Redis Cluster集群化架构演进v1
redis6种策略

redis6种策略Redis是一种流行的开源内存数据库,它提供了多种策略来处理数据。
本文将介绍Redis的六种策略,包括数据持久化、主从复制、高可用性、分布式缓存、事务处理和发布订阅。
一、数据持久化数据持久化是Redis的核心特性之一,它允许将内存中的数据保存到硬盘中,以防止数据丢失。
Redis提供了两种数据持久化策略:RDB和AOF。
1. RDB(Redis DataBase)是一种快照式的持久化策略,它会将数据保存为二进制文件。
RDB的优点是文件体积小、加载速度快,适合用于备份和恢复数据。
缺点是在发生故障时可能会有数据丢失。
2. AOF(Append Only File)是一种追加式的持久化策略,它会将每个写操作追加到文件末尾。
AOF的优点是可以提供更好的数据安全性,因为每个操作都会被记录下来。
缺点是文件体积相对较大,加载速度相对较慢。
二、主从复制主从复制是一种将数据从一个Redis服务器复制到多个Redis服务器的策略,用于提高系统的读写性能和可用性。
主从复制的过程分为三个步骤:复制初始化、全量复制和增量复制。
1. 复制初始化:从服务器连接主服务器,并通过发送SYNC命令来进行复制初始化。
2. 全量复制:主服务器将自己的数据发送给从服务器,从服务器接收并加载数据。
3. 增量复制:主服务器将自己的写操作发送给从服务器,从服务器接收并执行写操作,从而保持数据的一致性。
主从复制可以提高系统的读写性能,同时还可以提供故障切换和负载均衡的功能。
三、高可用性高可用性是指系统在发生故障时能够保持正常运行的能力。
Redis 提供了多种策略来实现高可用性,包括哨兵模式和集群模式。
1. 哨兵模式:哨兵模式是通过监控主服务器的状态来实现高可用性。
当主服务器发生故障时,哨兵会自动将一个从服务器升级为主服务器,从而保证系统的可用性。
2. 集群模式:集群模式是通过将数据分布在多个节点上来实现高可用性。
当某个节点发生故障时,其他节点会自动接管该节点的工作,从而保证系统的可用性。
Codis与RedisCluster的原理详解
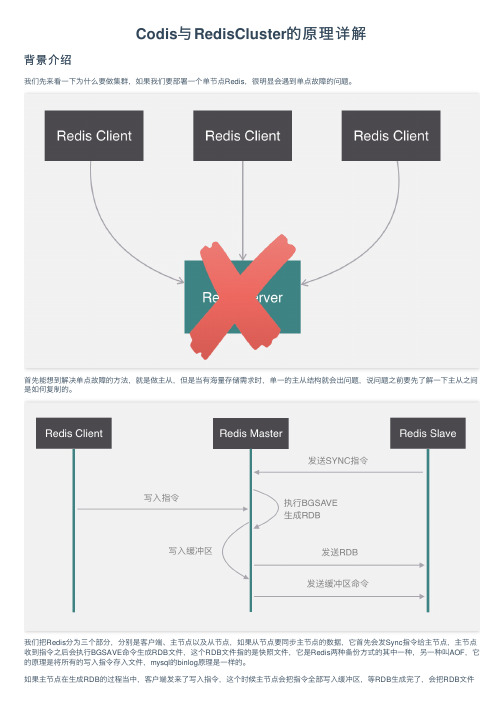
Codis与RedisCluster的原理详解背景介绍我们先来看⼀下为什么要做集群,如果我们要部署⼀个单节点Redis,很明显会遇到单点故障的问题。
⾸先能想到解决单点故障的⽅法,就是做主从,但是当有海量存储需求时,单⼀的主从结构就会出问题,说问题之前要先了解⼀下主从之间是如何复制的。
我们把Redis分为三个部分,分别是客户端、主节点以及从节点,如果从节点要同步主节点的数据,它⾸先会发Sync指令给主节点,主节点收到指令之后会执⾏BGSAVE命令⽣成RDB⽂件,这个RDB⽂件指的是快照⽂件,它是Redis两种备份⽅式的其中⼀种,另⼀种叫AOF,它的原理是将所有的写⼊指令存⼊⽂件,mysql的binlog原理是⼀样的。
如果主节点在⽣成RDB的过程当中,客户端发来了写⼊指令,这个时候主节点会把指令全部写⼊缓冲区,等RDB⽣成完了,会把RDB⽂件发送给从节点,最后再把缓冲区的指令发送给从节点。
这样就完成了整个的复制。
我们刚才说单纯地做主从是有缺陷的,这个缺陷就是如果我们要存储海量的数据,那么BGSAVE指令⽣成的RDB⽂件会⾮常巨⼤,这个⽂件传送给从节点也会⾮常慢,如果缓冲区命令很多的话,从节点同步数据时也会执⾏很久,所以,要解决单点问题和海量存储问题,还是要考虑做集群。
Redis常见集群⽅案Redis集群⽅案⽬前主流的有三种,分别是Twemproxy、Codis和Redis Cluster。
Twemproxy,是推特开源的,它最⼤的缺点就是⽆法平滑的扩缩容,⽽Codis解决了Twemproxy扩缩容的问题,⽽且兼容了Twemproxy,它是由豌⾖荚开源的,和Twemproxy都是代理模式。
其实Codis能发展起来的⼀个主要原因是它是在Redis官⽅集群⽅案漏洞百出的时候率先成熟稳定的。
以现在的Redis官⽅集群⽅案,这两个好像没有太⼤差别了,不过我也没有去做性能测试,不清楚哪个最好。
Redis Cluster是由官⽅出品的,⽤去中⼼化的⽅式实现,不属于代理模式,今天主要讲codis,redis cluster后⾯也会过⼀下。
redis cluster参数

redis cluster参数Redis Cluster是Redis提供的分布式解决方案,旨在为高可用性、可扩展性和可扩展性提供支持。
在使用Redis Cluster时,需要了解并设置一些参数,以便系统能够以最佳状态运行。
下面将介绍一些常用的Redis Cluster参数及其作用。
1. cluster-enabled:是否启用Redis Cluster。
默认值为no。
2. cluster-node-timeout:Redis集群节点超时时间。
超时时间内未收到节点的ACK消息,则将认为该节点无法正常工作。
默认为15秒。
3. cluster-replica-validity-factor:Redis集群副本的有效性因子。
当主节点宕机时,副本将被晋升为新的主节点。
该参数指定晋升后是否应该将新主节点的副本作为可用节点加入Redis集群。
默认为0,表示不添加。
4. cluster-migration-barrier:Redis集群迁移阈值。
当一次集群迁移操作的键值数量超过该阈值时,集群将被阻塞以防止过多节点同时执行迁移操作。
默认为1,即不阻塞。
5. cluster-require-full-coverage:Redis集群是否要求完全覆盖。
默认为yes,表示所有节点都必须可用。
设置为no则表示只需满足半数节点可用即可。
6. cluster-announce-ip:Redis节点通告的IP地址。
默认为空,Redis将自动使用绑定的IP地址。
7. cluster-announce-port:Redis节点通告的端口号。
默认值为0,Redis将自动使用随机端口。
8. cluster-announce-bus-port:Redis总线通告的端口号。
默认值为0,Redis将自动使用随机端口。
9. cluster-slave-validity-factor:Redis副本的有效性因子。
当最后一个主节点宕机后,副本将被晋升为新的主节点。
互联网架构的演变过程(一)

互联⽹架构的演变过程(⼀)简介web1.0时代web2.0时代互联⽹时代互联⽹+ --》智慧城市。
2012年提出。
云计算+⼤数据时代背景随着互联⽹的发展,⽹站应⽤的规模不断扩⼤,常规的垂直应⽤架构已⽆法应对,分布式服务架构以及流动计算架构势在必⾏,亟需⼀个治理系统确保架构有条不紊的演进。
1、第⼀时期单⼀应⽤架构all in one(所有的模块在⼀起,技术也不分层)⽹站的初期,也认为互联⽹发展的最早时期。
会在单机部署上所有的应⽤程序和软件。
所有的代码都是写在JSP⾥⾯,所有的代码都写在⼀起。
这种⽅式称为all in one。
特点:1、不具备代码的可维护性。
2、容错性差。
因为我们所有的代码都写在JSP页⾥。
当⽤户或某些原因发⽣异常。
(1、⽤户直接看到异常错误信息。
2、这个错误会导致服务器宕机)容错性,是指软件检测应⽤程序所运⾏的软件或硬件中发⽣的错误并从错误中恢复的能⼒,通常可以从系统的可靠性、可⽤性、可测性等⼏个⽅⾯来衡量。
单体地狱。
:只需⼀个应⽤,将所有功能都部署在⼀起,以减少部署节点和成本。
2 第⼀时期后阶段解决⽅案:1、分层开发(提⾼维护性)【解决容错性】2、MVC架构(Web应⽤程序的设计模式)3、服务器的分离部署特点:1、MVC分层开发(解决容错性问题)2、数据库和项⽬部署分离问题:随着⽤户的访问量持续增加,单台应⽤服务器已经⽆法满⾜需求。
解决⽅案:集群。
3 可能会产⽣的⼏个问题:1.1. ⾼可⽤“⾼可⽤性”(High Availability)通常来描述⼀个系统经过专门的设计,从⽽减少停⼯时间,⽽保持其服务的⾼度可⽤性。
(⼀直都能⽤)1.2. ⾼并发⾼并发(High Concurrency)是互联⽹分布式系统架构设计中必须考虑的因素之⼀,它通常是指,通过设计保证系统能够同时并⾏处理很多请求。
⾼并发相关常⽤的⼀些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发⽤户数等。
redis集群工作原理

redis集群工作原理Redis集群工作原理概述:Redis是一款高性能的键值存储系统,它的集群模式可以通过分布在不同节点的多个Redis实例来提高系统的性能和容量。
本文将介绍Redis集群的工作原理,包括数据分片、主从复制、故障转移等关键技术。
一、数据分片Redis集群通过数据分片来将数据分布在多个节点上。
具体来说,Redis使用哈希槽(hash slot)将数据划分为16384个槽位,每个键值对根据其键通过哈希算法分配到一个槽位上。
这样,每个Redis节点就负责管理部分槽位上的数据。
二、主从复制为了提供数据的高可用性,Redis集群使用主从复制机制。
每个主节点可以有多个从节点,主节点负责处理读写请求,从节点则负责复制主节点的数据。
主节点将数据通过异步复制的方式发送给从节点,从节点将接收到的数据写入自己的数据库中。
三、故障转移当一个主节点出现故障时,Redis集群需要进行故障转移,确保数据的可用性。
故障转移的过程如下:1. 当主节点失效时,集群中的某个从节点会被选举为新的主节点。
2. 新的主节点会将自己的身份广播给其他节点,并开始接收客户端的读写请求。
3. 其他从节点会将原来的主节点切换为新的主节点,并开始复制新的主节点的数据。
4. 如果原来的主节点恢复,它将成为新的从节点,并开始复制新的主节点的数据。
四、节点间通信Redis集群中的节点之间通过gossip协议进行通信。
每个节点会定期与其他节点交换信息,包括节点的状态、槽位分配情况等。
通过这种方式,集群中的每个节点都能了解整个集群的状态,并根据需要进行数据迁移、故障转移等操作。
五、客户端路由在Redis集群中,客户端需要将请求发送到正确的节点上。
为了实现这一点,客户端会通过集群的握手过程获取到集群的拓扑信息,包括每个节点的地址和槽位分配情况。
然后,客户端根据键的哈希值将请求发送到对应的节点上。
六、集群维护Redis集群提供了一些维护命令,用于管理集群的状态和配置。
redis cluster--redis集群模式原理

redis cluster--redis集群模式原理Redis Cluster是Redis官方推出的分布式架构,它可以将多台Redis服务器看作是一个整体来使用,提供了高可用性、高扩展性等优点。
Redis Cluster基于分区的思想,将key映射到集群中的某一个节点上,每个节点负责一部分key。
通过互相通信来维护全局一致性和去重。
Redis Cluster集群模式分为以下几个部分:1、集群的节点数量不同,可以由多个Master节点和多个Slave节点组成。
2、每个节点都有一个唯一的名称(注意是名称不是IP地址),通过名称进行通信。
3、Redis Cluster将整个数据集分成16384个hash slot,每个节点可以处理其中一部分,节点之间通过Gossip协议交换信息,保持整个集群信息的一致性。
4、一个Redis节点可以既是Master,也可以是Slave。
Master节点负责处理客户端请求,而Slave节点则仅用于备份和读取数据,Master节点操作的数据会被同步到Slave节点。
5、在Redis Cluster中,如果一个Master节点宕机,它上面的所有Slave节点都不能升级为Master节点。
而是会自动进行故障转移,将失效的Master节点的Slot分配给其他运行正常的Master节点,并将其对应的Slave节点降级为Master节点,从而保证整个集群的可用性。
6、对于新加入的节点,可以使用resharding命令进行Slot的再分配。
重新分配Slot会导致数据迁移,因此需要慎重考虑。
总之,Redis Cluster集群模式的优点在于它能够提供高可用性、高扩展性、自动故障转移等特性。
但同时也需要注意一些坑点,如节点名称不能重复、节点之间的网络延迟等问题。
Redis集群使用指南

Redis集群使用指南一、Redis集群简介Redis(Remote Dictionary Server)是一个开源的基于内存的键值对存储系统,经常用来作为缓存、消息队列和数据库。
在实际使用过程中,Redis可能会出现性能瓶颈和单点故障。
为了解决这些问题,Redis提供了集群模式。
Redis集群是对多个Redis节点进行逻辑分区和复制,从而实现高可用、高性能和可伸缩性。
Redis集群能够自动进行故障转移和重新分配,可以提供更好的可靠性和吞吐量。
二、Redis集群的工作原理Redis集群采用哈希槽(Hash Slot)的方式来实现数据的分片和复制。
一个Redis集群可以包含多个Redis节点,每个节点管理一部分哈希槽。
当客户端需要对某个键进行操作时,Redis首先计算该键对应的哈希值,然后将其分配到某个哈希槽中。
Redis集群根据哈希槽的分配情况,将该键的操作转发给相应的Redis节点进行处理。
如果某个节点出现故障,Redis集群会自动将该节点管理的哈希槽重新分配给其他节点。
Redis集群采用主从复制的方式来实现数据的持久化和高可用。
每个主节点可以有多个从节点,主节点负责处理读写请求,同时将数据复制到从节点。
如果主节点出现故障,其中的一个从节点会被自动选举为新的主节点,继续处理客户端请求。
三、搭建Redis集群的步骤1、安装Redis节点在Linux系统上安装Redis比较简单,可以使用以下命令:sudo apt-get updatesudo apt-get install redis-server安装完毕后,可以通过以下命令启动Redis服务:sudo service redis-server start2、配置Redis节点每个Redis节点都需要进行一些配置,以便加入到Redis集群中。
可以通过以下命令进入Redis配置文件:sudo vim /etc/redis/redis.conf需要修改的配置项有以下几个:cluster-enabled yes:启用Redis集群模式。
redis发展史

Redis是一个开源的内存数据结构存储系统,它提供了键值对存储、发布订阅、主从复制等功能。
下面是Redis的发展史:
2009年:Redis由Salvatore Sanfilippo开发并首次发布。
在最初的版本中,Redis只提供了基本的键值对存储功能。
2010年:Redis 2.0发布,引入了持久化功能,支持将内存中的数据保存到硬盘上。
这使得Redis不仅可以作为缓存系统,还可以用作持久化存储系统。
2012年:Redis 2.6发布,引入了虚拟内存功能,允许Redis将不常用的数据交换到磁盘上,从而提高内存利用率。
2014年:Redis 3.0发布,引入了集群功能,支持将数据分布在多个节点上,提高了系统的可扩展性和容错性。
2015年:Redis 3.2发布,引入了模块化功能,允许用户通过插件的方式扩展Redis的功能。
2016年:Redis 4.0发布,引入了多线程IO模型,提高了系统的并发性能。
2019年:Redis 5.0发布,引入了Stream数据类型、Bloom Filter等新功能,进一步丰富了Redis的功能。
除了官方版本的发展,Redis也有很多第三方扩展和插件,如Redisson、Lettuce等,为用户提供了更多的功能和工具。
总的来说,Redis在过去的几年中不断发展和改进,成为了一个功能强大、性能优越的数据存储系统,被广泛应用于缓存、消息队列、实时统计等场景。
redis集群面试题

redis集群面试题1. Redis集群的概念和作用Redis集群是为了解决单机Redis在性能和容量方面的限制而引入的一种架构。
通过将数据分布到多个节点上,并且提供数据的自动分片和故障转移功能,实现了高可用性和水平扩展。
2. Redis集群的工作原理Redis集群采用分布式哈希槽的方式来实现数据的分片和分布。
一共有16384个哈希槽,每个槽可以存储一个键值对。
当有新的节点加入或者节点下线时,Redis集群会重新计算哈希槽的分布。
3. Redis集群的节点角色Redis集群中的节点可以分为主节点和从节点。
每个主节点负责一部分哈希槽和与之相关的读写操作,而从节点负责复制主节点的数据,并且在主节点宕机时能够自动切换为主节点。
4. Redis集群的部署方式Redis集群可以通过手动搭建和使用第三方工具来进行部署。
手动搭建需要先安装并配置Redis服务器,然后将各个节点连接成集群。
而使用第三方工具如Redis Sentinel或者Redis Cluster Manager可以简化部署和管理的过程。
5. Redis集群的主从复制机制在Redis集群中,主从复制机制用于实现数据的复制和高可用性。
当主节点宕机时,从节点会自动切换为主节点,保证系统的正常运行。
同时,主节点会将自己的写操作同步到从节点,以保证数据的一致性。
6. Redis集群的故障转移当主节点宕机时,Redis集群会自动从从节点中选举一个新的主节点来替代,以保证集群的可用性。
这个过程称为故障转移,Redis集群采用Raft一致性算法来实现故障转移。
7. Redis集群的数据一致性由于Redis集群的分片机制,数据在多个节点之间是分散存储的。
因此,在进行写操作后,Redis集群会将该写操作同步到所有从节点上,以保证数据的一致性。
同时,Redis也提供了读写分离机制,可以将读操作发往从节点,减轻主节点的负载压力。
8. Redis集群的性能优化为了提高Redis集群的性能,可以采取以下措施:- 合理选择数据模型,避免使用过多的哈希槽。
redis集群模式原理

Redis集群模式是一种在多个Redis实例之间分布数据和负载的解决方案,它提供了高可用性和可伸缩性。
以下是Redis集群模式的基本原理:
数据分片(Sharding):
Redis集群将数据分散存储在多个Redis节点上。
采用哈希算法(如CRC16)对键进行分片,根据键的哈希值将数据分配到不同的节点上。
每个节点负责一部分数据。
节点间通信:
Redis集群使用Gossip协议实现节点间的信息交换和发现。
每个节点通过集群总线(cluster bus)广播自己的状态信息和集群拓扑结构。
通过交换信息,节点能够了解其他节点的状态、可用性和负载情况。
主从复制:
Redis集群中的每个节点都可以配置为主节点或从节点。
主节点负责接收写入请求,并将数据复制到从节点。
从节点负责处理读取请求,并复制主节点的数据。
主从复制提供了数据的冗余和高可用性。
故障检测和故障转移:
Redis集群会监控节点的可用性。
如果某个主节点出现故障,集群会自动将从节点升级为新的主节点,并将数据迁移到新的主节点上。
故障转移过程中,集群会通过选举机制选择新的主节点,并更新集群的拓扑结构。
客户端路由:
客户端通过与集群中的任一节点通信来访问Redis集群。
客户端会根据键的哈希值将请求路由到相应的节点上。
节点会返回请求的数据或将请求转发给适当的节点。
通过以上机制,Redis集群实现了数据的分布存储、负载均衡和高可用性。
它允许在需要大规模数据处理和高并发访问的场景下,提供稳定可靠的性能和服务。
redis cluster 操作命令

redis cluster 操作命令Redis Cluster 是 Redis 的分布式解决方案,它可以将数据分散存储在多个节点上,提供更高的性能和可靠性。
在使用Redis Cluster 进行操作时,可以使用以下命令来管理和操作集群。
1. CLUSTER MEET:用于将多个 Redis 节点连接成一个集群。
可以使用该命令将新的节点添加到集群中,以扩展集群的容量。
2. CLUSTER ADDSLOTS:用于将槽位分配给节点。
Redis Cluster 将数据分为 16384 个槽位,每个槽位可以存储一个键值对。
使用该命令可以将槽位分配给节点,以便节点可以接收和处理相应的数据。
3. CLUSTER SETSLOT:用于手动将槽位分配给指定的节点。
可以使用该命令来重新分配槽位,以便在节点故障或扩展时重新平衡数据。
4. CLUSTER FORGET:用于从集群中删除指定的节点。
如果某个节点发生故障或需要从集群中移除,可以使用该命令将其从集群中删除。
5. CLUSTER REPLICATE:用于设置节点的复制关系。
在Redis Cluster 中,每个主节点都有一个或多个从节点,用于实现数据的备份和故障恢复。
可以使用该命令将一个节点设置为另一个节点的从节点。
6. CLUSTER INFO:用于获取集群的信息。
该命令可以提供有关集群拓扑、节点状态和槽位分配等信息,以便进行集群的监控和管理。
7. CLUSTER KEYSLOT:用于计算给定键的槽位。
在 Redis Cluster 中,每个键都被映射到一个槽位,该命令可以根据键的哈希值计算出对应的槽位。
8. CLUSTER SLOTS:用于获取集群中所有槽位的分配情况。
该命令返回一个包含槽位分配信息的列表,可以了解到每个槽位所属的节点和复制关系。
9. CLUSTER COUNTKEYSINSLOT:用于获取指定槽位中的键数量。
可以使用该命令来统计指定槽位中的键数量,以便进行负载均衡和容量规划。
cluster集群原理

cluster集群原理Cluster集群原理一、引言随着云计算和大数据时代的到来,集群成为了一种重要的计算模式。
而Cluster集群作为其中的一种实现方式,在分布式计算中扮演着重要的角色。
本文将介绍Cluster集群的原理和相关概念。
二、Cluster集群概述Cluster集群是由多台服务器组成的计算机集合,这些服务器通过网络进行连接和通信。
集群中的各个服务器通过工作协同的方式,共同完成一项任务。
Cluster集群通过将大规模的计算任务分割成多个小任务,将其分配给不同的服务器进行并行计算,从而提高计算效率和性能。
三、Cluster集群的优势1. 高可靠性:Cluster集群由多台服务器组成,服务器之间可以相互备份和故障转移,当某台服务器发生故障时,可以自动切换到其他正常工作的服务器上,保证系统的持续稳定运行。
2. 高性能:Cluster集群可以将任务分配给多台服务器同时进行计算,充分利用了服务器的计算资源,大大提高了计算速度和吞吐量。
3. 可扩展性:Cluster集群可以根据需要随时增加或减少服务器节点,从而满足不同规模和计算需求的变化。
四、Cluster集群的工作原理1. 负载均衡:Cluster集群通过负载均衡的方式将任务均匀地分配给各个服务器,避免单个服务器负载过重,保证系统的稳定性和高效性。
2. 分布式存储:Cluster集群中的服务器可以共享存储空间,将数据分布存储在不同的服务器上,提高数据的可靠性和访问速度。
3. 任务调度:Cluster集群中的任务调度器负责将任务分配给空闲的服务器进行计算,并监控任务的执行情况。
当任务完成或服务器发生故障时,任务调度器会重新分配任务或切换到其他服务器上。
4. 数据同步:Cluster集群中的数据同步机制保证了数据在各个服务器之间的一致性。
当有新的数据写入或更新时,数据同步机制会将数据同步到其他服务器上,保证数据的完整性和准确性。
五、Cluster集群的应用场景1. 大规模数据处理:Cluster集群可以将大规模的数据分割成多个小数据块,分配给不同的服务器进行并行处理,提高数据处理的效率。
redis集群扩缩容方法

redis集群扩缩容方法Redis是一种开源的内存数据存储系统,常用于缓存、消息队列和数据存储等场景。
随着业务的发展,单个Redis实例的容量可能无法满足需求,这时候就需要对Redis进行扩容或缩容。
本文将介绍Redis集群的扩容和缩容方法。
一、Redis集群简介Redis集群是由多个Redis实例组成的分布式系统,它将数据分布在多个节点上,提供高可用性和扩展性。
每个节点负责存储部分数据,通过集群管理器进行协调和路由。
二、Redis集群的扩容方法1. 水平扩展:通过增加节点数量来增加集群容量。
具体步骤如下:(1) 安装并配置新的Redis实例。
(2) 将新的Redis实例添加到集群中。
(3) 对已有的Redis实例进行resharding,将部分数据迁移到新的节点上。
(4) 更新客户端配置,使其能够访问到新的节点。
2. 垂直扩展:通过增加单个节点的硬件资源(如内存、CPU等)来增加集群容量。
具体步骤如下:(1) 停止Redis实例。
(2) 根据需求增加硬件资源。
(3) 启动Redis实例。
三、Redis集群的缩容方法1. 水平缩容:通过减少节点数量来减少集群容量。
具体步骤如下:(1) 配置集群管理器,使其不再使用待缩容的节点。
(2) 将待缩容的节点标记为下线状态。
(3) 对其他节点进行resharding,将待缩容节点上的数据迁移到其他节点上。
(4) 更新客户端配置,使其不再访问到待缩容的节点。
(5) 停止并移除待缩容的节点。
2. 垂直缩容:通过减少单个节点的硬件资源来减少集群容量。
具体步骤如下:(1) 停止Redis实例。
(2) 根据需求减少硬件资源。
(3) 启动Redis实例。
四、注意事项1. 在进行扩容或缩容操作前,建议备份数据,以防意外发生。
2. 扩容和缩容过程中可能会对服务产生影响,建议在非高峰期进行操作。
3. 扩容和缩容操作涉及到数据迁移,可能会消耗较长的时间和网络带宽,需要做好相应的计划。
jediscluster初始化方法

jediscluster初始化方法JedisCluster是Jedis客户端的一个类,用于可以连接和操作Redis Cluster集群。
JedisCluster提供了一组方法来初始化和管理与Redis Cluster的连接。
1. 初始化JedisCluster对象:JedisCluster对象需要通过JedisPoolConfig和JedisClusterNodes 来初始化。
JedisPoolConfig用于配置连接池的参数,JedisClusterNodes指定了Redis Cluster中各个节点的信息。
首先,创建一个JedisPoolConfig对象,并设置相关的参数,如最大连接数、最大空闲连接数、连接超时时间等。
```javaJedisPoolConfig poolConfig = new JedisPoolConfig(;poolConfig.setMaxTotal(100);poolConfig.setMaxIdle(10);poolConfig.setMinIdle(5);poolConfig.setMaxWaitMillis(3000);poolConfig.setTestOnBorrow(true);```然后,创建一个HashSet<JedisClusterNode>对象,用于存储Redis Cluster中各个节点的信息。
可以通过添加多个JedisClusterNode对象来指定不同节点的主机和端口。
```javaHashSet<JedisClusterNode> jedisClusterNodes = new HashSet<>(;```最后,使用以上两个对象来初始化JedisCluster对象。
```javaJedisCluster jedisCluster = newJedisCluster(jedisClusterNodes, poolConfig);```这样就成功初始化了一个JedisCluster对象,可以通过该对象来操作Redis Cluster集群。
Redis集群(Cluster)_基础知识习题

Redis集群(Cluster)_基础知识习题(答案见尾页)一、选择题1. Redis Cluster由哪些部分组成?A. master节点B. slave节点C. 配置文件D. 数据库2. 在Redis Cluster中,master节点扮演什么角色?A. 数据写入B. 数据读取C. 协调slave节点D. 所有 above 角色的组合3. 在Redis Cluster中,slave节点扮演什么角色?A. 数据写入B. 数据读取C. 复制master节点的数据D. 所有 above 角色的组合4. Redis Cluster中的配置文件用于什么?A. 设置节点间通信参数B. 设置Redis服务器的最大内存C. 设置Redis服务器的最大逻辑连接数D. 所有 above 角色的组合5. 在Redis Cluster中,如何确定主从节点?A. 根据master节点的IP地址B. 根据slave节点的IP地址C. 根据master节点的端口号D. 根据slave节点的端口号6. 在Redis Cluster中,如何将数据迁移到集群?A. 使用redis-cli工具B. 使用Redis Sentinel工具C. 直接将数据复制到所有从节点D. 所有 above 角色的组合7. 如何提高Redis Cluster的性能?A. 增加Redis服务器的内存B. 增加Redis服务器的最大逻辑连接数C. 优化Redis Cluster的网络连接D. 所有 above 角色的组合8. 在Redis Cluster中,如何监控集群状态?A. 使用Redis Cluster自带的监控工具B. 使用Redis Sentinel工具C. 使用Redis CLI工具D. 所有 above 角色的组合9. 在Redis Cluster中,如何对集群进行故障排除?A. 重启master节点B. 重启slave节点C. 重新配置Redis Cluster的配置文件D. 所有 above 角色的组合10. 在Redis Cluster中,如何进行配置管理?A. 使用Redis Cluster自带的配置管理工具B. 使用Redis Sentinel工具C. 使用Redis CLI工具D. 所有 above 角色的组合11. 在进行Redis Cluster部署前,需要做哪些环境准备?A. 确保所有节点的网络连接正常B. 确保所有节点的操作系统版本一致C. 确保所有节点的硬件资源充足D. 确保所有节点的Redis版本一致12. 如何搭建Redis Cluster?A. 将所有节点都设置为slave模式B. 将所有节点都设置为master模式C. 分别将所有节点设置为master和slave模式D. 使用自动化工具来部署Redis Cluster13. 在初始化Redis Cluster时,需要完成哪些步骤?A. 配置所有节点的IP地址和端口号B. 配置所有节点的Redis版本号C. 启动所有节点的Redis服务D. 检查所有节点的Cluster状态14. 在Redis Cluster中,如何检测slave节点是否复制成功?A. 查看Redis Cluster自带的监控工具B. 查看Redis Sentinel工具C. 查看Redis CLI工具D. 所有 above 角色的组合15. 在Redis Cluster中,如何优化集群性能?A. 增加Redis服务器的内存B. 增加Redis服务器的最大逻辑连接数C. 优化Redis Cluster的网络连接D. 所有 above 角色的组合16. 在Redis Cluster中,如何处理Cluster节点故障?A. 重启master节点B. 重启slave节点C. 重新配置Redis Cluster的配置文件D. 所有 above 角色的组合17. 在Redis Cluster中,如何解决node-timeout错误?A. 调整Redis服务器的最大空闲时间B. 增加Redis服务器的内存C. 减少Redis服务器的最大逻辑连接数D. 所有 above 角色的组合18. 在Redis Cluster中,如何解决cluster-timeout错误?A. 调整Redis Cluster的时间同步间隔B. 增加Redis服务器的内存C. 减少Redis服务器的最大逻辑连接数D. 所有 above 角色的组合19. 在Redis Cluster中,如何解决“No nodes are available”错误?A. 调整Redis Cluster的时间同步间隔B. 增加Redis服务器的内存C. 增加Redis服务器的最大逻辑连接数D. 所有 above 角色的组合20. 如何优雅地关闭Redis Cluster?A. 使用Redis Cluster自带的关闭命令B. 使用Redis Sentinel工具的stop命令C. 使用Redis CLI工具的quit命令D. 所有 above 角色的组合21. 如何连接到Redis Cluster?A. 使用Redis CLI工具B. 使用Redis Sentinel工具C. 使用Redis Manager工具D. 所有 above 角色的组合22. 如何将数据迁移到Redis Cluster?A. 使用redis-cli工具B. 使用Redis Sentinel工具C. 直接将数据复制到所有从节点D. 所有 above 角色的组合23. 如何优化Redis Cluster的性能?A. 增加Redis服务器的内存B. 增加Redis服务器的最大逻辑连接数C. 优化Redis Cluster的网络连接D. 所有 above 角色的组合24. 如何升级Redis Cluster的Redis版本?A. 使用Redis CLI工具的redis-cli upgrade命令B. 使用Redis Sentinel工具的upgrade commandC. 重新编译并安装新的Redis版本D. 所有 above 角色的组合25. 如何降级Redis Cluster的Redis版本?A. 使用Redis CLI工具的redis-cli downgrade命令B. 使用Redis Sentinel工具的downgrade commandC. 重新编译并安装旧的Redis版本D. 所有 above 角色的组合26. 如何实现Redis Cluster的数据备份?A. 使用Redis Cluster自带的backup命令B. 使用Redis Sentinel工具的backup commandC. 使用Redis CLI工具的backup命令D. 所有 above 角色的组合27. 如何恢复Redis Cluster的数据?A. 使用Redis Cluster自带的restore命令B. 使用Redis Sentinel工具的restore commandC. 使用Redis CLI工具的restore命令D. 所有 above 角色的组合28. 如何监控Redis Cluster的运行状态?A. 使用Redis Cluster自带的监控工具B. 使用Redis Sentinel工具的monitor命令C. 使用Redis CLI工具的info命令D. 所有 above 角色的组合29. 如何监控Redis Cluster的性能?A. 使用Redis Cluster自带的监控工具B. 使用Redis Sentinel工具的metrics命令C. 使用Redis CLI工具的top命令D. 所有 above 角色的组合30. 如何解决Redis Cluster中的数据丢失问题?A. 重建Redis ClusterB. 使用Redis Cluster自带的rebuild命令C. 使用Redis Sentinel工具的rebuild命令D. 所有 above 角色的组合31. Redis Cluster中如何进行监控?A. 使用Redis Cluster自带的监控工具B. 使用Redis Sentinel工具的monitor命令C. 使用Redis CLI工具的info命令D. 所有 above 角色的组合32. Redis Cluster中如何进行配置管理?A. 使用Redis Cluster自带的配置管理工具B. 使用Redis Sentinel工具的config命令C. 使用Redis CLI工具的config命令D. 所有 above 角色的组合33. Redis Cluster中如何进行故障排查?A. 使用Redis Cluster自带的故障排查工具B. 使用Redis Sentinel工具的diagnose命令C. 使用Redis CLI工具的debug命令D. 所有 above 角色的组合34. 如何进行Redis Cluster的备份?A. 使用Redis Cluster自带的backup命令B. 使用Redis Sentinel工具的backup命令C. 使用Redis CLI工具的backup命令D. 所有 above 角色的组合35. 如何进行Redis Cluster的数据恢复?A. 使用Redis Cluster自带的数据恢复命令B. 使用Redis Sentinel工具的数据恢复命令C. 使用Redis CLI工具的数据恢复命令D. 所有 above 角色的组合36. Redis Cluster中如何进行日志管理?A. 使用Redis Cluster自带的log命令B. 使用Redis Sentinel工具的log命令C. 使用Redis CLI工具的log命令D. 所有 above 角色的组合37. Redis Cluster中如何进行节点升级?A. 使用Redis Cluster自带的upgrade命令B. 使用Redis Sentinel工具的upgrade命令C. 重新编译并安装新的Redis版本D. 所有 above 角色的组合38. Redis Cluster在金融行业的应用案例是什么?A. 缓存交易数据B. 实时数据分析C. 用户行为跟踪D. 所有 above 选项39. Redis Cluster在电商行业的应用案例是什么?A. 商品库存管理B. 订单处理C. 用户行为跟踪D. 所有 above 选项40. Redis Cluster在游戏行业的应用案例是什么?A. 玩家数据存储B. 游戏排行榜C. 实时匹配D. 所有 above 选项41. Redis Cluster在物流行业的应用案例是什么?A. 物流信息追踪B. 仓库库存管理C. 运输路线规划D. 所有 above 选项42. Redis Cluster在社交媒体的应用案例是什么?A. 用户数据存储B. 动态用户兴趣图谱C. 实时热门话题排行榜D. 所有 above 选项43. Redis Cluster在医疗领域的应用案例是什么?A. 病人数据管理B. 药品库存管理C. 医院排行榜D. 所有 above 选项44. Redis Cluster在教育领域的应用案例是什么?A. 学生课程表B. 教师绩效评估C. 学校排名D. 所有 above 选项45. Redis Cluster在智能家居的应用案例是什么?A. 家庭设备数据存储B. 远程控制家居设备C. 实时空气质量监测D. 所有 above 选项二、问答题1. 什么是Redis Cluster?2. Redis Cluster由哪些部分组成?3. Master节点在Redis Cluster中扮演什么角色?4. Slave节点在Redis Cluster中扮演什么角色?5. Redis Cluster的配置文件有什么作用?6. Redis Cluster如何进行部署?7. 连接Redis Cluster需要满足什么条件?8. 如何在Redis Cluster中迁移数据?9. 如何优化Redis Cluster的性能?10. Redis Cluster有哪些常见的监控指标?参考答案选择题:1. ABC2. D3. C4. A5. A6. A7. D8. A9. D 10. A11. A 12. C 13. D 14. A 15. D 16. D 17. A 18. A 19. B 20. A21. A 22. A 23. D 24. A 25. A 26. A 27. A 28. A 29. A 30. D31. A 32. A 33. A 34. A 35. A 36. A 37. A 38. D 39. D 40. D41. D 42. D 43. D 44. D 45. D问答题:1. 什么是Redis Cluster?Redis Cluster是一个高性能的分布式内存数据库系统,通过将数据分散存储在多个服务器上,提高了读写性能。
redis集群同步规则

redis集群同步规则Redis集群同步规则随着互联网应用的快速发展,数据存储和同步成为了一个重要的问题。
为了保证数据的高可用性和一致性,Redis引入了集群同步规则。
本文将详细介绍Redis集群同步规则的原理和实现方式。
一、Redis集群概述Redis是一个开源的高性能键值对存储系统,广泛应用于缓存、消息队列、实时统计等场景。
为了提高Redis的可用性和容量,Redis 引入了集群模式。
Redis集群由多个节点组成,每个节点都可以存储数据,并且节点之间可以相互同步数据,实现高可用性和负载均衡。
二、Redis集群同步规则的原理Redis集群同步规则的核心思想是主从同步。
每个Redis集群节点都有一个主节点和多个从节点。
主节点负责接收客户端请求,并将数据同步到从节点。
从节点负责接收主节点的数据同步,并提供读取服务。
当主节点出现故障时,从节点可以自动选举出一个新的主节点,保证系统的可用性。
Redis集群同步规则主要包括以下几个方面:1. 数据同步策略Redis集群使用的是异步复制方式进行数据同步。
当主节点收到写入请求时,会先将数据写入到本地内存中,然后再将数据异步地发送给从节点进行复制。
这种方式可以保证主节点的写入性能,并且不会阻塞客户端请求。
2. 数据同步延迟由于数据同步是异步进行的,所以从节点的数据可能会有一定的延迟。
Redis集群通过心跳机制来检测从节点的状态,当发现从节点延迟过高或者无法连接时,会自动将其标记为下线状态,并从其他从节点中选举一个新的主节点。
3. 数据一致性Redis集群通过复制日志来保证数据一致性。
主节点将每次写操作记录到复制日志中,并发送给从节点进行复制。
从节点在接收到复制日志后,会按照顺序执行其中的写操作,从而保证数据的一致性。
4. 主节点选举当主节点出现故障时,Redis集群会自动进行主节点选举。
选举过程中,会根据节点的复制偏移量和复制偏移量积压情况来选择新的主节点。
选举完成后,集群中的其他节点会自动将新的主节点设置为自己的从节点。
redis集群的节点通信机制

redis集群的节点通信机制Redis集群的节点通信机制主要采用两种方式:集群总线和Gossip协议。
1. 集群总线:Redis集群通过一个专门的集群总线来实现节点之间的通信。
这个总线可以通过Redis的Pub/Sub功能来实现,它使用了一个专门的频道(cluster.bus)进行消息发布和订阅。
当一个节点需要发送消息给其他节点时,它会将消息发布到该频道上,其他节点则会通过订阅这个频道,接收到这个消息。
这种方式的好处是实现简单,节点之间通过消息传递进行通信,并且可以快速地将消息广播给整个集群中的所有节点。
但是,由于该方式是异步的,节点之间的通信可能会有一定的延迟,并且消息的可靠性无法保证。
2. Gossip协议:Redis集群还引入了Gossip协议,用于节点之间的状态交换和信息传递。
每个节点周期性地向集群中的其他节点发送消息,这个消息中包含了节点自身的状态信息和集群中其他节点的状态信息。
通过这种方式,各个节点可以相互感知到彼此的存在,并及时更新自己的状态。
Gossip协议通过一种基于疏散算法的机制来实现节点信息的传递和状态同步。
当一个节点接收到其他节点的状态消息时,它会根据一定的规则来决定是否接受并将这个状态信息传播给其他节点。
同时,节点也会周期性地发送自身的状态信息给其他节点,以保持集群中节点状态的一致性。
Gossip协议具有良好的可扩展性和容错性,可以保证节点之间的状态一致性,并且可以自动适应节点的加入和离开。
通过使用集群总线和Gossip协议这两种机制,Redis集群可以实现节点之间的通信和状态同步,保证整个集群的高可用性和可靠性。
redis-cluster主从切换原理

redis-cluster主从切换原理主从切换的过程如下:1. 检测主节点失效: Redis-Cluster会定期对节点进行检测,如果发现主节点不可用,就会触发故障切换。
2. 选举新的主节点:从备份节点中选取一个做为新的主节点。
主节点的选举是通过投票机制来完成的:每个节点根据自己的状态和其他节点的信息选择一个对象发起投票,如果投票的对象获得了大多数的支持,则会成为新的主节点。
3. 数据同步:新的主节点会从旧的主节点中获取丢失的数据,在所有从节点中复制最新的数据以保证数据的一致性。
4. 更新客户端的视图:在切换完成后,Redis-Cluster会将新主节点的地址更新到客户端视图中,以确保客户端的请求被正确处理。
在上面的过程中,有几个需要注意的地方:1. 在节点选举的过程中,只选择没有故障的节点参与选举。
如果多个节点同时故障,选举过程可能需要等待故障恢复或手动干预才能完成。
2. 在数据同步的过程中,需要确保最新的数据都被同步到新的主节点中。
如果旧的主节点和新的主节点之间网络状况不好,同步可能会花费较长的时间,在这种情况下,需要手动干预以保证数据的完整性。
3. 在主从切换的过程中,需要确保客户端请求被正确处理。
如果客户端连接到的是失效的主节点,集群需要将客户端的请求重定向到新的主节点,以确保客户端请求的正确性。
总结:Redis-Cluster通过多副本的方式增加了系统的可用性,主从切换是其中的关键技术之一。
在自动切换的过程中,需要考虑多种情况,确保切换过程的正确性。
对于Redis-Cluster的使用者来说,在了解自动主从切换的基本原理的同时,还需要了解配置参数和自动切换的策略,以确保自动主从切换的正确性和可靠性。
k8s部署rediscluster集群的实现

k8s部署rediscluster集群的实现⽬录Redis 介绍为什么要⽤Redis什么是Redis Cluster集群k8s以StatefulSet⽅式部署redis cluster集群:部署nfs创建pv部署redis初始化redis集群Redis 介绍Redis代表REmote DIctionary Server是⼀种开源的内存中数据存储,通常⽤作数据库,缓存或消息代理。
它可以存储和操作⾼级数据类型,例如列表,地图,集合和排序集合。
由于Redis接受多种格式的密钥,因此可以在服务器上执⾏操作,从⽽减少了客户端的⼯作量。
它仅将磁盘⽤于持久性,⽽将数据完全保存在内存中。
Redis是⼀种流⾏的数据存储解决⽅案,并被GitHub,Pinterest,Snapchat,Twitter,StackOverflow,Flickr等技术巨头所使⽤。
为什么要⽤Redis它的速度⾮常快。
它是⽤ANSI C编写的,并且可以在POSIX系统上运⾏,例如Linux,Mac OS X和Solaris。
Redis通常被排名为最流⾏的键/值数据库和最流⾏的与容器⼀起使⽤的NoSQL数据库。
其缓存解决⽅案减少了对云数据库后端的调⽤次数。
应⽤程序可以通过其客户端API库对其进⾏访问。
所有流⾏的编程语⾔都⽀持Redis。
它是开源且稳定的。
什么是Redis Cluster集群Redis Cluster是⼀组Redis实例,旨在通过对数据库进⾏分区来扩展数据库,从⽽使其更具弹性。
群集中的每个成员(⽆论是主副本还是辅助副本)都管理哈希槽的⼦集。
如果主机⽆法访问,则其从机将升级为主机。
在由三个主节点组成的最⼩Redis群集中,每个主节点都有⼀个从节点(以实现最⼩的故障转移),每个主节点都分配有⼀个介于0到16,383之间的哈希槽范围。
节点A包含从0到5000的哈希槽,节点B从5001到10000,节点C从10001到16383。
群集内部的通信是通过内部总线进⾏的,使⽤协议传播有关群集的信息或发现新节点。
redis 集群原理

redis 集群原理Redis集群是通过分片技术实现数据的水平拆分和分布存储的一种方案。
它将数据分散存储在多个节点上,实现了横向扩展和负载均衡。
Redis集群的原理如下:1. 分片:Redis集群使用哈希槽(hash slot)来划分数据分片。
Redis Cluster 将整个数据分成16384个哈希槽,每个节点负责一部分槽的数据。
分片算法是将key通过CRC16计算出一个16位的哈希值,再对16384取模,将其分配到对应的槽中。
2. 槽迁移:当一个节点加入或离开集群时,槽的分配和迁移将自动进行。
当新节点加入集群时,集群会将一部分槽从现有节点中迁移到新节点上,实现负载均衡。
当节点离开或宕机时,集群会将该节点负责的槽迁移到其他节点上,保证数据的可用性。
3. 槽复制:Redis集群通过主从复制实现数据的高可用。
每个主节点都可以有一个或多个从节点。
主节点负责处理客户端请求和写操作,从节点则负责复制主节点的数据,实现读操作和故障转移。
4. 节点间通信:节点间通过Gossip协议进行通信,Gossip协议是一种去中心化的协议,节点之间相互交换集群信息,包括节点状态、槽分配和迁移等。
节点通过互相通信来保持集群的一致性。
5. 客户端路由:Redis集群的客户端会根据key的哈希值和槽的分布情况来决定将请求发送到哪个节点上。
客户端通过查询集群的槽分配表来确定数据所在的节点,并将请求直接发送到目标节点。
总体来说,Redis集群通过数据分片、槽迁移、槽复制和节点通信等技术来实现数据的分布存储和高可用性,提供了可扩展性和容错能力。
这些机制保证了Redis集群的性能和可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Redis 开发约定
• Key 格式约定:object-type:id:field。用":"分隔域,用"." 作为单词间的连接
• 禁止大k-v • 只用作cache, Key TTL设置 • 做好容量评估 • 设定集群上限 • 接入统一为本地goproxy
Redis 改造
• Redis 迁移cluster • 完善system、redis、corvus监控 • 拆分、扩容 • 非标机器腾挪下线 • 大key、热节点、大节点扫描 • 网卡Bond,多队列绑定 • 修改jedis源码,加入matrix埋点上报etrace
Redis(3.0.3)
OS
Centos 7.1 3.10.0-229.el7.x86_64
Centos 7.1 3.10.0-229.el7.x86_64
CPU
Intel(R) Xeon(R) CPU E5-2620 v3
Intel(R) Xeon(R) CPU E5-2620 v3
core mem
Corvus + redis cluster 逻辑架构
Corvus + redis cluster 部署
Redis 运维方式
• 移交数据库团队运维 • 统一redis 物理部署架构 • 标准化redis/corvus 服务器以及单机容量 • 设定redis 开发设计规范 • 设定redis资源申请流程,做好容量评估 • 完善监控,跟进全链路压测 • 隔离关键集群,分专用资源和公共资源 • 升级万兆网卡 • Redis Cluster集群appid
24
32G
24
32G
net
Bond 4 1G*2
Bond 4 1G*2
redis-benchmark -h 10.0.16.72 -p 8802 -n 90000000 -r 90000000 -t set -P 1000 -c 100 redis-benchmark -h 10.0.16.72 -p 8802 -n 90000000 -r 90000000 -t get -P 1000 -c 100
经验总结
• Redis 更适合cache,cluster下更不合适做持久化存储 • 一致性保证,不做读写分离(尽管corvus支持) • 单实例不宜过大,节点槽位要均衡 • 发现问题,复盘,积累经验 • 不跨机房部署,性能优先 • 异地多活通过订阅消息更新缓存 • 大部分的故障都是由于hot-key/big-key • 关心流量,必要时立刻升级万兆
Corvus + Redis Cluster
Corvus commands
• Pipeline support • Modified commands • Restricted commands • Unsupported comce
server
Corvus(0.2.4)
slot处于迁移状态
Corvus 时序设计
Corvus + Redis Cluster
Corvus
• 封装了redis cluster 协议,提供redis 协议 • 扩容缩容应用无感知 • 实时缓存了slots mapping • Multiple Thread • Lightweight • Reuseport support
使用场景
• 用户端 • 商户端 • 物流配送 • 搜索排序,热卖,画像等 • 各类cache等
问题很多
• 单点 • Db/cache混用 • 共用一个redis,大key阻塞整个实例 • 经常需要扩容,扩容很痛苦 • 使用复杂 • 基础环境非标,存在各种配置 • 监控缺失 • 不能统一配置
架构治理
遗留问题
• 还不够自动化 • 版本升级问题 • 大集群Reshard扩容慢 • Sam->corvus->redis链路分析 • 多活跨机房写缓存同步 • AOF/RDB • 冷数据 • 集群自愈
Redis 池化
• 公共池,专用池,资源buffer • 资源申请只需关注容量以及使用方式,无需关心机器 • 新申请以及扩容缩容按组(group)操作 • 运维操作自动化
Redis 自助
• 开发自助申请redis 资源 • 填入demo key/value,自动计算容量 • 状态,告警推送 • 各类文档齐全
Redis Cluster集群化架构演进
技术创新,变革未来
背景和数据
• 2015-2016饿了么的业务爆炸式增长 • 订单量从几十w到峰值900w/天 • 服务化治理诉求 • 应用性能和稳定诉求 • 人肉运维成本诉求 • 未来的PAAS平台池化准备
背景和数据
订单量和集群规模
背景和数据
订单量和请求
自研选型
• Redis vs redis Cluster • Twenproxy vs Codis vs Redis Cluster • Redis Cluster + proxy
Corvus + Redis Cluster
Redis Cluster 的优点
• 自带迁移功能 • Fast,高可用 • 支持在线分片 • 丰富集群管理命令
Set/get
set get
Corvus Cpu Corvus cpu Corvus cpu Redis cpu
util
kernel
user
util
94.7%
19.4
4.2
33%
94.9%
19.8
4.1
5%
Redis node Completed
cpu
command
43%
1427k/s
18%
1434k/s
Corvus + Redis Cluster
Redis Cluster 的缺点
• Client 实现复杂,需要缓存slot mapping关系并及时更新 • Client不成熟导致提高开发难度 • 存储和分布式逻辑耦合,节点太多时节点之间的检测
占大量网卡带宽 • 3.0.6版本前,只能单个key迁移,并且同时只允许一个