统计系统问题0325(1)
统计学(贾俊平)第五版课后习题答案(完整版)

统计学(第五版)贾俊平课后习题答案(完整版)第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第五版(贾俊平)课后习题答案 (1)

中位数位置
30 1 2
15.5 , M e
272
2
273
272.5 。
(2) QL 位置
30 4
7.5
, QL
258 2
261
259.5 。
QU 位置
3 30 4
22 .5 , QU
284 291 287.5 。 2
(3) s
n
(xi x)2
i 1
n 1
13002.7 21.17 。 30 1
4.2 172.1
0.024 ;
幼儿组身高的离散系数: vs
2.5 71.3
0.035 ;
由于幼儿组身高的离散系数大于成年组身高的离散系数,说明幼儿组身高的离
散程度相对较大。
4,11(1)应该从平均数和标准差两个方面进行评价。在对各种方法的离散程度进
行比较时,应该采用离散系数。
(2)下表给出了用 Excel 计算一些主要描述统计量。
550
18
9900
600 以上
650
11
7150
合计
—
120
k
x
Mi fi
i 1
51200
426.67 。
n
120
51200
标准差计算过程见下表:
按利润额分组 组中值 M i 企业数 fi (M i x)2 (M i x)2 fi
200~300
250
19
31212.3
593033.5
300~400
2 (25 1)
0.77 。
(5)分析:从众数、中位数和平均数来看,网民年龄在 23~24 岁的人数占多数。 由于标准差较大,说明网民年龄之间有较大差异。从偏态系数来看,年龄分布为右
统计学第五版课后题答案李金昌

统计学第五版课后题答案李金昌第1章绪论 1 .试述数据、数据库、数据库系统、数据库管理系统的概念。
答:( l )数据( Data ) :叙述事物的符号记录称作数据。
数据的种类存有数字、文字、图形、图像、声音、正文等。
数据与其语义就是不可分的。
解析在现代计算机系统中数据的概念就是广义的。
早期的计算机系统主要用作科学计算,处置的数据就是整数、实数、浮点数等传统数学中的数据。
现代计算机能够存储和处置的对象十分广为,则表示这些对象的数据也越来越繁杂。
数据与其语义就是不可分的。
500 这个数字可以表示一件物品的价格是 500 元,也可以表示一个学术会议参加的人数有 500 人,还可以表示一袋奶粉重 500 克。
( 2 )数据库( DataBase ,缩写 DB ) :数据库就是长期储存在计算机内的、存有非政府的、可以共享资源的数据子集。
数据库中的数据按一定的数据模型非政府、叙述和储存,具备较小的冗余度、较低的数据独立性和易扩展性,并可向各种用户共享资源。
( 3 )数据库系统( DataBas 。
Sytem ,缩写 DBS ) :数据库系统就是所指在计算机系统中导入数据库后的系统形成,通常由数据库、数据库管理系统(及其开发工具)、应用领域系统、数据库管理员形成。
解析数据库系统和数据库就是两个概念。
数据库系统就是一个人一机系统,数据库就是数据库系统的一个组成部分。
但是在日常工作中人们常常把数据库系统缩写为数据库。
期望读者能从人们讲话或文章的上下文中区分“数据库系统”和“数据库”,不要引发混为一谈。
( 4 )数据库管理系统( DataBase Management sytem ,简称 DBMs ) :数据库管理系统是位于用户与操作系统之间的一层数据管理软件,用于科学地组织和存储数据、高效地获取和维护数据。
DBMS 的主要功能包含数据定义功能、数据压低功能、数据库的运转管理功能、数据库的创建和保护功能。
解析 DBMS 就是一个大型的繁杂的软件系统,就是计算机中的基础软件。
统计学中的缺失数据处理与插补方法

统计学中的缺失数据处理与插补方法在统计学中,缺失数据是一种常见的问题。
缺失数据指的是在数据收集过程中,某些变量或观测值无法获取或丢失的情况。
这可能是由于实验条件、技术限制、调查对象的拒绝或其他原因导致的。
缺失数据的存在会对统计分析结果产生不良影响,因此需要采用适当的方法进行处理和插补。
一、缺失数据的类型在进行缺失数据处理之前,我们需要了解不同类型的缺失数据。
常见的缺失数据类型包括:1. 完全随机缺失(MCAR):缺失数据的出现与观测值本身或其他变量无关,是完全随机的。
在这种情况下,缺失数据对统计分析结果没有影响。
2. 随机缺失(MAR):缺失数据的出现与观测值本身无关,但与其他变量相关。
在这种情况下,缺失数据对统计分析结果可能产生偏差。
3. 非随机缺失(NMAR):缺失数据的出现与观测值本身相关,并且与其他变量相关。
在这种情况下,缺失数据对统计分析结果产生严重偏差。
二、插补方法针对不同类型的缺失数据,统计学家们提出了各种插补方法。
下面介绍几种常见的插补方法:1. 删除法:对于缺失数据较少且缺失数据是MCAR的情况,可以选择直接删除缺失数据所在的观测值。
这种方法简单快捷,但会导致样本容量减小,可能影响统计分析结果的准确性。
2. 最小二乘法插补:对于MAR类型的缺失数据,可以使用最小二乘法进行插补。
该方法通过建立一个回归模型,利用已有数据预测缺失数据的值。
然后,将预测值代替缺失数据进行分析。
3. 多重插补法:多重插补法是一种常用的处理缺失数据的方法。
该方法通过多次模拟生成多个完整的数据集,每个数据集都包含通过预测模型得到的不同插补值。
然后,基于这些完整的数据集进行统计分析,并将结果进行汇总。
4. 均值插补法:对于MCAR类型的缺失数据,可以使用均值插补法。
该方法将缺失数据的均值或中位数代替缺失值,使得数据集的整体分布不发生明显改变。
5. 模型法插补:对于NMAR类型的缺失数据,可以使用模型法进行插补。
统计学(第五版)课后答案
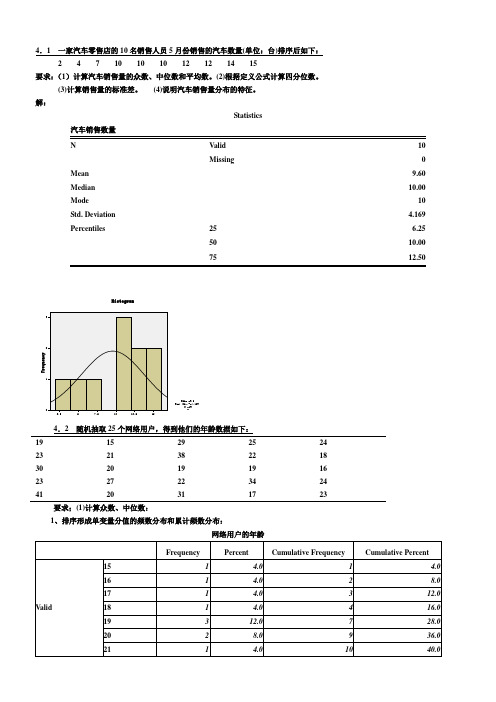
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0 Mean 9.60 Median 10.00 Mode 10 Std. Deviation 4.169 Percentiles 25 6.2550 10.0075 12.504.2 随机抽取25个网络用户,得到他们的年龄数据如下:19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25 和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差; Mean=24.00;Std. Deviation=6.652 (4)计算偏态系数和峰态系数: Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()lg 25lg() 1.398111 5.64lg(2)lg 20.30103n K=+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄(Binned)分组后的均值与方差:分组后的直方图:4.6 在某地区抽取120家企业,按利润额进行分组,结果如下:要求:(1)计算120家企业利润额的平均数和标准差。
公务员(干部)统计系统常见问题

公务员(干部)统计系统常见问题1.公务员(干部)统计系统安装后,当双击桌面快捷方式时,提示“无法定位程序输入点*******于动态链接库******上”。
答:请查看电脑的操作系统是否win2000,公务员(干部)统计系统目前暂不支持win2000,建议使用windows XP或win2003。
2.公务员(干部)统计系统安装后,当双击桌面快捷方式时,没有反应;双击安装目录(以安装在默认路径C盘为例:C:\Program Files\公务员统计系统)下的gwystatistics.exe,提示“缺少msvcr71.dll文件”或“缺少msvcp71.dll文件”。
答:说明该计算机安装的操作系统缺少部分系统组件,可以到网站 下载小工具解决。
3.安装《公务员(干部)统计系统》后,双击桌面快捷方式,提示“连接数据库失败,请检查数据库设置或重新启动计算机”。
答:一、查看您计算机的杀毒软件或防火墙是否禁止了数据库kdb.exe进程。
如果是,请设置防火墙,将kdb.exe放行。
二、目前发现如果使用了NOD32、熊猫卫士等杀毒软件,或安装了费尔防火墙,或城市热点宽带计费软件,或在上网的过程中被一些恶意程序,修改了电脑的winsock 通信接口,均会导致数据库无法正常启动。
此时,需要卸载相关软件,同时到技术支持网站—下载中心—使用工具中下载“winsock修复软件”,具体操作如下:(一)、电脑启动方式设置成诊断启动(1).在电脑桌面“开始”栏中选择“运行”如图:(2).在弹出的如图所示的“运行”窗口中输入msconfig,后点击“确定”。
(3).在弹出的“系统配置使用程序”中的“启动选择”项,选择“诊断启动”,确定。
(二)、winsock修复(1)在使用软件修复前,请先打开“控制面板——网络连接——本地连接——属性——internet协议——属性,记录自己当前的TCP/IP设置。
(2)网站下载winsock修复软件,先解压。
统计分析与SPSS课后习题课后习题汇总(第五版)

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
《统计学原理(第五版)》习题计算题答案详解

《统计学原理(第五版)》习题计算题答案详解第二章统计调查与整理1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404第三章综合指标1. 见教材P4322. %86.1227025232018=+++=产量计划完成相对数3.所以劳动生产率计划超额1.85%完成。
4. %22.102%90%92(%)(%)(%)===计划完成数实际完成数计划完成程度指标 一季度产品单位成本,未完成计划,还差2.22%完成计划。
5.6. 见教材P432 7. 见教材P433理工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相反,由于权数的作用,使得甲村的总平均单产高于乙村。
9.11.%74.94963.09222.09574.03=⨯⨯=G X 或参照课本P9912.%49.51X %49.105 08.107.105.104.102.1 X 1624632121=-=⨯⨯⨯⨯=∑⋅⋅⋅⋅⋅⋅=G ff n f f G nX X X 平均年利率:平均本利率为:(2)R=500-150=350(千克/亩) (3)“(4)根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/亩,即M 0>Me>X ,故资料分布为左偏(即下偏)。
(2) 15. 见教材P435 16. 见教材P40417.%86.1227025232018=+++=产量计划完成相对数18.%85.101%108%110%%(%)===计划为上年的实际为上年的计划完成程度指标 劳动生产率计划超额1.85%完成19. %22.102%90%92(%)(%)(%)===计划完成数实际完成数计划完成程度指标一季度产品单位成本未完成计划,实际单位成本比计划规定数高2.22%20. %105%103% %%(%) 计划为上年的计划为上年的实际为上年的计划完成程度指标=∴=1.94% %94.101103%105%% 即计划规定比上年增长计划为上年的解得:==21. 见教材P405 22. 见教材P405理工作做得好。
非参数统计第五版习题答案

非参数统计第五版习题答案非参数统计第五版习题答案非参数统计是统计学中的一个重要分支,与参数统计相对应。
在参数统计中,我们通常假设总体的分布形式,并根据样本数据来估计参数的值。
而在非参数统计中,我们不对总体的分布形式做任何假设,直接利用样本数据进行统计推断。
非参数统计方法的优势在于它的灵活性和广泛适用性。
它不依赖于特定的分布假设,因此适用于各种类型的数据。
在实际应用中,非参数统计方法常常用于处理那些不满足正态分布假设的数据,或者样本容量较小的情况。
在《非参数统计第五版》这本书中,作者对非参数统计的理论和方法进行了详细的介绍,并提供了大量的习题供读者练习。
以下是一些习题的答案和解析,希望能够帮助读者更好地理解和掌握非参数统计方法。
1. 习题:某城市的居民年龄分布情况如下:20岁以下的人数为1000人,20-30岁的人数为2000人,30-40岁的人数为3000人,40岁以上的人数为4000人。
试问该城市的年龄分布是否符合均匀分布?答案:首先,我们需要建立原假设和备择假设。
原假设(H0)是该城市的年龄分布符合均匀分布,备择假设(H1)是该城市的年龄分布不符合均匀分布。
然后,我们可以使用卡方检验来进行假设检验。
根据题目给出的数据,我们可以计算出每个年龄段的期望频数。
对于均匀分布的假设,每个年龄段的期望频数应该是相等的。
接下来,我们计算卡方统计量,并根据自由度和显著性水平查找卡方分布表,找到对应的临界值。
如果计算得到的卡方统计量大于临界值,则拒绝原假设,认为该城市的年龄分布不符合均匀分布;如果计算得到的卡方统计量小于临界值,则接受原假设,认为该城市的年龄分布符合均匀分布。
2. 习题:某医院进行了一项药物疗效的研究,随机选取了100名患者,并对其进行了治疗。
疗效被分为三个等级:显著改善、部分改善和无改善。
试问该药物的疗效是否显著?答案:为了判断该药物的疗效是否显著,我们可以使用秩和检验。
秩和检验是一种非参数检验方法,适用于两组或多组样本的比较。
统计学贾俊平课后习题答案完整版

统计学贾俊平课后习题答案HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】附录:教材各章习题答案第1章统计与统计数据1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5)分类数据。
1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”;(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。
1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。
1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者的月平均花费;(4)统计量;(5)推断统计方法。
1.5(略)。
1.6(略)。
第2章数据的图表展示2.1(1)属于顺序数据。
(2)频数分布表如下(4)帕累托图(略)。
2.2(1)频数分布表如下2.3频数分布表如下2.5(1)排序略。
(2)频数分布表如下2.6(3)食品重量的分布基本上是对称的。
2.72.8(1)属于数值型数据。
2.9(1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
2.10A 班分散,且平均成绩较A 班低。
2.11 (略)。
2.12 (略)。
2.13 (略)。
2.14 (略)。
2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量3.1(1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。
(3)2.4=s 。
(4)左偏分布。
3.2(1)190=M ;23=e M 。
(2)5.5=L Q ;12=U Q 。
(3)24=x ;65.6=s 。
(4)08.1=SK ;77.0=K 。
(5)略。
3.3 (1)略。
(2)7=x ;71.0=s 。
(3)102.01=v ;274.02=v 。
(4)选方法一,因为离散程度小。
3.4 (1)x =(万元);M e= 。
《统计学原理(第五版)》习题计算题答案详解参考word

《统计学原理(第五版)》习题计算题答案详解第二章 统计调查与整理1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404第三章 综合指标1. 见教材P4322. %86.1227025232018=+++=产量计划完成相对数3.所以劳动生产率计划超额1.85%完成。
4. %22.102%90%92(%)(%)(%)===计划完成数实际完成数计划完成程度指标 一季度产品单位成本,未完成计划,还差2.22%完成计划。
5.%85.011100%8%110%1=⨯++==计划完成数实际完成数计划完成程度指标计划完成数;所以计划完成数实际完成数标因为,计划完成程度指%105%103== 1.94%%94.101%103%105,比去年增长解得:计划完成数==()得出答案)将数值带入公式即可以计算公式,上的方程,给大家一个很多同学都不理解也可以得出答案,鉴于(根据第三章天)。
个月零天(也即是个月零(月)也就是大约)(上年同季(月)产量达标季(月)产量超出计划完成产量达标期完成月数计划期月数超计划提前完成时间达标期提前完成时间完成计划的时间万吨。
根据公式:提前多出万吨,比计划数万吨产量之和为:季度至第五年第二季度方法二:从第四年第三PPT PPT 6868825.8316-32070-7354-60--3707320181718=+=+=+==+++()天完成任务。
个月零年第四季度为止提前(天),所以截止第五)(根据题意可设方程:万吨完成任务。
天达到五年第二季度提前万吨。
根据题意,设第万吨达到原计划,还差万吨产量之和为:季度至第五年第一季度方法一:从第四年第二6866891-91*20)181718(1916707016918171816=++++=+++x xx6. 见教材P432 7. 见教材P433)/(2502500625000)/(2702500675000亩千克亩千克乙甲======∑∑∑∑f xf X x mm X在相同的耕地自然条件下,乙村的单产均高于甲村,故乙村的生产经营管理工作做得好。
统计学(第五版)课后答案
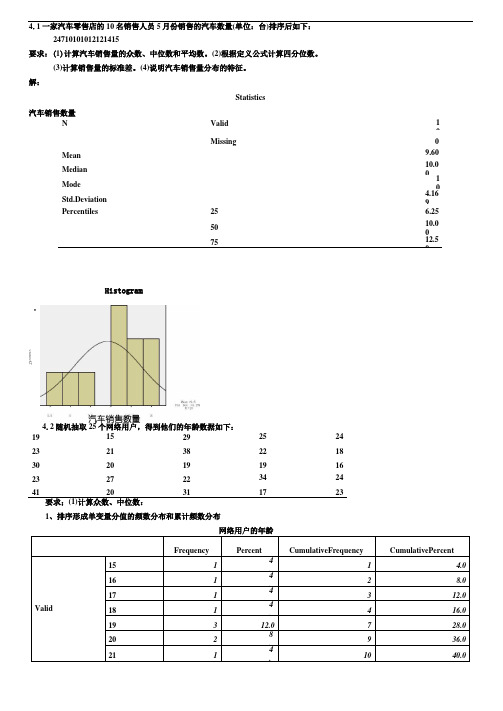
4.1一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:24710101012121415要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量NValid 10Missing0 Mean9.60 Median10.00 Mode10 Std.Deviation4.169 Percentiles25 6.25 5010.007512.5019 15 29 25 24 23 21 38 22 18 30 20 19 19 16 23 2722 34 24 4120311723要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布Histogram34.2随机抽取25个网络用户,得到他们的年龄数据如下:vcneuoeKT22 2 8.12 48.0 23 3 12.0 15 60.0 24 2 8.17 68.0 25 1 4.18 72.0 27 1 4.19 76.0 29 1 4.20 80.0 30 1 4.21 84.0 31 1 4.22 88.0 34 1 4.23 92.0 38 1 4.24 96.0 411 4.25100.0Total25100.0从频数看出,众数Mo 有两个:19、23;从累计频数看,中位数Me=23。
(2) 根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3X 25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75X 2=26.5。
(3) 计算平均数和标准差;Mean=24.00;Std.Deviation=6・652 (4) 计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5) 对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
统计学第五版 课后习题答案

H0:p1 - p2 0
H1 : p1 - p2 0
α= 0.05 n1 = n2 =11000 p1=0.95%, p2=1.72%
临界值(s): Z =1.645
抗压强度相同(α=0.05)?
解:大样本,σ²已知,采用Z统计量
H0 : 1 - 2 = 0
H1 : 1 - 2 ≠ 0
已知:α= 0.05 n1 = 81 n2 = 64
双侧检验:Z =1.96
2
Z (xA - xB ) - (A - B ) 1070 -1020 - 0 0.5 1.96
解:已知N=36,σ =60,x =680,μ =700 左侧检验 ∵是大样本,σ 已知 ∴采用Z统计量计算 H0 :μ ≥700 H1 :μ <700 ∵α =0.05∴ - Z0.05=-1.645
计算检验统计量: Z x / n
=(680-700)/(60/6)=-2
决策: ∵Z值落入拒绝域,
将Z的绝对值2.16录入,得到的函数值为0.9846 1-0.9846=0.0154=1.54%>1%
决策:在 α= 0.01的水平上接受 H0 。
结论: 贷款的平均规模维持着原来的水平。
8.13 有一种理论认为服用阿司匹林有助于减少心脏病的发生,为了进行验 证,研究人员把自愿参与实验的22000人员随机分成两组,一组人员每星 期服用三次阿司匹 林(样本1),另一组人员在相同的时间服用安慰剂 (样本2)。
Z=-0.77%/0.001466=-4.98<-1.645
《统计分析和SPSS的应用(第五版)》课后练习答案解析(第5章)

《统计分析与SPSS的应用〔第五版》〔薛薇课后练习答案第5章SPSS的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下: 80, 81, 72, 60, 78, 65, 56, 79, 77,87,76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss数据→分析→比较均值→单样本t检验→相关设置→输出结果〔Analyze->compare means->one-samples T test;采用单样本T检验〔原假设H0:u=u0=75,总体均值与检验值之间不存在显著差异;分析:N=11人的平均值〔mean为73.7,标准差〔std.deviation为9.55,均值标准误差<std error mean>为2.87.t统计量观测值为-4.22,t统计量观测值的双尾概率p-值〔sig.<2-tailed>为0.668,六七列是总体均值与原假设值差的95%的置信区间,为<-7.68,5.14>,由此采用双尾检验比较a和p。
T统计量观测值的双尾概率p-值〔sig.<2-tailed>为0.668>a=0.05所以不能拒绝原假设;且总体均值的95%的置信区间为<67.31,80.14>,所以均值在67.31~80.14内,75包括在置信区间内,所以经理的话是可信的。
2、在某年级随机抽取35名大学生,调查他们每周的上网时间情况,得到的数据如下〔单位:小时:〔1 请利用SPSS对上表数据进行描述统计,并绘制相关的图形。
〔2 基于上表数据,请利用SPSS给出大学生每周上网时间平均值的95%的置信区间。
〔1分析→描述统计→描述、频率〔2分析→比较均值→单样本T检验每周上网时间的样本平均值为27.5,标准差为10.7,总体均值95%的置信区间为23.8-31.2.3、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
《统计学原理(第五版)》习题计算题答案详解之欧阳引擎创编

《统计学原理(第五版)》习题计算题答案详解欧阳引擎(2021.01.01)第二章统计调查与整理1. 见教材P402 2. 见教材P402-403 3. 见教材P403-404第三章综合指标1. 见教材P432所以劳动生产率计划超额1.85%完成。
一季度产品单位成本,未完成计划,还差2.22%完成计划。
2. 见教材P432在相同的耕地自然条件下,乙村的单产均高于甲村,故乙村的生产经营管理工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相反,由于权数的作用,使得4.5.%74.94963.09222.09574.03=⨯⨯=G X 或参照课本P99(2)R=500-150=350(千克/亩)(3)“(4) 根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/X(2)6.见教材P4357. 见教材P404劳动生产率计划超额1.85%完成一季度产品单位成本未完成计划,实际单位成本比计划规定数高2.22% 8. 见教材P405在相同的耕地自然条件下,乙村的单产均高于甲村,故乙村的生产经营管理工作做得好。
但由于甲村的平原地所占比重大,山地所占比重小,乙村则相反,由于权数的作用,使得(2)R=500-150=350(千克/亩)(3)“标准差”不要求用组距数列的简捷法计算(4) 根据以上计算,294.5千克/亩>283.3千克/亩>277.96千克/(2) (1) (2)第四章动态数列1.见教材P4072. 见教材P407-4083. 见教材P4084. 见教材P4095. (1) 见教材P409-410(2) ①增减速度=发展速度-1(或100%)②0n1i i a an 1i a a =∏=- (环比发展速度的连乘积等于定基发展速度)③100%1基期发展水平的绝对值增长=④增减速度增减量的绝对值增长=%1⑤0n 1i i a a n1i )a (a -=∑=-- (逐期增减量之和等于累计增减量) ⑥n x x ∏= (平均发展速度等于环比发展速度的连乘积开n 次方)⑦平均增减速度=平均发展速度-1(或100%)6. 见教材P4107. 见教材P410-411 8. (1) 见教材P411(2)(1) 因为本资料二级增长量大体相等,所以投资额发展的趋势接近于抛物线型。
统计软件常见问题总结

统计软件常见问题总结目录统计软件常见问题总结 (1)10 软件下载 (3)11软件安装 (3)11001一个问题阻止windows正确检索此机器的许可证。
(3)11002 运行操作系统补丁时,安装程序无法继续进行。
(3)11003 应用程序正常初始化(0xc0000135)失败。
(4)11004操作系统补丁已经安装,运行统计软件时出现如图提示内容。
(5)11005 配置ODBC数据源SqlExpress是发生错误。
(6)12软件升级 (7)12001安装升级包时,提示无法打开登录所请求的数据库。
(7)12002升级包安装过程中,窗口提示“MSSQLSERVER存在”,升级无法进行。
(8)13软件配置 (8)13001导入代码时,导入失败。
(8)13002加载文件有误,无法导入。
(9)13003导入编码失败,提示核实当前数据库链接和上报学校的数据库版本及软件版本。
(9)13004创建账号时,“创建用户向导”一侧为空白。
(10)14数据录入 (11)14001软件无法实现保存功能,点击保存,提示“服务器XXX上的MCDTC不可用”。
(11)14002保存112表时,提示“从字符串转换XXX,转换失败”。
(11)14003数据保存后出现“-1000”的提示。
(12)14004表格列表中出现重复表的问题。
(12)14005浮动行表模板导入问题。
(13)14006填写数据类型有误。
(13)14007无法找到instanceID (14)14008在浮动行表导入或点开表格时提示序列不包含任何元素。
(15)15数据上报接收 (16)15001需要审批的办学类型无法显示。
(16)15002接收下级单位的上报文件失败,提示核实当前数据库链接和上报学校的数据库版本及软件版本。
(16)16数据导出导入 (17)17数据校验 (17)17001对数据进行校验时,出现约束冲突。
(17)17002校验错误:文件不可访问,无法打开数据库。
2014年统计软件应用问题集(陆续更新中9月24日)

2014年统计软件应用问题集2014年教育统计软件和“操作系统补丁及系统运行环境”下载地址:/,具体位置为“在线报送”栏目,“统计工作”中下载。
一、软件安装问题1:2013年已经安装过统计软件并且目前仍能够运行。
解决办法:直接安装2014年教育统计软件安装包,无需导入代码操作。
问题2:2013年未安装过统计软件或者重新安装操作系统。
解决办法:检查操作系统版本(1)windows xp sp2 专业版,并且是正版软件,先将操作系统升级至windows xp sp3,然后安装系统运行环境,然后再安装2014年教育统计软件,如果操作系统为盗版建议重新安装windows xp sp3操作系统;(2)windows xp sp3 专业版,直接安装系统运行环境,然后再安装2014年教育统计软件;(3)windows 7,直接安装系统运行环境,然后再安装2014年教育统计软件,运行软件时,右键以管理员身份运行。
另外,windows xp sp3的升级包、系统运行环境及安装具体流程及注意事项文档均在“操作系统补丁及系统运行环境”文件夹中。
二、软件启动问题3:软件启动过程中遇到的问题教育统计软件安装启动解决方案问题解决流程:三、各表填报问题4:基础基400表填报说明:对于老教职工而言,如果“岗位”发生变化,“变动情况”也要同时变化,选择14-校内调整,要想知道岗位变没变,看“原始岗位”就可以知道上年的岗位。
带有附设班的学校,附设班教师填报方法,例如:小学附设幼儿班,教幼儿班的老师,如果是小学编制教职工,“编制情况”选择11-在编,岗位类别只能选小学教职工的信息(12小学专任,中层干部等,不要选择11幼儿教师,因为他本是小学教职工),第一课程选择“81-附设幼儿班课程”;如果是学校长期聘只教幼儿班的,“编制情况”得填不计入本校教职工数的选项,“岗位”小学教职工信息即可,“第一课程”附设幼儿班课程。
小学举办的幼儿园,个别小学老师教幼儿园的,“编制”是小学编制,“岗位”小学教职工(专任、中层、教辅等),在幼儿园表中作为“兼任教师”,“第一课”程选择其他课,不要选“附设幼儿班课”新增教职工“变动情况”不能空,并且得填增加信息(例如:调入,录用毕业生)。
统计学(贾俊平,第四版)第五章习题答案

《统计原理》第五章练习题答案5.1 (1)平均分数是范围在0-100之间的连续变量,Ω=[0,100](2)已经遇到的绿灯次数是从0开始的任意自然数,Ω=N(3)之前生产的产品中可能无次品也可能有任意多个次品,Ω=[10,11,12,13…….]5.2 设订日报的集合为A ,订晚报的集合为B ,至少订一种报的集合为A ∪B ,同时订两种报的集合为A ∩B 。
P(A ∩B)=P(A)+ P(B)-P(A ∪B)=0.5+0.65-0.85=0.35.3 P(A ∪B)=1/3,P(A ∩B )=1/9, P(B)= P(A ∪B)- P(A ∩B )=2/95.4 P(AB)= P(B)P(A ∣B)=1/3*1/6=1/18 P(A ∪B )=P(B A )=1- P(AB)=17/18 P(B )=1- P(B)=2/3 P(A B )=P(A )+ P(B )- P(A ∪B )=7/18 P(A ∣B )= P(B A )/P(B )=7/125.5 设甲发芽为事件A ,乙发芽为事件B 。
(1)由于是两批种子,所以两个事件相互独立,所以有:P(AB)= P(B)P(B)=0.56(2)P(A ∪B)=P(A)+P(B)-P(A ∩B)=0.94(3)P(A B )+ P(B A )= P(A)P(B )+P(B)P(A )=0.385.6 设合格为事件A ,合格品中一级品为事件BP(AB)= P(A)P(B ∣A)=0.96*0.75=0.725.7 设前5000小时未坏为事件A ,后5000小时未坏为事件B 。
P(A)=1/3,P(AB)=1/2, P(B ∣A)= P(AB)/ P(A)=2/35.8 设职工文化程度小学为事件A ,职工文化程度初中为事件B ,职工文化程度高中为事件C ,职工年龄25岁以下为事件D 。
P(A)=0.1 P(B)=0.5, P(C)=0.4P(D ∣A)=0.2, P(D ∣B)=0.5, P(D ∣C)=0.7P(A ∣D)=2/55)C P(C)P(D )B P(B)P(D )A P(A)P(D )A P(A)P(D =++同理P(B ∣D)=5/11, P(C ∣D)=28/555.9 设次品为D ,由贝叶斯公式有:P(A ∣D)=)C P(C)P(D )B P(B)P(D )A P(A)P(D )A P(A)P(D ++=0.249同理P(B ∣D)=0.1125.10 由二项式分布可得:P (x=0)=0.25, P (x=1)=0.5, P (x=2)=0.255.11 (1) P (x=100)=0.001, P (x=10)=0.01, P (x=1)=0.2, P (x=0)=0.789(2)E(X)=100*0.001+10*0.01+1*0.2=0.45.13 答对至少四道题包含两种情况,对四道错一道,对五道。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.多余的图标
2.需要点击“重置”两次才能,完成取消数据筛选。
3.重置以后,再次筛选时,当时间日期上有蓝线时,选取时间无效。
4.在windows系统中,按“Fn”+“->”时,可以调出调试后台界面,需要去除。
5.取消链接和版本信息删除。
6.调整
,改为
“登录的用户名”,删除;改为修改密码。
数据验证
1.直投债权
2.活期债权
3.用户明细
4.活动数据
5.签到数据
6.抽奖红包
7.交易汇总
8.充值统计
9.活期投资统计
10.定期投资统计
11.赎回统计表
12.提现统计表
13.充值明细核对
14.提现明细核对和提现核对中,不平衡的笔数不一致。