PCIe_XAPP859_学习笔记(1)_待更新
PCIE3.0标准学习总结

11.介绍本章介绍了在PCI Express架构和关键概念的概述。
PCI Express是一种为多种类未来计算和通信平台互连而定义的高性能,通用I/ O。
关键的PCI属性,如它的使用模式,负载存储体系结构,软件接口,维持不变,而它的并行总线实施由一个高度可扩展的,完全串行接口取代。
利用PCI Express利用最新的点到点互连,基于交换机的技术,与分组交换协议,在性能和功能上提高到一个新水平。
PCI Express支持电源管理,服务质量(QoS),Hot-Plug/Hot-Swap支持,数据完整性,可信的配置质量和错误处理等高级功能。
1.1第三代I/O互连第三代I/ O互连的高级别要求如下:支持多种细分市场和新兴的应用:•统一桌面,移动,工作站,服务器,通信平台的I / O架构和嵌入式设备能够提供低成本,高容量的解决方案:•结构在系统级等于或低于PCI成本支持多平台互联用途:•芯片到芯片,板对板连接器或电缆通过新的机械形式的因素:•易于移动的,PCI般的外形和模块化,盒外形PCI兼容的软件模型:•能够使用不需要修改的PCI系统配置软件实现枚举和配置PCI Express硬件•能够不需要修改引导现有的操作系统,•能够不需要修改支持现有的任何的I / O设备驱动程序•能够采用PCI配置范例配置/启用新的PCI Express功能性能:•低开销,低延迟的通信带宽和有效载荷应用最大化链路效率•每个针脚高带宽,以减少设备和连接器接口的针脚数•通过聚合Lane和信号频率可扩展的性能高级功能:❑理解不同的数据类型和排序规则❑电源管理和预算✧能够识别电源管理能力通过一个给定的函数✧能够过渡到一个功能当进入特定的电源状态✧能够接收当前电源状态通知功能✧能够产生一个请求,唤醒从主电源断电状态✧能够为设备按照相应的平台电源预算策略顺序上电。
❑支持区分服务的能力,如:不同的服务质量(QoS)✧每个QoS数据流能有专用的链路资源,提高fabric效率和应用程序级的头面对队头阻塞的处理效率✧能够为每个组件配置fibric QoS仲裁策略✧能够为每个数据包端到端的QoS打上标记✧能够创建端到端的同步(基于时间,注入速率控制)解决方案❑可信配置支持✧能够支持受保护的从可信软件环境到可信配置空间的访问✧❑热插拔和热交换支持✧能够支持现有的PCI热插拔和热交换解决方案✧能够支持原生热插拔和热交换解决方案(没有边带信号需要)✧能够为所有形式因素支持统一的软件模型❑数据完整性✧能够支持所有的交易类型和数据链路链路数据包级别的数据完整性✧能够支持终端到终端的高可用性解决方案的数据完整性❑错误处理✧能够支持PCI -级的错误处理✧能够支持先进的错误报告和处理,以改善故障隔离和恢复解决方案❑独立工艺技术✧能够支持在发射器和接收器不同的直流共模电压❑易于测试✧能够通过简单的连接测试来测试设备电气规范1.2PCI Express链路一个链接表示两个组件之间的双-单工通信通道。
xilinxxdmapcie原理

xilinxxdmapcie原理PCIE是一种高速串行总线标准,用于连接计算机内部的各种硬件设备,如显卡、网卡和存储控制器等。
Xilinx XDMA通过PCIe接口连接到主机系统,利用DMA引擎直接访问系统内存以及外部设备的寄存器。
DMA 是一种不需要CPU参与的数据传输方式,可以大大减少CPU的负载。
Xilinx XDMA PCIE的架构基于FPGA(Field-Programmable Gate Array),可以根据用户的需求进行定制。
XDMA PCIE引擎在FPGA中包含一个或多个DMA通道,每个DMA通道可以进行高速的数据传输。
它们可以同时进行读取和写入操作,并支持多个无关的数据传输流。
DMA通道内部有多个功能模块,包括PCIe接口模块、DMA控制器、存储控制器以及数据转换模块等。
PCIe接口模块用于与主机系统的PCIe接口进行通信,包括配置寄存器的读写操作和中断处理等。
DMA控制器负责控制数据传输的流程,包括启动、停止和暂停等。
存储控制器用于管理数据的缓冲区,可以对应用程序提供高效的数据传输接口。
数据转换模块可选,用于实现数据格式的转换和处理,例如数据压缩和解压缩。
Xilinx XDMA PCIE引擎通过提供一组API和驱动程序,为用户应用程序提供了简化的接口。
用户可以通过这些接口配置和控制DMA通道,进行数据传输操作。
用户应用程序可以通过调用API函数来启动数据传输、获取已完成传输的状态以及处理错误情况。
驱动程序负责管理DMA通道的资源分配和释放,以及中断的处理。
Xilinx XDMA PCIE引擎的特点包括高性能、低延迟和灵活性。
它可以通过并行化和流水线化等技术来实现高效的数据传输。
Xilinx XDMA PCIE支持DMA传输的故障保护和恢复机制,可以处理传输过程中出现的错误。
此外,Xilinx XDMA PCIE还支持AXI(Advanced eXtensible Interface)和AMBA(Advanced Microcontroller Bus Architecture)等接口标准,以方便与其他硬件设备的集成。
pcie5.0的pll带宽和峰值原理

pcie5.0的pll带宽和峰值原理一、引言PCIExpress(PCIe)是一种高速、低延迟的串行通信协议,广泛应用于计算机和外部设备的接口中。
随着技术的不断进步,PCIe协议也在不断演进,以满足更高的数据传输需求。
PCIe5.0是其中的一种演进版本,其带宽和峰值原理与前一代相比有显著的不同。
二、PLL(相位锁定环路)带宽PCIe5.0的PLL带宽是其性能的关键因素之一。
PLL带宽定义为单位时间内环路能够处理的最大边带频率,它决定了PCIe5.0的传输速率和峰值性能。
PLL带宽越高,PCIe5.0的传输速率就越快,但同时也需要更高的时钟稳定性。
PCIe5.0的PLL带宽主要由以下几个因素决定:1.内部时钟源:PCIe5.0使用高精度的内部时钟源作为基准,其频率通常在几十MHz到几百MHz之间。
2.滤波器:滤波器用于滤除时钟信号中的高频噪声,保持时钟信号的稳定性。
3.相位检测器:相位检测器用于检测时钟信号与数据信号之间的相位差,这是PLL环路的关键部分。
4.控制器:控制器根据相位差信息调整PLL环路,以保持时钟信号与数据信号之间的相位匹配。
PCIe5.0的PLL带宽是PCIe通道性能的关键参数,因为它决定了PCIe设备能够传输的最大数据速率。
PCIe5.0设备在实现高速数据传输的同时,也需要考虑如何保证数据的完整性和稳定性。
三、峰值原理PCIe5.0的峰值原理主要涉及到如何将时钟信号和数据信号在正确的时刻进行匹配。
在PCIe链路中,每个设备都有一个自己的时钟源,设备之间的时钟源可能不同,这就需要在设备之间进行时钟同步。
PCIe5.0使用多阶段时钟树来达到这一目的,它使用PLL环路来保持时钟信号与数据信号之间的相位匹配。
当多个设备需要共享数据时,PCIe5.0采用了星形拓扑结构,这是一种点到点的通信方式,避免了多个设备同时访问共享资源时的冲突问题。
PCIe5.0设备的每一个端口都有一个独立的缓冲区,用于存储发送的数据和接收的数据,这样就保证了数据传输的独立性和完整性。
pcie命令语句的通用格式

pcie命令语句的通用格式在PCIe(Peripheral Component Interconnect Express)架构中,用于与PCIe 设备进行通信的命令语句通常是通过软件或驱动程序生成的,而不是用户手动输入的命令。
PCIe使用一种称为MMIO(Memory-Mapped I/O)的机制,通过写入和读取特定的寄存器来与设备进行通信。
通常,PCIe命令语句的通用格式涉及写入或读取特定的寄存器地址,以向设备发出命令或读取设备的状态。
以下是一个通用的PCIe 命令语句的简化形式:1. 写入命令:```bashwrite_to_pci_config_space BAR_ADDRESS COMMAND_DATA```- `write_to_pci_config_space`: 写入PCIe 配置空间的命令。
- `BAR_ADDRESS`: Base Address Register(BAR)地址,指定要写入的配置寄存器的位置。
- `COMMAND_DATA`: 要写入的数据或命令。
2. 读取命令:```bashread_from_pci_config_space BAR_ADDRESS```- `read_from_pci_config_space`: 读取PCIe 配置空间的命令。
- `BAR_ADDRESS`: Base Address Register(BAR)地址,指定要读取的配置寄存器的位置。
请注意,实际使用的PCIe 命令语句可能取决于所用的工具、驱动程序或编程语言。
对于PCIe 软件开发,通常会使用相关的API 或库来简化与PCIe 设备的通信。
以下是一个使用Linux 上的`setpci` 命令进行PCIe 配置空间读写的简单示例:```bash# 写入命令setpci -s PCI_BUS:PCI_DEVICE:PCI_FUNCTION COMMAND_DATA=w# 读取命令setpci -s PCI_BUS:PCI_DEVICE:PCI_FUNCTION COMMAND_DATA```请注意替换`PCI_BUS`、`PCI_DEVICE` 和`PCI_FUNCTION` 为实际PCIe 设备的地址信息。
uboot pcie驱动原理

uboot pcie驱动原理摘要:1.介绍uboot pcie 驱动2.详述uboot pcie 驱动的原理3.总结uboot pcie 驱动的重要性正文:1.介绍uboot pcie 驱动Uboot 是一种通用的bootloader,广泛应用于各种嵌入式系统中。
它可以从NAND flash、NOR flash 或硬盘启动系统,并支持多种文件系统。
在嵌入式系统中,PCIe(Peripheral Component Interconnect Express)是一种常见的高速串行计算机扩展总线标准,用于连接主板上的中央处理器(CPU)和各种外部设备,如显卡、声卡、硬盘等。
Uboot pcie 驱动就是用于支持PCIe 设备的驱动程序。
2.详述uboot pcie 驱动的原理Uboot pcie 驱动的原理主要基于PCIe 协议。
PCIe 协议是一种点对点(peer-to-peer)的串行通信协议,通过数据传输和数据校验来实现设备之间的通信。
Uboot pcie 驱动的工作流程如下:(1)初始化:首先,Uboot 将PCIe 设备添加到系统中,并初始化相关硬件资源。
(2)配置:Uboot 根据PCIe 设备的类型和配置空间,生成相应的配置空间表。
配置空间表包含了设备的基本信息,如设备类型、设备地址、设备配置空间等。
(3)数据传输:Uboot 通过PCIe 协议,实现与PCIe 设备的数据传输。
数据传输过程中,Uboot 将设备所需的启动代码、设备驱动等文件传输到PCIe 设备中。
(4)设备启动:Uboot 将PCIe 设备的控制权交给操作系统,由操作系统完成后续的设备驱动加载和设备启动。
3.总结uboot pcie 驱动的重要性Uboot pcie 驱动在嵌入式系统中具有重要作用,主要表现在以下几点:(1)支持PCIe 设备的启动:Uboot pcie 驱动支持各种PCIe 设备的启动,使得嵌入式系统能够兼容更多的外部设备。
pcie扫盲——物理层逻辑部分基础

pcie扫盲——物理层逻辑部分基础下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!PCIe扫盲——物理层逻辑部分基础引言PCIe(Peripheral Component Interconnect Express)是一种高速串行接口标准,用于连接计算机内部的外部设备和扩展卡。
PCIe XAPP859仿真波形分析

PCIe部分工作计划及总结工作计划基于PCIe + DMA的设计框架,以FPGA厂商Xilinx针对PCIe解决方案的参考设计为原型,结合本设计高速数据传输的需求,暂制定PCIe硬件部分的工作计划如下:1、设备端DMA控制器设计(FPGA实现)。
因为PCIe IP硬核是PCIe核心协议的封装,只留给用户应用层接口用来开发,用户层只要把数据。
设备端的DMA控制器就工作在PCIe 的应用层上,来实现数据的高效传输。
实现方式:以参考设计提供的DMA控制器为原型,结合本项目的实际需要设计自己的DMA控制器。
实现计划:看协议、读代码-> 改写代码 -> 仿真、验证2、 DMA+PCIe上板调试。
DMA控制器做好之后,开始上板调试,以能跑通、能传数据为主,暂不考虑传输效率的问题。
3、提高PCIe传输效率。
提高PCIe传输效率的关键在于实现流控制,电源管理等等PCIe协议的细节上,这些控制都是以数据包的形式去配置和实现。
另外,DMA部分的代码优化也很重要。
所以,在DMA控制器结合PCIe硬核实现数据传输的基础上,要想实现高速数据传输,这一部分的工作必不可少。
实现计划:读PCIe协议->改写代码->调试*4、Scatter_Gather DMA。
如果数据传输速率达不到要求的话,改进DMA控制器及驱动。
注:整个过程都是与PCIe驱动和GUI的实现分不开的。
工作进度1、根据tb.v源代码,结合仿真波形和PCIe协议细节看完了TestBench。
TestBench相当于PC机上Driver+GUI的功能,属于上游的激励信号产生器的内容。
发起的业务主要包括:读pcie配置空间,配置pcie寄存器,设备端DMA读操作,设备端DMA 写和设备端DMA读写全双工操作。
在知道PC端激励的情况下,观察设备端的响应的波形和数据,并结合PCIe协议的内容,验证了参考设计的正确性和通用性,加深了对系统框架和PCIe协议的理解。
PCIe的原理及体系架构_学习笔记
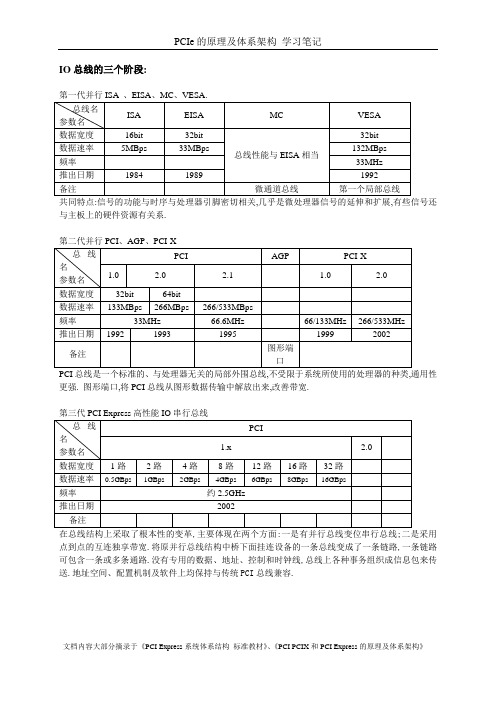
IO总线的三个阶段:第一代并行ISA 、EISA、MC、VESA.共同特点:信号的功能与时序与处理器引脚密切相关,几乎是微处理器信号的延伸和扩展,有些信号还与主板上的硬件资源有关系.第二代并行PCI、AGP、PCI-XPCI总线是一个标准的、与处理器无关的局部外围总线,不受限于系统所使用的处理器的种类,通用性更强. 图形端口,将PCI总线从图形数据传输中解放出来,改善带宽.第三代PCI Express高性能IO串行总线在总线结构上采取了根本性的变革,主要体现在两个方面:一是有并行总线变位串行总线;二是采用点到点的互连独享带宽.将原并行总线结构中桥下面挂连设备的一条总线变成了一条链路,一条链路可包含一条或多条通路.没有专用的数据、地址、控制和时钟线,总线上各种事务组织成信息包来传送.地址空间、配置机制及软件上均保持与传统PCI总线兼容.第一代和第二代都是并行总线,有多条地址线、数据线和控制线,挂接多个设备,称为下挂式总线(Multi-Drop),总线带宽由多个设备共享.通过提高数据宽度和频率来改善带宽的代价是挂接的电器负载减少(由于功耗增加和静态定时减少).PCIx与PCI相比:由于采用了PLL,频率更高性能更好;在地址和数据的基础上增加属性,从而可以高效管理缓冲区;分离事务协议相对延迟事务协议来说,提高了总线利用效率;可不需要中断引脚,改用消息信号中断(带内)体系结构,中断效率更高.基于PCI总线的结构最基本的PCI总线平台包含三级总线:FSB(Front-Side Bus)、PCI和ISA,FSB是处理器子系统的总线(Host总线),总线定义完全取决于系统所用的处理器;PCI局部总线是一个完全与处理器无关的总线,不受限微处理器的种类;ISA总线(IO扩展总线),也有采用EISA或MC总线的.不同的总线之间通过相应的桥芯片来连接.平台中两极桥是必须的,一是Host到PCI的(常称为主桥——Host桥),即北桥;另一个是PCI总线的桥(常称为扩展总线桥),即南桥.最基本的基于PCI总线的平台PCI地址空间映射x86 CPU的内存与I/O独立编址,I/O对应寄存器,内存对应RAM.因此,访问IO空间用IO读写指令,访问内存空间用内存读写指令.IO读写一般用于低速传输一些状态、控制寄存器的读写等。
pcie调试总结

PCIE调试总结Altera的pcie硬核从接口上来划分,有Avalon-ST和Avalon-MM两种。
Avalon-ST的接口,即Stream模式,这种模式下,用户可以操作的接口很多,但是需要对pcie协议以及接口时序有比较深入的理解,这种模式对于刚接触pcie的同学来说比较有难度;而Avalon-MM 接口,即Memory Map模式,相对来说则比较通俗易懂,用户侧的接口与双口RAM类似,有读写使能,读写时钟,读写地址,读写数据等;C260D这张卡使用了Avalon-MM这种接口模式,可以忽略pcie协议解析的部分。
另外,由于Avalon总线位宽的限制,器件不同,pcie IPCore的生成接口也不同。
比如arria II GX只能工作在Gen1x4模式下,而arria V GX 则可以工作在Gen2x8的模式下,而且在产生IPCore的时候,arria II GX需要一个固定时钟125MHz,而arria V则不需要。
首先从Qsys系统的使用开始。
由于altera fpga的SGDMA IPCore只有在Qsys系统下才能使用,所以整个pcie接口的设计需要借助Qsys系统来完成。
至于Qsys系统的使用方法,需要各位同学上网查资料了解,这里不做详细描述。
当然,也可以自己写SGDMA控制核,这样就不必使用Qsys系统了。
据不准确考证,Qsys系统应该从Quartus11.0开始才出现的,所以各位同学要首先检查下自己的Quartus版本。
介绍Qsys系统,首先从新建一个工程开始。
打开Quartus之后,在页面的上方工具栏位置,可以看到以下图标:其中即是Qsys工具的快捷图标,用鼠标点击该图标,即可进行Qsys系统的创建。
图1 Qsys系统新建页面该图就是打开Qsys系统的初始界面。
该图左上角的Library这个选项中,有各种Bridge,Adapter,Clock and Reset等Qsys系统提供的组件,以供搭建Qsys系统使用。
一文详解PCIe内存空间到AXI内存空间的转换

一文详解PCIe内存空间到AXI内存空间的转换UltraScale系列芯片包含PCIe的Gen3 Integrated Block IP核在内的多种不同功能的IP核都会有一页设置为PCIe:BARs,设置IP核的Base address register 的相关参数,如图1所示:图1 PCIe:BARs 配置图一般来说在FPGA中使用PCIe核都是Endpoint mode,我们的PC主机端是Rootpoint mode,一般会有一个Root Complex的混合管理器,来管理接入PCIe总线的端点设备。
对于PC 机来说,当PC机识别该PCIe设备后便会识别到BAR n相对应的基地址和地址空间(不过该基地址是PC机的Root Complex主动分配的,还是PCIe设备内部固定的还有疑问)。
设别基本配置信息后,PC机便可以对PCIe的内存空间进行读写操作了。
而PCIe IP核本身能够引出AXI总线接口,该AXI接口是memory map 型的,所以就肯定存在自己的地址空间,本文所提的PCIe to AXI Translation便是PCIe的地址空间到AXI的地址空间的转换。
这里就图1中的BAR0来说明下PCIe to AXI Translation的转换过程。
BAR0的配置为:64bit 数据位宽、32kilobytes地址范围、PCIe to AXI Translation为0x0000000012340000。
此时的PCIe IP核的BAR0是拓展连接到外部的AXI总线的,该总线连接到另外一个DDR4 MIG IP核,如图2所示。
图中重点标注的AXI总线便是PCIe核引出的AXI总线。
图2 PCIe核拓展AXI接口假设PC机设别到的PCIe BAR0的基地址为0x0000000000000000,在FPGA内部DDR4的AXI基地址为0x0000000012340000。
现在PC机想要往FPGA内部的DDR4地址空间的0x000000001234000F地址写入数据,那么PC机应该对PICe内存空间的0x000000000000000F写入数据,然后由PCIe to AXI Translation的关系,便会把0x000000000000000F转换到0x000000001234000F上实现对AXI总线的操作,进而实现对。
linux设备驱动之pci设备的IO和内存
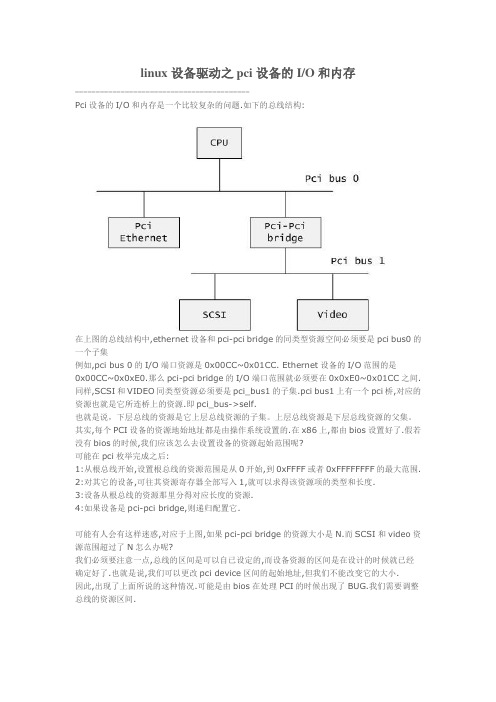
linux设备驱动之pci设备的I/O和内存------------------------------------------Pci设备的I/O和内存是一个比较复杂的问题.如下的总线结构:在上图的总线结构中,ethernet设备和pci-pci bridge的同类型资源空间必须要是pci bus0的一个子集例如,pci bus 0的I/O端口资源是0x00CC~0x01CC. Ethernet设备的I/O范围的是0x00CC~0x0xE0.那么pci-pci bridge的I/O端口范围就必须要在0x0xE0~0x01CC之间. 同样,SCSI和VIDEO同类型资源必须要是pci_bus1的子集.pci bus1上有一个pci桥,对应的资源也就是它所连桥上的资源.即pci_bus->self.也就是说,下层总线的资源是它上层总线资源的子集。
上层总线资源是下层总线资源的父集。
其实,每个PCI设备的资源地始地址都是由操作系统设置的.在x86上,都由bios设置好了.假若没有bios的时候,我们应该怎么去设置设备的资源起始范围呢?可能在pci枚举完成之后:1:从根总线开始,设置根总线的资源范围是从0开始,到0xFFFF或者0xFFFFFFFF的最大范围. 2:对其它的设备,可往其资源寄存器全部写入1,就可以求得该资源项的类型和长度.3:设备从根总线的资源那里分得对应长度的资源.4:如果设备是pci-pci bridge,则递归配置它.可能有人会有这样迷惑,对应于上图,如果pci-pci bridge的资源大小是N.而SCSI和video资源范围超过了N怎么办呢?我们必须要注意一点,总线的区间是可以自已设定的,而设备资源的区间是在设计的时候就已经确定好了.也就是说,我们可以更改pci device区间的起始地址,但我们不能改变它的大小.因此,出现了上面所说的这种情况.可能是由bios在处理PCI的时候出现了BUG.我们需要调整总线的资源区间.其实对于pci_bus的资源范围就是它的过滤窗口.对于过滤窗口的作用,我们在枚举的时候分析的很清楚了.CPU访问PC过程是这样的(只有一个根总线和pci-pci bridge过滤窗口功能打开的情况): 1:cpu向pci发出一个I/O请求.首先经过根总线.它会判断是否在它的资源范围内.如果在它的范围,它就会丢向总线所在的每一个设备.包括pci bridge. 如果没有在根总线的资源范围,则不会处理这个请求.2:如果pci设备判断该地址属于它的资源范围,则处理后发出应答4:pci bridge接收到这个请求,它会判断I/O地址是否在它的资源范围内.如果在它的范围,它会把它丢到它的下层子线.5:下层总线经过经过相同的处理后,就会找到这个PCI设备了一个PCI设备访问其它PCI设备或者其它外设的过程:1:首先这个PCI发出一个请求,这个请求会在总线上广播2:如果要请求的设备是在同级总线,就会产生应答3:请求的设备不是在同层总线,就会进行pci bridge.pci桥判断该请求不在它的范围内(目的地不是它下层的设备),就会将它丢向上层.4:这样辗转之后,就能找到对应的设备了经过这样的分析过来,相信对pci bridge的过滤窗口有更深的理解了.Linux中使用struct resource的结构来表示I/O端口或者是设备内存。
PCIE学习笔记

PCIE学习笔记PCIE学习笔记⽂档主要包括四个部分:1)Magwizard中例化模块的说明;2)内部结构;3)结合实际应⽤介绍应⽤层接⼝信号(我们主要帮客户解决这部分的问题,底层软件驱动部分由客户⾃⼰开发,Altera不负责⽀持);4)学习初期疑问及AE的解答。
PCI Express Compiler说明⼀〉system setting:1)Pcie core的类型:软核、硬核。
IVGX和2AGX包含硬核2)PHY type: 选择⽤不同的器件来实现,可以看到下⾯⽀持lane的数量的不同。
3)Port type: Native Endpoint是⽐较新的类型,⽀持MSI中断消息(推荐类型)。
LegacyEndpoint不⽀持。
Root point是源端,endpoint 是⽬的端。
4)Xcvr ref_clk: 设置reclk的输⼊时钟,可以在⼿册中清楚看到,对于不同的器件,输⼊参考时钟的区别。
5)Application Interface: ⽤于指定PCI Express中传输层和应⽤层的接⼝,如果⽤MegaWizard,建议采⽤Avalon-ST.6)Application clock: 指定应⽤的接⼝时钟,在选择硬核和软核时有区别。
7)Max rate: Gen1(2.5Gbps), Gen2(5.0Gbps)8)Test out width: 设置test_out的宽度,对于不同的核和lanes有不同的设置。
9)PCIe reconfig: 重配置硬核只读配置寄存器。
⼆〉PCI register1)BAR Type:主机以何种形式访问外部设备。
BAR的数量?2)参考设备管理器中/⽹络适配器/属性。
可以对应这些ID。
MSI消息中断,windows不⽀持,在Vista或linux中⽀持三〉Capabilities Parameters1)Tags supported 4-256设置⽀持non-posted 请求的tags数⽬。
pci学习笔记

pci学习笔记八.PCI枚举过程通过PCI枚举,CPU知道当前系统上有多少PCI设备,多少根PCI 总线,PCI配置空间初始化。
PCI 总线扫描的原理是从总线0 扫描到总线255,对于每条总线,系统都会扫描所有(总线号,设备号,功能号),读出每个设备配置空间的Device ID和Vendor ID寄存器,如果这两个寄存器的值是个无效值(0xFFFF),则说明当前位置上没有设备,接着扫描下一个位置。
如果是有效值(非0xFFFF),当前位置是个有效的PCI 设备/桥。
进而再读取该设备的 Header Type 寄存器,如果该寄存器为 1,则表示当前设备是 PCI 桥,否则是 PCI 设备。
Register Number:配置空间寄存器偏移量Function Number:多功能设备有多个功能号Device Number:设备编号Bus Number:总线编号对所有 PCI 总线进行编号PCI 桥如何知道它所连接的 PCI 总线情况呢?这就需要对 PCI 桥进行总线编号。
前面介绍过PCI 桥提供了Primary Bus Number、Secondary Bus Number 和 Subordinate Bus Number 三个寄存器用于标志该桥所连接的PCI 总线,下面通过一个示例来说明内核对于PCI 总线是如何进行编号的。
1.系统运行初始,Bus A 为 0,通过上面的 PCI 总线扫描得到连接在 Bus A 上的 PCI 桥(即图中Bridge 1)2.下面开始设置Bridge 1 的Bus 寄存器。
将Primary Bus Number 寄存器设置成Bus A 的编号,即0。
将Secondary BusNumber 寄存器设置成 Bus B 的编号,它的值等于(Bus A + 1),也就是1。
由于暂时无法知道该桥所能访问的所有下行总线数目,Subordinate Bus Number 寄存器暂时设置成 0xFF。
PCI_PCI-X_PCIE简单说明

3
ADC图 十一
四 、数据说明
标准
PCI 32bit
PCI 64bit
PCI-X PCI-E X1 PCI-E X2 PCI-E X3 PCI-E X4
总线
32bit
64bit
64bit
8bit 8bit 8bit 8bit
时钟 33Mhz 66MHZ 33Mhz 66MHZ
图四
图 五 64bit PCI 插槽
二、PCI-X
PCI-X 在外形上和 64bit 的 PCI 基本上是一样的,但是它们使用的是不同的标准, PCI-X 的插槽可以兼容 PCI 的卡(通过针脚区分),PCI-X 也是共享总线的,插多个 设备传输速率会下降。PCI-X 一般只出现在服务器主板上,不过现在也逐步被 PCI-E 取代,很多厂商的服务器都已经不提供 PCI-X 的插槽了。
66MHz 100MHz 133MHz
2.5GHz 2.5GHz 2.5GHz 2.5GHz
4
传输速度 133Mb/s 266Mb/s 266Mb/s 532Mb/s
533Mb/s 800Mb/s 1066Mb/s
512Mb/s(双工) 2Gb/s(双工) 4Gb/s(双工) 8Gb/s(双工)
2
ADCONTROL 研发部
图六
图七
三、PCI-E
PCI Express 是 INTEL 提出的新一代的总线接口,PCI Express 采用了目前业内流 行的点对点串行连接,比起 PCI 以及更早期的计算机总线的共享并行架构,每个 设备都有自己的专用连接,不需要向整个总线请求带宽,而且可以把数据传输率 提高到一个很高的频率,达到 PCI 所不能提供的高带宽。相对于传统 PCI 总线在 单一时间周期内只能实现单向传输,PCI Express 的双单工连接能提供更高的传输 速率和质量。PCI-E 插槽是可以向下兼容的,比如 PCI-E 16X 插槽可以插 8X、4X、 1X 的卡。现在的服务器一般都会提供多个 8X、4X 的接口,已取代以前的 PCI-X 接口。 图八 从上到下依次是 PCI-E 4X、PCI-E 16X、PCI-E 1X 图九 PCI-E 1X 的网卡 图十 PCI-E 4X 的双端口网卡 图十一 PCI-E 16X 的显卡
PCIE基础知识

PCIe总线概述随着现代处理器技术的发展,在互连领域中,使用高速差分总线替代并行总线是大势所趋。
与单端并行信号相比,高速差分信号可以使用更高的时钟频率,从而使用更少的信号线,完成之前需要许多单端并行数据信号才能达到的总线带宽。
PCI总线使用并行总线结构,在同一条总线上的所有外部设备共享总线带宽,而PCIe总线使用了高速差分总线,并采用端到端的连接方式,因此在每一条PCIe链路中只能连接两个设备。
这使得PCIe与PCI 总线采用的拓扑结构有所不同。
PCIe总线除了在连接方式上与PCI总线不同之外,还使用了一些在网络通信中使用的技术,如支持多种数据路由方式,基于多通路的数据传递方式,和基于报文的数据传送方式,并充分考虑了在数据传送中出现服务质量QoS (Quality of Service)问题。
PCIe总线的基础知识与PCI总线不同,PCIe总线使用端到端的连接方式,在一条PCIe链路的两端只能各连接一个设备,这两个设备互为是数据发送端和数据接收端。
PCIe总线除了总线链路外,还具有多个层次,发送端发送数据时将通过这些层次,而接收端接收数据时也使用这些层次。
PCIe总线使用的层次结构与网络协议栈较为类似。
1.1 端到端的数据传递PCIe链路使用“端到端的数据传送方式”,发送端和接收端中都含有TX(发送逻辑)和RX(接收逻辑),其结构如图4-1所示。
由上图所示,在PCIe总线的物理链路的一个数据通路(Lane)中,由两组差分信号,共4根信号线组成。
其中发送端的TX部件与接收端的RX部件使用一组差分信号连接,该链路也被称为发送端的发送链路,也是接收端的接收链路;而发送端的RX部件与接收端的TX部件使用另一组差分信号连接,该链路也被称为发送端的接收链路,也是接收端的发送链路。
一个PCIe 链路可以由多个Lane组成。
高速差分信号电气规范要求其发送端串接一个电容,以进行AC耦合。
该电容也被称为AC耦合电容。
pcie pba用法

pcie pba用法
PCIe PBA(Platform Boot Architecture)是一种用于PCIe设备的启动架构,它允许在系统启动时从PCIe设备加载操作系统或其他固件。
以下是PCIe PBA的用法:
1. 配置PCIe设备:在系统启动时,BIOS或UEFI固件会检测所有的PCIe 设备,并尝试确定哪些设备支持PCIe PBA。
这些设备通常会在设备的描述符中包含相应的标识符。
2. 加载启动固件:一旦确定支持PCIe PBA的设备,系统会从这些设备中加载启动固件。
这通常是一个压缩的固件映像,可以是操作系统内核、引导加载程序或其他启动固件。
3. 启动操作系统:加载的启动固件会负责进一步加载和启动操作系统。
这可能涉及解压缩固件映像、加载设备驱动程序、配置系统资源等。
一旦操作系统完全加载并准备好运行,用户就可以开始使用计算机了。
需要注意的是,使用PCIe PBA需要确保系统BIOS或UEFI固件支持该功能,并且PCIe设备支持相应的启动协议。
此外,由于PCIe PBA涉及到系统的启动过程,因此在使用之前应该仔细阅读相关的文档和指南,以确保正确配置和使用。
vivado_pcie_教程

vivado_pcie_教程器件型号要选 xc7v2000tflg1925-1工程建立好了之后是空的,开始添加IP点击图上左边红圈里面的IP Catalog,就会出现右边的IP列表在IP列表的搜索框里键入pcie四个字母,就可以看到有两个IP被搜到。
PB的参考设计用是下面一个IP, AXI Memory Mapped to PCI Express双击选中的这个IP,就可以打开配置界面。
全部采用默认设置即可这是IP配置界面的第二页,这个例子里用的是板子上的第二个GTH接口,所以第一个红圈里的block location设为X0Y1。
如果需要配置为第一个接口,就应该把第一个红圈里的blocklocation改为X0Y0。
下面两个红圈里的配置为PCIE X4 GEN2 模式。
第三页,默认设置即可第四页,默认设置即可第五页,默认设置即可依旧默认设置即可依旧默认设置即可最后一页依旧默认设置即可,最后在此对话框右下方点击OK点红圈里的Generate , 开始编译IP红圈内信息可知,编译此IP已经成功axi_pcie_0(axi_pcie_0.xci)上用右键点出右键菜单,然后左键点击右键菜单里面的“Open IP Example Design”(如红圈所示)这一步是为了让vivado自动生成xilinx官方的IP参考设计,用于上板子测试。
点击图中红圈,选择放置xilinx官方参考设计的目录。
最后点OK然后vivado会自动重新打开一个vivado窗口,窗口里面就是参考设计的工程。
这个参考工程的最终pin分配,供参考其实要改的就两个,就是最下面的sys_clk_p和sys_rst_nsys_clk_p的AG8是来自PC端的PCIE_REFCLK_P(参见子卡手册和板子手册)sys_rst_n的T24是板子上的按键SW2,下沿复位有效。
(参见板子手册)(无需另外设置时钟,上电连接PC即可)红框里的寄存器显示,这个xilinx的硬件的配置为 X4 GEN2的模式,已经被软件识别出来。
alter-PCI核学习总结

Altera PCI 核学习总结1.PCI核工作模式PCI核在生成时可选择两种工作模式:master/target模式和target模式;其中master/target模式下,PCI核可申请控制总线,作为master给其他PCI设备通信;也可以作为slave设备与master PCI设备通信;而在target模式,只能作为slave设备被其他PCI设备访问。
在以上两种工作模式下,根据读写数据位宽(32bit和64bit),把PCI核分为4种:PCI_mt64、PCI_t64、PCI_mt32、PCI_t32;在本设计中使用PCI_t32模式,即target工作模式,读写数据位宽32bit;故以下的介绍中主要针对PCI_t32模式的使用说明;2.在quartus中例化PCI核注意界面右边的IP Catalog部分,在这里选择你想要IP核,如果界面上没有这个选择部分,则通过点击Tools --> IP Catalog 调出来;在Library -> interface protocols 中点击PCI点开PCI后可以看到PCI Compiler v14.1,双击;填写PCI核的命名(pci_core),选择生成IP核的相关代码是VHDL 或 Verilog,按自己需求选;点击OK;跳转出此界面,有6个选项,(1)about this core :里面介绍了此IP 核的一些基本信息,例如版本、发布时间和能支持的FPGA器件型号;(2)documentation:PCI核使用的指导文档(3)quartus II constraints :关于PCI核的约束文件(4)step 1 :parameter :用来设置PCI核基本参数compact PCI为紧凑型PCI接口,在接口协议上没有区别,只是在硬件接口连接上有区别;故按照硬件设计选在PCI或CompactPCI。
Master/Target 或 Target Only,两者区别为:如:目前有3个CPU在PCI总线上,分别标号CPU1,CPU2,CPU3,其中CPU1为HOST,CPU2/3为Target,CPU1 HOST为PCI总线分配PCI空间等资源并赋予Target一定的读写权限;资源分配完毕,3个CPU可以相互访问,当CPU1访问(读写)CPU2/3时,CPU1是Master,当CPU2访问CPU1/3时,CPU2就是Master;被访问的对象就是Slaver;也就是CPUx要访问PCI总线上的设备时先要向PCI HOSTS(CPU1上的总线控制器)申请对总线的操作,占有了这总线的操作的CPU就是Master;在这个步骤下选择PCI和master/target,然后点击Next;填写参数值;填写Base address register值,点击Next;点击Finish;(5)step2 :set up simulation :生成仿真模型,点击OK(6)step3 :generate3.PCI核引脚信号说明以上信号列表中,PCI signal 是主设备端控制的信号;凡是local-side信号都是本地端控制的信号;在本设计中使用时,主设备端指CPU,本地端就是FPGA,所以在代码设计中,只要控制local_side信号就可以了。
pcie处理层协议中文详解

pcie(PCI-Express)处理层协议中文详解处理层协议(transaction Layer specification)◆TLP概况。
◆寻址定位和路由导向。
◆i/o,memory,configuration,message request、completion详解。
◆请求和响应处理机制。
◆virtual channel(vc)Mechanism虚拟通道机制。
◆data integrity数据完整性。
一.TLP概况处理层(transaction Layer specification)是请求和响应信息形成的基础。
包括四种地址空间,三种处理类型,从下图可以看出在transaction Layer 中形成的包的基本概括。
一类是对i/o口和memory的读写包(TLPS:transaction Layers packages),另一类是对配置寄存器的读写设置包,还有一类是信息包,描述通信状态,作为事件的信号告知用户。
对memory的读写包分为读请求包和响应包、写请求包(不需要存储器的响应包)。
而i/o类型的读写请求都需要返回I/O口的响应包,configuration包对配置寄存器的读写请求也有响应包。
这些请求包还可以按属性来分就是:NP-non posted ,即请求需要返回completion的响应包;还有一种就是;poste,即不需要completion返回响应包。
例如上面的存储器写入请求包和Message包都隶属于posted包。
包的主要格式结构如下:每种类型的包都有一定格式的包头(Tlp Header),根据不同的包的特性,还包括有效数据负荷(Data Payload)和tlp 开销块(Tlp Digest)。
包头中的数据用于对包的管理和控制。
有效数据负荷域存放有效数据信息。
具有数据的TLP传递是有一定规则的:以DW为长度单位,发送端数据承载量不得超过“Device Control Register”中的“Max_Payload_Size”数值,接收端中,所接收到的数据量也不能超过接收端“Device Control Register”中的“Max_Payload_Size”数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
TX Engine发送器负责发送并传输posted,non_posted和完成包。
本参考设计可以产生并传输MWR,MRd 和完成包,用来满足存储器读和DMA写请求。
消息和错误报告包,如不在支持范围内的请求,完成包超时和中断请求。
都由硬核通过一定的信号机制产生。
因此不需要用户逻辑去产生与这些类型的TLPs相对应的header;用户逻辑只需要监视这些情况是否发生了,一旦他们其中之一发生了,便通知硬核。
完成包超时的逻辑在本参考设计中将不会涉及到。
另外,I/O包在本参考设计中也不予支持。
数据包依靠来自 DMA Control/Status Register File的请求而产生,它们通过 TRN的TX 接口被传输到硬核上。
Posted Packet GeneratorPosted包生成器接受来自DMA Control/Status Register File的写DMA请求,并产生可以用来完成本次写DMA操作的header。
这些包头被放置在一个小的FIFO中,以便被TRN状态机读取。
该生成器由两个模块组成:●Posted包分割器●Posted合成器Posted包分割器分割器从DMA Control/Status Register File 接受写DMA请求,并根据PCIe总线协议把这些请求分割成多个数据包。
实际上,该分割器按照以下两个原则对写DMA请求进行分解:●包的有效载荷长度不能超过设备控制寄存器中的Max_Payload_Size。
●地址/数据的组合不能超过4KB地址界限。
分割器利用简单的握手协议把长度(Length[9:0])和地址(dmawad_reg[63:0])传给posted Pactet Builder。
源和目的地址必须分布在128字节的地址界限内。
Receive TRN State Machine事务层数据接收状态机模块执行以下功能:●接收来自PCIe事务层的数据,并在需要的时候把事务层接口throttle●传输64位的数据以及字节有效位●传输 data_valid位,用来对数据和字节使能●解码,寄存和验证包头信息在实现中,64bit宽度的数据直接连接到 memory fifo 上,并有data_valid信号用来标示数据的可写入性。
这样做的原因是因为所有的完成包数据都要被存储到DDR中。
在数据含有多重目的地址的情况下,用来驱动数据的额外的解码功能是必需的。
例如,在一个 SG-DMA或者链式DMA设计中,完成包数据需要被传送到多个地址中。
这时候,来自PCIe 的 bar_hit信号利于数据的路由和写入。
//源代码注释// Purpose: Receive TRN Data FSM.1、This module interfaces to the Block Plus RX TRN. It presents the 64-bit data from completer and and forwards that data with a data_valid signal.这个模块与RX 事务层接口相连接。
它接收来自完成包的64bit宽的数据,并把它们向后传输,data_valid信号用来标示信号的有效性。
2、This block also decodes packet header infomation and forwards it to the rx_trn_monitor block.这个模块还对包头进行解码并把它们传送给模块 rx_trn_monitor。
Receive TRN Monitor事务接收监测模块执行以下功能:●读取the read request RAM内容并检测何时读事务完全完成●利用the read request RAM中目的地址信息和完成包头中的长度信息计算DDR2的目的地址。
●计算何时读DMA被完成并通知DMA Control/Status Register File●为每一个完成接收到的完成包向receive memeory Data finit State Machine提供地址和传输大小。
//代码注释/ Purpose: Receive TRN Monitor module. This module interfaces to the DMA// Control/Status Register File and the Read Request Fifo to determine when a // DMA transfer has completed fully. This module could also monitor the TRN// Interface to determine any errors.// Reference: XAPP859// Revision History:// Rev 1.0 - First created, Kraig Lund, Apr. 1 2008.// Rev 1.1 - Changed the rd_dma_done_early comparison number to 0x0B0 (was// 0x070) for improved data throughput utilization, Kraig Lund, June 10th,//注释解释该模块连接DMA Control/Status Register File和the read Request Fifo并决定一个DMA 传输结束;该模块也可以检测TRN接口,判断错误。
Receive Memory Data FSMreceive memory data FSM执行以下两个任务:• Arbitrates for control of the DMA-to-DDR2 interface block• Reads data and transfers information from the data and Xfer TRN memory FIFOs and forwards it to the DMA-to-DDR2 interface blockData TRN Memory FIFO and Xfer TRN Memory FIFOData TRN memory FIFO 和 Xfer TRN Memory FIFO一起工作,data memory FIFO 有两项功能,第一,他把接收到的完成包数据暂存起来,第二,他把64位的数据转换为128位;Xfer TRN memory 保存着起始地址和传输大小信息。
每一个Xfer TRN memory的描述行都要有响应的数据与之对应。
DMA Control and Status WrapperDMA控制和状态文件夹是与PC处理器通信和对DMA操作进行控制的主要模块。
该文件夹有以下两个逻辑块组成:●DMA控制/状态寄存器组●内部控制逻辑本参考设计中的逻辑单元支持在一次DMA传输中最多传输4KB数据。
它包括posted包分割器,non_posted包分割器和DMA-DDR2接口模块。
想要通过该硬件实现传输大小超过4KB的数据量,必须把较大的DMA数据块进行分割,分割成DMA传输可以支持的数据大小。
DMA控制状态寄存器组和内部控制模块共同合作来完成传输大小超过4KB的数据块。
DMA控制/状态寄存器组提供以下功能:●利用一个基址寄存器(BAR0),以一个简单的寄存器文件的形式,提供了一个内存映射到主系统的接口。
●接收读/写DMA传输请求最大数据量为1MB。
●把DMA传输大于4KB的数据量分解成小的DMA传输块,并把这些小的传输块送到内部控制块中。
内部控制块提供以下功能:●接收来自DMA控制/状态寄存器组模块的最大数据量为4KB 的DMA读写请求。
●提供与RX和TX的控制接口着两个模块的细节描述如下:DMA Control/Status Register FileDMA控制和状态寄存器组是被映射并与用户应用逻辑相连的存储单元。
主处理器通过读写总线来访问这些存储器组。
端点模块的基址寄存器有利于访问DMA控制和状态寄存器组。
DMA操作被定义在DMA控制和状态寄存器组里。
主处理器通过初始化寄存器组来发起一次DMA 事务。
DMA完成通过状态寄存器通知主处理器。
所有寄存器都是32bit可读写的,除非有特殊说明。
●DMAWAS 0x00 DMA写操作时,DDR2的源地址;●DMAWAD_L 0x04 DMA写操作时,主存储器的低32bit地址;●DMAWAD_U 0x08 DMA写操作时,主存储器的高32bit地址;●DMARAS_L 0x0C DMA读操作时,主存储器的低32bit地址;●DMARAS_U 0x10 DMA读操作时,主存储器的高32bit地址;●DMARAD 0x14 DMA读操作时,DDR2的源地址;●DMAWXS 0X18 DMA写操作时,传输大小;●DMARXS 0x1C DMA读操作时,传输大小;●保留位0x20 保留;●保留位0x24 保留;●DMACST★0x28 DMA控制和状态寄存器,控制位为只写寄存器,状态位为只读。
●保留位0x2C 保留;●DMAWRP 0x30 DMA写操作时,写计数器;●DMARDP 0x34 DMA读操作时,读计数器;PC主处理器做以下操作用来执行DMA写操作:●验证DMA写操作开始位DMACST[0]为0;●根据用户在ML555GUI上填入的DMA传输请求选项,向寄存器DMAWAS,DMAWAD_L,DMAWAD_U和DMAWXS写入合适的值。
●向DMACST[0]位写入1,用来启动DMA写传输。
●监测写DMA完成位DMACST[1],确定当前写DMA过程何时完成。
●根据用户要求的传输大小和寄存器组中只读计数器的值,计算DMA写过程的效率。
并把结果输出到GUI窗口上。
PC主处理器做以下操作用来执行DMA读操作:●验证DMA读操作开始位DMACST[2]为0;●根据用户在ML555GUI上填入的DMA传输请求选项,向寄存器DMARAS_L,DMARAS_U,DMARAD和DMARXS写入合适的值。
●向DMACST[2]位写入1,用来启动DMA读传输。
●监测读DMA完成位DMACST[3],确定当前读DMA过程何时完成。
●根据用户要求的传输大小和寄存器组中只读计数器的值,计算DMA读过程的效率。
并把结果输出到GUI窗口上。
全双工的DMA传输可以通过同时向DMACST[0]和DMACST[2]写入1来实现。
为了保持传输和接收链路一直为满,硬件需要一直监测链路状态。
对于全双工传输4KB或者以下的大小,典型的做法是,FPGA端硬件要执行8个non_posted读接着执行8个posted写。