二叉树的创建与遍历问题
二叉树的基本操作

二叉树的基本操作二叉树是一种常见的数据结构,它由节点组成,每个节点最多有两个子节点。
二叉树在计算机领域中得到广泛应用,它的基本操作包括插入、删除、查找、遍历等。
1.插入操作:二叉树的插入操作是将一个新的节点添加到已有的二叉树中的过程。
插入操作会按照一定规则将新节点放置在正确的位置上。
插入操作的具体步骤如下:-首先,从根节点开始,比较新节点的值与当前节点的值的大小关系。
-如果新节点的值小于当前节点的值,则将新节点插入到当前节点的左子树中。
-如果新节点的值大于当前节点的值,则将新节点插入到当前节点的右子树中。
-如果当前节点的左子树或右子树为空,则直接将新节点插入到该位置上。
-如果当前节点的左子树和右子树都不为空,则递归地对左子树或右子树进行插入操作。
2.删除操作:二叉树的删除操作是将指定节点从二叉树中删除的过程。
删除操作有以下几种情况需要考虑:-如果待删除节点是叶子节点,则直接将其从二叉树中删除即可。
-如果待删除节点只有一个子节点,则将其子节点替换为待删除节点的位置即可。
-如果待删除节点有两个子节点,则需要找到其左子树或右子树中的最大节点或最小节点,将其值替换为待删除节点的值,然后再删除最大节点或最小节点。
3.查找操作:二叉树的查找操作是在二叉树中查找指定值的节点的过程。
查找操作的具体步骤如下:-从根节点开始,将待查找值与当前节点的值进行比较。
-如果待查找值等于当前节点的值,则返回该节点。
-如果待查找值小于当前节点的值,则在当前节点的左子树中继续查找。
-如果待查找值大于当前节点的值,则在当前节点的右子树中继续查找。
-如果左子树或右子树为空,则说明在二叉树中找不到该值。
4.遍历操作:二叉树的遍历操作是按照一定规则依次访问二叉树中的每个节点。
有三种常用的遍历方式:- 前序遍历(Preorder Traversal):先访问根节点,然后递归地前序遍历左子树和右子树。
- 中序遍历(Inorder Traversal):先递归地中序遍历左子树,然后访问根节点,最后递归地中序遍历右子树。
二叉树的建立与基本操作

二叉树的建立与基本操作二叉树是一种特殊的树形结构,它由节点(node)组成,每个节点最多有两个子节点。
二叉树的基本操作包括建立二叉树、遍历二叉树、查找二叉树节点、插入和删除节点等。
本文将详细介绍二叉树的建立和基本操作,并给出相应的代码示例。
一、建立二叉树建立二叉树有多种方法,包括使用数组、链表和前序、中序、后序遍历等。
下面以使用链表的方式来建立二叉树为例。
1.定义二叉树节点类首先,定义一个二叉树节点的类,包含节点值、左子节点和右子节点三个属性。
```pythonclass Node:def __init__(self, value):self.value = valueself.left = Noneself.right = None```2.建立二叉树使用递归的方法来建立二叉树,先构造根节点,然后递归地构造左子树和右子树。
```pythondef build_binary_tree(lst):if not lst: # 如果 lst 为空,则返回 Nonereturn Nonemid = len(lst) // 2 # 取 lst 的中间元素作为根节点的值root = Node(lst[mid])root.left = build_binary_tree(lst[:mid]) # 递归构造左子树root.right = build_binary_tree(lst[mid+1:]) # 递归构造右子树return root```下面是建立二叉树的示例代码:```pythonlst = [1, 2, 3, 4, 5, 6, 7]root = build_binary_tree(lst)```二、遍历二叉树遍历二叉树是指按照其中一规则访问二叉树的所有节点,常见的遍历方式有前序遍历、中序遍历和后序遍历。
1.前序遍历前序遍历是指先访问根节点,然后访问左子节点,最后访问右子节点。
```pythondef pre_order_traversal(root):if root:print(root.value) # 先访问根节点pre_order_traversal(root.left) # 递归访问左子树pre_order_traversal(root.right) # 递归访问右子树```2.中序遍历中序遍历是指先访问左子节点,然后访问根节点,最后访问右子节点。
二叉树的建立与先序中序后序遍历 求叶子节点个数 求分支节点个数 求二叉树的高度

/*一下总结一些二叉树的常见操作:包括建立二叉树先/中/后序遍历二叉树求二叉树的叶子节点个数求二叉树的单分支节点个数计算二叉树双分支节点个数计算二叉树的高度计算二叉树的所有叶子节点数*/#include<stdio.h> //c语言的头文件#include<stdlib.h>//c语言的头文件stdlib.h千万别写错了#define Maxsize 100/*创建二叉树的节点*/typedef struct BTNode //结构体struct 是关键字不能省略结构体名字可以省略(为无名结构体)//成员类型可以是基本型或者构造形,最后的为结构体变量。
{char data;struct BTNode *lchild,*rchild;}*Bitree;/*使用先序建立二叉树*/Bitree Createtree() //树的建立{char ch;Bitree T;ch=getchar(); //输入一个二叉树数据if(ch==' ') //' '中间有一个空格的。
T=NULL;else{ T=(Bitree)malloc(sizeof(Bitree)); //生成二叉树(分配类型*)malloc(分配元素个数*sizeof(分配类型))T->data=ch;T->lchild=Createtree(); //递归创建左子树T->rchild=Createtree(); //地柜创建右子树}return T;//返回根节点}/*下面先序遍历二叉树*//*void preorder(Bitree T) //先序遍历{if(T){printf("%c-",T->data);preorder(T->lchild);preorder(T->rchild);}} *//*下面先序遍历二叉树非递归算法设计*/void preorder(Bitree T) //先序遍历非递归算法设计{Bitree st[Maxsize];//定义循环队列存放节点的指针Bitree p;int top=-1; //栈置空if(T){top++;st[top]=T; //根节点进栈while(top>-1) //栈不空时循环{p=st[top]; //栈顶指针出栈top--;printf("%c-",p->data );if(p->rchild !=NULL) //右孩子存在进栈{top++;st[top]=p->rchild ;}if(p->lchild !=NULL) //左孩子存在进栈{top++;st[top]=p->lchild ;}}printf("\n");}}/*下面中序遍历二叉树*//*void inorder(Bitree T) //中序遍历{if(T){inorder(T->lchild);printf("%c-",T->data);inorder(T->rchild);}}*//*下面中序遍历二叉树非递归算法设计*/void inorder(Bitree T) //中序遍历{Bitree st[Maxsize]; //定义循环队列,存放节点的指针Bitree p;int top=-1;if(T){p=T;while (top>-1||p!=NULL) //栈不空或者*不空是循环{while(p!=NULL) //扫描*p的所有左孩子并进栈{top++;st[top]=p;p=p->lchild ;}if(top>-1){p=st[top]; //出栈*p节点,它没有右孩子或右孩子已被访问。
二叉树遍历操作的基本应用(复制、求深度、求叶子数、求节点数等)

二叉树遍历操作的基本应用(复制、求深度、求叶子数、求节点数等)1. 引言1.1 概述二叉树是计算机科学领域中常用的数据结构之一,具有广泛的应用场景。
在二叉树的操作中,遍历是其中最基本和常见的操作之一。
通过遍历,我们可以按照特定规则依次访问二叉树中的所有节点。
本文将探讨二叉树遍历操作的基本应用,包括复制、求深度、求叶子数、求节点数等。
这些操作不仅在实际开发中有重要意义,而且对于理解和掌握二叉树数据结构及其相关算法也具有重要作用。
1.2 文章结构本文将分为五个部分进行论述。
首先,在引言部分(第1节)我们将概述文章的主题和目标。
紧接着,在第2节中,我们将介绍二叉树遍历的基本应用,包括复制、求深度、求叶子数和求节点数等。
在第3节中,我们将详细解析这些基本应用,并给出相应算法和实例分析。
接下来,在第4节中,我们将通过实际案例应用来验证并讨论这些基本应用的性能与适用范围。
最后,在第5节中总结全文内容,并对未来研究方向进行展望。
1.3 目的本文的目的是通过对二叉树遍历操作的基本应用进行详细剖析,帮助读者深入理解和掌握二叉树数据结构及其相关算法。
同时,我们希望通过实际案例应用与讨论,探讨如何优化算法性能、提高效率以及适应大规模二叉树遍历问题。
通过本文的阅读,读者将能够全面了解并应用二叉树遍历操作的基本方法,在实际开发中解决相关问题,并为进一步研究和探索提供思路与参考。
该部分主要介绍了文章的概述、结构和目的,引导读者了解全文并明确阅读目标。
2. 二叉树遍历的基本应用:二叉树是一种常见的数据结构,其遍历操作可以应用于多种实际问题中。
本节将介绍四个基本的二叉树遍历应用:复制二叉树、求二叉树的深度、求二叉树的叶子数和求二叉树的节点数。
2.1 复制二叉树:复制一个二叉树意味着创建一个与原始二叉树结构完全相同的新二叉树。
该应用场景在涉及对原始数据进行修改或者对数据进行独立操作时非常有用。
复制操作可以以递归方式实现,通过先复制左子树,再复制右子树,最后创建一个与当前节点值相等的新节点来完成。
二叉树的遍历题目及答案

二叉树的遍历题目及答案1. 二叉树的基本组成部分是:根(N)、左子树(L)和右子树(R)。
因而二叉树的遍历次序有六种。
最常用的是三种:前序法(即按N L R次序),后序法(即按L R N 次序)和中序法(也称对称序法,即按L N R次序)。
这三种方法相互之间有关联。
若已知一棵二叉树的前序序列是BEFCGDH,中序序列是FEBGCHD,则它的后序序列必是 F E G H D C B 。
解:法1:先由已知条件画图,再后序遍历得到结果;法2:不画图也能快速得出后序序列,只要找到根的位置特征。
由前序先确定root,由中序先确定左子树。
例如,前序遍历BEFCGDH中,根结点在最前面,是B;则后序遍历中B一定在最后面。
法3:递归计算。
如B在前序序列中第一,中序中在中间(可知左右子树上有哪些元素),则在后序中必为最后。
如法对B的左右子树同样处理,则问题得解。
2.给定二叉树的两种遍历序列,分别是:前序遍历序列:D,A,C,E,B,H,F,G,I;中序遍历序列:D,C,B,E,H,A,G,I,F,试画出二叉树B,并简述由任意二叉树B的前序遍历序列和中序遍历序列求二叉树B的思想方法。
解:方法是:由前序先确定root,由中序可确定root的左、右子树。
然后由其左子树的元素集合和右子树的集合对应前序遍历序列中的元素集合,可继续确定root的左右孩子。
将他们分别作为新的root,不断递归,则所有元素都将被唯一确定,问题得解。
3、当一棵二叉树的前序序列和中序序列分别是HGEDBFCA和EGBDHFAC时,其后序序列必是A. BDEAGFHCB. EBDGACFHC. HGFEDCBAD. HFGDEABC答案:B4. 已知一棵二叉树的前序遍历为ABDECF,中序遍历为DBEAFC,则对该树进行后序遍历得到的序列为______。
A.DEBAFCB.DEFBCAC.DEBCFAD.DEBFCA[解析] 由二叉树前序遍历序列和中序遍历序列可以唯一确定一棵二叉树。
二叉树前中后序遍历做题技巧

二叉树前中后序遍历做题技巧在计算机科学中,二叉树是一种重要的数据结构,而前序、中序和后序遍历则是二叉树遍历的三种主要方式。
下面将分别对这三种遍历方式进行解析,并提供一些解题技巧。
1.理解遍历顺序前序遍历顺序是:根节点->左子树->右子树中序遍历顺序是:左子树->根节点->右子树后序遍历顺序是:左子树->右子树->根节点理解每种遍历顺序是解题的基础。
2.使用递归或迭代二叉树的遍历可以通过递归或迭代实现。
在递归中,每个节点的处理函数会调用其左右子节点的处理函数。
在迭代中,可以使用栈来模拟递归过程。
3.辨析指针指向在递归或迭代中,需要正确处理指针的指向。
在递归中,通常使用全局变量或函数参数传递指针。
在迭代中,需要使用栈或其他数据结构保存指针。
4.学会断点续传在处理大规模数据时,为了避免内存溢出,可以采用断点续传的方式。
即在遍历过程中,将中间结果保存在文件中,下次遍历时从文件中读取上一次的结果,继续遍历。
5.识别循环和终止条件在遍历二叉树时,要识别是否存在循环,并确定终止条件。
循环可以通过深度优先搜索(DFS)或广度优先搜索(BFS)避免。
终止条件通常为达到叶子节点或达到某个深度限制。
6.考虑边界情况在处理二叉树遍历问题时,要考虑边界情况。
例如,对于空二叉树,需要进行特殊处理。
又如,在处理二叉搜索树时,需要考虑节点值的最小和最大边界。
7.优化空间使用在遍历二叉树时,需要优化空间使用。
例如,可以使用in-place排序来避免额外的空间开销。
此外,可以使用懒加载技术来延迟加载子节点,从而减少内存占用。
8.验证答案正确性最后,验证答案的正确性是至关重要的。
可以通过检查输出是否符合预期、是否满足题目的限制条件等方法来验证答案的正确性。
如果可能的话,也可以使用自动化测试工具进行验证。
二叉树的建立方法总结

⼆叉树的建⽴⽅法总结之前已经介绍了⼆叉树的四种遍历(如果不熟悉),下⾯介绍⼀些⼆叉树的建⽴⽅式。
⾸先需要明确的是,由于⼆叉树的定义是递归的,所以⽤递归的思想建⽴⼆叉树是很⾃然的想法。
1. 交互式问答⽅式这种⽅式是最直接的⽅式,就是先询问⽤户根节点是谁,然后每次都询问⽤户某个节点的左孩⼦是谁,右孩⼦是谁。
代码如下(其中字符'#'代表空节点):#include <cstdio>#include <cstdlib>using namespace std;typedef struct BTNode *Position;typedef Position BTree;struct BTNode{char data;Position lChild, rChild;};BTree CreateBTree(BTree bt, bool isRoot){char ch;if (isRoot)printf("Root: ");fflush(stdin); /* 清空缓存区 */scanf("%c", &ch);fflush(stdin);if (ch != '#'){isRoot = false;bt = new BTNode;bt->data = ch;bt->lChild = NULL;bt->rChild = NULL;printf("%c's left child is: ", bt->data);bt->lChild = CreateBTree(bt->lChild, isRoot);printf("%c's right child is: ", bt->data);bt->rChild = CreateBTree(bt->rChild, isRoot);}return bt;}int main(){BTree bt;bt = CreateBTree(bt, true);LevelOrderTraversal(bt); /* 层序遍历 */return0;}2. 根据先序序列例如输⼊序列ABDH##I##E##CF#J##G##(#表⽰空),则会建⽴如下图所⽰的⼆叉树思路和第⼀种⽅式很相似,只是代码实现细节有⼀点区别,这⾥给出创建函数BTree CreateBTree(){BTree bt = NULL;char ch;scanf("%c", &ch);if (ch != '#'){bt = new BTNode;bt->data = ch;bt->lChild = CreateBTree();bt->rChild = CreateBTree();}return bt;}3. 根据中序序列和后序序列和⽅式⼆不同的是,这⾥的序列不会给出空节点的表⽰,所以如果只给出先序序列,中序序列,后序序列中的⼀种,不能唯⼀确定⼀棵⼆叉树。
二叉树遍历(前中后序遍历,三种方式)

⼆叉树遍历(前中后序遍历,三种⽅式)⽬录刷题中碰到⼆叉树的遍历,就查找了⼆叉树遍历的⼏种思路,在此做个总结。
对应的LeetCode题⽬如下:,,,接下来以前序遍历来说明三种解法的思想,后⾯中序和后续直接给出代码。
⾸先定义⼆叉树的数据结构如下://Definition for a binary tree node.struct TreeNode {int val;TreeNode *left;TreeNode *right;TreeNode(int x) : val(x), left(NULL), right(NULL) {}};前序遍历,顺序是“根-左-右”。
使⽤递归实现:递归的思想很简单就是我们每次访问根节点后就递归访问其左节点,左节点访问结束后再递归的访问右节点。
代码如下:class Solution {public:vector<int> preorderTraversal(TreeNode* root) {if(root == NULL) return {};vector<int> res;helper(root,res);return res;}void helper(TreeNode *root, vector<int> &res){res.push_back(root->val);if(root->left) helper(root->left, res);if(root->right) helper(root->right, res);}};使⽤辅助栈迭代实现:算法为:先把根节点push到辅助栈中,然后循环检测栈是否为空,若不空,则取出栈顶元素,保存值到vector中,之后由于需要想访问左⼦节点,所以我们在将根节点的⼦节点⼊栈时要先经右节点⼊栈,再将左节点⼊栈,这样出栈时就会先判断左⼦节点。
代码如下:class Solution {public:vector<int> preorderTraversal(TreeNode* root) {if(root == NULL) return {};vector<int> res;stack<TreeNode*> st;st.push(root);while(!st.empty()){//将根节点出栈放⼊结果集中TreeNode *t = st.top();st.pop();res.push_back(t->val);//先⼊栈右节点,后左节点if(t->right) st.push(t->right);if(t->left) st.push(t->left);}return res;}};Morris Traversal⽅法具体的详细解释可以参考如下链接:这种解法可以实现O(N)的时间复杂度和O(1)的空间复杂度。
树的遍历实验报告

实验项目:树的遍历1.实验目的:学会创建一棵二叉树,以及完成对树的简单操作。
2.实验内容:1)生成一棵以二叉链表存储的二叉树bt(不少于15个结点)2)分别用递归和非递归方法前序遍历bt,并以缩格形式打印bt 上各结点的信息。
3)编写算法,交换bt上所有结点的左、右子树,并以缩格形式打印出交换前后的bt结点信息。
3.程序简介:先创建一棵二叉树,递归非递归前序遍历,层次遍历,交换左右子树,缩格打印各结点的信息。
4.算法设计介绍:首先按照前序遍历的顺序递归创建一棵二叉树,然后序遍历的非递归使用堆栈完成的,即访问该结点的时候,如果有右孩子,让右孩子进栈,访问左孩子,当左孩子为空时,抛出栈顶的元素,访问出栈的这个元素的左右孩子。
缩格打印和层次遍历想法类似,都是借助队列完成的,把当前结点的左右孩子进队列之后,让这个结点出队列。
交换左右子树,就是当某个结点的左右子树不同时为空时,定义一个中间变量交换。
5.困难及解答一开始创建二叉树的参数我想用指向结构体的指针,后来才意识到得用指向指针的指针,想了好一段时间才想明白,因为某个结点的左右孩子是指向结点的指针,要想再指向一个指针,只能用指针的指针了。
6.心得树这一章我听得乱七八糟,上课能听懂,但就是不会编程,要不是书上有算法,我估计我肯定编不出来,看来还是得多编啊。
程序清单/*// 我真诚地保证:// 我独立完成了整个程序从分析、设计到编码的所有工作。
// 如果在上述过程中,我遇到了什么困难而求教于人,那么,我将在程序实习报告中// 详细地列举我所遇到的问题,以及别人给我的提示。
// 我的程序里中凡是引用到其他程序或文档之处,// 例如教材、课堂笔记、网上的源代码以及其他参考书上的代码段,// 我都已经在程序的注释里很清楚地注明了引用的出处。
// 我从未没抄袭过别人的程序,也没有盗用别人的程序,// 不管是修改式的抄袭还是原封不动的抄袭。
// 我编写这个程序,从来没有想过要去破坏或妨碍其他计算机系统的正常运转。
c语言二叉树的先序,中序,后序遍历
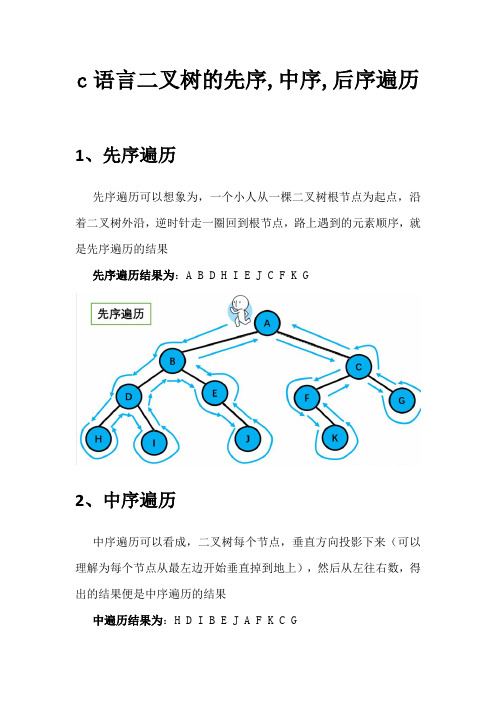
c语言二叉树的先序,中序,后序遍历1、先序遍历先序遍历可以想象为,一个小人从一棵二叉树根节点为起点,沿着二叉树外沿,逆时针走一圈回到根节点,路上遇到的元素顺序,就是先序遍历的结果先序遍历结果为:A B D H I E J C F K G2、中序遍历中序遍历可以看成,二叉树每个节点,垂直方向投影下来(可以理解为每个节点从最左边开始垂直掉到地上),然后从左往右数,得出的结果便是中序遍历的结果中遍历结果为:H D I B E J A F K C G3、后序遍历后序遍历就像是剪葡萄,我们要把一串葡萄剪成一颗一颗的。
还记得我上面提到先序遍历绕圈的路线么?(不记得翻上面理解)就是围着树的外围绕一圈,如果发现一剪刀就能剪下的葡萄(必须是一颗葡萄)(也就是葡萄要一个一个掉下来,不能一口气掉超过1个这样),就把它剪下来,组成的就是后序遍历了。
后序遍历中,根节点默认最后面后序遍历结果:H I D J E B K F G C A4、口诀先序遍历:先根再左再右中序遍历:先左再根再右后序遍历:先左再右再根这里的根,指的是每个分叉子树(左右子树的根节点)根节点,并不只是最开始头顶的根节点,需要灵活思考理解5、代码展示#include<stdio.h>#include<stdlib.h>typedef struct Tree{int data; // 存放数据域struct Tree *lchild; // 遍历左子树指针struct Tree *rchild; // 遍历右子树指针}Tree,*BitTree;BitTree CreateLink(){int data;int temp;BitTree T;scanf("%d",&data); // 输入数据temp=getchar(); // 吸收空格if(data == -1){ // 输入-1 代表此节点下子树不存数据,也就是不继续递归创建return NULL;}else{T = (BitTree)malloc(sizeof(Tree)); // 分配内存空间T->data = data; // 把当前输入的数据存入当前节点指针的数据域中printf("请输入%d的左子树: ",data);T->lchild = CreateLink(); // 开始递归创建左子树printf("请输入%d的右子树: ",data);T->rchild = CreateLink(); // 开始到上一级节点的右边递归创建左右子树return T; // 返回根节点}}// 先序遍历void ShowXianXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}printf("%d ",T->data);ShowXianXu(T->lchild); // 递归遍历左子树ShowXianXu(T->rchild); // 递归遍历右子树}// 中序遍历void ShowZhongXu(BitTree T) // 先序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowZhongXu(T->lchild); // 递归遍历左子树printf("%d ",T->data);ShowZhongXu(T->rchild); // 递归遍历右子树}// 后序遍历void ShowHouXu(BitTree T) // 后序遍历二叉树{if(T==NULL) //递归中遇到NULL,返回上一层节点{return;}ShowHouXu(T->lchild); // 递归遍历左子树ShowHouXu(T->rchild); // 递归遍历右子树printf("%d ",T->data);}int main(){BitTree S;printf("请输入第一个节点的数据:\n");S = CreateLink(); // 接受创建二叉树完成的根节点printf("先序遍历结果: \n");ShowXianXu(S); // 先序遍历二叉树printf("\n中序遍历结果: \n");ShowZhongXu(S); // 中序遍历二叉树printf("\n后序遍历结果: \n");ShowHouXu(S); // 后序遍历二叉树return 0;}。
二叉树教案

二叉树教案一、教学目标:1.了解二叉树的定义和性质。
2.学会二叉树的遍历算法(前序遍历、中序遍历、后序遍历)。
3.掌握二叉树的基本操作(创建二叉树、插入节点、删除节点)。
二、教学重点和难点:1.二叉树的定义和性质。
2.二叉树的遍历算法。
3.二叉树的基本操作。
三、教学准备:1.教师准备:PPT、计算机、投影仪。
2.学生准备:课前预习、纸笔。
四、教学过程:Step 1 导入新课教师通过提问的方式,引导学生回顾树的基本概念,并激发学生对二叉树的兴趣。
Step 2 二叉树的定义和性质教师给出二叉树的定义,并带领学生讨论二叉树的性质(每个节点最多有两个子节点,左子树和右子树)。
Step 3 二叉树的遍历算法1.前序遍历:先访问根节点,然后递归遍历左子树,再递归遍历右子树。
2.中序遍历:先递归遍历左子树,然后访问根节点,再递归遍历右子树。
3.后序遍历:先递归遍历左子树,然后递归遍历右子树,最后访问根节点。
Step 4 二叉树的基本操作1.创建二叉树:教师通过示例向学生展示二叉树的创建过程。
2.插入节点:教师通过示例向学生展示如何插入节点,并解释插入节点的规则。
3.删除节点:教师通过示例向学生展示如何删除节点,并解释删除节点的规则。
Step 5 练习与拓展1.教师设计练习题,让学生运用所学知识进行练习。
2.鼓励学生拓展二叉树的其他应用领域,并进行讨论。
五、教学反思本节课通过讲解二叉树的定义和性质,以及二叉树的遍历算法和基本操作,使学生对二叉树有了基本的了解和掌握。
通过练习和拓展,巩固了学生的学习成果,并培养了学生的分析和解决问题的能力。
但是,由于时间有限,学生的实际操作机会较少,可以在课后布置相关的作业,加深学生的理解和应用能力。
数据结构入门-树的遍历以及二叉树的创建

数据结构⼊门-树的遍历以及⼆叉树的创建树定义:1. 有且只有⼀个称为根的节点2. 有若⼲个互不相交的⼦树,这些⼦树本⾝也是⼀个树通俗的讲:1. 树是有结点和边组成,2. 每个结点只有⼀个⽗结点,但可以有多个⼦节点3. 但有⼀个节点例外,该节点没有⽗结点,称为根节点⼀、专业术语结点、⽗结点、⼦结点、根结点深度:从根节点到最底层结点的层数称为深度,根节点第⼀层叶⼦结点:没有⼦结点的结点⾮终端节点:实际上是⾮叶⼦结点度:⼦结点的个数成为度⼆、树的分类⼀般树:任意⼀个结点的⼦结点的个数都不受限制⼆叉树:任意⼀个结点的⼦结点个数最多是两个,且⼦结点的位置不可更改⼆叉数分类:1. ⼀般⼆叉数2. 满⼆叉树:在不增加树层数的前提下,⽆法再多添加⼀个结点的⼆叉树3. 完全⼆叉树:如果只是删除了满⼆叉树最底层最右边的连续若⼲个结点,这样形成的⼆叉树就是完全⼆叉树森林:n个互不相交的树的集合三、树的存储⼆叉树存储连续存储(完全⼆叉树)优点:查找某个结点的⽗结点和⼦结点(也包括判断有没有⼦结点)速度很快缺点:耗⽤内存空间过⼤链式存储⼀般树存储1. 双亲表⽰法:求⽗结点⽅便2. 孩⼦表⽰法:求⼦结点⽅便3. 双亲孩⼦表⽰法:求⽗结点和⼦结点都很⽅便4. ⼆叉树表⽰法:把⼀个⼀般树转化成⼀个⼆叉树来存储,具体转换⽅法:设法保证任意⼀个结点的左指针域指向它的第⼀个孩⼦,右指针域指向它的兄弟,只要能满⾜此条件,就可以把⼀个⼀般树转化为⼆叉树⼀个普通树转换成的⼆叉树⼀定没有右⼦树森林的存储先把森林转化为⼆叉树,再存储⼆叉树四、树的遍历先序遍历:根左右先访问根结点,再先序访问左⼦树,再先序访问右⼦树中序遍历:左根右中序遍历左⼦树,再访问根结点,再中序遍历右⼦树后续遍历:左右根后续遍历左⼦树,后续遍历右⼦树,再访问根节点五、已知两种遍历求原始⼆叉树给定了⼆叉树的任何⼀种遍历序列,都⽆法唯⼀确定相应的⼆叉树,但是如果知道了⼆叉树的中序遍历序列和任意的另⼀种遍历序列,就可以唯⼀地确定⼆叉树已知先序和中序求后序先序:ABCDEFGH中序:BDCEAFHG求后序:这个⾃⼰画个图体会⼀下就可以了,⾮常简单,这⾥简单记录⼀下1. ⾸先根据先序确定根,上⾯的A就是根2. 中序确定左右,A左边就是左树(BDCE),A右边就是右树(FHG)3. 再根据先序,A左下⾯就是B,然后根据中序,B左边没有,右边是DCE4. 再根据先序,B右下是C,根据中序,c左下边是D,右下边是E,所以整个左树就确定了5. 右树,根据先序,A右下是F,然后根据中序,F的左下没有,右下是HG,6. 根据先序,F右下为G,然后根据中序,H在G的左边,所以G的左下边是H再来⼀个例⼦,和上⾯的思路是⼀样的,这⾥就不详细的写了先序:ABDGHCEFI中序:GDHBAECIF已知中序和后序求先序中序:BDCEAFHG后序:DECBHGFA这个和上⾯的思路是⼀样的,只不过是反过来找,后序找根,中序找左右树简单应⽤树是数据库中数据组织⼀种重要形式操作系统⼦⽗进程的关系本⾝就是⼀棵树⾯向对象语⾔中类的继承关系哈夫曼树六、⼆叉树的创建#include <stdio.h>#include <stdlib.h>typedef struct Node{char data;struct Node * lchild;struct Node * rchild;}BTNode;/*⼆叉树建⽴*/void BuildBT(BTNode ** tree){char ch;scanf("%c" , &ch); // 输⼊数据if(ch == '#') // 如果这个节点的数据是#说明这个结点为空*tree = NULL;else{*tree = (BTNode*)malloc(sizeof(BTNode));//申请⼀个结点的内存 (*tree)->data = ch; // 将数据写⼊到结点⾥⾯BuildBT(&(*tree)->lchild); // 递归建⽴左⼦树BuildBT(&(*tree)->rchild); // 递归建⽴右⼦树}}/*⼆叉树销毁*/void DestroyBT(BTNode *tree) // 传⼊根结点{if(tree != NULL){DestroyBT(tree->lchild);DestroyBT(tree->rchild);free(tree); // 释放内存空间}}/*⼆叉树的先序遍历*/void Preorder(BTNode * node){if(node == NULL)return;else{printf("%c ",node->data );Preorder(node->lchild);Preorder(node->rchild);}}/*⼆叉树的中序遍历*/void Inorder(BTNode * node){if(node == NULL)return;else{Inorder(node->lchild);printf("%c ",node->data );Inorder(node->rchild);}}/*⼆叉树的后序遍历*/void Postorder(BTNode * node){if(node == NULL)return;else{Postorder(node->lchild);Postorder(node->rchild);printf("%c ",node->data );}}/*⼆叉树的⾼度树的⾼度 = max(左⼦树⾼度,右⼦树⾼度) +1*/int getHeight(BTNode *node){int Height = 0;if (node == NULL)return 0;else{int L_height = getHeight(node->lchild);int R_height = getHeight(node->rchild);Height = L_height >= R_height ? L_height +1 : R_height +1; }return Height;}int main(int argc, char const *argv[]){BTNode * BTree; // 定义⼀个⼆叉树printf("请输⼊⼀颗⼆叉树先序序列以#表⽰空结点:");BuildBT(&BTree);printf("先序序列:");Preorder(BTree);printf("\n中序序列:");Inorder(BTree);printf("\n后序序列:");Postorder(BTree);printf("\n树的⾼度为:%d" , getHeight(BTree));return 0;}// ABC##DE##F##G##。
二叉树的几个经典例题

⼆叉树的⼏个经典例题⼆叉树遍历1题⽬描述编⼀个程序,读⼊⽤户输⼊的⼀串先序遍历字符串,根据此字符串建⽴⼀个⼆叉树(以指针⽅式存储)。
例如如下的先序遍历字符串: ABC##DE#G##F### 其中“#”表⽰的是空格,空格字符代表空树。
建⽴起此⼆叉树以后,再对⼆叉树进⾏中序遍历,输出遍历结果。
输⼊描述:输⼊包括1⾏字符串,长度不超过100。
输出描述:可能有多组测试数据,对于每组数据,输出将输⼊字符串建⽴⼆叉树后中序遍历的序列,每个字符后⾯都有⼀个空格。
每个输出结果占⼀⾏。
输⼊abc##de#g##f###输出c b e gd f a思路:递归建树。
每次都获取输⼊字符串的当前元素,根据题⽬要求(先序、中序、后序等+其他限制条件)建树。
再根据题⽬要求输出即可。
1 #include<bits/stdc++.h>2using namespace std;3struct node{4char data;5 node *lchild,*rchild;6 node(char c):data(c),lchild(NULL),rchild(NULL){}7 };8string s;9int loc;10 node* create(){11char c=s[loc++];//获取每⼀个字符串元素12if(c=='#') return NULL;13 node *t=new node(c);//创建新节点14 t->lchild=create();15 t->rchild=create();16return t;17 }18void inorder(node *t){//递归中序19if(t){20 inorder(t->lchild);21 cout<<t->data<<'';22 inorder(t->rchild);23 }24 }25int main(){26while(cin>>s){27 loc=0;28 node *t=create();//先序遍历建树29 inorder(t);//中序遍历并输出30 cout<<endl;31 }32return0;33 }⼆叉树遍历2题⽬描述⼆叉树的前序、中序、后序遍历的定义:前序遍历:对任⼀⼦树,先访问跟,然后遍历其左⼦树,最后遍历其右⼦树;中序遍历:对任⼀⼦树,先遍历其左⼦树,然后访问根,最后遍历其右⼦树;后序遍历:对任⼀⼦树,先遍历其左⼦树,然后遍历其右⼦树,最后访问根。
二叉树的遍历及相关题目

⼆叉树的遍历及相关题⽬⼆叉树的遍历及相关题⽬1.1⼆叉树遍历的概念⼆叉树结构体的定义:typedef struct node{ ElemType data; struct node * lchild; struct node * rchild;}⼆叉树的遍历是指按照⼀定的次序访问⼆叉树中的所有的节点,并且每个节点仅访问⼀次的过程。
若规定先遍历左⼦树,后遍历右⼦树,则对于⾮空⼆叉树,可得到如下3种递归的遍历⽅法:(1)先序遍历访问根节点,先序遍历左⼦树,先序遍历右⼦树。
(根,左,右)(2)中序遍历中序遍历左⼦树,访问根节点,中序遍历右⼦树。
(左,根,右)(3)后序遍历后序遍历左⼦树,后序遍历右⼦树,访问根节点。
(左,右,根)除此之外也有层次遍历。
先访问根节点,在从左到右访问第⼆层的所有节点,从左到右访问第三层的所有节点......1.2⼆叉树遍历递归算法先序遍历递归算法:void PreOrder(BTNode * b){ if(n != NULL) { cout<<b->data; PreOrder(b->lchild); PreOrder(b->rchild); }}中序遍历递归算法void InOrder(BTNode * b){ if(n != NULL) { InOrder(b->lchild); cout<<b->data; InOrder(b->rchild); }}后序遍历递归算法:void PostOrder(BTNode * b){ if(b != NULL) { PostOrder(b->lchild); PostOrder(b->rchild); cout<<b->data; }}题⽬1:输出⼀个给定⼆叉树的所有的叶⼦节点:void DispLeaf(BTNode * b){ if(b != NULL) { if(b->lchild == NULL && b->rchild == NULL) cout<<b->data; DispLeaf(b->lchild); DispLeaf(b->rchild); }}以上算法采⽤先序遍历输出了所有的叶⼦节点,所以叶⼦节点是从左到右输出的。
二叉树的建立和遍历的实验报告

竭诚为您提供优质文档/双击可除二叉树的建立和遍历的实验报告篇一:二叉树遍历实验报告数据结构实验报告报告题目:二叉树的基本操作学生班级:学生姓名:学号:一.实验目的1、基本要求:深刻理解二叉树性质和各种存储结构的特点及适用范围;掌握用指针类型描述、访问和处理二叉树的运算;熟练掌握二叉树的遍历算法;。
2、较高要求:在遍历算法的基础上设计二叉树更复杂操作算法;认识哈夫曼树、哈夫曼编码的作用和意义;掌握树与森林的存储与便利。
二.实验学时:课内实验学时:3学时课外实验学时:6学时三.实验题目1.以二叉链表为存储结构,实现二叉树的创建、遍历(实验类型:验证型)1)问题描述:在主程序中设计一个简单的菜单,分别调用相应的函数功能:1…建立树2…前序遍历树3…中序遍历树4…后序遍历树5…求二叉树的高度6…求二叉树的叶子节点7…非递归中序遍历树0…结束2)实验要求:在程序中定义下述函数,并实现要求的函数功能:createbinTree(binTreestructnode*lchild,*rchild;}binTnode;元素类型:intcreatebinTree(binTreevoidpreorder(binTreevoidInorder(binTreevoidpostorder(binTreevoidInordern(binTreeintleaf(bi nTreeintpostTreeDepth(binTree2、编写算法实现二叉树的非递归中序遍历和求二叉树高度。
1)问题描述:实现二叉树的非递归中序遍历和求二叉树高度2)实验要求:以二叉链表作为存储结构3)实现过程:1、实现非递归中序遍历代码:voidcbiTree::Inordern(binTreeinttop=0;p=T;do{while(p!=nuLL){stack[top]=p;;top=top+1;p=p->lchild;};if(top>0){top=top-1;p=stack[top];printf("%3c",p->data);p=p->rchild;}}while(p!=nuLL||top!=0);}2、求二叉树高度:intcbiTree::postTreeDepth(binTreeif(T!=nuLL){l=postTreeDepth(T->lchild);r=postTreeDepth(T->rchil d);max=l>r?l:r;return(max+1);}elsereturn(0);}实验步骤:1)新建一个基于consoleApplication的工程,工程名称biTreeTest;2)新建一个类cbiTree二叉树类。
c++实现树(二叉树)的建立和遍历算法(一)(前序,中序,后序)

c++实现树(⼆叉树)的建⽴和遍历算法(⼀)(前序,中序,后序)最近学习树的概念,有关⼆叉树的实现算法记录下来。
不过学习之前要了解的预备知识:树的概念;⼆叉树的存储结构;⼆叉树的遍历⽅法。
⼆叉树的存储结构主要了解⼆叉链表结构,也就是⼀个数据域,两个指针域,(分别为指向左右孩⼦的指针),从下⾯程序1,⼆叉树的存储结构可以看出。
⼆叉树的遍历⽅法:主要有前序遍历,中序遍历,后序遍历,层序遍历。
(层序遍历下⼀篇再讲,本篇主要讲的递归法)下篇主要是,之后会有c++模板实现和。
如这样⼀个⼆叉树:它的前序遍历顺序为:ABDGHCEIF(规则是先是根结点,再前序遍历左⼦树,再前序遍历右⼦树)它的中序遍历顺序为:GDHBAEICF(规则是先中序遍历左⼦树,再是根结点,再是中序遍历右⼦树)它的后序遍历顺序为:GHDBIEFCA(规则是先后序遍历左⼦树,再是后序遍历右⼦树,再是根结点)如果不懂的话,可以参看有关数据结构的书籍。
1,⼆叉树的存储结构(⼆叉链表)//⼆叉树的⼆叉链表结构,也就是⼆叉树的存储结构,1个数据域,2个指针域(分别指向左右孩⼦)typedef struct BiTNode{ElemType data;struct BiTNode *lchild, *rchild;}BiTNode, *BiTree;2,⾸先要建⽴⼀个⼆叉树,建⽴⼆叉树必须要了解⼆叉树的遍历⽅法。
//⼆叉树的建⽴,按前序遍历的⽅式建⽴⼆叉树,当然也可以以中序或后序的⽅式建⽴⼆叉树void CreateBiTree(BiTree *T){ElemType ch;cin >> ch;if (ch == '#')*T = NULL; //保证是叶结点else{*T = (BiTree)malloc(sizeof(BiTNode));//if (!*T)//exit(OVERFLOW); //内存分配失败则退出。
二叉树的遍历(前序、中序、后序、已知前中序求后序、已知中后序求前序)

⼆叉树的遍历(前序、中序、后序、已知前中序求后序、已知中后序求前序)之前的⼀篇随笔()只对⼆叉树的遍历进⾏了笼统的描述,这篇随笔重点对前、中、后序的遍历顺序进⾏分析⼆叉树的遍历⼆叉树的深度优先遍历可细分为前序遍历、中序遍历、后序遍历,这三种遍历可以⽤递归实现(本篇随笔主要分析递归实现),也可使⽤⾮递归实现的前序遍历:根节点->左⼦树->右⼦树(根->左->右)中序遍历:左⼦树->根节点->右⼦树(左->根->右)后序遍历:左⼦树->右⼦树->根节点(左->右->根)在进⾏已知两种遍历顺序求另⼀种遍历顺序前,先看⼀下不同遍历顺序对应的代码前序遍历1/* 以递归⽅式前序遍历⼆叉树 */2void PreOrderTraverse(BiTree t, int level)3 {4if (t == NULL)5 {6return ;7 }8 printf("data = %c level = %d\n ", t->data, level);9 PreOrderTraverse(t->lchild, level + 1);10 PreOrderTraverse(t->rchild, level + 1);11 }中序遍历1/* 以递归⽅式中序遍历⼆叉树 */2void PreOrderTraverse(BiTree t, int level)3 {4if (t == NULL)5 {6return ;7 }8 PreOrderTraverse(t->lchild, level + 1);9 printf("data = %c level = %d\n ", t->data, level);10 PreOrderTraverse(t->rchild, level + 1);11 }后序遍历1/* 以递归⽅式后序遍历⼆叉树 */2void PreOrderTraverse(BiTree t, int level)3 {4if (t == NULL)5 {6return ;7 }8 PreOrderTraverse(t->lchild, level + 1);9 PreOrderTraverse(t->rchild, level + 1);10 printf("data = %c level = %d\n ", t->data, level);11 }三种遍历⽅式对应的代码⼏乎相同,只是⼀条语句的位置发⽣了变化printf("data = %c level = %d\n ", t->data, level);只看⽂字和代码来理解遍历的过程是⽐较困难的,建议读者亲⾃去遍历,为了理清遍历的过程下⾯上题(图⽚来源:)前序遍历前序的遍历的特点,根节点->左⼦树->右⼦树,注意看前序的遍历的代码printf语句是放在两条递归语句之前的,所以先访问根节点G,打印G,然后访问左⼦树D,此时左⼦树D⼜作为根节点,打印D,再访问D的左⼦树AA⼜作为根节点,打印A,A没有左⼦树或者右⼦树,函数调⽤结束返回到D节点(此时已经打印出来的有:GDA)D节点的左⼦树已经递归完成,现在递归访问右⼦树F,F作为根节点,打印F,F有左⼦树访问左⼦树E,E作为根节点,打印E,(此时已经打印出来的有:GDAFE),E没有左⼦树和右⼦树,函数递归结束返回F节点,F的左⼦树已经递归完成了,但没有右⼦树,所以函数递归结束,返回D节点,D节点的左⼦树和右⼦树递归全部完成,函数递归结束返回G节点,访问G节点的右⼦树M,M作为根节点,打印M,访问M的左⼦树H,H作为根节点,打印H,(此时已经打印出来的有:GDAFEMH)H没有左⼦树和右⼦树,函数递归结束,返回M节点,M节点的左⼦树已经递归完成,访问右⼦树Z,Z作为根节点,打印Z,Z没有左⼦树和右⼦树,函数递归结束,返回M节点,M节点的左⼦树右⼦树递归全部完成,函数递归结束,返回G节点,G节点的左右⼦树递归全部完成,整个⼆叉树的遍历就结束了(MGJ,终于打完了··)前序遍历结果:GDAFEMHZ总结⼀下前序遍历步骤第⼀步:打印该节点(再三考虑还是把访问根节点这句话去掉了)第⼆步:访问左⼦树,返回到第⼀步(注意:返回到第⼀步的意思是将根节点的左⼦树作为新的根节点,就好⽐图中D是G的左⼦树但是D也是A节点和F节点的根节点)第三步:访问右⼦树,返回到第⼀步第四步:结束递归,返回到上⼀个节点前序遍历的另⼀种表述:(1)访问根节点(2)前序遍历左⼦树(3)前序遍历右⼦树(在完成第2,3步的时候,也是要按照前序遍历⼆叉树的规则完成)前序遍历结果:GDAFEMHZ中序遍历(详细遍历过程就不再赘述了,(┬_┬))中序遍历步骤第⼀步:访问该节点左⼦树第⼆步:若该节点有左⼦树,则返回第⼀步,否则打印该节点第三步:若该节点有右⼦树,则返回第⼀步,否则结束递归并返回上⼀节点(按我⾃⼰理解的中序就是:先左到底,左到不能在左了就停下来并打印该节点,然后返回到该节点的上⼀节点,并打印该节点,然后再访问该节点的右⼦树,再左到不能再左了就停下来)中序遍历的另⼀种表述:(1)中序遍历左⼦树(2)访问根节点(3)中序遍历右⼦树(在完成第1,3步的时候,要按照中序遍历的规则来完成)所以该图的中序遍历为:ADEFGHMZ后序遍历步骤第⼀步:访问左⼦树第⼆步:若该节点有左⼦树,返回第⼀步第三步:若该节点有右⼦树,返回第⼀步,否则打印该节点并返回上⼀节点后序遍历的另⼀种表述:(1)后序遍历左⼦树(2)后序遍历右⼦树(3)访问根节点(在完成1,2步的时候,依然要按照后序遍历的规则来完成)该图的后序遍历为:AEFDHZMG(读者如果在纸上遍历⼆叉树的时候,仍然容易将顺序搞错建议再回去看⼀下三种不同遍历对应的代码)进⼊正题,已知两种遍历结果求另⼀种遍历结果(其实就是重构⼆叉树)第⼀种:已知前序遍历、中序遍历求后序遍历前序遍历:ABCDEF中序遍历:CBDAEF在进⾏分析前读者需要知道不同遍历结果的特点1、前序遍历的第⼀元素是整个⼆叉树的根节点2、中序遍历中根节点的左边的元素是左⼦树,根节点右边的元素是右⼦树3、后序遍历的最后⼀个元素是整个⼆叉树的根节点(如果读者不明⽩上述三个特点,建议再回去看⼀下三种不同遍历对应的代码,并在纸上写出⼀个简单的⼆叉树的三种不同的遍历结果,以加深对三种不同遍历的理解)⽤上⾯这些特点来分析遍历结果,第⼀步:先看前序遍历A肯定是根节点第⼆步:确认了根节点,再来看中序遍历,中序遍历中根节点A的左边是CBD,右边是EF,所有可以确定⼆叉树既有左⼦树⼜有右⼦树第三步:先来分析左⼦树CBD,那么CBD谁来做A的左⼦树呢?这个时候不能直接⽤中序遍历的特点(左->根->右)得出左⼦树应该是这个样⼦因为有两种情况都满⾜中序遍历为CBD⽆法直接根据中序遍历来直接得出左⼦树的结构,这个时候就要返回到前序遍历中去观察前序遍历ABCDEF,左⼦树CBD在前序遍历中的顺序是BCD,意味着B是左⼦树的根节点(这么说可能不太好理解,换个说法就是B是A的左⼦树),得出这个结果是因为如果⼀个⼆叉树的根节点有左⼦树,那么这个左⼦树⼀定在前序遍历中⼀定紧跟着根节点(这个是⽤前序遍历的特点(根->左->右)得出的),到这⾥就可以确认B是左⼦树的根节点第四步:再观察中序遍历CBDAEF,B元素左边是C右边是D,说明B节点既有左⼦树⼜有右⼦树,左右⼦树只有⼀个元素就可以直接确定了,不⽤再返回去观察前序遍历第五步:到这⾥左⼦树的重建就已经完成了,现在重建右⼦树,因为重建右⼦树的过程和左⼦树的过程⼀模⼀样,步骤就不像上⾯写这么细了((┬_┬)),观察中序遍历右⼦树为EF,再观察前序遍历ABCDEF中右⼦树的顺序为EF,所以E为A的右⼦树,再观察中序便利中E只有右边有F,所有F为E的右⼦树,最后得到的⼆叉树是这个样⼦的所有求得的后序遍历为:CDBFEA总结⼀下上述步骤:先观察前序遍历找到根节点->观察中序遍历将根节点左边归为左⼦树元素,右边归为右⼦树元素(可能会出现只有左⼦树或者右⼦树的情况)->观察前序遍历中左\右⼦树⼏个元素的顺序,最靠前的为左\右⼦树的根节点->重复前⾯的步骤第⼆种:已知中序遍历、后序遍历求前序遍历(题还是上⾯这道)中序遍历:CBDAEF后序遍历为:CDBFEA仍然是根据不同遍历⽅式结果的特点来重构⼆叉树,过程很相似这⾥就不详细说了,后序遍历的最后⼀个元素A是根节点,在中序遍历中以根节点A作为分界将元素分为左⼦树(CBD)和右⼦树(EF),再观察后序遍历中左⼦树的顺序是CDB,可以判断出B是左⼦树的根节点(因为后序遍历是:左->右->根),再观察中序遍历,B元素左边是C右边是D,说明B节点既有左⼦树⼜有右⼦树,左右⼦树只有⼀个元素就可以直接确定了,不⽤再返回去观察后序遍历,左⼦树重建完成,现在来看右⼦树,右⼦树有两个元素EF,观察后序遍历E在F的后⾯,所以E是右⼦树的根节点,然后看中序遍历中E只有右边⼀个F元素了,即F是E的右⼦树,此时整个⼆叉树重构完成总结⼀下上述步骤:先观察后序遍历找到根节点->观察中序遍历将根节点左边归为左⼦树元素,右边归为右⼦树元素(可能会出现只有左⼦树或者右⼦树的情况)->观察后序遍历中左\右⼦树⼏个元素的顺序,最靠后的为左\右⼦树的根节点->重复前⾯的步骤注意:已知前序遍历、后序遍历⽆法求出中序遍历(因为由前序后序重构出来的⼆叉树不⽌⼀种)举个栗⼦左图这两种⼆叉树前序(BEFA)和后序(AFEB)⼀样,但对应的中序遍历结果不⼀样(左边的是AFEB右边的是BEFA),所以仅靠前序后序是重构出唯⼀的⼆叉树。
二叉树的四种遍历算法

⼆叉树的四种遍历算法⼆叉树作为⼀种重要的数据结构,它的很多算法的思想在很多地⽅都⽤到了,⽐如STL算法模板,⾥⾯的优先队列、集合等等都⽤到了⼆叉树⾥⾯的思想,先从⼆叉树的遍历开始:看⼆叉树长什么样⼦:我们可以看到这颗⼆叉树⼀共有七个节点0号节点是根节点1号节点和2号节点是0号节点的⼦节点,1号节点为0号节点的左⼦节点,2号节点为0号节点的右⼦节点同时1号节点和2号节点⼜是3号节点、四号节点和五号节点、6号节点的双亲节点五号节点和6号节点没有⼦节点(⼦树),那么他们被称为‘叶⼦节点’这就是⼀些基本的概念⼆叉树的遍历⼆叉树常⽤的遍历⽅式有:前序遍历、中序遍历、后序遍历、层序遍历四种遍历⽅式,不同的遍历算法,其思想略有不同,我们来看⼀下这四种遍历⽅法主要的算法思想:1、先序遍历⼆叉树顺序:根节点 –> 左⼦树 –> 右⼦树,即先访问根节点,然后是左⼦树,最后是右⼦树。
上图中⼆叉树的前序遍历结果为:0 -> 1 -> 3 -> 4 -> 2 -> 5 -> 62、中序遍历⼆叉树顺序:左⼦树 –> 根节点 –> 右⼦树,即先访问左⼦树,然后是根节点,最后是右⼦树。
上图中⼆叉树的中序遍历结果为:3 -> 1 -> 4 -> 0 -> 5 -> 2 -> 63、后续遍历⼆叉树顺序:左⼦树 –> 右⼦树 –> 根节点,即先访问左⼦树,然后是右⼦树,最后是根节点。
上图中⼆叉树的后序遍历结果为:3 -> 4 -> 1 -> 5 -> 6 -> 2 -> 04、层序遍历⼆叉树顺序:从最顶层的节点开始,从左往右依次遍历,之后转到第⼆层,继续从左往右遍历,持续循环,直到所有节点都遍历完成上图中⼆叉树的层序遍历结果为:0 -> 1 -> 2 -> 3 -> 4 -> 5 -> 6下⾯是四种算法的伪代码:前序遍历:preOrderParse(int n) {if(tree[n] == NULL)return ; // 如果这个节点不存在,那么结束cout << tree[n].w ; // 输出当前节点内容preOrderParse(tree[n].leftChild); // 递归输出左⼦树preOrderParse(tree[n].rightChild); // 递归输出右⼦树}中序遍历inOrderParse(int n) {if(tree[n] == NULL)return ; // 如果这个节点不存在,那么结束inOrderParse(tree[n].leftChild); // 递归输出左⼦树cout << tree[n].w ; // 输出当前节点内容inOrderParse(tree[n].rightChild); // 递归输出右⼦树}pastOrderParse(int n) {if(tree[n] == NULL)return ; // 如果这个节点不存在,那么结束pastOrderParse(tree[n].leftChild); // 递归输出左⼦树pastOrderParse(tree[n].rightChild); // 递归输出右⼦树cout << tree[n].w ; // 输出当前节点内容}可以看到前三种遍历都是直接通过递归来完成,⽤递归遍历⼆叉树简答⽅便⽽且好理解,接下来层序遍历就需要动点脑筋了,我们如何将⼆叉树⼀层⼀层的遍历输出?其实在这⾥我们要借助⼀种数据结构来完成:队列。
用C语言编写二叉树的建立与遍历

用C语言编写二叉树的建立与遍历1.对题目要有需求分析在需求分析中,将题目中要求的功能进行叙述分析,并且设计解决此问题的数据存储结构,设计或叙述解决此问题的算法。
给出实现功能的一组或多组测试数据,程序调试后,将按照此测试数据进行测试的结果列出来。
如果程序不能正常运行,写出实现此算法中遇到的问题和改进方法;2.对题目要有相应的源程序源程序要按照写程序的规则来编写。
要结构清晰,重点函数的重点变量,重点功能部分要加上清晰的程序注释。
(注释量占总代码的四分之一)程序能够运行,要有基本的容错功能。
尽量避免出现操作错误时出现死循环;3.最后提供的主程序可以象一个应用系统一样有主窗口,通过主菜单和分级菜单调用课程设计中要求完成的各个功能模块,调用后可以返回到主菜单,继续选择其他功能进行其他功能的选择。
二叉树的建立与遍历[问题描述]建立一棵二叉树,并对其进行遍历(先序、中序、后序),打印输出遍历结果。
[基本要求]从键盘接受输入,以二叉链表作为存储结构,建立二叉树,并对其进行遍历(先序、中序、后序),将遍历结果打印输出。
以下是我的数据结构实验的作业:肯定好用,里面还包括了统计树的深度和叶子数!记住每次做完一个遍历还要重新输入你的树哦!#include "stdio.h"#include "string.h"#define NULL 0typedef struct BiTNode{char data;struct BiTNode *lchild,*rchild;}BiTNode,*BiTree;BiTree Create(BiTree T){char ch;ch=getchar();if(ch=='#')T=NULL;else{if(!(T=(BiTNode *)malloc(sizeof(BiTNode))))printf("Error!");T->data=ch;T->lchild=Create(T->lchild);T->rchild=Create(T->rchild); }return T;}void Preorder(BiTree T){if(T){printf("%c",T->data); Preorder(T->lchild); Preorder(T->rchild);}}int Sumleaf(BiTree T){int sum=0,m,n;if(T){if((!T->lchild)&&(!T->rchild)) sum++;m=Sumleaf(T->lchild);sum+=m;n=Sumleaf(T->rchild);sum+=n;}return sum;}void zhongxu(BiTree T){if(T){zhongxu(T->lchild);printf("%c",T->data); zhongxu(T->rchild);}}void houxu(BiTree T){if(T){houxu(T->lchild);houxu(T->rchild);printf("%c",T->data);}}int Depth(BiTree T){int dep=0,depl,depr;if(!T) dep=0;else{depl=Depth(T->lchild);depr=Depth(T->rchild);dep=1+(depl>depr?depl:depr);}return dep;}main(){BiTree T;int sum,dep;T=Create(T);Preorder(T);printf("\n");zhongxu(T);printf("\n");houxu(T);printf("\n");sum=Sumleaf(T);printf("%d",sum);dep=Depth(T);printf("\n%d",dep);}在Turbo C的环境下,先按Ctrl+F9运行程序,此时就是建立二叉树的过程,例如输入序列ABC##DE#G##F###(其中的“#”表示空,并且输入过程中不要加回车,因为回车也有对应的ASCII码,是要算字符的,但是输入完之后可以按回车退出),然后再按ALT+F5显示用户界面,这时候就能够看到结果了。
二叉树的遍历及例题

⼆叉树的遍历及例题⼆叉树的遍历及例题前序遍历就是根在前,中序是根在根在中,前序遍历根 --> 左 --> 右中序遍历左 --> 根 --> 右后序遍历左 --> 右 --> 根如图是⼀颗⼆叉树前序(根左右),中序(左根右),后序(左右根)它的前序遍历结果为: A B D F G H I E C 代表的含义为A( B ( D ( F ,G( H ,I ) ) ,E ) , C )所以第⼀个点⼀定是根节点它的中序遍历结果为: F D H G I B E A C它代表的含义,A(已知它不是叶⼦节点)在中间说明A的左边是左⼉⼦,A的右边是他的右⼉⼦它的后序遍历结果为:F H I G D E B C A解题:如果有前序和中序或者中序和后序可以得到⼆叉树,从⽽得到后序。
如果有前序和后序⽆法的得到⼆叉树。
1.已知前序、中序遍历求后序遍历例:前序遍历:A B G D E C F H中序遍历:G B E D A F C H构建⼆叉树的步骤:1.根据前序遍历特点,得到根节点A2.观察中序遍历结果:根节点左边节点为G B E D,根节点的右边节点为 F C H。
同时,两段也是左右⼦树的中序遍历的结果。
B G D E也是左⼦树前序遍历的结果。
C F H也是右⼦树前序遍历的结果。
3.重复 1 2的步骤,直到找到叶⼦结点就可以得到最后的⼆叉树。
例题:题意:给出中序遍历和前序遍历,让你找到后序遍历的结果。
#include <iostream>using namespace std;const int maxn = 105;int pre[maxn],in[maxn],pos[maxn];int infind(int root,int l,int r){//在中序遍历中找到当前根节点的位置for(int i=l;i<r;i++){if(in[i]==root){return i;}}}int cnt;void posorder(int prel,int prer,int inl,int inr){if(prel==prer) return ;int root=infind(pre[prel],inl,inr);//找当前的根的位置int len=root-inl;posorder(prel+1,prel+1+len,inl,inl+len);//prel的位置是root的位置,删去posorder(prel+1+len,prer,inl+1+len,inr);//inl+len+1的位置是root的位置,删去//进⾏完左边和右边的遍历之后,进⾏赋值。