Python网络爬虫技术教学进度表
《Python程序设计》教学进度表

Python程序设计一、教学内容及学时安排1.理论教学序号章节名称主要内容教学目标周数1 Python概述1.Python概述。
2.Python开发环境。
1. 了解什么是Python,为什么要学习Python。
2.了解Python的发展史及其特点。
3.掌握如何设置Python开发环境。
12 Python基本语法1.变量、数据类型。
2.运算符与表达式。
3.数据的输入与输出。
4.math库简介。
1.掌握Python的变量和数据类型。
2.掌握Python的运算符与表达式。
3.掌握Python的数据输入与输出方法。
4. 了解math库。
13选择结构和循环结构1.程序的基本结构。
2.选择结构。
3.异常处理。
4.循环结构概述。
5.while循环语句。
6.调试程序。
7.for循环语句。
8.random库概述。
1.掌握程序的基本结构组成。
2.掌握Python选择结构和异常处理。
3.掌握Python的while循环语句、for循环语句、调试方法。
4. 了解random库。
14 组合数据类型1.组合数据类型概述。
2.列表、元组、字符串。
3.集合、字典。
4.jieba库的使用。
1.掌握Python的列表、元组、字符串、集合和字典。
2.了解jieba库。
12.实验教学二、考核方式突出学生解决实际问题的能力,加强过程性考核。
课程考核的成绩构成=平时成绩 (30%)+期中成绩(20%)+期末考核(50%),期末考试建议采用开卷形式,试题应包括基本概念、绘图、分组聚合、数据合并、数据清洗、数据变换、模型构建等部分,题型可采用判断题、选择、简答、应用题等方式。
Python网络爬虫技术-教学大纲

《Python网络爬虫技术》教学大纲
课程名称:Python网络爬虫技术
课程类别:必修
适用专业:大数据技术类相关专业
总学时:32学时(其中理论14学时,实验18学时)
总学分:2.0学分
一、课程的性质
大数据时代已经到来,在商业、经济及其他领域中基于数据和分析去发现问题并做出科学、客观的决策越来越重要。
在数据分析技术的研究和应用中,爬虫作为数据获取来源之一,扮演着至关重要的角色。
为了推动我国大数据,云计算,人工智能行业的发展,满足日益增长的数据分析人才需求,特开设Python网络爬虫技术课程。
二、课程的任务
通过本课程的学习,使学生学会使用Python在静态网页、动态网页、需要登录后才能访问的网页、PC客户端、APP中爬取数据,将理论与实践相结合,为将来从事数据爬虫、分析研究工作奠定基础。
三、课程学时分配
四、教学内容及学时安排
1.理论教学
2.实验教学
五、考核方式
突出学生解决实际问题的能力,加强过程性考核。
课程考核的成绩构成= 平时作业(10%)+ 课堂参与(20%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括爬虫与反爬虫、网页前端基础等相关概念,在静态网页、动态网页、需要登录后才能访问的网页、PC客户端、APP中爬取数据的方法,题型可采用判断题、选择、简答、应用题等方式。
Python爬虫超详细实战攻略教学进度计划表
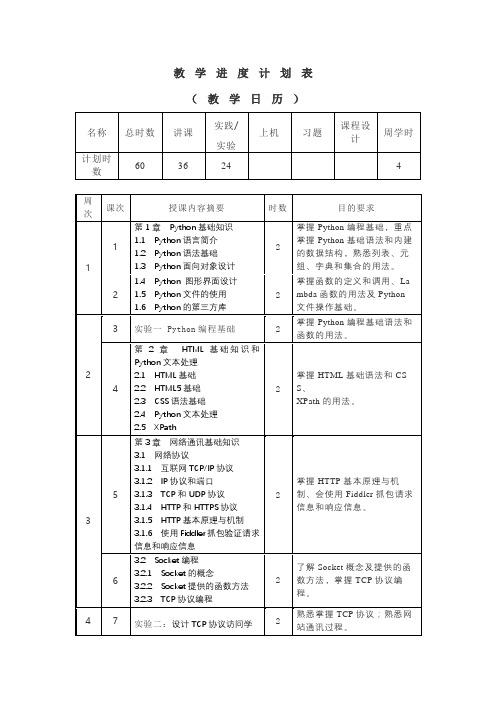
1.4 Python 图形界面设计
1.5 Python文件的使用
1.6 Python的第三方库
2
掌握函数的定义和调用、Lambda函数的用法及Python文件操作基础。
2
3
实验一Python编程基础
2
掌握Python编程基础语法和函数的用法。
4
第2章 HTML基础知识和Python文本处理
2.1 HTML基础
26
12.5 Scrapy数据容器
12.6 Scrapy常用命令行工具
12.7 Scrapy数据处理
12.8 爬取文件和图片
12.9 Scrapy模拟登录
2
掌握Scrapy选择器、数据容器和Item Pipeline的使用方法;了解常用的Scrapy命令;掌握爬取文件和图片的方法。
14
27
实验十一:深入了解Scrapy爬虫框架
2.2 HTML5基础
2.3 CSS语法基础
2.4 Python文本处理
2.5 XPath
2
掌握HTML基础语法和CSS、
XPath的用法。
3
5
第3章 网络通讯基础知识
3.1 网络协议
3.1.1 互联网TCP/IP协议
3.1.2 IP协议和端口
3.1.3 TCP和UDP协议
3.1.4 HTTP和HTTPS协议
13.3.1 安装WordCloud词云
13.3.2 使用WordCloud词云
2
熟悉WordCloud词云的安装与导入;熟悉WordCloud词云处理基本方法;
15
29
13.4 程序设计的步骤
2
熟悉文本分析、停用词、分词、Python可视化技术
Python学习课程安排表

从Python基础到数据清洗,到爬虫,到案例分析实战,还有Python量化与统计计量,all about Python:等级课程时间方式Level1 Python编程基础入门,从配置环境到能够上手5月6-9日四天北京/远程Level2Python数据清洗及统计描述数据思维和数据清洗5月13-15日三天北京/远程Level3 Python爬虫学会网络爬虫收集数据5月20-21日两天北京/远程Level4Python数据挖掘,算法及案例5月27-30日四天北京/远程专题Python量化投资基础+实战4 月 15-16,22-23日北京/远程专题Python统计计量4月28-5月1日上海/视频(课程详情请参照回复)Level1-Python编程基础 5月6-9日四天北京/远程3200/2600课程大纲:一,Python 概述(0.5 天)注:本部分课程主要为Python语言的介绍及基础环境的安装配置。
0.1Python语言介绍、Anaconda科学计算集成介绍安装0.2Python编译器、Shell、编辑器介绍0.3Python的第三方包的管理0.4Python在数据分析领域的生态介绍二,Python编程基础(3.5天)注:本部分主要为讲解Python的基础编程知识,侧重于Python数据分析常用的功能和知识点进行讲解。
课程安排:1.1Python语言特点1.2Python的数据类型和变量1.3Python中的运算1.4Python的数据结构1.5Python的控制流语句1.6Python中的异常处理和调试1.7函数调用和定义以及函数的参数1.8Python的类和面向对象编程1.9Python的文件、模块操作1.10其他高级特性练习项目:-蒙特卡罗模拟求圆周率-冒泡算法和二分查找-实现计算器-堆栈和队列的实现-模拟实现ATM机取钱-求阶乘-模拟管理学生成绩信息-编程实现24点扑克游戏-会员信息管理的实现-虚拟水果店进销存系统-投票系统-汉诺塔问题-离散事件模拟-堆排序的实现Level 2:Python数据清洗及统计描述5月13-15日三天北京/远程2400/2000课程大纲:一,Numpy(NumericalPython)是高性能科学计算和数据分析的基础包,是数据分析几乎所有的高级工具的构建基础。
python爬虫课程标准

“python爬虫”课程标准一、课程性质本课程是大数据技术与应用专业的一门专业核心课(技术技能课),旨在对学生的程序设计思想和技能进行强化,培养学生利用主流scrapy框架进行爬虫项目的设计和开发的能力。
先导课程:web应用开发技术、python基础、数据库基础建议学时:二、设计思路本课程依据网页爬虫开发岗位的PGSD能力要求而设置,主要工作时根据需求进行数据采集,获得有效数据,课程对应的职业能力分析具体如表1-1所示。
表1-1 “python爬虫”课程对应PGSD能力要求本课程以爬虫工程师岗位的基本要求为指导,依据该岗位真实业务内容与流程选取课程内容、构建学习单元,将目前爬虫程序必备功能组件如网页数据下载、数据分析、数据存储、网页地柜爬取等技术作为项目中的系列任务。
课程内容编排符合循序渐进的认知规律,培养学生的网页爬虫实际应用能力。
三、课程目标本课程内容涵盖了学生在“基本理论”、“基本技能”和“实战项目”三个层次的培养。
以网页爬虫开发岗位必备的开发技能为重点并具备相应的理论基础的同时,注意实际工作中业务场景,从而培养学生的数据爬取能力。
①掌握爬虫程序设计理念;②掌握数据提取与存储思想;③掌握scrapy爬虫框架设计思想;④熟练掌握ullib网页下载方法;⑤熟练掌握正则表达式选取数据的规则;⑥熟练掌握beautifulsoup工具选取数据的方法;⑦熟练掌握xpath、css选择数据的方法;⑧熟练掌握scrapy网页爬取的工作流程;⑨熟练掌握scrapy中item、pipeline数据的序列化输出方法;⑩熟练掌握scrapy中spider的网页递归爬取技术;11熟练掌握scrapy中间件的使用方法;12能够完成真实业务逻辑向代码的转化;13能够独立分析解决技术问题;14自学能力强,能够快速准确地查找参考资料;15能够安好规范编写技术文档;16沟通能力强,能够与小组其他人通力合作四、课程内容与要求本课程内容要求如表1-2所示:表1-2 “python爬虫”课程内容与要求五、课程考核方案本课程考核方案如表1-3所示。
3Python网络爬虫--教学日历(1-18)【17计网123】【周2】
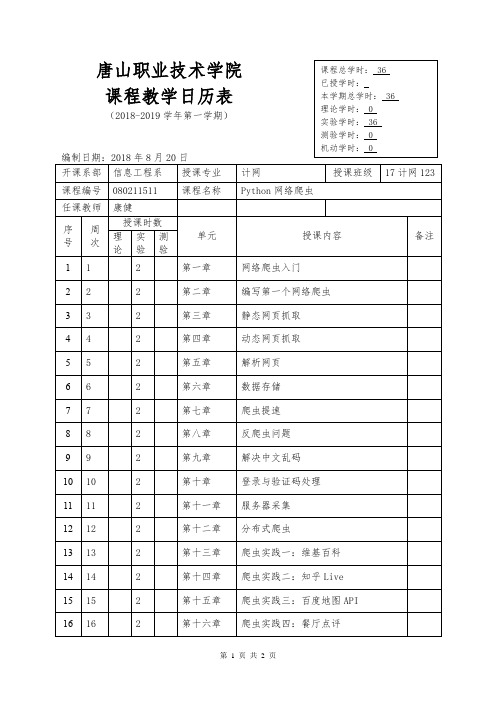
解析网页
6
6
2
第六章
数据存储
7
7
2
第七章
爬虫提速
8
8
2
第八章
反爬虫问题
9
9
2
第九章
解决中文乱码
10
10
2
第十章
登录与验证码处理
11
11
2
第十一章
服务器采集
12
12
2
第十二章
分布式爬虫
13
13
2
第十三章
爬虫实践一:维基百科
14
14
2
第十四章
爬虫实践二:知乎Live
15
15
2第十五章爬虫实践三:地图I编制日期:2018年8月20日
开课系部
信息工程系
授课专业
计网
授课班级
17计网123
课程编号
080211511
课程名称
Python网络爬虫
任课教师
康健
序号
周次
授课时数
单元
授课内容
备注
理论
实验
测验
1
1
2
第一章
网络爬虫入门
2
2
2
第二章
编写第一个网络爬虫
3
3
2
第三章
静态网页抓取
4
4
2
第四章
动态网页抓取
5
5
2
16
16
2
第十六章
爬虫实践四:餐厅点评
17
17
2
第十六章
数据清洗
18
18
2
第十六章
数据表达
教研室主任签字
《Python网络爬虫技术》教学进度表

学院课程教学进度计划表(20〜20学年第二学期)课程名称PVthOn网络爬虫技术授课学时64学时主讲(责任)教师___________________ 参与教学教师_______________________ 授课班级/人数______________________ 专业(教研室)_____________________ 填表时间___________________________ 专业(麴f室)主任 _________________教务处编印年月一、课程教学目的通过本课程的学习,掌握使用PythOn基本语法完成爬虫任务编写,使用ReqUeStS库向指定网址发送请求,XPath或BeaUtifUISoUP库对静态网页进行解析,Se1eniUm库爬取动态页面;使用JSoN 文件、MySQ1数据库、MongoDB数据库对爬取下来的数据进行存储;使用表单登录方法、Cookie登录方法实现模拟登录;使用HTTPAna1yzer和Fidd1er工具抓包,并分析终端协议;使用SCraPy框架进行网页内容爬取,理论结合实践,每个章节中都配有多个案例,为学生将来从事数据采集、数据爬取的工作、研究奠定基础。
二、教学方法及手段本课程将采用理论与实践相结合的教学方法。
在理论上,通过任务引入概念、原理和方法。
在实践上,充分地利用现有的硬件资源,发挥学生主观能动性,指导学生按照Pyeharm、MySQ1›Mo ngoDB作为数据爬取的基础环境,使用Requests或者UH1ib3发送请求,使用XpathxBeaUtifU1SOUP或者正则表达式进行页面解析,使用Se1eniUm进行动态页面解析,使用JSON文件、MySQ1数据库或者MongoDB 数据库进行数据存储,使用POST请求模拟登录网站,使用HTTPAna1yzer或者Fidd1er工具对终端数据进行爬取,使用Scrapy框架进行内容爬取解析,引导学生将所学知识与企业需求相结合,将知识活学活用。
Python3教学进度表
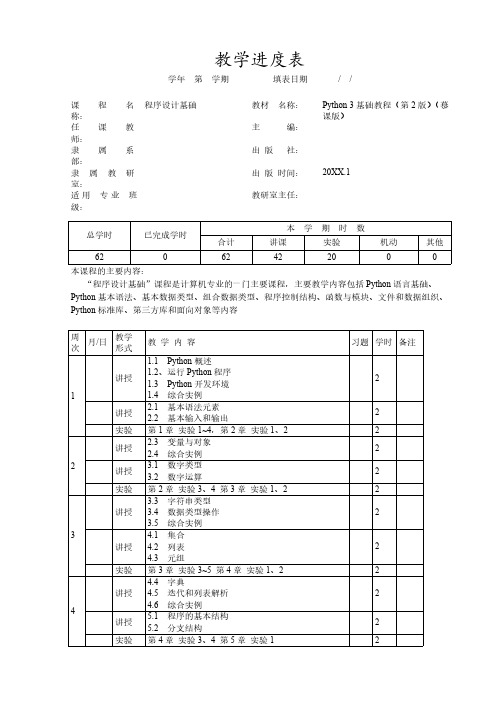
习题 学时 备注
2
2 2 2 2 2 2
2 2 2 2 2
5.3 循环结构
讲授 5.4 异常处理
2
5
5.5 综合实例
讲授 6.1 函数
2
实验 第 5 章 实验 2~4 第 6 章 实验 1
2
6.2 变量的作用域
6.3 模块
讲授
2
6
6.4 模块包
6.5 综合实例
讲授 7.1 文件
2
实验 第 6 章 实验 2、3 第 7 章 实验 1、2
实验
讲授
2
讲授
实验
讲授
3 讲授
实验
讲授
4 讲授
实验
教学内容
1.1 Python 概述 1.2、运行 Python 程序 1.3 Python 开发环境 1.4 综合实例 2.1 基本语法元素 2.2 基本输入和输出 第 1 章 实验 1~4,第 2 章 实验 1、2 2.3 变量与对象 2.4 综合实例 3.1 数字类型 3.2 数字运算 第 2 章 实验 3、4 第 3 章 实验 1、2 3.3 字符串类型 3.4 数据类型操作 3.5 综合实例 4.1 集合 4.2 列表 4.3 元组 第 3 章 实验 3~5 第 4 章 实验 1、2 4.4 字典 4.5 迭代和列表解析 4.6 综合实例 5.1 程序的基本结构 5.2 分支结构 第 4 章 实验 3、4 第 5 章 实验 1
0
62
42
20
0
0
本课程的主要内容: “程序设计基础”课程是计算机专业的一门主要课程,主要教学内容包括 Python 语言基础、
Python 基本语法、基本数据类型、组合数据类型、程序控制结构、函数与模块、文件和数据组织、 Python 标准库、第三方库和面向对象等内容
python简易爬虫课程设计

python简易爬虫课程设计一、课程目标知识目标:1. 学生能理解网络爬虫的基本概念,掌握Python爬虫的基本原理。
2. 学生能运用requests库进行网络请求,使用BeautifulSoup库进行网页解析。
3. 学生了解并掌握如何从网页中提取有用信息,如文本、链接、图片等。
技能目标:1. 学生能独立编写简单的Python爬虫程序,实现对特定网站数据的抓取。
2. 学生具备解决实际爬虫问题中常见异常和问题的能力,如请求异常、解析错误等。
3. 学生能够对抓取的数据进行初步分析和处理,如数据清洗、存储等。
情感态度价值观目标:1. 学生培养对网络信息的敏感度,学会从海量数据中挖掘有价值的信息。
2. 学生树立正确的网络道德观念,遵循我国相关法律法规,尊重网站版权和用户隐私。
3. 学生培养团队合作意识,学会在项目过程中互相交流、协作、解决问题。
课程性质分析:本课程为Python编程拓展课程,适用于已掌握Python基础的学生。
课程旨在帮助学生将Python技能应用于实际项目,提高学生解决实际问题的能力。
学生特点分析:学生已具备一定的编程基础,对Python语法有初步了解。
学生对网络爬虫感兴趣,但可能对实际操作中遇到的困难缺乏解决经验。
教学要求:1. 理论与实践相结合,注重学生动手实践能力的培养。
2. 结合实际案例,引导学生掌握爬虫技术的应用。
3. 注重培养学生的解决问题的能力,提高学生的网络素养。
二、教学内容1. 网络爬虫基础知识:介绍网络爬虫的概念、分类及应用场景,让学生了解爬虫的基本原理和重要性。
- 爬虫概念及分类- 爬虫应用场景及意义2. Python爬虫库:讲解Python中常用的爬虫库,如requests、BeautifulSoup等,并展示如何使用这些库进行网页请求和解析。
- requests库的使用- BeautifulSoup库的使用3. 网页解析与数据提取:教授如何从网页中提取所需信息,包括文本、链接、图片等,并介绍常用的解析方法。
Python关于爬虫课程设计

Python关于爬虫课程设计一、课程目标知识目标:1. 学生能理解网络爬虫的基本概念及其在数据获取中的应用。
2. 学生掌握使用Python编写简单的爬虫程序,能够从网站上抓取和解析数据。
3. 学生了解并能够运用常用的Python爬虫库,如requests、BeautifulSoup 等。
4. 学生理解并能够遵循网络爬虫的道德规范和法律法规。
技能目标:1. 学生能够运用Python语言编写基本的网络爬虫程序,具备数据抓取的能力。
2. 学生能够运用解析库对抓取的HTML页面进行分析,提取所需数据。
3. 学生能够解决简单的反爬虫策略,如设置用户代理、处理Cookies等。
4. 学生能够通过实践操作,培养编程思维和问题解决能力。
情感态度价值观目标:1. 学生培养对网络爬虫技术的兴趣,激发探索精神和创新意识。
2. 学生认识到网络爬虫技术在现实生活中的应用价值,增强学以致用的意识。
3. 学生树立正确的网络道德观念,遵循法律法规,尊重数据版权。
4. 学生通过小组合作,培养团队协作能力和沟通表达能力。
本课程针对高年级学生,结合Python编程知识,以实用性为导向,注重培养学生的实际操作能力和解决问题的能力。
课程目标旨在使学生在掌握爬虫技术的基础上,提升数据获取与分析的能力,为今后的学习和工作打下坚实基础。
二、教学内容1. 网络爬虫基础概念:介绍网络爬虫的定义、作用、分类及基本工作原理。
- 教材章节:第1章 网络爬虫概述2. Python爬虫环境搭建:讲解Python环境配置、爬虫库的安装及使用方法。
- 教材章节:第2章 Python爬虫环境准备3. 基本的网络请求:学习使用requests库发送HTTP请求,获取网页数据。
- 教材章节:第3章 网络请求与响应4. 数据解析与提取:学习BeautifulSoup库的使用,对HTML页面进行解析,提取所需数据。
- 教材章节:第4章 数据解析与提取5. 反爬虫策略应对:介绍常见的反爬虫策略及应对方法,如设置用户代理、处理Cookies等。
paython爬虫课程设计

paython爬虫课程设计一、课程目标知识目标:1. 理解网络爬虫的基本概念,掌握Python爬虫的基础知识;2. 学习并掌握常用的Python爬虫库,如requests、BeautifulSoup等;3. 了解HTML的基本结构和常用标签,能够分析网页结构提取所需数据;4. 学习数据存储与处理方法,掌握CSV、JSON等数据格式操作。
技能目标:1. 能够运用Python编写简单的爬虫程序,完成数据抓取任务;2. 学会使用爬虫库解析网页,提取目标数据;3. 能够处理常见的数据存储与处理问题,如数据清洗、去重等;4. 能够针对特定需求,设计并实现相应的爬虫策略。
情感态度价值观目标:1. 培养学生的信息素养,提高对网络资源的有效利用能力;2. 增强学生的实际操作能力,培养解决问题的信心和兴趣;3. 培养学生的团队协作精神,学会分享和交流;4. 培养学生遵守网络道德规范,尊重数据版权,合理使用爬虫技术。
课程性质:本课程为Python爬虫的入门课程,旨在让学生掌握爬虫的基本原理和方法,培养实际操作能力。
学生特点:学生具备一定的Python编程基础,对网络爬虫感兴趣,但缺乏实际操作经验。
教学要求:结合课程性质和学生特点,本课程注重理论与实践相结合,以实例为主线,引导学生动手实践,提高解决问题的能力。
在教学过程中,注重分层教学,满足不同层次学生的学习需求。
通过课程学习,使学生能够达到上述课程目标,为后续深入学习打下坚实基础。
二、教学内容1. 爬虫基本概念与原理:介绍爬虫的定义、作用及分类,分析爬虫的工作流程和基本原理。
- 教材章节:第1章 爬虫基础2. Python爬虫库:学习requests库发送网络请求,BeautifulSoup库解析HTML,lxml库的XPath语法。
- 教材章节:第2章 爬虫库的使用3. 网页结构分析:讲解HTML的基本结构,学习使用开发者工具分析网页,提取目标数据。
- 教材章节:第3章 网页结构分析4. 数据存储与处理:学习CSV、JSON等数据格式的操作,掌握数据清洗、去重等处理方法。
爬虫软件学习计划大学生

爬虫软件学习计划大学生一、学员信息姓名:XXX学号:XXXX专业:XXXXX院系:XXXXX联系方式:XXXXXXXXX二、学习目标掌握网络爬虫的基本原理和技术能够使用Python编程语言实现简单的爬虫程序具备分析和处理爬取数据的能力理解爬虫在信息收集和分析中的重要性三、学习内容1. 网络爬虫基础知识2. Python编程语言3. 爬虫实战项目4. 数据处理与分析四、学习时间安排1. 第一周:网络爬虫基础知识学习学习内容:了解网络爬虫的基本概念、原理、分类和应用场景,掌握常见的爬虫工具和技术。
学习任务:阅读相关教材和文章,收集网络爬虫的相关案例和资料,参与相关讨论和学习小组。
2. 第二周至第四周:Python编程语言学习学习内容:学习Python语法、基本数据类型、控制流、函数、模块、面向对象编程等知识。
学习任务:阅读Python编程教材,完成相关编程作业和练习,参与在线编程实践和讨论,制定个人学习计划和进度表。
3. 第五周至第八周:爬虫实战项目学习内容:实际操作,分析案例,动手编写简单的爬虫程序,学会使用相关爬虫工具和库。
学习任务:选择一个具体的爬虫实战项目,完成需求分析和方案设计,动手编写爬虫程序,收集和分析相关数据,撰写实验报告和总结。
4. 第九周至第十周:数据处理与分析学习内容:掌握数据清洗、处理和分析的基本方法和工具,学会使用Python的相关数据处理库和工具。
学习任务:参与相关实验和案例分析,掌握常见数据处理和分析技术,完成相关作业和实践项目。
五、学习评估和考核1. 在线学习小组交流和讨论2. 完成相关编程实验、作业和实战项目3. 定期进行学习总结和评估,及时调整学习计划和进度六、学习资源1. 电子教材和参考书籍2. 在线教学视频和资源3. 开放式课程和学习小组七、学习汇报1. 学习过程中的心得体会和问题反馈2. 学习成果和实践项目总结3. 学习经验和技能分享八、学习的困难和挑战1. 编程环境和工具的设置和调试2. 编程语言和算法的学习和实践3. 实战项目的需求分析和技术方案设计4. 数据处理和分析的复杂性和实际应用九、学习成果1. 掌握网络爬虫的基本原理和技术,能够使用Python编程语言实现简单的爬虫程序2. 具备分析和处理爬取数据的能力,理解爬虫在信息收集和分析中的重要性3. 能够参与相关实战项目和数据分析工作,并应用到实际工作和学习中十、学习后续计划1. 深入学习和应用数据挖掘、机器学习等技术和工具2. 加强编程实践和开源项目参与3. 参加相关技术和学术交流活动,与同行学者和专家分享经验和成果十一、学习计划执行人学员签名:______________ 日期:__________指导老师签名:______________ 日期:__________以上是爬虫软件学习计划,希望能够对您有所帮助。
python爬虫项目课程设计

python爬虫项目课程设计一、课程目标知识目标:1. 学生能理解网络爬虫的基本概念,掌握Python爬虫的基础知识;2. 学生能运用requests库进行网络请求,获取网页数据;3. 学生能使用BeautifulSoup库对获取的HTML内容进行解析,提取所需信息;4. 学生了解并遵循网络爬虫的道德规范与法律法规。
技能目标:1. 学生掌握Python编程基础,能运用爬虫技术独立完成数据采集任务;2. 学生能运用所学知识解决实际问题,具备一定的编程调试能力;3. 学生能通过实践项目,提高团队协作和沟通能力。
情感态度价值观目标:1. 学生培养对计算机编程的兴趣,激发学习积极性;2. 学生树立正确的网络安全意识,遵循网络道德规范;3. 学生通过项目实践,培养解决问题、不畏困难的精神品质。
分析课程性质、学生特点和教学要求:本课程为Python爬虫项目课程,旨在让学生掌握网络爬虫技术,培养实际编程能力。
学生为高年级学生,具备一定的Python基础,求知欲强,喜欢探索新知识。
教学要求注重实践操作,鼓励学生主动思考,培养解决实际问题的能力。
通过本课程的学习,使学生能够独立完成爬虫项目,为后续学习打下坚实基础。
二、教学内容1. 网络爬虫基本概念与原理- 爬虫的定义、分类与作用- 爬虫的合法性与道德规范2. Python基础回顾- Python基本语法- Python函数与模块3. 爬虫技术核心知识- HTTP请求与响应- requests库的使用- 网页解析与BeautifulSoup库- 数据存储(文本、数据库等)4. 实践项目:Python爬虫应用- 项目一:爬取某网站文章标题及链接- 项目二:爬取并解析某电商平台商品信息- 项目三:爬取并存储某电影网站电影数据5. 课程总结与拓展- 爬虫技术在实际应用中的注意事项- 爬虫技术进阶学习方向教学内容安排与进度:第一周:网络爬虫基本概念与原理,Python基础回顾第二周:爬虫技术核心知识(1),实践项目一第三周:爬虫技术核心知识(2),实践项目二第四周:爬虫技术核心知识(3),实践项目三第五周:课程总结与拓展教学内容与教材关联性:本教学内容与教材紧密相关,以《Python编程》教材中网络爬虫相关章节为基础,结合实际案例进行拓展和深入,确保学生学以致用。
《Python爬虫程序设计》课程标准

《Python爬虫程序设计》课程标准课程名称:Python爬虫程序设计适用专业:软件技术课程编码:参考学时:56一、课程概述随着互联网技术的飞速发展,以及国家产业信息化进程的大力推进下,在大数据时代背景下,产生了对基于Web网站的数据的大量需求。
快速、稳定、健壮、分布式的爬虫程序呼之欲出,业界对于爬虫程序的开发人员需求很大,而此类人才在目前的人才市场上比较稀缺,造成爬虫程序工程师等职位的需求缺口较大。
本门课程旨在通过学习与实践培养学生的爬虫程序开发能力,为社会输送急需人才;课程对应的网页爬虫开发工程师岗位有着相对较高的薪酬水平和较为广阔的发展前景,可以为参加学习的学生提供良好职业预期发展。
本课程主要面向岗位为网页爬虫开发工程师,能力辐射岗位有:Web开发工程师、数据分析师、测试工程师、文档工程师、售前/售后工程师等。
1.课程性质本课程注重对学生职业能力和创新精神、实践能力的培养。
本课程旨在对学生的程序设计思想和技能进行,培养学生利用主流scrapy框架进行爬虫项目的设计与开发。
《Python爬虫程序设计》课程是软件技术专业Python方向的专业核心课程,是融理论与实践一体化,教、学、做一体化的专业课程,是基于设计的工作过程系统化学习领域课程,是工学结合课程。
本课程的前续课程安排为:“Python程序设计基础”、“HTML5基础”、“数据库技术”;与本课程可以平行开展的课程为web后台技术类课程如:“PHP开发基础”、“Web应用开发技术”等相关课程;本课程的后续课程为“Python数据分析技术”。
2设计思路课程开发遵循的基于工作过程导向的现代职业教育指导思想,课程的目标是网页爬虫程序开发职业能力培养。
课程教学内容的取舍和内容排序遵循以工作需求为目标原则,务求反映当前网页爬虫开发的主流技术和主流开发工具,同时重视软件工程的标准规范,重视业内工作过程中的即成约定,努力使学生的学习内容与目标工作岗位能力要求无缝对接。
聚焦爬虫课程设计方案模板

#### 1. 课程名称《网络爬虫设计与实践》#### 2. 课程目标本课程旨在使学生掌握网络爬虫的基本原理、设计方法以及实际应用技巧,培养学生具备独立设计、开发网络爬虫的能力,提高信息获取和处理能力。
#### 3. 课程内容(1)网络爬虫基础知识(2)Python编程基础(3)HTML与XML解析(4)网络爬虫设计与实现(5)数据存储与处理(6)数据可视化(7)爬虫伦理与法律法规### 二、课程结构#### 1. 理论教学(1)每周2课时,共计16周(2)以课堂讲授为主,结合案例分析、讨论和实验#### 2. 实践教学(1)每周2课时,共计16周(2)以实验、项目实践为主,培养学生的实际操作能力#### 3. 课外辅导(1)每周1课时,共计8周(2)解答学生在学习过程中遇到的问题,提供必要的指导#### 1. 教材《Python网络爬虫开发实战》#### 2. 在线资源(1)国家精品在线开放课程(2)相关技术博客、论坛(3)在线实验平台#### 3. 实验环境(1)Python 3.x(2)requests、BeautifulSoup、lxml、pymongo等第三方库### 四、教学进度安排#### 1. 理论教学进度(1)第1-4周:网络爬虫基础知识(2)第5-8周:Python编程基础(3)第9-12周:HTML与XML解析(4)第13-16周:网络爬虫设计与实现、数据存储与处理、数据可视化#### 2. 实践教学进度(1)第1-4周:Python基础实验(2)第5-8周:HTML解析实验(3)第9-12周:网络爬虫设计与实现实验(4)第13-16周:数据存储与处理、数据可视化实验### 五、考核方式#### 1. 平时成绩(1)课堂表现:20%(2)实验报告:30%(3)项目实践:50%#### 2. 期末考试(1)笔试:60%(2)上机操作:40%### 六、教学评价#### 1. 教师评价(1)教学效果评价:根据学生平时成绩、项目实践成果进行评价(2)教学方法评价:根据学生反馈、教学日志进行评价#### 2. 学生评价(1)课程满意度调查(2)教学效果反馈### 七、总结本课程设计旨在培养学生的网络爬虫设计与实践能力,通过理论教学、实践教学和课外辅导相结合的方式,使学生掌握网络爬虫的基本原理、设计方法以及实际应用技巧。
Python网络爬虫技术 第7章 Scrapy爬虫 教案

第7章Scrapy爬虫教案课程名称:Python网络爬虫技术课程类别:必修适用专业:大数据技术类相关专业总学时:32学时(其中理论14学时,实验18学时)总学分:2.0学分本章学时:5学时一、材料清单(1)《Python网络爬虫技术》教材。
(2)配套PPT。
(3)引导性提问。
(4)探究性问题。
(5)拓展性问题。
二、教学目标与基本要求1.教学目标使用Scrapy框架爬取网站,学会Scrapy的数据流向、框架,以及框架各组成部分的作用。
Scrapy的常用命令及其作用。
创建Scrapy爬虫项目,创建爬虫模板的方法。
根据项目最终目标修改items/piplines脚本。
编写spider脚本,解析网页。
修改settings脚本,实现下载延迟设置等。
定制下载中间件,实现随机选择访问USER_AGENT与IP。
2.基本要求(1)了解Scrapy爬虫框架。
(2)熟悉Scrapy常用命令。
(3)修改items/piplines脚本存储数据。
(4)编写spider脚本解析网页信息。
(5)修改settings脚本设置爬虫参数。
(6)定制Scrapy中间件。
三、问题1.引导性提问引导性提问需要教师根据教材内容和学生实际水平,提出问题,启发引导学生去解决问题,提问,从而达到理解、掌握知识,发展各种能力和提高思想觉悟的目的。
(1)如何实现对爬取过的内容不重新爬取?2.探究性问题探究性问题需要教师深入钻研教材的基础上精心设计,提问的角度或者在引导性提问的基础上,从重点、难点问题切入,进行插入式提问。
或者是对引导式提问中尚未涉及但在课文中又是重要的问题加以设问。
(1)如何实现日志打印到文件中?(2)piplines脚本中item是什么数据类型?(3)如何实现保存数据到MongoDB数据库?3.拓展性问题拓展性问题需要教师深刻理解教材的意义,学生的学习动态后,根据学生学习层次,提出切实可行的关乎实际的可操作问题。
亦可以提供拓展资料供学生研习探讨,完成拓展性问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
学院
课程教学进度计划表(20 ~20 学年第二学期)
课程名称Python网络爬虫技术
授课学时32
主讲(责任)教师
参与教学教师
授课班级/人数
专业(教研室)
填表时间
专业(教研室)主任
教务处编印
年月
一、课程教学目的
通过本课程的学习,使学生学会使用Python在静态网页、动态网页、需要登录后才能访问的网页、PC客户端、APP中爬取数据,将理论与实践相结合,为将来从事数据爬虫、分析研究工作奠定基础。
二、教学方法及手段
本课程将采用理论与实践相结合的教学方法。
在理论上,通过任务引入概念、原理和方法。
在实践上,充分地利用现有的硬件资源,发挥学生主观能动性,结合真实例子,指导学生通过不同的方法在静态网页、动态网页、需要登录后才能访问的网页、PC客户端、APP中爬取数据。
要求学生自己动手分析实例,学习基本理论和方法,结合已有的知识,适当组织一些讨论,充分调动学生的主观能动性,以达到本课程的教学目的。
三、课程考核方法
突出学生解决实际问题的能力,加强过程性考核。
课程考核的成绩构成= 平时作业(10%)+ 课堂参与(20%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括爬虫与反爬虫、网页前端基础等相关概念,在静态网页、动态网页、需要登录后才能访问的网页、PC客户端、APP中爬取数据的方法,题型可采用判断题、选择、简答、应用题等方式。
《Python数据分析与应用》教学日历
注:教材:Python网络爬虫技术。