descriptive statistics
描述统计的相关定义

描述统计的相关定义
描述统计(Descriptive Statistics)是一种通过对数据进行整理、
归纳和总结来描述和展示数据分布、中心趋势、数据形态和离散程度等特
征的统计方法。
常见的描述统计方法包括:
1.频数和频率:指数据中各类别出现的次数和比例。
2.均值:指数据的平均值,是各数值之和除以总数。
3.中位数:指将数据从小到大排序后,位于中间位置的数。
4.众数:指在一组数据中出现次数最多的数。
5.极差:指一组数据最大值与最小值之差。
6.标准差:指一组数据的离散程度,是各数值偏差平方和的平均值的
平方根。
7.偏度和峰度:分别反映了数据分布的偏斜程度和尖锐程度。
通过描述统计的分析,可以更加直观地对数据的基本特征有一个了解,为后续进一步的统计分析提供重要的依据。
现代心理教育与统计学_第三版复习资料(张厚粲)

第一章绪论1.描述统计(descriptive statistics)主要研究如何将实验或调查得到的大量数据进行图表整理或简缩成有代表性的数字(即统计量数),使其能客观、全面地反映这组数据的全貌,将其所提供的信息充分显现出来,为进一步统计分析和推论提供可能。
2.描述统计只限于对试验样本所得观测数据的统计分析,不考察其总体的特性。
3.推论统计(inferential statistics)是以描述统计为基础,从而解决由局部到全体的推论问题,即通过对一组统计量的计算分析,推论该组数据所代表的总体特性。
4.变量(variables):一个可以取不同数值的物体属性/事件。
5.事前无法预期结果的变量——随机变量6.观测值(原始取值):事后测定的某一结果。
7.概念理解:[涉及“实验”] 自变量(及其各水平)& 因变量(及相应的反应指标);[涉及“调查”,粗略对应于] 属性变量& 反应变量8.计数资料(count data):计算个数的数据,(如人口数,学校数,男女数等)9.计量资料(measurement data):借助于一定的测量工具或一定的测量标准而获得的数据(如分数,身高,体重,IQ)10.称名数据(nominal data):只区分属性或类别上的不同,只可计数,不能排序(性别,学科,职业)11.等级/顺序数据(ordinal data):可排序,但无相等单位,不能加减。
(等级评定,受教育程度,职称)12.等距数据(interval data):具有相等单位,无绝对零的数据,能加减不能乘除。
13.比率数据(ratio data):既表明量的大小,又具有相等单位,可以加减乘除,具有绝对零点。
14.称名数据和顺序数据合称为离散数据。
15.等距数据和比率数据合称为连续数据。
16.离散数据(discrete data)又称为不连续数据,这类数据在任何两个数据点之间所取的数据的个数是有限的。
17.连续数据(continuous data)指任意两个数据点之间都可以细分出无限多个大小不同的数值。
描述统计学与推断统计学名词解释

描述统计学与推断统计学名词解释描述统计学(Descriptive Statistics)是统计学的一个分支,主要研究如何通过数据收集、处理、分析和解释,来描述和总结所观察到的现象的基本统计信息。
它包括统计数据的收集方法、数据的加工处理方法、数据的显示方法、数据分布特征的概括与分析方法等。
描述统计学通过数理统计方法来反映数据的特点,并通过图表形式对所收集的数据进行必要的可视化,进一步综合、概括和分析得出数据的客观规律。
推断统计学(Inferential Statistics)也是统计学的一个分支,主要研究如何根据样本数据去推断总体数量特征的方法。
它是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。
推断统计学通常用于对总体参数的估计和假设检验,其结果通常是为了得到下一步的行动策略。
描述统计学和推断统计学是统计学的两个重要分支,二者相辅相成。
描述统计学是推断统计学的基础,而推断统计学则是描述统计学的进一步发展。
在实际应用中,需要根据具体的研究目的和数据情况来选择合适的统计方法。
现代心理教育与统计学 第三版复习资料(张厚粲)

第一章绪论1.描述统计(descriptive statistics)主要研究如何将实验或调查得到的大量数据进行图表整理或简缩成有代表性的数字(即统计量数),使其能客观、全面地反映这组数据的全貌,将其所提供的信息充分显现出来,为进一步统计分析和推论提供可能。
2.描述统计只限于对试验样本所得观测数据的统计分析,不考察其总体的特性。
3.推论统计(inferential statistics)是以描述统计为基础,从而解决由局部到全体的推论问题,即通过对一组统计量的计算分析,推论该组数据所代表的总体特性。
4.变量(variables):一个可以取不同数值的物体属性/事件。
5.事前无法预期结果的变量——随机变量6.观测值(原始取值):事后测定的某一结果。
7.概念理解:[涉及“实验”] 自变量(及其各水平)& 因变量(及相应的反应指标);[涉及“调查”,粗略对应于] 属性变量& 反应变量8.计数资料(count data):计算个数的数据,(如人口数,学校数,男女数等)9.计量资料(measurement data):借助于一定的测量工具或一定的测量标准而获得的数据(如分数,身高,体重,IQ)10.称名数据(nominal data):只区分属性或类别上的不同,只可计数,不能排序(性别,学科,职业)11.等级/顺序数据(ordinal data):可排序,但无相等单位,不能加减。
(等级评定,受教育程度,职称)12.等距数据(interval data):具有相等单位,无绝对零的数据,能加减不能乘除。
13.比率数据(ratio data):既表明量的大小,又具有相等单位,可以加减乘除,具有绝对零点。
14.称名数据和顺序数据合称为离散数据。
15.等距数据和比率数据合称为连续数据。
16.离散数据(discrete data)又称为不连续数据,这类数据在任何两个数据点之间所取的数据的个数是有限的。
17.连续数据(continuous data)指任意两个数据点之间都可以细分出无限多个大小不同的数值。
描述性统计分析DescriptiveStatistics菜单详解

第六章:描述性统计分析--菜单详解描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。
的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在菜单中,最常用的是列在最前面的四个过程:过程的特色是产生频数表;过程则进行一般性的统计描述;过程用于对数据概况不清时的探索性分析;过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
本章讲述的四个过程在9.0及以前版本中被放置在菜单中。
§6.1 过程频数分布表是描述性统计中最常用的方法之一,过程就是专门为产生频数表而设计的。
它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。
和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。
如果想用过程得到我们所熟悉的频数表,请先用第二章学过的过程产生一个新变量来代表所需的各组段。
6.1.1 界面说明对话框的界面如下所示:该界面在中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【复选框】确定是否在结果中输出频数表。
【钮】单击后弹出对话框如下,用于定义需要计算的其他描述统计量。
现将各部分解释如下:o复选框组定义需要输出的百分位数,可计算四分位数()、每隔指定百分位输出当前百分位数( )、或直接指定某个百分位数(),如直接指定输出P2.5和P97.5。
o复选框组用于定义描述集中趋势的一组指标:均数()、中位数()、众数()、总和()。
o复选框组用于定义描述离散趋势的一组指标:标准差()、方差()、全距()、最小值()、最大值()、标准误()。
o复选框组用于定义描述分布特征的两个指标:偏度系数()和峰度系数()。
o复选框当你输出的数据是分组频数数据,并且具体数值是组中值时,选中该复选框以通知,免得它犯错误。
众数()指所有数值中出现频率最高的一个值,在国内用的非常少。
描述性统计分析DescriptiveStatistics

第二讲:一般数据分析教学目的:能应用SPSS软件进行:描述分析、频数分析、数据探索、交叉表分析、图形分析等教学内容:1)描述分析2)频数分析3)数据探索4)交叉表分析教学重点:描述分析、频数分析、交叉表教学难点:数据探索、交叉表分析教学时间:1学时描述性统计分析Descriptive Statistics描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。
SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:●Frequencies过程的特色是产生频数表;●Descriptives过程则进行一般性的统计描述;●Explore过程用于对数据概况不清时的探索性分析;●Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验,常用的X2 检验也在其中完成。
1.1 Frequencies过程频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。
它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图、饼图等统计图。
和国内常用的频数表不同,几乎所有统计软件给出的都是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。
如果想用Frequencies 过程得到熟悉的频数表,请先用第3章学过的Recode过程产生一个新变量来代表所需的各组段。
1.1.1 界面说明Frequencies对话框的界面如图1.1a所示。
选取Analyze→Descriptive Statistics →Frequencies,系统就会弹出该对话框,其各部分的功能如下:1.Variable(s)框:左侧的变量可全部选入右侧的Variable(s)框内,一次性完成所有变量的频数分析;也可逐一选入右侧,进行分析n次分析(这样就太累了)。
SPSS术语中英文对照

【常用软件】SPSS术语中英文对照SPSS的统计分析过程均包含在Analysis菜单中。
我们只学以下两大分析过程:Descriptive Statistics(描述性统计)和Multiple Response(多选项分析)。
Descriptive Statistics(描述性统计)包含的分析功能:1.Frequencies 过程:主要用于统计指定变量各变量值的频次(Frequency)、百分比(Percent)。
2.Descriptives过程:主要用于计算指定变量的均值(Mean)、标准差(Std.Deviation)。
3.Crosstabs 过程:主要用于两个或两个以上变量的交叉分类。
Multiple Response(多选项分析)的分析功能:1.Define Set过程:该过程定义一个由多选项组成的多响应变量。
2.Frequencies过程:该过程对定义的多响应变量提供一个频数表。
3.Crosstabs过程:该过程提供所定义的多响应变量与其他变量的交叉分类表。
Absolute deviation, 绝对离差Absolute number, 绝对数Absolute residuals, 绝对残差Acceleration array, 加速度立体阵Acceleration in an arbitrary direction, 任意方向上的加速度Acceleration normal, 法向加速度Acceleration space dimension, 加速度空间的维数Acceleration tangential, 切向加速度Acceleration vector, 加速度向量Acceptable hypothesis, 可接受假设Accumulation, 累积Accuracy, 准确度Actual frequency, 实际频数Adaptive estimator, 自适应估计量Addition, 相加Addition theorem, 加法定理Additivity, 可加性Adjusted rate, 调整率Adjusted value, 校正值Admissible error, 容许误差Aggregation, 聚集性Alternative hypothesis, 备择假设Among groups, 组间Amounts, 总量Analysis of correlation, 相关分析Analysis of covariance, 协方差分析Analysis of regression, 回归分析Analysis of time series, 时间序列分析Analysis of variance, 方差分析Angular transformation, 角转换ANOVA (analysis of variance), 方差分析ANOVA Models, 方差分析模型Arcing, 弧/弧旋Arcsine transformation, 反正弦变换Area under the curve, 曲线面积AREG , 评估从一个时间点到下一个时间点回归相关时的误差ARIMA, 季节和非季节性单变量模型的极大似然估计Arithmetic grid paper, 算术格纸Arithmetic mean, 算术平均数Arrhenius relation, 艾恩尼斯关系Assessing fit, 拟合的评估Associative laws, 结合律Asymmetric distribution, 非对称分布Asymptotic bias, 渐近偏倚Asymptotic efficiency, 渐近效率Asymptotic variance, 渐近方差Attributable risk, 归因危险度Attribute data, 属性资料Attribution, 属性Autocorrelation, 自相关Autocorrelation of residuals, 残差的自相关Average, 平均数Average confidence interval length, 平均置信区间长度Average growth rate, 平均增长率Bar chart, 条形图Bar graph, 条形图Base period, 基期Bayes‘ theorem , Bayes定理Bell-shaped curve, 钟形曲线Bernoulli distribution, 伯努力分布Best-trim estimator, 最好切尾估计量Bias, 偏性Binary logistic regression, 二元逻辑斯蒂回归Binomial distribution, 二项分布Bisquare, 双平方Bivariate Correlate, 二变量相关Bivariate normal distribution, 双变量正态分布Bivariate normal population, 双变量正态总体Biweight interval, 双权区间Biweight M-estimator, 双权M估计量Block, 区组/配伍组BMDP(Biomedical computer programs), BMDP统计软件包Boxplots, 箱线图/箱尾图Breakdown bound, 崩溃界/崩溃点Canonical correlation, 典型相关Caption, 纵标目Case-control study, 病例对照研究Categorical variable, 分类变量Catenary, 悬链线Cauchy distribution, 柯西分布Cause-and-effect relationship, 因果关系Cell, 单元Censoring, 终检Center of symmetry, 对称中心Centering and scaling, 中心化和定标Central tendency, 集中趋势Central value, 中心值CHAID -χ2 Automatic Interaction Detector, 卡方自动交互检测Chance, 机遇Chance error, 随机误差Chance variable, 随机变量Characteristic equation, 特征方程Characteristic root, 特征根Characteristic vector, 特征向量Chebshev criterion of fit, 拟合的切比雪夫准则Chernoff faces, 切尔诺夫脸谱图Chi-square test, 卡方检验/χ2检验Choleskey decomposition, 乔洛斯基分解Circle chart, 圆图Class interval, 组距Class mid-value, 组中值Class upper limit, 组上限Classified variable, 分类变量Cluster analysis, 聚类分析Cluster sampling, 整群抽样Code, 代码Coded data, 编码数据Coding, 编码Coefficient of contingency, 列联系数Coefficient of determination, 决定系数Coefficient of multiple correlation, 多重相关系数Coefficient of partial correlation, 偏相关系数Coefficient of production-moment correlation, 积差相关系数Coefficient of rank correlation, 等级相关系数Coefficient of regression, 回归系数Coefficient of skewness, 偏度系数Coefficient of variation, 变异系数Cohort study, 队列研究Column, 列Column effect, 列效应Column factor, 列因素Combination pool, 合并Combinative table, 组合表Common factor, 共性因子Common regression coefficient, 公共回归系数Common value, 共同值Common variance, 公共方差Common variation, 公共变异Communality variance, 共性方差Comparability, 可比性Comparison of bathes, 批比较Comparison value, 比较值Compartment model, 分部模型Compassion, 伸缩Complement of an event, 补事件Complete association, 完全正相关Complete dissociation, 完全不相关Complete statistics, 完备统计量Completely randomized design, 完全随机化设计Composite event, 联合事件Composite events, 复合事件Concavity, 凹性Conditional expectation, 条件期望Conditional likelihood, 条件似然Conditional probability, 条件概率Conditionally linear, 依条件线性Confidence interval, 置信区间Confidence limit, 置信限Confidence lower limit, 置信下限Confidence upper limit, 置信上限Confirmatory Factor Analysis , 验证性因子分析Confirmatory research, 证实性实验研究Confounding factor, 混杂因素Conjoint, 联合分析Consistency, 相合性Consistency check, 一致性检验Consistent asymptotically normal estimate, 相合渐近正态估计Consistent estimate, 相合估计Constrained nonlinear regression, 受约束非线性回归Constraint, 约束Contaminated distribution, 污染分布Contaminated Gausssian, 污染高斯分布Contaminated normal distribution, 污染正态分布Contamination, 污染Contamination model, 污染模型Contingency table, 列联表Contour, 边界线Contribution rate, 贡献率Control, 对照Controlled experiments, 对照实验Conventional depth, 常规深度Convolution, 卷积Corrected factor, 校正因子Corrected mean, 校正均值Correction coefficient, 校正系数Correctness, 正确性Correlation coefficient, 相关系数Correlation index, 相关指数Correspondence, 对应Counting, 计数Counts, 计数/频数Covariance, 协方差Covariant, 共变Cox Regression, Cox回归Criteria for fitting, 拟合准则Criteria of least squares, 最小二乘准则Critical ratio, 临界比Critical region, 拒绝域Critical value, 临界值Cross-over design, 交叉设计Cross-section analysis, 横断面分析Cross-section survey, 横断面调查Crosstabs , 交叉表Cross-tabulation table, 复合表Cube root, 立方根Cumulative distribution function, 分布函数Cumulative probability, 累计概率Curvature, 曲率/弯曲Curvature, 曲率Curve fit , 曲线拟和Curve fitting, 曲线拟合Curvilinear regression, 曲线回归Curvilinear relation, 曲线关系Cut-and-try method, 尝试法Cycle, 周期Cyclist, 周期性D test, D检验Data acquisition, 资料收集Data bank, 数据库Data capacity, 数据容量Data deficiencies, 数据缺乏Data handling, 数据处理Data manipulation, 数据处理Data processing, 数据处理Data reduction, 数据缩减Data set, 数据集Data sources, 数据来源Data transformation, 数据变换Data validity, 数据有效性Data-in, 数据输入Data-out, 数据输出Dead time, 停滞期Degree of freedom, 自由度Degree of precision, 精密度Degree of reliability, 可靠性程度Degression, 递减Density function, 密度函数Density of data points, 数据点的密度Dependent variable, 应变量/依变量/因变量Dependent variable, 因变量Depth, 深度Derivative matrix, 导数矩阵Derivative-free methods, 无导数方法Design, 设计Determinacy, 确定性Determinant, 行列式Determinant, 决定因素Deviation, 离差Deviation from average, 离均差Diagnostic plot, 诊断图Dichotomous variable, 二分变量Differential equation, 微分方程Direct standardization, 直接标准化法Discrete variable, 离散型变量DISCRIMINANT, 判断Discriminant analysis, 判别分析Discriminant coefficient, 判别系数Discriminant function, 判别值Dispersion, 散布/分散度Disproportional, 不成比例的Disproportionate sub-class numbers, 不成比例次级组含量Distribution free, 分布无关性/免分布Distribution shape, 分布形状Distribution-free method, 任意分布法Distributive laws, 分配律Disturbance, 随机扰动项Dose response curve, 剂量反应曲线Double blind method, 双盲法Double blind trial, 双盲试验Double exponential distribution, 双指数分布Double logarithmic, 双对数Downward rank, 降秩Dual-space plot, 对偶空间图DUD, 无导数方法Duncan‘s new multiple range method, 新复极差法/Duncan新法Effect, 实验效应Eigenvalue, 特征值Eigenvector, 特征向量Ellipse, 椭圆Empirical distribution, 经验分布Empirical probability, 经验概率单位Enumeration data, 计数资料Equal sun-class number, 相等次级组含量Equally likely, 等可能Equivariance, 同变性Error, 误差/错误Error of estimate, 估计误差Error type I, 第一类错误Error type II, 第二类错误Estimand, 被估量Estimated error mean squares, 估计误差均方Estimated error sum of squares, 估计误差平方和Euclidean distance, 欧式距离Event, 事件Event, 事件Exceptional data point, 异常数据点Expectation plane, 期望平面Expectation surface, 期望曲面Expected values, 期望值Experiment, 实验Experimental sampling, 试验抽样Experimental unit, 试验单位Explanatory variable, 说明变量Exploratory data analysis, 探索性数据分析Explore Summarize, 探索-摘要Exponential curve, 指数曲线Exponential growth, 指数式增长EXSMOOTH, 指数平滑方法Extended fit, 扩充拟合Extra parameter, 附加参数Extrapolation, 外推法Extreme observation, 末端观测值Extremes, 极端值/极值F distribution, F分布F test, F检验Factor, 因素/因子Factor analysis, 因子分析Factor Analysis, 因子分析Factor score, 因子得分Factorial, 阶乘Factorial design, 析因试验设计False negative, 假阴性False negative error, 假阴性错误Family of distributions, 分布族Family of estimators, 估计量族Fanning, 扇面Fatality rate, 病死率Field investigation, 现场调查Field survey, 现场调查Finite population, 有限总体Finite-sample, 有限样本First derivative, 一阶导数First principal component, 第一主成分First quartile, 第一四分位数Fisher information, 费雪信息量Fitted value, 拟合值Fitting a curve, 曲线拟合Fixed base, 定基Fluctuation, 随机起伏Forecast, 预测Four fold table, 四格表Fourth, 四分点Fraction blow, 左侧比率Fractional error, 相对误差Frequency, 频率Frequency polygon, 频数多边图Frontier point, 界限点Function relationship, 泛函关系Gamma distribution, 伽玛分布Gauss increment, 高斯增量Gaussian distribution, 高斯分布/正态分布Gauss-Newton increment, 高斯-牛顿增量General census, 全面普查GENLOG (Generalized liner models), 广义线性模型Geometric mean, 几何平均数Gini‘s mean difference, 基尼均差GLM (General liner models), 一般线性模型Goodness of fit, 拟和优度/配合度Gradient of determinant, 行列式的梯度Graeco-Latin square, 希腊拉丁方Grand mean, 总均值Gross errors, 重大错误Gross-error sensitivity, 大错敏感度Group averages, 分组平均Grouped data, 分组资料Guessed mean, 假定平均数Half-life, 半衰期Hampel M-estimators, 汉佩尔M估计量Happenstance, 偶然事件Harmonic mean, 调和均数Hazard function, 风险均数Hazard rate, 风险率Heading, 标目Heavy-tailed distribution, 重尾分布Hessian array, 海森立体阵Heterogeneity, 不同质Heterogeneity of variance, 方差不齐Hierarchical classification, 组内分组Hierarchical clustering method, 系统聚类法High-leverage point, 高杠杆率点HILOGLINEAR, 多维列联表的层次对数线性模型Hinge, 折叶点Histogram, 直方图Historical cohort study, 历史性队列研究Holes, 空洞HOMALS, 多重响应分析Homogeneity of variance, 方差齐性Homogeneity test, 齐性检验Huber M-estimators, 休伯M估计量Hyperbola, 双曲线Hypothesis testing, 假设检验Hypothetical universe, 假设总体Impossible event, 不可能事件Independence, 独立性Independent variable, 自变量Index, 指标/指数Indirect standardization, 间接标准化法Individual, 个体Inference band, 推断带Infinite population, 无限总体Infinitely great, 无穷大Infinitely small, 无穷小Influence curve, 影响曲线Information capacity, 信息容量Initial condition, 初始条件Initial estimate, 初始估计值Initial level, 最初水平Interaction, 交互作用Interaction terms, 交互作用项Intercept, 截距Interpolation, 内插法Interquartile range, 四分位距Interval estimation, 区间估计Intervals of equal probability, 等概率区间Intrinsic curvature, 固有曲率Invariance, 不变性Inverse matrix, 逆矩阵Inverse probability, 逆概率Inverse sine transformation, 反正弦变换Iteration, 迭代Jacobian determinant, 雅可比行列式Joint distribution function, 分布函数Joint probability, 联合概率Joint probability distribution, 联合概率分布K means method, 逐步聚类法Kaplan-Meier, 评估事件的时间长度Kaplan-Merier chart, Kaplan-Merier图Kendall‘s rank correlation, Kendall等级相关Kinetic, 动力学Kolmogorov-Smirnove test, 柯尔莫哥洛夫-斯米尔诺夫检验Kruskal and Wallis test, Kruskal及Wallis检验/多样本的秩和检验/H检验Kurtosis, 峰度Lack of fit, 失拟Ladder of powers, 幂阶梯Lag, 滞后Large sample, 大样本Large sample test, 大样本检验Latin square, 拉丁方Latin square design, 拉丁方设计Leakage, 泄漏Least favorable configuration, 最不利构形Least favorable distribution, 最不利分布Least significant difference, 最小显著差法Least square method, 最小二乘法Least-absolute-residuals estimates, 最小绝对残差估计Least-absolute-residuals fit, 最小绝对残差拟合Least-absolute-residuals line, 最小绝对残差线Legend, 图例L-estimator, L估计量L-estimator of location, 位置L估计量L-estimator of scale, 尺度L估计量Level, 水平Life expectance, 预期期望寿命Life table, 寿命表Life table method, 生命表法Light-tailed distribution, 轻尾分布Likelihood function, 似然函数Likelihood ratio, 似然比line graph, 线图Linear correlation, 直线相关Linear equation, 线性方程Linear programming, 线性规划Linear regression, 直线回归Linear Regression, 线性回归Linear trend, 线性趋势Loading, 载荷Location and scale equivariance, 位置尺度同变性Location equivariance, 位置同变性Location invariance, 位置不变性Location scale family, 位置尺度族Log rank test, 时序检验Logarithmic curve, 对数曲线Logarithmic normal distribution, 对数正态分布Logarithmic scale, 对数尺度Logarithmic transformation, 对数变换Logic check, 逻辑检查Logistic distribution, 逻辑斯特分布Logit transformation, Logit转换LOGLINEAR, 多维列联表通用模型Lognormal distribution, 对数正态分布Lost function, 损失函数Low correlation, 低度相关Lower limit, 下限Lowest-attained variance, 最小可达方差LSD, 最小显著差法的简称Lurking variable, 潜在变量Main effect, 主效应Major heading, 主辞标目Marginal density function, 边缘密度函数Marginal probability, 边缘概率Marginal probability distribution, 边缘概率分布Matched data, 配对资料Matched distribution, 匹配过分布Matching of distribution, 分布的匹配Matching of transformation, 变换的匹配Mathematical expectation, 数学期望Mathematical model, 数学模型Maximum L-estimator, 极大极小L 估计量Maximum likelihood method, 最大似然法Mean, 均数Mean squares between groups, 组间均方Mean squares within group, 组内均方Means (Compare means), 均值-均值比较Median, 中位数Median effective dose, 半数效量Median lethal dose, 半数致死量Median polish, 中位数平滑Median test, 中位数检验Minimal sufficient statistic, 最小充分统计量Minimum distance estimation, 最小距离估计Minimum effective dose, 最小有效量Minimum lethal dose, 最小致死量Minimum variance estimator, 最小方差估计量MINITAB, 统计软件包Minor heading, 宾词标目Missing data, 缺失值Model specification, 模型的确定Modeling Statistics , 模型统计Models for outliers, 离群值模型Modifying the model, 模型的修正Modulus of continuity, 连续性模Morbidity, 发病率Most favorable configuration, 最有利构形Multidimensional Scaling (ASCAL), 多维尺度/多维标度Multinomial Logistic Regression , 多项逻辑斯蒂回归Multiple comparison, 多重比较Multiple correlation , 复相关Multiple covariance, 多元协方差Multiple linear regression, 多元线性回归Multiple response , 多重选项Multiple solutions, 多解Multiplication theorem, 乘法定理Multiresponse, 多元响应Multi-stage sampling, 多阶段抽样Multivariate T distribution, 多元T分布Mutual exclusive, 互不相容Mutual independence, 互相独立Natural boundary, 自然边界Natural dead, 自然死亡Natural zero, 自然零Negative correlation, 负相关Negative linear correlation, 负线性相关Negatively skewed, 负偏Newman-Keuls method, q检验NK method, q检验No statistical significance, 无统计意义Nominal variable, 名义变量Nonconstancy of variability, 变异的非定常性Nonlinear regression, 非线性相关Nonparametric statistics, 非参数统计Nonparametric test, 非参数检验Nonparametric tests, 非参数检验Normal deviate, 正态离差Normal distribution, 正态分布Normal equation, 正规方程组Normal ranges, 正常范围Normal value, 正常值Nuisance parameter, 多余参数/讨厌参数Null hypothesis, 无效假设Numerical variable, 数值变量Objective function, 目标函数Observation unit, 观察单位Observed value, 观察值One sided test, 单侧检验One-way analysis of variance, 单因素方差分析Oneway ANOVA , 单因素方差分析Open sequential trial, 开放型序贯设计Optrim, 优切尾Optrim efficiency, 优切尾效率Order statistics, 顺序统计量Ordered categories, 有序分类Ordinal logistic regression , 序数逻辑斯蒂回归Ordinal variable, 有序变量Orthogonal basis, 正交基Orthogonal design, 正交试验设计Orthogonality conditions, 正交条件ORTHOPLAN, 正交设计Outlier cutoffs, 离群值截断点Outliers, 极端值OVERALS , 多组变量的非线性正规相关Overshoot, 迭代过度Paired design, 配对设计Paired sample, 配对样本Pairwise slopes, 成对斜率Parabola, 抛物线Parallel tests, 平行试验Parameter, 参数Parametric statistics, 参数统计Parametric test, 参数检验Partial correlation, 偏相关Partial regression, 偏回归Partial sorting, 偏排序Partials residuals, 偏残差Pattern, 模式Pearson curves, 皮尔逊曲线Peeling, 退层Percent bar graph, 百分条形图Percentage, 百分比Percentile, 百分位数Percentile curves, 百分位曲线Periodicity, 周期性Permutation, 排列P-estimator, P估计量Pie graph, 饼图Pitman estimator, 皮特曼估计量Pivot, 枢轴量Planar, 平坦Planar assumption, 平面的假设PLANCARDS, 生成试验的计划卡Point estimation, 点估计Poisson distribution, 泊松分布Polishing, 平滑Polled standard deviation, 合并标准差Polled variance, 合并方差Polygon, 多边图Polynomial, 多项式Polynomial curve, 多项式曲线Population, 总体Population attributable risk, 人群归因危险度Positive correlation, 正相关Positively skewed, 正偏Posterior distribution, 后验分布Power of a test, 检验效能Precision, 精密度Predicted value, 预测值Preliminary analysis, 预备性分析Principal component analysis, 主成分分析Prior distribution, 先验分布Prior probability, 先验概率Probabilistic model, 概率模型probability, 概率Probability density, 概率密度Product moment, 乘积矩/协方差Profile trace, 截面迹图Proportion, 比/构成比Proportion allocation in stratified random sampling, 按比例分层随机抽样Proportionate, 成比例Proportionate sub-class numbers, 成比例次级组含量Prospective study, 前瞻性调查Proximities, 亲近性Pseudo F test, 近似F检验Pseudo model, 近似模型Pseudosigma, 伪标准差Purposive sampling, 有目的抽样QR decomposition, QR分解Quadratic approximation, 二次近似Qualitative classification, 属性分类Qualitative method, 定性方法Quantile-quantile plot, 分位数-分位数图/Q-Q图Quantitative analysis, 定量分析Quartile, 四分位数Quick Cluster, 快速聚类Radix sort, 基数排序Random allocation, 随机化分组Random blocks design, 随机区组设计Random event, 随机事件Randomization, 随机化Range, 极差/全距Rank correlation, 等级相关Rank sum test, 秩和检验Rank test, 秩检验Ranked data, 等级资料Rate, 比率Ratio, 比例Raw data, 原始资料Raw residual, 原始残差Rayleigh‘s test, 雷氏检验Rayleigh‘s Z, 雷氏Z值Reciprocal, 倒数Reciprocal transformation, 倒数变换Recording, 记录Redescending estimators, 回降估计量Reducing dimensions, 降维Re-expression, 重新表达Reference set, 标准组Region of acceptance, 接受域Regression coefficient, 回归系数Regression sum of square, 回归平方和Rejection point, 拒绝点Relative dispersion, 相对离散度Relative number, 相对数Reliability, 可靠性Reparametrization, 重新设置参数Replication, 重复Report Summaries, 报告摘要Residual sum of square, 剩余平方和Resistance, 耐抗性Resistant line, 耐抗线Resistant technique, 耐抗技术R-estimator of location, 位置R估计量R-estimator of scale, 尺度R估计量Retrospective study, 回顾性调查Ridge trace, 岭迹Ridit analysis, Ridit分析Rotation, 旋转Rounding, 舍入Row, 行Row effects, 行效应Row factor, 行因素RXC table, RXC表Sample, 样本Sample regression coefficient, 样本回归系数Sample size, 样本量Sample standard deviation, 样本标准差Sampling error, 抽样误差SAS(Statistical analysis system ), SAS统计软件包Scale, 尺度/量表Scatter diagram, 散点图Schematic plot, 示意图/简图Score test, 计分检验Screening, 筛检SEASON, 季节分析Second derivative, 二阶导数Second principal component, 第二主成分SEM (Structural equation modeling), 结构化方程模型Semi-logarithmic graph, 半对数图Semi-logarithmic paper, 半对数格纸Sensitivity curve, 敏感度曲线Sequential analysis, 贯序分析Sequential data set, 顺序数据集Sequential design, 贯序设计Sequential method, 贯序法Sequential test, 贯序检验法Serial tests, 系列试验Short-cut method, 简捷法Sigmoid curve, S形曲线Sign function, 正负号函数Sign test, 符号检验Signed rank, 符号秩Significance test, 显著性检验Significant figure, 有效数字Simple cluster sampling, 简单整群抽样Simple correlation, 简单相关Simple random sampling, 简单随机抽样Simple regression, 简单回归simple table, 简单表Sine estimator, 正弦估计量Single-valued estimate, 单值估计Singular matrix, 奇异矩阵Skewed distribution, 偏斜分布Skewness, 偏度Slash distribution, 斜线分布Slope, 斜率Smirnov test, 斯米尔诺夫检验Source of variation, 变异来源Spearman rank correlation, 斯皮尔曼等级相关Specific factor, 特殊因子Specific factor variance, 特殊因子方差Spectra , 频谱Spherical distribution, 球型正态分布Spread, 展布SPSS(Statistical package for the social science), SPSS统计软件包Spurious correlation, 假性相关Square root transformation, 平方根变换Stabilizing variance, 稳定方差Standard deviation, 标准差Standard error, 标准误Standard error of difference, 差别的标准误Standard error of estimate, 标准估计误差Standard error of rate, 率的标准误Standard normal distribution, 标准正态分布Standardization, 标准化Starting value, 起始值Statistic, 统计量Statistical control, 统计控制Statistical graph, 统计图Statistical inference, 统计推断Statistical table, 统计表Steepest descent, 最速下降法Stem and leaf display, 茎叶图Step factor, 步长因子Stepwise regression, 逐步回归Storage, 存Strata, 层(复数)Stratified sampling, 分层抽样Stratified sampling, 分层抽样Strength, 强度Stringency, 严密性Structural relationship, 结构关系Studentized residual, 学生化残差/t化残差Sub-class numbers, 次级组含量Subdividing, 分割Sufficient statistic, 充分统计量Sum of products, 积和Sum of squares, 离差平方和Sum of squares about regression, 回归平方和Sum of squares between groups, 组间平方和Sum of squares of partial regression, 偏回归平方和Sure event, 必然事件Survey, 调查Survival, 生存分析Survival rate, 生存率Suspended root gram, 悬吊根图Symmetry, 对称Systematic error, 系统误差Systematic sampling, 系统抽样Tags, 标签Tail area, 尾部面积Tail length, 尾长Tail weight, 尾重Tangent line, 切线Target distribution, 目标分布Taylor series, 泰勒级数Tendency of dispersion, 离散趋势Testing of hypotheses, 假设检验Theoretical frequency, 理论频数Time series, 时间序列Tolerance interval, 容忍区间Tolerance lower limit, 容忍下限Tolerance upper limit, 容忍上限Torsion, 扰率Total sum of square, 总平方和Total variation, 总变异Transformation, 转换Treatment, 处理Trend, 趋势Trend of percentage, 百分比趋势Trial, 试验Trial and error method, 试错法Tuning constant, 细调常数Two sided test, 双向检验Two-stage least squares, 二阶最小平方Two-stage sampling, 二阶段抽样Two-tailed test, 双侧检验Two-way analysis of variance, 双因素方差分析Two-way table, 双向表Type I error, 一类错误/α错误Type II error, 二类错误/β错误UMVU, 方差一致最小无偏估计简称Unbiased estimate, 无偏估计Unconstrained nonlinear regression , 无约束非线性回归Unequal subclass number, 不等次级组含量Ungrouped data, 不分组资料Uniform coordinate, 均匀坐标Uniform distribution, 均匀分布Uniformly minimum variance unbiased estimate, 方差一致最小无偏估计Unit, 单元Unordered categories, 无序分类Upper limit, 上限Upward rank, 升秩Vague concept, 模糊概念Validity, 有效性VARCOMP (Variance component estimation), 方差元素估计Variability, 变异性Variable, 变量Variance, 方差Variation, 变异Varimax orthogonal rotation, 方差最大正交旋转Volume of distribution, 容积W test, W检验Weibull distribution, 威布尔分布Weight, 权数Weighted Chi-square test, 加权卡方检验/Cochran检验Weighted linear regression method, 加权直线回归Weighted mean, 加权平均数Weighted mean square, 加权平均方差Weighted sum of square, 加权平方和Weighting coefficient, 权重系数Weighting method, 加权法W-estimation, W估计量W-estimation of location, 位置W估计量Width, 宽度Wilcoxon paired test, 威斯康星配对法/配对符号秩和检验Wild point, 野点/狂点Wild value, 野值/狂值Winsorized mean, 缩尾均值Withdraw, 失访Youden‘s index, 尤登指数Z test, Z检验Zero correlation, 零相关Z-transformation, Z变换。
统计学概论主要术语

第1章统计学研究什么?主要术语1. 统计学(statistics):收集、处理、分析、解释数据并从数据中得出结论的科学。
2. 描述统计(descriptive statistics):研究数据收集、处理和描述的统计学方法。
3. 推断统计(inferential statistics):研究如何利用样本数据来推断总体特征的统计学方法。
4. 变量(variable):每次观察都会得到不同结果的某种特征。
5. 分类变量(categorical variable):又称无序分类变量,观测结果表现为某种类别的变量。
6. 顺序变量(rank variable):又称有序分类变量,观测结果表现为某种有序类别的变量。
7. 数值变量(metric variable):又称定量变量,观测结果表现为数字的变量。
8. 分类数据(categorical data):只能归于某一类别的非数字型数据。
9. 顺序数据(rank data):只能归于某一有序类别的非数字型数据。
10. 数值型数据(metric data):按数字尺度测量的数据。
11. 总体(population):包含所研究的全部个体(数据)的集合。
12. 样本(sample):从总体中抽取的一部分元素的集合。
13. 样本量(sample size):构成样本的元素的数目。
14. 简单随机抽样(simple random sampling):从含有N个元素的总体中,抽取n个元素组成一个样本,使得总体中的每一个元素都有相同的机会(概率)被抽中。
15. 分层抽样(stratified sampling):也称分类抽样,在抽样之前先将总体的元素划分为若干层(类),然后从各个层中抽取一定数量的元素组成一个样本。
16. 系统抽样(systematic sampling):也称等距抽样,先将总体各元素按某种顺序排列,并按某种规则确定一个随机起点,然后每隔一定的间隔抽取一个元素,直至抽取n个元素组成一个样本。
统计学专业词汇

描述统计(descriptive statistics)是来描绘(describe)或总结(summarize)的观察量的基本情况的统计总称。
描述统计学研究如何取得反映客观现象的数据,并通过图表形式对所收集的数据进行加工处理和显示,进而通过综合概括与分析得出反映客观现象的规律性数量特征。
推论统计学是指在统计学中,研究如何根据样本数据去推断总体数量特征的方法。
它是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出以概率形式表述的推断。
更概括地说,是在一段有限的时间内,通过对一个随机过程的观察来进行推断的。
调查对象与调查单位的关系是什么调查对象是要研究的总体范围 即调查总体。
调查单位是所要研究的总体单位 及所要等记标志的承担者。
调查单位与填报单位有何区别与联系。
试举例说明。
调查单位是所要研究的总体单位 是调查项目的承担者填报单位是负责上报调查资料的单位。
Eg调查全国人口时,全国人口是调查单位,每个省是填报单位。
3.简述统计指标与统计标志的区别与联系。
答:统计指标和统计标志是一对既有明显区别又有密切联系的概念。
两者的主要区别是:指标是说明总体特征的,标志是说明总体单位特征的;指标具有可量性,无论是数量指标还是质量指标,都能用数值表示,而标志不一定。
数量标志具有可量性,品质标志不具有可量性。
、1 简述标志与标志表现的区别?答:标志是总体中各单位所共同具有的某特征或属性,即标志是说明总体单位属性和特征的名称。
标志表现是标志特征在各单位的具体表现,是标志的实际体现者。
标志是所要调查的项目,标志表现是调查所得到的结果。
例如:学生的“成绩”是标志,而成绩为“90”分则是标志表现。
3 、什么是标志和指标?两者有何区别?指标是用来说明综合数量特征的(指标名称+指标数值) 区别:标志是说明总体单位特征的,指标是说明总体特征的。
指标志是用来说明总体单位特征的名称(品质标志、数量标志)标都能用数值表示,而标志中品质标志只能用属性表示。
描述性统计分析--Descriptive-Statistics

描述性统计分析--Descriptive-Statistics菜单详解第六章:描述性统计分析--Descriptive Statistics菜单详解描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。
SPSS的许多模块均可完成描述性分析,但专门为该目的而设计的几个模块则集中在Descriptive Statistics菜单中,最常用的是列在最前面的四个过程:Frequencies过程的特色是产生频数表;Descriptives过程则进行一般性的统计描述;Explore过程用于对数据概况不清时的探索性分析;Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的X2检验也在其中完成。
本章讲述的四个过程在9.0及以前版本中被放置在Summarize菜单中。
§6.1 Frequencies过程频数分布表是描述性统计中最常用的方法之一,Frequencies过程就是专门为产生频数表而设计的。
它不仅可以产生详细的频数表,还可以按要求给出某百分位点的数值,以及常用的条图,圆图等统计图。
和国内常用的频数表不同,几乎所有统计软件给出的均是详细频数表,即并不按某种要求确定组段数和组距,而是按照数值精确列表。
如果想用Frequencies过程得到我们所熟悉的频数表,请先用第二章学过的Recode过程产生一个新变量来代表所需的各组段。
6.1.1 界面说明Frequencies对话框的界面如下所示:该界面在SPSS中实在太普通了,无须多言,重点介绍一下各部分的功能如下:【Display frequency tables复选框】确定是否在结果中输出频数表。
【Statistics钮】单击后弹出Statistics对话框如下,用于定义需要计算的其他描述统计量。
现将各部分解释如下:o Percentile Values复选框组定义需要输出的百分位数,可计算四分位数(Quartiles)、每隔指定百分位输出当前百分位数(Cut pointsfor equal groups)、或直接指定某个百分位数(Percentiles),如直接指定输出P2.5和P97.5。
Descriptive_statistics

for one variable
描述性统计
统计方法的类型
Descriptive Statistics 通过数值和图的方式,清 楚明了地对样本数据进行 总结描述
Inferential Statistics
对数据来自的总体分布进行 推断
描述什么?
数据的“位置”或者“中心” (“measures of location”)
但是对极值点敏感
许多统计方法是基于平均值的
样本分位数
常见1/4, 3/4分位数 对极值点不敏感
Index of central tendency
Source: /psych/stat/5/skewnone.gif
例:开车最快速度调查数据
Sex N Mean Median TrMean StDev SE Mean female 126 91.23 90.00 90.83 11.32 1.01 male 100 96.79 110.00 105.62 17.39 1.74
This is the famous “Bell curve” where many cases fall near the middle of the distribution and few fall very high or very low I.Q.
Statistical properties of the normal distribution
标准偏差(SD)
A summary statistic of how much scores vary from the mean Square root of the Variance
使用SPSS求置信区间
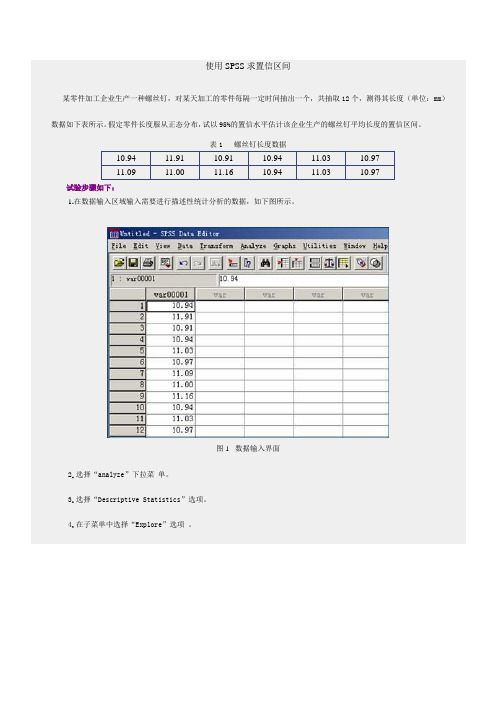
11.09
11.00
11.16
10.94
11.03
10.97
试验步骤如下:
1.在数据输入区域输入需要进行描述性统计分析的数据,如下图所示。
图1数据输入界面
2.选择“analyze”下拉菜单。
3.选择“Descriptive Statistics”选项。
4.在子菜单中选择“Explore”选项。
图2选择分析工具
5.在左侧选择需要进行区间估计的Var00001参数进入右侧的“Dependent List”。
图3选择变量进入右侧的分析列表
6.在“Statistics”选项中设定置信水平为95%。
图4进行分析参数设置
SPSS输出的结果及结果说明:
图5输出结果
表2输出结果及结果说明列表
Statistic
峰度
所以我们有95%把握认为该企业生产的螺丝钉的平均长度在10.9009mm~11.2475mm之间。
Std. Error
结果说明
Mean
11.0742
7.873E-02
均值、标准差
95% Confidence Interval for Mean
Lower Bound
10.9009
置信区间下限
Upper Bound
11.2475
置信区间上限
5%Trimmed Mean
11.0369
5%截尾均值
Median
使用SPSS求置信区间
某零件加工企业生产一种螺丝钉,对某天加工的零件每隔一定时间抽出一个,共抽取12个,测得其长度(单位:mm)数据如下表所示。假定零件长度服从正态分布,试以95%的置信水平估计该企业生产的螺丝钉平均长度的置信区间。
统计学基础知识(一)---描述统计(DescriptiveStatistics)

统计学基础知识(⼀)---描述统计(DescriptiveStatistics)描述统计(Descriptive Statistics):将数据的信息以表格,图形或数值的形式进⾏汇总。
数据类型:分为定量数据(数值型数据)和定性数据(类别型数据)。
数值型数据⼜可以分为连续型和离散型,类别型数据⼜可以分为有序型和⽆序型。
定性数据:频数(frequency):数据出现的次数。
相对频数(relative frequency):数据出现的次数/总次数。
百分数(percentage):数据出现的次数/总次数*100%。
定量数据:平均数(mean):总数值除以总数。
总体均值---µ;样本均值---。
注:这⾥说的平均数是算术平均数,其他还有加权平均数(weighted mean),⼏何平均数(geometric mean)和调和平均数。
中位数(median):将所有数据按升序排列,当数据个数是奇数时,中位数就是位于中间的数值,当数据个数是偶数时,中位数就是位于中间的两个数值的平均值。
众数(mode):出现次数最多的数据。
四分位数(quartile):将所有数据按升序排列,然后等分为四部分,处在25%位置上的数值称为下四分位数Q1,处在50%位置上的数值称为Q2,处在75%位置上的数值称为上四分位数Q3。
极差(range):最⼤值-最⼩值。
四分位间距(interquartile range, IQR):第三分位数(Q3)-第⼀分位数(Q1)。
⽅差(variance):⽤于度量数据间的变异程度。
总体⽅差---;样本⽅差---。
标准差(standard deviation):⽅差的平⽅根。
总体标准差---σ;样本标准差---s。
标准值(z-score):某个数值离开平均数有多少个标准差的距离。
注:定量数据可以⽤分箱的⽅式转换为定性变量,以此可以再⽤频数,百分数表⽰。
DescriptiveStatisticsExamples,TypesandDefinition

DescriptiveStatisticsExamples,TypesandDefinitionWhen it comes to descriptive statistics examples, problems and solutions, we can give numerous of them to explain and support the general definition and types.Let’s first clarify the main purpose of descriptive data analysis. It’s to help you get a feel for the data, to tell us what happened in the past and to highlight potential relationships between variables.On this page you will learn:•What is descriptive data analysis?•The different types of descriptive statistics: explained.•8 examples of descriptive statisticsIn the world of statistical data, there are two classifications: descriptive and inferential statistics.In a nutshell, descriptive statistics just describes and summarizes data but do not allow us to draw conclusions about the whole population from which we took the sample.You are simply summarizing the data with charts, tables, and graphs.Conversely, with inferential statistics, you are using statistics to test a hypothesis, draw conclusions and make predictions about a whole population, based on your sample.Let’s see the first of our descriptive statistics examples.Example 1:Descriptive statistics about a college involve the average math test score for incoming students. It says nothing about why the data is so or what trends we can see and follow.Descriptive statistics help you to simplify large amounts of data in a meaningful way. It reduces lots of data into a summary.Example 2:You’ve performed a survey to 40 respondents about their favorite car color. And now you have a spreadsheet with the results.However, this spreadsheet is not very informative and you want to summarize the data with some graphs and charts that can allow you to come up with some simple conclusions (e.g. 24% of people said that white is their favorite color).For sure, this would be much more representative and clear than an ugly spreadsheet. And you have a plenty of options to visualize data such as pie charts, line charts, etc.That’s the core of descriptive statistics. Note that you are not drawing any conclusions about the full population.The 2 Main Types of Descriptive Statistics (with Examples) Descriptive statistics has 2 main types:•Measures of Central Tendency (Mean, Median, and Mode).•Measures of Dispersion or Variation (Variance, Standard Deviation, Range).1. Central TendencyCentral tendency (also called measures of location or central location) is a method to des cribe what’s typical for a group (set) of data.It means central tendency doesn’t show us what is typical about each one piece of data, but it gives us an overview of thewhole picture of the entire data set.It tells us what is normal or average for a given set of data. There are three key methods to show central tendency: mean, mode, and median.•MeanAs the name suggests, mean is the average of a given set of numbers. The mean is calculated in two very easy steps:1. Find the whole sum as add the data together2. Divide the sum by the total number of dataThe below is one of the most common descriptive statistics examples.Example 3:Let’s say you have a sample of 5 girls and 6 boys.[su_note note_color=”#d8ebd6″]The girls’ heights in inches are: 62, 70, 60, 63, 66.[/su_note]To calculate the mean height for the group of girls you need to add the data together:62 + 70 + 60 + 63 + 65 = 320.Now, you take the sum (320) and divide it by the total number of girls (5): 320 / 5 = 64.So, our mean is 64.The best advantage of the mean is that it can be used to find both continuous and discrete numerical data (see our post about continuous vs discrete data).Of course, the mean has limitations. Data must be numerical in order to calculate the mean. You cannot work with the mean when you have nominal data (see our post about nominal vs ordinal data).•ModeThe mode of a set of data is the number in the set that occurs most often.Let’s see the next of our descriptive statistics examples, problems and solutions.Example 4:Consider you have a dataset with the retirement age of 10 people, in whole years:55, 55, 55, 56, 56, 57, 58, 58, 59, 60To illustrate this let’s see table below that shows the frequency of the retirement age data.As you see, the most common value is 55. That is why the mode of this data set is 55 years.The mode has one very important advantage over the median and the mean. It can be calculated for both numerical and categorical data (see our post about categorical data examples).Limitations of the mode: In some data sets, the mode may not reflect the centre of the set. In the above example, if we order the retirement age from lowest to the highest, would see that the centre of the data set is 57 years, but the mode is lower, at 53 years.•MedianSimply said, the median is the middle value in a data set. Asyou might guess, in order to calculate the middle, you need: – first listing the data in a numerical order– second, locating the value in the middle of the list.Example 5:The middle number in the below set is 26 as there are 4 numbers above it and 4 numbers below:21, 22, 24, 24, 26, 27, 28, 29, 31.But this was an odd set of data – you have 9 numbers. How to find the middle if you have an even set of data?Easily – you just need to find the average of the two middle numbers.For example, in the below dataset of 10 numbers, the average of the numbers is 26.5 (26 + 27) / 2.21, 22, 24, 24, 26, 27, 28, 29, 31, 32As an advantage of the median, we can say that it is less reflected by outliers and skewed data than the mean. We usually prefer the median when the data set is not symmetrical.And to point the limitation, we should say that as the median cannot be ordered in a logical way, it cannot be calculated for nominal data.Having trouble remembering the difference between the mode, mean, and median? Here are some hints:•The word MOde is very like MOst (the most frequent number)•“Mean” re quires you do some arithmetic (adding all the numbers together and dividing).•“Median” practically means “Middle” and has the same number of letters.Having trouble deciding which measure to use when you have nominal, ordinal or interval data? The above table can help.2. DispersionCentral tendency tells us important information but it doesn’t show everything we want to know about average values. Central tendency fails to reveal the extent to which the values of the individual items differ in a data set.Measures of dispersion do a lot more – they complement the averages and allow us to interpret them much better.Dispersion in statistics describes the spread of the data values in a given dataset. In other words, it shows how the data is “dispersed” a round the mean (the central value).Example 6:Imagine you have to compare the performance of 2 group of students on the final math exam. You find that the average math test results are identical for both groups.Is that mean the students in the two groups are performing equally? NO! Let’s see why.Group of students A: 56, 58, 60, 62, 64Group of students B: 40, 50, 60, 70, 80Both of these groups have mean scores of 60.However, in group A the individual scores are concentrated around the center –60. All students in A have a very similar performance. There is consistency.On the other hand, in group B the mean is also 60 but the individual scores are not even close to the center. One score is quite small – 40 and one score is very large – 80.We can conclude that there is greater dispersion in group B.Note:The study of dispersion has a key role in statistical data. If in a given country there are very poor people and very rich people, we say there is serious economic disparity. Dispersion also is very useful when we want to find the relation between the set of data.There are two popular measures of dispersion: standard deviation and range.Let’s see some more descriptive statistics examples and definitions for dispersion measures.•The RangeThe range is simply the difference between the largest and smallest value in a data set. It shows how much variation from the average exists.You might guess that low range tells us that the data points are very close to the mean. And a high range shows the opposite.Here is the formula for calculating the range:Range = max. value – min. valueLet’s see the next of our descriptive statistics examples.Example 7:If we use the math results from Example 6:Group of students A: 56, 58, 60, 62, 64Group of students B: 40, 50, 60, 70, 80we easily can calculate the range:Group A: 64 – 56 = 8Group B: 80 – 40 = 40You see that the data values in Group A are much closer to the mean than the ones in Group B.A serious disadvantage of the Range is that it only provides information about the minimum and maximum of the data set. Ittells nothing about the values in between.•The Standard DeviationStandard deviation also provides information on how much variation from the mean exists. However, the standard deviation goes further than Range and shows how each value in a dataset varies from the mean.As in the Range, a low standard deviation tells us that the data points are very close to the mean. And a high standard deviation shows the opposite.The standard deviation formula for a sample of a population is:Example 8:If we use the math results in Example 6:Group of students A: 56, 58, 60, 62, 64The mean is 60.Let’s find the standard deviation of the math exam scores by hand. We use simple values for the purposes of easy calculations.Now, let’s replace the values in the formula:The result above shows that, on average, every math exam score in The Group of students A is approximately 2.45 points away from the mean of 60.Of course, you can calculate the above values by calculator instead by hand.Note: The above formula is for a sample of a population. The standard deviation of an entire population is represented by the Greek lowercase letter sigma and looks like that:More examples of Standard Deviation, you can see in theExplorable site.Conclusion:The above 8 descriptive statistics examples, problems and solutions are simple but aim to make you understand the descriptive data better.As you saw, descriptive statistics are used just to describe some basic features of the data in a study.They provide simple summaries about the sample and enable us to present data in a meaningful way. It allows a simpler interpretation of the data.Together with some plain graphics analysis, they form a solid basis for almost every quantitative analysis of data.Descriptive statistics cannot, however, be used for making conclusions beyond the data we have analyzed or making conclusions regarding any hypotheses.Shop NowAds by AmazonPractical Statistics for Data Scientists: 50+ Essenti…$31.90$69.99(736)DEAL OF THE DAYENDS INHow to Summarize Data with Statistics$1.99(6)DEAL OF THE DAYENDS INThe Art of Statistics: How to Learn from Data $17.99$19.99(2908)DEAL OF THE DAYENDS INStatistics For Dummies (For Dummies (Lifestyle)) $11.99$19.99(1740)DEAL OF THE DAYENDS INEssential Math for Data Science: Take Control of … $43.49$59.99(57)DEAL OF THE DAYENDS INStatistics for People Who (Think They) Hate Statistics $57.16$85.00(758)DEAL OF THE DAYENDS INStatistics Laminate Reference Chart: Para…$6.95(2217)DEAL OF THE DAYENDS INHow to Lie with Statistics$8.89$13.95(2574)DEAL OF THE DAY ENDS INAds by Amazon。
《统计学》_各章关键术语(中英文对照)

《统计学》_各章关键术语(中英文对照)第二部分各章关键术语(中英文对照)第1章统计学(statistics)随机性(randomness)描述统计学(descriptive statistics)推断统计学(inferential statistics)总体(population)母体(parent)(parent population)样本、子样(sample)调查对象总体(respondents population)有限总体(finite population)调查的理论总体(survey’s heoretical population)超总体(super population)变量(variable)数据(data)原始数据(original data)派生数据(derived data)定类尺度(nominal scale)定类尺度变量(nominal scale level variable)定类尺度数据(nominal scale level data)定序尺度(ordinal scale)定序尺度变量(ordinal scale level variable)定序尺度数据(ordinal scale level data)定距尺度(interval scale)定距尺度变量(interval scale level variable)定距尺度数据(interval scale level data)定比尺度(ratio scale)定比尺度变量(ratio scale level variable)定比尺度数据(ratio scale level data)分类变量(categorical variable)定性变量、属性变量(qualitative variable)数值变量(numerical variable)定量变量、数量变量(quantitative variable)绝对数变量(absolute number level variable)绝对数数据(absolute number level data)比率变量(ratio level variable)比率数据(ratio level data)实验数据(experimental data)调查数据(survey data)观察数据(observed data)第2章随机性(randomness)随机现象(random phenomenon)随机试验(random experiment)事件(event)基本事件(elementary event)复合事件(union of event)必然事件(certain event)不可能事件(impossible event)基本事件空间(elementary event space)互不相容事件(mutually exclusive events)统计独立(statistical independent)统计相依(statistical dependence)概率(probability)古典方法概率(classical method probability)相对频数方法概率(relative frequency method probability)主观方法概率(subjective method probability)几何概率(geometric probability)条件概率(conditional probability)全概率公式(formula of total probability)贝叶斯公式(Bay es’ formula)先验概率(prior probability)后验概率(posterior probability)随机变量(random variable)离散型随机变量(discrete type random variable)连续型随机变量(continuous type random variable)概率分布(probability distribution)特征数(characteristic number)位置特征数(location characteristic number)数学期望(mathematical expectation)散布特征数(scatter characteristic number)方差(variance)标准差(standard deviation)变异系数(variable coefficient)贝努里分布(Bernoulli distribution)二点分布(two-point distribution) 0-1分布(zero-one distribution)贝努里试验(Bernoulli trials)二项分布(binomial distribution)超几何分布(hyper-geometric distribution)正态分布(normal distribution)正态概率密度函数(normal probability density function)正态概率密度曲线(normal probability density curve)正态随机变量(normal random variable)卡方分布(chi-square distribution)F_分布(F-distribution)t_分布(t-distribution)“学生”氏t_分布(Student’s t-distribution)列联表(contingency table)联合概率分布(joint probability distribution)边缘概率分布(marginal probability distribution)条件分布(conditional distribution)协方差(covariance)相关系数(correlation coefficient)第3章统计调查(statistical survey)数据收集(collection of data)统计单位(statistical unit)统计个体(statistical individual)社会经济总体(socioeconomic population)调查对象总体(respondents population)有限总体(finite population)标志(character)标志值(character value)属性标志(attributive character )品质标志(qualitative character )数量标志(numerical indication)不变标志(invariant indication)变异(variation)调查条目(item of survey)指标(indicator)统计指标(statistical indicator)总量指标(total amount indicator)绝对数(absolute number)统计单位总量(total amount of statistical unit )标志值总量(total amount of indication value)(total amount of character value)时期性总量指标(time period total amount indicator)流量指标(flow indicator)时点性总量指标(time point total amount indicator)存量指标(stock indicator)平均指标(average indicator)平均数(average number)相对指标(relative indicator)相对数(relative number)动态相对指标(dynamic relative indicator)发展速度(speed of development)增长速度(speed of growth)增长量(growth amount)百分点(percentage point)计划完成相对指标(relative indicator of fulfilling plan)比较相对指标(comparison relative indicator)结构相对指标(structural relative indicator)强度相对指标(intensity relative indicator)基期(base period)报告期(given period)分组(classification)(grouping)统计分组(statistical classification)(statistical grouping)组(class)(group)分组设计(class divisible design)(group divisible design)互斥性(mutually exclusive)包容性(hold)分组标志(classification character)(grouping character)按品质标志分组(classification by qualitative character)(grouping by qualitativecharacter)按数量标志分组(classification by numerical indication)(grouping by numericalindication)离散型分组标志(discrete classification character)(discrete grouping character)连续型分组标志(continuous classification character)(continuous grouping character)单项式分组设计(single-valued class divisible design)(single-valued group divisibledesign)组距式分组设计(class interval divisible design)(group interval divisible design)组界(class boundary)(group boundary)频数(frequency)(frequency number)频率(frequency)组距(class interval)(group interval)组限(class limit)(group limit)下限(lower limit)上限(upper limit)组中值(class mid-value)(group mid-value)开口组(open class)(open-end class)(open-end group)开口式分组(open-end grouping)等距式分组设计(equal class interval divisible design)(equal group interval divisibledesign)不等距分组设计(unequal class interval divisible design)(unequal group interval divisibledesign)调查方案(survey plan)抽样调查(sample survey)有限总体概率抽样(probability sampling in finite populations)抽样单位(sampling unit)个体抽样(elements sampling)等距抽样(systematic sampling)整群抽样(cluster sampling)放回抽样(sampling with replacement)不放回抽样(sampling without replacement)分层抽样(stratified sampling)概率样本(probability sample)样本统计量(sample statistic)估计量(estimator)估计值(estimate)无偏估计量(unbiased estimator)有偏估计量(biased estimator)偏差(bias)精度(degree of precision)估计量的方差(variance of estimates)标准误(standard error)准确度(degree of accuracy)均方误差(mean square error)估计(estimation)点估计(point estimation)区间估计(interval estimate)置信区间(confidence interval)置信下限(confidence lower limit)置信上限(confidence upper limit)置信概率(confidence probability)总体均值(population mean)总体总值(population total)总体比例(population proportion)总体比率(population ratio)简单随机抽样(simple random sampling)简单随机样本(simple random sample)研究域(domains of study)子总体(subpopulations)抽样框(frame)估计量的估计方差(estimated variance of estimates)第4章频数(frequency)(frequency number)频率(frequency)分布列(distribution series)经验分布(empirical distribution)理论分布(theoretical distribution)品质型数据分布列(qualitative data distribution series)数量型数据分布列(quantitative data distribution series)单项式数列(single-valued distribution series)组距式数列(class interval distribution series)频率密度(frequency density)分布棒图(bar graph of distribution)分布直方图(histogram of distribution)分布折线图(polygon of distribution)累积分布数列(cumulative distribution series)累积分布图(polygon of cumulative distribution)位置特征(location characteristic)位置特征数(location characteristic number)平均值、均值(mean)平均数(average number)权数(weight number)加权算术平均数(weighted arithmetic average)加权算术平均值(weighted arithmeticmean)简单算术平均数(simple arithmetic average)简单算术平均值(simple arithmetic mean)加权调和平均数(weighted harmonic average)加权调和平均值(weighted harmonicmean)简单调和平均数(simple harmonic average)简单调和平均值(simple harmonic mean)加权几何平均数(weighted geometric average)加权几何平均值(weighted geometricmean)简单几何平均数(simple geometric average)简单几何平均值(simple geometric mean)绝对数数据(absolute number data)比率类型数据(ratio level data)中位数(median)众数(mode)耐抗性(resistance)散布特征(scatter characteristic)散布特征数(scatter characteristic number)极差、全距(range)四分位差(quartile deviation)四分间距(inter-quartile range)上四分位数(upper quartile)下四分位数(lower quartile)在外截断点(outside cutoffs)平均差(mean deviation)方差(variance)标准差(standard deviation)变异系数(variable coefficient)第5章随机样本(random sample)简单随机样本(simple random sample)参数估计(parameter estimation)矩(moment)矩估计(moment estimation)修正样本方差(modified sample variance)极大似然估计(maximum likelihood estimate)参数空间(space of paramete)似然函数(likelihood function)似然方程(likelihood equation)点估计(point estimation)区间估计(interval estimation)假设检验(test of hypothesis)原假设(null hypothesis)备择假设(alternative hypothesis)检验统计量(statistic for test)观察到的显著水平(observed significance level)显著性检验(test of significance)显著水平标准(critical of significance level)临界值(critical value)拒绝域(rejection region)接受域(acceptance region)临界值检验规则(test regulation by critical value)双尾检验(two-tailed tests)显著水平(significance level)单尾检验(one-tailed tests)第一类错误(first-kind error)第一类错误概率(probability of first-kind error)第二类错误(second-kind error)第二类错误概率(probability of second-kind error)P_值(P_value)P_值检验规则(test regulation by P_value)经典统计学(classical statistics)贝叶斯统计学(Bayesian statistics)第6章方差分析(analysis of variance,ANOVA)方差分析恒等式(analysis of variance identity equation)单因子方差分析(one-factor analysis of variance)双因子方差分析(two-factor analysis of variance)总变差平方和(total variation sum of squares)总平方和SST (total sum of squares)组间变差平方和(among class(group) variation sum of squares),回归平方和SSR(regression sum of squares)组内变差平方和(within variation sum of squares)误差平方和SSE(error sum ofsquares)皮尔逊χ2统计量(Pearson’s chi-statistic)分布拟合(fitting of distrbution)分布拟合检验(test of fitting of distrbution)皮尔逊χ2检验(Pearson’s chi-square test)列联表(contingency table)独立性检验(test of independence)数量变量(quantitative variable)属性变量(qualitative variable)对数线性模型(loglinear model)回归分析(regression analysis)随机项(random term)随机扰动项(random disturbance term)回归系数(regression coefficient)总体一元线性回归模型(population linear regression model with a single regressor)总体多元线性回归模型(population multiple regression model with a single regressor)完全多重共线性(perfect multicollinearity)遗漏变量(omitted variable)遗漏变量偏差(omitted variable bias)面板数据(panel data)面板数据回归(panel data regressions)工具变量(instrumental variable)工具变量回归(instrumental variable regressions)两阶段最小平方估计量(two stage least squares estimator)随机化实验(randomized experiment)准实验(quasi-experiment)自然实验(natural experiment)普通最小平方准则(ordinary least squares criterion)最小平方准则(least squares criterion)普通最小平方(ordinary least squares,OLS)最小平方(least squares)最小平方法(least squares method)第7章简单总体(simple population)复合总体(combined population)个体指数:价比(price relative),量比(quantity relative)总指数(general index)(combined index)统计指数(statistical indices)类指数、组指数(class index)动态指数(dynamic index)比较指数(comparison index)计划完成指数(index of fulfilling plan)数量指标指数(quantitative indicator index)物量指数(quantitative index)(quantity index)(quantum index)质量指标指数(qualitative indicator index)价格指数、物价指数(price index)综合指数(aggregative index)(composite index)拉斯贝尔指数(Laspeyres’ index)派许指数(Paasche’s index)阿斯·杨指数(Arthur Young’s index)马歇尔—埃奇沃斯指数(Marshall-Edgeworth’s index)理想指数(ideal index)加权综合指数(weighted aggregate index)平均指数(average index)加权算术平均指数(weighted arithmetic average index)加权调和平均指数(weighted harmonic average index)因子互换(factor-reversal)购买力平价(purchasing power parity,PPP)环比指数(chain index)定基指数(fixed base index)连环替代因素分析法(factor analysis by chain substitution method)不变结构指数、固定构成指数(index of invariable construction)结构指数、结构影响指数(structural index)第8章截面数据(cross-section data)时序数据(time series data)动态数据(dynamic data)时间数列(time series)发展水平(level of development)基期水平(level of base period)报告期水平(level of given period)平均发展水平(average level of development)序时平均数(chronological average)增长量(growth quantity)平均增长量(average growth amount)发展速度(speed of development)增长速度(speed of growth)增长率(growth rate)环比发展速度(chained speed of development)定基发展速度(fixed base speed of development)环比增长速度(chained growth speed)定基增长速度(fixed base growth speed)平均发展速度(average speed of development)平均增长速度(average speed of growth)平均增长率(average growth rate)算术图(arithmetic chart)半对数图(semilog graph)时间数列散点图(scatter diagram of time series)时间数列折线图(broken line graph of time series)水平型时间数列(horizontal patterns in time series data)趋势型时间数列(trend patterns in time series data)季节型时间数列(season patterns in time series data)趋势—季节型时间数列(trend-season patterns in time series data)一次指数平滑平均数(simple exponential smoothing mean)一次指数平滑法(simple exponential smoothing method)最小平方法(leas square method)最小平方准则(least squares criterion)原资料平均法(average of original data method)季节模型(seasonal model)(seasonal pattern)长期趋势(secular trends)季节变动(变差)(seasonal variation)季节波动(seasonal fluctuations)不规则变动(变差)(erratic variation)不规则波动(random fluctuations)时间数列加法模型(additive model of time series)时间数列乘法模型(multiplicative model of time series)。
第2章Descriptive Statistics描述统计学表格和图形法-B

• one variable is categorical and the other is quantitative,
一个变量是分类的,另一份是数量的,
• both variables are categorical, or 都是分类变量,
• both variables are quantitative. 或都是数量变量。
Summarizing Data for Two Variables using Tables
▪ Thus far we have focused on methods that are used to summarize the data for one variable at a time.
之前我们关注怎么汇总一个变量的数据。
1
otherwise on a password-protected website or school-approved learning management system for classroom use.
Essentials of Modern Business Statistics (7e)
▪ Often a manager is interested in tabular and graphical methods that will help understand the relationship between two variables.
管理人员往往需要汇总两个变量的数据来揭示变量之间的关系。
2
otherwise on a password-protected website or school-approved learning management system for classroom use.
统计学的术语和简介

统计学的术语和简介 统计学是通过搜索、整理、分析、描述数据等⼿段,以达到推断所测对象的本质,甚⾄预测对象未来的⼀门综合性科学。
以下是由店铺整理关于什么是统计学的内容,希望⼤家喜欢! 统计学的起源 统计学的英⽂statistics最早源于现代拉丁⽂statisticum collegium(国会)、意⼤利⽂statista(国民或政治家)以及德⽂Statistik,最早是由Gottfried Achenwall于1749年使⽤,代表对国家的资料进⾏分析的学问,也就是“研究国家的科学”。
⼗九世纪,统计学在⼴泛的数据以及资料中探究其意义,并且由John Sinclair引进到英语世界。
统计学是⼀门很古⽼的科学,⼀般认为其学理研究始于古希腊的亚⾥斯多德时代,迄今已有两千三百多年的历史。
它起源于研究社会经济问题,在两千多年的发展过程中,统计学⾄少经历了“城邦政情”、“政治算数”和“统计分析科学”三个发展阶段。
所谓“数理统计”并⾮独⽴于统计学的新学科,确切地说,它是统计学在第三个发展阶段所形成的所有收集和分析数据的新⽅法的⼀个综合性名词。
概率论是数理统计⽅法的理论基础,但是它不属于统计学的范畴,⽽是属于数学的范畴。
统计学的主要术语 统计学(statistics):收集、处理、分析、解释数据并从数据中得出结论的科学。
描述统计(descriptive statistics):研究数据收集、处理和描述的统计学⽅法。
推断统计(inferential statistics):研究如何利⽤样本数据来推断总体特征的统计学⽅法。
变量(variable):每次观察会得到不同结果的某种特征。
分类变量(categorical variable):观测结果表现为某种类别的变量。
顺序变量(rank variable):⼜称有序分类变量,观测结果表现为某种有序类别的变量。
数值型变量(metric variable):⼜称定量变量,观测结果表现为数字的变量。
第二章统计描述DescriptiveStatistics20页PPT

率与构成比
率
构成比
概念 发生的频率或 各组成部分所占
强度
的比重
强调点 随机发生事件 各部分的构成
资料获得
较难
容易
特点
不一定
合计为100%
第四军医大学卫生统计学教研室 пятниц
率与构成比的例子
年龄 组 ⑴ 40~ 50~ 60~ 70~
受检 人数 ⑵
560 441 296 149
白内障 患者年龄构患病率(%)
第四军医大学卫生统计学教研室 пятниц
按年龄(2岁一组)与职业整理
年龄 工人 管理人员 农民 商业服务 无 知识分子 总计
18
2
0
0
0
3
0
5
20
9
2
6
10
18
0
45
22 28
7
10
24
70
11
150
24 50
34
28
52
153
44
361
26 50
43
25
45
133
70
366
28 34
35
10
34
第四军医大学卫生统计学教研室 пятниц
定义: 将统计分析的事物及指标
用表格列出。 特点: 1.避免长篇文字叙述,便于 阅读和对比分析。 2.数据具体。
定义: 用点的位置, 线段
的升降,直条的长短或 面积的大小等 形式表达 统计资料。
特点: 直观、醒目,常给人
以深刻印象。
第四军医大学卫生统计学教研室 пятниц
第四军医大学卫生统计学教研室 пятниц
统计表的结构
SPSS术语中英文对照

【常用软件】SPSS术语中英文对照SPSS的统计分析过程均包含在Analysis菜单中。
我们只学以下两大分析过程:DescriptiveStatistics(描述性统计)和MultipleResponse(多选项分析)。
? DescriptiveStatistics(描述性统计)包含的分析功能:1.?Frequencies过程:主要用于统计指定变量各变量值的频次(Frequency)、百分比(Percent)。
2.?Descriptives过程:主要用于计算指定变量的均值(Mean)、标准差(Std.Deviation)。
3.?Crosstabs过程:主要用于两个或两个以上变量的交叉分类。
?MultipleResponse(多选项分析)的分析功能:1.DefineSet过程:该过程定义一个由多选项组成的多响应变量。
2.Frequencies过程:该过程对定义的多响应变量提供一个频数表。
3.Crosstabs过程:该过程提供所定义的多响应变量与其他变量的交叉分类表。
Absolutedeviation,绝对离差Absolutenumber,绝对数Absoluteresiduals,绝对残差Accelerationarray,加速度立体阵Accelerationinanarbitrarydirection,任意方向上的加速度Accelerationnormal,法向加速度Accelerationspacedimension,加速度空间的维数Accelerationtangential,切向加速度Accelerationvector,加速度向量Acceptablehypothesis,可接受假设Accumulation,累积Accuracy,准确度Actualfrequency,实际频数Adaptiveestimator,自适应估计量Addition,相加Additiontheorem,加法定理Additivity,可加性Adjustedrate,调整率Adjustedvalue,校正值Admissibleerror,容许误差Aggregation,聚集性Alternativehypothesis,备择假设Amonggroups,组间Amounts,总量Analysisofcorrelation,相关分析Analysisofcovariance,协方差分析Analysisofregression,回归分析Analysisoftimeseries,时间序列分析Analysisofvariance,方差分析Angulartransformation,角转换ANOVA(analysisofvariance),方差分析ANOVAModels,方差分析模型Arcing,弧/弧旋Arcsinetransformation,反正弦变换Areaunderthecurve,曲线面积AREG,评估从一个时间点到下一个时间点回归相关时的误差ARIMA,季节和非季节性单变量模型的极大似然估计Arithmeticgridpaper,算术格纸Arithmeticmean,算术平均数Arrheniusrelation,艾恩尼斯关系Assessingfit,拟合的评估Associativelaws,结合律Asymmetricdistribution,非对称分布Asymptoticbias,渐近偏倚Asymptoticefficiency,渐近效率Asymptoticvariance,渐近方差Attributablerisk,归因危险度Attributedata,属性资料Attribution,属性Autocorrelation,自相关Autocorrelationofresiduals,残差的自相关Average,平均数Averageconfidenceintervallength,平均置信区间长度Averagegrowthrate,平均增长率Barchart,条形图Bargraph,条形图Baseperiod,基期Bayes‘theorem,Bayes定理Bell-shapedcurve,钟形曲线Bernoullidistribution,伯努力分布Best-trimestimator,最好切尾估计量Bias,偏性Binarylogisticregression,二元逻辑斯蒂回归Binomialdistribution,二项分布Bisquare,双平方BivariateCorrelate,二变量相关Bivariatenormaldistribution,双变量正态分布Bivariatenormalpopulation,双变量正态总体Biweightinterval,双权区间BiweightM-estimator,双权M估计量Block,区组/配伍组BMDP(Biomedicalcomputerprograms),BMDP统计软件包Boxplots,箱线图/箱尾图Breakdownbound,崩溃界/崩溃点Canonicalcorrelation,典型相关Caption,纵标目Case-controlstudy,病例对照研究Categoricalvariable,分类变量Catenary,悬链线Cauchydistribution,柯西分布Cause-and-effectrelationship,因果关系Cell,单元Censoring,终检Centerofsymmetry,对称中心Centeringandscaling,中心化和定标Centraltendency,集中趋势Centralvalue,中心值CHAID-χ2AutomaticInteractionDetector,卡方自动交互检测Chance,机遇Chanceerror,随机误差Chancevariable,随机变量Characteristicequation,特征方程Characteristicroot,特征根Characteristicvector,特征向量Chebshevcriterionoffit,拟合的切比雪夫准则Chernofffaces,切尔诺夫脸谱图Chi-squaretest,卡方检验/χ2检验Choleskeydecomposition,乔洛斯基分解Circlechart,圆图Classinterval,组距Classmid-value,组中值Classupperlimit,组上限Classifiedvariable,分类变量Clusteranalysis,聚类分析Clustersampling,整群抽样Code,代码Codeddata,编码数据Coding,编码Coefficientofcontingency,列联系数Coefficientofdetermination,决定系数Coefficientofmultiplecorrelation,多重相关系数Coefficientofpartialcorrelation,偏相关系数Coefficientofproduction-momentcorrelation,积差相关系数Coefficientofrankcorrelation,等级相关系数Coefficientofregression,回归系数Coefficientofskewness,偏度系数Coefficientofvariation,变异系数Cohortstudy,队列研究Column,列Columneffect,列效应Columnfactor,列因素Combinationpool,合并Combinativetable,组合表Commonfactor,共性因子Commonregressioncoefficient,公共回归系数Commonvalue,共同值Commonvariance,公共方差Commonvariation,公共变异Communalityvariance,共性方差Comparability,可比性Comparisonofbathes,批比较Comparisonvalue,比较值Compartmentmodel,分部模型Compassion,伸缩Complementofanevent,补事件Completeassociation,完全正相关Completedissociation,完全不相关Completestatistics,完备统计量Completelyrandomizeddesign,完全随机化设计Compositeevent,联合事件Compositeevents,复合事件Concavity,凹性Conditionalexpectation,条件期望Conditionallikelihood,条件似然Conditionalprobability,条件概率Conditionallylinear,依条件线性Confidenceinterval,置信区间Confidencelimit,置信限Confidencelowerlimit,置信下限Confidenceupperlimit,置信上限ConfirmatoryFactorAnalysis,验证性因子分析Confirmatoryresearch,证实性实验研究Confoundingfactor,混杂因素Conjoint,联合分析Consistency,相合性Consistencycheck,一致性检验Consistentasymptoticallynormalestimate,相合渐近正态估计Consistentestimate,相合估计Constrainednonlinearregression,受约束非线性回归Constraint,约束Contaminateddistribution,污染分布ContaminatedGausssian,污染高斯分布Contaminatednormaldistribution,污染正态分布Contamination,污染Contaminationmodel,污染模型Contingencytable,列联表Contour,边界线Contributionrate,贡献率Control,对照Controlledexperiments,对照实验Conventionaldepth,常规深度Convolution,卷积Correctedfactor,校正因子Correctedmean,校正均值Correctioncoefficient,校正系数Correctness,正确性Correlationcoefficient,相关系数Correlationindex,相关指数Correspondence,对应Counting,计数Counts,计数/频数Covariance,协方差Covariant,共变CoxRegression,Cox回归Criteriaforfitting,拟合准则Criteriaofleastsquares,最小二乘准则Criticalratio,临界比Criticalregion,拒绝域Criticalvalue,临界值Cross-overdesign,交叉设计Cross-sectionanalysis,横断面分析Cross-sectionsurvey,横断面调查Crosstabs,交叉表Cross-tabulationtable,复合表Cuberoot,立方根Cumulativedistributionfunction,分布函数Cumulativeprobability,累计概率Curvature,曲率/弯曲Curvature,曲率Curvefit,曲线拟和Curvefitting,曲线拟合Curvilinearregression,曲线回归Curvilinearrelation,曲线关系Cut-and-trymethod,尝试法Cycle,周期Cyclist,周期性Dtest,D检验Dataacquisition,资料收集Databank,数据库Datacapacity,数据容量Datadeficiencies,数据缺乏Datahandling,数据处理Datamanipulation,数据处理Dataprocessing,数据处理Datareduction,数据缩减Dataset,数据集Datasources,数据来源Datatransformation,数据变换Datavalidity,数据有效性Data-in,数据输入Data-out,数据输出Deadtime,停滞期Degreeoffreedom,自由度Degreeofprecision,精密度Degreeofreliability,可靠性程度Degression,递减Densityfunction,密度函数Densityofdatapoints,数据点的密度Dependentvariable,应变量/依变量/因变量Dependentvariable,因变量Depth,深度Derivativematrix,导数矩阵Derivative-freemethods,无导数方法Design,设计Determinacy,确定性Determinant,行列式Determinant,决定因素Deviation,离差Deviationfromaverage,离均差Diagnosticplot,诊断图Dichotomousvariable,二分变量Differentialequation,微分方程Directstandardization,直接标准化法Discretevariable,离散型变量DISCRIMINANT,判断Discriminantanalysis,判别分析Discriminantcoefficient,判别系数Discriminantfunction,判别值Dispersion,散布/分散度Disproportional,不成比例的Disproportionatesub-classnumbers,不成比例次级组含量Distributionfree,分布无关性/免分布Distributionshape,分布形状Distribution-freemethod,任意分布法Distributivelaws,分配律Disturbance,随机扰动项Doseresponsecurve,剂量反应曲线Doubleblindmethod,双盲法Doubleblindtrial,双盲试验Doubleexponentialdistribution,双指数分布Doublelogarithmic,双对数Downwardrank,降秩Dual-spaceplot,对偶空间图DUD,无导数方法Duncan‘snewmultiplerangemethod,新复极差法/Duncan新法Effect,实验效应Eigenvalue,特征值Eigenvector,特征向量Ellipse,椭圆Empiricaldistribution,经验分布Empiricalprobability,经验概率单位Enumerationdata,计数资料Equalsun-classnumber,相等次级组含量Equallylikely,等可能Equivariance,同变性Error,误差/错误Errorofestimate,估计误差ErrortypeI,第一类错误ErrortypeII,第二类错误Estimand,被估量Estimatederrormeansquares,估计误差均方Estimatederrorsumofsquares,估计误差平方和Euclideandistance,欧式距离Event,事件Event,事件Exceptionaldatapoint,异常数据点Expectationplane,期望平面Expectationsurface,期望曲面Expectedvalues,期望值Experiment,实验Experimentalsampling,试验抽样Experimentalunit,试验单位Explanatoryvariable,说明变量Exploratorydataanalysis,探索性数据分析ExploreSummarize,探索-摘要Exponentialcurve,指数曲线Exponentialgrowth,指数式增长EXSMOOTH,指数平滑方法Extendedfit,扩充拟合Extraparameter,附加参数Extrapolation,外推法Extremeobservation,末端观测值Extremes,极端值/极值Fdistribution,F分布Ftest,F检验Factor,因素/因子Factoranalysis,因子分析FactorAnalysis,因子分析Factorscore,因子得分Factorial,阶乘Factorialdesign,析因试验设计Falsenegative,假阴性Falsenegativeerror,假阴性错误Familyofdistributions,分布族Familyofestimators,估计量族Fanning,扇面Fatalityrate,病死率Fieldinvestigation,现场调查Fieldsurvey,现场调查Finitepopulation,有限总体Finite-sample,有限样本Firstderivative,一阶导数Firstprincipalcomponent,第一主成分Firstquartile,第一四分位数Fisherinformation,费雪信息量Fittedvalue,拟合值Fittingacurve,曲线拟合Fixedbase,定基Fluctuation,随机起伏Forecast,预测Fourfoldtable,四格表Fourth,四分点Fractionblow,左侧比率Fractionalerror,相对误差Frequency,频率Frequencypolygon,频数多边图Frontierpoint,界限点Functionrelationship,泛函关系Gammadistribution,伽玛分布Gaussincrement,高斯增量Gaussiandistribution,高斯分布/正态分布Gauss-Newtonincrement,高斯-牛顿增量Generalcensus,全面普查GENLOG(Generalizedlinermodels),广义线性模型Geometricmean,几何平均数Gini‘smeandifference,基尼均差GLM(Generallinermodels),一般线性模型Goodnessoffit,拟和优度/配合度Gradientofdeterminant,行列式的梯度Graeco-Latinsquare,希腊拉丁方Grandmean,总均值Grosserrors,重大错误Gross-errorsensitivity,大错敏感度Groupaverages,分组平均Groupeddata,分组资料Guessedmean,假定平均数Half-life,半衰期HampelM-estimators,汉佩尔M估计量Happenstance,偶然事件Harmonicmean,调和均数Hazardfunction,风险均数Hazardrate,风险率Heading,标目Heavy-taileddistribution,重尾分布Hessianarray,海森立体阵Heterogeneity,不同质Heterogeneityofvariance,方差不齐Hierarchicalclassification,组内分组Hierarchicalclusteringmethod,系统聚类法High-leveragepoint,高杠杆率点HILOGLINEAR,多维列联表的层次对数线性模型Hinge,折叶点Histogram,直方图Historicalcohortstudy,历史性队列研究Holes,空洞HOMALS,多重响应分析Homogeneityofvariance,方差齐性Homogeneitytest,齐性检验HuberM-estimators,休伯M估计量Hyperbola,双曲线Hypothesistesting,假设检验Hypotheticaluniverse,假设总体Impossibleevent,不可能事件Independence,独立性Independentvariable,自变量Index,指标/指数Indirectstandardization,间接标准化法Individual,个体Inferenceband,推断带Infinitepopulation,无限总体Infinitelygreat,无穷大Infinitelysmall,无穷小Influencecurve,影响曲线Informationcapacity,信息容量Initialcondition,初始条件Initialestimate,初始估计值Initiallevel,最初水平Interaction,交互作用Interactionterms,交互作用项Intercept,截距Interpolation,内插法Interquartilerange,四分位距Intervalestimation,区间估计Intervalsofequalprobability,等概率区间Intrinsiccurvature,固有曲率Invariance,不变性Inversematrix,逆矩阵Inverseprobability,逆概率Inversesinetransformation,反正弦变换Iteration,迭代Jacobiandeterminant,雅可比行列式Jointdistributionfunction,分布函数Jointprobability,联合概率Jointprobabilitydistribution,联合概率分布Kmeansmethod,逐步聚类法Kaplan-Meier,评估事件的时间长度Kaplan-Merierchart,Kaplan-Merier图Kendall‘srankcorrelation,Kendall等级相关Kinetic,动力学Kolmogorov-Smirnovetest,柯尔莫哥洛夫-斯米尔诺夫检验KruskalandWallistest,Kruskal及Wallis检验/多样本的秩和检验/H检验Kurtosis,峰度Lackoffit,失拟Ladderofpowers,幂阶梯Lag,滞后Largesample,大样本Largesampletest,大样本检验Latinsquare,拉丁方Latinsquaredesign,拉丁方设计Leakage,泄漏Leastfavorableconfiguration,最不利构形Leastfavorabledistribution,最不利分布Leastsignificantdifference,最小显着差法Leastsquaremethod,最小二乘法Least-absolute-residualsestimates,最小绝对残差估计Least-absolute-residualsfit,最小绝对残差拟合Least-absolute-residualsline,最小绝对残差线Legend,图例L-estimator,L估计量L-estimatoroflocation,位置L估计量L-estimatorofscale,尺度L估计量Level,水平Lifeexpectance,预期期望寿命Lifetable,寿命表Lifetablemethod,生命表法Light-taileddistribution,轻尾分布Likelihoodfunction,似然函数Likelihoodratio,似然比linegraph,线图Linearcorrelation,直线相关Linearequation,线性方程Linearprogramming,线性规划Linearregression,直线回归LinearRegression,线性回归Lineartrend,线性趋势Loading,载荷Locationandscaleequivariance,位置尺度同变性Locationequivariance,位置同变性Locationinvariance,位置不变性Locationscalefamily,位置尺度族Logranktest,时序检验Logarithmiccurve,对数曲线Logarithmicnormaldistribution,对数正态分布Logarithmicscale,对数尺度Logarithmictransformation,对数变换Logiccheck,逻辑检查Logisticdistribution,逻辑斯特分布Logittransformation,Logit转换LOGLINEAR,多维列联表通用模型Lognormaldistribution,对数正态分布Lostfunction,损失函数Lowcorrelation,低度相关Lowerlimit,下限Lowest-attainedvariance,最小可达方差LSD,最小显着差法的简称Lurkingvariable,潜在变量Maineffect,主效应Majorheading,主辞标目Marginaldensityfunction,边缘密度函数Marginalprobability,边缘概率Marginalprobabilitydistribution,边缘概率分布Matcheddata,配对资料Matcheddistribution,匹配过分布Matchingofdistribution,分布的匹配Matchingoftransformation,变换的匹配Mathematicalexpectation,数学期望Mathematicalmodel,数学模型MaximumL-estimator,极大极小L估计量Maximumlikelihoodmethod,最大似然法Mean,均数Meansquaresbetweengroups,组间均方Meansquareswithingroup,组内均方Means(Comparemeans),均值-均值比较Median,中位数Medianeffectivedose,半数效量Medianlethaldose,半数致死量Medianpolish,中位数平滑Mediantest,中位数检验Minimalsufficientstatistic,最小充分统计量Minimumdistanceestimation,最小距离估计Minimumeffectivedose,最小有效量Minimumlethaldose,最小致死量Minimumvarianceestimator,最小方差估计量MINITAB,统计软件包Minorheading,宾词标目Missingdata,缺失值Modelspecification,模型的确定ModelingStatistics,模型统计Modelsforoutliers,离群值模型Modifyingthemodel,模型的修正Modulusofcontinuity,连续性模Morbidity,发病率Mostfavorableconfiguration,最有利构形MultidimensionalScaling(ASCAL),多维尺度/多维标度MultinomialLogisticRegression,多项逻辑斯蒂回归Multiplecomparison,多重比较Multiplecorrelation,复相关Multiplecovariance,多元协方差Multiplelinearregression,多元线性回归Multipleresponse,多重选项Multiplesolutions,多解Multiplicationtheorem,乘法定理Multiresponse,多元响应Multi-stagesampling,多阶段抽样MultivariateTdistribution,多元T分布Mutualexclusive,互不相容Mutualindependence,互相独立Naturalboundary,自然边界Naturaldead,自然死亡Naturalzero,自然零Negativecorrelation,负相关Negativelinearcorrelation,负线性相关Negativelyskewed,负偏Newman-Keulsmethod,q检验NKmethod,q检验Nostatisticalsignificance,无统计意义Nominalvariable,名义变量Nonconstancyofvariability,变异的非定常性Nonlinearregression,非线性相关Nonparametricstatistics,非参数统计Nonparametrictest,非参数检验Nonparametrictests,非参数检验Normaldeviate,正态离差Normaldistribution,正态分布Normalequation,正规方程组Normalranges,正常范围Normalvalue,正常值Nuisanceparameter,多余参数/讨厌参数Nullhypothesis,无效假设Numericalvariable,数值变量Objectivefunction,目标函数Observationunit,观察单位Observedvalue,观察值Onesidedtest,单侧检验One-wayanalysisofvariance,单因素方差分析OnewayANOVA,单因素方差分析Opensequentialtrial,开放型序贯设计Optrim,优切尾Optrimefficiency,优切尾效率Orderstatistics,顺序统计量Orderedcategories,有序分类Ordinallogisticregression,序数逻辑斯蒂回归Ordinalvariable,有序变量Orthogonalbasis,正交基Orthogonaldesign,正交试验设计Orthogonalityconditions,正交条件ORTHOPLAN,正交设计Outliercutoffs,离群值截断点Outliers,极端值OVERALS,多组变量的非线性正规相关Overshoot,迭代过度Paireddesign,配对设计Pairedsample,配对样本Pairwiseslopes,成对斜率Parabola,抛物线Paralleltests,平行试验Parameter,参数Parametricstatistics,参数统计Parametrictest,参数检验Partialcorrelation,偏相关Partialregression,偏回归Partialsorting,偏排序Partialsresiduals,偏残差Pattern,模式Pearsoncurves,皮尔逊曲线Peeling,退层Percentbargraph,百分条形图Percentage,百分比Percentile,百分位数Percentilecurves,百分位曲线Periodicity,周期性Permutation,排列P-estimator,P估计量Piegraph,饼图Pitmanestimator,皮特曼估计量Pivot,枢轴量Planar,平坦Planarassumption,平面的假设PLANCARDS,生成试验的计划卡Pointestimation,点估计Poissondistribution,泊松分布Polishing,平滑Polledstandarddeviation,合并标准差Polledvariance,合并方差Polygon,多边图Polynomial,多项式Polynomialcurve,多项式曲线Population,总体Populationattributablerisk,人群归因危险度Positivecorrelation,正相关Positivelyskewed,正偏Posteriordistribution,后验分布Powerofatest,检验效能Precision,精密度Predictedvalue,预测值Preliminaryanalysis,预备性分析Principalcomponentanalysis,主成分分析Priordistribution,先验分布Priorprobability,先验概率Probabilisticmodel,概率模型probability,概率Probabilitydensity,概率密度Productmoment,乘积矩/协方差Profiletrace,截面迹图Proportion,比/构成比Proportionallocationinstratifiedrandomsampling,按比例分层随机抽样Proportionate,成比例Proportionatesub-classnumbers,成比例次级组含量Prospectivestudy,前瞻性调查Proximities,亲近性PseudoFtest,近似F检验Pseudomodel,近似模型Pseudosigma,伪标准差Purposivesampling,有目的抽样QRdecomposition,QR分解Quadraticapproximation,二次近似Qualitativeclassification,属性分类Qualitativemethod,定性方法Quantile-quantileplot,分位数-分位数图/Q-Q图Quantitativeanalysis,定量分析Quartile,四分位数QuickCluster,快速聚类Radixsort,基数排序Randomallocation,随机化分组Randomblocksdesign,随机区组设计Randomevent,随机事件Randomization,随机化Range,极差/全距Rankcorrelation,等级相关Ranksumtest,秩和检验Ranktest,秩检验Rankeddata,等级资料Rate,比率Ratio,比例Rawdata,原始资料Rawresidual,原始残差Rayleigh‘stest,雷氏检验Rayleigh‘sZ,雷氏Z值Reciprocal,倒数Reciprocaltransformation,倒数变换Recording,记录Redescendingestimators,回降估计量Reducingdimensions,降维Re-expression,重新表达Referenceset,标准组Regionofacceptance,接受域Regressioncoefficient,回归系数Regressionsumofsquare,回归平方和Rejectionpoint,拒绝点Relativedispersion,相对离散度Relativenumber,相对数Reliability,可靠性Reparametrization,重新设置参数Replication,重复ReportSummaries,报告摘要Residualsumofsquare,剩余平方和Resistance,耐抗性Resistantline,耐抗线Resistanttechnique,耐抗技术R-estimatoroflocation,位置R估计量R-estimatorofscale,尺度R估计量Retrospectivestudy,回顾性调查Ridgetrace,岭迹Riditanalysis,Ridit分析Rotation,旋转Rounding,舍入Row,行Roweffects,行效应Rowfactor,行因素RXCtable,RXC表Sample,样本Sampleregressioncoefficient,样本回归系数Samplesize,样本量Samplestandarddeviation,样本标准差Samplingerror,抽样误差SAS(Statisticalanalysissystem),SAS统计软件包Scale,尺度/量表Scatterdiagram,散点图Schematicplot,示意图/简图Scoretest,计分检验Screening,筛检SEASON,季节分析Secondderivative,二阶导数Secondprincipalcomponent,第二主成分SEM(Structuralequationmodeling),结构化方程模型Semi-logarithmicgraph,半对数图Semi-logarithmicpaper,半对数格纸Sensitivitycurve,敏感度曲线Sequentialanalysis,贯序分析Sequentialdataset,顺序数据集Sequentialdesign,贯序设计Sequentialmethod,贯序法Sequentialtest,贯序检验法Serialtests,系列试验Short-cutmethod,简捷法Sigmoidcurve,S形曲线Signfunction,正负号函数Signtest,符号检验Signedrank,符号秩Significancetest,显着性检验Significantfigure,有效数字Simpleclustersampling,简单整群抽样Simplecorrelation,简单相关Simplerandomsampling,简单随机抽样Simpleregression,简单回归simpletable,简单表Sineestimator,正弦估计量Single-valuedestimate,单值估计Singularmatrix,奇异矩阵Skeweddistribution,偏斜分布Skewness,偏度Slashdistribution,斜线分布Slope,斜率Smirnovtest,斯米尔诺夫检验Sourceofvariation,变异来源Spearmanrankcorrelation,斯皮尔曼等级相关Specificfactor,特殊因子Specificfactorvariance,特殊因子方差Spectra,频谱Sphericaldistribution,球型正态分布Spread,展布SPSS(Statisticalpackageforthesocialscience),SPSS统计软件包Spuriouscorrelation,假性相关Squareroottransformation,平方根变换Stabilizingvariance,稳定方差Standarddeviation,标准差Standarderror,标准误Standarderrorofdifference,差别的标准误Standarderrorofestimate,标准估计误差Standarderrorofrate,率的标准误Standardnormaldistribution,标准正态分布Standardization,标准化Startingvalue,起始值Statistic,统计量Statisticalcontrol,统计控制Statisticalgraph,统计图Statisticalinference,统计推断Statisticaltable,统计表Steepestdescent,最速下降法Stemandleafdisplay,茎叶图Stepfactor,步长因子Stepwiseregression,逐步回归Storage,存Strata,层(复数)Stratifiedsampling,分层抽样Stratifiedsampling,分层抽样Strength,强度Stringency,严密性Structuralrelationship,结构关系Studentizedresidual,学生化残差/t化残差Sub-classnumbers,次级组含量Subdividing,分割Sufficientstatistic,充分统计量Sumofproducts,积和Sumofsquares,离差平方和Sumofsquaresaboutregression,回归平方和Sumofsquaresbetweengroups,组间平方和Sumofsquaresofpartialregression,偏回归平方和Sureevent,必然事件Survey,调查Survival,生存分析Survivalrate,生存率Suspendedrootgram,悬吊根图Symmetry,对称Systematicerror,系统误差Systematicsampling,系统抽样Tags,标签Tailarea,尾部面积Taillength,尾长Tailweight,尾重Tangentline,切线Targetdistribution,目标分布Taylorseries,泰勒级数Tendencyofdispersion,离散趋势Testingofhypotheses,假设检验Theoreticalfrequency,理论频数Timeseries,时间序列Toleranceinterval,容忍区间Tolerancelowerlimit,容忍下限Toleranceupperlimit,容忍上限Torsion,扰率Totalsumofsquare,总平方和Totalvariation,总变异Transformation,转换Treatment,处理Trend,趋势Trendofpercentage,百分比趋势Trial,试验Trialanderrormethod,试错法Tuningconstant,细调常数Twosidedtest,双向检验Two-stageleastsquares,二阶最小平方Two-stagesampling,二阶段抽样Two-tailedtest,双侧检验Two-wayanalysisofvariance,双因素方差分析Two-waytable,双向表TypeIerror,一类错误/α错误TypeIIerror,二类错误/β错误UMVU,方差一致最小无偏估计简称Unbiasedestimate,无偏估计Unconstrainednonlinearregression,无约束非线性回归Unequalsubclassnumber,不等次级组含量Ungroupeddata,不分组资料Uniformcoordinate,均匀坐标Uniformdistribution,均匀分布Uniformlyminimumvarianceunbiasedestimate,方差一致最小无偏估计Unit,单元Unorderedcategories,无序分类Upperlimit,上限Upwardrank,升秩Vagueconcept,模糊概念Validity,有效性VARCOMP(Variancecomponentestimation),方差元素估计Variability,变异性Variable,变量Variance,方差Variation,变异Varimaxorthogonalrotation,方差最大正交旋转Volumeofdistribution,容积Wtest,W检验Weibulldistribution,威布尔分布Weight,权数WeightedChi-squaretest,加权卡方检验/Cochran检验Weightedlinearregressionmethod,加权直线回归Weightedmean,加权平均数Weightedmeansquare,加权平均方差Weightedsumofsquare,加权平方和Weightingcoefficient,权重系数Weightingmethod,加权法W-estimation,W估计量W-estimationoflocation,位置W估计量Width,宽度Wilcoxonpairedtest,威斯康星配对法/配对符号秩和检验Wildpoint,野点/狂点Wildvalue,野值/狂值Winsorizedmean,缩尾均值Withdraw,失访Youden‘sindex,尤登指数Ztest,Z检验Zerocorrelation,零相关Z-transformation,Z变换。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Intimate Partner Homicides
3,000 2,500
Victims
2,000 1,500 1,000 500 0 76 79 82 85 88 91 Year 94 97 00 03 06
Intimate Partner Homicides by Gender
1,800 1,500
4th Fl
3rd Fl
2nd Fl
1st Fl
•
•
Steps between 2nd Fl and 3rd Fl are same as between 1st and 2nd and between 3rd and 4th. Thus, the same interval between floors But 4th Fl is not 2X higher than 2nd Fl. What adjustment would?
– Hypothesis testing – Statistical significance – Testing differences and testing associations
Describing Data
Data Basics
• Level of Measurement
– Nominal scale
Different ways to measure
Nominal Level Q: Are you currently in pain? Yes or No Q: How would you characterize the type of pain? Sharp, Dull or Throbbing
– Crime clock
• Problematic comparisons
– Land, sea and rails
• Unreliable rates
– E.g., cancer rate map
• Rate of change hazards
Domestic violence deaths prompt action Patrick issues health advisory
• Special case of dichotomies
– Ordinal scale
• Special case of equal-appearing intervals
– Interval/Ratio scale
• Absolute zero matters only with percentage difference, percentage change, or log transformations
Functions of Statistics
• Description
– – – – Tables and charts Central tendency Dispersion Association
• Inference
– Samples and populations
• Decision-making
A painful picture
Measuring Political Interest
• Did you vote in 2008?
– Yes, No
• How active are you politically?
– Very, Somewhat, Not Very
• How much closely did you follow the campaign for president?
Interval or Ratio?
IQ (Intelligence Quotient) sure sounds like a ratio. But is it a ratio scale?
Mildly retarded
Mensa member
55
70
85
100
115
130
145
•Top 2%, or about 130+ •Is a Mensa member at 130 twice as smart as a mildly retarded person with 65 IQ?
– Data Types (SPSS)
• String • Numeric • Date
– Variable labels v. Value labels – Missing values
Does beef eating extend life?
Quality of Hand Scale 9
Card Configuration Royal flush
– From 1 to 9 where 1 Is not at all and 9 is as closely as possible
• How many of the presidential candidates can you name?
Not a pretty picture
The Shrinking Value of the Dollar
$150 $100 $50 $0
3 2 1
1
2
3
4
5
6
7
8
9
Hand Quality Rank
Pearson’s correlation r = .672 Spearma’s rank order correlation rs = 1.0
Equal appearing?
How often do you vote in statewide election? 4 3 2 Almost always Sometimes Seldom
Quantitative Methods Prof. James Alan Fox
Craft or Crafty?
They say “You can lie with statistics?” Is it really that “You can be lied to with statistics”?
Christopher Baxter Globe Correspondent, June 6, 2008
Declaring that "we have a public health emergency on our hands," Governor Deval Patrick yesterday unveiled plans to combat an alarming increase in deaths related to domestic violence. Patrick, in issuing the first-ever public health advisory on the issue, announced his plans to bolster police training and ordered a statewide review to determine the cause of the increase. Deaths related to domestic violence, which include homicides and suicides, have nearly tripled in Massachusetts during the past three years, from 19 in 2005 to 55 in 2007, according to Jane Doe Inc., the Massachusetts Coalition Against Sexual Assault and Domestic Violence, a nonprofit Boston-based network. There have been 24 deaths this year, Jane Doe officials said.
Ordinal Level Q: How bad is the pain right now? None, Mild, Moderate, Severe Q: Compared with yesterday, is the pain less severe, about the same, or more severe?
Interval Level 0-10 Numerical Scale
0 No pain
1
2
3
4
5
6
7
8
9
10 Worst pain imaginable
Visual Analog Scale
No pain Ask patient to indicate on the line where the pain is in relation to the two extremes. Qualification is only approximate; for example, a midpoint mark would indicate that the pain is approximately half of the worst possible pain. Worst pain
•
Other characteristics
– Unit of observation
• Micro-data v. aggregates
– Discrete or continuous (e.g., bathroom scales) – Rounding and precision
•
SPSS issues
Victims
1,200 900 600 300 0 76 79 82 85 88 91 Year 94 97 00 03 06 Male Female