实验3 查询(1)
计算机网络实验三参考答案

1. What is the IP address and TCP port number used by the client computer (source) that is transferring the file to ? To answer this questio n, it’s probably easiest to select an HTTP message and explore the details of the TCP packet used to carry this HTTP message, using the “details of the selected packet header window” (refer to Figure 2 in the “Getting Started with Wireshark” Lab if you’re uncertain about the Wireshark windows).Ans: IP address:192.168.1.102 TCP port:11612. What is the IP address of ? On what port number is it sending and receiving TCP segments for this connection?Ans: IP address:128.119.245.12 TCP port:80If you have been able to create your own trace, answer the following question:3. What is the IP address and TCP port number used by your client computer(source) to transfer the file to ?ANS: IP address :10.211.55.7 TCP port:492654. What is the sequence number of the TCP SYN segment that is used to initiate the TCP connection between the client computer and ? What is it in the segment that identifies the segment as a SYN segment?ANS: sequence number: 0 Syn Set = 1 identifies the segment as a SYN segment5. What is the sequence number of the SYNACK segment sent by to the client computer in reply to the SYN? What is the value of the ACKnowledgement field in the SYNACK segment? How did determine that value? What is it in the segment that identifies the segment as a SYNACK segment?ANS: The sequence number: 0ACKnowledgement number : 1 which is sequence number plus 1Both the sequence flag and the ACKnowledgement flag been set as 1, identifies the segment as SYNACK segment.6. What is the sequence number of the TCP segment containing the HTTP POST command? Note that in order to find the POST command, you’ll need to dig into the packet content field at the bottom of the Wireshark window, looking for a segment with a “POST” within its DATA field.Ans: The sequence number : 17. Consider the TCP segment containing the HTTP POST as the first segment in the TCP connection. What are the sequence numbers of the first six segments in the TCP connection (including thesegment containing the HTTP POST)? At what time was each segment sent? When was the ACK for each segment received? Given the difference between when each TCP segment was sent, and when its acknowledgement was received, what is the RTT value for each of the six segments? What is the EstimatedRTT value (see page 249 in text) after the receipt of each ACK? Assume that the value of the EstimatedRTT is equal to the measured RTT for the first segment, and then is computed using the EstimatedRTT equation on page 249 for all subsequent segments.Note: Wireshark has a nice feature that allows you to plot the RTT for each of the TCP segments sent. Select a TCP segment in the “listing of captured packets” window that is being sent from the client to the server. Then select: Statistics->TCP Stream Graph- >Round Trip Time Graph.Segment 1 Segment 2 Segment 3Segment 4Segment 5Segment 6After Segment 1 : EstimatedRTT = 0.02746After Segment 2 : EstimatedRTT = 0.875 * 0.02746 + 0.125*0.035557 = 0.028472 After Segment 3 : EstimatedRTT = 0.875 * 0.028472 + 0.125*0.070059 = 0.033670 After Segment 4 : EstimatedRTT = 0.875 * 0.033670 + 0.125*0.11443 = 0.043765 After Segment 5 : EstimatedRTT = 0.875 * 0.043765 + 0.125*0.13989 = 0.055781 After Segment 6 : EstimatedRTT = 0.875 * 0.055781 + 0.125*0.18964 = 0.072513 8. What is the length of each of the first six TCP segments?(see Q7)9. What is the minimum amount of available buffer space advertised at the received for the entire trace? Does the lack of receiver buffer space ever throttle thesender?ANS:The minimum amount of buffer space (receiver window) advertised at for the entire trace is 5840 bytes;This receiver window grows steadily until a maximum receiver buffer size of 62780 bytes.The sender is never throttled due to lacking of receiver buffer space by inspecting this trace.10. Are there any retransmitted segments in the trace file? What did you check for (in the trace) in order to answer this question?ANS: There are no retransmitted segments in the trace file. We can verify this by checking the sequence numbers of the TCP segments in the trace file. All sequence numbers are increasing.so there is no retramstmitted segment.11. How much data does the receiver typically acknowledge in an ACK? Can youidentify cases where the receiver is ACKing every other received segment (seeTable 3.2 on page 257 in the text).ANS: According to this screenshot, the data received by the server between these two ACKs is 1460bytes. there are cases where the receiver is ACKing every other segment 2920 bytes = 1460*2 bytes. For example 64005-61085 = 292012. What is the throughput (bytes transferred per unit time) for the TCP connection? Explain how you calculated this value.ANS: total amount data = 164091 - 1 = 164090 bytes#164091 bytes for NO.202 segment and 1 bytes for NO.4 segmentTotal transmission time = 5.455830 – 0.026477 = 5.4294So the throughput for the TCP connection is computed as 164090/5.4294 = 30.222 KByte/sec.13. Use the Time-Sequence-Graph(Stevens) plotting tool to view the sequence number versus time plot of segments being sent from the client to the server. Can you identify where TCP’s slow start phase begins and ends, and where congestion avoidance takes over? Comment on ways in which the measured data differs from the idealized behavior of TCP that we’ve studied in the text.ANS: Slow start begins when HTTP POST segment begins. But we can’t identify where TCP’s slow start phase ends, and where congestion avoidance takes over.14. Answer each of two questions above for the trace that you have gathered when you transferred a file from your computer to ANS: Slow start begins when HTTP POST segment begins. But we can’t identify where TCP’s slow start phase ends, and where congestion avoidance takes over.。
VF实验报告-关联、查询和数据库解析

实验课程名称 Visual Foxpro 实验项目名称关联、查询和数据库专业班级学生姓名学号指导教师第3章关联、查询和数据库实验3-1 多表关联与查询1.实验目的(1)理解关联的概念,掌握在数据工作期窗口中建立关联的方法。
(2)掌握SELECT-SQL查询命令。
(3)掌握用查询设计器建立查询的方法。
2.实验要求(1)在数据工作期窗口上建立以“订单”为父表,“订单明细”为子表的一多关系;再建立以“订单明细”为父表,“货物”为子表的多一关系的二级关联。
然后查看关联后的效果。
(2)用SELECT-SQL命令对上述5个表作多表查询练习。
①查询联系“东南实业”公司的员工姓名及联系电话。
②查询订购麻油的订单份数。
(3)用查询设计器查询公司订货情况。
3.实验准备(1)阅读主教材3.1.2节、3.2.3节、3.3节、3.5.1节和3.5.2节。
(2)创建好订单、订单明细、员工、客户和货物表(见实验2-2)。
4.实验步骤(1)为“关联”建立索引:为订单表的订单号字段建立索引,再为货物表的货号字段建立索引。
(2)建立关联:打开数据工作期窗口→分别用“打开”按钮打开订单表、订单明细表和货物表→在“别名”列表框中选定“订单”,单击“关系”按钮→在“别名”列表框中选定“订单明细”→随即弹出“设置索引顺序”对话框,其列表框中显示“订单明细.订单号”(参阅主教材图3.7)。
选定“确定”按钮→随即弹出“表达式生成器”对话框,其SET RELATION框中显示“订单号”(参阅主教材图3.8)。
选定“确定”按钮,多一关系建立完成→选定“一对多”按钮→在随即弹出的“创建一对多关系”对话框中→选定“确定”按钮,一多关系建立完成。
在“别名”列表框中选定“订单明细”→为确定以订单明细表为父表建立下一级关联,在“关系”列表框中也选定“订单明细”→单击“关系”按钮→在“别名”列表框中选定“货物”→在随即弹出的“设置索引顺序”对话框中选定“确定”按钮→在“表达式生成器”对话中选定“确定”按钮,多一关系(第2级)建立完成,如图2.3.1所示。
实验3 序列1-字符串 学号 姓名

实验3 序列1—字符串1.实验目的(1)掌握字符串数据类型;(2)掌握字符串处理方法和字符串格式化方法2.实验介绍练习字符串的切片及各种常见的处理方法。
3.实验内容1、给定一个字符串"Hello,China!"⑴写出表达式显示第一个字符⑵写出表达式显示最后一个字符⑶写出表达式显示"China"2、给定一个字符串"123456789"⑴写出显示所有奇数的表达式⑵写出逆向显示所有偶数的表达式⑶写出字符串的逆转字符串的表达式3、字符串的格式化1)练习使用%格式化方法实现如下图的输出效果。
输入:输入一个字符串输入一个整数输出:2)练习使用format格式化方法实现如下图的输出效果。
4、在交互环境中练习使用常量字符串处理方法。
对字符串”we like Python”做如下操作:1)全部小写2)全部大写3)在整个字符串中统计“e”的数量4)在指定范围内统计“e”的数量(范围“like Pyth”)5)测试字符串是否以“on’结尾6)测试字符串是否以“On” 结尾7)测试字符串是否以“We”开头8)测试字符串是否以“we”开头9)返回“e”第一次出现时的序号10)字符串不包含“E",返回-111)在指定范围内查找"e”,第一次出现时的序号(范围“like Pyth”)12)查找某个字符,不包含搜索对象时,产生错误13)从末尾开始查找,返回“e”第一次出现时的序号14)从末尾开始查找,返回“we”第一次出现时的序号15)删除首尾的字符之后字符串变为“like Pytho”16)用指定字符将字符串分解成列表[‘we’,’like’,’Python’]17)用指定的字符将列表[‘we’,’like’,’Python’]连接成字符串4. 实验步骤与代码(此部分由学生完成)5.实验结果(此部分由学生完成)。
数据库技术与应用第二版课后答案

数据库技术与应用第二版课后答案【篇一:数据库技术与应用sql习题答案】class=txt>4. 启动查询分析器,在查询分析器中使用transact-sql 语句create database创建studb数据库。
然后通过系统存储过程sp_helpdb查看系统中的数据库信息create database studbsp_helpdb5. 在查询分析器中使用transact-sql语句alter database修改studb数据库的设置,指定数据文件大小为5mb,最大文件大小为20mb,自动递增大小文1mb。
alter database studbmodify file(name=studb,size=5mb,maxsize=20mb,filegrowth=1mb)7. 使用企业管理器将studb数据库的名称更改为student_db。
alter database studbmodify name=student_db8. 使用transact-sql语句drop database删除student_db数据库。
drop database student_db实验3 sql server 数据表的管理5. 使用transact-sql语句create table在studentsdb数据库中创建grade表。
create table grade(学号 char(4),课程编号 char(4),分数 decimal(5))8. 使用transact_sql语句insert into...values向studentsdb数据库的grade表插入以下数据:学号课程编号分数0004 0001 80use studentsdbgoinsert into gradevalues(0004,0001,80)9. 使用transact_sql语句alter table修改curriculum表的“课程编号”列,使之为非空。
03实验3 水总硬度的测定(配位滴定法)

实验三水总硬度的测定(配位滴定法)实验日期:实验目的:1、学习EDTA标准溶液的配制方法及滴定终点的判断;2、掌握钙、镁测定的原理、方法和计算。
一、水硬度的表示法:一般所说的水硬度就是指水中钙、镁离子的含量。
最常用的表示水硬度的单位有:1、以度表示,1o=10 ppm CaO,相当10万份水中含1份CaO。
2、以水中CaCO3的浓度(ppm)计相当于每升水中含有CaCO3多少毫克。
MCaO—氧化钙的摩尔质量(56.08 g/mol),MCaCO3—碳酸钙的摩尔质量(100.09 g/mol)。
二、测定原理:测定水的总硬度,一般采用配位滴定法即在pH=10的氨性溶液中,以铬黑T作为指示剂,用EDTA标准溶液直接滴定水中的Ca2+、Mg2+,直至溶液由紫红色经紫蓝色转变为蓝色,即为终点。
反应如下:滴定前:EBT +Me(Ca2+、Mg2+)=Me-EBT(蓝色) pH=10 (紫红色)滴定开始至化学计量点前:H2Y2- + Ca2+= CaY2- + 2H+H2Y2- + Mg2+= MgY2- + 2H+计量点时:H2Y2- + Mg-EBT = MgY2- + EBT +2H+(紫蓝色)(蓝色)滴定时,Fe3+、Al3+等干扰离子用三乙醇胺掩蔽,Cu2+、Pb2+、Zn2+等重金属离子可用KCN、Na2S 或巯基乙酸掩蔽。
三、主要试剂1、0.02mol/LEDTA2、NH3-NH4Cl缓冲溶液 3、铬黑T:0.5%4、三乙醇胺(1:2)5、Na2S溶液 2% 6、HCl溶液 1:17、CaCO3固体A.R.四、测定过程1、EDTA溶液的标定准确称取在120度烘干的碳酸钙0.5~ 0. 55g 一份,置于250ml 的烧杯中,用少量蒸馏水润湿,盖上表面皿,缓慢加1:1HCl 10ml,加热溶解定量地转入250ml容量瓶中,定容后摇匀。
吸取25ml,注入锥形瓶中,加20ml NH3-NH4Cl缓冲溶液,铬黑T指示剂2~3滴,用欲标定的EDTA溶液滴定到由紫红色变为纯蓝色即为终点,计算EDTA溶液的准确浓度。
SQL数据库实验三_简单查询(1)解答

16.在订单数据库中,根据员工的薪水进行分类显示。(薪水小于2000元的,显示“低收入者”,大于等于2000元小于4000元的,显示“中等收入者”,大于等于4000元的,显示“高收入者”。
SQL语句:
SELECTemployeeNo,employeeName,salary,薪水级别=
CASE
FROMEmployee
WHEREyear(hireDate)=1991
查询结果:
其他:
selectemployeeNo,employeeName,sex,telephone=isnull(telephone,'不详'),
birthday=convert(char(10),birthday,120),year(getdate())-year(birthday)asage
fromEmployee
wheredepartment<>'业务科'anddepartment<>'财务科'
12.查询1991年被雇佣的职工号、姓名、性别、电话号码、出生日期以及年龄,如果电话号码为空,显示“不详”,出生日期按yyyy-mm-dd显示。
SQL语句:
SELECTemployeeNo,employeeName,sex,isnull(telephone,'不详')telephone,CONVERT(CHAR(10),birthday,120)birthday,year(getdate())-year(birthday)age
FROMEmployee
WHEREdepartment='业务科'ordepartment='财务科'
实验3-数据查询

《数据库原理》实验报告实验名称数据查询实验室实验日期查询学生的基本信息查询“CS”系学生的基本信息查询“CS”系学生年龄不在19到21之间的学生的学号、姓名找出所有学生中的最大年龄找出“CS”系年龄最大的学生,显示其学号、姓名找出各系年龄最大的学生,显示其学号、姓名统计“CS”系学生的人数统计各系学生的人数,结果按升序排列按系统计各系学生的平均年龄,结果按降序排列查询每门课程的课程名查询无先修课的课程的课程名和学时数统计无先修课的课程的学时总数统计每位学生选修课程的门数、学分及其平均成绩统计选修每门课程的学生人数及各门课程的平均成绩找出平均成绩在85分以上的学生,结果按系分组,并按平均成绩的升序排列查询选修了“1”或“2”号课程的学生学号和姓名查询选修了“1”和“2”号课程的学生学号和姓名查询选修了课程名为“数据库系统”且成绩在60分以下的学生的学号、姓名和成绩查询每位学生选修了课程的学生信息(显示:学号,姓名,课程号,课程名,成绩)查询没有选修课程的学生的基本信息查询选修了3门以上课程的学生学号查询选修课程成绩至少有一门在80分以上的学生学号查询选修课程成绩均在80分以上的学生学号查询选修课程平均成绩在80分以上的学生学号六、总结通过本次实验,我基本掌握了SQL语句中的各种查询方式,简单查询、连接查询、嵌套查询、使用聚合函数的查询、对数据的分组查询、对数据的排序查询等,但是对比较复杂的查询方式,还不能熟练运用,特别是其WHERE条件,有时,还不能够准确描述,这将在以后的练习中有所加强。
七、源程序清单建立S数据库CREATE DATABASE S;建立关系表StudentCREATE TABLE Student( Sno CHAR(9) PRIMARY KEY,Sname CHAR(20),Ssex CHAR(2),Sage SMALLINT,Sdept CHAR(20));建立关系表Coursecreate table Course( Cno char(4) primary key,Cname char(40),Cpno char(4),Ccredit smallint,foreign key (Cpno) references Course(Cno)。
实验3-高级查询

实验三高级查询1实验目的(1)掌握SQL的高级查询的使用方法,如分组统计、嵌套查询、集合查询等等。
2实验内容2.1 掌握SQL高级查询使用方法(1)分组统计。
(2)嵌套查询,包括IN查询、EXISTS查询。
(3)集合查询。
3实验要求(1)深入复习教材第三章SQL有关高级查询语句。
(2)根据书上的例子,针对TPCH数据库模式设计分组统计查询、嵌套查询(IN、EXISTS)语句和集合查询语句,每种类型的基本查询至少要设计一个查询,描述清楚查询要求,运行你所设计的查询语句,并截图相应的实验结果,每幅截图并要有较为详细的描述。
也可以按照附2所列示例查询做实验。
(3)实验步骤和实验总结中要详细描述实验过程中出现的问题、原因和解决方法。
4实验步骤4.1 掌握SQL高级查询使用方法(1)不带分组过滤条件的分组统计查询。
(2)带分组过滤条件的分组统计查询。
(3)IN嵌套查询。
(4)单层EXISTS嵌套查询。
(5)双层EXISTS嵌套查询。
(6)集合查询(交、并、差各设计一个)。
(7)FROM 子句中的嵌套查询5总结与体会5.1 实验中出现的问题及其解决方案5.2 总结5.3 体会附1:高级SQL查询(1)不带分组过滤条件的分组统计查询。
统计每个顾客订购金额。
(2)带分组过滤条件的分组统计查询。
查询平均每个订单金额超过1000元的顾客编号及其姓名。
(3)IN嵌套查询。
查询订购了“海大”制造的“船舶模拟驾驶舱”的顾客。
(4)单层EXISTS嵌套查询。
查询没有购买过“海大”制造的“船舶模拟驾驶舱”的顾客。
(5)双层EXISTS嵌套查询。
查询至少购买过顾客“张三”购买过的全部零件的顾客姓名。
(6)集合查询(交、并、差各设计一个)。
查询顾客“张三”和“李四”都订购过的全部零件的信息。
查询顾客“张三”和“李四”订购的全部零件的信息。
顾客“张三”订购过,而“李四”没订购过的零件的信息。
(7)FROM 子句中的嵌套查询查询平均每个订单金额超过1万元的顾客中属于中国的顾客信息。
实验3 氢氧化钠标准溶液浓度的配制与标定

实验3 氢氧化钠标准溶液的配制及标定一、实验目的1. 掌握碱式滴定管规范操作。
2. 学会氢氧化钠标准溶液浓度标定的方法。
3. 熟悉指示剂的变色观察,掌握滴定终点的控制。
二、实验原理固体氢氧化钠具有很强的吸湿性,且易吸收空气中的水分和二氧化碳,因而常含有Na2CO3,且含少量的硅酸盐、硫酸盐和氯化物,因此不能直接配制成准确浓度的溶液,而只能配制成近似浓度的溶液,然后用基准物质邻苯二甲酸氢钾(KHC8H4O4)进行标定,以获得准确浓度。
用邻苯二甲酸氢钾标定氢氧化钠溶液的反应式为:由反应可知,1mol (KHC8H4O4)与1mol (NaOH)完全反应。
到化学计量点时,溶液呈碱性,PH值约为9,可选用酚酞作指示剂,滴定至溶液由无色变为浅粉色,30s不褪即为滴定终点。
三、实验器材1. 试剂1)氢氧化钠固体:2)酚酞指示剂(10g/L乙醇溶液):3)邻笨二甲酸氢钾基准物:2.器具电子天平、50mL 碱式滴定管、250mL 锥形瓶、量筒、500mL 玻塞细口试剂瓶。
四、实验步骤1. 0.1 mol·/L NaOH溶液的配制(GB/T 601-2002)称取110 g氢氧化钠,溶于100 mL无二氧化碳的水中,摇匀,注入聚乙烯容器中,密闭放置至溶液清亮。
按下表的规定,用塑料管量取上层清液5.4mL,用无二氧化碳的水稀释至1000mL,摇匀。
表2-1 配制氢氧化钠标准溶液(GB/T 601-2002)氢氧化钠标准滴定溶液的浓度[c(NaOH)]/mol/L) 氢氧化钠溶液的体积V/mL1 54 0.5 27 0.1 5.42. NaOH 溶液的标定准确称取邻苯二甲酸氢钾 0. 4~ 0 .6g (精确准至 0.1mg )四份,分别放入已编号的四个 250mL 锥形瓶中,每份加入 50mL 蒸馏水,温热使之溶解,冷却。
加酚酞指示剂 2 滴,用 NaOH 溶液滴定至溶液呈现微红色,30s 内不褪色,即为终点。
实验3 砂岩(一)—石英砂岩

对砂岩成因的初步分析 要求以下几个方面:
(1)从碎屑的成分特征分析推断陆源区母岩的性 质及大地构造状况。 (2)从砂岩的成分成熟度和结构成熟度分析推断 风化作用、搬运沉积作用对碎屑的改造程度、搬运 距离的远近、搬运沉积介质的性质及搬运方式,并 推断沉积环境。 (3)从化学胶结物的成分、结构、胶结类型、自 生矿物、颗粒接触关系等分析推断成岩作用强度、 成岩环境及成岩演变历史。 (4)还可根据碎屑及填隙物的成分、颜色等特推 断古地理、古气候。
颜色+结构(粒度)+填隙物(特殊自生矿物)+基本名称 如:暗红色中粒铁质石英砂岩;绿色细粒海绿石石英砂岩等。
2.薄片的观察描述及作图要求
1)结构:根据碎屑颗粒的粒度测量的结果确定其 粒度结构名称和分选性。薄片内一般采用目镜微尺 测量根据视域直径估计其碎屑的大小。如测得碎屑 的粒度在0.5—0.25mm之间,则属于中砂级,应定 为中粒砂状结构。如所测粒级既有中砂级,又有粗 砂级,且以粗级砂为主,应定为中—粗粒砂状结构, 一般地分选中等。若碎屑的粒级混杂,则为不等粒 砂状结构,其相应的分选差。 观察并确定碎屑的磨圆程度,确定磨圆好坏。
5)支撑类型及胶结类型 6)成岩后生变化:砂岩的成岩后生变化见教材 P117—121。砂岩中常见的成岩后生变化作用有 以下类型。 (1)胶结作用与固结作用 (2)压实及压溶作用 (3)重结晶作用 (4)交代作用及自生矿物的形成
7)砂岩中孔隙的研究:应注意孔隙的类型、 成因、孔隙及其连通性。以便对砂岩的储集 性能作出评价。(详见教材P121—122) 8)砂岩成因的初步分析:通过对砂岩标本及 薄片的观察研究之后,应对砂岩的特点加以 总结,并在综合分析的基础上作出某些成因 推断和提出一些问题。
(完整word版)北京理工大学计算机实验三报告表
0000 C000
0000 C000
0400 800C
07FF FFFE
0C00 001C
0C00 0010
1C00 0020
3800 01C0
01FF FFC0
0000 0380
0000 0700
0000 0C00
0000 1800
0000 6000
0000 6004
0000 600E
0303 2007
0303 000E
0603 001C
0603 0038
0403 0060
0403 00C0
0803 0380
1003 0600
3003 0C00
0000 3000
0000 C000
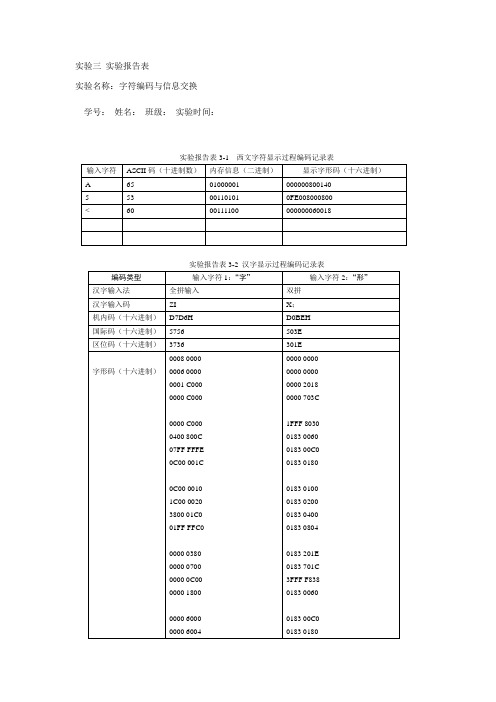
实验报告表3-3不同字体的字型码
字体
“字”的字型码
(十六进制表示)
“形”的字型码
(十六进制表示)
宋体
0008 0000
0400 800C
07FF FFFE
0C00 001C
0C00 0010
1C00 0020
3800 01C0
01FF FFC0
0000 0380
0000 0700
0000 0C00
0000 1800
0000 6000
0000 6004
0000 600E
7FFF FFFF
0000 6000
0000 6000
7FFF FFFF
0000 6000
0000 6000
0000 6000
0000 6000
0000 6000
0000 6000
0000 6000
0000 6000
实验三 蟾蜍实验(一)

于刺激电极方向),用滤纸片吸去标本上过多的任氏液。
五、动作电位和传导速度
13.测定参数
采样参数
刺激器参数
显示方式
记忆示波
刺激模式
自动幅度调节
采样间隔
25us
主周期
1s
X 轴显示压缩比
2:1
波宽
0.1ms
通道
通道 2
通道 4
初幅度
0.2V
DC/AC
AC
AC
增量
0.02V
处理名称
神经干 AP
AP 传导速度
1.毁脑脊髓 2.去躯干上部及内脏和皮肤 在荐尾关节前 1cm 处用剪 刀剪断脊柱,将前半躯干、皮肤和内脏一并拉右上图 蟾蜍坐骨神经腓肠肌标本制备甲、毁脑脊髓 剥弃之,仅保留一段腰背部脊柱及两后肢,并将其放入乙、丙 剪除躯干前段及内脏 丁、去皮肤 盛有任氏液的培养皿中。 3.洗净手和所用过的用具,以防沾染标本。 4.平分标本 沿脊柱正中线至耻骨联合中央将标本分为两半。放入任氏液中。 5.游离坐骨神经 任取一标本,用玻璃分针游离坐骨神经腹腔段。然后换至背侧向上,
实验三1-溴丁烷的制备
实验三 1-溴丁烷的制备一、实验目的1.学习由醇制备溴代烃的原理及方法。
2.练习回流及有害气体吸收装置的安装与操作。
3.进一步练习液体产品的纯化方法——洗涤、干燥、蒸馏等操作。
二、实验原理NaBr + H 2SO 4HBr + NaHSO 4C 4H 9OH + HBrC 4H 9Br + H 2O 主反应副反应C 4H 9OHC 2H 5CHCH 2+ H 2OC 4H 9OH+ H 2O 24H 9OC 4H 9HBr + H 2SO Br 2 + SO 2 + H 2O 2424本实验主反应为可逆反应,为了提高产率一方面采用HBr 过量;另一方面使用NaBr 和H 2SO 4代替HBr ,使HBr 边生成边参与反应,这样可提高HBr 的利用率,同时H 2SO 4还起到催化脱水作用。
反应中,为防止反应物正丁醇及产物1-溴丁烷逸出反应体系,反应采用回流装置。
由于HBr 有毒害且HBr 气体难以冷凝,为防止HBr 逸出,污染环境,需安装气体吸收装置。
回流后再进行粗蒸馏,一方面使生成的产品1-溴丁烷分离出来,便于后面的分离提纯操作;另一方面,粗蒸过程可进一步使醇与HBr 的反应趋于完全。
粗产品中含有未反应的醇和副反应生成的醚,用浓H 2SO 4洗涤可将它们除去。
因为二者能与浓H 2SO 4形成佯盐:+ H 2SO C 4H 9OH +C 4H 9OC 4H 9H 2SO 4C 4H 9OH 2HSO 4C 4H 9OC 4H 9H HSO 4如果1-溴丁烷中含有正丁醇,蒸馏时会形成沸点较低的前馏分(1-溴丁烷和正丁醇的共沸混合物沸点为98.6℃,含1-溴丁烷87%,正丁醇13%),而导致精制品产率降低。
三、实验药品及物理常数四、实验装置图制备1-溴丁烷的实验装置如图4-1~4-2所示。
五、实验流程图6.2ml10ml H 2O 10ml H 299-102度2六、实验步骤1.配制稀硫酸。
在烧杯中加入10 mL 水,将10 mL 浓硫酸分批加入水中,并振摇。
实验三-透析实验(一)——蛋白质的透析

2021/6/3
4
实验步骤
➢ 透析袋的前处理。
➢ 将蛋白质溶液做双缩脲反应。
➢ 取出透析袋,用三级水清洗透析袋内外,并检查透析袋是否有损坏。 用线将透析袋靠近末端的地方绑紧。
➢ 取8ml蛋白质溶液放入透析袋中,并将开口端同样用线绑住并放入盛 有蒸馏水的烧杯中。随时用玻棒搅拌液体。
➢ 每30min从烧杯中取水1ml,用10%HNO3酸化溶液,再加入 1%AgNO3 1-2d,检查氯离子的存在。另外取出1-2ml做双缩脲反应, 检查烧杯中是否有蛋白质存在。
➢ 蛋白质作为生物分子物质,不能透过透析膜 而小分子物质(比如离子等)可以自由通过。
2021/6/3
3
器具与试剂
➢ 烧杯;玻棒;试管;试管架;透析袋(宽 26cm,长8-10cm),线。
➢ 0.5mol/L EDTA;2%NaHCO3 ;1% AgNO3溶液;10%HNO3,10%NaOH; 1%CuSO4;鸡蛋清-NaCl溶液
2021/6/3
6
思考:
➢ 透析是去除小分子物质,那还有哪些去除小 分子物质的方法?
➢ 影响透析的因素整 理而来,供大家参考,
感谢您的关注!
实验原理透析是利用小分子能通过而大分子不能通过半透膜的原理把它们分开的一种重要手段是生物化学分离提纯过程经常使用的基本操作技术之一
实验三 透析实验(一) ——蛋白质的透析
2021/6/3 1
实验目的
➢ 掌握透析的基本原理和操作; ➢ 了解透析袋的使用方法。
2021/6/3
2
实验原理
➢ 透析是利用小分子能通过而大分子不能通过 半透膜的原理把它们分开的一种重要手段, 是生物化学分离提纯过程经常使用的基本操 作技术之一。
实验3 : 核酸和蛋白质序列为基础的数据库检索

实验 3 :核酸和蛋白质序列为基础的数据库检索一、实验目的:1.掌握已知或未知序列接受号的核酸序列检索的基本步骤2.熟悉基于核酸序列比对分析的真核基因结构分析(内含子/外显子分析)3.掌握BLAST的原理,了解如何利用Genbank数据库中提供的Blast功能完成同源性检索二、实验内容:作业(可以将演示一的结果记录并分析作为实验报告或作业4题中任意选两题作为报告上交)1、将上述演示二中核酸序列对应的蛋白质序列,分别进行BLASTP和PSI-BLAST搜索,说明你的参数设置,简明操作步骤,分析搜索结果,体会PSI-BLAST的优势。
2. 将第1题中的蛋白质序列利用TBLASTN程序进行搜索,说明你的参数设置,比较它与BLASTN结果有无差异。
3. 将第1题中的核酸序列利用BLASTX程序进行搜索,说明你的参数设置,比较它与BLASTP 搜索结果有无差异。
4. 将演示二中的核酸序列利用TBLASTX程序在默认数据库进行搜索,简要说明操作步骤,体会它与BLASTN搜索的差异。
三、作业:演示: 找一条你感兴趣的核酸序列(智人胰岛素(INS)),通过BLASTN搜索NR数据库,说明你的参数如何设置,分析搜索结果包含哪些信息。
答:使用的序列为:智人胰岛素(INS)>gi|297374822|ref|NM_001185098.1| Homo sapiens insulin (INS), transcript variant 3, mRNA。
Algorithm parameters设置如下:参数:Enter Query Sequence——NM_001185098Choose Search Set——Database: Nucleoctide collection(nr); Exclude: √Models(XM/XP),√Uncultured/environmental ample sequencesProgram Selection——Optimize fot: Highly similar sequences展开“Algorithm parameters”,依次设置:General Parameters——Max target sequence:100; Short queries:√ ; Expect threshold:10;Word size:28; Max matches in a query range:0Scoring Parameters——Matrix/Mismatch Scores:1,-2; Gap Costs: LinearFilters and Masking——Filter: √Low complexity regions; √Mask: mask for lookup table only搜索结果分析:使用智人胰岛素(INS)>gi|297374822|ref|NM_001185098.1| Homo sapiens insulin (INS), transcript variant 3, mRNA搜索NR数据库,搜索出100条符合条件的序列,序列来自的物种包括了Homo sapiens,Pan troglodytes,Gorilla gorilla,Pongo abelii,Pongo pygmaeus,Mus musculus等,其中根据得分高低排列,前7条序列如下所示:NM_001185098.1 Homo sapiens insulin (INS), transcript variant 3, mRNANM_001185097.1 Homo sapiens insulin (INS), transcript variant 2, mRNANM_000207.2 Homo sapiens insulin (INS), transcript variant 1, mRNANG_007114.1 Homo sapiens insulin (INS), RefSeqGene on chromosomeAC132217.15 Homo sapiens chromosome 11, clone RP11-889I17, complete sequence BC005255.1 Homo sapiens insulin, mRNAJ00265.1 Human insulin gene, complete cds上述序列的“Max ident”均为100%或99%,且E-Value值很低,可见搜索出来的序列与QUERY 序列匹配的相似度很高。
数据库实验《实验3》

8.
createruleprof_rule
as@pro=('助教'|'讲师'|'副教授'|'教授')
execsp_bindrule'prof_rule','teacher.pro'
9.
createdefaultEmail_defaultas'无'
2.
altertableteach_classaddforeignkey(teacherno)referencesteacher(teacherno)
altertableteach_classaddforeignkey(classno)referencesclass(classno)
altertableteach_classaddforeignkey(courseno)referencescourse(courseno)
8.利用Transact-SQL语句为teaching数据库创建规则prof_rule,规定教师职称取值只能为“助教”,“讲师”,“副教授”和“教授”,并将其绑定到teacher表的prof列上。
9.利用Transact-SQL语句为teaching数据库创建默认值对象Email_default,规定电子邮箱地址默认为“无”,并将其绑定到student表的Email列上。
实验名称
实验3
实验地点
8-318
实验类型
设计
实验学时
1
实验日期
2018.6.12
★撰写注意:版面格式已设置好(不得更改),填入内容即可。
一、实验目的
光纤通信实验3

∆U
2 ∆U U
∆T
2U
U − 2 ∆U 眼开启度 U
交叉点发散度
∆T T
眼图是由各段码元波形叠加而成的,眼图中央的垂直线表示最佳抽样时 刻,位于两峰值中间的水平线是判决门限电平。在无码间串扰和噪声的 理想情况下,波形无失真,“眼”开启得最大。当有码间串扰时,波形 失真,引起“眼”部分闭合。若再加上噪声的影响,则使眼图的线条变 得模糊,“眼”开启得小了,因此,“眼”张开的大小表示了失真的程 度。由此可知,眼图能直观地表明码间串扰和噪声的影响,可评价一个 基带传输系统性能的优劣。另外也可以用此图形对接收滤波器的特性加 以调整,以减小码间串扰和改善系统的传输性能。 (1)眼图张开的宽度决定了接收波形可以不受串扰影响而抽样再生的 时间间隔。显然,最佳抽样时刻应选在眼睛张开最大的时刻。 (2)眼图斜边的斜率,表示系统对定时抖动(或误差)的灵敏度,斜 边越陡,系统对定时抖动越敏感。 (3)眼图左(右)角阴影部分的水平宽度表示信号零点的变化范围, 称为零点失真量,在许多接收设备中,定时信息是由信号零点位置来 提取的,对于这种设备零点失真量很重要。 (4)在抽样时刻,阴影区的垂直宽度表示最大信号失真量。 (5)在抽样时刻上、下两阴影区间隔的一半是最小噪声容限,噪声瞬 时值超过它就有可能发生错误判决; (6)横轴对应判决门限电平。
三、实验原理
光收端机的灵敏度是指在保证一定的误码率前提下,光接收机所 允许接收的最小光功率。灵敏度的单位为分贝毫瓦(dBm)。 光接收机灵敏度主要决定于光接收机内部噪声(光检测噪声和前 置放大器噪声)。光接收机内部噪声是伴随光信号的接收检测与 放大过程产生的,它使接收机最小可接收平均光功率受到限制, 即它决定了光接收机的灵敏度。
6.打开系统电源,液晶菜单选择“光纤测量实验—接收灵敏度”,确认。 调节W201即改变送入光发端机信号(TX1310)幅度最大(不超过5V)。 慢慢调节可调衰减器(减少衰减量),直至在一定调节范围内,误码状 态一直显示为“正常”。保持此时可调衰减器状态。 7. 按“返回”键,选择“光纤测量实验—接收灵敏度”,确认。刷新误 码仪,此时误码状态应该一直显示为“正常”。慢慢调节可调衰减器, 增加衰减量,即使进入光收端机的光功率逐渐减小,出现误码率或者误 码率逐渐增大。当误码率达到时,误码状态显示即由“正常”切换为 “误码”。此时可以反调衰减器减少其衰减量,在误码状态切换点停止 调节,保持此时可调衰减器状态。 8. 断开光接收端机,测量可调衰减器的输出光功率Pmin(dBm),即为 此光收端机的灵敏度。注意操作过程中,不可改变可调衰减器状态。 9.重测量结构连接,重复步骤6、7,刷新误码仪。慢慢调节可调衰减器, 减小衰减量,使进入光收端机的光功率逐渐增大,出现误码率或者误码 率逐渐增大。当误码率达到时,误码状态显示即由“正常”切换为“误 码”。此时可以反调衰减器增大其衰减量,在误码状态切换点停止调节, 保持此时可调衰减器状态。 断开光接收端机,测量可调衰减器的输出光功率Pmax(mW)。 10. 算出此光收端机的动态范围D; 11. 关闭系统电源。
2025年贵州中考物理命题探究-电、磁学-第十五讲 电学实验实验3 用电流表和电压表测量电阻

返回目录
例 2 (2023江西改编)在“伏安法测量小灯泡电阻”的实验中,小明使 用的器材如下:额定电压为2.5V的小灯泡(正常发光时电阻约10Ω)、两节 新干电池、电流表、电压表、滑动变阻器(20Ω 1A)、开关、导线若干.
甲
乙
例2题图 (1)连接电路前,电流表有示数,应该对电流表进行_调__零__.
返回目录
2.在“测量小灯泡电功率”的实验中,小宏设计了如图甲所示的电 路,电源电压恒为3V,小灯泡额定电压为2.5V.
甲
乙
丙
第2题图 (1)连接电路时,开关应处于__断__开__状态.
返回目录
(2)通电后,无论怎样移动滑动变阻器的滑片,小灯泡亮度始终不变且电 压表指针保持在3V的位置.小宏检查电路发现连线时错将导线接在了如 图乙所示的滑动变阻器____C_、__D_(填写字母)两个接线柱上.
2.4
3.0
电流I/A
0.10
0.18
0.26
0.30
A.减小误差
B.寻找实验的普遍规律
返回目录
拓展 训 练 (6)第5次实验时,闭合开关发现电流表、电压表均无示数,同组的小东 同学断定是定值电阻断路.这个判断是_错__误__(选填“正确”或“错误”) 的,理由是_若__定__值__电__阻__断__路__,__电__压__表__测__电__源__电__压__,__仍__有__示__数____. (7)同组的同学查阅资料得知:虽然电压表内部电阻很大,但电路接通后 仍有微小电流流过电压表,请你根据这一事实并结合电路图分析判断, 实验中测得定值电阻的阻值比真实值偏_小___(选填“大”或“小”).
返回目录
特殊方法测电阻(定值电阻R0阻值已知,滑动变阻器R1的最大阻值为R1max)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验3查询(1)
一、实验目的
(1)掌握利用设计批视图创建单表和多表的查询。
(2)掌握利用向导创建查询。
(3)掌握创建查询的方法
(4)掌握使用SQL创建查询
(5)掌握查询准则的应用
二、实验内容
到天空教室资源中下“人才管理”文件,将该文件下载并解压缩到自己的文件夹中,进行下列操作。
1.创建不带条件的选择
(1)P56例3.5 (查询名称为:例3-5)
(2)用向导创建查找并显示学号、姓名,所在院校,数学的内容(查询名称为:数学成绩)
2.创建带条件的选择
(1)P56例3.6 (查询名称为:例3-6)
(2)查询女团员的相关信息,显示学号,姓名,数学(查询名称为:女团员)
(3)在学生信息表,学生成绩表,课程信息表中查询并显示所有女团员已参加考试的情况。
显示学号,姓名,课程编号,课程名,成绩,并按姓名排序。
(查询名称为:女团员考试情况)
(4)查找姓“王”或姓“张“的人(查询名称为:姓氏查找)
(5)显示英语,数学成绩在[70,90]的记录(查询名称为:数学成绩查找)
3.总计查询和分组查询
(1)P56例3.9 (查询名称为:例3-9)
(2)统计入学成绩600分以上学生的数量(查询名称为:600分以上查找)
(3)统计入学成绩的最高分,最低分,平均分(查询名称为:院系入学成绩统计) 4.分组查询
(1)统计每个院系入学的最高分(查询名称为:院系最高入学成绩统计查找)
(2)统计姓“王”的人数(查询名称为:姓“王”的人数统计)
5.添加新字段
(1)P63例3.11 (查询名称为:例3-11)
(2) 显示所有女同学的年龄(查询名称为:女生年龄)
(3)统计每个院系人数,提示:用count(*)(查询名称为:院系人数)。