根据url获取网站HTML内容
c#根据url获取网站内容

/// <summary>///根据url获取网站html内容/// </summary>/// <param name="url">网址</param>/// <returns>获取网站html内容</returns>public string GetHtmlContentByUrl(string url, out string msg){var htmlContent = string.Empty;try{var httpWebRequest = (HttpWebRequest)WebRequest.Create(url);httpWebRequest.Timeout = int.Parse(httpRequesttsdbTimeout);var httpWebResponse =(HttpWebResponse)httpWebRequest.GetResponse();var stream = httpWebResponse.GetResponseStream();if (stream != null){var streamReader = new StreamReader(stream,System.Text.Encoding.UTF8);htmlContent = streamReader.ReadToEnd();streamReader.Close();streamReader.Dispose();stream.Close();stream.Dispose();}httpWebResponse.Close();msg = "";return htmlContent;}catch (Exception ex){msg = "失败:" + ex.Message;return "";}}C#.Net 根据URL获取数据的方法(xml格式)第一种:string url = "";//请修改成实际路径,要确保该地址返回的是xml格式的字符串XmlDocument xmlDoc = new XmlDocument();xmlDoc.Load(url);第二种:string url = "";//请修改成实际路径,要确保该地址返回的是xml格式的字符串XmlDocument xmlDoc = new XmlDocument();WebRequest req = WebRequest.Create(url); WebResponse res = req.GetResponse();Stream receiveStream = res.GetResponseStream(); xmlDoc.Load(receiveStream);。
URL获取方法范文

URL获取方法范文在网络中,URL(Uniform Resource Locator)是一种用来唯一标识网络资源的字符串。
它可以用来定位和访问网络上的各种资源,如网页、图片、文件等。
获取URL是指通过其中一种方式获取和解析URL地址的操作。
本文将介绍几种获取URL的方法。
一、从浏览器地址栏获取URL最常见的获取URL的方法就是从浏览器的地址栏中复制URL地址。
当我们访问网页时,浏览器会将网页的URL显示在地址栏中,我们只需要复制地址栏中的URL即可。
二、从网页源代码获取URL有时我们想获取网页中一些资源的URL,可以通过查看网页源代码来获取。
在浏览器中,我们可以通过右键点击网页,选择“查看页面源代码”或者“检查元素”选项来打开开发者工具,然后在源代码中查找相应资源的URL。
三、使用网络抓包工具获取URL网络抓包工具可以用来监控和捕获网络数据包,并可以提取其中的URL地址。
常用的网络抓包工具包括Fiddler、Wireshark等。
这些工具可以在电脑上安装并运行,当我们访问网络资源时,它们会捕获到相应的数据包,然后可以在工具中查看和提取其中的URL地址。
四、使用编程语言获取URL我们可以使用编程语言来编写程序,通过程序来获取URL地址。
不同的编程语言提供了不同的方法和库来进行URL的获取和解析。
下面以Python语言为例,介绍如何使用编程语言获取URL。
Python提供了urllib库来处理URL相关的操作。
我们可以使用urllib库中的urlopen(函数来打开一个URL链接,并获取相应的内容。
以下是一个使用Python获取URL的示例代码:```pythonimport urllib.requestresponse = urllib.request.urlopen(url)#获取URL的内容content = response.read(.decodeprint(content)```以上代码中,首先我们导入了urllib.request库,然后指定需要获取的URL地址,并使用urlopen(函数打开URL链接,得到一个response 对象。
从url获取参数并超链接的方法

从url获取参数并超链接的方法在Web开发中,获取URL中的参数并在页面中创建超链接是一项常见的需求。
以下将详细介绍如何从URL中获取参数,并利用这些参数创建超链接的方法。
### 从URL获取参数在网页中获取URL的参数通常可以通过JavaScript来实现,以下是几种常用的方法:1.**使用JavaScript自带的URL对象**```javascript// 假设当前URL为:?name=JohnDoe&age=30const urlParams = newURLSearchParams(window.location.search);const name = urlParams.get("name"); // 返回"JohnDoe"const age = urlParams.get("age"); // 返回"30"```2.**传统方式解析查询字符串**```javascriptfunction getQueryVariable(variable) {var query = window.location.search.substring(1);var vars = query.split("&");for (var i=0;i<vars.length;i++) {var pair = vars[i].split("=");if(pair[0] == variable){return pair[1];}}return(false);}// 使用方法const name = getQueryVariable("name"); // 返回"JohnDoe"const age = getQueryVariable("age"); // 返回"30"```### 创建超链接一旦获取了URL中的参数,我们就可以使用这些参数来动态创建超链接。
url 查询或条件

URL查询或条件什么是URL查询?URL查询是指在一个URL(Uniform Resource Locator,统一资源定位符)中附加的参数或条件,用于向服务器请求特定的信息。
URL查询通常以问号(?)开头,后面跟着一个或多个键值对,每个键值对之间使用与号(&)分隔。
URL查询的作用是向服务器传递额外的信息,以便服务器能够根据这些信息返回特定的结果。
通过使用URL查询,我们可以实现在网页中进行搜索、过滤、排序等操作。
URL查询的语法URL查询的语法如下所示:其中,`是URL的基本地址,?` 后面是查询参数,每个参数由键和值组成,键和值之间使用等号(=)连接,多个参数之间使用与号(&)分隔。
例如,下面是一个使用URL查询的例子:在这个例子中,`是基本地址,q=keyword&page=1&sort=desc是查询参数。
其中,q 是键,keyword是值,page是键,1是值,sort是键,desc` 是值。
URL查询的用途URL查询在Web开发中有着广泛的应用。
以下是一些常见的用途:1. 搜索功能URL查询常用于实现搜索功能。
通过在URL查询中传递搜索关键词,可以将用户输入的关键词传递给服务器,服务器根据关键词进行搜索,并返回相关的结果。
例如,下面是一个搜索电影的URL查询的例子:在这个例子中,keyword参数用于指定搜索关键词,page参数用于指定返回结果的页数。
2. 过滤和排序URL查询还可用于过滤和排序结果。
通过在URL查询中传递过滤条件和排序方式,可以告诉服务器返回特定条件下的结果,并按照指定的方式进行排序。
例如,下面是一个按照价格从低到高排序的URL查询的例子:在这个例子中,category参数用于指定产品的类别,sort参数用于指定排序方式。
3. 分页URL查询还可用于分页功能。
通过在URL查询中传递页码参数,可以告诉服务器返回指定页码的结果,实现分页浏览。
html获取参数的几种方式

html获取参数的几种方式在HTML中,获取参数通常指的是从URL的查询字符串中获取参数。
这通常在使用GET请求时发生,参数被附加到URL的末尾。
以下是两种常见的方法来获取这些参数:使用正则表达式(正则法):通过编写一个正则表达式来解析URL的查询字符串,并提取出所需的参数和其对应的值。
这种方法相对复杂,需要对正则表达式有一定的了解。
以下是一个使用JavaScript和正则表达式来获取参数的示例:javascript复制代码function getQueryString(name) {var reg = new RegExp('(^|&)' + name + '=([^&]*)(&|$)', 'i');var r = window.location.search.substr(1).match(reg);if (r != null) {return unescape(r[2]);}return null;}在这个示例中,getQueryString函数接受一个参数名(name),并使用正则表达式来查找URL查询字符串中与该参数名匹配的参数。
如果找到了匹配的参数,它将返回参数的值;否则返回null。
使用split拆分法:另一种获取参数的方法是使用字符串的split函数来拆分查询字符串,并提取出参数和其对应的值。
这种方法相对简单,但可能不适用于包含特殊字符的参数值。
以下是一个使用JavaScript和split 函数来获取参数的示例:javascript复制代码function getQueryVariable(variable) {var query = window.location.search.substring(1);var vars = query.split('&');for (var i = 0; i < vars.length; i++) {var pair = vars[i].split('=');if (pair[0] === variable) {return decodeURIComponent(pair[1].replace(/\+/g, '%20'));}}return null;}在这个示例中,getQueryVariable函数接受一个变量名(variable),并使用split函数将查询字符串拆分为参数对。
网络爬虫技术
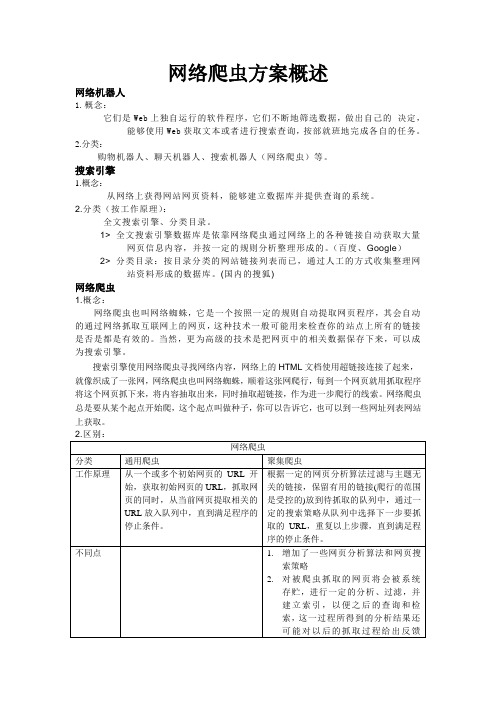
网络爬虫方案概述网络机器人1.概念:它们是Web上独自运行的软件程序,它们不断地筛选数据,做出自己的决定,能够使用Web获取文本或者进行搜索查询,按部就班地完成各自的任务。
2.分类:购物机器人、聊天机器人、搜索机器人(网络爬虫)等。
搜索引擎1.概念:从网络上获得网站网页资料,能够建立数据库并提供查询的系统。
2.分类(按工作原理):全文搜索引擎、分类目录。
1> 全文搜索引擎数据库是依靠网络爬虫通过网络上的各种链接自动获取大量网页信息内容,并按一定的规则分析整理形成的。
(百度、Google)2> 分类目录:按目录分类的网站链接列表而已,通过人工的方式收集整理网站资料形成的数据库。
(国内的搜狐)网络爬虫1.概念:网络爬虫也叫网络蜘蛛,它是一个按照一定的规则自动提取网页程序,其会自动的通过网络抓取互联网上的网页,这种技术一般可能用来检查你的站点上所有的链接是否是都是有效的。
当然,更为高级的技术是把网页中的相关数据保存下来,可以成为搜索引擎。
搜索引擎使用网络爬虫寻找网络内容,网络上的HTML文档使用超链接连接了起来,就像织成了一张网,网络爬虫也叫网络蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序将这个网页抓下来,将内容抽取出来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫总是要从某个起点开始爬,这个起点叫做种子,你可以告诉它,也可以到一些网址列表网站上获取。
现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。
根据种子样本获取方式可分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;(3)通过用户行为确定的抓取目标样例,分为:a) 用户浏览过程中显示标注的抓取样本;b) 通过用户日志挖掘得到访问模式及相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
获取url后面的内容

获取url后⾯的内容⼀、获取url内容//设置或获取对象指定的⽂件名或路径。
alert(window.location.pathname);//设置或获取整个 URL 为字符串。
alert(window.location.href);//设置或获取与 URL 关联的端⼝号码。
alert(window.location.port);//设置或获取 URL 的协议部分。
alert(window.location.protocol);//设置或获取 href 属性中在井号“#”后⾯的分段。
alert(window.location.hash);//设置或获取 location 或 URL 的 hostname 和 port 号码。
alert(window.location.host);//设置或获取 href 属性中跟在问号后⾯的部分。
alert(window.location.search);⼆、获取url=后⾯的内容(只有⼀个参数)let url = window.location.search;let neirong = url.substring(url.indexOf('=')+1, url.length);三、获取url后⾯的参数(有多个参数)把参数转成对象// console.log(location.search)//http://127.0.0.1:5500/into.html?userName=111&password=222333&submit=%E6%8F%90%E4%BA%A4 // 把问号去掉let removeMark=location.search.substr(1)//userName=111&password=222333&submit=%E6%8F%90%E4%BA%A4// console.log(removeMark)// 分割& 得到每组数据let group=removeMark.split('&')//["userName=111", "password=222333", "submit=%E6%8F%90%E4%BA%A4"]// console.log(group)let list=[]//最终得到的⾥卖弄是对象的数组数据// ⽤map把每组数据变成对象let data=group.map((groupItem,groupIndex)=>{// 获取等号的下标let eq=groupItem.indexOf('=')// console.log(eq)// 获取键值对的键和值let pre=groupItem.slice(0,eq)let back=groupItem.slice(eq+1)// console.log(pre,back)// 拼接成对象let obj={}obj[pre]=backlist.push(obj)})console.log(list)//) [{userName: "111"},{password: "222333"},{submit: "%E6%8F%90%E4%BA%A4"}]//得到url的值for(var i=0;i<list.length;i++){list[i].password&&console.log(list[i].password)}。
网络爬虫的概念及其工作流程

网络爬虫的概念及其工作流程在当今数字化时代,信息获取变得愈发便捷和快速,网络爬虫因此而应运而生。
网络爬虫是一种能够自动浏览互联网页面并提取特定信息的程序,也被称为网络蜘蛛或网络机器人。
这种技术被广泛运用在搜索引擎、数据挖掘、内容聚合等领域。
网络爬虫的概念网络爬虫作为一种自动化工具,通过不停地浏览网页,访问链接,抓取所需信息,实现对网页内容的自动化提取。
它们模拟人类对网页的浏览操作,从而获取数据,进行分析和处理。
网络爬虫的工作原理是通过编程实现自动化访问网页并提取其中的信息。
网络爬虫的工作流程1.种子URL获取:爬虫首先从一个或多个种子URL开始访问网页,然后根据这些页面中的链接继续访问其他页面。
2.网页下载:爬虫下载网页的方式类似于浏览器,它们发送HTTP请求来获取页面内容,并将其保存成文本格式。
3.HTML解析:爬虫接收到下载的网页后,需要解析HTML代码,提取出其中的文本信息和链接。
4.URL管理:爬虫将从当前页面提取到的URL添加到待访问的URL队列中,并定期选择下一个URL进行访问。
5.页面处理:爬虫对每个下载的页面进行处理,提取出所需的信息,如文本、图片、链接等。
6.数据存储:爬虫将提取到的数据保存到本地文件或数据库中,以备后续分析和处理。
7.去重和更新:在不断访问页面的过程中,爬虫需要进行去重处理,避免重复抓取同一页面;同时也需要定期更新抓取到的页面,获取最新信息。
8.反爬策略:爬虫在访问页面时需要注意网站的反爬虫机制,避免被封锁IP或反爬虫验证。
总的来说,网络爬虫通过以上流程不断地访问、解析、提取信息,实现对网页内容的自动化抓取。
它们在实现信息检索、数据收集、网站更新等方面发挥着重要作用。
网络爬虫的工作流程复杂而精密,需要兼顾速度和准确性,同时遵守网络道德和法律规定,否则可能会遭到封禁和法律制裁。
因此,在使用网络爬虫时,必须遵循相关规定,保证合法使用并遵循爬虫道德准则。
url的解释原理

url的解释原理
在计算机网络中,URL(统一资源定位符)是用于标识和定位互联网上的资源
的一种标识方式。
通过URL,我们可以快速准确地定位到特定的网页、文件或其
他资源。
URL的解释原理主要包括以下几个部分。
首先是方案,它表示要访问资源时使用的协议或方案,例如http://表示使用HTTP协议。
接下来是网络位置,指示了资
源所在的服务器或域名。
然后是路径,表示资源在服务器上的具体位置或目录结构。
URL还可以包含其他组成部分,如端口号、查询参数和片段标识符。
端口号用于指定服务器上的特定服务端口,查询参数可以用于向服务器传递额外的数据,片段标识符用于定位到页面中的特定位置。
当我们在浏览器地址栏中输入一个URL时,浏览器会按照以上原理解析该URL。
首先,浏览器会根据方案来确定使用哪种协议进行通信。
然后,浏览器会解析网络位置,找到对应的服务器或域名。
接着,浏览器会沿着路径查找资源所在的目录或文件。
如果URL中还包含端口号、查询参数或片段标识符,浏览器也会进
行相应的解析和处理。
URL的解释原理使得我们能够方便地访问互联网上的各种资源。
通过准确解析URL,我们可以在浏览器中打开网页、下载文件、发送请求等。
URL的简洁明了
的结构使得我们能够轻松地在互联网上进行各种操作,享受丰富的在线资源。
网络爬虫基本原理

网络爬虫基本原理(总9页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--网络爬虫基本原理网络爬虫根据需求的不同分为不同种类:1.一种是爬取网页链接,通过url链接得到这个html页面中指定的链接,把这些链接存储起来,再依次以这些链接为源,再次爬取链接指向html页面中的链接……如此层层递归下去,常用的方法是广度优先或者深度优先,根据爬取层次需求不同而选择不同的方法达到最优效果,爬虫的效率优化是一个关键。
搜索引擎的第一个步骤就是通过爬虫得到需要索引的链接或数据,存放于数据库,然后对这些数据建立索引,然后定义查询语句,解析查询语句并利用检索器对数据库里的数据进行检索。
2.一种是爬取数据信息,如文本信息、图片信息等,有时需要做数据分析,通过某种手段来获取数据样本以供后续分析,常用的方法是爬虫获取指定数据样本或利用现有的公共数据库。
本文的微博爬虫和新闻数据爬取都属于第二种类,根据自定义搜索关键字爬取微博信息数据。
3.对于网络爬虫原理,其实并不复杂。
基本思路是:由关键字指定的url把所有相关的html页面全抓下来(html即为字符串),然后解析html文本(通常是正则表达式或者现成工具包如jsoup),提取微博文本信息,然后把文本信息存储起来。
重点在于对html页面源码结构的分析,不同的html需要不同的解析方法;还有就是长时间爬取可能对IP有影响,有时需要获取代理IP,甚至需要伪装浏览器爬取。
(主要是针对像新浪等这些具有反扒功能的网站,新闻网站一般不会有这样的情况)。
对于微博,通常情况下是必须登录才能看到微博信息数据(比如腾讯微博),但是有的微博有搜索机制,在非登录的情况下可以直接通过搜索话题来查找相关信息(如新浪微博、网易微博)。
考虑到某些反爬虫机制,如果一个账号总是爬取信息可能会有些影响(比如被封号),所以本文采用的爬虫都是非登录、直接进入微博搜索页面爬取。
python网页爬虫系列(1):读取网页html代码

python网页爬虫系列(1):读取网页html代码如何不通过浏览器的帮助来格式化和理解数据?中国金融交流联盟cnfcu首先介绍向网络服务器发送GET请求以获得具体网页,再从网页中读取HTML内容,最后做一些简单的信息提取,将我们要寻找的内容分离出来。
网络浏览器是一个非常有用的应用,它创建信息的数据包,发送它们,然后把你获取的数据解释成漂亮的图像、声音、视频和文字。
但是,网络浏览器就是代码,而代码是可以分解的,可以分解成许多基本组件,可重写、重用,以及做成我们想要的任何东西。
网络浏览器可以让服务器发送一些数据,到那些对接无线(或有线)网络接口的应用上,但是许多语言也都有实现这些功能的库文件。
本文主要介绍利用python读取网页html代码的几种常见情况:1.比较简单的类型,直接利用urllib2.urlopen()便能完成的情况;2.需要加入请求头才能读取网页html代码的情况;3.需要加载JavaScript文件才能完全读取网页html 代码的情况。
注:1.本文会附上相应情况的代码,但是部分代码需要安装python第三方库才能使用,具体第三方库的安装方法也会附上网页链接;2.本文代码的运行是基于python(x,y)2.7(Win7系统),相应的python(x,情况一:import urllib2html=urllib2.urlopen("/pages/page1.html") print html.read()这个例子将会输出/pages/page1.html这个网页的全部html文件,更准确的说,会输出在域名为的服务器上<网络应用根地址>/pages文件夹里的HTML文件 page.html的源代码情况二:如果我们还是安装情况一的方式来读取"/web/gspt/newGSPTDetail3.aspx?ID=abf6f9e2da6149818ace8267b5ae95a4”该网页的html代码的话,我们会发现是读取不出来的,这时我们需要加上请求头伪装一下就可以了。
]网络爬虫:抓取网页的含义和URL基本构成
![]网络爬虫:抓取网页的含义和URL基本构成](https://img.taocdn.com/s3/m/c7d068621711cc7931b716e4.png)
[Python]网络爬虫(一):抓取网页的含义和URL基本构成一、网络爬虫的定义网络爬虫,即Web Spider,是一个很形象的名字。
把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。
网络蜘蛛是通过网页的链接地址来寻找网页的。
从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。
这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序。
网络爬虫的基本操作是抓取网页。
那么如何才能随心所欲地获得自己想要的页面?我们先从URL开始。
二、浏览网页的过程抓取网页的过程其实和读者平时使用IE浏览器浏览网页的道理是一样的。
比如说你在浏览器的地址栏中输入这个地址。
打开网页的过程其实就是浏览器作为一个浏览的“客户端”,向服务器端发送了一次请求,把服务器端的文件“抓”到本地,再进行解释、展现。
HTML是一种标记语言,用标签标记内容并加以解析和区分。
浏览器的功能是将获取到的HTML代码进行解析,然后将原始的代码转变成我们直接看到的网站页面。
三、URI和URL的概念和举例简单的来讲,URL就是在浏览器端输入的这个字符串。
在理解URL之前,首先要理解URI的概念。
什么是URI?Web上每种可用的资源,如HTML文档、图像、视频片段、程序等都由一个通用资源标志符(Universal Resource Identifier,URI)进行定位。
URI通常由三部分组成:①访问资源的命名机制;②存放资源的主机名;③资源自身的名称,由路径表示。
如下面的URI:/myhtml/html1223/我们可以这样解释它:①这是一个可以通过HTTP协议访问的资源,②位于主机上,③通过路径“/html/html40”访问。
四、URL的理解和举例URL是URI的一个子集。
网络爬虫技术

网络爬虫技术一、什么是网络爬虫技术?网络爬虫技术(Web Crawling)是一种自动化的数据采集技术,通过模拟人工浏览网页的方式,自动访问并抓取互联网上的数据并保存。
网络爬虫技术是一种基于Web的信息获取方法,是搜索引擎、数据挖掘和商业情报等领域中不可缺少的技术手段。
网络爬虫主要通过对网页的URL进行发现与解析,在不断地抓取、解析、存储数据的过程中实现对互联网上信息的快速获取和持续监控。
根据获取的数据不同,网络爬虫技术又可以分为通用型和特定型两种。
通用型爬虫是一种全网爬取的技术,能够抓取互联网上所有公开的网页信息,而特定型爬虫则是针对特定的网站或者领域进行数据采集,获取具有指定目标和意义的信息。
网络爬虫技术的应用范围非常广泛,例如搜索引擎、电子商务、社交网络、科学研究、金融预测、舆情监测等领域都能够运用网络爬虫技术进行数据采集和分析。
二、网络爬虫技术的原理网络爬虫技术的原理主要分为URL发现、网页下载、网页解析和数据存储四个过程。
1. URL发现URL发现是指网络爬虫在爬取数据时需要从已知的一个初始URL开始,分析该URL网页中包含的其他URL,进而获取更多的URL列表来完成数据爬取过程。
网页中的URL可以通过下列几个方式进行发现:1)页面链接:包括网页中的超链接和内嵌链接,可以通过HTML标签<a>来发现。
2)JavaScript代码:动态生成的链接需要通过解析JavaScript代码进行分析查找。
3)CSS文件:通过分析样式表中的链接来发现更多的URL。
4)XML和RSS文件:分析XML和RSS文件所包含的链接来找到更多的URL。
2.网页下载在获取到URL列表后,网络爬虫需要将这些URL对应的网页下载到本地存储设备,以便进行后续的页面解析和数据提取。
网页下载过程主要涉及 HTTP 请求和响应两个过程,网络爬虫需要向服务器发送 HTTP 请求,获取服务器在响应中返回的 HTML 网页内容,并将所得到的网页内容存储到本地文件系统中。
php解析url并得到url中的参数及获取url参数的四种方式

php解析url并得到url中的参数及获取url参数的四种方式PHP是一种支持解析URL并获取URL参数的强大编程语言。
在处理URL参数时,我们可以使用不同的方法来获取URL中的参数。
下面将介绍如何解析URL,并使用四种不同的方式获取URL参数。
首先,我们来看一下如何解析URL。
在PHP中,我们可以使用`parse_url(`函数来解析URL并将其分割成以下组成部分:协议,主机,路径,查询字符串等。
下面是一个例子:```php$parsed_url = parse_url($url);echo "协议:" . $parsed_url['scheme'] . "<br>";echo "主机:" . $parsed_url['host'] . "<br>";echo "路径:" . $parsed_url['path'] . "<br>";echo "查询字符串:" . $parsed_url['query'] . "<br>";```以上代码将输出以下结果:```路径:/path/to/file.php查询字符串:id=123&name=John+Doe```现在我们知道了如何解析URL,接下来我们将使用四种不同的方法来获取URL参数。
1.从`$_GET`数组中获取URL参数:`$_GET`是一个全局关联数组,用于获取通过GET方法传递的URL参数。
下面是一个例子:```php$id = $_GET['id'];$name = $_GET['name'];echo "ID:" . $id . "<br>";echo "姓名:" . $name . "<br>";``````ID:123姓名:John Doe```请注意,使用`$_GET`数组获取URL参数时,需要确保参数已经设置并存在于URL中,否则可能会引发错误。
Html获取Url参数

Html获取Url参数做web前端的开发很多的时候都会遇到的⼀个很简答的问题,就是两个页⾯之间的跳转,⼀般来说是:<a href = "www.baidu.con">测试</a>这样的没有参数的⼀般是最简单的,可以跳转是因为<a>的href属性,但是⼀般在做项⽬的时候是不会只仅仅跳转的⼀般是带有⼀个或者是多个参数的,然后在下⼀个页⾯将参数传递过去,这个时候很多的⽅法都是可以取到的,今天说的是基于jQuery取参数(虽然很简单,但是照顾新⼿,还是举个例⼦来说吧)<!DOCTYPE html><html><head><meta charset="UTF-8"><title></title><script src="../js/jquery-1.10.2.min.js" type="text/javascript"></script><script src="../js/getUrl.js" type="text/javascript"></script></head><body><a href="jieshouURL.html?name=123&id=1234">点击测试获取url参数</a></body></html>这是⼀个简单的H5页⾯,显⽰的效果是:这个时候我们是写了两个参数的,name和id,这个时候我们写⼀段js:/*获取到Url⾥⾯的参数*/(function ($) {$.getUrlParam = function (name) {var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)");var r = window.location.search.substr(1).match(reg);if (r != null) return unescape(r[2]); return null;}})(jQuery);然后我们将jieshouURL.html打开:<!DOCTYPE html><html><head><meta charset="UTF-8"><title></title><script src="../js/jquery-1.10.2.min.js" type="text/javascript"></script><script src="../js/getUrl.js" type="text/javascript"></script></head><script>var name = $.getUrlParam('name');var id = $.getUrlParam('id');window.onload = function(){$("#addname").val(name);$("#addid").val(id);}</script><body><label>测试URL中的name是:</label><input type="text" id="addname" /><label>测试URL中的id是:</label><input type="text" id="addid" /></body></html>我们点击测试URL参数页⾯:ok,总结⼀下就是:将js封装起来作为⼀个⼯具,以后需要取值的时候可以直接⽤,直接调⽤⾥⾯的函数就是可以的:$.getUrlParam('name');//name就是您参数⾥⾯的名字然后将取出来的参数赋值给⼀个变量,就可以在当前页⾯获取到了不要嫌我啰嗦,说那么简单的⼀个操作写的那么⿇烦,因为我也是从很菜的时候过来的,我知道很多的时候我们认为很简单的操作对于⼀个新⼿来说根本看不懂,所以赘述有时候是对⼤家的照顾。
chrome扩展程序获取当前页面URL和HTML内容

chrome扩展程序获取当前页⾯URL和HTML内容先交代⼀下manifest.json中的配置// 引⼊注⼊脚本"content_scripts": [{"js": ["content_script.js"],// 在什么情况下使⽤该脚本"matches": ["http://*/*","https://*/*"],// 什么情况下运⾏【⽂档加载开始】"run_at": "document_start"}],{"permissions": [ "tabs"]}1.获取当前页⾯的URL可在popup.js中获取(chrome.tabs.getCurrent已经out了,返回值是undefined)chrome.tabs.getSelected(null, function (tab) {console.log(tab.url);});2.获取当前页⾯的HTML内容content-script.js 是注⼊标签页内的脚本popup.js 是弹出框脚本相互通信的⽅式 sendMessage(msg, callback)、onMeassage(callback)(sendRequest、onRequest已经out了,API不再⽀持)popup.js:发送消息chrome.tabs.getSelected(null, function (tab) { // 先获取当前页⾯的tabIDchrome.tabs.sendMessage(tab.id, {greeting: "hello"}, function(response) {console.log(response); // 向content-script.js发送请求信息});});content-script.js:响应消息var html = document.body.innerHTML;chrome.extension.onMessage.addListener(function(request, sender, sendMessage) {if (request.greeting == "hello")sendMessage(html);elsesendMessage("FUCK OFF"); // snub them.});。
JS通过url地址栏获取html页面名称

JS通过url地址栏获取html页面名称有的时候需要获取页面名称,为此我在这里封装了一个方。
一、分别根据传递不同的参数,获取到html页面的名称。
1.通过传递参数,获取到html页面的名称;参数params2.以下是参数解释说明(1)params=1,只获取页面名称,不带.html后缀1.1 例如 url路径是 /home/index.html只返回页面名称: index(2)params=2,取页面名称,同时带.html后缀2.1 例如 url路径是 /home/index.html回页面名称+.html后缀: index.html(3)params=3,获取html父级路径与html名称,同时带.html后缀3.1 例如 url路径是 /home/index.html返回父级路径+页面名称+.html后缀: home/index.html(4)params=4,获取html父级路径与html名称,不带.html 后缀4.1 例如 url路径是 /home/index.html返回父级路径+页面名称,不带 .html后缀: home/index.html (5)params= undefined,params没有值,什么也不传,获取当前html父级路径与当前html页面名称,不带.html后缀//获取url的html页面名称/*params=1,只获取页面名称,不带.html后缀*params=2,取页面名称,同时带.html后缀*params=3,获取html父级路径与html名称,同时带.html后缀*params=4,获取html父级路径与html名称,不带.html后缀*params= undefined,params没有值,什么也不传,获取html父级路径与当前html页面名称,不带.html后缀*/function urlHtml(params) {//获取url地址var ts_href = window.location.href;var ts_mainText="";if(params==1){//获取地址最后一个“/”的下标var ts_indexof = ts_stIndexOf("/");//获取地址“/”之后的的内容var ts_indexText = ts_href.substring(ts_indexof + 1);//获取地址“.html”的下标var ts_htmlBeforeT ext = ts_indexText.indexOf(".html");//获取“/”到".html"之间的内容ts_mainText = ts_indexText.substring(0, ts_htmlBeforeText);}else if(params==2){//获取地址“/”的下标var ts_indexof = ts_stIndexOf("/");//获取地址“/”之后的的内容var ts_indexText = ts_href.substring(ts_indexof + 1);ts_mainText = ts_indexText;}else if(params==3){//获取地址中倒数二个“/”下标的位置的之后的内容var urlParents=ts_href.substr(ts_stIndexOf('/', ts_stIndexOf('/') - 1) + 1);ts_mainText=urlParents}else if(params==4){//获取地址中倒数二个“/”的下标之后的内容var urlParents=ts_href.substr(ts_stIndexOf('/', ts_stIndexOf('/') - 1) + 1);//取到倒数二个“/”的下标的位置和.html之间的内容var beforeHtml = urlParents.indexOf(".html");if(beforeHtml==-1){ts_mainText=urlParents;}else{ts_mainText=urlParents.substring(0, beforeHtml);}}else{var urlParents=ts_href.substr(ts_stIndexOf('/', ts_stIndexOf('/') - 1) + 1);var beforeHtml = urlParents.indexOf(".html");if(beforeHtml==-1){ts_mainText=urlParents;}else{ts_mainText=urlParents.substring(0, beforeHtml);}}return ts_mainText;}。
从输入一个url到浏览器页面展示都经历了哪些过程?

从输⼊⼀个url到浏览器页⾯展⽰都经历了哪些过程?⼀般会经历以下⼏个过程:
1、⾸先,在浏览器地址栏中输⼊url
2、浏览器先查看浏览器缓存-系统缓存-路由器缓存,如果缓存中有,会直接在屏幕中显⽰页⾯内容。
若没有,则跳到第三步操作。
3、在发送http请求前,需要域名解析(DNS解析),解析获取相应的IP地址。
4、浏览器向服务器发起tcp连接,与浏览器建⽴tcp三次握⼿。
5、握⼿成功后,浏览器向服务器发送http请求,请求数据包。
6、服务器处理收到的请求,将数据返回⾄浏览器
7、浏览器收到HTTP响应
8、读取页⾯内容,浏览器渲染,解析html源码
9、⽣成Dom树、解析css样式、js交互
10、客户端和服务器交互
11、ajax查询
其中,步骤2的具体过程是:
浏览器缓存:浏览器会记录DNS⼀段时间,因此,只是第⼀个地⽅解析DNS请求;
操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调⽤操作系统,获取操作系统的记录(保存最近的DNS查询缓存);
路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
ISP缓存:若上述均失败,继续向ISP搜索。
URL类

例如:
URL
myUni=URL(“http”,” ” ,80 ,”/
mydoc.html”);
这种方法与下列方法是等价的:
URL
myUni=URL(“http
:
//:80/mydoc.html”);
URL 类 的 构 造 方 中 的 参 数 , 如 果 无 效 就 会 抛 出 MalformedURLException 异常。一般情况下需要捕获并处理 这个异常。
java ReadURL 运行结果就可以看到中国矿业大学主页的 HTML 文件。
5.
用 URL 获取文本和图像 用 URL 可以方便地获取文本和图像。文本数据源可以是
网上或者本机上的任何文本文件。如果要用 URL 来获取图像 数据,就不能再使用 openStream()方法,而是要使用方法 getImage(URL)。这个方法会立即生成一个 Image 对象,并 返回程序对象的引用,但这并不意味着图像文件的数据已经 读到了内存之中,而是系统与此同时产生一个线程去读取图 像文件的数据。因此,就可能存在程序已经执行到了
{ //将数据信息显示到系统标准输出上 System.out.println(inputLine);} //关闭输入流 din.close();
}
catch(MalformedURLException me){}
catch(IOException ioe){}
}
}
}(点击运行)
运行下列 dos 命令:
1.2.2 URL 类
1. URL 类简介
URL(Uniform Resource Locator)是 WWW 资源统一资 源定位器的简写, 它规范了 WWW 资源网络定位地址的表示 方法。WWW 资源包括 Web 页、文本文件、图形文件、声 频片段等。
python 爬虫源代码

python 爬虫源代码以下是一个简单的Python爬虫源代码,它可以用来爬取网页的内容:```pythonimport requestsdef get_html(url):try:response = requests.get(url)return response.textexcept requests.exceptions.RequestException as e:print(e)return Nonedef parse_html(html):# 在这里添加你的解析代码passdef main():url = "https://exampleXXX" # 替换为你要爬取的网页URL html = get_html(url)if html:parse_html(html)if __name__ == "main__" main()```这段代码使用了requests库来发送HTTP请求并获取网页的HTML内容。
`get_html`函数接受一个URL作为参数,并返回该URL 对应网页的HTML内容。
`parse_html`函数用于解析HTML内容,你可以根据自己的需求进行相应的解析操作。
`main`函数是程序的入口,它调用`get_html`和`parse_html`函数来完成爬取和解析的任务。
你需要将代码中的`url`变量替换为你要爬取的网页的URL。
在`parse_html`函数中,你可以使用相关的HTML解析库(如BeautifulSoup)来提取网页中的数据。
请注意,爬取网页的行为需要遵守网站的Robots.txt文件和相关法律法规,以确保合法合规地进行爬取操作。