流式计算技术及应用
流式细胞术的原理和应用

RT
PCR
RT-PCR反应过程
反转录PCR: mRNA---cDNA---PCR
• 抽提RNA • 反转录合成cDNA • PCR 扩增
RT反应体系
• 模板:总RNA,mRNA • 引物:随机引物,Oligo(dT),基因特异性
引物(GSP) • 逆转录酶:AMV
M-MLV Quant Reverse Transcriptase
B. 集落形成法
• 其基本原理是应用骨髓干细胞体外半固体 培养系统,根据不同造血因子能诱导干细 胞或定向造血祖细胞形成某一种或某些种 类细胞的集落,通过对形成集落形态学、 酶学鉴定,计算不同种类集落形成的数量 和比例,反映待测标本中CSF的种类和活 性水平。
C. 直接杀伤靶细胞
• 细胞因子TNF-α、TNF-β具有直接杀伤某些 肿瘤细胞的作用,采用TNF敏感的细胞株如 小鼠成纤维细胞株L929,以WEHI164亚克 隆13(鼠纤维肉瘤细胞系)作为指示细胞, 通过3H-TdR释放法或染料染色等可检测待 检样品中TNF的活性水平。
– 标准品50%最大OD值 – 找出与标准品50%最大OD值相对应的标准品稀释度(S) – 找出与标准品50%最大OD值相对应的待测品稀释度(A)
• 待测品单位数=S/A×标准品单位
OD 值 100%OD
50%OD
标准品 待测品
1/8 1/4 S 1/2 A
1 稀释度
对生物学活性测定法的评价
• 优点:灵敏度高; 测定的是有生物活性的细胞因子
• 细胞因子与治疗:重组细胞因子做为生物 应答调节剂。已批准生产:IFN-α、β、 γ,Epo,GM-CSF,G-CSF,IL-2,正在进 行临床试验的:IL-1、3、4、6、11,MCSF,SCF,TGF-β等
超级计算机的发展历程及应用

超级计算机的发展历程及应用人类计算能力的进步始自最早的原始计算器,经过几千年的演进,发展出今天的各种计算机和计算机系统。
而在计算机历史中,超级计算机一直是科学技术领域里的大腕。
本文将对超级计算机的发展历程和应用进行探讨。
一. 超级计算机的起源早在20世纪50年代,美国国家安全局就在研究德国在二战期间使用的破译机Enigma。
为此,美军成立了IBM机器公司作为专门从事电子计算机技术研究和开发的机构。
在此后的几十年里,超级计算机得到了飞速的发展。
二. 超级计算机的发展历程从20世纪60年代以来,超级计算机的性能得到了极大的提高,各种改进的设备和算法使得超级计算机的速度和精度得到了飞跃式的突破。
1. 向量计算机20世纪60年代,日本钢铁公司首次提出向量计算机的概念。
向量计算机是一种流式计算顺序,在执行一系列向量操作时非常快速。
这种计算机可以同时执行多个操作,并执行复杂的数学函数。
同类的向量计算机还有美国的Cray研究中心和欧洲的德国Convex计算公司等。
2. 多处理器计算机1976年,美国Seymou Cray 提出了首台高性能计算机Cray-1,也是首款多处理器计算机。
它有九个处理器—八个用于计算和管理,另一个用于外部通信。
同时,它的并行访问和通信机制也非常优秀,允许多个计算任务同时运行并互相通信。
3. 超级计算机的并行性20世纪80年代中期,在并行架构的推动下,超级计算机在性能上又有了大幅提升。
并行计算是指将一个任务分成小任务,每个任务由多个处理器并行处理,这样就可以加快任务的计算速度。
这种方法大幅提高了超级计算机的计算速度和效率,成为目前超级计算机的主要发展方向。
4. 互联网络的发展互联网络也催生了超级计算机的发展。
20世纪90年代,以高速通信和高效易用性为特点的互联网络成功开发,这使得先进计算资源和算法可以在全球范围内共享。
这种大规模联网的架构使得不同地区的超级计算机可以并行处理不同的任务,从而加速整个计算过程。
大规模数据流处理与分析平台设计与实现

大规模数据流处理与分析平台设计与实现随着互联网的快速发展和大数据技术的迅猛进步,大规模数据流的处理和分析成为了当今科技领域的热点话题。
设计和实现一个高效可靠的大规模数据流处理与分析平台,具有极大的价值和意义。
本文将深入探讨该平台的设计与实现方法。
一、需求分析与需求定义要设计和实现一个大规模数据流处理与分析平台,首先需要对其需求进行充分的分析和定义。
在这个阶段,我们需要考虑以下几个方面的需求:1. 数据规模:确定平台需要处理的数据规模。
是否涉及海量的数据流,以确定平台的扩展性要求。
2. 实时性:确定数据流处理的实时性要求。
高实时性的处理要求需要考虑低延迟和高并发等方面的问题。
3. 数据安全:确保数据的安全性和可靠性,防止数据泄露和恶意攻击。
4. 数据分析需求:确定平台需要提供的数据分析功能,例如实时监控、异常检测、关联分析等。
5. 可扩展性:平台需要具备良好的可扩展性,以满足未来数据增长和业务需求的变化。
二、平台架构设计在对需求进行充分分析后,我们可以开始设计大规模数据流处理与分析平台的架构。
一个典型的架构设计包含以下几个主要组件:1. 数据采集器:负责从不同的数据源收集数据。
可以支持多种数据格式和通信协议,确保数据的高效采集和传输。
2. 分布式消息队列:用于接收和传输大量的数据流,以实现数据的异步处理。
消息队列具有高吞吐量和可靠性的特点。
3. 数据处理引擎:负责数据流的实时处理和分析。
可以采用流式计算引擎,如Apache Storm或Apache Flink,以支持高速的数据处理能力。
4. 存储系统:用于存储和管理处理后的数据。
可以采用分布式存储系统,如Apache Hadoop或Apache Cassandra,以支持海量数据的存储和快速检索。
5. 数据分析工具:提供各种数据分析功能,例如数据可视化、机器学习和数据挖掘等,以帮助用户深入挖掘数据的价值。
三、关键技术与挑战在设计与实现大规模数据流处理与分析平台时,需要面对一些关键技术和挑战。
九、流式细胞仪原理及应用、CD4绝对计数的原理、方法和质量控制

免疫聚合磁珠 Dynabeads (利用光镜和免 疫荧光染色) 细胞球 Cytosphere (利用计数板和光镜)
Dynabeads技术计数CD4细胞
原理
用抗CD4单克隆抗体(mAbs)包被的磁化粒子捕获与分 离全血中CD4T淋巴细胞 将125ml新鲜血液,放入EDTA管,加350mlPBS,再加 入25ml mAbs磁化悬浮粒子,在摇床(Dynal Mechnical Rotator) 上置室温10分钟混和,以便去掉血液中的单核 细胞。磁化粒子用专门的磁性浓度计分离,并用PBS 洗涤2次,加入50ml Lysing溶液,着色,用 epifluorescent显微镜计数。
功能特点
(1)多参数定量分析每一个细胞; (2)细胞分选; 高纯度:99%以上; 可分析小于1/10000比例的稀有细胞群; 单细胞克隆等。
(3)高通量(分析分选). 分析150,000个/ 秒 分选100,000个/秒
●流式细胞仪内部结构
▲光学系统 激光光源 光收集系统 ▲液流系统 流动室 液流驱动系统 ▲电子系统 光电转换 数据处理系统 ▲细胞分选系统
CD4+T细胞(Th细胞)绝对计数持续减少
CD8+T细胞(Ts细胞)增高,到疾病晚期时下降 T细胞亚群比例倒臵,CD4/ CD8 <1.0 CD4+细胞功能受损
外周血中CD4+T淋巴细胞的数量是HIV感染疾病分期、 预测疾病进程、制定抗病毒治疗和预防机会性感染方 案以及评价治疗效果的实验室标准指标。
光信号
FSC SSC FL1 FL2 FL3
电信号
对数 线性 线性 线性 对数
脉冲处理,模数转换
(面积,峰高,宽度)
一脉相承的高可用技术从 分布式系统到流式计算

泛认同 ,其特征是 :数据不宜用持久稳定关系建 除 了硬 件 故障和 软件 B g u ,数 据库 系统 还 T asci a ue ), o l 模 ,而适宜用瞬态数据流建模 。这些应用的实例 可 能遭受到事务故 障 (rn at nF i rs 原因可能 是完整性 约束 的违背和死 锁 。如 果发 包 括金融服务 、网络监控 、电信数据管理、We b 应用、传感检测等。在这种数据流模型中 ,单独 生这 种 故 障 ,数 据 库 的状 态 可 能 会 变得 不 一 的数据单元 可能是相 关的元组 (u ls T pe),例如 致 。因此 ,我们 需要恢 复机制 能够 保证 事务 的 网络测量 、呼叫记录 、网页访问等产生的数据 。 原子性 ,这通常分为 以下几种 。
致状态 。 通 过 定 期 产 生 C ek on,系 统 能 够 减 少 恢 hcp i t
究数 据流 系统 的前 提 。本 文从 布 朗大 学Jo g en .
t hcp i t H o wag y nH n 的博士论文F s adhg l—v i be 复时需要处理的 F志记录数量 。C ek on在持 at n ih aal l y a sra rcsi 为起点 ,谈谈分 布式系统和数 久化 存储 中保 存了一致性 状态 。基 于 日志的恢 t mp o esn e g 据流系统的高可用技术 。 复技术广 泛应用于数据 库产品 ,包 括I M 2 B DB  ̄Mi oot QLS re等。 l c sfS evr J r
S 、T t rSom、商用 的I M t a ae 4 wie tr t B Sr mB s及学 后者在事务提交后变成新的页表。 e
大数据处理技术

大数据处理技术随着信息技术的不断发展和应用的扩大,大数据已经成为当今信息社会的重要组成部分。
大数据处理技术作为解决海量数据存储、分析和应用的核心技术之一,正日益受到广泛关注和应用。
本文将介绍大数据处理技术的基本概念、发展现状以及未来趋势。
一、大数据处理技术的概念大数据处理技术是指对海量、复杂的数据进行收集、存储、分析、挖掘和应用的技术方法和工具。
与传统的数据处理方式相比,大数据处理技术具有以下特征:1.数据规模大:大数据处理技术主要应对的是数据规模巨大的问题,这些数据包括结构化数据、半结构化数据和非结构化数据。
2.数据速度快:大数据处理技术要求对数据的实时或准实时处理,以满足快速响应和实时决策的需求。
3.数据种类多:大数据处理技术需要处理多种类型的数据,如文本、图像、音频和视频等多媒体数据。
4.数据价值高:大数据处理技术通过对数据进行分析和挖掘,发现隐藏在数据背后的信息和价值,为决策提供科学依据。
二、大数据处理技术的发展现状当前,大数据处理技术已经广泛应用于各行各业,为企业和机构提供了巨大的商业价值。
以下是几个典型的大数据处理技术:1.分布式存储和计算:通过分布式存储和计算技术,将海量数据存储在多个节点上,并通过并行计算的方式进行处理,提高数据处理的效率和可靠性。
2.数据挖掘和机器学习:数据挖掘和机器学习技术能够从大数据中发现模式、规律和关联性,提供了对数据深入分析的方法和工具。
3.实时处理和流式计算:实时处理和流式计算技术可以对数据进行实时监控和处理,及时发现和处理异常情况,为实时决策提供支持。
4.云计算和边缘计算:云计算和边缘计算技术将大数据处理移动到云端和边缘设备,实现数据的高效利用和灵活部署。
三、大数据处理技术的未来趋势随着人工智能、物联网等新技术的发展,大数据处理技术将呈现出以下几个趋势:1.智能化:大数据处理技术将与人工智能技术相结合,实现智能化的数据处理和决策支持。
2.实时化:大数据处理技术将进一步提高处理速度,实现数据的实时处理和分析。
大数据分析平台中的实时数据处理技术研究

大数据分析平台中的实时数据处理技术研究随着科技的不断发展,大数据分析平台成为了许多企业和组织的重要工具。
在大数据分析平台中,实时数据处理技术起着至关重要的作用。
本文将对大数据分析平台中的实时数据处理技术进行深入研究,探讨其原理和应用。
1. 实时数据处理的意义和挑战实时数据处理是指在数据产生的同时进行分析和处理的一种技术。
与传统的批量处理相比,实时数据处理能够更快速地获取和处理数据,从而及时响应业务需求。
在大数据分析平台中,实时数据处理具有重要的意义和挑战。
首先,实时数据处理可以让企业及时发现和解决问题,提高决策的准确性和时效性。
其次,实时数据处理需要能够处理大量的数据流,并实时更新结果,这对于数据处理的性能和可扩展性提出了挑战。
此外,实时数据处理还需要保证数据的准确性和一致性,这要求在分布式环境中进行数据同步和容错处理。
2. 实时数据处理的核心技术2.1 流式计算实时数据处理的核心技术之一是流式计算。
流式计算可以将数据分成多个小的数据流,并通过并行处理来达到实时性的要求。
流式计算通常采用分布式计算框架,如Apache Storm、Flink等。
这些框架可以将计算任务分配到多个计算节点上,从而快速地处理大量的数据流。
此外,流式计算框架还支持容错处理和状态管理,保证系统的稳定性和准确性。
2.2 内存计算与传统的磁盘计算相比,内存计算在实时数据处理中具有更高的性能。
内存计算将数据存储在内存中,可以快速地读取和更新数据,从而加快数据处理的速度。
内存计算通常使用分布式内存数据库,如Redis、Memcached等。
这些数据库通过将数据分布在多个节点上,实现数据的快速存取和更新,并支持数据的持久化和备份,保证数据的安全性和可靠性。
2.3 数据流管理实时数据处理需要对数据流进行管理和调度。
数据流管理技术可以将数据流分成多个小的数据块,并将这些数据块分发到不同的计算节点上进行处理。
数据流管理还可以根据数据的优先级和处理的需求,对数据流进行优化调度,提高系统的性能和效率。
流式-荧光原位杂交(Flow-FISH)
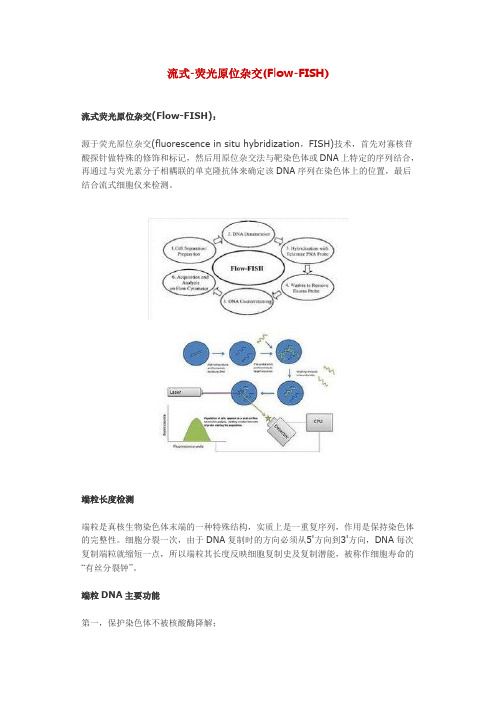
流式-荧光原位杂交(Flow-FISH)流式荧光原位杂交(Flow-FISH):源于荧光原位杂交(fluorescence in situ hybridization,FISH)技术,首先对寡核苷酸探针做特殊的修饰和标记,然后用原位杂交法与靶染色体或DNA上特定的序列结合,再通过与荧光素分子相耦联的单克隆抗体来确定该DNA序列在染色体上的位置,最后结合流式细胞仪来检测。
端粒长度检测端粒是真核生物染色体末端的一种特殊结构,实质上是一重复序列,作用是保持染色体的完整性。
细胞分裂一次,由于DNA复制时的方向必须从5'方向到3'方向,DNA每次复制端粒就缩短一点,所以端粒其长度反映细胞复制史及复制潜能,被称作细胞寿命的“有丝分裂钟”。
端粒DNA主要功能第一,保护染色体不被核酸酶降解;第二,防止染色体相互融合;第三,为端粒酶提供底物,解决DNA复制的末端隐缩,保证染色体的完全复制。
主要检测方法:DNA印迹法(Southern blot, SB):使用限制性核酸内切酶消化DNA, 然后琼脂糖电泳分离不同大小的片段, 转移到硝酸纤维或尼龙膜上。
用同位素或生物素、碱性磷酸酯酶标记的端粒特异探针与其杂交。
末端限制酶切片段(TRF)通过光密度计定量测量。
杂交保护分析法(hybridization protection assay, HPA) :需要制备基因组DNA、细胞或组织溶胞产物同吖啶酯(AE)标记端粒的探针进行杂交, 检测发光强度, 确定端粒在Alu序列中比例。
荧光原位杂交(FISH):FISH直接将寡核苷酸探针标记在端粒序列上. 标准的FISH包括制作分裂中期的染色体以及DNA变性, 与FITC或Cy3标记的寡核苷酸探针杂交, 用DAPI或PI复染, 最后用荧光显微镜检测信号。
流式-荧光原位杂交(Flow-FISH):包括6个基本步骤: 细胞分离, DNA变性并与PNA 探针杂交, 洗去多余探针, 复染后用流式细胞计量术采集和分析。
java 实现大模型问答结果流式输出的方法

一、概述随着人工智能技术的不断发展,大模型问答系统成为了近年来人工智能领域的热门研究方向之一。
然而,由于大模型问答系统需要处理大规模的数据和复杂的计算,使得实现其结果的流式输出成为了一个挑战。
本文将介绍如何利用Java语言实现大模型问答结果的流式输出的方法。
二、背景介绍大模型问答系统是一种能够根据自然语言问题从大规模语料库中找到并生成答案的系统。
在实际应用中,用户可能需要实时地获取问答系统的结果,而问答系统可能需要进行复杂的计算和分析。
为了解决这一问题,我们需要找到一种方法来实现大模型问答结果的流式输出,即在系统处理数据的不断地向用户输出部分的结果。
三、Java实现大模型问答结果流式输出的方法1. 使用流式处理技术Java 8引入了流式处理(Stream API)技术,可以极大地简化对集合的操作。
我们可以利用流式处理技术将问答系统的结果进行分块处理,并不断地输出给用户。
这样做不仅可以降低内存消耗,还可以实现实时输出结果。
2. 使用多线程对于大规模的数据处理,单线程往往无法满足要求。
我们可以利用Java的多线程技术,将问答系统的计算过程拆分成多个子任务,并行处理这些子任务,最后将结果合并输出给用户。
这样可以提高系统的响应速度和并发处理能力。
3. 使用异步IOJava提供了NIO(New I/O)框架,可以实现非阻塞的IO操作。
我们可以利用Java的异步IO技术,将问答系统的IO操作异步化,从而提高系统的吞吐量和响应速度。
通过将IO操作和计算操作分离,可以更好地实现大模型问答结果的流式输出。
四、案例分析为了验证上述方法的可行性,我们可以以一个简单的大模型问答系统为例进行分析和实验。
假设我们有一个包含大量知识的语料库,用户可以通过提问来获取相关的知识。
我们可以利用上述方法,将问答系统的结果进行流式输出,以验证这些方法的有效性。
五、总结与展望本文介绍了如何利用Java语言实现大模型问答结果的流式输出的方法。
流式分析实验报告

实验名称:流式分析仪器的原理与应用实验日期:2023年11月15日实验地点:流体力学实验室实验目的:1. 理解流式分析仪器的原理及其在流体力学中的应用。
2. 掌握流式分析仪器的操作方法及数据处理技术。
3. 分析流场参数,评估流场特性。
实验原理:流式分析仪器是一种用于测量流体流动参数的仪器,如流速、流量、温度、压力等。
本实验主要涉及基于激光多普勒测速仪(LDA)和粒子图像测速仪(PIV)的流场分析。
实验仪器:1. 激光多普勒测速仪(LDA)2. 粒子图像测速仪(PIV)3. 激光发射器4. 摄像机5. 流体动力学实验装置(如风洞、管道等)实验步骤:1. 准备工作:搭建实验装置,确保仪器正常工作。
2. 实验一:LDA测速:a. 在实验装置中设置待测流场。
b. 使用LDA仪器测量流场中的流速分布。
c. 通过数据处理软件分析LDA测量数据,得到流速分布图。
3. 实验二:PIV测速:a. 在实验装置中设置待测流场。
b. 使用PIV仪器测量流场中的流速分布。
c. 通过数据处理软件分析PIV测量数据,得到流速分布图。
4. 数据分析:a. 比较LDA和PIV测量得到的流速分布图,分析两种仪器的优缺点。
b. 计算流场关键参数,如平均流速、湍流强度等。
c. 分析流场特性,如是否存在涡流、分离区等。
实验结果与分析:1. LDA测速:a. 通过LDA测量得到的流速分布图,可以看出实验装置中流速的分布情况。
b. LDA仪器具有高测量精度和宽测量范围的特点,但在测量湍流时,可能会受到湍流脉动的影响。
2. PIV测速:a. 通过PIV测量得到的流速分布图,可以看出实验装置中流速的分布情况。
b. PIV仪器具有较高的测量精度和较高的空间分辨率,但在测量时需要添加示踪粒子,可能会对实验结果产生一定影响。
3. 数据分析:a. 比较LDA和PIV测量得到的流速分布图,可以看出两种仪器在测量流速分布方面具有一定的相似性。
b. 计算得到的流场关键参数,如平均流速、湍流强度等,可以为流体力学研究提供重要参考。
流式细胞技术原理和方法

流式DNA定量分析的染色原理
• 经DNA特异性染料染色的细胞群体, 通过测量区受激光照射后发出特异性 荧光,在一定条件下,荧光强度与细 胞内的DNA含量成正比。
流式细胞技术(Flow Cytometry)
流式细胞仪
流式细胞仪(Flow Cytometer, FCM),又名荧
光激活细胞分类器 (Fluorescence Activited Cell Sortor, FACS), 它是将流体喷射技术、激光技 术、空气计数、r--射线能谱术及电子计算机等 技术与显微荧光光度计密切结合的仪器,开创
藻胆蛋白藻胆蛋白phycobiliproteinphycobiliprotein是近年发现的用于是近年发现的用于免疫荧光分析和标记各类配体的一种新荧光染免疫荧光分析和标记各类配体的一种新荧光染待测细胞被制成单细胞悬液经特异性荧光待测细胞被制成单细胞悬液经特异性荧光染料染色后加入样品管中在气体压力推动染料染色后加入样品管中在气体压力推动下进入流动室流动室内充满鞘液在鞘液下进入流动室流动室内充满鞘液在鞘液的约束下细胞排成单列流出流动室喷嘴口的约束下细胞排成单列流出流动室喷嘴口并被鞘液包绕形成细胞液柱与水平方向的并被鞘液包绕形成细胞液柱与水平方向的激光光束垂直相交发出荧光同时产生散激光光束垂直相交发出荧光同时产生散射光被荧光光电倍增管接收被积分放大射光被荧光光电倍增管接收被积分放大反转换为电子信号输入电子信息接收器通反转换为电子信号输入电子信息接收器通过计算机快速而精确地将所测数据计算出来过计算机快速而精确地将所测数据计算出来结合多参数分析从而实现了细胞的定量分结合多参数分析从而实现了细胞的定量分http
常用的免疫荧光染料
• 异硫氰酸荧光素 (fluorescein isothiocyanate, FITC) 是检测细胞总蛋白最常用的荧光染料。 • 藻胆蛋白(phycobiliprotein) 是近年发现的用于
cd34细胞计数计算公式

cd34细胞计数计算公式CD34细胞计数计算公式。
在医学领域,CD34细胞计数是一项非常重要的指标,它可以用来评估造血干细胞的数量和质量,对于临床诊断和治疗具有重要意义。
CD34细胞是一种干细胞的标志物,它存在于骨髓、外周血和胎盘等组织中,是造血干细胞的一种表面标记物。
因此,CD34细胞计数的准确性对于临床诊断和治疗至关重要。
CD34细胞计数的公式是一种用来计算CD34细胞数量的数学公式,它可以通过实验室检测数据来计算CD34细胞的绝对数量,为临床诊断和治疗提供重要的参考依据。
下面我们将介绍CD34细胞计数的公式及其计算方法。
CD34细胞计数的公式如下:CD34细胞数(每微升)=(CD34细胞百分比×白细胞计数)/100。
其中,CD34细胞百分比是指在外周血或骨髓细胞中CD34阳性细胞所占的百分比,白细胞计数是指外周血或骨髓中白细胞的数量。
通过这个公式,可以计算出每微升外周血或骨髓中CD34细胞的数量。
在实际应用中,CD34细胞计数通常是通过流式细胞术来进行测定的。
流式细胞术是一种通过检测细胞表面标记物来分析细胞数量和类型的技术,它可以对CD34细胞进行准确的定量分析。
通过流式细胞术,可以得到CD34细胞的百分比和白细胞计数,从而可以利用上述公式计算出CD34细胞的绝对数量。
CD34细胞计数的结果对于临床诊断和治疗具有重要的指导意义。
在临床上,CD34细胞计数通常被用来评估造血干细胞的数量和质量,对于骨髓移植、干细胞移植以及造血干细胞采集等治疗方案的制定和评估起着关键的作用。
此外,CD34细胞计数还可以用来监测患者的疾病进展和治疗效果,对于临床预后评估和治疗效果监测具有重要的临床意义。
除了在临床诊断和治疗中的应用,CD34细胞计数还在科研领域具有广泛的应用价值。
科研人员可以利用CD34细胞计数来开展干细胞移植和再生医学等方面的研究,为临床治疗提供更多的科学依据。
因此,CD34细胞计数不仅在临床上具有重要的应用意义,同时也在科研领域具有广阔的发展前景。
如何使用Go语言进行实时数据处理和流式计算的实现指南

如何使用Go语言进行实时数据处理和流式计算的实现指南Go语言是一种开发高性能实时数据处理和流式计算的理想编程语言。
它的简洁性、并发性和快速编译特性使其成为处理大数据和实时事件的流行选择。
本文将介绍如何使用Go语言进行实时数据处理和流式计算的实现指南。
首先,让我们了解一下Go语言的一些特性,这些特性使其成为一个强大的工具,用于构建实时数据处理和流式计算应用程序。
Go语言拥有一种轻量级的线程模型,称为goroutine。
它可以在单个线程上并发运行成千上万个goroutine。
这种并发模型使得Go语言非常适合处理大量的实时数据和事件。
此外,Go语言还提供了通道(channel)机制,用于在goroutine之间安全地传输数据。
通道可以在goroutine之间进行同步和通信,这对于构建实时数据处理和流式计算应用程序至关重要。
接下来,让我们探讨一些实时数据处理和流式计算的常见应用场景,并看看如何使用Go语言来实现这些应用。
1. 实时日志分析实时日志分析是一个常见的需求,尤其是在大规模分布式系统和云环境中。
使用Go语言,你可以编写一个能够实时收集、解析和分析日志的应用程序。
通过使用goroutine和通道,你可以并发处理大量的日志事件,并可以实时地提取有价值的信息。
2. 实时流媒体处理随着在线视频和音频的流行,实时流媒体处理变得越来越重要。
Go语言提供了强大的库和工具,可以帮助你构建高性能的实时流媒体处理应用程序。
你可以使用goroutine和通道来处理流式数据,并通过使用其他开源库(如FFmpeg)来实现音视频处理功能。
3. 实时监控和警报实时监控和警报是保持系统运行稳定和高可用性的关键部分。
使用Go语言,你可以编写一个实时监控和警报系统,该系统可以实时监测关键指标和事件,并在达到预定的阈值时触发警报。
通过使用goroutine和通道,你可以实现高效的事件处理和警报功能。
在实现这些实时数据处理和流式计算应用程序时,还有一些实用的Go语言库可供选择。
Flink概述

Flink概述计算引擎⼤数据计算引擎分为离线计算和实时计算,离线计算就是我们通常说的批计算,代表是Hadoop MapReduce、Hive等⼤数据技术。
实时计算也被称作流计算,代表是Storm、Spark Streaming、Flink等⼤数据技术。
计算引擎也在不断更新迭代,下图展⽰的是每⼀代计算引擎的代表,从第⼀代的Hadoop MapReduce,到第⼆代的Spark,再到第三代的Flink技术,从批处理到微批,再到真正的流式计算。
实时计算实时计算是相对离线计算的概念,重要是时效性。
举个例⼦,我们知道离线计算通常是天级别的计算任务,⽐如统计⼀天的新增⽤户,商品销量,销售收⼊等。
但是实时计算是只要有事件发⽣,统计结果就会发⽣变化,⽐如有⼀个新⽤户注册登录了,那么我们的新增⽤户数就发⽣了变化,商品只要新增⼀个销售,销量就会发⽣变化,销售收⼊也会变化。
所以实时计算让我们能更及时了解我们的现状,以及根据实时的统计结果做出决策,决策也更加具有时效性。
Flink介绍Apache Flink是⼀个开源的流处理框架,应⽤于分布式、⾼性能、⾼可⽤的数据流应⽤程序。
可以处理有限数据流和⽆限数据,即能够处理有边界和⽆边界的数据流。
⽆边界的数据流就是真正意义上的流数据,所以Flink是⽀持流计算的。
有边界的数据流就是批数据,所以也⽀持批处理的。
不过Flink在流处理上的应⽤⽐在批处理上的应⽤更加⼴泛,统⼀批处理和流处理也是Flink⽬标之⼀。
Flink可以部署在各种集群环境,可以对各种⼤⼩规模的数据进⾏快速计算。
随着⼤数据技术在各⾏各业的⼴泛应⽤,要求能对海量数据进⾏实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理⽅式和早期的流式处理框架也越来越难以在延迟性、吞吐量、容错能⼒以及使⽤便捷性等⽅⾯满⾜业务⽇益苛刻的要求。
其中流式计算的典型代表是Storm和Flink技术。
它们数据处理的延迟都是亚秒级低延迟,但是Flink相⽐Storm还有其他的⼀些优势,⽐如⽀持exactly once语义,确保数据不会重复。
流式计算应用场景

流式计算应用场景流式计算应用场景:提升实时数据处理和分析的效率引言:随着互联网的快速发展和技术的不断进步,数据量的爆发式增长已成为当今社会的一个重要特征。
在这个大数据时代,对于实时数据的处理和分析需求越来越迫切。
流式计算应运而生,它以其高效的实时处理能力和强大的数据分析功能,广泛应用于各个领域,为各行各业提供了更多可能性。
本文将从几个典型的流式计算应用场景入手,探讨流式计算技术的应用和价值。
一、金融行业在金融行业,流式计算被广泛应用于实时风险管理、高频交易监控和反欺诈等领域。
通过对金融市场的实时数据进行流式计算,可以实时监测市场风险,预警系统可以在市场异常波动时发出及时的警报,帮助投资者避免损失。
同时,流式计算还可以实时计算交易数据,对高频交易进行监控和分析,以便发现异常交易和操纵市场行为。
此外,流式计算还可以应用于反欺诈领域,通过实时监测用户行为和交易数据,识别出潜在的欺诈行为,保护用户的资金安全。
二、物联网领域物联网是指通过互联网将各种物理设备、传感器和其他设备连接起来,实现设备之间的数据交互和智能控制。
在物联网领域,流式计算可以实时处理大量的传感器数据,并根据数据分析结果做出实时的响应。
例如,在智能家居领域,通过流式计算可以实时分析家庭成员的行为和偏好,智能调节家居设备,提供个性化的居住体验。
在智能交通领域,通过对交通传感器数据的实时分析,可以实现交通拥堵的预测和优化交通调度,提高交通效率。
在智能工厂中,流式计算可以监测设备运行状态和生产线效率,及时发现故障并进行处理,提高生产效率和产品质量。
三、广告推荐在互联网广告领域,流式计算被广泛应用于广告投放和个性化推荐。
通过实时分析用户的浏览行为、兴趣偏好和社交网络数据,流式计算可以实现对用户的精准定向广告投放。
同时,利用流式计算可以实时处理大量的广告数据,根据用户实时的反馈和行为数据进行实时的广告调整和优化。
在电商领域,流式计算可以根据用户的购物行为和偏好,实时推荐相关的商品,提升用户的购物体验和购买转化率。
探索大数据处理中的实时计算技术

探索大数据处理中的实时计算技术在大数据处理中,实时计算技术扮演着至关重要的角色。
当前,大数据的应用场景越来越广泛,各行各业对实时数据分析和决策的需求也越来越迫切。
本文将探索大数据处理中的实时计算技术,并分析其应用和挑战。
一、实时计算技术概述实时计算技术是指能够在数据产生的同时进行处理和分析,实时地提供计算结果的能力。
相比传统的批处理技术,实时计算技术更加迅速和高效。
它可以帮助企业快速响应市场变化、实时监控业务运营、实现精细化管理等。
在实时计算技术中,数据流式处理是一种常见的方式。
数据流式处理将大数据分割成一段段的数据流,通过流水线式的处理方式,实时地对数据进行计算和分析。
同时,实时计算技术通常会结合复杂事件处理(CEP)和实时决策等能力,实现更加智能、高效的数据处理。
二、实时计算技术的应用1. 金融行业在金融行业,实时计算技术可以帮助机构实时监测市场动态和用户行为,从而进行风险识别和预警,高效处理交易请求,提供实时智能决策支持。
2. 物流行业物流行业对于实时计算技术的需求也非常迫切。
通过实时计算技术,物流企业可以对货物运输、仓储和配送等环节进行实时监控和优化,提高物流的运作效率和运输安全性。
3. 电商行业电商平台需要实时计算技术来处理大量的用户交易数据和行为数据,以实现个性化推荐、实时库存管理和交易风险控制等功能,提升用户体验和企业竞争力。
4. 智能制造在智能制造中,实时计算技术可以帮助企业实时监控生产线状态、预测设备故障,并进行实时调度和优化,提高生产效率和质量。
三、实时计算技术的挑战实时计算技术在应用过程中也面临着一些挑战。
1. 数据量大:大数据环境下,数据量庞大,实时处理和分析的数据量更是巨大。
为了保证实时响应和高效运算,需要应用分布式计算和多台服务器集群等技术手段。
2. 数据质量:大数据中往往存在各种异常和噪声数据,这些数据可能会影响实时计算的准确性和可靠性。
因此,需要对数据进行预处理和清洗,确保实时计算的数据质量。
流式计算应用场景

流式计算应用场景1.什么是流式计算流式计算是一种异步、非阻塞且具有连续的数据处理技术。
它专注于在数据产生时及时处理它,而不像批处理那样等待一段时间再处理。
这种技术有助于将海量的数据分散到分布式系统中,以便能够方便高效地进行处理。
随着互联网的发展和移动设备的普及,大量数据被产生并进入系统中,为了追求更高的数据处理效率,流式计算被提出并日益得到应用。
它已经广泛应用于许多领域,例如金融、医疗、物流等,而下面就是一些流式计算的应用场景。
2.物流业物流公司需要处理大量的数据来进行实时跟踪和处理整个过程中的运输、交换和交付。
为了确保客户的订单及时到达,流式计算就能够实时地跟踪物流的事件,并根据需要采取相应的行动。
这种技术对于保障物流的稳定运作至关重要。
3.金融业在金融交易中,秒级响应是必须的。
由于在同时进行的交易中,一个迟疑或一个延迟可能会导致可接受范围内的交易失败,流式计算便能够胜任这一任务。
它可以在实时处理交易接收和处理过程中检测并查找潜在的风险。
4.健康医疗流式计算技术同样应用于医疗领域。
通过设备监测,预警系统等数据收集和分析,可以分析患者的情况,及时提示专业人士并支持治疗过程。
此外,通过分析长期的数据审计和历史数据,还可以有效识别潜在的健康风险,进行预测和预防控制。
5.电子商务电子商务中,购买、结帐、库存、订单处理等活动都需要实现快速反应。
商家需要快速对订单数据进行处理,以便及时管理和更新。
同时,也需要根据客户行为、购买历史等数据,推送相应的商品或服务,以满足客户的需求。
流式计算能够帮助企业及时处理海量数据,为客户提供更好的购物体验。
6.社交网络流式计算也适用于社交网络,对于保证数据安全和内容过滤非常重要。
通过不断收集、分析和处理数据,可以帮助社交网络平台监测和审核发布内容,管理和推荐用户信息。
7.汽车行业随着智能汽车的发展,其应用的场景也变得越来越广泛。
汽车的传感器可收集车辆的各种数据,帮助驾驶员识别驾驶模式、路况、油耗等信息。
trill技术工作原理

trill技术工作原理Trill技术工作原理一、引言Trill技术是一种用于实时数据分析的流处理引擎,它具有高性能和高扩展性,被广泛应用于大规模数据分析和实时监控领域。
本文将介绍Trill技术的工作原理,包括数据处理流程、核心算法和优势特点。
二、数据处理流程Trill技术的数据处理流程包括数据输入、数据分区、数据计算和数据输出四个主要步骤。
1. 数据输入:Trill技术接受实时数据流输入,可以从各种数据源获取数据,如传感器、日志文件、数据库等。
数据输入的方式包括数据推送和数据拉取两种方式,可以根据实际需求选择合适的方式。
2. 数据分区:Trill技术将输入的数据流按照指定的规则进行分区,以便并行处理。
数据分区可以根据数据的某个属性进行,如时间、地理位置等。
通过数据分区,可以将数据分配给不同的计算节点进行并行计算,提高计算效率。
3. 数据计算:Trill技术使用一种称为“时间表”的数据结构来存储和处理数据。
时间表是一种时间有序的、流式的数据结构,可以高效地进行数据查询和聚合操作。
Trill技术通过时间表来实现实时数据分析,包括数据过滤、数据聚合、数据变换等操作。
4. 数据输出:Trill技术将计算得到的结果输出到指定的目标,可以是数据库、存储系统、可视化工具等。
输出的结果可以用于实时监控、数据分析和决策支持等应用领域。
三、核心算法Trill技术的核心算法包括增量计算、流数据压缩和时间戳管理等。
1. 增量计算:Trill技术使用增量计算的方式对数据进行实时处理。
增量计算是指将数据分成若干个时间窗口,每次处理一个时间窗口的数据,并将计算结果累积到最终结果中。
这种方式可以大大降低计算复杂度,提高计算效率。
2. 流数据压缩:Trill技术使用流数据压缩算法对输入的数据流进行压缩,减少存储和传输的开销。
流数据压缩算法可以根据数据的特点和分布进行压缩,提高数据处理效率。
3. 时间戳管理:Trill技术使用时间戳管理算法来保证数据的时序性。
百度爱番番基于图技术流式计算的实时CDP建设实践

百度爱番番基于图技术流式计算的实时CDP建设实践导读:随着营销3.0时代的到来,企业愈发需要依托强大CDP能力解决其严重的数据孤岛问题,帮助企业加温线索、促活客户。
但什么是CDP、好的CDP应该具备哪些关键特征?本文在回答此问题的同时,详细讲述了爱番番租户级实时CDP 建设实践,既有先进架构目标下的组件选择,也有平台架构、核心模块关键实现的介绍。
一、CDP是什么1.1 CDP由来CRM、DMP、CDP三个平台核心作用不同,但纵向来对比,更容易理解CDP。
三者之间在数据属性、数据存储、数据用途等方面都较大差异。
有几个关键区别如下:1.CRM vs CDP–客户管理:CRM侧重于销售跟单;CDP更加侧重于营销。
2.DMP vs CDP–数据类型:DMP是匿名数据为主;CDP以实名数据为主。
–数据存储:DMP数据只是短期存储;CDP数据长期存储。
1.2 CDP定义2023年MarTech分析师 David Raab首次提出CDP这个概念,后来其发起的CDP Institute给出权威定义:packaged software that creates a persistent, unified customer database that is accessible to other systems。
这里面主要包含三个层面:•Packaged software:基于企业自身资源部署,使用统一软件包部署、升级平台,不做定制开发。
•Persistent, unified customer database:抽取企业多类业务系统数据,基于数据一些标识形成客户的统一视图,长期存储,并且可以基于客户行为进行个性化营销。
•Accessible to other systems:企业可以使用CDP数据分析、管理客户,并且可以通过多种形式取走重组、加工的客户数据。
1.3 CDP分类CDP本身的C(Customer)是指all customer-related functions, not just marketing。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
流式计算技术及应用研究报告
学校代码:10248
作者姓名:叶稳定
学号:115372050
第一导师:
第二导师:
学科专业:软件工程
上海交通大学软件学院
2016年 5 月
目录
1 流式计算技术综述 (2)
1.1 流式计算技术概述 (2)
1.2 流式计算框架Storm的架构分析 (3)
1.3 流式计算框架Spark Streaming的架构分析 (4)
1.3 Storm与Spark Streaming的架构对比 (6)
2 流式计算技术在实际项目中的应用 (6)
2.1 基于流式计算框架Spark Streaming的数据实时处理应用的系统架构 (6)
2.2 基于复杂事件处理CEP框架的数据实时处理应用的系统架构 (7)
2.3 基于其他流式计算框架的数据实时处理应用的系统架构 (7)
参考文献 (9)
1 流式计算技术综述
1.1 流式计算技术概述
流数据处理应用要求我们的系统可以接受大量的,不间断的数据称为流式数据。
流式计算中,无法确定数据的到来时刻和到来顺序,也无法全部数据存储起来.因此,不再进行流式数据的存储,而是当流动的数据到来后在内存中直接进行数据的实时计算.如 Twitter 的 Storm、Yahoo 的 S4[6] 就是典型的流式数据计算架构,数据在任务拓扑中被计算,并输出有价值的信息. 对于无需先存储,可以直接进行数据计算,实时性要求很严格,但数据的精确度要求稍微宽松的应用场景,流式计算具有明显优势.流式计算中,数据往往是最近一个时间窗口内的,因此数据延迟往往较短,实时性较强。
1.2 流式计算框架Storm的架构分析
Apache Storm[5],在Storm中,先要设计一个用于实时计算的图状结构,我们称之为拓扑(topology)。
这个拓扑将会被提交给集群,由集群中的主控节点(master node)[5]分发代码,将任务分配给工作节点(worker node)执行。
一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成计算、过滤等操作,bolt自身也可以随机将数据发送给其他bolt。
由spout发射出的tuple是不可变数组,对应着固定的键值对。
Spark的设计思想是将流式计算分解成一系列短小的批处理作业,也就是把Spark Streaming的输入数据按照时间分成一段一段的数据,每一段数据都转换成Spark中的RDD,然后在Spark[6]内部对RDD进行处理操作,结果可以放到内存中继续处理或者存储到外部设备。
1.3 流式计算框架Spark Streaming的架构分析
Spark Streaming是核心Spark API的一个扩展,它并不会像Storm那样一次一个地处理数据流,而是在处理前按时间间隔预先将其切分为一段一段的批处理作业。
Spark针对持续性数据流的抽象称为DStream(DiscretizedStream),一个DStream是一个微批处理(micro-batching)的RDD(弹性分布式数据集);而RDD 则是一种分布式数据集,能够以两种方式并行运作,分别是任意函数和滑动窗口数据的转换。
Storm将计算逻辑抽象为拓扑Topology,Spout是Topology的数据源,数据源可以是日志或者消息队列,也可以是数据库中的表等等数据,Bolt负责数据的整个传递方向,也叫消息处理者,Bolt可能由另外2个Bolt进行join得到,在Storm中数据流的单位就是Tuple(元组),这个Tuple可能是由多个Fields字段构成,每个字段都由Bolt定义,Storm中工作进程叫做worker,一个Topology 实际上实在多个worker中运行的,在集群中每个Spout和Bolt都是由多个Tasks(任务)组成的,对于宏观的节点,分为Nimbus主节点和Supervisor从节点,Nimbus通过Zookeeper管理集群所有的Supervisor,Storm提供很多配置来调整Nimbus、Supervisor进程和正在运行的Topology的行为。
1.3 Storm与Spark Streaming的架构对比
以上2种实时计算系统都是开源的分布式系统,具有低延迟、可扩展和容错性诸多优点,它们的共同特色在于:允许你在运行数据流代码时,将任务分配到一系列具有容错能力的计算机上并行运行。
此外,它们都提供了简单的API来简化底层实现的复杂程度。
所以,总结一下Storm[2]的计算流程,首先是用户使用Storm提供的API编写Topology计算逻辑,然后使用Storm提供的Client将Topology提交给Nimbus,然后Nimbus将Task作业指派给Supervisor,Supervisor在得到Task 后,为Task启动Worker由Worker执行具体的Task,最后完成计算任务。
2流式计算技术在实际项目中的应用
2.1 基于流式计算框架Spark Streaming的数据实时处理应用的系统架构
SPARK大数据框架融合了流式计算技术、内存计算技术,利用SPARK streaming建立大规模监控视频流分析系统,利用流式计算和内存计算的技术,结合OPENCV视频分析算法[2],达到对多路监控视频流进行实时分析。
平台组成如图所示,分为三大部分:数据传输、数据处理和数据存储。
智能视频监控很多情况下是要对采集的图像进行实时处理。
数量众多的监控摄像头,庞大的监控网络,很短时间之内就会产生海量的图像视频数据,如何从这些海量数据中高效地提取出有用的信息,就成为智能视频监控技术要解决的问题。
本系统利用Spark Straming框架构建分布式视频流处理的平台,实现了从数据的传输、处理和存储。
2.2 基于复杂事件处理CEP框架的数据实时处理应用的系统架构
2.3 基于其他流式计算框架的数据实时处理应用的系统架构
根据云计算平台下智能视频分析的实时性需求,设计一个基于 Storm[2] 流计算框架的实时视频分析系统。
采用合并解码单元和视频分析单元的方法避免耗尽集群带宽,并利用工作窃取机制加速算法执行。
通过节点性能监控并利用贪心置换策略动态调节 workerNode负载,改进 Storm 的默认调度器,降低消息的处理延时。
实验结果表明,在运行人脸检测算法的 Storm 集群中接入多路监控设备,实现100ms之内的消息处理延时和低于1s的整体延时,能够为云环境下多路监控终端提供实时稳定的视频分析服务。
首先缓存主要考虑到设备码率的波动,添加缓存可以保证集群均匀地订阅视
频流,改善集群性能和稳定性,对整体时延的增加也不明显;另外对设备和Storm 集群进行隔离,并且方便应用层对系统进行控制。
参考文献
[1] Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A.
Wallach.Bigtable: A Distributed Storage System for Structured Data[D].OSDI, 2006.
[2] Jeffrey Dean and Sanjay Ghemawat.MapReduce: Simplified Data
Processing on Large Clusters[D].OSDI, 2004.
[3] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung.The Google File
System[D].Bolton Landing, New York, USA:ACM, 2003.
[4] 申海洋;基于内容的监控视频检索算法研究[D];山西大学;2014年
[5] 袁冠红;基于异常事件检测的交通监控视频摘要[D];浙江大学;2015年
[6] 李招昕;基于流式计算的大规模监控视频分析关键技术研究[D];上海大学;2015年
(注:文档可能无法思考全面,请浏览后下载,供参考。
可复制、编制,期待你
的好评与关注!)。