C语言版的排序方法---基数排序
基数排序算法了解基数排序的原理和应用场景

基数排序算法了解基数排序的原理和应用场景基数排序算法:了解基数排序的原理和应用场景基数排序算法是一种非比较排序算法,它通过将待排序的数据分割成一系列的位数来进行排序。
基数排序的原理是将待排序的元素按照每个位上的数值进行排序,从低位到高位进行比较和排序。
下面将介绍基数排序的原理和应用场景。
一、基数排序的原理基数排序的原理是将待排序的元素按照每个位上的数值进行排序。
其基本思想是将所有待比较的元素统一为同样的位数长度,然后按照低位到高位的顺序依次进行排序。
具体步骤如下:1. 将待排序的元素按照个位数的数值进行排序,将它们分别放到相应的桶中。
2. 按照十位数的数值对上一步排序后的元素进行排序,再将它们放到相应的桶中。
3. 按照百位数的数值对上一步排序后的元素进行排序,再将它们放到相应的桶中。
4. 依次类推,直到对最高位排序完成。
5. 最后将所有桶中的元素按照顺序取出,即得到排好序的序列。
基数排序的时间复杂度是O(d(n+r)),其中n是待排序的元素个数,d是最大的位数,r是基数,一般是10。
从时间复杂度来看,基数排序是一种高效的排序算法。
二、基数排序的应用场景1. 大量数据的排序:基数排序适用于大量数据的排序,特别是当数据范围较小,位数较少的情况下。
因为基数排序不需要数据之间的比较操作,只需要按照每个位上的数值进行排序,所以在数据量较大时,基数排序的效率较高。
2. 数字序列的排序:基数排序适用于对数字序列进行排序的场景,尤其是当数字序列的位数较小且数字范围较小的情况下。
例如,对学生成绩进行排序、对手机号码进行排序等都可以使用基数排序。
3. 字符串的排序:基数排序也可以应用于对字符串序列进行排序的场景。
可以按照每个字符的ASCII码值进行排序,从而实现字符串的排序功能。
例如,对字符串列表进行排序、对文件名进行排序等都可以使用基数排序。
总结:基数排序是一种比较高效的非比较排序算法,通过按照每个位上的数值进行排序,可以对大量数据、数字序列和字符串序列进行排序。
基数排序详解

基数排序详解1.前言排序是计算机科学中最基本的概念之一。
常见的排序算法包括冒泡排序、插入排序、选择排序、归并排序、快速排序等。
这些算法的时间复杂度大多数是O(n²)或O(n log n)。
事实上,在实际的应用中,我们往往会遇到需要排序的数列中元素的范围很小的情况,例如在一张成绩单中,成绩的范围是0-100。
此时,可以采用基数排序,它的时间复杂度是O(n)。
2.基数排序的基本概念基数排序是一种线性排序算法,它的思想是根据元素的位数进行排序。
比如,在排序1000个数时,如果所有数的位数都一样,则只需要做一次排序;如果位数不同,则需要进行多轮排序。
基数排序的每一轮排序都是根据元素的某一位进行排序,最终排完最高位时,数列便有序了。
3.基数排序的具体实现基数排序的具体实现有两种方法,分别是LSD(LeastSignificant Digit)和MSD(Most Significant Digit)。
3.1 LSD基数排序LSD基数排序是从最低位开始排序,依次按照低位到高位的顺序进行排序。
比如对于一个数列{170,45,75,90,802,24,2,66},LSD基数排序在某一轮排序时,按照个位的数字进行排序,结果为{170,90,802,2,24,45,75,66}。
此时,再按照十位的数字进行排序,结果为{2,170,24,45,66,75,802,90}。
依次类推,一直排完最高位后,数列就有序了。
3.1.1 LSD基数排序的代码实现```pythondef radix_sort_LSD(lst):if not lst:return []def get_digit(x, k):return x // 10 ** k % 10for k in range(3): # 最多3位数,循环3次s = [[] for i in range(10)]for num in lst:s[get_digit(num, k)].append(num)lst = [j for i in s for j in i]return lst```3.2 MSD基数排序MSD基数排序是从最高位开始排序,按照高位到低位的顺序进行排序。
C语言简单查找排序方法及代码

第一部分查找1、线性查找法:import java.util.Scanner;public class SearchDataElement {public static void main(String[] args) {Scanner scanner=new Scanner(System.in);int[]array;array=new int[]{8,7,5,4,1,5,9,6,3,4};for(int i=0;i<array.length;i++)System.out.println(""+array[i]);System.out.println();int replay=0;do{System.out.print("请输入要查找的数字0-10");int num=scanner.nextInt();lable:{for(int t=0;t<array.length;t++){if(num==array[t]){System.out.println("array["+t+"]="+array[t]);break lable;}}System.out.println("输入的数字数组中不存在");}System.out.println("重新查找1:继续 0:结束?");replay=scanner.nextInt();}while(replay==1);}}2、二分查找算法import java.util.Scanner;public class SearchBinary {public static int searchB(int[]arr,int key){int low=0;int high=arr.length-1;//while(high>=low){int mid=(low+high)/2;if(key<arr[mid])high=mid-1;else if(key==arr[mid])return mid;elselow=mid+1;}return-1;}public static void main(String[] args) {// TODO Auto-generated method stubint[]array=new int[]{2,4,7,11,14,25,33,42,55,64,75,88,89,90,92};int key;Scanner scanner=new Scanner(System.in);System.out.println("\n 请输入关键字:");key=scanner.nextInt();//int result=searchB(array,key);if(result!=-1)System.out.printf("\n%d found in arrray element %d\n", key,result);elseSystem.out.printf("\n %d not found in array\n",key);}}C语言排序方法学的排序算法有:插入排序,合并排序,冒泡排序,选择排序,希尔排序,堆排序,快速排序,计数排序,基数排序,桶排序(没有实现)。
C语言八大排序算法
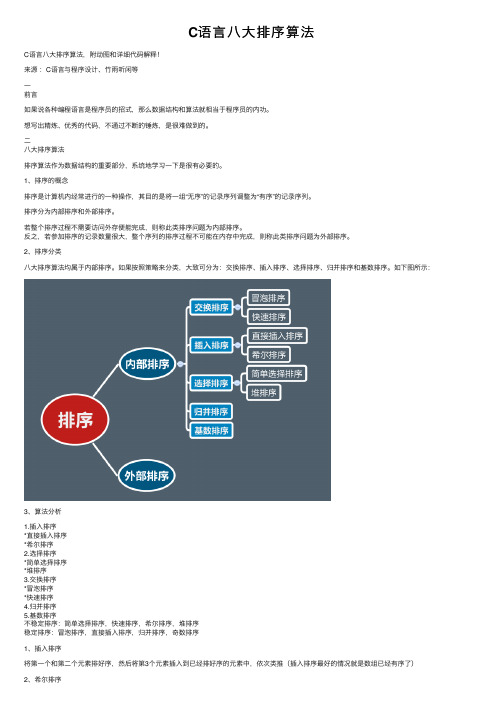
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
c语言运算符的优先级顺序表格

在C语言中,运算符的优先级顺序如下(从高到低):
1. 括号运算符:()
2. 数组下标运算符:[]
3. 结构体成员运算符:.
4. 指针成员运算符:->
5. 后缀递增/递减运算符:++,--
6. 前缀递增/递减运算符:++,--
7. 一元运算符:+(正号),-(负号),!(逻辑非),~(按位取反),*(指针取值),&(取地址),sizeof
8. 类型转换运算符:(type)
9. 乘法运算符:*,/,%
10. 加法运算符:+,-
11. 移位运算符:<<,>>
12. 关系运算符:>,>=,<,<=
13. 相等运算符:==,!=
14. 按位与运算符:&
15. 按位异或运算符:^
16. 按位或运算符:|
17. 逻辑与运算符:&&
18. 逻辑或运算符:||
19. 条件运算符:?:
20. 赋值运算符:=,+=,-=,*=,/=,%=,<<=,>>=,&=,^=,|=
21. 逗号运算符:,
请注意,优先级较高的运算符会先于优先级较低的运算符进行计算。
当有多个运算符出现时,可以使用括号来明确指定计算顺序,从而避免由于优先级导致的歧义或错误。
数据结构C语言版_链式基数排序

{
int j,p;
for(j=0;j<RADIX;++j)for(p=r[0].next;p;p=r[p].next)
{
// ord将记录中第i个关键字映射到[0..RADIX-1]
keys=083 otheritems=10 next=0
第1趟收集后:
930 063 083 184 505 278 008 109 589 269
第2趟收集后:
505 008 109 930 063 269 278 083 184 589
第3趟收集后:
008 063 083 109 184 269 278 505 589 930
// L是采用静态链表表示的顺序表。对L作基数排序,使得L成为按关键字
// 自小到大的有序静态链表,L.r[0]为头结点。
void RadixSort(SLList *L)
{
int i;
ArrType f,e;
for(i=0;i<(*L).recnum;++i)
(*L).r[i].next=i+1;
; // 找下一个非空子表
if(f[j])
{
// 链接两个非空子表
r[t].next=f[j];
t=e[j];
}
}
r[t].next=0; // t指向最后一个非空子表中的最后一个结点
}
// 按链表输出静态链表
void printl(SLList L)
print(l);
c语言实现简单排序(8种方法)

#include<stdio.h>#include<stdlib.h>//冒泡排序voidbubleSort(int data[], int n);//快速排序voidquickSort(int data[], int low, int high); intfindPos(int data[], int low, int high);//插入排序voidbInsertSort(int data[], int n);//希尔排序voidshellSort(int data[], int n);//选择排序voidselectSort(int data[], int n);//堆排序voidheapSort(int data[], int n);void swap(int data[], inti, int j);voidheapAdjust(int data[], inti, int n);//归并排序voidmergeSort(int data[], int first, int last);void merge(int data[], int low, int mid, int high); //基数排序voidradixSort(int data[], int n);intgetNumPos(intnum, intpos);int main() {int data[10] = {43, 65, 4, 23, 6, 98, 2, 65, 7, 79}; inti;printf("原先数组:");for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");/*printf("冒泡排序:");bubleSort(data, 10);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");printf("快速排序:");quickSort(data, 0, 9);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");printf("插入排序:");bInsertSort(data,10);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");printf("希尔排序:");shellSort(data, 10);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");printf("选择排序:");selectSort(data, 10);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");int data[11] = {-1, 43, 65, 4, 23, 6, 98, 2, 65, 7, 79}; inti;printf("原先数组:");int data[11] = {-1, 43, 65, 4, 23, 6, 98, 2, 65, 7, 79}; for(i=1;i<11;i++) {printf("%d ", data[i]);}printf("\n");printf(" 堆排序:");heapSort(data, 10);for(i=1;i<11;i++) {printf("%d ", data[i]);}printf("\n");printf("归并排序:");mergeSort(data, 0, 9);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");*/printf("基数排序:");radixSort(data, 10);for(i=0;i<10;i++) {printf("%d ", data[i]);}printf("\n");return 0;}/*--------------------冒泡排序---------------------*/ voidbubleSort(int data[], int n) {inti,j,temp;//两个for循环,每次取出一个元素跟数组的其他元素比较//将最大的元素排到最后。
基数排序算法的链表实现

程 序 中 包 含 下 述 主 要 模 块 : 建 单 链 表 创 C e t In L s( rT p )基数 排序算 法 r ae J k i A r y e a 、 i t 的 核心 模块Ra i S r( rT p ) dx o tA r y e a 。
=
一
排 序 是 计 算 机 处 理 数 据 序 列 最 常 用 的 种 操 作 。 序 操 作 将 一 组 无 序 的 数 据 序 排
1基数排序算 法的基 本思想
列 按 某 种 次 序 重 新 排 列 , 而 得 到 一 组 有 从
设 有一 个 由RAD x个单 链 表 组成 的链 到 链 表 集 L 的 数 据 结 点 的 分 布位 置 : [】 I 中 L0 { , 3 8 } L 1= l 9 1 4 , [1 { 6 , 8 6 , 3 , [】 { 0 , 8 } L 2= 2 9 表 集 L 【 01 .R DI 一1和 一 个 由 ,., A X ,.
{ 7 , O 6 9 0 5 9 l 4, 0 2 9, 2 8 1 9, 3, 3 , 8 , 8 5 5, 6 8, 3 8}
排 序 在 处 理 数据 序 列 的 计 算 机 程 序 中 占 用 的 时 间较 长 , 计 高 效 的 排 序 算 法 是 设 提 高 这 些 程 序 执 行 效 率 的 关 键 。 常 , 序 通 排 算 法 通 过 两 个 基 本操 作 实现 对 数据 序 列 排 序 : 个 是 通 过 比较 关 键 字 来 确 定 数 据 在 一
复 杂性 。 关键 词 : 算法 排序 基数排 序 链表
中 图分类 号 : P I T 3 2
文 献标 识 码 : A
文 章编号 : 6 4 0 ( 0 10 () 0 3 0 1 7 - 9 X 2 1 ) 8b一0 2 — 2 8 3 按百 位 数 分 配 和 收集 数 据 结 点 , 配 ) 分
c语言数组排序方法

c语言数组排序方法
以下是 8 条关于“C 语言数组排序方法”的内容:
1. 嘿,知道冒泡排序不?就像水里的泡泡一个一个往上冒一样,比如有个数组{5,3,8,1},通过不断比较相邻元素并交换来把小的数字往上推,最后不就排好序了嘛!这多有趣呀!
2. 哎呀呀,插入排序其实也不难理解呀!就好比你整理扑克牌,一张张插入到合适的位置,像数组{2,6,1,9},依次把元素插入到已排序的部分,慢慢就排好序啦,是不是很神奇?
3. 选择排序呀,就像是选美比赛!在数组{7,4,2,5}里面,每次选出最小的放到前面,一轮一轮下来,不就变得有序啦,这不是很形象嘛!
4. 哈哈,快速排序可厉害啦!把数组像切蛋糕一样分成两部分,递归地去处理,比如数组{9,3,7,6},那速度,杠杠的!
5. 归并排序就如同溪流汇聚成大河!先把数组分成小块,再一点点合并起来,像处理数组{8,2,4,10}时,最后就能得到有序的结果啦,想想就很妙哇!
6. 计数排序呢,有点特别哦!假如有数组{3,1,3,2},就根据元素的值来计数,然后按计数顺序排好,多有意思呀!
7. 桶排序,这就像把东西分类放到不同的桶里!对于数组{5,7,1,8},根据一定规则分到桶里,再整理,这不就整齐啦?
8. 基数排序也很有特点呀!像是给数字们排座位一样,从低位到高位依次处理,面对数组{12,56,8,34},一步一步搞定排序,是不是很牛?
我的观点结论就是:C 语言的这些数组排序方法都各有特点和用途,学会掌握它们,能让我们在编程中更加得心应手呀!。
算法22-- 内部排序--基数排序

a<c no
c<a<b
c<b<a
• 注意:树高代表比较的代价。因此只要知道了树高和结点数 n 的关系,就可以求出 用比较法进行排序时的时间代价。另外,n 个结点的分类序列,其叶子结点 共有 n! 片。
17
9.7 内部排序方法的比较
比较次数 排序方法 最好 最差 最好 最差 移动次数
269
184 278 f[7] 083 f[8] f[9]
930
f[3] f[4] f[5]
063 f[6]
r[0]→ 505
008
109
930
063
269
278
083
184
589
2018/10/16
第二趟收集的结果:
r[0]0
063
269
278
083
184
589
第三趟分配(按最高位 i = 1 ) e[0] 083 063 008 f[0] 第三趟收集 184 109 f[1] 278 269 f[2] f[3] f[4] 589 505 f[5] f[6] f[7] f[8] 930 f[9] e[1] e[2] e[3] e[4] e[5] e[6] e[7] e[8] e[9]
2018/10/16
j = 0; // 开始从0号队列(总共radix个队)开始收集 while ( f [j] == 0 ) j++; // 若是空队列则跳过 r[0].next=p = f [j]; //建立本趟收集链表的头指针 int last = e[j]; //建立本趟收集链表的尾指针 for ( k = j+1; k < radix; k++) // 逐个队列链接(收集) if ( f [k] ) { //若队列非空 r[last].next=f [k]; last = e[k]; //队尾指针链接 } r[last].next=0; //本趟收集链表之尾部应为0 } } // RadixSort
【C语言简单排序】——整数奇偶排序

【C语⾔简单排序】——整数奇偶排序7-1 整数奇偶排序 给定10个整数的序列,要求对其重新排序。
排序要求: 1.奇数在前,偶数在后; 2.奇数按从⼤到⼩排序; 3.偶数按从⼩到⼤排序。
输⼊格式: 输⼊⼀⾏,包含10个整数,彼此以⼀个空格分开,每个整数的范围是⼤于等于0,⼩于等于30000。
输出格式: 请在这⾥描述输出格式。
例如:对每⼀组输⼊,在⼀⾏中输出A+B的值。
输⼊样例: 按照要求排序后输出⼀⾏,包含排序后的10个整数,数与数之间以⼀个空格分开。
4731311120473498输出样例: 在这⾥给出相应的输出。
例如:4713117304123498思路: 这⾥分析题⽬,发现有三种情况下需要进⾏排序: 1.a[j]为奇数,a[j+1]为偶数 2.a[j]为奇数,a[j+1]为奇数且a[j] < a[j+1] 3.a[j]为偶数,a[j+1]为偶数且a[j] > a[j+1]代码:#include<stdio.h>int main(){int n = 10,i,j,tmp;int a[10];for(i = 0; i < n; i++){scanf("%d",&a[i]);}for(i = 0; i < n-1; i++){for(j = 0; j < n-1; j++){if(a[j] % 2 == 0 && a[j+1] % 2 != 0 || a[j] % 2 != 0 && a[j+1] % 2 != 0 && a[j] < a[j+1] || a[j] % 2 == 0 && a[j+1] % 2 ==0 && a[j] > a[j+1]) {tmp = a[j];a[j] = a[j+1];a[j+1] = tmp;}}}for(i = 0; i < n; i++){printf("%d ",a[i]);}return0;}。
c语言的排序方法

c语言的排序方法C语言的排序方法排序是计算机科学中非常重要的一个基本操作,它用于将一组无序的数据按照一定的规则进行重新排列,以便更方便地进行查找、插入和删除等操作。
C语言作为一种广泛应用的编程语言,提供了多种排序算法的实现方式,本文将介绍几种常用的排序方法及其实现。
一、冒泡排序(Bubble Sort)冒泡排序是最简单的排序算法之一,它的基本思想是重复地比较相邻的两个元素,如果它们的顺序错误就交换位置,直到没有需要交换的元素为止。
冒泡排序的时间复杂度为O(n^2)。
二、选择排序(Selection Sort)选择排序每次从待排序的数据中选择最小(或最大)的元素放到已排序的数据末尾,直到全部元素排序完成。
选择排序的时间复杂度也为O(n^2)。
三、插入排序(Insertion Sort)插入排序的思想是将一个记录插入到已经排好序的有序表中,形成一个新的有序表。
插入排序的时间复杂度为O(n^2),但在实际应用中,插入排序常常比其他排序算法更有效。
四、快速排序(Quick Sort)快速排序是一种基于分治法的排序算法,它通过选择一个基准元素,将待排序的数据分割成两部分,其中一部分的所有元素都比基准元素小,另一部分的所有元素都比基准元素大,然后对这两部分继续进行快速排序。
快速排序的时间复杂度为O(nlogn)。
五、归并排序(Merge Sort)归并排序采用分治法的思想,将待排序的数据分为两个子序列,分别进行排序,然后将两个有序的子序列合并成一个有序的序列。
归并排序的时间复杂度为O(nlogn)。
六、堆排序(Heap Sort)堆排序利用堆这种数据结构进行排序,它将待排序的数据构建成一个大顶堆或小顶堆,然后依次将堆顶元素与最后一个元素交换,并对剩余的元素重新调整堆,重复这个过程直到所有元素都排序完成。
堆排序的时间复杂度为O(nlogn)。
七、希尔排序(Shell Sort)希尔排序是一种改进的插入排序算法,它通过将待排序的数据分组,分组内进行插入排序,然后逐渐缩小分组的间隔,最终完成排序。
基数排序 算法

基数排序(Radix Sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。
以下是基数排序算法的步骤:确定要排序的数字的位数,例如对于非负整数,通常有10位(0-9)。
从最低位开始,按照每一位上的数字进行排序。
这可以通过使用“桶排序”或“计数排序”等方法实现。
重复步骤2,直到最高位排序完成。
基数排序的时间复杂度为O(d(n+k)),其中d是数字的位数,n是要排序的数字的数量,k是每个位数上可能的最大值。
基数排序是一种稳定的排序算法,即相等的元素在排序后保持其原始顺序。
以下是一个简单的基数排序算法的Python实现:pythondef radix_sort(arr):# 获取最大值,以便确定要排序的位数max_val = max(arr)# 获取最大值的位数digit = len(str(max_val))# 对每一位进行计数排序for i in range(digit):# 创建一个空的桶列表buckets = [[] for _ in range(10)]# 将数字分配到对应的桶中for num in arr:digit_val = (num // (10**i)) % 10buckets[digit_val].append(num)# 将桶中的数字重新放回数组中arr = [num for bucket in buckets for num in bucket]return arr这个实现使用计数排序作为每个位上的排序方法,时间复杂度为O(n)。
如果需要更高效的实现,可以使用桶排序或其他更快的排序方法。
C语言三种基本排序方法

C语言三种基本排序方法
一、选择排序法。
选择排序法的第一层循环从起始元素开始选到倒数第二个元素,主要是在每次进入的第二层循环之前,将外层循环的下标赋值给临时变量,接下来的第二层循环中,如果发现有比这个最小位置处的元素更小的元素,则将那个更小的元素的下标赋给临时变量,最后,在二层循环退出后,如果临时变量改变,则说明,有比当前外层循环位置更小的元素,需要将这两个元素交换。
二、冒泡排序法。
冒泡排序算法的运作如下:(从后往前)比较相邻的元素。
如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。
在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
三、插入排序法。
所谓插入排序法,就是检查第i个数字,如果在它的左边的数字比它大,进行交换,这个动作一直继续下去,直到这个数字的左边数字比它还要小,就可以停止了。
插入排序法主要的回圈有两个变数:i和j,每一次执行这个回圈,就会将第i个数字放到左边恰当的位置去。
插入排序的基本思想是:每步将一个待排序的纪录,按其关
键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止(分为直接插入法和折半插入法)。
数据结构(C语言)第八章 排序

直接插入排序过程
0 21 1 25 2 49 3 4 25* 16 5 08 temp
i=1
0 21
21
1 25
25 25
2 49
49 49
3 4 25* 16
25* 16 25* 16
5 08
08 08
temp 25
i=2
21
49
21
25
25 25
49
49 25*
25* 16
25* 16 49 16
希尔排序 (Shell Sort)
基本思想设待排序对象序列有 n 个对象, 首 先取一个整数 gap < n 作为间隔, 将全部对 象分为 gap 个子序列, 所有距离为 gap 的对 象放在同一个子序列中, 在每一个子序列中 分别施行直接插入排序。然后缩小间隔 gap, 例如取 gap = gap/2,重复上述的子序列划 分和排序工作。直到最后取 gap == 1, 将所 有对象放在同一个序列中排序为止。 希尔排序方法又称为缩小增量排序。
第八章 排序
概述
插入排序
交换排序 选择排序 归并排序 基数排序 各种内排方法比较
概 述
排序: 将一个数据元素的任意序列,重新
排列成一个按关键字有序的序列。
数据表(datalist): 它是待排序数据对象的
有限集合。
主关键字(key): 数据对象有多个属性域,
即多个数据成员组成, 其中有一个属性域可用 来区分对象, 作为排序依据,称为关键字。也 称为关键字。
直接插入排序 (Insert Sort)
基本思想 当插入第i (i 1) 个对象时, 前面的 R[0], R[1], …, R[i-1]已经排好序。这时, 用 R[i]的关键字与R[i-1], R[i-2], …的关键字顺 序进行比较, 找到插入位臵即将R[i]插入, 原 来位臵上的对象向后顺移。
c语言基本数据类型从小到大排序

c语言基本数据类型从小到大排序C语言是一种广泛应用于嵌入式系统和系统级编程的计算机编程语言。
在C语言中,基本数据类型是程序中用来存储和处理数据的基本单元。
这些基本数据类型按照其所占用的内存空间大小可以从小到大进行排序。
本文将按照这个顺序介绍C语言中的基本数据类型。
**1. 字符类型(char)**字符类型用来表示单个字符,它占用一个字节的内存空间。
在C语言中,字符类型可以用来存储ASCII码中的字符。
例如,可以使用字符类型来存储字母、数字、特殊字符等。
**2. 短整型(short)**短整型是用来存储整数的数据类型,它占用两个字节的内存空间。
短整型可以表示的整数范围比字符类型更大,通常为-32768到32767。
**3. 整型(int)**整型是C语言中最常用的数据类型之一,它用来存储整数。
整型占用四个字节的内存空间,可以表示的整数范围更广,通常为-2147483648到2147483647。
**4. 长整型(long)**长整型也用来存储整数,它占用的内存空间比整型更大,通常为八个字节。
长整型可以表示的整数范围更广,通常为-9223372036854775808到9223372036854775807。
**5. 单精度浮点型(float)**单精度浮点型用来存储小数,它占用四个字节的内存空间。
单精度浮点型可以表示的小数范围较大,通常为1.2E-38到3.4E+38。
**6. 双精度浮点型(double)**双精度浮点型也用来存储小数,它占用八个字节的内存空间。
双精度浮点型可以表示的小数范围更广,通常为 2.3E-308到 1.7E+308。
**7. 空类型(void)**空类型用来表示无类型的指针。
空类型不占用任何内存空间,通常用于函数返回类型或指针类型。
通过以上介绍,我们可以看出C语言中的基本数据类型按照所占用的内存空间大小从小到大分别是字符类型、短整型、整型、长整型、单精度浮点型、双精度浮点型和空类型。
c语言十大排序算法

c语言十大排序算法C语言是一种广泛应用于计算机领域的编程语言,在数据处理过程中,排序算法是最常用的操作之一。
在C语言中,有许多经典的排序算法,下面将介绍十大排序算法并讨论其特点和适用场景。
1.冒泡排序算法冒泡排序算法是一种简单的排序方法,其基本思想是将要排序的数组分为两部分:已排序部分和未排序部分。
进入排序过程后,每一次排序将未排序部分中的第一个数与第二个数进行比较,若第二个数小于第一个数,则交换它们的位置,依次往后,直到最后一个未排序的数。
冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1),适用于数据量较小的排序场景。
2.插入排序算法插入排序算法是一种稳定的排序方法,其中以第一个元素作为基准,与后面的元素进行比较,若后面的元素小于前一个元素,则将其插入到合适位置,依次往后,直到最后一个元素。
插入排序的时间复杂度为O(n^2),空间复杂度为O(1),适用于数据量较小的排序场景。
3.选择排序算法选择排序算法是一种简单的排序算法,其基本思想是每次选择一个最小(或最大)的元素,在未排序部分找出最小的元素,并放到已排序部分的最后一个位置。
选择排序的时间复杂度为O(n^2),空间复杂度为O(1),适用于数据量较小的排序场景。
4.归并排序算法归并排序算法是一种稳定的排序算法,其基本思想是将数组分成两半,然后递归地将每个子数组排序,最后将两个排好序的子数组归并到一起。
归并排序的时间复杂度为O(nlogn),空间复杂度为O(n),适用于数据量较大的排序场景。
5.快速排序算法快速排序算法是一种常用的排序算法,其基本思想是将待排序的数组分为两个子数组,设置一个基准值,小于基准值的元素放到左边,大于基准值的元素放到右边,然后递归地对左右两个子数组进行排序。
快速排序的时间复杂度为O(nlogn),空间复杂度为O(nlogn),适用于数据量较大的排序场景。
6.计数排序算法计数排序算法是一种稳定的排序算法,其基本思想是先统计序列中每个元素出现的次数,将其存入临时数组中,然后从临时数组中按照顺序取出元素。
基数排序c语言

基数排序c语言基数排序是一种非比较排序算法,它按照数据的每个位数进行排序。
这个算法需要有一个用于存储临时数据的辅助数组。
以下是基数排序的C语言实现代码:c获取数组中最大的数int getMax(int arr[], int n) {int max = arr[0];for (int i = 1; i < n; i++)if (arr[i] > max)max = arr[i];return max;}使用计数排序对数组按照指定位进行排序void countSort(int arr[], int n, int exp) {int output[n]; 存储排序结果的临时数组int count[10] = {0}; 用于计数的数组统计每个数字的出现次数for (int i = 0; i < n; i++)count[(arr[i] / exp) % 10]++;计算每个数字在输出数组中的位置for (int i = 1; i < 10; i++)count[i] += count[i - 1];将数字按照指定位数排序到临时数组中for (int i = n - 1; i >= 0; i) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10];}将临时数组的内容拷贝回原数组for (int i = 0; i < n; i++)arr[i] = output[i];}基数排序函数void radixSort(int arr[], int n) {int max = getMax(arr, n);对数组每个位数进行排序for (int exp = 1; max / exp > 0; exp *= 10)countSort(arr, n, exp);}测试代码int main() {int arr[] = {170, 45, 75, 90, 802, 24, 2, 66};int n = sizeof(arr) / sizeof(arr[0]);radixSort(arr, n);printf("排序后的数组:\n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;}以上代码实现了基数排序算法,通过测试代码可以看到排序结果。
基数排序原理

基数排序原理基数排序是一种非比较性的排序算法,它将整数按照位数切割成不同的数字,然后按每个位数分别比较。
基数排序的实现可以采用桶排序或计数排序的方法,它适用于整数和字符串的排序。
基数排序的原理是将待排序的数字按照个位、十位、百位等位数进行比较和排序。
首先,将所有待排序的数字统一为同样的位数,不足位数的高位补0。
然后,从最低位开始,按照当前位数的大小将数字分配到对应的桶中。
接着,将所有桶中的数字按照顺序依次取出,形成新的待排序序列。
重复这个过程,直到所有位数都比较完毕,最后得到一个有序的序列。
基数排序的时间复杂度为O(d(n+r)),其中d为位数,n为待排序数字个数,r为基数。
当待排序数字的位数较小,而且基数较小时,基数排序的效率会非常高。
但是,当待排序数字的位数较大时,基数排序的效率会大大降低。
基数排序的优点是稳定性高,适用于大量数据的排序。
但是,它也有一些缺点,比如需要额外的存储空间来存放桶,当待排序数字的位数较大时,需要进行多次分配和收集,效率会受到影响。
总的来说,基数排序是一种比较适用于整数和字符串排序的算法,它的原理简单,实现也相对容易。
但是在实际应用中,需要根据具体情况来选择合适的排序算法,以达到最优的排序效果。
基数排序的思想是将整数按照位数切割成不同的数字,然后按每个位数分别比较。
这种排序方法的优势在于它是一种稳定的排序算法,适用于整数和字符串的排序。
基数排序的时间复杂度为O(d(n+r)),其中d为位数,n为待排序数字个数,r为基数。
在待排序数字的位数较小、基数较小的情况下,基数排序的效率会非常高。
但是当待排序数字的位数较大时,基数排序的效率会大大降低。
基数排序的原理简单,实现也相对容易,但在实际应用中需要根据具体情况选择合适的排序算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基数排序
#include <stdio.h>
#include <stdlib.h>
//计数排序,npRadix为对应的关键字序列,nMax是关键字的范围。
npData是具体要//排的数据,nLen是数据的范围,这里必须注意npIndex和npData对应的下标要一致//也就是说npIndex[1] 所对应的值为npData[1]
int RadixCountSort(int* npIndex, int nMax, int* npData, int nLen)
{
//这里就不用说了,计数的排序。
不过这里为了是排序稳定
//在标准的方法上做了小修改。
int* pnCount = (int*)m alloc(sizeof(int)* nMax); //保存计数的个数
for (int i = 0; i < nMax; ++i)
{
pnCount[i] = 0;
}
for (int i = 0; i < nLen; ++i) //初始化计数个数
{
++pnCount[npIndex[i]];
}
for (int i = 1; i < 10; ++i) //确定不大于该位置的个数。
{
pnCount[i] += pnCount[i - 1];
}
int * pnSort = (int*)m alloc(sizeof(int) * nLen); //存放零时的排序结果。
//注意:这里i是从nLen-1到0的顺序排序的,是为了使排序稳定。
for (int i = nLen - 1; i >= 0; --i)
{
--pnCount[npIndex[i]];
pnSort[pnCount[npIndex[i]]] = npData[i];
}
for (int i = 0; i < nLen; ++i) //把排序结构输入到返回的数据中。
{
npData[i] = pnSort[i];
}
free(pnSort); //记得释放资源。
free(pnCount);
return 1;
}
//基数排序
int RadixSort(int* nPData, int nLen)
{
//申请存放基数的空间
int* nDataRadix = (int*)m alloc(sizeof(int) * nLen);
int nRadixBase = 1; //初始化倍数基数为1
bool nIsOk =false; //设置完成排序为false
//循环,知道排序完成
while (!nIsOk)
{
nIsOk =true;
nRadixBase *= 10;
for (int i = 0; i < nLen; ++i)
{
nDataRadix[i] = nPData[i] % nRadixBase;
nDataRadix[i] /= nRadixBase / 10;
if (nDataRadix[i] > 0)
{
nIsOk = false;
}
}
if (nIsOk) //如果所有的基数都为0,认为排序完成,就是已经判断到最高位了。
{
break;
}
RadixCountSort(nDataRadix, 10, nPData, nLen);
}
free(nDataRadix);
return 1;
}
int m ain()
{
//测试基数排序。
int nData[10] = {123,5264,9513,854,9639,1985,159,3654,8521,8888}; RadixSort(nData, 10);
for (int i = 0; i < 10; ++i)
{
printf("%d ", nData[i]);
}
printf("\n");
system("pause");
return 0;
}。