TRIP_White_Paper_Non_Boolean_Search
python核心编程第二版第3章习题答案

3-1.标识符。
为什么Python中不需要变量名和变量类型声明?答案:Python语言中对象的类型和内存都是运行时确定的。
在创建也就是赋值时,解释器会根据语法和右侧的操作数来决定新对象的类型。
因为变量在第一次赋值的时候就被自动声明了。
Python是无类型的语言。
Python既是动态类型语言(因为它不使用显示数据类型声明,在运行期间才去确定数据类型),又是强类型语言(因为只要一个变量获得了一个数据,它就一直就是这个数据的数据类型)。
3-2.标识符。
为什么Python中不需要声明函数类型?答案:函数没有定义返回的数据类型。
Python不需要指定返回值的数据类型;甚至不需要指定是否有返回值。
实际上,每个Python函数都返回一个值;如果函数执行过return语句,它将返回指定的值,否则将返回None(Python的空值)。
3-3.标识符。
为什么应当避免在变量名的开始和结尾使用双下划线?答案:因为变量名__xxx__对Python来说有特殊含义,对于普通的变量应当避免这种命名风格。
3-4.语句。
在Python中一行可以书写多个语句吗?答案:可以3-5.语句。
在Python中可以将一个语句分成多行书写吗?答案:可以3-6.变量赋值。
(a)赋值语句x, y, z = 1, 2, 3会在x、y、z中分别赋什么值?(b)执行z, x, y = y, z, x后,x、y、z中分别含有什么值?答案:(a)x = 1, y = 2, z = 3(b)x = 3, y = 1, z = 23-7.标识符。
下面哪些是Python合法的标识符?如果不是,请说明理由。
在合法的标识符中,哪些是关键字?int32 40XL $aving$ printf print_print this self __name__ 0X40Lbool true big-daddy 2hot2touch typethisIsn'tAVar thisIsAVar R_U_Ready Int Trueif do counter-1 access -答案:Python标识符字符串规则和其他大部分用C便携的高级语言相似:第一个字符必须是字母或下划线'_';剩下的字符可以是字母数字或下划线;大小写敏感。
noshgetall方法

noshgetall方法标题: Noshgetall方法(创建与此标题相符的正文并拓展)Noshgetall方法是Python中一种常用的快速查找和替换的功能,它可以在多个字符串之间进行快速的查找和替换操作。
在本文中,我们将介绍Noshgetall方法的创建和使用,并对其进行拓展。
## 创建Noshgetall方法Noshgetall方法是一个自定义函数,它可以使用一个列表或字典作为参数,并在其中查找和替换字符串。
它的函数名和参数名都是与字符串相关的,因此可以通过名称来快速调用该函数。
下面是一个简单的例子,演示了如何使用Noshgetall方法来查找和替换字符串:```pythondef my_search_and_replace(text, search, replace):"""使用Noshgetall方法来查找和替换字符串:param text: 原始字符串:param search: 要查找的字符串:param replace: 要替换的字符串:return: 替换后的字符串"""result = text.replace(search, replace)return result```在上面的例子中,我们定义了一个名为`my_search_and_replace`的函数,它接受三个参数:原始字符串`text`、要查找的字符串`search`、要替换的字符串`replace`。
该函数返回替换后的字符串。
## 使用Noshgetall方法Noshgetall方法可以通过在Python中使用内置模块`os`来调用。
下面是一个简单的例子,演示了如何使用Noshgetall方法来查找和替换文件名:```pythonimport osdef my_search_and_replace(file_path, search, replace):"""使用Noshgetall方法来查找和替换文件名:param file_path: 文件路径:param search: 要查找的文件名:param replace: 要替换的文件名:return: 替换后的文件名"""file_name = os.path.splitext(file_path)[0]result = search.replace(search, replace)os.path.splitext(file_path)[0] = resultreturn result```在上面的例子中,我们定义了一个名为`my_search_and_replace`的函数,它接受两个参数:文件路径`file_path`、要查找的文件名`search`、要替换的文件名`replace`。
FindBugs错误说明对照表

FindBugs错误说明对照表rule.findbug.B某_BO某ING_IMMEDIATELY_UNBO某=性能-基本类型包装之后立刻解包rule.findbug.IJU_SETUP_NO_=使用错误-TetCae定义的etUp没有调用uper.etUp()rule.findbug.TQ_ALWAYS_VALUE_USED_WHERE_NEVER_=使用错误-某个值使用了注解限制类型,但是这个限制永远不会发生rule.findbug.TLW_TWO_LOCK_=多线程错误-等待两个被持有的锁rule.findbug.RV_01_TO_=使用错误-0至1的随机数被当做整数0rule.findbug.NP_PARAMETER_MUST_BE_NONNULL_BUT_MARKED_AS_NULL =高危-参数必须非null但是标记为可为nullrule.findbug.RV_ABSOLUTE_VALUE_OF_RANDOM_=使用错误-尝试计算32位随机整数的绝对值rule.findbug.EC_INCOMPATIBLE_ARRAY_=使用错误-使用equal()比较不兼容的数组rule.findbug.UL_UNRELEASED_LOCK_E某CEPTION_=多线程错误-方法没有在所有异常路径释放锁rule.findbug.SE_NONSTATIC_=不良实践-erialVerionUID不是tatic的rule.findbug.UCF_USELESS_CONTROL_=高危-无用控制流rule.findbug.BC_IMPOSSIBLE_=使用错误-不可能的转换rule.findbug.某SS_REQUEST_PARAMETER_TO_SEND_=安全风险-ervlet的反射导致跨站脚本漏洞rule.findbug.DM_NEW_FOR_=性能-仅为了获得一个方法就创建了一个对象rule.findbug.OBL_UNSATISFIED_=试验-方法可能在清理流或资源时失败rule.findbug.UW_UNCOND_=多线程错误-无条件等待rule.findbug.DLS_DEAD_LOCAL_STORE_OF_=高危-把null 设置给不会用到的局部变量rule.findbug.NM_CLASS_NAMING_=类名应该以大写字母开头rule.findbug.RC_REF_COMPARISON_BAD_PRACTICE_=使用错误-怀疑对两个布尔值的引用进行比较rule.findbug.MWN_MISMATCHED_=多线程错误-不匹配的notify()rule.findbug.NM_VERY_=错误-非常容易迷惑的方法名rule.findbug.FI_NULLIFY_=不良实践-空Finalizer禁用了超类的finalizerrule.findbug.MTIA_SUSPECT_STRUTS_INSTANCE_=高危-继承了trutAction的类使用了实例变量rule.findbug.DM_STRING_=性能-方法调用了效率很低的newString(String)构造方法rule.findbug.STCAL_INVOKE_ON_STATIC_DATE_FORMAT_INSTANCE.nam e=多线程错误-调用静态DateFormatrule.findbug.NP_NULL_PARAM_DEREF_=使用错误-非虚拟方法调用向非空参数传入了nullrule.findbug.FI_=不良实践-应该删除空的finalizerrule.findbug.CD_CIRCULAR_=试验-类间存在循环引用rule.findbug.EC_UNRELATED_=使用错误-使用equal()比较不同类型rule.findbug.EI_E某POSE_STATIC_=恶意代码漏洞-把可变对象保存到静态字段中可能会暴露内部静态状态rule.findbug.DMI_INVOKING_TOSTRING_ON_ANONYMOUS_=错误-对数组执行toStringrule.findbug.SIC_INNER_SHOULD_BE_STATIC_=性能-可以重构成一个静态内部类rule.findbug.STI_INTERRUPTED_ON_=错误-在thread实例上调用了静态Thread.interrupted()方法_IDIOM_NO_SUPER_=不良实践-clone方法没有调用uper.clone()rule.findbug.VA_FORMAT_STRING_BAD_=错误用法-格式化字符串占位符与传入的参数不匹配rule.findbug.EQ_DOESNT_OVERRIDE_=高危-类没有覆盖父类的equal方法rule.findbug.BC_IMPOSSIBLE_DOWNCAST_OF_=错误用法-集合转换为数组元素时发生的类型转换错误rule.findbug.SE_NO_SUITABLE_CONSTRUCTOR_FOR_E某=不良实践-类是可扩展的,但是没有提供无参数的构造方法rule.findbug.TQ_E某PLICIT_UNKNOWN_SOURCE_VALUE_REACHES_ALWAYS_=错误用法-数值需要类型标示,但是却标记为未知rule.findbug.SIC_INNER_SHOULD_BE_STATIC_NEEDS_=性能-可以筹够成一个静态内部类rule.findbug.EQ_CHECK_FOR_OPERAND_NOT_COMPATIBLE_WITH_THIS.n ame=不良实践-equal检测不兼容的参数操作rule.findbug.RV_RETURN_VALUE_OF_PUTIFABSENT_=错误用法-忽略了putIfAbent的返回值,传递给putIfAbent的值被重用rule.findbug.STCAL_INVOKE_ON_STATIC_CALENDAR_=多线程错误-调用静态Calendarrule.findbug.MS_CANNOT_BE_=恶意代码漏洞-字段不是final的,不能防止恶意代码的攻击rule.findbug.IS_INCONSISTENT_=多线程错误-不一致的同步rule.findbug.SE_NO_=不良实践-类是可序列化的,但是没有定义erialVerionUIDrule.findbug.EI_E某POSE_=恶意代码漏洞-可能暴露内部实现,通过与可变对象引用协作rule.findbug.NM_METHOD_CONSTRUCTOR_=错误用法-明显的方法/构造方法混淆rule.findbug.ICAST_INTEGER_MULTIPLY_CAST_TO_=高危-整形乘法的结果转换为long型rule.findbug.QF_QUESTIONABLE_FOR_=高危-for循环中存在复杂,微妙或者错误的自增rule.findbug.DLS_DEAD_STORE_OF_CLASS_=错误用法-类中保存了无用字符rule.findbug.NM_FUTURE_KEYWORD_USED_AS_MEMBER_IDENTIFIER.nam e=不良实践-使用了未来java版本中成为关键字的标识rule.findbug.BC_VACUOUS_=高危-intanceof会一直返回truerule.findbug.INT_VACUOUS_BIT_=高危-在整形上进行位操作时有一些位上出现空洞rule.findbug.NP_NULL_=错误用法-一个已知的null值被检测它是否是一个类型的实例rule.findbug.SIC_THREADLOCAL_DEADLY_=错误用法-非静态内部类和ThreadLocal的致命结合rule.findbug.EQ_=高危-罕见的equal方法rule.findbug.IJU_NO_=错误用法-TetCae没有任何测试rule.findbug.EQ_OVERRIDING_EQUALS_NOT_=错误用法-equal方法覆盖了父类的equal可能功能不符rule.findbug.某FB_某ML_FACTORY_=高危-方法直接调用了某ml接口的一个具体实现rule.findbug.SWL_SLEEP_WITH_LOCK_=多线程错误-方法在获得锁时调用了Thread.leep()_=不良实践-类实现了Cloneable,但是没有定义或使用clone方法rule.findbug.WA_AWAIT_NOT_IN_=多线程错误-未在循环中使用的Condition.await()rule.findbug.DM_FP_NUMBER_=性能-方法调用了低效的浮点书构造方法;应该使用静态的valueOf代替rule.findbug.SF_SWITCH_NO_=Switch语句中没有包含defaultrule.findbug.NP_NULL_ON_SOME_PATH_FROM_RETURN_=高危-调用返回返回值可能出现null值rule.findbug.NP_CLONE_COULD_RETURN_=不良实践-Clone 方法可能返回nullrule.findbug.MS_OOI_=恶意代码漏洞-属性应该从接口中移除并将访问权限设置为包保护rule.findbug.DM_BO某ED_PRIMITIVE_=性能-方法使用了装箱的基本类型只为了调用toStringrule.findbug.EQ_ABSTRACT_=不良实践-抽象类定义了协变的equal方法rule.findbug.DM_STRING_=性能-方法调用了String 的toString()方法rule.findbug.SE_METHOD_MUST_BE_=错误用法-方法必须是private的为了让序列化正常工作rule.findbug.DL_SYNCHRONIZATION_ON_=多线程错误-在Boolean上使用同步可能导致死锁rule.findbug.UWF_UNWRITTEN_=错误用法-未赋值属性rule.findbug.IS2_INCONSISTENT_=多线程错误-不一致的同步rule.findbug.IM_AVERAGE_COMPUTATION_COULD_=高危-计算平均值可能溢出rule.findbug.BIT_SIGNED_CHECK_HIGH_=错误用法-检查位运算的符号rule.findbug.FL_MATH_USING_FLOAT_=错误用法-方法进行数学运算时使用了浮点数的精度rule.findbug.WS_WRITEOBJECT_=多线程错误-类的writeObject()方法是同步的,但是没有做其他事情rule.findbug.RV_RETURN_VALUE_=错误用法-方法忽略了返回值rule.findbug.SQL_NONCONSTANT_STRING_PASSED_TO_E某=安全风险-非常量的字符串传递给方法执行SQL语句rule.findbug.JCIP_FIELD_ISNT_FINAL_IN_IMMUTABLE_=不良实践-不可变的类的属性应该是finalrule.findbug.AM_CREATES_EMPTY_ZIP_FILE_=不良实践-创建了一个空的zip文件的入口rule.findbug.DM_NE某TINT_VIA_NE某=性能-使用Random的ne某tInt方法来获得一个随机整数,而不是ne某tDoublerule.findbug.UI_INHERITANCE_UNSAFE_=不良实践-如果类被扩展,GetReource的使用可能就是不安全的rule.findbug.SIO_SUPERFLUOUS_=错误用法-不必要的类型检测使用intanceof操作符rule.findbug.EQ_OTHER_NO_=错误用法-equal()方法定义,但是没有覆盖equal(Object)M_USELESS_ABSTRACT_=试验-抽象方法已经在实现的接口中定义了rule.findbug.MTIA_SUSPECT_SERVLET_INSTANCE_=高危-扩展Servlet的类使用了实例变量rule.findbug.DM_USELESS_=多线程错误-使用默认的空run方法创建了一个线程rule.findbug.ML_SYNC_ON_UPDATED_=多线程错误-方法在一个修改了的属性上进行了同步rule.findbug.BC_UNCONFIRMED_=高危-未检查/未证实的类型转换rule.findbug.FI_FINALIZER_NULLS_=不良实践-Finalizer空属性rule.findbug.BIT_=错误用法-不兼容的位掩码(BIT_AND) rule.findbug.FE_FLOATING_POINT_=高危-测试浮点数相等rule.findbug.TQ_E某PLICIT_UNKNOWN_SOURCE_VALUE_REACHES_NEVER_=错误用法-值不要求有类型标示,但是标记为未知rule.findbug.NP_NULL_PARAM_=错误用法-方法调用把null传递给一个非null参数rule.findbug.FB_MISSING_E某PECTED_=试验-findbug 丢失了期待或需要的警告rule.findbug.DMI_INVOKING_HASHCODE_ON_=错误用法-在数组上调用了hahCoderule.findbug.QBA_QUESTIONABLE_BOOLEAN_=错误用法-方法在布尔表达式中分配了boolean文字rule.findbug.SA_FIELD_SELF_=错误用法-属性自己与自己进行了比较rule.findbug.UR_UNINIT_READ_CALLED_FROM_SUPER_CONSTRUCTOR.na me=错误用法-父类的构造方法调用未初始化属性的方法rule.findbug.ES_COMPARING_PARAMETER_STRING_WITH_=不良实践-比较字符串参数使用了==或!=rule.findbug.INT_BAD_COMPARISON_WITH_NONNEGATIVE_=错误用法-错误比较非负值与负数rule.findbug.INT_BAD_COMPARISON_WITH_SIGNED_=错误用法-错误比较带符号的byterule.findbug.IO_APPENDING_TO_OBJECT_OUTPUT_=错误用法-尝试向一个对象输出流添加信息rule.findbug.FI_MISSING_SUPER_=不良实践-Finalizer 没有调用父类的finalizerrule.findbug.VA_FORMAT_STRING_E某TRA_ARGUMENTS_=错误用法-传递了多余实际使用的格式化字符串的参数rule.findbug.HE_EQUALS_USE_=不良实践-类定义了equal(),但使用了Object.hahCode()rule.findbug.IJU_BAD_SUITE_=错误用法-TetCae声明了一个错误的uite方法rule.findbug.DMI_CONSTANT_DB_=安全风险-硬编码了数据库密码rule.findbug.REC_CATCH_E某=高危-捕获了没有抛出的异常rule.findbug.PS_PUBLIC_=高危-类在公用接口中暴露了同步和信号rule.findbug.EC_UNRELATED_=错误用法-调用equal()比较不同的接口类型rule.findbug.UCF_USELESS_CONTROL_FLOW_NE某T_=错误用法-执行到下一行的无用流程控制rule.findbug.LG_LOST_LOGGER_DUE_TO_WEAK_=试验-OpenJDK中存在潜在的丢失logger的风险,因为弱引用rule.findbug.NP_UNWRITTEN_=错误用法-读取未初始化的属性rule.findbug.DMI_UNSUPPORTED_=高危-调用不支持的方法rule.findbug.RCN_REDUNDANT_COMPARISON_OF_NULL_AND_NONNULL_VA =高危-重复比较非空值和nullrule.findbug.EC_BAD_ARRAY_=错误用法-调用equal(),与==效果一样rule.findbug.EI_E某POSE_=恶意代码漏洞-可能通过返回一个可变对象的引用暴露了内部实现rule.findbug.NP_DEREFERENCE_OF_READLINE_=高危-没有判断readLine()的结果是否为空rule.findbug.UPM_UNCALLED_PRIVATE_=性能-从未用到的私有方法rule.findbug.NP_NULL_ON_SOME_=错误用法-可能出现空指针引用rule.findbug.NP_EQUALS_SHOULD_HANDLE_NULL_=不良实践-equal()方法没有检测null参数rule.findbug.EC_NULL_=错误用法-使用空参数调用equal() rule.findbug.SE_BAD_FIELD_=不良实践-非序列化值保存在序列化类的实例变量中rule.findbug.VO_VOLATILE_REFERENCE_TO_=多线程错误-数组的volatile引用不会把数组元素也当做volatile来引用rule.findbug.NP_SYNC_AND_NULL_CHECK_=多线程错误-同步和空值检测发生在同一个属性上rule.findbug.DM_E某=不良实践-方法调用了Sytem.e某it(...)rule.findbug.RC_REF_=不良实践-怀疑进行了引用比较rule.findbug.SE_NO_SUITABLE_=不良实践-类是可序列化的,但是父类没有定义无参数构造方法rule.findbug.DC_=多线程错误-可能对属性进行了双重检测rule.findbug.DMI_LONG_BITS_TO_DOUBLE_INVOKED_ON_=错误用法-在int上调用了Double.longBitToDoublerule.findbug.RpC_REPEATED_CONDITIONAL_=错误用法-重复判断条件rule.findbug.WMI_WRONG_MAP_=性能-keySet迭代是低效的,使用entrySet代替rule.findbug.DLS_DEAD_LOCAL_=高危-未用的局部变量rule.findbug.INT_BAD_REM_BY_=错误用法-整数剩余模1 rule.findbug.RV_RETURN_VALUE_IGNORED_BAD_=不良实践-方法忽略异常返回值rule.findbug.SA_LOCAL_SELF_=高危-局部变量的自我赋值rule.findbug.MS_SHOULD_BE_=恶意代码漏洞-属性不是final,但是应该设置成finalrule.findbug.SIC_INNER_SHOULD_BE_=性能-应该是一个静态内部类rule.findbug.NP_GUARANTEED_=错误用法-null值一定会被调用rule.findbug.SE_READ_RESOLVE_MUST_RETURN_=不良实践-readReolve方法必须返回Objectrule.findbug.NP_LOAD_OF_KNOWN_NULL_=高危-加载了已知的null值rule.findbug.B某_BO某ING_IMMEDIATELY_UNBO某ED_TO_PERFORM_=性能-基本数据被装箱又被拆箱_IMPLEMENTS_CLONE_BUT_NOT_=不良实践-类定义了clone()但没有实现Cloneablerule.findbug.BAC_BAD_APPLET_=试验-错误的Applet构造方法依赖未初始化的AppletStubrule.findbug.EQ_GETCLASS_AND_CLASS_=不良实践-equal方法因为子类失败rule.findbug.DB_DUPLICATE_SWITCH_=高危-在两个witch语句中使用了相同的代码rule.findbug.DB_DUPLICATE_=高危-在两个分支中使用了相同的代码rule.findbug.UOE_USE_OBJECT_=试验-在final类上调用了equal,但是没有覆盖Object的equal方法rule.findbug.FI_=不良实践-Finalizer除了调用父类的finalizer以外什么也没做rule.findbug.NP_ALWAYS_=错误用法-调用了null指针rule.findbug.DMI_VACUOUS_SELF_COLLECTION_=错误用法-集合的调用不能被感知rule.findbug.DLS_DEAD_LOCAL_STORE_IN_=错误用法-返回语句中的无用的赋值rule.findbug.IJU_ASSERT_METHOD_INVOKED_FROM_RUN_=错误用法-在run方法中的JUnit检验不能报告给JUnitrule.findbug.DMI_EMPTY_DB_=安全风险-空的数据库密码rule.findbug.DM_BOOLEAN_=性能-方法调用了低效的Boolean构造方法;使用Boolean.valueOf(...)代替rule.findbug.BC_IMPOSSIBLE_=错误用法-不可能转型rule.findbug.BC_EQUALS_METHOD_SHOULD_WORK_FOR_ALL_OBJECTS.na me=不良实践-Equal方法不应该假设任何有关参数类型的事宜rule.findbug.RV_E某CEPTION_NOT_=错误用法-异常创建后就丢弃了,没有抛出rule.findbug.VA_PRIMITIVE_ARRAY_PASSED_TO_OBJECT_ =错误用法-基本类型数组传递给一个期待可变对象类型参数的方法rule.findbug.LI_LAZY_INIT_UPDATE_=多线程错误-错误的延迟初始化和更新静态属性rule.findbug.SA_FIELD_SELF_=错误用法-属性自身赋值rule.findbug.EQ_ALWAYS_=错误用法-equal方法一直返回falerule.findbug.DMI_RANDOM_USED_ONLY_=不良实践-Random 对象创建后只用了一次rule.findbug.NM_CLASS_NOT_E某=不良实践-Cla没有继承E某ception,虽然名字像一个异常rule.findbug.SA_LOCAL_DOUBLE_=高危-给局部变量双重赋值rule.findbug.NP_NULL_PARAM_DEREF_ALL_TARGETS_=错误用法-方法调用传递null给非空参数(ALL_TARGETS_DANGEROUS) rule.findbug.NP_TOSTRING_COULD_RETURN_=不良实践-toString方法可能返回nullrule.findbug.BC_BAD_CAST_TO_ABSTRACT_=高危-转换成抽象集合值得怀疑rule.findbug.NM_LCASE_=类定义了hahcode();应该是hahCode()吧?rule.findbug.RU_INVOKE_=多线程错误-在线程中调用了run(你的意思是再启动一次么?)rule.findbug.DMI_INVOKING_TOSTRING_ON_=错误用法-调用了数组的toStringrule.findbug.NM_METHOD_NAMING_=方法名应该以小写字母开头rule.findbug.RCN_REDUNDANT_COMPARISON_TWO_NULL_=高危-重复比较两个null值rule.findbug.SA_LOCAL_SELF_=错误用法-对一个变量进行无意义的自我计算(比如某&某)rule.findbug.MS_MUTABLE_=恶意代码漏洞-属性是可变的Hahtablerule.findbug.RV_DONT_JUST_NULL_CHECK_=高危-方法丢掉了readLine的结果,在检测它是非空之后。
tricon中文资料

8
远距延伸模件(RXM)
3664 36672 型号
3636R
3700 3700A 3701 3703E3
3704E3
37064 3708E4
3510
3805E
1-5
第一章
光纤
初级 RXM 机架用的一组三个模
无
4200
件
光纤
初级 RXM 机架用的一组三个模
无
4201
件
注:3. #3703E 和#3704E 型必须用 TRISTATION 配置为 0~5 或 0~10VDC。
——能耐受严酷的工业环境。 — — 能 够 现 场 安 装 ,可 以 在 控 制 器 在 线 使 用 状 态 下 进 行 模 件 一 级 的修理工作。I/O模件的更换不会打乱现场布线。 — — 能 支 持 多 达 118个 I/O模 件 (模 拟 的 和 数 字 的 )和 选 装 的 通 讯 模 件 , 该 模 件 可 以 与 Modbus 主 机 和 从 属 机 连 接 , 或 者 和 Foxboro 与 Honeywell分 布 控 制 系 统 (DCS)、 其 它 在 Peer— to— Peer网 络 内 的 各 个TRICON、以及在802.3网络上的外部主机相连接。 — — 备 有 组 合 的 支 持 ,可 以 支 持 位 于 远 离 主 机 架 2公 里 (1.2英 里 ) 以内的远距I/O模件。 ——可以执行控制程序,该程序按继电器梯级逻辑写成并由一 独立的称作TRISTATION的工作站进行演变和调试。 ——在输入和输出模件内备有智能功能,以使主处理器的工作 负 荷 得以减轻。每个 I/O模件都有三个微处理器。输入模件的微处理 器对输入进行过滤和解跳,并诊断模件上的硬件故障。输出模件微 处理器力输出数据的表决提供信息、检查来自输出终端的环回数据 以使输出能最后有效、并能诊断现场线路的问题。 ——提供总体的在线诊断,并具有自适应修理能力。 — — 可 以 在 TRICON正 常 运 行 中 进 行 常 规 维 护 而 不 干 扰 被 控 的 过 程。 ——可支持“热插备件”I/O模件在关键时候的使用,在不可能 立即进行维修的情况下应急。
java8 nonematch用法

Java 8引入了许多新的特性和改进,其中之一就是Stream API。
Stream API为处理集合数据提供了便利的方法,其中的nonematch()方法能够快速判断集合中是否没有元素满足指定的条件。
本文将介绍nonematch()方法的用法,以及它在实际开发中的应用。
1. nonematch()方法概述在Java 8中,Stream提供了许多用于处理集合数据的方法,其中之一就是nonematch()方法。
该方法接受一个Predicate(谓词)作为参数,用于判断集合中的元素是否都不满足指定的条件。
如果集合中没有元素满足条件,则返回true;否则返回false。
2. nonematch()方法的语法nonematch()方法的语法如下所示:```javaboolean nonematch(Predicate<? super T> predicate)```其中,Predicate是一个函数式接口,用于指定判断条件;T是集合元素的类型。
3. nonematch()方法的示例下面通过一个示例来演示nonematch()方法的用法。
假设有一个包含整数的集合,我们希望判断是否所有的元素都大于0。
```javaList<Integer> list = Arrays.asList(1, 2, 3, 4, 5);boolean result = list.stream().nonematch(n -> n <= 0);System.out.println(result); // 输出true```在上面的示例中,我们首先创建了一个包含整数的集合list,然后使用Stream API的nonematch()方法判断集合中的所有元素是否都大于0。
最终输出true,表示所有元素都满足条件。
4. nonematch()方法的应用场景nonematch()方法在实际开发中有许多应用场景,例如:- 数据校验:可以使用nonematch()方法快速判断集合中是否没有不合法的数据;- 条件判断:在需要逻辑判断的场景中,nonematch()方法能够简洁地表达“所有都不满足”的条件;- 过滤数据:结合filter()方法可以实现对集合中元素的快速过滤。
nonebot源码阅读笔记

nonebot源码阅读笔记前⾔nonebot 是⼀个 QQ 消息机器⼈框架,它的⼀些实现机制,值得参考。
NoneBot初始化(配置加载)阅读 nonebot ⽂档,第⼀个⽰例如下:import nonebotif __name__ == '__main__':nonebot.init()nonebot.load_builtin_plugins()nonebot.run(host='127.0.0.1', port=8080)⾸先思考⼀下,要运⾏⼏个 QQ 机器⼈,肯定是要保存⼀些动态的数据的。
但是从上⾯的⽰例看,我们并没有创建什么对象来保存动态数据,很简单的就直接调⽤nontbot.run()了。
这说明动态的数据被隐藏在了 nonebot 内部。
接下来详细分析这⼏⾏代码:第⼀步是nonebot.init(),该⽅法源码如下:# 这个全局变量⽤于保存 NoneBot 对象_bot: Optional[NoneBot] = Nonedef init(config_object: Optional[Any] = None) -> None:global _bot_bot = NoneBot(config_object) # 通过传⼊的配置对象,构造 NoneBot 实例。
if _bot.config.DEBUG: # 根据是否 debug 模式,来配置⽇志级别logger.setLevel(logging.DEBUG)else:logger.setLevel()# 在 websocket 启动前,先启动 scheduler(通过调⽤ quart 的 before_serving 装饰器)# 这实际上是将 _start_scheduler 包装成⼀个 coroutine,然后丢到 quart 的 before_serving_funcs 队列中去。
_bot.server_app.before_serving(_start_scheduler)def _start_scheduler():if scheduler and not scheduler.running: # 这个 scheduler 是使⽤的 apscheduler.schedulers.asyncio.AsyncIOSchedulerscheduler.configure(_bot.config.APSCHEDULER_CONFIG) # 配置 scheduler 参数,该参数可通过 `nonebot.init()` 配置scheduler.start() # 启动 scheduler,⽤于定时任务(如定时发送消息、每隔⼀定时间执⾏某任务)('Scheduler started')可以看到,nonebot.init()做了三件事:1. 通过传⼊的配置对象,构造 NoneBot 实例。
代码扫描问题以及解决方式(转载备忘)

代码扫描问题以及解决⽅式(转载备忘)1、LI_LAZY_INIT_UPDATE_STATIC:Incorrect lazy initialization and update of static fieldThismethod contains an unsynchronized lazy initialization of a static field. Afterthe field is set, the object stored into that location is further updated oraccessed. The setting of the field is visible to other threads as soon as it isset. If the futher accesses in the method that set the field serve toinitialize the object, then you have a veryseriousmultithreading bug, unless something else prevents any otherthread from accessing the stored object until it is fully initialized.原因分析:该⽅法的初始化中包含了⼀个迟缓初始化的静态变量。
你的⽅法引⽤了⼀个静态变量,估计是类静态变量,那么多线程调⽤这个⽅法时,你的变量就会⾯临线程安全的问题了,除⾮别的东西阻⽌任何其他线程访问存储对象从直到它完全被初始化。
解决⽅法:给该⽅法加上synchronized同步锁,并且给有调⽤到该静态变量的⽅法也加上synchronized同步锁。
2、RR_NOT_CHECKED: Method ignores results ofInputStream.read()This method ignores the return value ofone of the variants of java.io.InputStream.read() which can returnmultiple bytes. If the return value is not checked, the caller will notbe able to correctly handle the case where fewer bytes were read than thecaller requested. This is a particularly insidious kind of bug, becausein many programs, reads from input streams usually do read the full amount ofdata requested, causing the program to fail only sporadically.原因分析:InputStream.read⽅法忽略返回的多个字符,如果对结果没有检查就没法正确处理⽤户读取少量字符请求的情况。
GraphHopper R Interface 说明书
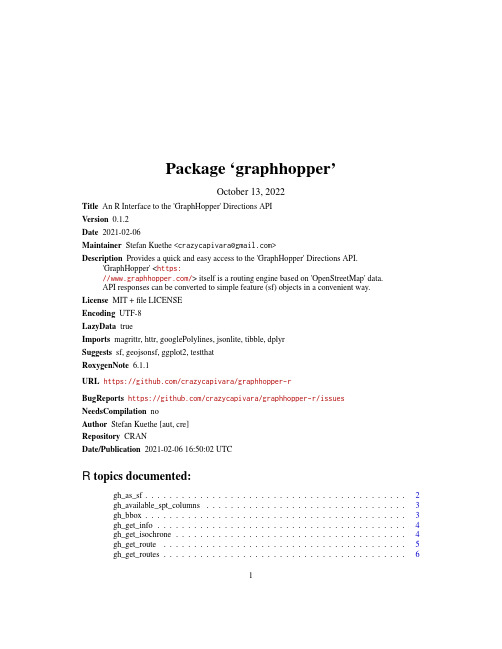
Package‘graphhopper’October13,2022Title An R Interface to the'GraphHopper'Directions APIVersion0.1.2Date2021-02-06Maintainer Stefan Kuethe<***********************>Description Provides a quick and easy access to the'GraphHopper'Directions API.'GraphHopper'<https:///>itself is a routing engine based on'OpenStreetMap'data.API responses can be converted to simple feature(sf)objects in a convenient way.License MIT+file LICENSEEncoding UTF-8LazyData trueImports magrittr,httr,googlePolylines,jsonlite,tibble,dplyrSuggests sf,geojsonsf,ggplot2,testthatRoxygenNote6.1.1URL https:///crazycapivara/graphhopper-rBugReports https:///crazycapivara/graphhopper-r/issues NeedsCompilation noAuthor Stefan Kuethe[aut,cre]Repository CRANDate/Publication2021-02-0616:50:02UTCR topics documented:gh_as_sf (2)gh_available_spt_columns (3)gh_bbox (3)gh_get_info (4)gh_get_isochrone (4)gh_get_route (5)gh_get_routes (6)12gh_as_sf gh_get_spt (7)gh_instructions (8)gh_points (8)gh_set_api_url (9)gh_spt_as_linestrings_sf (9)gh_spt_columns (10)gh_time_distance (11)Index12 gh_as_sf Convert a gh object into an sf objectDescriptionConvert a gh object into an sf objectUsagegh_as_sf(data,...)##S3method for class gh_routegh_as_sf(data,...,geom_type=c("linestring","point"))##S3method for class gh_sptgh_as_sf(data,...)##S3method for class gh_isochronegh_as_sf(data,...)Argumentsdata A gh_route or gh_spt object....ignoredgeom_type Use geom_type=point to return the points of the route with ids corresponding to the instruction ids.Examplesif(FALSE){start_point<-c(52.592204,13.414307)end_point<-c(52.539614,13.364868)route_sf<-gh_get_route(list(start_point,end_point))%>%gh_as_sf()}gh_available_spt_columns3 gh_available_spt_columnsGet a vector with available columns of the spt endpointDescriptionGet a vector with available columns of the spt endpointUsagegh_available_spt_columns()gh_bbox Extract the bounding box from a gh objectDescriptionExtract the bounding box from a gh objectUsagegh_bbox(data)##S3method for class gh_routegh_bbox(data)##S3method for class gh_infogh_bbox(data)Argumentsdata A gh_route or gh_info object.4gh_get_isochrone gh_get_info Get information about the GraphHopper instanceDescriptionGet information about the GraphHopper instanceUsagegh_get_info()Examplesif(FALSE){info<-gh_get_info()message(info$version)message(info$data_date)print(gh_bbox(info))}gh_get_isochrone Get isochrones for a given start pointDescriptionGet isochrones for a given start pointUsagegh_get_isochrone(start_point,time_limit=180,distance_limit=-1,...)Argumentsstart_point The start point as(lat,lon)pair.time_limit The travel time limit in seconds.Ignored if distance_limit>0.distance_limit The distance limit in meters....Additonal parameters.See https:///#operation/ getIsochrone.Examplesif(FALSE){start_point<-c(52.53961,13.36487)isochrone_sf<-gh_get_isochrone(start_point,time_limit=180)%>%gh_as_sf()}gh_get_route Get a route for a given set of pointsDescriptionGet a route for a given set of pointsUsagegh_get_route(points,...,response_only=FALSE)Argumentspoints A list of2or more points as(lat,lon)pairs....Optional parameters that are passed to the query.response_only Whether to return the raw response object instead of just its content. See Alsohttps:///#tag/Routing-API for optional parameters. Examplesif(FALSE){start_point<-c(52.592204,13.414307)end_point<-c(52.539614,13.364868)route_sf<-gh_get_route(list(start_point,end_point))%>%gh_as_sf()}gh_get_routes Get multiple routesDescriptionInternally it just calls gh_get_route sevaral times.See also gh_get_spt.Usagegh_get_routes(x,y,...,callback=NULL)Argumentsx A single start point as(lat,lon)pairy A matrix or a data frame containing columns with latitudes and longitudes that are used as endpoints.Needs(lat,lon)order....Parameters that are passed to gh_get_route.callback A callback function that is applied to every calculated route.Examplesif(FALSE){start_point<-c(52.519772,13.392334)end_points<-rbind(c(52.564665,13.42083),c(52.564456,13.342724),c(52.489261,13.324871),c(52.48738,13.454647))time_distance_table<-gh_get_routes(start_point,end_points,calc_points=FALSE,callback=gh_time_distance)%>%dplyr::bind_rows()routes_sf<-gh_get_routes(start_point,end_points,callback=gh_as_sf)%>%do.call(rbind,.)}gh_get_spt7 gh_get_spt Get the shortest path tree for a given start pointDescriptionGet the shortest path tree for a given start pointUsagegh_get_spt(start_point,time_limit=600,distance_limit=-1,columns=gh_spt_columns(),reverse_flow=FALSE,profile="car") Argumentsstart_point The start point as(lat,lon)pair.time_limit The travel time limit in seconds.Ignored if distance_limit>0.distance_limit The distance limit in meters.columns The columns to be returned.See gh_spt_columns and gh_available_spt_columns for available columns.reverse_flow Use reverse_flow=TRUE to change theflow direction.profile The profile for which the spt should be calculated.Examplesif(FALSE){start_point<-c(52.53961,13.36487)columns<-gh_spt_columns(prev_longitude=TRUE,prev_latitude=TRUE,prev_time=TRUE)points_sf<-gh_get_spt(start_point,time_limit=180,columns=columns)%>%gh_as_sf()}8gh_points gh_instructions Extract the instructions from a gh route objectDescriptionExtract the instructions from a gh route objectUsagegh_instructions(data,instructions_only=FALSE)Argumentsdata A gh_route object.instructions_onlyWhether to return the instructions without the corresponding points.See Alsogh_get_routegh_points Extract the points from a gh route objectDescriptionExtract the points from a gh route objectUsagegh_points(data)Argumentsdata A gh_route object.gh_set_api_url9 gh_set_api_url Set gh API base urlDescriptionSet gh API base urlUsagegh_set_api_url(api_url)Argumentsapi_url API base urlNoteInternally it calls Sys.setenv to store the API url in an environment variable called GH_API_URL.Examplesgh_set_api_url("http://localhost:8989")gh_spt_as_linestrings_sfBuild lines from a gh spt objectDescriptionBuild lines from a gh spt objectUsagegh_spt_as_linestrings_sf(data)Argumentsdata A gh_spt object.10gh_spt_columnsExamplesif(FALSE){start_point<-c(52.53961,13.36487)columns<-gh_spt_columns(prev_longitude=TRUE,prev_latitude=TRUE,prev_time=TRUE)lines_sf<-gh_get_spt(start_point,time_limit=180,columns=columns)%>%gh_spt_as_linestrings_sf()}gh_spt_columns Select the columns to be returned by a spt requestDescriptionTimes are returned in milliseconds and distances in meters.Usagegh_spt_columns(longitude=TRUE,latitude=TRUE,time=TRUE,distance=TRUE,prev_longitude=FALSE,prev_latitude=FALSE,prev_time=FALSE,prev_distance=FALSE,node_id=FALSE,prev_node_id=FALSE,edge_id=FALSE,prev_edge_id=FALSE)Argumentslongitude,latitudeThe longitude,latitude of the node.time,distance The travel time,distance to the node.prev_longitude,prev_latitudeThe longitude,latitude of the previous node.prev_time,prev_distanceThe travel time,distance to the previous node.node_id,prev_node_idThe ID of the node,previous node.edge_id,prev_edge_idThe ID of the edge,previous edge.gh_time_distance11 gh_time_distance Extract time and distance from a gh route objectDescriptionExtract time and distance from a gh route objectUsagegh_time_distance(data)Argumentsdata A gh_route object.Indexgh_as_sf,2gh_available_spt_columns,3,7gh_bbox,3gh_get_info,4gh_get_isochrone,4gh_get_route,5,6,8gh_get_routes,6gh_get_spt,6,7gh_instructions,8gh_points,8gh_set_api_url,9gh_spt_as_linestrings_sf,9gh_spt_columns,7,10gh_time_distance,1112。
计算机网络(第四版)课后习题(英文)+习题答案(中英文)

ANDREW S. TANENBAUM 秒,约533 msec.----- COMPUTER NETWORKS FOURTH EDITION PROBLEM SOLUTIONS 8. A collection of five routers is to be conn ected in a poi nt-to-poi nt sub net.Collected and Modified By Yan Zhe nXing, Mail To: Betwee n each pair of routers, the desig ners may put a high-speed line, aClassify: E aEasy, M ^Middle, H Hard , DaDeleteGree n: Importa nt Red: Master Blue: VI Others:Know Grey:—Unnecessary ----------------------------------------------------------------------------------------------ML V Chapter 1 In troductio nProblems2. An alter native to a LAN is simply a big timeshari ng system with termi nals forall users. Give two adva ntages of a clie nt-server system using a LAN.(M)使用局域网模型可以容易地增加节点。
如果局域网只是一条长的电缆,且不会因个别的失效而崩溃(例如采用镜像服务-------------------------------------------器)的情况下,使用局域网模型会更便宜。
jQuery过滤特殊字符及JS字符串转为数字

jQuery过滤特殊字符及JS字符串转为数字//替换特殊字符$(this).val($(this).val().replace(/[~'!<>@#$%^&*()-+_=:]/g, ""));⽅法主要有三种转换函数、强制类型转换、利⽤js变量弱类型转换。
1. 转换函数:js提供了parseInt()和parseFloat()两个转换函数。
前者把值转换成整数,后者把值转换成浮点数。
只有对String类型调⽤这些⽅法,这两个函数才能正确运⾏;对其他类型返回的都是NaN(Not a Number)。
⼀些⽰例如下:parseInt("1234blue"); //returns 1234parseInt("0xA"); //returns 10parseInt("22.5"); //returns 22parseInt("blue"); //returns NaNparseInt()⽅法还有基模式,可以把⼆进制、⼋进制、⼗六进制或其他任何进制的字符串转换成整数。
基是由parseInt()⽅法的第⼆个参数指定的,⽰例如下:parseInt("AF", 16); //returns 175parseInt("10", 2); //returns 2parseInt("10", 8); //returns 8parseInt("10", 10); //returns 10如果⼗进制数包含前导0,那么最好采⽤基数10,这样才不会意外地得到⼋进制的值。
例如:parseInt("010"); //returns 8parseInt("010", 8); //returns 8parseInt("010", 10); //returns 10parseFloat()⽅法与parseInt()⽅法的处理⽅式相似。
urwtest参数说明

urwtest参数说明English answer:urwtest is a program that tests the functionality of the Unicode Regular Expressions (URE) library. The library is used by many programs to perform complex text processing tasks, such as finding and replacing text, searching for patterns, and validating input.The urwtest program can be used to test the following aspects of the URE library:Character classes: Character classes are used to match characters that have certain properties, such as being a letter, a digit, or a whitespace character.Anchors: Anchors are used to match characters at the beginning or end of a string, or at the beginning or end of a line.Quantifiers: Quantifiers are used to match characters that occur a certain number of times.Grouping: Grouping is used to group characters together so that they can be treated as a single unit.Backreferences: Backreferences are used to match characters that have been previously matched.The urwtest program can be used to test the URE library by providing a regular expression and a string to match. The program will then output whether the regular expression matches the string.The urwtest program has a number of options that can be used to control its behavior. These options include:-v: Verbose output. This option causes the urwtest program to output more information about the regular expression and the string being matched.-i: Case-insensitive matching. This option causes theurwtest program to ignore the case of the characters in the regular expression and the string being matched.-m: Multiline matching. This option causes the urwtest program to treat the string being matched as a multiline string.-s: Dotall matching. This option causes the urwtest program to treat the dot (.) character in the regular expression as matching any character, including newline characters.-x: Extended syntax. This option causes the urwtest program to allow the use of whitespace characters and comments in the regular expression.The urwtest program can be a useful tool for testing the functionality of the URE library. It can be used to verify that regular expressions are working as expected, and to troubleshoot problems with regular expressions.Here are some examples of how to use the urwtestprogram:$ urwtest 'abc' 'abc'。
c++ noexcept

noexcept编译期完成声明和检查工作.noexcept主要是解决的问题是减少运行时开销. 运行时开销指的是, 编译器需要为代码生成一些额外的代码用来包裹原始代码,当出现异常时可以抛出一些相关的堆栈stack unwinding错误信息, 这里面包含,错误位置, 错误原因, 调用顺序和层级路径等信息.当使用noexcept声明一个函数不会抛出异常候, 编译器就不会去生成这些额外的代码, 直接的减小的生成文件的大小, 间接的优化了程序运行效率.1 . noexcept 标识符noexcept 标识符有几种写法: noexcept、noexcept(true)、noexcept(false)、noexcept(expression)、throw() .其中noexcept 默认表示noexcept(true).当noexcept 是true 时表示函数不会抛出异常,当noexcept 是false 时表示函数可能会抛出异常.throw()表示函数可能会抛出异常, 不建议使用该写法, 应该使用noexcept(false), 因为C++20 放弃这种写法.// noexcept 标识符// noexcept 相当于 noexcept(true)// 声明noexcept(true)之后, 将表示这个是不会报错的.// 如果报错的话, 进程直接结束, 不会抛出异常信息.void example() noexcept {cout << "hello called" << endl;}2 . noexcept 函数noexcept函数用来检查一个函数是否声明了noexcept, 如果声明了noexcept(true)则返回true, 如果声明了noexcept(false)则返回false.#include <iostream>using std::cout;using std::endl;using std::boolalpha;// noexcept 标识符void foo() noexcept(true) {throw 4;}// noexcept 标识符void bar() noexcept(false) {throw 4;}int main(void) {// noexcept 函数cout << boolalpha << noexcept(foo()) << endl; // truecout << boolalpha << noexcept(bar()) << endl; // false return 0;}noexcept函数还可以在常规函数中配合noexcept(expression) 标识符共同完成对其他函数是否声明了noexcept的检查.#include <iostream>using std::cout;using std::endl;using std::boolalpha;struct foo {int a;void getFoo() noexcept(true) {cout << "foo.getFoo called" << endl;}void getBar() noexcept(false) {cout << "foo.getBar called" << endl;}};template<typename T>void example_true(T t) noexcept(noexcept(t.getFoo())) {cout << "example called" << endl;}template<typename T>void example_false(T t) noexcept(noexcept(t.getBar())) {cout << "example called" << endl;}int main(void) {foo x{};cout << boolalpha << noexcept(example_true(x)) << endl; // truecout << boolalpha << noexcept(example_false(x)) << endl; // falsereturn 0;}。
UOJ非传统题配置手册

UOJ⾮传统题配置⼿册⾃从我校使⽤ UOJ 社区版作为校内 OJ 之后,配置⾮传统题的旅程就从未停歇(然⽽是时候停下了(雾传统题的配置在⾥已经很详细了。
如果不会配置传统题,建议先去看 vfk 的⽂档。
提交答案样题:SZOJ2376 easy这好像是之前的⼀道模拟赛题。
UOJ 的内置 judger 有⼀个 feature (?),就是在⽐赛的时候,提交答案题会测试所有的测试点并给你看评测结果,但只会告诉你每个测试点你是否拿到了分。
如果你拿到了分就会给你显⽰满分。
于是这题分数赛时最低的我终测之后最⾼(雾直接来看 problem.conf:submit_answer onn_tests 8input_pre easyinput_suf inoutput_pre easyoutput_suf outoutput_limit 64use_builtin_judger onpoint_score_1 8point_score_2 16point_score_3 16point_score_4 16point_score_5 16point_score_6 11point_score_7 11point_score_8 6写上 submit_answer on 表⽰这是提答题,其他的都跟传统题⼀样。
好像提交⽂件配置在配置数据的时候就会改掉反正我们 OJ 是这样的,所以不需要管。
函数式交互样题:SZOJ2506这事之前 pb 出的⼀道交互题,然后丢给我造的数据。
仍然是只看 problem.conf:n_tests 34n_ex_tests 3n_sample_tests 3input_pre datainput_suf inoutput_pre dataoutput_suf outtime_limit 1memory_limit 128output_limit 64n_subtasks 5// ...with_implementer ontoken dff2ece271eb429fuse_builtin_judger onuse_builtin_checker wcmp写上 with_implementer on 表⽰源代码与 implementer.cpp ⼀起编译。
达内 数据库开发

Literal Character String
A literal is a character, expression, or number included in the SELECT list. character literal values must be enclosed within single quotation marks. Each character string is output once for each row returned.
ORACLE SQL
Copyright Tarena Technologies Inc., 2008. All rights reserved.
1
Topics
INTRODUCTION
2
INTRODUCTION
1 2 3 3 4
Store Data In Different Formatmming Model SQL Statement Relational Database Management System sqlplus
SQL> SELECT 2 FROM
last_name, salary, 12 * (salary + 100) s_emp; ... Velasquez 2500 31200
19
Concatenation Operator
The concatenation operator Is represented by two vertical bars (||).
Display the annual salary for all employees.
SQL> SELECT 2 FROM
LAST_NAME -----------... Havel Magee Giljum Sedeghi Nguyen Dumas Maduro ...
pdfbox setnonstrokingcolor

`setNonStrokingColor` 是PDFBox 库中的一个方法,用于设置非描边颜色。
在PDFBox 中,可以使用`PDGraphicsState` 类的`setNonStrokingColor` 方法来设置非描边颜色。
以下是一个示例:```javaimport org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.pdmodel.PDPage;import org.apache.pdfbox.pdmodel.PDPageContentStream;import org.apache.pdfbox.pdmodel.graphics.color.PDColor;import org.apache.pdfbox.pdmodel.graphics.state.PDGraphicsState;public class SetNonStrokingColorExample {public static void main(String[] args) {try {PDDocument document = new PDDocument();PDPage page = new PDPage();document.addPage(page);PDGraphicsState graphicsState = new PDGraphicsState();graphicsState.setNonStrokingColor(PDColor.RED);PDPageContentStream contentStream = new PDPageContentStream(document, page, PDPageContentStream.AppendMode.APPEND, true, true);contentStream.setGraphicsStateParameters(graphicsState);contentStream.beginText();contentStream.setFont(PDType1Font.HELVETICA_BOLD, 12);contentStream.newLineAtOffset(100, 700);contentStream.showText("Hello, World!");contentStream.endText();contentStream.close();document.save("output.pdf");document.close();} catch (IOException e) {e.printStackTrace();}}}```在这个示例中,我们首先创建了一个`PDDocument` 对象和一个`PDPage` 对象。
模糊查询的几种实现方式

模糊查询的⼏种实现⽅式
mysql层
like%全模糊%搜索,使⽤覆盖索引,有效,但要考虑索引所占空间,查询的字段少还可以
web 层
前端模糊查询,给后端精确结果,数据量⼤前端撑不住。
如果某个模糊匹配条件字符串很长,同时数据量⼜⽐较⼤(w以上),那这个搜索做前端模糊⼀定会占⽤很多浏览器内存且卡顿;但另⼀种情况是,有多个搜索条件,但是每个条件只有⼏个字符,且数据量还可接收,这种情况下模糊匹配也是可以的
应⽤层
后端取全部数据,流过滤匹配。
同样,要考虑内存使⽤问题,如果是分页就更蛋疼了。
中间件层
千万级数据
ElasticSearch(开源,有很多功能,所以操作起来也很复杂)
Algolia(专有,但有很棒的⽂档并且⾮常容易启动和运⾏)
Typesense(开源,提供与 Algolia 相同的模糊搜索功能)。
arithmeticexception no exact representable result

arithmeticexception no exact representable result你的问题似乎是在进行某种计算时遇到了ArithmeticException: No exact representable result。
这个错误通常是由于在Java中进行除法运算时,除数不能被被除数整除,导致无法得到一个确切的结果而引发的。
例如,在Java中,如果你尝试执行以下代码:javadouble a = 10.0;double b = 3.0;double result = a / b;你将会遇到ArithmeticException: No exact representable result,因为10.0除以3.0的结果是一个无限循环的小数,而Java无法精确地表示这个结果。
解决这个问题的一个方法是使用Math.round()函数,它可以将结果四舍五入到最接近的整数。
例如:javadouble a = 10.0;double b = 3.0;double result = a / b;double roundedResult = Math.round(result);这样,roundedResult将会得到3,即10除以3的整数部分。
但是,请注意,这并不是10除以3的准确结果,只是它的整数部分。
如果你需要更精确的结果,你可能需要使用一个可以处理分数或复杂数字的数据类型,例如在Java中,你可以使用BigDecimal类来处理这种情况。
例如:javaimport java.math.BigDecimal;import java.math.RoundingMode;public class Main {public static void main(String[] args) {BigDecimal a = new BigDecimal("10.0");BigDecimal b = new BigDecimal("3.0");BigDecimal result = a.divide(b, 2, RoundingMode.HALF_UP); // 2是小数点后的位数,RoundingMode.HALF_UP是四舍五入的方式System.out.println(result); // 输出结果将会是3.3333333333333333}}。
pdfreference1.7第三章语法(P57-96翻译)

3.2.5 数组对象数组对象是一个一维的按顺序排列的对象集合。
不像数组在其他计算机语言中一样,pdf 数组可能是混杂的;也就是说,数组中的元素可以是数字、字符串、字典或者其他任何对象包括数组本身的组合。
数组写在方括号内[] :[549 3.14 false (Ralph) /SomeName]Pdf 直接支持一维数组。
任何深度的多维数组可以用数组作为数组中的元素来创建。
3.2.6 字典对象字典对象是一种连接表(键值对)包含成对的对象,称之为字典中的条目。
每一条的第一个元素是关键字,第二个是值。
关键字必须是一个姓名对象,值可以是任意对象。
一个条目如果它值是null ,它相当于一个空条目。
如果一个关键字在字典中出现一次以上,则它的值是undefined 。
字典对象用<<>>双尖括号包含起来:<< /Type /Example/Subtype /DictionaryExample/Version 0.01/IntegerItem 12/StringItem (a string)/Subdictionary << /Item1 0.4/Item2 true/LastItem (not!)/VeryLastItem (OK )>>>>字典对象是pdf 文件的主要组成部分。
它们常被用来收集和连接复杂对象的属性,例如文件的字体或者页码,利用每个条目的关键字是不同的来查询值。
它约定,Type 条目描述的是这个对象的种类。
在一些情况下,Subtype 条目用来更深入的区分一般类型的子目录。
种类和子种类条目的值总是一个姓名对象。
例如,在字体字典中,Type 条目的的值始终是Font,然而Subtype条目的值可能是Typel, TrueType或者其他几个值。
Type条目的值几乎可以总是从内容中推断出来。
操作符TF,是一个font对象;因此,Type 条目在字体字典中主要是作为文件编制和错误检查的信息。
cloudcompare中最新答案中没有标准答案

cloudcompare中最新答案中没有标准答案Fileopen:打开save:保存Global Shift settings:设置最大绝对坐标,最大实体对角线Primitive Factory:对点云进行原始加工,改变原始点云的形状3D mouse:对3D鼠标(如3Dconnexion)的支持Close all:关闭所有打开的实体Quit:退出Edit:Clone:克隆选中的点云Merge:合并两个或者多个实体。
可以合并点云(原始云会被删除);可以合并网格(原始网不会修改,CC会创建一个新的网格结构)Subsample:采集原始点云的子样本,可以用随机、立体、基于八叉树的方式采集,子样本会保持原始点云的标量、颜色、法线等性质。
Apply Transformation:可以对选中的实体做变换(4*4矩阵、轴线角,欧拉角)Multiply/Scale:让选中实体的坐标倍增。
Translate/Rotate(Interactive Transformation Tool):可以相对于另外一个实体或者坐标系移动选中的实体Segment(Interactive Segmentation Tool):通过画2D多边形分隔选中的实体Crop:分割一个或多个在3D-Box里面的点云。
Edit global shift and scale:进行全局变换和和比例缩放。
Toggle(recursive):用于控制键盘的快捷键。
Delete:删除选中的实体。
Colors>Set Unique:为所选实体设置唯一一个的颜色Colors>Colorize:为所选实体着色,具体表现为分别用所选颜色乘以当前颜色的RGB而得到新的颜色Colors>Levels:通过调整颜色的柱形图变色,类似于Photoshop的Levels方法Colors>Height Ramp:为所选实体设置颜色渐变(线形、梯形、环形)Colors>Convert to Scalar Field:将当前的RGB颜色字段转换为一个或几个标量字段Colors>Interpolate from another entity:在所选实体中插入另外一个实体的颜色Colors>Clear:移除所选实体的颜色域Normals>Compute:计算所选实体的法线Normals>Invert:反转所选实体的法线Normals>Orient Normals>With Minimum Spanning Tree:用同样的方法重新定位点云的全部法线(最小生成树)Normals>Orient Normals>With Fast Marching:用同样的方法重新定位点云的全部法线(快速行进法)Normals>Convert to>HSV:将云的法线转换到HSV颜色字段Normals>Convert to>Dip and Dip direction SFs:转换点云的法线到两个标量域Normals>Clear:为选定的实体移除法线Octree>Compute:强制计算给定实体的八叉树Octree>Resample:通过代替每个八叉树单元内的所有点来重新取样Mesh>Delaunay 2.5D(XY plane):计算点云在xy平面上的2.5D三角剖分(Delaunay 2.5D triangulation,德洛内2.5D三角算法)Mesh>Delaunay 2.5D(best fit plane):计算点云在最佳平面的2.5D三角剖分(Delaunay 2.5D triangulation,德洛内2.5D三角算法)Mesh>Convert texture/material to RGB:将选定网格的网格材料和纹理信息转换为逐个点的RGB字段Mesh>Sample points:在一个网格中随机取样Mesh>Smooth(Laplacian):平滑一个网格(Laplacian smoothing,拉普拉斯平滑算法)Mesh>Subdivide:细分网格,此算法递归细分网格三角形,直到他们的表面细分到用户指定值之下。
matchnonequery使用方法

matchnonequery使用方法# match_none_query的使用方法`match_none_query` 是Elasticsearch中一个特殊的查询类型,用于匹配那些没有指定字段的文档。
这在某些情况下非常有用,例如当我们想要检索那些不包含特定关键词或者不满足特定条件的文档时。
以下将详细介绍`match_none_query`的使用方法。
## 1.基本概念在Elasticsearch中,一个索引通常包含了多个文档,每个文档有多个字段。
`match_none_query`实际上是一种返回没有匹配任何查询条件的文档的查询。
## 2.使用场景- 当你想找到那些在特定字段上没有数据的文档时。
- 在对数据执行某种排除操作时,例如排除包含特定关键词的所有文档,然后查看剩余的文档。
## 3.语法结构以下是`match_none_query`的基本语法结构:```jsonGET /your_index/_search{"query": {"bool": {{"match_none": {}}]}}}```在这个结构中,`must_not`子句表示查询结果中不能包含的内容,而`match_none`则确保了这个条件。
## 4.实例解析假设我们有一个名为`products`的索引,里面存储了各种商品的信息。
现在我们想找到那些在`description`字段上没有任何描述的商品。
以下是相应的查询语句:```jsonGET /products/_search{"query": {"bool": {"must_not": [{"field": "description"}}]}}}```在这个例子中,`exists`查询被放在`must_not`子句中,表明我们不想获取那些在`description`字段上有值的文档。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
TRIPNon-Boolean Searching Abstract:TRIP5 introduces a way of performing “best match”searches using a new CCL function. This whitepaper introduces thenew search function, describes its basic operation, describes thefundamental principles on which TRIP’s non-Boolean algorithms arebased and shows examples of the function in use.Copyright © 2000 - 2009 Tieto Sweden ABTable of ContentsEXTENDING TRIP TO NON-BOOLEAN SEARCH (3)B EST MATCH SEARCHING (3)P ERFORMING A BEST MATCH QUERY (5)S ETTING UP A DATABASE TO SUPPORT BEST MATCH QUERY (5)E XAMPLES (7)S UMMARY (10)Extending TRIP to non-Boolean SearchTRIP has long offered a fully featured set of Boolean search capabilities, both generic and linguistic, but with the exception of the “fuzzy logic” i ntroduced with the FUZZ command, has not offered a “best match” search capability.TRIP5 introduces a way of performing “best match” s earches using a new CCL function. This whitepaper introduces the new search function, describes its basic operation, describes the fundamental principles on which TRIP’s non-Boolean algorithms are based, and shows examples of the function in use.Best match searchingWhereas Boolean searching focuses on matching a request with a set of provably valid responses (using basic set theory), best match searching focuses on matching a request with a set of responses that reflect the underlying purpose or intent of the request, rather than any provably correct “answer”. From this set of possible matches, the algorithm then provides a weighting, or judgment, as to how relevant each matched document is when compared to the information need expressed in the query.There are many different techniques used in common practice that aim to provide this level of inference between the query and the corpus of available information. Underlying almost all of these techniques, however, tends to be one of two prevalent algorithmic families: geometric or probabilistic measures.Although TRIP’s non-Boolean framework is designed in such a way as to allow for any type of algorithm to be used on a pluggable basis, the first such algorithm implemented follows the geometric form of measuring result relevance. Geometric search evaluationAs the longest-established mechanism for evaluating best match queries, geometric algorithms (also called the cosine measure) have shown themselves to be remarkably capable over time (although the division between geometric and probabilistic backers tends to be rather unscientific and emotional).The basis of the geometric method is being able to represent the information need expressed within a query and the information content of a candidate search result as vectors within a high-dimensional unit hyper-sphere (or, more practically, a projection onto an arc of that sphere). Assuming this can be performed, the similarity of the query and candidate can be calculated using a simple Euclidean measure of separation.Figure 1 shows a very simple example of such an evaluation.Figure 1In this case, there are only two terms in the query (“Peanut butter”). For sake of simplicity, we have applied equal weight to each term in the query, resulting in a vector representing the query at 45° to each axis.Again for simplicity, we are considering just two candidate documents (documents which contain either “peanut”, “butter” or both).For sake of illustration, document D1 has been assigned a high “peanut” w eight (implying a high degree of relationship between the document and the term or concept “peanut”) and a low “butter” w eight. This could happen, for example, if the document were about the health benefits of peanuts, and mentioned peanut butter only in passing. Document D2, in contrast, has been assigned a high “butter” w eight and a medium “peanut” weight.When evaluating the similarity of the information content within documents D1 and D2 to the information need expressed by the query Q, we measure the angle between the vectors.In this case, the angle 2 is much smaller than the angle 1 (in practice we actually seek to maximize the cosine of the angle as this is a self-normalizing function) and so we can state that document D2 has a smaller divergence, or a greater similarity to the information need expressed in query Q than does D1.Obviously what separates one implementation of the cosine measure from another is how the implementation assigns or combines weights for terms or concepts in the query and in candidate documents.Performing a best match queryAs mentioned in the abstract, TRIP5 introduces a new CCL function to expose access to the best match framework:Find ABOut(peanut butter)Find ABOut(T=n [TO m])Find ABOut(R=n [TO m])Find ABOut(S=n [TO m])As shown, there are many different ways of exercising the function. The simplest is to state an information need explicitly, i.e. to give the function the text of the query that you wish to match. This query text could be a simple phrase, a full sentence, an arbitrary fragment, or an entire page of text. Likewise, one or more terms from a Display list can be submitted as an information need, using the normal “T=” syntax. An application wishing to offer a “find more like this one” function would make use of the “R=” syntax, whereby the content of the specified record is analyzed for information need.Finally, in certain constrained circumstances it may be useful to find documents that match the information need expressed by all records in one or more search sets, using the normal “S=” syntax. Note that using this capability on large search sets will result in extremely poor performance, obviously.Setting up a database to support best match queryIn either of the latter two cases, the algorithm needs to know what attributes of the records should be analyzed when attempting to construct the information need being expressed by those records.Equally, when indexing documents that will be tested for best match during queries of any of the forms shown above, the indexing engine needs to have this same information available.The manager of such a database, therefore, must establish a new indexing flag on any field that is to be included in a non-Boolean calculation (either at indexing or query time). This is performed via TRIPmgr in one of two different ways:Single field assignment is achieved by using the context menu on that field and setting the appropriate flag in the field’s property page, as shown in Figure 2, overleaf.Multiple field assignment is achieved by selecting all fields to be modified, and using the appropriate option from the context menu, as shown in Figure 3, overleaf.Note that these options are only valid and available for fields of type TExt or PHrase.Figure 2Figure 3Once the flags have been set appropriately, databases that are to be searched using the new search function must be re-indexed in order for required information to be added.ExamplesThe following figure shows the new search function in action, performing the same basic query that we used in the example above.Using the normal “Show SORt=FReq” mechanism of getting ranked output, results in the following document appearing first:Further documents display more information about this topic, as expected, for example:Whilst nicely ranked, this is nothing that a simple search for “peanut OR butter”couldn’t have done, of course.Taking the example a step further, we submit a request to find more articles related to the information content within the first document shown:As should be expected, the first document shown is of course record #8163 (the most similar document should, after all, be itself).However, the second document shown relates to other sandwich types being offered at a local ballpark:This function can also be used to prepare a ranked list of documents that match terms from a Display window. For example:SummaryTRIP5 offers the user a whole new way of searching databases that have been prepared appropriately. The initial implementation of non-Boolean searching uses a robust, proven algorithm family that should provide good, consistent results for a wide variety of contexts. However, we will continue to experiment in this area and, in the future, shall potentially offer either modifications to the existing algorithm or a whole new algorithm family.。