熟悉常用的Linux操作和Hadoop操作
数据库开发岗位职责

数据库开发岗位职责数据库开发岗位职责11、熟悉PHP语言开发,有PHP项目开发经验,熟悉面向对象的设计方法,开发经验3-5年;2、掌握JS、HTML、CSS等相关Web开发技术知识;3、掌握MySQL数据库应用,具有相关应用开发经验及数据库规划能力;4、具备良好的.代码编程习惯及较强的文档编写能力;5、具备强烈的进取心、求知欲及团队合作精神,有较强的沟通及协调能力;能够准确了解需求;6、熟悉ThinkPHP、Laravel框架优先;7、熟悉前端框架如AngularJs,jQuery,Bootstrap,jQueryMobile等优先。
8、熟悉memcache,redis,mysql/postgresql,mongodb。
如对NoSQL有深入了解者尤佳;9、对个人和团队代码质量要很高要求,习惯并喜欢codereview10、熟悉常用设计模式,有大型分布式、高并发、高负载、高可用性系统设计开发经验者优先;11、有商城系统开发、熟悉微擎系统经验者优先数据库开发岗位职责2职责:1、参与项目需求分析,研究项目技术细节,进行系统框架和核心模块的详细设计;编写相应的技术文档;2、根据公司要求规范,编写相应的技术文档;编制项目文档、记录质量测试结果3、完成项目初始至终结的全部技术跟踪协调工作4、根据开发进度和任务分解完成软件编码工作,配合测试工程师进行软件测试工作;5、参与客户沟通、项目需求调研分析并维持良好的客户关系;编写需求分析报告。
6、进行用户现场软件的.部署和实施7、完成公司领导交办的其他工作。
岗位要求:1、计算机相关专业,数学专业优先,本科以上学历;2、熟悉Oracle、Sqlserver等数据库及SQL语言;3、良好的团队合作精神和社交技巧及沟通协调能力;4、能适应经常出差。
数据库开发岗位职责3职责1.数据库安装、配置、故障处理、备份与恢复;2.数据库性能监控与优化、数据库安全加固、数据库空间管理等(包括线上、线下环境);3.负责项目数据ETL整合与数据库设计;4.审核数据库设计方案和SQL语句,对上线数据库质量进行管理;5.负责数据库操作标准化流程制定,并遵照执行;(如数据库设计规范、数据库变更管理规范)6.负责跟进、试用厦门数据组产出的工具、数据整合方案,以及在重庆团队中推广使用;7.提升实施团队数据库运维相关技能。
hadoop命令及使用方法

hadoop命令及使用方法Hadoop是一个分布式计算框架,用于存储和处理大规模数据集。
下面是一些常用的Hadoop命令及其使用方法:1. hdfs命令:- hdfs dfs -ls <路径>:列出指定路径下的文件和目录。
- hdfs dfs -mkdir <路径>:创建一个新的目录。
- hdfs dfs -copyFromLocal <本地路径> <HDFS路径>:将本地文件复制到HDFS 上。
- hdfs dfs -copyToLocal <HDFS路径> <本地路径>:将HDFS上的文件复制到本地。
- hdfs dfs -cat <文件路径>:显示HDFS上的文件内容。
2. mapred命令:- mapred job -list:列出当前正在运行的MapReduce作业。
- mapred job -kill <job_id>:终止指定的MapReduce作业。
3. yarn命令:- yarn application -list:列出当前正在运行的应用程序。
- yarn application -kill <application_id>:终止指定的应用程序。
4. hadoop fs命令(与hdfs dfs命令功能相似):- hadoop fs -ls <路径>:列出指定路径下的文件和目录。
- hadoop fs -cat <文件路径>:显示HDFS上的文件内容。
- hadoop fs -mkdir <路径>:创建一个新的目录。
- hadoop fs -put <本地文件路径> <HDFS路径>:将本地文件复制到HDFS上。
- hadoop fs -get <HDFS路径> <本地文件路径>:将HDFS上的文件复制到本地。
linux实习心得

linux实习心得在开始这篇文档之前,我首先想要强调的是,如果有机会得到参加Linux实习的机会,绝对不要错过它。
这是一次非常有价值、让人收益匪浅的学习机会。
下面,我将结合自己的经验和感悟,分享一下我的Linux实习心得。
一、前期准备在参加Linux实习之前,我们需要做好一些准备工作。
首先是基础知识的掌握。
虽然在实习期间会有专业的老师进行指导,但是对于已有一定基础的同学,熟悉Linux 的基本操作和概念,能够更快地适应工作环境。
其次是准备好适用的笔记本电脑,最好是安装了Linux系统的,以便更加方便地进行实验和操作。
另外,我们还需要做好心理准备,有一定的耐心和细心,敢于尝试和探索。
二、实习过程在实习期间,我们主要进行了以下几方面的学习和实践:1. Linux基础操作和常用命令的掌握在Linux实习过程中,我们首先学习了Linux的基本操作和常用命令,如文件管理、用户管理、进程管理等。
在学习过程中,我们结合了实际操作,通过setuid、setgid、chmod、chown等命令实践了文件的权限管理,也尝试了各种各样的命令来实现相应的目的。
在学习的过程中,我们学到了很多实用的技巧,也发现了很多命令的互相之间的关系,大大提升了我们的操作和管理效率。
2. Shell编程和脚本编写除了掌握基本的命令和操作之外,我们也通过实践学习了Shell编程和脚本编写。
通过学习Shell的逻辑判断语句和循环语句,在实践中逐渐掌握了Shell程序的编写和调试技巧。
同时,在实践中我们也了解了Linux下常用的脚本语言,如Perl、Python等,并尝试了使用这些脚本语言编写一些小型的工具和脚本文件。
3. 网络与安全作为服务器操作系统,Linux的网络和安全是我们必须掌握的重要内容。
在学习的过程中,我们深入了解了Linux下网络协议的实现和网络安全相关的知识,包括iptables防火墙的设置、网络抓包分析工具的使用、加密和解密等内容。
大数据运维需要掌握的技能

大数据运维需要掌握的技能随着大数据技术的不断发展,数据量的飞速增长以及大数据应用场景的不断拓展,对大数据运维的挑战也越来越大。
对于一个大数据运维工程师,仅仅了解基本的数据处理和服务器操作是远远不够的,必须掌握更多的技能才能应对现实的挑战。
本文将介绍大数据运维需要掌握的技能,以期帮助大数据运维工程师更加高效地管理和维护大数据系统。
1.熟悉操作系统和网络技术大型数据处理集群通常需要部署在多个服务器上,而这些服务器需要连通,所以掌握操作系统和网络技术是必要的。
操作系统包括Linux、Unix、Windows等,掌握它们的命令行操作,能够熟练运用磁盘管理、网络配置、软件安装等基础操作;同时需要了解TCP/IP、HTTP、DNS等网络协议,掌握网络架构,对网络故障有基本的分析和调试能力。
2.掌握分布式系统原理在大数据处理领域,分布式系统是非常重要的,因为大数据量往往需要在分布式系统中进行分配、存储和处理。
掌握分布式系统原理可以帮助我们理解数据处理和存储的内部原理,了解数据分区、数据复制、容错和一致性等重要问题,同时也能更好地选择合适的数据处理框架。
3.精通Hadoop技术Hadoop是大数据处理中最常用的技术之一,掌握Hadoop生态系统的技术可以帮助我们更加高效地进行数据存储、处理和分析。
Hadoop包括HDFS、MapReduce、YARN 等组件,熟练掌握这些组件的安装、配置、优化和调优等技能,能够有效地解决在数据处理中遇到的问题,并提高处理效率和质量。
4.熟悉数据库操作数据库是大数据系统中最常用的数据存储方式。
掌握数据库操作技能可以帮助我们处理不同类型的数据,并提供高效且可靠的数据访问方式。
常见的数据库包括MySQL、MongoDB、Redis、Cassandra等,掌握它们的基本操作和调优技巧可以提高大数据系统的效率和可靠性。
5.熟悉监控和性能分析工具大数据系统需要经常进行监控和分析,以帮助我们及时发现问题并做出采取行动。
liunx实验总结 -回复

liunx实验总结-回复Liunx实验总结在本次Linux实验中,我们主要学习了Linux操作系统的常用命令和一些基本操作。
在实验过程中,我逐渐熟悉了Linux的命令行界面,学会了如何在Linux系统上进行文件和目录的管理,同时也了解了一些系统配置和网络操作。
在本文中,我将分享一些我在实验过程中的体会和总结。
1. Linux系统的基本操作使用Linux系统时,我们首先需要熟悉一些基本的命令和操作。
在实验中,我练习了常用的命令,如cd、ls、mkdir、rm等。
通过这些命令,我可以轻松地切换目录、查看目录内容以及创建和删除目录和文件。
此外,我还了解了一些特殊的命令,如mv、cp和cat等。
这些命令可以帮助我们移动和复制文件,以及查看文件的内容。
通过练习这些命令,我发现Linux系统可以通过简单的命令完成许多复杂的任务。
2. Linux文件和目录的管理Linux系统以文件和目录的方式来管理数据。
在实验中,我了解了如何创建、复制、删除和移动文件和目录。
通过这些操作,我可以轻松地整理和管理我的数据。
另外,我学习了一些重要的目录,如根目录(/)和家目录(~)。
根目录是Linux系统的最高目录,所有其他的目录和文件都存在于根目录的下级目录中。
家目录是Linux系统中每个用户的个人目录,用于存储该用户的个人文件和配置信息。
此外,我还学习了如何使用通配符来匹配文件名。
在实验中,我使用了*和?等通配符来批量操作文件。
这让我感到非常方便,因为我可以一次操作多个文件,而不需要逐个文件进行处理。
3. 系统配置和管理除了文件和目录的管理外,我还学习了一些系统配置和管理的技巧。
在实验中,我了解了如何修改用户密码并创建新用户。
这对于保护系统安全和管理用户非常重要。
此外,我还学习了如何使用文本编辑器编辑配置文件。
在实验中,我使用了vi编辑器来编辑配置文件,并学习了一些基本的编辑命令,如插入、删除和保存等。
通过这些操作,我可以修改系统的配置,以适应特定的需求。
6个大数据开发工程师的岗位要求

6个大数据开发工程师的岗位要求岗位要求1:1.精通阿里Dataphin,阿里大数据软件相关开发经验3年以上,有丰富的参数配置及调优经验。
2. 具有商业类客户交付经验ETL开发3. 具有数据上云经验4. 使用过阿里RDS 有建模经验岗位要求2:1)熟悉Linux/Unix平台,熟练使用常用命令;2)精通Java开发,对多线程、消息队列等并有较为深刻的理解和实践;3)熟练使用Tomcat等常见中间件;4)精通Doris数据库,有数据仓库相关经验者优先;5)熟悉kettle、datax、sqoop、flume等数据同步工具的一种或多种;6)良好的沟通能力、团队精神和服务意识;7)善于学习新知识,动手能力强,有进取心。
岗位要求3:1. 计算机基础知识扎实,包括操作系统、计算机网络、数据结构、基础算法、数据库等。
2. 编程能力扎实,至少熟练掌握Java/Python一门以上编程或脚本语言,有清晰的编程思路。
3. 热衷于并擅长troubleshooting 和performance tuning,喜好专治各种性能和异常的疑难杂症,并乐于做技术剖析、总结沉淀。
4. 具备良好的沟通协调能力,和很强的责任心,具备优秀的推动力。
在提供改进和落地的同时,提供可量化的手段和指标5. 对代码的健壮性和可运维性有高要求;足够“偷懒”,热爱coding,擅长以技术解决人力问题,支撑海量服务器运行优化加分项1.精通linux文件系统、内核、linux性能调优、TCP/IP、HTTP 等协议,有良好的网络、数据存储、计算机体系结构方面的知识,对常见的系统隐患、系统故障有系统性总结和实际处理经验2.熟悉一种或者多种大数据生态技术(Kafka、HBase、Hive、Hadoop、Spark等),熟悉源码者优先。
岗位要求4:1、本科以上学历,计算机或相关专业,2年以上Hadoop架构开发经验;2、愿意学习先进技术与新架构,如TiDB,有基于TiDB HTAP 的数据平台开发经验优先;3、精通Java或Scala开发,熟悉Linux/Unix环境,熟悉容器;4、基于Hadoop大数据体系有深入认识,具备相关产品(Hadoop、Hive、Hbase、Spark等)项目开发经验,有Hadoop集群搭建和管理经验,读过Hadoop或Hbase源码或二次开发经验的优先;5、态度端正,有较强责任心,具有较强的沟通表达能力、逻辑思维能力和文档编写能力。
熟悉常用的linux操作和hadoop操作实验报告

熟悉常用的linux操作和hadoop操作实验报告本实验主要涉及两个方面,即Linux操作和Hadoop操作。
在实验过程中,我深入学习了Linux和Hadoop的基本概念和常用操作,并在实际操作中掌握了相关技能。
以下是我的实验报告:一、Linux操作1.基本概念Linux是一种开放源代码的操作系统,它允许用户自由地使用、复制、分发和修改系统。
Linux具有更好的性能、更高的安全性和更好的可定制性。
2.常用命令在Linux操作中,一些常用的命令包括:mkdir:创建目录cd:更改当前目录ls:显示当前目录中的文件cp:复制文件mv:移动文件rm:删除文件pwd:显示当前所在目录chmod:更改文件权限chown:更改文件所有者3.实验操作在实验中,我对Linux的文件系统、文件权限、用户与组等进行了学习和操作。
另外,我还使用Linux命令实现了目录创建、文件复制、删除等操作。
二、Hadoop操作1.基本概念Hadoop是一种开源框架,用于处理大规模数据和分布式计算。
它使用Hadoop分布式文件系统(HDFS)来存储数据,使用MapReduce来处理大规模数据集。
2.常用命令在Hadoop操作中,一些常用的命令包括:hdfs dfs:操作HDFS文件系统hadoop fs:操作Hadoop分布式文件系统hadoop jar:运行Hadoop任务hadoop namenode -format:格式化文件系统start-all.sh:启动所有Hadoop服务3.实验操作在实验中,我熟悉了Hadoop的安装过程、配置过程和基本概念。
我使用Hadoop的命令对文件系统进行操作,如创建、删除、移动文件等。
此外,我还学会了使用MapReduce处理大规模数据集。
总结通过本次实验,我巩固了Linux和Hadoop操作的基本知识和技能。
我深入了解了Linux和Hadoop的基本概念和常用操作,并学会了使用相关命令进行实际操作。
五个运维工程师的任职资格

五个运维工程师的任职资格任职资格1:1.精通Linux操作系统;熟悉Nginx、Oracle、MySQL等的配置及优化和常用服务配置,并能够快速部署、配置及排错2.熟练掌握服务器相关监控系统,熟悉常用的自动化运维工具3.熟练掌握Linux服务器集群,负载均衡,容灾部署等应用,有高并发,高流量的架构设计经验者优先4. 具备责任心,能够快速分析解决问题任职资格2:计算机及相关专业学历;熟练使用Windows/Linux等操作系统、常用办公软件、工具软件、安全防护软件、主流虚拟化及数据库。
熟悉TCP/IP协议、主流网络设备、网络安全设备的使用;善于学习、具有分析、解决问题的能力;具有较强的沟通能力与团队合作精神;良好的沟通能力和文档写作能力,可以独立收集和分析业务数据,输出运维报告;任职资格3:•至少3年以上网络管理或系统维护的工作经验,具有2年以上云计算管理经验,熟悉TCP/IP、DNS、DHCP、VPN、防火墙等网络技术,具有网络规划、架构能力。
•熟悉主流厂家网络设备和网络安全设备,能够独立完成设备的配置、调试、优化及故障排错工作。
•熟悉阿里云、电信云等主流云计算平台,能够熟练操作云服务器、负载均衡器、CDN、对象存储等云服务。
•对于Linux系统有较深入的了解,在系统维护、排错方面具有丰富的经验。
•熟悉MySQL、Redis等主流数据库,在系统部署、配置、维护和性能调优方面具有一定的经验。
•具有良好的团队合作精神和沟通能力,能够快速响应和解决问题。
•具有较强的沟通表达能力和团队协作能力,具有较强的责任心和安全保密意识。
加分项•熟悉Docker、Kubernetes等容器技术,并有使用经验,能够独立完成容器化应用的部署、维护和升级。
任职资格4:1、本科以上学历,3年以上的桌面、机房运维经验,有强烈的责任心和主动工作的态度;2、具有良好的计算机系统硬件、软件、电子邮件、网络及日常办公设备的问题解决能力;了解企业级病毒和邮件客户端维护与管理;3、良好的服务意识及团队合作意识;善于表达,能够与用户进行有效沟通及协调。
hadoop的基本操作命令

hadoop的基本操作命令Hadoop是目前最流行的分布式计算框架之一,其强大的数据处理能力和可扩展性使其成为企业级应用的首选。
在使用Hadoop时,熟悉一些基本操作命令是必不可少的。
以下是Hadoop的基本操作命令:1. 文件系统命令Hadoop的文件系统命令与Linux系统类似,可以用于管理Hadoop的文件系统。
以下是一些常用的文件系统命令:- hdfs dfs -ls:列出文件系统中的文件和目录。
- hdfs dfs -mkdir:创建一个新目录。
- hdfs dfs -put:将本地文件上传到Hadoop文件系统中。
- hdfs dfs -get:将Hadoop文件系统中的文件下载到本地。
- hdfs dfs -rm:删除文件系统中的文件或目录。
- hdfs dfs -du:显示文件或目录的大小。
- hdfs dfs -chmod:更改文件或目录的权限。
2. MapReduce命令MapReduce是Hadoop的核心计算框架,用于处理大规模数据集。
以下是一些常用的MapReduce命令:- hadoop jar:运行MapReduce作业。
- hadoop job -list:列出所有正在运行的作业。
- hadoop job -kill:终止正在运行的作业。
- hadoop fs -copyFromLocal:将本地文件复制到Hadoop文件系统中。
- hadoop fs -copyToLocal:将Hadoop文件系统中的文件复制到本地。
- hadoop fs -rmr:删除指定目录及其所有子目录和文件。
3. YARN命令YARN是Hadoop的资源管理器,用于管理Hadoop集群中的资源。
以下是一些常用的YARN命令:- yarn node -list:列出所有节点的状态。
- yarn application -list:列出所有正在运行的应用程序。
- yarn application -kill:终止正在运行的应用程序。
hadoop 操作手册

hadoop 操作手册Hadoop 是一个分布式计算框架,它使用 HDFS(Hadoop Distributed File System)存储大量数据,并通过 MapReduce 进行数据处理。
以下是一份简单的 Hadoop 操作手册,介绍了如何安装、配置和使用 Hadoop。
一、安装 Hadoop1. 下载 Hadoop 安装包,并解压到本地目录。
2. 配置 Hadoop 环境变量,将 Hadoop 安装目录添加到 PATH 中。
3. 配置 Hadoop 集群,包括 NameNode、DataNode 和 JobTracker 等节点的配置。
二、配置 Hadoop1. 配置 HDFS,包括 NameNode 和 DataNode 的配置。
2. 配置 MapReduce,包括 JobTracker 和 TaskTracker 的配置。
3. 配置 Hadoop 安全模式,如果需要的话。
三、使用 Hadoop1. 上传文件到 HDFS,使用命令 `hadoop fs -put local_file_path/hdfs_directory`。
2. 查看 HDFS 中的文件和目录信息,使用命令 `hadoop fs -ls /`。
3. 运行 MapReduce 作业,编写 MapReduce 程序,然后使用命令`hadoop jar my_` 运行程序。
4. 查看 MapReduce 作业的运行结果,使用命令 `hadoop fs -cat/output_directory/part-r-00000`。
5. 从 HDFS 中下载文件到本地,使用命令 `hadoop fs -get/hdfs_directory local_directory`。
6. 在 Web 控制台中查看 HDFS 集群信息,在浏览器中打开7. 在 Web 控制台中查看 MapReduce 作业运行情况,在浏览器中打开四、管理 Hadoop1. 启动和停止 Hadoop 集群,使用命令 `` 和 ``。
物联网数据处理实验指导书

《物联网数据处理》实验指导书实验一:熟悉常用的Linux操作(2学时)一、实验目的与要求1、熟悉安装和配置Linux。
2、熟悉常用的Linux操作。
6、总结在调试过程中的错误。
二、实验类型验证型三、实验原理及说明通过实际操作,使学生对Linux的使用有一个更深刻的理解;熟悉Linux的开发环境及程序结构。
四、实验仪器安装操作系统:Linux五、实验内容和步骤熟悉常用的Linux操作请按要求上机实践如下linux基本命令。
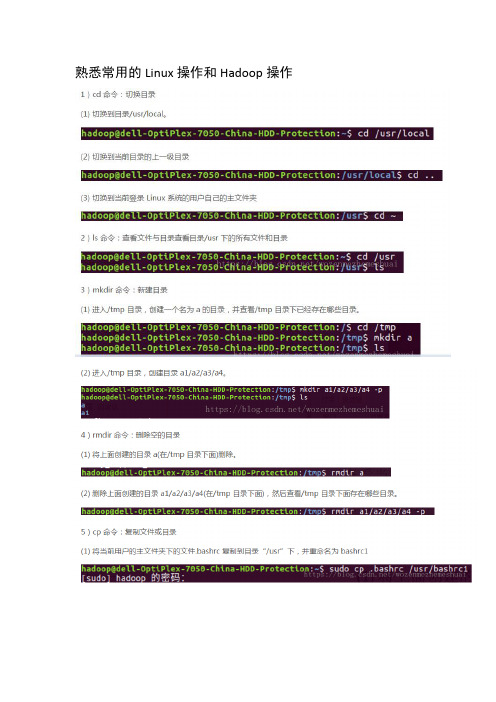
cd命令:切换目录(1)切换到目录/usr/local(2)去到目前的上层目录(3)回到自己的主文件夹ls命令:查看文件与目录(4)查看目录/usr下所有的文件mkdir命令:新建新目录(5)进入/tmp目录,创建一个名为a的目录,并查看有多少目录存在(6)创建目录a1/a2/a3/a4rmdir命令:删除空的目录(7)将上例创建的目录a(/tmp下面)删除(8)删除目录a1/a2/a3/a4,查看有多少目录存在cp命令:复制文件或目录(9)将主文件夹下的.bashrc复制到/usr下,命名为bashrc1(10)在/tmp下新建目录test,再复制这个目录内容到/usrmv命令:移动文件与目录,或更名(11)将上例文件bashrc1移动到目录/usr/test(12)将上例test目录重命名为test2rm命令:移除文件或目录(13)将上例复制的bashrc1文件删除(14)rm -rf 将上例的test2目录删除cat命令:查看文件内容(15)查看主文件夹下的.bashrc文件内容tac命令:反向列示(16)反向查看主文件夹下.bashrc文件内容more命令:一页一页翻动查看(17)翻页查看主文件夹下.bashrc文件内容head命令:取出前面几行(18)查看主文件夹下.bashrc文件内容前20行(19)查看主文件夹下.bashrc文件内容,后面50行不显示,只显示前面几行tail命令:取出后面几行(20)查看主文件夹下.bashrc文件内容最后20行(21)查看主文件夹下.bashrc文件内容,只列出50行以后的数据touch命令:修改文件时间或创建新文件(22)在/tmp下创建一个空文件hello并查看时间(23)修改hello文件,将日期调整为5天前chown命令:修改文件所有者权限(24)将hello文件所有者改为root帐号,并查看属性find命令:文件查找(25)找出主文件夹下文件名为.bashrc的文件tar命令:压缩命令tar -zcvf /tmp/etc.tar.gz /etc(26)在/目录下新建文件夹test,然后在/目录下打包成test.tar.gz(27)解压缩到/tmp目录tar -zxvf /tmp/etc.tar.gzgrep命令:查找字符串(28)从~/.bashrc文件中查找字符串'examples'(29)配置Java环境变量,在~/.bashrc中设置(30)查看JA V A_HOME变量的值六、注意事项命令的名称。
linux运维简历

linux运维简历作为一名Linux运维工程师,我深知运维工作的重要性和责任感。
我具备扎实的Linux操作系统基础知识和丰富的实际运维经验,熟悉各种常用的运维工具和技术。
在这篇文章中,我将详细介绍我的技能和经验,以及我在Linux运维领域的成就。
教育背景我拥有计算机科学学士学位,并在大学期间学习了Linux操作系统和网络管理课程。
这些课程帮助我打下了扎实的技术基础,并深入了解了Linux的工作原理和常用命令。
在大学期间,我还参与了几个Linux开源项目,对系统配置和管理有了更深入的了解。
技能和专业知识- 熟悉Linux操作系统,包括安装、配置、管理和故障排除。
- 熟练掌握Shell脚本编程,能够编写自动化脚本来提高工作效率。
- 熟悉网络协议和网络设备的配置和管理,包括TCP/IP、DNS、DHCP等。
- 熟悉虚拟化技术,如VMware和KVM,能够创建和管理虚拟机。
- 熟练使用监控工具,如Nagios和Zabbix,能够监控服务器和网络设备的状态。
- 熟悉版本控制工具,如Git和SVN,能够协作开发和管理代码。
- 具备良好的故障排除和问题解决能力,能够快速定位和解决系统故障。
工作经验我有三年的Linux运维工作经验,在这期间积累了丰富的实践经验和解决问题的能力。
以下是我在两家知名互联网公司工作期间的主要职责和成就:ABC公司Linux运维工程师,2018年-至今- 负责公司服务器的日常维护和管理,包括操作系统升级、安全补丁打补丁等。
- 设计和部署监控系统,定期检查监控报警,保证服务器的稳定性和可用性。
- 协助开发团队进行应用程序和数据库的部署和迁移。
- 优化服务器性能,通过调整配置和优化代码,提高系统响应速度。
XYZ公司Linux运维实习生,2016年-2018年- 提供技术支持和维护日常系统运行,解决用户的问题。
- 参与公司服务器的规划和设计,提出改进建议,提高系统的可靠性和稳定性。
- 开发自动化脚本,简化日常维护任务,提高工作效率。
linux操作系统比赛适合用的知识点

linux操作系统比赛适合用的知识点
1.Linux基础:了解Linux的历史、特点和优势,熟悉Linux的
常用命令和操作。
2.文件和目录管理:掌握Linux中文件和目录的管理方法,包括
创建、删除、重命名、移动、复制等操作,以及文件和目录的权限设置。
3.系统管理:了解Linux系统的基本管理,包括用户管理、进程
管理、内存管理、磁盘管理等方面的知识。
4.软件安装和管理:掌握Linux中软件的安装和管理方法,包括
使用包管理器、编译源代码等方式。
5.网络配置和管理:了解Linux中的网络配置和管理,包括IP
地址设置、网络连接、网络服务和防火墙配置等。
6.系统安全:了解Linux中的系统安全知识,包括权限管理、文
件和目录的隐藏、密码管理等,以及如何防范常见的安全威胁。
7.Shell编程:掌握Shell编程的基本语法和技巧,包括变量、
循环、条件判断、函数等方面的知识。
8.系统性能优化:了解Linux系统的性能优化方法,包括磁盘性
能、CPU性能、内存性能等方面的优化。
9.版本控制:了解和使用版本控制工具,如Git,以便在比赛时
更好地协作和管理代码。
10.Linux服务器管理:了解Linux服务器的基本知识和管理方
法,如Web服务器、数据库服务器等。
计算机操作学习心得体会

计算机操作学习心得体会
学习计算机操作的过程中,我有一些心得体会:
1. 熟悉常用操作系统:在学习计算机操作之前,先要熟悉常用的操作系统,例如Windows、MacOS或Linux。
了解操作系统的界面、文件管理、软件安装等基本操作,可以帮助我们更快地适应和使用计算机。
2. 学会使用快捷键:快捷键可以极大地提高工作效率,在操作计算机时应当尽量使用
快捷键而不是鼠标。
掌握常用的快捷键,可以让我们更高效地完成各种任务。
3. 熟悉文件管理:文件管理是计算机操作的基础。
学会创建、复制、移动、重命名和
删除文件,以及建立文件夹和目录结构等操作,可以使我们更好地组织和管理自己的
文件。
4. 学会使用常用软件:学习和掌握一些常用软件是非常重要的。
例如文档处理软件(如Microsoft Word)、电子表格软件(如Microsoft Excel)、演示软件(如Microsoft PowerPoint)等。
这些软件在学校、工作和生活中都有广泛应用,掌握它们
可以提高我们的工作效率和处理信息的能力。
5. 不断练习和实践:计算机操作是一个实践性很强的技能,需要不断地练习和实践才
能掌握。
在学习过程中,可以选择一些实际的任务来进行操作,例如写一篇论文、做
一个简单的数据分析、制作一个演示文稿等,通过实际操作来加深对计算机操作的理
解和掌握。
总结起来,学习计算机操作需要耐心和实践,通过不断地练习和实践,掌握基本的操
作技能,熟练使用常用的软件和工具,可以极大地提高我们的工作效率和处理信息的
能力。
实验一-熟悉Linux操作系统环境及常见命令的使用

实验一、熟悉Linux操作系统环境及常见命令的使用一、实验目的(1)练习进入和退出系统的操作;学习linux联机帮助命令的使用,学会怎样利用借助联机帮助命令随时查阅系统说明文档。
(2)熟悉Linux下的基本操作,学会使用各种Shell命令去操作Linux,对Linux有一个感性认识。
二、实验准备知识1.登录Linux系统必须要输入用户的账号,在系统安装过程中可以创建以下两种帐号:1〕root--超级用户帐号〔系统管理员〕,使用这个帐号可以在系统中做任何事情。
2〕普通用户--这个帐号供普通用户使用,可以进行有限的操作。
一般的Linux使用者均为普通用户,而系统管理员一般使用超级用户帐号完成一些系统管理的工作。
如果只需要完成一些由普通帐号就能完成的任务,建议不要使用超级用户帐号,以免无意中破坏系统。
影响系统的正常运行。
用户登录分两步:第一步,输入用户的登录名,系统根据该登录名识别用户;第二步,输入用户的口令,该口令是用户自己设置的一个字符串,对其他用户是保密的,是在登录时系统用来区分真假用户的关键字。
当用户正确地输入用户名和口令后,就能合法地进入系统。
屏幕显示:[root@loclhost /root] #这时就可以对系统做各种操作了。
注意超级用户的提示符是“#”,其他用户的提示符是“$”。
2.修改口令为了更好的保护用户帐号的安全,Linux允许用户随时修改自己的口令,修改口令的命令是passwd,它将提示用户输入旧口令和新口令,之后还要求用户再次确认新口令,以防止用户无意中按错键。
如果用户忘记了口令,可以向系统管理员申请为自己重新设置一个。
例如:[root@loclhost /root] # passwd <CR>3.退出系统不管是超级用户,还是普通用户,需要退出系统时,在shell提示符下,键入exit命令即可。
例如:[root@loclhost /root] # exit <CR>4.获取帮助linux 带有联机手册,可以用man 命令查阅各系统命令及系统调用的语法。
熟悉常用的linux操作和hadoop操作实验报告

熟悉常用的linux操作和hadoop操作实验报告通过本次实验,熟悉常用的Linux操作和Hadoop操作,掌握基本的Linux命令和Hadoop命令,了解Hadoop的安装和配置,以及Hadoop集群的搭建和使用。
实验步骤:1. Linux操作1.1 Linux系统介绍Linux是一种自由和开放源代码的类Unix操作系统。
它是一个基于POSIX和UNIX的多用户、多任务、支持多线程和多处理器的操作系统。
1.2 常用Linux命令在Linux系统中有很多常用的命令,例如ls、cd、cat、grep等,这些命令常常用于查看文件和目录、移动和复制文件、编辑文件、搜索文件和文件夹等。
2. Hadoop操作2.1 Hadoop介绍Hadoop是一个开源的分布式计算系统,它可以处理大规模数据的存储和处理。
Hadoop包括两个主要的组件:HDFS和MapReduce。
2.2 Hadoop安装和配置Hadoop的安装和配置需要进行以下步骤:1)下载Hadoop软件包并解压缩2)设置Hadoop的环境变量3)配置Hadoop的主机名和IP地址4)配置Hadoop的核心配置文件5)启动Hadoop服务2.3 Hadoop集群的搭建和使用Hadoop集群的搭建需要进行以下步骤:1)配置每个节点的主机名和IP地址2)在每个节点上安装Hadoop软件包并解压缩3)配置Hadoop的核心配置文件4)启动Hadoop服务在Hadoop集群中,可以使用Hadoop的命令行工具来进行数据的上传和下载、数据的处理和分析等操作。
实验结论:通过本次实验,我们掌握了基本的Linux命令和Hadoop命令,了解了Hadoop的安装和配置,以及Hadoop集群的搭建和使用。
这些知识将有助于我们更好地理解和应用Hadoop分布式计算系统,提高我们的数据处理和分析能力。
云计算实验题
33
37
12
40
输入文件2的样例如下:
4
16
39
5
输入文件3的样例如下:
1
45
25
根据输入文件1、2和3得到的输出文件如下:
1 1
2 4
3 5
4 12
5 16
6 25
7 33
8 37
9 39
10 40
11 45
3. 对给定的表格进行信息挖掘
下面给出一个child-parent的表格,要求挖掘其中的父子辈关系,给出祖孙辈关系的表格。
输入文件内容如Leabharlann :child parent
Steven Lucy
Steven Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Frank
Jack Alice
Jack Jesse
David Alice
David Jesse
Philip David
Philip Alma
Mark David
(4)modifyData(String tableName, String row, String column)
修改表tableName,行row(可以用学生姓名S_Name表示),列column指定的单元格的数据。
(5)deleteRow(String tableName, String row)
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
大数据实验——精选推荐

⼤数据实验实验⼀:熟悉常⽤的Linux操作和Hadoop操作⼀、实验⽬的Hadoop运⾏在Linux系统上,因此,需要学习实践⼀些常⽤的Linux命令。
本实验旨在熟悉常⽤的Linux操作和Hadoop操作,为顺利开展后续其他实验奠定基础。
⼆、实验平台l 操作系统:Linux;l Hadoop版本:2.7.1。
三、实验步骤(⼀)熟悉常⽤的Linux操作l cd命令:切换⽬录(1)切换到⽬录“/usr/local”(2)切换到当前⽬录的上⼀级⽬录(3)切换到当前登录Linux系统的⽤户的⾃⼰的主⽂件夹l ls命令:查看⽂件与⽬录(4)查看⽬录“/usr”下的所有⽂件和⽬录l mkdir命令:新建⽬录(5)进⼊“/tmp”⽬录,创建⼀个名为“a”的⽬录,并查看“/tmp”⽬录下已经存在哪些⽬录(6)进⼊“/tmp”⽬录,创建⽬录“a1/a2/a3/a4”l rmdir命令:删除空的⽬录(7)将上⾯创建的⽬录a(在“/tmp”⽬录下⾯)删除(8)删除上⾯创建的⽬录“a1/a2/a3/a4” (在“/tmp”⽬录下⾯),然后查看“/tmp”⽬录下⾯存在哪些⽬录l cp命令:复制⽂件或⽬录(9)将当前⽤户的主⽂件夹下的⽂件.bashrc复制到⽬录“/usr”下,并重命名为bashrc1(10)在⽬录“/tmp”下新建⽬录test,再把这个⽬录复制到“/usr”⽬录下l mv命令:移动⽂件与⽬录,或更名(11)将“/usr”⽬录下的⽂件bashrc1移动到“/usr/test”⽬录下(12)将“/usr”⽬录下的test⽬录重命名为test2l rm命令:移除⽂件或⽬录(13)将“/usr/test2”⽬录下的bashrc1⽂件删除(14)将“/usr”⽬录下的test2⽬录删除l cat命令:查看⽂件内容(15)查看当前⽤户主⽂件夹下的.bashrc⽂件内容 xQWl tac命令:反向查看⽂件内容(16)反向查看当前⽤户主⽂件夹下的.bashrc⽂件的内容l more命令:⼀页⼀页翻动查看(17)翻页查看当前⽤户主⽂件夹下的.bashrc⽂件的内容l head命令:取出前⾯⼏⾏(18)查看当前⽤户主⽂件夹下.bashrc⽂件内容前20⾏(19)查看当前⽤户主⽂件夹下.bashrc⽂件内容,后⾯50⾏不显⽰,只显⽰前⾯⼏⾏l tail命令:取出后⾯⼏⾏(20)查看当前⽤户主⽂件夹下.bashrc⽂件内容最后20⾏(21)查看当前⽤户主⽂件夹下.bashrc⽂件内容,并且只列出50⾏以后的数据l touch命令:修改⽂件时间或创建新⽂件(22)在“/tmp”⽬录下创建⼀个空⽂件hello,并查看⽂件时间(23)修改hello⽂件,将⽂件时间整为5天前l chown命令:修改⽂件所有者权限(24)将hello⽂件所有者改为root帐号,并查看属性l find命令:⽂件查找(25)找出主⽂件夹下⽂件名为.bashrc的⽂件l tar命令:压缩命令(26)在根⽬录“/”下新建⽂件夹test,然后在根⽬录“/”下打包成test.tar.gz(27)把上⾯的test.tar.gz压缩包,解压缩到“/tmp”⽬录l grep命令:查找字符串(28)从“~/.bashrc”⽂件中查找字符串'examples'l 配置环境变量(29)请在“~/.bashrc”中设置,配置Java环境变量(30)查看JAVA_HOME变量的值(⼆)熟悉常⽤的Hadoop操作(31)使⽤hadoop⽤户登录Linux系统,启动Hadoop(Hadoop的安装⽬录为“/usr/local/hadoop”),为hadoop⽤户在HDFS中创建⽤户⽬录“/user/hadoop”./sbin/start -all.sh(32)接着在HDFS的⽬录“/user/hadoop”下,创建test⽂件夹,并查看⽂件列表Hadoop fs -mkdir /test(33)将Linux系统本地的“~/.bashrc”⽂件上传到HDFS的test⽂件夹中,并查看testHadoop fs -put ~/.bashrc /testHadoop fs -ls /test(34)将HDFS⽂件夹test复制到Linux系统本地⽂件系统的“/usr/local/hadoop”⽬录下Hadoop fs -get test /usr/local四、实验报告实验报告题⽬:实验⼀姓名郭⼦鹏⽇期:2020年6⽉实验环境:l 操作系统:Linux;l Hadoop版本:2.7.1。
阿里巴巴 java 岗位要求

阿里巴巴 java 岗位要求
阿里巴巴的Java岗位要求通常包括以下几个方面:
1. 学历要求:一般要求计算机科学、软件工程或相关专业本科及以上学历。
2. 技术要求:精通Java编程语言,熟悉常用的开发框架和工具,如Spring、Hibernate等。
熟悉分布式架构、微服务架构
和高并发系统设计。
具备深厚的面向对象编程和设计模式基础。
3. 数据库:熟悉关系型数据库(如MySQL、Oracle)的使用
和优化,对NoSQL数据库(如Redis、MongoDB)有一定了解。
4. 操作系统和网络:熟悉常见操作系统(如Linux、Windows)和网络协议,对网络编程有一定了解。
5. 大数据技术:有大数据处理经验或熟悉Hadoop、Spark等大数据技术者优先。
6. 前端技术:熟悉HTML、CSS、JavaScript等前端开发技术
者优先。
7. 设计和架构能力:具备良好的系统设计和架构能力,能根据业务需求进行系统设计和性能优化。
8. 团队合作能力:具备良好的沟通能力和团队合作精神,能够与团队成员进行有效的协作。
9. 学习能力:具备快速学习和适应新技术的能力,对新技术有较好的敏感度。
以上是一般情况下的要求,不同职位可能会有一些特定的要求。
具体的岗位要求可以参考阿里巴巴的招聘信息或职位描述。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《云计算与大数据实验》实验报告
实验一熟悉常用的Linux操作和Hadoop操作
学号 201710610 姓名:分数
实验目的:熟练使用Linux常用命令
Linux设置静态ip地址
搭建NTP服务器
实验环境:
Centos6.5
1.实验内容与完成情况:
在Jack文件夹执行命令unmame和uname-r来查看系统名称和版本号
2.ifconfig命令查看linux系统的网卡信息
3.ls命令,查看当前目录下的文件夹和文件。
4.在指定的目录下创建文件夹
5.touch命令和echo命令。
6.在linux系统命令终端,执行命令:cd /etc/sysconfig/network-scriptscha
7.查看配置效果
7.安装ntp服务器:
8.修改ntp服务器配置文件:
9.ntp服务器采用upd协议开放端口:
出现的问题:
1.指令格式出现混淆,空格在实验中注意不到,导致指令报错。
2.
解决方案(列出遇到的问题和解决办法,列出没有解决的问题):
1.注意查看指令格式,在具体实验操作中要仔细认真。