数据库第二次
第二次土地调查数据库建设技术报告

第二次土地调查数据库建设技术报告XXX国土资源局二○○九年七月目录洛阳市XXX第二次农村土地调查数据库建设技术报告洛阳市XXX第二次土地调查外业工作从2008年10月至2009年12月,数据库建设工作从2009年1月至2009年2月28日,经过6个月的不懈努力工程现已全部结束,特编写本数据库建设技术报告,对第二次土地调查数据库实施过程、技术方法、技术管理等工作进行全面的总结。
1.建库概述根据《第二次全国土地调查总体方案》和《第二次全国土地调查技术规程》及《江苏省第二次土地调查总体方案》的要求,按照《XXX第二次土地调查实施方案》的具体方法,进行洛阳市XXX第二次农村土地调查工程,根据国土资源部土地利用数据库标准的要求,建立洛阳市XXX农村土地调查数据库。
数据库建库目的和任务第二次土地农村调查目的是全面查清土地利用状况,掌握真实的土地基础数据,并对调查成果实行信息化、网络化管理,建立和完善土地调查、土地统计和登记制度,实现土地调查信息的社会化服务,满足经济社会发展及国土资源管理的需要。
通过第二次农村土地调查,建立集影像、图形、地类、面积、权属和基本农田、后备资源为一体的第二次土地调查数据库及管理系统,建立规范化、信息化、城乡一体化的土地管理体系,为我局实现高效、准确的动态国土资源管理工作奠定基础,为用途管制、农用地转用和农业产业结构调整提供依据,为城市建设发展、土地利用总体规划修编及制订土地利用计划提供依据。
洛阳市XXX第二次农村土地调查数据库建设的任务是建立洛阳市XXX第二次农村土地调查数据库,包括基础地理、土地利用、土地权属、基本农田、后备资源等内容,集图形、图像、属性、表格和文档资料等数据为一体的、互联共享的农村土地调查数据库。
数据库建设依据GB/T 2260中华人民共和国行政区划代码;GB/T 13923-2006基础地理信息要素分类与代码;GB/T 13989国家基本比例尺地形图分幅和编号;GB/T 16820-1997地图学术语;GB/T 17798地球空间数据交换格式;GB/T 19231土地基本术语;GB/T 21010-2007土地利用现状分类;CH/T 1007基础地理信息数字产品元数据;TD/T 1014-2007第二次全国土地调查技术规程;TD/T 1016-2003国土资源信息核心元数据标准;TD/T 1026-2007土地利用数据库标准;2.数据库总体设计数据库逻辑结构洛阳市XXX第二次土地调查数据库由应用数据库和元数据组成。
浅谈ArcGIS在全国第二次土地调查数据库建库中l的应用

Mut eC vrdB et eCasO -jzw层 MutN t vr s B oe yF a r l f c d e u s x s o e- O 第二次土地调查的主要任务是 : 农村土地调查 , 查清每块土地的地 类、 位置 、 范围、 面积分布和权属等情况 ; 城镇土地调查, 掌握每宗土地 lp不能有线重合; a 的界址 、 范围、 、 界线 数量和用途 ; 基本农 田调查 , 将基本农 田保护地块 M s N tr c 不 能 有线交叉 ; ut o I es t t n e M s N t e- vr p ut o Sl O e a 要素不能 自覆盖; f l ( 区块 ) 落实到土地利用现状图上 , 并登记上证 、 造册 ; 建立土地利用数 M s N t e-ne et ut o Sl It c 线状地物不能 自交叉 同要素间) f s r 据库和地籍信息系统 , 实现调查信 息 的互联共享。在调查 的 基础上 , 建 立土地资源变化信息的统计 、 监测与决j更新等机制。由于国图软件是 瘟 2 -构建拓扑关系后 ,rG S .5 2 A c I 会根据所设定的规则对相关对象进 在 rGS中修改拓扑错误比较简单 。 检查完毕后 , A c a 在 rm p 介于 A c I平 台基础上二次开发的软件 ,因此必须经过 A c I 进行 行检查。 A c I rGS rG S 中将数据集中被检查对象和拓扑检查结果 同时加载,在视图窗 口中会 数据建库。 1概述 A c S rGI 显示相关的拓扑错误, 设置好相应的捕捉方式和捕捉参数, 双击有拓扑 A c I 产品线为用户提供一个可伸缩的,全面的 G S rGS I 平台。A 卜 错误的对象, 通过调整节点可以较容易地修正错误 , 同时可以通过点击 ai t T pl yI C r t t t de o n e Ee c bet包含了大量的可编程组件, O js s 从细粒度的对象到粗粒度的对象涉 拓扑工具栏中的在 V l a oo g urn x n命令 ,快速地 及面极广‘ ,这些对象为开发者集成了全面的 GS功能。每一个使用 查看拓扑错误是否 已修正 , I 若显示拓扑错误 的粉红色点、 线消失 , 证明 譬如 , 行政界线与线状地 Ac I 产品都为开发者提供了一个应用开发的容器 , rG S 包括 G S嵌入式 拓扑错误已被修正 。若要同时修改两个对象, I, G S以及服务端 G S rGS I I。A c I 是美国开发的, 全球领先的具有强大空间 物或者行政区与行政界线 , 这时可在 A e a rm p中通过临时设置地图拓扑 数据处理能力的一款 G S I 软件 。 关系, 通过拓扑修改进行联动修改 , 一次调整好两fx 象。对于图斑套 -,  ̄ 2 基于 ArGI c S的二调 数据 库的 建立 图斑的情况要 注意关闭村界层及线状地物层, 用选中图斑( i 反选大 sf ht 土地调查的 目的是全面查清土地资源和利用状况 ,掌握真实准确 斑 应用 E ir ̄l 解决。对于图斑 、 dt - i o- p 线状地物多点问题, 可以用双击 的土地。土地调查基础数据 , 为科学规划 、 合理利用 、 有效保护土地资 该图斑或线状地物选 择要删除的点, 一 e t V  ̄ x 右键 D l e e e 解决。对于图 e 源, 实施最严格的耕地保护制度 , 加强和改善宏观调控提供依据, 促进 斑间存在缝隙问题夏 依据图形进行修改增加或删除节点。 经济社会全面协调可持续发展。因为确保实现土地调查的管理性和可 2 数据入库 3 . 数据入库 的基本流程是首先填写土地的屙I 生数据; 其次进行面提 视l 生,必须保证土地利用数据库成果的完整性 、准确性和逻辑性的统 特别是空间位置关系的正确性。 在第二次全国土地调查数据库建设 点, 出零星地物; 提 再次进行合斑处理, 出了零星地物外 围与地类图 把提 中, 除一般空间数据 的线拓扑关系外还必须考虑点线 、 面、 点 线面 、 线 斑合为整体 后填写权属宗地。本次土地调查要注意的是数据人库时 线、 面面之间拓扑关系的正确性 , 这对土地利用数据库的建设提出了更 要插入光栅图像 检查地类图斑的一致 I。 生 不一致的地方进行修改, 同时 高要求。 在入库时要注意地类图斑标注规定。 2 第二次土地调查作业流程 . 1 2 入库 检查 . 4 利用数据库建设的技术流程及方法根据外业调查成果对 内业预判 入库检查的流程是首先备份数据库, 然后填写单位信息表, 修正行 把数据转入检查软件。 进入检查软件后打开所要检查的图层, 数据进行修改, 通过旧 动剪断线卜 清除微短线卜 除线重叠坐标卜 政区代码, } 青 创建索引图层 、 图幅索引图层 、 动屙 『赋值 、 创建 自 生 咱 动线结点平差卜 线转弧段卜 叫 — 装入转换后的弧段文件l 等一系列步 进行更新座落索引、 骤进行拓扑错误检查, 构建图形拓扑结构, 形成全覆盖和不重不漏的土 批量填写线物扣除图斑信息 、 根据图幅面积计算行政区面积、注记处 最后进行各种检查, 检查项包括数学基础 地利用图斑层 , 建立空间图形数据库 , 同时录入外业调查的各种信息 , 理 、 更新标识码等一系列操作 。 如零星地物的地类、 面积, 线状地物的宽度等, 建立屙 l数据库 , 生 并建立 检查、 要素层齐全检查 、 要素层内容正确性检查 、 要素层几何特征检查 、 图形与属性的关联, 进行面积统计, 最后建立图幅索引、 数据字典 , 同已 点状要素重叠检查 、 线状要素重叠检查 、 要素层拓扑关系检查 、 数据结 经处理好行政界线 、 权属界线 、 地类界 、 线状地物等各层数据文件加入 构检查 、 属性完整性 和正确性检查 、 地籍调查表检查 、 错误 图形记录检 到库文件中, 完成土地利用数据库的建设。 查 、 图形要素检查、 组合 最小上图面积及长度检查 、 图形节点过密检查 、 2 . 2数据 库的建 立 宗地界址线界址点存在检查 、 数据完整性检查 、 宗地面积一致性检查 、 2 .建立数据库。 目 .1 2 在 标文肚 J- i盘 中新建 sp文肚血.  ̄ i. h iJ ,  ̄ 建立子库并导 宗地调查表一致性检查 、 i 地类图斑面积一致 l检查、 生 线状地物长度一致 人坐标系。在所建库上右键一N w  ̄ etr D tst ) e- F a e a e- , u a (  ̄ 名称可中文。 性检查 、 内图廓线接边检查 、 理论 图幅接边检查 、 线物扣除图斑检查 、 行 下 一 步 叫 mpr r‘ t oria ytm -guskye i 政区控制面积检查, 0t o c e codnt ss s +as rgr j d e e e — 图斑面积检查 、 图斑地类面积正确性检查 、 面积综合 a 8 【 n 1 8 e reG N 1 3 — n i 9 0 3 d ge K C 2 } a 下一 步_ 下一 步— i s 。 检查等。在检查的时候要注意检查零星地物。 ÷ n h i 次土地调查数据库建库中l应用 r S G 的
(测绘行业)全国第二次土地调查:数据库中各类成果图件制作方法
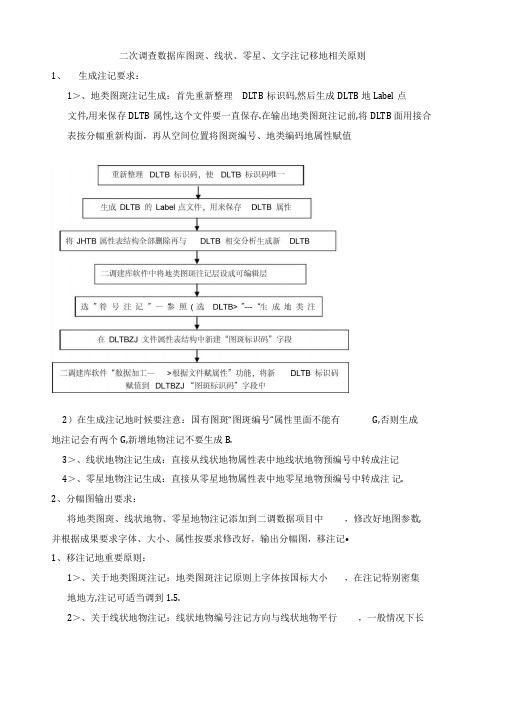
二次调查数据库图斑、线状、零星、文字注记移地相关原则1、生成注记要求:1>、地类图斑注记生成:首先重新整理DLTB标识码,然后生成DLTB地Label点文件,用来保存DLTB属性,这个文件要一直保存.在输出地类图斑注记前,将DLTB 面用接合表按分幅重新构面,再从空间位置将图斑编号、地类编码地属性赋值2)在生成注记地时候要注意:国有图斑“图斑编号”属性里面不能有G,否则生成地注记会有两个G,新增地物注记不要生成B.3>、线状地物注记生成:直接从线状地物属性表中地线状地物预编号中转成注记4>、零星地物注记生成:直接从零星地物属性表中地零星地物预编号中转成注记.2、分幅图输出要求:将地类图斑、线状地物、零星地物注记添加到二调数据项目中,修改好地图参数, 并根据成果要求字体、大小、属性按要求修改好,输出分幅图,移注记•1、移注记地重要原则:1>、关于地类图斑注记:地类图斑注记原则上字体按国标大小,在注记特别密集地地方,注记可适当调到1.5.2>、关于线状地物注记:线状地物编号注记方向与线状地物平行,一般情况下长□32033度小于50M 不标注线状地物编号,即线状地物编号注记长于线状时不表示;线状 地物宽度一般在外业量测点处标注宽度,字头朝北,如外业无线宽量算点地补上并 加注宽度,字头朝北•3>、关于零星地物注记4>、移注记时请强调能放在图框内地注记尽量不要移到图框外.一、土地利用现状分幅图制作1、土地利用现状图地图式规范笫二次全国土地调查十.地分类图式、團例、色标地娄 ttk 炎ir011 041ITHO El012013021023031* i#d sj z IP"DOG 皿R2SO GL 酣日20042051A 0□&1RB <■□ m052Q&3063n I4»□ I3D BK D>H 235 G IM B 150日eR 210 G I 朋日 135R 21町 n I 沪 R 115:|0 0 | 创 B I-hi R 310 a145 B 1350402地类 编号071RGB【数据]地类 编号RGB【数据]城饿住宅用地RO GO B0 R 240 G 110 B 125072农村宅基地3 0R24O G 110 B 125091081 札关团体川地R220 G40 B30R255 G 170 B200092093082出版川地RO GO BO R255 G 170 B200083科教用地084氏卫慈祥用地085上体娱乐用地086公共设施用地087088R22O G22O B 210 R255 G )70 B200R22O G3O B80 R255 G 170 B200RO GO BO R 255 G 170 B200R210 G 120 B 140 R255 G 170 B200R1A0 G24O B50 R255 G 170 B200R255 G 170 B2000940951011020402K 城军事设施用地使旗馆用地监教场听用地宗«用地铁踣用地 面状线状公路用地 面状线状 高速公路W 道县乡<<V) 以上公略0 )2rzi so 加(3®R 0 GOBOR 0 Q 0 BO R 240 G 100B200R24O G100 B200R 240 G 100 B 200R 240 G 100 B200R 24() O 100 B200RO G 0 B 0R 178 G 170 B 176R 178 G 170 BI76RO G 0 B 0 R 170 G85B80RI7O G85 B8OR 170 G85 B80R 170 G85 B8OR 150 G24O B25502地类地类 式样编号名称 RGB【数据]地类 编号RGB[数据]103 104 105 街卷MJ 地 农村道路 面状 线状机场用地RO R 180 GO G80BO B30114坑塘水面106 107 111 港口码头用地管道运输用地而状线状河流水而 112 湖泊水而 113水库水ifii200 |6。
广东省第二次土地调查数据库系统的建设

广东省第二次土地调查数据库系统的建设作者:刘立君来源:《城市建设理论研究》2013年第31期摘要:广东省建设第二次土地调查数据库管理信息系统,使省级国土资源部门充分掌握全省土地资源的利用状况,为实现高效土地资源管理提供有力的技术支撑。
本文针对土地利用的特点,提出建立适用于省、市、县三级结构的广东省土地利用数据库系统,从系统框架设计、功能模块及数据库建设关键问题等方面,阐述了如何将GIS技术和网络技术相结合来构建土地利用数据库系统。
关键字:第二次土地调查;数据库;管理系统中图分类号:C37 文献标识码:A1.背景广东省经济和社会发展速度加快,土地利用变化日趋频繁,自2001年开始,广东省逐步开展县级土地利用更新调查和第二次土地调查数据库建设工作。
广东省123个县市,采用了1:2000、1:5000、1:10000三种比例尺的正射影像底图数据,县级土地利用数据的格式包括mapgis、arcgis、geostar、vct四种。
现有的广东省土地利用数据库是将全省不同比例尺、不同数据格式的县(市)土地利用数据库通过统一的标准加工整合后汇总到省级数据平台建立数据库,但此系统不能满足全国二次土地调查的数据库标准,对县市提交的新标准的数据无法进行管理和应用,因此,迫切的需要建立全省第二次土地调查数据库,实现对全省土地利用数据的管理和更新,从而更好地保护土地资源,发挥土地的最大效益。
2.系统的建设情况广东省土地利用调查数据库系统主要目标是实现对土地利用数据的信息化管理和信息共享,为土地调查、土地统计等业务活动提供支持。
因此应结合广东省的实际情况,综合运用GIS技术、OA技术、数据库技术、网络技术、系统集成技术等主要技术,设计出符合本省数据交换、数据更新模式的系统。
总体思路是以地理信息系统为图形平台,以大型的关系型数据库为后台管理数据库,存储各类土地调查成果数据,实现对土地利用现状数据、基本农田、权属调查数据的图形、属性、栅格影像空间数据及其它非空间数据的一体化管理;借助网络技术,采用集中式与分布式相结合方式,有效存储与管理调查数据;考虑到土地变更调查需求,采用多时域空间数据管理技术,实现对土地利用数据的历史回溯;另外,为了保证土地调查成果的现势性,利用对遥感影像数据的动态监测技术,进行数据的快速更新工作。
第二次全国土地调查数据库更新标准

14
14.1
土地调查数据库数据库更新是指两个时点对比参与变化的要素所产生的数据变化更新,包括土地利用类型的流向和流量、土地权属和界线的变更、土地属性和图形的变化等内容。两个时点之间的数据变更过程视作为长事务。
XX
XX
XX
XX
X
X
|
|
|
|
|
|
大
类
码
小
类
码
一
级
类
要
素
码
二
级
类
要
素
码
三
级
类
要
素
码
四
级
类
要
素
码
其中:
(1)大类码为专业代码,设定为二位数字码,其中:基础地理专业码为10,土地专业码为20;小类码为业务代码,设定为二位数字码,空位以0补齐。土地利用的业务代码为01,土地利用遥感监测的业务代码为02,土地权属的业务代码为06;一至四级类码为要素分类代码,其中:一级类码为二位数字码、二级类码为二位数字码、三级类码为一位数字码、四级类码为一位数字码,空位以0补齐。
3.6
矢量数据vector data
用x,y(或x, y, z)坐标表示地图图形或地理实体的位置和形状的数据 [GB/T 16820-1997 5.18 矢量数据]。
3.7
栅格数据Raster data
按照栅格单元的行和列排列的有不同“灰度值”的像片数据 [GB/T 16820-1997 5.19 栅格数据]。
GB/T13989 国家基本比例尺地形图分幅和编号
2014年9月份考试数据库原理第二次作业

题号 一 二 合计
已做/题量 0 / 30 0 / 10 0 / 40
得分/分值 0 / 90 0 / 10 0 / 100
一、单项选择题 (共30题、总分90分、得分0分)1. 后援副本的用途是( )。 (本题分数:3 分,本题得分:0 分。)
A、 安全性
B、 完整性
C、 并发控制
D、 恢复
题目信息
难度: 6
正确答案: B
解题方案: 数据库的完整性是指数据的正确性和相容性。本题答案为B。
17. 设计性能较优的关系模式称为规范化,规范化主要的理论依据是( )。 (本题分数:3 分,本题得分:0 分。)
A、 1NF
B、 2NF
C、 3NF
D、 BCNF
题目信息
难度: 5
正确答案: A
解题方案: 参见范式概念,本题答案为A。
3. 事务日志是用于保存( )。 (本题分数:3 分,本题得分:0 分。)
A、 程序运行过程
B、 程序运行结果
C、 数据查询操作
D、 对数据库的更新操作
题目信息
难度: 5
正确答案: D
解题方案: 每个事务开始的标记、每个事务的结束标记和每个更新操作均作为日志文件中的一个日志记录。每个日志记录的内容主要包括事务标识(标明是哪个事务)操作的类型(插入、删除或修改)操作对象更新前数据的旧值(对插入操作而言,此项为空值)更新后数据的新值(对插入操作而言,此项为空值)
A、 部门总经理
B、 部门成员
C、 部门名
D、 部门号
题目信息
难度: 7
第二次土地调查土地利用数据库建库数据质量控制方法

2数 据质 量 问题 的来 源
i 外 业调 查 )
外业调 查 需要逐 地 块实地 调 查土地 的 地类 、面积 和权 属, 掌握 各类用 地 的分布和 利用 状况 , 以及 国有土地 使 用权 、集 体土 地所 有权状 况 。如 果外 业 调 查不 细致或 存在错 误 , 导致 界址 不清 、权 属不 明 、地 块面 积 不准 和地 类 会 编 码 错误 等 数 据 信息 损 失 。 2 图形数 据采集 ) 在 外业调 查 的基础 上, 运用 相关 的行 业软件 ( M P I 、A CG IS等) 如 A G S R 矢量 化调查 底 图 ( 射影像 图 DOM图) 的权属 界线 、地类 图班和 现状 地物 正 上 等 。其 中的矢量 化过 程尤 为重 要, 它可 能会 产生 缺失 地物 线 、地类 编码 、 图 班号 或遗漏 零 星地物 、现 状地 物等 错误 以及 面积 不准 确 等 问题 , 而给 属 性 进 录入 、 数据 检 查 及 入 库工 作 带 来 不 必 要 的麻 烦 。 3 属性 数据采 集 ) 按规 定 的数据结 构输 入属性 数据 。这 部分 工作主 要是 人为 因素产 生 的失 误, 属性 录入 工作 量 大, 常是 多人 合作 完成 。不 同的操 作 习惯和 理解 能 力, 通 使 得操 作 的 自由度很 大 , 因此地 籍属 性 表 中可 能出现 遗 漏或 内容错 误 。 4 分幅数 据接边 ) 分幅采集 的 矢量数 据在接 边时, 若属 性数据 不 统一或接 边误 差较 大, 将会 给 最后 的检 查 和 入库 工 作带 来 极 大 的 困难 。 3数 据质量 控 制的 方 法 3 1 内业 数据质 量控 制措施 . 1 图形 数据 采集检 查 ) 参 照农村 土 地调 查记录 手簿 , 查矢 量化 调查 底 图上 的权属 界线 、地 类 检 图斑 线和 线状地 物 的基本 要求 有 : 多边形 须 闭合 、线段 ( 弧段 ) 能相 交 、线 不 段( 弧段) 能打 折 、公共 边 不 能有重 复 、不 能有 悬 点或 伪 节点 、不 能有 碎 不 片多边 形 。对 于 面状 图层 在土 地利用 数据 库 中, 首先 要检 查 的就是 统计 面积 是否满 足面积 逻 辑 一致性 。 因此 面 状 图层 拓 扑规 则就 需满 足 : 图斑 之 间不 能 相互重 叠并且 面要 素之 间没有 缝隙, 图形上 看, 从 面状对 象 的边界 线就 是构 面
第二次土地调查县级数据库建设研究——以浙江省上虞市为例

第33卷第6期2010年12月测绘与空间地理信息G EO M A Tl C S&S PA TI A L I N FoR M A T I oN T E c H N O t oG YV01.33,N o.6D ec.,2010第二次土地调查县级数据库建设研究——以浙江省上虞市为例戴韫卓(浙江省土地资源调查办公室,浙江杭州310007)摘要:县级土地调查数据库是各级土地调查数据汇总统计的基础,也是国土资源各项日常管理工作的重要依据。
通过上虞市二次土地调查数据库建设的全过程研究,总结了具有操作性的建库技术流程。
同时,对数据库建设的关键环节进行了重点分析,并提出了数据库持续更新的思路。
关键词:土地调查;县级;数据库中图分类号:TP311.13文献标识码:B文章编号:1672—5867(2010)06—0059—05R e se ar c h on C ount y L eve l L and I nvest i gat i on D a t abas e C ons t r uct i oni n t he Second N at i onal L and Sur ve y+一TaI【i ng Shangyu i n Z hej i a ng as a n E xam pl eD A I Y an—zhuo(Zhej i ang L a nd R e sourc e I n ves t i gat i on O ff i ce,H angzhou310007,C hi na)A bs t r ac t:C ount y l evel l a nd i nves t i gat i on da t abas e i s t he basi s of dat a s ta ti s ti cs of a l l l evel s l an d i nvest i gat i on,al s o t he i m por t ant basi s of t he dai l y m a n a ge m ent of l a nd a nd r es our c es w or k.T h i s paper sum m ar i zes t he t ec hni cal pr o cess and t he key l i nks of dat aba se c on—s t r uct i on,and put f or w ar d t he i dea of updat ed dat aba se by r es ear c hi ng t he pr o cess of dat aba se cons t r u ct i on i n Shangyu.K e y w or ds:l a nd i nves t i gat i on;cou nt y l evel;dat aba s e0引言土地调查数据库是根据数据库建设规程,按照一定的数据模型对土地调查数据内容进行有效的组织和管理,是调查成果统计、汇总、分析、变更管理的基础¨J,对于提高土地调查数据的准确性、及时性和加快实现国土资源信息化、规范化、科学化都具有重要意义。
第二次全国土地调查数据库建设技术规范(国土)

第二次全国土地调查数据库建设技术规范国务院第二次全国土地调查领导小组办公室二00七年十二月为规范第二次全国土地调查数据库建设的内容、程序、方法及要求,保证数据库成果质量,促进第二次全国土地调查数据的管理和共享,根据《中华人民共和国土地管理法》等法律、法规,按照《第二次全国土地调查技术规程》(TD/T 1014-2007)(以下简称《规程》)的相关要求,制定《第二次全国土地调查数据库建设技术规范》。
其中,农村土地调查数据库建设依据《基本农田数据库标准》(金土工程试行)、《土地利用数据库标准》(TD/T 1016-2007 ),城镇土地调查数据库建设依据《城镇地籍数据库标准》(TD/T 1015-2007 )。
省(自治区、直辖市)可根据本地区实际需要,对本规范的未尽事宜制定补充规定,但不得与本规范相抵触,并须报国务院第二次全国土地调查领导小组办公室(以下简称“全国土地调查办”)备案。
本规范的附录A、附录B附录C .................. .... 附录R均为规范性附录。
本规范由国土资源部提出并归口。
本规范起草单位:全国土地调查办本规范主要起草人:温明炬、韩永顺、张炳智、孙毅、曾珏、高莉、李琪、吴明辉、辛丽璇参加编写人员:杨祝晖、戴建旺、胡小华、陈红兵、梁耘、曾巍、陈金、王莉、王永俊、刘凤君1 范围 (1)2 规范性引用文件 (1)3 术语和定义 (1)第一部分农村土地调查数据库建设 (2)4 总体设计 (2)4.1 建设任务 (2)4.2 数据库体系结构 (2)4.3 数据库逻辑结构 (3)4.4 数据库内容及分层 (4)4.5 数据字典 (5)4.6 数据库管理系统设计 (5)4.7 基本要求及技术指标 (5)4.8 数据库建设主要步骤 (6)5 准备工作 (8)5.1 方案制定 (8)5.2 人员准备 (8)5.3 软硬件准备. (8)5.4 管理制度建立 (9)5.5 数据源准备. (9)6 数据采集与处理 (12)6.1 数据采集原则 (12)6.2 数据采集方法 (12)6.3 各要素数据采集 (22)7 数据入库 (26)7.1 数据入库流程 (26)7.2 数据检查 (27)7.3 数据库参数设置 (28)7.4 矢量数据入库 (28)7.5 DEM数据入库 (29)7.6 正射影像数据入库 (29)7.7 元数据入库 (29)7.8 系统运行测试 (29)8 质量控制 (30)8.1 质量控制原则 (30)8.2 数据源质量控制 (30)8.3 数据采集质量控制 (30)8.4 接边拓扑处理质量控制 (30)8.5 数据入库质量控制 (31)8.6 数据建库信息管理 (31)9 数据库成果要求 (31)9.1 成果内容及要求 (31)9.2 成果质量评价 (33)10 数据库更新 (36)10.1 更新目的与原则 (36)10.2 更新方法及要求 (36)11 数据库管理功能 (36)11.1 数据处理功能 (36)11.2 数据管理与应用功能 (37)第二部分城镇土地调查(城镇地籍)数据库建设 (38)12 总体设计 (38)12.1 建设任务 (38)12.2 数据库逻辑结构 (38)12.3 数据库内容. (39)12.4 数据库管理系统设计 (40)12.5 基本要求及技术指标 (40)12.6 数据库建设主要步骤 (40)13 准备工作 (41)13.1 方案制定 (41)13.2 人员准备 (41)13.3 软硬件准备. (41)13.4 管理制度建立 (42)13.5 数据源准备. (42)14 数据建库 (44)14.1 数据建库过程 (44)14.2 数据采集方法 (45)14.3 数据采集方式选择 (48)14.4 各要素数据采集 (49)14.5 数据检查 (49)14.6 数据入库 (50)14.7 成果输出 (51)15 质量控制 (51)15.1 质量控制原则 (51)15.2 数据源质量控制 (51)15.3 数据采集质量控制 (51)15.4 数据入库质量控制 (52)15.5 数据建库信息管理 (52)16 数据库成果 (52)16.1 成果内容及要求 (52)16.2 成果质量评价 (54)17 数据库更新 (55)17.1 数据库更新目的与依据 (55)17.2 数据更新方法及要求 (55)18 数据库管理功能 (55)18.1 数据采集与处理功能 (55)18.2 数据管理与应用功能 (56)第三部分:土地调查数据库安全管理与维护 (57)19 土地调查数据库安全管理与维护 (57)19.1 基本要求 (57)19.2 管理制度 (57)19.3 数据库安全. (58)19.4 数据库维护. (60)附录A (规范性附录)作业情况记录表 (61)附录B (规范性附录)重大问题协商解决处理情况记录表 (62)附录C (规范性附录)图历簿. (63)附录D (规范性附录)数据源说明表 (64)附录E (规范性附录)数字形式数据源说明表 (65)附录F (规范性附录)农村土地调查数据库检查内容表 (66)附录G (规范性附录)数据源质量检查表 (68)附录H (规范性附录)质量控制检查及处理表 (69)附录I (规范性附录)交接检查卡 (70)附录J (规范性附录)数据入库前质量检查表 (71)附录K (规范性附录)数据入库后质量检查表 (72)附录L (规范性附录)数据库安全运行检查表 (73)附录M (规范性附录)文字报告编写参考提纲 (74)附录N (规范性附录)农村土地调查数据库成果质量评价指标 (76)附录O (规范性附录)农村土地调查数据库缺陷分类表 (77)附录P (规范性附录)城镇土地调查数据库成果质量评价指标表 (78)附录Q (规范性附录)城镇土地调查数据库成果扣分标准表 (79)附录R (规范性附录)土地调查数据库管理员日志登记表 (81)1 范围本规范规定了第二次全国土地调查数据库建设的内容、程序、方法、成果质量要求、成果质量评价及数据库管理系统功能要求等,适用于全国范围内县级农村土地调查数据库和城镇土地调查(城镇地籍)数据库建设、更新与维护。
数据库上机题

(1)统计每个同学的平均分,按平均分的降序排列。
select Sno,AVG(Grade) from SC group by Sno order by Grade Desc;
(2)查询总分最高的学生的学号。
select Sno from SC GROUP BY Sno having SUM(Grade)>=ALL (
( 3)查询选修了 1 号课程并且选修了以 1 号课程为先行课的课程的学生学号。
select Sno from SC where Cno='1' and Sno in (select Sno from SC where Cno in (Select Cno from Course where Cpno='1'));
select Cno,Cname from Course where Cpno='6' and Ccredit='4';
( 2)查询选修了 1 号课程的学生学号与选修成绩不及格的学生学号的差集。
select Sno from SC where Cno='1' and Grade>=60;
认值等列级数据约束;③实现相关约束:借阅表与图书表之间、借阅表与读者表之间的外码
约束;读者性别只能是“男”或“女”的约束(通过帮助自学)。
create table Book(
Bno varchar(20) primary key,
Bclass varchar(20) unique,
Rno varchar(20),
Lentdate date not null,
primary key (Bno,Rno),
数据库基础与应用第2次形考作业_0001-四川电大-课程号:5108643-正确答案

数据库基础与应用第2次形考作业_0001-四川电大-课程号:
5108643-正确答案
数据库基础与应用第2次形考作业_0001
四川形成性测评系统课程代码:5108643 试卷答案
、单项选择题(共 10 道试题,共 20 分。
)
1. 在数据库应用系统设计的需求分析阶段,不需要做的事情是()。
A. 编写需求说明书
B. 创建基本表
C. 建立数据字典
D. 画出数据流图
【正确答案】:B
2. 在SQL的查询语句中,order by选项实现对结果表的功能是()。
A. 投影
B. 求和
C. 排序
D. 分组统计
【正确答案】:C
3. 向基本表插入数据时,可以在命令中使用()子句得到待插入的一个结果表。
A.
GROUP
B. SELECT
C. FROM
D. WHERE
【正确答案】:B
4. 在带有保留字INDEX的SQL语句中,其操作对象是()。
A. 查询
B. 索引
C. 基本表
D. 视图
【正确答案】:B
5. 在SQL的建立基本表操作中,定义检查约束所使用的保留字为()。
A. UNIQUE。
NetTiers学习总结2--数据库

第二次数据库建库原则:表名称采用单数和Pascal命名法。
当然。
例如: FirstName, LastName, MiddleInitial;为表提供表描述,列和键等扩展属性;使用默认值,默认情况下,您的实体属性使用您的数据库默认值。
紧记,默认值只有简单的常量和少数职能是支持,如 getdate() ;.nettiers不能建议关系,可以使用建立外键关联。
如:建立以下表:Person和Contact1-- Create the Base Relationship, has a unique primary key 2CREATE345CONSTRAINT6(78)9)1012--Create the other side of the 1:1 relationship13CREATE141516CONSTRAINT17(1819)20)212223-- Example of 1:1 relationship24-- The contact primary key is the is also a foreign key 25-- Therefore creating a 1:1 relationship.2627ALTER28FOREIGN29REFERENCES创建Contact实体:5[BindableAttribute()]6publicFor every Contact entity, since you are working with the actual foreign key, that is your primary key, you would get a PersonId and a PersonIdSource of type Parent.1private27[Browsable(8public索引的作用:Indexes are not only a powerful feature to help improve your query execution become more performant, it's also used to create handy data access API methods based on those indexes. The important features of an index is that it can contain 1-n columns and has has the ability to be set as a UNIQUE index.For example, in the Person Table we created above, if we added an index to the Name column, and said that column was Unique. Then in my data access API I would get a method called Person GetByName(string name). If i had not added that the index was unique, then the method would return a collection of type TList.12 (34 )OUTPUT:1234567 {89101112 }存储过程There are several times when you want to extend the data access API, but you still want to leverage much of the generated approach to the data layer. .netTiers offeres the ability to write your own procedures and be able to do things that .netTiers can not do out of the box or are specialized to your application. An easy example would be if you wanted to create a custom stored procedure to handle getting all products below a certain inventory. When you begin the generationprocess, the CodeSmith SchemaExplorer will attempt to discover all of the rich meta data provided to determine of this procedure returns a resultset, which parameters it takes (input & output).123456789101112131415161718192021Output:12 {345678910 }NOTE: There are some situations where the procedure will not return results as expected. The Custom Stored procedures don't work when using temp tables within the custom stored procedure. This is because when CodeSmith's SchemaExplorer is discovering this information, it doesn't have necessary priveldges to create a temp table. One workaround is to use a table variable in the stored procedure instead of a temp table. Warning: Table variables are held in memory on the server so do not load too many rows in the table variable or the servers performance will be impacted.Important In order for .netTiers to return an entity that maps to the table you've created the Custom Stored Procedure for, all of the columns being returned must match type and be in the correct order.If you notice that the generated code for your csp starts returning "void" instead of what you expect check that you csp is still validEnum Tables.netTiers will create enums based on table data for the tables that you designate. This is useful for fairly static data or type tables.Rules: The tables you would like to generate as enums must meet the following rules.1. The first column must be a primary key (typically this would be an int Identity column),2. The second column must have a unique column constraint index, the optional third column will be the description of the generated enum.3. You must also select this table in the SourceTable as well in order to generate the enum. Example:1CREATE23456(78)910(1112)13)1415-- Add Table Description 16EXEC171819Some20INSERT21INSERTGenerated Enumeration:12345 [Serializable]67 {89101112 [EnumTextValue(13 Checking =14151617181920 [EnumTextValue(21 Savings =22 }第三次实体 Entity LayerYou can think of an Entity as the Reflection of a Database-table exposed in Object Oriented fashion. The Word Entity is the same which is commonly used and mostly for a Database-Table. So in the .Net environment an object reflecting a Database-table cascadingly, Exposing its Columns asclass-Properties, Carefully matching the Data Types between a database-column and a .Net-Type(Let say string for varchar and Int16 for smallint).Now think of a Database-Table 'USERS' where, definitely, each row of table is representing a single User's complete information(like her ID, Name, Age and Address) and on the other hand in .Net imagine an Object 'User' (with properties ID, Name, Age and Address). It actually is representing One User from database-table 'Users' or One Row of database-table..netTiers' architecture provides us an environment where we can Control the database entities by passing in these .Net entities in special methods.In fact those special methods which Control these .Net entities are called Controller Objects. We'll be studying about them in next articles. for now we should make sure that we know that we can call some dedicated methods from Controller objects to Retrieve an Entity or List of Entities. We can pass in an Entity into Controller behaviors to perform *CRUD actions.CRUD::Create, Read, Update, Delete(I've recorded a Video over Entities and Controllers, Discussing Entity, Its Providers, Entity Relations and Entity State) Download Link Basics of Entity, Provider, Relationships and EntityStates如何定义实体.netTiers uses the notion of the entity along with the TableModule & Data Transfer Object (DTO) Patterns in order to expose your database as entities. Meaning, for every table in your database, an entity will be generated for that table. The DTO allows you to pass the lightweight entities through the many tiers while still maintaining the loosely coupled open ended architecture of the Entity Layer, since it doesn't depend on any DataProvider..netTiers will also attempt to discover all of the relationships that your table has with other tables in the database and will create child properties of those relationships. This will build out your entire entity domain. Currently the relationship types supported are one to one, one to many, and many to many relationships. These relationships make it easy for you to intuitively work with your entities and now have a logical object graph. There are several ways to create a certain relationship, but we'll discuss the rules in the Database Model section.Example: Customer Entity///An example object graph of a customer entity looks like this./// Customer Parent/// Order 1:1/// OrderDetails //1:M/// ProductCollection //1:M/// CustomerDemographics //1:M/// CustomerDemographicsCollection_From_CustomerCustomerDemo //M:M EntityBaseThe entities all inherit from two parent classes, the user classcalled EntityBase.cs which inherits from EntityBaseCore.generated.cs, the generated class. As mentioned earlier, every .generated class will be generated over and over again, do not modify these classes as your work will be lost when you regenerate your code.These base classes implement the base behavior across all entities. The EntityBase class provides you with exclusive access to modify the behavior across all entities. You can override our default implementation and these changes will not get overwritten. This is a way for you to make changes and extend the behavior while at the same time, safeguarding your work.EntityBase The EntityBase classes provide behavior to manage state using the EntityState property.What is Entity State?Entity State provides a way to track the current status of an entity in it's entity lifecycle, which differs from the CLR object lifecycle. There are 4 main EntityStates, found in the EntityState enumeration, Unchanged, Added, Changed, and Deleted. You do not have to manually keep track of state, when you modify a property, or create a new entity, or read an entity from the database .netTiers will automatically change the state and keep track for you.12345 {6789 Unchanged=1011121314 Added=1516171819 Changed=2021222324 Deleted=25 }EditEntity LifeCycleAssuming you have no data in your database, the very first thing you will do is add data to the database. In order to do this, you will have to create a new entity. Let's use the Customer entity that we've generated from the Northwind database, and create a new Customers entity and walk through the different states of the entity, which as mentioned earlier is different than the objectlifecycle.123 Customers customer =4 customer.Address =5 customer.City =6 customer.Region =7 customer.Phone =8 Response.Write(customer.EntityState);91011 DataRepository.CustomersProvider.Save(customer); 1213141516171819 Response.Write(customer.CustomerID);20 Response.Write(customer.EntityState);212223242526 customer.Region =27 Response.Write(customer.EntityState);28 DataRepository.CustomersProvider.Save(customer); 29303132333435363738394041 DataRepository.CustomersProvider.Delete(customer); 424344 customer.MarkToDelete();45 Response.Write(customer.EntityState);46 DataRepository.CustomersProvider.Save(customer);474849505152 TList<Customers> myList =535455 {56 Response.Write(myList[i].EntityState);57 myList.RemoveEntity(myList[i]);5859 Response.Write(myList[i].EntityState);60 }616263 Response.Write(myList.Count);646566 Response.Write(myList.DeletedItems.Count);676869 DataRepository.CustomersProvider.Save(myList); 707172 myList.ForEach(7374 {75 c.MarkToDelete();76 }77 );7879808182 DataRepository.CustomersProvider.Save(myList);EditBase State BehaviorYou can override the default behavior if you wanted and managed how EntityState was used. Perhaps if you wanted to use a StateMachine instead to manage state. Overall, it's a flexible approach that should let you customize however you need to..There are also some entity state descriptor properties such as IsDeleted, IsDirty, IsNew. One other thing to note, is that you can remove the flag after using MarkToDelete by calling RemoveDeleteMark().Excerpt from EntityBase.generated.cs1234 [BrowsableAttribute( 56 {78 }9101112131415 [BrowsableAttribute( 1617 {1819 {2021 &&22 }23 }242526272829 [BrowsableAttribute( 3031 {323334 }35363738394041 [BrowsableAttribute(4243 {444546 }4748495051525354555657 {585960 OnPropertyChanged(61 }62636465666768697071727374 { 757677 } 78798081828384 {8586 {8788 }89 }EditInterface ImplementationsThe entities themselves implement several interfaces to provide the full featured needs of consuming layers. The first two layers are custom .netTiers interfaces, the rest are from the ponentModel and System.Runtime.Serialization namespaces.Some of these interfaces are :∙IEntityId - Gives exposure to an encapsulated primary key for your entity. Supports containment of composite primary keys.∙IEntity- A .netTiers interface that provides all the functionality required for a .netTiers entity.∙IComparable - Implements the ability to compare two entities types.∙ICloneable - Implements the ability to clone an entity∙IEditableObject - Implements the ability to commit or rollback changes to an object that is used as a datasource.∙IComponent - Implements functionality required by all .Net ponentModel Components.∙INotifyPropertyChanged - Notifies subscribed clients that a property value has changed.∙IDataErrorInfo - Provides the functionality to offer custom error information that a user interface can bind to.∙IDeserializationCallback - Indicates that a class is to be notified when deserialization of the entire object graph has been completed.EditWhat about generated views? Are they entities?Generated views object types are not considered entities, although they share many similar attributes. View objects do not maintain state because they currently can not be persisted back into the database.EditEntity Validation Rule EngineOne of the most powerful features that .netTiers provides to manage the integrity of your data is the Entity Rule Engine. This implements IDataErrorInfo in the EntityBase.generated.cs class. It provides the framework for managing entity business rules and custom error information that a user interface can bind to. Controls such as the DataGridView automatically detect this interface and provide error icons along with descriptions about the error.There are several properties that assist you in managing your business rules. There are several built in validators ready to use out of the box.∙NotNull - Determines the if the database column accepts null values.∙StringMaxLength - Compares against the column width for the property.∙StringRequired - Determines if the column allows empty string entries.∙MaxWords - Determines whether the property has exceeted the maximum number of words∙RegexIsMatch - Determines whether current property matches the regular expression ∙LessThanOrEqualToValue - Less than or equal to current value of property∙LessThanValue - - Less than current value of property∙EqualsValue - Equals current value of property∙GreaterThanValue - Greater than current value of property∙GreaterThanOrEqualToValue - Greater than or equal to current value of property∙CompareValues - Compares values of T using a comparer∙InRange - Ensures T is within a min and max of a Range using a Comparer.However, we certainly understand that while those are all very useful, they do not cover the spectrum of potentially business rules. There is most important aspect of the rule engine that all of the Validators are validated by a delegate which is called ValidationRuleHandler, through which you can set up any ValidationRule, so long as it returns a bool value.The target parameter is the object being validated, while e is a ValidationRuleArgs object that contians information about the rule (property to validate, error description). There are a couple of more properties that are of interest. There is now a property called IsValid that checks the rules to see if any have been broken. You can also get all of the broken rules through the BrokenRulesList property in your entity.Validation/ValidationRuleHandler.cs1234567891011121314EditExample of Auto-Generated Rules.netTiers will automatically detect the rules that apply for the database to maintain data integrity. However it's still extremely easy for you to add your own. Here's an example of automatically added rules for the Customer Entity we were working with.1protected2{3//Validation rules based on database schema.45678910111213 141516 171819 2021 22 2324 25 26 27 28 29 30 31 32 33 34 35 36 3738394041}EditThat's great, but, how do I add my own rules?Adding your own rules is easy. There are really several ways to do it since the properties are exposed. The easiest is perhaps to simply override the AddRules() method in your entities and add your own rules along with ones that were generated for you. Here's an example of the Orders entity from the Northwind generation.Orders.cs -> The User customizable file for your entity class.1///2///3///4protected5{678910111213 ValidationRules.AddRule(141516171819 ValidationRules.AddRule(ValidateOrderDate, 20}212223///24///25///26///27///28///29private30{3132 {33 e.Description3435 }363738}EditSo, how do I validate and see the error message?The easiest way to validate is when using a single entity is just to call the IsValid property. It will automatically trigger the validation process. You can also force the validation process by calling Validate();1 Orders o =2 o.OrderDate =3 o.ShipAddress =4 o.ShipCity =5 o.ShipCountry =6 o.ShipName =7 o.ShipPostalCode =8 o.ShipRegion =91011 o.Validate();121314 lblMessage.Text = o.Error;151617181920 {21 lblMessage.Text =22 rule.Property, rule.Description);23 }242526272829 TList<Orders> ordersList = GetOrdersFromVender();3031 {32 StringBuilder sb =33 sb.Append(3435 {36 sb.Append(o.Error.Replace(37 }38 lblMessage.Text = sb.ToString();3940 }Overall, the important thing to remember is that since the Rules engine uses delegates, your logic can live any place you would like it to. There will be more coverage with complex business processes and validation in the Component Layer chapter.EditUsing Collections in .netTiers, TList & VList:.netTiers has two generic lists that it exclusively uses for your entities. TList and VList. The TList is the most full featured and only works with Types that implement IEntity, which are entities thatare generated from a table as formerly stated. VList is a list for limited View Entities that don't maintain EntityState.1 Orders order =2 order.OrderDate =3 order.ShipAddress =4 order.ShipCity =5 order.ShipCountry =6 order.ShipName =7 order.ShipPostalCode =8 order.ShipRegion =910111213141516 ordersList.FindIndex(1718 {1920 });2223242526 ordersList.Insert(27282930 ordersList.Add(order);3132333435 ordersList.AddNew();36 ordersList[ordersList.Count -3738394041 ordersList.RemoveEntity(order);434445 ordersList.RemoveAt(46474849 ordersList.Remove(order);50515253 ordersList.ListChanged +=54555657585960 Debug.Assert(deletedCount == 616263646566 Response.Write(676869707172 Response.Write(737475767778 TList<Orders> sList =79 OrdersColumn.ShipCity, 8081 TList<Orders> cList =82 OrdersColumn.ShipCity,8384 TList<Orders> eList85 OrdersColumn.ShipCity,86878889 TList<Orders> eqList =90 ordersList.FindAll(OrdersColumn.ShipCity, 9192939495 TList<Orders> eqList2 = ordersList.FindAll( 969798 o2.OrderDetailsCollection.Count >99 o2.OrderDate == DateTime.Today;100 });101102103104105106 {107108 o3.OrderDetailsCollection.Count > 109 o3.OrderDate == DateTime.Today; 110 }))111 {112 Response.Write(113 }114115116117 Orders[] orderArray = ordersList.ToArray(); 118119120121 DataSet ds = ordersList.ToDataSet(122123124125126127 ordersList.Filter =128 ordersList.ApplyFilter();129 ordersList.ForEach(130131 {132 Debug.Assert(filteredOrder.ShipCity == 133 });134135136 ordersList.RemoveFilter();137138139140141 ordersList.ApplyFilter(GetValidAtlantisOrders);142 ordersList.ForEach(143144 {145 Debug.Assert(filteredOrder.IsValid146 && filteredOrder.ShipCity ==147 });148149}150151152153154155156157158 {159160 && o.ShipCity ==161 && o.OrderDetailsCollection.Count > 162 && o.OrderDetailsCollection.IsValid); 163 }164165166 {167168 }169170171172173174175 {176177178 }179}EditEntity Management Framework:In any application there are often several aspects of your application that you commonly have to do in order to optimize your application.EditEntityFactoryBaseThe EntityFactoryBase is a creational construct that exists to assist the creation of entities of an unknown type at runtime. Entities are/were normally created in the DataRepository in a given EntityProvider's Fill method. So if I had DataRepository.MyEntityProvider, there would be a method called Fill that took an IDataReader, an TList (EntityCollection) and a row params. This method is actually going to hydrate the entities when coming back from the DataRepository.This version of the templates allow you to create component business objects which inherit from the entity objects. Since these component objects live in the tier on top of the Data Access Layer and Entities. Since the DataRepository creates entities for usage, it's not possible to create those types because the DAL doesn't know about the smart component business objects, only the Entity DTO objects. The role the EntityFactory is used for is you have the ability to define which factory will be used to create your objects to be filled in the app/web.config.Example:1entityFactoryType=2// OR3Each factory will use the namespace of the factory to create unknown types at runtime using an Activator. This type discovery is cached and so you only face a perf hit once.There are events that you can subscribe to during this process to inject some logic before the object is created and just after it's created but before being hydrated. This is useful if you wanted to attach your own events to the entity.EditEntityCacheThe EntityCache class manages the lifetime of entities that you would like to not have to be queried for all the time. In reality, this class simply wraps the Enterprise Library Cache. EntLib offers a full featured and configurable object cache. The entity cache can be used by any object,and does not have to be an entity. More info can be found here: Enterprise Library Caching BlockYou don't "Have" to configure the cache to work, .netTiers will generate a default cache configuration at runtime if one does not exist, but it's recommended that you do create a configuration for your caching block to optimize the cache settings for your application. The entity cache can easily be configured by pointing your Enterprise Library Configurator tool at your app/web.config. We've also recently started including a sample default settings entlib.config in the MyNamespace.UnitTest project.EditIEntityCacheItemWhen this marker interface is applied to an entity, the entity will automatically be placed into cache. The interface provides lifetime and callback parameters used to manage the caching of your entities. This is an interface that you would have to apply yourself to the entity at the concrete class level.EditEntityLocatorThe EntityLocator sits on top of the Locator class of the Microsoft Patterns and Practices Group's ObjectBuilder Framework. The locator is responsible for creating a WeakReference'd Object Store so that as your application is handling a high volume of entities, which many are of the same record, we will return to you the same object for all references until that entity is persisted to the DataRepository. Combining this feature with Optimistic Concurrency with a Timestamp on your Table, you'll end up saving quite a bit on memory consumption. And for those that might not know, a weak reference means that the objects will still be garbage collected as soon as there are no more actual references to that entity any longer.This feature has to be enabled in the app/web.config under enableEntityTracking="true/false"EditEntityManagerThe EntityManager is the glue that holds it all together, and should be considered the entry point to most of these features, with the exception of the EntityCache. When an object is about to be created, and DataRepository.Provider.EntityTracking is enabled, the EntityManager get's called. The EntityManager contains a single EntityLocator object and a collection of EntityCache objects, for all of your different entity cache providers. Most likely though, there will only be a singleEntityCache object in there.The EntityManager contains a LocateOrCreate method that determine if an entity already exists and is currently being referenced, if so, then return that entity, otherwise, create a new one using the entity factory defined and begin tracking the entity.There are several yet to be implemented features which we have in mind for the EntityManager such as managing meta data amongst the entities and being able to determine relationship boundaries at runtime.。
数据库基础与应用形成性考核册及答案

数据库基础与应⽤形成性考核册及答案数据库基础与应⽤作业及答案数据库基础与应⽤第⼀次练习⼀、填空题1.数据处理是将数据转换成信息的过程。
2.计算机数据处理技术经历了⼈⼯管理,⽂件系统,数据库系统,和分布式数据库系统四个阶段。
3.数据库系统的主要特点是实现数据_共享_,减少数据_冗余_,采⽤特定的数据_模型_,具有较⾼的数据_独⽴性_,具有统⼀的数据控制功能。
4.数据库系统由_硬件,软件,数据库_,数据库管理员和⽤户组成。
5.数据库系统具有数据的___外模式(数据的局部逻辑结构),模式(数据的整体逻辑结构)和内模式(数据存储结构)__等三级模式结构。
6.数据的物理独⽴性是指当数据的_内模式__改变时,通过系统内部的⾃动映象或转移功能,保持了数据的_模式_不变。
7.数据的逻辑独⽴性是当数据的_模式_改变时,通过系统内部的⾃动映象或转换功能,保持了数据的__外模式__ 不变。
8.数据库管理系统提供了数据库的_定义,操纵,运⾏控制__ 功能9.数据完整性控制包括___域完整性,和关联完整性_ _ 控制功能。
10.数据库运⾏控制功能包括数据的__安全性__ 控制,__完整性 _ 控制_并发控制控制和数据恢复等四个⽅⾯。
11.数据库并发操作控制包括以__独占__ ⽅式打开数据库和对数据库或记录_加锁_两种⽅法。
12.数据安全包括__系统安全__和__环境安全_ 两个⽅⾯。
13.⼀个公司只能有⼀个经理,公司和总经理职位之间为__1:1__ 的联系。
14.描述实体的特性称为___属性__。
15.如果⼀个实体集中某个属性或属性组合的值能够唯⼀的标识出每个实体,则可把他选作为__关键字__。
16.实体之间的联系归结为___1:1___ ,__1:n __,和__ n:m _三种。
17.E_R模型是描述概念世界,建⽴___概念世界____ 的实⽤⼯具18.数据库管理系统所⽀持的数据模型被分为__层次,⽹状,关系_ _和⾯向对象四种类型。
数据库原理与应用A第2次作业

数据库原理与应用A第2次作业(注意:若有主观题目,请按照题目,离线完成,完成后纸质上交学习中心,记录成绩。
在线只需提交客观题答案。
)本次作业是本门课程本学期的第2次作业,注释如下:一、单项选择题(只有一个选项正确,共14道小题)1. 关系代数的四个组合操作是:交、连接、自然连接和()。
(A) 笛卡儿积(B) 并(C) 差(D) 除法正确答案:D解答参考:2. 在数据库设计的需求分析阶段,描述数据与处理之间关系的方法是()。
(A) E-R图(B) 业务流程图(C) 数据流图(D) 程序框图正确答案:C解答参考:3. 全局E-R模型的设计,需要消除属性冲突、命名冲突和()。
(A) 结构冲突(B) 联系冲突(C) 类型冲突(D) 实体冲突正确答案:A解答参考:4. 关系模式设计理论主要解决的问题是()。
(A) 插入异常、删除异常和数据冗余(B) 提高查询速度(C) 减少数据操作的复杂性(D) 保证数据的安全性和完整性正确答案:A解答参考:5. 物理结构设计阶段的任务应考虑的主要因素不包括()(A) 选择存取路径(B) 选择存储结构(C) 分析用户要求(D) 确定存取方法正确答案:C解答参考:6. 数据模型是()(A) 文件的集合(B) 记录的集合(C) 数据的集合(D) 记录及其联系的集合正确答案:D解答参考:7. 有且仅有一个结点无父结点的模型是()(A) 层次模型(B) 关系模型(C) 数据模型(D) 实体模型正确答案:A解答参考:8. 在关系运算中,查找满足一定条件的元组的员算是()(A) 重建(B) 选取(C) 投影(D) 连接正确答案:C解答参考:9. 物理结构设计阶段与具体的DBMS( )(A) 无关(B) 关系不确定(C) 部分相关(D) 密切相关正确答案:D解答参考:10. 数据库维护阶段的故障维护工作是指()(A) 排除设备故障(B) 恢复遭到破坏的数据库(C) 修改不适当的库结构(D) 修改应用程序正确答案:B解答参考:11. 数据库系统的基础是()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
作业二.程序设计:写SQL
◆一.教材P112—3.2
◆T(T#,TNAME,TITLE)
◆C(C#,CNAME,CREDIT,T#)
◆S(S#,SNAME,AGE,SEX,DEPT)
◆SC(S#,C#,SCORE)
检索年龄小于 岁的女学生的学号和姓名。
检索男学生所学课程的课程号和课程名
检索男学生所学课程的任课教师的工号和姓名
.检索至少选修两门课程的学生学号
检索至少有学号为 和 学生选修的课程的课程号
检索 ✌☠☝同学不学的课程的课程号
二.教材P112—3.7
T(T#,TNAME,TITLE)
C(C#,CNAME,T#)
S(S#,SNAME,AGE,SEX)
SC(S#,C#,SCORE)
1.统计有学生选修的课程门数
2.求选修C4课程的女学生的平均年龄.
3.求LIU老师所授课程的每门课程的平均成绩
4.统计每门课程的学生选修人数(超过10人的课程才统计).要求显示课程号和人数,查询结
果按人数降序排列,若人数相同,按课程号升序排列.
5.检索学号比W ANG同学大,而年龄比他小的学生姓名
6.在表SC中检索成绩为空值的学生学号和课程号
7.检索姓名以L打头的所有学生的姓名和年龄
8.求年龄大于女同学平均年龄的男同学姓名和年龄
9.求年龄大于所有女同学年龄的男同学姓名和年龄。
三.教材P114—3.12
T(T#,TNAME,TITLE)
C(C#,CNAME,T#)
S(S#,SNAME,AGE,SEX)
SC(S#,C#,SCORE)
1.往关系C中插入一个课程元组(’C8’,’VC++’,’T6’)
2.检索所授每门课程平均成绩大于80分的教师姓名,并把检索到的值送往另一个已存在的表FACULTY(TNAME)中
3.在SC中删除尚无成绩的选课元组
4.把选修LIU老师课程的女同学选课元组全部删去.
5.把MATH课不及格的成绩全改为60分
6.把低于所有课程总平均成绩的女同学成绩提高5%。
7.在表SC中修改C4课程的成绩,当成绩小于等于70分时提高5%,若成绩大于70分时提高4%。
8.在表SC中,当某个成绩低于全部课程的平均成绩时,提高5%。
四..教材P114—3.13
职工表EMP(E#,ENAME,AGE,SEX,ECITY) 其属性分别表示职工工号,姓名,年龄,性别和籍贯
工作表WORKS(E#,C#,SALARY) 其属性分别表示职工工号,工作的公司编号和工资
公司表COMP(C#,CNAME,CITY) 其属性分别表示公司编号,公司名称和公司所在城市
1.用CREATE TABLE 语句创建上述三个表需指出主键和外键
2.检索超过50岁的男职工的工号和姓名
3.假设每个职工只能在一个公司工作,检索工资超过1000元的男性职工工号和姓名
4.假设每个职工可在多个公司工作,检索至少在编号为C4和C8公司兼职的职工工号和姓
名.
5.检索在”联华公司”工作,工资超过1000元的男性职工的工号和姓名
6.假设每个职工可在多个公司工作,检索每个职工的兼职公司数目和工资总数,显示
7.检索联华公司中低于本公司平均工资的职工工号和姓名
8.在每一公司中为50岁以上职工加薪100元(若职工为多个公司工作,可重复加)
9.在EMP表和WORKS表中删除年龄大于60岁的职工的有关元组.
综合应用题
整理题目给定信息,画出E-R图,并将E-R图转换为关系模式,主键
和外键必须标出
1.假设要建立一个企业数据库,
该企业有多个下属单位每一单位有多个职工,一个职工仅隶属于一个单位,且一个职工仅在一个工程中工作,但一个工程中有很多职工参加工作,有多个供应商为各个工程供应不同设备。
单位的属性有:单位名、电话。
职工的属性有:职工号、姓名、性别。
设备的属性有:设备号、设备名、产地。
供应商的属性有:姓名、电话。
工程的属性有:工程名、地点。
2. 设计项目数据库,
包含实体集如下:
●仓库: 包含属性仓库号,所在地区和电话
●配件:包含属性配件号,配件名,规格,价格和说明
●供货商: 包含属性供货商号,供货商名,地址,电话和帐号.
●项目 : 包含属性项目号和预算
●员工 : 包含属性员工号,员工名和年龄
实体间联系如下:
●一种配件可以存放在多个仓库内,一个仓库内可以存储多种配
件
●一个仓库可以有多个雇员,一个雇员只能工作在一个仓库.
●一个员工可以领导多个员工.
一个供货商可以提供多种配件给不同的项目,一个项目可以使用不同供货商的配件.一种配件可被不同的供货商提供.
3.图书管理系统:
每本图书可被不同的读者借阅,当图书被借出时,图书状态为“借出”,当书被归还时,状态为“在库”;每个读者每次可以借多本书,而且读者可以在不同的时间借同一本书;当读者借一本书时,借出时间将被记录下来,当书被归还时,归还时间也被记录下来。
读者的属性包含读者ID,姓名,电话和所在单位;图书的属性包含图书ID,书名,作者,出版时间和状态。
4.一个简单的银行业务数据库,对客户的储蓄和贷款行为进行记录。
假设客户以客户ID作为标识,还具有属性:客户名和客户地址;贷款以贷款号标识,还有一个属性为贷款额;每个储蓄账户由账号标识,另有一个属性为余额。
假设一个客户可能贷多笔款,一笔贷款可能与多个客户有关;一个客户可以有多个储蓄账户,但是一个储蓄帐户只能归一个客户所有。
5.大学学分管理系统。
学生可根据自己实际情况进行选课。
每个学生可以同时选几门课,每门课可同时被几位老师讲授,每位老师可教多门课程,每名学生有一名导师,每位老师可以同时做多名学生的导师。
学生的属性包括:学号,姓名,年龄和电话;
课程的属性包括课程号,课程名,学分和开课学期;
老师有属性:老师号,老师名,职称和电话;
系有属性:系号,系名和系主任。
6.设计图书销售数据库。
该系统中有实体集“出版社”,其属性分别为出版社名、地址;
实体集“图书”,其属性分别为书号、书名、作者、单价;
实体集“书店”,其属性分别为书店编号、书店名、经理、地址。
出版社与图书间的出版联系应反映印数和出版时间,书店与图书间的销售联系应反映销售量。
7.假设某公司的业务规则如下:
公司下设几个部门,如技术部、财务部、市场部等。
每个部门承担多个工程项目,每个工程项目属于一个部门。
每个部门有多名职工,每一名职工只能属于一个部门。
一个部门可能参与多个工程项目,且每个工程项目有多名职工参与施工。
根据职工在工程项目中完成的情况发放酬金。
工程项目有工程号、工程名两个属性;部门有部门号、部门名称两个属性;职工有职工号、姓名、性别属性;
8.教材P179-5.13
9.教材P180-5.14
10.教材P180-5.15。