第九章 聚类分析
聚类分析方法

聚类分析方法聚类分析是一种常用的数据分析方法,它可以将数据集中的对象按照其相似性进行分组,形成若干个簇。
通过聚类分析,我们可以发现数据中的内在结构,帮助我们更好地理解数据集的特点和规律。
在实际应用中,聚类分析被广泛应用于市场分割、社交网络分析、图像处理等领域。
本文将介绍聚类分析的基本原理、常用方法和应用场景,希望能够帮助读者更好地理解和应用聚类分析。
聚类分析的基本原理是将数据集中的对象划分为若干个簇,使得同一簇内的对象相似度较高,不同簇之间的对象相似度较低。
在进行聚类分析时,我们需要选择合适的相似性度量方法和聚类算法。
常用的相似性度量方法包括欧氏距离、曼哈顿距离、余弦相似度等,而常用的聚类算法包括K均值聚类、层次聚类、DBSCAN等。
不同的相似性度量方法和聚类算法适用于不同的数据类型和应用场景,选择合适的方法对于聚类分析的效果至关重要。
K均值聚类是一种常用的聚类算法,它通过不断迭代更新簇中心的方式,将数据集中的对象划分为K个簇。
K均值聚类的优点是简单、易于理解和实现,但是它对初始簇中心的选择较为敏感,容易收敛到局部最优解。
层次聚类是另一种常用的聚类算法,它通过逐步合并或分裂簇的方式,构建一棵层次化的聚类树。
层次聚类的优点是不需要事先确定簇的个数,但是它对大数据集的处理效率较低。
DBSCAN是一种基于密度的聚类算法,它能够发现任意形状的簇,并且对噪声数据具有较强的鲁棒性。
不同的聚类算法适用于不同的数据特点和应用场景,我们需要根据具体情况选择合适的算法进行聚类分析。
聚类分析在实际应用中有着广泛的应用场景。
在市场分割中,我们可以利用聚类分析将顾客分为不同的群体,从而制定针对性的营销策略。
在社交网络分析中,我们可以利用聚类分析发现社交网络中的社区结构,从而发现潜在的影响力人物。
在图像处理中,我们可以利用聚类分析对图像进行分割和特征提取,从而实现图像内容的理解和识别。
聚类分析在各个领域都有着重要的应用,它为我们理解和利用数据提供了有力的工具。
聚类分析_精品文档

1聚类分析内涵1.1聚类分析定义聚类分析(Cluste.Analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术.也叫分类分析(classificatio.analysis)或数值分类(numerica.taxonomy), 它是研究(样品或指标)分类问题的一种多元统计方法, 所谓类, 通俗地说, 就是指相似元素的集合。
聚类分析有关变量类型:定类变量,定量(离散和连续)变量聚类分析的原则是同一类中的个体有较大的相似性, 不同类中的个体差异很大。
1.2聚类分析分类聚类分析的功能是建立一种分类方法, 它将一批样品或变量, 按照它们在性质上的亲疏、相似程度进行分类.聚类分析的内容十分丰富, 按其聚类的方法可分为以下几种:(1)系统聚类法: 开始每个对象自成一类, 然后每次将最相似的两类合并, 合并后重新计算新类与其他类的距离或相近性测度. 这一过程一直继续直到所有对象归为一类为止. 并类的过程可用一张谱系聚类图描述.(2)调优法(动态聚类法): 首先对n个对象初步分类, 然后根据分类的损失函数尽可能小的原则对其进行调整, 直到分类合理为止.(3)最优分割法(有序样品聚类法): 开始将所有样品看成一类, 然后根据某种最优准则将它们分割为二类、三类, 一直分割到所需的K类为止. 这种方法适用于有序样品的分类问题, 也称为有序样品的聚类法.(4)模糊聚类法: 利用模糊集理论来处理分类问题, 它对经济领域中具有模糊特征的两态数据或多态数据具有明显的分类效果.(5)图论聚类法: 利用图论中最小支撑树的概念来处理分类问题, 创造了独具风格的方法.(6)聚类预报法:利用聚类方法处理预报问题, 在多元统计分析中, 可用来作预报的方法很多, 如回归分析和判别分析. 但对一些异常数据, 如气象中的灾害性天气的预报, 使用回归分析或判别分析处理的效果都不好, 而聚类预报弥补了这一不足, 这是一个值得重视的方法。
第九章SPSS的聚类分析

第九章SPSS的聚类分析1.引言聚类分析是一种数据分析方法,用于将相似的对象划分到同一组中,同时将不相似的对象划分到不同的组中。
SPSS是一种常用的统计软件,提供了聚类分析的功能。
本章将介绍SPSS中的聚类分析方法及其应用。
2.数据准备在进行聚类分析之前,需要准备好待分析的数据。
数据应该是定量变量或者定性变量,可以包含多个变量。
如果存在缺失值,需要处理之后才能进行聚类分析。
3.SPSS中的聚类分析方法在SPSS中,聚类分析方法有两种:基于距离的聚类和基于密度的聚类。
基于距离的聚类方法将对象划分到不同的组中,使得组内的对象之间的距离最小,组间的对象之间的距离最大。
常见的基于距离的聚类方法包括单链接聚类、完全链接聚类和平均链接聚类。
基于密度的聚类方法则通过考虑对象周围的密度来划分对象所属的组。
在SPSS中,可以使用层次聚类和K均值聚类这两种方法进行聚类分析。
3.1层次聚类层次聚类又称为分级聚类,它将对象分为一个个的层级,直到每个对象都成为一个单独的组为止。
层次聚类分为两种方法:凝聚层次聚类和分化层次聚类。
凝聚层次聚类是从每个对象作为一个单独的组开始,然后根据对象之间的距离逐渐合并组,直到所有的对象都合并到一个组为止。
凝聚层次聚类的最终结果是一个层级的分组结构,可以根据需要确定分组的层数。
分化层次聚类是从所有的对象开始,然后根据对象之间的距离逐渐分离成不同的组,直到每个对象都成为一个单独的组为止。
在SPSS中,可以使用层次聚类方法进行聚类分析。
通过选择合适的距离度量和链接方法,可以得到不同的聚类结果。
3.2K均值聚类K均值聚类是一种基于距离的聚类方法,通过计算对象之间的距离,将对象分为K个组。
K均值聚类的基本思想是:首先随机选择K个对象作为初始的聚类中心,然后将每个对象分配到离它最近的聚类中心,重新计算聚类中心的位置,直到对象不再发生变化为止。
K均值聚类的结果是每个对象所属的聚类,以及聚类的中心。
在SPSS中,可以使用K均值聚类方法进行聚类分析。
第九章聚类分析

• 例:下表是同一批客户对经常光顾的五座商场在购物环境和
服务质量两方面的平均得分,现希望根据这批数据将五座商
7、如果参与聚类分析的变量存在数量级上的差异, 应在Transform Values框中的Standardize选项 中选择消除数量级差的方法。并指定处理是针对变 量的还是针对样本的。By variable表示针对变量, 适于 Q 型聚类分析;By case 表示针对样本,适 于R型聚类分析。
8、单击Statistics按钮指定输出哪些统计量
R型聚类:对变量进行聚类,使具有相似性的变量聚集在 一起,差异性大的变量分离开来,可在相似变量中选择 少数具有代表性的变量参与其他分析,实现减少变量个 数,达到变量降维的目的。
凝聚方式聚类:其过程是,首先,每个个体自成一类; 然后,按照某种方法度量所有个体间的亲疏程度,并将 其中最“亲密”的个体聚成一小类,形成n-1个类;接下 来,再次度量剩余个体和小类间的亲疏程度,并将当前 最亲密的个体或小类再聚到一类;重复上述过程,直到 所有个体聚成一个大类为止。可见,这种聚类方式对n个 个体通过n-1步可凝聚成一大类。
平方欧式距离(Squared Euclidean distance ) 切比雪夫(Chebychev)距离
max xi yi max( 7366 , 6864 )
Block距离
k
xi yi 73 66 68 64 i1
2、计数变量个体间距离的计算方式
卡方(Chi-Square measure)距离 Phi方(Phi-Square measure)距离
聚类分析原理及步骤

聚类分析原理及步骤
一,聚类分析概述
聚类分析是一种常用的数据挖掘方法,它将具有相似特征的样本归为
一类,根据彼此间的相似性(相似度)将样本准确地分组为多个类簇,其中
每个类簇都具有一定的相似性。
聚类分析是半监督学习(semi-supervised learning)的一种,半监督学习的核心思想是使用未标记的数据,即在训
练样本中搜集的数据,以及有限的标记数据,来学习模型。
聚类分析是实际应用中最为常用的数据挖掘算法之一,因为它可以根
据历史或当前的数据状况,帮助组织做出决策,如商业分析,市场分析,
决策支持,客户分类,医学诊断,质量控制等等,都可以使用它。
二,聚类分析原理
聚类分析的本质是用其中一种相似性度量方法将客户的属性连接起来,从而将客户分组,划分出几个客户类型,这样就可以进行客户分类、客户
细分、客户关系管理等,更好地实现客户管理。
聚类分析的原理是建立在相似性和距离等度量概念之上:通过对比一
组数据中不同对象之间的距离或相似性,从而将它们分成不同的类簇,类
簇之间的距离越近,则它们之间的相似性越大;类簇之间的距离越远,则
它们之间的相似性越小。
聚类分析的原理分为两类,一类是基于距离的聚类。
聚类分析详解ppt课件

以上我们对例6.3.1采用了多种系统聚类法进行聚类,其结果 都是相同的,原因是该例只有很少几个样品,此时聚类的过 程不易有什么变化。一般来说,只要聚类的样品数目不是太 少,各种聚类方法所产生的聚类结果一般是不同的,甚至会 有大的差异。从下面例子中可以看到这一点。
动态聚类法(快速聚类)
(4) 对D1 重复上述对D0 的两步得 D2,如此下去 直至所有元素合并成一类为止。
如果某一步Dm中最小的元素不止一个,则称此现 象为结(tie),对应这些最小元素的类可以任选一对 合并或同时合并。
27
二、最长距离法
类与类之间的距离定义为两类最远样品间的距离, 即
DKL
max
iGK , jGL
聚类分析应注意的问题
(1)所选择的变量应符合聚类的要求
如果希望依照学校的科研情况对高校进行分类,那么可以 选择参加科研的人数、年投入经费、立项课题数、支出经 费、科研成果数、获奖数等变量,而不应选择诸如在校学 生人数、校园面积、年用水量等变量。因为它们不符合聚 类的要求,分类的结果也就无法真实地反映科研分类的情 况。
主要内容
引言 聚类分析原理 聚类分析的种类 聚类分析应注意的问题 聚类分析应用 聚类分析工具及案例分析
聚类分析的种类
(1)系统聚类法(也叫分层聚类或层次聚类) (2)动态聚类法(也叫快速聚类) (3)模糊聚类法 (4)图论聚类法
系统聚类法
对比
常用的系统聚类方法
一、最短距离法 二、最长距离法 三、中间距离法 四、类平均法 五、重心法 六、离差平方和法(Ward方法)
对比
k均值法的基本步骤
(1)选择k个样品作为初始凝聚点,或者将所有样品分成k 个初始类,然后将这k个类的重心(均值)作为初始凝聚点。
聚类分析(ClusterAnalysis)

聚类分析(ClusterAnalysis)(一)什么是聚类聚类,将相似的事物聚集在一起,将不相似的事物划分到不同的类别的过程。
是将复杂数据简化为少数类别的一种手段。
(二)聚类的基本思想:•有大量的样本。
•假定研究的样本之间存在程度不同的相似性,可以分为几类;相同类别的样本相似度高,不同类别的样本相似度差。
•用一些数据指标来描述样本的若干属性,构成向量。
•用某种方法度量样本之间或者类别之间的相似性(或称距离),依据距离来进行分类。
•根据分类来研究各类样本的共性,找出规律。
(三)聚类的应用•商业领域-识别顾客购买模式,预测下一次购买行为,淘宝商品推荐等。
•金融领域-股票市场板块分析•安全和军事领域•o破解GPS伪随机干扰码和北斗系统民用版的展频编码密码o识别论坛马甲和僵尸粉o追溯网络谣言的源头•生物领域•o进化树构建o实验对象的分类o大规模组学数据的挖掘o临床诊断标准•机器学习•o人工智能(四)聚类的对象设有m个样本单位,每个样本测的n项指标(变量),原始资料矩阵:image.png指标的选择非常重要:必要性要求:和聚类分析的目的密切相关,并不是越多越好代表性要求:反映要分类变量的特征区分度要求:在不同研究对象类别上的值有明显的差异独立性要求:变量之间不能高度相关(儿童生长身高和体重非常相关)散布性要求:最好在值域范围内分布不太集中(五)数据标准化在各种标准量度值scale差异过大时,或数据不符合正态分布时,可能需要进行数据标准化。
(1)总和标准化。
分别求出各聚类指标所对应的数据的总和,以各指标的数据除以该指标的数据的总和。
image.png这种标准化方法所得到的的新数据满足:image.png(2)标准差标准化,即:image.png这种标准化方法得到的新数据,各指标的平均值为0,标准差为1,即有:image.pngimage.pngPS:比如说大家的身高差异(3)极大值标准差经过这种标准化所得到的新数据,各指标的极大值为1,其余各数值小于1.image.pngPS:课程难易,成绩高低。
第九章SPSS的聚类分析PPT课件

中心位置变化较小.其中最大的变化率小于2%.
29
K-means快速聚类
(三)基本操作步骤
A.菜单选项:analyze->classify->k means cluster B.选定参加快速聚类分析的变量到variables框 C.确定快速聚类的类数(number of clusters).类数应小
第九章 SPSS的聚类分析
1
聚类分析概述
• 概念:
– 聚类分析是统计学中研究“物以类聚”的一种方法,属多元统计分析方法. – 例如:细分市场、消费行为划分
• 聚类分析是建立一种分类,是将一批样本(或变量)按照在性质上的“亲疏” 程度,在没有先验知识的情况下自动进行分类的方法.其中:类内个体具有 较高的相似性,类间的差异性较大.
•(张三,李四) 2: a=0 b=0 c=1 d=2 J(x,y)=1/1=1 (不相同)
11
聚类分析概述
• 品质型个体间的距离
– Jaccard系数举例:根据临床表现研究病人是否有类似的病
•姓名 性别 发烧 咳嗽 检查1 检查2 检查3 检查4
•张三 男 1 0 1 0 0
0
•李四 女 1 0 1 0 1
•姓名 授课方式 上机时间 选某门课程
•张三
1
1
1
•李四
1
1
0
•王五
0
0
1
•(张三,李四):a=2 b=1 c=0 d=0 d(x,y)=1/(1+2)=1/3
•(张三,王五):a=1 b=2 c=0 d=0 d(x,y)=2/(1+2)=2/3
聚类分析解析课件

类间距的度量
类:一个不严格的定义
定义9.1:距离小于给定阀值的点的集合 类的特征
◦ 重心:均值 ◦ 样本散布阵和协差阵 ◦ 直径
类间距的定义
最短距离法 最长距离法 重心法 类平均法 离差平方和法 等等
最小距离法(single linkage method)
极小异常值在实际中不多出现,避免极 大值的影响
类的重心之间的距离
对异常值不敏感,结果更稳定
离差平方和法(sum of squares
method或ward method)
W代表直径,D2=WM-WK-WL
即
DK2L
nL nk nM
XK XL XK XL
Cluster K
Cluster M
Cluster L
◦ 对异常值很敏感;对较大的类倾向产生较大的距 离,从而不易合并,较符合实际需要。
如表9.2所示,每个样品有p个指标,共 有n个样品
每个样品就构成p维空间中的一个点
:第i个样品的第k个指标对应的取值
◦ i=1……n; k=1……p
:第i个样品和第j个样品之间的距离
◦ i=1……n; j=1……n
点间距离测量问题
样品间距离与指标间距离 间隔尺度、有序尺度与名义尺度 数学距离与统计距离 相似性与距离:一个硬币的两面
类图上发现相同的类
饮料数据
16种饮料的热量、咖啡因、钠及价格四种变量
SPSS实现
选择Analyze-Classify-Hierarchical Cluster, 然 后 把 calorie ( 热 量 ) 、 caffeine ( 咖 啡
因)、sodium(钠)、price(价格)选入 Variables, 在Cluster选Cases(这是Q型聚类:对观测 值聚类),如果要对变量聚类(R型聚类) 则选Variables, 为 了 画 出 树 状 图 , 选 Plots , 再 点 Dendrogram等。 可以在Method中定义点间距离和类间距 离
聚类分析数据

聚类分析数据聚类分析是一种数据挖掘技术,用于将相似的数据对象归类到同一个簇中。
通过对数据进行聚类分析,可以发现数据中的隐藏模式、结构和关系,匡助我们更好地理解数据。
本文将介绍聚类分析的基本概念、常用方法和步骤,并通过一个示例来演示如何进行聚类分析。
1. 聚类分析的基本概念聚类分析是一种无监督学习方法,不需要事先标记好的训练数据。
它根据数据样本之间的相似性,将它们划分为不同的簇。
聚类分析的目标是使同一簇内的数据对象相似度较高,而不同簇之间的相似度较低。
2. 聚类分析的常用方法聚类分析有多种方法,常见的包括层次聚类和K均值聚类。
2.1 层次聚类层次聚类是一种自底向上的聚类方法,它从每一个数据对象作为一个簇开始,逐步合并最相似的簇,直到所有数据对象都被合并为一个簇或者达到预设的簇数目。
2.2 K均值聚类K均值聚类是一种迭代的聚类方法,它将数据对象划分为K个簇,每一个簇由一个质心代表。
初始时,随机选择K个质心,然后迭代地将每一个数据对象分配到最近的质心所在的簇,再更新质心的位置,直到质心的位置再也不变化或者达到预设的迭代次数。
3. 聚类分析的步骤聚类分析通常包括以下步骤:3.1 数据准备首先,需要采集和整理要进行聚类分析的数据。
数据可以是数值型、分类型或者混合型的。
确保数据的质量和完整性,处理缺失值和异常值。
3.2 特征选择根据分析目标和数据特点,选择合适的特征作为聚类分析的输入。
特征应该具有代表性,能够区分不同的数据对象。
3.3 数据标准化对于具有不同量纲的特征,需要进行数据标准化,以消除量纲影响。
常用的标准化方法包括最小-最大标准化和Z-score标准化。
3.4 选择聚类方法和参数根据数据的特点和分析目标,选择合适的聚类方法和参数。
不同的聚类方法适合于不同类型的数据和分析需求。
3.5 执行聚类分析根据选择的聚类方法和参数,执行聚类分析。
对于层次聚类,可以使用聚类树或者热图来可视化聚类结果。
对于K均值聚类,可以绘制簇内离散度图或者簇间离散度图来评估聚类的质量。
第九章 聚类分析和判别分析 讲过

第九章 聚类分析与判别分析在实际工作中, 我们经常遇到分类问题.若事先已经建立类别, 则使用判别分析, 若事先没有建立类别, 则使用聚类分析.聚类分析主要是研究在事先没有分类的情况下,如何将样本归类的方法.聚类分析的内容包含十分广泛,有系统聚类法、动态聚类法、分裂法、最优分割法、模糊聚类法、图论聚类法、聚类预报等多种方法.聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。
它是一种重要的人类行为。
聚类分析的目标就是在相似的基础上收集数据来分类。
聚类源于很多领域, 包括数学, 计算机科学, 统计学, 生物学和经济学。
在不同的应用领域, 很多聚类技术都得到了发展, 这些技术方法被用作描述数据, 衡量不同数据源间的相似性, 以及把数据源分类到不同的簇中。
聚类与分类的不同在于, 聚类所要求划分的类是未知的。
聚类是将数据分类到不同的类或者簇这样的一个过程, 所以同一个簇中的对象有很大的相似性, 而不同簇间的对象有很大的相异性。
从统计学的观点看, 聚类分析是通过数据建模简化数据的一种方法。
§9.1 聚类分析基本知识介绍在MA TLAB 软件包中, 主要使用的是系统聚类法.系统聚类法是聚类分析中应用最为广泛的一种方法.它的基本原理是:首先将一定数量的样品(或指标)各自看成一类, 然后根据样品(或指标)的亲疏程度, 将亲疏程度最高的两类合并, 然后重复进行, 直到所有的样品都合成一类.衡量亲疏程度的指标有两类:距离、相似系数.一、常用距离1)欧氏距离假设有两个 维样本 和 , 则它们的欧氏距离为∑=-=nj j jx xx x d 122121)(),(2)标准化欧氏距离假设有两个 维样本 和 , 则它们的标准化欧氏距离为T x x D x x x x sd )()(),(2112121--=-其中: 表示 个样本的方差矩阵, , 表示第 列的方差. 3)马氏距离假设共有 个指标, 第 个指标共测得 个数据(要求 ):⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=im i i i x x x x 21, 11211122121212(,,,)n n n mmnn x x x xx x X x x x x x x ⎛⎫ ⎪ ⎪== ⎪ ⎪⎝⎭于是, 我们得到 阶的数据矩阵 , 每一行是一个样本数据. 阶数据矩阵 的 阶协方差矩阵记做.两个 维样本 和 的马氏距离如下:T x x X Cov x x x x mahal )())()((),(2112121--=-马氏距离考虑了各个指标量纲的标准化, 是对其它几种距离的改进.马氏距离不仅排除了量纲的影响, 而且合理考虑了指标的相关性.4)布洛克距离两个 维样本 和 的布洛克距离如下:∑=-=nj j j x x x x b 12121||),(5)闵可夫斯基距离两个 维样本 和 的闵可夫斯基距离如下:pn j p j j x x x x m 112121||),(⎪⎪⎭⎫ ⎝⎛-=∑= 注: 时是布洛克距离; 时是欧氏距离.6)余弦距离⎪⎪⎭⎫⎝⎛-=TT T x x x x x x x x d 221121211),( 这是受相似性几何原理启发而产生的一种标准, 在识别图像和文字时, 常用夹角余弦为标准. 7)相似距离TTTx x x x x x x x x x x x x x d ))(())(())((1),(22221111221121-------=二、MATLAB 中常用的计算距离的函数假设我们有 阶数据矩阵 , 每一行是一个样本数据.在MATLAB 中计算样本点之间距离的内部函数为y=pdist(x) 计算样本点之间的欧氏距离y=pdist(x,'seuclid') 计算样本点之间的标准化欧氏距离 y=pdist(x,'mahal') 计算样本点之间的马氏距离 y=pdist(x,'cityblock') 计算样本点之间的布洛克距离 y=pdist(x,'minkowski') 计算样本点之间的闵可夫斯基距离y=pdist(x,'minkowski',p) 计算样本点之间的参数为p 的闵可夫斯基距离 y=pdist(x,'cosine') 计算样本点之间的余弦距离 y=pdist(x,'correlation') 计算样本点之间的相似距离另外, 内部函数yy=squareform(y)表示将样本点之间的距离用矩阵的形式输出.三、常用的聚类方法常用的聚类方法主要有以下几种: 最短距离法、最长距离法、中间距离法、重心法、平方和递增法等等.四、创建系统聚类树假设已经得到样本点之间的距离y, 可以用linkage函数创建系统聚类树, 格式为z=linkage(y).其中: z为一个包含聚类树信息的(m-1) 3的矩阵.例如:z=2.000 5.000 0.23.0004.000 1.28则z的第一行表示第2.第5样本点连接为一个类, 它们距离为0.2;则z的第二行表示第3.第4样本点连接为一个类, 它们距离为1.28.在MA TLAB中创建系统聚类树的函数为z=linkage(y) 表示用最短距离法创建系统聚类树z=linkage(y,'complete') 表示用最长距离法创建系统聚类树z=linkage(y,'average') 表示用平均距离法创建系统聚类树z=linkage(y,'centroid') 表示用重心距离法创建系统聚类树z=linkage(y,'ward') 表示用平方和递增法创建系统聚类树§9.2 聚类分析示例例1 在MA TLAB中写一个名为opt_linkage_1的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];y=pdist(x,'mahal');yy=squareform(y)%Reformat a distance matrix between upper triangular and square form z=linkage(y,'centroid')h=dendrogram(z) %Plot dendrogram graphs 画树状图存盘后按F5键执行, 得到结果如下:yy =0 2.3879 2.1983 1.6946 2.1684 2.2284 0.88952.3879 0 2.6097 2.0616 0.2378 0.6255 2.37782.1983 2.6097 0 0.6353 2.5522 2.0153 2.98901.69462.0616 0.6353 0 1.9750 1.5106 2.41722.1684 0.2378 2.5522 1.9750 0 0.6666 2.14002.2284 0.6255 2.0153 1.5106 0.6666 0 2.45170.8895 2.3778 2.9890 2.4172 2.1400 2.4517 0z =2.0000 5.0000 0.23786.0000 8.0000 0.63533.00004.0000 0.63531.0000 7.0000 0.88959.0000 10.0000 2.106311.0000 12.0000 2.0117按重心距离法得到的系统聚类树为其中: h=dendrogram(z)表示输出聚类树形图的冰状图.一、根据系统聚类树创建聚类假设已经求出系统聚类树z, 我们根据z来创建聚类, 使用cluster函数.例2 在MA TLAB中写一个名为opt_cluster_1的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];y=pdist(x,'mahal');yy=squareform(y)z=linkage(y,'centroid')h=dendrogram(z)t=cluster(z,3)其中: “t=cluster(z,3)”表示分成3个聚类, 需要分成几个由人工选择.存盘后按F5键执行, 得到结果如下:t =3122113即第1.第7样本点为第3类, 第2.第5.第6样本点为第1类, 第3.第4样本点为第2类.二、根据原始数据创建分类在MA TLAB软件包中, 内部函数clusterdata对原始数据创建分类, 格式有两种:1)clusterdata(x,a), 其中0<a<1, 表示在系统聚类树中距离小于a的样本点归结为一类;2)clusterdata(x,b), 其中b>1是整数, 表示将原始数据x分为b类.例3 在MA TLAB中写一个名为opt_clusterdata_1的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];t= clusterdata(x,0.5)z= clusterdata(x,3)存盘后按F5键执行, 得到结果如下:t =4322314z =2311332其中: t的结果表示距离小于0.5的样本点归结为一类, 这样, 共有四类, 第1类: 样本点6;第2类: 样本点3.4;第3类: 样本点2.5;第4类: 样本点1.7.而z的结果表示首先约定将原始数据x分为3类, 然后计算, 结果如下: 第1类: 样本点3.4;第2类: 样本点1.7;第3类: 样本点2.5.6.利用内部函数clusterdata对原始数据创建分类, 其缺点是不能更改距离的计算法.比较好的方法是分步聚类法.三、分步聚类法假设有样本数据矩阵x,第一步对于不同的距离, 利用pdist函数计算样本点之间的距离:y1=pdist(x)y2=pdist(x,'seuclid')y3=pdist(x,'mahal')y4=pdist(x,'cityblock')第二步计算系统聚类树以及相关信息:z1=linkage(y1)z2=linkage(y2)z3=linkage(y3)z4=linkage(y4)第三步利用cophenet函数计算聚类树信息与原始数据的距离之间的相关性, 这个值越大越好: %cophenet Cophenetic correlation coefficient 同表象相关系数, 同型相关系数, 共性分类相关系数CPCCt1=cophenet(z1,y1)t2=cophenet(z2,y2)t3=cophenet(z3,y3)t4=cophenet(z4,y4)注: z在前, y在后, 顺序不能颠倒.第四步选择具有最大的cophenet值的距离进行分类.利用函数clusterdata(x,a)对数据x进行分类, 其中0<a<1, 表示在系统聚类树中距离小于a的样本点归结为一类.例4 在MA TLAB中写一个名为opt_cluster_2的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];y1=pdist(x);y2=pdist(x,'seuclid');y3=pdist(x,'mahal');y4=pdist(x,'cityblock');z1=linkage(y1);z2=linkage(y2);z3=linkage(y3);z4=linkage(y4);t1=cophenet(z1,y1)t2=cophenet(z2,y2)t3=cophenet(z3,y3)t4=cophenet(z4,y4)存盘后按F5键执行, 得到结果如下:t1 =0.9291t2 =0.9238t3 =0.9191t4 =0.9242结果中t1=0.9291最大, 可见此例利用欧式距离最合适.于是, 在MA TLAB中另写一个名为opt_cluster_3的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];y1=pdist(x);z1=linkage(y1)存盘后按F5键执行, 得到结果如下:z1 =2.0000 5.0000 0.20003.00004.0000 0.50006.0000 8.0000 0.50991.0000 7.0000 0.70009.0000 11.0000 1.280610.0000 12.0000 1.3454矩阵z1的第1行表示样本点2.5为一类, 在系统聚类树上的距离为0.2, 其它类推.考察矩阵z1的第3列, 系统聚类树上的6个距离, 可以选择0.5作为聚类分界值.在MATLAB中另写一个名为opt_cluster_4的M文件:x=[3 1.7;1 1;2 3; 2 2.5; 1.2 1; 1.1 1.5; 3 1];y1=pdist(x);z1=linkage(y1)b1=cluster(z1,0.5)存盘后按F5键执行, 得到结果如下:b1 =4322314结果表示将原始数据x分为4类, 第1类: 样本点6;第2类: 样本点3.4;第3类: 样本点2.5;第4类: 样本点1.7.主要应用商业聚类分析被用来发现不同的客户群, 并且通过购买模式刻画不同的客户群的特征。
聚类分析课件

聚类分析课件聚类分析课件聚类分析是一种常用的数据分析方法,它可以将一组数据分成不同的类别或簇,每个簇内的数据点具有相似的特征,而不同簇之间的数据点具有较大的差异。
聚类分析在各个领域都有广泛的应用,如市场细分、社交网络分析、医学诊断等。
在本文中,我们将介绍聚类分析的基本概念、常用算法和实际应用案例。
一、聚类分析的基本概念聚类分析的目标是通过对数据进行分组,使得每个组内的数据点相似度较高,而不同组之间的相似度较低。
聚类分析的基本概念包括距离度量和聚类算法。
1. 距离度量距离度量是衡量数据点之间相似度或差异度的标准。
常用的距离度量方法包括欧氏距离、曼哈顿距离和闵可夫斯基距离等。
欧氏距离是最常用的距离度量方法,它计算数据点在多维空间中的直线距离。
曼哈顿距离则计算数据点在坐标轴上的绝对距离,而闵可夫斯基距离则是这两种距离的一种泛化形式。
2. 聚类算法常用的聚类算法包括K-means算法、层次聚类算法和DBSCAN算法等。
K-means算法是一种迭代的、基于距离的聚类算法,它将数据点分成K个簇,使得每个簇内的数据点与该簇的中心点的距离最小。
层次聚类算法则是一种自底向上的聚类算法,它通过计算数据点之间的相似度来构建一个层次结构。
DBSCAN算法是一种基于密度的聚类算法,它将数据点分为核心点、边界点和噪声点三类,具有较好的鲁棒性和灵活性。
二、常用的聚类分析算法1. K-means算法K-means算法是一种迭代的、基于距离的聚类算法。
它的基本思想是随机选择K个初始中心点,然后将每个数据点分配到距离其最近的中心点所对应的簇中。
接着,重新计算每个簇的中心点,并重复这个过程直到收敛。
K-means算法的优点是简单易实现,但它对初始中心点的选择敏感,并且需要预先指定簇的个数K。
2. 层次聚类算法层次聚类算法是一种自底向上的聚类算法。
它的基本思想是将每个数据点看作一个独立的簇,然后通过计算数据点之间的相似度来构建一个层次结构。
第九章地理系统聚类分析模型

第九章地理系统聚类分析模型第一节聚类分析的方法及变量模型聚类分析(Cluster Analysis)是数理统计中研究物以类聚”的一种方法。
一、地理系统分类的意义对地理系统的研究很重要的一个问题就是进行地理分区与分类。
聚类分析法可避免传统分类法的主观性和任意性的特点。
但应特别引起注意的是,对地理数据处理不当,或只要求方法的新颖,有时分类的结果可能与地理实际不符合。
一种科学的分类法,应能正确地反映客观地理事物的内在联系,并能表达出它们之间的相似性和差异性。
聚类分析法的基本特点二、聚类分析的方法聚类分析的职能是建立一种分类方法,它是将地理样品或变量,按它们在性质上的亲疏程度进行分类。
描述亲疏程度的两个途径当确定了样品或变量的距离或相似系数后,就要对样品或变量进行分类,分类的方法很多,主要的两种是:分类方法分类方法(续)在进行聚类分析处理时,样品间的相似系数和距离有各种不同的定义,而这些定义与变量的类型关系极大,通常按照它们的特性分类,变量的特性有三种类型:变量特性的三种类型1、名义特性(无序多态)2、顺序特性(有序多态)它是由一个有序状态序列所确定,指标量度时没有明确的数量关系,只有次序关系,如对某种地理要素的定性评价为“好的、比较好的、一般的、差的”,又如对某一事件的量度估价为“罕见的、偶然的、一般的、大量的”等。
3、数值特性(定量)它是由测量或计数、统计所得的量,如长度、重量、压力、经济统计数字、人口普查数字、抽样调查数据等。
不同类型的变量在定义距离相似性测度时有很大的差异,这里主要研究具有数值特性的变量的聚类分析问题。
聚类分析的分类R 型聚类分析的作用选择变量的方法:在聚合的每类变量中,各选出一个有代表性的变量作为典型变量,为此计算每一个变量与其同类的其它变量的决定系数r2(即相关系数的平方)的均值:r2=艺『/(K-1)式中,K为该类的变量个数。
挑选r2值最大的变量X i作为该类的典型变量。
Q 型聚类分析优点第二节系统聚类分析系统聚类分析(Hierachical Cluster Analysis)是聚类分析中应用最广泛的一种方法,凡是具有数值特征的变量和样品都可以采用系统聚类法。
第九章 聚类分析

51
K-平均聚类算法
算法的特点:
只适用于聚类均值有意义的场合,在某些应用中,如:数据集中
包含符号属性时,直接应用k-means算法就有问题;
用户必须事先指定k的个数; 对噪声和孤立点数据敏感,少量的该类数据能够对聚类均值起到
很大的影响。
52
示例
53
示例
54
示例
55
示例
56
2. k-中心点(k-mediods) 聚类算法?
的M个状态是以有意义的顺序进行排列的。
如专业等级是一个顺序变量,是按照助教、讲师、副教授和教授 的顺序排列的。
一个连续的顺序变量,值的相对位置要比它的实际数值有意 义的多,如某个比赛的相对排名(金牌、银牌和铜牌)可能比 实际得分更重要。
35
顺序变量的相异度
顺序变量的处理与区间标度变量非常类似,假设f是用于描述n 个对象的一组顺序变量之一,关于f的相异度计算如下:
如:给定变量smoker,用以描述一个病人是否吸烟的情况,如用
smoker为1表示病人吸烟;若smoker为0表示病人不吸烟。
24
二元变量的相异度计算
差异矩阵法:
如果假设所有的二元变量有相同的权重,则可以得到一个两
行两列(2*2)的条件表。源自25二元变量的相异度计算其中: q表示在对象i和对象j中均取1的二值变量个数;
9.1 什么是聚类分析
聚类与分类的区别:
聚类是一 种无(教师)监督的学习方法。与分类不同,其 不依赖于事先确定的数据类别,以及标有数据类别的学习训 练样本集合。 因此,聚类是观察式学习,而不是示例式学习。
9.1 什么是聚类分析
聚类分析的应用:
市场分析:帮助市场分析人员从客户基本库中发现不同的客户
spss第九章作业聚类分析
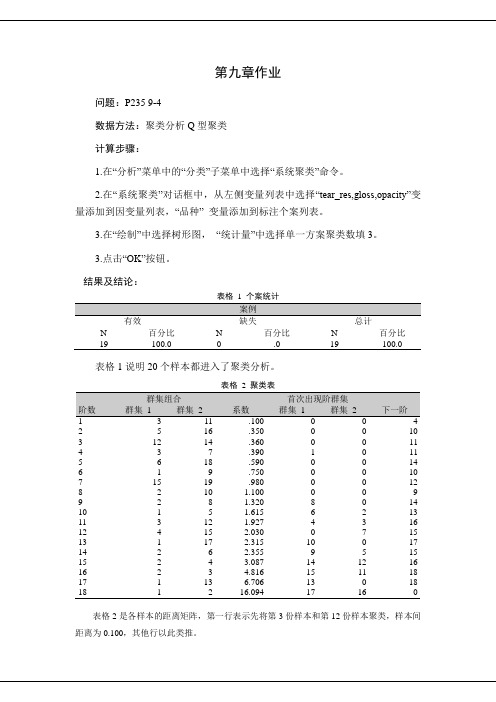
第九章作业问题:P235 9-4数据方法:聚类分析Q型聚类计算步骤:1.在“分析”菜单中的“分类”子菜单中选择“系统聚类”命令。
2.在“系统聚类”对话框中,从左侧变量列表中选择“tear_res,gloss,opacity”变量添加到因变量列表,“品种” 变量添加到标注个案列表。
3.在“绘制”中选择树形图,“统计量”中选择单一方案聚类数填3。
3.点击“OK”按钮。
结果及结论:表格 1 个案统计表格1说明20个样本都进入了聚类分析。
表格 2 聚类表阶数群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 21 3 11 .100 0 0 42 5 16 .350 0 0 103 12 14 .360 0 0 114 3 7 .390 1 0 115 6 18 .590 0 0 146 1 9 .750 0 0 107 15 19 .980 0 0 128 2 10 1.100 0 0 99 2 8 1.320 8 0 1410 1 5 1.615 6 2 1311 3 12 1.927 4 3 1612 4 15 2.030 0 7 1513 1 17 2.315 10 0 1714 2 6 2.355 9 5 1515 2 4 3.087 14 12 1616 2 3 4.816 15 11 1817 1 13 6.706 13 0 1818 1 2 16.094 17 16 0表格2是各样本的距离矩阵,第一行表示先将第3份样本和第12份样本聚类,样本间距离为0.100,其他行以此类推。
表格 3 群集成员案例:成员 3 群集1: 2 12: 3 23: 4 24: 5 25: 6 16: 7 27: 8 28: 9 29: 10 110: 11 211: 12 212: 13 213: 14 314: 15 215: 16 216: 17 117: 18 118: 19 219: 20 2表格3说明样本2,6,10,17,18属于第一类,样本3,4,5,7,8,9,11,12,13,15,16,19,20属于第二类,样本14属于第三类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
层 次 聚 类 的 冰挂 图 Ve rtical Icicle Ca se
4:D商 厦
3:C商 厦
5:E商 厦
2:B商 厦
Nu mber of clusters 1 X 2 X 3 X 4 X
X X X X
X X X X
X X
X X X X
X
X X X X
X X X
X X X X
1:A商 厦
10、单击Save按钮可以将聚类分析的结果以变量的 形式保存到数据编辑窗口中。生成的变量名为 clun_m(如clu2_1),其中n表示类数(如2), m表示是第m次分析(如1)。 由于不同的距离计算方法会产生不同的聚类分 析结果,即使聚成n类,同一样本的类归属也会因 计算方法的不同而不同。因此实际分析中应反复尝 试以最终得到符合实际的合理解,并保存于SPSS 变量中。
层 次 聚 类 中 的类 成 员 Cl uster M embership Ca se 1:A商厦 2:B商厦 3:C商厦 4:D商厦 5:E商厦 3 Clusters 1 1 2 3 3 2 Clusters 1 1 2 2 2
9、单击Plot按钮指定输出哪种聚类分析图。
Dendrogram选项表示输出聚类分析树形图;在Icicle 框中指定输出冰挂图,其中,All clusters表示输出聚类分 析每个阶段的冰挂图,Specified range of clusters表示 只输出某个阶段的冰挂图,输入从第几步开始,到第几步结 束,中间间隔几步;在Orientation框中指定如何显示冰挂 图,其中,Vertical表示纵向显示,Horizontal表示横向水 平显示。 树形图以躺倒树的形式展现了聚类分析中的每一次类 合并的情况。SPSS自动将各类间的距离映射到0~25之间, 并将凝聚过程近似地表示在图上。
例如,学校里有些同学经常在一起,关系比较 密切,而他们与另一些同学却很少来往,关系比较 疏远。究其原因可能会发现,经常在一起的同学的 家庭情况、性格、学习成绩、课余爱好等方面有许 多共同之处,而关系比较疏远的同学在这些方面有 较大的差异性。为了研究家庭情况、性格、学习成 绩、课余爱好等是否会成为划分学生小群体的主要 决定因素,可以从有关这些方面的数据入手,进行 客观分组,然后比较所得的分组是否与实际相吻合。 对学生的客观分组就可采用聚类分析方法。
最近邻居(Nearest Neighbor)距离:个体与小类中每 个个体距离的最小值。 最远邻居(Furthest Neighbor )距离:个体与小类中 每个个体距离的最大值。 组间平均链锁(Between-groups linkage)距离:个 体与小类中每个个体距离的平均值。 组内平均链锁(Within-groups linkage)距离:个体 与小类中每个个体距离以及小类内各个体间距离的平均值。 重心(Centroid clustering)距离:个体与小类的重心 点的距离。重心点通常是由小类中所有样本在各变量上的均 值所确定的点。 离差平方和法(Ward’s method):聚类过程中使小类 内离差平方和增加最小的两小类应首先合并为一类。
• 9.2.2 个体与小类、小类与小类间“亲疏程度”的
度量方法 SPSS中提供了多种度量个体与小类、小类与 小类间“亲疏程度”的方法。与个体间“亲疏程度” 的测度方法类似,应首先定义个体与小类、小类与 小类的距离。距离小的关系亲密,距离大的关系疏 远。这里的距离是在个体间距离的基础上定义的, 常见的距离有:
9.2 层次聚类
• 9.2.1 层次聚类的两种类型和两种方式
层次聚类又称系统聚类,简单地讲是指聚类过程是按 照一定层次进行的。层次聚类有两种类型,分别是Q型聚类 和R型聚类;层次聚类的聚类方式又有两种,分别是凝聚方 式聚类和分解方式聚类。 Q型聚类:对样本进行聚类,使具有相似特征的样本聚 集在一起,差异性大的样本分离开来。 R型聚类:对变量进行聚类,使具有相似性的变量聚集 在一起,差异性大的变量分离开来,可在相似变量中选 择少数具有代表性的变量参与其他分析,实现减少变量 个数,达到变量降维的目的。
• 例:下表是同一批客户对经常光顾的五座商场在购物环境和
服务质量两方面的平均得分,现希望根据这批数据将五座商 场分类。
编号 A商场 B商场 C商场 D商场 E商场
购物环境 73 66 84 91 94
服务质量 68 64 82 88 90
1、定距型变量个体间距离的计算方式 7.1.2 聚类分析中“亲疏程度”的度量方法
层 次 聚 类 中 的凝 聚 状 态 表 Agglomeration S chedule Cl uster Combin ed Cl uster 1 Cl uster 2 4 5 1 2 3 4 1 3 St age Cl uster First Ap pears Cl uster 1 Cl uster 2 0 0 0 0 0 1 2 3
1、选择菜单Analyze-Classify-Hierarchical Cluster,出现窗口:
2、把参与层次聚类分析的变量选到Variable(s)框中。 3、把一个字符型变量作为标记变量选到Label Cases by框中,它将大大增强聚类分析结果的可读 性。 4、在Cluster框中选择聚类类型。其中Cases表示进 行Q型聚类(默认类型);Variables表示进行R型 聚类。 5、在Display框中选择输出内容。其中Statistics表 示输出聚类分析的相关统计量;Plot表示输出聚类 分析的相关图形。
St age 1 2 3 4
Co efficients 3.606 8.062 11.01 3 28.90 8
Ne xt Stage 3 4 4 0
上表中,第一列表示聚类分析的第几步;第二、 三列表示本步聚类中哪两个样本或小类聚成一类; 第四列式个体距离或小类距离;第五、六列表示本 步聚类中参与聚类的是个体还是小类,0表示样本, 非0表示由第n步聚类生成的小类参与本步聚类;第 七列表示本步聚类的结果将在以下第几步中用到。
9.1.2 聚类分析中“亲疏程度”的度量方法
• 聚类分析中,个体之间的“亲疏程度”是极为重要
的,它将直接影响最终的聚类结果。对“亲疏”程 度的测度一般有两个角度:第一,个体间的相似程 度;第二,个体间的差异程度。衡量个体间的相似 程度通常可采用简单相关系数等,个体间的差异程 度通常通过某种距离来测度。 • 为定义个体间的距离应先将每个样本数据看成k维 空间的一个点,通常,点与点之间的距离越小,意 味着他们越“亲密”,越有可能聚成一类,点与点 之间的距离越大,意味着他们越“疏远”,越有可 能分别属于不同的类。
6、单击Method按钮指定距离的计算方法。
Measure框中给出的是不同变量类型下的个体 距离的计算方法。其中Interval框中的方法适用于 连续型定距变量;Counts框中的方法适用于品质 型变量;Binary框中的方法适用于二值变量。 Cluster Method框中给出的是计算个体与小类、 小类与小类间距离的方法。 7、如果参与聚类分析的变量存在数量级上的差异, 应在Transform Values框中的Standardize选项 中选择消除数量级差的方法。并指定处理是针对变 量的还是针对样本的。By variable表示针对变量, 适于 Q 型聚类分析;By case 表示针对样本,适 于R型聚类分析。
• 9.2.4 层次聚类的应用举例
1、利用31个省市自治区小康和现代化指数数据进 行层次聚类分析。 利用SPSS层次聚类Q型聚类对31个省市自治 区进行分类分析。其中个体距离采用平方欧式距离, 类间距离采用平均组间链锁距离,由于数据不存在 数量级上的差异,因此无需进行进行标准化处理。 • 2、利用裁判打分数据进行聚类分析。
Block距离
x i yi 73 66 68 64
i 1
k
2、计数变量个体间距离的计算方式
卡方(Chi-Square measure)距离 Phi方(Phi-Square measure)距离
3、二值(Binary)变量个体间距离的计算方式
简单匹配系数(Simple Matching) 雅科比系数(Jaccard)
第九章
SPSS聚类分析
本章内容
• 9.1 聚类分析的一般问题 • 9.2 层次聚类 • 9.3 K-Means聚类
9.1 聚类分析的一般问题
• 9.1.1 聚类分析的意义
聚类分析是统计学中研究“物以类聚”问题的多元统 计分析方法。 聚类分析是一种建立分类的多元统计分析方法,它能 够将一批样本(或变量)数据根据其诸多特征,按照在性质 上的亲疏程度(各变量取值上的总体差异程度)在没有先验 知识(没有事先指定的分类标准)的情况下进行自动分类, 产生多个分类结果。类内部的个体在特征上具有相似性,不 同类间个体特征的差异性较大。
8、单击Statistics按钮指定输出哪些统计量
Agglomeration schedule表示输出聚类分 析的凝聚状态表;Proximity matrix表示输出个体 间的距离矩阵;Cluster Membership框中, None表示不输出样本所属类,Single Solution表 示指定输出当分成n类时各样本所属类,是单一解。 Range of solution表示指定输出当分成m至n类 (m小于等于n)时各样本所属类,是多个解。
Ca se 1:A商厦 2:B商厦 3:C商厦 4:D商厦 5:E商厦
1:A商厦 .000 8.062 17.80 4 26.90 7 30.41 4
5:E商厦 30.41 4 38.21 0 12.80 6 3.606 .000
Th is is a dissimilari ty m atrix
• 9.2.3 层次聚类的基本操作
注:聚类分析的几点说明
பைடு நூலகம்
所选择的变量应符合聚类的要求:所选变量应能够从不同的侧面反映 我们研究的目的; 各变量的变量值不应有数量级上的差异(对数据进行标准化处理): 聚类分析是以各种距离来度量个体间的“亲疏”程度的,从上述各种 距离的定义看,数量级将对距离产生较大的影响,并影响最终的聚类 结果。 各变量间不应有较强的线性相关关系