hadoop 2.6.0详细安装过程和实例(有截图)
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
centos下hadoop2.6.0配置

Hadoop-2.6.0配置前面的部分跟配置Hadoop-1.2.1的一样就可以,什么都不用变,完全参考文档1即可。
下面的部分就按照下面的做就可以了。
hadoop-2.6.0的版本用张老师的。
下面的配置Hadoop hadoop-2.6.0的部分1.修改hadoop-2.6.0/etc/hadoop/hadoop-env.sh,添加JDK支持:export JAVA_HOME=/usr/java/jdk1.6.0_45如果不知道你的JDK目录,使用命令echo $JAVA_HOME查看。
2.修改hadoop-2.6.0/etc/hadoop/core-site.xml注意:必须加在<configuration></configuration>节点内<configuration><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-2.6.0/tmp</value><description>Abase for other temporary directories.</description></property><property><name></name><value>hdfs://master:9000</value></property></configuration>3.修改hadoop-2.6.0/etc/hadoop/hdfs-site.xml<property><name>.dir</name><value>/home/hadoop/hadoop-2.6.0/dfs/name</value><description>Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently.</description></property><property><name>dfs.data.dir</name><value>/home/hadoop/hadoop-2.6.0/dfs/data</value><description>Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.</description></property><property><name>dfs.replication</name><value>1</value></property>4.修改hadoop-2.6.0/etc/hadoop/mapred-site.xml<property><name>mapred.job.tracker</name><value>master:9001</value><description>Host or IP and port of JobTracker.</description></property>5. 修改hadoop-2.6.0/etc/hadoop/masters列出所有的master节点:master6.修改hadoop-2.6.0/etc/hadoop/slaves这个是所有datanode的机器,例如:slave1slave2slave3slave47.将master结点上配置好的hadoop文件夹拷贝到所有的slave结点上以slave1为例:命令如下:scp -r ~/hadoop-2.6.0slave1:~/安装完成后,我们要格式化HDFS然后启动集群所有节点。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
简单梳理hadoop安装流程文字

简单梳理Hadoop安装流程
今儿个咱们来简单梳理下Hadoop的安装流程,让各位在四川的兄弟姐妹也能轻松上手。
首先,你得有个Linux系统,比如说CentOS或者Ubuntu,这点很重要。
然后在系统上整个Java环境,Hadoop 是依赖Java运行的。
把JDK下载安装好后,记得配置下环境变量,就是修改`/etc/profile`文件,把Java的安装路径加进去。
接下来,你需要在系统上整个SSH服务,Hadoop集群内部的通信要用到。
安好SSH后,记得配置下无密钥登录,省得每次登录都要输密码,多麻烦。
Hadoop的安装包可以通过官方渠道下载,也可以在网上找现成的。
下载好安装包后,解压到你的安装目录。
然后就开始配置Hadoop的环境变量,跟配置Java环境变量一样,也是在
`/etc/profile`文件里加路径。
配置Hadoop的文件是重点,都在Hadoop安装目录下的`etc/hadoop`文件夹里。
有`hadoop-env.sh`、`core-site.xml`、`hdfs-site.xml`这些文件需要修改。
比如`core-site.xml`里要设置HDFS的地址和端口,`hdfs-site.xml`里要设置临时目录这些。
最后,就可以开始格式化HDFS了,用`hdfs namenode-format`命令。
然后启动Hadoop,用`start-all.sh`脚本。
如果一
切配置正确,你就可以用`jps`命令看到Hadoop的各个进程在运行了。
这整个过程看似复杂,但只要你跟着步骤来,注意配置文件的路径和内容,相信你也能轻松搞定Hadoop的安装。
Hadoop的安装与配置及示例wordcount的运行

Hadoop的安装与配置及示例程序wordcount的运行目录前言 (1)1 机器配置说明 (2)2 查看机器间是否能相互通信(使用ping命令) (2)3 ssh设置及关闭防火墙 (2)1)fedora装好后默认启动sshd服务,如果不确定的话可以查一下[garon@hzau01 ~]$ service sshd status (3)2)关闭防火墙(NameNode和DataNode都必须关闭) (3)4 安装jdk1.6(集群中机子都一样) (3)5 安装hadoop(集群中机子都一样) (4)6 配置hadoop (4)1)配置JA V A环境 (4)2)配置conf/core-site.xml、conf/hdfs-site.xml、conf/mapred-site.xml文件 (5)3)将NameNode上完整的hadoop拷贝到DataNode上,可先将其进行压缩后直接scp 过去或是用盘拷贝过去 (7)4)配置NameNode上的conf/masters和conf/slaves (7)7 运行hadoop (7)1)格式化文件系统 (7)2)启动hadoop (7)3)用jps命令查看进程,NameNode上的结果如下: (8)4)查看集群状态 (8)8 运行Wordcount.java程序 (8)1)先在本地磁盘上建立两个文件f1和f2 (8)2)在hdfs上建立一个input目录 (9)3)将f1和f2拷贝到hdfs的input目录下 (9)4)查看hdfs上有没有f1,f2 (9)5)执行wordcount(确保hdfs上没有output目录) (9)6)运行完成,查看结果 (9)前言最近在学习Hadoop,文章只是记录我的学习过程,难免有不足甚至是错误之处,请大家谅解并指正!Hadoop版本是最新发布的Hadoop-0.21.0版本,其中一些Hadoop命令已发生变化,为方便以后学习,这里均采用最新命令。
hadoop2.6完全分布式安装

系统准备Hadoop完全分布式安装,服务器最好都是基数,我用了三台虚拟机。
hadoop2.6.0完全分布式masterhadoop2.6.0完全分布式salves01hadoop2.6.0完全分布式salves02系统环境设置修改虚拟机的主机名称代码如下:1、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=masterGAREWAY=192.168.83.22、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves01GAREWAY=192.168.83.23、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves02GAREWAY=192.168.83.2配置IP地址1、修改第一台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.100GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.22、修改第二台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.101GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.23、修改第三台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.102GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.2service network restart //使配置的ip起作用修改主机名和IP的映射关系以及其他虚拟机的关系(hosts)vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.83.100 master192.168.83.101 salves01192.168.83.102 salves02三台虚拟机都需要配置,三台虚拟机的hosts一样关闭防火墙三台虚拟机都需要关闭防火墙重启系统安装jdk准备jdk在网上下载64位的jdk,下载好了之后上传到虚拟机中在Ubuntu下切换到root用户解压jdk(jdk-7u55-linux-x64.tar.gz)代码如下:配置坏境变量代码如下:重启/etc/profile代码如下:查看是否配置成功(jdk的版本) java –version统默认自己配置的jdk代码如下:配置ssh免密码登录代码如下:ssh-keygen -t rsa//创建keycat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys//把key写在authorized_keys中ll ~/.ssh/authorized_keys//查看是否有这个文件chmod 600 authorized_keys//给这个文件赋予权限ssh localhost //执行切换,看是否是免密码登录把三台服务器中的id_rsa.pub(key),分别加入三台服务器中的authorized_keys文件中,打通三台服务器免密码登录。
hadoop 2.6.0详细安装过程和实例(有截图)

Hadoop 环境搭建时间:2015—07—26作者:周乐相环境搭建之前准备工作我的笔记本配置:硬盘:500G (实际上用不完)CPU: Intel(R) Core(TM)i5-2450M CPU @ 2。
50GHz内存:10G操作系统:WIN7 (64位)软件准备1)。
虚拟机软件:vmwareworkstation64.exe (VMware work station 64 bit V 11。
0)2). Linux 版本: Red Hat Enterprise Linux Server release 6.5 (Santiago)(rhel-server-6.5—x86_64-dvd.iso)3). hadoop 版本: hadoop—2.6。
0。
tar。
gz4)。
JAVA 版本:java version "1。
6.0_32" (jdk—6u32-linux-x64.bin)安装VMware 软件傻瓜操作下一步。
安装Linux操作系统傻瓜操作下一步。
...。
安装完成.1)。
创建hadoop操作系统安装hadoop的用户第一台操作系统命主机名为: master2) 拷贝该虚拟机master 分别为node01 、node02 两个节点数3)分别对拷贝的node01 、node02 修改IP和主机名称主机名: IPmaster : 192。
168.2。
50node01: 192.168.2.51node02: 192。
168.2.52jdk安装并设置好环境变量##设置JAVA_HOME环境变量配置ssh 免密码通信三台服务器SSH关系上面这个图可以表达这三台服务器之间的关系.对master主节点SSH配置执行:ssh-keygen –t dsa 回车一直回车下去会在$HOME/。
ssh目录生成id_dsa 和id_dsa.pub两个文件将id_dsa。
pub文件放到authorized_keys文件,注意需要修改权限chmod 600 authorized_keys依次将node01、node02两台的密码追加到authorized_keys 文件里面对node01节点SSH配置这样master与node01就可以正常的互通无需密码对node02节点SSH配置这样master与node02就可以正常的互通无需密码Hadoop安装配置修改配置文件用红线框起来的都需要修改配置修改:mapred-site。
(完整word版)Hadoop 2.6.0分布式部署参考手册

Hadoop 2。
6.0分布式部署参考手册1。
环境说明 (2)1。
1安装环境说明 (2)2。
2 Hadoop集群环境说明: (2)2。
基础环境安装及配置 (2)2.1 添加hadoop用户 (2)2.2 JDK 1.7安装 (2)2.3 SSH无密码登陆配置 (3)2.4 修改hosts映射文件 (3)3.Hadoop安装及配置 (4)3.1 通用部分安装及配置 (4)3。
2 各节点配置 (4)4。
格式化/启动集群 (4)4.1 格式化集群HDFS文件系统 (4)4。
2启动Hadoop集群 (4)附录1 关键配置内容参考 (5)1 core-site.xml (5)2 hdfs-site。
xml (5)3 mapred—site.xml (6)4 yarn-site。
xml (6)5 hadoop-env。
sh (6)6 slaves (6)附录2 详细配置内容参考 (7)1 core-site.xml (7)2 hdfs-site.xml (7)3 mapred—site。
xml (8)4 yarn-site。
xml (9)5 hadoop-env。
sh (12)6 slaves (12)附录3 详细配置参数参考 (12)conf/core—site.xml (12)conf/hdfs-site。
xml (12)o Configurations for NameNode: (12)o Configurations for DataNode: (13)conf/yarn—site。
xml (13)o Configurations for ResourceManager and NodeManager: (13)o Configurations for ResourceManager: (13)o Configurations for NodeManager: (15)o Configurations for History Server (Needs to be moved elsewhere): 16 conf/mapred—site.xml (16)o Configurations for MapReduce Applications: (16)o Configurations for MapReduce JobHistory Server: (16)1。
(完整版)Hadoop安装教程_伪分布式配置_CentOS6.4_Hadoop2.6.0

Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0都能顺利在CentOS 中安装并运行Hadoop。
环境本教程使用CentOS 6.4 32位作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS)。
如果用的是Ubuntu 系统,请查看相应的Ubuntu安装Hadoop教程。
本教程基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1, Hadoop 2.4.1等。
Hadoop版本Hadoop 有两个主要版本,Hadoop 1.x.y 和Hadoop 2.x.y 系列,比较老的教材上用的可能是0.20 这样的版本。
Hadoop 2.x 版本在不断更新,本教程均可适用。
如果需安装0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
新版是兼容旧版的,书上旧版本的代码应该能够正常运行(我自己没验证,欢迎验证反馈)。
装好了CentOS 系统之后,在安装Hadoop 前还需要做一些必备工作。
创建hadoop用户如果你安装CentOS 的时候不是用的“hadoop” 用户,那么需要增加一个名为hadoop 的用户。
首先点击左上角的“应用程序” -> “系统工具” -> “终端”,首先在终端中输入su,按回车,输入root 密码以root 用户登录,接着执行命令创建新用户hadoop:如下图所示,这条命令创建了可以登陆的hadoop 用户,并使用/bin/bash 作为shell。
CentOS创建hadoop用户接着使用如下命令修改密码,按提示输入两次密码,可简单的设为“hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:如下图,找到root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:为hadoop增加sudo权限添加上一行内容后,先按一下键盘上的ESC键,然后输入:wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
Hadoop的安装与环境搭建教程图解
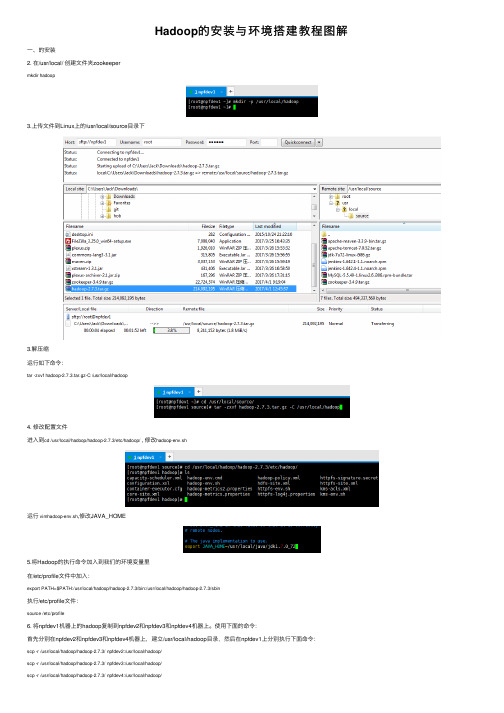
Hadoop的安装与环境搭建教程图解⼀、的安装2. 在/usr/local/ 创建⽂件夹zookeepermkdir hadoop3.上传⽂件到Linux上的/usr/local/source⽬录下3.解压缩运⾏如下命令:tar -zxvf hadoop-2.7.3.tar.gz-C /usr/local/hadoop4. 修改配置⽂件进⼊到cd /usr/local/hadoop/hadoop-2.7.3/etc/hadoop/ , 修改hadoop-env.sh运⾏vimhadoop-env.sh,修改JAVA_HOME5.将Hadoop的执⾏命令加⼊到我们的环境变量⾥在/etc/profile⽂件中加⼊:export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin执⾏/etc/profile⽂件:source /etc/profile6. 将npfdev1机器上的hadoop复制到npfdev2和npfdev3和npfdev4机器上。
使⽤下⾯的命令:⾸先分别在npfdev2和npfdev3和npfdev4机器上,建⽴/usr/local/hadoop⽬录,然后在npfdev1上分别执⾏下⾯命令:scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev2:/usr/local/hadoop/scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev3:/usr/local/hadoop/scp -r /usr/local/hadoop/hadoop-2.7.3/ npfdev4:/usr/local/hadoop/记住:需要各⾃修改npfdev2和npfdev3和npfdev4的/etc/profile⽂件:在/etc/profile⽂件中加⼊:export PATH=$PATH:/usr/local/hadoop/hadoop-2.7.3/bin:/usr/local/hadoop/hadoop-2.7.3/sbin执⾏/etc/profile⽂件:source /etc/profile然后分别在npfdev1和npfdev2和npfdev3和npfdev4机器上,执⾏hadoop命令,看是否安装成功。
hadoop安装流程

hadoop安装流程Hadoop是一种开源的分布式数据处理框架,它的出现极大地简化了大数据处理的流程,成为了数据科学家们的有力工具。
在使用Hadoop之前,需要先完成其安装,在这里,我们将详细阐述Hadoop的安装流程。
第一步:下载Hadoop。
在Hadoop官网上,可以找到最新的Hadoop版本,选择合适的版本后进行下载。
下载完成后,需要进行解压操作,可以使用命令tar -zxvf xxxx.tar.gz 进行解压,其中xxxx 为Hadoop的安装包名称。
第二步:配置环境变量。
完成解压后,需要设置环境变量。
在bashrc文件中配置,export HADOOP_HOME=/usr/local/hadoopexport PATH=$HADOOP_HOME/bin:$PATHexport CLASSPATH=$HADOOP_HOME/lib/*:$CLASSPATH最后执行命令source ~/.bashrc,让环境变量立刻生效。
第三步:修改配置文件。
进入解压后文件夹中的/etc/hadoop文件夹,将其中的core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml配置文件进行修改。
以core-site.xml为例,需要加入以下内容:<property><name></name><value>hdfs://localhost:9000</value></property>以hdfs-site.xml为例,需要加入以下内容:<property><name>dfs.replication</name><value>1</value></property><property><name>.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</valu e></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</valu e></property>以mapred-site.xml为例,需要加入以下内容:<property><name></name><value>yarn</value></property>以yarn-site.xml为例,需要加入以下内容:<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>第四步:格式化NameNode。
hadoop安装指南(非常详细,包成功)

➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
Hadoop详细安装配置过程

1.下载并安装安装sshsudo apt-get install openssh-server openssh-client3.搭建vsftpd#sudo apt-get update#sudo apt-get install vsftpd配置参考???????????????????的开始、关闭和重启$sudo /etc/vsftpd start?? #开始$sudo /etc/vsftpd stop??? #关闭$sudo /etc/vsftpd restart?? #重启4.安装sudo chown -R hadoop:hadoop /optcp /soft/ /optsudo vi /etc/profilealias untar='tar -zxvf'sudo source /etc/profilesource /etc/profileuntar jdk*环境变量配置# vi /etc/profile●在profile文件最后加上# set java environmentexport JAVA_HOME=/opt/export CLASSPATH=.:$JAVA_HOME/lib/:$JAVA_HOME/lib/export PATH=$JAVA_HOME/bin:$PATH配置完成后,保存退出。
●不重启,更新命令#source /etc/profile●测试是否安装成功# Java –version?其他问题:出现unable to resolve host 解决方法参考??开机时停在 Starting sendmail 不动了的解决方案参考? 安装软件时出现 E: Unable to locate package vsftpd 参考? vi/vim 使用方法讲解--------------------------------------------克隆master虚拟机至node1 、node2分别修改master的主机名为master、node1的主机名为node1、node2的主机名为node2 (启动node1、node2系统默认分配递增ip,无需手动修改)分别修改/etc/hosts中的ip和主机名(包含其他节点ip和主机名)---------配置ssh免密码连入hadoop@node1:~$ ssh-keygen -t dsa -P ''-f ~/.ssh/id_dsaGenerating public/private dsa key pair.Created directory '/home/hadoop/.ssh'.Your identification has been saved in/home/hadoop/.ssh/id_dsa.Your public key has been saved in/home/hadoop/.ssh/.The key fingerprint is:SHA256:B8vBju/uc3kl/v9lrMqtltttttCcXgRkQPbVoU hadoop@node1The key's randomart image is:+---[DSA 1024]----+|....|| o+.E .||. oo +||..++||o +. o ooo +||=o.. o. ooo. o.||*o....+=o .+++.+|+----[SHA256]-----+hadoop@node1:~$ cd .sshhadoop@node1:~/.ssh$ ll总用量16drwx------ 2 hadoop hadoop 4096 Jul 24 20:31 ./drwxr-xr-x 18 hadoop hadoop 4096 Jul 2420:31../-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31hadoop@node1:~/.ssh$ cat >> authorized_keyshadoop@node1:~/.ssh$ ll总用量20drwx------ 2 hadoop hadoop 4096 Jul 24 20:32 ./drwxr-xr-x 18 hadoop hadoop 4096 Jul 2420:31../-rw-rw-r-- 1 hadoop hadoop 602 Jul 24 20:32 authorized_keys-rw------- 1 hadoop hadoop 668 Jul 24 20:31 id_dsa-rw-r--r-- 1 hadoop hadoop 602 Jul 24 20:31单机回环ssh免密码登录测试hadoop@node1:~/.ssh$ ssh localhostThe authenticity of host'localhost ()' can't be established.ECDSA key fingerprint is SHA256:daO0dssyqt12tt9yGUauImOh6tt6A1SgxzSfSmpQqJVEiQTxas.Are you sure you want to continue connecting (yes/no) yesWarning: Permanently added 'localhost'(ECDSA)to the list of known hosts.Welcome to Ubuntu (GNU/Linux x86_64)* Documentation: packages can be updated.178 updates are security updates.New release' LTS' available.Run 'do-release-upgrade'to upgrade to it.Last login: Sun Jul 2420:21:392016fromhadoop@node1:~$ exit注销Connection to localhost closed.hadoop@node1:~/.ssh$出现以上信息说明操作成功,其他两个节点同样操作让主结点(master)能通过SSH免密码登录两个子结点(slave)hadoop@node1:~/.ssh$ scp hadoop@master:~/.ssh/./The authenticity of host'master ()' can't be established.ECDSA key fingerprint is SHA256:daO0dssyqtt9yGUuImOh646A1SgxzSfatSmpQqJVEiQTxas.Are you sure you want to continue connecting (yes/no) yesWarning: Permanently added 'master,'(ECDSA)to the list of known hosts.hadoop@master's password:100%603 s 00:00 hadoop@node1:~/.ssh$ cat >> authorized_keys如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。
CentOS(64位)环境下Hadoop2.6.0分布式部署说明

1,准备工作1,部署CentOS 7.0(64位)环境;需配置静态IP地址。
1),设置虚拟机网络。
首先打开本机的”打开网络和共享中心”:选择打开”本地连接”,并点击”属性”,勾选”允许其他网络用户通过此计算机的Internet连接来连接”,从下拉框中选择”VMware Network Adapter VMnet8”:虚拟机菜单->编辑->虚拟网络编辑:选择WMnet8 (NAT模式)设置静态IP地址,进入CentOS系统,打开”系统工具”->”设置”->”网络”,选择”手动”,输入IP地址,地址和网关参考上图的子网IP及网关设置。
设置完毕之后,再开启就可以发现网络IP地址已经变为设置后的地址。
测试网络是否连通:2),设置主机名。
在root下,打开/etc/hostname改为namenode,保存。
2,Hadoop -2.6.0 下载,下载地址:/hadoop/common/hadoop-2.6.0/ 2,安装Java1),搜索jdk开发环境yum search jdk2),安装jdkyum install java-1.8.0-openjdk-devel.x86_643),检查是否安装成功java -version可以看见当前的jdk版本已经是”1.8.0_91”。
表示已经安装成功。
3,安装Hadoop1),将第一步下载的hadoop版本安装包上传至/usr/local/ 文件夹,并解压。
cd /usr/localgunzip hadoop-2.6.0.tar.gztar -xvf hadoop-2.6.0.tar2),配置环境打开/etc/profile在文件的最后位置,追加上如下配置:#set java environmentexport JAVA_HOME=/usr/lib/jvm/javaexport JRE_HOME=$JAVA_HOME/jreexport P ATH=$P ATH:$JAVA_HOME/binexport CLASSP ATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport HADOOP_HOME=/usr/local/hadoop-2.6.0export HADOOP_CONF_DIR=/usr/local/hadoop-2.6.0/etc/hadoop export YARN_CONF_DIR=/usr/local/hadoop-2.6.0/etc/hadoopexport P ATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$P ATH3),激活配置source /etc/profile4),创建hdfs相关目录mkdir /home/hadoop/hd_space/tmp -pmkdir /home/hadoop/hd_space/hdfs/name -pmkdir /home/hadoop/hd_space/hdfs/data -pmkdir /home/hadoop/hd_space/mapred/local -pmkdir -p /home/hadoop/hd_space/mapred/systemchown -R hadoop:hadoop /home/hadoop/hd_space/chown -R hadoop:hadoop /usr/local/hadoop-2.6.04,虚拟机克隆1),选择菜单栏中的“虚拟机->管理->克隆”。
Hadoop 2.6.0伪分布式配置详解分享_光环大数据培训

Hadoop 2.6.0伪分布式配置详解分享_光环大数据培训首先先不看理论,搭建起环境之后再看;搭建伪分布式是为了模拟环境,调试方便。
电脑是Windows 10,用的虚拟机VMware Workstation 12 Pro,跑的Linux 系统是CentOS6.5 ,安装的hadoop2.6.0,jdk1.8;1.准备工作准备工作:把JDK和Hadoop安装包上传到linux系统(hadoop用户的根目录)系统环境:IP:192.168.80.99,linux用户:root/123456,hadoop/123456主机名:node把防火墙关闭,root执行:service iptables stop2.jdk安装1 .在 hadoop 用户的根目录, Jdk 解压,( hadoop 用户操作)tar -zxvfjdk-8u65-linux-x64.tar.gz 解压完成后,在 hadoop 用户的根目录有一个 jdk1.8.0_65目录2.配置环境变量,需要修改 /etc/profile 文件( root 用户操作)切到 root 用户,输入 su 命令 vi /etc/profile 进去编辑器后,输入 i ,进入 vi 编辑器的插入模式在 profile 文件最后添加JAVA_HOME=/home/hadoop/jdk1.8.0_65export PATH=$PATH:$JAVA_HOME/bin编辑完成后,按下 esc 退出插入模式输入:,这时在左下角有一个冒号的标识q 退出不保存wq 保存退出q! 强制退出3. 把修改的环境变量生效( hadoop用户操作)执行 source /etc/profile4.执行java -version 查看版本,如果成功证明jdk配置成功3.Hadoop 安装1.在 hadoop 用户的根目录,解压( hadoop 用户操作)tar -zxvf hadoop-2.6.0.tar.gz解压完成在 hadoop 用户的根目录下有一个 hadoop-2.6.0目录2.修改配置文件hadoop-2.6.0/etc/hadoop/hadoop-env.sh ( hadoop 用户操作)export JAVA_HOME=/home/hadoop/jdk1.8.0_653.修改配置文件hadoop-2.6.0/etc/hadoop/core-site.xml ,添加( hadoop 用户操作)<property><name>fs.defaultFS</name><value>hdfs://node:9000</value></property>4.修改配置文件hadoop-2.6.0/etc/hadoop/hdfs-site.xml ,添加( hadoop 用户操作)<property><name>dfs.replication</name><value>1</value></property>5.修改修改配置文件hadoop-2.6.0/etc/hadoop/mapred-site.xml ( hadoop 用户操作),这个文件没有,需要复制一份cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml添加<property><name></name><value>yarn</value></property>6.修改配置文件hadoop-2.6.0/etc/hadoop/yarn-site.xml ,添加( hadoop 用户操作)<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>7.修改主机名称(root 用户操作),重启生效vi /etc/sysconfig/network修改HOSTNAME 的值为用户名8.修改 /etc/hosts 文件( root 用户操作) , 添加: ip 主机名称192.168.44.199(用自己的ip,下边讲如何获得) node附:查看ip地址编辑-->虚拟网络编辑器net模式,选DHCP设置,得到ip地址起始net设置,得到网关点右边小电脑,选择VPN Connections-->Configue VPN选中eth0,点有右边edit选择IP Settings ,根据自己的ip按图修改,Address就是你的ip地址,在起始ip地址和结束ip地址之间选一个就行9. 格式化 HDFS ,在 hadoop 解压目录下,执行如下命令:( hadoop 用户操作)bin/hdfs namenode -format注意:格式化只能操作一次,如果因为某种原因,集群不能用,需要再次格式化,需要把上一次格式化的信息删除,在 /tmp 目录里执行 rm –rf *10. 启动集群,在 hadoop 解压目录下,执行如下命令:( hadoop 用户操作,截图用机后来改过,主机为gp )启动集群: sbin/start-all.sh 需要输入四次当前用户的密码 ( 通过配置 ssh 互信解决,截图用机已经配置过ssh不用输密码 )启动后,在命令行输入 jps 有以下输出关闭集群: sbin/stop-all.sh 需要输入四次当前用户的密码 ( 通过配置 ssh 互信解决,我的同上)4.SSH互信配置(hadoop用户操作)rsa加密方法,公钥和私钥1.生成公钥和私钥在命令行执行ssh-keygen,然后回车,然后会提示输入内容,什么都不用写,一路回车在hadoop用户根目录下,有一个.ssh目录id_rsa 私钥id_rsa.pub 公钥known_hosts 通过SSH链接到本主机,都会在这里有记录2.把公钥给信任的主机(本机)在命令行输入ssh-copy-id 主机名称ssh-copy-id hadoop复制的过程中需要输入信任主机的密码3.验证,在命令行输入:ssh 信任主机名称ssh hadoop如果没有提示输入密码,则配置成功为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。
hadoop2.6.0安装

hadoop2.6.0安装搭建hadoop2.6.0开发环境前言:因为没有物理机器要测试,所以学习如何构建Hadoop环境并在本地笔记本中创建三个Linux虚拟机是一个不错的选择。
安装VMware并准备三台相同的Linux虚拟机Linux虚拟机ISO:虚拟机平台服务器版本:PS:关于软件,软件描述如下:本地笔记本:t420,8g内存,64位操作系统,配置如下:1.安装虚拟机1.1安装vmware-workstation,一路下一步即可,导入centos,使用iso方式搭建linux虚拟机2.安装Linux虚拟机2.1安装vmware-workstation完成后,选择新建虚拟机,导入centos,使用iso方式搭建linux虚拟机选择路径选择多核选择2G内存选择桥连接的方式选择磁盘I/O模式创建全新的虚拟机选择磁盘类型虚拟机文件存储方式设置虚拟机文件的存储路径完成打开,报错如下:无法准备安装说明:\\software\\wmware\\centos-6.5-x86 64-bin-dvd1。
iso。
确保您正在使用有效的Linux安装光盘。
如果出现错误,您可能需要安装VMWareWorkstation。
原因是笔记本没有开启虚拟机功能选项,重启电脑,然后按住f1键,进入bios设置,找到virtual选项,设置成enable,然后保存退出。
打开时出现错误消息:EDD:Error8000ReadingSector 2073976原因是:vmwareworkstation9,版本太老,升级到10版本,就ok了。
设置虚拟机网络连接(固定IP),并将连接模式设置为NAT模式看下是否能上外网,左键点击笔记本右下角无线图标,再点击打开网络与共享中心,关闭vmnet01,只保留vmnet08,然后使用默认的ipv4的ip地址192.168.52.1像两颗豌豆一样克隆另一颗。
在虚拟机name02上右键弹出菜单里点击”管理(m)”,然后点击右边下拉菜单”克隆(c)”,如下所示:继续下一步选择创建完成克隆(f)设置名称和位置,然后单击finish开始复制,时间较长,耐心等待,如下单击“关闭”按钮以完成克隆。
RedHat7 Hadoop-2.6.0

一、服务器版本查看cat /etc/redhat-release二、新建目录:mkdir -p /softwares上传hadoop-2.6.0.tar.gz三、解压cd /softwarestar zxvf hadoop-2.6.0.tar.gz四、设置环境变量分别修改主机名称vim /etc/hostname(修改主机名)修改host名称vim /etc/hosts192.168.18.202 Master.Hadoop192.168.18.203 Slave1.Hadoop192.168.18.208 Slave2.Hadoop192.168.18.202 192.168.18.203 192.168.18.208 五、设置免密登录创建hadoop用户【在master\slave1\slave2上】# useradd hadoop --创建用户名为hadoop的用户# passwd hadoop --为用户hadoop设置密码# su - hadoop --切换到root用户# cd ~ --打开用户文件夹# ssh-keygen -t rsa -P '' --生成密码对,/home/hadoop/.ssh/id_rsa和/home/hadoop/.ssh/ id_rsa.pub# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys --把id_rsa.pub追加到授权的k ey里面去# chmod 600 ~/.ssh/authorized_keys --修改权限# chmod 700 ~/.ssh# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.203:~/.ssh/master# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.208:~/.ssh/master# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.202:~/.ssh/slave1# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.202:~/.ssh/slave2# su root --切换到root用户# vim /etc/ssh/sshd_config --修改ssh配置文件RSAAuthentication yes #启用RSA认证PubkeyAuthentication yes #启用公钥私钥配对认证方式AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径# systemctl restart sshd.service ---重启 sshd 服务在slave1、slave2上# su hadoop --切换到hadoop用户# cat ~/.ssh/master >> ~/.ssh/authorized_keys在master上# su hadoop --切换到hadoop用户# cat ~/.ssh/slave1 >> ~/.ssh/authorized_keys# cat ~/.ssh/slave2 >> ~/.ssh/authorized_keys重启sshd 服务:systemctl restart sshd.service验证无密码登陆,在slave1和slave2上# su hadoop --切换到hadoop用户# ssh Master.Hadoop验证无密码登陆,在master上# su - hadoop# ssh Slave1.Hadoop# ssh Slave2.Hadoop六、修改hadoop文件mkdir -p /softwares/hadoop/tmpcd /softwares/hadoop-2.6.0/etc/hadoopvim core-site.xml<property><name>hadoop.tmp.dir</name><value>/softwares/hadoop/tmp</value><description>Abase for other temporary directories.</description> </property><property><name>fs.defaultFS</name><value>hdfs://Master.Hadoop:9000</value></property><property><name>io.file.buffer.size</name><value>4096</value></property>vim hadoop-env.sh和yarn-env.sh在开头添加如下环境变量cd /softwares/hadoop-2.6.0/etc/hadoopvim hadoop-env.shvim yarn-env.shexport JAVA_HOME=/usr/local/java/jdk1.8.0_112mkdir -p /softwares/hadoop/dfs/namemkdir -p /softwares/hadoop/dfs/datamkdir -p /softwares/hadoop/dfs/name/currentcd /softwares/hadoop-2.6.0/etc/hadoopvim hdfs-site.xml<property><name>.dir</name><value>file:///softwares/hadoop/dfs/name</value> </property><property><name>dfs.datanode.data.dir</name><value>file:///softwares/hadoop/dfs/data</value> </property><property><name>dfs.replication</name><value>2</value></property><property><name>services</name><value>Master.Hadoop:9000</value></property><property><name>node.secondary.http-address</name> <value>Master.Hadoop:50090</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>cd /softwares/hadoop-2.6.0/etc/hadoopcp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml<property><name></name><value>yarn</value><final>true</final></property><property><name>mapreduce.jobtracker.http.address</name><value>Master.Hadoop:50030</value></property><property><name>mapreduce.jobhistory.address</name><value>Master.Hadoop:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name> <value>Master.Hadoop:19888</value></property><property><name>mapred.job.tracker</name><value>http://Master.Hadoop:9001</value></property>cd /softwares/hadoop-2.6.0/etc/hadoopvim yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>Master.Hadoop</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>Master.Hadoop:8042</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>Master.Hadoop:8040</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name> <value>Master.Hadoop:8041</value></property><property><name>yarn.resourcemanager.admin.address</name><value>Master.Hadoop:8043</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>Master.Hadoop:8048</value></property>配置Hadoop的集群cd /softwares/hadoop-2.6.0/etc/hadoopvim slavesSlave1.HadoopSlave2.Hadoop在master上把hadoop 目录的权限交给hadoopsu - rootchown -R hadoop:hadoop /softwares/hadoop-2.6.0chown -R hadoop:hadoop/softwares/hadoop将hadoop-2.6.0整个的copy到另外两台机器上面scp -r /softwares/hadoop-2.6.0 192.168.18.203:/softwares/ scp -r /softwares/hadoop 192.168.18.203:/softwares/scp -r /softwares/hadoop-2.6.0 192.168.18.208:/softwares/ scp -r /softwares/hadoop 192.168.18.208:/softwares/在slave1和slave2上把hadoop 目录的权限交给hadoopchown -R hadoop:hadoop /softwares/hadoop-2.6.0chown -R hadoop:hadoop /softwares/hadoop在master上格式化HDFS 系统su - hadoopcd /softwares/hadoop-2.6.0/bin./hadoop namenode -format启动整个Hadoop集群及其验证在master上su - hadoopcd /softwares/hadoop-2.6.0/sbin./start-dfs.sh./start-yarn.sh或者用下面的./start-all.sh(./stop-all.sh)使用java 的jps 小工具可以看到ResourceManager , NameNode 都启动了:master上【ResourceManager、NameNode】slave1上【DataNode、NodeManager】slave2上【DataNode、NodeManager】如果都运行了,就可以用浏览器查看了http://192.168.18.202:8048/cluster/nodes用./bin/hdfs dfsadmin -report查看状态cd /softwares/hadoop-2.6.0/bin./hdfs dfsadmin -report在系统中使用下面的命令可以看到hadoop 使用的端口:netstat -tnulp | grep java概念说明NamenodeNamenode 管理文件系统的Namespace。
hadoop完全分布式配置过程详解

hadoop完全分布式配置过程详解Hadoop全分布搭建⼀.今⽇任务hadoop完全分布式系统搭建⼆.任务内容1.准备软件hadoop-2.6.0-cdh5.7.0.tar.gzjdk-8u161-linux-x64.tar.gzCentos-6.5VirtualBox-5.2.18-124319-Win.exe1. 配置过程第⼀步:配置免密登录1. 新建虚拟机,设置静态ip地址,主机名master,ip以及主机名映射1. 配置免密登陆1. 启动ssh服务Service sshd start1. 配置免密登录,更新公钥第⼆步:复制虚拟机,更改ip主机名和ip映射,分别配置56.2 主机名master,56.3 主机名 slaver1,56.4 主机名slaver2第三步:上传jdk和hadoop到 hadoop⽤户⽬录使⽤sftp上传jdk和hadoop的压缩包到hadoop⽤户⽬录下第四步:jdk和hadoop配置1. 解压⽂件1. 配置环境变量1. 配置hadoop⽂件1. core-site.xml2.hdfs-site.Xml1. mapred-site.xml1. Yarn-site.xml1. Slaver1. 将jdk和hadoop⽂件分发到slaver1 和slaver21. 在master格式化hdfs的namenode 并且启动hdfs,使⽤jps验证启动三.遇到问题1.复制虚拟机后需要⼀个个更改ip包括映射等2.配置好之后启动 slaver1 和slaver2 均没有Java环境,但是jdk已配好四.处理⽅式Slaver1 和slaver2 配置成功环境变量但是启动时提⽰没有java环境的问题,解决⽅式是在master配置好之后,启动时显⽰6个进程,表⽰master主机hadoop⽂件已经全部配置,然后使⽤远程将 master配置好的 hadoop⽂件分发到slaver1和slaver2总结:1. 此处配置主机名和ip映射时,直接将所有的全部配置,以便复制虚拟机时不需要继续修改2. 配置java环境时,确保系统本⾝没有已经安装好的jdk安装包,有则删除3. 配置好环境变量,需要使⽤ source使其⽣效4. 分发⽂件时,最好是将master配置好的hadoop⽂件分发过去,避免出现其他问题5. 启动成功后,master有5个进程,slaver都只有2个进程。
Hadoop2.6.0安装----环境准备

Hadoop2.6.0安装----环境准备准备工作:1、笔记本4G内存,操作系统WIN7 (屌丝的配置)2、工具VMware Workstation3、虚拟机:CentOS6.4共四台虚拟机设置:每台机器:内存512M,硬盘40G,网络适配器:NAT模式选择高级,新生成虚机Mac地址(克隆虚拟机,Mac地址不会改变,每次最后手动重新生成)编辑虚拟机网络:点击NAT设置,查看虚机网关IP,并记住它,该IP在虚机的网络设置中非常重要。
NAT设置默认IP会自动生成,但是我们的集群中IP需要手动设置。
本机Win7 :VMnet8 网络设置注意:克隆的虚拟机网卡MAC地址已经改变,但是文件里面没有修改,我们启动网络服务会遇到下面错误:Bringing up interface eth0: Error: No suitable device found: no device found for cone解决办法:# vi /etc/udev/rules.d/70-persistent-net.rules(内容如下图)查看ifcfg-eth0 中的“HWADDR ”是否和第一个网卡启动信息中的ATTR{address}值相同,如果两个值相同则删除eth0中的所有内容在eth1中进行相关IP配置安装JDK72.1下载JDK安装包安装版本:jdk-7u60-linux-x64.gz查看最新:/technetwork/java/javase/downloads/ind ex.html2.2解压安装我们把JDK安装到这个路径:/usr/lib/jvm如果没有这个目录,我们就新建一个目录cd /usr/libsudomkdirjvm将jdk-7u60-linux-x64.tar.gz复制到linux桌面tarzxvf jdk-7u60-linux-x64.tar.gz -C /usr/lib/jvm2.3配置环境变量(1)只对当前用户生效vim ~/.bashrcexport JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH保存退出,然后输入下面的命令来使之生效source ~/.bashrc(2)对所有用户生效(root用户登录)vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH保存退出,然后输入下面的命令来使之生效source /etc/profile2.4配置默认JDK(一般情况下这一步都可以省略)由于一些Linux的发行版中已经存在默认的JDK,如OpenJDK等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop环境搭建
时间:2015-07-26
作者:周乐相
环境搭建之前准备工作
我的笔记本配置:
硬盘:500G (实际上用不完)
CPU: Intel(R)Core(TM) i5-2450M CPU@ 2.50GHz
内存:10G
操作系统:WIN7(64位)
软件准备
1). 虚拟机软件:vmwareworkstation64.exe (VMware work station 64bit V 11.0)
2).Linux 版本: Red HatEnterprise Linux Server releas
e 6.5 (Santiago) (rhel-server-6.5-x86_64-dvd.iso)
3).hadoop 版本: hadoop-2.6.0.tar.gz
4). JAVA版本:java version"1.6.0_32"(jdk-6u32-linux-x64.bin)
安装VMware软件
傻瓜操作下一步。
安装Linux操作系统
傻瓜操作下一步。
安装完成。
1).创建hadoop操作系统安装hadoop的用户第一台操作系统命主机名为: master
2)拷贝该虚拟机master 分别为node01 、node02两个节点数
3) 分别对拷贝的node01、node02 修改IP和主机名称主机名: IP
master: 192.168.2.50
node01:192.168.2.51
node02: 192.168.2.52
jdk安装
并设置好环境变量
##设置JAVA_HOME环境变量
配置ssh 免密码通信
三台服务器SSH关系
上面这个图可以表达这三台服务器之间的关系。
对master主节点SSH配置
执行:ssh-keygen–t dsa 回车一直回车下去会在$HOME/.ssh目录生成id_dsa和id_dsa.pu b两个文件
将id_dsa.pub文件放到authorized_keys文件,注意需要修改权限chmod 600 authorized_keys
依次将node01、node02两台的密码追加到authorized_keys 文件里面
对nod e01节点SSH配置
这样master与node01就可以正常的互通无需密码对node02节点SSH配置
这样master与node02就可以正常的互通无需密码Hadoop安装配置
修改配置文件
用红线框起来的都需要修改配置
修改:mapred-site.xml
修改:yarn-site.xml
修改:hadoop-env.sh
修改:mapred-env.sh
修改:yarn-env.sh
修改:master&slaves
创建空文件夹
节点数据拷贝
对节点node01、node02数据文件拷备
在master节点格式化
Hadoop启动&停止Hadoop启动
后台查看
前台查看
Hadoop停止
Hadoop应用
实例:WordCount 执行前
执行之后
后台查看
前台浏览器查看。