50YearsDataScience
林业院校中“数据科学导论”的课程改革探索

计算机教学与教育信息化本栏目责任编辑:王力林业院校中“数据科学导论”的课程改革探索熊飞,曹涌,孙永科(西南林业大学大数据与智能工程学院,云南昆明650224)摘要:数据科学导论是数据科学与大数据专业中很重要的导论性课程,课程中涉及了统计学、计算机、机器学习和深度学习的大量前沿内容,具有理论复杂、知识点繁多的特点。
理工科基础较为薄弱的林业院校学生掌握难度较大。
本文提出了数据分析基础、机器学习与深度学习和数据管理与产品开发的三大模块构成的课程体系以及相应的教学模式,侧重于培养学生以数据为中心的思维模式,形成了符合林业院校特色的导论课程。
关键词:数据科学导论;课程改革;导论课程;林业院校;思维模式中图分类号:TP391文献标识码:A文章编号:1009-3044(2021)15-0147-03开放科学(资源服务)标识码(OSID ):Exploration on Course Reform of Introduction to Data Science in Forestry Universities XIONG Fei,CAO Yong,SUN Yong-ke(College of Big Data and Intelligent Engineering,Southwest Forestry University,Kunming 650224,China)Abstract:Introduction to Data Science is an important introductory course for Data Science and Big Data Technology,which covers a wide range of cutting-edge content in statistics,computers,machine learning,and deep learning.Therefore learning of this course is a challenging work for students that whitweak foundations in science and engineering in forestry universities.A teaching model focus on cultivating a data-centric mindset is introduced in this paper,which includes three parts:data analysis,Machine learning and deep learning,data management and product development.The redesign of Introduction to Data Science makes it con⁃form to the characteristics of forestry university.Key words:introduction to data science;course reform;introductory course;forestry universities;1引言2015年由国务院印发了《国务院关于印发促进大数据发展行动纲要的通知》标志着国家把大数据上升到了国家战略的层面,随后在2016年教育部在《教育部高等教育司关于2016年度普通高等学校本科专业设置工作有关问题的说明》中增加了数据科学与大数据技术专业(专业代码:08910T )来促进数据科学专业人才的培养。
2024年的辉煌与成就

医疗保障制度更加健全
医疗保险覆盖面进一步扩大,报销比例和报销范 围不断提高,有效减轻了居民的医疗负担。
3
医疗卫生人才队伍建设加强
政府重视医疗卫生人才的培养和引进,加强了医 疗卫生人才队伍建设,提高了医疗卫生服务的质 量和水平。
社会保障体系更加完善
社会保险覆盖面扩大
01
社会保险制度不断完善,覆盖面进一步扩大,保障了更多人的
政府和企业加大了对科技研发 的投入力度,推动产学研深度 融合,加速了科技成果转化和 应用。
创新驱动发展战略深入实施, 创新创业生态持续优化,为经 济社会发展提供了强大的科技 支撑。
对外贸易扩展
2024年,中国的对外贸易实现了快速 增长,进出口总额再创新高。
随着“一带一路”建设的深入推进和 自由贸易试验区的不断扩围,中国的 对外贸易结构进一步优化,与沿线国 家的经贸合作日益紧密。
中国积极参与全球经济治理和贸易投 资合作,推动建设开放型世界经济, 为全球贸易增长作出了重要贡献。
03
科技领域的突破与进步
BIG DATA EMPOWERS TO CREATE A NEW
ERA
人工智能技术应用广泛
01
02
03
智能家居
人工智能技术将广泛应用 于家居领域,实现家庭设 备的自动化和智能化管理 ,提高生活便利性。
05
社会民生领域的改善与提升
BIG DATA EMPOWERS TO CREATE A NEW
ERA
居民收入水平提高
01
经济增长带动居民收入增长
随着国家经济的持续稳定增长,居民收入水平普遍提高,生活质量得到
显著改善。
02
工资性收入和财产性收入双增长
Computer-Vision计算机视觉英文ppt

Its mainstream research is divided into three stages:
Stage 1: Research on the visual basic method ,which take the model world as the main object;
Stage 2: Research on visual model ,which is based on the computational theory;
the other is to rebuild the three dimensional object according to the two-dimensional projection images .
History of computer vision
1950s: in this period , statistical pattern recognition is most applied in computer vision , it mainly focuse on the analysis and identification of two-dimensional image,such as: optical character recognition, the surface of the workpiece, the analysis and interpretation of the aerial image.
新视野第三版大学英语第二册课文翻译

新视野大学英语第二册读写教程课文翻译Unit 1 Text A An impressive Engli lsesson标题: 一堂难忘的英语课1. 如果我是唯一一个还在纠正小孩英语的家长,那么我儿子也许是对的。
对他而言,我是一个乏味的怪物:一个他不得不听其教诲的父亲,一个还沉湎于语法规则的人,对此我儿子似乎颇为反感。
2. 我觉得我是在最近偶遇我以前的一位学生时,才开始对这个问题认真起来的。
这个学生刚从欧洲旅游回来。
我满怀着诚挚期待问她:“欧洲之行如何?”3. 她点了三四下头,绞尽脑汁,苦苦寻找恰当的词语,然后惊呼:“真是,哇!”4. 没了。
所有希腊文明和罗马建筑的辉煌居然囊括于一个浓缩的、不完整的语句之中!我的学生以“哇!”来表示她的惊叹,我只能以摇头表达比之更强烈的忧虑。
5. 关于正确使用英语能力下降的问题,有许多不同的故事。
学生的确本应该能够区分诸如 their/there/they're 之间的不同,或区别 complimentary 跟complementary 之间显而易见的差异。
由于这些知识缺陷,他们承受着大部分不该承受的批评和指责,因为舆论认为他们应该学得更好。
6. 学生并不笨,他们只是被周围所看到和听到的语言误导了。
举例来说,杂货店的指示牌会把他们引向 stationary(静止处),虽然便笺本、相册、和笔记本等真正的 stationery(文具用品)并没有被钉在那儿。
朋友和亲人常宣称 They've just ate。
实际上,他们应该说 They've just eaten。
因此,批评学生不合乎清理。
7. 对这种缺乏语言功底而引起的负面指责应归咎于我们的学校。
学校应对英语熟练程度制定出更高的标准。
可相反,学校只教零星的语法,高级词汇更是少之又少。
还有就是,学校的年轻教师显然缺乏这些重要的语言结构方面的知识,因为他们过去也没接触过。
学校有责任教会年轻人进行有效的语言沟通,可他们并没把语言的基本框架一一准确的语法和恰当的词汇一一充分地传授给学生。
生物系统工程师:克雷格·文特尔(J. Craig Venter)人物简介

03
克雷格·文特尔在合成生物学领域的突破
首次合成细菌基因组的研究
2002年,文特尔领导的团队成功合成了第一个细菌基因组
• 标志着合成生物学的诞生 • 为合成生物学的研究提供了重要基础
合成的细菌基因组具有完整的生物学功能
• 能够指导细菌的生长和繁殖 • 为合成生物学的研究提供了重要证据
合成生物学技术在医学、能源等领域的应用
CREATE TOGETHER
DOCS
DOCS SMART CREATE
生物系统工程师:克雷格·文特尔(J. Craig Ve n t e r ) 人 物 简 介
01
克雷格·文特尔的人生经历
早期的学术背景与兴趣培养
大学时期,进入加州大学圣迭戈分校学习
• 主修生物学,辅修化学和数学 • 对遗传学和分子生物学产生浓厚兴趣
退役后,进入圣迭戈的索尔克生物研究所工作
• 开始研究DNA重组技术 • 对基因组学产生了浓厚兴趣
成为生物系统工程师的历程
1986年,加入 美国能源部下 属的研究所
01
• 开始研究生物系统工程技术 • 对合成生物学和基因组学产 生浓厚兴趣
1992年,成立 私人研究机构 The Institute for Genomic
出生于1946年,美国加利福尼亚州
• 成长于一个军人家庭,经常搬家 • 对科学和探险产生浓厚兴趣
高中时期,表现出对化学和生物学的热爱
• 参加化学竞赛并获得奖项 • 对生物学的研究产生浓厚兴趣
转向生物学领域的研究
大学毕业后,进入美国海军服役
• 参与研究海洋生物学和生物传感技术 • 对生物学的研究有了更深入的了解
• 能够解决许多重要科学问题和实际问题 • 为人类社会的可持续发展提供新的机遇
数据科学导论 lesson1
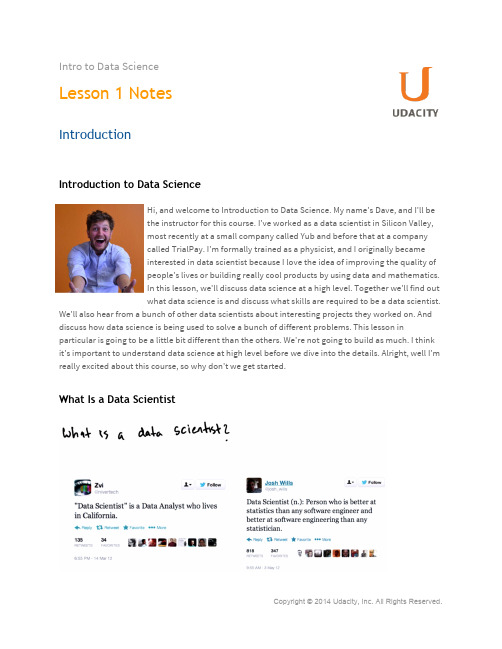
Intro to Data ScienceLesson 1 NotesIntroductionIntroduction to Data ScienceHi, and welcome to Introduction to Data Science. My name's Dave, and I'll bethe instructor for this course. I've worked as a data scientist in Silicon Valley,most recently at a small company called Yub and before that at a companycalled TrialPay. I'm formally trained as a physicist, and I originally becameinterested in data scientist because I love the idea of improving the quality ofpeople's lives or building really cool products by using data and mathematics.In this lesson, we'll discuss data science at a high level. Together we'll find outwhat data science is and discuss what skills are required to be a data scientist. We'll also hear from a bunch of other data scientists about interesting projects they worked on. And discuss how data science is being used to solve a bunch of different problems. This lesson in particular is going to be a little bit different than the others. We're not going to build as much. I think it's important to understand data science at high level before we dive into the details. Alright, well I'm really excited about this course, so why don't we get started.What Is a Data ScientistPeople have many different conceptions of what data scientists do. Some might say that a data scientist is just a data analyst who lives in California. While others might say that a data scientist is a person who's better at statistics than any software engineer, and better at software engineering than any statistician. As you can see, definitions vary wildly from place to place, and from person to person.Quiz: What Is a Data ScientistSo before we get started, let me ask you a question. What do you think data scientists do in theirday-to-day work? Type your thoughts in the text box below. Don't worry, there are no right or wrong answers and this quiz will not be graded.Answer:Let me tell you my perspective. From personal experience, data scientists today are people who have a blend of many different skills. This Venn diagram shows a definition of a data scientist that I like a lot. A data scientist is someone who knows mathematics and statistics, which allows them to identify interesting insights in a sea of data. They also have theprogramming skills to code up statistical models and getdata from a variety of different data sources. Furthermore,a data scientist is someone who knows how to ask theright questions and translate those questions into a soundanalysis. After doing the analysis, they have thecommunication skills to report their findings in a way thatpeople can easily understand. In other words, datascientists have the ability to perform complicated analysison huge data sets. Once they've done this, they also havethe ability to write and make informative graphs tocommunicate their findings to others.What Does a Data Scientist DoHere are some things that a data scientist may do in his or her daily work. They mightwrangle data. That is, collect data from the real world, process it, and create a data setthat can be analyzed. Once they have a data set, they may analyze trends in the existingdata or try to make data driven predictions about the future using the data at hand.Based on this models or predictions, they cannot only build data driven products but also communicate their findings to those other data scientists and the general public. File visualizations, reports or blog posts. But hey, this is my point of view. Why don't we talk to some other data scientists and hear their thoughts.Pi Chuan IntroductionMy name is Pi-Chaun Chang. My background, so I've been doing Computer Science ever since college.I did a PhD CS PhD at Stanford, and I worked at Google for four years. Now I'm in a startup called AltSchool.Pi Chuan - What Is Data Sciencenow I think about it, I have been doing data science since the day I was at inTaiwan doing a Masters in speech recognition. The way we wouldunderstand speech is to collect a lot of data and understand how to modelthings like a phoneme in speech. And how to understand people's languageprocessing requires a lot of data collection as well. And at Google, which isa company that collects a lot of data, I also did personalization there which requires a lot of data to understanding a person's behavior. So, that to me is data science. Using data to build a useful model or to understand a particular pattern that is useful, then later on, for othersoftware applications.Gabor IntroductionSo my name is Gabe Savo, I work at Twitter, and I am data scientist. Iactually come from a background that's towards natural sciences. I didstatistical physics, and I have a PhD in statistical physics. And anything thatgoes with that. Obviously, I was looking at like a lot of big, big systems as aninteraction of, of very small very small entities composing of these systems.And and later on I did complex network research. So that means that wehave interactions again. Imagine like a big gas composed of molecules. Butinstead here we have like, the humans interacting with, with each other through social networks. Through mobile communication networks. So that was the main focus of my research all year.Gabor - What is Data ScienceThat's a great question. So what do data scientists do? I think it's it's really hard to to pinpoint exactly what they do because it's going to be tailored to their actual application area that they work. But in general, what they do is they take data and they find meaning in the data. And what the meaningis going to be really geared towards what they would like to explain. So it could be that a particular company, if they are looking at a company or, or the project. If they are looking for some, some particular signal or something. I think in general in my mind what data science does is use is usethis data. Data sciences uses data to essentially explain and perhaps predict behavior be it human behavior or even the behavior of a more machine generated system, anything could be like that.Quiz: Basic Data Scientist SkillsJust to recap, let me ask you a quick question. What does it mean for adata scientist to have substantive expertise and why is it important? Typeyour answer in the box below. Don't worry, your response won't be graded.Answer:As we discussed earlier in this lesson, a data scientist needs to have substantive expertise. What does that mean? Well typically it means that a data scientist knows which questions to ask, can interpret the data well and understands the structure of the data. You can imagine that a data scientistneeds to know about the problem that solving. For example, if you are solving an online advertising problem, you want to make sure you understand what types of people are coming to your website. How they are interacting with the website and what different data means that can help you ask the right questions like, Are people falling off and not completing our ads at a certain point in the flow,or do people complete more ads at a certain time of the day? You would also, then, be very familiar with how the data is stored and structured. And that could help you work more efficiently and more effectively. This is why it's important for a data scientist to have substantive expertise. It's important to note that data scientists usually work in teams. So it's normal for data scientists to be stronger in some areas and weaker in others. So even if you, as a data scientist, don't have a tons of substantive expertise, if you have great hacking skills or know a lot of statistics you can still be a valuable member of a data science team.Problems Solved by Data ScienceNow that you have a better Ideaof what data science is, and whatdata scientist do, let's talk abouthow data science can be appliedacross a wide spectrum ofindustries. You might havesigned up for this class under thenotion that if you become a datascientist, you'll end up workingfor a Silicon Valley startup. Wellit's true that most techcompanies do employ datascientists. Data science can alsobe used to solve problems in many different fields. What are some examples of the types of problems being solved using data science? Well for one, Netflix uses collaborative filtering algorithms to recommend movies to users based on things they've previously watched. Also, elements of many popular social media websites are powered by data science. Things like recommending new connections on Linkedin, constructing your Facebook newsfeed or suggesting new people to follow on Twitter. Many other online services or apps such as dating websites like OKCupid or ride sharing services like Uber uses the vast amount of user data available to them, not only need to customize and improve the user experience but also to publish interesting anthropological findings regarding people's behavior in the offline world on their blogs.Okay, so I know what you're thinking. So far, all of these seem like problems data scientists are expected to solve, but data scientists work in many domains. Data science concepts are integral in processing and modeling data in the field bioinformatics where scientists are working on projects like annotating genomes and analyzing data sequences. This past summer, data science for social good fellows in Chicago worked on a project attempting to solve Chicago's bus crowding issues using data. In addition, physicists use data science concepts when building a 100 terabyte database of astronomical data collected by the Sloan digital sky server. This one's cool. Analyzing electronic medical records allowed the city of Camden, New Jersey to save enormous amounts of money by targeting their efforts towards specific buildings accounting for a majority of emergency admission. Finally, NBA teams like the Toronto Raptors are installing a new technology, sports view cameras, on the basketball courts. They collect huge amounts of data on players movement and playing styles. This helps teams to better analyze game trends and improve coaching decisions. You've probably noticed by now that data science is making an impact in areas far and wide. Data science isn't simply a trendy new way to think about tech problems. It's a tool that can be used to solve problems in a variety of fields. Data scientists are working at Silicon Valley start-ups to enrich our online experiences, but they're also doing important work in our cities, in our laboratories and in our sports stadiums.PandasAs you can imagine, since data science is being deployed in such a wide range of fields. Data scientists use many different tools. Depending on the task at hand. One of the most versatile and ubiquitous is a Python package called Pandas. Which we'll use in order to handle and manipulate data during this course. You might wonder why we'll beusing Pandas as opposed to anothertool. Pandas allows us to structure andmanipulate our data in ways that areparticularly well suited for dataanalysis. If you happen to be familiarwith the scripting language R, Pandastakes a lot of the best elements from Rand implements them in python.DataframesFirst of all, data in Pandas is often contained in a structure called a dataframe. A dataframe is atwo-dimensional labeled data structure with columns which can be different types if necessary. Forexample types like string, int, float, and Boolean. You can think of a dataframe as being similar to an Excel spreadsheet. We'll talk about making dataframes in a bit. For now, here's what an example dataframe might look like. Using data describing passengers on the Titanic, and whether or not they survived the Titanic's tragic collision with an iceberg. Note that there are numerous columns. Name,age, fare, and survived? Thesecolumns have different data-types. There are also some Not-a-Number entries which happenwhen we don't specify a value.There are a bunch of cool thingswe can do with this data frame.Let's jump to the command line.Say that I had already loaded thisdata into a data frame called DF.We can operate on specific columns by calling on them as if they were keys in a dictionary. For example, DFH and we can call on specific rows by calling a data frame objects loc method, and passing the row index as an argument, for example, df.loc('a').Create a New DataframePanda also allows us to operate on your data frame in a vectorized item by item way. What does it mean to operate on a data frame in a vectorized way? Well first let's create a new data frame. Note that first I want to create a dictionary where the keys are going to be my column names and the values are series corresponding to their values and then the indexes for the rows where these values should appear. In order to make a data frame, I can simply say df equals data frame of this dictionary d. Let's see what this data frame looks like. We can call dataframe.apply and pass in some arbitrary function. In this case, numpy.mean to perform that function on every single column in the data frame. So when we df.apply numpy.mean, what we get back is the mean of each column in our data frame df. There are also some operations that simply cannot be vectorized in this way, that is, take a numpy.meanas their input, and then return an array or a value. So we can also call map on particular columns or apply map on entire data frames. These methods also accept functions, but functions that take in a single value and return a single value. For example, if I were to type df1.map lambda x, x greater than or equal to 1, what I get back here is whether or not every single value in the column 1 is greater than or equal to 1. Now say that I were to call df.applymap lambda x, x greater than or equal to 1, whatthis function returns is whether or not every single value in the data frame df is greater than or equal to 1. This is just the tip of the iceberg when it comes to Panda's functionality. If you're interested to read more about what the library can do, you should check out the full documentation at the URLcontained in the instructor notes. Now, we know some of the very basics when it comes to handling the data, but how do we acquire the data that we wish to handle and analyze?Lesson Project - Titanic DataAlright. Before we get started on the class project, this lesson's assignment will allow you to get comfortable with the type of work that data scientists do using a small and classic data set. This data set describes the riders on the Titanic and a bunch of information about them. For example, what class they were in, whether they were male or female, how old they were, etcetera. Over the courseof the assignment, you'll build a few different models. The models will start out simple, but they'll get increasingly complex. To see if using data science, we can predict who will survive and who won't survive the Titanic tragedy. This may sound complicated, but don't worry. We'll give you plenty of help. This assignment is meant to get you in the habit of thinking like a data scientist.Class ProjectThrough the class project, you'll investigate New York City subway ridership as a data scientist might. First, you'll pull some publicly available data on subway ridership, and also on New York weather conditions, using the New York MTA website and the Weather Underground API. Then, you'll answer some questions about subway ridership using statistics and machine learning. Does the weather influence how many people ride the subway? Is the subway busier at certain times than others? Can we predict subway ridership? Finally,you'll develop some charts andgraphics that communicate yourfindings, and synthesize everythinginto a cohesive write-up that yourfriends or family might find usefuland informative. This may sounddaunting, but we'll be going throughthis step by step, and learning how touse the necessary tools as we goalong.Pi Chuans Advice for Aspiring StudentsSo for me, the reason why I even come into this field of data science is my passion for something specific, which is natural language. Right, so I observe the people who work around me who knows about data science. I think one thing that's very important is they either have a passion for the particular data they're looking at. Like, you know, natural language, or like speech recognition kind ofdata. Or some people are just very interested in patterns in data. Like when they see some data they would try to calculate the mean of the data, the variance of data. It comes natural to them because they want to find patterns to the data. So I think for anyone who wants to become a data scientist, it's good to think about, what kind of data you are interested in doing, and start with that. And then later on when you have this skill of analyzing data, you can apply it to any other kind of thing.Gabors Advice for Aspiring Data ScientistI think the, the most important thing that, that inspired me to start to start keep In mind is that they should have a very curious mind. They should have the ability to ask questions, to formulate these questions as it pertains to them, as they would see these questions being raised in their own lives.So if, if there's a problem they see with the pieces that they are working with or with the project that they're working with, they should try to ask these questions in terms of and how they can understand for themselves. And once they understand, once they know what is the gist of the question is, then they can go and use algorithms. Obviously it helps tremendously if you have experience about allthe arguments that are out there to attack these questions. But I think the most important ability is that you should have the mindset as a data scientist, and you could obviously improve throughout your career in this if you have this inquisitive mindset, where you are trying to ask the right questions. While you are trying to, to see what is important, you should also have an overview of what kind of data can support your conclusions and draw conclusions with the help of these algorithms that you are going to use to solve these problems.Recap of Lesson 1To recap today's lesson, data science is a discipline that incorporates methods and expertise froma variety of different fields, to glean insights from large data sets, and then use those insights to build data driven products, or to create action items. There's no cookie cutter way to become a data scientist, but a lot of data scientists have a very strong background in mathematics and statistics, and also have the programming skills to handle these data sets and also to perform analysis. Currently, data science is most closely associated with the tech field, but more and more data science is being used all over the world in a variety of different fields. In order to solve new and old problems, more efficiently and effectively. Now I know what you're thinking. This sounds awesome, data science sounds really cool, I want to work on a project get me some data. Unfortunately, data seldom comes in formats that we want. It might be in a format we've never seen, it might come from a weird source. There might be missing or erroneous values. Because of this, any data scientist worth their salt is skilled at acquiring data. And then massaging it into a workable format. That's what we're going to be covering in the next lesson.。
光全息数据存储——新发展时机已至

Opto-Electronic Engineering光电工程Review2019 年,第 46 卷,第 3 期DOI: 10.12086/oee.2019.180642光全息数据存储——新发展时机已至林 枭 1,2,郝建颖 1,郑明杰 1,3,戴天贵 1,3,李 晖 1,2,任宇红 1*1 福建师范大学光电与信息工程学院,福建 福州 350117; 2 福建省光子技术重点实验室,福建 福州 350117; 3 医学光电科学与技术教育部重点实验室,福建 福州 350117摘要:本文对过去 50 年中光全息数据存储技术的发展进行了综述。
随着关键器件和材料的不断发展,光全息数据存储技术也日臻成熟。
当下正值大数据时代,对数据存储密度和数据存取速度的需求比以往任何时候都要大,光全息数据存储以其超大存储容量、超快读取速度、超长保存寿命等优势,成为下一代数据存储技术的有力候选者。
其中同轴全息存储系统以其结构紧凑、操作简单、兼容性强等特点将成为全息存储技术进一步实用化的基石。
同时新型的相位调制光全息数据存储系统正成为研究热点,新一轮的飞速发展时机已至。
关键词:光全息;数据存储;大数据;相位调制中图分类号:O436.3;O438.1文献标志码:A引用格式:林枭,郝建颖,郑明杰,等. 光全息数据存储——新发展时机已至[J]. 光电工程,2019,46(3): 180642Optical holographic data storage —The time for new developmentLin Xiao1,2, Hao Jianying1, Zheng Mingjie1,3, Dai Tiangui1,3, Li Hui1,2, Ren Yuhong1*1College of Photonic and Electronic Engineering, Fujian Normal University, Fuzhou, Fujian 350117, China; 2Fujian Provincial Key Laboratory of Photonics Technology, Fuzhou, Fujian 350117, China; 3Fujian Provincial Engineering Technology Research Center of Photoelectric Sensing Application, Fuzhou, Fujian 350117, ChinaAbstract: The development of optical holographic data storage technology in the past 50 years is reviewed in this paper. With the continuous development of key devices and materials, optical holographic data storage technology is becoming more and more mature. At present, in the era of Big Data, the demands for data storage density and data transfer rate are greater than ever before. Optical holographic data storage has become a potential candidate for the next generation of data storage technology because of its advantages of superhigh storage capacity, superfast data transfer rate, and superlong storage life. The coaxial holographic storage system will become the cornerstone of further practicality of holographic storage technology because of its compact structure, simple operation and strong compatibility. Meanwhile, new phase modulated holographic data storage system is becoming the research hotspot. The new round of rapid development has arrived. Keywords: optical holography; data storage; big data; phase modulation Citation: Lin X, Hao J Y, Zheng M J, et al. Optical holographic data storage—The time for new development[J]. Opto-Electronic Engineering, 2019, 46(3): 180642—————————————————— 收稿日期:2018-12-05; 收到修改稿日期:2019-02-21 基金项目:国家自然科学基金项目(61475019);中央引导地方科技发展专项(2017L3009) 作者简介:林枭(1989-),男,博士,讲师,主要从事光全息存储、偏光全息的研究。
生物技术2024年的新生命科学

对宿主健康有益的活性微生物,能够定殖于 肠道并发挥有益作用。
益生菌功效
调品、保健品、药品等,如酸奶、乳酸 菌饮料等。
益生菌产品开发挑战
菌种筛选、功效验证、安全性评价等方面的 问题需要解决。
未来发展趋势预测
技术创新
个性化医疗
随着生物技术的不断发展,微生物组学研 究方法和技术将不断创新和完善。
政策法规及市场趋势分析
政策法规
各国对细胞疗法和再生医学的监管政策不同,需关注相关法规变化。
市场趋势
随着技术不断成熟和成本降低,细胞疗法和再生医学市场将不断扩大。同时, 竞争也将更加激烈,企业需要不断创新和提高产品质量以获取市场份额。
04
免疫疗法与肿瘤防治
BIG DATA EMPOWERS TO CREATE A NEW
开发新型药物、疫苗、生物传感器等,提高疾病 诊断和治疗水平。
基因治疗与疾病防治
遗传性疾病的基因治疗
针对遗传性疾病,利用基因编辑和合 成生物学技术,实现基因修复、替代 或增强,达到治疗目的。
抗感染性疾病的基因治疗
利用基因编辑技术,破坏病原体的基 因组或增强宿主的抗感染能力,防治 感染性疾病。
肿瘤免疫治疗的基因改造
03
新生命科学将推动医疗、制药、农业等领域的创新发展,提高
人类生活质量。
生物技术发展现状
基因编辑技术的突破
CRISPR-Cas9等基因编辑技术的出现,使得精准、高效地修改生 物体基因成为可能。
细胞培养与再生医学的进展
干细胞技术、3D生物打印等技术为再生医学提供了新途径。
生物信息学的发展
大数据、人工智能等技术在生物信息学领域的应用,加速了生命科 学研究的进程。
国际教育大数据研究的热点、前沿和趋势基于WOS数据库的量化分析

国际教育大数据研究的热点、前沿和趋势基于WOS数据库的量化分析一、本文概述Overview of this article随着信息技术的飞速发展和全球教育交流的日益密切,国际教育大数据研究已经成为教育领域的重要议题。
本文旨在通过量化分析的方法,基于WOS(Web of Science)数据库,深入探讨国际教育大数据研究的热点、前沿和趋势。
我们将从文献计量学角度出发,分析近年来国际教育大数据研究领域的论文发表情况、关键词共现网络、研究主题演变等方面,以期为全球教育大数据研究提供科学的参考和启示。
With the rapid development of information technology and the increasingly close global educational exchanges, international education big data research has become an important topic in the field of education. This article aims to explore the hotspots, frontiers, and trends in international education big data research through quantitative analysis based on the WOS (Web of Science) database. We will analyze thepublication status, keyword co-occurrence networks, and research topic evolution of international education big data research in recent years from the perspective of bibliometrics, in order to provide scientific reference and inspiration for global education big data research.我们将对WOS数据库中关于国际教育大数据研究的论文进行梳理和统计,分析论文的发表数量、引用情况、作者分布等,揭示该领域的研究现状和发展趋势。
尼科莱特 I S50 FT-IR 光谱仪:通过紧凑型自动化提高生产力 应用笔记 52416说明书

Thermo Scientific Nicolet iS50 FT-IRSpectrometer: Improving Productivity through Compact Automation Application Note 52416 Key WordsAutomation, Far-IR, FT-IR, Full-spectral, Infrared, Mid-IR, Multi-range,Multiple Methods, Near-IR, Workflow OptimizationChallenges Facing Industrial Analytical LabsMany routine QC/QA laboratories can perform materialanalyses with single range, basic Fourier transform-infrared (FT-IR) instrument configurations. However,modern analytical laboratories face increasing workloadsfrom a broad range of sample types with a simultaneousdrive for faster results and more complex samplecharacterization needs. Flexibility to analyze multiplesample types becomes mandatory when rapidly respondingto these different application requests. Such diversityrequires laboratory instruments to be reconfigured forspecific measurements multiple times per day, taking timeaway from other critical activities. This also implies thatlaboratory personnel possess the necessary skills andexperience to make decisions on how best to configure the instrument for a given application. In addition, frequent handling of delicate optics components presents a costly risk for instrument failure. As a result, many industrial laboratories choose to outsource complex analyses. These limitations inevitably slow the laboratory’s ability to respond to urgent business needs.The Thermo Scientific™ Nicolet™ iS™50 FT-IR spectrometer alleviates many of these productivity concerns by automating setup of the FT-IR system for multi-spectral range experiments (>20,000 cm-1 to 80 cm-1) and fori ntegrating techniques like FT-Raman, near-IR and mid/far-IR attenuated total reflectance (ATR) into a single workflow. Intelligent design behind the Nicolet iS50 spectrometer permits unattended, risk-free operation, increasing lab efficiency, sample throughput, and operational consistency between users. This capability is delivered in an economical, compact system (63 cm of linear bench space) enabling any laboratory to employ multiple techniques for their analysis.Flexibility and Value-added ActivitiesWorking labs need analytical flexibility to respond toa variety of situations where answers are critical for decision-making. Examples include deformulating mixtures to build a case for patent infringement, identifying counterfeit materials for product safety alerts, analyzing forensic samples for criminal investigations, performing failure analysis to minimize production run delays, assessing process scale-up options for a new product launch, or troubleshooting customer complaints. Such diversity of applications requires the selection and installation of the correct instrument accessory as well as choosing the optimal source, beamsplitter, detector, optical path, and experimental conditions. Manually changing components and sampling parameters requires skill and may risk exposure of expensive optics to the external environment (i.e., dust, fingerprints or water vapor). In addition, changing these parameters can result in extensive wait times to equilibrate the instrument before the next measurement.These manual reconfigurations provide little added value to the laboratory workflow. Users must plan and set up batch experiments to minimize the number of steps. This creates bottlenecks, limiting access to the full capability of the instrument. As a result, labs are less able to address “emergency situations” without interrupting the batch run and resetting the instrument parameters. For instance, analysis of a polymer with additives requires mid-IR and far-IR plus Raman spectroscopy. This would entail three beamsplitter changes with associated risks in handling expensive components and instrument recovery times between changes.The productivity improvements with the Nicolet iS50 FT-IR spectrometer come from two main sources. First, the internally mounted iS50 ABX Automated Beamsplitter Exchanger uses one-button simplicity (described as a Touch Point) to perform instrument setup and operation, providing a “one touch and done” workflow. The removal of manual handling and exposure of the optics to the environment means instant readiness. Second, the user need no longer care about which optics are installed. As seen in Table 1, the potential for error in manual operations is apparent when the array of possible component combinations is considered. With the Nicolet iS50 spectrometer, however, a user simply presses the Touch Point on the instrument to automate the configuration and ready the instrument for the experiment. For example, pressing the Touch Point on the iS50 NIR module automates the setup without requiring any understanding of which optics are used. What matters is performing NIR analysis – not worrying about choosing the right components. The instrument takes care of this step. Integration of the spectrometer with its modules and components allows the user to expand capabilities, increasing productivity with tools such as:• Up to three detectors (such as near-, mid- and far-IR)• The iS50 Raman sample compartment module• The built-in diamond iS50 ATR sampling station• T he iS50 NIR module with integrating sphere or fiber optics• The iS50 GC-IR module• A sample compartment thermal gravimetric analysis-IR (TGA-IR Interface)Figure 1 describes the analytical power the user can achieve with the iS50 spectrometer to obtain answers needed for time-sensitive decisions. With a single user interaction, the instrument can perform multiple measurements and analyses, resulting in a final report, even when unattended. The Thermo Scientific OMNIC™software provides a user-friendly interface to set up applications quickly and generate spectra for definitive answers. By adding powerful analytical tools like the Thermo Scientific OMNIC Specta™ software with a library of over 30,000 spectra and multi-component searching (or the TQ Analyst™ software for chemometrics), a complete analytical workflow from sampling to results can often be achieved in less than 60 seconds.This paper will demonstrate how the integration and automation of the Nicolet iS50 spectrometer leads to new levels of productivity, while minimizing risk to costly components. Unlike most spectrometers, operating the Nicolet iS50 instrument becomes simpler as modules are added and as more manual steps are removed even when unattended.Experiment Source Beamsplitter Detector AccessoryMid-IR Transmission Thermo Scientific Polaris™KBr KBr-DLaTGS Standard Cells Far-IR Transmission Polaris Solid Substrate Polyethylene DLaTGS Cells w/Far-IR Windows Near-IR Transmission White Light CaF2InGaAs CuvettesMid-IR ATR Polaris KBr Dedicated DLaTGS iS50 ATRFar-IR ATR Polaris Solid Substrate Dedicated DLaTGS iS50 ATRFT-Raman Raman Laser CaF2Raman InGaAs iS50 RamanTable 1: Experiments made possible with the Nicolet iS50 FT-IR SpectrometerFigure 1: Nicolet iS50 analysis workflowAutomated Multi-spectral Analysis:Mid- and Far-IR ATR plus Near-IRMost FT-IR users understand the utility of the mid-IR spectral range for qualitative and quantitative analyses. Less well known, the far-IR region can provide new and unique information. Simply put, as the mass of atoms involved in vibrations increases, the wavenumber decreases.1Thus, for materials like organometallics or metal oxides, the IR absorption shifts below 400 cm-1 and below the range of standard KBr optics. Numerous polymers, sugars, and other large molecules also have far-IR information which may be useful or definitive to the analyst. Traditionally, collecting FT-IR spectra in both the mid-IR and far-IR region entailed significant sample preparation. This included changing hygroscopic optics and multiple detectors, and risking altered system performance from water vapor. The Nicolet iS50 spectrometer enables rapid analysis over the full mid-IR and well into thefar-IR region (4,000 cm-1 to 80 cm-1) when equipped with the iS50 ABX, iS50 ATR, and the correct beamsplitters. The typical, multi-range FT-IR application requires opening the spectrometer to swap beamsplitters. This requires care in handling costly components and exposesthe internal optics to the environment by disrupting purge or desiccation. This activity adds a recovery period tore-equilibrate the instrument before quality data can be collected. These wait times add no value to operations, wasting the analyst’s precious time. Integration and automation on the spectrometer eliminate non-productive wait times, improving efficiency.As an example, Table 2 compares the steps needed to perform a full spectral analysis from far-IR to near-IR between the manual method (Typical) and the Nicolet iS50 method with built-in iS50 ATR and iS50 NIR module. This represents three spectral ranges in one sampling operation, a unique power of the instrument. Most important the built-in iS50 ATR optics and detector permit spectral data collection in both the mid- and far-IR regions. The analysis time decreases from around 30 minutes to less than seven. With the Nicolet iS50 spectrometer, the user is able to load two sampling locations (the built-in ATR and the Integrating Sphere module), start the macro and walk away, while in the manual operation, continuous attention is needed to swap the beamsplitters at the right moments. This seemingly hidden improvement allows unattended operation, permitting productivity through automation. Figure 2 shows just the mid- and far-IR spectra collected from acetylferrocene analyzed using an OMNIC macro-controlled workflow. The additional information from the far-IR spectra is clear – the low end triplet verifies that the iron is sandwiched between the cyclopentadiene rings. The NIR data is not shown, but the entire process required seven minutes, including collection of themid- and far-IR backgrounds. Automation also reduced the total hands-on time of the user (pressing buttons, loading sample) to ≈20 seconds. Figure 2: Mid-IR and far-IR spectra of Acetylferrocene. The far-IR optics permit collection to 1700 cm-1, which may be sufficient (fingerprint and far-IR) for many applications.Time Nicolet iS50 Time Process Step Typical (minutes) with Built-in ATR (minutes) Sample Preparation Grind, Mix 10 None 0 Mid-IR Background Collect BKG 0.5 Collect BKG (2nd)* 1. Mid-IR Collect Load Sample, 2 Load Sample, 1Collect Spectrum Collect SpectrumChange Optics Manual Exchange 0.5 Automated 0.5 Recovery Time Wait for Purge 5–10 No Recovery Time 0 Far-IR Background Collect BKG 0.5 Collect BKG (1st)* 0.5 Far-IR Collect Load Sample, 2 Load Sample, 1Collect Spectrum Collect SpectrumChange Optics (NIR) Manual Exchange 0.5 Automated 0.5 Recovery Time Wait for Purge 5 No Recovery Time 0 Collect Background Collect BKG 0.5 Collect BKG 0.5 Collect Sample Load Sample, 1 Collect SAM 0.5Collect SAMData Analysis (Search) Perform Search 2 Automated Search 0.5 Total Time 29.5–34.5 6.5 Table 2: Far-infrared analysis: Typical versus Nicolet iS50 process* W ith the iS50 ATR present, the far-IR background (BKG) is collected, the iS50 ABX swaps beamsplitters, and themid-IR background is collected in <1.5 minutes. The sample is loaded and the spectra are collected in sequence.All times are approximate.Figure 3: The Thermo Scientific Nicolet iS50 FT-IR spectrometer configured for FT-Raman, near-IR, and mid/far-IR ATR with the automated beamsplitter exchanger.Figure 4: Touch Points on the Nicolet iS50 spectrometer employ one-button switching between modules and the iS50 ABX automates optics set-up Touch Point A – NIR module Touch Point B – Raman moduleTouch Point C – Built-in diamond ATRComponent D – ABX Automated Beamsplitter ExchangerMultiple Techniques and Multi-range Analysis: Enhanced FlexibilityThe Nicolet iS50 spectrometer can be configured with FT-Raman, NIR, and wide-range diamond ATR. Switching between these experiments raises concerns of instrument recovery time (purge), exposure/handling of optics, and potential confusion or user error. The experiments are often seen as independent activities for these reasons. The spectrometer with iS50 ABX simplifies this apparently complex situation to one step – initiation of a macro. The Nicolet iS50 instrument shown in Figure 3 is configured with the iS50 NIR, iS50 Raman, iS50 ATR and the iS50 ABX modules and shows how easy sample loading and analysis can be done.For operating one module at a time, the user need only press the associated Touch Point. Seen more closely in Figure 4, Touch Points make one-button operation effortless when switching between modules (sampling stations) and automating optics exchange. Rather than thinking through the components needed (light source, beamsplitter, optical path and detector) to run anexperiment, the user simply presses the Touch Point to switch from an ATR to an NIR measurement and waits until the instrument indicates that it is ready to begin. This error-free operation is done in 30 seconds.The Nicolet iS50 analytical power in Figure 1 becomes clear when the four data collections – mid-IR and far-IR ATR, NIR, and Raman – are performed in one workflow. Collecting spectra from each of these modules using a conventional manual approach required about 50 minutes, including sample loading, optical changes, time forequilibration, and optimization of the Raman signal. The analyst needed to be present throughout the experiment to perform the beamsplitter changes and collect various backgrounds for each sampling station. At the end of the 50 minutes, four spectra and their analyses were available. Actual data collection took 5 minutes and total hands-on time was 45 minutes, representing inefficient use of the analyst’s time.In contrast, the results shown in Figure 5 emerged from a single OMNIC-macro operation. The macro wasprogrammed to begin by collecting backgrounds for the mid- and far-IR ATR, and then switched to the iS50 Raman module. Next the samples were loaded on the ATR, NIR, and Raman sampling stations. After optimizing the signal using the autofocus feature of the Ramanmodule, the macro was initiated, and the analyst walked away. From starting the macro to completion of the final report, the analysis took less than 12 minutes, representing a time savings of over 70%. The actual data collection time was again 5 minutes, however, total hands-on time for the analyst was only 2 minutes – a highly efficient use of the analyst’s (and the instrument’s) time.ABC DApplication Note 52416AN52416_E 12/12MAfrica +27 11 822 4120Australia +61 3 9757 4300Austria +43 1 333 50 34 0Belgium +32 53 73 42 41Canada +1 800 530 8447China +86 10 8419 3588Denmark +45 70 23 62 60Europe-Other +43 1 333 50 34 0Finland/Norway/Sweden +46 8 556 468 00France +33 1 60 92 48 00Germany +49 6103 408 1014India +91 22 6742 9434Italy +39 02 950 591Japan +81 45 453 9100Latin America +1 561 688 8700Middle East +43 1 333 50 34 0Netherlands +31 76 579 55 55New Zealand +64 9 980 6700Russia/CIS +43 1 333 50 34 0Spain +34 914 845 965Switzerland +41 61 716 77 00UK +44 1442 233555USA +1 800 532 4752©2012 Thermo Fisher Scientific Inc. All rights reserved. All trademarks are the property of Thermo Fisher Scientific Inc. and its subsidiaries.This information is presented as an example of the capabilities of Thermo Fisher Scientific Inc. products. It is not intended to encourage use of these products in any manners that might infringe the intellectual property rights of others. Specifications, terms and pricing are subject to change. Not all products are available in all countries. Please consult your local sales representative for details.ConclusionMany forces contribute to new pressures on industrial analytical laboratories: increased sample loads, decreased staffing, retirement of experts, and shrinking budgets. The Thermo Scientific Nicolet iS50 FT-IR spectrometer makes a significant contribution to alleviating these challenges through automation in a multi-tasking, single platform instrument. The Nicolet iS50 spectrometer greatly simplifies and streamlines workflows by decreasing the number of steps with one-button ease and macro operations performed by the analyst. In addition, risks inherent in manual operations (e.g., user error, environmentalexposure) and long recovery times are eliminated. Analysts of any skill level can successfully obtain meaningful results with minimal hands-on time.Technology designed to improve workflow can be found in the iS50 ABX and task-specific modules (i.e., Raman, NIR, TGA-IR etc.). The Touch Point operation simplifies access to the full range of capabilities by automatically configuring the optics (near-, mid- and far-IR) andswitching between sampling stations (modules) in secondsfor enhanced productivity. For the modern industrial lab, the Nicolet iS50 FT-IR spectrometer offers a powerful new tool that goes beyond routine FT-IR to more comprehensive analyses (e.g., FT-Raman and far-IR), adding value to laboratory activities in a compact, easy-to-operate platform.References1. H eavy atoms or groups of atoms shift the IR wavenumber value lower, according to the relationshipwhere ˜v is the IR wavenumber (cm -1) and μ is the reduced mass. As the mass (μ) increases, the IR peak shifts to lower wavenumbers.GlossaryCaF 2– calcium fluorideDLaTGS – d euterated L-alanine doped triglycene sulphate InGaAs – Indium gallium arsenide KBr– potassium bromideFigure 5: Multi-technique data for a recyclable plastic component using the spectrometer pictured in Figure 3. Inset shows NIRindependently for clarity.。
大数据时的大变革

+ 《红楼梦》含标点87万字(不含标点853509字) + 每个汉字占两个字节:1汉字=16bit = 2*8位
=2bytes + 1GB 约等于671部红楼梦 + 1TB 约等于631,903 部 + 1PB 约等于647,068,911部 + 美国国会图书馆藏书(151,785,778册)(2011年4
大数据时代 ----生活、工作与思维的大变革
• 一、认识大数据 • 二、大数据时代的变革 • 三、大数据时代的挑战 • 四、大数据的应用
+ 何为大 —数据度量 + 1Byte = 8 Bit + 1KB = 1,024 Bytes + 1MB = 1,024 KB = 1,048,576 Bytes + 1GB = 1,024 MB = 1,048,576 KB = 1,073,741,824 Bytes + 1TB = 1,024 GB = 1,048,576 MB = 1,099,511,627,776 Bytes + 1PB = 1,024 TB = 1,048,576 GB =1,125,899,906,842,624 Bytes + 1EB = 1,024 PB = 1,152,921,504,606,846,976 Bytes + 1ZB = 1,024 EB = 1,180,591,620,717,411,303,424 Bytes + 1YB = 1,024 ZB = 1,208,925,819,614,629,174,706,176 Bytes
21世纪是数据信息大发展的时代,移动 互联、社交网络、电子商务等极大拓展 了互联网的边界和应用范围,各种数据 正在迅速膨胀并变大。
系统分析师考试复习资料

系统分析师考试复习资料南昌大学计算中心武夷河E_Mail:wuyihe5304@说明:本文所有资料均收集于网络,由本人整理而成,在此对原作者表示衷心的感谢!网友们可自由传播此资料,但不得用于商业目的。
1 开发技术:语言与平台 (6)JavaBean 组件模型特点 (6)Enterprise JavaBean (EJB)组件模型特点: (6)JSP 胜过servlet 的关键的优点: (6)J2EE 的重要组成部分: (6)RMI 和RPC 的区别: (7)XML 和HTML 的主要区别: (7)XML 技术和JSP技术集成的方案: (7)XML 与JSP 技术联合的优越性: (7)XML 的特点: (7)SAX (Simple API for XML) 和DOM (Document Object Model) (7)什么DOM? (7)什么SAX? (8)什么类型的SAX 事件被SAX解析器抛出了哪? (9)什么时候使用DOM? (9)什么时候使用SAX? (9)HTML 的缺点: (10)经验结论 (10)用ASP、JSP、PHP 开发的缺陷: (10)XML 的优缺点: (10)XML 主要有三个要素:模式、XSL、XLL。
(10)2 Web Service 相关技术 (10)Web Service (10)创建简单的Web Service 的方法: (11)Web Service 主要目标是跨平台和可互操作性,其特点: (11)Web Service 应该使用的情况: (11)UDDI (统一描述、发现和集成Universal Description,Discovery,andIntegration) (11)SOAP (12)Web Service 技术(SOAP、UDDI、WSDL、EBXML) (12)3 软件工程、软件架构及软件体系结构 (12)3.1 面向对象技术 (12)一组概念 (12)OOA 的主要优点: (12)OOA 过程包括以下主要活动: (12)3.2 UML: (12)UML 包含了3 个方面的内容 (13)UML 提供了3类基本的标准模型建筑块 (13)UML 规定四种事物表示法 (13)UML 提供的建筑块之间的基本联系有四种 (13)UML 图形提供了9 种图形 (13)UML 规定了语言的四种公共机制 (13)UML 的特点: (13)USE CASE: (13)对象类图: (13)交互图: (14)状态图: (14)组件图和配置图: (15)UML 开发工具:ilogix Rhapsody (15)Rational Rose家族成员有: (15)3.3 OMT 方法: (15)OMT 方法有三种模型:对象模型、动态模型、功能模型。
人类基因组概况ppt课件

2.91Gbp
54% 38% 9% 35% 26588 42% Titin(234) 约300万个 1/12500 bp
最长的染色体 最短的染色体 基因最多的染色体 基因最少的染色体 基因密度最大的染色体 基因密度最小的染色体 重复序列含量最高的染色体
It is essentially immoral not to get it (the human genome sequence) done as fast as possible.
James Watson
人类基因组计划的完成,使得我们今天有可能来探 讨基因组的概,但我们仍然无法来谈论细节。
重复序列含量最低的染色体
编码外显子序列的比例 基因的平均长度
2(240 Mbp) Y(19 Mbp) 1(2453) Y(104) 19(23/Mb) 13,Y(5/Mb) 19(57%)
2,8,10,13,18(36%)
1.1~1.4% 27 Kb
女 平均 男
染色体上距着丝粒越远,重组率越高
4. Francis S. Collins, Eric D. Green, Alan E. Guttmacher, Mark S. Guyer :A Vision for the Future of Genomics Research. A blueprint for the genomic era. Nature Apr 24 2003: 835.
而 Celera 的测序样本来自5个人:分别属于西班牙裔、 亚洲裔、非洲裔、美洲裔和高加索裔(2男3女),是从21个志 愿者样本中挑选的。
数据科学家的英语

数据科学家的英语
数据科学家(Data Scientist)是指那些专门从事数据挖掘、机器学习、人工智能等方面工作的科学家。
他们主要利用大数据的技术和工具研究和解决实际业务中的问题,包括但不限于市场营销、金融预测、医学统计、社交网络等。
数据科学家需要具备良好的编程和数学能力,熟悉相关的算法和模型,并能够进行数据预处理、探索性分析、模型训练及评估等一系列工作。
在实践中,他们需要灵活运用各种数据分析工具和技术,如R、Python、SQL、Hadoop等,并能够独立思考和解决问题,具有良好的团队协作能力和沟通能力。
由于大数据时代的到来,数据科学家在各行各业都有巨大需求和广泛应用。
作为一种新兴职业,数据科学家为企业提供了更为准确、迅速的业务决策和更高效的业务流程,成为了数字化时代下不可或缺的专业人才。
北京周口店遗址博物馆英文导游词

北京周口店遗址博物馆英文导游词Each visitor:How are you, welcome you to Peking to travel, I am your guide DAVID.Week store Peking Man ruins, be located in the southwest of Peking City about 50,000 meters, was peaceably placed in a mountain area to border part at first.The southeast side is a north China big plain, the northwest side is a mountainous country.Week store the nearby mountainous country is mostly a limestone, under the water power function, form size the natural hole that don't wait settle and become the warehouse that buries "main beam of boat", the mountain past main beam of boat mountain.The top of hill has a thing long about 140 meterses, southern north breadth 2.5~42 meters don't wait of the natural cave is an ape person of Peking 50 ten thousand yearses ago dwell for rest of place, they successively lived together more than 40 ten thousand yearses in the cave and left behind they ate to remain of cripple remaining food and once used of tool, there are also their remainses.Afterwards, this hole drive the sediment of landslide and collapse to fall of piece of stone cover up.After being as early as in 1918 and discovering a first location, through the two exhumation in 1921, 1923 discovered many mammal fossils, special importance of is the tooth that there are two people in these fossils, it is an ape person of Peking to loose osseous of first detection.Since 1927, again through for many times large-scale discover, specially on December 2, 1929, Chinese archeologist Fei Sir in text at Peking Man ruins north the crack pile up a fossil in the Peking Man skull of discovering the first integrity.This discovers that the behavior evolution theory provides an emollient substantial evidence, is praised as Chinese what scientist seized the first science Olympic gold medal.Close currently, all Peking Man fossils sprouting have 6 more complete skulls, 12 decrepit noodles bones, 15 next Han bones, 157 teeth and 10 a few cripple limb bones, body bones.These fossilsrepresent more than 40 both sexes and all ages corpses.Week store then rise in the world by Chinese ape person's house.According to discovering of location, the scientists entitle"Peking Man" to this kind of original mankind and call this cave that it is "Peking Man ruins".The People's Republic of China after establishing, and then once carried on large-scale exhumation for many times, clean up more than 40 old little ape person's fossils in Peking to men and women, 100 various animal fossils, more than 100,000 pieces are various stone implement, and still keep a few ashes layers in the cave, the thickest 1 F reserves in great quantities burnt ground bone and charcoal broken bits in the ashes layer more than 6 meters, it is thus clear that"Peking Man" has already known to roast to eat a find and keep warm to defend with the fire cold.Ape person's ruins in Peking is above, in cave near the summit of hill the summit of hill hole person's ruins, discovered three adulthoods here men and women integrity of skull and remnants bone.Around discover the red iron mine powder that the Sa has red in the summit of hill hole person's skeleton.Still discover inside the hole bone needle that person of summit of hill hole once uses, bore hole of the bone fall to, fish bone, tooth decoration, the stone"necklace" of bead establish but become, these are good enough to prove they already learn to stitch skin clothes cold resisting, know to attire oneself, reflect a summit of hill hole original art of person of embryonic.Estimate to measure according to science:The summit of hill hole person's body Qu the characteristic and modern people have no obvious differentiation, he is an original yellow race person;Their living is being apart from now 18,000 year agos and compare "Peking Man" and consumedly went forward an one step.In 1961, week store ruins drive State Department list as a whole country point cultural object protection unit, 1987, United Nations teaches the section text the organization week store Peking Man the ruins are included in 《inheritance in the world records 》 .1953 week store ruins the museum outward open.In 1992, people's government in Peking City will list as "teenager education in Peking City base" here.In 1997, drive medium Xuan Bu list as 100 whole country patriotisms to demonstrate to educate one of the bases.Week store ruins the museum locate at southwest week store main beam of boat in building mountain area in city in Peking under the foot of a hill, is an ancients ruins museum, start to set up in 1953.In 1929, in Chinese the thou anthropologist Fei text first the lord dig out the skull fossil of"ape person of Peking" of the first integrity in the main beam of boat mountain and shocked in the world.Cultural inheritance, national AAAA class view area in world, national point cultural object protection unit and whole country 100 patriotisms educate a model base.Be apart from downtown about 48 kilometers in Peking.Being famous world the ancients and thou vertebrates to study of ancient relics ruins is the place of origin of "Peking Man".In 1987 according to cultural inheritance select standard C(III)(VI) be been included in 《inheritance in the world records 》The week store ruins belong to the national point cultural object protection unit and is located in southwest main beam of boat mountain in the week store town in building mountain area in Peking City north, is a material in the world most abundant, most system, the most worthy old stone age mankind's ruins in early days.1921-1927 years, the archeologist successively three times discovers three mankind outside"Peking Man" cave ruinstooth fossil, 1929, and then discovered a Peking Man skull fossil, and artificial creation of tool and use fire historic relic, hence become the important cist detection of shocked world.In the week in 1930 the store ruins still discover to be apart from now the summit of hill hole person's fossil and cultural keepsake about 2 ten thousand yearses ago.But follow for successive years to fight latest, lost the fossil specimen of all Peking men and summit of hill hole persons of detection since 1927, among the missing up to the present, this affairs becomes in 20th century a riddle of studying of ancient relics the world on the history.New China resumed the exhumation research of the store ruins to the week after establishing and obtained in great quantities precious data, up to the present, the archeologists have already dug out to represent more than 40 skulls of corpses and descend a Han bone, tooth to equalize stone and abundant stone implement, bone machine and Cape machine with use fire historic relic.Week the store Peking Man ruins museum systematically toward"Peking Man" that we introduced 60 ten thousand yearses ago, "new hole person"10 ten thousand yearses ago, the living environment, living condition of "summit of hill hole person" of 18000 year agos.The preface hall is face to face a main beam of boat mountain stereoscopic model, put a week's store region from various rock specimen of 400,000,000-100,000,000 year agos in the exhibition cabinet, reflected the geology variety of the cannon area's sea change process.The first exhibition hall displays the skull fossil model, the ancients of person from ape in Peking to chop down Zhuo, incise with the simple and crude stone system of fire historic relic and coarseness and pares and carves tool indiscriminately.Second exhibition hall with recover the model displayed theape person of Peking lives of cave and they of living place The third exhibition hall mainly introduces a main beam of boat top of hill detection of more than 20 vertebrates fossil the ruins and the ancients activity lead of the ruins distribute a point, and a 18000 the year ago summit of hill hole person's keepsake-string green shell, monster tooth, stone head ancient necklace for making into.The fourth exhibition hall displays the ancient mankind's fossil, old stone implement of each period of our country and world-wide locations detection, and old stone age later period the mankind's art objects, such as painting and carvings...etc..The location that the week store discovered at the earliest stage is 6 locations, what Sweden's scientist Anne livinged to discover in 1918 especially.Anne livings especially in 1921, space orchid rank in American paleontology house and Si Dan Si radicle in Austrian paleontology house, discovered a week store l location, discovered a week at the same year store 2 locations.Step in 1927 reaches to living week store detection of three people's tooth formally named after Chinese ape person Peking to grow, the this year is formal week store ruins to start exhumation, Chinese geologist Li Jie takes part in to discover a work and erupted now a week the store 3rd and 4 locations, Sweden paleontology step wood in the house is also the finder of new location, in 1929 in the Pei text discovered 5, 7, 8 locations, found out "Peking Man" the first skull.The location that will have been already discovered at the same year take"Peking Man" ruins as one location, rest of one after another serial number and go to 9 locations.At No.20 location before, included summit of hill hole, or for led bottom or was the Gu orchid ascent leadership in the Pei text detection of.20-24 locations find out under the Guorchid ascent leadership."Peking Man" ruins' aring located in an of week store village is western.There is the hillock that two things are juxtaposed, one of east contains a Tashan hole and is so called the ape person's hole, 1929 after, is week store first location, thing long about 140 meters, central part most the breadth place is about 20 meters."Peking Man" lives in the store in week of time, about from be apart from now more than 60 ten thousand yearses to start, until be apart from now more than 20 ten thousand yearses;"Peking Man" culture in early days from be apart from now more than 60 ten thousand yearses to be apart from now before more than 40 ten thousand yearses, middle in order to be apart from now for 40-30 ten thousand yearses, later period for be apart from now before more than 30-20 ten thousand yearses.Week store one location discover from 1921 with start to discover, have already descended to dig more than 40 rices.Just like one mouthful deep well.Already dig to pile up still don't arrive the half that the whole holeses pile up a thing."Peking Man" fossil from the ll layer go to 3 F and all have been already discovered, totally sprout bone 6, skull fragment 12, descend a Han bone 15, the tooth is 157, the bone is 7, shin l piece, Gong bone 3, lock bone and month bone 1 for each and some skulls and noodles bone rag.These"Peking Man"s loose a bone to accordingly belong to more than 40 individuals.But the great majority person's fossil, at Pearl Harbor the front and back of the incident, among the missing.Person's fossil of one location existingly and, keep at our country of have 7 teeth, a Gong bone and shin a , parietal bones and back part of skull 1 for each and a conservancy intactly under Han bone;1927 ago discover of three teeth are in Sweden then, was maintained by the step wood of earlier periodweek store work.In the week store the l location discover to use fire historic relic and use the fiery history to the mankind several 100,000 years in advance.Include five ashes layer, two ash with good conservancy heaps to loose to save, burn a bone then Be seen to each one of someone activity, in addition, also discover burnt plain tree son and burn a stone and burn clod, even the individual stone implement has already roasted bright trace.To the research used fire historic relic, can know"Peking Man" not only knows to use fire, but also has the ability of control fire and conservancy material for new fire.The fuel of building a fire is mainly a herbs, also make a salary with tree branch and fresh bone.The stone implement is "Peking Man" cultural of main representative, "Peking Man" created three kinds of different dozens slice method, mainly use to hit a shot method, produce to grow 20 a 30 millimeters of stone slice;The familiar length is 20-40 millimeters;The tool divides two major types, Category 1 includes the hammer shot stone hammer and hit a shot stone the hammer and stone drill, Category 2 has already pared away a machine, the point form machine, chop down to hit a machine and carve machine, stone awl and spheroid machine.Week store Peking Man the ruins are located in week store main beam of boat in building mountain area mountain in Peking City.Rise in the world because this 20's in century sprouted more complete ape person's fossil in Peking, particularly discover the first Peking Man skull in 1929 and provide solid foundation for the existence of the Peking Man thus and become the ancients research the milestone on the history.So far, mankind's fossil sprouting includes 6 skulls, 15 next Han bones and 157 teeth and a great deal of skeleton broken bits and represents ape person'sindividual in about 40 Peking.For studied mankind the biology in early days to evolve early a development of expecting culture to provide a real object basis.The research of thing according to depositing to culture, the Peking Man life is being apart from now 70-20 ten thousand yearses of.The average amount of brain of the Peking Man reaches to 1088 milliliters(the modern people brain measures to 1400), according to reckon the Peking Man height as 156 Li rice(male)s, 150 Li rice(female)s.The Peking Man belongs to stone age and process the method of stone implement mainly for the hammer shot method, secondly in order to hit a shot method, accidentally see a Zhen shot method.The Peking Man still kept using fiery ancients at the earliest stage, and can catch to hunt a large animal.The life span of the Peking Man is shorter, according to the statistics, 68.2% dies in 14 before the year old, over 50-year-old the shortage is 4.5%.77 after the incident, week the store be captured by the Japan's Imperial Army, discover a personnel be killed, Pei text's moderating the office of Gu orchid ascent is ruined by the Dao and discover a work to terminate.War against Japan period, six more complete skulls having already dug out deposit inside concord medical college in Peking that starts in the United States, the Pacific War breaks out an eve, and Central America both parties plan to transport his United States, in order to prevent it falls into Japanese hand.On the way skull disappearance, among the missing up to now.After the People's Republic of China builds up, and then carried on exhumation to the store ruins in week, discovered that a great deal of ashes piles up a layer and prove that the Peking Man has already use fire.Was finished in the store Peking Manruins neighborhood in week in 1953 week store ruins museum, open to the public.Dig out a life in 1930 at the main beam of boat summit of hill department front and back ancient mankind's fossil during 2 ten thousand yearses, and named after "summit of hill hole person".Discover to lie "new hole person" between two age ofs again in 1973, express continuing of Peking Man and develop.In 1936, Sir Gu Lan Po and then discovered the skull fossil of 3"summit of hill hole person" here.60's don't, it are now to discover to be apart from again here 10 ten thousand yearses of the ruins of"new hole person".This a series of importance discovers that for studied the mankind's origins problem to provide importance basis.Week store ruins drive State Department list as a whole country point cultural object protection the unit be taught the section text the organization by United Nations to list as "cultural inheritance in world".Week store ruins the museum is an AAAA class tourist spot Week store ruins the museum is a whole country point the cultural object protect unit.。
石城县近50 年气候趋势变化分析

农业灾害研究2021,11(6)作者简介 董志询(1995-),男,江西乐安人,助理工程师,主要从事气象服务与应用气象工作。
收稿日期 2021-03-09Analysis of Climate Trend Change in Shicheng County in the Past 50 YearsDONG Zhi-xun et al (Meteorological Bureau of Shicheng County, Shicheng, Jiangxi 342700)Abstract Using data from the National Meteorological Observatory of Shicheng County from 1971 to 2020, such as annual temperature, precipitation, and sunshine hours, the linear trend method and Mann-Kendall mutation test method were used to analyze the characteristics of climate change in Shicheng County in the past 50 years. The results show that the climate warming trend in Shicheng County has been significant since 1970, the linear trend rate of the annual average temperature is 0.19℃/10 a, and an abrupt change occurred in 2002, and the temperature increased significantly after the abrupt change; The annual precipitation showed a slight increase trend, which was not significant, but the time distribution is extremely uneven. In 1998 and 2015, there were serious southern floods; the annual sunshine hours showed a decreasing trend. There is no obvious sudden change in annual precipitation and annual sunshine hours. Therefore, the comprehensive abrupt time of climate change in Shicheng County in the past 50 years is judged to be 2002.Key words Changing climate trends; Meteorological data analysis; Mann-Kendall mutation test; Shicheng count石城县近50年气候趋势变化分析董志询1,符志军2,温田超1,刘凤凤1,王 超31.江西省石城县气象局,江西石城 342700;2.江西省抚州市气象局,江西抚州 344000;3.东华理工大学地球物理与测控技术学院,江西南昌 330000摘要 利用石城县国家气象观测站1971—2020年逐年气温、降水、日照时数等资料,采用线性趋势法、Mann-Kendall突变检验法分析了石城县近50年的气候变化特征。
国际单克隆抗体研究文献分析

国际单克隆抗体研究文献分析通过比较分析1999-2008年单克隆抗体主要研究国家和机构的科研产出及单克隆抗体的研究领域、热点等,为科研工作者和科研管理者提供参考。
方法利用文献计量学方法,对Web of Science(SCIE)收录的单克隆抗体论文的时间、国家、机构、期刊进行分析;同时结合共词分析、聚类分析和可视化分析方法,对单克隆抗体研究有关的论文开展主题分析。
结果SCIE收录单克隆研究文献50357篇,美国在文献数量和质量上遥遥领先,中国与美国等发达国家差距较大;单克隆抗体研究属多学科交叉领域,CD40分子、EGFR等是当前研究的热点。
结论中国应加大单克隆抗体资金投入,加强与顶级科研院所的交流合作,紧跟研究热点,提高自主创新能力。
Analysis of Monoclonal Antibody Research Literatures in the WorldLI Hai-cun, WANG Min ,XU Pei-yangInstitute of medical information, Peking Union medical college, Beijing 100020, ChinaAbstract Objective To compare the outputs on monoclonal antibody research of the major research institute and countries in which the research were conducted from 1999 to 2008 and find the major research field and hot topics, provide reference for the monoclonal antibody research and the management in China. Methods The papers on monoclonal antibody were searched in web of science database (SCIE), and by using bibliometric method, the publishing years, the author's countries/institutes and the publishing journals of the papers were analyzed; The main subjects and topics were analyzed by using co-word analysis, cluster analysis and visualization analysis. Results A total of 50357 papers were searched in SCIE, the papers from USA were in the largest quantity and with the best quality. The monoclonal antibody research in China was lagging compared with the developed countries. Monoclonal antibody research is a multidisciplinary field and with the hot topics of CD40 molecule, EGFR and others at present . Conclusion It is necessary to increase the investment on monoclonal antibody research in China, strengthen the cooperation between scientific research institutes and conduct researches on hot topics to make the initiatives on monoclonal antibody research.Key words Monoclonal antibody; Information visualization; Bibliometrics; Cluster analysis; Co-word analysis《国家中长期科学和技术发展规划纲要(2006-2020)》将提高自主创新能力作为国家长期战略,并把生物技术作为未来重点发展的前沿技术[1]。
人物信息检索

3、中国人物库 (bjinfobank/IrisBin/Select.dll?Special ?db=RW) 中国资讯行编制,数据库提供详尽的中 国主要政治人物, 工业家, 银行家, 企业家, 科学家以及其他著名人物的简历及有关的 资料,其内容主要根据对中国八百多种公 开发行刊物的搜集而生成。
资源推荐 人物信息检索篇(二)
五、人物资料数据库
人物资料数据库是有关机构或个人为特 定目的编制的专门用于人物资料检索的事 实型数据库。数据库是可供计算机快速检 索的、有组织的、可共享的数据集合。就 查找人物资料而言,利用数据库是最为简 捷和有效的途径。
1、地方志人物传记索引数据库 (/newpages/database/dfzrw.ht m) 国家图书馆编制,提供1949年以后新编 地方志中所见人物的姓名、性别、民族、
报电子出版中心联合编辑制作,资料来源 于人民网丰富的新闻资源,内容权威、可 靠,检索方便,需注册使用。
6、搜狐经济人物库 (business./7/0304/57/column2196157 68.shtml) 设有人物库分类导航(官员、经济学家、
企业家、经理人、国际人物、经济传媒人、 业界人士、专栏作家),提供分类浏览、 姓名拼音字顺查找和关键词快速检索。
六、网络传记辞典
传记辞典由来已久种类繁多,近年来随着网络的飞速发 展,可在线阅读的传记辞典不断增多,其中英文传记辞 典最为人称道。例如我们可以在dmoz(/)中 检出47种biographical dictionary(传记辞典)、 YAHOO“Directory”( search.yahoo/dir)中列举了97 类与“"Biographical Dictionary"”(英文双引号phical Dictionary等等。我们可以通过搜索引擎 对传记辞典的数量有一个大致的了解,并利用搜索结果 选择适合自己需要的网络传记辞典。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
50years of Data ScienceDavid DonohoSept.18,2015Version1.00AbstractMore than50years ago,John Tukey called for a reformation of academic statistics.In‘The Future of Data Analysis’,he pointed to the existence of an as-yet unrecognized science,whose subject of interest was learning from data,or‘data analysis’.Ten to twenty years ago,John Chambers,Bill Cleveland and Leo Breiman independently once again urged academic statistics to expand its boundaries beyond the classical domain of theoretical statistics;Chambers called for more emphasis on data preparation and presentation rather than statistical modeling;and Breiman called for emphasis on prediction rather than inference.Cleveland even suggested the catchy name“Data Science”for his envisionedfield.A recent and growing phenomenon is the emergence of“Data Science”programs at major universities,including UC Berkeley,NYU,MIT,and most recently the Univ.of Michigan,which on September8,2015announced a$100M“Data Science Initiative”that will hire35new faculty. Teaching in these new programs has significant overlap in curricular subject matter with tradi-tional statistics courses;in general,though,the new initiatives steer away from close involvement with academic statistics departments.This paper reviews some ingredients of the current“Data Science moment”,including recent commentary about data science in the popular media,and about how/whether Data Science is really different from Statistics.The now-contemplatedfield of Data Science amounts to a superset of thefields of statistics and machine learning which adds some technology for‘scaling up’to‘big data’.This chosen superset is motivated by commercial rather than intellectual developments.Choosing in this way is likely to miss out on the really important intellectual event of the nextfifty years.Because all of science itself will soon become data that can be mined,the imminent revolution in Data Science is not about mere‘scaling up’,but instead the emergence of scientific studies of data analysis science-wide.In the future,we will be able to predict how a proposal to change data analysis workflows would impact the validity of data analysis across all of science,even predicting the impactsfield-by-field.Drawing on work by Tukey,Cleveland,Chambers and Breiman,I present a vision of data science based on the activities of people who are‘learning from data’,and I describe an academic field dedicated to improving that activity in an evidence-based manner.This newfield is a better academic enlargement of statistics and machine learning than today’s Data Science Initiatives, while being able to accommodate the same short-term goals.Based on a presentation at the Tukey Centennial workshop,Princeton NJ Sept182015:Contents1Today’s Data Science Moment4 2Data Science‘versus’Statistics42.1The‘Big Data’Meme (6)2.2The‘Skills’Meme (7)2.3The‘Jobs’Meme (8)2.4What here is real? (9)2.5A Better Framework (9)3The Future of Data Analysis,196210 4The50years since FoDA124.1Exhortations (12)4.2Reification (14)5Breiman’s‘Two Cultures’,200115 6The Predictive Culture’s Secret Sauce166.1The Common Task Framework (16)6.2Experience with CTF (17)6.3The Secret Sauce (18)6.4Required Skills (18)7Teaching of today’s consensus Data Science19 8The Full Scope of Data Science228.1The Six Divisions (22)8.2Discussion (25)8.3Teaching of GDS (26)8.4Research in GDS (27)8.4.1Quantitative Programming Environments:R (27)8.4.2Data Wrangling:Tidy Data (27)8.4.3Research Presentation:Knitr (28)8.5Discussion (28)9Science about Data Science299.1Science-Wide Meta Analysis (29)9.2Cross-Study Analysis (30)9.3Cross-Workflow Analysis (31)9.4Summary (32)10The Next50Years of Data Science3210.1Open Science takes over (32)10.2Science as data (33)10.3Scientific Data Analysis,tested Empirically (34)10.3.1DJ Hand(2006) (35)10.3.2Donoho and Jin(2008) (35)10.3.3Zhao,Parmigiani,Huttenhower and Waldron(2014) (36)10.4Data Science in2065 (37)11Conclusion37 Acknowledgements:Special thanks to Edgar Dobriban,Bradley Efron,and Victoria Stodden for comments on Data Science and on drafts of this mss.Thanks to John Storey,Amit Singer,Esther Kim,and all the other organizers of the Tukey Centennial at Princeton,September18,2015.Belated thanks to my undergraduate statistics teachers:Peter Bloomfield,Henry Braun,Tom Hettmansperger, Larry Mayer,Don McNeil,GeoffWatson,and John Tukey.Supported in part by NSF DMS-1418362and DMS-1407813.Acronym MeaningASA American Statistical AssociationCEO Chief Executive OfficerCTF Common Task FrameworkDARPA Defense Advanced Projects Research AgencyDSI Data Science InitiativeEDA Exploratory Data AnalysisFoDA The Furure of Data Analysis,1962GDS Greater Data ScienceHC Higher CriticismIBM IBM Corp.IMS Institute of Mathematical StatisticsIT Information Technology(thefield)JWT John Wilder TukeyLDS Lesser Data ScienceNIH National Institutes of HealthNSF National Science FoundationPoMC The Problem of Multiple Comparisons,1953QPE Quantitative Programming EnvironmentR R–a system and language for computing with dataS S–a system and language for computing with dataSAS System and lagugage produced by SAS,Inc.SPSS System and lagugage produced by SPSS,Inc.VCR Verifiabe Computational ResultTable1:Frequent Acronyms1Today’s Data Science MomentOn Tuesday September8,2015,as I was preparing these remarks,the University of Michigan an-nounced a$100Million“Data Science Initiative”(DSI),ultimately hiring35new faculty.The university’s press release contains bold pronouncements:“Data science has become a fourth approach to scientific discovery,in addition to experimentation,modeling,and computation,”said Provost Martha Pollack.The web site for DSI gives us an idea what Data Science is:“This coupling of scientific discovery and practice involves the collection,manage-ment,processing,analysis,visualization,and interpretation of vast amounts of het-erogeneous data associated with a diverse array of scientific,translational,and inter-disciplinary applications.”This announcement is not taking place in a vacuum.A number of DSI-like initiatives started recently,including(A)Campus-wide initiatives at NYU,Columbia,MIT,...(B)New Master’s Degree programs in Data Science,for example at Berkeley,NYU,Stanford,...There are new announcements of such initiatives weekly.12Data Science‘versus’StatisticsMany of my audience at the Tukey Centennial where these remarks were presented are applied statisticians,and consider their professional career one long series of exercises in the above“... collection,management,processing,analysis,visualization,and interpretation of vast amounts of heterogeneous data associated with a diverse array of...applications.”In fact,some presentations atthe Tukey Centennial were exemplary narratives of“...collection,management,processing,analysis, visualization,and interpretation of vast amounts of heterogeneous data associated with a diverse array of...applications.”To statisticians,the DSI phenomenon can seem puzzling.Statisticians see administrators touting,as new,activities that statisticians have already been pursuing daily,for their entire careers;and which were considered standard already when those statisticians were back in graduate school.The following points about the U of M DSI will be very telling to such statisticians:•U of M’s DSI is taking place at a campus with a large and highly respected Statistics Depart-ment•The identified leaders of this initiative are faculty from the Electrical Engineering and ComputerScience Department(Al Hero)and the School of Medicine(Brian Athey).1For an updated interactive geographic map of degree programs,see http://data-science-university-programs.silk.co•The inagural symposium has one speaker from the Statistics department(Susan Murphy),out of more than20speakers.Seemingly,statistics is being marginalized here;the implicit message is that statistics is a partof what goes on in data science but not a very big part.At the same time,many of the concrete de-scriptions of what the DSI will actually do will seem to statisticians to be bread-and-butter statistics. Statistics is apparently the word that dare not speak its name in connection with such an initiative!2 Searching the web for more information about the emerging term‘Data Science’,we encounter the following definitions from the Data Science Association’s“Professional Code of Conduct”3‘‘Data Scientist"means a professional who uses scientific methods to liberate and create meaning from raw data.To a statistician,this sounds an awful lot like what applied statisticians do:use methodology to make inferences from data.Continuing:‘‘Statistics"means the practice or science of collecting and analyzing numerical data in large quantities.To a statistician,this definition of statistics seems already to encompass anything that the def-inition of Data Scientist might encompass,but the definition of Statistician seems limiting,since alot of statistical work is explicitly about inferences to be made from very small samples—this been true for hundreds of years,really.In fact Statisticians deal with data however it arrives-big or small.The statistics profession is caught at a confusing moment:the activities which preoccupied it over centuries are now in the limelight,but those activities are claimed to be bright shiny new, and carried out by(although not actually invented by)upstarts and strangers.Various professional statistics organizations are reacting:•Aren’t we Data Science?Column of ASA President Marie Davidian in AmStat News,July,20134•A grand debate:is data science just a‘rebranding’of statistics?Martin Goodson,co-organizer of the Royal Statistical Society meeting May11,2015on the relation of Statistics and Data Science,in internet postings promoting that event.•Let us own Data Science.IMS Presidential address of Bin Yu,reprinted in IMS bulletin October201452At the same time,the two largest groups of faculty participating in this initiative are from EECS and Statistics. Many of the EECS faculty publish avidly in academic statistics journals–I can mention Al Hero himself,Raj Rao Nadakaduti and others.The underlying design of the initiative is very sound and relies on researchers with strong statistics skills.But that’s all hidden under the hood.3/code-of-conduct.html4/blog/2013/07/01/datascience/5/2014/10/ims-presidential-address-let-us-own-data-science/One doesn’t need to look far to see click-bait capitalizing on the befuddlement about this newstate of affairs:•Why Do We Need Data Science When We’ve Had Statistics for Centuries?Irving Wladawsky-BergerWall Street Journal,CIO report,May2,2014•Data Science is statistics.When physicists do mathematics,they don’t say they’re doing number science.They’re doing math.If you’re analyzing data,you’re doing statistics.You can call it data scienceor informatics or analytics or whatever,but it’s still statistics....You may not like what some statisticians do.You may feel they don’t share your values.They may embarrass you.But that shouldn’t lead us to abandon the term‘‘statistics’’.Karl Broman,Univ.Wisconsin6On the other hand,we canfind pointed comments about the(near-)irrelevance of statistics:•Data Science without statistics is possible,even desirable.Vincent Granville,at the Data Science Central Blog7•Statistics is the least important part of data science.Andrew Gelman,Columbia University8Clearly,there are many visions of Data Science and its relation to Statistics.In discussions one recognizes certain recurring‘Memes’.We now deal with the main ones in turn.2.1The‘Big Data’MemeConsider the press release announcing the University of Michigan Data Science Initiative with whichthis article began.The University of Michigan President,Mark Schlissel,uses the term‘big data’repeatedly,touting its importance for allfields and asserting the necessity of Data Science for handlingsuch data.Examples of this tendency are near-ubiquitous.We can immediately reject‘big data’as a criterion for meaningful distinction between statisticsand data science9.•History.The very term‘statistics’was coined at the beginning of modern efforts to compilecensus data,prehensive data about all inhabitants of a country,for example Franceor the United States.Census data are roughly the scale of today’s big data;but they havebeen around more than200years!A statistician,Hollerith,invented thefirst major advance in 6https:///2013/04/05/data-science-is-statistics/7/profiles/blogs/data-science-without-statistics-is-possible-even-desirable 8/2013/11/14/statistics-least-important-part-data-science/9One sometimes encounters also the statement that statistics is about‘small datasets,while Data Science is about‘big datasets.Older statistics textbooks often did use quite small datasets in order to allow students to make hand calculations.big data:the punched card reader to allow efficient compilation of an exhaustive US census.10 This advance led to formation of the IBM corporation which eventually became a force pushing computing and data to ever larger scales.Statisticians have been comfortable with large datasets for a long time,and have been holding conferences gathering together experts in ‘large datasets’for several decades,even as the definition of large was ever expanding.11•Science.Mathematical statistics researchers have pursued the scientific understanding of big datasets for decades.They have focused on what happens when a database has a large number of individuals or a large number of measurements or both.It is simply wrong to imagine that they are not thinking about such things,in force,and obsessively.Among the core discoveries of statistics as afield were sampling and sufficiency,which allow to deal with very large datasets extremely efficiently.These ideas were discovered precisely because statisticians care about big datasets.The data-science=‘big data’framework is not getting at anything very intrinsic about the re-spectivefields.122.2The‘Skills’MemeComputer Scientists seem to have settled on the following talking points:(a)data science is concerned with really big data,which traditional computing resources could notaccommodate(b)data science trainees have the skills needed to cope with such big datasets.The CS evangelists are thus doubling down on the‘Big Data’meme13,by layering a‘Big Data skills meme’on top.What are those skills?Many would cite mastery of Hadoop,a variant of Map/Reduce for use with datasets distributed across a cluster of computers.Consult the standard reference Hadoop: The Definitive Guide.Storage and Analysis at Internet Scale,4th Edition by Tom White.There we learn at great length how to partition a single abstract dataset across a large number of processors. Then we learn how to compute the maximum of all the numbers in a single column of this massive dataset.This involves computing the maximum over the sub database located in each processor, followed by combining the individual per-processor-maxima across all the many processors to obtain an overall maximum.Although the functional being computed in this example is dead-simple,quite a few skills are needed in order to implement the example at scale.10/2014/10/ims-presidential-address-let-us-own-data-science/11During the Centennial workshop,one participant pointed out that John Tukey’s definition of‘Big Data’was:“anything that won’tfit on one device”.In John’s day the device was a tape drive,but the larger point is true today, where device now means‘commodityfile server’.12It may be getting at something real about the Masters’degree programs,or about the research activities of individuals who will be hired under the new spate of DSI’s.13...which we just dismissed!Lost in the hoopla about such skills is the embarrassing fact that once upon a time,one could do such computing tasks,and even much more ambitious ones,much more easily than in this fancy new setting!A dataset couldfit on a single processor,and the global maximum of the array‘x’could be computed with the six-character code fragment‘max(x)’in,say,Matlab or R.More ambitious tasks,like large-scale optimization of a convex function,were easy to set up and use.In those less-hyped times,the skills being touted today were unnecessary.Instead,scientists developed skills to solve the problem they were really interested in,using elegant mathematics and powerful quantitative programming environments modeled on that math.Those environments were the result of50or more years of continual refinement,moving ever closer towards the ideal of enabling immediate translation of clear abstract thinking to computational results.The new skills attracting so much media attention are not skills for better solving the real problem of inference from data;they are coping skills for dealing with organizational artifacts of large-scale cluster computing.The new skills cope with severe new constraints on algorithms posed by the multiprocessor/networked world.In this highly constrained world,the range of easily constructible algorithms shrinks dramatically compared to the single-processor model,so one inevitably tends to adopt inferential approaches which would have been considered rudimentary or even inappropriate in olden times.Such coping consumes our time and energy,deforms our judgements about what is appropriate,and holds us back from data analysis strategies that we would otherwise eagerly pursue.Nevertheless,the scaling cheerleaders are yelling at the top of their lungs that using more data deserves a big shout.2.3The‘Jobs’MemeBig data enthusiasm feeds offthe notable successes scored in the last decade by brand-name global Information technology(IT)enterprises,such as Google and Amazon,successes currently recognized by investors and CEOs.A hiring‘bump’has ensued over the last5years,in which engineers with skills in both databases and statistics were in heavy demand.In‘The Culture of Big Data’[1],Mike Barlow summarizes the situationAccording to Gartner,4.4million big data jobs will be created by2014and only a third of them will befilled.Gartner’s prediction evokes images of“gold rush”for big datatalent,with legions of hardcore quants converting their advanced degrees into lucrativeemployment deals.While Barlow suggests that any advanced quantitative degree will be sufficient in this environ-ment,today’s Data Science initiatives per se imply that traditional statistics degrees are not enough to land jobs in this area-formal emphasis on computing and database skills must be part of the mix.14We don’t really know.The booklet‘Analyzing the Analyzers:An Introspective Survey of Data Scientists and Their Work’[20]points out thatDespite the excitement around“data science”,“big data”,and“analytics”,the ambi-guity of these terms has led to poor communication between data scientists and those whoseek their help.14Of course statistics degrees require extensive use of computers,but often omit training in formal software develop-ment and formal database theory.Yanir Seroussi’s blog15opines that“there are few true data science positions for people with no work experience.”A successful data scientist needs to be able to become one with the databy exploring it and applying rigorous statistical analysis...But good data scientists also understand what it takes to deploy production systems,andare ready to get their hands dirty by writing code that cleans up the dataor performs core system functionality...Gaining all these skills takes time [on the job].Barlow implies that would-be data scientists may face years of further skills development post masters degree,before they can add value to their employer’s organization.In an existing big-data organization,the infrastructure of production data processing is already set in stone.The databases, software,and workflow management taught in a given Data Science Masters program are unlikely to be the same as those used by one specific employer.Various compromises and constraints were settled upon by the hiring organizations and for a new hire,contributing to those organizations is about learning how to cope with those constraints and still accomplish something.Data Science degree programs do not actually know how to satisfy the supposedly voracious demand for graduates.As we show below,the special contribution of a data science degree over a statistics degree is additional information technology training.Yet hiring organizations face diffi-culties making use of the specific information technology skills being taught in degree programs.In contrast,Data Analysis and Statistics are broadly applicable skills that are portable from organiza-tion to organization.2.4What here is real?We have seen that today’s popular media tropes about Data Science don’t withstand even basic scrutiny.This is quite understandable:writers and administrators are shocked out of their wits. Everyone believes we are facing a zero-th order discontinuity in human affairs.If you studied a tourist guidebook in2010,you would have been told that life in villages in India (say)had not changed in thousands of years.If you went into those villages in2015,you would see that many individuals there now have mobile phones and some have smartphones.This is of course the leading edge fundamental change.Soon,8billion people will be connected to the network,and will therefore be data sources,generating a vast array of data about their activities and preferences.The transition to universal connectivity is very striking;it will,indeed,generate vast amounts of commercial data.Exploiting that data seems certain to be a major preoccupation of commercial life in coming decades.2.5A Better FrameworkHowever,a science doesn’t just spring into existence simply because a deluge of data will soon be filling telecom servers,and because some administrators think they can sense the resulting trends in hiring and government funding.15/2014/10/23/what-is-data-science/Fortunately,there is a solid case for some entity called‘Data Science’to be created,which would be a true science:facing essential questions of a lasting nature and using scientifically rigorous techniques to attack those questions.Insightful statisticians have for at least50years been laying the groundwork for constructing that would-be entity as an enlargement of traditional academic statistics.This would-be notion of Data Science is not the same as the Data Science being touted today,although there is significant overlap.The would-be notion responds to a different set of urgent trends-intellectual rather than commercial.Facing the intellectual trends needs many of the same skills as facing the commercial ones and seems just as likely to match future student training demand and future research funding trends.The would-be notion takes Data Science as the science of learning from data,with all that this entails.It is matched to the most important developments in science which will arise over the coming50years.As science itself becomes a body of data that we can analyze and study,there are staggeringly large opportunities for improving the accuracy and validity of science,through the scientific study of data analysis.Understanding these issues gives Deans and Presidents an opportunity to rechannel the energy and enthusiasm behind today’s Data Science movement towards lasting,excellent programs canoni-calizing a new scientific discipline.In this paper,I organize insights that have been published over the years about this new would-befield of Data Science,and put forward a framework for understanding its basic questions and procedures.This framework has implications both for teaching the subject and for doing scientific research about how data science is done and might be improved.3The Future of Data Analysis,1962This paper was prepared for the John Tukey centennial.More than50years ago,John prophecied that something like today’s Data Science moment would be coming.In“The Future of Data Anal-ysis”[42],John deeply shocked his readers(academic statisticians)with the following introductory paragraphs:16For a long time I have thought I was a statistician,interested in inferences from the particular to the general.But as I have watched mathematical statistics evolve,I havehad cause to wonder and to doubt....All in all I have come to feel that my centralinterest is in data analysis,which I take to include,among other things:proceduresfor analyzing data,techniques for interpreting the results of such procedures,ways ofplanning the gathering of data to make its analysis easier,more precise or more accurate,and all the machinery and results of(mathematical)statistics which apply to analyzingdataThis paper was published in1962in“The Annals of Mathematical Statistics”,the central venue for mathematically-advanced statistical research of the day.Other articles appearing in that journal16One questions why the journal even allowed this to be published!Partly one must remember that John was a Professor of Mathematics at Princeton,which gave him plenty of authority!Sir Martin Rees,the famous as-tronomer/cosmologist once quipped that“God invented space just so not everything would happen at Princeton”.JL Hodges Jr.of UC Berkeley was incoming editor of Annals of Mathematical Statistics,and deserves credit for publishing such a visionary but deeply controversial paper.at the time were mathematically precise and would present definitions,theorems,and proofs.John’s paper was instead a kind of public confession,explaining why he thought such research was too narrowly focused,possibly useless or harmful,and the research scope of statistics needed to be dramatically enlarged and redirected.Peter Huber,whose scientific breakthroughs in robust estimation would soon appear in the same journal,recently commented about FoDA:Half a century ago,Tukey,in an ultimately enormously influential paper redefined our subject...[The paper]introduced the term“data analysis”as a name for what appliedstatisticians do,differentiating this term from formal statistical inference.But actually,as Tukey admitted,he“stretched the term beyond its philology”to such an extent that itcomprised all of statistics.Peter Huber(2010)So Tukey’s vision embedded statistics in a larger entity.Tukey’s central claim was that this new entity,which he called‘Data Analysis’,was a new science,rather than a branch of mathematics: There are diverse views as to what makes a science,but three constituents will be judged essential by most,viz:(a1)intellectual content,(a2)organization in an understandable form,(a3)reliance upon the test of experience as the ultimate standard of validity.By these tests mathematics is not a science,since its ultimate standard of validity is an agreed-upon sort of logical consistency and provability.As I see it,data analysis passes all three tests,and I would regard it as a science, one defined by a ubiquitous problem rather than by a concrete subject.Data analysisand the parts of statistics which adhere to it,must then take on the characteristics of ascience rather than those of mathematics,...These points are meant to be taken seriously.Tukey identified four driving forces in the new science:Four major influences act on data analysis today:1.The formal theories of statistics2.Accelerating developments in computers and display devices3.The challenge,in manyfields,of more and ever larger bodies of data4.The emphasis on quantification in an ever wider variety of disciplinesJohn’s1962list is surprisingly modern,and encompasses all the factors cited today in press releases touting today’s Data Science initiatives.Shocking at the time was item#1,implying that statistical theory was only a(fractional!)part of the new science.Tukey and Wilk1969compared this new science to established sciences and further circumscribed the role of Statistics within it:。