Hibernate4(关系映射,事务,原理,性能和二级缓存,最佳实践)
Struts、Spring、Hibernate三大框架的原理和优点

Struts的原理和优点.Struts工作原理MVC即Model—View—Controller的缩写,是一种常用的设计模式。
MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。
MVC的工作原理,如下图1所示:Struts 是MVC的一种实现,它将Servlet和JSP 标记(属于J2EE 规范)用作实现的一部分。
Struts继承了MVC的各项特性,并根据J2EE的特点,做了相应的变化与扩展.Struts的工作原理,视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开表现逻辑和程序逻辑。
控制:在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。
ActionServlet是一个通用的控制组件。
这个控制组件提供了处理所有发送到Struts的HTTP请求的入口点。
它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。
另外控制组件也负责用相应的请求参数填充Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。
动作类实现核心商业逻辑,它可以访问java bean 或调用EJB。
最后动作类把控制权传给后续的JSP 文件,后者生成视图。
所有这些控制逻辑利用Struts-config.xml文件来配置。
模型:模型以一个或多个java bean的形式存在。
这些bean分为三类:Action Form、Action、JavaBean or EJB.Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。
Action通常称之为ActionBean,获取从ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
hibernate框架的工作原理

hibernate框架的工作原理Hibernate框架的工作原理Hibernate是一个开源的ORM(Object-Relational Mapping)框架,它将Java对象映射到关系型数据库中。
它提供了一种简单的方式来处理数据持久化,同时也提供了一些高级特性来优化性能和可维护性。
1. Hibernate框架的基本概念在开始讲解Hibernate框架的工作原理之前,需要先了解一些基本概念:Session:Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
SessionFactory:SessionFactory是一个线程安全的对象,它用于创建Session对象。
通常情况下,应用程序只需要创建一个SessionFactory对象。
Transaction:Transaction是对数据库操作进行事务管理的接口。
在Hibernate中,所有对数据库的操作都应该在事务中进行。
Mapping文件:Mapping文件用于描述Java类与数据库表之间的映射关系。
它定义了Java类属性与数据库表字段之间的对应关系。
2. Hibernate框架的工作流程Hibernate框架主要分为两个部分:持久化层和业务逻辑层。
其中,持久化层负责将Java对象映射到数据库中,并提供数据访问接口;业务逻辑层则负责处理业务逻辑,并调用持久化层进行数据访问。
Hibernate框架的工作流程如下:2.1 创建SessionFactory对象在应用程序启动时,需要创建一个SessionFactory对象。
SessionFactory是一个线程安全的对象,通常情况下只需要创建一个即可。
2.2 创建Session对象在业务逻辑层需要进行数据访问时,需要先创建一个Session对象。
Session是Hibernate与数据库交互的核心接口,它代表了一个会话,可以用来执行各种数据库操作。
2.3 执行数据库操作在获取了Session对象之后,就可以执行各种数据库操作了。
hibernate4学习笔记

hibernate4学习笔记Hibernate4学习笔记本⼈全部以⾃学为主,在⽹上收集各种学习资料,总结归纳学习经验,现将学习路径给予⼤家分享。
此次学习的hibernate的版本是:hibernate-release-4.2.4.Final(截⽌2015年7⽉31⽇最新版),JAVA的版本是:java8.0,使⽤的开发⼯具是:Eclipse Mars Release (4.5.0)。
第⼀天:Hibernate4基础知识和HelloWorld简单编程Hibernate是⼀种半成品ORM框架,对数据库持久化操作,程序员对数据库的操作转换成对对象的操作。
ORM 采⽤元数据来描述对象-关系映射细节, 元数据通常采⽤XML 格式, 并且存放在专门的对象-关系映射⽂件中。
HelloWorld简单编程1、准备Hibernate环境(1)导⼊Hibernate的Jar包,如下:(2)导⼊Mysql驱动包,我⽤的数据库是:Mysql 5.0,数据库驱动包如下:以上所有Jar加完毕之后,需要加⼊到Eclipse⾃⾝系统⾥⾯,具体如下:以上操作完毕之后,Hibernate的环境就算搭建完毕,下⾯就可以进⼀步操作。
2、配置hibernate.cfg.xml⽂件,主要是对数据库的连接,具体如下:"-//Hibernate/Hibernate Configuration DTD 3.0//EN""/doc/63fa364d5022aaea998f0fde.html /hibernate-configuration-3.0.dtd ">rootmysqlname="connection.driver_class">com.mysql.jdbc.Driver jdbc:mysql:///Test(或者:jdbc:mysql://localhost:3306/Test)name="dialect">org.hibernate.dialect.MySQLInnoDBDialecttruetrueupdate3、编写⼀个实例类News.java,具体代码如下:package com.hibernate.helloworld;import java.sql.Date;public class News {private Integer id;private String title;private Date date;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String getAuthor() {return author;}public void setAuthor(String author) {this.author = author;}public Date getDate() {return date;}public void setDate(Date date) {this.date = date;}public News(String title, String author, Date date) { super();this.title = title;this.author = author;this.date = date;}public News(){}@Overridereturn"News [id="+ id+ ", title="+ title+ ", author="+ author + ", date=" + date + "]";}}4、创建News.hbm.xml配置映射⽂件,具体代码如下:"/doc/63fa364d5022aaea998f0fde.html /hibernate-mapping-3.0.dtd">5、将映射⽂件News.hbm.xml指定到hibernate.cfg.xml配置⽂件⾥⾯,即在hibernate.cfg.xml⽂件⾥加⼊⼀⾏映射代码,具体如下:6、创建hibernate API操作测试类(Juit测试),验证hibernate的优势效果,具体代码如下:package com.hibernate.helloworld;import java.sql.Date;import org.hibernate.Session;import org.hibernate.SessionFactory;import org.hibernate.Transaction;import org.hibernate.cfg.Configuration;import org.hibernate.service.ServiceRegistry;import org.hibernate.service.ServiceRegistryBuilder;import org.junit.Test;public class HibernateTest {@Testpublic void test() {//1. 创建⼀个 SessionFactory 对象SessionFactory sessionFactory=null;//1). 创建 Configuration 对象: 对应 hibernate 的基本配置信息和对象关系映射信息Configuration configuration=new Configuration().configure();//4.0 之前这样创建//sessionFactory=configuration.buildSessionFactory();//2). 4.0以后创建⼀个 ServiceRegistry 对象: hibernate 4.x 新添加的对象//hibernate 的任何配置和服务都需要在该对象中注册后才能有效.ServiceRegistry serviceRegistry=newServiceRegistryBuilder().applySettings(configuration.getProperties() ).buildServiceRegistry();sessionFactory=configuration.buildSessionFactory(serviceRegistry) ;//2. 创建⼀个 Session 对象Session session=sessionFactory.openSession();//3. 开启事务Transaction transaction=session.beginTransaction();//4. 执⾏保存操作News news = new News("Java12345", "ATGUIGU", new Date(new java.util.Date().getTime()));session.save(news);//5. 提交事务/doc/63fa364d5022aaea998f0fde.html mit();//6. 关闭 Sessionsession.close();//7. 关闭 SessionFactory 对象sessionFactory.close();}}7、测试结果如下:(1)数据库⾥⾯的结果如下:(2)Eclipse下的语句⽣成如下:以上就是简单Hibernate的测试,总结:1、不需要在数据库⾥⾯创建任何数据,由hibernate ⾃动⽣成;2、代码简单易理解,不复杂,测试数据只需要先创建以下⼏个步骤:SessionFactory-→Session-→Transaction-→session操作数据库-→提交-→关闭;3、不需要写SQL 语句,从头到尾没有写⼀条SQL语句,反⽽Hibernate帮我们⽣成SQL语句。
hibernate缓存机制详细分析(一级、二级、查询缓存,非常清晰明白)

hibernate缓存机制详细分析(⼀级、⼆级、查询缓存,⾮常清晰明⽩)您可以通过点击右下⾓的按钮来对⽂章内容作出评价, 也可以通过左下⽅的关注按钮来关注我的博客的最新动态。
如果⽂章内容对您有帮助, 不要忘记点击右下⾓的推荐按钮来⽀持⼀下哦如果您对⽂章内容有任何疑问, 可以通过评论或发邮件的⽅式联系我:****************/**********************如果需要转载,请注明出处,谢谢!!在本篇随笔⾥将会分析⼀下hibernate的缓存机制,包括⼀级缓存(session级别)、⼆级缓存(sessionFactory级别)以及查询缓存,当然还要讨论下我们的N+1的问题。
随笔虽长,但我相信看完的朋友绝对能对hibernate的 N+1问题以及缓存有更深的了解。
⼀、N+1问题⾸先我们来探讨⼀下N+1的问题,我们先通过⼀个例⼦来看⼀下,什么是N+1问题:list()获得对象: /** * 此时会发出⼀条sql,将30个学⽣全部查询出来*/ List<Student> ls = (List<Student>)session.createQuery("from Student").setFirstResult(0).setMaxResults(30).list();Iterator<Student> stus = ls.iterator();for(;stus.hasNext();){Student stu = (Student)stus.next();System.out.println(stu.getName());}如果通过list()⽅法来获得对象,毫⽆疑问,hibernate会发出⼀条sql语句,将所有的对象查询出来,这点相信⼤家都能理解Hibernate: select student0_.id as id2_, student0_.name as name2_, student0_.rid as rid2_, student0_.sex as sex2_ from t_student student0_ limit ?那么,我们再来看看iterator()这种情况iterator()获得对象 /** * 如果使⽤iterator⽅法返回列表,对于hibernate⽽⾔,它仅仅只是发出取id列表的sql* 在查询相应的具体的某个学⽣信息时,会发出相应的SQL去取学⽣信息* 这就是典型的N+1问题* 存在iterator的原因是,有可能会在⼀个session中查询两次数据,如果使⽤list每⼀次都会把所有的对象查询上来* ⽽是要iterator仅仅只会查询id,此时所有的对象已经存储在⼀级缓存(session的缓存)中,可以直接获取*/ Iterator<Student> stus = (Iterator<Student>)session.createQuery("from Student").setFirstResult(0).setMaxResults(30).iterate();for(;stus.hasNext();){Student stu = (Student)stus.next();System.out.println(stu.getName());}在执⾏完上述的测试⽤例后,我们来看看控制台的输出,看会发出多少条 sql 语句:Hibernate: select student0_.id as col_0_0_ from t_student student0_ limit ?Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?沈凡Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?王志名Hibernate: select student0_.id as id2_0_, student0_.name as name2_0_, student0_.rid as rid2_0_, student0_.sex as sex2_0_ from t_student student0_ where student0_.id=?叶敦.........我们看到,当如果通过iterator()⽅法来获得我们对象的时候,hibernate⾸先会发出1条sql去查询出所有对象的 id 值,当我们如果需要查询到某个对象的具体信息的时候,hibernate此时会根据查询出来的 id 值再发sql语那么这种 N+1 问题我们如何解决呢,其实我们只需要使⽤ list() ⽅法来获得对象即可。
java学习经验Hibernate总结

Hibernate工作原理及为什么要用?一原理:1.读取并解析配置文件2.读取并解析映射信息,创建SessionFactory3.打开Sesssion4.创建事务Transaction5.持久化操作6.提交事务7.关闭Session。
8.关闭SessionFactory为什么要用:1. 对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
2. Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。
他很大程度的简化DAO层的编码工作3. hibernate使用Java反射机制,而不是字节码增强程序来实现透明性。
4. hibernate的性能非常好,因为它是个轻量级框架。
映射的灵活性很出色。
它支持各种关系数据库,从一对一到多对多的各种复杂关系。
二Hibernate 的核心接口及其作用1 Configuration类:配置Hibernate启动Hibernate创建SessionFactory对象2 SessionFactory:初始化Hibernate创建Session对象线程安全—同一实例被多个线程共享重量级:代表一个数据库内部维护一个连接池2.1 openSession():总是创建新的session,需要手动close()2.2 getCurrentSession() : 必须在hibernate.cfg.xml设置session 上下文事务自动提交并且自动关闭session.从上下文环境中获得session,如果当时环境中不存就创建新的.如果环境中存在就使用环境中的,而且每次得到的都是同一个session (在session提交之前,提交之后就是新的了) 应用在一个session中有多个不同DAO操作处于一个事务时3 Session:负责保存、更新、删除、加载和查询对象轻量级--可以经常创建或销毁3.1 Load与get方法的区别:简单理解:load是懒加载,get是立即加载.load方法当使用查出来的对象时并且session未关闭,才会向数据库发sql, get会立即向数据库发sql返回对象3.3 merge(); 合并对象更新前会先select 再更新3.4clear()清空缓存,flush()将session中的数据同步到数据库两者组合使用于批量数据处理3.4Transaction commit() rollback()JPA: java persistence API 提供了一组操作实体bean的注解和API规范SchemaExporthiberante的生成数据库表(及其他ddl)的工具类可以通过这个工具类完成一些ddl四Hibernate查询查询语言主要有:HQL 、QBC (Query By Criteria条件查询) 、 Native SQLHql:1、属性查询2、参数查询、命名参数查询3、关联查询4、分页查询5、统计函数五优化抓取策略连接抓取(Join fetching)使用 OUTER JOIN(外连接)来获得对象的关联实例或者关联集合查询抓取(Select fetching)另外发送一条 SELECT 语句抓取当前对象的关联实体或集合另外可以配置hibernate抓取数量限制批量抓取(Batch fetching)另外可以通过集合过滤来限制集合中的数据量使用session.createFilter(topic.getReplies(),queryString).list();检索策略延迟检索和立即检索(优先考虑延迟检索)N+1问题指hibernate在查询当前对象时查询相关联的对象查询一端时会查询关联的多端集合对象解决方案:延迟加载连接抓取策略二级缓存集合过滤 BatchSize限制记录数量映射建议使用双向一对多关联,不使用单向一对多灵活使用单向一对多关联不用一对一,用多对一取代配置对象缓存,不使用集合缓存一对多集合使用Bag,多对多集合使用Set继承类使用显式多态表字段要少,表关联不要怕多,有二级缓存撑腰Hibernbate缓存机制性能提升的主要手段Hibernate进行查询时总是先在缓存中进行查询,如缓存中没有所需数据才进行数据库的查询.Hibernbate缓存:一级缓存 (Session级别)二级缓存(SessionFactory级别)查询缓存 (基于二级缓存存储相同参数的sql查询结果集)一级缓存(session缓存)Session缓存可以理解为session中的一个map成员, key为OID ,value为持久化对象的引用在session关闭前,如果要获取记录,hiberntae先在session缓存中查找,找到后直接返回,缓存中没有才向数据库发送sql三种状态的区别在于:对象在内存、数据库、session缓存三者中是否有OID临时状态内存中的对象没有OID, 缓存中没有OID,数据库中也没有OID 执行new或delete()后持久化状态内存中的对象有OID, 缓存中有OID,数据库中有OIDsave() load() get() update() saveOrUpdate() Query对象返回的集合游离(脱管)状态内存中的对象有OID, 缓存中没有OID,数据库中可能有OIDflush() close()后使用session缓存涉及三个操作:1将数据放入缓存2从缓存中获取数据3缓存的数据清理4二级缓存SessionFactory级别SessionFactory级别的缓存,它允许多个Session间共享缓存一般需要使用第三方的缓存组件,如: Ehcache Oscache、JbossCache等二级缓存的工作原理:在执行各种条件查询时,如果所获得的结果集为实体对象的集合,那么就会把所有的数据对象根据OID放入到二级缓存中。
JavaWeb开发中的最佳实践

JavaWeb开发中的最佳实践在当今日益发展的互联网世界,JavaWeb开发已经成为了开发者们不可或缺的技能之一。
作为一门广泛应用于企业级开发的编程语言,JavaWeb已经在企业应用开发中扮演着重要的角色。
在JavaWeb开发过程中,如何实现最佳实践成为了关注的焦点。
下面将从技术选型、代码实践、性能优化三个方面为大家分析JavaWeb开发中的最佳实践。
一、技术选型JavaWeb开发中,技术选型是至关重要的一个环节。
选择一些可靠、稳定的技术框架既可以提升开发效率,也可以保证系统的安全性和可扩展性。
以下是一些常用的JavaWeb技术框架:1. Spring框架:Spring是一个轻量级的Java开发框架,可以用来构建Web应用、RESTful API、企业级应用等。
它提供了IoC容器,用来管理对象之间的依赖关系,简化了代码。
Spring还提供了MVC框架,用于构建Web应用。
2. Hibernate框架:Hibernate是一个ORM框架,用于将Java对象映射到关系型数据库中。
它提供了一种简单的方式来执行增、删、改、查操作,减少了传统的JDBC编程的工作量。
3. MyBatis框架:MyBatis是一个持久层框架,也是一种ORM框架,用于将Java对象映射到关系型数据库中。
相比Hibernate,MyBatis更加灵活,支持自定义SQL语句和动态查询,可以更好地控制SQL执行。
4. Struts2框架:Struts2是一个MVC框架,用于构建Web应用。
它提供了分离前端和后端的解决方案,使开发人员可以专注于业务逻辑的实现,提高代码的可读性和可维护性。
二、代码实践在JavaWeb开发中,代码实践对于开发一个成功的Web应用来说是至关重要的。
以下提供一些代码实践的最佳实践:1. 符合MVC设计模式:MVC(Model-View-Controller)设计模式是一种常用的软件架构模式,用于分离应用程序的逻辑、数据和表示。
Hibernate基础知识详解

Hibernate基础知识详解<hibernate-mapping><class name="*.*.*" table="t_customer" catalog="***"><id name="id" column="c_id"><generator class="identity"/></id><property name="name" column="c_name" length="20"/><set name="orders" inverse="false" cascade="save-update"><key column="c_customer_id"/></set></class></hibernate-mapping>(1)统⼀声明包名,这样在<class>中就不需要写类的全名。
(2)关于<class>标签配置name 属性:类的全名称table 表的名称,可以省略,这时表的名称就与类名⼀致catalog 属性:数据库名称可以省略.如果省略,参考核⼼配置⽂件中 url 路径中的库名称(3)关于<id>标签,<id>是⽤于建⽴类中的属性与表中的主键映射。
name 类中的属性名称column 表中的主键名称 column 它也可以省略,这时列名就与类中属性名称⼀致length 字段长度type 属性指定类型<generator>它主要是描述主键⽣成策略。
Hibernate

a. Session.evict
将某个特定对象从内部缓存中清楚
b. Session.clear
清空内部缓存
当批量插入数据时,会引发内存溢出,这就是由于内部缓存造成的。例如:
For(int i=0; i<1000000; i++){
For(int j=0; j<1000000; j++){
session.iterate(…)方法和session.find(…)方法的区别:session.find(…)方法并不读取ClassCache,它通过查询语句直接查询出结果数据,并将结果数据put进classCache;session.iterate(…)方法返回id序列,根据id读取ClassCache,如果没有命中在去DB中查询出对应数据。
User user = new User();
user.setUserName(“gaosong”);
user.setPassword(“123”);
session.save(user);
}
}
在每次循环时,都会有一个新的对象被纳入内部缓存中,所以大批量的插入数据会导致内存溢出。解决办法有两种:a 定量清除内部缓存 b 使用JDBC进行批量导入,绕过缓存机制。
user.setLoginName("jonny");
mit();
session2 .close();
这种方式,关联前后是否做修改很重要,关联前做的修改不会被更新到数据库,
比如关联前你修改了password,关联后修改了loginname,事务提交时执行的update语句只会把loginname更新到数据库
hibernate高级用法

hibernate高级用法Hibernate是一种Java持久化框架,用于将对象转换为数据库中的数据。
除了基本的用法,Hibernate还提供了一些高级的用法,以下是一些常见的Hibernate高级用法:1、继承Hibernate支持类继承,可以让子类继承父类的属性和方法。
在数据库中,可以使用表与表之间的关系来实现继承,例如使用一对一、一对多、多对一等关系。
使用继承可以让代码更加简洁、易于维护。
2、聚合Hibernate支持聚合,可以将多个对象组合成一个对象。
例如,一个订单对象可以包含多个订单行对象。
在数据库中,可以使用外键来实现聚合关系。
使用聚合可以让代码更加简洁、易于维护。
3、关联Hibernate支持关联,可以让对象之间建立关联关系。
例如,一个订单对象可以关联一个客户对象。
在数据库中,可以使用外键来实现关联关系。
使用关联可以让代码更加简洁、易于维护。
4、延迟加载Hibernate支持延迟加载,可以在需要时才加载对象。
延迟加载可以减少数据库的负担,提高性能。
Hibernate提供了多种延迟加载的策略,例如按需加载、懒惰加载等。
5、事务Hibernate支持事务,可以确保数据库的一致性。
事务是一组数据库操作,要么全部成功,要么全部失败。
Hibernate提供了事务管理的方法,例如开始事务、提交事务、回滚事务等。
6、缓存Hibernate支持缓存,可以减少对数据库的访问次数,提高性能。
Hibernate提供了多种缓存策略,例如一级缓存、二级缓存等。
使用缓存需要注意缓存的一致性和更新问题。
7、HQL查询语言Hibernate提供了HQL查询语言,可以让开发人员使用面向对象的查询方式来查询数据库。
HQL查询语言类似于SQL查询语言,但是使用的是Java类和属性名,而不是表名和列名。
HQL查询语言可以更加灵活、易于维护。
以上是一些常见的Hibernate高级用法,它们可以帮助开发人员更加高效地使用Hibernate进行开发。
Hibernate4在开发当中的一些改变

Hibernate4的改动较大只有spring3.1以上版本能够支持,Spring3.1取消了HibernateTemplate,因为Hibernate4的事务管理已经很好了,不用Spring再扩展了。
这里简单介绍了hibernate4相对于hibernate3配置时出现的错误,只列举了问题和解决方法,详细原理如果大家感兴趣还是去自己搜吧,网上很多。
1. Spring3.1去掉了HibernateDaoSupport类。
hibernate4需要通过getCurrentSession()获取session。
并且设置<propkey="hibernate.current_session_context_class">org.springframework.orm.hibe rnate4.SpringSessionContext</prop>(在hibernate3的时候是thread和jta)。
2. 缓存设置改为<propkey="hibernate.cache.provider_class">net.sf.ehcache.hibernate.EhCacheProvi der</prop><propkey="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhC acheRegionFactory</prop>3. Spring对hibernate的事务管理,不论是注解方式还是配置文件方式统一改为:<bean id="txManager"class="org.springframework.orm.hibernate4.HibernateTransactionManager" ><property name="sessionFactory"><ref bean="sessionFactory"/></property></bean>4. getCurrentSession()事务会自动关闭,所以在有所jsp页面查询数据都会关闭session。
软件工程专业实习日记十篇

软件工程专业实习日记十篇软件工程专业实习日记一今天,我怀着激动的心情来到单位,这是我第一天工作,实习的第一天,我很早就来到了单位,经理给我找来了名签让我带上,安排了我的工作位置和工作任务。
我上午工作,下午接受培训,在这里,我才真正的意识到实施一个软件工程并不是说简单的会编码就能够解决问题的,更多的精力不是放在编码上,编码只是一个很小的模块,只占用那么小的一个部分。
这个事实在很大程度上颠覆了我以前的思想,在我以前的认识中,似乎整个软件就只是编码,想想真是可笑。
下午,我接受了公司的基本培训。
很忙碌紧张的一天,不过我受益匪浅。
软件工程专业实习日记二今天,是我实习的第二天,同样,我怀着激动的心情来到公司,开始我这一天的工作。
我费了很多时间来完成一些前端工作,如:需求分析和可行性分析,这块工作在别人看来可能是无关紧要的,甚至是多余的,其实,换做是以前,我也会这么认为。
可是,我现在算是深深的明白了磨刀不误砍柴工的道理,这些工作的完成太有必要了,太重要了,要想你的软件有市场,能被别人接受和认可,在进行过程中不会出现崩溃性的问题,这些工作缺一不可。
下午,我接受公司的礼仪培训。
又是忙碌的一天!软件工程专业实习日记三今天,我很早的来到公司,开始我一天的工作,每天给我安排的工作量很少,做完之后,最重要的是进行公司业务和礼仪,专业知识的培训。
我今天接受公司培训的内容是:计算机病毒,它是一个程序,一段可执行代码。
病毒的生命周期包括4个环节:1潜伏阶段2繁殖阶段3触发阶段4执行阶段。
病毒的种类:寄生病毒2存储器驻留病毒3引导区病毒4隐形病毒5多1态病毒。
常见的病毒有:1宏病毒2电子邮件病毒3特洛伊木马4计算机病毒蠕虫。
今天我受益匪浅。
软件工程专业实习日记四今天,我高高兴兴地来到公司,经理给我安排了我今天要做的工作,完成后需要马上接受培训,以最快的速度接受完培训,能尽快上岗。
今天,我学的是网络管理的功能:1配置管理,包括资源清单管理,资源开通以及业务开通2故障管理3计费管理4性能管理5安全管理。
Hibernate的工作原理

Hibernate的工作原理Hibernate是一个开源的Java持久化框架,它能够将Java对象映射到关系型数据库中,并提供了一套简单而强大的API,使得开辟人员能够更加方便地进行数据库操作。
Hibernate的工作原理主要包括以下几个方面:1. 对象关系映射(ORM):Hibernate使用对象关系映射技术将Java对象与数据库表之间建立起映射关系。
开辟人员只需要定义好实体类和数据库表之间的映射关系,Hibernate就能够自动地将Java对象持久化到数据库中,或者将数据库中的数据映射成Java对象。
2. 配置文件:Hibernate通过一个配置文件来指定数据库连接信息、映射文件的位置以及其他一些配置信息。
配置文件通常是一个XML文件,其中包含了数据库驱动类、连接URL、用户名、密码等信息。
开辟人员需要根据自己的数据库环境进行相应的配置。
3. SessionFactory:Hibernate的核心组件是SessionFactory,它负责创建Session对象。
SessionFactory是线程安全的,通常在应用程序启动时创建一次即可。
SessionFactory是基于Hibernate配置文件和映射文件来构建的,它会根据配置文件中的信息来创建数据库连接池,并加载映射文件中的映射信息。
4. Session:Session是Hibernate的另一个核心组件,它代表了与数据库的一次会话。
每一个线程通常会有一个对应的Session对象。
Session提供了一系列的方法,用于执行数据库操作,如保存、更新、删除、查询等。
开辟人员通过Session对象来操作数据库,而不直接与JDBC打交道。
5. 事务管理:Hibernate支持事务的管理,开辟人员可以通过编程方式来控制事务的提交或者回滚。
在Hibernate中,事务是由Session来管理的。
开辟人员可以通过调用Session的beginTransation()方法来启动一个事务,然后根据需要进行提交或者回滚。
hibernate原理

Hibernate开发步骤
4. 通过 Hibernate API 编写访问数据库的代码 1. 创建持久化类
hibernate.cfg.xml
*.hbm.xml
2. 创建对象-关系映 射文件
3. 创建 Hibernate 配 置文件
1. 创建持久化 Java 类
• 提供一个无参的构造器:使Hibernate可以使用 Constructor.newInstance() 来实例化持久化类 • 提供一个标识属性(identifier property): 通常映射为数 据库表的主键字段. 如果没有该属性,一些功能将不起作用 ,如:Session.saveOrUpdate() • 为类的持久化类字段声明访问方法(get/set): Hibernate对 JavaBeans 风格的属性实行持久化。 • 使用非 final 类: 在运行时生成代理是 Hibernate 的一个 重要的功能. 如果持久化类没有实现任何接口, Hibnernate 使用 CGLIB 生成代理. 如果使用的是 final 类, 则无法生 成 CGLIB 代理. • 重写 eqauls 和 hashCode 方法: 如果需要把持久化类的实 例放到 Set 中(当需要进行关联映射时), 则应该重写这两 个方法
1. 创建持久化 Java 类
• Hibernate 不要求持久化类继承任何父类或实现接口 ,这可以保证代码不被污染。这就是Hibernate被称 为低侵入式设计的原因
2. 创建对象-关系映射文件
• Hibernate 采用 XML 格式的文件来指定对象和关系数据之间 的映射. 在运行时 Hibernate 将根据这个映射文件来生成各 种 SQL 语句 • 映射文件的扩展名为 .hbm.xml
hibernate 生成数据库表的原理

hibernate 生成数据库表的原理Hibernate是一个Java持久化框架,它提供了一种方便的方式来映射Java对象到关系数据库中的表结构。
当使用Hibernate时,它可以根据预定义的映射文件或注解配置自动创建、更新和管理数据库表。
Hibernate生成数据库表的原理如下:1. 对象关系映射(Object-Relational Mapping,ORM):Hibernate使用ORM技术将Java类和关系数据库表之间建立起映射关系。
通过在实体类中定义注解或XML映射文件,Hibernate可以知道哪个Java类对应哪个数据库表以及类中的属性与表中的列之间的映射关系。
2. 元数据分析:当应用程序启动时,Hibernate会对实体类进行元数据分析。
它会扫描实体类中的注解或XML映射文件,获取实体类的名称、属性名、属性类型等信息,并根据这些信息生成相应的元数据。
3. 数据库模式生成:根据元数据,Hibernate可以自动生成数据库表的DDL语句。
它会根据实体类的名称创建表名,根据属性名创建列名,并根据属性类型确定列的数据类型、长度、约束等。
生成的DDL语句可以包括创建表、添加索引、外键约束等操作。
4. 数据库表管理:Hibernate可以根据生成的DDL语句来创建数据库表。
在应用程序启动时,Hibernate会检查数据库中是否已存在相应的表,如果不存在则创建表;如果已存在但结构与元数据不匹配,则根据需要进行表结构的更新或修改。
总的来说,Hibernate生成数据库表的原理是通过分析实体类的元数据,自动生成对应的DDL语句,并根据需要创建、更新和管理数据库表。
这种自动化的方式大大简化了开发人员的工作,提高了开发效率。
JAVA程序设计中常用的框架技术介绍

JAVA程序设计中常用的框架技术介绍JAVA是一种广泛使用的编程语言,常用于开发各种应用程序,包括Web应用、移动应用、企业应用等。
为了提高开发效率和代码质量,JAVA 程序设计中常使用各种框架和技术。
下面将介绍JAVA程序设计中常用的框架和技术。
1. Spring框架:Spring框架是一个开源的Java平台,用于简化企业级Java应用程序的开发。
它提供了一种强大的依赖注入(DI)机制,可以简化类之间的依赖关系,并提供了一种轻量级的容器,可以管理和协调Java对象的生命周期。
Spring还提供了MVC框架,用于开发Web应用程序。
Spring还支持事务管理、安全性、缓存等各种功能。
2. Hibernate框架:Hibernate是一个基于Java的对象关系映射(ORM)框架,可以帮助开发人员将Java对象映射到数据库表中。
Hibernate提供了一个简单易用的API,可以处理对象和数据库之间的映射关系,从而使得开发人员可以更专注于业务逻辑而不必关心数据库操作。
Hibernate还提供了查询语言(HQL)和面向对象的查询API,以及缓存和事务管理等功能。
3. Struts框架:Struts是一个MVC框架,用于开发Web应用程序。
它将应用程序分为模型、视图和控制器三个部分,通过控制器将请求分发到合适的处理程序,再通过模型将数据提供给视图展示。
Struts提供了强大的表单验证和数据绑定机制,使得开发人员可以很方便地处理用户输入数据。
Struts 还支持国际化、资源管理等功能。
4. Spring Boot框架:Spring Boot是一个用于创建和运行独立的、生产级的Spring应用程序的框架。
它采用约定优于配置的方式,提供了各种自动化配置和快速启动的能力。
Spring Boot可以帮助开发人员快速地创建Java应用程序,并提供了许多有用的功能和工具,如嵌入式Web服务器、注解驱动的开发、自动化配置、健康检查等。
Hibernete基本概念
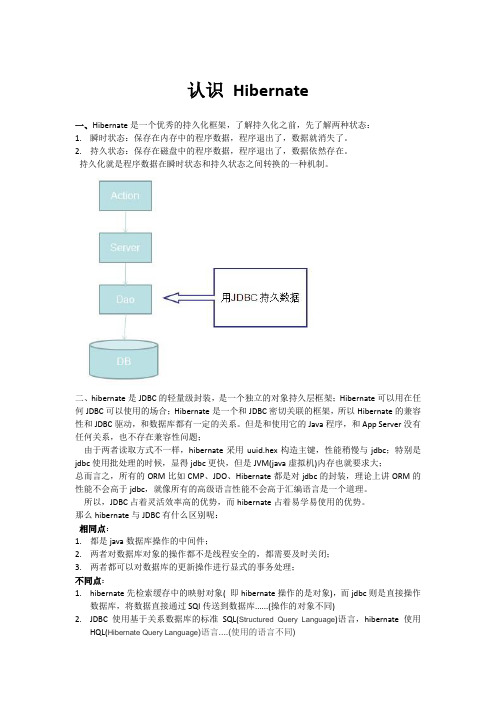
认识Hibernate一、Hibernate是一个优秀的持久化框架,了解持久化之前,先了解两种状态:1.瞬时状态:保存在内存中的程序数据,程序退出了,数据就消失了。
2.持久状态:保存在磁盘中的程序数据,程序退出了,数据依然存在。
持久化就是程序数据在瞬时状态和持久状态之间转换的一种机制。
二、hibernate是JDBC的轻量级封装,是一个独立的对象持久层框架;Hibernate可以用在任何JDBC可以使用的场合;Hibernate是一个和JDBC密切关联的框架,所以Hibernate的兼容性和JDBC驱动,和数据库都有一定的关系。
但是和使用它的Java程序,和App Server没有任何关系,也不存在兼容性问题;由于两者读取方式不一样,hibernate采用uuid.hex构造主键,性能稍慢与jdbc;特别是jdbc使用批处理的时候,显得jdbc更快,但是JVM(java虚拟机)内存也就要求大;总而言之,所有的ORM比如CMP、JDO、Hibernate都是对jdbc的封装,理论上讲ORM的性能不会高于jdbc,就像所有的高级语言性能不会高于汇编语言是一个道理。
所以,JDBC占着灵活效率高的优势,而hibernate占着易学易使用的优势。
那么hibernate与JDBC有什么区别呢:相同点:1.都是java数据库操作的中间件;2.两者对数据库对象的操作都不是线程安全的,都需要及时关闭;3.两者都可以对数据库的更新操作进行显式的事务处理;不同点:1.hibernate先检索缓存中的映射对象( 即hibernate操作的是对象),而jdbc则是直接操作数据库,将数据直接通过SQl传送到数据库......(操作的对象不同)2.JDBC使用基于关系数据库的标准SQL(Structured Query Language)语言,hibernate使用HQL(Hibernate Query Language)语言....(使用的语言不同)3.Hibernate操作的数据是可持久化的,也就是持久化的对象属性的值,可以和数据库中保持一致,而jdbc操作数据的状态是瞬时的,变量的值无法和数据库中一致....(数据状态不同)三、ORM(Object Relational Mapping)对象关系映射完成对象数据到关系型数据映射的机制,称为:对象·关系映射,简ORM总结:Hibernate是一个优秀的对象关系映射机制,通过映射文件保存这种关系信息;在业务层以面向对象的方式编程,不需要考虑数据的保存形式。
Hibernate4开发文档

hibernate4简介开源的对象关系映射框架(ORM)hibernate 核心接口Session接口Session接口负责执行被持久化对象的CRUD操作(CRUD的任务是完成与数据库的交流SessionFactory接口SessionFactory接口负责初始化Hibernate。
它充当数据存储源的代理,并负责创建Session对象Configuration类Configuration类负责配置并启动Hibernate,创建SessionFactory 对象。
在Hibernate的启动的过程中,Configuration类的实例首先定位映射文档位置、读取配置,然后创建SessionFactory对象Transaction接口Transaction接口负责事务相关的操作Query和Criteria接口Query和Criteria接口负责执行各种数据库查询。
它可以使用HQL语句或SQL语句两种表达方式。
hibernate 访问持久化类属性的策略accessproperty:field:hibernate 主键策略generator 主键生成器increment 自动增长数据类型long short intidentity sql server mysql自动增长long shorintnative 根据数据库的支持自动选择identity sequence hilo uuidhilo<generator class="hilo"><param name="table">hi_value</param><param name="column">next_value</param><param name="max_lo">100</param></generator>sequence 序列必须有一个序列名称assigned 自然主键主键由java程序指定hibernate 对象状态瞬时态瞬时对象在内存孤立存在,它是携带信息的载体,不和数据库的数据有任何关联关系new 对象delete()持久态处于该状态的对象在数据库中具有对应的记录,并拥有一个持久化标识save() saveOrUpdate() get() load()脱管态当一个session执行close()或clear()、evict()之后当与某持久对象关联的session被关闭后,该持久对象转变为脱管对象关系hibernate4 注解和关系hibernate4 注解@Entity 表示该类是一个实体类@Table 映射成一张表不写参数默认表名跟类名相同@Table(name="t_people")@Id 表示主键@GeneratedValue(strategy=GenerationType.AUTO)(native)@Id@GeneratedValue(generator="seq_ganerator")@GenericGenerator(name="seq_ganerator",strategy="sequence",parameters={@Parameter(name="sequence",value="seq_people")})1、native@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "native")2、uuid@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "uuid") 3、hilo@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "hilo") 4、assigned@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "assigned")5、identity@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "identity")6、select@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name="select", strategy="select",parameters = { @Parameter(name = "key", value = "idstoerung") })7、sequence@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "sequence",parameters = { @Parameter(name = "sequence", value = "seq_payablemoney") })8、seqhilo@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "seqhilo", parameters = { @Parameter(name = "max_lo", value = "5") })9、increment@GeneratedValue(generator = "paymentableGenerator")@GenericGenerator(name = "paymentableGenerator", strategy = "increment")10、foreign@GeneratedValue(generator = "idGenerator")@GenericGenerator(name = "idGenerator", strategy = "foreign", parameters = { @Parameter(name = "property", value = "employee") })@Transient该注解可以屏蔽属性的映射hibernate 延迟加载getget方法一要一执行就会发出sql get没有延迟加载如果对象不存在会抛出ng.NullPointerExceptionload调用load方法时并不会发出sql语句,只有在使用该对象时才发会sql, 当完成load之后,其实拿到的是一个代理对象,这个代理对象只有一个id值,获取对象的其它值时,才会发sql 语句load 用到了hibernate的延迟加载如果对象不存会抛出org.hibernate.ObjectNotFoundException:一对一关联OneToOne单向关联<!--oneToone是many-to-one的一个特例只须要增加unique=true(唯一) cascade 表示级联(all delete none save saveorupdate--><many-to-one name="person" column="pid" unique="true" cascade="delete" ></many-to-one> 单向关联注解@OneToOne@JoinColumn(name="pid",unique=true)cascade属性的可选值:all : 所有情况下均进行关联操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Java私塾《深入浅出学Hibernate4》——系列精品教程本节课程概览n Hibernate的关系映射包括:关系的表示、集合映射、关系映射、双向一对多映射示例、过滤器真正高质量培训签订就业协议网址:第四部分:关系映射真正高质量培训签订就业协议网址:真正高质量培训签订就业协议网址: 关系的数据库表示n 数据表之间的关系分为三类:一对一、一对多、多对多n 一对一数据表(部门表和部门主管表)n 一对多数据表(部门表和部门下的人员表)n 多对多数据表(部门表和人员表)开发部Dep1depName uuid Dep1张三1depUuid Name Uuid 开发部Dep1depName Uuid Dep1张三User1Dep1李四User2depUuid userName Uuid 开发部Dep1销售部Dep2depName Uuid 李四User2张三User1userName uuid User1Dep23User2Dep12User1Dep11UserUuid DepUuid Uuid 1*1*关系的对象表示n根据相互寻找的关系又分:单向和双向n对象一对一(双向)public class A {private B b = null; }public class B {private A a = null; }n对象一对多(双向)public class A {private B b = null; }public class B {private Collection<A> colA= null; }n对象多对多(双向)public class A {private Collection<B> colB= null; }public class B {private Collection<A> colA= null; }n双向一对多是最常用的映射关系真正高质量培训签订就业协议网址:key的配置n<key>元素<key> 元素在父映射元素定义了对新表的连接,并且在被连接表中定义了一个外键引用原表的主键的情况下经常使用。
<keycolumn="columnname"(1)on-delete="noaction|cascade"(2)property-ref="propertyName"(3)not-null="true|false"(4)update="true|false"(5)unique="true|false"(6)/>(1)column(可选):外键字段的名称。
也可以通过嵌套的<column> 指定。
(2)on-delete(可选,默认是noaction):表明外键关联是否打开数据库级别的级联删除。
(3)property-ref(可选):表明外键引用的字段不是原表的主键(提供给遗留数据)。
(4)not-null(可选):表明外键的字段不可为空,意味着无论何时外键都是主键的一部分。
(5)update(可选):表明外键决不应该被更新,这意味着无论何时外键都是主键的一部分。
(6)unique(可选):表明外键应有唯一性约束,这意味着无论何时外键都是主键的一部分。
对那些看重删除性能的系统,推荐所有的键都应该定义为on-delete="cascade",这样Hibernate 将使用数据库级的ON CASCADE DELETE 约束,而不是多个DELETE 语句真正高质量培训签订就业协议网址:集合映射的配置-1n用于映射集合类的Hibernate映射元素取决于接口的类型。
比如,<set>元素用来映射Set类型的属性:<class name="Product"><id name="serialNumber" column="productSerialNumber"/><set name="parts"><key column="productSerialNumber" not-null="true"/><one-to-many class="Part"/></set></class>n除了<set>,还有<list>, <map>, <bag>, <array> 和<primitive-array> 映射元素。
<map>具有代表性,如下:真正高质量培训签订就业协议网址:集合映射的配置-2n<mapname="propertyName" (1)table="table_name" (2)schema="schema_name" (3)lazy="true|extra|false" (4)inverse="true|false" (5)cascade=“all|none|save-update|delete|all-delete-orphan|delete-orphan”(6)sort="unsorted|natural|comparatorClass" (7)order-by="column_name asc|desc" (8)where="arbitrary sql where condition" (9)fetch="join|select|subselect" (10)batch-size="N" (11)access="field|property|ClassName" (12)optimistic-lock="true|false" (13)mutable="true|false" (14)><key .... /> <map-key .... /><element .... /></map>真正高质量培训签订就业协议网址:集合映射的配置-3(1) name 集合属性的名称(2) table (可选——默认为属性的名称)这个集合表的名称(不能在一对多的关联关系中使用)(3) schema (可选) 表的schema的名称, 他将覆盖在根元素中定义的schema(4) lazy (可选--默认为true) 可以用来关闭延迟加载(false),(5) inverse (可选——默认为false) 标记这个集合作为双向关联关系中的方向一端。
(6) cascade (可选——默认为none) 让操作级联到子实体(7) sort(可选)指定集合的排序顺序(8) order-by (可选, 仅用于jdk1.4) 指定表的字段(一个或几个)再加上asc或者desc(可选), 定义Map,Set和Bag的迭代顺序(9) where (可选) 指定任意的SQL where条件, 该条件将在重新载入或者删除这个集合时使用(当集合中的数据仅仅是所有可用数据的一个子集时这个条件非常有用)(10) fetch (可选, 默认为select) 用于在外连接抓取、通过后续select抓取和通过后续subselect抓取之间选择。
(11) batch-size (可选, 默认为1) 指定通过延迟加载取得集合实例的批处理块大小(12) access(可选-默认为属性property):Hibernate取得集合属性值时使用的策略(13) 乐观锁(可选-默认为true): 对集合的状态的改变会是否导致其所属的实体的版本增长。
(对一对多关联来说,关闭这个属性常常是有理的)(14) mutable(可变)(可选-默认为true): 若值为false,表明集合中的元素不会改变(在某些情况下可以进行一些小的性能优化)。
真正高质量培训签订就业协议网址:集合映射的配置-4n集合外键集合实例在数据库中依靠持有集合的实体的外键加以辨别。
此外键作为集合关键字段加以引用。
集合关键字段通过<key> 元素映射。
在外键字段上可能具有非空约束。
对于大多数集合来说,这是隐含的。
对单向一对多关联来说,外键字段默认是可以为空的,因此你可能需要指明not-null=“true”。
示例如下:<key column="productSerialNumber" not-null="true"/>外键约束可以使用ON DELETE CASCADE,示例如下:<key column="productSerialNumber" on-delete="cascade"/>真正高质量培训签订就业协议网址:关系映射-1n one-to-one通过one-to-one 元素,可以定义持久化类的一对一关联。
<one-to-onename="propertyName"(1)class="ClassName"(2)cascade="cascade_style"(3)constrained="true|false"(4)fetch="join|select"(5)property-ref="propertyNameFromAssociatedClass"(6)access="field|property|ClassName"(7)formula="any SQL expression"(8)lazy="proxy|no-proxy|false"(9)entity-name="EntityName"(10)/>真正高质量培训签订就业协议网址:关系映射-2(1)name:属性名。
(2)class(可选—默认是通过反射得到的属性类型):被关联的类的名字。
(3)cascade(级联)(可选)表明操作是否从父对象级联到被关联的对象。