对图进行深度优先搜索
深度优先搜索探索中的路径

深度优先搜索探索中的路径深度优先搜索(Depth First Search,DFS)是一种用于图和树等数据结构的搜索算法。
在图的深度优先搜索过程中,寻找一条从起始顶点到目标顶点的路径是常见且重要的问题。
本文将探讨深度优先搜索中如何找到路径的方法和实现。
一、路径的定义和表示在深度优先搜索中,路径是指从起始顶点到目标顶点的一条通路。
路径可以用顶点序列或边的序列来表示。
以图为例,设图G=(V,E)表示一个有向图,其中V为顶点集合,E为边集合。
对于路径P={v1,v2,v3,...,vn},其中vi∈V且(vi,vi+1)∈E。
路径中的第一个顶点为起始顶点,最后一个顶点为目标顶点。
二、深度优先搜索中的路径探索1. 基本思想深度优先搜索是一种递归的搜索方式,它以某个顶点为起始点,深度优先地遍历该顶点的邻接顶点,然后递归地遍历邻接顶点的邻接顶点,直到找到目标顶点或遍历完所有路径。
2. 算法步骤(1)判断当前顶点是否为目标顶点。
如果是,则找到了一条路径;(2)如果当前顶点不是目标顶点,继续遍历当前顶点的邻接顶点;(3)对于每个邻接顶点,重复步骤(1)和步骤(2),直到找到目标顶点或遍历完所有路径。
三、路径搜索的实现深度优先搜索中的路径搜索可以通过编程实现。
下面以Python语言为例,给出一个简单的深度优先搜索算法的实现:```pythondef dfs(graph, start, end, path=[]):path = path + [start]if start == end:return [path]if start not in graph:return []paths = []for vertex in graph[start]:if vertex not in path:new_paths = dfs(graph, vertex, end, path)for new_path in new_paths:paths.append(new_path)return paths```在上述代码中,graph为表示图的字典,start为起始顶点,end为目标顶点,path为当前路径。
拓扑排序深度优先算法

拓扑排序通常用于具有定向无环图(Directed Acyclic Graph,简称DAG)的场景,例如确定一系列活动的执行顺序,满足前置条件。
深度优先搜索(Depth-First Search,简称DFS)是实现拓扑排序的一种常用算法。
以下是基于深度优先搜索的拓扑排序的基本步骤:创建一个空的结果列表(或者称为输出列表)。
使用深度优先搜索遍历图。
对于每个访问过的节点,将其添加到结果列表的开头。
如果图中仍然有未访问的节点,则返回步骤2。
返回结果列表。
这就是拓扑排序的结果。
以下是该算法的Python实现:pythonfrom collections import defaultdict, dequeclass Graph:def __init__(self, vertices):self.graph = defaultdict(list)self.V = verticesdef addEdge(self, u, v):self.graph[u].append(v)def topologicalSortUtil(self, v, visited, stack):visited[v] = Truefor i in self.graph[v]:if visited[i] == False:self.topologicalSortUtil(i, visited, stack)stack.insert(0, v)def topologicalSort(self):visited = [False] * (self.V)stack = []for i in range(self.V):if visited[i] == False:self.topologicalSortUtil(i, visited, stack)print("Topological Sort: ")print(stack)在这个代码中,我们首先创建一个有向图,然后使用深度优先搜索遍历图,并对每个节点执行拓扑排序。
浅谈深度优先搜索算法优化

浅谈深度优先搜索算法优化深度优先算法是一种常用的图算法,其基本思想是从起始节点开始,不断地深入到图的各个分支直到无法继续深入,然后回溯到上一个节点,继续深入其他未探索的分支,直到遍历完整个图。
然而,深度优先算法在应用中可能会面临一些问题,例如空间过大导致的效率低下等。
因此,需要对深度优先算法进行优化。
一种常见的深度优先算法优化方法是剪枝技术。
剪枝是指在过程中对一些节点进行跳过,从而减少空间。
具体来说,可以通过设置一些条件,只符合条件的节点,从而跳过一些不必要的路径。
例如,在解决八皇后问题时,可以设置一些约束条件,如不同行、不同列和不同对角线上不能同时存在两个皇后,然后在过程中只考虑符合条件的节点,这样就能够有效地减少空间,提高效率。
另一种常见的深度优先算法优化方法是使用启发式。
启发式是一种基于问题特征的方法,通过引入评估函数来估计状态的潜在价值,从而指导方向。
启发式在深度优先算法中的应用主要是通过选择有潜在最优解的节点进行,从而减少次数和空间。
例如,在解决旅行商问题时,可以使用贪心算法选择距离当前节点最近的未访问的节点,然后向该节点进行深度,这样就能够更快地找到最优解。
此外,可以通过使用数据结构进行优化。
深度优先算法使用递归的方式进行,但递归在实现上需要使用系统栈,当空间非常大时,会占用大量的内存。
为了解决这个问题,可以使用迭代的方式进行,使用自定义的栈来存储路径。
这样,可以节省内存并提高效率。
另外,也可以使用位运算来替代传统的数组存储状态,从而节省空间。
例如,在解决0-1背包问题时,可以使用一个整数表示当前已经选择了哪些物品,这样就能够大大减小空间,提高效率。
最后,可以通过并行计算来优化深度优先算法。
并行计算是指使用多个处理器或多个线程同时进行计算,从而加快速度。
在深度优先算法中,并行计算可以通过将空间划分为多个子空间,每个子空间由一个处理器或一个线程负责,然后汇总结果,得到最终的解。
这样就能够充分利用计算资源,提高效率。
dfs通用步骤-概述说明以及解释

dfs通用步骤-概述说明以及解释1.引言1.1 概述DFS(深度优先搜索)是一种常用的图遍历算法,它通过深度优先的策略来遍历图中的所有节点。
在DFS中,从起始节点开始,一直向下访问直到无法继续为止,然后返回到上一个未完成的节点,继续访问它的下一个未被访问的邻居节点。
这个过程不断重复,直到图中所有的节点都被访问为止。
DFS算法的核心思想是沿着一条路径尽可能深入地搜索,直到无法继续为止。
在搜索过程中,DFS会使用一个栈来保存待访问的节点,以及记录已经访问过的节点。
当访问一个节点时,将其标记为已访问,并将其所有未访问的邻居节点加入到栈中。
然后从栈中取出下一个节点进行访问,重复这个过程直到栈为空。
优点是DFS算法实现起来比较简单,而且在解决一些问题时具有较好的效果。
同时,DFS算法可以用来解决一些经典的问题,比如寻找图中的连通分量、判断图中是否存在环、图的拓扑排序等。
然而,DFS算法也存在一些缺点。
首先,DFS算法不保证找到最优解,有可能陷入局部最优解而无法找到全局最优解。
另外,如果图非常庞大且存在大量的无效节点,DFS可能会陷入无限循环或者无法找到解。
综上所述,DFS是一种常用的图遍历算法,可以用来解决一些问题,但需要注意其局限性和缺点。
在实际应用中,我们需要根据具体问题的特点来选择合适的搜索策略。
在下一部分中,我们将详细介绍DFS算法的通用步骤和要点,以便读者更好地理解和应用该算法。
1.2 文章结构文章结构部分的内容如下所示:文章结构:在本文中,将按照以下顺序介绍DFS(深度优先搜索)通用步骤。
首先,引言部分将概述DFS的基本概念和应用场景。
其次,正文部分将详细解释DFS通用步骤的两个要点。
最后,结论部分将总结本文的主要内容并展望未来DFS的发展趋势。
通过这样的结构安排,读者可以清晰地了解到DFS算法的基本原理和它在实际问题中的应用。
接下来,让我们开始正文的介绍。
1.3 目的目的部分的内容可以包括对DFS(Depth First Search,深度优先搜索)的应用和重要性进行介绍。
信息学竞赛 题目

信息学竞赛题目
当提到信息学竞赛时,通常指的是计算机和算法相关的竞赛,如国际信息学奥林匹克竞赛(IOI)等。
以下是一些可能的信息学竞赛题目,包括算法设计、编程、数据结构等方面的内容:
最短路径问题:
设计一个算法,找到加权图中两点之间的最短路径。
可以考虑使用Dijkstra 算法或Floyd-Warshall算法。
排序算法的比较:
实现不同排序算法(如快速排序、归并排序、冒泡排序等),并比较它们在不同数据集上的性能。
动态规划问题:
解决一个动态规划问题,例如背包问题、最长公共子序列等。
图论问题:
给定一个图,设计算法检测是否存在环路,或者找到图中的最小生成树。
字符串处理:
编写一个程序,实现字符串的模式匹配或编辑距离计算。
并查集应用:
使用并查集解决一个集合合并或划分问题,例如朋友圈问题。
图的遍历:
设计一个算法,对图进行深度优先搜索(DFS)或广度优先搜索(BFS)。
动态规划背包问题:
给定一组物品的重量和价值,设计一个动态规划算法解决背包问题,最大化所装物品的总价值。
树的遍历与操作:
对一棵树进行先序、中序或后序遍历,并进行相应的操作,例如计算树的高度、直径等。
最大流问题:
设计一个算法解决最大流问题,例如Ford-Fulkerson算法或Edmonds-Karp 算法。
这些题目涉及了算法设计、数据结构、图论等多个方面,是信息学竞赛中常见的类型。
挑战性强,需要竞赛者具备深厚的计算机科学知识和解决问题的能力。
希望这些题目能够激发你在信息学竞赛中的学习兴趣。
广度优先和深度优先的例子

广度优先和深度优先的例子广度优先搜索(BFS)和深度优先搜索(DFS)是图遍历中常用的两种算法。
它们在解决许多问题时都能提供有效的解决方案。
本文将分别介绍广度优先搜索和深度优先搜索,并给出各自的应用例子。
一、广度优先搜索(BFS)广度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,逐层扩展,先访问起始节点的所有邻居节点,再依次访问其邻居节点的邻居节点,直到遍历完所有节点或找到目标节点。
例子1:迷宫问题假设有一个迷宫,迷宫中有多个房间,每个房间有四个相邻的房间:上、下、左、右。
现在我们需要找到从起始房间到目标房间的最短路径。
可以使用广度优先搜索算法来解决这个问题。
例子2:社交网络中的好友推荐在社交网络中,我们希望给用户推荐可能认识的新朋友。
可以使用广度优先搜索算法从用户的好友列表开始,逐层扩展,找到可能认识的新朋友。
例子3:网页爬虫网页爬虫是搜索引擎抓取网页的重要工具。
爬虫可以使用广度优先搜索算法从一个网页开始,逐层扩展,找到所有相关的网页并进行抓取。
例子4:图的最短路径在图中,我们希望找到两个节点之间的最短路径。
可以使用广度优先搜索算法从起始节点开始,逐层扩展,直到找到目标节点。
例子5:推荐系统在推荐系统中,我们希望给用户推荐可能感兴趣的物品。
可以使用广度优先搜索算法从用户喜欢的物品开始,逐层扩展,找到可能感兴趣的其他物品。
二、深度优先搜索(DFS)深度优先搜索是一种遍历或搜索图的算法,它从起始节点开始,沿着一条路径一直走到底,直到不能再继续下去为止,然后回溯到上一个节点,继续探索其他路径。
例子1:二叉树的遍历在二叉树中,深度优先搜索算法可以用来实现前序遍历、中序遍历和后序遍历。
通过深度优先搜索算法,我们可以按照不同的遍历顺序找到二叉树中所有节点。
例子2:回溯算法回溯算法是一种通过深度优先搜索的方式,在问题的解空间中搜索所有可能的解的算法。
回溯算法常用于解决组合问题、排列问题和子集问题。
例子3:拓扑排序拓扑排序是一种对有向无环图(DAG)进行排序的算法。
深度优先搜索实验报告

深度优先搜索实验报告引言深度优先搜索(Depth First Search,DFS)是图论中的一种重要算法,主要用于遍历和搜索图的节点。
在实际应用中,DFS被广泛用于解决迷宫问题、图的连通性问题等,具有较高的实用性和性能。
本实验旨在通过实际编程实现深度优先搜索算法,并通过实际案例验证其正确性和效率。
实验中我们将以迷宫问题为例,使用深度优先搜索算法寻找从入口到出口的路径。
实验过程实验准备在开始实验之前,我们需要准备一些必要的工具和数据。
1. 编程环境:我们选择使用Python语言进行编程实验,因其语法简洁而强大的数据处理能力。
2. 迷宫地图:我们需要设计一个迷宫地图,包含迷宫的入口和出口,以及迷宫的各个路径和墙壁。
实验步骤1. 首先,我们需要将迷宫地图转化为计算机可处理的数据结构。
我们选择使用二维数组表示迷宫地图,其中0表示墙壁,1表示路径。
2. 接着,我们将编写深度优先搜索算法的实现。
在DFS函数中,我们将使用递归的方式遍历迷宫地图的所有路径,直到找到出口或者遇到墙壁。
3. 在每次遍历时,我们将记录已经访问过的路径,以防止重复访问。
4. 当找到出口时,我们将输出找到的路径,并计算路径的长度。
实验结果经过实验,我们成功地实现了深度优先搜索算法,并在迷宫地图上进行了测试。
以下是我们的实验结果:迷宫地图:1 1 1 1 11 0 0 0 11 1 1 0 11 0 0 0 11 1 1 1 1最短路径及长度:(1, 1) -> (1, 2) -> (1, 3) -> (1, 4) -> (2, 4) -> (3, 4) -> (4, 4) -> (5, 4)路径长度:7从实验结果可以看出,深度优先搜索算法能够准确地找到从入口到出口的最短路径,并输出了路径的长度。
实验分析我们通过本实验验证了深度优先搜索算法的正确性和有效性。
然而,深度优先搜索算法也存在一些缺点:1. 只能找到路径的一种解,不能确定是否为最优解。
数据结构练习(二)答案

数据结构练习(二)答案一、填空题:1.若一棵树的括号表示为A(B(E,F),C(G(H,I,J,K),L),D(M(N))),则该树的度为(1)4,树的深度为(2)4 ,树中叶子结点的个数为(3)8。
2.一棵满二叉树中有m个叶子,n个结点,深度为h,请写出m、n、h之间关系的表达式(4)n=2h-1,m=n+1-2h-1 n=2m-1 。
3.一棵二叉树中如果有n个叶子结点,则这棵树上最少有(5)2n-1 个结点。
一棵深度为k的完全二叉树中最少有2k-1(6)个结点,最多有(7)2k-1个结点。
4.具有n个结点的二叉树,当它是一棵(8)完全二叉树时具有最小高度(9) log2n」+1,当它为一棵单支树时具有高度(10) n 。
5.对具有n个结点的完全二叉树按照层次从上到下,每一层从左到右的次序对所有结点进行编号,编号为i的结点的双亲结点的编号为_(11)__[i/2]__,左孩子的编号为___2i____,右孩子的编号为__2i+1______。
6.若具有n个结点的二叉树采用二叉链表存储结构,则该链表中有__2n_个指针域,其中有_n-1_个指针域用于链接孩子结点,__n+1_个指针域空闲存放着NULL 。
7.二叉树的遍历方式通常有__先序__、___中序__、__后序__和___层序___四种。
8.已知二叉树的前序遍历序列为ABDCEFG,中序遍历序列为DBCAFEG,其后序遍历序列为___DCBFGEA__。
9.已知某完全二叉树采用顺序存储结构,结点的存放次序为A,B,C,D,E,F,G,H,I,J,该完全二叉树的后序序列为___HIDJEBFGCA____。
10.若具有n个结点的非空二叉树有n0个叶结点,则该二叉树有__n0-1_个度为2的结点,____n-2n0+1____个度为1的结点。
11.任何非空树中有且仅有一个结点没有前驱结点,该结点就是树的__根____。
度为k的树中第i层最多有___k i-1_______个结点(i>=1),深度为h的k叉树最多有___k0+k1+....+k h-1____个结点。
环路识别 算法

环路识别算法
环路识别算法是指通过分析一个给定的网络或图结构,判断其中是否存在环路。
以下是几种常见的环路识别算法:
1. 深度优先搜索(DFS):从一个节点开始进行深度优先搜索,记录访问过的节点并标记为已访问。
如果在搜索路径中遇到已访问的节点,则说明存在环路。
2. 广度优先搜索(BFS):从一个节点开始进行广度优先搜索,使用队列来保存待访问的节点。
在搜索过程中,如果遇到已访问的节点,则说明存在环路。
3. 强连通分量算法:强连通分量是指一个图中的节点集合,其中的任意两个节点都可以相互到达。
通过使用强连通分量算法(如Tarjan算法或Kosaraju算法),可以将图划分为多个强连通分量。
如果存在一个强连通分量的大小大于1,则说明存在环路。
4. 拓扑排序:拓扑排序是一种对有向无环图(DAG)进行排序的算法。
在拓扑排序过程中,将入度为0的节点依次加入排序结果中,并将其邻接节点的入度减1。
如果最终排序结果包含所有的节点,则说明不存在环路;反之,存在环路。
这些算法可以根据具体的需求和应用场景进行选择和优化。
原题目:描述深度优先搜索算法的过程。

原题目:描述深度优先搜索算法的过程。
描述深度优先搜索算法的过程深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索图的算法,它是一种递归算法,通过深度的方式探索图的节点以获得解决方案。
步骤使用深度优先搜索算法来遍历图的节点的步骤如下:1. 选择一个起始节点作为当前节点,并将其标记为已访问。
2. 检查当前节点是否是目标节点。
如果是目标节点,则算法结束。
3. 如果当前节点不是目标节点,则遍历当前节点的邻居节点。
4. 对于每个未访问的邻居节点,将其标记为已访问,并将其加入到待访问节点的列表中。
5. 从待访问节点的列表中选择一个节点作为新的当前节点,并重复步骤2-4,直到找到目标节点或所有节点都被访问。
6. 如果所有节点都被访问但没有找到目标节点,则算法结束。
递归实现深度优先搜索算法可以使用递归的方式来实现。
以下是一个递归实现深度优先搜索的示例代码:def dfs(graph, node, visited):visited.add(node)print(node)for neighbor in graph[node]:if neighbor not in visited:dfs(graph, neighbor, visited)在上述代码中,`graph` 是表示图的邻接表,`node` 是当前节点,`visited` 是已访问节点的集合。
算法以起始节点作为参数进行递归调用,并在访问每个节点时打印节点的值。
非递归实现除了递归方式,深度优先搜索算法还可以使用栈来实现非递归版本。
以下是一个非递归实现深度优先搜索的示例代码:def dfs(graph, start_node):visited = set()stack = [start_node]while stack:node = stack.pop()if node not in visited:visited.add(node)print(node)for neighbor in graph[node]:if neighbor not in visited:stack.append(neighbor)在上述代码中,`graph` 是表示图的邻接表,`start_node` 是起始节点。
信息学竞赛中的深度优先搜索算法

信息学竞赛中的深度优先搜索算法深度优先搜索(Depth First Search, DFS)是一种经典的图遍历算法,在信息学竞赛中被广泛应用。
本文将介绍深度优先搜索算法的原理、应用场景以及相关的技巧与注意事项。
一、算法原理深度优先搜索通过递归或者栈的方式实现,主要思想是从图的一个节点开始,尽可能地沿着一条路径向下深入,直到无法继续深入,然后回溯到上一个节点,再选择其他未访问的节点进行探索,直到遍历完所有节点为止。
二、应用场景深度优先搜索算法在信息学竞赛中有广泛的应用,例如以下场景:1. 图的遍历:通过深度优先搜索可以遍历图中的所有节点,用于解决与图相关的问题,如寻找连通分量、判断是否存在路径等。
2. 剪枝搜索:在某些问题中,深度优先搜索可以用于剪枝搜索,即在搜索的过程中根据当前状态进行一定的剪枝操作,提高求解效率。
3. 拓扑排序:深度优先搜索还可以用于拓扑排序,即对有向无环图进行排序,用于解决任务调度、依赖关系等问题。
4. 迷宫求解:对于迷宫类的问题,深度优先搜索可以用于求解最短路径或者所有路径等。
三、算法实现技巧在实际应用深度优先搜索算法时,可以采用以下的一些技巧和优化,以提高算法效率:1. 记忆化搜索:通过记录已经计算过的状态或者路径,避免重复计算,提高搜索的效率。
2. 剪枝策略:通过某些条件判断,提前终止当前路径的搜索,从而避免无效的搜索过程。
3. 双向搜索:在某些情况下,可以同时从起点和终点进行深度优先搜索,当两者在某个节点相遇时,即可确定最短路径等。
四、注意事项在应用深度优先搜索算法时,需要注意以下几点:1. 图的表示:需要根据实际问题选择合适的图的表示方法,如邻接矩阵、邻接表等。
2. 访问标记:需要使用合适的方式标记已经访问过的节点,避免无限循环或者重复访问造成的错误。
3. 递归调用:在使用递归实现深度优先搜索时,需要注意递归的结束条件和过程中变量的传递。
4. 时间复杂度:深度优先搜索算法的时间复杂度一般为O(V+E),其中V为节点数,E为边数。
深度优先搜索算法利用深度优先搜索解决迷宫问题

深度优先搜索算法利用深度优先搜索解决迷宫问题深度优先搜索算法(Depth-First Search, DFS)是一种常用的图遍历算法,它通过优先遍历图中的深层节点来搜索目标节点。
在解决迷宫问题时,深度优先搜索算法可以帮助我们找到从起点到终点的路径。
一、深度优先搜索算法的实现原理深度优先搜索算法的实现原理相当简单直观。
它遵循以下步骤:1. 选择一个起始节点,并标记为已访问。
2. 递归地访问其相邻节点,若相邻节点未被访问,则标记为已访问,并继续访问其相邻节点。
3. 重复步骤2直到无法继续递归访问,则返回上一级节点,查找其他未被访问的相邻节点。
4. 重复步骤2和3,直到找到目标节点或者已经遍历所有节点。
二、利用深度优先搜索算法解决迷宫问题迷宫问题是一个经典的寻找路径问题,在一个二维的迷宫中,我们需要找到从起点到终点的路径。
利用深度优先搜索算法可以很好地解决这个问题。
以下是一种可能的解决方案:```1. 定义一个二维数组作为迷宫地图,其中0代表通路,1代表墙壁。
2. 定义一个和迷宫地图大小相同的二维数组visited,用于记录节点是否已经被访问过。
3. 定义一个存储路径的栈path,用于记录从起点到终点的路径。
4. 定义一个递归函数dfs,参数为当前节点的坐标(x, y)。
5. 在dfs函数中,首先判断当前节点是否为终点,如果是则返回True,表示找到了一条路径。
6. 然后判断当前节点是否越界或者已经访问过,如果是则返回False,表示该路径不可行。
7. 否则,将当前节点标记为已访问,并将其坐标添加到path路径中。
8. 依次递归访问当前节点的上、下、左、右四个相邻节点,如果其中任意一个节点返回True,则返回True。
9. 如果所有相邻节点都返回False,则将当前节点从path路径中删除,并返回False。
10. 最后,在主函数中调用dfs函数,并判断是否找到了一条路径。
```三、示例代码```pythondef dfs(x, y):if maze[x][y] == 1 or visited[x][y] == 1:return Falseif (x, y) == (end_x, end_y):return Truevisited[x][y] = 1path.append((x, y))if dfs(x+1, y) or dfs(x-1, y) or dfs(x, y+1) or dfs(x, y-1): return Truepath.pop()return Falseif __name__ == '__main__':maze = [[0, 1, 1, 0, 0],[0, 0, 0, 1, 0],[1, 1, 0, 0, 0],[1, 1, 1, 1, 0],[0, 0, 0, 1, 0]]visited = [[0] * 5 for _ in range(5)]path = []start_x, start_y = 0, 0end_x, end_y = 4, 4if dfs(start_x, start_y):print("Found path:")for x, y in path:print(f"({x}, {y}) ", end="")print(f"\nStart: ({start_x}, {start_y}), End: ({end_x}, {end_y})") else:print("No path found.")```四、总结深度优先搜索算法是一种有效解决迷宫问题的算法。
算法考试试题

算法考试试题算法考试试题在计算机科学领域中,算法是一种解决问题的方法或过程。
算法考试试题是评估学生对算法设计和分析的理解和能力的重要方式。
本文将探讨算法考试试题的一些常见类型和解决方法,以及如何在考试中取得好成绩。
一、基础知识题基础知识题旨在考察学生对算法的基本概念和术语的理解。
例如,以下是一道基础知识题:题目:请解释以下术语的含义:时间复杂度、空间复杂度、最坏情况时间复杂度。
解答:时间复杂度是衡量算法执行时间的度量,通常用大O表示法表示。
空间复杂度是衡量算法所需内存空间的度量。
最坏情况时间复杂度是指算法在最不利的情况下所需的最长时间。
对于这类题目,学生需要对术语进行准确的定义和解释,以展示他们对基本概念的理解。
二、分析题分析题旨在考察学生对算法的分析和评估能力。
例如,以下是一道分析题:题目:给定一个整数数组,设计一个算法找到数组中的最大值。
解答:一种简单的方法是遍历整个数组,将每个元素与当前最大值进行比较,如果大于当前最大值,则更新最大值。
这个算法的时间复杂度是O(n),其中n 是数组的长度。
对于这类题目,学生需要能够分析算法的时间复杂度和空间复杂度,并选择最优的算法来解决问题。
三、编程题编程题旨在考察学生对算法的实现和应用能力。
例如,以下是一道编程题:题目:给定一个字符串,设计一个算法判断它是否是回文串。
解答:一个简单的方法是将字符串反转,然后与原字符串进行比较,如果相等则是回文串。
另一种方法是使用双指针,一个指向字符串的起始位置,另一个指向字符串的末尾位置,逐个比较字符是否相等。
这两种方法的时间复杂度都是O(n),其中n是字符串的长度。
对于这类题目,学生需要能够将算法转化为具体的代码实现,并考虑边界情况和优化算法的可能性。
四、应用题应用题旨在考察学生将算法应用于实际问题的能力。
例如,以下是一道应用题:题目:给定一个有向图,设计一个算法找到图中的所有强连通分量。
解答:可以使用深度优先搜索算法来解决这个问题。
深度优先搜索和广度优先搜索

深度优先搜索和广度优先搜索深度优先搜索(DFS)和广度优先搜索(BFS)是图论中常用的两种搜索算法。
它们是解决许多与图相关的问题的重要工具。
本文将着重介绍深度优先搜索和广度优先搜索的原理、应用场景以及优缺点。
一、深度优先搜索(DFS)深度优先搜索是一种先序遍历二叉树的思想。
从图的一个顶点出发,递归地访问与该顶点相邻的顶点,直到无法再继续前进为止,然后回溯到前一个顶点,继续访问其未被访问的邻接顶点,直到遍历完整个图。
深度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 递归访问该顶点的邻接顶点,直到所有邻接顶点均被访问过。
深度优先搜索的应用场景较为广泛。
在寻找连通分量、解决迷宫问题、查找拓扑排序等问题中,深度优先搜索都能够发挥重要作用。
它的主要优点是容易实现,缺点是可能进入无限循环。
二、广度优先搜索(BFS)广度优先搜索是一种逐层访问的思想。
从图的一个顶点出发,先访问该顶点,然后依次访问与该顶点邻接且未被访问的顶点,直到遍历完整个图。
广度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 将该顶点的所有邻接顶点加入一个队列;4. 从队列中依次取出一个顶点,并访问该顶点的邻接顶点,标记为已访问;5. 重复步骤4,直到队列为空。
广度优先搜索的应用场景也非常广泛。
在求最短路径、社交网络分析、网络爬虫等方面都可以使用广度优先搜索算法。
它的主要优点是可以找到最短路径,缺点是需要使用队列数据结构。
三、DFS与BFS的比较深度优先搜索和广度优先搜索各自有着不同的优缺点,适用于不同的场景。
深度优先搜索的优点是在空间复杂度较低的情况下找到解,但可能陷入无限循环,搜索路径不一定是最短的。
广度优先搜索能找到最短路径,但需要保存所有搜索过的节点,空间复杂度较高。
需要根据实际问题选择合适的搜索算法,例如在求最短路径问题中,广度优先搜索更加合适;而在解决连通分量问题时,深度优先搜索更为适用。
图的连通性检测方法

图的连通性检测方法图论是数学的一个分支,研究图形结构以及图形之间的关系。
在图论中,连通性是一个重要的概念,用于描述图中的节点或顶点之间是否存在路径相连。
连通性检测方法是用来确定一个图是否是连通图的方法。
本文将介绍几种常用的图的连通性检测方法。
一、深度优先搜索(DFS)深度优先搜索是一种常用的图遍历算法,也可以用来检测图的连通性。
该方法从图中的一个顶点开始,沿着一条路径尽可能深的搜索,直到到达无法继续搜索的节点,然后回溯到上一个节点,继续搜索其他路径。
具体步骤如下:1. 选择一个起始节点作为根节点。
2. 遍历该节点的邻接节点,并标记为已访问。
3. 递归的访问未访问过的邻接节点,直到所有节点都被访问过。
4. 如果所有节点都被访问过,则图是连通的;否则,图是不连通的。
DFS算法的时间复杂度为O(V+E),其中V是节点数,E是边数。
二、广度优先搜索(BFS)广度优先搜索也是一种常用的图遍历算法,同样可以用来检测图的连通性。
该方法从图中的一个顶点开始,先访问其所有邻接节点,然后再依次访问它们的邻接节点。
具体步骤如下:1. 选择一个起始节点作为根节点。
2. 将该节点加入一个队列中。
3. 从队列中取出一个节点,并标记为已访问。
4. 遍历该节点的邻接节点,将未访问过的节点加入队列中。
5. 重复步骤3和步骤4,直到队列为空。
6. 如果所有节点都被访问过,则图是连通的;否则,图是不连通的。
BFS算法的时间复杂度同样为O(V+E)。
三、并查集并查集是一种数据结构,常用于解决图的连通性问题。
它可以高效地合并集合和判断元素是否属于同一个集合。
具体步骤如下:1. 初始化并查集,每个节点都是一个独立的集合。
2. 遍历图中的每条边,将边的两个节点合并到同一个集合中。
3. 判断图是否连通的方法是查找两个节点是否属于同一个集合。
并查集的时间复杂度为O(V+E)。
四、最小生成树最小生成树是指一个连通图的生成树,其所有边的权值之和最小。
数据结构与算法(13):深度优先搜索和广度优先搜索
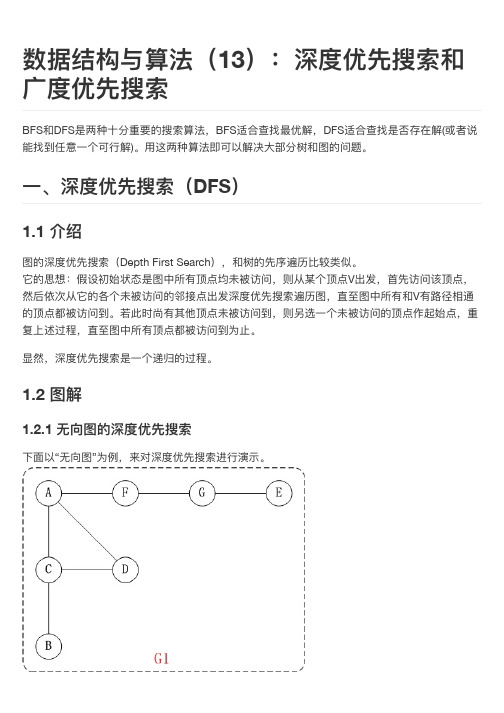
2.2.2 有向图的广广度优先搜索
下面面以“有向图”为例例,来对广广度优先搜索进行行行演示。还是以上面面的图G2为例例进行行行说明。
第1步:访问A。 第2步:访问B。 第3步:依次访问C,E,F。 在访问了了B之后,接下来访问B的出边的另一一个顶点,即C,E,F。前 面面已经说过,在本文文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访 问E,F。 第4步:依次访问D,G。 在访问完C,E,F之后,再依次访问它们的出边的另一一个顶点。还是按 照C,E,F的顺序访问,C的已经全部访问过了了,那么就只剩下E,F;先访问E的邻接点D,再访 问F的邻接点G。
if(mVexs[i]==ch)
return i;
return -1;
}
/* * 读取一一个输入入字符
*/
private char readChar() {
char ch='0';
do {
try {
ch = (char)System.in.read();
} catch (IOException e) {
数据结构与算法(13):深度优先搜索和 广广度优先搜索
BFS和DFS是两种十十分重要的搜索算法,BFS适合查找最优解,DFS适合查找是否存在解(或者说 能找到任意一一个可行行行解)。用用这两种算法即可以解决大大部分树和图的问题。
一一、深度优先搜索(DFS)
1.1 介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比比较类似。 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点V出发,首首先访问该顶点, 然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至至图中所有和V有路路径相通 的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一一个未被访问的顶点作起始点,重 复上述过程,直至至图中所有顶点都被访问到为止止。 显然,深度优先搜索是一一个递归的过程。
深度优先搜索和广度优先搜索的比较和应用场景

深度优先搜索和广度优先搜索的比较和应用场景在计算机科学中,深度优先搜索(DFS)和广度优先搜索(BFS)是两种常用的图搜索算法。
它们在解决许多问题时都能够发挥重要作用,但在不同的情况下具有不同的优势和适用性。
本文将对深度优先搜索和广度优先搜索进行比较和分析,并讨论它们在不同应用场景中的使用。
一、深度优先搜索(DFS)深度优先搜索是一种通过遍历图的深度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,依次遍历该节点的相邻节点,直到到达目标节点或者无法继续搜索为止。
如果当前节点有未被访问的相邻节点,则选择其中一个作为下一个节点继续进行深度搜索;如果当前节点没有未被访问的相邻节点,则回溯到上一个节点,并选择其未被访问的相邻节点进行搜索。
深度优先搜索的主要优势是其在搜索树的深度方向上进行,能够快速达到目标节点。
它通常使用递归或栈数据结构来实现,代码实现相对简单。
深度优先搜索适用于以下情况:1. 图中的路径问题:深度优先搜索能够在图中找到一条路径是否存在。
2. 拓扑排序问题:深度优先搜索能够对有向无环图进行拓扑排序,找到图中节点的一个线性排序。
3. 连通性问题:深度优先搜索能够判断图中的连通分量数量以及它们的具体节点组合。
二、广度优先搜索(BFS)广度优先搜索是一种通过遍历图的广度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,先遍历起始节点的所有相邻节点,然后再遍历相邻节点的相邻节点,以此类推,直到到达目标节点或者无法继续搜索为止。
广度优先搜索通常使用队列数据结构来实现。
广度优先搜索的主要优势是其在搜索树的广度方向上进行,能够逐层地搜索目标节点所在的路径。
它逐层扩展搜索,直到找到目标节点或者遍历完整个图。
广度优先搜索适用于以下情况:1. 最短路径问题:广度优先搜索能够在无权图中找到起始节点到目标节点的最短路径。
2. 网络分析问题:广度优先搜索能够在图中查找节点的邻居节点、度数或者群组。
三、深度优先搜索和广度优先搜索的比较深度优先搜索和广度优先搜索在以下方面有所不同:1. 搜索顺序:深度优先搜索按照深度优先的顺序进行搜索,而广度优先搜索按照广度优先的顺序进行搜索。
拓扑排序的技巧

拓扑排序的技巧拓扑排序是对有向无环图(Directed Acyclic Graph, DAG)进行排序的一种算法。
具体来说,拓扑排序可以找出一个满足所有依赖关系的顺序,使得在该顺序下,任意一个节点都排在其依赖节点之后。
拓扑排序的实现可以使用两种方法:深度优先搜索(DFS)和广度优先搜索(BFS)。
这里我们将主要讨论DFS的实现方法和一些常用的技巧。
一、深度优先搜索实现拓扑排序:1. 创建一个栈,用于存储已经被访问过的节点;2. 对于图中的每一个节点,如果该节点没有被访问过,就对该节点进行一次深度优先搜索;3. 在深度优先搜索的过程中,首先将当前节点标记为已访问,并递归地对当前节点的所有邻接节点进行深度优先搜索;4. 当一个节点的所有邻接节点都被访问过后,将该节点压入栈中;5. 当所有节点都被访问过后,按照栈的顺序依次弹出节点,即得到了拓扑排序的结果。
二、拓扑排序的应用场景:1. 项目管理:拓扑排序可以用于确定项目中的先后顺序,其中每个节点代表一个项目,每个有向边表示一个依赖关系。
通过拓扑排序,可以确定项目的执行顺序,避免出现依赖关系冲突或循环依赖。
2. 任务调度:在任务调度中,可以使用拓扑排序确定任务的执行顺序。
每个任务表示一个节点,每个有向边表示任务之间的依赖关系。
通过拓扑排序,可以保证任务的依赖关系得到满足,从而实现任务的自动调度。
3. 编译顺序:在编译程序中,源文件之间存在依赖关系,需要按照正确的顺序进行编译。
通过拓扑排序,可以确定源文件的编译顺序,确保每个源文件在被编译之前其依赖的源文件已经被编译。
4. 课程规划:在规划学习课程时,有些课程可能会有先修课程的要求,需要按照正确的顺序进行学习。
通过拓扑排序,可以确定课程的学习顺序,保证先修课程被先学习。
三、解决常见问题的技巧:1. 判断是否存在环:在进行拓扑排序之前,可以通过DFS或BFS判断图中是否存在环。
如果存在环,则无法进行拓扑排序。
数据结构之的遍历深度优先搜索和广度优先搜索的实现和应用

数据结构之的遍历深度优先搜索和广度优先搜索的实现和应用深度优先搜索和广度优先搜索是数据结构中重要的遍历算法,它们在解决各种问题时起着关键作用。
本文将介绍深度优先搜索和广度优先搜索的实现方法以及它们的应用。
一、深度优先搜索的实现和应用深度优先搜索(Depth First Search,DFS)是一种用于图或树的遍历算法。
它的基本思想是从起始节点开始,一直沿着某一分支深入直到不能再深入为止,然后回溯到前一个节点,再沿另一分支深入,直到遍历完所有节点。
深度优先搜索可以通过递归或者栈来实现。
在实现深度优先搜索时,可以采用递归的方式。
具体的实现步骤如下:1. 创建一个访问数组,用于标记节点是否已经被访问过。
2. 从起始节点开始,将其标记为已访问。
3. 遍历当前节点的邻接节点,对于每个邻接节点,如果该节点未被访问过,则递归调用深度优先搜索函数。
4. 重复步骤3,直到所有节点都被访问过。
深度优先搜索的应用非常广泛,以下是几个常见的应用场景:1. 图的连通性判断:深度优先搜索可以用于判断图中的两个节点是否连通。
2. 拓扑排序:深度优先搜索可以用于对有向无环图进行拓扑排序,即按照一种特定的线性顺序对节点进行排序。
3. 岛屿数量计算:深度优先搜索可以用于计算给定矩阵中岛屿的数量,其中岛屿由相邻的陆地单元组成。
二、广度优先搜索的实现和应用广度优先搜索(Breadth First Search,BFS)是一种用于图或树的遍历算法。
它的基本思想是从起始节点开始,逐层遍历,先访问当前节点的所有邻接节点,然后再依次访问下一层的节点,直到遍历完所有节点。
广度优先搜索可以通过队列来实现。
在实现广度优先搜索时,可以采用队列的方式。
具体的实现步骤如下:1. 创建一个访问数组,用于标记节点是否已经被访问过。
2. 创建一个空队列,并将起始节点入队。
3. 当队列不为空时,取出队首节点,并标记为已访问。
4. 遍历当前节点的邻接节点,对于每个邻接节点,如果该节点未被访问过,则将其入队。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/******************************** 声明区********************************/#include<stdio.h>#include<string.h>#include<stdlib.h>#define FALSE 0#define TRUE 1#define OK 1#define ERROR 0#define MAX_VERTEX_NUM 20#define MAX_NAME 20#define STACK_INIT_SIZE 10 // 存储空间初始分配量#define STACKINCREMENT 2 // 存储空间分配增量#define STACK_INIT_SIZE 10 //定义最初申请的内存的大小#define STACK_INCREMENT 2 //每一次申请内存不足的时候扩展的大小#define OVERFLOW false //异常抛出返回值typedef int TElemType;typedef int InfoType;typedef int VertexType;typedef bool Boolean;typedef bool Status;typedef int SElemType;/******************************** 数据结构区********************************/typedef struct CSNode //孩子兄弟树结点类型{TElemType data;CSNode *firstchild, *nextsibling;}CSNode, *CSTree; //CSTree是孩子兄弟树类型struct ArcNode{int adjvex; // 该弧所指向的顶点的位置ArcNode *nextarc; // 指向下一条弧的指针InfoType *info; // 网的权值指针}; // 表结点typedef struct VNode{VertexType data; // 顶点信息ArcNode *firstarc; // 第一个表结点的地址,指向第一条依附该顶点的弧的指针}VNode, AdjList[MAX_VERTEX_NUM]; // 头结点typedef struct{AdjList vertices; //以头结点表示邻接表int vexnum, arcnum; // 图的当前顶点数和弧数int kind; // 图的种类标志} ALGraph;struct Stack{//栈的数据元素类型在应用程序中定义typedef int SElemType;SElemType *base; // 栈底指针//在栈构造之前和销毁之后,base为NULLSElemType *top; // 栈顶指针//初值指向栈底,top = base可做栈空标记//插入新栈顶元素时,top增1;删除栈顶元素时,top减1//非空栈的top始终在栈顶元素的下一个位置上int stacksize; // 当前已分配的存储空间,以元素为单位//栈当前可使用的最大容量}; // 顺序栈/******************************** 基本函数********************************/ Boolean visited[MAX_VERTEX_NUM];VertexType& GetVex(ALGraph G, int v){ // 初始条件: 无向图G存在,v是G中某个顶点的序号。
操作结果: 返回v的值if (v >= G.vexnum || v < 0)exit(ERROR);return G.vertices[v].data;}int LocateVex(ALGraph G, VertexType u){ // 初始条件: 图G存在,u和G中顶点有相同特征// 操作结果: 若G中存在顶点u,则返回该顶点在图中位置;否则返回-1int i;for (i=0; i<G.vexnum; ++i) //依次扫描每个头结点的顶点信息if (u== G.vertices[i].data) //如果当前头结点的顶点信息等于ureturn i; //返回当前头结点的序号return -1;}Status CreateGraph(ALGraph &G){ // 采用邻接表存储结构,构造没有相关信息的图G(用一个函数构造4种图) int i, j, k;int w; // 权值VertexType va, vb; //顶点va、vbArcNode *p; //表结点指针pprintf("请输入图的类型(有向图:0,有向网:1,无向图:2,无向网:3):(这里以无向网为例)\n ");scanf("%d", &G.kind);printf("请输入图的顶点数边数: ");scanf("%d%d", &G.vexnum, &G.arcnum);//MAX_NAME,顶点字符串的最大长度+1printf("请输入%d个顶点的值(<%d个字符):\n", G.vexnum, MAX_NAME);for (i=0; i<G.vexnum; ++i) // 构造顶点向量,构造各个头结点{scanf("%d",&G.vertices[i].data); //为各个头结点输入名字G.vertices[i].firstarc = NULL; //链域置空}if (G.kind == 1 || G.kind == 3) // 网printf("请顺序输入每条弧(边)的权值、弧尾和弧头(以空格作为间隔):\n");else // 图printf("请顺序输入每条弧(边)的弧尾和弧头(以空格作为间隔):\n");for (k=0; k<G.arcnum; ++k) // 构造表结点链表{if (G.kind == 1 || G.kind == 3) // 网scanf("%d%d%d", &w,&va,&vb); //接收每条弧(边)的权值、弧尾和弧头else // 图scanf("%d%d",&va,&vb); //接收每条弧(边)的弧尾和弧头i = LocateVex(G, va); // i取弧尾序号j = LocateVex(G, vb); // j取弧头序号//p指向新分配的表结点空间p = (ArcNode*) malloc(sizeof (ArcNode));p->adjvex = j; //该弧所指向的顶点的位置,为什么是弧头?为求入度,假如是弧尾,则是求出度if (G.kind == 1 || G.kind == 3) // 网{p->info = (int *) malloc(sizeof (int)); //分配网的权值的空间*(p->info) = w; //网的权值取w}elsep->info = NULL; // 图//新弧p的下一条弧取当前头结点的第一条弧p->nextarc = G.vertices[i].firstarc; // 插在表头G.vertices[i].firstarc = p; //当前头结点的第一条弧取新弧pif (G.kind >= 2) // 无向图或网,产生第二个表结点{p = (ArcNode*) malloc(sizeof (ArcNode)); //分配表结点p->adjvex = i; //该弧所指向的顶点的位置,取弧尾if (G.kind == 3) // 无向网{p->info = (int*) malloc(sizeof (int)); //分配网的权值的空间*(p->info) = w; //网的权值取w}elsep->info = NULL; // 无向图//新弧p的下一条弧取当前头结点的第一条弧p->nextarc = G.vertices[j].firstarc; // 插在表头G.vertices[j].firstarc = p; //当前头结点的第一条弧取新弧p}}return OK;}int FirstAdjVex(ALGraph G, VertexType v){ // 初始条件: 图G存在,v是G中某个顶点// 操作结果: 返回v的第一个邻接顶点的序号。
若顶点在G中没有邻接顶点,则返回-1 ArcNode *p;int v1;v1 = LocateVex(G, v); // v1取顶点v的序号p = G.vertices[v1].firstarc; //p指向顶点v的第一条弧if (p)return p->adjvex; //返回顶点v的第一条弧所指向顶点的序号elsereturn -1;}int NextAdjVex(ALGraph G, VertexType v, VertexType w){ // 初始条件: 图G存在,v是G中某个顶点,w是v的邻接顶点// 操作结果: 返回v的(相对于w的)下一个邻接顶点的序号。
// 若w是v的最后一个邻接点,则返回-1ArcNode *p;int v1, w1;v1 = LocateVex(G, v); // v1取顶点v的序号w1 = LocateVex(G, w); // w1取顶点w的序号p = G.vertices[v1].firstarc; //p指向顶点v的第一条弧while (p && p->adjvex != w1) // 顶点v的第一条弧存在、且顶点v的第一条弧所指顶点不是wp = p->nextarc; //p后移,依次指向顶点v的第二、第三、第...条弧//循环结束时,顶点v的第...条弧不存在、或者顶点v的第...条弧所指顶点是wif (!p || !p->nextarc) // 没找到w、或w是最后一个邻接点//p->nextarc为NULL说明w是最后一个邻接点return -1;else // p->adjvex == wreturn p->nextarc->adjvex; // 返回v的(相对于w的)下一个邻接顶点的序号}void DFSTree(ALGraph G, int v, CSTree &T){ // 从第v个顶点出发深度优先遍历图G,建立以T为根的生成树。