hibernate2
跟我学Hibernate框架技术——在Hibernate中实现二进制和mem类型的字段的数据访问(MySQL数据库)

目录1.1在Hibernate中实现二进制和mem类型的字段的数据访问 (2)1.1.1数据库系统的二进制数据和大文本数据 (2)1.1.2编程项目相关的POJO类 (7)1.1.3构建数据库表和POJO类之间的映射配置文件 (12)1.1.4编程相关的DAO类程序代码 (15)1.1.5应用单元测试用例测试本示例的应用效果 (21)1.1.6执行单元测试用例 (26)1.1.7java.sql包中的Blob和Clob接口 (29)1.1在Hibernate中实现二进制和mem类型的字段的数据访问1.1.1数据库系统的二进制数据和大文本数据1、二进制数据和大文本数据的存储对数据库中涉及“mem”类型的字段,一般在设计时定为V ARCHAR2类型,但其最大长度为4000 bytes,即可以支持两千汉字以内的长度,而我们在实际的应用中,可能往往会超过两千汉字,从而导致超出的部分不能写入数据库中,因此我们有必要改为大字段类型。
另外的一个问题是,就是在数据库中V ARCHAR和V ARBINARY的存取是将全部内容从全部读取或写入,对于100K或者说更大数据来说这样的读写方式,远不如用流进行读写来得更现实一些。
通常,要解决超过4000字节的数据,一种做法是将数据写入文件,xml或plain file都可以,数据表中保存文件的路径即可。
这种做法不必处理clob(Character Large Object),blob (Binary Large Object)等格式的字段类型,但不易做transaction的控制,而且增加了对文件的处理操作,不算是较佳的一个方案。
另一个做法是使用clob, blob等字段类型。
下面给出实现的说明和过程。
2、设计一个数据库表(1)本示例的数据库表结构如下其中所应该注意的是image类型和ntext类型的含义。
在Oracle中如何表示?在MySQL 中如何表示?(为longblob和longtext)(2)对应的SQL语句如下DROP TABLE IF EXISTS `tuser`;CREATE TABLE `tuser` (`id` int(11) NOT NULL,`name` varchar(50) DEFAULT NULL,`age` int(11) DEFAULT NULL,`picture` longblob,`resume` longtext,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=gb2312;-- ------------------------------ Records of tuser-- ----------------------------INSERT INTO `tuser` V ALUES ('1', '张三', '20', 0xFFD8FFE000104A46494600010101004800480000FFDB004300070404040504070505070A070 5070A0C090707090C0D0B0B0C0B0B0D110D0D0D0D0D0D110D0F1011100F0D141416161414 1E1D1D1D1E22222222222222222222FFDB0043010807070D0C0D181010181A1511151A20202 02020202020202020202021202020202020212121202020212121212121212122222222222222222 2222222222222FFC0001108003F00C403011100021101031101FFC4001C0001000105010100000 000000000000000000402030506070801FFC400411000010303020405010504050D000000000102030400051106120713213114223241516108234271811516249137527275B13336434462638492B 2B3B4C1E1FFC4001A010100020301000000000000000000000000030401020506FFC4002B1101 000201030303030305000000000000000102030411210512312232410651611314427181B1D1F0F FDA000C03010002110311003F00F481ED41F12B41594839527D43E282AA05044B8DC99861B 49CAA43EAD8C329F52D5FFA007527D856264486C39B46FC6EC79B1DB35915D028140A050 28140A05028140A05028140A05028141F1690A494A86527A11F4A0D4B51DAB50D99DFDBD A5FEFD31D2BF156370FDDBCDF7FE1D5D4B4B1DF6FA4FB0F9D278172C7C52D1F75D22E6 AB12B916E8DD2707461C8EBCED287123A83B8D67BB813E46B8D30CE92735778C42AC0D B25F1293D9481D3CBDBA93D00F9ACEF031FC3D5DCEEB6FF00DEBBDB7C89B724EF8B14 FF00AB43272D23FB4A1E657FF2B4A57E46D29502323B1ED520AA8140A05028140A0502814 0A05028140A05028140A0B7210A7185A12B2DA94920389C6E4E7DC672323F2A0E61AAB59 EA1D017103F6B0D4715C3972D7212D3335947BA9121A0868FF65C40CFCD55CDABA639DA 657F4BD2F36A2B36A4711FF70E37AD756459B22F17BB0FF0F6EBC32A66F36B6C942DA59E CE29B57AC157A8A463DC5578CB36B7D9B6AB474A56369DEDF3131B4C29B48B86A3D216 7B53118C87220F395AC88DE4C8694E63D581D4213EFDEAB66CB14BDA667CAF697166CF8 EB5DA2B4AFCCFCFFB6C91E1DEA135E0EF124BD18F6E4B8B43493F1CB4F41F438AA56C F3E2378877F1692BEFF75FF31FE17AD3C57D41A3AE296DA94E5CAD591CD87255BCA53FE ED5DC1F8AB5A6D65EBFD11EB7A362CF5DF6EDB7E1DF74DEA0B6EA0B3C7BBDB97BE2 C94EE4FC83EE93F515DBC7922D1BC3C56A305B15E6B6F30C956E88A05028140A05028140 A05028140A05028140A0D6388BAC3F766CEDBED6152E4381A651EE73DCFE954BA86A2D8 E9E9F32E8F48D07EE72EDFC63CB92BB6D81710FC9BB2CC99CF12A53CB3F8B3EC3B015E 7AD333CCF97B3ACCD36AD3DB1F08B72B4E9B7596D298C848491BFE4803B63EB5B562598 EE9F772B8F5F22B310331D0965B40E884F4159AD0FD3E79E5ABDD751AC950DDD2A5AE3 4DDD10D4674F53AF9567353D71A2B66777FB2E5D249B3CCB63B92CA55CE673ED9F50AB DA1B7330F31D7A9BED7FECE957DDEABF5A23F31C430F97C3A96DC5A02B6345433B08F7 AE8B808303505CD018888FE216F4894D4790BEBB9A63AA3F120127B77A093FBC3744C98C CC86911D0FF291CDFF002C9E72CF99B250BF2F4F4D042B76A0BB8B446119A4ADE71A94E 0F2BAF6E5B4E94A518DFB8027F1134175ED4B7D61D909750C7F0C6205A762C13E2BD43D640DA6825EA9764226DB12C174F35D7029A6DD535BF0D9201208F7A04399764DD05AD92D8 65A659795CEDEB770A5E1682BDDDC0EC714119BD59715C666425B6F6CA625BCD270ACB 7E1BB6FF37981C7D282CBBABAF4D4471F2860ED891E601B57D9E50494FABDBE6836C141 F68140A05028140A050718FB43CB7D172B76CF430824FE6AAE2F53E6F0F5FF004B563B2DF 973E1AA4168051C2BDEB9F157A0B561065EA94A73EF52D6AD27662266A8796309A92B447 6B43132EE0E38327B9A9AB557BE4458E14EBC3F3A93655B5DE85FB3B33CA90EA523A06C E6A5D247ADC7EAF3E86C9ACB8BDA52C973762DEB4FDCDFF0CE725133C1B4B614A50E CD38E389CE6BA4E0B296ED6F61BC697B8DDA4D926C4B7DA1A5BCB8D708ADB6B525A6 CB9F7482A524F41D3A8A0CBE9A9F64D456685A82145D8CCB6C38D735080EA53E900EDD DEDF068309A964E9787AAAD1A79F8A7C45D9B79B889432DA986F679D6A3E64292A3F201 A0D923D82D2D474B2A8EDB984A52A5B884A94AE58C24A8E3A91ED4129D8711D5B6E3C CA16B6BAB4A524129FECE7B5013162A6419096D024286D53A00DE47C1577A0A05BADE37 E186C73461CF28F303DC1F9A0A0D9ED18C784671808C72D1E949C81DBB023*********C00 3091D00A0AA8140A05028140A050732E3A598C88D1A62539032DA8FF0085733A8E3E625E8 3E9ED46DBD5C0EED0D6CA8E2A8D61E9E72B0B27998A962A82F950D7CCA962156F91486 944F5ACA29B3236D63EF451ABD27C02B23B1ED0EDC5C180EE108FD3BD59D155C5EAD9 39ED57F68EFF0031A1FF007A45FF0005D5D729B6711BFA3DD45FDD733FF1D741C4556C6B 4FF0AB4EEB9B4DCA4FEF187DA6908E71285A77AC18C1ACE309DBD7F5F9A0E85C40FE99 7427FC77FDAA089A8612758F195FD2B7C94FB363816E4C98B05974B21F75446E70EDC13B3 71FE541F3879A82F70B4B6B6851E43970674EB92D16694E9E62941B6D6A4B5BBF16D281FC E8343BFDBE344E0CC1D591EF52CDFEEAF8F1C4C9594BEADEBDC828CFFA2DBDFF003F9 A0F45BB2A2B2B6DB79D436E3A70D254A00ACFC241EA7BD0732D55013ABB8CC349DEA4 BED58A35ABC5C78ACBAA683CF97305676E376013FF002FE74131CBBAEC1C17B9C9D3F7 A37C7EDCDBADB3713E65A09501D719CF242F23E941A95C6D4DE92D35A5B5958AE72A46 A1B9C88899616F975338494153A828248E8AE9F4F7EB8A0D8F89309EBAF1874AD9552E447 833234BF1223BAA694A4A1A714465247A80DA7E868347469C0BD2BAE16AB84EE56979EF3 76567C42F633CB748DD8CF994768EFF00A77A0ED9A42EDBF42D96E7739090EC8B7C575F7 DE504EE71C652A2493EE4D06A7C5F7644ED59A4F4B3D25E8B63BB3EF78E532B2D174B694F2DA2A1ECA52B18A0CD70E2D366B1BF77B2DB2F4AB9351A46EF02E2F7AA0EE07EEB7 124E0E3DFE0FD6838E42B3BEFF02646B27AE13557AB7CA1E057CF5ED68192D34404F639D E4E4F5A0F42D99F7A4D9E1487705D763B4B593FD65201341F2FB668D78B6BB0640F2AC74 3F07DAA3CB8FBABB25C19E71DE2D1F0F3F710343CDB3495B4FB7E4FC0E7B115C7BE29A CF2F5DA4D5D72D7873D990B6935984D663D6C62A4857B290DD65A371E17E85B96ACBF22 2C649115A20CA93F8509FAFF00B47D856D5A774ECADA8D4462AEF3E5EA7B45AE2DAED CCDBE2276B0C242123F2F73F9D74A94ED8D9E7325E6D3BCA3EA3D2F63D470510EF2C788 8ADB897D08DCB461C47A5594149E99AD9AA5DC6DF12E16F916E9A8E64394D2D87DBCA 86E6DC4ED52729208C83EC7341AC42E0CF0DA0DCA2CF8B6A4A1F87831C731D520293D96 50A514A943A7522833970D2F62B85E60DEA5C7E65CED9BFC13DBD6397CC1857952A09564 7C8A085AB3877A4355A9A72F50F9AFB030CC84294D3A949EE9DE82938EB412AD5A62D96 1B02ACFA7996E134942F9391BD216A1EB5E7AAFAF7C9A0E3CFF0005F55DC91FB2DCD3D 6BB6AE4484AE7DF63BEB3BDA4AB38663A8A8B5BBA640C0FA0A0EC777D2F63BC4C813 AE4C73A55B1CE7427372D3CB70E32AC20807D23A1A087AB7879A4B5616577C87CF7A3F4 69E4AD6D38907B8DC820E0E7B504FB4E99B15A6C89B2408A866D49414786EE92957AB76E C9567DF34183B2707F87B65BBA6EF6FB6844C6C9531BD6E38868ABB96D0B514A7E9D3A7 B5066A6696B1CCBFC2D41218DF77B7A5C44391BD7E40EA4A57E40A08390A3DC50444F0F B49261DD61261FF0D7B714FDD11CC77EF9C5AB72959DF94E49FC381415DCF43698BA69B 634D4E8BCDB2464B48663F31C1B43030DF992A0B3803DCD05DD51A3F4F6A880205F23092 C215BDA395256858ECA4AD24281FD6829D2DA2F4DE9682B83638DE1DA755B9D3B94B5A D5F2A5AC951FE74119AE1BE8C6F4A3BA51107160797CC762F35EEAADE1CCEFDFCCF5A 41F550671888CC78EDC7646D65A484369EF84A4600C9C9ED4174D041BCD92DB7986A893D B0E347F98FCAB4C98E2D1B4A4C19AD8E77AB8DEB5E015EDB5A9FB1A9B96C1ECDAC86 DC1FA9C24D50BE9263C3B9A7EAF5B47AB896947823C4E90F7299B6A064FA8C8631FF005E 6B15C16497EA346D7A53ECB57275C4BFAA6E28699CF58B0BCCA23E0B8B000FD01AB15D 328E6EA9F676BD37A6ACDA76DA8B6DA23A63C56FD93DC9FEB28FB93566B48AF872F264 9BCEF2C956CD4A05028140A05028140A05028140A05028140A0507FFD9, '这是用户的个人简历的文本信息字符串.....');1.1.2编程项目相关的POJO类1、设计TUser表相匹配的PO类——添加PO类2、在该PO类中添加如下的成员属性private Integer id; // private int id; private String name;private Integer age;private Blob picture;private Clob resume;private InputStream userPictureIOStream; private String userResumeText;3、为这些成员属性添加get/set方法4、添加hashcode/equals方法5、POJO类最终的代码package com.px1987.sshwebcrm.dao.pobject; import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException; import java.io.InputStream;import java.sql.Blob;import java.sql.Clob;public class TUser {@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + ((age == null) ? 0 : age.hashCode());result = prime * result + ((id == null) ? 0 : id.hashCode());result = prime * result + ((name == null) ? 0 : name.hashCode());result = prime * result + ((picture == null) ? 0 : picture.hashCode());result = prime * result + ((resume == null) ? 0 : resume.hashCode());return result;}@Overridepublic boolean equals(Object obj) {if (this == obj)return true;if (obj == null)return false;if (getClass() != obj.getClass())return false;TUser other = (TUser) obj;if (age == null) {if (other.age != null)return false;} else if (!age.equals(other.age))return false;if (id == null) {if (other.id != null)return false;} else if (!id.equals(other.id))return false;if (name == null) {if ( != null)return false;} else if (!name.equals())return false;if (picture == null) {if (other.picture != null)return false;} else if (!picture.equals(other.picture)) return false;if (resume == null) {if (other.resume != null)return false;} else if (!resume.equals(other.resume)) return false;return true;}public Integer getId() {return id;}private void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) { = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}public Blob getPicture() {return picture;}public void setPicture(Blob picture) {this.picture = picture;}public Clob getResume() {return resume;}public void setResume(Clob resume) {this.resume = resume;}private Integer id; // private int id; private String name;private Integer age;private Blob picture;private Clob resume;private InputStream userPictureIOStream;private String userResumeText;public String getUserResumeText() {return userResumeText;}public void setUserResumeText(String userResumeText) {erResumeText = userResumeText;}public void setUserPictureIOStream(InputStream userPictureIOStream) {erPictureIOStream = userPictureIOStream;}public InputStream getUserPictureIOStream() {return userPictureIOStream;}public TUser() {}}1.1.3构建数据库表和POJO类之间的映射配置文件1、针对上面的TUser数据库表的映射文件为(TUser.hbm.xml)——添加TUser.hbm.xml文件2、设计该文件的内容<?xml version='1.0' encoding='gb2312'?><!DOCTYPE hibernate-mappingPUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN""/hibernate-mapping-3.0.dtd"><hibernate-mapping><class name="com.px1987.sshwebcrm.dao.pobject.TUser" table="TUser"> <id name="id"><column name="id"></column><generator class="increment"></generator></id><property name="name"></property><property name="age"></property><property name="picture"></property><property name="resume"></property></class></hibernate-mapping>或者采用下面的配置<?xml version="1.0"?><!DOCTYPE hibernate-mappingPUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN""/hibernate-mapping-3.0.dtd"><hibernate-mapping><class name="com.px1987.sshwebcrm.dao.pobject.TUser" table="TUser"> <id name="id" type="ng.Integer" ><column name="id" not-null="true"/><generator class="increment"/></id><property name="name" type="ng.String" column="name"/><property name="age" type="ng.Integer" column="age"/><property name="picture" type="java.sql.Blob" column="picture"/><property name="resume" type="java.sql.Clob" column="resume"/> </class></hibernate-mapping>3、在hibernate.cfg.xml中添加对TUser.hbm.xml文件的引用。
hibernate的基本用法

hibernate的基本用法Hibernate是一个开源的Java框架,用于简化数据库操作。
它为开发人员提供了一个更加简单、直观的方式来管理数据库,同时也提高了应用程序的性能和可维护性。
本文将逐步介绍Hibernate的基本用法,包括配置、实体映射、数据操作等。
一、配置Hibernate1. 下载和安装Hibernate:首先,我们需要下载Hibernate的压缩包并解压。
然后将解压后的文件夹添加到Java项目的构建路径中。
2. 创建Hibernate配置文件:在解压后的文件夹中,可以找到一个名为"hibernate.cfg.xml"的文件。
这是Hibernate的主要配置文件,我们需要在其中指定数据库连接信息和其他相关配置。
3. 配置数据库连接:在"hibernate.cfg.xml"文件中,我们可以添加一个名为"hibernate.connection.url"的属性,用于指定数据库的连接URL。
除此之外,还需要指定数据库的用户名和密码等信息。
4. 配置实体映射:Hibernate使用对象关系映射(ORM)来将Java类映射到数据库表。
我们需要在配置文件中使用"mapping"元素来指定实体类的映射文件。
这个映射文件描述了实体类与数据库表之间的对应关系。
二、实体映射1. 创建实体类:我们需要创建一个Java类,用于表示数据库中的一行数据。
这个类的字段通常与数据库表的列对应。
同时,我们可以使用Hibernate提供的注解或XML文件来配置实体的映射关系。
2. 创建映射文件:可以根据个人喜好选择使用注解还是XML文件来配置实体类的映射关系。
如果使用XML文件,需要创建一个与实体类同名的XML文件,并在其中定义实体类与数据库表之间的映射关系。
3. 配置实体映射:在配置文件中,我们需要使用"mapping"元素来指定实体类的映射文件。
hibernate配置

目录
1 Hibernate概述 2 第一个Hibernate程序 3 Hibernate的配置文件 4 深入理解持久化对象 5 Hibernate的映射文件 6持久化对象 如果PO 实例与Session实例关联起来,且该实例关联到数据库的记录
脱管对象 如果PO实例曾经与Session实例关联过,但是因为Session的关闭等原 因,PO实例脱离了Session 的管理
Hibernate全面解决方案架构解释
事务(Transaction) 代表一次原子操作,它具有数据库事务的概念 但它通过抽象,将应用程序从底层的具体的JDBC、JTA和CORBA 事务中隔离开。 一个Session 之内可能包含多个Transaction对象。 所有的持久化操作都应该在事务管理下进行,即使是只读操作。
管态,对该对象操作无须锁定数据库,不会造成性能的下降。
持久化对象的状态迁移
持久化实体: 1、Serializable save(object obj) 将对象变为持久化状态 2、void persist(object obj) 将对象转化为持久化状态 3、Serializable save(object obj,object pk) 将obj对象转化为持久化状态,该对象保存到数据库,指定主键值 4、void persist(object obj,object pk) 也加了一个设定主键
Hibernate工作原理
Configuration cfg = new Configuration().configure();
开始
启动hibernate
构建Configuration 实例,初始 化该实例中的所有变量
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
Hibernate教程_从入门到精通_第二篇(共四篇)

目标: •Hibernate API简介
Hinernate的体系结构(运行时)
SessionFactory:它保存了对当前数据库配置的所有映射关系,它是将某 个数据库的映射关系经过编译之后全部保存在内存中的。 它还是生成 Session的工厂,它在进行实例化的过程中将会用到ConnectionProvider。 一个SessionFactory对应一个数据库连接,当数据库连接改变时需要修改 SessionFactory Sesion: 是进行持久化操作的基础,所有的持久化操作都是在Session的 基础上进行的。它相当与JDBC中的Connection。它是Hibernate的持 久化 管理器的核心,提供了一系列的持久化操作方法。另外,它还持有一个针 对持久化对象的一级缓存,在遍历持久化对象或者根据持久化标识查找对 象的时候会用 到。 Transation:功能上和数据库中的事务完全一样,通过它实现对数据库中 事务的控制。Transation对象是Session对象产生的,所以他的生命周期比 Session短。一个Session的生命周期中可以有多个Transaction对象。 ConnectonProvider:主要作用是生成与数据库建立了连接的JDBC对象 ,同时他还作为数据库连接的缓冲池。通过ConnectionProvider实现了应 用程序和底层的DataSource和DriverManager的隔离。 TransactionFactory:是生成Transaction对象的工厂,通过 TransactionFactory实现了事务的封装,使其具体的实现方法与应用程序无 关。
判断一个实体对象是否处于瞬态: 该实体对象的<id>属性(如果存在)的值为空 如果在映射文件中为<id>设置了unsaved-value属性,并且 实体对象的id属性的值与unsaved-value属性的值相同 如果这个实体对象配置version属性,并且version属性的 空 在映射文件中为version属性设置了unsaved-value属性,并且 version属性的值与unsaved-value属性的值相同。 如果设置了interceptor,并且interceptor的isUnsaved() 方法的返回值为true
hibernate配置文件说明

create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行。会导致数据库表数据丢失。
create-drop: 每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除。
(2)hibernate.show_sql打印所有的SQL语句到控制台,可以通过设置org.hibernate.SQL类的日志策略到DEBUG级,实现同样的效果。取值 true|false。
(3)hibernate.format_sql 格式化SQL语句在打印到控制台或写入日志文件时。取值true|false。
hibernate.cache.provider_class=org.hibernate.cache.SingletonEhCacheProvider
hibernate.cache.provider_class=org.hibernate.cache.EhCacheProvider
# 二级缓存配置文件
#Batch Size越大,批量操作的向数据库发送sql的次数越少,速度就越快。
hibernate.jdbc.batch_size=50
#设置外连接抓取树的最大深度取值. 建议设置为0到3之间
#hibernate.max_fetch_depth
#是否显示最终执行的SQL(开发环境)
hibernate.show_sql=false
# 格式化显示的SQL
hibernate.format_sql=false
# 如果设置为true,Hiberante将为SQL产生注释,这样更利于调试。默认值为false。取值为true|false。
Java高级工程师面试题及答案

Java高级工程师面试题及答案1.Hibernate工作原理及为什么要用?工作原理: 1.读取并解析配置文件 2.读取并解析映射信息,创建SessionFactory 3.打开Session 4.创建事务Transation 5.持久化操作 6.提交事务 7.关闭Session 8.关闭SesstionFactory为什么要用: 1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。
他很大程度的简化DAO层的编码工作 3. hibernate 使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。
映射的灵活性很出色。
它支持各种关系数据库,从一对一到多对多的各种复杂关系。
2.Hibernate是如何延迟加载?1. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)2. Hibernate3 提供了属性的延迟加载功能当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而提高了服务器的性能。
3.Hibernate中怎样实现类之间的`关系?(如:一对多、多对多的关系)类与类之间的关系主要体现在表与表之间的关系进行操作,它们都市对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的many-to-one、one-to-many、many-to-many4.Struts1流程:1、客户端浏览器发出HTTP请求。
2、根据web.某ml配置,该请求被ActionServlet接收。
3、根据struts-config.某ml配置, ActionServlet先将请求中的参数填充到ActionForm中,然后ActionServlet再将请求发送到Action 进行处理。
struts2+spring+hibernate整合步骤

引用struts2、hibernate、spring所需jar包struts-core-2.x.x.jar ----struts核心包xwork-core-2.x.x.jar -----身体ruts在其撒很难过构建ognl-2.6.x.jar ----对象导航语言freemarker-2.3.x.jar ------struts2的ui标签的模板使用commons-fileupload-1.2.x.jar ----文件上传组件 2.1.6版本后需加入此文件struts-spring-plugin-2.x.x.jar ---用于struts2继承spring的插件hibernate核心安装包下的(下载路径:/ ,点击Hibernate Core 右边的download)hibernate2.jarlib\bytecode\hibernate-cglib-repack-2.1_3.jarlib\required\*.jarhibernate安装包下的(下载路径:/;点击Hibernate Annotations 右边的下载)hibernate-annotations.jarlib\ejb3-persistence.jar、hibernate-commons-annotations.jar hibernate针对JPA的实现包(下载路径:/ ,点击Hibernate Entitymanager右边下载)hibernate-entitymanager.jarlib\test\log4j.jar、 slf4j-log4j12.jarspring安装包下的dist\spring.jarlib\c3p0\c3p0-0.9.1.2.jarlib\aspecti\aspectjweaver.jaraspectjrt.jarlib\colib\cglib-nodep-2.1_3.jarlib\j2ee\common-annotations.jarvlib\log4j\log4j-1.2.15.jarlib\jakarta-commons\commons_loggin.jar数据库驱动包引用创建mysql数据库ssh 设置编码为utf-8 语句:create database ssh character set 'utf8' collate 'utf8_general_ci'引用1.先整合spring和hibernate*将spring和hibernate的jar包放入lib下;*创建spring的beans.xml配置文件Java代码1.<?xml version="1.0" encoding="UTF-8"?>2.<beans xmlns="/schema/beans"3. xmlns:xsi="/2001/XMLSchema-instance"xmlns:context="/schema/context"4. xmlns:aop="/schema/aop"xmlns:tx="/schema/tx"5. xsi:schemaLocation="/schema/beans6./schema/beans/spring-beans-2.5.xsd7. /schema/context8./schema/context/spring-context-2.5.xsd 9. /schema/aop/schema/aop/spring-aop-2.5.xsd10. /schema/tx/schema/tx/spring-tx-2.5.xsd">11.12. <!-- 将bean交由spring管理可以用<bean></bean>和扫描加注 -->13. <!--14. 扫描该包及该包下的子包15. -->16. <context:component-scanbase-package="com.yss"></context:component-scan>17.18.19. <!-- 集成hibernate sessionFactory单例模式线程安全创建耗内存-->20. <!-- 将hibernate的事务也交由spring管理 -->21. <bean id="dataSource"class="boPooledDataSource"22. destroy-method="close">23. <property name="driverClass"value="org.gjt.mm.mysql.Driver" />24. <property name="jdbcUrl"25.value="jdbc:mysql://localhost:3306/ssh?useUnicode=true&characterE ncoding=UTF-8" />26. <property name="user" value="root" />27. <property name="password" value="root" />28. <!--初始化时获取的连接数,取值应在minPoolSize与maxPoolSize 之间。
jpa二级缓存设置专业资料

共 12 页
第 2 页
sheagle@
ehcache 缓存设置
缓存的软件实现 在 Hibernate 的 Session 的实现中包含了缓存的实现 由第三方提供, Hibernate 仅提供了缓存适配器(CacheProvider)。 用于把特定的缓存插件集成到 Hibernate 中。 启用缓存的方式 只要应用程序通过 Session 接口来执行保存、更新、删除、加载和查 询数据库数据的操作,Hibernate 就会启用第一级缓存,把数据库中的数据以对象的形式拷 贝到缓存中,对于批量更新和批量删除操作,如果不希望启用第一级缓存,可以绕过 Hibernate API,直接通过 JDBC API 来执行指操作。 用户可以在单个类或类的单个集合的 粒度上配置第二级缓存。 如果类的实例被经常读但很少被修改, 就可以考虑使用第二级缓存。 只有为某个类或集合配置了第二级 缓存,Hibernate 在运行时才会把它的实例加入到第二 级缓存中。 用户管理缓存的方式 第一级缓存的物理介质为内存,由于内存容量有限,必须通过恰 当的检索策略和检索方式来限制加载对象的数目。 Session 的 evit()方法可以显式清空缓存 中特定对象,但这种方法不值得推荐。 第二级缓存的物理介质可以是内存和硬盘,因此第 二级缓存可以存放大量的数据, 数据过期策略的 maxElementsInMemory 属性值可以控制内存 中 的对象数目。管理第二级缓存主要包括两个方面:选择需要使用第二级缓存的持久类, 设置合适的并发访问策略:选择缓存适配器,设置合适的数据过期策略。
2.3.5 配置二级缓存的主要步骤: 1) 选择需要使用二级缓存的持久化类,设置它的命名缓存的并发访问策略。这是最值 得认真考虑的步骤。 2) 选择合适的缓存插件,然后编辑该插件的配置文件。
Hibernate

a. Session.evict
将某个特定对象从内部缓存中清楚
b. Session.clear
清空内部缓存
当批量插入数据时,会引发内存溢出,这就是由于内部缓存造成的。例如:
For(int i=0; i<1000000; i++){
For(int j=0; j<1000000; j++){
session.iterate(…)方法和session.find(…)方法的区别:session.find(…)方法并不读取ClassCache,它通过查询语句直接查询出结果数据,并将结果数据put进classCache;session.iterate(…)方法返回id序列,根据id读取ClassCache,如果没有命中在去DB中查询出对应数据。
User user = new User();
user.setUserName(“gaosong”);
user.setPassword(“123”);
session.save(user);
}
}
在每次循环时,都会有一个新的对象被纳入内部缓存中,所以大批量的插入数据会导致内存溢出。解决办法有两种:a 定量清除内部缓存 b 使用JDBC进行批量导入,绕过缓存机制。
user.setLoginName("jonny");
mit();
session2 .close();
这种方式,关联前后是否做修改很重要,关联前做的修改不会被更新到数据库,
比如关联前你修改了password,关联后修改了loginname,事务提交时执行的update语句只会把loginname更新到数据库
有没有HIbernate的大神,为什么用HIbernate自带查询进行关联查询,关联表数据查不到?

有没有精通Hibernate的大神,为什么用Hibernate自带查询进行关联查询,关联表数据查不到?这个问题是很多Hibernate开发者经常遇到的问题。
我们将深入探讨这个问题的根本原因,以及如何避免这个问题。
让我们来了解一下Hibernate的自带查询。
Hibernate提供了多种查询方式,其中一种就是自带查询。
自带查询是指Hibernate提供的一系列查询方法,这些方法可以通过Hibernate的Session对象进行调用。
使用自带查询的好处是可以减少代码量,提高开发效率。
使用Hibernate自带查询进行关联查询时,可能会出现关联表数据查不到的情况。
这是因为Hibernate自带查询默认使用的是左外连接(left outer join)的方式进行关联查询。
左外连接是指返回左表中所有记录和右表中匹配的记录。
如果右表中没有匹配的记录,那么就会返回一个NULL值。
当使用Hibernate自带查询进行关联查询时,如果关联表中没有匹配的记录,那么就会返回一个NULL值。
这就是为什么我们无法查到关联表数据的原因。
那么,如何避免这个问题呢?一种解决方法是使用Hibernate的Criteria查询。
Criteria 查询是一种类型安全的查询方式,可以通过编程方式构建查询条件,同时也可以进行关联查询。
在进行关联查询时,Criteria查询使用的是内连接(inner join)的方式,这样就可以避免关联表数据查不到的问题。
还可以使用Hibernate的HQL查询。
HQL查询是一种基于面向对象的查询方式,可以使用实体类的属性名进行查询。
在进行关联查询时,HQL查询使用的也是内连接的方式,因此也可以避免关联表数据查不到的问题。
使用Hibernate自带查询进行关联查询时,可能会出现关联表数据查不到的问题。
为了避免这个问题,我们可以使用Hibernate的Criteria查询或HQL查询。
这些查询方式都使用内连接的方式进行关联查询,可以保证查询结果的准确性。
hibernate高级用法

hibernate高级用法Hibernate是一种Java持久化框架,用于将对象转换为数据库中的数据。
除了基本的用法,Hibernate还提供了一些高级的用法,以下是一些常见的Hibernate高级用法:1、继承Hibernate支持类继承,可以让子类继承父类的属性和方法。
在数据库中,可以使用表与表之间的关系来实现继承,例如使用一对一、一对多、多对一等关系。
使用继承可以让代码更加简洁、易于维护。
2、聚合Hibernate支持聚合,可以将多个对象组合成一个对象。
例如,一个订单对象可以包含多个订单行对象。
在数据库中,可以使用外键来实现聚合关系。
使用聚合可以让代码更加简洁、易于维护。
3、关联Hibernate支持关联,可以让对象之间建立关联关系。
例如,一个订单对象可以关联一个客户对象。
在数据库中,可以使用外键来实现关联关系。
使用关联可以让代码更加简洁、易于维护。
4、延迟加载Hibernate支持延迟加载,可以在需要时才加载对象。
延迟加载可以减少数据库的负担,提高性能。
Hibernate提供了多种延迟加载的策略,例如按需加载、懒惰加载等。
5、事务Hibernate支持事务,可以确保数据库的一致性。
事务是一组数据库操作,要么全部成功,要么全部失败。
Hibernate提供了事务管理的方法,例如开始事务、提交事务、回滚事务等。
6、缓存Hibernate支持缓存,可以减少对数据库的访问次数,提高性能。
Hibernate提供了多种缓存策略,例如一级缓存、二级缓存等。
使用缓存需要注意缓存的一致性和更新问题。
7、HQL查询语言Hibernate提供了HQL查询语言,可以让开发人员使用面向对象的查询方式来查询数据库。
HQL查询语言类似于SQL查询语言,但是使用的是Java类和属性名,而不是表名和列名。
HQL查询语言可以更加灵活、易于维护。
以上是一些常见的Hibernate高级用法,它们可以帮助开发人员更加高效地使用Hibernate进行开发。
hibernate常用方法

hibernate常用方法Hibernate是一个开源的对象-关系映射框架,用于简化Java应用程序与数据库之间的交互。
Hibernate提供了丰富的API来执行通用的数据库操作,包括插入、更新、删除和查询。
下面是Hibernate常用的方法:1. save(:将一个新的对象插入到数据库中,返回一个唯一标识符。
2. update(:更新数据库中的一个对象。
3. delete(:从数据库中删除一个对象。
4. get(:根据给定的唯一标识符查询数据库中的一个对象。
5. load(:根据给定的唯一标识符查询数据库中的一个对象并加载它。
6. saveOrUpdate(:根据对象的状态来决定是插入还是更新数据库中的对象。
7. merge(:将给定对象的状态合并到数据库中的对象。
8. persist(:将一个新的对象插入到数据库中,并立即执行同步。
9. lock(:锁定一个对象,防止其他会话对其进行修改。
10. clear(:清除会话缓存中的所有对象。
11. evict(:从会话缓存中移除给定的对象。
12. refresh(:强制会话重新从数据库中加载对象的状态。
13. flush(:将会话缓存中的所有操作发送到数据库中。
14. Criteria API:用于创建复杂的查询条件。
15. HQL(Hibernate Query Language):类似于SQL的查询语言,用于查询对象。
16. Native SQL:直接执行SQL语句来操作数据库。
17. Transaction API:用于管理事务的开始、提交和回滚。
18. Session API:用于管理Hibernate会话的生命周期。
19. SessionFactory API:用于创建和销毁Hibernate会话工厂。
20. Dialect API:用于不同数据库间的差异性处理。
这些方法涵盖了Hibernate的核心功能,开发者可以根据具体的需求选择合适的方法来操作数据库。
Hibernate的工作原理

Hibernate的工作原理Hibernate是一个开源的Java持久化框架,它能够将Java对象映射到关系型数据库中,并提供了一套简单而强大的API,使得开辟人员能够更加方便地进行数据库操作。
Hibernate的工作原理主要包括以下几个方面:1. 对象关系映射(ORM):Hibernate使用对象关系映射技术将Java对象与数据库表之间建立起映射关系。
开辟人员只需要定义好实体类和数据库表之间的映射关系,Hibernate就能够自动地将Java对象持久化到数据库中,或者将数据库中的数据映射成Java对象。
2. 配置文件:Hibernate通过一个配置文件来指定数据库连接信息、映射文件的位置以及其他一些配置信息。
配置文件通常是一个XML文件,其中包含了数据库驱动类、连接URL、用户名、密码等信息。
开辟人员需要根据自己的数据库环境进行相应的配置。
3. SessionFactory:Hibernate的核心组件是SessionFactory,它负责创建Session对象。
SessionFactory是线程安全的,通常在应用程序启动时创建一次即可。
SessionFactory是基于Hibernate配置文件和映射文件来构建的,它会根据配置文件中的信息来创建数据库连接池,并加载映射文件中的映射信息。
4. Session:Session是Hibernate的另一个核心组件,它代表了与数据库的一次会话。
每一个线程通常会有一个对应的Session对象。
Session提供了一系列的方法,用于执行数据库操作,如保存、更新、删除、查询等。
开辟人员通过Session对象来操作数据库,而不直接与JDBC打交道。
5. 事务管理:Hibernate支持事务的管理,开辟人员可以通过编程方式来控制事务的提交或者回滚。
在Hibernate中,事务是由Session来管理的。
开辟人员可以通过调用Session的beginTransation()方法来启动一个事务,然后根据需要进行提交或者回滚。
韩顺平 hibernate第2讲

hibernate 从入门到精通
主讲: 韩顺平
■
Criteria接口
Criteria接口也可用于面向对象方式的查询,关于它的具体用法我们 这里先不做介绍,简单看几个案例. 最简单案例:返回50条记录 Criteria crit = sess.createCriteria(Cat.class); crit.setMaxResults(50); List cats = crit.list(); 限制结果集内容 List cats = sess.createCriteria(Cat.class) .add( Restrictions.like("name", "Fritz%") ) .add( Restrictions.between("weight", minWeight, maxWeight) ) .list();
hibernate 从入门到精通
主讲: 韩顺平
hibernate 从入门到精通
主讲: 韩顺平
■ConfiguraFra bibliotekon类①负责管理hibernate的配置信息 ②读取hibernate.cfg.xml ③加载hibernate.cfg.xml配置文件中 配置的驱动,url,用户名,密码,连接池. ④管理 *.hbm.xml对象关系文件.
hibernate 从入门到精通
主讲: 韩顺平
■
对象关系映射文件(*.hbm.xml) ①该文件主要作用是建立表和类的映射关系,是不可或缺的重要文件. ②一般放在其映射的类同一个目录下,但不是必须的。 ③命名方式一般是 类名.hbm.xml,但不是必须的。 ④示意图:
*.hbm.xml 表
某个类
hibernate 从入门到精通
hibernate 生成数据库表的原理

hibernate 生成数据库表的原理Hibernate是一个Java持久化框架,它提供了一种方便的方式来映射Java对象到关系数据库中的表结构。
当使用Hibernate时,它可以根据预定义的映射文件或注解配置自动创建、更新和管理数据库表。
Hibernate生成数据库表的原理如下:1. 对象关系映射(Object-Relational Mapping,ORM):Hibernate使用ORM技术将Java类和关系数据库表之间建立起映射关系。
通过在实体类中定义注解或XML映射文件,Hibernate可以知道哪个Java类对应哪个数据库表以及类中的属性与表中的列之间的映射关系。
2. 元数据分析:当应用程序启动时,Hibernate会对实体类进行元数据分析。
它会扫描实体类中的注解或XML映射文件,获取实体类的名称、属性名、属性类型等信息,并根据这些信息生成相应的元数据。
3. 数据库模式生成:根据元数据,Hibernate可以自动生成数据库表的DDL语句。
它会根据实体类的名称创建表名,根据属性名创建列名,并根据属性类型确定列的数据类型、长度、约束等。
生成的DDL语句可以包括创建表、添加索引、外键约束等操作。
4. 数据库表管理:Hibernate可以根据生成的DDL语句来创建数据库表。
在应用程序启动时,Hibernate会检查数据库中是否已存在相应的表,如果不存在则创建表;如果已存在但结构与元数据不匹配,则根据需要进行表结构的更新或修改。
总的来说,Hibernate生成数据库表的原理是通过分析实体类的元数据,自动生成对应的DDL语句,并根据需要创建、更新和管理数据库表。
这种自动化的方式大大简化了开发人员的工作,提高了开发效率。
hibernate jar包详解

(3)dom4j.jar:
dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的dom4j是一个非常非常优秀的Java XML API,具有性能优异功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它在IBM developerWorks上面可以找到一篇文章,对主流的Java XML API进行的性能功能和易用性的评测,dom4j无论在那个方面都是非常出色的我早在将近两年之前就开始使用dom4j,直到现在如今你可以看到越来越多的Java软件都在使用dom4j来读写XML,特别值得一提的是连Sun的JAXM也在用dom4j这是必须使用的jar包,Hibernate用它来读写配置文件
(8)commons-logging.jar:
Apache Commons包中的一个,包含了日志功能,必须使用的jar包这个包本身包含了一个Simple Logger,但是功能很弱在运行的时候它会先在CLASSPATH找log4j,如果有,就使用log4j,如果没有,就找JDK1.4带的java.util.logging,如果也找不到就用Simple Loggercommons-logging.jar的出现是一个历史的的遗留的遗憾,当初Apache极力游说Sun把log4j加入JDK1.4,然而JDK1.4项目小组已经接近发布JDK1.4产品的时间了,因此拒绝了Apache的要求,使用自己的java.util.logging,这个包的功能比log4j差的很远,性能也一般
Hibernate一共包括了23个jar包,令人眼花缭乱下载Hibernate,例如2.0.3稳定版本,解压缩,可以看到一个hibernate2.jar和lib目录下有22个jar包:
Hibernete基本概念
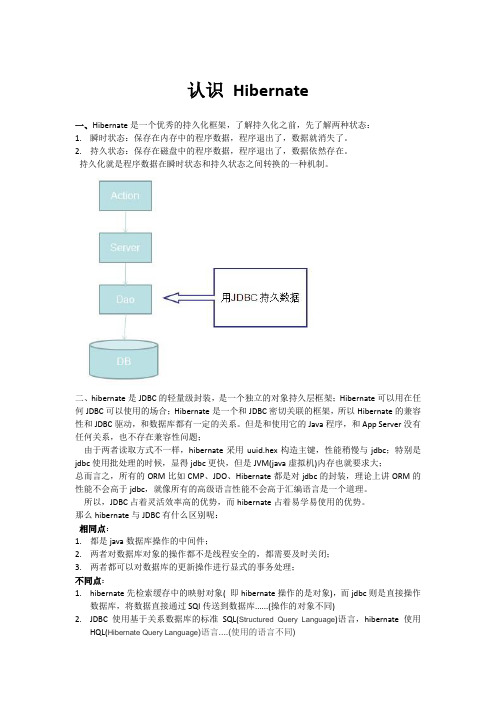
认识Hibernate一、Hibernate是一个优秀的持久化框架,了解持久化之前,先了解两种状态:1.瞬时状态:保存在内存中的程序数据,程序退出了,数据就消失了。
2.持久状态:保存在磁盘中的程序数据,程序退出了,数据依然存在。
持久化就是程序数据在瞬时状态和持久状态之间转换的一种机制。
二、hibernate是JDBC的轻量级封装,是一个独立的对象持久层框架;Hibernate可以用在任何JDBC可以使用的场合;Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系。
但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题;由于两者读取方式不一样,hibernate采用uuid.hex构造主键,性能稍慢与jdbc;特别是jdbc使用批处理的时候,显得jdbc更快,但是JVM(java虚拟机)内存也就要求大;总而言之,所有的ORM比如CMP、JDO、Hibernate都是对jdbc的封装,理论上讲ORM的性能不会高于jdbc,就像所有的高级语言性能不会高于汇编语言是一个道理。
所以,JDBC占着灵活效率高的优势,而hibernate占着易学易使用的优势。
那么hibernate与JDBC有什么区别呢:相同点:1.都是java数据库操作的中间件;2.两者对数据库对象的操作都不是线程安全的,都需要及时关闭;3.两者都可以对数据库的更新操作进行显式的事务处理;不同点:1.hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库,将数据直接通过SQl传送到数据库......(操作的对象不同)2.JDBC使用基于关系数据库的标准SQL(Structured Query Language)语言,hibernate使用HQL(Hibernate Query Language)语言....(使用的语言不同)3.Hibernate操作的数据是可持久化的,也就是持久化的对象属性的值,可以和数据库中保持一致,而jdbc操作数据的状态是瞬时的,变量的值无法和数据库中一致....(数据状态不同)三、ORM(Object Relational Mapping)对象关系映射完成对象数据到关系型数据映射的机制,称为:对象·关系映射,简ORM总结:Hibernate是一个优秀的对象关系映射机制,通过映射文件保存这种关系信息;在业务层以面向对象的方式编程,不需要考虑数据的保存形式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 其中id是个特殊的属性,Hibernate会使用 它来作为主键识别,您可以定义主键产 生的方式,这是在XML映像文件中完成, 为了告诉 Hibernate您所定义的User实例 如何映射至数据库表格,您撰写一个 XML映射文件名是User.hbm.xml,如下 所示:
•
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <class name="er" table="user"> <id name="id" column="id" type="ng.Integer"> <generator class="native"/> </id> <property name="name" column="name" type="ng.String"/> <property name="age" column="age" type="ng.Integer"/> </class> </hibernate-mapping>
• 配置文件中已经加上注释为每一个项目 作了说明,其中对象与数据库表格映像 文件还有待加入
• 这边以一个简单的单机程序来示范Hibernate的 配置与功能,首先作数据库的准备工作,在 MySQL中新增一个demo数据库,并建立user表 格: • CREATE TABLE user ( id INT(11) NOT NULL auto_increment PRIMARY KEY, name VARCHAR(100) NOT NULL default '', age INT );
• 同样的,<property>标签中的column与 type都各自指明了表格中字段与对象中属 性的对应。 • 接着必须在Hibernate配置文件 hibernate.cfg.xml中指明映射文件的位置, 如下加入映射文件位置:
•
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> .... <!-- 对象与数据库表格映像文件 --> <mapping resource=“com/cstp/User.hbm.xml"/> </session-factory> </hibernate-configuration>
• • •
对于这个表格,您有一个User类别与之对应,表格中的每一个字段将对应至User实例上的Field成员。 User.java public class User { private Integer id; private String name; private Integer age; // 必须要有一个预设的建构方法 // 以使得Hibernate可以使用Constructor.newInstance()建立对象 public User() { } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { = name; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } }
• 解开zip文件后,当中的hibernate3.jar是必要的, 而在lib目录中还包括了许多jar文件,您可以在 Hibernate 3.0官方的参考手册 上找到这些jar的 官方的参考手册 相关说明,其中必要的是 antlr、dom4j、 CGLIB、asm、Commons Collections、 Commons Logging、 EHCache,Hibernate底层 还需要Java Transaction API,所以您还需要 jta.jar,到这边为止,总共需要以下的jar文件:
• 如您所看到的,程序中只需要直接操作 User对象,并进行Session与Transaction的 相关操作,Hibernate就会自动完成对数 据库的操作,您看不到任何一行JDBC或 SQL的声明产生,编写好以上的各个文 件之后,各文件的放置位置如下:
• 接着可以开始运行程序,结果如下: • Hibernate: insert into user (name, age) values (?, ?) 新增记录OK!请先用MySQL观看结果! • 执行结果中显示了Hibernate所实际使用的SQL,由于这个程序还 没有查询功能,所以要进入MySQL中看看新增的数据,如下: • mysql> select * from user; +----+-------------+------+ | id | name | age | +----+-------------+------+ | 1 | caterpillar | 30 | +----+-------------+------+ 1 row in set (0.03 sec)
Hibernate பைடு நூலகம்久化框架
目标
• O/R 映射入门 • 第一个 Hibernate 程序很简单,将一 个对象映射至一个数据表。
– 配置 Hibernate – 第一个 Hibernate – 第二个 Hibernate
• Hibernate是ORM的解决方案,其底层对数据库 的操作依赖于JDBC,所以您必须先取得JDBC 驱动程序,在这边所使用的是MySQL,所以您 必须至 MySQL网站 取得MySQL的JDBC驱动 网站 程序。 接下来至 Hibernate 官方网站 取得hibernate 3.0。
• 在 第一个 Hibernate 中介绍如何使用 Hibernate在不使用SQL的情况下,以Java 中操作对象的习惯来插入数据至数据库 中,当然储存数据之后,更重要的是如 何将记录读出,Hibernate中也可以让您 不写一句SQL,而以Java中操作对象的习 惯来查询数据。
• 接下来编写一个测试的程序,这个程序 直接以Java程序设计人员熟悉的语法方式 来操作对象,而实际上也直接完成对数 据库的操作,程序将会将一条数据存入 表格之中:
•
public class FirstHibernate { public static void main(String[] args) { // Configuration 负责管理 Hibernate 配置讯息 Configuration config = new Configuration().configure(); // 根据 config 建立 SessionFactory // SessionFactory 将用于建立 Session SessionFactory sessionFactory = config.buildSessionFactory(); // 将持久化的对象 User user = new User(); user.setName(“hhp”); user.setAge(new Integer(30)); // 开启Session,相当于开启JDBC的Connection Session session = sessionFactory.openSession(); // Transaction表示一组会话操作 Transaction tx= session.beginTransaction(); // 将对象映像至数据库表格中储存 session.save(user); mit(); session.close(); sessionFactory.close(); System.out.println(“新增记录OK!请先用MySQL观看结果!"); } }
• Hibernate可以运行于单机之上,也可以运行于Web应 用程序之中,如果是运行于单机,则将所有用到的jar 文件(包括JDBC驱动程序)设定至 CLASSPATH中, 如果是运行于Web应用程序中,则将jar文件置放于 WEB-INF/lib中。 如果您还需要额外的Library,再依需求加入,例如 JUnit、Proxool等等,接下来可以将etc目录下的 log4j.properties复制至Hibernate项目的Classpath下,并 修改一下当中的.hibernate为error,也就 是只在在错误发生时显示必要的信息。
• 接着设置基本的Hibernate配置文件,可 以使用XML或Properties文件,这边先使 用XML,文件名预设为 hibernate.cfg.xml: