processings are completed, the next child cuboids are computed in the same way. In this way, processings continue until the computation of all cuboids is completed. The parent cuboid from which the cuboid is computed is determined based on the smallest parent. This is achieved by solving a minimum spanning tree problem where thecost of each node is the estimated cuboid size.Figure 2: Subtrees in Dependency TreeIf hash tables cannot fit into main memory, cuboids have to be partitioned on some dimension attributes so that the memory space required for hash tables to be constructed from tuples in these partitions becomes smaller than the available memory space. In this case, however, only cuboids containing the partitioning dimension attributes can be computed simultaneously. For this reason, we have to divide the cuboids into some groups that can be computed at the same time. For example, we assume to compute a datacube which have 4 dimension attributes A, B, C and D. If we partition tuples on A and B, the cuboids are divided into 3 groups. Figure 2 depicts the dependency tree divided into 3 subtrees as a result of partitioning. First, since we partition raw data on A, only cuboids in the subtree 1 can be computed in this pass. In the next pass, partitioning on the attribute B is applied to ABCD and the computation of cuboids in the subtree 2 is done. Other remaining cuboids can be computed from BCD without partitioning as shown in subtree 3. When partitioning is performed, we have to determine how to divide the dependency tree into subtrees. A greedy algorithm is used in PipeHash for the decomposition of the tree.3. PARALLELIZING DATACUBE COMPUTATIONIn this section, we describe a simple parallelization algorithm for datacube computation. Although there are several kinds of architectures for multiprocessor systems, we assume that our algorithm is used on shared-nothing multiprocessors, which can provide higher scalability than the other architectures.Figure 3 shows a parallel algorithm for PipeHash. Input to this algorithm is a dependency tree divided into subtrees based on the greedy algorithm used in the PipeHash. For the first subtree, we partition the root of this tree on some dimensions and allocate each partition to any one of processors based on the values of the partitioning dimensions. Once the partitions are sent to each processor, cuboids in this subtree are computed in a pipelined fashion using the PipeHash algorithm. This computation is performed independently among the processors on a partition by partition basis. If a cuboid corresponding to the root of the next subtree has been created from the partitions, the result is partitioned on some dimensions to distribute to each of the processors and cuboids in the next subtree are computed in the same way. Other remaining subtrees are also computed by repeating these processes.Note that this algorithm is described in the abstract way. Although we chose the PipeHash algorithm, some other algorithms based on other techniques such as sort or array can be applied to this parallelization. This is true for load balancing strategies we will describe in the next section.Algorithm ParallelPipeHash(subtrees S)foreach subtree s in S doPartition the root of s on some dimensions;foreach partition p doAllocate p to the processor determined by the values of the partitioning dimensions;endforeach processor doforeach partition p doCompute cuboids in s from p using PipeHash;endendendFigure 3: Parallel PipeHash Algorithm4. LOAD BALANCING STRATEGIESIf data is skewed, this simple parallelization method causes inefficient resource utilization, because the performance is bounded by the processor whose load is much higher than other processors due to data skew. To make effective use of the other processors which might be in the idle state, a load balancing mechanism should be incorporated into the parallel algorithm described above. We introduce load balancing strategies in this section. A Static approach and a dynamic approach can be considered as a load balancing method for parallel datacube computation. We describe each strategy in turn in the following subsections. 4.1 Definitions of Data SkewBefore describing each load balancing strategy, we first define the types of data skew that could arise in the parallel computation of datacubes. In [14], several kinds of data skew are classified for parallel join processing. [12] distinguishes the types of data skew in parallel aggregation. In the context of parallel datacube computation, two types of data skew are considered as follows.Partition Skew: Skew of the number of tuples generated from the partitioning process in the parallel algorithm. This skew will occur when the number of each distinct value of partitioning dimensions is not uniformly distributed.Cuboid Skew: Skew of the size of a cuboid created from each partition. This skew can occur due to the characteristics of data in each partition of the parent cuboid from which the cuboid can be derived. The number of tuples generated from the partition is determined by a data density of the partition and correlations of each of dimension attribute values in the partition.4.2 A Static Load Balancing StrategyAlgorithm StaticLoadBalancing(subtrees S)foreach subtree s in S doPartition the root of s on some dimensions;foreach partition p doAllocate p to the processor determined by the values of thepartitioning dimensions;endlet t max = the largest number of tuples per processor;let t min = the smallest number of tuples per processor;let p max = a processor which has t max;let p min = a processor which has t min;let d = difference between t max and t min;while d is reduced by reallocation of a partition doreallocate one of the partitions on p max to p min;endforeach processor doforeach partition p doCompute cuboids in s from p using PipeHash;endendendFigure 4: Static Load Balancing AlgorithmThis subsection presents the description of a static load balancing strategy, which is provided especially for handling partition skew. The algorithm of this strategy is shown in Figure 4. The difference point from the simple parallel algorithm is in the partitioning phase. The simple partitioning method would cause load imbalances among processors in the presence of partition skew. In this algorithm, once a cuboid is partitioned on some dimensions, the part of these partitions are redistributed so that distribution of the number of tuples is as flat as possible among the processors. Since it is NP-hard to solve the optimal allocation of the partitions, we used a heuristic method, which allocates one of the partitions on the processor which has the largest number of tuples to the processor which has the smallest number of tuples.This procedure is repeated while the difference in the number of tuples between the two processors selected for reallocation of a partition is reduced. However, if partition skew becomes higher, the load of datacube processing might concentrate on a small number of the processors even if the balancing mechanism of this algorithm is applied. To avoid this situation, we assume that the number of partitions to be created is sufficiently larger than the number of processors. This finer granularity of partitions contributes to reduce the concentrated load to few processors. 4.3 A Dynamic Load Balancing Strategy Algorithm DynamicLoadBalancing(subtrees S)foreach subtree s in S doPartition the root of s on some dimensions;foreach partition p doAllocate p to the processor determined by the values of the partitioning dimensions;endlet t max = the largest number of tuples per processor;let t min = the smallest number of tuples per processor;let p max = a processor which has t max;let p min = a processor which has t min;let d = difference between t max and t min;while d is reduced by reallocation of a partition doreallocate one of the partitions on p max to p min;endforeach processor doforeach partition p doStart the computation of cuboids in s from p usingPipeHash;endendwhile there are unprocessed partitions doif one of the processors p dest complete the computation dochoose the processor p src which has the largest numberof unprocessed partitions;reallocate one of the unprocessed partitions on p src top dest;endendendFigure 5: Dynamic Load Balancing AlgorithmIn the parallel algorithm described above, processing of tuples on each processor, disk I/O for reading or writing each partition and network I/O for transferring partitions can be overlapped completely. It is also possible to overlap computation of cuboids in a subtree and partitioning of a root cuboid of the next subtree. As the number of dimensions increases, the number of cuboids that should be created increases exponentially. Processor costs for executing aggregation operation for the cuboids are expected to dominate in computing datacubes. We assume that the performance is bounded by processor loads the most of which are occupied by aggregation costs. The aggregation costs depend on the number of tuples to be processed. Thus load imbalances among processors will be caused by the effect of skewed aggregation costs if there is cuboid skew. This type of skew effect cannot be avoided by the static load balancing because the sizes of cuboids to be produced cannot be predicted in advance unless we resort to any kind of estimation methods as developed in [13].In this subsection, we introduce further enhancement to the static load balancing scheme to achieve more effective parallelization even in the presence of cuboid skew. We attempt to alleviate influence of this type of skew by dynamically transferring partitions between processors during computation. The algorithm is described in Figure 5. The partitioning method in the first phase is the same as the static approach. For the computation phase, a dynamic load balancing mechanism is incorporated. After reallocation of partitions for evenly distributing tuples across processors, each processor starts the processing of its own allocated partitions. If one of the processors completes its processing of the partitions, the processor sends a complete signal to a master processor, which is responsible for the control of transfers of partitions between the processors. The master processor holds statistical information about how many partitions have been processed on each processor at that point. If the master processor receives the complete signal, a transfer signal with the destination information is sent to the processor on which the largest number of partitions is not processed. If the processor receives the transfer signal, the processor sends one of the unprocessed partitions to the processor which has already completed its processing. Likewise, every time one of the processors finishes the computation, a partition is dynamically migrated to the processor to prevent the waste of processor resources.5. EXPERIMENTAL RESULTSWe made experiments based on simulations to examine the effectiveness of load balancing strategies in parallel datacube computation. For simplification, we assume that performance of the computation is bounded by processor costs except for the first partitioing process for raw data, which can be assumed to be disk I/O dominant. Aggregation costs are simply estimated by counting the number of tuples processed. Although simulations are under simplifying assumptions, it will be sufficient to compare relative performance of our strategies. Parameter values we used in these experiments are listed in Table 1. Disk I/O rate and time for aggregation are observed on IBM SP-2. When a value of a parameter is not changed in the experiment, the value in this table is used for the parameter.Parameter Valuenumber of processors 16number of dimensions 10number of tuples 108cardinality 100cuboid size factor 0.4165disk read rate6.45(MB/s)disk write rate 3.5 (MB/s)aggregation time per tuple 7.89 (ms)attribute size 4 (B)partition size 64 (KB)Table 1: Parameter ValuesTo study effects of partition skew, we varied a distribution of the number of tuples among processors in a partitioning step. We assume each partition is of the same size on each processor. For cuboid skew, we varied a distribution of aggregation costs among processors in a computation step. Likewise, each aggregation cost per partition is assumed to be equal on each processor. These distributions are varied based on a Zipf distribution, which is commonly used in experiments to investigate performance of skew handling techniques. The Zipf distribution is formulated as follows.∑==p i i ini Zipf 1)1()(ααrepresents a zipf factor which indicates the degree of skew. As a value of this factor increases, the degree of skew becomes large. We assigned values from 0 to 0.5 to this factor in these experiments. p is used as the number of processors. When this distribution is used for partition skew, n represents the number of tuples of root cuboids to be partitioned in a partitioning step. For cuboid skew, n is assigned the number of tuples of child cuboids to be produced in a computation step.We assume that all cardinalities of dimensions are equal. Suppose that the number of tuples and dimensions of raw data is t and n , and each cardinality is c , we determined the size in tuples of d dimensional cuboid s (d ) as follows.},min{)(1d d n c tf d s +−=In this equation, f denotes a cuboid size factor which indicates the difference in size between cuboids in different levels. We assume that the size of all cuboids in the same level are equal. The value of this factor should be determined such that the size of a child cuboid in a partition does not exceed the size of a parent cuboid of the child cuboid in that partition especially for the case of skewed data. We chose 0.4165 as a value of this factor because the largest partition size produced as a child cuboid in a computation step is equal to the partition size balanced in a partitioning step when this value is used under the condition where p is 16,is 0.5.Figure 6: Effect of Data SkewIn the first experiment, we examine the impact of data skew. The results for various degrees of partition skew and cuboid skew areshown in Figure 6. The estimated execution time is normalized to observe the efficiency of processor resource utilization. Let p , t e and t s denote the number of processors, estimated execution time, and execution time calculated by summing the costs of all participating processors. The relative execution time t r is formulated as follows.pt t t s e r =If the value of t r is closer to 1, this means that the load of processors is well balanced. For the change in the degree of partition skew, t r is not so affected because of the balancing mechanism of both strategies in the partitioning phase, however, the performance becomes slightly worse as the degree of partition skew increases. This is because a large amount of transfers of partitions in the partitioning phase result in the increased disk I/O cost if partition skew becomes higher. For cuboid skew, the performance of the dynamic load balancing strategy is almost constant regardless of the degree of cuboid skew, while the performance of the static strategy degrades with increase in the degree of cuboid skew due to the load imbalancesof the aggregation costs.Figure 7: SpeedupIn the following experiments, we fixed the degree of partition skew constantly to 1 to compare the static and dynamic load balancing algorithm for various degrees of cuboid skew. Figure 7 shows the speedup ratio to the number of processors. With the dynamic algorithm, the load balancing is effectively achieved as indicated in the results.Figure 8: Performance for Various Number of Tuples Finally, we performed experiments varying the number of tuples and dimensions as a parameter under the condition where the different degrees of cuboid skew exists. The results of these experiments are shown in Figure 8 and Figure 9. Clearly, the dynamic load balancing algorithm is not suffered from the effect of cuboid skew for the various values of these parameters, whilethe static algorihtm is very sensitive to cuboid skew.Figure 9: Performance for Various Number of Dimensions6. RELATED WORKThere has been a considerable amont of work on dynamic load balancing on multiprocessor systems in database applications. In particular, dynamic load balancing in parallel join processing has been well studied before[4][7][9][14]. The basic idea of our method is based on these algorithms. However, to our knowledge, there has been no work on dynamic load balancing techniques for parallel datacube computation.7. CONCLUSIONSIn this paper, we presented a dynamic load balacing strategy for parallel datacube computation in the presence of data skew. The computation of datacube can be easily parallelized, however, the effectiveness of the parallelization deteriorates in the case of skewed data. We presented the static strategy and the dynamic strategy for load balancing in the parallelized PipeHashalgorithm, which makes it possible to avoid the concentration of processing load on some of the processors. We performed experiments based on simulations and it is shown that datacube computation was effectively parallelized by applying our strategy. As future work, we plan to actually implement our algorithms and evaluate the performance based on the implementation under various conditions.8. REFERENCES[1] S. Agarwal, R. Agrawal, P. M. Deshpande, A. Gupta, J. F.Naughton, R. Ramakrishnan and S. Sarawagi, "On the Computation of Multidimentional Aggregates", In Proceedings of the International Conference on Very Large Databases , pages 506-521, 1996.[2] K. S. Beyer and R. Ramakrishnan, "Bottom-UpComputation of Sparse and Iceberg CUBEs", In Proceedings of the ACM SIGMOD Conference on Management of Data , pages 359-370, 1999.[3] P. M. Deshpande, S. Agarwal, J. F. Naughton and R.Ramakrishnan, "Computation of Multidimensional Aggregates", Technical Report 1314, University of Wisconsin, Madison, 1996.[4] D. J. DeWitt, J. F. Naughton, D. A. Schneider and S.Seshadri, "Practical Skew Handling in Parallel Joins", In Proceedings of the International Conference on Very Large Databases , pages 27-40, 1992.[5] J. Gray, A. Bosworth, A. Layman and H. Pirahesh, "ARelational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals", In Proceedings of the IEEE International Conference on Data Engineering , pages 152-159, 1996.[6] S. Goil and A. Choudhary, "High Performance OLAP andData Mining on parallel computers", Journal of Data Mining and Knowledge Discovery , 1(4):391-417, 1997.[7] K. A. Hua and C. Lee, "Handling Data Skew inMultiprocessor Database Computers Using Partition Tuning", In Proceedings of the International Conference on Very Large Databases , pages 525-535, 1991.[8] V. Harinarayan, A. Rajaraman and J. D. Ullman,“Implementing Data Cubes Efficiently”, In Proceedings of the ACM SIGMOD Conference on Management of Data , pages 205-216, 1996.[9] M. Kitsuregawa and Y. Ogawa, "Bucket Spreading ParallelHash: A New, Robust, Parallel Hash Join Method for Data Skew in the Super Database Computer (SDC)", In Proceedings of the International Conferen ce on Very Large Databases , pages 210-221, 1990.[10] K. A. Ross and D. Srivastava, "Fast Computation of SparseDatacubes", In Proceedings of the International Conference on Very Large Databases , pages 116-125, 1997.[11] S. Sarawagi, R. Agrawal and A. Gupta, "On Computing theData Cube", Research Report RJ10026, IBM Almaden Research Center, San Jose, CA, 1996.。