如何定位死循环高CPU使用率
CPU利用率高的定位思路和方法

CPU利用率高的定位思路和方法一、确定CPU利用率高的原因:1.1 监测CPU利用率:使用操作系统或第三方的监控工具来实时监控CPU利用率。
可以使用Windows操作系统的任务管理器、Linux操作系统的top命令、第三方工具如SolarWinds等。
1.2分析CPU利用率:根据监测结果,分析CPU利用率的波动趋势、峰值出现的时间、对应的进程或服务等,找到CPU利用率异常高的原因。
二、定位CPU利用率高的可能原因:2.1进程或服务过多:检查系统中运行的进程或服务数量是否过多,特别是一些占用较多CPU资源的进程或服务,如数据库服务、网络服务等。
2.2病毒或恶意软件:使用杀毒软件对系统进行全面扫描,查杀病毒或恶意软件。
2.3资源竞争:检查系统中的其他资源使用情况,如内存、硬盘、网络等,是否存在资源竞争现象,导致CPU利用率高。
2.4CPU风扇散热不良:检查CPU风扇是否正常运转,散热是否良好。
如果CPU温度过高,会导致CPU频繁降频,进而导致CPU利用率上升。
2.5软件升级或安装问题:检查是否有最近安装或升级的软件可能引起了CPU利用率高的问题。
如果有,可以尝试回滚或卸载该软件,观察是否有改善。
2.6执行任务过多或任务调度不当:检查系统中是否有大量线程或进程同时执行,如果任务调度策略不合理,可能导致CPU利用率高。
可以调整任务的调度策略或限制任务的并发数。
三、解决CPU利用率高的方法:3.1优化进程或服务:分析CPU利用率高的进程或服务,优化其代码或配置,减少对CPU资源的占用。
3.2执行资源清理工作:定期清理系统中不需要的临时文件、日志文件、缓存文件等,释放磁盘空间和内存资源。
3.3增加硬件资源:如果CPU利用率高的原因是因为系统资源不足,可以考虑增加硬件资源,如增加CPU核心数、内存容量等。
3.4优化任务调度:根据实际需求和系统性能,调整任务的优先级和调度策略,合理分配CPU资源。
3.5部署负载均衡:如果是因为并发请求过多导致CPU利用率高,可以考虑使用负载均衡的方式将请求分散到多台服务器上,减轻单台服务器的负载压力。
对死循环的认识

2008-03-14 17:26今天队友在系统测试的时候,不小心发现了一个问题:我的Mail进程CPU占有率高达90%。
问题十分严重,肯定是程序出了问题,不用多想,马上定位。
仔细分析了一下:首先我的程序并不复杂,系统开销不会太大,至少不会达到占用90%的地步,那什么情况下CPU占用会到这种境界呢?经过一段时间的分析和定位,问题得到了解决,于是抽出时间,写下这篇文章。
首先说一下什么叫做空死循环,因为这是我自己取的名字,所以我想有必要先解释一下。
空死循环即"在循环体内部什么都不做的死循环"。
死循环并不可怕,可怕的就是在死循环里面什么都不干!对于头脑还正常的程序员来说,我想不会有人故意写个程序,在自己的程序里面加个死循环,循环里面什么都不干吧。
这种"站着茅坑不拉屎",一点都不含蓄的做法,咱就不说了。
我们来点含蓄的,不过结果都一样,就是产生了空死循环。
通常,在程序的入口处(如进程或线程的第一层函数),经常会出现这样一段代码。
while (1){if (/* 条件1 */){/* 处理函数1 */}if (/* 条件2 */){/* 处理函数2 */}/* ...... */}在while循环内,我们不断的扫描,当满足某个入口条件时执行相应的处理函数。
如果while循环里面全是这种if代码,而没有其他必定执行的代码,那可能出现的一种情况就是程序运行期间,长期不满足所有if条件,从而产生空死循环。
那么,空死循环会对系统产生什么影响呢?我在linux环境下做了几个实验,下面我们就随着实验过程来解答这个问题。
一、实验内容:程序1:内存占用1%,正常#include <stdio.h>void main (){while (1){/* do something */}}程序2:内存占用90%,且不断增加,异常void main (){while (1){;}}程序3:内存占用90%,且不断增加,异常#include <stdio.h>void main (){while (1){if (0){/* do something */}if (0){/* do something */}}}程序4:内存占用1%,正常#include <stdio.h>void main (){while (1){if (0){/* do something */}if (0){/* do something */}sleep (1);}}二、实验结论:程序1和程序4运行正常,程序2和程序3运行的时候CPU占有率出现异常,原因是出现了空死循环。
postgresql定位分析消耗CPU高的SQL语句

postgresql定位分析消耗CPU⾼的SQL语句第⼀步:使⽤TOP命令查看占⽤CPU⾼的postgresql进程,并获取该进程的ID号,如图该id号为3640第⼆步:切换到postgres⽤户,并且psql连接到数据库,执⾏如下查询语句SELECT procpid, START, now() - START AS lap, current_query FROM ( SELECT backendid, pg_stat_get_backend_pid (S.backendid) AS procpid,pg_stat_get_backend_activity_start (S.backendid) AS START,pg_stat_get_backend_activity (S.backendid) AS current_query FROM (SELECTpg_stat_get_backend_idset () AS backendid) AS S) AS S WHERE current_query <> '<IDLE>' and procpid=25400 ORDER BY lap DESC; procpid:进程id 如果不确认进程ID,将上⾯的条件去掉,可以逐条分析start:进程开始时间lap:经过时间current_query:执⾏中的sql怎样停⽌正在执⾏的sql :SELECT pg_cancel_backend(进程id);或者⽤系统函数kill -9 进程id;第三步:查看该sql的执⾏计划(使⽤explain analyze + sql语句的格式)第四步:分析执⾏计划,本项⽬是由于该语句没有⾛索引,导致查询时间过长,具体原因可以查看执⾏计划来处理。
如:。
数据库cpu过高 排查方法

数据库cpu过高排查方法
随着现代社会发展,信息化发展迅速,数据库也变得越来越重要,尤其是数据库CPU。
但是,由于应用的复杂性,数据库CPU的运行效率不高也是很常见的情况。
如果不及时发现和解决方案,将会影响数据库的正常运行,甚至出现系统故障。
那么,数据库CPU过高排查方法有哪些呢?
首先,需要理解数据库CPU过高的原因。
一般来说,数据库CPU 过高的原因有很多。
可能是内存不足,可能是缓存不足,也可能是磁盘读写性能较差等原因。
系统设计的问题也会导致CPU过高,例如SQL语句语法错误或者优化不当等行为。
其次,要查看系统的负载情况。
可以使用top、iostat和vmstat 命令来查看系统的负载情况,用来判断系统负载是否真的过高,以及系统的负载是由哪些进程产生的。
此外,还可以使用sar监控系统负载,使用sar可以查看系统CPU、内存、硬盘等负载情况,如果发现负载不正常,可以更准确的定位问题,找出问题的根源。
最后,如果数据库的CPU负载过高,可以考虑进行性能优化。
可以使用SQL语句优化工具检查SQL语句,以及优化缓存策略,分配更多CPU和内存等。
另外,还可以将数据库分库分表,采用分布式集群来提高数据库的性能,这样也可以有效减少CPU负载。
总之,数据库CPU过高是一个很常见的问题,如果不及时发现和解决方案,将会影响数据库的正常运行,甚至出现系统故障,因此,
需要及时找出原因,以及采取有效的排查方法分析并解决问题,才能提高数据库的性能。
linux cpu使用率高排查思路

linux cpu使用率高排查思路
1. 检查系统中运行的进程和服务:使用top或htop命令查看当前系统中运行的进程,按照CPU使用率排序,找出占用CPU
资源较高的进程或服务。
2. 检查定时任务:使用crontab -l命令查看系统中的定时任务,检查是否有定时任务频繁运行,占用了大量的CPU资源。
3. 检查系统负载:使用uptime命令查看系统负载情况,如果
系统负载过高,可能是因为CPU资源不足导致的。
4. 检查系统日志:使用/var/log目录下的日志文件,查找是否
有异常日志或报错信息,可能是某个进程或服务出现了问题导致的CPU使用率高。
5. 检查应用程序:如果是某个特定的应用程序导致CPU使用
率高,可以查看应用程序的日志文件,查找错误信息或异常情况。
6. 检查系统性能:使用工具如sar、vmstat、iostat等监控系统
各项指标,查看是否有其他系统资源(如内存、磁盘)出现问题,间接导致CPU使用率高。
7. 检查CPU亲和性:某些程序可能只使用特定的CPU核心,
导致其他核心空闲而某个核心使用率高。
使用taskset命令查
看进程是否有CPU亲和性设置。
8. 检查硬件问题:可能是CPU散热不良导致的高CPU使用率。
检查CPU温度、风扇运转情况,确保硬件正常工作。
9. 检查恶意软件:运行恶意软件可能会导致CPU使用率异常高,使用杀毒软件对系统进行全面扫描。
10. 系统优化:对系统进行优化,如调整内核参数、升级软件
版本、合理配置服务等,以提高系统的整体性能。
java 消耗cpu的算法

java 消耗cpu的算法Java是一种高级编程语言,支持多线程并发编程。
在Java中,我们可以利用多线程技术来实现CPU的高效利用。
本文将介绍几种Java消耗CPU的算法,以及如何使用它们来提高CPU的利用率。
1.死循环死循环是一种简单但非常有效的算法,可以将CPU的利用率提高到100%。
在Java中,死循环可以通过while循环或for循环来实现。
例如:```while (true) {// do nothing}for (;;) {// do nothing}```在这两种情况下,循环条件永远为真,程序将一直执行循环体中的代码,从而使CPU保持繁忙状态。
这种算法非常适合用于测试系统的稳定性和性能。
2.计算密集型任务计算密集型任务是指那些需要大量计算的任务,例如矩阵乘法、排序算法等。
在Java中,我们可以使用多线程技术来并行执行这些任务,从而提高CPU的利用率。
例如:```public class MatrixMultiplication implements Runnable {private final int[][] m1;private final int[][] m2;private final int[][] result;private final int row;private final int column;public MatrixMultiplication(int[][] m1, int[][] m2, int[][] result, int row, int column) {this.m1 = m1;this.m2 = m2;this.result = result;this.row = row;this.column = column;}@Overridepublic void run() {for (int i = 0; i < m2.length; i++) {result[row][column] += m1[row][i] * m2[i][column]; }}}public class Main {public static void main(String[] args) {int[][] m1 = { { 1, 2 }, { 3, 4 } };int[][] m2 = { { 5, 6 }, { 7, 8 } };int[][] result = new int[2][2];Thread[] threads = new Thread[4];int threadCount = 0;for (int i = 0; i < m1.length; i++) {for (int j = 0; j < m2[0].length; j++) {threads[threadCount] = new Thread(new MatrixMultiplication(m1, m2, result, i, j));threads[threadCount].start();threadCount++;}}for (int i = 0; i < threads.length; i++) {try {threads[i].join();} catch (InterruptedException e) {e.printStackTrace();}}for (int i = 0; i < result.length; i++) {for (int j = 0; j < result[0].length; j++) {System.out.print(result[i][j] + " ");}System.out.println();}}}```这段代码实现了矩阵乘法的并行计算。
服务器CPU负载过高,如何定位问题

服务器CPU负载过⾼,如何定位问题⼀、排查 CPU 故障的常⽤命令1. top:。
可以实时查看各个进程的 CPU 使⽤情况。
也可以查看最近⼀段时间的 CPU 使⽤情况。
默认按 CPU 使⽤率排序。
2. ps:Linux 命令。
强⼤的进程状态监控命令。
可以查看进程以及进程中线程的当前 CPU 使⽤情况。
属于当前状态的采样数据。
3. jstack:Java 提供的命令。
可以查看某个进程的当前线程栈运⾏情况。
根据这个命令的输出可以定位某个进程的所有线程的当前运⾏状态、运⾏代码,以及是否死锁等等。
4. pstack:Linux 命令。
可以查看某个进程的当前线程栈运⾏情况。
⼆、应⽤负载⾼的时候怎么办?⼀个应⽤占⽤ CPU 很⾼,除了确实是计算密集型应⽤之外,通常原因都是出现了死循环。
CPU 负载过⾼解决问题过程:1. 使⽤【top】命令定位异常进程,可发现 PID 为 12836 的 CPU 和内存占⽤率都⾮常⾼:备注: top 命令默认每 3 秒刷新⼀次。
可以通过top -d <刷新时间间隔>来指定刷新频率,如top -d 0.1或top -d 0.01等。
top 执⾏时,也可以按“s”键,修改时间间隔。
2. 使⽤top -Hp PID查看该 PID 对应进程下各个线程的 CPU 使⽤情况:PID(Process Identification)操作系统⾥指进程识别号,也就是进程标识符。
操作系统⾥每打开⼀个程序都会创建⼀个进程 ID,即 PID。
PID 是各进程的代号,每个进程有唯⼀的 PID 编号。
它是进程运⾏时系统分配的,并不代表专门的进程。
在运⾏时 PID 是不会改变标识符的,但是进程终⽌后 PID 标识符就会被系统回收,就可能会被继续分配给新运⾏的程序。
3. 使⽤【printf "%x\n" 线程号】将异常线程号转化为 16 进制4. 使⽤【jstack 进程号|grep 16进制异常线程号 -A90】来定位异常代码的位置(最后的-A90是⽇志⾏数,也可以输出为⽂本⽂件或使⽤其他数字)。
服务器监控指标解读CPU利用率、内存使用率等详解

服务器监控指标解读CPU利用率、内存使用率等详解在服务器运行过程中,监控服务器的性能指标是非常重要的,其中CPU利用率和内存使用率是两个最为关键的指标。
通过监控这些指标,管理员可以及时了解服务器的运行状态,发现问题并进行相应的优化和调整,以确保服务器的稳定性和性能。
本文将详细解读CPU利用率、内存使用率等监控指标,帮助管理员更好地理解和应用这些指标。
一、CPU利用率CPU利用率是指CPU在单位时间内被使用的比例,通常以百分比表示。
在服务器监控中,CPU利用率是一个非常重要的性能指标,它反映了服务器CPU的负载情况。
当CPU利用率过高时,表示CPU正在承担较大的工作负荷,可能会导致服务器性能下降甚至系统崩溃。
因此,管理员需要密切关注CPU利用率,及时发现并解决CPU负载过高的问题。
1.1 CPU利用率的计算方法CPU利用率的计算方法通常是通过监控工具实时采集CPU的运行状态数据,并根据这些数据计算得出。
一般来说,CPU利用率的计算公式如下:CPU利用率 = (CPU总时间 - CPU空闲时间) / CPU总时间 * 100%其中,CPU总时间表示CPU运行的总时间,CPU空闲时间表示CPU处于空闲状态的时间。
通过这个公式,可以得出CPU的利用率。
1.2 CPU利用率的监控工具在实际监控中,管理员可以使用各种监控工具来监控服务器的CPU 利用率,常用的监控工具包括Zabbix、Nagios、Cacti等。
这些监控工具可以实时采集服务器的性能数据,并以图表的形式展示出来,帮助管理员直观地了解服务器的运行状态。
1.3 CPU利用率的优化方法为了降低CPU利用率,提升服务器性能,管理员可以采取一些优化方法,例如:- 优化代码:对服务器上运行的程序进行优化,减少不必要的计算和资源消耗,降低CPU的负载。
- 增加CPU核心数:如果服务器的CPU核心数较少,可以考虑升级CPU 或增加CPU核心数,以提升服务器的计算能力。
cpu过高的排查经历

在排查CPU过高的问题时,可以按照以下步骤进行:1. 查看物理机进程id:首先,通过使用top指令,可以查看物理机的进程ID。
在获得堡垒机权限后,登上机器运行top指令,可以发现CPU占用率高的进程。
例如,如果进程为623的机器CPU一直在高位,但内存不是很高,那么需要进一步查看该进程的相关信息。
2. 查看进程下各线程情况:通过使用top-H -p 623命令,可以查看该进程下所有线程的具体执行情况。
如果并没有非常突出的占用CPU高的线程存在,但CPU使用率仍然很高,那么需要继续查看具体执行情况。
3. 指定其中一个线程查看具体的执行情况:将指定的线程转换为16进制后,可以使用jstack命令查看具体的线程执行情况。
例如,可以通过这些信息来查看线程在执行什么任务,以及任务执行的具体情况。
如果排查后问题仍然存在,建议采取以下措施:1. 重启机器:在非线上环境出现CPU超过90%的告警时,首先尝试重启机器。
在重启后,如果CPU如期的下降了下来,那么可以暂时高枕无忧。
但需要注意的是,如果重启后问题仍然存在,那么需要继续进行排查。
2. 检查系统环境:在排查过程中,需要注意检查系统的环境变量设置是否正确。
同时,也需要确保系统中的其他软件或应用没有占用大量的CPU资源。
3. 检查应用程序:如果系统中没有其他软件或应用占用大量的CPU资源,那么需要进一步检查应用程序是否存在问题。
例如,可以尝试更新应用程序或重新安装应用程序,以解决可能存在的bug或问题。
4. 检查硬件设备:如果以上措施都无法解决问题,那么需要检查硬件设备是否存在问题。
例如,可以检查CPU的温度是否过高、风扇是否正常运转等。
如果硬件设备存在问题,那么需要采取相应的措施进行维修或更换。
总之,在排查CPU过高的问题时,需要一步步地进行排查,并采取相应的措施进行解决。
同时,也需要注意系统的环境变量设置是否正确、系统中是否存在其他软件或应用占用大量的CPU资源等问题。
shell的while死循环写法 -回复

shell的while死循环写法-回复Shell编程是一种非常强大的脚本语言,其中的循环结构在程序开发中起到了至关重要的作用。
本文将详细介绍如何使用Shell语言中的while循环来创建一个死循环,并讲解每个步骤的具体实现方法。
一、Shell编程简介Shell编程是一种运行在Unix和类Unix系统上的脚本语言,它提供了命令行界面与底层操作系统进行交互。
Shell脚本可以通过一个或多个命令组成,用于处理文本和执行系统操作等任务。
二、Shell中的while循环while循环是Shell编程中最常用的循环结构之一。
它的作用是根据给定条件循环执行一段代码块,直到条件不再满足为止。
在这里,我们将使用while循环来创建一个死循环。
三、创建一个死循环要创建一个死循环,我们需要定义一个永远为真的条件。
在Shell编程中,通常可以使用true命令作为条件来实现这一点。
下面是一个简单的死循环示例:shellwhile truedoecho "This is an infinite loop"done在上面的示例中,`while true`定义了一个永远为真的条件。
而`do`和`done`之间的代码块将会被无限循环执行。
每次循环执行时,会打印一行文本:"This is an infinite loop"。
四、让死循环可退出如果我们希望能够通过某种方式退出死循环,可以在循环体内加入一个退出条件。
下面是一个示例,展示如何使用`break`关键字来退出循环:shellwhile truedoecho "This is an infinite loop"read -p "Do you want to exit? (y/n)" choiceif [ "choice" = "y" ]; thenbreakfidone在上面的示例中,我们在循环体内添加了一行代码`read -p "Do you want to exit? (y/n)" choice`,它会提示用户输入一个选择("y"或"n")。
Java进程CPU占用率高的排查和常见解决方案

Java进程CPU占⽤率⾼的排查和常见解决⽅案以下验证当系统出现卡顿或者应⽤程序的响应速度⾮常慢,就可能要考虑到服务器上排查⼀番,以下是我常⽤的排查流程:1、top:观察占⽤CPU或者MEN(内存)使⽤情况最⾼的进程,记录PID;TIP:(1)、“1” 显⽰出多个逻辑CPU使⽤情况;(2)、“X” ⾼亮显⽰CPU列,并排序,"Z"红⾊展⽰;(3)、“shift + <” 或者 “shift + >” 变更⾼亮的列;(4)、“F”配合 “空格”指定需要展⽰的列;(5)、“S”设置刷新的间隔时间;2、top -Hp PID:观察该PID对应进程的占⽤情况。
“shift + h” 开启线程显⽰,观察CPU占⽤较⾼的线程有哪些,记录对应TID;3、printf "%x\n" TID :将线程对应PID转为 16进制数(TID16);4、jstack -F PID | grep -A 30 "nid=0x + TID16" > /java/PID.txt:查看该线程的堆栈信息;jstack -F PID > /java/PID.txt:查看该线程的堆栈信息;5、通过线程的堆栈信息,定位到CPU占⽤过⾼的代码,分析其原因。
TIP:(1)、通常可以结合jstat来分析JVM中的内存信息;(如jstat -gcutil PID 1000 10 、jstat -gc PID 1000 10、jstat -gccause PID 1000 10)(2)、jmap -heap PID来查看整个JVM内存状态;(要注意的是在使⽤CMS GC情况下,jmap -heap的执⾏有可能会导致JAVA进程挂起)(3)、jmap -histo PID 查看JVM堆中对象详细占⽤情况;(4)、jmap -dump:format=b,file=⽂件名 [pid]导出整个JVM中内存信息。
Python技术的CPU利用率优化技巧

Python技术的CPU利用率优化技巧在现代计算机应用中,CPU 是计算资源的核心。
对于使用 Python 进行编程的开发者来说,能够优化 CPU 的利用率是提高程序性能的关键。
CPU 利用率指的是CPU 在执行特定任务时的使用率,即CPU 被程序使用的时间与总执行时间的比例。
高效利用 CPU 资源可以提高程序的运行速度、响应能力和效率。
下面将介绍一些优化 Python 技术的 CPU 利用率的技巧。
1. 使用适当的数据结构选择适当的数据结构对于优化CPU 利用率至关重要。
对于大规模的数据操作,如列表、字典和集合等,选择正确的数据结构可以大大提高程序的执行效率。
例如,使用字典代替列表可以显著提高查找元素的速度。
2. 合并重复的计算在编写代码时,应该尽量避免重复计算相同的数据。
如果发现多次运算相同的表达式,可以将其计算结果存储在一个变量中,从而避免重复计算,提高 CPU 利用率。
3. 使用生成器和迭代器生成器和迭代器是 Python 中非常强大的工具,它们可以帮助减少内存使用和提高 CPU 利用率。
通过使用生成器和迭代器,可以逐个地生成数据,而不是一次性地生成所有数据并存储在内存中。
这样可以减少内存消耗,提高程序执行效率。
4. 并发和并行编程利用并发和并行编程技术可以更好地利用多核 CPU。
Python 提供了一些库和模块,如 Multiprocessing、Threading 和 Asyncio,可以帮助实现并发和并行操作。
通过将任务分解为多个子任务,然后并行或并发地执行这些子任务,可以提高CPU 利用率和程序的整体性能。
5. 利用缓存在编写程序时,可以使用缓存技术来存储中间结果。
如果某个函数的计算结果是可以预测的或不变的,可以将该结果缓存起来,下次需要时可以直接使用缓存的结果,而不需要重新计算。
这样可以减少CPU 的计算负担,提高程序的执行效率。
6. 优化算法和循环优化算法和循环也是提高 CPU 利用率的关键。
Docker容器的CPU和内存使用情况如何监控?

Docker容器的CPU和内存使用情况如何监控?在当今的云计算和容器化技术盛行的时代,Docker 容器已经成为了部署应用程序的重要方式之一。
然而,为了确保容器化应用的高效运行和资源的合理利用,对 Docker 容器的 CPU 和内存使用情况进行监控就显得至关重要。
首先,我们需要明白为什么要监控 Docker 容器的 CPU 和内存使用情况。
简单来说,这是为了确保系统的稳定性和性能优化。
如果一个容器过度占用 CPU 或内存资源,可能会导致整个系统的性能下降,影响其他容器或服务的正常运行。
此外,通过监控,我们可以及时发现资源瓶颈,进行调整和优化,提高资源利用率,降低成本。
那么,有哪些常见的方法可以用来监控 Docker 容器的 CPU 和内存使用情况呢?一种常用的方法是使用 Docker 自带的命令行工具。
通过`docker stats` 命令,我们可以实时获取正在运行的容器的 CPU、内存、网络I/O 和块 I/O 等关键资源的使用情况。
执行该命令后,会返回一个包含容器ID、CPU 使用率、内存使用量等信息的列表。
这个方法简单直接,但可能不够直观和详细。
另一种方式是利用 Docker 的 API。
通过编程访问 Docker 的 API,我们可以获取更丰富和定制化的资源使用数据,并将其集成到自己的监控系统中。
不过,这需要一定的开发工作和对 Docker API 的熟悉程度。
除了 Docker 自身提供的工具和 API,还有一些第三方监控工具可以选择。
例如,Prometheus 结合 Grafana 就是一个非常强大的组合。
Prometheus 可以从 Docker 中抓取资源使用数据,并将其存储起来。
而Grafana 则可以用于创建美观直观的监控仪表盘,将数据以图表的形式展示出来,方便我们直观地了解容器的资源使用趋势。
在使用这些监控方法时,还需要注意一些要点。
对于 CPU 使用率的监控,我们不仅要关注瞬时的使用率,还要关注一段时间内的平均使用率,以更准确地评估容器对CPU 资源的需求。
在windows下揪出java程序占用cpu很高的线程并完美解决
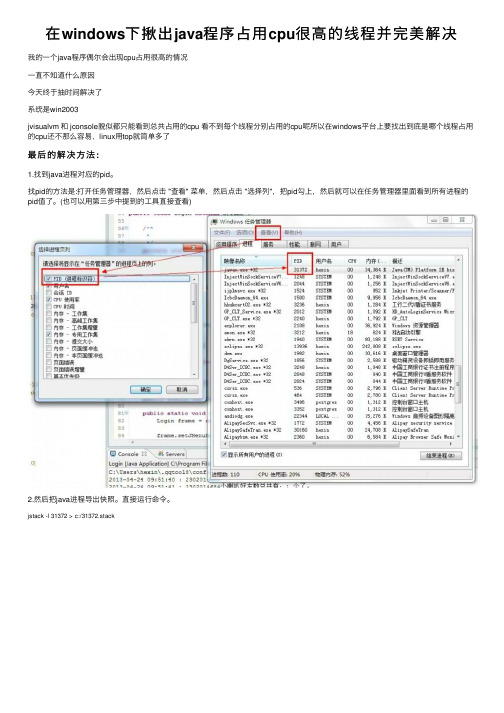
在windows下揪出java程序占⽤cpu很⾼的线程并完美解决我的⼀个java程序偶尔会出现cpu占⽤很⾼的情况⼀直不知道什么原因今天终于抽时间解决了系统是win2003jvisualvm 和 jconsole貌似都只能看到总共占⽤的cpu 看不到每个线程分别占⽤的cpu呢所以在windows平台上要找出到底是哪个线程占⽤的cpu还不那么容易,linux⽤top就简单多了最后的解决⽅法:1.找到java进程对应的pid。
找pid的⽅法是:打开任务管理器,然后点击 "查看" 菜单,然后点击 "选择列",把pid勾上,然后就可以在任务管理器⾥⾯看到所有进程的pid值了。
(也可以⽤第三步中提到的⼯具直接查看)2.然后把java进程导出快照。
直接运⾏命令。
jstack -l 31372 > c:/31372.stack我这⾥是指定把java所有的信息导出到c盘的31372.stack的⽂件⾥。
3.在windows下只能查看进程的cpu占⽤率,要查看线程的cpu占⽤率要借助其他的⼯具,我这⾥⽤的是微软提供的 Process Explorer v15.3下载完后解压运⾏右键点击需要查看的进程---properties4.然后选择 Threads 选项卡,找到占⽤cpu的线程的tid,⽐如我这⾥是 31876 的线程5.把pid转换成16进制,我这⾥直接⽤系统⾃带的计算器转换,置于为什么要转换,是因为先前⽤jstack导出的信息⾥⾯线程对应的tid是16进制的。
最后得到的线程pid的16进制的值为 7C846.在 c盘的31372.stack⽂件中查找 7C84由于是我的程序已经该过了,这⾥没有异常的东西,所以这⾥没有什么异常内容。
我的问题没解决之前,找到到这⾥的内容为:"Thread-23" prio=6 tid=0x03072400 nid=0x1b68 runnable [0x0372f000]ng.Thread.State: RUNNABLEat com.horn.util.MyEncrypt.encode(MyEncrypt.java:17)at mon.OrderUtil.hisExp(OrderUtil.java:228)at com.horn.util.MsgManage.receiveMsg(MsgManage.java:961)at com.horn.util.PollMessageThread.run(PollMessageThread.java:74)Locked ownable synchronizers:- None于是打开 t com.horn.util.MyEncrypt.encode(MyEncrypt.java:17)分析了下代码,问题找到了。
触发cup过高的方法

触发cup过高的方法一、检查系统配置是否偏高1.检查CPU使用率是否过高,使用任务管理器检查CPU使用率,重要系统服务,如IIS,MySQL,运行的软件等,是否有异常情况。
2.检查操作系统内存使用情况,以及虚拟内存使用情况,是否有过多的内存泄漏存在。
3.检查硬件配置,比如机器的总性能,CPU配置是否太低,内存配置是否太低等,是否有必要提升总体配置。
4.查看CRT文件(如果有使用),查看它们是否有过多的调用,有没有被误用或者太多的空调用。
二、检查是否有软件问题1.检查是否有死循环程序存在,系统中是否有运行的系统服务或者定时任务被死循环,而不断消耗CPU时间。
2.查看系统中是否有运行的非法软件,木马病毒等,如果有,就会占用较多CPU时间。
3.查看应用程序是否运行正常,是否出现了内存泄漏或者死循环,从而耗费大量的CPU时间。
4.查看数据库是否存在性能问题,如运行的SQL语句太多,或者SQL语句运行太慢导致的问题。
三、检查系统服务是否异常1.检查系统日志,查看是否有系统服务出错导致异常,如重启服务、增加内存分配等导致的问题。
2.检查系统服务状态,查看是否有服务不正常,而该服务正在耗费CPU时间,如把关联应用程序删除,但是服务却没有正常关闭。
3.检查系统是否更新,系统是否安装了最新的系统补丁,是否有Windows安全中心组件被禁用,是否存在系统漏洞等。
四、检查网络流量是否异常1.检查网络连接,查看是否有大量的网络流量被浪费(如不必要的UDP流量)。
2.检查系统是否被暴力破解,可能存在的DoS攻击,是否被向系统发出大量的请求,消耗大量的CPU时间。
3.检查是否有大量的垃圾邮件,spam病毒导致的问题,导致服务器和网络流量过大,影响系统性能。
五、检查硬件是否有问题1.检查系统机箱是否散热不足,是否发生了硬件过热,引起CPU 过高。
2.检查硬件设备是否存在故障,如硬件设备故障,在系统正常工作期间可能会造成CPU过高。
排查Java高CPU占用原因

排查Java⾼CPU占⽤原因近期java应⽤,CPU使⽤率⼀直很⾼,经常达到100%,通过以下步骤完美解决,分享⼀下。
⽅法⼀:1.jps 获取Java进程的PID。
2.jstack pid >> java.txt 导出CPU占⽤⾼进程的线程栈。
3.top -H -p PID 查看对应进程的哪个线程占⽤CPU过⾼。
4.echo “obase=16; PID” | bc 将线程的PID转换为16进制,⼤写转换为⼩写。
5.在第⼆步导出的Java.txt中查找转换成为16进制的线程PID。
找到对应的线程栈。
6.分析负载⾼的线程栈都是什么业务操作。
优化程序并处理问题。
⽅法⼆:1.使⽤top 定位到占⽤CPU⾼的进程PIDtop通过ps aux | grep PID命令2.获取线程信息,并找到占⽤CPU⾼的线程ps -mp pid -o THREAD,tid,time | sort -rn3.将需要的线程ID转换为16进制格式printf "%x\n" tid4.打印线程的堆栈信息jstack pid |grep tid -A 30⼀个应⽤占⽤CPU很⾼,除了确实是计算密集型应⽤之外,通常原因都是出现了死循环。
以我们最近出现的⼀个实际故障为例,介绍怎么定位和解决这类问题。
根据top命令,发现PID为28555的进程占⽤CPU⾼达200%,出现故障。
通过ps aux | grep PID命令,可以进⼀步确定是tomcat进程出现了问题。
但是,怎么定位到具体线程或者代码呢?⾸先显⽰线程列表:ps -mp pid -o THREAD,tid,time找到了耗时最⾼的线程28802,占⽤CPU时间快两个⼩时了!其次将需要的线程ID转换为16进制格式:printf "%x\n" tid最后打印线程的堆栈信息:jstack pid |grep tid -A 30找到出现问题的代码了!现在来分析下具体的代码:ShortSocketIO.readBytes(ShortSocketIO.java:106)ShortSocketIO是应⽤封装的⼀个⽤短连接Socket通信的⼯具类。
CPU占用率高的定位思路

CPU 占用率高的定位思路常见原因CPU 占用率,就是一个时间段内,CPU 执行代码的时间与时间段总长度的比率。
CPU占用率常常是衡量设备性能的重要指标之一。
CPU 占用率高,是设备本身的一种现象,直观表现为display cpu-usage 命令查询结果中整机CPU 占用率“CPU usage”偏高,如超过70%。
或者产生告警basetrap_1.3.6.1.4.1.2011.5.25.129.2.4.1 hwCPUUtilizationRisingAlarm,默认超过90% 会产生此告警。
但是在网络运行中CPU 高常常会导致其他业务异常,如BGP震荡、VRRP频繁切换、单板复位、甚至设备无法登录。
业务异常的故障,请根据具体表现查看相应的故障处理章节。
以下讨论的原因及步骤基于CPU 占用率高这个现象。
通常,整机CPU 占用率过高,是由于某些任务的CPU 占用率居高不下导致的。
具体导致某任务CPU 占用率高的可能原因:l 上送CPU 报文过多,如环路或DoS 报文攻击l STP网络频繁震荡,收到大量TC 报文,造成设备频繁删除MAC表和ARP 表项l 设备产生海量日志,占用大量CPU 资源故障诊断流程详细处理流程如图3-1 所示。
图3-1 CPU 占用率高故障诊断流程图故障处理步骤说明请保存以下步骤的执行结果,以便在故障无法解决时快速收集和反馈信息。
以下的步骤之间并没有严格的顺序关系,实际操作中并不一定要遵守文中所给的顺序。
设备型号不同,以下步骤中命令的显示信息也会有差异,请以设备实际显示信息为准。
文中示例旨在告诉读者如何查看相关信息。
操作步骤步骤1 检查占用CPU 高的任务名称执行命令display cpu-usage,查看主用主控板各任务的CPU 占用率。
执行命令display cpu-usage slot slot-id 查看接口板各任务的CPU 占用率。
记录CPU 占用率超过70%的任务名称。
cpu使用率预测方法

cpu使用率预测方法
CPU使用率预测属于监督式机器学习领域,常用的预测方法主要包括时间序列预测和回归模型。
时间序列预测是一种常用的预测方法,它主要考虑时间序列中的趋势、季节性和周期性等因素。
其中,ARIMA是一种强大的时间序列预测模型,它可以利用历史数据建立模型,对未来的CPU使用率进行预测。
LSTM是一种递归神经网络的变体,特别适合处理具有时间序列特性的数据,也可以用于CPU使用率的预测。
另外,回归模型也是预测CPU使用率的一种方法。
在回归模型中,我们需要确定输入变量和输出变量,例如,可以选择系统负载、历史CPU使用率等作为输入变量,将未来的CPU使用率作为输出变量。
然后,通过训练数据集建立回归模型,并对测试数据集进行预测,以评估模型的准确性。
在实际应用中,可以根据具体的情况选择适合的预测方法。
如果数据具有明显的时间序列特征,可以选择时间序列预测方法;如果数据具有可观察的趋势或模式,可以选择回归模型。
同时,也可以结合多种方法进行预测,以提高预测的准确性和稳定性。
电脑cpu占用内存怎么查看

电脑cpu占用内存怎么查看
由于电脑配置不高或工作需要较高的cpu等原因,cpu经常占用很高,很多人都不知道如何解决cpu使用率占用高的问题,为此店铺为大家整理推荐了相关的知识,希望大家喜欢。
电脑cpu占用内存的查看方法
1电脑过慢,有时候是打开的文件进入死循环,造成电脑CPU占用率过高。
2在电脑桌面下方点击右键。
在弹出的对话框点击启动任务管理器。
3打开任务管理器后,在进程面板中,将CPU占用率过高的程序结束。
电脑启动程序
1第二种原因是电脑启动时启动的程序过多,造成电脑过慢。
2在电脑桌面右下角选择不需要的程序。
3结束不需要启动的程序。
利用第三方软件
有时候一些隐性程序的运行或隐性文件的存在造成电脑过慢,此时我们可以借用第三方软件优化电脑。
这里介绍一下一款大家经常用到的电脑管理软件,大家看界面应该能猜到是哪款软件。
O(∩_∩)O~
点击软件优化加速按钮。
选择需要优化的选项,点击开始扫描按钮。
性能测试--压测中问题定位思路

性能测试--压测中问题定位思路1、刚开始压测报错,停了之后重新压测不报错这种情况经常遇到,特别是重启服务之后,因为系统刚重启,需要做⼀些初始化的动作,如果⼀下上很多并发⽤户数难免会报错,只要压测⼏次之后不再报错,就是正常的,服务器也需要“预热”⼀段时间。
2、少⽤户并发不报错,⼤⽤户并发报错可能有两种情况引起这种问题,⼀是脚本的问题:参数设置不够或者错误;⼆是连接池设置的不合理。
⼀定要先排除脚本的问题之后,再去查找其他问题,不要给开发⼈员带来不必要的⿇烦。
3、服务器资源利⽤率⾼服务器资源利⽤最常见的是CPU利⽤率⾼,内存利⽤率⾼常见于数据库服务器,应⽤服务器的内存⼀般会在长时间压测时出现问题。
I/O⼀般常见磁盘被⽤完的情况,对于应⽤服务器可能是有⼤量的⽇志读写,对于数据库服务器可能是表空间增长过⼤,磁盘空间不⾜。
这⾥主要是分析CPU利⽤率⾼的问题,分别对数据库CPU利⽤率⾼和应⽤服务器利⽤率⾼的情况进⾏说明。
4、数据库服务器CPU利⽤率⾼数据库CPU利⽤率⾼⼀般是⼤量的逻辑读或者物理读引起的,也有可能是解析⽐较复杂的SQL,如果是Oracle 数据库,可以通过抓取AWR 报告进⾏,重点看下⾯两项:SQL ordered by GetsSQL ordered by Physical Reads (UnOptimized)这⼀部分,通过Buffer Gets对SQL语句进⾏排序,即通过它执⾏了多少个逻辑I/O来排序。
顶端的注释表明⼀个PL/SQL单元的缓存获得(Buffer Gets)包括被这个代码块执⾏的所有SQL语句的Buffer Gets。
⼤量的逻辑读往往伴随着较⾼的CPU消耗,在这⾥的Buffer Gets是⼀个累积值,所以这个值⼤并不⼀定意味着这条语句的性能存在问题。
通常我们可以通过对⽐该条语句的Buffer Gets和physical reads值,如果这两个⽐较接近,肯定这条语句是存在问题的,如果对⽐差别不⼤,可以关注 **gets per exec的值,这个值如果太⼤,表明这条语句可能使⽤了⼀个⽐较差的索引或者使⽤了不当的表连接。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
确定是CPU过高
使用top观察是否存在CPU使用率过高现象
找出线程
对CPU使用率过高的进程的所有线程进行排序
ps H -e -o pid,tid,pcpu,cmd --sort=pcpu |grep xxx得到如下结果,其中线程2909使用了7.8%的CPU. 2907 2913 0.0 ./xxx 2907 2909 7.8 ./xxx也可以通过查看/proc中的信息来确定高CPU线程. 打印了4列,线程ID,线程名,用户时间和内核时间(排名未分先后) awk '{print
$1,$2,$14,$15}' /proc/2907/task/*/stat
找出调用栈
使用gdb attach nmsagent所在的进程,在gdb中使用 info threads显示所有线程
gdb
gdb>attach 2907
gdb>info threads
得到如下结果,可以发现2909线程的编号是12
13 Thread 0xad5f2b70 (LWP 2908) 0x004ef0d7 in mq_timedreceive () from
/lib/tls/i686/cmov/librt.so.1
12 Thread 0xad58eb70 (LWP 2909) 0x006e0422 in __kernel_vsyscall ()
11 Thread 0xad52ab70 (LWP 2910) 0x006e0422 in __kernel_vsyscall ()
10 Thread 0xad4f8b70 (LWP 2911) 0x006e0422 in __kernel_vsyscall ()
9 Thread 0xad4c6b70 (LWP 2912) 0x006e0422 in __kernel_vsyscall ()
8 Thread 0xad3feb70 (LWP 2913) 0x004ef0d7 in mq_timedreceive () from
/lib/tls/i686/cmov/librt.so.1
7 Thread 0xace08b70 (LWP 2914) 0x004ef0d7 in mq_timedreceive () from
/lib/tls/i686/cmov/librt.so.1
6 Thread 0xac607b70 (LWP 2915) 0x006e0422 in __kernel_vsyscall ()
5 Thread 0xac5e6b70 (LWP 2916) 0x006e0422 in __kernel_vsyscall ()
4 Thread 0xac361b70 (LWP 2917) 0x006e0422 in __kernel_vsyscall ()
3 Thread 0xac2fdb70 (LWP 2918) 0x006e0422 in __kernel_vsyscall ()
2 Thread 0xac1fcb70 (LWP 2919) 0x004ef0d7 in mq_timedreceive () from
/lib/tls/i686/cmov/librt.so.1
* 1 Thread 0xb78496d0 (LWP 2907) 0x006e0422 in __kernel_vsyscall ()
使用thread 切换线程,使用bt显示线程栈
gdb>thread 12
gdb>bt
得到如下线程栈
#0 0x006e0422 in __kernel_vsyscall ()
#1 0x001cca26 in nanosleep () from /lib/tls/i686/cmov/libc.so.6
#2 0x001fc2dc in usleep () from /lib/tls/i686/cmov/libc.so.6
#3 0x0806b510 in OspTaskDelay ()
#4 0x0805c710 in CDispatchTask::NodeMsgSendToSock() ()
#5 0x0805cc74 in DispatchTaskEntry ()
#6 0x0806a8e9 in OspTaskTemplateFunc(void*) ()
#7 0x00d4780e in start_thread () from /lib/tls/i686/cmov/libpthread.so.0
#8 0x002027ee in clone () from /lib/tls/i686/cmov/libc.so.6
ps + strace
得到进程ID 21465
ps -e |grep cmu
4996 ? 00:00:25 cmu_fjga_sp3
21465 pts/5 00:08:10 cmu
得到线程时间, 其中最占CPU的是 EpollRecvTask 21581
ps -eL |grep 21465 21465 21579 pts/5 00:00:00 CamApp 21465 21580 pts/5 00:00:00 TimerMan Task 21465 21581 pts/5 00:09:02 EpollRecvTask 21465 21582 pts/5 00:00:00 使用 strace -p 21581 得到线程栈
Rock Wang。