计算语言学7_790805368
计算语言学讲义(03)词法分析(一)

6
序列标注问题
• 输入:一个符号序列 • 输出:给每一个输入符号赋予一个标记 • 常见具体问题:
– 音字转换:拼音序列 – 词性标注:词语序列 – 词义排歧:词语序列 汉字序列 词性序列 词义标记序列
计算语言学讲义(04)词法分析I
7
序列结构化
• 输入:一个符号序列 • 输出:一个结构,刻划符号之间的关系 • 常见具体问题:
• 输入:一段文本 • 输出:单词串 • 算法:(略)
计算语言学讲义(04)词法分析I
21
Stemming
屈折型语言的词语变化形式: • 屈折变化:即由于单词在句子中所起的语法作用的不同而 发生的词的形态变化,而单词的词性基本不变的现象,如 ( take, took, takes)。识别这种变化是词法分析的最 基本的任务。 • 派生变化:即一个单词从另外一个不同类单词或词干衍生 过来,如morphological morphology,英语中派生变化 主要通过加前缀或后缀的形式构成;在其他语言中,如德 语和俄语中,同时还伴有音的变化。 • 复合变化:两个或更多个单词以一定的方式组合成一个新 的单词。这种变化形式比较灵活,如well-formed, 6year-old等等。 Stemming的目的:将上述变化还原
– 成分句法分析:词语序列 短语结构树 – 依存句法分析:词语序列 依存树 – 语义分析:词语序列 语义网络
计算语言学讲义(04)词法分析I
8
问题与方法
• 计算语言学常用方法:
– 规则方法
• 形式语法理论 • 形式逻辑 • ……
– 统计方法
• • • • n元语法模型 隐马尔科夫模型 最大熵模型 ……
计算语言学讲义(04)词法分析I
计算语言学术语500条
processing of speech signal
语音信号输入计算机后对其进行分析处理的过程。语音通过话筒转换成电信号,再经放大或转换变成数字信号,用模式分类方法分析和识别这些信号。
神经网络
neural net
神经系统的一种逻辑及数学模型,是一种具有学习和自组织能力的智能机构。模仿生物神经系统的神经元建立,试图模拟大脑处理信息、学习和记忆的方式,主要用于模式识别、语音识别和语音综合等领域。
文法推断
grammar inference
确定词在句子中的语法范畴和作用的过程。
计算语音学
computational phonetics
计算语言学的一个分支学科。是通过建立形式化的数学模型利用计算机来处理语音的一门学科。
隐式马尔可夫模型
hidden Markov model
是描述连续符号序列的条件概率的一个统计模型,是马尔可夫模型的扩展。该模型由两个随机变量序列组成:一个是观测不到的马尔可夫链,另一个是可以观测到的随机序列。
对词汇意义、语言成分之间的逻辑意义、语法意义的描述。
超文本置标语言
①hyperText markup language ②HTML
标准通用置标语言(SGML)的一种文件类型。它对一类特定的文件定义描述信息的方法,用于互联网上电子文本的传输和共享。
超文本标记语言
词法歧义
morphological ambiguity
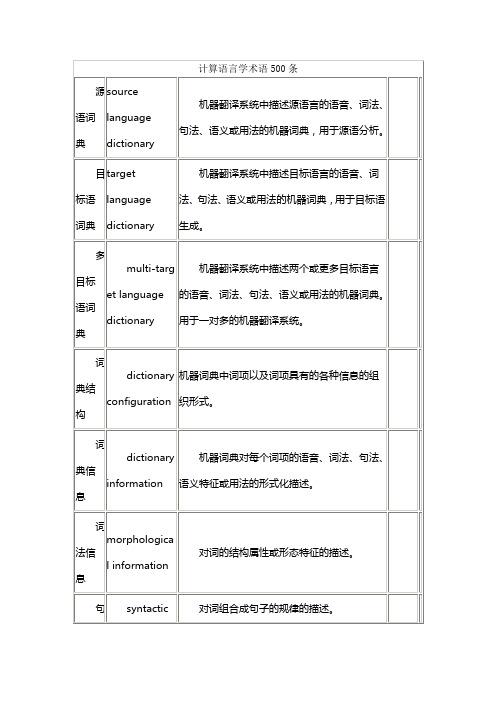
词典信息
dictionary information
机器词典对每个词项的语音、词法、句法、语义特征或用法的形式化描述。
词法信息
morphological information
对词的结构属性或形态特征的描述。
计算语言学及其近义术语详解

一、计算语言学的起源及其发展从世界上第一台电子计算机诞生至今,计算机的功能已经远远超出了最初的数值计算范围,进入到了更广泛的非数值领域,例如语言处理领域。
而在计算机出现之前,对语言的研究大都是由语言学家来完成的。
利用计算机这一现代计算工具来研究语言,仿佛给计算机赋予了更多的智能化色彩,而“计算语言学”(Computational Linguis-tics,CL)这一语言学和计算机科学的交叉学科此时则应运而生。
当然,在计算语言学的研究过程中,还涉及到数学、认知科学、逻辑学、心理学等许多其他学科。
实际上,“计算语言学”这一术语是伴随着“机器翻译”这一应用而出现的。
传说中,上帝为阻止人类建造通天塔的壮举,故意让不同种族的人讲不同的语言,使人类不能自由交流,无法齐心协力。
为了跨越语言的障碍,远在古希腊时代,就有人提出要用机器来代替人进行不同语言之间的翻译。
1933年,前苏联发明家特罗扬斯基设计了一种用于翻译的机器,但是并没有成功。
事实上,真正的机器翻译研究是在计算机发明之后开始的,1954年,美国Georgetown大学与IBM公司合作开发了世界上第一个机器翻译的原型系统,当时的目的主要是将其用于美俄之间军事情报的翻译工作,该系统首次通过机器将俄语翻译为英文并取得了初步的成功。
这项工作使学者们备受鼓舞,也吸引了政府大量资金的注入,计算语言学的研究也开始了其萌芽时期。
初期的机器翻译系统大都是以词典驱动,直接采用词对词的模式匹配的翻译方式,由于不同的语言之间词法、句法都存在很大差异,显然,这样的翻译结果不会令人满意。
1966年,ALPAC报告中指出,机器翻译的研究在当时的条件下并不具备很好的前景,不宜给予大力支持。
另外,后来有学者认为,虽然“计算语言学”一词之前早已出现,但作为术语第一次正式提出“计算语言学”及其近义术语详解*◇邵艳秋(北京大学)摘要:本文介绍了计算语言学的起源及其发展历史,对该领域的一些相近术语概念及其各概念之间的关系进行了详细的解释,包括计算语言学、自然语言处理、自然语言理解、人类语言技术、语言信息处理、中文信息处理等等。
计算机语言学

计算机语言学
1、计算机语言学:计算语言学(Computational Linguistics)指的是这样一门学科,它通过建立形式化的数学模型,来分析、处理自然语言,并在计算机上用程序来实现分析和处理的过程,从而达到以机器来模拟人的部分乃至全部语言能力的目的。
2、计算机语言都可以用来控制计算机来解决一些实际问题。
这些问题可以是数值计算问题,其操作对象就是一些由符号构成的符号串;也可以是非数值计算问题如声音、图像处理问题,其操作对象就是声音和图像等。
我们应知道各种计算机语言都不是万能的,每种计算机语言都有自己的特点、优势及运行环境,有自己的应用和操作对象。
计算语言学(2024)

造性。
18
2024/1/29
05
CATALOGUE
语音识别与合成
19
语音识别的原理
声学建模
将输入的语音信号转换为声学特 征向量,如梅尔频率倒谱系数( MFCC),以描述语音的声学特
性。
2024/1/29
语言建模
构建语言模型来描述词与词之间的 概率关系,常用的有N-gram模型 和神经网络语言模型。
2024/1/29
12
句法分析
句子结构分析
确定句子中词汇之间的结构关系,如主谓宾、定状补 等。
依存关系分析
分析句子中词汇之间的依存关系,如动词与其宾语、 形容词与其修饰的名词等。
短语结构分析
识别并分析句子中的短语结构,如名词短语、动词短 语等。
2024/1/29
13
语义理解
词汇语义
理解词汇在特定上下文中的含义和用法。
1 2
个性化语言处理技术的发展
随着个性化需求的不断增长,计算语言学将更加 注重个性化语言处理技术的研究和应用,如个性 化推荐、情感分析等。
多模态语言处理的深度融合
未来计算语言学将更加注重多模态语言处理的深 度融合,实现文本、语音、图像等多种信息的联 合处理和应用。
语言智能的进一步提升
3
随着计算语言学技术的不断发展,语言智能将得 以进一步提升,实现更加自然、高效的人机交互 和智能应用。
基于规则的翻译
通过预设的语法和词汇规则进行翻译,这种方法需要大量的手工编 码规则。
基于统计的翻译
利用大量的双语语料库进行统计学习,构建翻译模型。这种方法可 以自动从语料库中学习翻译规则,避免了手工编码的繁琐。
基于神经网络的翻译
通过深度学习技术,构建大规模的神经网络模型进行翻译。这种方法 可以自动学习语言的复杂特征,并实现更加准确的翻译。
计算语言学

语音合成: 语音合成:将可视的文本信息转化为可听的 语音信息。 语音信息。 现在语音识别技术还在发展, 现在语音识别技术还在发展,据说可以哑人 手语识别系统借助数据手套, 手语识别系统借助数据手套,将哑人在会话过 程中的手的运动信息提取出来进行识别, 程中的手的运动信息提取出来进行识别 , 提 取其中的语义,并通过语音合成, 取其中的语义,并通过语音合成,最终将他们 的手语信息翻译成语音并输出, 的手语信息翻译成语音并输出 , 便于听力健 全人理解。 全人理解。
印刷汉字识别技术主要包括:
(1) 扫描输入文本图象。 扫描输入文本图象 输入文本图象。 (2) 图象的预处理,包括倾斜校正和滤除干扰噪声等。 图象的预处理 包括倾斜校正和滤除干扰噪声等。 预处理, (3) 图象版面分析和理解。区分出文本段落及排版顺序,图象、 图象版面分析和理解。区分出文本段落及排版顺序,图象、 表格的区域;对于文本区域将进行识别处理, 表格的区域;对于文本区域将进行识别处理,对于表格区域进行 专用的表格分析及识别处理,对于图象区域进行压缩或简单存储。 专用的表格分析及识别处理,对于图象区域进行压缩或简单存储。 (4)行字切分:图象的行切分和字切分。 行字切分: 行字切分 图象的行切分和字切分。 (5)特征提取:提取单字图象统计特征或结构特征。 特征提取: 特征提取 提取单字图象统计特征或结构特征。 (6)文字识别:基于单字图象特征的模式分类。将被分类的模式 文字识别: 文字识别 基于单字图象特征的模式分类。 赋予识别结果。 赋予识别结果。 (7)后处理:识别结果的编辑修改后处理。利用词义、词频、语 后处理:识别结果的编辑修改后处理。利用词义、词频、 后处理 法规则或语料库等语言先验知识对识别结果进行校正的过程。 法规则或语料库等语言先验知识对识别结果进行校正的过程。 其中(4)、(5)和(6),是印刷汉字识别中最为核心的技术。 、 其中 和 ,是印刷汉字识别中最为核心的技术。
计算语言学

1955年,第一个演示系统在 IBM & Georgetown Univ.开发成功,包含250 个词和 6 条句法规则,实 现了 Russia — English的翻译;
1950s:理论基础建设
计算语言学
目录
导入 定义 研究内容 发展历史 代表人物及著作 研究成果
导入
我们可以期待,总有一天机器会同人在所有 的智能领域里竞争起来。但是,如何开始呢?这 是一个很难决定的问题。许多人以为可以把下棋 之类的极为抽象的活动作为最好的出发点,不过, 还有一种办法也应加以考虑,就是为机器配备具 有智能的、可用钱买到的意识器官,然后,教这 种机器理解并且说英语。这个过程可以仿效通常 小孩子学话的方式进行。我不能确定到底哪个出 发点更好,但应该都值得一试。 —— A. M. Turing, Computing Machinery and Intelligence ,Mind Vol.59, 1950. 阿兰. 图灵(英国数学家)《计算装置与智能》
思考
你认为机器会思考吗?
计算语言学的定义
计算语言学(Computational Linguistics) 指的是这样一门学科,它通过建立形式化 的数学模型,来分析、处理自然语言,并 在计算机上用程序来实现分析和处理的过 程,从而达到以机器来模拟人的部分乃至 全部语言能力的目的。
பைடு நூலகம்
思考
人用来交际的“语言”具有什么样的性质? 这些性质又是如何影响交际过程的?
计算语言学的发展简史
1950 - 1960年代 Warren Weaver(1949) Turing Test(1950)The first MTs(1954)
计算语言学-厦大应用语言

分析结果
基于规则的方法在特定领域表现较好, 但泛化能力较差。
基于统计的方法具有较好的泛化能力, 但需要大量标注数据进行训练。
深度学习方法能够自动学习句子的深 层特征,具有更好的性能表现。
05
语义理解与信息抽取
词汇语义表示和消歧技术
词汇语义表示
研究如何将自然语言中的词汇映射到计算机可理解的语义空 间,包括词义表示、词向量表示等方法。
词法分析方法
词法分析方法主要分为基于规则的方法和基于统计的方法。基于规则的方法依赖于人工编 写的规则,而基于统计的方法则利用机器学习算法从大量语料库中学习规则和模式。
词性标注任务及实现方法
词性标注任务
词性标注是词法分析的核心任务之一,旨在为文本中的每个单词标注其词性标签 ,如名词、动词、形容词等。词性标注对于句法分析和语义理解等任务至关重要 。
计算语言学-厦大应 用语言
目录
• 引言 • 基础知识与方法 • 词法分析与词性标注 • 句法分析与依存关系解析 • 语义理解与信息抽取 • 情感分析与观点挖掘 • 总结与展望
01
引言
计算语言学定义与发展
计算语言学定义
计算语言学是语言学、计算机科学和 人工智能等多学科交叉融合的产物, 旨在运用计算机技术和方法来研究自 然语言及其处理。
技术原理
观点挖掘是一种从文本中抽取人们对某 个主题、事件或产品的看法和态度的技 术。它通常涉及文本预处理、特征提取 、情感词典构建和机器学习算法等步骤 。
VS
实现方法
观点挖掘的实现方法包括基于规则的方法、 基于统计的方法和深度学习方法等。其中, 基于深度学习的方法在近年来取得了显著 进展,如卷积神经网络(CNN)和循环神 经网络(RNN)等模型在观点挖掘任务中 表现出色。
计算语言学

计算机语言学来说,全国有几所高校开设了这个方向,一般下设自然语言处理,机器翻译,信息检索等分支。
论实力来说北大,哈工大,复旦大学在这方面有很强的实力,区别在于北大计算语言所侧重语言学资源的构造,比如汉语词典,什么人民日报词性标注语料库等等,要知道研究计算语言学,资源是必不可少的。
哈工大拥有全世界最大的自然语言研究中心(其实就是全国规模最大的,当然就是全世界最大的了,呵呵!)主要以应用为主,资源不及北大,主要是因为北大有北大中文系为依托。
因为计算机语言学会涉及很多语言学的知识,这是工科院校所不具备的。
所以哈工大以应用为主,要知道微软拼音输入法就是由哈工大王晓龙教授研发的,所以在这方面,哈工大实力也是不容小视,只是地理位置上稍稍欠缺一点。
复旦大学有个上海市智能信息处理重点实验室,里面很多牛人,其中有搞自然语言处理的。
其他的开设院校有,中科院计算机所,清华,北语,东北大学,大连理工大学,山西大学等等。
南京大学好像有机器翻译。
基本上就是这些了,每个学校不管名气如何,都是有一两个很厉害的导师做支撑的,比如东北大学,山西大学。
这些教授的相关信息都是可以从网上查得到的。
一学校北京语言大学(国内对外汉语系第一!)南京大学北京大学北京师范大学北京外国语大学上海外国语大学吉林大学黑龙江大学厦门大学暨南大学广东外语外贸大学这几个大学从师资到生源到环境, 一流.北京语言大学,2006年中国大学研究生院文学类A等学校排名13,“对外汉语”教学界的“大哥大”。
顺便提一句,“对外汉语”教学现在还不是一个专业,而仅是一个研究方向,因为到目前为止它仍是一个三级学科,通常都设置在“语言学及应用语言学”这个专业下面,作为它的一个研究方向。
北京语言大学招收属于文学硕士的“对外汉语”教学的研究生和属于教育学硕士的“课程与教学论”专业的“对外汉语”教学的研究生。
考试的内容基本相同,语言学概论,现代汉语,古代汉语。
“课程与教学论”专业要多考一个“对外汉语教学概论”。
计算语言学导论

第一章计算语言学导论计算语言学(ComputationalLinguistics)指的是这样一门学科,它通过建立形式化的数学模型,来分析、处理自然语言,并在计算机上用程序来实现分析和处理的过程,从而达到以机器来模拟人的部分乃至全部语言能力的目的。
计算语言学的研究内容:(1)从计算的角度来研究语言的性质(2)将语言作为计算对象来研究相应的算法。
从计算角度研究语言:所谓从计算的角度来看语言的性质,就是要求将人们对语言的结构规律的认识以精确的、形式化的、可计算的方式呈现出来,而不是像其他语言学研究那样,在表述语言的结构规律时一般采用非形式化的表达形式。
将语言作为计算对象来研究相应的算法,是研究如何以机械的、规定了严格操作步骤的程序来处理语言对象(主要是自然语言对象,当然也可以是形式语言对象),包括一个语言片断(比如词组、句子或篇章)中大小语言单位的识别,该语言片断的结构和意义的分析(自然语言理解),以及如何生成一个语言片断来表达确定的意思(自然语言生成),等等。
第二章语言知识的形式化表示1.有限状态自动机(FSA)的形式定义:一个有限状态自动机M是一个五元组:(Q, Σ, q0, F, δ)有限个状态组成的状态集: Q有限字母组成的字母表: Σ开始状态q0 ∈Q终止状态的集合F ⊆Q状态转移函数δ(q,i): Q xΣ→Q但是FSA:无法描述自然语言的层次结构特性2.上下文无关文法符号字母表:有限个任意符号组成的非空集合Σ例1:所有汉字组成的集合构成一个字母表。
例2:汉语中所有的词也构成一个字母表。
例3:字母a, b, c也组成一个字母表。
字符串:由字母表Σ上的字符组成的长度有限的序列若字母表Σ={a, b},则a, b, ab, aba, aabb 等等都是字母表上的字符串。
语言:是字母表上的字符串的任意集合。
3.形式文法:形式文法:一个形式文法G由四个部分组成,可记作G={VN , VT , S , P },其中:VN :称为文法G的非终结符号字母表,VN不出现在G所表示的语言集合的句子中;VT :称为文法G的终结符号字母表,G所表示的语言的句子由VT中的元素组成,VN ∩VT =φ;S :代表句子符号,S∈VN 。
计算语言学概论课件

计算语言学的重要性
社会需求
随着信息技术的快速发展,社会 对自然语言处理的需求日益增长 ,计算语言学在信息检索、机器 翻译、语音识别等领域具有广泛
的应用前景。
学术价值
计算语言学为语言学、计算机科 学等相关学科提供了新的研究方 法和思路,有助于推动相关学科
的发展。
技术创新
计算语言学的技术突破和创新, 将推动人工智能、大数据等领域 的进步,为社会发展带来更多机
信息抽取是从非结构化文本中提 取结构化信息的过程,如从新闻 报道中提取事件、时间、地点等
关键信息。
信息抽取技术广泛应用于知识图 谱构建、问答系统等领域。
信息抽取的关键技术包括实体识 别、关系抽取、事件抽取等。
机器翻译
机器翻译是利用计算机自动将一 种语言的文本转换为另一种语言
的文本的过程。
机器翻译技术已经取得了显著的 进步,如基于神经网络的机器翻
深度学习在NLP领域的应用取得了显著成果,如词向量表示、序列标注、生成模型 等。
文本挖掘
文本挖掘是从大量文本数据中 提取有用信息的过程,包括文 本分类、聚类、情感分析等。
文本挖掘技术广泛应用于信息 检索、舆情分析、企业竞争情 报等领域。
文本挖掘的关键技术包括特征 提取、文本表示、模型评估等 。
信息抽取
感谢观看
REPORTING
情感分析
计算语言学可以帮助智能客服系统识别用户的情感倾向,从而提供 更加贴心、个性化的服务。
自动回复
利用计算语言学的方法,智能客服系统可以自动回复用户的咨询, 提高服务效率。
在机器翻译中的应用
1 2
语言对齐
计算语言学可以帮助机器翻译系统识别源语言和 目标语言之间的对应关系,提高翻译的准确度。
计算机语言学导论

计算机语言学导论全文共四篇示例,供读者参考第一篇示例:计算机语言学导论是计算机科学领域中的一个重要分支,它研究的是计算机与人类语言之间的相互关系以及如何让计算机理解和处理人类语言。
计算机语言学导论的研究内容涉及计算机的自然语言处理、文本挖掘、语音识别、语义分析等多个方面,是一个极具挑战性和前景广阔的领域。
在计算机语言学导论中,我们首先要了解计算机语言的种类。
计算机语言主要分为两类:自然语言和形式语言。
自然语言是人类使用的语言,如中文、英文等,它具有复杂的语法和语义规则,是人类交流思想和情感的主要方式。
形式语言是为了解决特定问题而设计的语言,如编程语言、逻辑语言等,它具有严格的语法和语义规则,能够被计算机直接处理和执行。
计算机语言学导论涉及的一个重要领域是自然语言处理(Natural Language Processing,NLP)。
自然语言处理是研究如何让计算机理解和处理人类语言的技术,它包括词法分析、句法分析、语义分析、文本生成等多个方面。
自然语言处理在机器翻译、信息检索、问答系统等领域有着广泛的应用,是人工智能领域的重要研究方向之一。
另一个重要的研究领域是文本挖掘(Text Mining)。
文本挖掘是一种从大量文本数据中发现有价值信息的技术,它包括文本分类、情感分析、主题模型等多个技术。
文本挖掘在舆情分析、新闻推荐、舆情分析等领域有着广泛的应用,可以帮助人们从海量的文本数据中挖掘出有用的信息。
计算机语言学导论还涉及语音识别、语音合成、自然语言生成等多个方面。
语音识别是研究如何让计算机识别和理解人类语音的技术,语音合成是研究如何让计算机生成自然流畅的语音的技术,自然语言生成是研究如何让计算机生成符合语法和语义规则的自然语言文本的技术。
这些技术在语音助手、语音识别系统、智能对话系统等领域都有广泛的应用。
计算机语言学导论是一个涵盖面广、实用性强的研究领域,它涉及计算机与人类语言之间的交互,旨在让计算机更好地理解和处理人类语言。
公共基础知识计算语言学基础知识概述

《计算语言学基础知识概述》一、引言计算语言学是一门融合了语言学、计算机科学和数学等多学科的交叉领域,旨在利用计算机技术来处理和分析自然语言。
随着信息技术的飞速发展,计算语言学在自然语言处理、机器翻译、语音识别、信息检索等众多领域发挥着至关重要的作用。
本文将对计算语言学的基本概念、核心理论、发展历程、重要实践以及未来趋势进行全面的阐述与分析。
二、基本概念1. 自然语言自然语言是人类日常交流所使用的语言,如汉语、英语、法语等。
它具有复杂性、歧义性和多样性等特点。
与形式语言不同,自然语言的语法和语义规则较为灵活,且存在大量的模糊性和不确定性。
2. 计算语言学计算语言学是研究如何利用计算机技术来处理和分析自然语言的学科。
它涉及自然语言的理解、生成、翻译、检索等多个方面,旨在实现人与计算机之间的自然语言交互。
3. 语言模型语言模型是计算语言学中的一个重要概念,它用于描述自然语言的概率分布。
语言模型可以预测一个句子或文本序列出现的概率,从而为自然语言处理任务提供基础。
常见的语言模型有 n-gram 语言模型、神经网络语言模型等。
三、核心理论1. 形式语言理论形式语言理论是计算语言学的基础理论之一,它主要研究形式语言的语法和语义。
形式语言是一种严格定义的语言,具有明确的语法规则和语义解释。
形式语言理论为自然语言的形式化表示和分析提供了方法和工具。
2. 统计语言模型统计语言模型是基于统计方法的语言模型,它通过对大量文本数据的统计分析来学习语言的概率分布。
统计语言模型在自然语言处理中得到了广泛的应用,如机器翻译、语音识别、信息检索等。
3. 深度学习理论深度学习是近年来发展迅速的一种机器学习方法,它在计算语言学中也取得了显著的成果。
深度学习模型如卷积神经网络(CNN)、循环神经网络(RNN)、长短时记忆网络(LSTM)等被广泛应用于自然语言处理任务中,如文本分类、情感分析、机器翻译等。
四、发展历程1. 早期阶段计算语言学的早期发展可以追溯到 20 世纪 50 年代,当时人们开始尝试利用计算机来进行自然语言处理。
计算语言学

1型语法
2型语法
3型语法
计算语言学讲义(03上)形式语言与自动机
10
乔姆斯基0型语法
• 短语结构语法,无限制重写语法 PSG:Phrasal Structure Grammar • 对规则形式的约束
– 对于规则形式没有任何限制
计算语言学讲义(03上)形式语言与自动机
11
乔姆斯基1型语法
• 上下文有关语法,上下文敏感语法 CSG:Context Sensitive Grammar • 对规则形式的约束:
……
· · · …… · ·
词典正文
啊
啊哈
啊呀
啊哟
啊唷
阿
阿Q
……
酣睡
• 索引结构简单,占用空间小 • 不能实现增量式索引:每增加一个词需重新排序
计算语言学讲义(03上)形式语言与自动机
30
词典顺序索引的查找算法
• 整词二分查找
– 时间复杂度O(log2N) – 无法按前缀查找:查找时精确匹配
• 改进的整词二分查找
6
计算语言学讲义(03上)形式语言与自动机
形式语法 (1)
• 形式语法:四元组 G = < VT, VN, S, P > • 终结符(Terminals)的有限集合VT
– 终结符是句子中实际出现的符号 – 相当于单词表(有时也称为字母表)
• 非终结符(Non-terminals)的有限集合VN
– 非终结符在句子中不实际出现 – 但在推导中起变量作用 – 相当于语言中的语法范畴
14
乔姆斯基语法层级-例子
• P={S A1, A A0, A 0}
– L(G)={0m1|m>=1} – 是正则语法
计算语言学(全套课件114P)

计算语言学的发展简史
• 1950 - 1960年代 Warren Weaver(1949) Turing Test(1950)The first MTs(1954) • 1960 - 1970年代 ALPAC(1964-1966) • 1970 - 1990年代 Searle’s Chinese Room(1980) The first PC version of MTs(early 1980s) • 1990 - 至今 MT is available on the Web(1994)
主要的技术和方法基于知识的方法17上下文无关文法的扩充hpsg文法headdrivenphrasestructuregrammar对文法增加复杂特征主要的技术和方法基于知识的方法18上下文无关文法的扩充hpsg主要的技术和方法基于知识的方法19上下文无关文法的扩充hpsg主要的运算合一运算1检查特征属性是否兼容2如果兼容那么将两个负责特征集的信息合并主要的技术和方法基于知识的方法20上下文无关文法的扩充hpsg主要的技术和方法基于知识的方法21树邻接文法初始树i树
6
思考 • 人用来交际的“语言”具有什么样的性质? 这些性质又是如何影响交际过程的? • 人用来交际的“语言”跟机器可以“理解” 的语言有什么样的关系? • 人是如何运用“语言”进行交际的? • 人运用语言进行交际的过程是否可以描述 为一个机械的过程? • 什么叫做“理解”一种语言?
7
机器语言 vs自然语言
我是四川大学的老师。
27
主要的技术和方法 – 基于知识的方法(7) • 汉语句子切分存在的问题 交集型歧义 AB和BC都是词典中的词,如果待切分字串 中包含ABC,则可能切分成AB和C,以及A 和BC。如 网球场 组合型歧义 AB和A,B都是词典中的词,如果待切分字 串中包含AB,则可能切分为AB以及A和B。 如 个人
12 第十二讲 计算语言学

• 它是用计算机来研究和处理自然语言 的一门新兴边缘学科,涉及语言学、 计算机科学、数学、心理学等多个领 域。
• 通过建立形式化的数学模型,来分析、 处理自然语言,并在计算机上用程序 来实现分析和处理的过程,从而实现 以机器来模拟人的部分乃至全部语言 能力。 • 以“自然语言”为主的计算语言学可 以看作是“人工智能”的一个分支。
• 首先,计算语言学不是研究“计算机 语言”的学问,而是面向计算机的自 然语言处理,所以研究的是自然语言。 • 语言 :人工语言、自然语言
• “计算机语言”是一种人工语言,也 是一种机器语言,用于人和机器交换 信息。比如Basic语言、C语言等等,都 是人们专门设计出来用于计算机进行 信息处理的机器语言。
2015-05-25
一、什么是计算语言学 二、计算语言学的发展历史 三、我国计算语言学发展历程 四、计算语言学的研究特点
一、什么是计算语言学
• 计算语言学(Computational Linguistics),也 称自然语言处理(Natural Language Processing by Computer,NLP)或自然语言理解(Natural Language Understanding by Computer,NLU), 有时也叫计量语言学(Quantitative Linguistics)、数理语言学(Mathematical Linguistics)、人类语言技术(Human Language Technology,HLT)等。
• 一个好的机器翻译系统应该把原语的语义 准确无误地在译语中表现出来。这样,语 义分析在机器翻译中越来越受到重视。 • 随着计算语言学研究水平的提高,机器翻 译的研究走向了实用化,出现了一大批实 用化的机器翻译系统。
计算机语言学

1. 什么是计算机语言学?发展史?计算语言学:指的是这样一门学科,它通过建立形式化的数学模型来分析,处理自然语言,并在计算机上用程序来实现分析和处理的过程,从而达到一机器来模拟人的全部或者部分语言能力的目的。
计算语言学是利用电子数字计算机进行的语言分析。
虽然许多其他类型的语言分析也可以运用计算机,计算分析最常用于处理基本的语言数据-例如建立语音、词、词元素的搭配以及统计它们的频率。
计算语言学是语言学的一个研究分支,用计算技术和概念来阐述语言学和语音学问题。
已开发的领域包括自然语言处理,言语识别,自动翻译,语法的检测,以及许多需要统计分析的领域。
发展史:第一个时期是计算语言的萌芽期(1950 -1960年代)第二个时期是计算语言的发展期(1970 -1980年代)第三那个时期是计算语言的繁荣期(1990 -至今)2什么是语言资料库?它与语言知识库有什么区别?语言库在自然语言处理方面有什么应用?答:语料库顾名思义就是存放语言材料的仓库。
它是以电子计算机为载体承载语言知识的基础资源;语料库中存放的是在语言的实际使用中真实出现过的语言材料;真实语料需要经过加工(分析和处理),才能成为有用的资源;语言资料库与语言知识库的区别是:语料库是一种承载自然语言的形式,它的特点是以语言的真实材料为基础来呈现语言知识的。
语言知识库可以说是由专家从大量的实例中提炼、概括出来的系统的语言知识,语料库则基本上是以知识的原始形态表现出来。
在自然语言处理方面的应用如:基于大规模语料库的语音识别;基于大规模语料库的音字转换技术(中文输入);基于大规模语料库的自动文本校对技术;利用语料库训练HMM模型进行分词,词性标注,词义标注等等;基于语料库的句法分析;局域原料库的机器翻译;基于机器学习技术,通过语料库获取语言知识,包括搭配特征,句法规则,等等;基于语料钜的语言模型训练以及语言模型的评价;3. 中文自动分词的重要性;举例说明分词算法中的主要难点有哪些类型?答:中文分词的重要性:首先自动分词是汉语信息处理系统的重要组成部分;其次,自动分词是中文信息处理的基础。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
8.2. Some Basic Feature Systems for English
Since number and person features always co-occur, it is convenient to combine the two into a single feature, AGR, that has six possible values: first person singular (1s), second person singular (2s), third person singular (3s), and first, second and third person plural (1p, 2p, and 3p, respectively). „is‟: its AGR feature would be 3s. „are‟, its AGR feature would be a variable ranging over the values {2s 1p 2p 3p}.
NP -> ART N only when NUMBER1 agrees with NUMBER2 NP-SING -> ART-SING N-SING NP-PLURAL -> ART-PLURAL N-PLURAL
Doubling the size of the grammar. 失去简洁性,可理解性
8.2. Some Basic Feature Systems for English
Binary Features For example, the INV feature is a binary feature that indicates whether or not an S structure has an inverted subject (as in a yes/no question). The S structure for the sentence Jack laughed. will have an INV value - , for the sentence Did Jack laugh? will have the INV value. Often, the value is used as a prefix, and we would say that a structure has the feature +INV or -INV. The Default Value for Features
8.2. Some Basic Feature Systems for English
Verb-Form Features and Verb Subcategorization Feature values for the feature VFORM (关于动词自身)
base - base form (for example, go, be, say, decide) pres - simple present tense (for example, go, goes, am, is, say, says, decide) past - simple past tense (for example, went, was, said, decided) fin - finite (that is, a tensed form, equivalent to {pres past}) ing - present participle (for example, going, being, saying, deciding) pastprt - past participle (for example, gone, been, said, decided) inf - a special feature value that is used for infinitive forms with the word to
计算语言学 Computational Linguistics
教师:孙茂松 Tel:62781286 Email:sms@ TA:赵宇 Email:zhaoyu62188@
郑重声明
此课件仅供选修清华大学计算机系研究生课 《计算语言学》(70240052)的学生个人学习使用, 所以只允许学生将其下载、存贮在自己的电脑中。 未经孙茂松本人同意,任何人不得以任何方式扩 散之(包括不得放到任何服务器上)。否则,由 此可能引起的一切涉及知识产权的法律责任,概 由该人负责。 此课件仅限孙茂松本人讲课使用。除孙茂松本 人外,凡授课过程中,PTT文件显示此《郑重声 明》之情形,即为侵权使用。
8.2. Some Basic Feature Systems for English
SUBCAT
If the category is restricted by a feature value, then the feature value follows the constituent separated by a colon.
8.1. Feature Systems and Augmented Grammars
Feature structure - a mapping from features to values that defines the relevant properties of the constituent. ART1: (CAT ART ROOT a NUMBER s)
NP1:(NP NUMBER s 1 (ART ROOT a NUMBER s) 2 (N ROOT fish NUMBER s)) 1, 2, 3, and so on - will stand for the first subconstituent, second subconstituent, and so on, as needed.
8.1. Feature Systems and Augmented Grammars
Variables are allowed as feature values so that a rule can apply to a wide range of situations. For example, a rule for simple noun phrases would be as follows: (NP NUMBER ?n) -> (ART NUMBER ?n) (N NUMBER ?n) This says that an NP constituent can consist of two subconstituents, the first being an ART and the second being an N, in which the NUMBER feature in all three constituents is identical.
8.1. Feature Systems and Augmented Grammars
* (NP 1 (ART NUMBER s) 2 (N NUMBER s))
*(NP NUMBER s 1 (ART NUMBER s) 2 (N NUMBER p)) (N ROOT fish NUMBER ?n{s p})
8.2. Some Basic Feature Systems for English
Person and Number Features
First Person (1): The noun phrase refers to the speaker, or a group of people including the speaker (for example, I, we, you and I). Second Person (2): The noun phrase refers to the listener, or a group including the listener but not including the speaker (for example, you, all of you). Third Person (3): The noun phrase refers to one or more objects, not including the speaker or hearer.
8.2. Some Basic Feature Systems for English
The rule for verbs with a SUBCAT value of _np_vp:inf would be: (VP) -> (V SUBCAT _np_vp:inf) (NP) (VP VFORM inf)
Or, more simply as (N ROOT fish NUMBER {s p})
8.1. Feature Systems and Augmented Grammars
An interesting issue: whether an augmented context-free grammar can describe languages that cannot be described by a simple context-free grammar. The answer depends on the constraints on what can be a feature value: If the set of feature values is finite, then it would always be possible to create new constituent categories for every combination of features. Thus it is expressively equivalent to a context-free grammar. If the set of feature values is unconstrained, then such grammars have arbitrary computational power.