论文经典方法:Logistic回归分析及其应用
LOGISTIC回归分析

LOGISTIC回归分析前⾯的博客有介绍过对连续的变量进⾏线性回归分析,从⽽达到对因变量的预测或者解释作⽤。
那么如果因变量是离散变量呢?在做⾏为预测的时候通常只有“做”与“不做的区别”、“0”与“1”的区别,这是我们就要⽤到logistic分析(逻辑回归分析,⾮线性模型)。
参数解释(对变量的评价)发⽣⽐(odds): ODDS=事件发⽣概率/事件不发⽣的概率=P/(1-P)发⽣⽐率(odds ratio):odds ratio=odds B/odds A (组B相对于组A更容易发⽣的⽐率)注:odds ratio⼤于1或者⼩于1都有意义,代表⾃变量的两个分组有差异性,对因变量的发⽣概率有作⽤。
若等于1的话,该组变量对事件发⽣概率没有任何作⽤。
参数估计⽅法线性回归中,主要是采⽤最⼩⼆乘法进⾏参数估计,使其残差平⽅和最⼩。
同时在线性回归中最⼤似然估计和最⼩⼆乘发估计结果是⼀致的,但不同的是极⼤似然法可以⽤于⾮线性模型,⼜因为逻辑回归是⾮线性模型,所以逻辑回归最常⽤的估计⽅法是极⼤似然法。
极⼤似然公式:L(Θ)=P(Y1)P(Y2)...p(Y N) P为事件发⽣概率P I=1/(1+E-(α+βX I))在样本较⼤时,极⼤似然估计满⾜相合性、渐进有效性、渐进正太性。
但是在样本观测少于100时,估计的风险会⽐较⼤,⼤于100可以介绍⼤于500则更加充分。
模型评价这⾥介绍拟合优度的评价的两个标准:AIC准则和SC准则,两统计量越⼩说明模型拟合的越好,越可信。
若事件发⽣的观测有n条,时间不发⽣的观测有M条,则称该数据有n*m个观测数据对,在⼀个观测数据对中,P>1-P,则为和谐对(concordant)。
P<1-P,则为不和谐对(discordant)。
P=1-P,则称为结。
在预测准确性有⼀个统计量C=(NC-0.5ND+0.5T)/T,其中NC为和谐对数,ND为不和谐对数,这⾥我们就可以根据C统计量来表明模型的区分度,例如C=0.68,则表⽰事件发⽣的概率⽐不发⽣的概率⼤的可能性为0.68。
多分类有序反应变量Logistic回归及其应用

3、社会心理因素:老年人的心理状态、生活环境、生活习惯等也会对其睡 眠质量产生影响。例如,孤独、抑郁、生活压力等心理问题可能导致睡眠障碍。
有序多分类Logistic回归分析
为了探讨上述因素对老年人睡眠质量的影响,我们采用有序多分类Logistic 回归分析方法进行建模和分析。有序多分类Logistic回归是一种统计方法,它能 够根据有序类别变量的取值来估计多个类别的影响因素,并计算各因素的影响方 向和作用大小。
还应注意其他潜在影响因素的作用,以便更好地预防和改善公务员的亚健康 状况。
谢谢观看
பைடு நூலகம்
(2)数据拟合:将数据带入Logistic回归模型,用最大似然估计法对模型 参数进行估计。
(3)模型评估:通过交叉验证、准确率、AUC值等指标对模型进行评估,判 断其预测性能。
(4)模型优化:根据模型评估结果,对模型进行优化调整,包括特征选择、 参数调整等。
3、结果解读
多分类有序反应变量Logistic回归的结果解读包括以下几个方面:
影响因素
老年人睡眠质量受到多种因素的影响,包括身体健康状况、药物使用、社会 心理因素等。
1、身体健康状况:老年人往往存在各种健康问题,如慢性疾病、疼痛、呼 吸困难等,这些疾病会直接或间接影响睡眠质量。
2、药物使用:部分老年人在日常生活中需要使用药物来控制血压、治疗疼 痛等。然而,某些药物可能导致不良反应,从而影响睡眠质量。
1、因变量的处理:将亚健康状况分为5个等级(非常健康、健康、轻微不健 康、不健康、非常不健康),并将其作为有序分类变量进行统计处理。
2、自变量的选择:选择工作压力、生活方式、心理状况等作为自变量,并 将其进行标准化处理,以便进行比较和分析。
3、模型的建立:采用有序多分类logistic回归分析方法,建立模型并拟合 数据。通过模型的结果,可以观察各个自变量对因变量的影响程度及比较各个自 变量之间的相对重要性。
(整理)多项分类Logistic回归分析的功能与意义1.
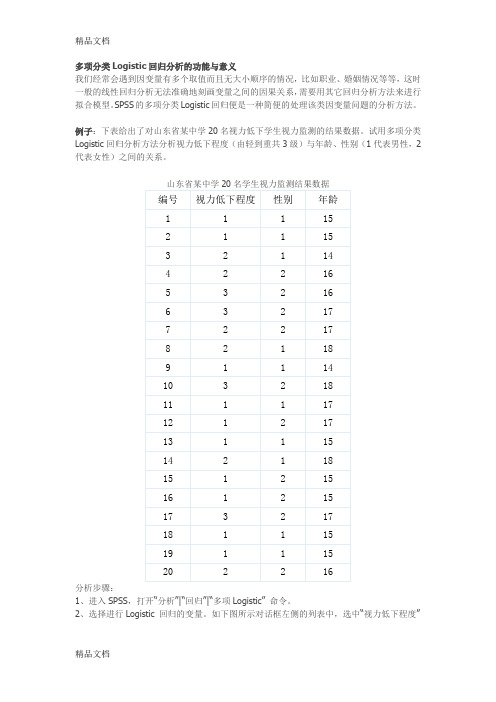
多项分类Logistic回归分析的功能与意义我们经常会遇到因变量有多个取值而且无大小顺序的情况,比如职业、婚姻情况等等,这时一般的线性回归分析无法准确地刻画变量之间的因果关系,需要用其它回归分析方法来进行拟合模型。
SPSS的多项分类Logistic回归便是一种简便的处理该类因变量问题的分析方法。
例子:下表给出了对山东省某中学20名视力低下学生视力监测的结果数据。
试用多项分类Logistic回归分析方法分析视力低下程度(由轻到重共3级)与年龄、性别(1代表男性,2代表女性)之间的关系。
并单击向右的箭头按钮使之进入“因变量”列表框,选择“性别”使之进入“因子”列表框,选择“年龄”使之进入“协变量”列表框。
还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示:上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic 回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下:1:设置随机抽样的随机种子,如下图所示:选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面:在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件”点击“如果”按钮,进入如下界面:如果“违约”变量中,确实存在缺失值,那么当使用"missing”函数的时候,它的返回值应该为“1”或者为“true",为了剔除”缺失值“所以,结果必须等于“0“也就是不存在缺失值的现象点击”继续“按钮,返回原界面,如下所示:将是“是否曾经违约”作为“因变量”拖入因变量选框,分别将其他8个变量拖入“协变量”选框内,在方法中,选择:forward.LR方法将生成的新变量“validate" 拖入"选择变量“框内,并点击”规则“设置相应的规则内容,如下所示:设置validate 值为1,此处我们只将取值为1的记录纳入模型建立过程,其它值(例如:0)将用来做结论的验证或者预测分析,当然你可以反推,采用0作为取值记录点击继续,返回,再点击“分类”按钮,进入如下页面在所有的8个自变量中,只有“教育水平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育水平分为:初中,高中,大专,本科,研究生等等, 参考类别选择:“最后一个”在对比中选择“指示符”点击继续按钮,返回再点击—“保存”按钮,进入界面:在“预测值"中选择”概率,在“影响”中选择“Cook距离” 在“残差”中选择“学生化”点击继续,返回,再点击“选项”按钮,进入如下界面:分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1,sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为129,选定案例总和为489那么:y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216 则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372 则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 =7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR方的值!提示:将Hosmer 和Lemeshow 检验和“随机性表” 结合一起来分析1:从 Hosmer 和Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看:0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
logic回归分析

因变量的选取:“是 否愿意退出闲置宅 基地”,
答案设为“愿意” 、“不愿意”和“ 不确定”3种情况。
愿意的定义为P=1, 不愿意的定义为P=0
因素
因变量 是否愿意退出宅基地 自变量 性别 年龄 文化程度 职业技能 家庭年收入
变量 名
农业收入比重 家庭人口数量 外出打工人数 赡养的老人数量 抚养的子女数量 宅基地数量 宅基地来源
完全不了解=0, 了解一些=1,非常了解=2 现金补偿=1,地价浮动补偿=2,置换住房=3,其他=4
1.048
4.506
1
.034
.108
常量
-2.629
1.554
2.862
1
.091
.072
a. 在步骤 1 中输入的变量: x3, x2, x1.
p exp(2.629 0.102x1 2.224x2 ) 1 exp(2.629 0.102x1 2.224x2 )
以本论文的研究方法为例
B
步骤 1a x3
2.502
x2
.002
x1
.082
常量 -6.157
S.E, 1.158 .002 .052 2.687
Wald 4.669 .661 2.486 5.251
df 1 1 1 1
Sig. Exp (B)
.031 12.205
.416 1.002
.115 1.086
.022
.002
B表示回归系数的参数,S.E.表示回归系数估计量的标准差,
2
因变量 y=1 表示乘坐
3 4
公共汽车上下班
5
变量y=0 表示要乘自
Logistic回归分析及应用-精选文档

•
注:是否患病中,‘0’代表否,‘1’代表是。 性别中‘1’代表男,‘0’代表女,吸烟中‘1’ 代表吸烟,‘0’代表不吸烟。地区中,‘1’代 表农村,‘0’代表城市。
•
• • • • • • • • • • •
表4 配对资料(1:1) 对子号 病例 对照 x1 x2 x3 x1 x2 x3 1 1 3 0 1 0 1 2 0 3 1 1 3 0 3 0 1 2 0 2 0 … … … … … … … 10 2 2 2 0 0 0 注:X1蛋白质摄入量,取值:0,1,2,3 X2不良饮食习惯,取值:0,1,2,3 X3精神状况 ,取值:0,1,2
'
b Si为 Xi的标准差 i b i *S i / Sy ,其中 Sy为 y 的标准差。
5.假设检验
• (1)回归方程的假设检验 i 0 0 , i 0 , 1 , 2 , , p • H0:所有 H :某个 i 1 • 计算统计量为:G=-2lnL,服从自由度等于n-p 2 • 的 分布 • (2)回归系数的假设检验 • H0: i 0 H1:i 0 2 计算统计量为:Wald ,自由度等于1。
第十六章 Logistic回归分析
Logistic
regression
1
复习
•
多元线性回归
(multiple linear regression)
在医学实践中,常会遇到一个应变量与 多个自变量数量关系的问题。如医院住院 人数不仅与门诊人数有关 , 而且可能与病 床周转次数 , 床位数等有关;儿童的身高 不仅与遗传有关还与生活质量,性别,地 区,国别等有关;人的体表面积与体重、 身高等有关。
2
• 1
表1 y1
Logistic回归分析

Logistic 回归分析Logistic 回归分析是与线性回归分析方法非常相似的一种多元统计方法。
适用于因变量的取值仅有两个(即二分类变量,一般用1和0表示)的情况,如发病与未发病、阳性与阴性、死亡与生存、治愈与未治愈、暴露与未暴露等,对于这类数据如果采用线性回归方法则效果很不理想,此时用Logistic 回归分析则可以很好的解决问题。
一、Logistic 回归模型设Y 是一个二分类变量,取值只可能为1和0,另外有影响Y 取值的n 个自变量12,,...,n X X X ,记12(1|,,...,)n P P Y X X X ==表示在n 个自变量的作用下Y 取值为1的概率,则Logistic 回归模型为:[]0112211exp (...)n n P X X X ββββ=+-++++它可以化成如下的线性形式:01122ln ...1n n P X X X P ββββ⎛⎫=++++ ⎪-⎝⎭通常用最大似然估计法估计模型中的参数。
二、Logistic 回归模型的检验与变量筛选根据R Square 的值评价模型的拟合效果。
变量筛选的原理与普通的回归分析方法是一样的,不再重复。
三、Logistic 回归的应用(1)可以进行危险因素分析计算结果各关于各变量系数的Wald 统计量和Sig 水平就直接反映了因素i X 对因变量Y 的危险性或重要性的大小。
(2)预测与判别Logistic回归是一个概率模型,可以利用它预测某事件发生的概率。
当然也可以进行判别分析,而且可以给出概率,并且对数据的要求不是很高。
四、SPSS操作方法1.选择菜单2.概率预测值和分类预测结果作为变量保存其它使用默认选项即可。
例:试对临床422名病人的资料进行分析,研究急性肾衰竭患者死亡的危险因素和统计规律。
Logistic回归分析.sav解:在SPSS中采用Logistic回归全变量方式分析得到:(1)模型的拟合优度为0.755。
Logistic回归分析概要

多项无序分类:肝炎分型 甲、乙、丙、丁、 戊
研究分类反应变量与多个影响因素之间的 相互关系的一种多变量分析方法,进行疾病的 病因分析。
• Logistic回归的分类
Logistic回归 二分类 有序反应变量 多分类 无序反应变量
非条件 1:1配对资料
条件Logistic回归 1:m配对资料 m:n配对资料
Logistic回归模型是一种概率模型, 通常以疾病,死亡等结果发生的概率为因变 量, 影响疾病发生的因素为自变量建立回 归模型。
• 例:为了探讨糖尿病与血压、血脂等因素 的关系,研究者对56例糖尿病病人和65例 对照者进行病例对照研究,收集了性别、 年龄、学历、体重指数、家族史、吸烟、
一、Logistic回归方程 Logistic回归的logit模型
P= 1x1 2 x2 n xn
Logit变换 P转换为ln[P/(1-P)]
logit (P)= 1x1 2 x2 n xn ln[P/(1-P)]= 1x1 2 x2 n xn
• (1)取值问题
• (2)曲线关联
• Logit变换
也称对数单位转换
logit P=
ln
P 1 P
( 1x1 2 x2 n xn )
P 1 e e( 1x1 2x2 n xn ) 1
1 P 1 e( 1x1 2x2 nxn )
其中,为常数项,为偏回归系数。
二、参数估计
• 建立Logistic回归方程就是求和i • 意义 常数项是当各种暴露因素为0时,个体发
得出参数 j 的估计值 b j 和 b j 的渐进标准误 Sbj 。
最大似然法的基本思想是先建立似然 函数与对数似然函数,再通过使对数 似然函数最大求解相应的参数值(使 得一次抽样中获得现有样本的概率为 最大),所得到的估计值称为参数的 最大似然估计值。
Logistic回归的实际应用

Logistic回归的介绍与实际应用摘要本文通过对logistic回归的介绍,对logistic回归模型建立的分析,以及其在实际生活中的运用,我们可以得出所建立的模型对实际例子的数据拟合结果不错。
关键词:logistic回归;模型建立;拟合;一、logistic回归的简要介绍1、Logistic回归的应用范围:①适用于流行病学资料的危险因素分析②实验室中药物的剂量-反应关系③临床试验评价④疾病的预后因素分析2、Logistic回归的分类:①按因变量的资料类型分:二分类、多分类;其中二分较为常用②按研究方法分:条件Logistic回归、非条件Logistic回归两者针对的资料类型不一样,后者针对成组研究,前者针对配对或配伍研究。
3、Logistic回归的应用条件是:①独立性。
各观测对象间是相互独立的;②Logit P与自变量是线性关系;③样本量。
经验值是病例对照各50例以上或为自变量的5-10倍(以10倍为宜),不过随着统计技术和软件的发展,样本量较小或不能进行似然估计的情况下可采用精确logistic回归分析,此时要求分析变量不能太多,且变量分类不能太多;④当队列资料进行logistic回归分析时,观察时间应该相同,否则需考虑观察时间的影响(建议用Poisson回归)。
4、拟和logistic回归方程的步骤:①对每一个变量进行量化,并进行单因素分析;②数据的离散化,对于连续性变量在分析过程中常常需要进行离散变成等级资料。
可采用的方法有依据经验进行离散,或是按照四分、五分位数法来确定等级,也可采用聚类方法将计量资料聚为二类或多类,变为离散变量。
③对性质相近的一些自变量进行部分多因素分析,并探讨各自变量(等级变量,数值变量)纳入模型时的适宜尺度,及对自变量进行必要的变量变换;④在单变量分析和相关自变量分析的基础上,对P≤α(常取0.2,0.15或0.3)的变量,以及专业上认为重要的变量进行多因素的逐步筛选;模型程序每拟合一个模型将给出多个指标值,供用户判断模型优劣和筛选变量。
多项分类Logistic回归分析的功能与意义 (1)
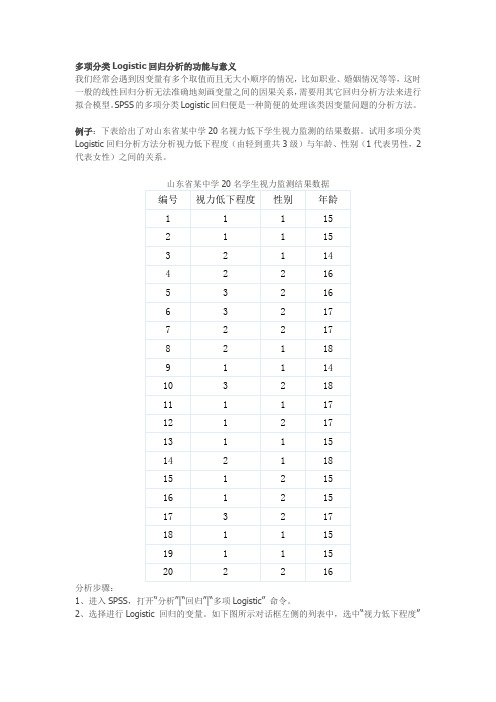
多项分类Logistic回归分析的功能与意义我们经常会遇到因变量有多个取值而且无大小顺序的情况,比如职业、婚姻情况等等,这时一般的线性回归分析无法准确地刻画变量之间的因果关系,需要用其它回归分析方法来进行拟合模型。
SPSS的多项分类Logistic回归便是一种简便的处理该类因变量问题的分析方法。
例子:下表给出了对山东省某中学20名视力低下学生视力监测的结果数据。
试用多项分类Logistic回归分析方法分析视力低下程度(由轻到重共3级)与年龄、性别(1代表男性,2代表女性)之间的关系。
并单击向右的箭头按钮使之进入“因变量”列表框,选择“性别”使之进入“因子”列表框,选择“年龄”使之进入“协变量”列表框。
还是以教程“blankloan.sav"数据为例,研究银行客户贷款是否违约(拖欠)的问题,数据如下所示:上面的数据是大约700个申请贷款的客户,我们需要进行随机抽样,来进行二元Logistic回归分析,上图中的“0”表示没有拖欠贷款,“1”表示拖欠贷款,接下来,步骤如下:1:设置随机抽样的随机种子,如下图所示:选择“设置起点”选择“固定值”即可,本人感觉200万的容量已经足够了,就采用的默认值,点击确定,返回原界面、2:进行“转换”—计算变量“生成一个变量(validate),进入如下界面:在数字表达式中,输入公式:rv.bernoulli(0.7),这个表达式的意思为:返回概率为0.7的bernoulli分布随机值如果在0.7的概率下能够成功,那么就为1,失败的话,就为"0"为了保持数据分析的有效性,对于样本中“违约”变量取缺失值的部分,validate变量也取缺失值,所以,需要设置一个“选择条件”点击“如果”按钮,进入如下界面:如果“违约”变量中,确实存在缺失值,那么当使用"missing”函数的时候,它的返回值应该为“1”或者为“true",为了剔除”缺失值“所以,结果必须等于“0“也就是不存在缺失值的现象点击”继续“按钮,返回原界面,如下所示:将是“是否曾经违约”作为“因变量”拖入因变量选框,分别将其他8个变量拖入“协变量”选框内,在方法中,选择:forward.LR方法将生成的新变量“validate" 拖入"选择变量“框内,并点击”规则“设置相应的规则内容,如下所示:设置validate 值为1,此处我们只将取值为1的记录纳入模型建立过程,其它值(例如:0)将用来做结论的验证或者预测分析,当然你可以反推,采用0作为取值记录点击继续,返回,再点击“分类”按钮,进入如下页面在所有的8个自变量中,只有“教育水平”这个变量能够作为“分类协变量” 因为其它变量都没有做分类,本例中,教育水平分为:初中,高中,大专,本科,研究生等等, 参考类别选择:“最后一个”在对比中选择“指示符”点击继续按钮,返回再点击—“保存”按钮,进入界面:在“预测值"中选择”概率,在“影响”中选择“Cook距离” 在“残差”中选择“学生化”点击继续,返回,再点击“选项”按钮,进入如下界面:分析结果如下:1:在“案例处理汇总”中可以看出:选定的案例489个,未选定的案例361个,这个结果是根据设定的validate = 1得到的,在“因变量编码”中可以看出“违约”的两种结果“是”或者“否” 分别用值“1“和“0”代替,在“分类变量编码”中教育水平分为5类,如果选中“为完成高中,高中,大专,大学等,其中的任何一个,那么就取值为1,未选中的为0,如果四个都未被选中,那么就是”研究生“ 频率分别代表了处在某个教育水平的个数,总和应该为489个1:在“分类表”中可以看出:预测有360个是“否”(未违约)有129个是“是”(违约)2:在“方程中的变量”表中可以看出:最初是对“常数项”记性赋值,B为-1.026,标准误差为:0.103那么wald =( B/S.E)²=(-1.026/0.103)² = 99.2248, 跟表中的“100.029几乎接近,是因为我对数据进行的向下舍入的关系,所以数据会稍微偏小,B和Exp(B) 是对数关系,将B进行对数抓换后,可以得到:Exp(B) = e^-1.026 = 0.358, 其中自由度为1,sig为0.000,非常显著1:从“不在方程中的变量”可以看出,最初模型,只有“常数项”被纳入了模型,其它变量都不在最初模型内表中分别给出了,得分,df , Sig三个值, 而其中得分(Score)计算公式如下:(公式中(Xi- X¯) 少了一个平方)下面来举例说明这个计算过程:(“年龄”自变量的得分为例)从“分类表”中可以看出:有129人违约,违约记为“1”则违约总和为129,选定案例总和为489那么:y¯ = 129/489 = 0.2638036809816x¯ = 16951 / 489 = 34.664621676892所以:∑(Xi-x¯)² = 30074.9979y¯(1-y¯)=0.2638036809816 *(1-0.2638036809816 )=0.19421129888216 则:y¯(1-y¯)* ∑(Xi-x¯)² =0.19421129888216 * 30074.9979 = 5 840.9044060372 则:[∑Xi(yi - y¯)]^2 = 43570.8所以:=43570.8 / 5 840.9044060372 =7.4595982010876 = 7.46 (四舍五入)计算过程采用的是在EXCEL 里面计算出来的,截图如下所示:从“不在方程的变量中”可以看出,年龄的“得分”为7.46,刚好跟计算结果吻合!!答案得到验证~1:从“块1” 中可以看出:采用的是:向前步进的方法,在“模型系数的综合检验”表中可以看出:所有的SIG 几乎都为“0”而且随着模型的逐渐步进,卡方值越来越大,说明模型越来越显著,在第4步后,终止,根据设定的显著性值和自由度,可以算出卡方临界值,公式为:=CHIINV(显著性值,自由度) ,放入excel就可以得到结果2:在“模型汇总“中可以看出:Cox&SnellR方和Nagelkerke R方拟合效果都不太理想,最终理想模型也才:0.305 和0.446,最大似然平方的对数值都比较大,明显是显著的似然数对数计算公式为:计算过程太费时间了,我就不举例说明计算过程了Cox&SnellR方的计算值是根据:1:先拟合不包含待检验因素的Logistic模型,求对数似然函数值INL0 (指只包含“常数项”的检验)2:再拟合包含待检验因素的Logistic模型,求新的对数似然函数值InLB (包含自变量的检验)再根据公式:即可算出:Cox&SnellR方的值!提示:将Hosmer 和Lemeshow 检验和“随机性表” 结合一起来分析1:从 Hosmer 和Lemeshow 检验表中,可以看出:经过4次迭代后,最终的卡方统计量为:11.919,而临界值为:CHINV(0.05,8) = 15.507卡方统计量< 临界值,从SIG 角度来看:0.155 > 0.05 , 说明模型能够很好的拟合整体,不存在显著的差异。
回归分析理论的发展与应用

回归分析理论的发展与应用回归分析是重要统计推断方法。
在实际应用中,回归分析是数理统计学与实际问题联系最为紧密,应用范围最为广泛,也是收效最为显著的统计分析方法;是分析数据,寻求变量之间关系有力的工具。
随着科学技术的发展,生物、医学、农业、林业、经济、管理、金融、社会等领域的许多实际新问题提出,有力地推动了回归分析的发展。
回归分析的研究主要是回归模型的参数估计、假设检验、模型选择等理论和有关计算方法。
一、经典回归模型经典回归模型分为线性回归模型和非线性回归模型。
线性回归模型是最基本的,也最简单的情形。
线性回归模型是回归模型学习的起点,在现行的概率统计教材和其它应用性的教材中都有该模型的分析和应用。
线性回归模型虽然简单,但比较有用,在许多实际应用工作发挥了很大作用。
非线性回归模型是上世纪六十年代初提出的,它是线性模型的自然推广,非线性回归模型现已发展成为近代回归分析的一个重要研究分支。
在实际应用中严格符合线性回归模型规律的问题并不多见,大多数问题可以近似为线性回归模型,在不少情形下,用非线性回归模型去拟合给定的数据集可能更加符合实际。
在经典回归模型研究中,通常假设响应变量的期望关于模型的未知参数是线性的或非线性的,随机误差是相互独立的,随机误差服从期望为零,方差相同的正态分布,其模型为:,t=1,2,…,n (1)其中为m维回归系数向量,(t=1,2,…,n)为随机误差,且满足Gauss-Markov假设:(1)随机误差期望为零,即,t=1,2,…,n;(2)随机误差具有等方差,即,t=1,2,…,n;(3)随机误差彼此不相关,即i≠j,i,j=1,2,…,n。
在Gauss-Markov假设中,假设(1)表明误差项不包含任何系统的趋势,因而,响应变量的均值,t=1,2,…,n。
即响应变量的大于或小于其均值的波动完全是一种随机性的,这种随机性来自误差;假设(2)表明误差项是等方差,即要求响应变量在其均值附近的波动完全是一样的,这种要求比较苛刻,一般情况,应该放松,t=1,2,…,n;假设(3)表明响应变量在不同次的观测是不相关的,这种假设在实际应用中比较容易满足,但在一些实际问题中,特别是与时间相联系的问题中,误差往往是相关的。
SPSS Logistic回归分析及其应用 图文

gi
ln(
p(y i) ) p(y J)
bi0
bi1x1
bi2 x2
bip xp
•而对于参考类别, 其模型中的所有系数均为0。
•最后,求得第i类的概率值:
p( yi )
exp( gi )
J
exp( gk )
k 1
•另:参数估计表(Parameter Estimates) 中的Exp(B) 表示某 因素(自变量) 内该类别是其相应参考类别具有某种倾向性的 倍数。
分析的一般步骤
• 变量的编码 • 哑变量的设置和引入(设置参照类) • 各个自变量的单因素分析 • 变量的筛选 • 交互作用的引入 • 建立多个模型 • 选择较优的模型 • 模型应用条件的评价 • 输出结果的解释
Logistic回归的分类
• 二项Logistic回归 (Binary Regression)
•
log it( p)
ln( p ) 1 p
b0
b1x1
bpxp
ez
eb0 b1x1 bp x p
p 1 e z 1 eb0 b1x1 bp x p
建立回归模型:
ln( p 1
p
)
b0
b1x
其中,p=p(y=1)
1 拥有住房 y=
0 其它情况
5
4.909
4
5.548
5
4.281
6
4.406
2
1.816
0
1.313
1
1.011
1
.537
0
.179
住房Y = 1
Logistic回归模型的应用_大学生就业状况因素分析

Logistic 回归模型的应用 ———大学生就业状况因素分析金林 (中南财经政法大学信息学院 湖北 武汉)【摘要】 本文在简要介绍了Logistic 回归模型后,利用从某高校取得的数据,运用多元Logistic 回归分析方法,对在高校扩招条件下影响大学生就业的因素进行了分析。
结果显示,在所有被考虑的自变量相同的情况下,被调查学生能否成功就业与性别、籍贯、是否为党员以及英语水平的高低等因素密切相关。
【关键词】 Logistic 回归 就业 多项l ogit 模型 Logistic 回归模型是在分析分类因变量时最常使用的统计分析模型之一。
1 Logistic 回归模型Logistic回归模型的Logit 形式为当有个自变量时,模型就扩展为通常意义上的Logistic 回归要求因变量y 只有两种取值即二分类变量。
其实,Logistic 回归模型并不局限于应用在二分类反应变量。
对于多分类反应变量,即分类数在三类或三类以上的分类反应变量),只要对模型稍作改进,Logistic 回归同样适用。
而且多分类反应变量既可以是次序测量也可以是名义测量。
在多分类反应变量类别不存在次序关系时,可以采用多项Logit 模型;当多分类反应变量类别之间有次序关系时,应该采用累积Logistic 回归模型或序次Logistic 回归模型。
下面主要讨论一下多项Logit 模型。
如果非次序分类因变量y 有个值,多项Logit 模型可以通过以下l ogit 形式描述:即在多项Logit 模型中l ogit 是由反应变量中的不重复的类别的对比所形成的。
因此如果以其中一个类别作为参考类别,其他类别都同它相比较可生成J -1个的Logit 变换模型。
在有J 个类别的多项Logit 模型中,J -1个l ogit 可表述为:其中最后一个类别就是参照类别。
2 Logistic 回归模型应用实证分析本案例利用某大学一个系某年140名应届毕业生的就业情况和在大学四年在学习,思想上的综合数据,运用Logistic 多元回归分析方法,对影响应届大学毕业生就业成功的因素进行分析。
复杂抽样数据的logistic回归分析方法及其应用

复杂抽样数据的logistic回归分析方法及其应用
缪凡;童峰
【期刊名称】《中国卫生统计》
【年(卷),期】2008(025)006
【摘要】目的探讨抽样权重在复杂抽样数据logistic回归分析中的重要性.方法采用SAS中PROC LOGIS-TIC和PROC SURVEYLOGISTIC语句对数据进行统计分析,并对结果进行比较.结果在未考虑和考虑抽样权重的lo-gistic回归模型拟合结果中,自变世的偏回归系数和OR值大小及其可信区间都有所不同.结论在logistic模型拟合中,纳入调查数据的抽样权重进行统计分析,从而能更加准确地进行统计推断.
【总页数】3页(P577-579)
【作者】缪凡;童峰
【作者单位】杭州市疾病预防控制中心传防所,310006;宁波市卫生局疾控处【正文语种】中文
【中图分类】R1
【相关文献】
1.复杂抽样数据统计分析方法回顾 [J], 姜博;王丽敏;刘艳;李镒冲
2.复杂抽样数据多水平模型分析方法及其应用 [J], 于石成;廖加强;于妺;郭莹;肖革新;金承刚;冯国双;胡跃华;马林茂
3.复杂抽样Poisson回归分析方法及应用 [J], 胡跃华;匡翔宇;金承刚;Hasanat Alamgir;马林茂;冯国双;于石成
4.大数据复杂事件分析方法研究与应用 [J], 赵会群;乔玉衡
5.抽样信息在复杂调查数据中的应用研究 [J], 吕萍
因版权原因,仅展示原文概要,查看原文内容请购买。
logistic回归模型讲稿

logistic回归模型讲稿Logitic回归分析模型2022-10-241各位老师,同学们大家上午好:非常感谢大家抽出宝贵的时间来参加沙龙,感谢我的导师对沙龙内容及PPT制作过程中的悉心指导,今天和大家一起分享的是在课题中用到的一种统计学分析方法,Logitic回归分析。
2这是CNKI学术搜索给出的近年来Logitic回归分析方法的学术关注度,由此可见,Logitic回归分析方法在当前学术研究中应用比较广泛、流行,关注度比较高,是进行科研数据分析不可缺少的利器。
3下面我将分以下几个部分对回归模型做详细的介绍:1.Logitic回归的基本概念与原理;2.Logitic回归的应用范畴;3.Logitic回归的类型及实例分析;这是本次沙龙的重点部分。
4.应用Logitic回归的注意事项;5.小结与答疑。
4首先来了解一下Logitic回归模型的基本概念与原理:Logitic回归又称「Logitic回归分析」,是一种「概率型非线性回归」,主要用于危险因素分析以及预后评估等方面,是目前流行病学和医学中最常用的分析方法之一。
近年来已逐渐成为发表高质量SCI论文必不可少的重要统计学分析利器。
Logitic回归本质上是一种用于研究二分类(或多分类)结局(y,因变量)与有关影响因素(某,自变量)之间关系的多因素分析方法。
5用比较通俗的话来解释它的基本原理,也就是说:用一组观察数据拟合Logitic模型,然后揭示若干个自变量某与一个因变量y之间的关系,结果反应了y对某的依存关系。
统计学的东西比较抽象,下面通过两张图再来重复解说一下。
6(1)与某一事件或某一疾病的结局有关的,存在很多可疑的影响因素,在这些可疑因素中包括促使结局发生的有关的一些危险因素、也包括抑制结局发生的有关的一些保护因素。
那么这些因素到底哪些是危险因素,哪些是保护因素呢?它们的危险及保护的程度大概有多少呢?7通过Logitic回归分析我们就可以看到详细的结果。
多元回归分析与Logistic回归分析的应用研究的开题报告

多元回归分析与Logistic回归分析的应用研究的开题报告一、研究背景及意义随着社会经济的快速发展,人民生活水平不断提高,需求日益复杂多样。
各个行业也面临着挑战和机遇。
在经济研究领域,多元回归分析和Logistic回归分析是两种常用的分析方法,它们对于对人们在实际生活和工作中进行数据分析和决策具有积极的推动作用。
多元回归分析是一种很常用的统计分析方法,它在社会科学领域有广泛的应用。
多元回归分析是在研究两个或两个以上自变量与因变量的关系时使用的,它可以解决多个变量之间的共线性问题,同时能够测定变量之间的相关性和影响力。
而Logistic回归分析则是一种分类算法,在预测二元分类变量时应用广泛。
它能够通过建立数学模型来预测某一个事件的发生概率,并给出相应的概率值。
这种算法广泛应用于人口普查、医学、金融以及市场营销等领域。
因此,本文旨在对多元回归分析和Logistic回归分析的应用进行研究,以期提升分析方法的效率和准确性,并为实际决策提供科学依据。
二、研究内容与目标本文将从以下两个方面进行研究:1. 多元回归分析的应用研究(1)研究多元回归分析的基本概念和方法,以及其在社会科学领域的应用。
(2)以某公司的销售数据为例,运用多元回归分析法,探究产品销售量与价格、广告费用等自变量之间的关系,分析自变量的线性关系以及各自变量的影响大小。
2. Logistic回归分析的应用研究(1)研究Logistic回归分析的基本概念和方法,以及其在分类预测领域的应用。
(2)以一个银行的信用评级为例,运用Logistic回归分析法,预测客户违约的概率,设置相应的阈值,以提高贷款风险管理的能力。
三、研究方法与步骤在本文中,将使用如下的研究方法:1.文献综述法:通过查阅相关文献,深入了解多元回归分析和Logistic回归分析的基本概念、方法以及应用领域。
2.数据分析法:通过实际案例应用多元回归分析和Logistic回归分析,分析数据之间的相互关系,总结规律,得出结论。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
温泽淮 DME中心 中心
2011-3-21 1
概述
1967年Truelt J,Connifield J和 年 , 和 Kannel W在《Journal of Chronic 在 Disease》上发表了冠心病危险因素 》 的研究,较早将Logistic回归用于医 的研究,较早将 回归用于医 学研究。 学研究。 一般概念
p
2011-3-21
7
logit(p) = ln( —— )
1-p
ห้องสมุดไป่ตู้
p
p=0或1时,此式失效 或 时
以 p = r/n 代之 logit(p) = ln [ (r + 0.5) / (n – r + 0.5) ]
此称经验 此称经验logistic变换 经验 变换
代上式的logit(p), 以Z代上式的 代上式的
2011-3-21
10
概述小结
logistic回归对因变量的比数的对数值 回归对因变量的比数的对数值 回归 ( logit值)建立模型 值 因变量的logit值的改变与多个自变量的 因变量的 值 加权和呈线性关系 加权和呈线性关系 因变量呈二项分布
2011-3-21
11
分析的一般步骤
变量的编码 哑变量的设置和引入 各个自变量的单因素分析 变量的筛选 交互作用的引入 建立多个模型 选择较优的模型 模型应用条件的评价 输出结果的解释
2011-3-21
19
3.自变量的单因素分析 3.自变量的单因素分析
了解自变量与因变量的分布 检验是否符合建立模型的应用条件
偏离应用条件时,进行数据变换 偏离应用条件时,
各个自变量两组间的比较
计数资料 计量资料
双变量分析
2011-3-21
20
4.变量的筛选 4.变量的筛选
变量筛选的原则
专业上考虑 测量上考虑
正确选择预测概率界值, 正确选择预测概率界值,简单地以 0.5为界值,但并不是最好的。 为界值, 为界值 但并不是最好的。
C指数 指数
预测结果与观察结果的一致性的度 值越大( ),模型预 量。C值越大(最大为 ),模型预 值越大 最大为1), 测结果的能力越强。 测结果的能力越强。
2011-3-21
2011-3-21
'问卷序号' '录入序号' '病人编号' '住院号/门诊号' '患者中文姓名' '组别' '患者姓名' '患者性别' '患者年龄' '男' 2 '女' '是' 0 '否' 9 '无法判断' '正常' 0 '异常' 9 '未检' '有' 0 '无' '无' 1 '危险性' 2 '可能' 3 '很可能' ‘文盲’ 1 ‘小学程度’ 2 ‘初中及以上'
Z = a + b1x1 + b2x2 + … + bkxk
称此为logistic回归模型 回归模型 称此为
2011-3-21
8
P = ez / (1 + ez ) ea+b1x1+b2x2+… +bkxk P= 1 + ea+b1x1+b2x2+… +bkxk 此为非条件logistic回归模型 回归模型 此为非条件 应用于成组数据的分析
21
变量的筛选
变量筛选的可用方法
逐步logistic回归:自动选择有显著性的自变 回归: 逐步 回归 不仅用于自变量的剔选, 量,不仅用于自变量的剔选,也用于交互作 用项是否显著的判断。 用项是否显著的判断。 前进法:逐个引入模型外的变量 前进法: 后退法:放入所有变量, 后退法:放入所有变量,再逐个筛选
交互作用的定义
当自变量和因变量的关系随第三个变量 的变化而改变时, 的变化而改变时,则存在交互作用
交互作用项的引入
基于临床实际认为对结果有重要影响 基于模型应用条件的分析 引入两个自变量的乘积项
交互作用的检验 交互作用的解释
2011-3-21 23
6.建立多个模型 6.建立多个模型
饱和模型 自定义的模型
输出结果的解释
回归系数的解释
系数的正负值: 系数的正负值:正(负)系数表示随自变量的 增加因变量logit值的增加(减少)。 值的增加( 增加因变量 值的增加 减少)。 二分类自变量 系数为比数比的对数值,由此比数比=e 系数为比数比的对数值,由此比数比 b 多分类自变量 以第i类作参照 比较相邻或相隔的两个类别。 类作参照, 以第 类作参照,比较相邻或相隔的两个类别。 连续型自变量 当自变量改变一个单位时,比数比为e 当自变量改变一个单位时,比数比为 b
2011-3-21 28
输出结果的解释
模型拟合的优劣
自变量与结果变量(因变量) 自变量与结果变量(因变量)有无关系
确认因变量与自变量的编码 模型包含的各个自变量的临床意义 由模型回归系数计算得到的各个自变 量的比数比的临床意义
2011-3-21
29
输出结果的解释
模型的预测结果的评价 敏感度、 敏感度、特异度和阳性预测值
2011-3-21
5
简单的解决方法
固定其他因素, 固定其他因素,研究有影响的一两个因 素; 分层分析: 分层分析:按1~2个因素组成的层进行 个因素组成的层进行 层内分析和综合。 层内分析和综合。 统计模型
2011-3-21
6
寻找合适的模型
进行logit变换 变换 进行
logit(p) = ln( 1 - p ), p为y=1所对应的概率 —— , 为 所对应的概率 0.1 logit(0.1) = ln( ——— ) = ln(0.1/0.9) 1 - 0.1
2011-3-21 12
1.变量的编码 1.变量的编码
变量的编码要易于识别 注意编码的等级关系 改变分类变量的编码, 改变分类变量的编码,其分析的意 义并不改变。 义并不改变。 牢记编码
使用变量数值标识( 使用变量数值标识(value labels) ) 记录编码内容
2011-3-21 13
变量的编码
2011-3-21
9
自变量取定一些值时,因变量取0 自变量取定一些值时,因变量取0、1的概率就 是条件概率,对条件概率进行logistic回归, logistic回归 是条件概率,对条件概率进行logistic回归,称 条件logistic logistic回归 为条件logistic回归
表达式: 表达式: eb1x1+b2x2+… +bkxk P= 1 - eb1x1+b2x2+… +bkxk 常用于分析配比的资料
研究中有N个配比组,每组中 个病 研究中有 个配比组,每组中n个病 个配比组 例配m个对照者 这时, 个对照者。 例配 个对照者。这时,各个研究 对象发生某事件的概率即为条件概 率。 适用于 配比设计的病例-对照研究 配比设计的病例 对照研究 精细分层设计的队列研究
2011-3-21
25
8.模型应用条件的评价 8.模型应用条件的评价
残差分析
残差是观察值与估计值之差
合理的logistic回归模型也可能得到 回归模型也可能得到 合理的 不理想的残差, 不理想的残差,这在自变量是二分类 变量时更易出现。 变量时更易出现。 增加交互作用项可能增加模型的效能
2011-3-21
15
1 1 1 1 0 0
2.哑变量的设置和引入 2.哑变量的设置和引入
哑变量,又称指示变量或 哑变量,又称指示变量或设计矩 指示变量 阵。 有利于检验等级变量各个等级间 的变化是否相同。 的变化是否相同。 一个k分类的分类变量 可以用k分类的分类变量, 一个 分类的分类变量,可以用 1个哑变量来表示。 个哑变量来表示。 个哑变量来表示
0.00 -4.00 -2.00 0.00 2.00 4.00
X:自变量
2011-3-21 4
一般直线回归难以解决的问题
医学数据的复杂、 医学数据的复杂、多样
连续型和离散型数据
医学研究中疾病的复杂性
一种疾病可能有多种致病因素或与多种危 险因素有关 疾病转归的影响因素也可能多种多样 临床治疗结局的综合性
2011-3-21 16
哑变量的设置
文盲,小学,初中, 教育程度:文盲,小学,初中,高中以上 教育程度
X1 0 1 0 0
X2 0 0 1 0
X3 0 0 0 1
文盲:0 小学:1 初中:2 高中:3
2011-3-21
17
以高中作为参照
教育程度
X1 1 0 0 0
X2 0 1 0 0
X3 0 0 1 0
变量名 SEX EDU 变量标识 性别 教育程度 变量值 1 2 0 1 2 值标识 男 女 文盲 小学 初中及以上
2011-3-21
14
variable labels qnum rnum pnum hnum chname drugroup name sex age value labels sex /hisc /nsex /demdx /addx /edu
26
9.输出结果的解释 9.输出结果的解释
模型中各个系数的显著性检验
Wald检验:类似于直线回归系数的 检验: 检验 t检验 检验 Wald x2检验:同上 检验: 似然比检验: 似然比检验:自变量不在模型中与 在模型中的似然值比较。 在模型中的似然值比较。 Score检验 检验