PDF文件页面可以怎么提取 PDF页面提取方法
PDF文件使用技巧大全

PDF文件使用技巧大全如果你经常使用计算机,就不可能不知道PDF格式。
它是公认的分享文档的最佳格式。
但是,这种格式的文件,必须用专门的阅读器打开,而且不能编辑,所以对使用者来说,会遇到很多问题。
下面是一个外国作者总结的常见问题清单,基本上涵盖了普通用户的大多数问题,而且解决方法全部都是免费的。
我觉得对我很有用,所以将它翻译了出来,也供大家参考。
需要说明的是,里面的解决方法,完全都是针对英语文档的,我没有试验过它们是否支持中文文档。
Adobe公司的PDF格式是分享文件的最佳格式,因为它体积适中,能够保存样式,在绝大多数平台下都能够打开和处理。
下面,我们将告诉你,如何应对你在使用PDF文件过程中,遇到的几乎所有问题,而且完全不需要你去购买Adobe Acrobat。
内容包括编辑PDF文件、合并多个PDF文件、在PDF中加入签名、如何在线填写PDF表格、在PDF中加入超级链接等等。
Q:我没有Adobe Acrobat,如何创建PDF文件?A:安装免费的DoPDF(该网站被屏蔽,中国大陆用户点击此处下载)软件,它会在Windows中增加一个虚拟打印机。
你通过它,以打印方式生成PDF文件。
Q:我不想安装任何软件,如何创建PDF文件?A: 将你的文档通过浏览器,上传到Google Docs,然后选择以PDF格式export,非常简单。
Q: 客户用Email发送给我一个PPT文件,但是我在出差,无法使用电脑,而我的智能手机打不开PPT文件,怎么办?A:将这封Email转发给pdf@(包括附件),他们会自动将附件转成PDF格式,然后再寄回给你。
大多数智能手机都能打开简单的PDF文件。
事实上,pdf@这个邮件地址,还接受.doc、.docx、.pptx、.xls、.xlsx、JPEG、GIF、RTF、TXT等格式的文档。
Q:我能否直接将一个网页存成PDF格式?A:访问PrimoPDF,直接键入你要保存的网址即可。
提取pdf每一页中的身份信息的方法

提取pdf每一页中的身份信息的方法全文共四篇示例,供读者参考第一篇示例:提取PDF文档中的身份信息是一项有用的技能,可以帮助我们快速而准确地处理大量文档,特别是在需要对文档进行分析或整理的情况下。
在本文中,我们将介绍一种方法来提取PDF文档中每一页的身份信息,以帮助您更好地利用这些信息。
我们需要明确身份信息通常指的是什么。
在这里,我们指的是文档中包含的姓名、地址、电话号码、电子邮件等与个人身份相关的信息,这些信息通常用于识别或联系文档中的相关人员。
接下来,我们将概述一种基本的方法来提取PDF文档中的身份信息。
请注意,这种方法可能需要一定的编程知识和技能。
步骤一:安装必要的工具和库我们需要安装一些用于处理PDF文档的工具和库。
一个常用的Python库是PyPDF2,它可以帮助我们读取和处理PDF文档。
您可以通过pip install PyPDF2 命令来安装该库。
步骤二:编写Python脚本接下来,我们可以编写一个Python脚本来提取PDF文档中的身份信息。
以下是一个简单的Python脚本示例,用于提取PDF文档中的身份信息:```pythonimport PyPDF2def extract_info(pdf_file):pdf = PyPDF2.PdfFileReader(pdf_file)for page_num in range(pdf.numPages):page = pdf.getPage(page_num)text = page.extract_text()# 这里可以添加您自己的代码来提取身份信息# 使用正则表达式来匹配姓名、地址、电话号码等信息print(f"Page {page_num + 1}: {text}")在这个示例中,我们使用PyPDF2库来读取PDF文档,并循环遍历每一页的文本内容。
您可以在注释的位置编写自己的代码来提取身份信息。
您可以使用正则表达式来匹配电话号码、邮箱地址等信息。
PDF页面抽取及保存高分辨率图片教程

2、解压foxit-phantom.rar文件,得到如下图:
双击Foxit Phantom PDF 5.0.4 _Hans_注册版_里的 运行软件.
二、使用方法
1、运行软件后,打开所பைடு நூலகம்PDF文件
2、点击文件-导出为-图片-JPEG
3、选择需要的页面
4、弹出保存位置窗口,点击设置,弹出对话框中设置质量最高,分辨率设置600像素/英寸
二使用方法1运行软件后打开所需pdf文件2点击文件导出为图片jpeg弹出保存位置窗口点击设置弹出对话框中设置质量最高分辨率设置600像素英寸5最后选好保存位置即可
将PDF文件里需要的页面保存成高分辨率的图片,请按如下操作:
一、安装软件
1、首先下载FTP内09_项目工具/foxit-phantom.rar
如何提取多个PDF页面

在使用PDF文件的时候我们不止要使用PDF文件还需要会编辑PDF文件,那么如何对PDF页面进行提取呢?估计有很多小伙伴都很好奇吧,今天就来跟大家分享一下!
操作软件:PDF编辑器
1.在百度中搜索一款编辑器安装在电脑上。
迅捷PDF编辑器安装成功之后,打开运行之后点击左上角的打开工具,把需要提取页面的文档打开。
2.文件打开之后我们就需要提取页面了,找到文档工具中的提取页面选项。
然后点击提取页面。
3.选择之后会弹出提取页面的设置弹框,在页面范围的位置可以设置好需要提取的页面。
4.然后在目标文件夹的位置设置好提取之后的页面保存位置,所有的都设置完成之后点击确定。
5.还可以点击菜单栏中的视图工具中的页面缩略图工具。
6.然后可以看到软件的左边有页面的缩略图显示,然后去到需要提取的那个页面,然后单击鼠标右键也是可以提取页面的。
还可以使用快捷键Ctrl+Shift+E也是可以直接打开提取页面工具的。
7.其实还有一个工具也可以提取PDF页面,那就是拆分文档工具。
8.点击拆分文档工具之后,在拆分方式的位置设置每次拆分的页数为一页,然后设置好保存位置,之后点击确定。
这样PDF文件就拆分为一页一页的了。
如何提取多个PDF页面就为大家分享完了,小伙伴们看完之后是
不是觉得PDF文件的编辑也没有很难,大家也可以根据上面文章中的步骤来进行编辑操作哦。
[文档可能无法思考全面,请浏览后下载,另外祝您生活愉快,工作顺利,万事如意!]。
提取pdf每一页中的身份信息的方法

提取pdf每一页中的身份信息的方法
提取PDF每一页中的身份信息是一个常见的需求,特别是当处理包含个人身份信息的文件时。
以下是一种有效的方法来提取PDF 每一页中的身份信息。
一、使用OCR技术
首先,您可以使用OCR(Optical Character Recognition)技术将PDF文件中的文本转换为可编辑的文本。
OCR工具可以将扫描件、图片中的文本识别为可编辑的文本,并将其保存为图像文件或文本文件。
这种方法对于提取身份信息非常有效,因为许多身份信息都以文本形式出现在图像文件中。
二、使用专门的PDF提取工具
如果您想从PDF文件中提取每一页的身份信息,可以考虑使用专门的PDF提取工具。
这些工具可以将PDF文件中的每一页提取出来,并将每一页中的文本转换为可编辑的文本。
这些工具通常具有高级功能,如OCR技术,可以帮助您更准确地提取身份信息。
三、手动提取
如果您不想使用专门的工具或OCR技术,也可以手动提取PDF 每一页中的身份信息。
这种方法需要您逐页查看PDF文件,并手动
识别和提取身份信息。
您可以使用截图工具或文本编辑器来提取文本,并手动进行识别和整理。
无论您选择哪种方法,确保在进行提取之前备份原始文件以防止意外数据丢失。
另外,处理含有个人身份信息的文件时,务必遵守相关的法律法规,确保合法合规地处理这些信息。
四、整合处理
在完成每一页的身份信息提取后,可以考虑将提取的数据进行整合处理,比如导入数据库或使用相关软件进行处理。
这样可以更方便地进行后续的数据分析和利用。
以上就是提取PDF每一页中的身份信息的一些方法,希望能对您有所帮助。
怎么从pdf中提取几页?一定要知道的技巧

网上下载文件很方便,但是也有很多不需要的,就比如下载的PDF文件,当我们只需要其中几页的时候该怎么办呢?怎么从PDF中提取几页呢?这几个技巧你一定要知道。
需要准备的有:电脑,PDF文件
方法一:【截取屏幕】
截取屏幕大家都不陌生,是我们很常用的功能之一
当然,大家最熟悉的还是Ctrl+Alt+A的截取屏幕的方法,可以进行简单的编辑。
方法是简单的,但是缺陷很明显,就是尺寸把握不好,还有就是截取屏幕之后的是以图片格式存在的,还需要把图片转换成PDF文件,就很麻烦
方法二:【迅捷 PDF转换器】
借助工具:迅捷PDF转换器
下载地址:https:///converter
软件介绍:这是一款可以对PDF文件进行各种操作的软件,不仅仅可以进行文件格式的转换,还可以对PDF进行一系列的操作,页面提取,分割合并等
步骤如下:
1.打开迅捷PDF转换器
2.选择PDF操作,点击PDF页面提取
3.添加文件,可以拖拽或者是点击添加文件,进行文件的添加
4.选择提取的页面,选择输出目录
5.点击开始提取
6.等待进度条完成后,提取就完成了
7.打开文件开一下效果
那么怎么从pdf中提取页面的方法,你懂了吗?。
PDF转TXT 提取PDF文件中文字的方法

我们都知道,在PDF文件中是不可以进行操作的,所以想要对文件中的内容进行操作编辑之类的,那么就需要将里面的文件进行提取,一般会用到PDF转TXT或是PDF OCR识别,下面就给大家讲解一下,如何使用这两种方法进行PDF文字提取
首先无论是使用哪种转换方法,我们都需要转换工具的帮助,在这里推荐大家使用的是“迅捷caj转换器”,专业的办公工具,支持多种文件格式相互转换
PDF转TXT
打开PDF文件,可以看到其中的内容是图文结合的
然后在迅捷caj转换器中,点击“PDF转TXT”的转换选项
将PDF文件上传到页面中,之后就可以开始转换了,
完成转换后,打开TXT文档,可以看到之前在PDF文件中的文字内容已经提取到TXT文档中了
PDF OCR识别
在迅捷caj转换其中,点击最后一个功能选项“更多操作”,然后选择里面的“PDF OCR识别”
将PDF文件上传到页面中,也可以进行多个文件批量上传转换
文件转换可以自由选择为Word或是TXT文档
最后点击开始转换,转换完成后,可以在Word文档中看到PDF文件
提取的文字。
acrobat pro dc 拆分大型 pdf 文件的技巧

acrobat pro dc 拆分大型 pdf 文件的技巧
拆分大型PDF文件的技巧有以下几种:
1. 使用“拆分文档”功能:在Adobe Acrobat Pro DC的“工具”菜单中,选择“打开”按钮,然后选择要拆分的PDF文件。
在“工具”菜单中,选择“页面”下的“拆分文档”,然后设置要拆分的页面范围,点击“拆分”按钮即可完成拆分。
2. 使用“提取页面”功能:在Adobe Acrobat Pro DC的“工具”菜单中,选择“打开”按钮,然后选择要拆分的PDF文件。
在“工具”菜单中,选择“页面”下的“提取”,然后设置要提取的页面范围,并选择一个文件夹保存拆分后的页面,最后点击“提取”按钮即可完成拆分。
3. 使用“分割PDF文件”功能:在Adobe Acrobat Pro DC的“文件”菜单中,选择“分割PDF文件”选项。
在弹出的对话框中,选择要拆分的PDF文件,设置拆分的方式(按页面数、文件大小、书签等)和范围,然后选择一个文件夹保存拆分后的文件,最后点击“分割”按钮即可完成拆分。
4. 使用命令行工具:Adobe Acrobat Pro DC还提供了命令行工具(AcroSplit),可以通过命令行方式拆分大型PDF文件。
具体的命令和参数可以在Adobe官方文档中找到。
需要注意的是,在拆分大型PDF文件时,建议先备份原始文件,以免意外操作导致文件丢失或损坏。
另外,拆分后的小文件可能会包含部分共享元数据和设置,如果需要完全独立的文
件,可以选择在保存拆分后的文件时,选择"作为新文件保存"选项。
福昕pdf截取其中几页

福昕pdf截取其中几页在现代社会,电子文档的使用越来越广泛,而PDF作为一种常见且易于传播的电子文档格式,备受人们喜爱。
福昕PDF阅读器作为一款常见的PDF阅读软件,具有丰富的功能,其中包括截取PDF文件中的部分页面。
本文将介绍如何使用福昕PDF截取其中几页的操作步骤,并提供一些相关的小贴士。
首先,确保你已经安装了最新版本的福昕PDF阅读器,并将需要截取页面的PDF文件准备好。
接下来,按照以下步骤进行操作:步骤一:打开PDF文件在电脑上找到你要截取页面的PDF文件,双击打开,系统会默认使用福昕PDF阅读器进行打开。
步骤二:选择截取工具在福昕PDF阅读器的界面上方工具栏中,找到"截取"按钮,并点击打开。
选择工具栏中的"截取页面"按钮。
步骤三:设置截取范围当你点击了"截取页面"按钮后,你的鼠标会变成一个十字准星的形状。
此时,你可以在页面上任意拖动鼠标,划定想要截取的页面范围。
可以通过调整拖动框的大小和位置来精确选择。
步骤四:确认截取页面在你完成了页面范围的选择之后,可以点击鼠标右键,选择"复制选择内容到剪贴板"进行确认。
此时,所选页面会被复制到系统的剪贴板中。
步骤五:粘贴截取页面打开你喜欢编辑或粘贴的工具,例如Microsoft Word文档或是其他的文本编辑软件,然后点击鼠标右键,选择"粘贴"(或者使用快捷键Ctrl+V)将截取的页面粘贴到文档中。
通过以上五个步骤,你就可以使用福昕PDF阅读器准确截取PDF文件中的部分页面。
下面是一些小贴士,可以帮助你更好地使用这个功能:1. 调整截取页面的范围时,可以按住Shift键来保持截取框的纵横比例,避免页面变形。
2. 如果你只需要截取连续的多个页面,可以先选择第一个页面,然后按住Shift键选择最后一个页面,这样可以一次性截取多个连续页面。
3. 截取的页面可以直接粘贴到其他编辑工具中,例如Microsoft Word、PowerPoint或是其他的图像编辑软件中,方便进行编辑和调整。
从pdf文件中提取数据的方法

从PDF文件中提取数据的方法一、引言PDF文件以其跨平台、易于阅读和传输的特点,已成为数据存储和交换的重要格式。
然而,由于PDF文件的封闭性,直接从中提取数据并非易事。
本文将详细介绍从PDF文件中提取数据的方法,以帮助用户高效地获取所需信息。
二、方法1.使用文本识别软件:对于包含可文本内容的PDF,可以使用OCR(Optical Character Recognition,光学字符识别)软件进行转换。
这类软件能够将PDF中的图像内容转化为可编辑的文本格式,方便用户提取数据。
常用的OCR软件有Adobe Acrobat、ABBYY FineReader 等。
2.使用PDF编辑软件:对于某些PDF文件,尤其是那些可编辑的PDF,我们可以直接使用PDF编辑软件(如Adobe Acrobat)来手动选择和复制所需的数据。
3.使用Python脚本:Python提供了许多库,如PyPDF2和PDFMiner,可以用来解析和提取PDF文件中的数据。
这些库可以解析PDF的结构,提取文本、图像和其他元素。
4.使用命令行工具:对于那些熟悉命令行的用户,有一些命令行工具可用于提取PDF数据。
例如,pdftk、pdfgrep和pdftohtml等工具可以用来处理PDF文件。
5.网络服务:有一些在线服务,如Google Drive、Microsoft OneDrive等,提供了从PDF中提取数据的功能。
用户只需上传PDF 文件,网站就会自动提取其中的数据。
三、注意事项1.数据准确性:在使用OCR软件时,需要注意软件的准确性。
虽然大多数情况下OCR能提供准确的结果,但也可能出现识别错误的情况。
因此,在提取数据后需要进行校验。
2.PDF格式:不同的PDF文件格式会影响提取数据的难度。
例如,可编辑的PDF文件通常比扫描的PDF文件更容易提取数据。
3.版权问题:在提取和使用PDF中的数据时,需要注意版权问题。
如果所使用的PDF文件包含受版权保护的内容,那么在提取和使用这些数据时需要遵守相关的版权法律。
如何将PDF文件中的某几页提取出来

如何将PDF⽂件中的某⼏页提取出来
如何将PDF⽂件中的某⼏页提取出来
当我们从⽹上下载⼀份PDF⽂件时,会发现很多内容都不是我们需要的,只有其中的某⼏页对我们有⽤,这个时候就需要对⽂件进⾏页⾯提取,那么我们如何将PDF⽂件中的某⼏页提取出来呢?
下⾯就分享⼀个页⾯提取的⽅法,感兴趣的可以⼀起来学习⼀下。
1.在百度中搜索迅捷PDF转换器,找到之后下载并安装到电脑中。
2.打开安装完成的软件,找到操作界⾯中的PDF的其他操作,然后点击PDF页⾯提取。
3.然后将PDF⽂件添加进⼊操作界⾯,点击或拖拽⽂件添加即可。
4.⽂件选择好之后,⾃动跳转到操作界⾯,有⼤、中、⼩三种查看⽂件的⽅式,⿏标移动到⽂件页⾯上可进⾏删除和旋转操作。
5.然后点击范围提取按钮,弹出⼀个页⾯范围选择框,输⼊要提取的页⾯,再点击开始提取即可。
6.最后就可以在相应的PDF阅读器⾥查看提取完成的⽂件了。
如何将PDF⽂件中的某⼏页提取出来的⼩⽅法有帮助到你吗?需要的⼩伙伴不妨试⼀试,⽅法很简单,让有⽤的⽂件迅速提取出来⽅便查看。
pymupdf提取指定区域文字

pymupdf提取指定区域文字要使用PyMuPDF提取指定区域的文字,你可以按照以下步骤进行操作:1. 首先,确保你已经安装了PyMuPDF库。
你可以使用以下命令在终端或命令提示符中安装它:pip install pymupdf2. 导入所需的库和模块:python复制代码:import fitz # 导入PyMuPDF库3. 打开PDF文件并选择要提取文字的页面:python复制代码:pdf_file = "path/to/your/pdf/file.pdf" # 替换为你的PDF文件路径pdf_doc = fitz.open(pdf_file) # 打开PDF文件page = pdf_doc[0] # 选择第一页,你可以根据需要选择其他页面4. 定义要提取文字的区域。
你可以使用fitz.Rect类创建一个矩形区域,指定左上角的坐标和右下角的坐标。
例如,要提取页面左下角的一部分区域,你可以这样做:python复制代码:rect = page.rect # 获取页面的矩形区域clip = fitz.Rect(0, 0.87 * rect.height, rect.width * 0.8, rect.height) # 定义要提取的区域5. 使用getPageText方法提取指定区域的文字:python复制代码:text = page.getText(clip=clip) # 提取指定区域的文字print(text) # 打印提取的文字完整的示例代码如下:python复制代码:import fitz # 导入PyMuPDF库pdf_file = "path/to/your/pdf/file.pdf" # 替换为你的PDF文件路径pdf_doc = fitz.open(pdf_file) # 打开PDF文件page = pdf_doc[0] # 选择第一页,你可以根据需要选择其他页面rect = page.rect # 获取页面的矩形区域clip = fitz.Rect(0, 0.87 * rect.height, rect.width * 0.8, rect.height) # 定义要提取的区域text = page.getText(clip=clip) # 提取指定区域的文字print(text) # 打印提取的文字请确保将path/to/your/pdf/file.pdf替换为你实际的PDF 文件路径。
VBA与PDF文件的交互与数据提取方法与实例

VBA与PDF文件的交互与数据提取方法与实例VBA(Visual Basic for Applications)是一种用于自动化Microsoft Office应用程序的编程语言,它可以帮助我们在Excel、Word等应用软件中进行各种自定义操作。
在实际应用中,我们常常需要与PDF文件进行交互,并且从中提取数据。
本文将介绍使用VBA与PDF文件交互的方法,并提供一些实例来演示如何使用VBA从PDF文件中提取数据。
一、VBA中使用Acrobat对象实现PDF交互Adobe Acrobat是一款流行的用于创建、编辑和查看PDF文件的软件。
在VBA中,我们可以通过创建和操作Acrobat对象来实现与PDF文件的交互。
以下是一些常用的操作:1. 打开PDF文件:使用`CreateObject`函数创建Acrobat对象,并使用`Open`方法打开PDF文件。
```vbaSub OpenPDF()Dim AcroApp As ObjectDim Part1 As ObjectSet AcroApp = CreateObject("AcroExch.App")Set Part1 = AcroApp.GetAVDoc("C:\example.pdf")Part1.Open TrueEnd Sub```2. 导出PDF页面为图片:使用`ExportAsFixedFormat`方法将PDF页面以图片格式保存。
```vbaSub ExportPDFAsImage()Dim AcroApp As ObjectDim Part1 As ObjectSet AcroApp = CreateObject("AcroExch.App")Set Part1 = AcroApp.GetAVDoc("C:\example.pdf")Part1.Open TruePart1.PDDoc.ExportAsFixedFormat 0, "C:\example.jpg", 0,Part1.PDDoc.GetNumPages - 1End Sub```3. 提取PDF文本:使用`GetAVDoc`方法获取文档对象,通过`GetPDDoc`方法获取PDDoc对象,使用PDDoc对象的`GetPageContent`方法获取PDF页面内容。
PDF页面的提取该怎么操作
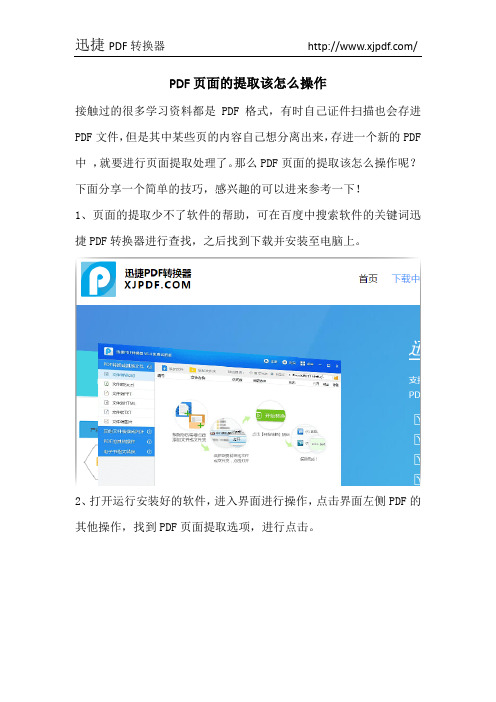
PDF页面的提取该怎么操作
接触过的很多学习资料都是PDF格式,有时自己证件扫描也会存进PDF文件,但是其中某些页的内容自己想分离出来,存进一个新的PDF 中,就要进行页面提取处理了。
那么PDF页面的提取该怎么操作呢?下面分享一个简单的技巧,感兴趣的可以进来参考一下!
1、页面的提取少不了软件的帮助,可在百度中搜索软件的关键词迅捷PDF转换器进行查找,之后找到下载并安装至电脑上。
2、打开运行安装好的软件,进入界面进行操作,点击界面左侧PDF 的其他操作,找到PDF页面提取选项,进行点击。
3、之后将PDF文件添加到要处理的界面中,点击或拖拽文件即可进行文件添加。
4、之后就可以跳转到操作页面了,对文件的查看它提供了三种形式,分别为大、中、小。
鼠标放至页面上时,会显示删除按钮,还可以实
现旋转页面的操作。
5、之后点击界面右下方的范围提取按钮,会弹出一个选项框,然后选择需要提取的页面,点击开始提取即可。
6、之后就可以至源文件中点击查看提取好的PDF文件页面。
上述就是PDF页面的提取该怎么操作的操作过程,如有需要的小伙伴可以按照这个方法来进行操作哦!。
将PDF文档中的每一个单独提取为一个PDF文件

将PDF文档中的每一个单独提取为一个PDF文件1.存在问题日常工作中,经常碰到一些PDF文档,页面数量较大,需要将每一页单独提炼为PDF 文档,并按相关的规定来命名,如果用PDF编辑软件进行一页页提炼并命名,工作量太大,因为如何通过VBA代码来实现这种重复性工作,具体想法为执行代码后弹出对话框,选择要一页页提取PDF的文档,可以多选几个PDF文档,然后将选中的文档进行一页页提取并命名。
2.具体操作步骤这段代码实现了将选定的多个PDF文件中的每一页提取并保存为单独的PDF文件。
以下是该代码的操作步骤:创建文件对话框并选择PDF文件:代码通过创建文件对话框,让用户选择一个或多个要处理的PDF文件。
选择的文件路径将被存储到一个数组中。
如果没有选择任何文件,则会显示提示信息并退出子程序。
创建Acrobat应用程序对象:使用CreateObject("AcroExch.App")方法创建Acrobat应用程序对象,用于后续的PDF 文件操作。
处理每个选定的PDF文件:使用For Each循环遍历用户选择的每个PDF文件。
通过AcroExch.A VDoc对象打开PDF文档,并获取PDDoc对象和JavaScript对象,用于操作PDF文件内容。
获取PDF的总页数,准备提取页面。
提取每一页并保存为单独的PDF文件:使用For循环遍历每一页,将每页单独提取并保存为单独的PDF文件。
输出文件的命名格式为“原文件名_页码.pdf”。
关闭当前PDF文档:在完成对当前PDF文档的操作后,关闭该文档以释放资源。
退出Acrobat应用程序:处理完所有文件后,退出Acrobat应用程序并清除所有对象以释放内存。
显示提取完成提示:提取操作完成后,显示一个提示信息框,告知用户页面提取已完成。
3.源代码。
pdf提取表格 python

在Python中,提取PDF文件中的表格需要使用一些库。
最常用的库是tabula-py 和PyPDF2。
以下是一个使用tabula-py的示例代码:
python复制代码
from tabula import read_pdf
# 读取PDF文件中的所有表格
tables = read_pdf("example.pdf", pages="all")
# 打印第一个表格的内容
print(tables[0])
在上面的代码中,我们首先导入了tabula-py库。
然后,我们使用read_pdf()函数读取PDF文件中的所有表格。
pages参数可以设置为要提取的页码或页面范围。
最后,我们打印第一个表格的内容。
如果您只想提取特定页码的表格,可以将pages参数设置为所需的页码。
例如,要提取第3页的表格,可以将pages参数设置为"3"。
如果您需要提取多个表格,可以使用循环遍历所有表格并处理它们。
例如:python复制代码
from tabula import read_pdf
# 读取PDF文件中的所有表格
tables = read_pdf("example.pdf", pages="all")
# 遍历所有表格并处理它们
for table in tables:
# 处理表格数据(例如,将数据写入CSV文件)
pass
在上面的代码中,我们使用循环遍历所有表格并处理它们。
您可以根据需要自定义处理每个表格的代码。
pdf 提取 表格

pdf 提取表格
要提取PDF中的表格,可以使用以下几种方法:
1. 使用在线工具:有一些免费的在线PDF转表格工具可以直接将PDF文件转换为Excel或CSV格式的表格。
只需上传PDF文件,选择转换格式,然后下载即可。
2. 使用专门的PDF工具:有些PDF处理软件(如Adobe Acrobat Pro)提供了表格识别功能,可以自动检测PDF中的表格,并将其转换为编辑或导出表格格式。
3. 使用Python编程进行表格提取:可以使用Python中的一些库(如Tabula、PDFMiner、PyPDF2等)来读取PDF文件并提取其中的表格数据,然后保存为Excel或CSV格式。
无论使用哪种方法,提取表格时可能会遇到一些挑战,例如表格中的特殊格式、合并单元格等。
因此,提取表格前最好先预览PDF文件,了解其中的表格结构和特点,然后选择适当的方法进行提取。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PDF文件页面可以怎么提取 PDF页面提取方法说起PDF格式我们大概都知道,它作为我们常用的文档格式之一我们平常将一些重要的文件保存为PDF的格式,但有时候我们对PDF 文件里的页面进行提取这可能大部分人都不会,在这里我教给大家一个提取PDF文件页面的方法。
如下:
1、进行文件格式的转换,首先我们需要借助于辅助工具,在百度浏览器上搜索PDF转换器,点击下载到电脑桌面。
2、打开PDF转换器后,在左侧存在一个栏目框,鼠标移动到栏目PDF 其它操作,打开这个栏目页后点击选择子类目PDF页面提取。
3、接着我们可以点击添加文件按钮,添加需要进行提取页面的PDF 文件,点击打开或者直接拖拽PDF文件到转换框内。
4、文件添加成功后,进入另一个页面。
在页面顶端设置文件保存路径,选择点击原文件或者自定义,进入浏览框设置路径。
5、设置好保存路径后,在下方勾选需要转换的页面,完成以上步骤基本上完成了,点击右下角开始转换按钮。
以上五个步骤就是如何提取PDF页面的方法了。