HanLP
HanLP关键词提取。总结

HanLP关键词提取。
总结原理:依托HanLP的核⼼词典和⾃定义词典根据TF*IDF算法计算每个命名实体和名词短语的得分score,按score倒排返回前⾯若⼲个关键词解释: TF 称为词频,表⽰词在⼀篇⽂档中出现的频率=词在该⽂档中出现的次数 / 该⽂档中单词的总数---TF越⼤,表⽰该词对⽂档越重要DF称为⽂档频率,⼀个词在多少篇⽂章中出现过本系统⽤的公式是:⽐重 k * 关键词在本⽂出现的次数 t / 词典中的词频 fIDF 称为逆⽂档频率=Ln(总⽂档数/出现该次的⽂档数)⾸先解析出标题和正⽂⽤HanLP的分词器⼀句词典,初始化内容,⽣成⼀个数组 wordList,⾥⾯是分好的词,有各⾃的词性,和各⾃词在内容中所在的位置 index 把标题⾥的词单独分⼀下,降低词频 f关键词:先分短语:遍历wordList,取每个词的词性和下词词性,可以组合起来的,拼接为⼀个短语,降低词频f,放到候选关键词数组 parsePhrase ⾥⾯机构名不做组合形容词,名形词,动名词,习⽤语,简称略语,后跟助词,名词,动词,动名词且词的长度都⼤于1 则组合为短语动词后跟助词,名词,动名词,则组合短语名词后跟助词,名词,动名词,动词,则组合短语数词后跟量词,名词,专有名词,或者形容词则组合短语其余都不进⾏组合组合短语长度⼤于8或者构成的某个单词在词库词频超过300,则此短语词频为5其余的短语默认词频为3再分单词:遍历wordlist,取每个单独的词,根据词性,降低或者增加词频。
同时判断是否已存在于parsePhrase的某个短语⾥,避免重复放⼊parsePhrase。
名词,动词,形容词,长度⼤于2的动名词,习⽤语,⼈名,简称略语,从核⼼词典和扩展词典取,取不到就默认词频为3.或4排除单字符的关键字,去除包含有第+数词的,词频增⼤带**讯,**摄等不进⾏添加所以想添加⾃定义词典的关键词,只需要设定为单词为名词 n,动词 v,形容词 a,长度⼤于2的动名词 vn,习⽤语 l,⼈名 nr,简称略语 j在⾃定义词.txt⾥词频 < 3 即可。
hanlp相似度算法

hanlp相似度算法
HanLP是一个自然语言处理工具包,其中包含了一些常见的文本相似度算法。
1. 词袋模型(Bag of Words)
词袋模型将文本表示为一个词的集合,将每个词转换为一个向量,然后计算向量之间的余弦相似度。
词袋模型忽略了词的顺序和句法信息,只考虑词的频率,适用于大部分文本分类和聚类任务。
2. Word2Vec
Word2Vec是一种将词语映射为低维向量表示的深度学习模型。
通过训练大量的语料库,Word2Vec可以将语义相似的词映射到相似的向量空间中。
计算文本的相似度可以通过计算词向量的平均值或加权平均值来得到。
3. TF-IDF
TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征提取算法。
它计算每个词在文档中的频率,并乘以一个逆文档频率的权重,用于衡量词对整个语料库的重要性。
可以通过比较两个文本的TF-IDF向量来计算相似度。
4. Edit Distance
编辑距离是一种测量两个字符串相似度的方法,它可以通过一系列的插入、删除和替换操作将一个字符串转换为另一个字符串。
编辑距离越小,表示两个字符串
越相似。
5. Cosine Similarity
余弦相似度是一种常用的向量相似度度量方法,它计算两个向量之间的夹角余弦值作为它们的相似度。
余弦相似度的范围是[-1,1],值越接近1表示两个向量越相似。
以上是HanLP中一些常见的文本相似度算法,可以根据具体需求选择适合的算法进行计算。
hanlp中文分词器解读

中文分词器解析hanlp分词器接口设计:提供外部接口:分词器封装为静态工具类,并提供了简单的接口标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下:HanLP.segment其实是对StandardTokenizer.segment的包装。
/*** 分词** @param text 文本* @return切分后的单词*/publicstatic List<Term>segment(String text){return StandardTokenizer.segment(text.toCharArray());}/*** 创建一个分词器<br>* 这是一个工厂方法<br>* 与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器* @return一个分词器*/publicstatic Segment newSegment()}publicclass StandardTokenizer{/*** 预置分词器*/publicstaticfinalSegment SEGMENT = HanLP.newSegment();/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(String text){return SEGMENT.seg(text.toCharArray());}/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(char[]text){return SEGMENT.seg(text);}/*** 切分为句子形式* @param text 文本* @return句子列表*/publicstatic List<List<Term>>seg2sentence(String text){return SEGMENT.seg2sentence(text);}}publicstatic Segment newSegment(){returnnew ViterbiSegment();// Viterbi分词器是目前效率和效果的最佳平衡}/*** Viterbi分词器<br>* 也是最短路分词,最短路求解采用Viterbi算法** @author hankcs*/publicclass ViterbiSegment extends WordBasedGenerativeModelSegmentNLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
hanlp的作用-解释说明

hanlp的作用-概述说明以及解释1.引言1.1 概述HanLP(即“Han Language Processing”)是一个开源的自然语言处理(NLP)工具包,最初由人民日报社自然语言处理实验室开发,并已经在众多大型项目和企业中被广泛应用。
自然语言处理是人工智能领域中一个重要的研究方向,涉及到对人类语言的理解和处理。
HanLP作为一款功能强大的NLP工具包,集成了一系列中文文本的处理和分析功能,能够帮助开发者快速、准确地处理中文文本数据。
HanLP具备多项核心功能,包括分词、词性标注、命名实体识别、依存句法分析、关键词提取等。
这些功能能够协助用户完成诸如文本分析、信息提取、机器翻译、情感分析、智能问答等各种任务。
HanLP具有以下几个显著特点:1. 智能高效:HanLP采用了深度学习和统计机器学习等先进的技术,能够实现高效、准确的文本处理。
它精心训练的模型和优化算法确保了在不同场景下的稳定性和效果。
2. 针对中文:HanLP是专门为中文设计的工具包,充分考虑了中文的特殊性。
它支持繁简体转换、拼音转换等特殊处理,并基于大规模中文语料库进行训练,以获得更好的中文处理效果。
3. 可定制性:HanLP提供了丰富的功能和参数设置,允许用户根据自己的需求进行个性化定制。
用户可以选择不同的模型、配置和插件,以满足特定场景下的需求。
4. 强大的生态系统:HanLP的社区活跃,拥有众多用户和开发者参与其中。
在HanLP的基础上,还衍生出了丰富的周边工具和应用,形成了一个庞大的生态系统。
总之,HanLP作为一款功能全面、性能出色的中文NLP工具包,为中文文本处理和分析提供了便捷、高效的解决方案。
无论是学术研究还是商业应用,HanLP都是一个不可或缺的利器。
它的出现大大降低了中文自然语言处理的门槛,为中文信息处理领域的发展做出了重要贡献。
1.2 文章结构文章结构部分的内容如下:2. 正文在这一部分,我们将详细介绍HanLP的作用和功能。
开发ElasticSearch的HanLP中文插件
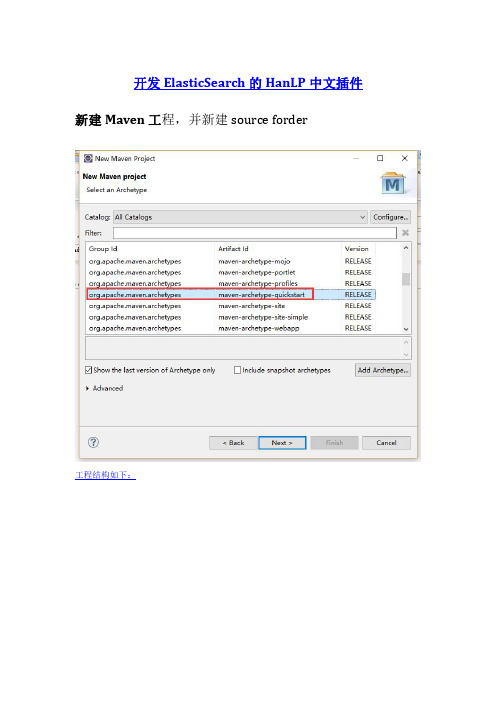
开发ElasticSearch的HanLP中文插件新建Maven工程,并新建source forder工程结构如下:新建lib目录,将hanlp的开发包hanlp-1.2.4.jar(版本可以自己选)拷入并加入buildpath。
选用jdk1.7源码说明ElasticSearch的plugin管理器从es-plugin.properties中找到要加载的插件类AnalysisHanlpPlugin,然后从AnalysisHanlpPlugin中添加要绑定的插件处理器HanLPAnalysisBinderProcessor,在HanLPAnalysisBinderProcessor中绑定解析器提供类HanLPAnalyzerProvider和分词器提供类HanLPTokenizerFactory。
HanLPAnalyzerProvider负责新建HanLPAnalyzer,HanLPTokenizerFactory负责新建HanLPTokenizer。
pom.xml选用自己项目适合的elasticsearch版本、依赖的lucene版本、hanlp版本。
另外保证maven-source-plugin包括attach-sources。
<project xmlns="/POM/4.0.0"xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-analysis-hanlp</artifactId><version>1.2.4</version><packaging>jar</packaging><name>elasticsearch-analysis-hanlp</name><url></url><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncod ing><elasticsearch.version>1.7.1</elasticsearch.version></properties><repositories><repository><id></id><name>OSS Sonatype</name><releases><enabled>true</enabled></releases><snapshots><enabled>true</enabled></snapshots><url>/content/repositories/releases/</u rl></repository></repositories><dependencies><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>4.10.4</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>${elasticsearch.version}</version><scope>compile</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.16</version><scope>runtime</scope></dependency><dependency><groupId>com.HanLP</groupId><artifactId>hanlp</artifactId><version>1.2.4</version><systemPath>${pom.basedir}/lib/hanlp-1.2.4.jar</systemPath> <scope>system</scope></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.7</source><target>1.7</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.11</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-source-plugin</artifactId><version>2.1.2</version><executions><execution><id>attach-sources</id><goals><goal>jar</goal></goals></execution></executions></plugin></plugins></build></project>es-plugin.propertiesplugin=org.elasticsearch.plugin.analysis.hanlp.AnalysisHanlpPlugin该文件必须放在resource forder中,才能打包进jar包。
HanLP分词研究

HanLP分词研究这篇⽂章主要是记录HanLP标准分词算法整个实现流程。
HanLP的核⼼词典训练⾃⼈民⽇报2014语料,语料不是完美的,总会存在⼀些错误。
这些错误可能会导致分词出现奇怪的结果,这时请打开调试模式排查问题:HanLP.Config.enableDebug();那什么是语料呢?通俗的理解,就是HanLP⾥⾯的⼆个核⼼词典。
假设收集了⼈民⽇报若⼲篇⽂档,通过⼈⼯⼿⼯分词,统计⼈⼯分词后的词频:①统计分词后的每个词出现的频率,得到⼀元核⼼词典;②统计两个词两两相邻出现的频率,得到⼆元核⼼词典。
根据贝叶斯公式:\[P(A|B)=\frac{P(A,B)}{P(B)}\qquad=\frac{count(A,B)}{count(B)}\qquad \]其中\(count(A,B)\)表⽰词A和词B 在语料库中共同出现的频率;\(count(B)\)表⽰词B 在语料库中出现的频率。
有了这两个频率,就可以计算在给定词B的条件下,下⼀个词是 A的概率。
关于HanLP的核⼼词典、⼆元⽂法词典出现错误时如何处理可参考关于分词算法的平滑问题,可参考分词流程采⽤维特⽐分词器:基于动态规划的维特⽐算法。
List<Term> termList = HanLP.segment(sentence);在进⼊正式分词流程前,可选择是否进⾏归⼀化,然后进⼊到正式的分词流程。
if (HanLP.Config.Normalization){CharTable.normalization(text);}return segSentence(text);第⼀步,构建词⽹WordNet,参考:词⽹包含起始顶点和结束顶点,以及待分词的⽂本内容,⽂本内容保存在charArray数组中。
vertexes表⽰词⽹中结点的个数:vertexes = new LinkedList[charArray.length + 2],加2的原因是:起始顶点和结束顶点。
hanlp 中文分词

hanlp 中文分词
摘要:
一、引言
1.介绍hanlp
2.中文分词的重要性
二、hanlp 的中文分词功能
1.什么是中文分词
2.hanlp 分词原理
3.hanlp 分词算法优势
三、hanlp 在中文分词领域的应用
1.搜索引擎
2.文本挖掘
3.语音识别
四、中文分词的未来发展
1.人工智能技术的发展
2.中文分词技术的挑战与机遇
正文:
一、引言
随着互联网的普及,大量的中文文本需要进行处理和分析。
然而,中文文本没有明确的词语边界,导致计算机难以直接理解。
为了解决这个问题,中文分词技术应运而生。
HanLP 是一款强大的中文自然语言处理工具,其中包含的
中文分词功能尤为突出。
二、hanlp 的中文分词功能
1.什么是中文分词
中文分词是将连续的中文文本切分成有意义的独立词汇的过程。
这些词汇可以是名词、动词、形容词等,具备一定的语义信息。
中文分词是自然语言处理的基础任务,对于后续的文本分析、检索、翻译等功能至关重要。
2.hanlp 分词原理
HanLP 采用基于词性标注的分词算法,结合隐马尔可夫模型(HMM)和最大熵模型(MaxEnt)。
hanlp和jieba 的原理

hanlp和jieba 的原理汉语分词是中文自然语言处理的一项重要任务,被广泛应用于搜索引擎、文本分类、信息提取等领域。
HanLP和jieba都是中文分词工具,本文将分别介绍它们的原理及特点。
一、HanLPHanLP是由中国科学院计算技术研究所自然语言处理实验室开发的中文自然语言处理工具包。
其核心分词模块采用的是基于最大熵模型和条件随机场(CRF)的中文分词算法。
最大熵模型是一种概率模型,其基本思想是在满足已知条件的前提下,使不确定性最小化。
在HanLP中,最大熵模型用于对分词候选的概率进行估计,选择概率最大的分词结果作为最终输出。
该方法不依赖于词典和规则,具有较强的自适应能力,能够处理一些新词、专有名词等难以预料的情况。
除了最大熵模型,HanLP还引入了条件随机场(CRF)模型。
CRF是一种无向图模型,能够对序列标注问题进行建模。
在HanLP中,CRF用于对分词结果进行校验和修正,提高分词准确性。
HanLP还具有实体识别、依存分析等多种功能,并且支持多种编程语言接口,如Java、Python等。
它已经成为中文自然语言处理领域的一大瑰宝。
二、jiebajieba是一款基于Python的中文分词工具。
它采用的是基于前缀匹配算法和最大匹配算法的分词方法。
前缀匹配算法是一种字符串匹配算法,能够对较长的字符串进行快速的匹配和查找。
在jieba中,前缀匹配算法用于对待切分的文本进行预处理,将其转化为一棵字典树。
最大匹配算法则是指对字典树上查找长度最大的词或成语作为分词结果。
jieba还提供了基于HMM(隐马尔科夫模型)和CRF的分词算法可选,使得分词结果更加准确。
与HanLP相比,jieba的分词速度较快,因为它基于前缀匹配算法进行文本预处理,能够快速实现分词结果的计算。
jieba也很容易使用,具有Python特有的简洁、易读的语法,适合快速构建中小型项目。
但是,jieba的分词效果相对于HanLP要逊色一些,因为它缺乏对分词结果进行校验和修正的功能。
hanlp相似度算法

hanlp相似度算法
HanLP中有多种相似度算法可以使用,主要包括余弦相似度、欧式距离、编辑距离等。
其中,余弦相似度是常用的一种计算文本相似度的算法。
它基于向量空间模型,通过计算两个文本向量的夹角来衡量它们的相似程度。
具体而言,设两个文本向量A和B,余弦相似度
计算公式为:
cos_sim = A·B / (||A|| * ||B||)
其中,A·B表示向量A和B的点积,||A||表示向量A的模。
余弦相似度的取值范围在[-1,1]之间,数值越大表示相似度越高。
在HanLP中,可以通过使用Similarity类来计算相似度。
例如
可以使用TFIDFSimilarity计算两篇文章之间的相似度:
```java
// 创建一个TFIDFSimilarity实例
TFIDFSimilarity similarity = new TFIDFSimilarity();
// 计算两篇文章的相似度
String text1 = "文章1的内容";
String text2 = "文章2的内容";
double sim = similarity.similarity(text1, text2);
System.out.println("相似度:" + sim);
```
除了余弦相似度外,HanLP还提供了其他相似度算法的实现,如BM25相似度、编辑距离等,可以根据具体需求选择合适
的算法来计算相似度。
HanLP2.0

HanLP2.0大快搜索是一个相对年轻的公司,组建时间不算很长,我们公司主要是聚焦大数据底层软件、大数据开发框架、人工智能这几个方向。
在大数据底层软件方面,有D K H大数据分析处理平台,在人工智能方面的主要产品就是HanLP。
HanLP从2015年开始进行研发,目前,我们已经开源了全部源代码。
由于H a n L P1.x的开发主要以传统方式进行,我们可以直接在工程里面进行调用。
从HanLP2.0开始,我们走入深度学习技术路线,把以前的算法重新用C++进行打造。
由于深度学习、神经网络时代的到来,H a n L P2.0全面拥抱深度学习,采用P y t h o n作为主要开发语言,以前的对外接口是Java,现在可以提供多种语言支持。
以前的C语言开发模块,通过这个接口传送出来,或者用P y t h o n来进行调用,其他开发语言也一样可以调用。
因为都是开源的,大家可以尽情地使用,都是不收费的。
HanLP2.0里面利用C++实现了高速算法,用SWIG实现Python语言的接口。
双数组字典树/A C自动机词典匹配是Ha nLP1.x的优良传统,在Ha nLP2.0会继续保持,大家还可以继续使用这个。
在多语言这个方面,我们用P y thon重新写了外部框架。
以前我们要把一段话进行分词处理,也要建立一个工程,HanLP2.0支持直接向服务端发送一个请求,可以直接返回分词结果,这个就非常方便了。
我说多语言指的是自然语言,比如英文、日文、韩文和西班牙文,在底层框架的设计上,不在一个编码体系里,我们底层的架构跟语言无关,你可以使用任何语言,只要提供语料库就可以处理语言,不论是什么语言。
语料库决定了HanLP最后所支持的语言,如果是西班牙语,将西班牙语语料库放在里面训练,建立训练模型,最后调用模型就可以了。
所以说,H a n LP2.0充分体现了这么一个人工智能和神经网络机器学习编程的思路。
HanLP预先存放的模型有繁体中文、简体中文、英文、日文,如果有更好的语料库也可以进行训练。
hanlp 英文分词

hanlp 英文分词Hanlp, short for Han Language Processing, is an open-source natural language processing (NLP) library developed by the Institute of Computing Technology at the Chinese Academy of Sciences. It aims to provide efficient and accurate tools for Chinese language processing, including word segmentation, part-of-speech tagging, named entity recognition, syntactic parsing, and so on.Word segmentation, also known as tokenization, is an essential step in many NLP tasks as it forms the basis of text analysis. In English, words are usually separated by spaces or punctuation marks, making the tokenization process relatively straightforward. However, Chinese is a morphologically rich language, where words are not explicitly separated, posing a significant challenge for segmentation.Hanlp adopts various techniques to tackle this challenge and achieve high accuracy in Chinese word segmentation. Firstly, it utilizes a statistical approach called maximum matching, which splits sentence into words by matching against a dictionary. This method is based on the observation that common words tend to occur together in texts. Hanlp uses a large-scale corpus to construct a comprehensive dictionary containing millions of Chinese words, ensuring high coverage and accuracy.Secondly, Hanlp employs several advanced models, such as conditional random fields (CRF) and long short-term memory (LSTM), to enhance segmentation performance. These models are trained using machine learning algorithms on annotated data,allowing the system to learn patterns and make better predictions. CRF, in particular, is effective in capturing contextual information and improving the accuracy of word boundaries.Furthermore, Hanlp leverages linguistic rules and heuristics to address cases where statistical methods may fall short. For example, it can handle ambiguous words that can be both a single word or a combination of multiple words. It also considers the part of speech information to improve segmentation results. By combining statistical methods, machine learning models, and rule-based approaches, Hanlp achieves state-of-the-art performance in Chinese word segmentation.Besides word segmentation, Hanlp provides a range of other NLP functionalities. Part-of-speech tagging assigns grammatical tags to words in a sentence, aiding in syntactic analysis. Named entity recognition identifies and classifies named entities, such as persons, locations, dates, and organizations, in text. Dependency parsing analyzes the grammatical relationships between words and constructs a syntactic tree. These tools are essential for various NLP applications, such as information retrieval, sentiment analysis, machine translation, and text summarization.Hanlp's extensive features, high accuracy, and open-source nature have made it popular among researchers and developers in both academia and industry. It offers Java and Python APIs, allowing for easy integration into applications and systems. Additionally, Hanlp has an active community that continuously updates and improves the library, ensuring its quality and usability.In conclusion, Hanlp provides robust and efficient tools for Chinese language processing, particularly in word segmentation. Its combination of statistical methods, machine learning models, and linguistic rules enables accurate and reliable segmentation results. With its wide range of functionalities and user-friendly APIs, Hanlp has become a valuable resource for NLP researchers and practitioners.。
hanlp中文分词器解读_计算机软件及应用_it计算机_专业资料
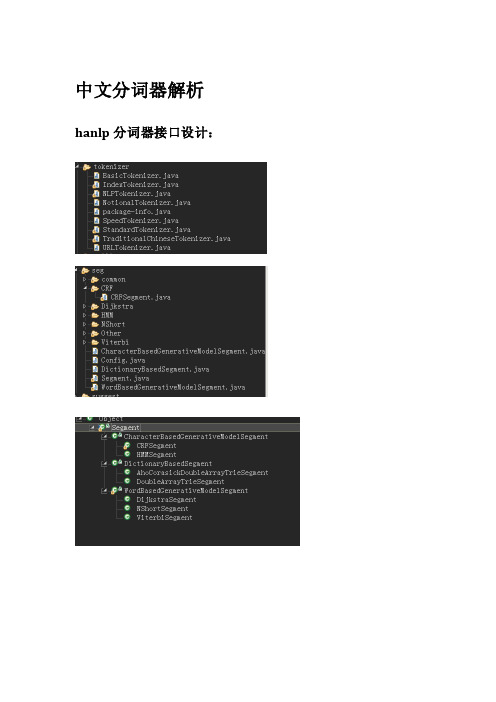
中文分词器解析hanlp分词器接口设计:提供外部接口:分词器封装为静态工具类,并提供了简单的接口标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下:HanLP.segment其实是对StandardTokenizer.segment的包装。
/*** 分词** @param text 文本* @return切分后的单词*/publicstatic List<Term>segment(String text){return StandardTokenizer.segment(text.toCharArray());}/*** 创建一个分词器<br>* 这是一个工厂方法<br>* 与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器* @return一个分词器*/publicstatic Segment newSegment()}publicclass StandardTokenizer{/*** 预置分词器*/publicstaticfinalSegment SEGMENT = HanLP.newSegment();/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(String text){return SEGMENT.seg(text.toCharArray());}/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(char[]text){return SEGMENT.seg(text);}/*** 切分为句子形式* @param text 文本* @return句子列表*/publicstatic List<List<Term>>seg2sentence(String text){return SEGMENT.seg2sentence(text);}}publicstatic Segment newSegment(){returnnew ViterbiSegment();// Viterbi分词器是目前效率和效果的最佳平衡}/*** Viterbi分词器<br>* 也是最短路分词,最短路求解采用Viterbi算法** @author hankcs*/publicclass ViterbiSegment extends WordBasedGenerativeModelSegmentNLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
hanlp 文本分类实践

hanlp 文本分类实践HanLP是一个开源的自然语言处理工具包,它提供了多种功能,包括分词、词性标注、命名实体识别、依存句法分析、关键词提取、文本分类等。
在本文中,我们将介绍如何使用HanLP进行文本分类实践。
1. 数据准备首先,我们需要准备用于训练和测试的数据。
在本文中,我们将使用一个公开的中文新闻分类数据集,该数据集包含10个类别的新闻文章,每个类别包含1000篇文章。
我们可以从以下链接下载数据集:下载完成后,我们需要解压缩数据集,并将数据集分为训练集和测试集。
在本文中,我们将使用80%的数据作为训练集,20%的数据作为测试集。
我们可以使用以下代码将数据集分为训练集和测试集:pythonimport osimport randomdata_dir = 'THUCNews'train_dir = 'train'test_dir = 'test'if not os.path.exists(train_dir):os.makedirs(train_dir)if not os.path.exists(test_dir):os.makedirs(test_dir)categories = os.listdir(data_dir)for category in categories:category_dir = os.path.join(data_dir, category)files = os.listdir(category_dir)random.shuffle(files)train_files = files[:int(len(files)*0.8)]test_files = files[int(len(files)*0.8):]for train_file in train_files:src_file = os.path.join(category_dir, train_file)dst_file = os.path.join(train_dir, category, train_file)if not os.path.exists(os.path.join(train_dir, category)):os.makedirs(os.path.join(train_dir, category))os.symlink(os.path.abspath(src_file), os.path.abspath(dst_file)) for test_file in test_files:src_file = os.path.join(category_dir, test_file)dst_file = os.path.join(test_dir, category, test_file)if not os.path.exists(os.path.join(test_dir, category)):os.makedirs(os.path.join(test_dir, category))os.symlink(os.path.abspath(src_file), os.path.abspath(dst_file)) 2. 特征提取在进行文本分类之前,我们需要将文本转换为数值特征。
分词工具Hanlp基于感知机的中文分词框架

分词⼯具Hanlp基于感知机的中⽂分词框架结构化感知机标注框架是⼀套利⽤感知机做序列标注任务,并且应⽤到中⽂分词、词性标注与命名实体识别这三个问题的完整在线学习框架,该框架利⽤1个算法解决3个问题,时⾃治同意的系统,同时三个任务顺序渐进,构成流⽔线式的系统。
本⽂先介绍中⽂分词框架部分内容。
中⽂分词训练只需指定输⼊语料的路径(单⽂档时为⽂件路径,多⽂档时为⽂件夹路径,灵活处理),以及模型保存位置即可:命令⾏java -cp hanlp.jar com.hankcs.hanlp.model.perceptron.Main -task CWS -train -reference data/test/pku98/199801.txt -model data/test/perceptron/cws.binAPIpublic void testTrain() throws Exception{PerceptronTrainer trainer = new CWSTrainer();PerceptronTrainer.Result result = trainer.train("data/test/pku98/199801.txt",Config.CWS_MODEL_FILE);// System.out.printf("准确率F1:%.2f\n", result.prf[2]);}事实上,视语料与任务的不同,迭代数、压缩⽐和线程数都可以⾃由调整,以保证最佳结果:/*** 训练** @param trainingFile 训练集* @param developFile 开发集* @param modelFile 模型保存路径* @param compressRatio 压缩⽐* @param maxIteration 最⼤迭代次数* @param threadNum 线程数* @return ⼀个包含模型和精度的结构* @throws IOException*/public Result train(String trainingFile, String developFile,String modelFile, final double compressRatio,final int maxIteration, final int threadNum) throws IOException单线程时使⽤AveragedPerceptron算法,收敛较好;多线程时使⽤StructuredPerceptron,波动较⼤。
hanlp中文分词器解读
中文分词器解析hanlp分词器接口设计:提供外部接口:分词器封装为静态工具类,并提供了简单的接口标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下:HanLP.segment其实是对StandardTokenizer.segment的包装。
/*** 分词** @param text 文本* @return切分后的单词*/publicstatic List<Term>segment(String text){return StandardTokenizer.segment(text.toCharArray());}/*** 创建一个分词器<br>* 这是一个工厂方法<br>* 与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器* @return一个分词器*/publicstatic Segment newSegment()}publicclass StandardTokenizer{/*** 预置分词器*/publicstaticfinalSegment SEGMENT = HanLP.newSegment();/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(String text){return SEGMENT.seg(text.toCharArray());}/*** 分词* @param text 文本* @return分词结果*/publicstatic List<Term>segment(char[]text){return SEGMENT.seg(text);}/*** 切分为句子形式* @param text 文本* @return句子列表*/publicstatic List<List<Term>>seg2sentence(String text){return SEGMENT.seg2sentence(text);}}publicstatic Segment newSegment(){returnnew ViterbiSegment();// Viterbi分词器是目前效率和效果的最佳平衡}/*** Viterbi分词器<br>* 也是最短路分词,最短路求解采用Viterbi算法** @author hankcs*/publicclass ViterbiSegment extends WordBasedGenerativeModelSegmentNLP分词NLPTokenizer会执行全部命名实体识别和词性标注。
自然语言分析工具Hanlp依存文法分析python使用总结(附带依存关系英文简写的中文解释)

⾃然语⾔分析⼯具Hanlp依存⽂法分析python使⽤总结(附带依存关系英⽂简写的中⽂解释)最近在做⼀个应⽤依存⽂法分析来提取⽂本中各种关系的词语的任务。
例如:text=‘新中国在马克思的思想和恩格斯的理论阔步向前’:我需要提取这个text中的并列的两个关系,从⽂中分析可知,“马克思的思想”和“恩格斯的理论”是两个并列关系的短语,所以想要将其提取出来;⾸先⼤致了解⼀下依存⽂法分析的前提条件,将句⼦分词并进⾏词性标注,这⼀步⾮常关键,直接决定分析结果的好坏。
看⼀下不修改分词字典情况下直接进⾏并列关系提取的结果:text= "新中国在马克思的思想和恩格斯的理论指导下阔步向前"java = JClass('com.hankcs.hanlp.dependency.nnparser.NeuralNetworkDependencyParser') # 调⽤原始类接⼝进⾏句法分析dp_result = pute(seg_result1)print('java提取结果:'+'\n',dp_result)word_array = dp_result.getWordArray()final= []for word in word_array:result = [word.LEMMA, word.DEPREL, word.HEAD.LEMMA]print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA)) # 输出依存关系if result[1]=='COO': # 提取并列关系COOfinal.append(word.LEMMA)final.append(word.HEAD.LEMMA)final_set = set(final)print(final_set)结果:{'思想','理论'}虽然提取出来的结果也算合理,但是还是不够准确,我希望的结果是{'马克思的思想','恩格斯的理论'}接下来我将需要⽬标词动态添加到分词字典中,然后再来进⾏依存⽂法分析text= "新中国在马克思的思想和恩格斯的理论指导下阔步向前"segment =HanLP.newSegment('viterbi')CustomDictionary.insert('马克思的思想', 'n 1024') # insert会覆盖字典中已经存在的词,add会跳过已经存在的词CustomDictionary.insert('恩格斯的理论', 'n 1024')segment.enableCustomDictionaryForcing(True) # 强制执⾏seg_result1 = segment.seg(text) # 分词结果print('分词结果:',seg_result1)java = JClass('com.hankcs.hanlp.dependency.nnparser.NeuralNetworkDependencyParser') # 调⽤原始类接⼝进⾏句法分析dp_result = pute(seg_result1)print('java提取结果:'+'\n',dp_result)word_array = dp_result.getWordArray()final= []for word in word_array:result = [word.LEMMA, word.DEPREL, word.HEAD.LEMMA]print("%s --(%s)--> %s" % (word.LEMMA, word.DEPREL, word.HEAD.LEMMA)) # 输出依存关系if result[1]=='COO':final.append(word.LEMMA)final.append(word.HEAD.LEMMA)final_set = set(final)print(final_set)结果:{'马克思的思想','恩格斯的理论'}以上实现了正确的并列关系提取。
HanLP下载和配置

HanLP下载和配置⽅式⼀、Maven为了⽅便⽤户,特提供内置了数据包的Portable版,只需在pom.xml加⼊:<dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.7.8</version></dependency>零配置,即可使⽤基本功能(除由字构词、依存句法分析外的全部功能)。
如果⽤户有⾃定义的需求,可以参考⽅式⼆,使⽤hanlp.properties进⾏配置(Portable版同样⽀持hanlp.properties)。
⽅式⼆、下载jar、data、hanlp.propertiesHanLP将数据与程序分离,给予⽤户⾃定义的⾃由。
1、下载:下载后解压到任意⽬录,接下来通过配置⽂件告诉HanLP数据包的位置。
HanLP中的数据分为词典和模型,其中词典是词法分析必需的,模型是句法分析必需的。
data│├─dictionary└─model⽤户可以⾃⾏增删替换,如果不需要句法分析等功能的话,随时可以删除model⽂件夹。
模型跟词典没有绝对的区别,隐马模型被做成⼈⼈都可以编辑的词典形式,不代表它不是模型。
GitHub代码库中已经包含了data.zip中的词典,直接编译运⾏⾃动缓存即可;模型则需要额外下载。
2、下载jar和配置⽂件:配置⽂件的作⽤是告诉HanLP数据包的位置,只需修改第⼀⾏root=D:/JavaProjects/HanLP/为data的⽗⽬录即可,⽐如data⽬录是/Users/hankcs/Documents/data,那么root=/Users/hankcs/Documents/。
最后将hanlp.properties放⼊classpath即可,对于多数项⽬,都可以放到src或resources⽬录下,编译时IDE会⾃动将其复制到classpath中。
hanlp 分句

hanlp 分句摘要:一、汉语言处理简介1.汉语言处理的意义2.汉语言处理的应用领域二、分句在汉语言处理中的作用1.分句的定义和作用2.分句在自然语言处理任务中的应用三、hanlp 分句工具介绍1.hanlp 工具的背景和特点2.hanlp 分句工具的使用方法3.hanlp 分句工具在汉语言处理任务中的应用示例四、hanlp 分句工具的优势与不足1.优势:高效、准确、灵活2.不足:可能存在的误分句现象五、展望汉语言处理技术的发展1.汉语言处理技术的现状与趋势2.分句技术在未来的发展方向正文:汉语言处理是一项涉及计算机科学、人工智能、语言学等多个领域的交叉学科研究。
通过对汉语言进行处理,可以使计算机理解和处理中文文本,进而实现诸如机器翻译、情感分析、文本分类等自然语言处理任务。
分句作为汉语言处理的基本步骤之一,对于后续的自然语言处理任务具有重要意义。
分句是指将连续的文本切分成独立的句子,以便进行句法分析和语义分析。
在自然语言处理任务中,分句能够帮助计算机更好地理解文本的结构和意义。
然而,由于中文文本没有明显的句子边界,分句任务具有一定的挑战性。
在这样的背景下,hanlp 分句工具应运而生。
hanlp 是一款基于深度学习的汉语言处理工具,具有高效、准确、灵活的特点。
它采用基于规则和统计相结合的方法进行分句,能够有效地处理复杂的中文文本,满足多样化的自然语言处理需求。
使用hanlp 分句工具非常简单,用户只需将待处理的中文文本输入工具,即可得到分好句的文本。
在此基础上,用户可以进一步利用hanlp 工具进行词性标注、命名实体识别、依存句法分析等自然语言处理任务。
然而,虽然hanlp 分句工具具有较高的准确率,但在某些特殊情况下仍然可能出现误分句现象。
这需要用户在使用过程中注意检查和修正分句结果,以确保自然语言处理任务的准确性。
总之,hanlp 分句工具为中文自然语言处理提供了强大的支持。
Hanlp配置自定义词典遇到的问题与解决方法

Hanlp配置自定义词典遇到的问题与解决方法本文是整理了部分网友在配置hanlp自定义词典时遇到的一小部分问题,同时针对这些问题也提供另一些解决的方案以及思路。
这里分享给大家学习参考。
要使用hanlp加载自定义词典可以通过修改配置文件hanlp.properties来实现。
要注意的点是:1.root根路径的配置:hanlp.properties中配置如下:#本配置文件中的路径的根目录,根目录+其他路径=完整路径(支持相对路径)#Windows用户请注意,路径分隔符统一使用/root=D:/Project/public_sentiment_monitor/plugin/hanlp1.6. 8/2.自定义词典路径的配置,配置文件中已经指明了相应的用法。
hanlp.properties中配置如下:#自定义词典路径,用;隔开多个自定义词典,空格开头表示在同一个目录,使用“文件名词性”形式则表示这个词典的词性默认是该词性。
优先级递减。
#所有词典统一使用UTF-8编码,每一行代表一个单词,格式遵从[单词] [词性A] [A的频次] [词性B] [B的频次] ... 如果不填词性则表示采用词典的默认词性。
CustomDictionaryPath=data/dictionary/custom/hanlp_cust om.txt; 搜狗金融词库.txt n; CustomDictionary.txt; 现代汉语补充词库.txt; 全国地名大全.txt ns; 人名词典.txt3.配置文件做好以后,自定义词典不起作用问题(1). 需要先删除custom文件夹下的所有bin文件,然后再使用hanlp,hanlp会自动加载一个新的bin文件,自定义词典就可以使用了。
貌似加载出的bin文件只有CustomDictionaryPath这一行配置中的第一个文件对应的bin,但是内容应该是将所有的自定义词典都包含了的。
(2). 如果自定义词典txt文件中存在含有空格的词,比如说"16 金立债nz 100"这种配置,回导致自定义词典加载程序将"16"认为是词,"金立债"认为是词性,"nz"认为是词频,然后出现Java报错: ng.NumberFormatException: For input string: "nz"虽然仍然生成了bin文件,但是实际上自定义词典中的所有词都是无法使用的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
HanLP
HanLP下载
文档
联系
关于调用简单欢迎使用HanLP HanLP v1.2.7HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言
处理在生产环境中的应用。
不仅仅是分词,而是提供词法分析、句法分析、语义理解等完备的功能。
HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
Download Free & Open SourceHanLP完全开源,包括词典。
不依赖其他jar,底层采用了一系列高速的数据结构,如双数组Trie树、DAWG、AhoCorasickDoubleArrayTrie等,这
些基础件都是开源的。
官方模型训练自2014人民日报语料库,您也可以使用内置的工具训练自己的模型。
Star Me Easy to Use
通过工具类HanLP您可以一句话调用所有功能,文档详细,开箱即用。
底层算法经过精心优化,极速分词模式下可达2,000万字/秒,内存仅需120MB。
在IO方面,词典加载速度极快,只需500
ms即可快速启动。
HanLP经过多次重构,欢迎二次开发。
Documentation组件一览技术参数
HanLP v1.2.7的特征:
最高分词速度2,000万字/秒(极速分词,2.0GHz i7)
35万词典,覆盖现代汉语常用词、网络新词等
337万接续BiGram文法模型
500 ms 词典加载
训练自2014年人民日报切分语料
词语标注集兼容《ICTPOS3.0汉语词性标记集》
词语标注集兼容《现代汉语语料库加工规范——词语切分与词性标注》
最低内存要求120 MB(-Xms120m -Xmx120m -Xmn64m)基于双数组Trie的AhoCorasick自动机算法实现O(n)多模
式匹配
运行于Java6+
提供Lucene插件,兼容Lucene4.x
Apache License Version 2.0
HanLP产品初始知识产权归上海林原信息科技有限公司所有,任何人和企业可以无偿使用,可以对产品、源代码进行任何形式的修改,
可以打包在其他产品中进行销售。
任何使用了HanLP的全部或部分功能、词典、模型的项目、产品或文章等形式的成果必须显式注明HanLP及此项目主页。
最新版本:HanLP v1.2.7
下载Copyright ? 上海林原信息科技有限公司2014HanLP 下载
文档
联系
关于调用简单欢迎使用HanLP HanLP v1.2.7HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言
处理在生产环境中的应用。
不仅仅是分词,而是提供词法分析、句法分析、语义理解等完备的功能。
HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
Download Free & Open SourceHanLP完全开源,包括词典。
不依赖其他jar,底层采用了一系列高速的数据结构,如双数组Trie树、DAWG、AhoCorasickDoubleArrayTrie等,这
些基础件都是开源的。
官方模型训练自2014人民日报语料库,您也可以使用内置的工具训练自己的模型。
Star Me Easy to Use
通过工具类HanLP您可以一句话调用所有功能,文档详细,开箱即用。
底层算法经过精心优化,极速分词模式下可达
2,000万字/秒,内存仅需120MB。
在IO方面,词典加载速度极快,只需500
ms即可快速启动。
HanLP经过多次重构,欢迎二次开发。
Documentation组件一览技术参数
HanLP v1.2.7的特征:
最高分词速度2,000万字/秒(极速分词,2.0GHz i7)
35万词典,覆盖现代汉语常用词、网络新词等
337万接续BiGram文法模型
500 ms 词典加载
训练自2014年人民日报切分语料
词语标注集兼容《ICTPOS3.0汉语词性标记集》
词语标注集兼容《现代汉语语料库加工规范——词语切分与词性标注》
最低内存要求120 MB(-Xms120m -Xmx120m -Xmn64m)基于双数组Trie的AhoCorasick自动机算法实现O(n)多模式匹配
运行于Java6+
提供Lucene插件,兼容Lucene4.x
Apache License Version 2.0
HanLP产品初始知识产权归上海林原信息科技有限公司所有,任何人和企业可以无偿使用,可以对产品、源代码进行任何形式的修改,
可以打包在其他产品中进行销售。
任何使用了HanLP的全
部或部分功能、词典、模型的项目、产品或文章等形式的成果必须显式注明HanLP及此项目主页。
最新版本:HanLP
v1.2.7
下载Copyright ? 上海林原信息科技有限公司2014HanLP
下载
文档
联系
关于调用简单欢迎使用HanLP HanLP v1.2.7HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言
处理在生产环境中的应用。
不仅仅是分词,而是提供词法分析、句法分析、语义理解等完备的功能。
HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
Download Free & Open SourceHanLP完全开源,包括词典。
不依赖其他jar,底层采用了一系列高速的数据结构,如双数
组Trie树、DAWG、AhoCorasickDoubleArrayTrie等,这些基础件都是开源的。
官方模型训练自2014人民日报语料库,您也可以使用内置的工具训练自己的模型。
Star Me Easy to Use
通过工具类HanLP您可以一句话调用所有功能,文档详细,开箱即用。
底层算法经过精心优化,极速分词模式下可达2,000万字/秒,内存仅需120MB。
在IO方面,词典加载速度极快,只需500
ms即可快速启动。
HanLP经过多次重构,欢迎二次开发。
Documentation组件一览技术参数
HanLP v1.2.7的特征:
最高分词速度2,000万字/秒(极速分词,2.0GHz i7)
35万词典,覆盖现代汉语常用词、网络新词等
337万接续BiGram文法模型
500 ms 词典加载
训练自2014年人民日报切分语料
词语标注集兼容《ICTPOS3.0汉语词性标记集》
词语标注集兼容《现代汉语语料库加工规范——词语切分与词性标注》
最低内存要求120 MB(-Xms120m -Xmx120m -Xmn64m)基于双数组Trie的AhoCorasick自动机算法实现O(n)多模式匹配
运行于Java6+
提供Lucene插件,兼容Lucene4.x
Apache License Version 2.0
HanLP产品初始知识产权归上海林原信息科技有限公司所有,任何人和企业可以无偿使用,可以对产品、源代码进行任何形式的修改,
可以打包在其他产品中进行销售。
任何使用了HanLP的全部或部分功能、词典、模型的项目、产品或文章等形式的成果必须显式注明HanLP及此项目主页。
最新版本:HanLP v1.2.7
下载Copyright ? 上海林原信息科技有限公司2014。