生物序列联配中的算法全版.ppt
序列分析(二)

例:
((LYCES, SPIOL 84), (YEAST, (XENLA, (((RAT, MOUSE 96), HUMAN 83), CHICK 71) 66), DROVI 58))
相关树
多序列比对
目前使用最广泛的多重序列比对程序是 ClustalW
– ClustalW是一种渐进的比对方法,先将多个序 ClustalW是一种渐进的比对方法,先将多个序 列进行两两比对,基于这些比较,计算得到 一个距离矩阵,该矩阵反映了每对序列的关 系
多重序列比对投影
2、多重比对的动态规划算法
• 多重序列比对的最终目标是通过处理得到一个得分最
高(或代价最小)的序列对比排列,从而分析各序列 或代价最小)的序列对比排列, 之间的相似性和差异。 之间的相似性和差异
前趋节点的个数等于2 前趋节点的个数等于 k - 1
假设以k维数组 存放超晶格 则计算过程如下: 假设以 维数组A存放超晶格,则计算过程如下: 维数组 存放超晶格, a[ 0, 0, … ,0 ] = 0 a[ i ] = max {a[ i - b ] + SP-score(Column(s, i, b))}
另一种计算方式: 另一种计算方式:先处理每一个序列对 在处理序列对时,逐个计算字符对, 在处理序列对时,逐个计算字符对,最后加和 得分模型的计算公式如下: 则SP得分模型的计算公式如下: 得分模型的计算公式如下
SP − score(α ) = ∑α ij
i< j
α 是一个多重比对 αij是由α推演出来的序列 i 和s j的两两比对 是由α推演出来的序列s
∑ sim( si, sc )
时间复杂度为O 时间复杂度为O(k2n2 + kn2)
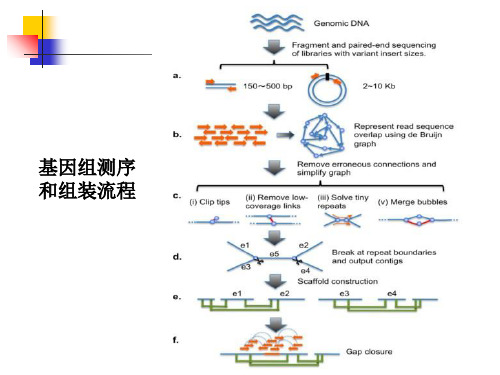
细菌全基因组测序 ppt课件
基因家族(gene family) 和基因簇(gene cluster)分析
基因组中来源相同,结构和功能相关的基因 聚集在一起形成基因家族。
基因家族的各个成员紧密成簇排列成大段的串联 重复单位,分布在某一条染色体的特殊区域
genefamily.xls
基因家族聚类结果
genefamily.stat
各基因家族统计信息
培养条件① 培养条件②
或活性较低
测定转录 组mRNA
细菌全基因组测序
比较 新 差异 基因
其他方面的应用研究
❖ 应用NMR、FTIR、UV, 14C标记的木质 素降解机理方面的研究; ❖农药残留物以及其他一些难降解有机物的 降解; ❖ 重金属有机物化合物的降解。
② 木质素降解过程中涉及到的细胞外酶主要有:木质素过氧化物酶
(LiP)和锰过氧化物酶(MnP),以及漆酶(Lac)。此外,一 些附属酶参与过氧化氢的产生,乙二醛氧化酶(glyoxal oxidase, 缩写作GLOX)和芳基醇氧化酶(aryl alcohol oxidase,缩写作 AAO)属于这类酶。
对4株菌的亲缘关系进行分析,确定菌株之间的相互关 系;
通过对4株菌进行进化分析,判定是否为古菌或新的菌 种。
细菌全基因组测序
基因分离
下一步的实验安排
对已注释出的基因进行验证
载体
酶切
酶切
连接
转化
筛选 表达
细菌全基因组测序
未注释出功能的基因鉴定,挖掘新基因
DNA 转录 RNA 翻译 Protein
细菌全基因组测序
“一个物种基因组计划的完成, 就意味着这一物种学科和产业 发展的新开端”
向仲怀院士
谢谢!!
细菌全基因组测序
生物信息学 第四章 序列比对与算法

T
C A G A T 1 1 1
1
1
1
1 1 1 1 1 1 1 1 1
1
1
1
1
A A C C G T C A G A T 1 0 A A C C G T C A G A T 4 3 4 0 1 1 1
C
T
G
C
T
A 1
A 1
A 1
C
G
T A
A 1
C
T
G
C
T
A 1
A 1
A 1
C
G
T
1 1 1 1 1
矩阵的元素表示由原来的氨基酸(上行,蓝色)替换为另一个氨
基酸(左列,绿色)的概率
例
Score with PAM 250 and gap penalty -10
计算如下比对
CKHVFCRVCI CKKCFCKCV
CKHVFCRVCI CKKCFC-KCV CKHVFCRVCI CKKCFCK-CV C-KHVFCRVCI CKKC-FC-CKV CKH-VFCRVCI CKKC-FC-KCV
A R N D C Q E G H I L K M F P S T W Y V 4 -1 -2 -2 0 -1 -1 0 -2 -1 -1 -1 -1 -2 -1 1 0 -3 -2 0 A
5 0 -2 -3 1 0 -2 0 -3 -2 2 -2 -3 -2 -1 -1 -3 -2 -3 R
6 1 -3 0 0 0 1 -3 -3 0 -2 -3 -2 1 0 -4 -2 -3 N
1 1 1 1 1
1 1
1 1 1 1 1 1 1 1 1 1
1
1
1
1 3 0 C 2 1 T 2 0 G 2 0 C 1 1 T 2 0 A 1 1 1 1 1 1 1 1 2 3 0 2 2 1 3 2 0 2 2 0 2 1 1 2 2 0 1 2 2 0 1 1 2 0 1 1 0 1 1 1 1 2 0 A 1 2 0 A 1 1 1 1 0 C
生物信息学中的序列比对算法原理与实践

生物信息学中的序列比对算法原理与实践序列比对是生物信息学中常用的基本技术之一,用于在生物学研究中比较两个或多个生物序列的相似性和差异性。
在分子生物学和基因组学等领域中,序列比对被广泛应用于基因分析、蛋白质结构预测、物种分类、进化分析以及新基因和功能区域的发现等重要任务。
本文将介绍序列比对算法的基本原理和常用实践技术。
序列比对算法的基本原理序列比对的目标是找到两个序列之间的匹配部分,并根据匹配的相似性和差异性进行评分。
序列比对算法的基本原理主要有两种方法:全局比对和局部比对。
全局比对算法(例如Needleman-Wunsch 算法)是一种通过将匹配、不匹配和间隙等操作分配给两个序列的每个字符来寻找最佳比对的方法。
它能够比较整个序列的相似性,但对于较长的序列来说,计算量较大,因此对于较短的序列和相似度较高的序列,全局比对更为合适。
局部比对算法(例如 Smith-Waterman 算法)则通过寻找两个序列中的最佳子序列来找到最佳比对。
该算法适用于较长的序列和不太相似的序列,因为它只关注相似的区域。
局部比对算法能够发现序列中的重复结构和片段,对于在序列之间插入或缺失元素的情况下非常有用。
序列比对算法的实践技术在实践应用中,为了处理大规模的序列数据并提高比对效率,还发展出了一些改进和优化的序列比对算法和技术。
1. 基于哈希表的算法:这种方法通过构建哈希表来加速相似性搜索。
算法将序列切分成较小的片段,并将每个片段哈希为独特的数字,然后根据相似性检索相关的哈希数字。
这种方法能够快速找到相似的序列片段,并进行比对和匹配。
2. 快速比对算法:这些算法通过减少比对的搜索空间或采用启发式的策略,来降低比对的计算复杂度。
例如,BLAST(Basic Local Alignment Search Tool)算法通过提取关键特征,如k-mer或频繁子序列,将序列比对问题转化为查找数据库中相似序列的问题。
3. 并行比对算法:随着计算机科学的发展,利用并行计算技术可以大幅提高比对效率。
生物信息学和计算生物学中的算法和模型

生物信息学和计算生物学中的算法和模型生物信息学和计算生物学是生物学领域的重要分支,致力于通过计算机科学的方法和技术来研究生物学中的各种问题。
从基因组学和蛋白质组学到系统生物学和进化生物学,生物信息学和计算生物学都发挥着重要的作用。
而算法和模型则是生物信息学和计算生物学的重要组成部分,为生物学研究提供了有效的理论和工具。
在本文中,将探讨生物信息学和计算生物学中的算法和模型的重要性和应用。
一、基于生物信息学的算法1.1 基因序列分析算法DNA的序列解码是生物信息学中最基本的问题之一。
基于生物学的算法广泛应用于基因序列的比对、组装和批量序列评估等领域。
基因序列分析算法涉及到与蛋白质互作、基因功能等生物学问题的关系。
基因组学技术的快速发展和大规模数据的产生,加速了基于生物信息学算法的研究进程。
1.2 蛋白质序列分析算法蛋白质是生命现象中不可或缺的一种物质,通过化学键形成了相对稳定的三维构型进行其特定的功能。
因此,分析蛋白质序列的方法与分析基因序列的方法有很多相似之处,但同时也存在很多不同之处。
蛋白质分析的目的是根据蛋白质的序列和三维结构,以推断其功能和保守区域。
研究者可以通过蛋白质序列分析算法和模型,预测蛋白质的结构和特性,以及通过相互作用和信号途径的分析,揭示蛋白质之间的关联性和影响性。
1.3 基于机器学习的算法机器学习是人工智能领域的一种重要技术,也是生物信息学中的重要方法之一。
生物信息学中的机器学习算法,例如基于神经网络的模型和基于支持向量机的学习算法,可以应用于生物学的数据分析中。
这些算法可以从数据中挖掘出结构,预测结果,并为生物学研究提供更加精确的计算分析。
二、基于生物信息学的模型2.1 基因调控模型基因调控模型是生物信息学中最为广泛应用的模型之一,因为大多数基因表达是在特定的环境条件下被调控的。
基因调控模型能够解析基因表达的模式和相应的信号途径,从而为生物学研究揭示更深层次的机制。
这些模型可以基于不同生物体在特定条件下的基因表达指标和外部条件,判断基因表达事件是否具有缓冲和分化的特性。
生物信息学中的序列比对算法使用方法解析

生物信息学中的序列比对算法使用方法解析序列比对在生物信息学中是一项重要的技术,用于寻找DNA、RNA或蛋白质序列之间的相似性和差异性。
它是理解生物学结构和功能的基石之一。
在本文中,我们将解析生物信息学中常用的序列比对算法的使用方法。
序列比对算法主要分为全局比对和局部比对。
全局比对用于比较完整的序列,而局部比对则更适用于在序列中查找相似区域。
在这两个主要类别中,有几种经典的序列比对算法,包括Pairwise Sequence Alignment、BLAST、Smith-Waterman算法和Needleman-Wunsch算法等。
首先,我们来看Pairwise Sequence Alignment(两两序列比对)算法。
这个算法是基本的序列比对方法,通过比较两个序列中的每一个碱基、氨基酸或核苷酸,并根据其相似性和差异性对它们进行排列。
Pairwise Sequence Alignment算法使用动态规划的思想,通过计算匹配、替代和插入/删除的分数,来确定两个序列的最佳匹配方案。
在生物信息学中,常用的实现包括Needleman-Wunsch算法和Smith-Waterman算法。
Needleman-Wunsch算法是一种全局比对算法,用于比较两个序列的整个长度。
它是通过填充一个二维矩阵来计算最佳匹配路径的。
算法的核心思想是,通过评估每个格子的分数,根据路径选择的最佳分数进行全局比对。
这个算法不仅可以计算序列的相似性,还可以计算每个位置的分数,从而获得两个序列的对应二面的对应关系。
Smith-Waterman算法是一种局部比对算法,用于寻找两个序列中的最佳匹配片段(子序列)。
它与Needleman-Wunsch算法的计算思路相同,但不同之处在于允许负分数,这使得算法能够确定具有高分数的局部匹配片段。
通过动态规划计算,Smith-Waterman算法可以寻找到两个序列中的相似片段,并生成比对的结果。
另一种常用的序列比对算法是基本本地搜索工具(BLAST)。
生物信息学中的基因组序列比对算法

生物信息学中的基因组序列比对算法生物信息学是一门研究生物数据的组织、分析和解释的学科,而基因组序列比对是生物信息学中的一项重要工作。
随着测序技术的飞速发展,已经可以获得大规模的基因组序列数据。
对这些海量数据进行比对,可以帮助科研人员更好地理解基因组的结构和功能,寻找与遗传疾病相关的基因变异,以及探索物种演化的关键基因。
基因组序列比对是指将已知的基因组序列与未知的基因组序列进行比较,找出相似的部分并进行对应的分析。
这个过程旨在寻找两个序列之间的共有特征,甚至找出它们之间的差异。
为了实现这个目标,生物信息学中发展了许多基因组序列比对算法。
本文将介绍几种常用的基因组序列比对算法和它们的特点。
1. Smith-Waterman算法:Smith-Waterman算法是最常用且最经典的基因组序列比对算法之一。
该算法的主要思想是通过动态规划的方式,找出两个序列之间的最优匹配。
它考虑了每个位置的匹配得分、插入得分和删除得分,并计算出匹配的最大得分。
然后,根据得分矩阵的反向路径,将匹配的结果进行回溯和确认。
Smith-Waterman算法的优点在于它能够找到最优的匹配结果,但缺点是计算复杂度较高,对于长序列的比对可能需要很长时间。
2. BLAST算法:BLAST(Basic Local Alignment Search Tool)算法是基因组序列比对中最常用的算法之一。
与Smith-Waterman算法相比,BLAST算法采用了一种快速比对的策略,以减少计算的时间复杂度。
BLAST算法首先将序列按照k-mer(由k个连续核苷酸组成的子串)进行分割,并将其转化为哈希表格式存储。
然后,在查询阶段,BLAST算法将查询序列的k-mer与目标序列的k-mer进行比较,从而找到相似的片段。
最后,根据相似片段的得分和位置信息,生成比对结果。
BLAST算法的优点是比较快速,但可能会因为基于k-mer的比对策略而丧失一些准确性。
生物信息学分析方法介绍PPT课件

目录
• 生物信息学概述 • 基因组学分析方法 • 转录组学分析方法 • 表观遗传学分析方法 • 蛋白质组学分析方法 • 生物信息学分析流程和方法比较
01
生物信息学概述
生物信息学的定义和重要性
定义
生物信息学是一门跨学科的学科,它利用计算机科学、数学和工程学的原理和 技术,对生物学数据进行分析、建模和解读,以揭示生命现象的本质和规律。
研究蛋白质的序列、结构 和功能,以及蛋白质相互 作用和蛋白质组表达调控 机制。
研究基因转录本的序列、 结构和表达水平,以及转 录调控机制。
研究基因表达的表观遗传 调控机制,如DNA甲基化 、组蛋白修饰等。
通过对患者基因组、蛋白 质组和转录组等数据的分 析,为个性化医疗和精准 医学提供支持。
02
基因组学分析方法
基因组注释
基因组注释是指对基因组序列中的各 个区域进行标记和描述的过程,包括 基因、转录单元、重复序列、调控元 件等。
注释信息可以通过数据库(如RefSeq、 GeneBank等)或注释软件(如GATK、 ANNOVAR等)获取。注释信息对于 理解基因组的生物学功能和进化关系 具有重要意义。
基因组变异检测
基因组变异检测是指检测基因组序列 中的变异位点,包括单核苷酸变异、 插入和缺失等。
VS
变异检测对于遗传疾病研究、进化生 物学和生物进化研究等领域具有重要 意义。常用的变异检测方法有SNP检 测、CNV检测等,它们基于不同的原 理和技术,具有不同的适用范围和精 度。
03
转录组学分析方法
RNA测序技术
利用生物信息学方法和算法,对 RNA测序数据进行基因融合检测, 寻找融合基因及其融合方式。
基因融合检测结果可以为研究肿 瘤等疾病提供重要线索,有助于 深入了解疾病发生发展机制。
实验04:串应用KMP算法PPT课件

在生物信息学中的应用
在生物信息学中,KMP算法被广泛应用于基因序列的比对和拼接,以及蛋白质序列 的匹配和比对。
通过构建基因序列或蛋白质序列的索引表,KMP算法可以在O(n+m)的时间复杂度 内完成序列的比对和拼接,提高了比对和拼接的准确性和效率。
KMP算法在生物信息学中的应用有助于深入了解基因和蛋白质的结构和功能,为生 物医学研究和疾病诊断提供了有力支持。
06 实验总结与展望
KMP算法的优缺点
优点
高效:KMP算法在匹配失败时能跳过 尽可能多的字符,减少比较次数,从
而提高匹配效率。
适用范围广:KMP算法适用于各种模 式串匹配问题,不受模式串长度的限 制。
缺点
计算量大:KMP算法需要计算和存储 部分匹配表,对于较长的模式串,计 算量较大。
不适合处理大量数据:KMP算法在处 理大量数据时可能会占用较多内存, 导致性能下降。
匹配失败的处理
当模式串中的某个字符与主串中的对应字符不匹配时,模式串向右 滑动,与主串的下一个字符重新对齐,继续比较
next[ j]表示当模式串中第j个字符与主 串中的对应字符不匹配时,模式串需 要向右滑动的位置。
next数组的构建
next数组的作用
在匹配过程中,通过next数组可以快 速确定模式串需要滑动到哪个位置, 从而提高了匹配效率。
通过已知的next值,递推计算出next 数组中其他位置的值。
KMP算法的时间复杂度
01
02
03
04
时间复杂度分析
KMP算法的时间复杂度取决 于模式串在主串中出现的次数 以及每次匹配所花费的时间。
最佳情况
当模式串在主串中连续出现时 ,KMP算法的时间复杂度为
第三章序列比对

生物软件网: /
• 当然,DNAStar、DNAMan等软件也 可以进行比对。
• 载入的序列必须是fasta格式, 存储在记事本(.txt)中。
参数可以选择,或者默 认。
Clustal比对后的结果
3.3 多条序列比对方法
3.3.1 序列对数据库的比对检索分析 3.3.2 多重序列的本地化软件对齐 3.3.3 Clustal比对结果的编辑
Clustal的工作原理
Clustal输入多个序列
快速的序列两两比对,计算序列间的 距离,获得一个距离矩阵。
采用邻接法(NJ)构建一个树(引导树)
根据引导树,渐进比对多个序列。
Clustal的输入输出格式
• 输入序列的格式比较灵活,可以是前面介 绍过的FASTA格式,还可以是PIR、 SWISS-PROT、GDE、Clustal、 GCG/MSF、RSF等格式。
相似性 (similarity)
• 相似性是指序列比对过程中用来描述检测序列和目标序列之间相同 DNA碱基或氨基酸残基顺序所占比例的高低。
• 相似性本身的含义,并不要求与进化起源是否同一,与亲缘关系的 远近、甚至于结构与功能有什么联系。
• 当相似程度高于50%时,比较容易推测检测序列和目标序列可能是 同源序列;而当相似性程度低于20%时,就难以确定或者根本无法 确定其是否具有同源性。
• “Bl2Seq”是NCBI上Blast程序的一部分, 允许两条序列之行局部双序列比对,使 用这个程序执行蛋白质(或DNA序列) 的双序列比对非常容易。
• 网络服务如NCBI的“bl2seq”程序,地址: /Blast.cgi
点!
特殊BLAST
10
20
30
40
50
生物序列联配中的算法ppt课件

联配A的分值Score为:Scor el (S'[i],T'[i]) i1
精品ppt
19
•全局联配(2)-原始算法
输入:序列S和T,其中 | S | = | T | = n 输出:S和T的最优联配
for i=0 to n do for (S的所有的子序列A,其中| A | = i ) do for (T的所有的子序列B,其中| B | = i ) do
3 g -3 0 0 -1 2 1
4 c -4 -1 -1 -1 1 1
5 t -5 -2 -2 1 0 3
6 g -6 -3 -3 0 3 2
精品ppt
24
三种可能的最优联配序列:
1. S: a c g c t g 2. T: - c – a t g t 2. S: a c g c t g -
T: - c a – t g t 3. S: - a c g c t g
T: c a t g - t -
精品ppt
25
•局部联配(1)
两条序列在一些局部的区域内具有 很高的相似度。
在生物学中局部联配比全局联配更 具有实际的意义。
转录:DNA链 → RNA链 信使RNA(mRNA),启动子。
翻译: mRNA上携带遗传信息在核糖体 中合成蛋白质的过程。
精品ppt
7
•变异
进化过程中由于不正确的复制,使DNA 内容发生局部的改变。
变异的种类主要有以下三种: 替代(substitution) 插入或删除(insertion or deletion) indel 重排(rearrangement)
精品ppt
生物信息学中的序列比对算法技巧

生物信息学中的序列比对算法技巧序列比对是生物信息学中最重要的任务之一,它对于理解生物序列的功能,关系到生物学、医学和农业等领域的许多研究。
序列比对的目的是确定两个或多个生物序列之间的相似性和差异性,揭示它们之间的结构和功能关系。
在生物信息学的研究中,序列比对被广泛应用于基因组学、蛋白质学、进化生物学等领域。
虽然序列比对是一个复杂的任务,但是许多算法和技巧被发展用于解决这个问题。
下面将介绍一些在生物信息学中常用的序列比对算法技巧。
1. 精确匹配算法精确匹配算法是最简单的序列比对算法之一。
它通过遍历目标序列中的每一个位置,以及参考序列中的相同长度的子序列,进行比较。
当两个子序列完全相同时,算法会判定它们匹配。
常见的精确匹配算法有贪婪算法、Boyer-Moore算法和Knuth-Morris-Pratt算法。
它们通过不同的方式优化了序列比对的速度和效率。
2. 近似匹配算法近似匹配算法用于比对在序列中具有一些差异的区域。
这些差异可能是由于突变、插入或缺失等引起的。
近似匹配算法可以通过引入一些容错性来允许在序列比对中出现一定的误差。
最常用的近似匹配算法是Smith-Waterman算法和Needleman-Wunsch算法。
它们可以找到两个序列之间的最佳匹配,即使在存在一定差异的情况下也能准确地比对。
3. 多序列比对算法多序列比对是将多个序列进行比对以寻找它们之间的相似性和差异性。
这种比对常用于进化生物学中,用于研究不同物种或个体间的共同点与差异。
多序列比对算法的目标是寻找最佳的共同序列,并对其进行比较。
其中一种常见的算法是ClustalW,它使用了多种优化技术来提高比对的准确性和效率。
4. 基于碱基质量的序列比对在一些生物信息学研究中,需要考虑序列中碱基的质量。
质量分数描述了测量序列中每个碱基的准确程度,特别是在测序中。
基于碱基质量的序列比对算法可以根据质量分数调整比对过程中的权重,更准确地确定序列的相似性。
第08章-生物计算机ppt课件(全)

8.2.3 双稳态开关
最早的基因开关模型是由Gardner等人在2000年构造 的 , 主 要 由 两 个 启 动 子 ( Promoter ) 和 一 个 抑 制 子 (Repressor)构成,启动子可以诱导基因表达生成相应的 抑制子,抑制子通过结合对方基因的启动子而抑制它的表达。
DNA计算机的特点主要表现在6个方面。 (1)工作的并行性(最大优点) (2)极低的能耗 (3)极高的集成度 (4)运算速度快 (5)抗电磁干扰能力强 (6)成本低廉
8.4.2 DNA计算机的模型
(1)粘贴模型 粘贴模型是一种被证明具有计算完备性的DNA检索模
型,配对识别操作是按照DNA碱基互补特性完成的。该模 型的优势是运算过程不需要酶的参与。
初等细胞自动机是状态集S只有两个元素{s1,s2},即 状态个数k=2,邻居半径r=1的一维细胞自动机。
图8.10 冯· 诺依曼的初等细胞自动机
(2)细胞自动机的基本组成
细胞自动机最基本的组成:细胞、细胞空间、邻居及规 则四部分。另外,还应包含状态和时间。可以视为由一个细 胞空间和定义于该空间的变换函数所组成。
图8.1 Gardner等构造的基因开关模型
该 数 学 模 型 由 一 组 微 分 方 程 组 成 , 如 式 ( 8.1 ) 、
(8.2)。其中U、V分别表示两种阻遏蛋白的量;α1、α2为
两种启动子(包含核糖体结合位点共同作用)在没有阻遏蛋
白时的表达速率;-U、-V表示两种阻遏蛋白的自然降解速 率;而β、γ为启动子的抑制参数,数值越大,表示阻遏蛋白
生物信息处理中的基因序列对齐算法研究

生物信息处理中的基因序列对齐算法研究基因序列对齐是一项重要的生物信息学任务,它可以帮助科学家们理解生物体的进化关系、功能和结构。
随着技术的发展和基因测序数据的不断增加,对基因序列对齐算法的研究变得尤为重要。
本文将对常见的基因序列对齐算法进行介绍,包括全局对齐、局部对齐和多序列对齐,并探讨它们在生物信息处理中的应用。
一、全局对齐算法全局对齐算法是最早被开发的一类对齐算法,它将两个序列的整个长度进行比对,并生成一个最佳的对齐结果。
常用的全局对齐算法包括Smith-Waterman算法和Needleman-Wunsch算法。
Smith-Waterman算法通过动态规划的方式,计算出两个序列间的最佳匹配。
这个算法引入了一个打分矩阵,根据两个序列中相应位置的碱基或氨基酸的相似性,给出相应的得分。
然后通过计算累积得分的最大值和对应的位置,找到两个序列的最佳匹配。
类似地,Needleman-Wunsch算法也是通过动态规划的方式进行两个序列的全局对齐。
该算法引入了一个打分矩阵,并考虑了序列间的间隙惩罚。
通过计算累积得分的最大值和对应的位置,找到两个序列的全局最佳匹配。
全局对齐算法在多个领域有广泛的应用,例如基因进化树的构建、蛋白质结构预测以及疾病相关基因的发现等。
二、局部对齐算法局部对齐算法将重点放在两个序列的相似片段上,忽略了序列的其他部分。
在生物学研究中,局部对齐算法常用于比较具有相同功能或结构域的序列。
常见的局部对齐算法有Smith-Waterman局部对齐算法和BLAST算法。
Smith-Waterman局部对齐算法是一种高效的算法,它在全局对齐算法的基础上进行了改进。
该算法通过从得分矩阵中选择最大的得分区域,找到两个序列中的最佳局部匹配。
BLAST(Basic Local Alignment Search Tool)是一种基于快速滑动窗口的局部对齐算法。
该算法通过预处理数据和使用快速查找表,在大规模序列数据库中高效地搜索相似片段。
生物信息学中的序列比对和基因组拼接算法研究

生物信息学中的序列比对和基因组拼接算法研究序列比对和基因组拼接是生物信息学领域中的重要算法研究。
它们在基因测序、蛋白质结构预测以及进化研究等方面起着关键作用。
本文将深入探讨序列比对和基因组拼接的原理、方法和应用。
一、序列比对算法研究序列比对是将一个序列与参考序列或其他已知序列进行对比,以找出相似性和差异性的过程。
常见的序列比对算法包括全局比对、局部比对和多序列比对。
1. 全局比对算法全局比对算法适用于两个相对较短的序列进行比对。
其中最著名的算法是Needleman-Wunsch算法,它采用动态规划的方式,计算序列间的最佳匹配。
该算法考虑了所有可能的匹配和错配,并给出一个最优的比对结果。
2. 局部比对算法局部比对算法可用于在长序列中找到某一片段与参考序列的最佳匹配。
著名的算法有Smith-Waterman算法,它是Needleman-Wunsch算法的改进版,引入了负惩罚和局部最优解的概念。
该算法非常适用于寻找序列中的保守区域和发现序列间的重复模式。
3. 多序列比对算法多序列比对是比对超过两个序列的过程,用于研究序列的进化关系和功能区域。
CLUSTALW和MAFFT是两个常用的多序列比对算法。
它们采用多种方法,如多序列比对的逐步方法和迭代方法,以在多个序列之间建立最优的比对。
二、基因组拼接算法研究基因组拼接是将测序得到的碎片化DNA序列拼接成完整的基因组序列的过程。
基因组拼接算法的研究主要涉及DNA序列的重叠区域的识别、序列拼接和错误修正等步骤。
1. 重叠区域的识别重叠区域是指两个碎片DNA序列中相互重叠的区域。
重叠区域的识别是基因组拼接的第一步。
传统方法是通过比对序列之间的相似性来寻找重叠区域。
而现代的方法则利用图论和概率模型等技术,提高了重叠区域的识别准确性。
2. 序列拼接在识别到重叠区域后,基因组拼接算法会将碎片化的DNA序列进行拼接。
常用的拼接方法包括Greedy算法和Overlap-Layout-Consensus算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
.精品课件.
14
生物序列相似性的比较
.精品课件.
15
•动机
在生物学的研究中,将未知序列同已知 序列进行比较分析已经成为一种强有力 的研究手段 ,生物学领域中绝大部分的 问题在计算机科学领域中主要体现为序 列或字符串的问题 。
.精品课件.
16
•序列联配问题的分类
如果两个序列具有足够的相似性, 则认为两者具有同源性。
.精品课件.
8
•蛋白质
由氨基酸依次链接形成在生物体中总共 有20种氨基酸。
蛋白有十分复杂的三维结构。其三维机 构决定了蛋白质的功能。
.精品课件.
9
•基 因
什么是基因?
DNA上具有特定功能的一个片断,负 责一种特定性状的表达。一般来讲, 一个基因只编码一个蛋白质。
.精品课件.
10
•基因组
-
序列相似性的比较 (两条序列的联配) 序列的分类 序列的排列 多序列的联配
.精品课件.
17
•两条序列联配问题的分类
全局联配(Global Alignment) 局部联配(Local Alignment) 空位处罚(Gap Penalty)
.精品课件.
18
•全局联配(1)-定义
定义1:两个任意的字符 x和y,(x,y)表示
表x和y比较时的分值。
(x,x)=2, (x,y)= (x,-)= (-,y)=-1
定可义以2用:序S列= sS1’…和sTn和’来T表=t示1…,tm其,中其:全局联配A (1) | S’ | = | T’ |; (2) 将S’和T’中的空字符除去后所得到的序 列分别为S和T;
联配A的分值Score为:
.精品课件.
19
•全局联配(2)-原始算法
输入:序列S和T,其中 | S | = | T | = n 输出:S和T的最优联配
for i=0 to n do for (S的所有的子序列A,其中| A | = i ) do for (T的所有的子序列B,其中| B | = i ) do
……
.精品课件.
0
0 -1 -2 -3 -4 -5
1 a -1 -1 1 0 -1 -2
2 c -2 1 0 0 -1 -2
3 g -3 0 0 -1 2 1
4 c -4 -1 -1 -1 1 1
5 t -5 -2 -2 1 0 3
6 g -6 -3 -3 0 3 2
.精品课件.
24
三种可能的最优联配序列:
1. S: a c g c t g T: - c – a t g t
转录:DNA链 → RNA链 信使RNA(mRNA),启动子。
翻译: mRNA上携带遗传信息在核糖体 中合成蛋白质的过程。
.精品课件.
7
•变异
进化过程中由于不正确的复制,使DNA 内容发生局部的改变。
变异的种类主要有以下三种: 替代(substitution) 插入或删除(insertion or deletion) indel 重排(rearrangement)
.精品课件.
4
•DNA(3)
DNA的双螺旋结构
碱基对之间的互补能力
.精品课件.
5
•DNA(4)
DNA的复制 在DNA解旋酶的作用 下两条链分离开,分 别作为一个模板,在 聚合酶的作用下合成 一条新链。
.精品课件.
6
•RNA、转录和翻译
RNA(核糖核酸):单链结构、尿嘧啶U代 替胸腺嘧啶T、位于细胞核和细胞质中。
2. S: a c g c t g T: - c a – t g t
3. S: - a c g c t g T: c a t g - t -
.精品课件.
25
•局部联配(1)
两条序列在一些局部的区域内具有 很高的相似度。
在生物学中局部联配比全局联配更 具有实际的意义。
两条DNA长序列,可能只在很小的区 域内(密码区)存在关系。
任何一条染色体上都带有许多基因,一 条高等生物的染色体上可能带有成千上 万个基因,一个细胞中的全部基因序列 及其间隔序列统称为genomes(基因组)。
.精品课件.
11
•DNA上的基因
基因
.精品课件.
12
•基因的编码
基因编码是一个逻辑的映射,表明存储 在DNA和mRNA中的基因信息决定什么 样的蛋白质序列。
不同家族的蛋白质往往具有功能和结 构上的相同的一些区域。
.精品课件.
26
•局部联配(2)
前提条件: V(i, 0) = 0; V(0, j) = 0;
20
•全局联配(3)
动态规划DP(Dynamic Programming) Smith-Waterman 算法
计算出两个序列的相似分值,存于一 个矩阵中。(相似度矩阵、DP矩阵)
根据此矩阵,按照动态规划的方法寻 找最优的联配序列。
.精品课件.
21
•全局联配(4)
前提条件
递归关系
.精品课件.
22
•全局联配(5)
在得到相似度矩阵后,通过动态规划回 溯(Traceback)的方法可获得序列的最 优联配序列 。
例: S = “a c g c t g”和T = “c a t g t”
(x,x)=2, (x,y)= (x,-)= (-,y)=-1
.精品课件.
23
j0 1 2 3 4 5
i
ca t g t
一种碱基
• 腺嘌呤(Adenine)
• 鸟嘌呤(Guanine)
• 胞嘧啶(Cytosine)
• 胸腺嘧啶(Thymine)
.精品课件.
3
•DNA(2)
碱基的配对原则 A(腺嘌呤)—T(胸腺嘧啶) C(鸟嘌呤)—G(胞嘧啶)
一个嘌呤基与一个嘧啶基通 过氢键联结成一个碱基对。
DNA分子的方向性 5'→3'
生物序列联配中的算法
张法
.精品课件.
1
•提 纲
背景知识 序列相似性的比较
两条序列的联配问题 多序列的联配问题 一些启发式的算法 生物序列联配中的并行算法
.精品课件.
2
•DNA(1) 脱氧核糖核酸
DNA的分子组成
核甘(nucleotides)
磷酸盐(phosphate)
糖(sugar)
每个碱基三元组称为一个密码子(codon) 碱基组成的三元组的排列共有43=64种,
而氨基酸共有20种类型,所以不同的密 码子可能表示同一种氨基酸。
.精品课件.
13
•带来的问题
序列排列问题 基因组的重排问题 蛋白质结构和功能的预测 基因(外显子、内含子)查找问题 序列装配(Sequence Assembly)问题