关系数据库中的XML关键字检索技术
xml名词术语

xml名词术语以下是一些常见的XML名词术语:1. 标签(Tag):XML中的标识符,用于标识一个元素的开始和结束,通常是用尖括号包围的名称。
2. 元素(Element):指在XML文档中定义的结构化数据单元,由标签、属性和内容组成。
3. 属性(Attribute):XML元素中的数据项,用于提供有关元素的更多信息,通常是作为键值对的形式出现。
4. 命名空间(Namespace):XML中的一个机制,用于避免不同XML文档中的元素和属性名称重复的问题。
5. 文档模型(Document Model):用于将XML数据当作树型对象进行解析和操纵的技术,也称作“拉”模型。
DOM是XML文档的一种特殊树型结构编程模型。
DOM标准目前分成三个级别。
6. 事件模型(Event Model):用于通过使用回调或处理程序对XML数据进行解析的技术,也称作“推”模型。
7. 名称空间(Namespace):明确从不同的DTD或模式中标识出XML标记的方法,这样它们可以混合在同一个XML文档中。
8. RDF:资源描述框架,用于将XML属性数据和通常驻留在别处的信息相关联的一种压缩XML方言。
9. SOAP:“简单对象访问协议”是类似于XML-RPC(请参阅XML-RPC)的网络协议。
通过使用SOAP,应用程序可以创建远程对象、调用该对象上的方法,以及检索结果。
10. 验证:关于DTD和模式,验证结构良好的XML文档是否正确。
11. 结构良好:一个XML文档,它的标记和数据符合XML 1.0语法。
12. W3C:世界万维网联盟,它已经成为大多数XML相关技术的重要标准主体。
W3C将最终认可的规范称作“推荐”(而不是标准)。
XML与关系数据库数据转换技术初探

XML与 关系 数 据 库 数据 转 换 技 市 初 搽
中 国矿 业大 学( 州 ) 徐 计算机 学院 王 博
一
、
× Mபைடு நூலகம்简 介
X ML是一种专 门在 Wo d d b传递信息的语 言,它使得现有 r eWe l Wi 的因特网协议 和软件更为协调, 而简化 了剥数据的处 理和传输 。X 从 ML 所拥有 的可扩展性 、 自描述性 、 自相容性 以及跨文种等优点 , 得它非 使 常适 于 We 上 的数据交换与 信息发布 , b 被广 泛应用 到电子商务 、 电子 政务 、 b服务 等许多领域 。目前很 多国际著名的公司 已完全加入 到 We X ML支持者 的行列 , 如微软 I . E60已广 泛使用 了 XMI N / ae新版本 es p , e 也将会支持 XML 其它公司, , 包括 IM, oeS n和 X rx等也宣布支 B Adb ,u eo 持X ML, 并都在着手相关产 品的研制 。相对于 H ML的“ 见即所得” T 所 , X L将数 据和显示 信息分离 , M 被称为“ 文档数据库 ” 这就使 X L文档 , M 很适合于描述数据库 中的数据。 而 它非标准化 、 非结构化的数据转换 为X MI文档后 , 就可以将 大量遗 留数据实现信息共享和交换 。X 解 ML 析 技 术 是操 作 X ML文 档 的 重 要 环节 , 在 实 现 把 非结 构 化数 据 转换 为 它 X ML数据的过程中有着重要的作用。 二、 ML与关 系型数据的联 系 × X I M 的特性支持网络传输 。X L M 是一个 国际标准 , 任何人都可免 费使用 ; ML的结构性和标签性解决 r网络数据的边界和意义问题 , X 具 有可移植性 , ML克服 了先前不同开发平 台、 同通讯协议造成 的数据 X 不 结构 的差异 , 使得数据层在 XML技术 的支持 下统一起来 ; 比如要传送 个包括姓名 、 性别 、 年龄的个人信息。如果使用 XML传输 , 由于每一 个 字段 都 有 标 签 , 当 于数 据 都 钉 自我 描 述 , 到 标 签 读 者 自然 明 白标 相 看 签中数据的意 义。标 签的存在 , 自然指 明了数据 的边界 . 然 , 也 . 闽为 X MI中添枷 r 多标记 , 许 传输同样的信息 , 『 斓络传输量会大~些 。 但是 , 传输 量的增大 , 换来 的是 良好 的结 构 , 而凡 X ML文件 由于结 构的特殊 性 , 据 压 缩 比例 也 比较 大 。 数 关系数据库存储数据仍是 目前的主流 。 对于数据的存储 , 系数据 关 库 技 术 成 熟 而 稳健 。 虽然 XML数 据 库 也已 初 具 规 模 , 它 低 效 的存 储 但 组织 和索 引查询技术 , 不提供事务 、 全恢复机制 , 安 无法保 证数据的完 整性和一致性 , 没有并发控制 、 移植丁具等 缺点 , XML数据库与关系 使 数 据 库 竞 争起 来显 得 力 不 从 心 。而 且 许 多测 试 结 果 也 表 明 X ML在 处 理 数据 、 特别是大规模数据的时候 , 性能要比关 系数据库差得多。就 目前 来看 ,大多数系统存储和管理数据还是使用 关系数据库 。基于以上原 因, 使用关系数据库存储数据 、 X 用 ML记录, 移植, 传输数据这样一种系
基于XML信息检索技术的研究

Ab t a t h mp r n e o n omain r t e a a e n XML s o l sa l h t e mo e e ce t s c :T e i o t c f i fr t er v lb s d o r a o i h u d e tb i h r f i n s i
自从万维 网协 会 ( C) 出 X W3 推 ML以来 , 多 许 行业 已经把 X L作为基 本 的 文档形 式 。X M ML以其 所具有 的 自描述 性 、 活 的数据 结 构 以及 丰 富 的数 灵 据表示 能力等特点 , 现在 已经 被广 泛应 用到 It n t ne e r
g tfo c m p r t n l ss s o ha h e k n fi v re n e a e e tb l n e o u r o r m o aa i a ay i h ws t tt e n w i d o n e d i d x c n g tb s aa c f q e ne t y e ce c n p c o tb a . i f in y a d s a e c s y d t a Ke r s: XM L; r tiv l p i ia in; i e y wo d ere a ;o t z t m o nd x
0 引 言
随着 It nt 术 的 发 展 , ne e 技 r 网络 逐 渐 融 人 人 们 的生活 , 为 日常工 作和学 习 中不 可或缺 的一部分 , 成 It n t n re 是一个 巨大 的 、 放 的数 据 平 台 , 何组 织 e 开 如 和消化如此 大量 的信 息 , 直 是 困扰 着最 终 用 户 的 一 难题 。如何 帮助用 户 准确 提 出信 息需 求 , 快 速获 并 得“ 满意 ” 的查 询 结果 , 而 提 高 检 索 的效 率 , 直 从 一
XML与关系数据库之间转换技术的研究
年月(下)1X ML 技术介绍XML (Exte nsible Markup Language ,可扩展标记语言)是由W3C (W orld Wide We b Cons ortium )组织于1998年2月制定的一种通用语言规范,它是专门为W eb 应用程序而设计的SGML 的简化子集。
X ML 作为一种可扩展性标记语言,其描述性使其非常适用于不同应用间的数据交换,而这种交换不是以预先规定一组数据结构定义为前提的。
X ML 最大的优点在于它的数据描述和传送能力,因此具有很强的开放性。
2关系数据库与XML 之间的映射方法根据映射关系的建立方式不同,我们可以得到两种数据转换方法:基于模板驱动的转换方法和基于模型驱动的转换方法。
基于模板的映射方法并不事先定义好X ML 文档与其他数据之间的映射关系,而是在X ML 文档中嵌入带参数的SQL 命令。
这些命令在转换过程中被系统所识别和执行,执行的结果被替换到指令所在的位置,从而生成目标X ML 文档,并用数据传输诸如中间件等实体软件进行处理。
基于模型驱动的映射,当把数据从数据库传送到X ML 文档或把数据从XML 文档传送到数据库时,不是仅仅依赖内嵌SQL 命令,而是用一个具体的模型实现的。
基于模型的转换方法用这个事先定义好的数据模型来映射X ML 与关系数据库数据之间的关系。
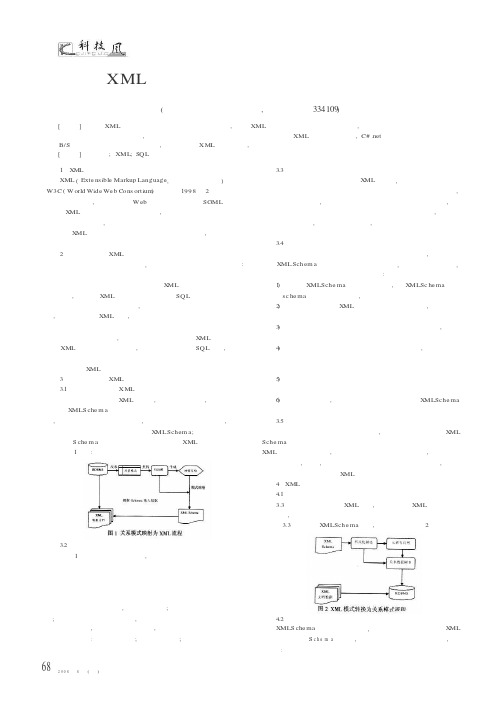
3关系数据库到XML 的转换技术3.1关系模式转换为XML 模式在将关系模式映射为X ML 模式时,由两条路线组成,第一条路线是得到X MLS che m a 首先需要从具体的关系数据库中反求出关系模式,再根据关系模式重构其有向图,由有向图再生成映射的结构,根据映射结构和有向图将关系模式映射为X MLSchem a ;第二条路线是根据得到的S che m a 从关系数据库中提取数据嵌入XML 事例文档。
整个流程如图1所示:图1关系模式映射为XM L 流程3.2关系模式的提取和重构由图1表达的流程图可以看出,由具体的关系数据库提取出关系模式是整个算法实现的前提。
XML关键字检索的访问控制规则和索引

法 , 理 了原 有文 章 问题 的 同时 还考 虑 了以 下两 个 问 题 : 处 ① Sh m c e a中当前节点不 可访 问 , 而其子 节点可 访 问 ; 基 于多 角 ②
色的访问控制 问题 。
SC L A结果有 , 分别为 :a et( . . . . ) ptn ( . . . , ptn 0 0 0 2 0 ,ae t0 0 10) i i ptn( .. . ) nre 00 2 0 0 , a et00 11 ,us( . .. . ) 而这 四个结 果中并 不是每 i 个 都满足例 1中对 nr us e用户所定义的安全规范 , 比如 :L A节 SC
T 313 P 9 . 文献标识码 A
ACCES S CoNT RoL PoLI CY AND NDEX I OF XM L K E YW ORD EARCH S
L a d n Hu n o Z u Ha ra g W e d n iXio o g a g Ha h o n io g
图2 X ML文档 树
( R C ) 建立新的索 引 ( R C — dx 和新 的 S L A查询 算 SA P 、 S A PI e ) n SC
假设当前 w rN a o=‘000 1 的某个 nre 色 的用 户登 d n920 ’ us 角
录系统 , 提交 三个 关键 字 “ a N ” “ o , tm r , 到 四个 w r o , T m” “u o” 得 d
访问 , 则其所有子节点都不 可访 问。比如 : 1 示 的 Shm . 图 所 ce a
如果 ta节点不 可访 问 , 其所有 子节 点 t t bl节 点都 不 rl i 则 e和 i s l 可访 问 , 但其实仍然存在子节点 中某些节点可 以被访 问的情况 。
XML与关系数据库

XML与关系数据库前面我们讲到了XML的数据存取机制,从一个较高的层面上分析了数据存取的多种方式。
作为其中的一种,数据库的数据存取机制似乎倍受青睐,但我们并未对此作比较深入的探讨,这一节里我们对XML与数据库的关系进行更进一步的详细分析。
我们知道,关系数据库提供了对于大批量数据的有效存储管理和快速信息检索、查询的功能。
从体系结构上看,数据库技术的发展历经了网络型数据库、层次型数据库、关系数据库、面向对象数据库。
虽然面向对象数据库融入了面向对象技术,但是到目前为止,在各个领域使用最广的还是关系数据库。
关系数据库管理系统(RDBMS)采用二维表格作为存储数据的模型,如下图10-1所示,字段字段字段行行行行图10-1 关系数据库二维表表格由行和列组成,一般情况下,列被称作“字段”,用于表示组成数据有效信息的属性,而行则用于指示一条完整的数据记录。
由于数据间的相关性可以通过表与表之间关键字(外键)来关联,由此产生了“关系”类型数据库的由来。
关系数据库有自己的查询语言——结构化查询语言(Structured Query Languag e,SQL)。
SQL最初由IBM提出,后经不断发展,已于1986年成为业界标准并被广泛采用。
SQL 是非过程性的。
当SQL语句传送到数据库服务器后,服务器返回满足条件的结果或结果集(视具体查询项目而定)。
一般情况下,大多数支持SQL 的服务器系统均采用客户/服务器架构,现在又发展到更为先进的分布式处理架构。
这样一来,SQL服务器既可以接收客户应用程序发送的查询请求,也可以接收其他服务器的查询请求,这些服务器可能是其他SQL服务器,也可以是XML服务器。
就数据存储而言,关系型数据库已经是相当成熟的应用,从80年代商用产品出现至今,早已深入企业储存及数据应用的核心。
相较之下,XML部分技术尚且在发展阶段。
关系型数据库是透过详细定义和控制结构化数据的方式,达到数据增、删、查询的目的。
mysql一对多关联查询xml写法

mysql一对多关联查询xml写法MySQL是一种开源的关系型数据库管理系统,它提供了丰富的功能和灵活的查询语言,可以方便地进行一对多关联查询。
在这篇文章中,我们将介绍如何使用XML来写一对多关联查询。
一、什么是一对多关联查询一对多关联查询是指在两个表之间存在一对多的关系,并且需要根据某个条件来进行查询。
在关系型数据库中,通常使用外键来建立一对多的关联关系。
在MySQL中,我们可以通过使用JOIN语句来进行一对多的关联查询。
二、XML写法示例假设我们有两个表,一个是"orders"表,存储订单信息,包括订单号、订单日期和客户ID等字段;另一个是"order_details"表,存储订单明细信息,包括订单号、商品ID和数量等字段。
我们需要查询某个客户的所有订单信息,包括订单明细。
以下是使用XML写法的示例:```xml<query><select>orders.order_id,orders.order_date,order_details.product_id,order_details.quantity</select><from>orders</from><join>order_details ON orders.order_id = order_details.order_id</join><where>orders.customer_id = 100</where></query>```在上面的示例中,我们使用了XML的标签来表示查询的各个部分。
其中,<select>标签表示选择查询的字段,<from>标签表示选择查询的表,<join>标签表示表的连接条件,<where>标签表示筛选条件。
基于关系数据库的XML存储技术

、
X ML与 关 系数 据 库 结构 上 的差 异
X L 档 是 半 结 构 化 的数 据 ,是 一 个 树 模 型 , 如 果 考 M文
定义 ; ( )简 化 变 换 : 将 连 续 的 多 个 一 元 操 作 转 换 为 一 2
个 … 元 操 作 ; ( ) 聚 集 变 换 : 将 多 个 具 有 相 同 名 称 的 3 子 元 素 聚 在 一 起 , 形 成 一 个 子 元 素 。一 个 D D 表 示 的 T图 是 一 个 D D 结构 , 图 的 结 点 表 示 D D 的 元 素 、 属 性 或 T的 T中 操 作 符 ,D D 的 元 素 在 D D 中 只 出现 一 次 ,属 性 和 操 T中 T图 作 符 在 D D 中 出 现 的 次 数 则 与 它 们 在 D D 出现 的 次 数 T图 T中
在 信 息 技 术 与 网 络 技 术 高 速 发 展 的 今 天 , 网 络 已经 成 为 新 一代 操 作 平 台 。信 息 正 全 面 地 以互 联 网 方 式 展 开 , 互 联 网 的信 息 传播 , 极 大 地 加 速 了人 类 发 展 的 进程 。随 着 W B 术 的 日益 发 展 ,W B 经 成 为 信 息 制 造 、 发 布 、 加 E技 E已
相 同。
虑  ̄ X L 素 次 序 , 则 是 一 棵 有 序 树 模 型 , 其 数据 结 构 是 OM 元
非结 构化 的 ,而关 系数据 库管 理 系统 是采 用 二维 表格 作
为 存 储 数 据 的 模 型 , 表 格 由行 和 列 组 成 , 列 被 称 作 “ 字 段 ” 用 于 表 示 组 成 数 据 有 效 信 息 的属 性 , 行: 第 一 步 : 简 化 D D 生 成 D D 。 因 为 X L T 的元 T并 T图 M D D 素 是 相 当 复 杂 的 , 需 要 对 复 杂 的 D D 行 简 化 。 D D 简 T进 T的
图结构XML文档的关键字检索方法

( ) 设 计 了 基 于 层 次 连 接 实 体 语 义 的 H 4 J
算 法
1 问题描述和相关工作
存 在一条 引用 边 , 引用 边从 ( ) 向 z m) 且 n指 T 。 (
12 相 关工作 .
基于 图结构 的 X ML文 档 信 息 检 索 研 究 包 括
2 1 年 1 6日 0 0 2月 收到 , 1 1 修改 2月 4日 83 6 国家重点基金项 目
2 1 SiT c. nn. 0 c. eh E gg 1
图 结构 X ML文档 的关 键 字 检 索 方法
李 少亮 陈 群 崔 海 文 ,
( 西北工业大学计算 机学院 , 西安 7 07 ; 10 2 西安科技大学计算机科学与技术学 院 , 西安 70 5 ) 10 4
摘
第 1 1卷
第 6期
21 0 1年 2 月
科
学
技
术
与
工
程
⑥
Vo_1 No 6 F b. 011 I 1 . e 2
17— 1 1 (0 1 6 12 —6 6 1 85 2 1 )—2 50
Si c eh o g n n ef g c neT cn l yadE  ̄ne n e o i
XRa k… n
,
EA E S [
,
X ew r 等 。X ak提 出 了 K y od Rn
(0 9 1 14 、 家 自然 科 学 基 金 (00 0 3 、 20 AA Z 3 ) 国 6 8 34 )
国家 自然 科 学基 金 (0 2 16 0 ) 助 67 0 00 1 资
Ee ak l l mR n _ 概念 , X 对 ML文 档 区 别 对 待 引 用 和 属
XML数据库的查询技术研究

I n d e x i n g ) 。S B X I 充分利用 了 X ML S c h e ma 建立 X ML索引从而提高路径查询 的效率 , 并进一步展望未来的研究方
向。
关键词 : X ML数据库 ; X ML查询 ; X ML索 引;S B X I 中图分类号 : T P 3 1 1 文献标 识码 : A 文章编号 :1 6 7 4 — 8 5 2 2 ( 2 0 1 3 ) 0 4 — 0 0 0 7 — 0 6
第 1 9 卷 4期 2 0 1 3 年第 8 月
江 苏 技 术 师 范 学 院 学 报
J OURNAL OF J I ANGS U T EACHERS UNI VERS I T Y OF T ECHNOL OGY
V0 1 . 1 9. No. 4
Aug . , 2 01 3
站管理 、 个性化出版、 电子文档交换等多个领域得到 了广泛应用。X M L 不仅能够存储数据 , 而且能够存储 结构和语义信息 , 具有通用 的数据表示能力 , 能表示结构化、 半结构化及元结构化数据 , 然而 X M L 对数据 的处 理能 力却 相 当有 限 。 因此 , 解决 好 X ML文档 的存 储 、 管理 和查 询等 问题 特别是 查 询 问题 , 构 造一 个 能
部模 型是基 于 X ML文档格 式 的 。
实 际上 , X ML本 源数 据库 系统 也并 非是 一 定要 建立 一个 新 的特殊 的数 据 库 系统 。关 于 XML本 源数 据库 , R . B o u r r e t 给 出了一 个 定 义 , 即 只有 满 足 以下 三 个 条 件 的 X ML数 据 库 才 能 称 之 为 X ML本 源数 据
XML数据库的查询技术研究
xml sql 字符串

xml sql 字符串
XML和SQL是两种不同的数据存储和查询方式。
XML是一种可扩展标记语言,用于描述数据的结构和内容。
XML使用标签来定义数据的层次结构和关系,可以存储复杂的数据类型和嵌套关系。
XML可以通过解析器解析成树状的数据结构,方便对数据进行操作和查询。
SQL(Structured Query Language)是一种用于管理关系型数据库的语言。
SQL使用表、行和列的概念来组织和存储数据,通过使用SQL语句可以对数据库进行查询、插入、更新和删除等操作。
在处理XML数据时,可以使用SQL的一些功能来操作和查询XML 数据。
例如,可以使用SQL语句来提取XML中的特定元素或属性,或者使用SQL函数来处理和转换XML数据。
字符串是一种数据类型,可以用来存储文本或字符序列。
在处理XML或SQL数据时,常常需要使用字符串来表示和操作数据。
例如,可以使用字符串函数来处理XML或SQL查询的结果,或者将XML 或SQL数据转换为字符串进行存储或传输。
sql xml解析

sql xml解析XML(可扩展标记语言)是一种用于存储和交换数据的语言。
SQL (结构化查询语言)是一种用于管理关系数据库管理系统(RDBMS)的编程语言。
在关系数据库管理系统中,可以将XML文档存储为文本列,并可以使用SQL查询语句来解析XML数据。
本文将介绍如何使用SQL解析XML数据以及一些有用的XML解析函数。
1. SQL中的XML数据类型在SQL Server中,可以使用XML作为数据类型来存储XML数据。
XML数据类型被定义为用于存储XML文档的数据类型。
当使用XML数据类型存储XML值时,可以使用XML文档中的关系数据来查询整个文档或基于元素的查询。
下面是SQL Server中的XML数据类型的定义:XML [ (n) ]其中,n是可选参数,用于指定XML数据类型的最大大小(以字节为单位)。
2.使用OPENXML解析XML数据OPENXML是SQL Server中的一个内置函数,用于解析XML数据。
使用OPENXML可以将XML文档转换为关系表,并使用SQL查询语言访问数据。
下面是使用OPENXML解析XML数据的一般步骤:步骤1:创建XML文档的表结构。
在创建XML文档之前,需要定义一个表来存储XML文档中的数据。
该表应包含与XML文档元素和属性相对应的列。
步骤2:使用OPENXML将XML数据转换为关系表。
使用OPENXML可以将XML文档转换为关系表。
OPENXML函数需要三个参数:XML文档的标识符,表示文档中节点的XPath表达式,以及一个指示节点的ID的列名。
步骤3:使用T-SQL查询解析XML文档。
一旦将XML文档转换为关系表,就可以使用SQL查询语言来访问数据。
可以使用SELECT语句选择特定的列并应用任何必要的过滤条件。
下面是使用OPENXML解析XML文档的示例:DECLARE @xml XMLSET @xml = N'<employees><employee id="1" fullname="John Smith"><department>Accounting</department><hiredate>2000-01-01</hiredate><salary>50000</salary></employee><employee id="2" fullname="Jane Doe"><department>Human Resources</department><hiredate>2001-01-01</hiredate><salary>60000</salary></employee></employees>'-- Define table structure to store XML data CREATE TABLE #Employees(ID INT IDENTITY(1, 1),EmployeeID INT,FullName VARCHAR(100),Department VARCHAR(50),HireDate DATE,Salary DECIMAL(10, 2))-- Convert XML to relational tableINSERT INTO #Employees (EmployeeID, FullName, Department, HireDate, Salary)SELECTx.value('@id', 'int'), -- Get value of 'id' attributex.value('@fullname', 'varchar(100)'), -- Get value of'fullname' attributex.value('department[1]', 'varchar(50)'), -- Get value of'department' elementx.value('hiredate[1]', 'date'), -- Get value of'hiredate' elementx.value('salary[1]', 'decimal(10,2)') -- Get value of'salary' element**************('/employees/employee')ASt(x)-- Query the XML dataSELECT * FROM #Employees WHERE Salary > 55000-- Clean upDROP TABLE #Employees此示例将XML文档转换为关系表,然后使用T-SQL查询检索数据。
对关系数据库与XML数据库的比较研究

然科学版, 0 32 ( : 5— . 2 0 , 96 7 6 78 ) 5 [ 4】董 东 ,马 丽 .x 据 库 和 关 系 L数 M 数 据 库 之 比 较 [ 计 算 机 工 程 与 设 J].
计 , 0 5 2 8 : 9— 0 9 2 0 , 6() 2 2 2 9 0
(r c s i g n tu to ) [ D T 段 。 其 中 p o e s n i sr c i n  ̄ C A A I
标 记 是 用 一 对 尖 括 号 来 表 示 ,元 素 内 容 可 以 是 文 本 数 据 , 也 可 以 是 X L 素 , 甚 至 是 该 M 元 元素 本身 。其语 法和 H M 类似 ,但是 X L TL M 的 优 势 在 于 其 允 许 用 户 可 以根 据 需 要 自 行 定 义
2 0 . 1 ) -1 . 0 8 1 :1 8( 6 2 4
[] 2 邓华梅 , 肖锋 , 海 平. 关 于x L 李 袁 M 数据 的存储 研究 【] 科技 情报 开发 与经济, J.
20 8 8( 4 :1 -1 5 0 ,1 2 ) 3 . 5 5
由 上 可 知 X L 关 系 数 据 库 进 行 数 据 转 M 与
3 M 数据库与关系数据库的 比较 、X L x ML数 据 库 与 关 系 数 据 库 系 统 相 比 [ — ], 有 如 F几 方 面 的 差 异 : 1 存 储 形 23 . 式 :X L M 数据存储在 层次化结构化 的文档中, 而关 系数据库将数据存 储在多个表 中。2 .存 储数据 :X L 点具有 元素和属性 二种值,而 M结 关系数据库 中记录 单元只有 单一 的值 。3 .存 储顺 序:X L 素是有顺序的 ,而 关系数据库 M元 中记录 元是 无序 的 。4 .存 储 数据 特 点 : XL M 中元素是可 以嵌 套的,而关系数 据库中记 录 单元是 原子 的。5 .递 归 性 : X L 素 是 可 M元 递 归的,而关系数据库 [ 几乎不支持递 归。6 『 l 数据检 索:XL M 中可 以直 接 检 索 一 个 文 件 中 的数 据 ,而 关系 数据库 往往 需要关 联检 索多 个表的数据 。7 .数据查询 :X L M 标准查 M 用X L 询语言X a h q e y p t 或X u r 查询 ,而关 系数据库用 标准查询语言SL 数据进行查询 。 Q对 4 M 向关系数据库 的转换 方案 、X L
XML文档在关系数据库中存储与查询的实现

①将 XML文 档作为一个整体存 储在
数据库的某一列 中,它的基本存储单 元是
XML文 档 。 ⑦将XMI 文档看成一种 图结构 , 进行
一
4 ̄ ML数据 的查 询
5 结束 语
XML 已经逐渐 成为Itme上数据 现 ne t 现 已 提 出 多 种 查 询 语 言 , 如 XP t a h、 定的分解 ,然后将其元素和值存 储在关 f XQ ey u r 、XML QL等 ,这 些语 言均是通 i 表示 和交换的新的标准 ,而关 系数据库 则 2
引 言
XMLe e s l Mak pL n u g ) ( ni e Xt b ru a g a e 即可扩 展标记 语言 ,是 由 w 3 WO i C( r d wie we o s rim) 19 年2月发 d b C n ot u 于 98
向的超 链接 等等方面的一些不足之处。
32 . 基于关 系数据 库系统的存储 方法
目前提 出 的 XML RD — B存 储 方 法 主
要3 : 类
XML 据的存储和查询 , 面向对象数据 数 而 库在查询 优化上 存在的 问题 制约 了 XM L 数据的查询分解 和优化。
档 。XML数据 类型提 供 了四个检索 XML 值或 实例的方法 : u r (、 au (、 x s q ey ) v le) e i t
2 ML与关 系数据 库 X
XML 文档属于半结构化的数据 , 而关 系数据库管理 系统(RDB ) 用二 维表 MS采 作 为存 储数 据 的模 型 ,表格 由行和 列组
成 ,列 用 于 表 示 组 成 数 据 有 效 信 息 的 属 性 ,行 则是 用于 指示 一 条完整 的数 据 记 录。 XML 档 与 结 构 化 的关 系数 据 库 进 行 文 转 换 时 , 键 问题 是 如 何 将 X L 档 的结 关 M 文
基于全文检索的XML存储查询系统

连 接 查 询 算 法 的 问题 , 时借 助全 文 检 索 技 术 达 到 X 同 ML查询 加 速 的 效 果 。该 方 案 应 用 于 实 际软 件 开 发 项 目中 , 很好 地 解 决 了 X ML 文档 的关 系数 据 库 存 储 管理 工 作 , 并且 具 有 很 高 的查 询 效 率。 关 键 词 关 系数 据 库 X ML索 引编 码 结 构连 接 查 询 全 文 检 索
( eatetfC m ue Si c a dE gnei S ag a i tn nvrt,hn h i 0 2 0.hn ) Dp r n o p tr c ne n n i r g,h nh i a og U i sy S aga 0 4 C ia m o e e n Jo ei 2
S OR N A D T I G N QUE YI R NG Y T M OR XML B E ON F L T X E R E AL S SE F AS D UL E T R T I V
Qa h n za La hn i C a gh o i C a g o o
q ey n f ce c . u r ig ef in y i
Ke w r s y o d
R l i a d t ae X d xe c dn S u tr i u r F l t t e e a e t n l a s ML i e n o i ao a b n g t c a j nq e u x r r vl r u lo y le t i
sqlserver2008 xml 查询条件

在 SQL Server 2008 中,可以使用 XML 查询条件来过滤和检索 XML 数据。
以下是一些常用的 XML 查询条件的示例:1.查询 XML 元素的值:SELECT XMLColumn.value('local-name(.)', 'nvarchar(100)') AS ElementNameFROM YourTableWHERE YourTable.XMLColumn.value('local-name(.)', 'nvarchar(100)') = 'ElementValue'上述查询将返回名为 "ElementName" 的 XML 元素值为 "ElementValue" 的所有行。
2.查询 XML 属性的值:SELECT XMLColumn.value('local-name(.)', 'nvarchar(100)') AS AttributeNameFROM YourTableWHERE YourTable.XMLColumn.value('local-name(.)', 'nvarchar(100)') = 'AttributeValue'上述查询将返回名为"AttributeName" 的XML 属性值为"AttributeValue" 的所有行。
3.使用路径表达式查询嵌套的 XML 元素:SELECT XMLColumn.value('(./Element1/Element2)[1]', 'nvarchar(100)') AS NestedElementValueFROM YourTableWHERE YourTable.XMLColumn.value('local-name(.)', 'nvarchar(100)') = 'Element1'上述查询将返回名为 "Element1" 的 XML 元素中名为 "Element2" 的子元素的值。
XML在关系数据库中存储技术研究的开题报告

XML在关系数据库中存储技术研究的开题报告摘要:XML(Extensible Markup Language)是一种用于描述数据的标记语言,被广泛应用于互联网上的数据交换和数据存储中。
随着XML的应用范围不断扩大,如何在关系数据库中存储XML数据成为了研究的热点问题。
本文从XML的特点出发,阐述了在关系数据库中存储XML数据的意义和挑战,并分析了目前主流的XML存储技术,包括将XML 数据存储为文本、存储为二进制、存储为对象以及使用特殊的XML数据库等。
最后,本文提出了基于对象的存储方式在处理XML数据方面的优越性,并对进一步的研究方向进行了展望。
关键词:XML;关系数据库;存储技术一、研究背景XML是一种用于描述数据的标记语言,它使用简单的文本格式描述结构化数据,并可扩展性强,被广泛应用于Internet上的数据交换。
随着XML的应用得到不断扩大,如何在关系数据库中存储XML数据成为了研究的一个热点问题。
传统的关系数据库如Oracle、MySQL等不支持直接存储XML数据,需要将XML数据转化为关系数据(文本、二进制或对象)存储。
因此,如何处理和存储XML数据在关系数据库中成为了一个挑战。
二、XML在关系数据库中存储的意义XML是一种可以描述各种结构的数据的标记语言,与关系数据库中的表、行、列相比,XML具有更多的灵活性。
XML文档可以根据需要添加、删除或修改各自的元素和属性,也可以根据需要添加或删除整个分支。
因此,在关系数据库中存储XML数据可以让用户更加自由地存储和查询数据。
同时,XML具有强大的自我描述性,允许数据与其自身的描述关联在一起。
这个特性使得XML更适合于存储复杂的数据结构和大量的元数据。
因此,XML在关系数据库中的应用也可以增强数据的可扩展性和可维护性。
三、XML在关系数据库中存储的挑战在关系数据库中存储XML数据也有一些挑战和难点。
首先,XML文档本身就很大,其中可能含有大量的嵌套和重复的结构。
检索数据库和方法

检索数据库和方法在信息时代,数据库是组织和存储数据的核心。
在大数据时代,检索数据库和方法变得尤为重要。
本文将介绍数据库的基本概念和检索方法,以帮助人们更好地搜索和获取所需信息。
首先,我们需要了解什么是数据库。
数据库是按照一定的数据模型组织和存储的数据集合,可通过计算机进行访问和管理。
常见的数据库类型包括关系型数据库和非关系型数据库。
关系型数据库使用表格来组织数据,并通过SQL语言进行操作。
而非关系型数据库则采用不同的数据结构(如键值对、文档、图形等)来存储数据。
根据不同的需求和应用场景,选择适合的数据库类型非常重要。
当我们需要检索数据库时,通常需要使用一些方法和技术来提高效率和准确性。
以下是几种常见的数据库检索方法:1. 关键字搜索:关键字搜索是最常见和简单的数据库检索方法。
用户可以输入关键字来搜索相关的记录。
关键字搜索的效果依赖于数据库中的索引和搜索算法。
通过合理建立索引和选择适当的搜索算法,可以提高搜索的速度和准确性。
2. 数据过滤:数据过滤是根据特定的条件筛选数据库中的记录。
例如,可以根据时间范围、地理位置、价格范围等条件来过滤数据。
数据过滤可以帮助用户快速获取符合特定条件的数据,减少不必要的信息。
3. 数据排序:数据排序是基于指定的字段对数据库中的记录进行排序。
例如,可以按照销售额、评分等字段对产品进行排序。
数据排序可以帮助用户更好地了解和比较数据。
4. 数据聚合:数据聚合是将数据库中的多个记录合并为一个结果。
例如,可以计算某个区域的总销售额、平均价格等。
数据聚合可以帮助用户获取更高层次的信息和统计结果。
5. 数据分析:数据分析是对数据库中的数据进行统计和挖掘,以获取有用的信息和洞察力。
例如,可以进行趋势分析、预测分析、关联分析等。
数据分析可以帮助用户发现隐藏在数据背后的规律和模式。
除了以上提到的方法,还有一些高级的数据库检索方法和技术,如全文搜索、模糊搜索、推荐系统等。
这些方法和技术可以根据实际需求来选择和应用。
XML技术在数字图书馆跨库检索中的应用

22 检 索界 面 的 整 合 .
索结 果进行 整合 , 在经过 去重 和排序 等操 作后 , 以统 结 果呈现 给用户 。跨 库检 索的发 展不仅 方便 了用 户 的信 息获取 。而 且还在 一定 程度 上提高 了数据库 的利用率 , 促进 了资源共 享 。
一
目前 数字 图书馆 的跨库 检索 主要研 究如何 屏蔽 各个 异构 数据源 的差别 ,提供一致 的检 索界 面和和 检索技术 , 由系统 自 动执行跨数据库系统的检索, 在 系统 间不 同的信 息格式 、 索方式 等方 面进 行转换 。 检 然后 对检索结 果进行整 理去重并 显示 给用户 。 2 跨 库检 索的数据整 合 数 字 图书 馆所使 用 的数据库 具有异 构性 和多样 性 , 同数字 图书馆 的数据 源在数 据结 构 、 索机制 不 检 方面各 自不 同。在进 行异 构数据 库跨库 检索 时必须 考虑如何 将这些 有差 异 的数据进 行整合 。以便 于用 户 统一检 索 。异 构数 据库 的数据 整合方式 主要 有两 种: 对数据源 的整合 [ 对检索 界面 的整合 。 1 和
收 稿 日期 :0 O 1 1 2 1一1— 2
检索 界面整 合是指在 不改 变原 始数据 的存储 和 管理 方式 的情况 下 。形 成一个 异构 数据库 跨库检 索 系统 [, 2 通过 一个 统一 的检 索界 面 , 用户 输入 的检 】 将 索词 、检 索式按 照各个数 据库 的要求转 换 成其能够 接受 的检索 式和检 索指令 .提供 给各个 数 据库进行 检 索 ; 取各个 数据库 返 回的检索 结果 , 按 照统一 获 并 检 索平 台要求 的数 据格式 进行转 换 ;将转 换后 的数 据提 供 给数 据处 理层进 一步 的处理 , 最后 , 以统 一格 式将结 果呈 现给用户 , 即提供 “ 一站式 ” 检索服务 。 实现 检索 界 面整 合 的 常见模 式 是 构建 中间件 。 利用 中 间件 技术进 行异 构数据库 数据 整合 。采用 中 间件技 术 。 把来 自用户 的查 询请 求 , 分解 成 对不 同原 始 数据 库 的独 立访 问请求 .通过 标准或 非标 准的数 据访 问接 口对 原始数 据库 进行实 时访 问并将 结果整 合 后通 过 发布 系统 ( 直接 ) 回给用 户 , 不改 变 或 返 在 现有 系统 的数 据组织 结 构 和检 索方 法 的条 件 下 , 实 现对 异构 的多数 据源 的统一访 问 。利用 中间件技 术 整合 的特点 是实 时性好 。任何 原始数 据 的更 改都 可 以在 用户查 询 时及 时得 到反 映 :原文 获取 可 以直 接 通过 中 间件 获得从 而省 去原文 数据库 的原文 发布 服 务 ; 应用局 限于原 始数据 库必 须提供访 问接 口 , 但 而 且 由于各数据 库 的速度 问题 而影 响到用 户得 到结果 的时 间。 目前 用于异 构数据 库数 据集成 的数据 库 中 间件 技 术使 用 较 为广 泛 的 有 [: 共 网关 接 口技 术 3公 】 C I开放 式数据 库互连 技术 O B J V G: D C; A数据库 互 A 连 技 术 J B A P技 术 和 J P技 术 ; O B D C; S S C R A技 术 ; X ML中间件技 术 等 。本文 着 重探讨 基 于 X ML中间 件 技术 的数据整 合技术在 跨库检 索中 的应用 。 3 基于 X ML技术 的跨库检 索
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
图.
?+@$8*(%1 片段
图!
生成 >#+$,-./ 表的示意图
?+@$8*(%1 方 法:对 于 元 素 关 键 字 0’$8$#- 9 $’(),A*/$#-(),:$!"#,$#% & 以及关键字 ;$/8 9 $’() 谓词 2.#-*"#, ( 0’$8$#-,;$/8) 为真, 当且仅当满 &, 足如下条件之一: (4)0’$8$#- 是叶子节点, 且 0’$8$#- 直接包含 关键字 ;$/8, 或者: (C)0’$8$#- 包含后继元素节点 04 ,0C , …, 0#, 且 2.#-*"#, ( 04, ( 0C, ;$/8)./ 2.#-*"#, ;$/8)./ … ./ ( 0#, 为真。 2.#-*"#, ;$/8) 图 D 给出一个 );) 例子和它的图示, 元素 > 拥 有直接后继元素 E 和 2, 而 E 包含后继元素 ) 和 0。 对任一个符合此 );) 的 567 文档, 在检索元素 E 是否包含关键字 -$/8 时, 即, 计算谓词 2.#-*"#, ( E, 的时候, 我们只需考虑 E, -$/8) ), 0 是否直接包含关 键字 -$/8 即可, 而不需考虑其他任何元素。
记录所有关键字与其父元素的直接包含关系, 同时 用四元组 0’$8$#- 9 $’(),A*/$#-(),:$!"#,$#% & 记 录元素的位置, 属性 A*/$#-() 是该元素的父元素标 识, 用于记录元素间的父子关系。 该方法称为基于模式的倒排索引技术 (简称为 。图 B 给出了对应于图 4 567 文档样例 ?+@$8*(%1) 的 ?+@$8*(%1 倒 排 索 引 表 片 段, 可以看到它与 这就 01-2.#-*"#(%1 的最大区别是取消了 >#+$,-./ 表, 进 一 步 减 小 了 倒 排 索 引 的 空 间 开 销。 使 用 ?+@$8*(%1 计算包含谓词的方法如下。
用关系数据库存储 &’( 数据 不但可以利用已经很成熟的数据库 技术如查询优化、 并发控制, 还可以 使 &’( 数据与传统的关系数据共 存于同一应用中。这种存储方法在 数据库界内得到了广泛认同
[# - ,"]
。
" !
(!"",MM#,,,N", 资助项目。 %N$ 计划 !""!MM,,N"!") 男, 博士, 讲师; 研究方向: 商业智能, 知识管理, ( AMD) ; 联系人。 ,KL$ 年生, )*+ 服务和企业应用集成 (收稿日期: !""$5"N5,N)
[$] 使得传输的数据量大大减小 。
用来记录 &’( 文档中任意关键字相对于其祖先 G, [$] 元素的包含关系 , 称为基于包含关系的倒排索引 (简称为 :4;<=>;DBH) 。其中 *3D/ 是元素的标识, ?46B 表示关键字, B*E<F 表示该关键字相对于 *3D/ 所标识 元素的深度。对于某个关键字, :4;<=>;DBH 用多条记 录分别记录它与不同祖先元素之间的包含关系, 利 用这些包含关系信息就可以完成包含谓词的计算。 为了提高查询效率, 他们还对关系表 C *3D/, 对于任 <*6I,B*E<F G 按 <*6I 进行了水平分割。即, 意的关键字 <*6I, 建立一个只包含两个属性列的关 键字表 6J*6I C *3D/,B*E<F G 。 :4;<=>;DBH 的最大优点是使用该倒排索引的查 询效率很高, 但是它的存储开销非常巨大, 有时索引
[,,] 统的倒排文件 扩展为 C *3D/,?46B,B*E<F,348=<>4;
扩展标记语言 ( &’() 正快速成为 )*+ 上数据 [,] 表示、 集成和交换的标准 。随着互联网上 &’( 文 档的不断增多, 对这些数据的使用越来越依赖于互 联网搜索引擎强大的检索能力, 研究检索 &’( 文档 的搜索引擎甚为迫切
表 =5C8 6 57*2 < 记录关键字与其父元素关系数据库中的 567 关键字检索技术
而 !"#,$#% & 记录其信息。这里 $’() 是元素的标识, 是该元素祖先元素的标识。 *#+$,-./() 该方法称为扩展的基于包含关系的倒排索引技 术 (简称为 01-2.#-*"#(%1) 。图 3 给出了对应于图 4 567 文档样例的 01-2.#-*"#(%1 倒排索引表片段。使 用 01-2.#-*"#(%1 计算包含谓词的方法如下: 01-2.#-*"#(%1 方 法:对 于 元 素 0’$8$#- 9 $’(), 当且仅当 ;$/8< :$!"#,$#% & 和关键字 ;$/8 9 $’() & , $’() = 0’$8$#- < $’() 或 ;$/8< $’() = *#+$,-./ < $’() 且 谓 词 2.#-*"#, 0’$8$#-< $’() = *#+$,-./ < *#+$,-./(), ( 0’$8$#-,;$/8) 为真。
胥正川等: 关系数据库中的 &’( 关键字检索技术
关系数据库中的 !"# 关键字检索技术 !
胥正川 ! 陈忠民! 孙 海
! 周傲英!
(复旦大学管理学院信息管理与信息系统系 (! 上海烟草 (集团) 公司计算机信息中心
! 复旦大学计算机科学与工程系 (!
上海 !""#$$) 上海 !"""%!)
上海 !""#$$)
的倒排索引技术。这种索引技术在进一步减小索引 文件空间开销的基础上, 大大提高了关键字的检索 效率, 取得了存储空间与查询效率的最佳权衡。 本文结构如下, 第 ? 节介绍了本文提出的两种 新的倒排索引; 第 @ 节对各种倒排索引的性能进行 了试验比较和分析; 第 A 节是结论。
?
两种新的倒排索引
为了解决现有的两种倒排索引的不足, 特别是
文件的大小甚至是文档本身的几十倍。这一点在实 验中也有证明。其原因是, 对于 !"# 文档中的任意 一个关键字, $%&’()&*+, 记录了它和所有祖先元素之 间的包含关系, 造成了大量存储冗余。 (简称 -.(&/ 等提出了基于位置关系的倒排索引 为 0%1*+,) 。根据关键字在 !"# 文档中位置的不同, 把它们分为两类: 在元素位置上的元素关键字和在 元素内容中的文本关键字。通过深度优先遍历, 同 时增量维护一个访问次序, 得到任意文本关键字在 (因为文本关键字在 23" !"# 文档中的一个序号 树中是叶子节点) , 和任意元素关键字的两个序号 (前序遍历和后序遍历) 。文本关键字的序号可以标 识它在文档中的位置, 而元素关键字的两个序号作 为它的起始序号和结束序号, 也可以标识出它的位 置。因此可以构建基于位置关系的倒排索引, 元素 关键字表 4 )&+5, 6 57585&’,95/)&,5&+,75:;57 < 和 文本关键字表 = )&+5, 6 ’5,’,>%1)’)%&,75;57 < 。这 里的 75;57 是一个辅助属性, 记录关键字相对于 !"# [?@] 文档根节点的深度, 用于控制查询深度 。 这种倒排索引技术根据文本关键字和元素关键 字在 !"# 文档中的位置嵌套关系来计算包含谓词, 它的最大优点是存储开销少, 但由于所有的关键字 都只存放在两个关系表中, 使得这两个表过于庞大, 查询效率很低。即使在这两个倒排表上构建各种聚 簇索引, 查询效果仍然很不理想。 为了解决上述两种倒排索引的不足, 本文提出 了两种新的倒排索引技术。考虑到 !"# 文档具有 固定结构 (即元素之间具有相对固定的包含关系) , 提出了扩展的基于包含关系的倒排索引。这种索引
摘
要
研究了关系数据库中 &’( 文档的关键字检索技术, 提出了两种新的倒排索引技
术: 扩展的基于包含关系的倒排索引和基于模式的倒排索引。前者利用元素之间的包含 关系, 大大减少了现有倒排索引的存储开销, 而后者利用 &’( 的模式信息, 在进一步降低 倒排索引空间开销的同时, 还大大提高了关键字检索的效率。实验证明本文提出的基于 模式的倒排索引技术在空间开销和查询效率之间取得了最佳权衡。 关键词 &’(,搜索引擎,关键字检索,关系数据库
图"
01-2.#-*"#(%1 片段
#$!
基于模式的倒排索引技术 ( %&’()*+,-) 本文中前面已经提到的三种倒排索引都没有考
虑 567 文档的模式信息, 而 567 文档作为一种半 结构化数据是有一定模式的。 );) 就可以看作是 ( 567 模式 ( ?+@$8*) 可以看作 567 文档的模式信息 是 );) 的扩展) 。对于符合某个 );) 的 567 文档, 根据 );) 就可以得到任意元素的所有可能后继元 素类别。为了查询某元素是否包含特定的关键字, 可以通过查询该元素及其所有后继元素类别中的元 素是否直接包含该特定的关键字来完成该查询。所 只要记录 以在 567 文档符合某个 );) 的情况下, 关键字与其父元素的直接包含关系和每个元素的位 置信息, 就可以完成包含谓词的计算, 这样就避免了 大量不必要的包含关系查询。我们用 ;$/8 9 $’() & 万方数据
本文研究的就是如何将关键字检索技术与关系数据
"