DB2数据库日常维护-REORG_TABLE
DB2数据库日常维护-REORG_TABLE

转)DB2日常维护——REORG TABLE命令优化数据库性能2009-04-24 16:18一个完整的日常维护规范可以帮助 DBA 理顺每天需要的操作,以便更好的监控和维护数据库,保证数据库的正常、安全、高效运行,防止一些错误重复发生。
由于DB2使用CBO作为数据库的优化器,数据库对象的状态信息对数据库使用合理的 ACCESS PLAN至关重要。
DB2 优化器使用目录统计信息来确定任何给定查询的最佳访问方案。
如果有关表或索引的统计信息已过时或者不完整,则会导致优化器选择不是最佳的方案,并且会降低执行查询的速度。
当数据库里某个表中的记录变化量很大时,需要在表上做REORG操作来优化数据库性能一、完整的REORG表的过程值得注意的是,针对数据库对象的大量操作,如反复地删除表,存储过程,会引起系统表中数据的频繁改变,在这种情况下,也要考虑对系统表进行REORG 操作。
一个完整的REORG表的过程应该是由下面的步骤组成的:RUNSTATS -> REORGCHK -> REORG -> RUNSTATS -> BIND或REBIND注:执行下面命令前要先连接数据库1 RUNSTATS由于在第二步中REORGCHK时可以对指定的表进行RUNSTATS操作(在REORGCHK时指定UPDATE STATISTICS),所以第一步事实上是可以省略的。
2 REORGCHK在对表数据进行许多更改之后,逻辑上连续的数据可能会位于不连续的物理数据页上,在许多插入操作创建了溢出记录时尤其如此。
按这种方式组织数据时,数据库管理器必须执行其他读操作才能访问顺序数据。
另外,在删除大量行后,也需要执行其他的读操作。
表重组操作会整理数据碎片来减少浪费的空间,并对行进行重新排序以合并溢出记录,从而加快数据访问速度并最终提高查询性能。
还可以指定根据特定索引来重新排序数据,以便查询时通过最少次数据读取操作就可以访问数据。
db2 reorg table 用法

db2 reorg table 用法DB2是一种关系型数据库管理系统,它是IBM公司开发的一款数据库软件。
在使用DB2时,我们经常需要对表进行重组(reorg),以优化表的性能和提高数据库的效率。
本文将介绍DB2 reorg table 的用法,包括什么是reorg table、为什么需要reorg table、如何使用reorg table等方面。
什么是reorg table?Reorg table是DB2中的一个命令,它用于重组表。
重组表是指将表中的数据重新组织,以优化表的性能和提高数据库的效率。
重组表可以消除表中的碎片,使表的数据更加紧凑,从而提高查询和更新的速度。
为什么需要reorg table?在使用DB2时,表的数据会随着时间的推移而不断变化。
当表中的数据被删除或更新时,表中的碎片会逐渐增多。
这些碎片会占用表的空间,使表的数据分散在不同的磁盘块中,从而降低查询和更新的速度。
此外,当表的数据量很大时,查询和更新的速度也会变慢。
因此,我们需要使用reorg table命令来优化表的性能和提高数据库的效率。
如何使用reorg table?使用reorg table命令可以重组表,以优化表的性能和提高数据库的效率。
下面是使用reorg table命令的步骤:1. 打开DB2命令行窗口。
2. 输入以下命令:reorg table tablename其中,tablename是要重组的表的名称。
3. 按Enter键执行命令。
4. 等待命令执行完成。
5. 关闭DB2命令行窗口。
在执行reorg table命令时,我们可以使用一些选项来控制重组的方式。
下面是一些常用的选项:1. INPLACE:使用INPLACE选项可以在不创建新表的情况下重组表。
这可以减少重组表所需的时间和空间。
但是,使用INPLACE 选项可能会导致表的性能下降。
2. SHRLEVEL:使用SHRLEVEL选项可以控制重组表时是否允许其他用户访问表。
DB2数据库管理最佳实践笔记-10日常运维

10.1 日常运维工具概述Runstats是run statistics的缩写,意思是收集统计信息,目的是为DB2优化器提供最佳路径选择;Reorg是重组的意思,目的是减少表和索引在物理存储上的碎片,提供性能;Reorgchk是重组前的检查Rebind是对一些包、存储过程或静态程序进行重新绑定。
几个工具的执行流程:首先通过Runstats收集表和索引的统计信息,然后执行Reorg重组,如果有必要则执行,然后再次收集统计信息。
最后,对于静态语句、存储过程等,执行Rebind绑定.10.2 Runstats在系统运行一个查询的时候,优化器需要决定用某种方式来访问数据。
只有当DB2对表中的数据有一个大概的了解,才能知道每一步操作大约需要处理多少数据,返回多少行。
当优化器了解了这些信息后,就会根据一系列的运算,判定出各种访问途径所需要消耗的资源,然后从中选择一个消耗资源最少的方法.最普通的Runstats就是统计表和索引中有多少行数据,有多少不同的数值.Runstats命令使用DISTRIBUTION参数手机数据分布.数据分布分为两种,一种叫做频率采样(Frequency),一种叫做百分比采样(Quantile)。
当收集数据分布时,两种采样方式都会被收集.其中频率采样是手机表中拥有相同数量最多的几行,比如10000行数据中9000行为10,然后500行为9,然后100行为8,剩下的部分平均分布.如果我们制定Frequency为3的话,那么系统就会记录下来有9000行10,500行9,然后100行8,剩下的部分在估算时则假定平均分布。
而百分比采样则是将整个10000行数据分成相等大小的若干段,然后记录每一段的段首和段尾的数值,当需要查询一个数据段时(比如C1〉10 AND C1<15),就可以根据每一个数据段的启始数值加上段落的大小,估算出符合查询条件的记录数量。
理论上,数据分布收集的越细致越好.但是经过细致的数据分布信息可能会导致DB2在优化SQL时需要处理更多的信息,并占用更多的系统存储空间,可能会导致性能的下降。
db2字段修改(增,删,改)操作

4.修改字段类型 alter table [table_name] alter column [column_name] set data type [column_type];
5.将原表列not null属性修改为null属性 alter table [table_name] alter column [column_name] drop not null; 以上所有的修改都会将表处于reorg pending状态所以我们必须进行reorg才能使该表恢复到正常状态。否则表不可以使用,查询或更新报错 DB2 sqlstate 57016
2.添加字段带默认值 alter table [table_name] add column [column_name] [column_type] not nul3.删除字段 alter table [table_name] drop column [column_name];
如果我们不是dba的话好多链接数据库的客户端工具是不能执行reorgtabletablename的我们可以用下面的语句执行reorg操作
db2字 段 修 改 ( 增 , 删 , 改 ) 操 作
1.添加字段 alter table [table_name] add [column_name] [column_type] add [column_name] [column_type];
DB2数据库的简单优化

内存配置优化a) 缓冲池(Buffer Pool)增加缓冲池大小以减少磁盘I/O:sql代码:ALTER BUFFERPOOL IBMDEFAULTBP SIZE 250000为不同的表空间创建专用缓冲池:sql代码:CREATE BUFFERPOOL BP_USERDATA SIZE 100000 PAGESIZE 32K b) 排序堆(Sort Heap)调整SORTHEAP参数:sql代码:UPDATE DB CFG FOR database_name USING SORTHEAP 1024 c) 包缓存(Package Cache)增加PCKCACHESz参数:sql代码:UPDATE DB CFG FOR database_name USING PCKCACHESz 640 I/O 优化a) 预读(Prefetch)调整PREFETCHSIZE参数:sql代码:UPDATE DB CFG FOR database_name USING PREFETCHSIZE 32 b) 异步I/O启用DFTDBHEAP参数:sql代码:UPDATE DB CFG FOR database_name USING DFTDBHEAP AUTOMATIC日志配置a) 日志缓冲区增加LOGBUFSZ参数:sql代码:UPDATE DB CFG FOR database_name USING LOGBUFSZ 1024 b) 日志文件大小调整LOGFILSIZ参数:sql代码:UPDATE DB CFG FOR database_name USING LOGFILSIZ 16384 锁管理a) 最大锁数增加MAXLOCKS参数:sql代码:UPDATE DB CFG FOR database_name USING MAXLOCKS 20 b) 锁列表大小调整LOCKLIST参数:sql代码:UPDATE DB CFG FOR database_name USING LOCKLIST 8192 并发控制a) 最大应用程序数增加MAXAPPLS参数:sql代码:UPDATE DB CFG FOR database_name USING MAXAPPLS 400 b) 代理数调整NUM_POOLAGENTS参数:sql代码:UPDATE DBM CFG USING NUM_POOLAGENTS 100统计信息收集a) 自动统计信息收集启用AUTO_RUNSTATS:sql代码:UPDATE DB CFG FOR database_name USING AUTO_RUNSTATS ON b) 统计信息采样调整统计信息采样率:sql代码:UPDATE DB CFG FOR database_name USING AUTO_SAMPLING YES 查询优化器a) 优化级别设置OPTLEVEL参数:sql代码:UPDATE DB CFG FOR database_name USING OPTLEVEL 5表空间管理a) 自动存储启用自动存储:sql代码:CREATE TABLESPACE ts_name MANAGED BY AUTOMATIC STORAGE b) 表空间扩展设置自动扩展:sql代码:ALTER TABLESPACE ts_name AUTORESIZE YES索引优化a) 索引重组定期重组索引:sql代码:REORG INDEXES ALL FOR TABLE table_name分区表对大表使用分区:sql代码:CREATE TABLE table_name (...) PARTITION BY RANGE(column_name) (...)压缩启用表压缩:sql代码:ALTER TABLE table_name COMPRESS YES并行度调整INTRA_PARALLEL参数:sql代码:UPDATE DB CFG FOR database_name USING INTRA_PARALLEL YES 监控和诊断a) 启用活动监控:sql代码:UPDATE DBM CFG USING DFT_MON_BUFPOOL ONUPDATE DBM CFG USING DFT_MON_LOCK ONUPDATE DBM CFG USING DFT_MON_SORT ONUPDATE DBM CFG USING DFT_MON_STMT ONb) 使用db2top工具实时监控性能c) 定期检查db2diag.log文件。
db2 rename table语句

db2 rename table语句在DB2数据库中,可以使用RENAME TABLE语句来修改表的名称。
RENAME TABLE语句允许您更改表的名称,而不会影响表的结构或数据。
下面是一个示例,展示了如何使用RENAME TABLE语句来重命名表。
假设我们有一个名为"employees"的表,现在我们想将其重命名为"staff"。
我们可以使用以下RENAME TABLE语句来实现:```RENAME TABLE employees TO staff;```在执行此语句之后,表"employees"的名称将被更改为"staff"。
这意味着我们可以使用新的表名"staff"来引用该表,而不再使用旧的表名"employees"。
需要注意的是,RENAME TABLE语句只能用于重命名表,不能用于重命名其他数据库对象,如列、索引或约束等。
如果需要重命名其他数据库对象,需要使用其他相应的ALTER语句。
此外,还需要注意以下几点:1. RENAME TABLE语句是一个DDL(数据定义语言)语句,因此在执行此语句之前,需要确保具有足够的权限来修改表的名称。
2. RENAME TABLE语句是一个原子操作,即要么全部成功,要么全部失败。
如果在执行此语句期间发生错误,将会回滚所有的更改,表的名称将保持不变。
3. RENAME TABLE语句不会影响表的结构或数据。
它只是修改了表的名称,所有与表相关的索引、触发器、约束等都将保持不变。
4. RENAME TABLE语句可以在一个事务中执行,也可以作为单独的语句执行。
如果在一个事务中执行,需要确保在事务提交之前,其他会话中不会引用被重命名的表。
总结起来,使用DB2的RENAME TABLE语句可以方便地修改表的名称,而不会影响表的结构或数据。
这是一个简单而强大的功能,可以帮助我们更好地管理数据库对象的命名。
db2中联机重组语法

db2中联机重组语法DB2是一种关系型数据库管理系统,它支持联机重组语法。
联机重组是一种将数据库中的数据进行重新组织的方法,以提高查询性能和数据访问效率。
在DB2中,可以使用联机重组语法来定义和执行重组操作。
联机重组的语法结构如下:1. CREATE INDEX:创建索引,用于加快数据的查询速度。
可以指定索引的名称、表名以及要索引的列名。
2. DROP INDEX:删除索引,用于删除不再需要的索引。
需要指定要删除的索引的名称。
3. REORG TABLE:重组表,用于重新组织表中的数据以提高查询性能。
可以指定要重组的表的名称以及重组的选项,如SORTKEY和BUILD2PCT。
4. REORG INDEX:重组索引,用于重新组织索引以提高查询性能。
可以指定要重组的索引的名称以及重组的选项,如SORTKEY和BUILD2PCT。
5. REBIND PACKAGE:重新绑定包,用于重新生成存储过程或触发器的执行计划。
需要指定要重新绑定的包的名称。
6. RUNSTATS:更新统计信息,用于更新表和索引的统计信息以优化查询性能。
可以指定要更新统计信息的表或索引的名称。
7. FLUSH PACKAGE CACHE:清除包缓存,用于清除存储在内存中的包缓存。
需要指定要清除的包的名称。
通过使用这些联机重组语法,可以优化数据库的性能,提高查询效率。
但是,在使用联机重组语法时,需要注意以下几点:需要根据具体的需求和数据库结构选择合适的重组操作。
不同的重组操作适用于不同的情况,需要根据实际情况进行选择。
需要谨慎使用重组操作,特别是在生产环境中。
重组操作可能会对数据库的性能产生影响,需要在合适的时间和环境下进行操作,以避免对现有业务造成影响。
需要定期监控和维护数据库的性能。
随着时间的推移,数据库中的数据会不断增加,查询性能可能会下降。
因此,需要定期进行性能监控和维护,及时进行重组操作以保持数据库的良好性能。
DB2中的联机重组语法是一种优化数据库性能的重要手段。
DB2数据库性能优化

DB2数据库性能优化
一、建立索引
(1)添加新索引
在DB2中,可以使用CREATEINDEX命令来建立索引。
通过添加索引来提高SQL语句的执行效率。
建议在经常使用的字段上建立索引,例如,WHERE子句中的字段,GROUPBY子句中的字段,ORDERBY子句中的字段或者连接条件中的字段。
(2)更新索引
如果表中的数据经常发生变化,则建议定期更新索引。
DB2有一项特殊的REORG操作,可以重新建立表中的索引,以提高查询效率。
(3)复合索引
在DB2中,可以使用复合索引来建立索引,以便提高查询效率。
复合索引可以使用多个字段,比普通索引更有效地提高查询速度。
二、查询优化
(1)使用合适的连接方式
(2)使用合适的排序方式
(3)使用子查询
(4)尽量少使用通配符
(5)尽量少使用函数
(6)查询中使用表别名
(7)使用EXISTS和NOTEXISTS
(8)使用适当的索引
三、周期性维护
(1)定期检查磁盘空间
(2)定期检查表和索引
(3)定期更新统计信息
(4)定期重新排序和重新组织表
(5)定期检查死锁
四、构造良好的数据模型
(1)正确定义数据字段
(2)使用算法优化数据存储
(3)及时删除无用的数据
(4)构造适当的表结构
五、其他
(1)设置合理的日志文件。
DB2数据库的常用操作指令

DB2数据库的常用操作指令DB2是一种关系型数据库管理系统,其常用操作指令可以帮助用户在数据库中执行各种操作。
以下是DB2数据库的一些常用操作指令。
1.连接数据库:CONNECT TO database_name [USER username USING password]2.断开数据库连接:CONNECTRESET3.创建表:CREATE TABLE table_name (column1 datatype, column2 datatype, ...)4.删除表:DROP TABLE table_name5.修改表结构:ALTER TABLE table_name ALTER COLUMN column_name SET DATA TYPE datatype6.插入数据:INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)7.更新数据:UPDATE table_name SET column1 = value1, column2 = value2 WHERE condition8.删除数据:DELETE FROM table_name WHERE condition9.查询数据:SELECT column1, column2, ... FROM table_name WHERE condition 10.创建索引:CREATE INDEX index_name ON table_name (column1, column2, ...)11.删除索引:DROP INDEX index_name12.创建视图:CREATE VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition13.修改视图:ALTER VIEW view_name AS SELECT column1, column2, ... FROM table_name WHERE condition14.删除视图:DROP VIEW view_name15.创建存储过程:CREATE PROCEDURE procedure_name (parameter1 datatype, parameter2 datatype, ...)LANGUAGESQLBEGIN--存储过程代码END16.删除存储过程:DROP PROCEDURE procedure_name17.创建触发器:CREATE TRIGGER trigger_name BEFORE/AFTERINSERT/UPDATE/DELETE ON table_nameREFERENCING OLD ROW AS old NEW ROW AS newFOREACHROW--触发器代码18.删除触发器:DROP TRIGGER trigger_name19.提交事务:COMMIT20.回滚事务:ROLLBACK21.创建数据库:CREATE DATABASE database_name22.删除数据库:DROP DATABASE database_name以上是DB2数据库的一些常用操作指令,可以帮助用户在数据库中执行各种操作。
循序渐进db2笔记-日常维护

14.1.1 查看是否有僵尸进程
在UNIX中,若父进程在一定的时间内无法收集到状态信息,则系统就会残留一个defunct进程。因为defunct进程是已经停止的,所以使用杀死进程的方法来杀defunct进程是无效的。defunct进程不使用CPU或硬盘等系统资源,而只使用极少量的内存用于存储退出状态和资源使用信息。
select * from sysibmadm.TOP_DYNAMIC_SQL order by NUM_EXECUTIONS desc fetch first 5 rows only;
此语句返回执行频率最高的5个动态SQL语句的所有执行时间、排序执行次数和语句文本详细信息。
为了标识执行时间最长的动态SQL语句,请检查AVERAGE_EXECUTION_TIME_S值最大的5个查询:
select * from sysibmadm_EXECUTION_TIME_S desc fetch first 5 rows only;
14.2.7 监控排序次数最多的SQL语句
select STMT_SORTS,SORTS_PER_EXECUTION,substr(STMT_TEXT,1,60) as STMT_TEXT from TOP_DYNAMIC_SQL order by STMT_SORTS desc fetch first 5 rows only;
通过inspect命令检查数据库是否一致:
db2 inspect check database results keep db_check.out
db2inspf db_check.out db_check.txt #检查文件,查看数据库是否一致
14.1.3 查看诊断日志判断是否有异常
db2重组表结构命令

DB2中重组表结构的命令是 `REORG TABLE`。
这个命令用于重构表的行,以消除分段数据和压缩信息。
在分区表上,可以对单个分区进行重组。
使用`REORG TABLE`命令时,需要具备以下权限之一:SYSADM、SYSCTRL、SYSMAINT、DBADM、SQLADM或表模式上的SCHEMAADM,以及对表的CONTROL特权。
以下是`REORG TABLE`命令的基本语法:
```sql
REORG TABLE table-name [, ...] [IN [SCHEMA] schema-name] [INDEX INCLUDING | INDEX EXCLUDING | INDEX ALL | INDEX NONE] [RECLAIM EXTENTS]
```
其中:
1. `table-name`:指定要重组的表的名称,该表可以位于本地数据库或远程数据库中。
2. `[IN [SCHEMA] schema-name]`:可选参数,指定表所在的模式名称。
如果省略模式名称,将使用默认模式。
3. `INDEX INCLUDING | INDEX EXCLUDING | INDEX ALL | INDEX NONE`:可选参数,指定是否包括索引的重组。
4. `RECLAIM EXTENTS`:按列组织的表支持的参数,用于回收未使用的空间。
需要注意的是,对于类型表,指定的表名必须是层次结构的根表的名称。
对于多维集群(MDC)或插入时间集群(ITC)表的重组,不能指定索引。
db2数据库常用语句

db2数据库常用语句【db2数据库常用语句】是一个涉及DB2数据库的常用查询语句和操作语句集合。
在以下文章中,我将逐步回答关于DB2数据库常用语句的问题,以帮助读者更深入了解和使用DB2数据库。
第一部分:介绍DB2数据库和SQL语言首先,让我们了解一下DB2数据库和SQL语言。
DB2是IBM公司开发的一种关系型数据库管理系统(RDBMS),已经成为很多企业和组织中使用得最广泛的数据库之一。
它支持SQL(结构化查询语言),这是一种用于管理数据库的通用语言。
第二部分:DB2数据库常用查询语句在DB2数据库中,我们可以使用各种查询语句来检索和过滤数据。
以下是一些常用的查询语句:1. SELECT语句:SELECT语句用于从数据库中检索数据。
例如,SELECT * FROM 表名将返回该表中的所有行和列。
2. WHERE子句:WHERE子句用于添加筛选条件到查询语句中。
例如,SELECT * FROM 表名WHERE 列名= 值将只返回符合条件的行。
3. ORDER BY语句:ORDER BY语句用于对结果进行排序。
例如,SELECT * FROM 表名ORDER BY 列名ASC将按升序对结果集进行排序。
4. GROUP BY语句:GROUP BY语句用于根据一个或多个列对结果进行分组。
例如,SELECT 列名FROM 表名GROUP BY 列名将返回每个不同值的分组。
第三部分:DB2数据库常用操作语句除了查询语句,我们还可以使用操作语句来修改和管理数据库。
以下是一些常用的操作语句:1. INSERT语句:INSERT语句用于向数据库中插入新的行。
例如,INSERT INTO 表名(列名1, 列名2, ...) VALUES (值1, 值2, ...)将在指定的列中插入新的值。
2. UPDATE语句:UPDATE语句用于更新数据库中的现有数据。
例如,UPDATE 表名SET 列名= 新值WHERE 列名= 条件将更新满足条件的行中的列的值。
db2 9.5数据库日常操作
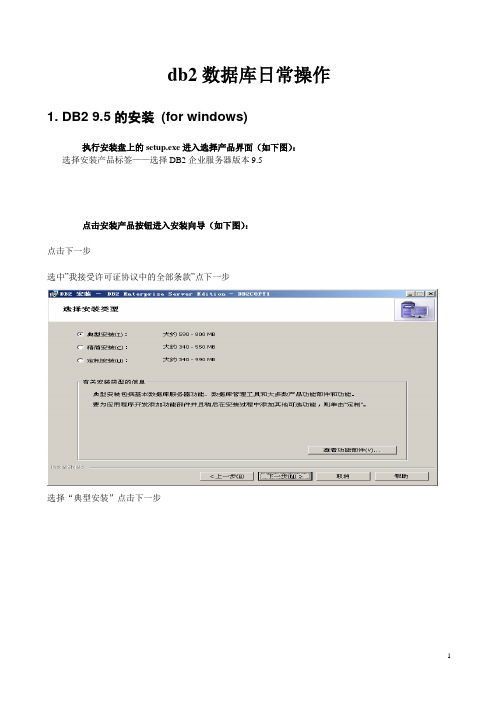
db2数据库日常操作1. DB2 9.5的安装(for windows)执行安装盘上的setup.exe进入选择产品界面(如下图):选择安装产品标签——选择DB2企业服务器版本9.5点击安装产品按钮进入安装向导(如下图):点击下一步选中”我接受许可证协议中的全部条款”点下一步选择“典型安装”点击下一步域用户选择默认使用本地用户账户设置用户名和密码注意:这里设置的用户名和密码要和windows里的帐户相对应.帐户也可自定义,如果是新加的windows用户,必须授予用户管理员权限(如下图)创建windwos用户勾选密码永不过期选项授予用户权限点击添加按钮确定后权限授予完成实例名可以按需要配置去掉准备DB2工具目录的选项去掉设置DB2服务器以发送通知的选项去掉启用操作系统安全性的选项安装完成2. DB2的日常操作执行脚本时需打开命令编辑器(1)建库CREA TE DA TABASE [database] AUTOMA TIC STORAGE NO ON 'D:\' USING CODESET GBK TERRITORY CN COLLA TE USING SYSTEM PAGESIZE 4096;创建用户并授予权限(在用其它管理员用户登陆的情况下)CONNECT TO NCDB;GRANTDBADM,CREA TET AB,BINDADD,CONNECT,CREA TE_NOT_FENCED_ROUTINE,IMPLICIT_SCHEM A,LOAD,CREA TE_EXTERNAL_ROUTINE,QUIESCE_CONNECT,SECADM ON DA TABASE TO USER db2admin;CONNECT RESET;(2)建立缓冲池、表空间用户临时表空间及系统表空间(目录可自定义)登陆到服务器connect to MSL user [用户名] using [password]——创建4K和16K的缓冲池,立即建立。
db2 reorg表优化

APPEND OFF -- 禁用追加模式(为缺省值)
NOT VOLATILE -- 优化器基于现有的统计信息进行优化(为缺省值)
对表进行任何操作都不被允许,提示SQLSTATE=57016 SQLCODE=-668 ,原因码 "7"的错误:SQL0668N Operation not allowed for reason code "7" on table XXX. 解决方法为:执行命令:reorg table XXX;即可。
>>> rg 和runstats 都是单个表优化,初始化的命令:
runstats on table administrator.test;
reorg table administrator.test;
其中:
reorg table <tablename> 通过重构行来消除“碎片”数据并压缩信息,对表进行重组。
runstats on table <tbschema>.<tbname> 收集表 <tbname> 的统计信息。
reorgchk on table all 确定是否需要对表进行重组,对于对所有表自动执行 runstats 很有用。
ALTER TABLE "ANYLINK"."TMP_AL_BIZ_HKUBA"
DATA CAPTURE NONE
LOCKSIZE ROW
APPEND OFF
NOT VOLATILE;
DATA CAPTURE NONE -- 不在日志中为复制记录额外的信息(为缺省值)
db2修改表字段

db2修改表字段db2表字段修改1:删除字段⾮空属性alter table XXX alter column XXX drop not null2:添加字段⾮空属性alter table XXX alter column XXX set not null3:添加⼀个新字段alter table XXX add column XXXX varchar(100)4:删除⼀个字段alter table XXX drop column XXX5:增加字段的长度alter table XXX alter column XXX set data type varchar(100)注意:1:不允许修改字段的名称(只能先删除,再添加)。
2:不允许减⼩字段的长度。
3:不允许修改字段类型(如把 Integer 修改成 varchar)。
4:如果必须修改上三条中的情况,只能重新建表(第⼀条有简单⽅法)。
1. 1.更改类型(设置为主键的列不能更改类型)2. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" SET DATA TYPE VARCHAR(32);3. 2.更改默认值4. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" SET DEFAULT 'ABC';5. 系统默认值:6. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" SET DEFAULT; --设置默认值7. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" DROP DEFAULT; --删除默认值8. 3.更改是否允许空值9. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" SET NOT NULL;10. ALTER TABLE "SCHEMA"."TABLENAME" ALTER COLUMN "COL" DROP NOT NULL;11. 更改列类型,是否允许空值后,需要执⾏REORG TABLE "TABLENAME";12. 更改默认值后,通常需要执⾏UPDATE "SCHEMA"."TABLENAME" SET "COL" = DEFAULT WHERE "COL" IS NULL;。
db2中delete删除数据后释放表空间

db2中delete删除数据后释放表空间在DB2数据库中,delete语句用于删除表中的数据。
然而,当我们使用delete语句删除数据时,并不会立即释放表空间。
这是因为DB2数据库采用了一种称为“延迟删除”的机制。
所谓延迟删除,是指当我们执行delete语句删除数据时,DB2并不会立即从磁盘上删除这些数据所占用的空间,而是将这些空间标记为可重用。
这样做的目的是为了提高删除操作的性能,避免频繁地进行磁盘操作。
当我们执行delete语句删除数据后,DB2会将这些被删除的数据所占用的空间标记为可重用,并将这些空间的信息记录在一个称为“回收链表”的数据结构中。
回收链表中记录了可重用空间的位置和大小等信息。
当我们执行insert语句插入新数据时,DB2会首先查找回收链表,看是否有足够的可重用空间。
如果有,DB2会将新数据插入到这些可重用空间中,而不是分配新的空间。
这样做可以减少磁盘操作,提高插入操作的性能。
然而,当回收链表中的可重用空间不足以容纳新数据时,DB2就会分配新的空间。
这时,我们就会发现,虽然我们执行了delete语句删除了数据,但是表空间的大小并没有减少。
这是因为被删除的数据所占用的空间并没有被立即释放,而是被标记为可重用。
那么,如何释放被删除数据所占用的空间呢?在DB2中,我们可以使用reorg命令来重新组织表空间,从而释放被删除数据所占用的空间。
reorg命令会重新组织表空间,将被删除数据所占用的空间释放出来。
具体来说,reorg命令会重新组织表空间中的数据,将有效数据移到一起,将被删除数据所占用的空间释放出来。
这样做可以减少表空间的大小,提高数据库的性能。
使用reorg命令释放表空间的步骤如下:1. 首先,我们需要连接到DB2数据库,并切换到要操作的数据库中。
2. 然后,我们可以使用reorg命令来重新组织表空间。
具体的命令格式如下:reorg tablespace 表空间名其中,表空间名是要重新组织的表空间的名称。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
转)DB2日常维护——REORG TABLE命令优化数据库性能2009-04-24 16:18一个完整的日常维护规范可以帮助 DBA 理顺每天需要的操作,以便更好的监控和维护数据库,保证数据库的正常、安全、高效运行,防止一些错误重复发生。
由于DB2使用CBO作为数据库的优化器,数据库对象的状态信息对数据库使用合理的 ACCESS PLAN至关重要。
DB2 优化器使用目录统计信息来确定任何给定查询的最佳访问方案。
如果有关表或索引的统计信息已过时或者不完整,则会导致优化器选择不是最佳的方案,并且会降低执行查询的速度。
当数据库里某个表中的记录变化量很大时,需要在表上做REORG操作来优化数据库性能一、完整的REORG表的过程值得注意的是,针对数据库对象的大量操作,如反复地删除表,存储过程,会引起系统表中数据的频繁改变,在这种情况下,也要考虑对系统表进行REORG 操作。
一个完整的REORG表的过程应该是由下面的步骤组成的:RUNSTATS -> REORGCHK -> REORG -> RUNSTATS -> BIND或REBIND注:执行下面命令前要先连接数据库1 RUNSTATS由于在第二步中REORGCHK时可以对指定的表进行RUNSTATS操作(在REORGCHK时指定UPDATE STATISTICS),所以第一步事实上是可以省略的。
2 REORGCHK在对表数据进行许多更改之后,逻辑上连续的数据可能会位于不连续的物理数据页上,在许多插入操作创建了溢出记录时尤其如此。
按这种方式组织数据时,数据库管理器必须执行其他读操作才能访问顺序数据。
另外,在删除大量行后,也需要执行其他的读操作。
表重组操作会整理数据碎片来减少浪费的空间,并对行进行重新排序以合并溢出记录,从而加快数据访问速度并最终提高查询性能。
还可以指定根据特定索引来重新排序数据,以便查询时通过最少次数据读取操作就可以访问数据。
下列任何因素都可能指示用户应该重组表:1)自上次重组表之后,对该表进行了大量的插入、更新和删除活动。
2)对于使用具有高集群率的索引的查询,其性能发生了明显变化。
3)在执行 RUNSTATS 命令以刷新统计信息后,性能没有得到改善。
4)REORGCHK 命令指示需要重组表(注意:在某些情况下,REORGCHK 总是建议重组表,即使在执行了重组后也是如此)。
例如,如果使用 32KB 页大小,并且平均记录长度为 15 字节且每页最多包含 253 条记录,则每页具有 32700- (15 x 253)=28905 个未使用字节。
这意味着大约 88% 的页面是可用空间。
用户应分析 REORGCHK 的建议并针对执行重组所需的成本平衡利益。
5)db.tb_reorg_req(需要重组)运行状况指示器处于 ATTENTION 状态。
此运行状况指示器的集合详细信息描述通过重组可获得好处的表和索引的列表。
REORGCHK 命令返回有关数据组织的统计信息,并且可以建议您是否需要重组特定表。
然而,定期或在特定时间对目录统计信息表运行特定查询可以提供性能历史记录,该记录使用户可以发现可能具有更广性能隐含的趋势。
DB2 V9.1 引入了自动重组功能,可以对表和索引进行自动重组。
自动重组通过使用 REORGCHK 公式来确定何时需要对表进行重组。
它会定期评估已经更新了统计信息的表,以便了解是否需要重组。
REORGCHK命令的语法如下:. -UPDATE STATISTICS--.>>-REORGCHK--+--------------------+----------------------------->'-CURRENT STATISTICS-'.-ON TABLE USER-----------------.>--+-------------------------------+---------------------------><'-ON--+-SCHEMA--schema-name---+-'| .-USER-------. |'-TABLE--+-SYSTEM-----+-'+-ALL--------+'- table-name-'下面我们来看一下各个选项的含义:UPDATE STATISTICS:更新表的统计数据,根据该统计数据判断是否需要重组表。
CURRENT STATISTICS:根据当前表统计数据判断是否需要重组表。
TABLE table_name:对单个表进行分析。
TABLE ALL:对数据库所有的表进行分析。
TABLE SYSTEM:对系统表进行分析。
TABLE USER:对当前用户模式下的所有表进行分析。
如果数据库中数据量比较大,在生产系统上要考虑REORGCHK的执行时间可能较长,需安排在非交易时间执行。
可以分为对系统表和用户表两部分分别进行REORGCHK:1) 针对系统表进行REORGCHKdb2 reorgchk update statistics on table system使用UPDATE STATISTICS参数指定数据库首先执行RUNSTATS命令。
2) 针对用户表进行REORGCHKdb2 reorgchk update statistics on table userREORGCHK是根据统计公式计算表是否需要重整。
对于每个表有3个统计公式,对索引有3个统计公式(版本8开始有5个公式),如果公式计算结果该表需重整,在输出的REORG字段中相应值为*,否则为-。
reorgchk 所使用的度量的考虑因素包括:(当查看 reorgchk 工具的输出时,找到用于表的 F1、F2 和 F3 这几列,以及用于索引的 F4、F5、F6、F7 和F8 这几列。
如果这些列中的任何一列有星号 (*),则说明当前的表和/或索引超出了阈值。
)F1:属于溢出记录的行所占的百分比。
当这个百分比大于 5% 时,在输出的F1 列中将有一个星号 (*)。
F2:数据页中使用了的空间所占的百分比。
当这个百分比小于 70% 时,在输出的 F2 列上将有一个星号 (*)。
F3:其中含有包含某些记录的数据的页所占的百分比。
当这个百分比小于80% 时,在输出的 F3 列上将有一个星号 (*)。
F4:群集率,即表中与索引具有相同顺序的行所占的百分比。
当这个百分比小于 80% 时,那么在输出的F4 列上将有一个星号 (*)。
F5:在每个索引页上用于索引键的空间所占的百分比。
当这个百分比小于50% 时,在输出的 F5 列上将有一个星号 (*)。
F6:可以存储在每个索引级的键的数目。
当这个数字小于 100 时,在输出的 F6 列上将有一个星号 (*)。
F7:在一个页中被标记为 deleted 的记录 ID(键)所占的百分比。
当这个百分比大于 20% 时,在输出的 F7 列上将有一个星号 (*)。
F8:索引中空叶子页所占的百分比。
当这个百分比大于 20% 时,在输出的F8 列上将有一个星号 (*)。
下面是执行的部分结果db2 reorgchk update statistics on table user执行 RUNSTATS ....表统计信息:F1: 100 * OVERFLOW / CARD < 5F2: 100 * (Effective Space Utilization of Data Pages) > 70F3: 100 * (Required Pages / Total Pages) > 80SCHEMA NAME CARD OV NP FPACTBLK TSIZE F1 F2 F3 REORG----------------------------------------------------------------------------------------DB2INST1STAFF - - - - - - - - -*-...索引统计信息:F4: CLUSTERRATIO 或正常化的 CLUSTERFACTOR > 80F5: 100 * (KEYS * (ISIZE + 9) + (CARD - KEYS) * 5) / ((NLEAF - NUMEMPTY LEAFS) * INDEXPAGESIZE) > 50F6: (100 - PCTFREE) * ((INDEXPAGESIZE - 96) / (ISIZE + 12)) ** (NLEVELS - 2) * (INDEXPAGESIZE - 96) / (KEYS * (ISIZE + 9) + (CARD - KEYS) * 5) < 100F7: 100 * (NUMRIDS DELETED / (NUMRIDS DELETED + CARD)) < 20F8: 100 * (NUM EMPTY LEAFS / NLEAF) < 20SCHEMA NAME CARD LEAF ELEAF LVLS ISIZENDEL KEYS F4 F5 F6 F7 F8 REORG-------------------------------------------------------------------------------------------------表:DB2INST1.STAFFDB2INST1 ISTAFF - - - - - - - - - - - - -----...从上面的例子来看,对于表DB2INST1.STAFF,根据统计公式F2计算结果,有必要对表进行REORG。
3、对需要重组的表进行重组(REORG TABLE)DB2 V9 可以对表和索引进行自动重组。
要进行高效率的数据访问和获得最佳工作负载性能,具有组织良好的表数据是很关键的。
在对表数据进行许多更改之后,逻辑上连续的数据可能会位于不连续的物理数据页上,在许多插入操作创建了溢出记录时尤其如此。
按这种方式组织数据时,数据库管理器必须执行其他读操作才能访问顺序数据。
另外,在删除大量行后,也需要执行其他的读操作。
表重组操作会整理数据碎片来减少浪费的空间,并对行进行重新排序以合并溢出记录,从而加快数据访问速度并最终提高查询性能。
还可以指定根据特定索引来重新排序数据,以便查询通过最少次数据读取操作就可以访问数据。
既可重组系统目录表,也可以重组数据库表。
由 RUNSTATS 收集的统计信息与其他信息一起来显示表中的数据分布情况。
特别是,通过分析这些统计信息可以知道何时需要执行哪种类型的重组。