【用友】SQL创建表视图索引存储过程
实验7 索引、存储过程、触发器、关系图等的基本操作

实验7 索引、存储过程、触发器、关系图等的基本操作1实验7 索引、存储过程、触发器、关系图等的基本操作 实验示例1.索引1、创建索引(1)利用向导创建索引启动企业管理器,连接服务器,单击“工具(T)”→“向导(W)…”命令,在弹出的“选择向导”对话框中,展开“数据库”文件夹,如图7-1,双击“创建索引向导”项,打开欢迎对话框,如图7-2,在这个对话框中按先后顺序列出了使用向导创建索引的步骤。
单击“下一步”按钮,展开创建步骤,从图7-3到图7-8。
图7-1 选择索引向导 图7-2 欢迎使用创建索引向导数据库原理与应用实验指导2图7-3 选择数据库和表图7-4 已存在的索引信息图7-5 选择表中的列图7-6 指定索引选项图7-7 正在完成创建索引 图7-8 成功创建索引 (2)在企业管理器中创建索引在企业管理器中创建索引的步骤为:实验7 索引、存储过程、触发器、关系图等的基本操作3 ①在数据库关系图中选择要创建索引的表,右击该表,然后从快捷菜单中选择“索引/键”命令;或为要创建索引的表打开表设计窗口,在表设计窗口上部字段定义区域右击,然后从快捷菜单中选择“索引/键”命令,如图7-9;或在打开表设计窗口时,按工具栏上的属性按钮,都能打开表属性窗口,如图7-10。
图7-9 表设计窗口中的快捷菜单 图7-10 表属性窗口中创建索引/键 ②在图7-10中,选择"新建"命令。
“选定的索引”框显示系统分配给新索引的名称,“索引名”文本框中能修改系统已自动给出的索引名。
③在“列名”下选择要创建索引的列。
可以选择多达16列。
为获得最佳性能,最好只选择一列或两列。
对所选的每一列,可指出索引是按升序还是降序组织列值。
④为索引指定任何其它需要的设置,然后单击“确定”按钮。
当保存表或关系图时,索引即创建在数据库中。
在企业管理器中创建索引还有如下方法:如图7-11,直接在相应表上按鼠标右键→“所有任务”→“管理索引”→出现管理索引对话框,如图7-12,在该对话框上对表索引能进行“新建”、“编辑”、“删除”等一系列管理操作。
创建索引、视图、存储过程及触发器

6.1.2索引的分类
聚簇索引 数据表的物理顺序和索引表的顺序相同,它根据表中的
一列或多列的值排列记录。每一个表只能有一个聚簇 索引,因为一个表的记录只能以一种物理顺序存放, 在通常情况下,使用的都是聚簇索引。 聚簇索引有利于范围搜索,由于聚簇索引的顺序与数据 行存放的物理顺序相同,因此,聚簇索引最适合于范 围搜索,因为相邻的行将被物理地存放在相同或相邻 近的页面上。 创建聚簇索引的几个注意事项: 每张表只能有一个聚簇索引 由于聚簇索引改变表的物理顺序,所以应先建聚簇索
引,后创建非聚簇索引 创建索引所需的空间来自用户数据库,而不是
TEMPDB数据库 主键是聚簇索引的良好候选者
6.1.2索引的分类
索引页
根结点
数据页
6.1.2索引的分类
非聚簇索引
对于非聚簇索引,表的物理顺序与索引顺序不同,即表 的数据并不是按照索引列排序的。索引是有序的,而 表中的数据是无序的。一个表可以同时存在聚簇索引 和非聚簇索引,而且,一个表可以有多个非聚簇索引。 例如对记录网站活动的日志表可以建立一个对日期时 间的聚簇索引和多个对用户名的非聚簇索引。
在一个表的一个或多个列上创建索引时,应考虑以下几点: ① 当在一个表上创建PRIMARY KEY约束或UNIQUE约 束时,SQL Server自动创建唯一性索引。不能在已经创 建PRIMARY KEY约束或UNIQUE约束的列上创建索引。 定义PRIMARY KEY 约束或UNIQUE约束与创建标准索 引相比应是首选的方法。 ② 必须是表的拥有者才能创建索引。 ③ 在一个列上创建索引之前,确定该列是否已经存在 索引。
系部名称 社会科学部 经济管理系
建筑系 基础科学部 传播技系
农林系 机电工程系
sql 索引的建立与使用

sql 索引的建立与使用SQL索引的建立与使用一、引言在数据库中,索引是一种提高查询效率的重要工具。
它可以加速数据的查找和检索过程,减少数据库的I/O操作,提高系统的响应速度。
本文将介绍SQL索引的建立与使用,包括索引的概念、建立索引的方法、索引的使用场景以及索引的优缺点。
二、索引的概念索引是一种特殊的数据结构,它通过存储列值和对应的行指针,可以快速地定位和访问目标数据。
在数据库中,索引通常是在表的某一列或多列上创建的,以提高查询操作的速度。
通过使用索引,数据库可以避免全表扫描,而是直接定位到满足查询条件的数据。
三、建立索引的方法1. 唯一索引:在列上建立唯一索引,可以确保该列的值在表中是唯一的。
在创建唯一索引时,数据库会自动检查索引列的唯一性,并在插入或更新数据时进行验证。
可以使用CREATE UNIQUE INDEX 语句来创建唯一索引。
2. 非唯一索引:在列上建立非唯一索引,可以加速查询操作。
非唯一索引允许重复的值存在,但仍然可以通过索引来快速定位数据。
可以使用CREATE INDEX语句来创建非唯一索引。
3. 聚集索引:在表中的主键列上建立聚集索引,可以按照主键的顺序物理存储数据。
聚集索引可以加速主键查询和范围查询操作,但只能在一个表上建立一个聚集索引。
4. 非聚集索引:在表的非主键列上建立非聚集索引,可以加速非主键查询操作。
非聚集索引通过存储列值和对应的行指针,可以快速定位满足查询条件的数据。
四、索引的使用场景1. 频繁的查询操作:对于经常需要进行查询操作的列,可以建立索引来加速查询速度。
例如,在一个订单表中,经常需要根据订单号进行查询,可以在订单号列上建立索引。
2. 大数据量表的查询:对于包含大量数据的表,建立索引可以显著提高查询效率。
例如,在一个用户表中,如果用户数量非常大,可以在用户名列上建立索引。
3. 关联查询:对于需要进行关联查询的表,建立索引可以加速查询操作。
例如,在一个订单表和商品表的关联查询中,可以在订单号和商品编号列上建立索引。
SQL建表、视图、索引

char(size)
容纳固定长度的字符串(可容纳字母、数字以及特殊字符)。 在括号中规定字符串的长度。
varchar(size) 容纳可变长度的字符串(可容纳字母、数字以及特殊的字符)。 在括号中规定字符串的最大长度。
date(yyyymmdd) 容纳T NULL 约束强制列不接受 NULL 值。 NOT NULL 约束强制字段始终包含值。这意味着,如果不向字段 添加值,就无法插入新记录或者更新记录。
CREATE INDEX PersonIndex ON Person (LastName DESC)
CREATE INDEX PersonIndex ON Person (LastName, FirstName)
ALTER TABLE table_name DROP INDEX index_name
CREATE TABLE Persons( Id_P int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255) )
UNIQUE
UNIQUE 约束唯一标识数据库表中的每条记录。 UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的 保证。
一个表中的 FOREIGN KEY 指向另一个表中的 PRIMARY KEY。
CREATE TABLE Orders( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int, PRIMARY KEY (Id_O), FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) ) CREATE TABLE Orders( Id_O int NOT NULL, OrderNo int NOT NULL, Id_P int, PRIMARY KEY (Id_O), CONSTRAINT fk_PerOrders FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) ) 如果在 "Orders" 表已存在的情况下为 "Id_P" 列创建 FOREIGN KEY 约束,请使用下面的 SQL: ALTER TABLE Orders ADD FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) 如果需要命名 FOREIGN KEY 约束,以及为多个列定义 FOREIGN KEY 约束,请使用下面的 SQL 语法: ALTER TABLE Orders ADD CONSTRAINT fk_PerOrders FOREIGN KEY (Id_P) REFERENCES Persons(Id_P) 撤销 FOREIGN KEY 约束 MySQL: ALTER TABLE Orders DROP FOREIGN KEY fk_PerOrders
SQL创建索引的作用以及如何创建索引

SQL创建索引的作用以及如何创建索引索引是用于加快数据库查询速度的一种数据结构。
它可以帮助数据库系统快速定位到需要的数据记录,减少了数据库的扫描和比较操作,提高了查询效率。
在数据库中,如果没有适当的索引,查询操作可能需要遍历整个表,导致查询效率低下,尤其是在处理大量数据量的情况下。
因此,索引的创建对于提高数据库性能和查询速度非常重要。
索引可以降低查询的时间复杂度,提高数据库的响应速度。
它可以用于加速SELECT、JOIN或WHERE子句等查询操作,还可以提高数据的唯一性约束,避免数据冗余。
另外,对于经常被用到的查询语句,可以通过创建索引来优化查询效率。
在关系型数据库中,创建索引可以通过以下几个步骤实现:1.建表时创建索引:在建表语句中使用CREATEINDEX语句来创建索引。
例如:```CREATE TABLE tableNamecolumn1 datatype,column2 datatype,...CREATE INDEX indexName ON tableName (columnName);```columnName 是要创建索引的列名。
2.修改表时创建索引:通过ALTERTABLE语句来为已有的表增加索引。
例如:```ALTER TABLE tableNameADD INDEX indexName (columnName);```在这里,indexName 是索引的名称,tableName 是要为之添加索引的表名,columnName 是要创建索引的列名。
3.删除索引:通过DROPINDEX语句来删除索引。
```DROP INDEX indexName ON tableName;```在这里,indexName 是要删除的索引的名称,tableName 是要删除索引的表名。
4.多列索引:可以为多列创建联合索引,以更好地满足查询的需要。
```CREATE INDEX indexName ON tableName (column1, column2);```column1 和 column2 是要创建索引的列名。
sql数据库创建表步骤

sql数据库创建表步骤创建表的步骤如下:1. 确定表格的设计:确定表格的名称以及要包含的列和列的数据类型。
考虑列的约束、默认值和索引等。
2. 打开SQL数据库管理工具:使用适当的SQL数据库管理工具,如MySQL Workbench、Microsoft SQL Server Management Studio等打开数据库连接。
3. 创建数据库(可选):如果尚未有数据库存在,你可以使用CREATE DATABASE语句创建一个新的数据库。
例如:CREATE DATABASE 数据库名称;4. 切换到目标数据库:如果已经存在目标数据库,你可以使用USE语句切换到该数据库。
例如:USE 数据库名称;5. 创建表:使用CREATE TABLE语句创建表。
在CREATE TABLE语句中,指定表的名称和列的定义。
例如:```sqlCREATE TABLE 表名 (列1 数据类型列1约束,列2 数据类型列2约束,...);```其中,"表名"是你想要创建的表的名称,"列1"、"列2"等是列的名称,"数据类型"是列的数据类型,"列1约束"、"列2约束"等是可选的列约束,如主键、唯一性、非空约束等。
6. 定义表的列与约束:根据设计需求,在CREATE TABLE语句中为每个列定义数据类型和约束。
例如,下面的示例为一个名为"students"的表定义了四个列:id、name、age和gender。
```sqlCREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(50) NOT NULL,age INT,gender CHAR(1));```7. 执行CREATE TABLE语句:在SQL数据库管理工具中,选中CREATE TABLE 语句,并执行它。
用友SQL培训资料(U8、U9)

引言本专刊主要针对于刚刚加入用友维护队伍、希望快速提高个人面向U8软件维护工作的SQLServer应用能力的人员而编写,特别适用于SQLServer初学者。
注意:本专刊是为SQLServer快速入门而编写,内容简单概括,读者要使自己的SQLServer水平有质的提高,在实际工作中要充分利用SQLServer联机帮助,它是最具权威的参考资料。
本专刊主要内容:第一章概述U8数据库特点、常用的SQL工具、语法格式,以及SQLServer数据库中的一些常用的术语。
第二章和第三章主要介绍SQL的基础、高级应用。
第四章简要介绍事件探查器的使用。
事件探查器是U8维护工作中最为常用的分析工具。
附录内容包括组成数据库对象的概念、SQLSERVER的系统组成以及Transact_SQL小手册,可以作为查询SQLServer信息的快速参考。
目录第一章概述 (4)第一节U8数据库简述 (4)第二节常用的SQL工具简介 (6)第三节数据库中的常用术语和概念 (8)第四节SQL语法格式说明 (9)第二章SQL基础应用 (11)第一节简单的SELECT查询 (12)第二节S ELECT语句中的常用子句及函数 (12)第三节连接(J OIN)语句 (14)第四节数据操作语句 (19)第五节S ELECT子查询语句 (20)第三章SQL高级应用 (23)第一节创建、删除数据库和表 (23)第二节创建视图和索引 (24)第三节创建和执行存储过程、触发器和游标 (26)第四节系统存储过程、系统表 (30)第四章事件探查器 (33)第一节创建跟踪 (33)第二节事件探查器的精确跟踪 (39)第三节实际工作中事件探查器的应用 (40)附录: (42)第一章概述SQL(Structured Query Language,结构化查询语言)是一种现今流行的数据库语言,目前主流的数据库产品都支持这种语言,如常见的Microsoft Access、Microsoft SQLServer、Oracle、Sybase、MySQL等,并且这些数据库产品都不同程度上对标准的SQL进行了扩展,以使SQL应用更为高效。
【用友】SQL创建表视图索引存储过程

SQL内部培训
内容介绍
创建和操作表 创建视图和索引 高级SQL
视图与索引是两个完全不同的对象。但是它们有一点是相同的:它们都与表关联(不能脱离表单独存在)。 尽管每
创建视图和索引
使用视图 你可以对封装的复合查询应用视图。当对一组数据建立视图以后你可以像处理另 外一
个表一样去处理视图。但是在视图中修改数据时要受到一些限制(修改我们不做解 释),
当表(基础表)中的数据改变以后你将会在查询视图时发现相应的改变。
< filespec > ::=
[ PRIMARY ] ( [ NAME = logical_file_name , ] FILENAME = 'os_file_name' [ , SIZE = size ] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ] ) [ ,...n ]
< filegroup > ::= FILEGROUP filegroup_name < filespec > [ ,...n ]
以上就是具体的语法,其中的参数可以参照SQL的帮助。
创建和操作表
对数据库我们还需要了解的一点是:Microsoft® SQL Server使用一组操作系统文件映射数据库。数 据库 中的所有数据和对象(如表、存储过程、触发器和视图)都存储在下列操作系统文件中: 主要
sql存储过程及视图创建实例及语法

SQL Server 存储过程Transact-SQL中的存储过程,非常类似于Java语言中的方法,它可以重复调用。
当存储过程执行一次后,可以将语句缓存中,这样下次执行的时候直接使用缓存中的语句。
这样就可以提高存储过程的性能。
Ø存储过程的概念存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句块要快。
同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担。
1、存储过程的优点A、存储过程允许标准组件式编程存储过程创建后可以在程序中被多次调用执行,而不必重新编写该存储过程的SQL语句。
而且数据库专业人员可以随时对存储过程进行修改,但对应用程序源代码却毫无影响,从而极大的提高了程序的可移植性。
B、存储过程能够实现较快的执行速度如果某一操作包含大量的T-SQL语句代码,分别被多次执行,那么存储过程要比批处理的执行速度快得多。
因为存储过程是预编译的,在首次运行一个存储过程时,查询优化器对其进行分析、优化,并给出最终被存在系统表中的存储计划。
而批处理的T-SQL语句每次运行都需要预编译和优化,所以速度就要慢一些。
C、存储过程减轻网络流量对于同一个针对数据库对象的操作,如果这一操作所涉及到的T-SQL语句被组织成一存储过程,那么当在客户机上调用该存储过程时,网络中传递的只是该调用语句,否则将会是多条SQL语句。
从而减轻了网络流量,降低了网络负载。
D、存储过程可被作为一种安全机制来充分利用系统管理员可以对执行的某一个存储过程进行权限限制,从而能够实现对某些数据访问的限制,避免非授权用户对数据的访问,保证数据的安全。
数据库 视图和索引的创建及使用

实验五视图和索引的创建及使用实验目的:1、理解视图和索引的概念2、学会使用企业管理器和T-SQL语句创建视图和索引3、理解视图和索引的优缺点,掌握视图和索引的管理和维护。
实验内容:一视图1、使用企业管理器建立视图,进入“添加表”对话框,选择表student,在“视图设计器”界面的表选择区中选择所有列选型,在SQL语句区,编辑并执行,查看视图显示结果。
2、保存视图名为view_student.3、建立学生学号、姓名、性别、课程号、成绩的视图v_sc,查看v_sc中的数据。
4、建立学生学号、姓名、出生年份的视图v_age查看V_age中的数据。
5、建立…JSJ‟ 系的学生学号、姓名、性别、年龄的视图v_JSJ6、建立每门课程的平均分的视图v_avggrade二索引1、使用企业管理器为学生表student创建一个以stud_id 为索引关键字的惟一聚簇索引。
2、将上一步所建立的索引名称修改为new_index。
3、将前述所建立的new_index 索引删除。
4、使用T-SQL 语句为课程表Course 创建一个名为Course_Index 的惟一非聚簇索引,索引关键字为教师编号Course_id,降序,填充因子为80%。
5、使用T-SQL 语句将课程表中的Course_Index 删除。
6、为student表创建一个基于“年龄,学号”组合列的非聚集、复合索引cj_xh_index。
7、为lesson_info 创建一个基于“课程号course_id,课程类型course_type” 组合列的惟一、聚集、复合索引kc_lx_index。
实验结果中记录结果,不能省略。
附:建立实验相关数据库与表CREATE DATABASE TESTDBON PRIMARY(NAME='TESTDB',FILENAME='d:\TESTDB.mdf',SIZE=3072KB,MAXSIZE='UNLIMITED',FILEGROWTH=1024KB)LOG ON(NAME='TESTDB_LOG',FILENAME='d:\TESTDB_LOG.ldf',SIZE=1024KB,MAXSIZE=2048GB,FILEGROWTH=10%)COLLATE Chinese_PRC_CI_ASCREATE TABLE Student(Stu_ID CHAR(12) NOT NULL PRIMARY KEY,Stu_Name VARCHAR(50),Stu_Passwd V ARCHAR(50),Ssex CHAR(2),Sage INT,Sdept V ARCHAR(50))CREATE TABLE Course(Course_ID [char](9) NOT NULL,Course_Name [varchar](50) NULL,Course_Credit [int] NULL,Course_Pro_ID [char](9) NULL,Teacher_ID [char](8) NULL,Books_ID [char](12) NULL,)use TESTDB1CREATE TABLE Stu_Course(Stu_ID CHAR(12) NOT NULL,Course_ID CHAR(9) NOT NULL,Term CHAR(6),Score DECIMAL(3,2),Credit INT,CONSTRAINT PK_Stu_Course PRIMARY KEY(Stu_ID,Course_ID))USE [TESTDB]GOINSERT INTO student V ALUES('11012901','杜月梅','147258','女',21,'物理系'); INSERT INTO student V ALUES('11012902','李建丽','258369','女',22,'物理系'); INSERT INTO student V ALUES('11012903','高勇','369789','女',23,'物理系'); INSERT INTO student V ALUES('12023001','王军雅','123456','男',20,'计算机'); INSERT INTO student V ALUES('12023002','王晓玲','456789','女',21,'计算机');INSERT INTO course V ALUES('1','高等数学',6,null,'1','1');INSERT INTO course V ALUES('2','C语言',3,null,'2','2');INSERT INTO course V ALUES('3','数据结构',2,2,'3','3');INSERT INTO Stu_Course V ALUES('11012901','1','1',82,6);INSERT INTO Stu_Course V ALUES('11012902','1','1',90,6); INSERT INTO Stu_Course V ALUES('11012903','1','1',75,6); INSERT INTO Stu_Course V ALUES('12023001','1','1',96,6); INSERT INTO Stu_Course V ALUES('12023002','1','1',90,6); INSERT INTO Stu_Course V ALUES('12023001','2','1',86,3); INSERT INTO Stu_Course V ALUES('12023002','2','1',70,3);。
SQL存储过程、视图

SQL存储过程、视图存储过程:存储过程(stored procedure)有时也称为sproc。
存储过程存储于数据库中⽽不是在单独的⽂件中,有输⼊参数、输出参数以及返回值等。
在数据库中,创建存储过程和创建其他对象的过程⼀样,除了它使⽤的AS关键字外。
存储过程的基本语法如下:CREATE PROCDUER|PROC <sproc name>[<parameter name>[schema.]<data type>[VARYING][=<default value>][OUT [PUT]][,[<parameter name>[schema.]<data type>[VARYING][=<default value>][OUT [PUT]][,...]][WITHRECOMPILE|ENCRYPTION|[EXECUTE AS {CALLER|SELF|OWNER|<'user name'>}][FOR REPLICATION]AS<code>|EXTERNAL NAME <assembly name>.<assembly class>存储过程⽰例⼀:执⾏存储过程⽅法⼀:执⾏存储过程⽅法⼆:上⾯说过,存储过程可以定义返回值。
⽰例:修改存储过程⽰例:利⽤存储过程查找三个表内的信息⽰例:⽰例:⽰例⼆:练习:超市管理系统:表⼀:门店仓库表 MenDian列名:商品编号scode、商品名称sname、商品数量sshu、商品单价sprice、商品进货商sgong表⼆:进货商的表 Gongying列名:进货商的编号gcode、进货商名称gname,进货商联系⼈glian、进货商的电话gtel表三:⼩票表 Xiaopiao列名:⼩票编号pcode、商品名称pname、商品单价pprice、数量pshu、总价pzong、时间ptime要求,写⼀个存储过程,买东西,⾃动添加⼩票进⼊。
sql创建储存过程的语句

sql创建储存过程的语句SQL是一种强大的数据库语言,既可以执行操作,也可以创建存储过程,本文向大家介绍如何使用SQL语句创建储存过程。
什么是储存过程?在SQL中,储存过程是一组预编译SQL语句的集合。
它们可以被存储在数据库中,可用于多次执行相同的操作并返回结果。
储存过程是用于控制数据库访问和数据处理逻辑的一种重要工具。
如何创建储存过程?创建储存过程可以使用以下步骤:1.首先,连接到数据库,并在查询窗口中输入以下语法:CREATE PROCEDURE proc_nameASBEGIN-- SQL语句块END注释:proc_name是您要创建的存储过程的名称。
2. 接下来,在BEGIN和END之间编写SQL语句块。
这个SQL语句块可以包含许多SQL语句。
下面是一个简单的示例:CREATE PROCEDURE spInsertEmployee@EmployeeName VARCHAR(50),@Salary MONEYASBEGININSERT INTO Employee(EmployeeName,Salary) VALUES(@EmployeeName,@Salary)END注释:在此示例中,我们创建一个名为spInsertEmployee的存储过程,它将员工姓名和薪资添加到Employee表中。
3. 编写完存储过程后,可以通过以下命令执行它:EXECUTE proc_name注释:执行存储过程的方法是在查询窗口中输入EXECUTE命令,后面跟着存储过程的名称。
总结:在SQL中,储存过程是一种非常有用的工具。
使用SQL语句创建存储过程是一项简单但功能强大的任务。
创建存储过程需要遵循简单的语法规则,并编写SQL语句块。
使用存储过程可以大大简化数据库维护,让我们更好地控制访问和处理数据的逻辑。
希望这篇文章能够帮助您更好地理解SQL中存储过程的概念并掌握如何创建它们。
视图、索引、存储过程、触发器、游标及事务
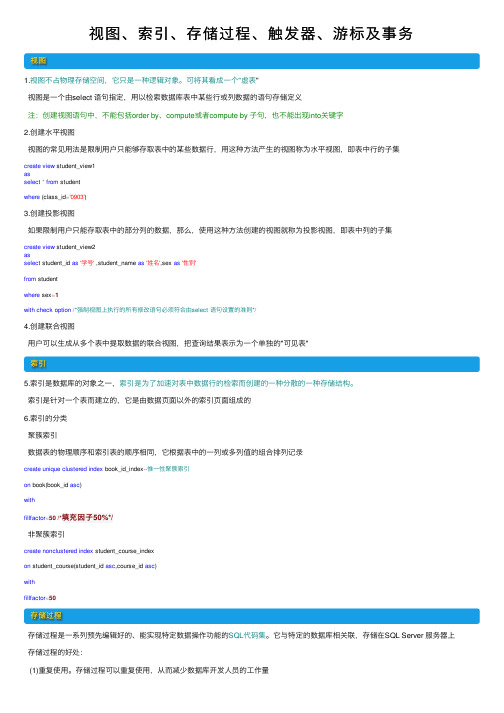
视图、索引、存储过程、触发器、游标及事务视图1.视图不占物理存储空间,它只是⼀种逻辑对象。
可将其看成⼀个"虚表"视图是⼀个由select 语句指定,⽤以检索数据库表中某些⾏或列数据的语句存储定义注:创建视图语句中,不能包括order by、compute或者compute by ⼦句,也不能出现into关键字2.创建⽔平视图视图的常见⽤法是限制⽤户只能够存取表中的某些数据⾏,⽤这种⽅法产⽣的视图称为⽔平视图,即表中⾏的⼦集create view student_view1asselect*from studentwhere (class_id='0903')3.创建投影视图如果限制⽤户只能存取表中的部分列的数据,那么,使⽤这种⽅法创建的视图就称为投影视图,即表中列的⼦集create view student_view2asselect student_id as'学号' ,student_name as'姓名',sex as'性别'from studentwhere sex=1with check option/*强制视图上执⾏的所有修改语句必须符合由select 语句设置的准则*/4.创建联合视图⽤户可以⽣成从多个表中提取数据的联合视图,把查询结果表⽰为⼀个单独的"可见表"索引5.索引是数据库的对象之⼀,索引是为了加速对表中数据⾏的检索⽽创建的⼀种分散的⼀种存储结构。
索引是针对⼀个表⽽建⽴的,它是由数据页⾯以外的索引页⾯组成的6.索引的分类聚簇索引数据表的物理顺序和索引表的顺序相同,它根据表中的⼀列或多列值的组合排列记录create unique clustered index book_id_index--惟⼀性聚簇索引on book(book_id asc)withfillfactor=50 /*填充因⼦50%*/⾮聚簇索引create nonclustered index student_course_indexon student_course(student_id asc,course_id asc)withfillfactor=50存储过程存储过程是⼀系列预先编辑好的、能实现特定数据操作功能的SQL代码集。
sql创建存储过程语句

sql创建存储过程语句SQL(Structured Query Language)是一种用于操作关系型数据库的计算机程序语言。
它可以用于创建表、插入数据、更新数据等操作。
在SQL中,存储过程是一种被预编译的数据库对象,它可以在数据库中被重复使用,大大提高了数据库的执行效率。
本文将介绍如何创建SQL存储过程语句。
创建存储过程的步骤:1.打开SQL Server Management Studio,连接到需要创建存储过程的数据库。
2.在对象资源管理器中,右键单击“存储过程”文件夹,选择“新建存储过程”。
3.输入存储过程的名称,并在编辑器中撰写代码。
4.在SQL Server Management Studio中运行存储过程。
在查询窗口中输入“EXEC 存储过程名称”命令来运行存储过程。
存储过程的语法:CREATE PROCEDURE 存储过程名称(参数1 数据类型, 参数2 数据类型) AS BEGIN 存储过程代码 END 在创建存储过程时,可以指定参数。
参数是一种用于向存储过程传递外部值的机制。
通过指定参数,可以使存储过程变得更加通用和灵活。
例如,可以定义一个存储过程来根据日期范围检索订单:CREATE PROCEDURE GetOrdersByDateRange( @StartDate DATETIME, @EndDate DATETIME ) AS BEGIN SELECT * FROM Orders WHERE OrderDate BETWEEN@StartDate AND @EndDate END上面的存储过程定义了两个参数:@StartDate和@EndDate。
这两个参数的数据类型均为DATETIME。
在存储过程代码中,可以使用这两个参数来限制SELECT语句的结果集。
存储过程的优势:1.提高执行效率。
由于存储过程是被预编译的,因此每次调用存储过程时,都可以直接执行编译后的代码,而无需重新编译。
sql 中使用存储过程

sql 中使用存储过程在SQL中,存储过程是一组预编译的SQL语句,它们被存储在数据库中,可以在需要时被多次调用。
存储过程可以帮助简化复杂的数据库操作,并提高数据库的性能和安全性。
下面我将从多个角度来介绍SQL中使用存储过程的相关内容。
首先,我们可以讨论存储过程的创建和语法。
在SQL中,创建存储过程的语法通常如下:sql.CREATE PROCEDURE procedure_name.AS.BEGIN.-在这里编写存储过程的SQL语句。
END.在这个语法中,`CREATE PROCEDURE`关键字用于创建存储过程,`procedure_name`是存储过程的名称,`AS`关键字用于指示存储过程的开始,`BEGIN`和`END`之间的部分是存储过程的实际SQL代码。
其次,我们可以讨论存储过程的参数和返回值。
存储过程可以接受输入参数,并且可以返回一个或多个输出参数。
在创建存储过程时,可以指定参数的名称、数据类型和方向(输入、输出或输入/输出)。
下面是一个简单的存储过程,它接受一个输入参数并返回一个输出参数的示例:sql.CREATE PROCEDURE get_employee_name.@employee_id INT,。
@employee_name NVARCHAR(50) OUTPUT.AS.BEGIN.SELECT @employee_name = name.FROM employees.WHERE id = @employee_id.END.在这个示例中,`@employee_id`是输入参数,`@employee_name`是输出参数。
此外,我们还可以讨论存储过程的优点。
存储过程可以提高数据库的性能,因为它们在数据库中预编译并存储,减少了每次执行相同操作时的解析和编译时间。
此外,存储过程还可以提高数据库的安全性,因为用户只能通过存储过程执行特定的操作,而无法直接访问数据库表。
最后,我们还可以讨论存储过程的用途。
MySQL高级——索引、视图、存储过程和函数、触发器

MySQL⾼级——索引、视图、存储过程和函数、触发器零、前导知识0.1 SQL语⾔的分类SQL语⾔共分为四⼤类:数据查询语⾔DQL,数据操纵语⾔DML,数据定义语⾔DDL,数据控制语⾔DCL。
1. 数据查询语⾔DQL数据查询语⾔DQL基本结构是由SELECT⼦句,FROM⼦句,WHERE⼦句组成的查询块:SELECT <字段名表>FROM <表或视图名>WHERE <查询条件>2 .数据操纵语⾔DML数据操纵语⾔DML主要有三种形式:1) 插⼊:INSERT2) 更新:UPDATE3) 删除:DELETE3. 数据定义语⾔DDL数据定义语⾔DDL⽤来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:CREATE TABLE / VIEW / INDEX / SYN / CLUSTER| 表视图索引同义词簇。
DDL操作是隐性提交的!不能rollback4. 数据控制语⾔DCL数据控制语⾔DCL⽤来授予或回收访问数据库的某种特权,并控制数据库操纵事务发⽣的时间及效果,对数据库实⾏监视等。
如:1) GRANT:授权。
2) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某⼀点。
回滚---ROLLBACK回滚命令使数据库状态回到上次最后提交的状态。
其格式为:SQL>ROLLBACK;3) COMMIT [WORK]:提交。
在数据库的插⼊、删除和修改操作时,只有当事务在提交到数据库时才算完成。
在事务提交前,只有操作数据库的这个⼈才能有权看到所做的事情,别⼈只有在最后提交完成后才可以看到。
提交数据有三种类型:显式提交、隐式提交及⾃动提交。
下⾯分别说明这三种类型。
(1) 显式提交⽤COMMIT命令直接完成的提交为显式提交。
其格式为:SQL>COMMIT;(2) 隐式提交⽤SQL命令间接完成的提交为隐式提交。
这些命令是:ALTER,AUDIT,COMMENT,CONNECT,CREATE,DISCONNECT,DROP,EXIT,GRANT,NOAUDIT,QUIT,REVOKE,RENAME。
SQL如何创建存储过程

SQL如何创建存储过程谢⼤哥USE CMS----Use 是跳转到哪个数据库,对这个数据库进⾏操作。
GO----GO向 SQL Server 实⽤⼯具发出⼀批 Transact-SQL 语句结束的信号,相当于提交上⾯的SQL语句。
----GO是把t-sql语句分批次执⾏。
(⼀步成功了才会执⾏下⼀步,即⼀步⼀个GO)/****** Object: StoredProcedure [dbo].[PROC_four_five_hr] Script Date: 07/30/2018 13:44:55 ******/----这⼀段是介绍本存储过程名字和创建时间----/* */ 是注释掉很多⾏内容的符号----object 对象的意思----storeprocedure 存储过程的意思----dbo 是每个数据库的默认⽤户,具有所有者权限----dbo后⾯是存储过程的名称----script date 脚本创建时间SET ANSI_NULLS ONGO----SET QUOTED_IDENTIFIER ONGO----/*⾸先准备数据,测试存储过程use ssqadm;--创建测试books表create table books_test (book_id int identity(1,1) primary key,book_name varchar(20),book_price float,book_auth varchar(10));--插⼊测试数据insert into books_test(book_name,book_price,book_auth)values('论语',25.6,'孔⼦'),('天龙⼋部',25.6,'⾦庸'),('雪⼭飞狐',32.7,'⾦庸'),('平凡的世界',35.8,'路遥'),('史记',54.8,'司马迁');select * from books_test;*/--1.创建⽆参存储过程if (exists (select * from sys.objects where name = 'getAllBooks'))drop proc getAllBooksgocreate procedure getAllBooksasbeginselect * from books_test;--调⽤,执⾏存储过程exec getAllBooks;endgo--2、修改存储过程alter procedure getallbooksasselect book_name from books_test;--3、删除存储过程drop procedure getallbooks;go--4、修改存储过程的名称sp_rename getallbooks,proc_get_allbooks;goexec proc_get_allbooks;go--5、创建带参数的存储过程use ssqadmgoif (exists (select * from sys.objects where name = 'searchbooks'))drop proc searchbooks-- exec searchbooks 1;--执⾏存储searchbooks得到如下结果:gocreate procedure searchbooks (@bookid int)--括号⾥⾯是asbegindeclare @book_id int;----定义⼀个标量变量,只是保证存储过程的完整性,在本存储是多此⼀举的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
我们可以在以下系统表中找到数据库对应文件的信息: MASTER库中的sysaltfiles表,记载了所有该服务器上的数据库对应的文件信息; 每个数据库中的sysfiles、sysfiles1记载了自身的文件信息,其中sysfiles表中的 信息较详细;
但是知道在这些鼠标操作的背后数据库是如何响应的对我们来说并不是什么坏处。
CREATE DATABASE database_name:几乎所有的流行了功能强大的关系型数据库系统 都支持它,SQLSERVER也一样。
创建和操作表
CREATE DATABASE
创建一个新数据库及存储该数据库的文件,或从先前创建的数据库的文件中附加数据库。
当然,我们也可以图形化的查看这些信息,我们可以在企业管理器里用鼠标右键“属性”来查看:
创建和操作表
建立关键字段 在接下来的数据库设计工作中,最主要的目标就是建立你的表的结构。
表最基本的内容就是字段。没有字段就没有表,一个表里至少要有一个字段。
对于关系数据库,表的结构主要包括主关键字和外关键字。
其中主关键字用于完成下列目标: 保证表中的第一条记录都是唯一的(没有一条记录的内容完全与另一条相同,至少主键
该文件包含数据库的启动信息,并用于存储数据。每个数据库都有一个主要数据文件。
次要 这些文件含有不能置于主要数据文件中的所有数据。如果主文件可以包含数据库中的所有数
据,那么数据库就不需要次要数据文件。有些数据库可能足够大故需要多个次要数据文件,或使用位 于不同磁盘驱动器上的辅助文件将数据扩展到多个磁盘。
和创建数据库一样,我们也可以利用图形界面工具(如企业管理器来创建),但理解其具体的操作并不是一件坏事。
创建表的最基本语法(详细的语法见帮助)就是 CREATE TABLE table_name (
field1 datatype [ NOT NULL ], field2 datatype [ NOT NULL ], field3 datatype [ NOT NULL ], 。。。。 )
外键 (FK) 是用于建立和加强两个表数据之间的链接的一列或多列。
通过将保存表中主键值的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表 的外 键。
注意:一个外键对应的另外一个表的对应字段必须是另外一个表的主键。
FOREIGN KEY 约束并不仅仅只可以与另一表的 PRIMARY KEY 约束相链接,它还可以定义为引用另一表的 UNIQUE 约束。FOREIGN KEY 约束不允许空值,但是,如果任何组合 FOREIGN KEY 约束的列包含空值,则将跳过 FOREIGN KEY 约束的校验。
不能相 同);
对于一个特定的记录,它的所有的列都是必须的。列的内容不应出现重复;
在第二个目标中如果列的内容在表中从头至尾都没有重复,那它就可以是主关键字。
一个表里只能有一个主键,但是一个主键可以由多个字段构成。
创建和操作表
外关键字则是在自己的关系中不唯一标识记录,但在其它关系中可用作对匹配字段链接的一种 关键 字。
< filegroup > ::= FILEGROUP filegroup_name < filespec > [ ,...n ]
以上就是具体的语法,其中的参数可以参照SQL的帮助。
创建和操作表
对数据库我们还需要了解的一点是:Microsoft® SQL Server使用一组操作系统文件映射数据库。数 据库 中的所有数据和对象(如表、存储过程、触发器和视图)都存储在下列操作系统文件中: 主要
SQL内部培训
内容介绍
创建和操作表 创建视图和索引 高级SQL
创建和操作表
• CREATE DATABASE 语句
在任何数据库项目中管理数据的第一步工作就是建立数据库。
虽然我们今天讲的是创建和操作表,但是没有库也就没有表,所以我们还是先简单的 介绍一下创建库。
根据你的要求和你的数据库管理系统的情况,这个工作可以很简单也可以很复杂。 许多现代的数据库系统都提供了图形工具使你可以通过按鼠标按键来完成数据库的建立 工作。这对于节省时间是相当有益处的。
语法 CREATE DATABASE database_name
[ ON [ < filespec > [ ,...n ] ] [ , < filegroup > [ ,...n ] ]
] [ LOG ON { < filespec > [ ,...n ] } ] [ COLLATE collation_name ] [ FOR LOAD | FOR ATTACH ]
我们来看一个简单的例子,如下:
CREATE TABLE BILLS
(
NAME
பைடு நூலகம்
CHAR(30),
AMOUNT
INT,
ACCOUNT_ID INT
)
分析 该语句创建了一个名字叫BILLS的表,在BILLS 表中有三个字段NAME,ACCOUNT和ACCOUNT_ID。
其中NAME 字段为字符类型可以存储长度30 的字符串,而AMOUNT和AMOUNT_ID 则只参存储整数。
也许你会把外键和连接混淆,我们在做查询的时候,往往也会利用外键字段来在两表间建立连接关系,注意 外键 只是一中数据库里的约束,它要求该字段的值要么为另外一个表中存在的值,要么为NULL(该列允许NULL的情 况 下)。
个人建议:任何需要在连接中使用到的字段都应该加上外键约束。
创建和操作表
CREATE TABLE 创建新表。
创建和操作表
ALTER TABLE 语句 没有道理为每件事对你的数据库进行多次的设计。但又确实需要对数据库和应用程序进行改动。
< filespec > ::=
[ PRIMARY ] ( [ NAME = logical_file_name , ] FILENAME = 'os_file_name' [ , SIZE = size ] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ] ) [ ,...n ]