数据库-SQL Server 2014 新特性之内存优化表--嘉为科技
SQL Server数据库性能调整与优化

摘要:数据库技术是计算机系统的核心技术,数据库的稳定性与否直接影响计算机的运行效果,SQL SERVER数据库具有广泛的应用平台,作为高度可优化的软件产品———SQL SERVER数据库,其性能的调整与优化对提高计算机运行效果具有重要的现实意义。
关键词:数据库性能调整与优化SQL SERVER数据库作为计算机系统的核心,基于SQL SERVER数据库性性能的调整与优化主要目的就是通过将网络流通、磁盘I/O和CPU时间减到最低,减少每个查询时间,以此提高数据库服务的吞吐量。
SQL SERVER 数据库性能调整与优化是提高计算机系统稳定性的重要技术支撑。
1SQL SERVER数据库的特点①具有高性能设计和先进的管理系统。
高性能设计就是说其可以利用windows NT为计算机提供优越的服务,并且通过先进的管理系统实现计算机功能的全面,比如可以为计算机使用者提供支持本地以及远程的管理与配置,同时也具有图形化管理功能。
②具有强大的处理功能和兼容性。
SQL SERVER数据库性具有事务处理功能,它可以根据具体的计算机系统要求正确的保持数据的完整,实现相关数据的安全,同时SQL SERVER数据库性可以兼容不同的计算机系统,能够根据不同的计算机系统为使用者提供一个稳定的数据库平台。
2SQL SERVER数据库性能调整与优化的方法无论什么原因导致计算机数据管理系统出现问题都会影响数据库的运行效率,因此要想提高SQL Server数据库性能发挥最大效率,应该不断调整与优化SQL Server数据库系统,实现SQL Server数据库系统各个功能的最大发挥。
2.1SQL SERVER数据库设计优化要想提高SQL SERVER数据库性能的稳定性,就必须首先提高数据库的设计,保证数据库设计方案的性能做大优化。
2.1.1数据库的事务设计。
数据库事务系统是由不同的SQL语句模块所构成的,事务处理是由计算机系统的应用程序实现的,因此事务处理的起止点也应该由应用系统完成,基于此程序,数据库事务设计,要遵循运行效率的最大化原则,要保证数据库短事务,实现事务中的SQL语句能够科学的占有与释放系统资源,避免在系统运行中占用过多的资源而导致系统运行速度的下降。
转载:SqlServer数据库性能优化详解

转载:SqlServer数据库性能优化详解本⽂转载⾃:性能调节的⽬的是通过将⽹络流通、磁盘 I/O 和 CPU 时间减到最⼩,使每个查询的响应时间最短并最⼤限度地提⾼整个数据库服务器的吞吐量。
为达到此⽬的,需要了解应⽤程序的需求和数据的逻辑和物理结构,并在相互冲突的数据库使⽤之间(如联机事务处理 (OLTP) 与决策⽀持)权衡。
对性能问题的考虑应贯穿于开发阶段的全过程,不应只在最后实现系统时才考虑性能问题。
许多使性能得到显著提⾼的性能事宜可通过开始时仔细设计得以实现。
为最有效地优化 Microsoft? SQL Server? 2000 的性能,必须在极为多样化的情形中识别出会使性能提升最多的区域,并对这些区域集中分析。
虽然其它系统级性能问题(如内存、硬件等)也是研究对象,但经验表明从这些⽅⾯获得的性能收益通常会增长。
通常情况下,SQL Server ⾃动管理可⽤的硬件资源,从⽽减少对⼤量的系统级⼿动调节任务的需求(以及从中所得的收益)。
设计联合数据库服务器为达到⼤型 Web 站点所需的⾼性能级别,多层系统⼀般在多个服务器之间平衡每⼀层的处理负荷。
Microsoft? SQL Server? 2000通过对SQL Server 数据进⾏⽔平分区,在⼀组服务器之间分摊数据库处理负荷。
这些服务器相互独⽴,但也可以相互协作以处理来⾃应⽤程序的数据库请求;这样的⼀组协作服务器称为联合体。
只有当应⽤程序将每个 SQL 语句发送到拥有该语句所需的⼤部分数据的成员服务器时,联合数据库层才可以达到⾮常⾼的性能级别。
这称为使⽤语句所需的数据配置 SQL 语句。
使⽤所需的数据配置 SQL 语句不是联合服务器所独有的要求;在群集系统中同样有此要求。
虽然服务器联合体与单个数据库服务器呈现给应⽤程序的图像相同,但在实现数据库服务层的⽅式上存在内部差异。
单个服务器层联合服务器层⽣产服务器上有⼀个 SQL Server 实例。
SQLServer数据库性能调优技巧

SQLServer数据库性能调优技巧第一章:SQLServer数据库性能调优概述SQLServer是一种常用的关系型数据库管理系统,在大型企业和云计算环境中广泛应用。
为了确保数据库的高性能和可靠性,进行数据库性能调优非常重要。
本章将介绍SQLServer数据库性能调优的概念和目标。
1.1 数据库性能调优的概念数据库性能调优是指通过分析和优化数据库的结构、查询、索引、存储和配置等方面的问题,以提高数据库系统的效率和性能。
优化数据库性能可以显著提升数据的访问速度、减少系统响应时间和提高数据库的处理能力。
1.2 数据库性能调优的目标数据库性能调优的主要目标是提高数据库的运行效率和用户的体验,具体目标包括:- 提高数据的访问速度:通过合理的查询优化和索引设计,加快数据的检索速度。
- 减少系统响应时间:通过调整数据库配置、优化SQL 查询和提高硬件性能等措施,缩短系统响应时间。
- 提高数据库的处理能力:通过合理的分区设计、并行处理和负载均衡等措施,提高数据库的并发处理能力。
第二章:SQLServer数据库性能调优基础在进行SQLServer数据库性能调优之前,有几个基础概念需要了解,包括数据库的结构、查询执行计划和索引等。
2.1 数据库的结构SQLServer数据库由多个表组成,每个表由多个行和列组成。
表有一定的关系,通过主键和外键来建立关联。
了解数据库的结构对于进行性能调优非常重要。
2.2 查询执行计划查询执行计划是SQLServer数据库执行查询语句时的执行路径和操作过程的详细描述。
通过分析查询执行计划,可以找到潜在的性能问题,并进行相应的优化。
2.3 索引索引是一种特殊的数据库对象,用于加快查询速度。
常见的索引类型包括聚集索引、非聚集索引和全文索引等。
合理设计索引可以提高查询的性能。
第三章:SQLServer数据库性能调优技巧本章将介绍一些常用的SQLServer数据库性能调优技巧,包括查询优化、索引优化、配置优化和硬件优化等。
浅谈优化SQLServer数据库服务器内存

浅谈优化SQLServer数据库服务器内存配置的策略发布: 2007-6-07 23:59 | 作者: seanhe | 来源: 不详软件测试论坛讨论农业银行总行1998年以来正式推广了新版网络版综合业务统计信息系统,该系统是基于WindowsNT4.0平台,采用客户/服务器模式,以Microsoft SQL Server为基础建立起来的大型数据库应用程序,系统界面友好、操作简便,计算、分析、检索功能非常强大,为保证农业银行系统及时进行纵向和横向业务数据采集、按照不同要求生成统计报表,进行全面业务活动分析提供了强有力的保障。
但在这套程序的推广、维护中笔者发现系统有时运行速度较慢,特别是在Win95客户端操作时尤为严重,经过排除网线连接等硬件可能带来的影响后上述问题仍然存在。
笔者经过仔细摸索,发现系统对硬、软件的要求较高,为充分发挥设计效能,达到最佳运作效果,需要对计算机硬、软件系统进行较为完备的性能测试与最佳配置,特别是内存配置的好坏对系统的运行速度具有决定性的作用。
下面,笔者就如何优化SQLServer数据库服务器的内存配置提出一些认识和看法。
一、有关内存的基本概念1物理内存与虚拟内存WindowsNT使用两类内存:物理内存与虚拟内存。
物理内存:作为RAM芯片安装在计算机内部的存储器。
虚拟内存:用于模拟RAM芯片功能的磁盘(硬盘)空间,其实质是通过将内存中当前没有使用的部分内容临时存储到磁盘上,使系统可以使用到比机器物理内存更多的内存。
2分页和分页文件WindowsNT系统通过使用磁盘空间使得对内存的需求得到部分缓解,从而使用到比物理内存更多内存的技术就称为“交换”或分页,也就是通常所说的虚拟内存技术。
通常Windows NT 4.0系统安装时将在引导驱动器上设置一个大小为16MB的交换(分页)文件(pagefile.sys)。
二、优化Windows NT 4.0系统内存配置在大多数情况下,为了充分发挥Windows NT 4.0系统效能,内存的作用比起处理器的处理能力更具有影响力,特别是在客户/服务器模式环境下更是如此,因为通常在这种环境下并不十分强调处理器的能力,相反却十分注重是否采用足够的内存来满足各个客户的应用需要。
当sqlserver数据量很大时,如何优化表格能加快处理速度

表设计和查询的一些参考1.合理使用索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。
现在大多数的数据库产品都采用IBM最先提出的ISAM索引结构。
索引的使用要恰到好处,其使用原则如下:●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
●在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引。
●在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。
比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就无必要建立索引。
如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
●如果待排序的列有多个,可以在这些列上建立复合索引(compound index)。
● 使用系统工具。
如Informix数据库有一个tbcheck工具,可以在可疑的索引上进行检查。
在一些数据库服务器上,索引可能失效或者因为频繁操作而使得读取效率降低,如果一个使用索引的查询不明不白地慢下来,可以试着用tbcheck工具检查索引的完整性,必要时进行修复。
另外,当数据库表更新大量数据后,删除并重建索引可以提高查询速度。
2.避免或简化排序应当简化或避免对大型表进行重复的排序。
当能够利用索引自动以适当的次序产生输出时,优化器就避免了排序的步骤。
以下是一些影响因素:●索引中不包括一个或几个待排序的列;●group by或order by子句中列的次序与索引的次序不一样;●排序的列来自不同的表。
为了避免不必要的排序,就要正确地增建索引,合理地合并数据库表(尽管有时可能影响表的规范化,但相对于效率的提高是值得的)。
如果排序不可避免,那么应当试图简化它,如缩小排序的列的范围等。
3.消除对大型表行数据的顺序存取在嵌套查询中,对表的顺序存取对查询效率可能产生致命的影响。
比如采用顺序存取策略,一个嵌套3层的查询,如果每层都查询1000行,那么这个查询就要查询10亿行数据。
SQLServer数据库的性能优化

SQLServer数据库的性能优化随着企业数据量不断增长,数据库系统已经成为企业不可或缺的一部分。
随之而来的问题是,在应对海量数据的同时,如何保证数据库系统的高效运行,以满足业务需要。
而数据库性能优化就是为了解决这一问题而存在的。
但是,由于SQLServer数据库系统具有复杂性和高度的可配置性,使得数据库性能优化成为了非常复杂的工作。
如果我们没有足够的知识与技巧,很容易导致不经意间影响数据库系统的正常工作。
本文将介绍SQLServer数据库性能优化的关键点。
1. 容量规划在数据库性能优化的开始阶段,我们需要明确数据库的容量规划,该规划应该包含这些内容:- 确认数据库的大小和增长趋势;- 选择合适的服务器硬件配置;- 选择合适的存储设备和存储配置;- 确认数据库备份和还原方案。
当确认好这些规划后,我们可以愉快地开启数据库系统的优化之旅了。
2. 关注I/O操作I/O操作是数据库性能优化中最重要的因素之一。
在SQLServer 中,我们需要通过以下几点来关注IO操作:- 确认合适的RAID配置;- 选择合适的磁盘类型;- 确认合适的磁盘块大小。
对于I/O操作的优化,我们可以在两个方面进行,一个是硬件方面,另一个则是SQLServer配置。
硬件方面,我们需要考虑到一下几个方面:- 升级服务器硬件设备;- 将磁盘储存设备升级为SSD硬盘;- 增加内存的容量。
对于SQLServer的配置,则可以通过以下几点进行:- 合适的磁盘和RAID配置;- 合适的max degree of parallelism 配置;- 合适的max server memory配;3. 使用合适的索引在SQLServer中,索引的作用是加速数据查询和数据修改,从而提高整个数据库系统的运行效率。
而在使用索引时,我们需要特别注意这些要素:- 创建索引可以减少IO操作;- 索引优化的关键点是选择合适的包含数据条目最多的列;- 在大型多元素表中使用Clustered Index;- 对于包含大量重复元素的列,可以直接采用非聚集索引。
当SqlServer数据量很大时如何优化表格能加快处理速度

表设计和查询的一些参考1.合理使用索引索引是数据库中重要的数据结构,它的根本目的就是为了提高查询效率。
现在大多数的数据库产品都采用IB M最先提出的ISAM索引结构。
索引的使用要恰到好处,其使用原则如下:●在经常进行连接,但是没有指定为外键的列上建立索引,而不经常连接的字段则由优化器自动生成索引。
●在频繁进行排序或分组(即进行gro up by或ord er by操作)的列上建立索引。
●在条件表达式中经常用到的不同值较多的列上建立检索,在不同值少的列上不要建立索引。
比如在雇员表的“性别”列上只有“男”与“女”两个不同值,因此就无必要建立索引。
如果建立索引不但不会提高查询效率,反而会严重降低更新速度。
●如果待排序的列有多个,可以在这些列上建立复合索引(compou nd index)。
● 使用系统工具。
如Infor mix数据库有一个t bchec k工具,可以在可疑的索引上进行检查。
在一些数据库服务器上,索引可能失效或者因为频繁操作而使得读取效率降低,如果一个使用索引的查询不明不白地慢下来,可以试着用t bchec k 工具检查索引的完整性,必要时进行修复。
另外,当数据库表更新大量数据后,删除并重建索引可以提高查询速度。
2.避免或简化排序应当简化或避免对大型表进行重复的排序。
当能够利用索引自动以适当的次序产生输出时,优化器就避免了排序的步骤。
以下是一些影响因素:●索引中不包括一个或几个待排序的列;●groupby或ord er by子句中列的次序与索引的次序不一样;●排序的列来自不同的表。
为了避免不必要的排序,就要正确地增建索引,合理地合并数据库表(尽管有时可能影响表的规范化,但相对于效率的提高是值得的)。
MS SQL Server数据库空间优化指南

在SQL Server 2005数据库中,当日志文件大小达到一定的容量时(暂时还没有找到临界值,目前都是在10G以上的日志文件中收缩时发现无法收缩成功),已经无法通过自动收缩日志的(收缩过程中会报错导致收缩失败,同时也无法分离),对于这种情况,只能先停止SQL Server数据库,然后手工直接删除对应的ldf日志文件。然后再重启SQL Server数据库,在加载时会自动报告该数据库缺少日志文件,按照提示生成一个新的日志文件即可,此步骤直接腾出了12G磁盘空间;
SQL Server
由于新的持续集成测试需要同时配置SQL Server、Oracle、DB2三种数据库,但是在目前的测试环境中,只有一台可用的SQL Server数据库服务器,上面安装了数十个数据库,空间已经几乎耗尽(总共120G的数据文件空间,只剩下3G左右的磁盘空间),随时都可能出现磁盘空间不足的问题。为了解决磁盘空间的问题,对安装在此服务器上的数据库进行了初步分析,通过对日志文件和数据文件的大小进行整理,结果如下:
通过上面两步的处理,磁盘空间从原来的4G增加到了25G,腾出了21G的磁盘空间。
结论与体会:平时我们可能对测试环境的优化与监控并不是很重视,但在实际测试中,常常会碰到资源争用与资源不足的情况,因此,对测试环境的优化不仅是必要的,而且是必须的。同时在优化的过程中,也可以形成对环境优化类知识的积累,既可以促进产品设计的改善,还可以帮助客户进行环境的定期优化与改善,提高用户的满意度(比如上面的BOS63Nanche,如果及时进行了日志文件的截断,则不会存在日志文件无法收缩的问题)。
a)界面操作——(选中该表->索引->全部重新生成(右健)),重建完成后,结果如下:
b)通过SQL命令操作:
sql sever 2014教程

sql sever 2014教程SQL Server是由Microsoft开发的关系数据库管理系统,其最新版本为SQL Server 2019。
本教程将重点介绍SQL Server 2014的一些基本概念、功能和用法。
1. SQL Server 2014的新特性SQL Server 2014引入了许多新的功能和改进,提高了性能、可靠性和实用性。
其中一些新特性包括:In-Memory OLTP(内存中的在线事务处理)、缓冲区池中的扩展事件、总体数据压缩和备份,以及实时操作分析。
2. 安装和配置SQL Server 2014在安装SQL Server 2014之前,您需要了解其硬件和软件要求。
本教程将指导您通过安装向导来完成SQL Server 2014的安装过程,并讲解一些常用的配置选项。
3. 创建数据库和表数据库是存储数据的容器,而表是数据在数据库中的结构化组织方式。
本教程将演示如何使用SQL Server管理工具(如SQL Server Management Studio)创建数据库和表,并介绍如何定义表的结构和约束。
4. 插入、更新和删除数据一旦数据库和表创建完毕,我们就可以向数据库中插入数据、更新数据和删除数据了。
本教程将演示如何使用SQL的INSERT INTO、UPDATE和DELETE语句来操作数据。
5. 查询数据查询是SQL的核心功能之一,它使我们能够从数据库中检索所需的数据。
本教程将介绍SELECT语句的用法,包括如何过滤、排序和分组数据,以及如何使用聚合函数和子查询。
6. 创建索引和优化查询索引是加快查询速度的一种重要手段。
本教程将讲解如何在表上创建索引,并介绍SQL Server提供的一些性能优化工具和技术,以帮助您提升查询性能。
7. 数据库备份和还原数据库备份和还原是保护数据免受意外丢失的重要措施。
本教程将演示如何使用SQL Server的备份与还原工具来创建和还原数据库备份。
SQL 2014 各版本功能对比
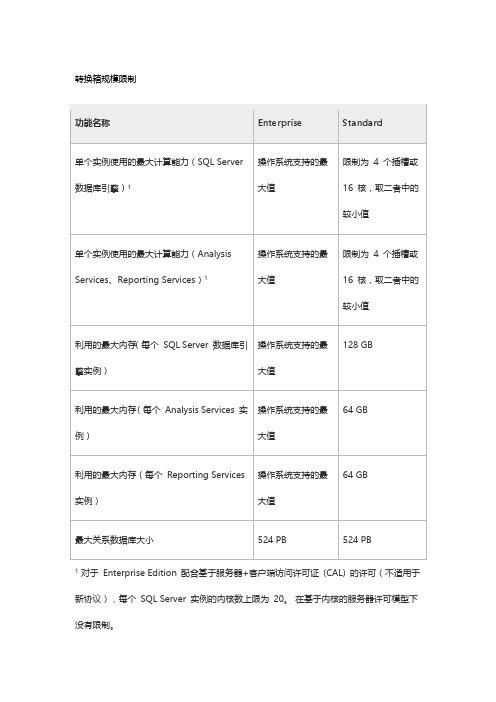
转换箱规模限制功能名称Enterprise Standard单个实例使用的最大计算能力(SQL Server 数据库引擎)1操作系统支持的最大值限制为4 个插槽或16 核,取二者中的较小值单个实例使用的最大计算能力(Analysis Services、Reporting Services)1操作系统支持的最大值限制为4 个插槽或16 核,取二者中的较小值利用的最大内存(每个SQL Server 数据库引擎实例)操作系统支持的最大值128 GB利用的最大内存(每个Analysis Services 实例)操作系统支持的最大值64 GB利用的最大内存(每个Reporting Services 实例)操作系统支持的最大值64 GB最大关系数据库大小524 PB 524 PB1对于Enterprise Edition 配合基于服务器+客户端访问许可证(CAL) 的许可(不适用于新协议),每个SQL Server 实例的内核数上限为20。
在基于内核的服务器许可模型下没有限制。
高可用性功能名称Enterprise Standard Server Core 支持1是是日志传送是是数据库镜像是支持(仅支持“完全”安全级别)备份压缩是是数据库快照是是(节点支持:2)AlwaysOn 故障转移群集实例是(节点支持:操作系统支持的最大值AlwaysOn 可用性组支持(最多8 个辅助副本,包括2 个同步辅助副本)连接控制器(Connection Director) 是联机页面和文件还原是联机索引是联机架构更改是快速恢复是镜像备份是热添加内存和CPU2是数据库恢复顾问是是加密备份是是智能备份是是1有关在Server Core 上安装SQL Server 2014 的详细信息,请参阅在Server Core 上安装SQL Server 2014。
2此功能仅可用于64 位SQL Server。
可伸缩性和性能功能名称Enterprise Standard多实例支持50 50表和索引分区是数据压缩是资源调控器是分区表并行度是多个Filestream 容器是是可识别NUMA 的大型页内存和缓冲区数组分配缓冲池扩展1是是IO 资源调控是内存中OLTP 1是延迟持续性是是1此功能仅可用于64 位SQL Server。
SQL Server内存性能调整推荐配置(Ver 0.2)

SQL Server内存性能调整推荐配置(Ver 0.2)本文试图给出各种内存情况下的SQL Server内存推荐配置。
分别针对物理内存2G以内,4G及4G以上的情况。
典型操作系统为Windows Server 2003 Enterprise Edition 32bit。
SQL Server是2000 SP4以上版本。
配置SQL Server内存之前需要根据物理内存情况修改操作系统启动文件。
如果使用的是64位的操作系统,不需要配置/3GB、/PAE和AWE的相关设置。
一、物理内存小于2G的情况。
物理内存小于2G的情况下不需要进行SQL Server手动内存配置,使用SQL Server的缺省配置就可以。
操作系统也不用做改动。
在SQL Server 2005的官方文档中,对“最大服务器内存(MB)”有如下描述最大服务器内存(MB)指定在SQL Server 启动和运行时它可以分配的内存最大量。
如果知道有多个应用程序与SQL Server 同时运行,并且要保证这些应用程序有足够的内存运行,则可以将此配置选项设置为特定值。
如果这些应用程序(如Web 服务器或电子邮件服务器)只是按需请求内存,则不必设置该选项,因为SQL Server 将会根据需要向它们释放内存。
但是,应用程序通常在启动时使用全部可用内存,并且也不会根据需要请求更多内存。
如果以这种方式运行的应用程序与SQL Server 同时运行在同一台计算机上,则请设置该选项的值,保证应用程序所需的内存不会由SQL Server 来分配。
能够以上描述可以看出SQL Server 2005可以自动申请内存,也可以在其它应用程序需要内存的时候释放内存,跟操作系统配合得很好,所以不需要手工对内存再进行配置。
对于SQL Server 2000的情况,暂时没有找到有关的表述。
根据以往经验,跟2005类似。
二、物理内存为4G及4G以上的情况。
由于32位Windows的限制,SQL Server最多能使用1.75G的内存。
SQLServer的性能优化技巧

SQLServer的性能优化技巧随着IT技术的快速发展,数据库作为系统的核心组成部分,在各行各业的信息化建设中扮演着至关重要的角色。
作为一种重要的关系型数据库管理系统,SQLServer的性能往往直接影响着系统的运行效率和稳定性。
本文将介绍一些SQLServer的性能优化技巧,供读者参考。
一、使用恰当的数据库引擎SQLServer支持多种不同的数据库引擎,如MyISAM、InnoDB 等。
每一种引擎都有自己的特点和适用范围。
在进行数据建模时,要根据应用场景的需要选择最适合的引擎。
一般来说,InnoDB引擎支持事务、外键以及行级锁等特性,适合于对数据完整性要求比较高的系统;而MyISAM引擎则适合于读写比例较低的系统。
选择恰当的数据库引擎可以提高SQLServer的性能。
二、适当调整缓存参数SQLServer有多种缓存,包括查询缓存、表缓存、索引缓存等等。
合理的调整这些缓存参数,可以提高系统的性能。
其中,查询缓存可以减少重复查询的时间,提高响应速度;表缓存可以满足多次使用同样的查询所需的表缓存需求;索引缓存则可以提供快速的查询性能。
在具体的应用中,需要根据场景和需求选择不同的缓存参数,以达到最优的性能表现。
三、使用合适的索引策略索引是SQLServer中非常重要的性能优化策略。
适当的索引可以提高系统的查询速度和效率。
但是,在使用索引时,需要考虑到索引对插入、修改、删除等操作的影响。
如果索引过多,会导致这些操作的性能下降。
因此,必须在保证查询速度和效率的基础上,综合考虑索引对系统整体运行的影响。
四、合理使用分区技术对于大型的数据库系统,分区技术可以将数据划分为多个小段,降低系统的压力和负载,提高系统的处理速度。
在SQLServer中,可以根据表大小或者数据时间等因素进行分区。
通过使用分区技术,可以实现数据存储和查询的快速响应,同时有效地缓解系统的负载压力。
五、使用恰当的查询语句查询语句在SQLServer中起着至关重要的作用。
SQL内存优化-最大化使用内存

SQL内存优化-最⼤化使⽤内存1. 重启sql server第⼀步,打开记事本,输⼊下列2⾏命令:net stop mssqlservernet start mssqlserver将其存为⼀个.bat的⽂件。
第⼆步,在Windows的“任务计划”功能⾥,添加⼀条新的任务计划,让系统在每天的 03:00执⾏⼀次这个.bat 这个批处理⽂件即可。
2. 内存调优SQL Server占⽤的内存主要由三部分组成:数据缓存(Data Buffer)、执⾏缓存(Procedure Cache)、以及SQL Server引擎程序。
SQL Server 引擎程序所占⽤缓存⼀般相对变化不⼤,则我们进⾏内存调优的主要着眼点在数据缓存和执⾏缓存的控制上。
对于减少执⾏缓存的占⽤,主要可以通过使⽤参数化查询减少内存占⽤。
1、使⽤参数化查询减少执⾏缓存占⽤我们通过如下例⼦来说明⼀下使⽤参数化查询对缓存占⽤的影响。
为⽅便试验,我们使⽤了⼀台没有其它负载的SQL Server进⾏如下实验。
下⾯的脚本循环执⾏⼀个简单的查询,共执⾏10000次。
⾸先,我们清空⼀下SQL Server已经占⽤的缓存:dbcc freeproccache然后,执⾏脚本: DECLARE @t datetimeSET @t = getdate()SET NOCOUNT ONDECLARE @i INT, @count INT, @sql nvarchar(4000)SET @i = 20000WHILE @i <= 30000BEGINSET @sql = 'SELECT @count=count(*) FROM P_Order WHERE MobileNo = ' + cast( @i as varchar(10) )EXEC sp_executesql @sql ,N'@count INT OUTPUT', @count OUTPUTSET @i = @i + 1ENDPRINT DATEDIFF( second, @t, current_timestamp )输出:DBCC 执⾏完毕。
SQLServer2014新功能

新的基数评估方式优势1
如果自增列由于统计信息不新估计行数为0,新的评估方 式会采用平均密度。(新评估方式中没有行数为0的估计 情况,除非平均值为0,也就是列值全为NULL,解决所谓 的Ascending Keys Problem) 对于多表连接的过滤值,比如a join b join c on a.a=bb and b.b=c.c,传统估计方式会将这三列的选择性相乘,会导 致估计行数的低估,而新的基数估计会假设这种连接是以其 中最大的表为中心,和其他小表做连接,连接操作符的估 计行数等于最大表的行数,从而造成估计行数的高估(大 多数情况是好事,因为低估往往采用Loop Join 在行数不 准时相比hash join有极大的性能开销)
新基数的TroubleShooting(扩展事件)
使用sqlserver.query_optimizer_estimate_cardinality
CREATE EVENT SESSION [CardinalityEstimate] ON SERVER ADD EVENT sqlserver.query_optimizer_estimate_cardinality ADD TARGET package0.ring_buffer
的基数评估方式的使用
数据库兼容级别为120时,所有的语句都会自动使用新的 基数估计方式。 数据库兼容级别为120时,如果希望在语句级别使用传统 的基数估计方式,使用跟踪标记9481。 数据库兼容级别为110时,如果希望在语句级别使用新的 基数估计方式,使用跟踪标记2312。 最佳实践:升级后对重点语句测试,如果发现性能下降, 对下降的语句使用9481使得该语句使用传统的行估计方式 。
在SQL Server 2014上,如果使用的是.Net Framework 4.5.1,会引入自动连接机制 出现背景
SQLServer2014简介

1.2 SQL Server 2014服务器组件和管理工具
3.产品文档 SQL Server 2014产品文档包括: (1)SQL Server 2014联机丛书。 (2)SQL Server 2014的开发人员参考。 (3)SQL Server 2014安装。 (4)安装程序和服务安装。 (5)升级顾问。 (6)SQL Server 2014教程。 (7)SQL Server的Microsoft JDBC Driver。 (8)Microsoft Drivers for PHP for SQL Server。 (9)Microsoft ODBC Driver for SQL Server。 (10)DB2 5.0版本的Microsoft OLE DB提供程序。
1.1 SQL Server 2014之前版本
1.SQL Server 6.0、SQL Server 6.5、SQL Server 7.0 SOL Server从20世纪80年代后期开始开发,SQL Server 6.0是第一个完全由 Microsoft公司开发的版本,1996年发布了SOL Server 6.5,该版本提供了廉价的可 以满足众多小型商业应用的数据库方案。SQL Server 7.0在数据存储和数据库引擎 方面发生了根本性的变化,提供了面向中、小型商业应用数据库功能支持。 2.SQL Server 2000 SQL Server 2000继承了SQL Server 7.0的优点,具有使用方便、可伸缩性好、 相关软件集成程度高等优点,可跨越从运行 Windows 98的膝上型电脑到运 行 Windows 2000的大型多处理器的服务器等多种平台使用。
服务器
Analysis Services
包括用于创建和管理联机分析处理(OLAP)以及数据挖掘应用程序的工具
理解内存----优化SQLServer内存配置

理解内存----优化SQLServer内存配置最小和最大Server内存Min Server Memory (MB) 和 Max Server Memory (MB)控制所有SQL Server内存使用的许可大小。
比起之前的版本,SQL Server 2012的Memory Manager可以更简单地设置SQL Server内存需求的大小。
SQL Server服务是以所需的最小量启动的,并根据需要增长。
一旦内存使用增长超过Min Server Memory设置,SQL Server将不会释放任何低于该量的内存。
Min Server Memory设置内存使用的下限,而Max Server Memory则设置上限。
这两个值可以使用sp_configure或通过Management Studio中的SQL Server属性窗口的内存页面进行设置。
两个设置中,配置缓冲池的最大值更重要,它会阻止SQL Server占用过多的内存。
这在64位系统中尤其重要,因为缺少可用物理内存能够导致Windows裁剪SQL Server的工作集。
后面的“锁定内存页”有关于这个问题的完整描述。
对于配置Max Server Memory,有一些不同的方法来计算合适的值,最直接的方法是看看SQL Server的最大使用量,及确定SQL Server之外内存需求的最大潜在用量。
查看SQL Server的最大使用量设置SQL Server动态管理内存,然后使用性能监视器监视计数器MSSQL$<instance>:Memory Manager\Total ServerMemory (KB)。
这个计数器测量SQL Server的总缓冲池使用量。
如果SQL Server以外的其他需求需要比当前可用内存更多的物理内存时,T otal Server Memory值会降低,然后使用任何可用内存再增加。
如果您监视此计数器一段时间(包括忙时和淡时),然后你就可以将Max Server Memory设置为你观察到的Total Server Memory (KB)的最低值,你不必担心SQL Server在正常操作期间收缩它的使用量。
试试SQLServer2014的内存优化表

试试SQLServer2014的内存优化表试试SQLServer 2014的内存优化表SQL Server2014存储引擎:⾏存储引擎,列存储引擎,内存引擎SQL Server 2014中的内存引擎(代号为Hekaton)将OLTP提升到了新的⾼度。
现在,存储引擎已整合进当前的数据库管理系统,⽽使⽤先进内存技术来⽀持⼤规模OLTP⼯作负载。
就算如此,要利⽤此新功能,数据库必须包含“内存优化”⽂件组和表即所配置的⽂件组和表使⽤Hekaton技术。
幸运的是,SQL Server 2014使这⼀过程变得⾮常简单直接。
要说明其⼯作原理,我们来创建⼀个名为TestHekaton的数据库,然后添加⼀个内存优化⽂件组到此数据库测试环境:Microsoft Azure ⼤陆版虚拟机4核,7G内存,Windows2012R2SQLSERVER2014企业版实验第⼀个实验:内存表的简单使⽤步骤1:创建数据库和MEMORY_OPTIMIZED_DATA⽂件组USE master;GOCREATE DATABASE TestHekaton;GOALTER DATABASE TestHekatonADD FILEGROUP HekatonFG CONTAINS MEMORY_OPTIMIZED_DATA;GO注意ALTER DATABASE语句中的ADD FILEGROUP 语句包含⽂件组的名称(HekatonFG)和关键字CONTAINS MEMORY_OPTIMIZED_DATA它会指导SQL Server去创建⽀持内存OLTP引擎所必需的⽂件组类型。
注意:每个数据库只能有⼀个MEMORY_OPTIMIZED_DATA⽂件组!!要确认此⽂件组已经创建,可以访问SSMS中数据库属性的Filegroups 界⾯,如下图所⽰。
步骤2:添加⼀个存放数据⽂件的⽂件夹到⽂件组,可以通过ALTER DATABASE语句来实现。
添加⼀个存放内存优化表数据的⽂件夹到HekatonFG⽂件组:--执⾏下⾯语句之后会在C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA路径下创建⼀个⽂件夹--⽂件夹名为HekatonFile--请不要预先创建好这个⽂件夹ALTER DATABASE TestHekatonADD FILE(NAME ='HekatonFile',FILENAME ='C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\HekatonFile')TO FILEGROUP [HekatonFG];GO注意:在ADD FILE 语句中,我们只为⽂件路径提供了⼀个友好的名称。
sql server 2014策略

sql server 2014策略SQL Server 2014 策略SQL Server 2014 是微软推出的一款关系型数据库管理系统,它提供了一系列的策略来帮助用户管理和优化数据库的性能、安全性和可靠性。
本文将介绍 SQL Server 2014 的一些重要策略,并说明它们的作用和使用方法。
一、备份和恢复策略备份和恢复是数据库管理中非常重要的方面。
SQL Server 2014 提供了多种备份和恢复策略,以保护数据库免受数据丢失或损坏的影响。
用户可以根据自己的需求选择完整备份、差异备份或者事务日志备份等不同的备份方式,并设置备份计划以定期执行备份操作。
此外,还可以使用SQL Server Management Studio 工具来恢复数据库,选择恢复到特定的时间点或者特定的事务。
二、性能优化策略SQL Server 2014 提供了多种性能优化策略,可以提升数据库的查询性能和响应速度。
其中包括索引优化、查询优化和统计信息维护等策略。
索引优化可以提高查询的效率,减少查询的时间。
查询优化可以通过修改查询语句或者调整查询计划来提高查询的性能。
统计信息维护可以保证查询优化器能够根据最新的数据统计信息做出最优的查询计划选择。
三、安全性策略数据库的安全性是用户非常关注的问题。
SQL Server 2014 提供了多种安全性策略,以保护数据库免受未经授权的访问和数据泄露的威胁。
其中包括访问控制、身份验证和加密等策略。
访问控制可以通过设置权限、角色和登录账户来限制用户对数据库的访问权限。
身份验证可以通过使用Windows 身份验证或者SQL Server 身份验证来验证用户的身份。
加密可以保护数据库中的敏感数据,防止数据泄露。
四、容灾和高可用性策略容灾和高可用性是数据库管理中非常重要的方面。
SQL Server 2014 提供了多种容灾和高可用性策略,以确保数据库的连续可用性和数据的安全性。
其中包括镜像、复制和集群等策略。
如何利用SQL语句实现数据库容量扩展和优化

如何利用SQL语句实现数据库容量扩展和优化在当今数字化的时代,数据库扮演着至关重要的角色,存储着大量宝贵的信息。
随着业务的不断发展和数据量的持续增长,数据库容量的扩展和优化成为了至关重要的任务。
而 SQL 语句作为与数据库交互的强大工具,为我们实现这一目标提供了有力的支持。
接下来,让我们一起深入探讨如何利用 SQL 语句来实现数据库容量的扩展和优化。
首先,我们来了解一下为什么需要进行数据库容量扩展和优化。
当数据库中的数据量不断增加时,如果不及时处理,可能会导致性能下降、查询变慢、存储空间不足等问题。
这不仅会影响用户的体验,还可能会对业务的正常运行造成严重的影响。
在进行数据库容量扩展之前,我们需要对当前数据库的状况进行全面的评估。
这包括了解数据库的架构、表结构、数据增长趋势、当前的存储空间使用情况以及性能指标等。
通过这些信息,我们可以确定需要扩展的方向和规模。
一种常见的扩展方式是增加存储介质的容量。
例如,如果当前使用的是磁盘存储,可以考虑更换更大容量的磁盘或者添加更多的磁盘来扩展存储空间。
在这个过程中,我们可以使用 SQL 语句来监测存储空间的使用情况。
例如,通过以下语句可以查看数据库中各个表所占用的空间大小:```sqlSELECTtable_name,round((data_length + index_length) / 1024 / 1024, 2) AS 'size_in_mb'FROMinformation_schemaTABLESWHEREtable_schema ='your_database_name';```这将帮助我们了解哪些表占用了较多的空间,从而有针对性地进行处理。
另一种扩展方式是对数据库进行分区。
分区可以将一个大表按照特定的规则拆分成多个小的部分,从而提高查询和管理的效率。
例如,按照时间或者范围进行分区。
以下是一个按照时间分区的示例:```sqlCREATE TABLE your_table_name (column1 INT,column2 VARCHAR(50),create_time TIMESTAMP)PARTITION BY RANGE (YEAR(create_time))(PARTITION p_2020 VALUES LESS THAN (2021),PARTITION p_2021 VALUES LESS THAN (2022),PARTITION p_2022 VALUES LESS THAN (2023));```通过分区,我们可以在查询时只针对特定的分区进行操作,减少了数据的扫描范围,提高了查询性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
方勇
【摘要】
2013年6月25日,微软发布了SQL Server 2014 CTP1。
本文将为您介绍SQL Server 2014 的重点新特性——内存优化表。
【正文】
如果说SQL Server 2012 的数据库引擎最大的亮点是Always On的话,那么SQL Server 2014 最大的亮点就是内存优化表(Memory-optimized tables)了。
1. 内存表的背景
在SQL Server 2000 的年代,我们还可以通过这种方式,将表驻留在内存中:DBCC PINTABLE ( database_id , table_id )
DBCC PINTABLE 会导致将表读入到内存中。
当表中的页由普通的Transact-SQL 语句读入到高速缓存中时,这些页将标记为内存驻留页。
当SQL Server 需要空间以读入新页时,不会清空内存驻留页。
但是这种方式在SQL Server 2005 已经不被支持了,内存表这种概念消失了,直到SQL Server 2014。
2. 文件和存储
内存优化表必须存储到文件流文件组中,SQL Server 提供了一种MEMORY_OPTIMIZED_DATA 文件组类型专门用于指定内存优化表的逻辑存储位置。
内存优化表的文件流文件组可以包含一个或多个容器,每个容器有可以包含一个或多个
文件。
文件包含了三种类型的文件:
●根文件(Root File):包含了数据文件和增量文件的元数据
●数据文件(Data File):存储内存优化表的记录和新插入的记录
●增量文件(Delta File):按照事务日志顺序存储从内存优化表中删除的记录的
最小信息(行号),每个数据文件对应一个增量文件
内存优化表会使用到事务日志,同样任何增删改等操作都会写入日志,这可能是导致即使使用内存优化表,性能也无法显著提升的最大原因,可以考虑使用闪存或者SSD来解决该问题
3. 原理和机制
SQL Server 2014 新增的内存优化表让我们眼前一亮,可以改善基于磁盘的表的低性能。
通过以下的原理和机制让我们获得更好的性能和可扩缩性:
●通过数据页和索引页驻留在内存,减少IO瓶颈
●采用乐观并发控制,消除了逻辑锁,提高了并发性
●本机编译存储过程,执行效率更高
我们一定会担心,使用内存优化表会不会导致因为驻留在内存中,系统宕机或者断电的时候,导致数据无法及时写回内存而丢失。
内存优化表保留了关系型数据库的事务所有ACID 特征:原子性、一致性、隔离性和持久性。
SQL Server和内存优化表的持久化上下文提供了以下保证:
●事务持久化:提交DDL或DML更改内存优化表的事务,更改是永久性的(不
丢失);
●重启持久化:在系统崩溃恢复或计划重新启动后,内存优化表重新实例化以恢
复到关闭或崩溃时的状态;
●介质失败持久化:当磁盘损坏时,我们可以通过数据库的备份和还原来恢复内
存优化表到新存储
当然,内存优化表有两种持久化选项,其中有一种是不保证持久化的:
●SCHEMA_ONLY(非持久化表):只持久化表结构和索引,重启后所有数据丢
●SCHEMA_AND_DATA(持久化表):持久化结构和数据,类似于基于磁盘的表
接下来我们来分析一下增删改操作的流程:
●增、删、改操作执行先写入事务;
●插入操作:先插入到内存中,在CheckPoint 的时才写回数据文件
●删除操作:先在内存中删除,并记录行号到Delta文件,随后Delta文件中记
录的删除会合并到数据文件
●更新操作:更新操作在SQL Serer 中以先删除、然后插入执行
可以看到,SQL Server 的内存表主要改善的是查询性能和IO瓶颈。
4. 硬件和软件要求:
●在SQL Server 2014 x64 版中,因为x64版可以直接使用更多的内存空间
●服务器必须有足够的内存,内存优化表不能使用超过最大服务器内存的80%
5. 内存优化表使用和语法
内存优化表也不是可以随便使用的,也有着其限制条件或越发约束。
1) 创建数据库需要有一个内存优化表文件组:
CREATE DATABASE CanwayDemo
ON
PRIMARY(NAME = [hekaton_demo_data],
FILENAME = 'C:\DATA\hekaton_demo_data.mdf', size=500MB)
, FILEGROUP [hekaton_demo_fg] CONTAINS MEMORY_OPTIMIZED_DATA(
NAME = [hekaton_demo_dir],
FILENAME = 'C:\DATA\hekaton_demo_dir')
LOG ON (name = [hekaton_demo_log], Filename='C:\DATA\hekaton_demo_log.ldf', size=500MB)
COLLATE Latin1_General_100_BIN2;
GO
2) 创建表时必须创建一个非空的主键,并且必须建立非聚集的Hash索引和
BUCKET_COUNT参数
Use CanwayDemo
Go
CREATE TABLE Destination
(
col1 INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH
(BUCKET_COUNT = 100000),
col2 INT NOT NULL,
col3 INT NOT NULL
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY =
SCHEMA_AND_DATA)
GO
3) 创建一个本机编译存储过程访问内存优化表
Use CanwayDemo
Go
CREATE PROCEDURE SelectT able_Destination
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'us_english')
SELECT col1, col2, col3 FROM dbo.Destination;
END
GO。