数据结构第五章查找
数据结构第五章 查找 答案

数据结构与算法上机作业第五章查找一、选择题1、若构造一棵具有n个结点的二叉排序树,在最坏情况下,其高度不超过 B 。
A. n/2B. nC. (n+1)/2D. n+12、分别以下列序列构造二叉排序数(二叉查找树),与用其他3个序列所构造的结果不同的是 C :A. (100, 80, 90, 60, 120, 110, 130)B. (100, 120, 110, 130, 80, 60, 90)C. (100, 60, 80, 90, 120, 110, 130)D. (100, 80, 60, 90, 120, 130, 110)3、不可能生成下图所示的二叉排序树的关键字的序列是 A 。
A. 4 5 3 1 2B. 4 2 5 3 1C. 4 5 2 1 3D. 4 2 3 1 54、在二叉平衡树中插入一个结点造成了不平衡,设最低的不平衡点为A,并已知A的左孩子的平衡因子为0,右孩子的平衡因子为1,则应作 C 型调整使其平衡。
A. LLB. LRC. RLD. RR5、一棵高度为k的二叉平衡树,其每个非叶结点的平衡因子均为0,则该树共有 C 个结点。
A. 2k-1-1B. 2k-1+1C. 2k-1D. 2k+16、具有5层结点的平衡二叉树至少有 A 个结点。
A. 12B. 11C. 10D. 97、下面关于B-和B+树的叙述中,不正确的是 C 。
A. B-树和B+树都是平衡的多叉树B. B-树和B+树都可用于文件的索引结构C. B-树和B+树都能有效地支持顺序检索D. B-树和B+树都能有效地支持随机检索8、下列关于m阶B-树的说法错误的是 D 。
A. 根结点至多有m棵子树B. 所有叶子结点都在同一层次C. 非叶结点至少有m/2(m为偶数)或m/2+1(m为奇数)棵子树D. 根结点中的数据是有序的9、下面关于哈希查找的说法正确的是 C 。
A. 哈希函数构造得越复杂越好,因为这样随机性好,冲突小B. 除留余数法是所有哈希函数中最好的C. 不存在特别好与坏的哈希函数,要视情况而定D. 若需在哈希表中删去一个元素,不管用何种方法解决冲突都只要简单地将该元素删去即可10、与其他查找方法相比,散列查找法的特点是 C 。
数据结构第五章参考答案

习题51.填空题(1)已知二叉树中叶子数为50,仅有一个孩子的结点数为30,则总结点数为(___________)。
答案:129(2)3个结点可构成(___________)棵不同形态的二叉树。
答案:5(3)设树的度为5,其中度为1~5的结点数分别为6、5、4、3、2个,则该树共有(___________)个叶子。
答案:31(4)在结点个数为n(n>1)的各棵普通树中,高度最小的树的高度是(___________),它有(___________)个叶子结点,(___________)个分支结点。
高度最大的树的高度是(___________),它有(___________)个叶子结点,(___________)个分支结点。
答案:2 n-1 1 n 1 n-1(5)深度为k的二叉树,至多有(___________)个结点。
答案:2k-1(6)(7)有n个结点并且其高度为n的二叉树的数目是(___________)。
答案:2n-1(8)设只包含根结点的二叉树的高度为0,则高度为k的二叉树的最大结点数为(___________),最小结点数为(___________)。
答案:2k+1-1 k+1(9)将一棵有100个结点的完全二叉树按层编号,则编号为49的结点为X,其双亲PARENT (X)的编号为()。
答案:24(10)已知一棵完全二叉树中共有768个结点,则该树中共有(___________)个叶子结点。
答案:384(11)(12)已知一棵完全二叉树的第8层有8个结点,则其叶子结点数是(___________)。
答案:68(13)深度为8(根的层次号为1)的满二叉树有(___________)个叶子结点。
答案:128(14)一棵二叉树的前序遍历是FCABED,中序遍历是ACBFED,则后序遍历是(___________)。
答案:ABCDEF(15)某二叉树结点的中序遍历序列为ABCDEFG,后序遍历序列为BDCAFGE,则该二叉树结点的前序遍历序列为(___________),该二叉树对应的树林包括(___________)棵树。
《刘大有数据结构》 chapter 5 数组字符串和集合类

再例如三维数组 再例如三维数组D[3][3][4],可以把它看作一维 , 数组 B1[3] = { D[0][3][4],D[1][3][4],D[2][3][4] } , ,
下面我们给出一个 下面我们给出一个Array类的应用例子 类的应用例子. 类的应用例子 例5.1 编写一个函数,要求输入一个整数 , 编写一个函数,要求输入一个整数N, 用动态数组A来存放 来存放2~ 之间所有 之间所有5或 的倍数 的倍数, 用动态数组 来存放 ~N之间所有 或7的倍数, 输出该数组. 输出该数组 说明 : 因为 由用户给出 , 编写程序时无法知 说明:因为N由用户给出 由用户给出, 道需要多大的数组来存放数据, 道需要多大的数组来存放数据,因此采用动态 数组(初始时大小为10) 数组(初始时大小为 ),每当数组满时就调 整数组大小,给它增加10个元素 个元素. 整数组大小,给它增加 个元素
数组在内存中一般是以顺序方式存储的 数组在内存中一般是以顺序方式存储的. 设一维数组 设一维数组A[n]存放在 个连续的存储单元中 , 存放在n个连续的存储单元中 存放在 个连续的存储单元中, 每个数组元素占一个存储单元(不妨设为C个 每个数组元素占一个存储单元 ( 不妨设为 个 连续字节) 如果数组元素A[0]的首地址是 , 的首地址是L, 连续字节). 如果数组元素 的首地址是 则 A[1] 的 首 地 址 是 L+C , A[2] 的 首 地 址 是 L+2C,… …,依次类推,对于 0 ≤ i ≤ n 1 有: , ,依次类推,
B[i]={ A[i][0],A[i][1],…,A[i][n-2],A[i][n-1] } -
数据结构答案 第5章 串学习指导

第5章串5.1 知识点分析1.串的定义串(String)是由零个或多个任意字符组成的有限序列。
一般记作:s="a1 a2 …a i…a n"。
其中s 是串名,用双引号括起来的字符序列为串值,但引号本身并不属于串的内容。
a i(1<=i<=n)是一个任意字符,它称为串的元素,是构成串的基本单位,i是它在整个串中的序号;n为串的长度,表示串中所包含的字符个数。
2.几个术语(1)长度串中字符的个数,称为串的长度。
(2)空串长度为零的字符串称为空串。
(3)空格串由一个或多个连续空格组成的串称为空格串。
(4)串相等两个串相等,是指两个串的长度相等,且每个对应字符都相等。
(5)子串串中任意连续字符组成的子序列称为该串的子串。
(6)主串包含子串的串称为该子串的主串。
(7)模式匹配子串的定位运算又称为串的模式匹配,是一种求子串的第一个字符在主串中序号的运算。
被匹配的主串称为目标串,子串称为模式。
3.串的基本运算(1)求串长:LenStr(s)。
(2)串连接:ConcatStr(s1,s2) 。
(3)求子串:SubStr (s,i,len)。
(4)串比较:EqualStr (s1,s2)。
(5)子串查找:IndexStr (s,t),找子串t在主串s中首次出现的位置(也称模式匹配)。
(6)串插入:InsStr (s,t,i)。
(7)串删除:DelStr(s,i,len)。
4.串的存储(1)定长顺序存储。
(2)链接存储。
(3)串的堆分配存储。
5.2 典型习题分析【例1】下面关于串的的叙述中,哪一个是不正确的?()A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储分析:空串是不含任何字符的串,即空串的长度是零。
空格串是由空格组成的串,其长度等于空格的个数。
答案为B。
【例2】两个串相等的充分必要条件是( )。
A.两个串长度相等B.两个串有相同字符C.两个串长度相等且有相同字符D.以上结论均不正确分析:根据串相等定义,两个串是相等是指两个串的长度相等且对应字符都相等,故A、B、C均不正确,答案为D。
数据结构(c语言版)第五章答案

第五章1、设二维数组A【8】【10】是一个按行优先顺序存储在内存中的数组,已知A【0】【0】的起始存储位置为1000,每个数组元素占用4个存储单元,求:(1)A【4】【5】的起始存储位置。
A【4】【5】的起始存储位置为1000+(10*4+5)*4=1180;(2)起始存储位置为1184的数组元素的下标。
起始存储位置为1184的数组元素的下标为4(行下标)、6(列下标)。
2、画出下列广义表D=((c),(e),(a,(b,c,d)))的图形表示和它们的存储表示。
略,参考第5·2节应用题第5题分析与解答。
3、已知A为稀疏矩阵,试从时间和空间角度比较采用两种不同的存储结构(二维数组和三元组表)实现求∑a(i,j)运算的优缺点。
稀疏矩阵A采用二维数组存储时,需要n*n个存储单元,完成求∑ii a(1≤i≤n)时,由于a【i】【i】随机存取,速度快。
但采用三元组表时,若非零元素个数为t,需3t+3个存储单元(t个分量存各非零元素的行值、列值、元素值),同时还需要三个存储单元存储存稀疏矩阵A的行数、列数和非零元素个数,比二维数组节省存储单元;但在求∑ii a(1≤i≤n)时,要扫描整个三元组表,以便找到行列值相等的非零元素求和,其时间性能比采用二维数组时差。
4、利用三元组存储任意稀疏数组时,在什么条件下才能节省存储空间?当m行n列稀疏矩阵中非零元素个数为t,当满足关系3*t<m*n时,利用三元组存储稀疏数组时,才能节省存储空间。
5、求下列各广义表的操作结果。
(1)GetHead((a,(b,c),d))GetHead((a,(b,c),d))=a(2)GetTail((a,(b,c),d))GetTail((a,(b,c),d))=((b,c),d)(3)GetHead(GetTail((a,(b,c),d)))GetHead(GetTail((a,(b,c),d)))=(b,c)(4)GetTail(GetHead((a,(b,c),d)))GetTail(GetHead((a,(b,c),d)))=()第六章1、已知一棵树边的集合为{(i,m),(i,n),(e,i),(b,e),(b,d),(a,b),(g,j),(g,k),(c,g),(c,f),(h,l),(c,h),(a,c)}用树形表示法画出此树,并回答下列问题:(1)哪个是根结点?(2)哪些是叶结点?(3)哪个是g的双亲?(4)哪些是g的祖先?(5)哪些是g的孩子?(6)哪些是e的子孙?(7)哪些是e的兄弟?哪些是f的兄弟?(8)结点b和n的层次号分别是什么?(9)树的深度是多少?(10)以结点c为根的子树的深度是多少?(11)树的度数是多少?略。
《数据结构及其应用》笔记含答案 第五章_树和二叉树

第5章树和二叉树一、填空题1、指向结点前驱和后继的指针称为线索。
二、判断题1、二叉树是树的特殊形式。
()2、完全二叉树中,若一个结点没有左孩子,则它必是叶子。
()3、对于有N个结点的二叉树,其高度为。
()4、满二叉树一定是完全二叉树,反之未必。
()5、完全二叉树可采用顺序存储结构实现存储,非完全二叉树则不能。
()6、若一个结点是某二叉树子树的中序遍历序列中的第一个结点,则它必是该子树的后序遍历序列中的第一个结点。
()7、不使用递归也可实现二叉树的先序、中序和后序遍历。
()8、先序遍历二叉树的序列中,任何结点的子树的所有结点不一定跟在该结点之后。
()9、赫夫曼树是带权路径长度最短的树,路径上权值较大的结点离根较近。
()110、在赫夫曼编码中,出现频率相同的字符编码长度也一定相同。
()三、单项选择题1、把一棵树转换为二叉树后,这棵二叉树的形态是(A)。
A.唯一的B.有多种C.有多种,但根结点都没有左孩子D.有多种,但根结点都没有右孩子解释:因为二叉树有左孩子、右孩子之分,故一棵树转换为二叉树后,这棵二叉树的形态是唯一的。
2、由3个结点可以构造出多少种不同的二叉树?(D)A.2 B.3 C.4 D.5解释:五种情况如下:3、一棵完全二叉树上有1001个结点,其中叶子结点的个数是(D)。
A.250 B. 500 C.254 D.501解释:设度为0结点(叶子结点)个数为A,度为1的结点个数为B,度为2的结点个数为C,有A=C+1,A+B+C=1001,可得2C+B=1000,由完全二叉树的性质可得B=0或1,又因为C为整数,所以B=0,C=500,A=501,即有501个叶子结点。
4、一个具有1025个结点的二叉树的高h为(C)。
A.11 B.10 C.11至1025之间 D.10至1024之间解释:若每层仅有一个结点,则树高h为1025;且其最小树高为⎣log21025⎦ + 1=11,即h在11至1025之间。
数据结构:第5章 数组与广义表1-数组

中的元素均为常数。下三角矩阵正好相反,它的主对
数据结构讲义
第5章 数组与广义表
—数组
数组和广义表
数组和广义表可看成是一种特殊的 线性表,其特殊在于,表中的数据 元素本身也是一种线性表。
几乎所有的程序设计语言都有数组 类型。本节重点讲解稀疏矩阵的实 现。
5.1 数组的定义
由于数组中各元素具有统一的类型,并且 数组元素的下标一般具有固定的上界和下 界,因此,数组的处理比其它复杂的结构 更为简单。
nm
aa1221
aa2222
…………....
aam2n2 ………………..
aamm11 aamm22 ………….... aammnn LLoocc(a( iaj)ij=)L=Loco(ca(a111)1+)[+([j(-i1-)1m)n++((i-j1-1)])*]*l l
aa1mn 1 aa2mn2 …………....
其存储形式如图所示:
15137 50800 18926 30251
a00 a10 a 11 a20 a21 a23 ………………..
70613
an-1 0 a n-1 1 a n-1 2 …a n-1 n-1
图 5.1 对称矩阵
在这个下三角矩阵中,第i行恰有i+1个元素,元素总
数为:
n(n+1)/2
5.2 数组的顺序表示和实现
由于计算机的内存结构是一维的,因此用 一维内存来表示多维数组,就必须按某种 次序将数组元素排成一列序列,然后将这 个线性序列存放在存储器中。
又由于对数组一般不做插入和删除操作, 也就是说,数组一旦建立,结构中的元素 个数和元素间的关系就不再发生变化。因 此,一般都是采用顺序存储的方法来表示 数组。
《数据结构与算法》第五章-数组和广义表学习指导材料

《数据结构与算法》第五章数组和广义表本章介绍的数组与广义表可视为线性表的推广,其特点是数据元素仍然是一个表。
本章讨论多维数组的逻辑结构和存储结构、特殊矩阵、矩阵的压缩存储、广义表的逻辑结构和存储结构等。
5.1 多维数组5.1.1 数组的逻辑结构数组是我们很熟悉的一种数据结构,它可以看作线性表的推广。
数组作为一种数据结构其特点是结构中的元素本身可以是具有某种结构的数据,但属于同一数据类型,比如:一维数组可以看作一个线性表,二维数组可以看作“数据元素是一维数组”的一维数组,三维数组可以看作“数据元素是二维数组”的一维数组,依此类推。
图5.1是一个m行n列的二维数组。
5.1.2 数组的内存映象现在来讨论数组在计算机中的存储表示。
通常,数组在内存被映象为向量,即用向量作为数组的一种存储结构,这是因为内存的地址空间是一维的,数组的行列固定后,通过一个映象函数,则可根据数组元素的下标得到它的存储地址。
对于一维数组按下标顺序分配即可。
对多维数组分配时,要把它的元素映象存储在一维存储器中,一般有两种存储方式:一是以行为主序(或先行后列)的顺序存放,如BASIC、PASCAL、COBOL、C等程序设计语言中用的是以行为主的顺序分配,即一行分配完了接着分配下一行。
另一种是以列为主序(先列后行)的顺序存放,如FORTRAN语言中,用的是以列为主序的分配顺序,即一列一列地分配。
以行为主序的分配规律是:最右边的下标先变化,即最右下标从小到大,循环一遍后,右边第二个下标再变,…,从右向左,最后是左下标。
以列为主序分配的规律恰好相反:最左边的下标先变化,即最左下标从小到大,循环一遍后,左边第二个下标再变,…,从左向右,最后是右下标。
例如一个2×3二维数组,逻辑结构可以用图5.2表示。
以行为主序的内存映象如图5.3(a)所示。
分配顺序为:a11 ,a12 ,a13 ,a21 ,a22,a23 ; 以列为主序的分配顺序为:a11 ,a21 ,a12 ,a22,a13 ,a23 ; 它的内存映象如图5.3(b)所示。
数据结构预算法 第5章习题解答
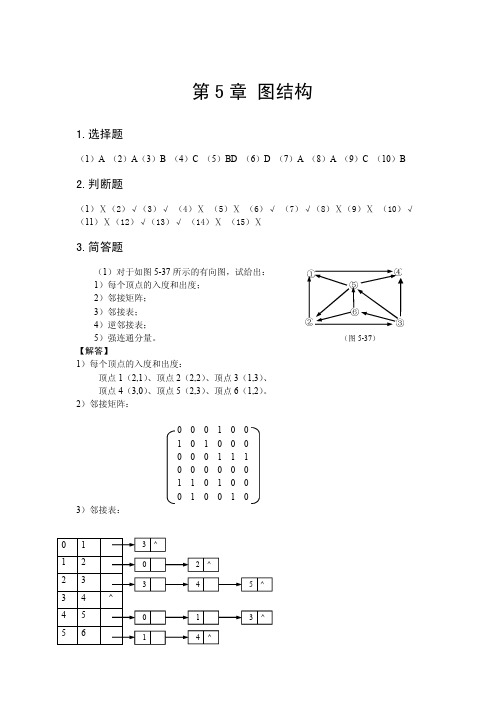
④
③
0 1 2 3 4 5
1 2 3 4 5 6 ^
3 0 3
^ 2 4 ^ 5 ^
0 1
1 4 ^
3 ^
4)逆邻接表: 0 1 2 3 4 5 1 2 3 4 5 6 5)强连通分量:
1 4 1 0 2 2 ^ ^ 2 5 ^ 4 ^ 4 5 ^ ^
(2)设无向图 G 如图 5-38 所示,试给出: 1)该图的邻接矩阵; 2)该图的邻接表; 3)该图的多重邻接表; 4)从 V1 出发的“深度优先”遍历序列; 5)从 V1 出发的“广度优先”遍历序列。 【解答】 1) 该图的邻接矩阵: 0 1 1 0 0 0 0 1 0 0 1 0 0 0 1 1 0 1 0 0 0 0 0 1 0 1 1 0 0 0 0 1 0 0 1 0 0 0 1 0 0 1 0 0 0 0 1 1 0
{if(p!=s) p->next=s->next; else (G->adjlist[e->adjvex].firstedge=s->next;)} if(s) free(s); break; } } for(i=v;i<G->n;i++) /*删除顶点值*/ {G->adjlist[i].vertex=G->adjlist[i+1].vextex; G->adjlist[i].first[i].firstedge=G->adjlist[i+1].firstedge; } } void DeleteArc(AALGraph *G,int v,int w) /*在图 G 中删除序号为 v,w 的顶点之的边*/ {EdgeNode *s,*p; s=G->adjlist[v].firstedge; p=s; for(;s;s=s->next); /*在与 m 邻接的点中找 n*/ {if(s->adjvex==w) /*若找到邻接点 n,则将该边从边表中脱出*/ {if(p!=s) p->next=s->next; else G->adjlist[v].firstedge=s->next; } if(s) free(s); /*释放要删除的边结点*/ } s=G->adjlist[w].firstedge;p=s; for(;s;p=s,s=s->next) /*在与 n 邻接的点中找 m*/ {if(s->adjvex==v) /*若找到邻接点 m,则将该边从边表中脱出*/ {if(p!=s) p->next=s->next; else G->adjlist[w].firstedge=s->next; } if(s) free(s); /*释放要删除的边结点*/ } G->e--; } (3)试以十字链表为存储结构实现算法设计题(1)中所列图的基本操作。 算法略。 (4)试以邻接多重表为存储结构实现算法设计题(1)中所列图的基本操作。 算法略。 (5)对于含有 n 个顶点的有向图,编写算法由其邻接表构造相应的逆邻接表。 【解答】 Void InvertAdjList(ALGraph G, ALGraph *H) /*由有向图的邻接表 G 建立其逆邻接表 H*/ {for (i=1;i<=n;i++) /*设有向图有 n 个顶点,建逆邻接表的顶点向量*/ {H[i]->vertex=G.adjlist[i].vertex; H->firstedge=NULL;} for (i=0; i<n; i++) /*邻接表转为逆邻接表*/ {p= G.adjlist[i].firstedge; /*取指向邻接表的指针*/ while (p!=null) {j=p->adjvex;
数据结构第5章

第5章:数组和广义表 1. 了解数组的定义;填空题:1、假设有二维数组A 6×8,每个元素用相邻的6个字节存储,存储器按字节编址。
已知A 的起始存储位置(基地址)为1000,则数组A 的体积(存储量)为 288 B ;末尾元素A 57的第一个字节地址为 1282 。
2、三元素组表中的每个结点对应于稀疏矩阵的一个非零元素,它包含有三个数据项,分别表示该元素的 行下标 、 列下标 和 元素值 。
2. 理解数组的顺序表示方法会计算数组元素顺序存储的地址;填空题:1、已知A 的起始存储位置(基地址)为1000,若按行存储时,元素A 14的第一个字节地址为 (8+4)×6+1000=1072 ;若按列存储时,元素A 47的第一个字节地址为 (6×7+4)×6+1000)=1276 。
(注:数组是从0行0列还是从1行1列计算起呢?由末单元为A 57可知,是从0行0列开始!) 2、设数组a[1…60, 1…70]的基地址为2048,每个元素占2个存储单元,若以列序为主序顺序存储,则元素a[32,58]的存储地址为 8950 。
答:不考虑0行0列,利用列优先公式: LOC(a ij )=LOC(a c 1,c 2)+[(j-c 2)*(d 1-c 1+1)+i-c 1)]*L 得:LOC(a 32,58)=2048+[(58-1)*(60-1+1)+32-1]]*2=8950选择题:( A )1、假设有60行70列的二维数组a[1…60, 1…70]以列序为主序顺序存储,其基地址为10000,每个元素占2个存储单元,那么第32行第58列的元素a[32,58]的存储地址为 。
(无第0行第0列元素)A .16902B .16904C .14454D .答案A, B, C 均不对 答:此题(57列×60行+31行)×2字节+10000=16902( B )2、设矩阵A 是一个对称矩阵,为了节省存储,将其下三角部分(如下图所示)按行序存放在一维数组B[ 1, n(n-1)/2 ]中,对下三角部分中任一元素a i,j (i ≤j), 在一维数组B 中下标k 的值是:A .i(i-1)/2+j-1B .i(i-1)/2+jC .i(i+1)/2+j-1D .i(i+1)/2+j3、从供选择的答案中,选出应填入下面叙述 ? 内的最确切的解答,把相应编号写在答卷的对应栏内。
数据结构——第五章查找:01静态查找表和动态查找表

数据结构——第五章查找:01静态查找表和动态查找表1.查找表可分为两类:(1)静态查找表:仅做查询和检索操作的查找表。
(2)动态查找表:在查询之后,还需要将查询结果为不在查找表中的数据元素插⼊到查找表中;或者,从查找表中删除其查询结果为在查找表中的数据元素。
2.查找的⽅法取决于查找表的结构:由于查找表中的数据元素之间不存在明显的组织规律,因此不便于查找。
为了提⾼查找效率,需要在查找表中的元素之间⼈为地附加某种确定的关系,⽤另外⼀种结构来表⽰查找表。
3.顺序查找表:以顺序表或线性链表表⽰静态查找表,假设数组0号单元留空。
算法如下:int location(SqList L, ElemType &elem){ i = 1; p = L.elem; while (i <= L.length && *(p++)!= e) { i++; } if (i <= L.length) { return i; } else { return 0; }}此算法每次循环都要判断数组下标是否越界,改进⽅法:加⼊哨兵,将⽬标值赋给数组下标为0的元素,并从后向前查找。
改进后算法如下:int Search_Seq(SSTable ST, KeyType kval) //在顺序表ST中顺序查找其关键字等于key的数据元素。
若找到,则函数值为该元素在表中的位置,否则为0。
{ ST.elem[0].key = kval; //设置哨兵 for (i = ST.length; ST.elem[i].key != kval; i--) //从后往前找,找不到则返回0 { } return 0;}4.顺序表查找的平均查找长度为:(n+1)/2。
5.上述顺序查找表的查找算法简单,但平均查找长度较⼤,不适⽤于表长较⼤的查找表。
若以有序表表⽰静态查找表,则查找过程可以基于折半进⾏。
算法如下:int Search_Bin(SSTable ST, KeyType kval){ low = 1; high = ST.length; //置区间初值 while (low <= high) { mid = (low + high) / 2; if (kval == ST.elem[mid].key) { return mid; //找到待查元素 } else if (kval < ST.elem[mid].key) { high = mid - 1; //继续在前半区间查找 } else { low = mid + 1; //继续在后半区间查找 } } return 0; //顺序表中不存在待查元素} //表长为n的折半查找的判定树的深度和含有n个结点的完全⼆叉树的深度相同6.⼏种查找表的时间复杂度:(1)从查找性能看,最好情况能达到O(logn),此时要求表有序;(2)从插⼊和删除性能看,最好情况能达到O(1),此时要求存储结构是链表。
《数据结构》第五章习题参考答案

《数据结构》第五章习题参考答案一、判断题(在正确说法的题后括号中打“√”,错误说法的题后括号中打“×”)1、知道一颗树的先序序列和后序序列可唯一确定这颗树。
( ×)2、二叉树的左右子树可任意交换。
(×)3、任何一颗二叉树的叶子节点在先序、中序和后序遍历序列中的相对次序不发生改变。
(√)4、哈夫曼树是带权路径最短的树,路径上权值较大的结点离根较近。
(√)5、用一维数组存储二叉树时,总是以前序遍历顺序存储结点。
( ×)6、完全二叉树中,若一个结点没有左孩子,则它必是叶子结点。
( √)7、一棵树中的叶子数一定等于与其对应的二叉树的叶子数。
(×)8、度为2的树就是二叉树。
(×)二、单项选择题1.具有10个叶结点的二叉树中有( B )个度为2的结点。
A.8 B.9 C.10 D.112.树的后根遍历序列等同于该树对应的二叉树的( B )。
A. 先序序列B. 中序序列C. 后序序列3、二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG 。
该二叉树根的右子树的根是:( C )A. EB. FC. GD. H04、在下述结论中,正确的是( D )。
①具有n个结点的完全二叉树的深度k必为┌log2(n+1)┐;②二叉树的度为2;③二叉树的左右子树可任意交换;④一棵深度为k(k≥1)且有2k-1个结点的二叉树称为满二叉树。
A.①②③B.②③④C.①②④D.①④5、某二叉树的后序遍历序列与先序遍历序列正好相反,则该二叉树一定是( D )。
A.空或只有一个结点B.完全二叉树C.二叉排序树D.高度等于其结点数三、填空题1、对于一棵具有n个结点的二叉树,对应二叉链接表中指针总数为__2n____个,其中___n-1_____个用于指向孩子结点,___n+1___个指针空闲着。
2、一棵深度为k(k≥1)的满二叉树有_____2k-1______个叶子结点。
数据结构第五章
5.3.1 特殊矩阵
是指非零元素或零元素的分布有一定规律的矩阵。
1、对称矩阵 在一个n阶方阵A中,若元素满足下述性质: aij = aji 0≦i,j≦n-1 则称A为对称矩阵。
对称矩阵中的元素关于主对角线对称,故只 要存储矩阵中上三角或下三角中的元素,这样, 能节约近一半的存储空间。
2013-7-25 第4章 18
5.3 矩阵的压缩存储
在科学与工程计算问题中,矩阵是一种常用 的数学对象,在高级语言编制程序时,常将 一个矩阵描述为一个二维数组。 当矩阵中的非零元素呈某种规律分布或者矩 阵中出现大量的零元素的情况下,会占用许 多单元去存储重复的非零元素或零元素,这 对高阶矩阵会造成极大的浪费。 为了节省存储空间,我们可以对这类矩阵进 行压缩存储:
5.2 数组的顺序表示和实现 由于计算机的内存结构是一维的, 因此用一维内存来表示多维数组,就必 须按某种次序将数组元素排成一列序列 ,然后将这个线性序列存放在存储器中 。 又由于对数组一般不做插入和删除 操作,也就是说,数组一旦建立,结构 中的元素个数和元素间的关系就不再发 生变化。因此,一般都是采用顺序存储 的方法来表示数组。
即为多个相同的非零元素只分配一个存储空间; 对零元素不分配空间。
课堂讨论: 1. 什么是压缩存储? 若多个数据元素的值都相同,则只分配一个元素值的 存储空间,且零元素不占存储空间。 2. 所有二维数组(矩阵)都能压缩吗? 未必,要看矩阵是否具备以上压缩条件。 3. 什么样的矩阵具备以上压缩条件? 一些特殊矩阵,如:对称矩阵,对角矩阵,三角矩阵, 稀疏矩阵等。 4. 什么叫稀疏矩阵? 矩阵中非零元素的个数较少(一般小于5%)
通常有两种顺序存储方式:
⑴行优先顺序——将数组元素按行排列,第i+1个行 向量紧接在第i个行向量后面。以二维数组为例,按 行优先顺序存储的线性序列为: a11,a12,…,a1n,a21,a22,…a2n,……,am1,am2,…,amn 在PASCAL、C语言中,数组就是按行优先顺序存 储的。 ⑵列优先顺序——将数组元素按列向量排列,第j+1 个列向量紧接在第j个列向量之后,A的m*n个元素按 列优先顺序存储的线性序列为: a11,a21,…,am1,a12,a22,…am2,……,an1,an2,…,anm 在FORTRAN语言中,数组就是按列优先顺序存储的。
数据结构与算法第5章课后答案

page: 1The Home of jetmambo - 第 5 章树和二叉树第 5 章树和二叉树(1970-01-01) -第 5 章树和二叉树课后习题讲解1. 填空题⑴树是n(n≥0)结点的有限集合,在一棵非空树中,有()个根结点,其余的结点分成m (m>0)个()的集合,每个集合都是根结点的子树。
【解答】有且仅有一个,互不相交⑵树中某结点的子树的个数称为该结点的(),子树的根结点称为该结点的(),该结点称为其子树根结点的()。
【解答】度,孩子,双亲⑶一棵二叉树的第i(i≥1)层最多有()个结点;一棵有n(n>0)个结点的满二叉树共有()个叶子结点和()个非终端结点。
【解答】2i-1,(n+1)/2,(n-1)/2【分析】设满二叉树中叶子结点的个数为n0,度为2的结点个数为n2,由于满二叉树中不存在度为1的结点,所以n=n0+n2;由二叉树的性质n0=n2+1,得n0=(n+1)/2,n2=(n-1)/2。
⑷设高度为h的二叉树上只有度为0和度为2的结点,该二叉树的结点数可能达到的最大值是(),最小值是()。
【解答】2h -1,2h-1【分析】最小结点个数的情况是第1层有1个结点,其他层上都只有2个结点。
⑸深度为k的二叉树中,所含叶子的个数最多为()。
【解答】2k-1【分析】在满二叉树中叶子结点的个数达到最多。
⑹具有100个结点的完全二叉树的叶子结点数为()。
【解答】50【分析】100个结点的完全二叉树中最后一个结点的编号为100,其双亲即最后一个分支结点的编号为50,也就是说,从编号51开始均为叶子。
⑺已知一棵度为3的树有2个度为1的结点,3个度为2的结点,4个度为3的结点。
则该树中有()个叶子结点。
【解答】12【分析】根据二叉树性质3的证明过程,有n0=n2+2n3+1(n0、n2、n3分别为叶子结点、度为2的结点和度为3的结点的个数)。
⑻某二叉树的前序遍历序列是ABCDEFG,中序遍历序列是CBDAFGE,则其后序遍历序列是()。
计算机科学概论 第5章 数据结构与算法

2 线性结构
2.3 串和数组 2.数组的定义和操作 • 数组的操作 initarray(&A,n,bound1,bound2...boundn) ——初始化 Destroyarray(&A) —— 删除数组 value(A,&e,index1,index2......indexn) —— 赋值 assign(&A,e,index1,index2......indexn) —— 分配数组
1 数据结构概述
1.4 算法及其描述和算法分析
5、算法与数据结构的关系: • 计算机科学家沃斯(N.Wirth)提出的: “算法+数据结构=程序” 揭示了程序设计的本质:对实际问题选择一种好的数据结构, 加上设计一个好的算法,而好的算法很大程度上取决于描述 实际问题的数据结构。算法与数据结构是互相依赖、互相联 系的。
2 线性结构
2.3 串和数组 1.串的定义和表示方法 • 串的表示方法 定长顺序存储表示 两种表示方法: 1)下标为0的数组存放长度 (pascal) typedef unsigned char SString[MAXSTLEN+1] ; 2)在串值后面加‘\0’结束 (C语言) 堆分配存储表示 串变量的存储空间是在程序执行过程中动态分配的, 程序中出现的所有串变量可用的存储空间是一个共享空 间,称为“堆”。
R={<1,2>,<1,3>,<2,4>,<2,5>,<2,6>,<2,8>,<3,2>,<3,4>,
<4,5>,<5,7>,<6,7>,<6,9>,<7,9>,<8,9>}
数据结构讲义第5章-数组和广义表

5.4 广义表
5)若广义表不空,则可分成表头和表尾,反之,一对表头和表尾 可唯一确定广义表 对非空广义表:称第一个元素为L的表头,其余元素组成的表称 为LS的表尾; B = (a,(b,c,d)) 表头:a 表尾 ((b,c,d)) 即 HEAD(B)=a, C = (e) D = (A,B,C,f ) 表头:e 表尾 ( ) TAIL(B)=((b,c,d)),
5.4 广义表
4)下面是一些广义表的例子; A = ( ) 空表,表长为0; B = (a,(b,c,d)) B的表长为2,两个元素分别为 a 和子表(b,c,d); C = (e) C中只有一个元素e,表长为1; D = (A,B,C,f ) D 的表长为4,它的前三个元素 A B C 广义表, 4 A,B,C , 第四个是单元素; E=( a ,E ) 递归表.
以二维数组为例:二维数组中的每个元素都受两个线性关 系的约束即行关系和列关系,在每个关系中,每个元素aij 都有且仅有一个直接前趋,都有且仅有一个直接后继. 在行关系中 aij直接前趋是 aij直接后继是 在列关系中 aij直接前趋是 aij直接后继是
a00 a01 a10 a11
a0 n-1 a1 n-1
a11 a21 ┇ a12 a22 ┇ ai2 ┇ … amj … amn … aij … ain … … a1j a2j … … a1n a2n β1 β2 ┇ βi ┇ βm
第五章 数据结构基础

数据的组织和处理过程是影响程序开发的最重要因素, 也是主要控制程序设计的原始材料。简洁而高效的程序设计, 自然依赖于数据的组织形式,这便是数据结构产生的背景。
5.1.1 什么是数据结构
所谓数据结构是指数据之间的相互关系;它包括三方面 内容:数据的逻辑结构、数据的存储结构和数据的运算。 例如,一个线性表,它的逻辑结构是指表中每个元素前 后之间的逻辑关系;它的存储结构是指表中元素在存储器中 的存储方式(是顺序存储还是链式存储);对它的运算包括插 入、删除、检索、更新、排序等等。
学号 1001 1002 … … 姓名 张三丰 貂蝉 … … 性别 男 女 … … 出生时间 … … 入学时间 … … 籍贯 辽宁 山西 … … 院系 计算机系 计算机系 … … 班级 计061 计061 … …
5.1.1 什么是数据结构
表中每个学生各占一行,每行的信息说明一个学生的情况,是学生 档案表的基本单位,我们把整个学生档案为一个数据结构。表中的每一 行称为一个结点(也称为元素、记录表目等,是数据结构中的基本单位)。 每一行由一系列数据项组成,数据项又称字段,能唯一确定一个结点的 字段称为关键码。上例中学号字段就是关键码,它能唯一确定一个学生 的情况。
5.2.3 队列
队列也是一种线性表,对于它所有的插入都在表的一端 进行,而所有的删除都在表的另一端进行。插入数据的一端 称为队列的头,删除数据的一端称为队列的尾。满足先进先 出的原则,简称为先进先出(FIFO)表。队列总日常生活中到 处可见,银行、快餐店中顾客的队都是队列。队列在程序设 计中也经常出现,例如操作系统中作业排队。在可运行多道 程序的计算机系统中,同时有几个作业运行,运行的结果都 需要通过通道输出。若通道未完成传输,则作业等待,并按 请求输出的先后顺序排队。当通道传输完毕可接受新的传输 任务时,排头的作业便从队列中退出,并准备输出。排头的 作业是下次要输出的作业,排尾的作业是刚进入队列的作业。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
补充:
数 据 结 构 第 五 章 查 找
{ int i; for(i=0;i<t->length;i++) if(t->elem[i].key==kx) {*p=i; return(1);} *p=i; return(0);}
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
若找到的是第一个元素data[1],则比较次 数c1=n;若找到的是第i个元素data[i],则 比较次数ci=n-i+1;在不考虑检索失败的情 况下,顺序检索的平均检索长度为 ASL =1*pn+2*pn-1+…+n*p1 =(1+2+…+n)/n (pi=1/n) =(n+1)/2 T(n)=O(n) 优点是算法简单且适应面广,无论查找 表中元素是否有序均可使用。 缺点是平均检索长度较大,特别是当n 很大时,检索效率较低。
例{18,27,1,20,22,6,10, 13 ,41,15,25}
h(key)=key mod 11
0 1 2 3 4 5 6 7 8 9 10 22 1 13 25 15 27 6 18 41 20 10
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
3.乘余取整法
Hash(key)=
b * (a * key mod1)
数 据 结 构 第 五 章 查 找
查找是为了得到某个信息而进行的工作,也称检索
基本概念与术语 静态查找表 动态查找表 哈希表查找
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
基本概念
关键码
关键码是数据元素(或记录)中某个数据项的值,用它 可以标识一个数据元素。 主关键码:能唯一确定一个数据元素的关键码。 次关键码:不能唯一确定一个数据元素的关键码。
平均查找长度
查找是给定一个值key,在查找表中找出关键码 等于key的元素,如果找到,则查找成功; 否则查找失败(主关键字)。
徐 晓 晖 制
查找效率的标准是指查找过程中和关键码的平均 比较次数,即平均查找长度ASL,定义为:
ASL( n) pi ci
i 1
n
数 据 结 构 第 五 章 查 找
5-1 线性表查找
表结构
将数据元素组织为一个线性表,可以是基于数组的 顺序存储或以线性链表存储 首先,关键码类型和数据元素类型约定如下描述:
徐 晓 晖 制
Typedef int KeyType; typedef struct { KeyType key; DataType other; }ElemType;
数 据 结 构 第 五 章 查 找
顺序查找
基本思想是从查找表的一端开始顺序扫描,将查找表中 元素的关键码同给定的值比较,如果相等,则查找成功; 当扫描结束时,还未找到关键码等于给定值的元素, 则查找失败。
顺序查找算法结束时,返回查找成功或失败的标志, 若查找成功,指出找到元素的位臵,否则,给出失败信息。 顺序查找既适合于顺序存储的静态查找表, 又适合于链式存储的静态查找 。
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
0 7
1 14
2 18
3 21
4 23
5 29
Байду номын сангаас
6 31
7 35
8 38
9 42
10 46
11 49
12 52
lowhigh mid
high mid
high
mid low
mid
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
徐 晓 晖 制
status BinSearch(SeqTable t,KeyType kx) { int low ,high,mid; int flag; low=0; high=t->length-1; while(low<=high) {mid=(low+high)/2; if(kx<t->elem[mid]) high=mid-1; else if(kx>t->elem[mid]) low=mid+1; else { flag=mid; break; } } return flag; }
设n个数据元素查找表分为m个子表, 分块检索的平均检索长度为
徐 晓 晖 制
ASL ASL索引表 ASL子表 1 1 n 1 n = m 1 1 m 1 2 2m 2 m
5-2 哈希表查找
数 据 结 构 第 五 章 查 找
哈希表与哈希方法
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
分块查找
分块检查找(索引顺序查找), 是顺序查找的一个改进方法。
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
索引表的整个表分成三个子表,对每个子表建立一个索引项, 其中包括两项内容:关键字项(其值为该子表内的最大关键字) 和指针项(指示该子表的第一个记录在表中的位臵)。 索引表按关键字有序,表或者有序或者分块有序。 分块有序指的是后一个子表中所有记录的关键字均 大于前一个子表中的最大关键字。
数 据 结 构 第 五 章 查 找
若表中元素个数n为:有 20 21 2 j 1 2 j 1
则最大检索长度为j ;若 2 1 n 2 1
j
j 1
则最大检
索长度为j+1,所以 log2 (n 1) 设检索每个元素的概率相同,则平均检索长度为: 1 h n 1 i 1 ASL i 2 log 2(n 1) 1 n i 1 n T(n)=O(log2n)
Hash(key)=a.key+b 例:{100,300,500,700,800,900}
Hash(key)=1/100*key
0 1
100
徐 晓 晖 制
2
3
300
4
5
500
6
7
700
8
800
9
900
2.除余法
数 据 结 构 第 五 章 查 找
除余法是取关键码被某个不大于散列表长度m的 数P除后所得余数为散列地址。数p的选取,一般 可选P为小于基本区域长度m的最大素数比较好。
数 据 结 构 第 五 章 查 找
静态查找表的顺序存储结构描述如下:
typedef struct { ElemType *data; int length; }SeqTable;
静态查找表的链式存储结构及其结点类型描述如下:
徐 晓 晖 制
typedef struct node { ElemType data; struct node *next; }NodeType;
数 据 结 构 第 五 章 查 找
6.折叠法 折叠法是将关键码分割成倍数相等的几部分,最后一部分的倍 数可以短点,将这几部分叠加求和,取后几位为哈希地址。
徐 晓 晖 制
移位叠加法:将各部分的最后一位对齐相加; 间界叠加法:从一端向另一端沿各部分分界来回折叠, 最后一位对齐相加。 例:key=25346358705 分割:253 463 587 05 253 253 364 463 587 587 + 50 + 05 1254 1308 Hash(key)=254 Hash(key)=308
哈希表查找法即散列法又称为杂凑法或关键码—地址转换法。 用散列法表示的查找表称为(哈希表)散列表。 散列函数使每个关键码都和结构中存储位臵对应, 这样的一个对应关系称为散列(哈希Hash)函数。
关键码 h 存储地址
徐 晓 晖 制
例{18,27,1,20,22,6,10, 13 ,41,15,25}
h(key)=key mod 11
数 据 结 构 第 五 章 查 找
顺序查找算法 int S_Search(SeqTable *t,KeyType kx) { int i; t->elem[0]=kx; for(i=t->length;t->elem[i].key!=kx;i--); return i; } int seqSearch(SeqTable *t, KeyType kx, int *p)
取上式的整数部分作为哈希地址。
1 a一般取值为: a 2
5 1
徐 晓 晖 制
4.中平方法 先求出关键码的平方,然后取中间几位作为地址。 例如,关键码key=4731 (4731)2 = 22382361 h(key)=382
数 据 结 构 第 五 章 查 找
徐 晓 晖 制
5.数字分析法 数字分析法是关键码位数比存储区的地址码的位数多, 这时可以对关键码的各位进行分析,丢掉分布不均匀的位 留下均匀位作为地址。 例如:对下列关键码集合进行关键码到地址的转换。 关键码是9位的,地址是3位的,需要经过分析丢掉 6位。 Key h(key) 000319426 326 000718309 709 000629443 643 000758615 715 000919697 997 000310329 329
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
查找表
查找表是一种以集合为逻辑结构、以查找为核心的数据结构。
查找表的基本操作:建表、查找、读表元、插入与删除 静态查找表:指一经建立就基本保持不变的查找表, 主要操作是检索。
动态查找表:经常需要改动的查找表,常进行插入删除操作。
徐 晓 晖 制
数 据 结 构 第 五 章 查 找
徐 晓 晖 制
若key1≠key2,有h(key1)=h(key2),这种现象称为冲突(碰撞)。 key1和key2称为同义词。 h(key)的值域所对应的地址空间称为基本区域。 发生碰撞时,同义词可以存放在基本区域中未被占用 的单元,也可以存放到另外的区域中