Chapter_3_生物数据库简介
生物数据库介绍
Protein Sequence Records from SWISS-PROT and PIR
All are six characters: Character/Format 1 [O,P,Q] 2 [0-9] 3 [A-Z,0-9] 4 [A-Z,0-9] 5 [A-Z,0-9] 6 [0-9] e.g.: P12345 and Q9JJS7
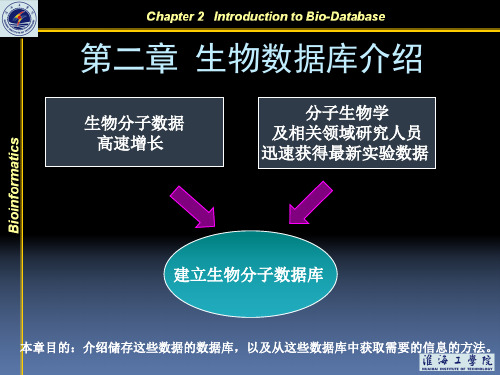
第二章 生物数据库介绍
生物分子数据 高速增长
分子生物学 及相关领域研究人员 迅速获得最新实验数据
建立生物分子数据库
本章目的:介绍储存这些数据的数据库,以及从这些数据库中获取需要的信息的方法。
数据库(database)是存储在某种存储介质上的相关数 据的有组织的集合。 存储生物大分子信息数据的数据库称为分子生物学数据 库(molecular biology database),也称生物信息学数据 库(bioinformatics database)。 数据库,特别是分子生物学数据库,具有三个特征: (1)数据库是可以检索的,即具有检索(index)功能; (2)数据库应该是定时更新的,即不断有新版内容发布 (release);(3)数据库是交叉引用的(crossreferenced),特别是在互联网时代,数据库应该通过超链 接(hyperlinks)与其他数据库相连。
二级数据库
在一级数据库、实验数据和理论分析的基
础上,针对不同的研究内容和需要,对生 物学知识和信息的进一步整理得到的数据 库,旨在使基本数据库更加便于使用。 人类基因组图谱库GDB、转录因子和结合 位点库TRANSFAC、蛋白质序列功能位点 数据库Prosite等。
生物信息学数据库
一级数据库
What is an accession number?
生物学数据库

生物学数据库生物学数据库是存储和管理生物学数据的系统,可以帮助科研人员和学生在生物学领域的研究中获取和分析大量的生物学数据。
随着生物学研究的不断发展和进步,生物学数据库在科学研究中发挥着重要的作用。
本文将介绍生物学数据库的定义、分类、应用以及未来的发展前景。
一、定义生物学数据库是指用于收集、存储、管理和处理生物学数据的电子化系统。
生物学数据可以包括基因组序列、蛋白质结构、代谢途径等各种不同类型的数据。
通过生物学数据库,科研人员可以方便地访问和查询大量的生物学数据,为生物学研究提供了重要的数据支持。
二、分类生物学数据库根据数据类型和应用领域的不同,可以分为不同的分类。
以下是几种常见的生物学数据库分类:1. 基因组数据库:存储和管理各种生物体的基因组序列数据,如NCBI(美国国家生物技术信息中心)的GenBank数据库。
2. 蛋白质数据库:存储和管理蛋白质序列、结构和功能等相关信息的数据库,如PDB(蛋白质数据银行)。
3. 代谢数据库:存储和管理生物体的代谢途径和代谢产物等相关数据的数据库,如KEGG(京都基因与基因组百科全书)数据库。
4. 基因调控数据库:存储和管理基因表达调控相关数据的数据库,如ENCODE(人类基因组的功能元件)数据库。
5. 生物图谱数据库:存储和管理植物和动物生物图谱数据的数据库,如PlantGDB(植物基因数据库)和AnimalTFDB(动物转录因子数据库)。
三、应用生物学数据库在生物学研究中有着广泛的应用。
以下是一些常见的应用领域:1. 基因组学研究:通过基因组数据库,研究人员可以分析不同生物体的基因组序列,并进行基因组比较、基因功能预测等研究。
2. 蛋白质学研究:蛋白质数据库可以帮助研究人员了解蛋白质的序列、结构和功能等信息,以及进行蛋白质互作网络分析等研究。
3. 基因调控研究:基因调控数据库可以帮助研究人员预测和分析基因的转录调控网络,并研究基因的表达调控机制。
4. 代谢途径研究:通过代谢数据库,研究人员可以了解生物体的代谢途径和代谢产物,并分析代谢途径的调控机制等。
生物信息学数据库分类整理汇总

生物信息学数据库分类整理汇总生物信息学数据库是存储和管理生物学领域的大量数据的重要工具和资源,对于生物信息学研究、基因组学、蛋白质组学、转录组学等领域的研究具有重要的意义。
本文将对生物信息学数据库进行分类整理和汇总,方便生物信息学研究者更好地使用和了解这些数据库。
1.基因组数据库:- GenBank:美国国家生物技术信息中心(NCBI)维护的基因序列数据库,包含已知基因的核酸序列。
- Ensembl:英国恩格斯尔基因组项目维护的一个综合性基因组数据库,包含多种物种的基因组数据。
- UCSC Genome Browser:加利福尼亚大学圣克鲁兹分校开发的一个基因组浏览器,提供多种物种的基因组序列和注释信息。
2.蛋白质数据库:- UniProt:一个综合性的蛋白质数据库,集成了多个蛋白质序列和注释信息资源。
- Protein Data Bank (PDB):存储大量已解析的蛋白质结构数据的数据库,提供原子级别的结构信息。
- Protein Information Resource (PIR):收集和整理蛋白质序列、结构和功能信息的数据库。
3.转录组数据库:- NCBI Gene Expression Omnibus (GEO):存储和共享大量的高通量基因表达数据的数据库。
- ArrayExpress:欧洲生物信息学研究所(EBI)开发的一个基因表达数据库,包含多种生物组织和疾病的表达数据。
4.疾病数据库:- Online Mendelian Inheritance in Man (OMIM):记录人类遗传疾病和相关基因的数据库。
- Orphanet:收集和整理罕见疾病和相关基因的数据库。
5.代谢组数据库:- Human Metabolome Database (HMDB):一个综合性的人类代谢物数据库,包括代谢产物的结构和功能信息。
- Kyoto Encyclopedia of Genes and Genomes (KEGG):包含多种生物体代谢途径的数据库。
生物化学英文课件Biochemistry-chapter 3

(1)Proteases cleavage:
1.Trypsin:C-terminal of Arg, Lys. High specificity
2.Chymotrypsin: C-terminal of Phe, Trp, Tyr.
1. Separation of amino acids by ion exchange chromatography
Amino Acid Separation
Unfortunately, amino acids are not colored as described in this overhead. Therefore, what methods would you use to first check if an amino acid is indeed present?
A-E-F-S-G-I-T-P-K
L-V-G-K
• Chymotrypsin Cleavage:
L-V-G-K-A-E-F S-G-I-T-P-K
• Edman degradation: L
• Correct sequence:
L-V-G-K-A-E-F-S-G-I-T-P-K
<2> Enzymatic hydrolysis:
7. Clostripain(Arg protease ): c-terminal of Arg.
(2)Chemical cleavage:
1.CNBr: c-terminal of Met.
CNBr is useful because proteins usually have only few Met residues.
生物化学英文课件Biochemistry-chapter 3

(3) Physical cell support and shape (tubulin, actin, collagen)
(4) Mechanical movement (flagella, mitosis, muscles)
➢ (2) According to polymerization of protein molecules;
➢ Monomeric proteins ➢ Oligomeric proteins (multimeric proteins)
➢ (3) According to conjugation of protein molecules;
106 Da or more。 ➢ Usually insulin (5700 Da) or RNase (126000 Da)
was as the boundary of proteins and polypeptides. ➢ Mr of proteins ≈ Mr of amino acid ×110.
➢Mirror image pairs of amino acids are designated L (levo) and D (dextro)
➢Proteins are assembled from L-amino acids (few D-amino acids occur in nature)
Chapter 3 Amino Acids and the Primary
Structures of Proteins
3.1 Outline of Proteins 3.2 Structures of Amino Acids 3.3 Other Amino Acids and Amino
生物化学课件Chapter 3 Amino acids and Peptides

DNA replication
Immune response (defending)
Light production (Luciferase)
O2 transport (Hemoglobin)
Support (keratin)
All proteins are constructed from the same set of 20 standard amino acids!
a
Common structure
1.
3.
The 20 amino acids are commonly categorized into five groups based on side chain features.
2. 4.
5.
Each amino acid possesses: 1. a common name 2. a three-letter abbreviation 3. an one-letter symbol
Biochemistry lecture 2 (Sept. 18, 2014)
Part I Structure and Catalysis
Chapter 3 Amino acids and Peptides
By Prof. Zengyi Chang (昌增益)
a-amino acid
Proteins are structurally and
生物信息数据库

NCBI:
二、重要生物信息数据库
生物信息学数据的表示形式
生物信息学数据的表示形式
平面文件 (flat-file)
– 信息在文件中顺序存放且具有特定格式 – 记录(Entry)通过“获得号”(accession #)
唯一确定 – 同一文件间和不同文件间信息的联系均
通过ac认为这些蛋白质具有 相同的折叠方式。在这些情况下,结构的相似性主要依 赖于二级结构单元的排列方式或拓扑结构。
蛋白质结构分类数据库CATH
类型Class、构架Architecture 、拓扑结构Topology和 同源性Homology 。
分类基础是蛋白质结构域。与SCOP不同的是,CATH 把蛋白质分为4类,即a主类、b主类,a-b类(a/b型 和a+b型)和低二级结构类。低二级结构类是指二级 结构成分含量很低的蛋白质分子。
描述了结构和进化关系。 SCOP数据库从不同层次对蛋白质结构进行分类,以反
映它们结构和进化的相关性。 第一个分类层次为家族,通常将序列相似性程度在30%
以上的蛋白质归入同一家族,有比较明确的进化关系。 超家族:序列相似性较低,结构和功能特性表明它们有
共同的进化起源,将其视作超家族。 折叠类型:无论有无共同的进化起源,只要二级结构单
EMBL格式: 欧洲分子生物学EMBL数据库的每个条目是一份纯文 本文件,每一行最前面是由两个大写字母组成的识别 标志,常见的识别标志列举在后面的表中。识别标志 “特性表”FT包含一批关键字,它们的定义已经与 GenBank和DDBJ统一。下欧洲国家的许多数据库如 SWISS-PROT、ENZYME、TRANSFAC等,都采用 与EMBL一致的格式。
1)头部包含关于整个序列的信息(描述字符),从 LOCUS行到 ORIGIN行;
常用生物数据库及数据格式

10
FASTQ sequence format
与fasta格式类似 一条序列一般占用四行 序列和质量值各占一行
11
GenBank028 bp DNA linear PLN 21-JUN-1999 DEFINITION Saccharomyces cerevisiae TCP1-beta gene, partial cds; and Axl2p (AXL2) and Rev7p (REV7) genes, complete cds. ACCESSION U49845 VERSION U49845.1 GI:1293613 KEYWORDS . SOURCE Saccharomyces cerevisiae (baker's yeast) ORGANISM Saccharomyces cerevisiae Eukaryota; Fungi; Ascomycota; Saccharomycotina; Saccharomycetes; Saccharomycetales; Saccharomycetaceae; Saccharomyces. REFERENCE 1 (bases 1 to 5028) AUTHORS Torpey,L.E., Gibbs,P.E., Nelson,J. and Lawrence,C.W. TITLE Cloning and sequence of REV7, a gene whose function is required for DNA damage-induced mutagenesis in Saccharomyces cerevisiae JOURNAL Yeast 10 (11), 1503-1509 (1994) PUBMED 7871890 ...... FEATURES Location/Qualifiers CDS <1..206 /codon_start=3 /product="TCP1-beta" /protein_id="AAA98665.1" /db_xref="GI:1293614" /translation="SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEA AEVLLRVDNIIRARPRTANRQHM" gene 687..3158 /gene="AXL2" ...... ORIGIN 1 gatcctccat atacaacggt atctccacct caggtttaga tctcaacaac ggaaccattg 61 ccgacatgag acagttaggt atcgtcgaga gttacaagct aaaacgagca gtagtcagct ...... 4981 tgccatgact cagattctaa ttttaagcta ttcaatttct ctttgatc //
生命科学中最常用的5个数据库介绍

生命科学中最常用的5个数据库介绍生命科学是一个庞大而复杂的学科,其中包含了关于生命现象的各种研究。
对于生命科学的研究,特别是在分子水平上进行的研究,需要大量的数据支持。
这些数据包括分子序列、蛋白质结构、代谢途径等等。
为了有效地管理这些数据,生命科学中广泛应用了各种数据库。
本文将介绍生命科学中最常用的5个数据库。
1. GenBankGenBank是全球最大的分子生物学数据库,包含了全球各地实验室提交的DNA和RNA序列。
它由美国国家生物技术信息中心(NCBI)维护。
GenBank包含了数十亿条序列记录,其中包括了不同物种的基因组、蛋白质序列、DNA和RNA序列等。
与DNA和RNA序列相关的信息包括序列长度、基序、带电的特殊域、结构域、转录因子结合位点以及其他数据。
GenBank还包含了元数据,如物种和菌株的信息、文献引用以及序列的提交日期。
2. PubMedPubMed是美国国家医学图书馆(NLM)维护的一个生命科学文献数据库,包括了生命科学、医学和健康相关的数百万篇论文。
PubMed提供了对文献的全文搜索和存储,使科学家在查找特定话题时更加方便。
除了搜索全文的功能,PubMed还提供了很多额外的服务,如翻译摘要、相关文章推荐、绘制图表等。
3. EnsemblEnsembl是一种数据库、搜索引擎和分析平台,专门用于处理各种生命科学的数据。
Ensembl已经成为了全球最大的基因组数据库之一,包含了人类、其他哺乳动物、鸟类、篮球、双子蝎、无脊椎动物等近700个物种的基因组信息。
Ensembl提供的数据包括生物序列、调控区域、基因家族、基因结构、基因组的变异和基因表达信息等。
4. Protein Data Bank (PDB)蛋白质数据银行(PDB)是一个三维蛋白结构数据库,由改华大学、美国罗格斯大学和欧洲生物信息研究所等机构共同维护。
PDB存储了全球各地实验室提交的蛋白质晶体结构和生化分析,包括了大多数已知的蛋白质家族和酶。
Chapter 3C 化能自养微生物的能量代谢【微生物生理学】

一、氨的氧化
1. 氨氧化为亚硝酸——亚硝酸细菌Nitrosomonas
NH3 + 1 .5 O2
HNO2 + H2O
2. 亚硝酸氧化为硝酸——硝酸细菌Nitrobacter
NO2-
NO3-
亚硝化细菌:
细菌浸矿的原理: 氧化亚铁硫杆菌氧化元素硫与Fe2+时产 生H2SO4和Fe2(SO4)3,这两者是良好的矿 质浸出溶剂。反应过程为:
S0 + 1.5 O2 + H2O H2SO4
2FeSO4 + 0.5O2 + H2SO4 Fe2(SO4)3 + H2O
形成的H2SO4和Fe2(SO4)3可以把矿石中 的金属以硫酸盐的形式溶出。如黄铜矿
和硝化细菌一样,硫细菌也是通过电子的逆呼吸 链传递来生成还; H+ + 1/4O2 Fe3+ +1/2H2O + 167KJ
E0(Fe2+/ Fe3+)=770mv E0(H2O/O2)=810mv
但铁如果和某些有机物如草酸形成络合物 则E0(Fe2+/ Fe3+)会大大降低。
可溶性氢化酶催化H2氧化形成NADH。生成的 NADH主要用于还原CO2的生物合成。
除氧以外,氢细菌还可以利用 硝酸盐(上述脱氮副球菌)、 硫酸盐(硫酸盐还原细菌)、 二氧化碳(甲烷细菌)等作为 电子传递系统的最终电子受体 进行无氧呼吸。
周质空间
细胞膜
细胞质
2Fe2+ 2Fe3+
pH2
RC
CytC
PH4.5
常用的生物数据库(二)

常用的生物数据库(二)引言概述:生物数据库是生物信息学领域的重要工具,可以帮助研究人员存储、管理和共享生物数据。
本文将介绍常用的生物数据库(二),以便研究人员更好地利用这些资源进行生物学研究。
正文内容:一、蛋白质相互作用数据库1. STRING数据库:提供蛋白质相互作用预测和注释功能。
2. IntAct数据库:收集整理蛋白质相互作用数据,提供数据检索和分析工具。
3. BioGRID数据库:整合多种物种的蛋白质相互作用数据,并提供丰富的功能注释。
二、基因组数据库1. GenBank数据库:包含大量的序列数据,包括基因组、转录本和蛋白质序列等。
2. ENSEMBL数据库:集成了各种生物信息学工具,提供全面的基因组注释信息。
3. UCSC数据库:基于人类基因组构建的浏览器,提供详细的基因组注释和可视化功能。
三、表达谱数据库1. GEO数据库:收集了大量的基因表达谱数据,可进行数据检索和分析。
2. ArrayExpress数据库:包含了来自各种高通量技术的表达谱数据,提供数据下载和分析工具。
3. TCGA数据库:整合了多种癌症的基因表达数据,可进行差异表达和生存分析等研究。
四、突变数据库1. dbSNP数据库:记录了常见的单核苷酸多态性(SNP)数据,是研究遗传变异的重要资源。
2. COSMIC数据库:专注于癌症相关的突变数据,包含了大量的突变谱系和功能注释信息。
3. ClinVar数据库:整合了与人类疾病相关的遗传变异数据,提供临床相关的注释信息。
五、药物数据库1. DrugBank数据库:收录了大量的药物信息,包括结构、作用机制和药理学数据等。
2. PubChem数据库:提供了大量的小分子化合物数据,可进行化学结构搜索和药物筛选等研究。
3. ChEMBL数据库:整合了化合物活性数据和药物靶点信息,可用于药物发现和优化。
总结:生物数据库为生物学研究提供了丰富的数据资源和分析工具。
蛋白质相互作用数据库、基因组数据库、表达谱数据库、突变数据库和药物数据库是常用的生物数据库之一。
现代分子生物学试题

现代分子生物学试题Chapter 3 生物信息的传递——从DNA到RNA一、名词解释:1、Transcription2、Coding strand (Sense strand)3、Intron4、RNA editing5、Messenger RNA (mRNA)二、判断正误:1、基因表达包括转录和翻译两个阶段2、mRNA是以有义链为模板进行转录的3、转录起始就是RNA链上第一个核苷酸键的产生4、σ因子的作用是负责模板链的选择和转录的起始5、聚合酶可以横跨40个碱基对,所以解旋的DNA区域也是40个碱基对6、流产式起始是合成并释放2~9个核苷酸的短RNA转录物7、启动子是有义链上结构基因5’端上游区的DNA序列8、大肠杆菌基因中存在-10bp处的TTCACA区9、-35区是指5’到3’方向-35区最后一个碱基离+1碱基为35个bp10、真核基因几乎都是单顺反子三、单选:1、_______号帽子存在于所有帽子结构中A、0号B、1号C、2号D、以上全不是2、在对启动子识别中起关键作用的是_______A、α亚基B、β亚基C、σ因子D、β’亚基3、RNA聚合酶中提供催化部位的是_______A、α+αB、α+βC、α+β’D、β+β’4、_______是细胞内更新率极高不稳定的RNAA、mRNAB、rRNAC、tRNAD、snRNA5、mRNA由细胞核进入细胞质所必需的形式是_______A、5’端帽子B、多聚腺苷酸尾C、ρ因子D、以上都不是6、真核生物RNA聚合酶II所形成的转录起始复合物不包括_______A、TBPB、TFIIAC、TFIICD、TFIID7、真核生物转录的所在空间是_______A、细胞质B、细胞核C、核孔D、线粒体8、ρ因子本质上是一种_______A、核苷酸B、蛋白质C、多糖类D、碱基9、下列不属于原核生物mRNA特征的是_______A、半衰期短B、多顺反子存在C、5’端没有帽子结构D、有内含子10、原核生物中抑制转录延伸的物质是_______A、利福平B、利迪链霉素C、肝素D、α-鹅膏蕈碱四、多选1、生物体内的RNA主要有:A、mRNAB、rRNAC、tRNAD、snRNA2、大肠杆菌的RNA聚合酶全酶是由_______组成A、2α+β+β+σB、2α+β+β’+ωC、σD、核心酶+σ3、三元复合物包括_______A、RNA聚合酶B、DNAC、新生RNAD、开放复合物4、原核生物的起始密码子有_______A、AUGB、AGUC、GUGD、UUG5、下列关于原核生物mRNA的说法正确的是_______A、基因转录一旦开始,核糖体就结合到新生RNA链的5’端B、绝大多数细菌mRNA的半衰期很短C、mRNA降解的速度等于转录的速度D、mRNA以多顺反子的形式存在6、真核生物mRNA中,上游启动子元件是指_______A、TA TA序列B、CCAA T序列C、GC序列D、以上都是7、mRNA前体加工包括_______A、5’端加帽B、3’端加polyA尾C、RNA的剪接D、RNA的切割8、RNA的编辑形式有_______A、尿苷酸的缺失B、内含子的切除C、单碱基突变D、尿苷酸的添加9、真核生物mRNA的特点_______A多顺反子 B 单顺反子 C 5’帽子结构 D 3’多聚腺苷酸尾巴10、操纵子包括_______A启动子 B 调控基因 C 结构基因 D 终止子五、简答题1、指出DNA多聚酶催化的反应和RNA多聚酶催化的反应之间的差别2、解释两种类型的启动子突变3、为什么RNA聚合酶不需要单链结合蛋白4、开放启动子复合物和封闭启动子复合物间的差别是什么?5、试比较真核生物原核生物mRNA的特征现代分子生物学试题答案Chapter 3 生物信息的传递——从DNA到RNA一、名词解释:1、Transcription:转录是指DNA指导下,由依赖DNA(或DNA指导)的RNA聚合酶催化RNA合成的过程。
第三章(Chapter 3)排列与组合(Permutations and Combinations)

[注 ]: 1、加法原理也可描述如下:若具有性质A的事件 加法原理也可描述如下: 具有性质B 有m个,具有性质B的事件有n个(性质A与性质B 无关), ),则具有性质 无关),则具有性质A或性质B的事件有m+n个。 (或者可描述为书P29页所述的形式)。 或者可描述为书P29页所述的形式 页所述的形式)。
例3.1.8: ⑴求小于10000的含数字1的正整数 3.1.8: 求小于10000的含数字1 的个数;⑵求小于10000的含数字0 的个数;⑵求小于10000的含数字0的正整数的 个数。 解: 3.1.9: 例3.1.9:确定数 n = 3 4 × 5 2 × 117 × 138 的正整数因 子的个数。(书P29页例题) 解: 子的个数。(书P29页例题) 3.1.10: a,b,c,d,e这五个字符,从中取6 例3.1.10:由a,b,c,d,e这五个字符,从中取6 个按字典顺序构成字符串,要求:⑴ 个按字典顺序构成字符串,要求:⑴第1个和第 6个字符必为辅音字符b,c,d;⑵每一字符串必有 个字符必为辅音字符b,c,d; 两个元音字符a 两个元音字符a或e,且两个元音字符不相邻;⑶ ,且两个元音字符不相邻;⑶ 相邻的两个字符必不相同。求字符串的总数目。 解:
2、若原理中的划分的部分S1,S2,……Sm可以 若原理中的划分的部分S ……S
重叠,则S中的元素个数需用容斥原理来计数。 中的元素个数需用容斥原理来计数。 重叠, 具体见第六章) (具体见第六章) 3、应用加法原理的关键在于:将计数的集合S 应用加法原理的关键在于:将计数的集合S 合理地划分为若干较容易计数的部分。 合理地划分为若干较容易计数的部分。
3.2集合的排列 3.2集合的排列
一、集合的r-排列(亦称线性排列):令r为一个 集合的r 排列(亦称线性排列):令r 正整数,集合S含有n个元素(n≥r),则集合S 正整数,集合S含有n个元素(n≥r),则集合S 的一个r 排列可以理解为:n个元素中的r 的一个r-排列可以理解为:n个元素中的r个元素 的一种有序摆放。 例如:设集合S={a,b,c},则 例如:设集合S={a,b,c},则 S有3个1-排列:a , b , c ; 排列:a S有6个2-排列:ab ,ac, ba, bc, ca, cb ; 排列:ab S有6个3-排列:abc, acb, bac, bca, cab, 排列:abc, cba; cba;
chapter2-3

38Байду номын сангаас
兴奋性突触后电位的产生
39
抑制性突触后电位
(inhibitory postsynaptic potential, IPSP)
定义:突触后膜在递质作用下发生超极化,使该
突触后神经元对其它刺激的兴奋性降低— IPSP。
机制:某种抑制性递质作用突触后膜,使膜上的 Cl-通道开放,引起Cl-离子内流,从而使膜 电位发生超极化。
14
局部兴奋
—阈下刺激引起膜的轻度去极化
Na+通道少量开放
引起的局部反应被外流K+所抵消
15
局部反应的特点:
相对较小(通常为几个毫伏)
彼此间可以加和 反应强度会因产生该反应的刺激大小不同而异
当达到足够的强度后即可引起动作电位
神经系统的所有输入信号和细胞间通讯都依靠局部反应完成。 如感受器电位、突触后膜、肌肉终板。
静息时-内负外正
发生兴奋时-内正外负
传导过程中-和该段神经相邻接 神经段仍处于安静时的极化状态
在已兴奋的神经段和与它相邻的未兴奋的神经段之间,由于 电位差的存在而有电荷移动,称为局部电流。
21
内正外负-发生兴奋 内正外负的移动-兴奋传导
动作电位的传导 已兴奋的膜部分 通过局部电流
刺激了未兴奋的膜部分
42
非突触性化学传递过程
接头传递——兴奋从神经细胞传递给效应器 神经-平滑肌和神经-心肌接头传递结构—非突触性化学传递 曲张体
轴突末梢分成许多分支,分支上形成串珠样膨大结构。 曲张体外无施万氏细胞包裹,内含大量突触小泡,是递质释放 的部位,与周围的平滑肌膜不形成突触联系 神经冲动到达曲张体,递质从曲张体释放出来,通过扩 散到达平滑肌膜受体,使平滑肌细胞发生反应。
生物信息学常用数据资源介绍

生物信息学常用数据资源介绍
生物信息学是一门跨学科的学科,它将计算机科学与生物学有机地结合起来,为生命科学研究提供了新的方法和手段。
在生物信息学中,数据资源是非常重要的,因为数据资源直接关系到生物信息学研究的深度和广度。
本文将介绍生物信息学中常用的数据资源,包括基因组数据库、蛋白质数据库、序列数据库、文献数据库等。
1. 基因组数据库
基因组数据库是基因组信息的集大成者。
基因组数据库收集了各种生物的基因组序列、基因注释、基因组结构等信息。
常用的基因组数据库有:GenBank、EMBL、DDBJ、NCBI、Ensembl、UCSC Genome Browser 等。
2. 蛋白质数据库
蛋白质数据库是收集了各种生物的蛋白质序列、蛋白质结构、蛋白质功能等信息的数据库。
常用的蛋白质数据库有:UniProt、PDB、Swiss-Prot、TrEMBL等。
3. 序列数据库
序列数据库主要收集了各种生物的核酸序列和蛋白质序列。
常用的序列数据库有:NCBI GenBank、EMBL、DDBJ、RefSeq、UniProtKB 等。
4. 文献数据库
文献数据库主要收集了各种与生物学相关的学术文献,包括期刊论文、会议论文、书籍等。
常用的文献数据库有:PubMed、Web of
Science、Google Scholar等。
总结
生物信息学中的数据资源非常丰富,为生物信息学研究提供了非常重要的数据支持。
除了以上介绍的常用数据资源,还有很多其他的数据资源,例如代谢组数据库、蛋白质互作数据库等等。
研究者可以根据自己的需要选择合适的数据资源,以便更好地开展生物信息学研究。
PDB数据库简介

,进一步应用于研究,
第二十页,共20页,
第十六页,共20页,
PDB数据库的详细 xiángxì 字段说明
第十七页,共20页,
详细信息体小分子
β-折叠
α-螺旋 luóxuán
第十九页,共20页,
三、结构 jiégòu 模型显示
生物大分子三维立体 lìtǐ 结构显示的软件: PyMol、RasMol、Chimera、VMD、SwissPdbViewer等
PDB数据库简介 jiǎn jiè
It is applicable to work report, lecture and teaching
第一页,共20页,
生物 shēngwù 数据库的种类
第二页,共20页,
生物 shēngwù 数据库的种类
序列数据库
核酸 hé suān 序列数据库 EMBL、GenBank 、DDBJ
名称、参考文献、 序列、一级结构、 二级结构和原子坐 标等信息,
显式序列 信息
隐式序列
信息
以关键字SEQRES 作为显式序列标 记,以该关键字
打头的每一行都
是关于序列的信 息,
第七页,共20页,
即为立体化学 数据,包括每 个原子的名称 和原子的三维 坐标,
3、数据 shùjù 查询是pdb文件在数据库中的编号, 从PDB数据库下载结构常会得 到一个以这个编号命名的 pdb文件,如1LDM.pdb
关键字列表
测定结构所用的试验方法
第十二页,共20页,
以关键字SEQRES打头 dǎ tóu 306个氨基酸的显式序列信息
第十三页,共20页,
X轴坐标 zuòbiāo
分子生物学英文版Chapter3

CHAPTER 3 Transcription3.1 Outline of Transcription3.2 Transcription in Prokaryotes 3.3 Transcription in Eukaryotes 3.4 RNA Splicing and ProcessingCentral Dogma3.1 Outline of TranscriptionKey Terms•Transcription: a DNA segment that constitutes a gene is read and transcribed into a single stranded sequence of RNA.•The sense strand(coding strand)of DNA has the same sequence as the mRNA and is related by the genetic code to the protein sequence that it represents.•The antisense strand(Template strand)of DNA is complementary to the sense strand, and is the one that acts as the template for synthesis of mRNA.•A promoteris a region of DNA where RNA polymerase binds to initiate transcription.•Startpoint (startsite) refers to the position on DNAcorresponding to the first base incorporated into RNA. •A terminator is a sequence of DNA that causes RNA polymerase to terminate transcription.Key TermsTranscription unitEnzymatic synthesis of RNADNA templaterN′TP+n rNTP rN′TP-(rNMP)n +nPPiRNA-P, Mg2+RNA合成:前体为4种5′-核苷三磷酸(rNTP) —ATP,GTP,CTP和UTP;模板为DNA双链分子中的一条链;催化合成的酶为RNA polymerase;不需要引物,直接开始新生RNA链的延伸;碱基配对原则:A-U(T), C-G;聚合反应中生成磷酸二酯键,释放出PPi;新生RNA链的延伸方向: 5′→3′3.2 Transcription in Prokaryotes3.2.1 RNA polymerases3.2.2 Promoter recognition3.2.3 Initiation and elongation of transcription 3.2.4 Two types of terminators in E.coli3.2.1 RNA polymeraseRNA聚合酶核心酶:α2ββ′RNA聚合酶全酶:α2ββ′σRNA聚合酶各亚基的功能(见左图)Sigma factor changes the DNA-binding properties of RNApolymerase so that its affinity for general DNA is reduced and its affinity for promoters is increased. E.coli has several sigma factors, each of which causes RNApolymerase to initiate at a set of promoters defined by specific –35 and –10 sequences.The sigma subunit is required only fortranscription initiation3.2.2 Promoter recognitionThe promoter has three components1)-10区, 又称Pribnow Box保守序列为T80A95T45A60A50T96。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 数据库使用高度计算机化和网络化
• 几乎所有的数据库都可以在国际互联网上访问 • 有的系统则将多个生物信息数据库整合在一起,形 成集成的生物信息数据库系统
9
生物信息数据库
• 生物信息数据库的特点
– 面向应用
• 各个数据库服务器除了提供数据,还提供许多分析 工具 – 核酸数据库提供的序列搜索 – 基因识别程序 – 蛋白质结构数据库提供的结构比较程序 – 结构模拟程序 – ………
24
文献数据库
25
文献数据库
• ISI Web of Science
– 通常所说的SCI是其中的一部分 – 我校图书馆有订阅 – /
• Science Direct
– Elsevier Science出版公司的ScienceDirect系统, 收录 1,200多种全文电子期刊,学科涵盖数学、物理、化学、 天文学、医学、生命科学、商业及经济管理、计算机 科学、工程技术、能源科学、环境科学、材料科学、 社会科学等。 –
26
27
常见序列格式
28
核苷酸IUB/IUPAC代码
A C G T U R Y K --> adenosine/腺嘌呤 M --> cytidine/胞嘧啶 S --> guanine/鸟嘌呤 W --> thymidine/胸腺嘧啶 B --> uridine/尿嘧啶 D --> G A (purine,嘌呤) H --> T C (pyrimidine,嘧啶) V --> G T (keto,酮基) N gap of indeterminate length --> --> --> --> --> --> --> --> A G A G G A G A C C T T A C C G (amino,氨基) (strong,强键) (weak,弱键) C T T A C T (任意碱基)
23
文献数据库
• MEDLINE/PubMed文献数据库
– PubMed是NCBI提供的对MEDLINE数据库的 在线访问服务。 – PubMed包含了世界上70多个国家出版的4600 多种生物医学期刊的文献引用和作者信息,总 共超过1200万条文献引用信息,早期的数据可 至20世纪60年代中期。 – OLDMEDLINE包含150多万条从1953到1965 年间的国际生物医学期刊文献引用和原文 – /PubMed/
2015/12/20生物信息学 概论讲义
10
生物信息数据库
• 生物信息数据库分类
– 一次数据库(primary database)
• 直接来源于实验获得的原始数据,只经过简单的归类整理和注 释 • 基本数据库或初始数据库
– 三类一次数据库
• 基因组数据库 • 核酸和蛋白质一级结构序列数据库 • 生物大分子(主要是蛋白质)三维空间结构数据库
5
生物信息数据库
6
生物分子数据 高速增长
分子生物学 及相关领域研究人员 迅速获得最新实验数据
建立生物分子 数据库
2015/12/20
7
生物信息数据库
• 生物信息数据库的特点
– 数据库的更新速度不断加快,数据量呈指数增 长趋势 – 数据库种类的多样性。生物信息学各类数据库 几乎覆盖了生命科学的各个领域
2015/12/20生物信息学 概论讲义
11
生物信息数据库
• 生物信息数据库分类
– 二次数据库(secondary database)
• 对原始生物信息数据进行分析、整理、归纳而形成 的数据库
– 二次数据库种类繁多
• • • • • 以核酸数据库为基础构建的二次数据库 以蛋白质序列数据库为基础构建的二次数据库 以具有特殊功能的蛋白质为基础构建的二次数据库 以三维结构原子坐标为基础构建的数据库 ……
– 主要实验室设在德国海德堡 – http://www.embl-heidelberg.de
• NIG 日本国立遗传学研究所,National Institute of Genetics
– 维护和管理日本DNA数据库DDBJ。该数据库首先反映 日本产生的数据,同EMBL、GenBank有合作关系。 – http://www.ddbj.nig.ac.jp
12
2015/12/20生物信息学 概论讲义
生物信息数据库
染色体
基因组作图
基因组图谱
基因组 数据库
核酸 序列测定
DNA序列
核酸序列 数据库
生 物 信 息 学 数 据 库 工 具
二 级 数 据 库 复 合 数 据 库
蛋白质序列
蛋白质序列 数据库
蛋白质
结构测定 蛋白质结构 数据库
2015/12/20
蛋白质结构
• EMBnet, 欧洲分子生物学信息网
– 建立于1988年,在荷兰注册。中国在1996年加入其成员国, EMBnet的中国节点设在北京大学生物信息中心PKUCBI。 – /
4
主要生物信息中心
• EMBL,欧洲分子生物学实验室,European Molecular Biology Laboratory
19
蛋白质序列数据库
– PIR (Protein Identification Resource)
• 维护者为美国华盛顿的全国生物医学研究基金 (NBRF)、德国马普学会的慕尼黑蛋白质序列信息中 心(MIPS)和日本国际蛋白质序列数据库(JIPID)。 • 包含所有序列已知的自然界中野生型蛋白质的信息, 该数据库的主要目的是提供按同源性和分类学组织 的综合的、非冗余的数据库。每周更新,每季度发 行新版。 • 内容分为四级,即:PIR1(完全分类清楚); PIR2(已 检查和分类); PIR3(未检查); PIR4(未解码翻译)。 • /
Nomenclature and Symbolism for Amino Acids and Peptides /iupac/AminoAcid/
29
氨基酸IUB/IUPAC代码
A B C D E F G H I K L M N alanine aspartate or asparagines cystine aspartate glutamate phenylalanine glycine histidine isoleucine lysine leucine methionine asparagine P Q R S T U V W Y Z X * proline glutamine arginine serine threonine selenocysteine valine tryptophan tyrosine glutamate or glutamine any translation stop gap of indeterminate length
• • • • • 核酸序列数据库 蛋白质序列数据库 蛋白质、核酸、多糖三维结构数据库 基因组数据库 ……..
8
2015/12/20生物信息学 概论讲义
生物信息数据库
• 生物信息数据库的特点
– 数据库的复杂性增加、层次加深
• 数据库之间相互引用,如PDB 与文献库、蛋白质二 级数据库、蛋白质结构分类数据库、蛋白折叠库等 十几种数据库直接关联
20
蛋白质序列数据库
21
结构数据库
• PDB: /
22
Байду номын сангаас
文献数据库
• 文献数据库包含已发表的科技论文的题录 和摘要,有时也提供全文及图表等信息。 可通过标题、文摘、关键字或正文、作者、 作者单位等字段对文献数据库进行检索。
– MEDLINE/PubMed – ISI Web of Science – Science Direct
第三章 生物信息学数据库
1
内容提要
• • • • • 主要的生物信息中心 生物信息数据库 常见序列格式 数据库信息检索系统 向数据库提交数据
2
主要的生物信息中心
3
主要生物信息中心
• NCBI 美国国家生物技术信息中心,National Center for Biotechnology Information
15
GenBank
• 美国国家生物技 术信息中心的数 据库 • 提供Entrez检索 工具、BLAST序 列搜索等服务
16
EMBL/EBI
• EMBL Database 欧洲分子生物学实验室 (European Molecular Biology Laboratory )核酸序 列数据库,为欧洲最主要的核酸序列数据库,世界 两大核酸数据库之一。目前此数据库由其分支机 构—EBI(the European Bioinformatics Institute, 欧洲生物情报研究所)维护。 • 北京大学已建立了EMBL中国镜像数据库,将该数 据库移植到中国本地,并提供部分的检索服务
13
• 从1994年开始,牛津大学出版的“核酸研 究 (Nucleic Acids Research)‖每年第一期是 生物数据库专辑,对每一个数据库的性质、 内容和更新状况进行综合描述。 • /nar/
14
NAR对数据库的分类(2006)
• • • • • • • • • • • • • • DNA序列库/Nucleotide Sequence Databases RNA序列库/RNA sequence databases 蛋白质序列库/Protein sequence databases 结构数据库/Structure Databases 基因组数据库/Genomics Databases (non-vertebrate) 代谢与信号转导/Metabolic and Signaling Pathways 人类及其它脊椎动物基因组/Human and other Vertebrate Genomes 人类基因与疾病/Human Genes and Diseases 芯片数据及表达数据/Microarray Data and other Gene Expression Databases 蛋白质组资源/Proteomics Resources 其它分子生物学库/Other Molecular Biology Databases 细胞器数据/Organelle databases 植物数据库/Plant databases 免疫学数据库/Immunological databases