基于嵌入式eCos多核平台的OpenMP并行算法的研究
基于多核的OpenMp并行程序设计

基 于 多核 的O p enMp并 行 程 序 设 计
彭 曦 顾炳根 李展 涛 (桂林理工大学 信 息科 学与工程 学院 广西 桂林 541004)
摘 要 : 介绍 多核计算 的出现和 一种面 向共享存储 器的 多处理器 多线程并行 编程语 言OpenMp,然后再 以一个 实例来说 " ̄OpenMp在多核 下如何进 行并行程 序设 计,通过计算 加速 比说 明使用OpenMp编程后程序 执行效率得 到显著提 高
OpenMP是 一种 面 向共 享存 储器 的多处 理器 多 线程 并行 编程 语 言 ,线 程 间通 过共 享变 量传 递数 据结 果 。OpenMP标 准形 成 于1997年 ,它 是一 种API, 用于 编 写可 移植 的 多线 程应 用 程序 。OpenMP程 序 设计 模 型提 供 了一 组 与平 台无 关 的编 译指 令 、指 导命 令 、 函数 调用 和环 境变 量 ,可 以显 式地 指 导编 译器 如何 以及何 时利 用 应用 程 序 中的 并行 性 。OpenMP通 过对 原有 的 串行 代 码 插 入 一 些 指 导 性 的注 释 ,并 进 行必 要 的修 改 ,可 以 快 速 的 实现 并 行 编 程 ,而 这些 注释 的解 析 由编译 器所 完成 。 目前 ,C,c++,Fortran语 言都 支 持OpenMp,所 有OpenMp的并 行化 都 是通 过使用 嵌 入到c,c++或 Fortran源 代 码 中 的编 译制 导语 句来 达到 的 。
Structured—block
OpenMP的所有 编 译指 导 语句 以#pragma omp开 始 ,其 中directive部分 就 包 含 Openllel for、
section、 sections、 single、 master、 critical、 flush、 ordered,
基于多核集群的MPI+OpenMP混合并行编程模型研究

模 式 包 括 共 享 内 存 .5671/*8,-99*(,/:;<6=>*$, 消 息 传 递 /?1*@,数 据 并 行 A/B*C,1=5D6>EF6*",等
在诸多的并行编程模式中目前比较流行的是 基 于 分 布 式 内 存 的 1/2 和 基 于 共 享 内 存 的 .567 1/ 关于这方面的研究已经有许多丰硕的成果 文 献*+&G+',主 要 研 究 了 1/2H.5671/ 混 合 编 程 模 式 并 用许多基准程序对这种混合编程模式在诸如包括 IJ2KL:MN8@&&2915(@(H和 IJ2KL:MN2OPC%&&PQ 等各 种计算机平台上做了相应的性能测试 经过测试表 明利用这种 混合编程模 式 比 单 纯 使 用 1/2 可 以 得 到更好的性能 文献*+&,中还提出了对 .5671/ 的 一种扩展 文献*+3,中除了研究 1/2.5671/ 并行 编程模式外主要介绍了目前非常流行的针对 J/R 加速的 ORSK 编程模型 通过将 O/R 加 速效果通 J/R 加速效果比较得知在计算密集型的应用中利 用 J/R 加速比 O/R 能够取得更加好的效果
面向嵌入式系统的并行处理器架构设计与优化

面向嵌入式系统的并行处理器架构设计与优化嵌入式系统已经成为现代社会中不可或缺的一部分。
从智能手机到汽车,从家用电器到医疗设备,嵌入式系统无处不在。
随着技术的不断发展,嵌入式系统对于高性能和低功耗的需求也越来越高。
并行处理器作为提高系统性能的关键技术之一,正在成为嵌入式系统设计中的研究热点。
本文将探讨面向嵌入式系统的并行处理器架构设计与优化。
嵌入式系统的特点包括有限的资源、严格的实时性要求、低功耗等。
因此,设计面向嵌入式系统的并行处理器需要充分考虑这些特点。
首先,需要对嵌入式系统的应用场景进行分析,并确定系统的性能要求。
例如,某些场景可能对实时性要求非常严格,而其他场景可能更注重系统的功耗以延长电池寿命。
基于这些需求,可以选择适应性较高的多核处理器架构或面向特定应用的定制处理器架构。
在设计并行处理器架构时,代码并行性的挖掘是至关重要的。
优秀的架构设计应该能够充分利用应用程序中的并行性。
一种常见的并行性是数据并行性,即将任务划分为多个数据并行的子任务。
为实现数据并行性,可以使用SIMD(单指令多数据流)或向量指令集。
这样可以通过一条指令对多个数据进行操作,从而提高计算效率。
此外,还可以尝试将任务划分为多个线程或处理核,并采用线程级并行的方式来实现任务并行性。
另一个重要的设计考虑因素是内存体系结构。
在嵌入式系统中,内存访问的效率对系统性能有着重要的影响。
并行处理器架构的设计应该能够有效地利用多级缓存,以减少内存访问的延迟和能耗。
此外,采用片上存储器(On-Chip Memory)或异构内存架构也是优化内存访问的有效手段。
片上存储器可以提供低延迟和高带宽,从而加速数据传输和处理。
并行处理器架构设计还应该考虑功耗优化。
嵌入式系统通常有着较低的功耗要求,因此,设计低功耗的并行处理器架构非常重要。
一种常见的低功耗技术是动态电压频率调整(Dynamic Voltage and Frequency Scaling,DVFS),它可以根据任务的需求动态调整处理器的电压和频率。
嵌入式图形处理器的多核并行计算研究

嵌入式图形处理器的多核并行计算研究嵌入式图形处理器(Embedded Graphics Processing Unit,简称eGPU)是一种专门用于处理图形计算任务的处理器。
随着科技的不断发展,嵌入式图形处理器在移动设备、游戏主机和智能家居等领域得到了广泛应用。
然而,随着计算任务的复杂化和对实时性能要求的提高,单核的嵌入式图形处理器已经无法满足需求。
因此,研究人员开始探索多核并行计算在嵌入式图形处理器中的应用。
多核并行计算是指将一个计算任务分解成多个子任务,并通过多个处理核心同时执行这些子任务,以提高计算效率。
在嵌入式图形处理器中,多核并行计算可以用于加速图形渲染、物理模拟和图像处理等任务。
例如,在游戏中,多核并行计算可以实现更加逼真的光影效果和物理碰撞模拟;在智能家居中,多核并行计算可以提高图像识别和人脸识别的速度。
然而,多核并行计算在嵌入式图形处理器中的应用也面临一些挑战。
首先,多核并行计算需要合理的任务划分和负载均衡,以充分利用每个核心的计算能力。
其次,多核并行计算需要高效的数据通信和同步机制,以确保各个核心之间的数据一致性和计算结果的正确性。
最后,多核并行计算还需要考虑功耗和散热等问题,以保证嵌入式设备的稳定性和长时间运行。
为了解决这些挑战,研究人员提出了一些优化策略和技术。
首先,他们通过任务划分和负载均衡算法,将计算任务合理地分配给各个处理核心,以充分发挥每个核心的计算能力。
其次,他们设计了高效的数据通信和同步机制,如共享内存和消息传递机制,以确保各个核心之间的数据一致性和计算结果的正确性。
最后,他们还提出了一些节能和散热技术,如动态电压调节和热管散热,以减少功耗和保持设备的稳定性。
通过这些优化策略和技术,多核并行计算在嵌入式图形处理器中的应用取得了一些成果。
例如,英伟达的Tegra X1芯片采用了256个CUDA核心,可以实现高效的图形渲染和物理模拟;苹果的A14芯片采用了6个核心的GPU,可以实现更快速的图像处理和机器学习。
面向高性能计算的OpenMP并行编程技术研究

面向高性能计算的OpenMP并行编程技术研究OpenMP是一种用于共享内存计算机体系结构中的并行编程接口,它可以大大提高程序的性能和并发处理能力。
在高性能计算领域,OpenMP并行编程技术已成为一个必备的技能。
本文将探讨面向高性能计算的OpenMP并行编程技术研究。
1. OpenMP简介OpenMP全称为Open Multi-Processing,是一种围绕共享内存体系结构的并行编程接口,它提供了一种简单而高效的方法,使程序能够利用具有多个处理器和内存共享的计算机体系结构。
OpenMP的优点在于其易用性和高效性。
由于OpenMP是基于共享内存的并行模型,程序员可以使用简单的指令和指令集,轻松地将程序中的特定部分并行化。
同时,OpenMP的高效性使其成为开发高性能计算应用程序的理想工具。
2. 面向高性能计算的OpenMP并行编程技术在高性能计算领域,OpenMP并行编程技术通常用于提高应用程序的性能和并发处理能力。
以下是面向高性能计算的OpenMP并行编程技术的一些主要方面:2.1 并行循环在OpenMP中,最常见的并行化技术是并行循环。
程序员可以简单地将循环指令指定为OpenMP中的并行循环指令,并利用多个处理器同时执行循环的不同迭代。
这种技术可用于提高程序的性能,特别是在涉及大量迭代的程序中。
2.2 数据分区在高性能计算领域,数据分区是一种将数据分成多个块的技术。
在OpenMP中,程序员可以使用指令集将数据分成多个块,并将每个块分配给不同的处理器。
这种技术被用于处理具有大量数据的应用,以提高处理速度和效率。
2.3 核函数性能优化在OpenMP中,核函数指的是程序中由许多线程并行执行的代码段。
在高性能计算领域,核函数是非常重要的,因为它们占用了整个程序中大量的计算时间。
因此,优化核函数的性能是提高程序性能的一项关键技术。
2.4 内存管理高性能计算应用程序需要使用大量的内存。
在OpenMP中,程序员可以使用指令集来管理一个线程使用的内存。
面向嵌入式多核存储层次的OpenMP优化探讨

yt (pue) s m ”as”; e
}
( )嵌入 式 多核 存储 层 次结构 一
行编 程 的难度 和 复杂度 ,这样 程序 员可 以把更 多 的精力 投 入到 并
言 包括 C语言 、 + 和 F ra ; C+ o rn 而支 持 O eMp的编 译器 包括 S n t pn u
}
it i it g , c a a v] { n ma ( c n n a hr r [ r g )
C m ir G o pl 和 It o i r 。 p n o pl , NUC m ir ne C mpl 等 O eMp提 供 了对 e e l e
T s i et ) (; y t ” a s”; s m( u e) e p }
并行 化处 理 程序 框架 为 :
#i ude<o pI ncl m h #icud n l e<sdo.> ti h #icud n l e<sdi h t l > bI
共享 C ce ah 和拥有二级共享 C ce的多核存储层次结构,以及它 ah
编写、运行并行程序也 变得相当普遍 ,如何充分认识与利用嵌入式多核 的并行计算效率已经成为 目前计算机研究的一个重点工作。
关键 词 : 多核 存储 ;Op n ;优化 e MP
中图分类号:T 3 3 P 3
一
文献标识码 :A 文章编号:10 - 5 9 21) 2 07 — 2 07 99 (02 1— 0 5 0
o ( t =0 i 00 ;+ i r n i i : 多核 处理 器 的运行 速度 不 可 以无 限制 的提 升 ,所 以当速 度 达 到一 个极 限 的时候 ,想 要提 高 计算 机 的能 力最 好 的方法 就 是 增 加 处理 器 的数量 。在 芯片 上 安装 两个 或两 个 以上 的 内核又 称 为 C ,安装 多个 处理 器后 能够 满足 线程 在这 些 处理 器 内核上 并行 MP 执 行 ,这样 系 统性 能大 大提 升 了。 如 何使 用 多核 资源 才会 获得 最 大化 效率 呢 ?这 需要注 意 几个
基于OpenMP的多核系统并行程序设计方法研究

南华 大学学 报( 自然科学版 ) J o u r n a l o f U n i v e r s i t y o f S o u t h C h i n a ( S c i e n c e a n d T e c h n o l o g y )
h o w t o ma k e f ul l u s e o f mu l t i — c o r e c o mp u t i n g p o we r , mi n i n g a pp l i c a t i o n i n p a r a l l e l , t o g i v e
s t a n d a n d ma s t e r . T h i s p a p e r d e s c r i b e s a O p e n MP b a s e d o n mu l t i — c o r e p ra a ll e l p r o g r a m d e — s i g n me t h o d s , a n d p u t s f o r w rd a t wo k i n d s o f n u c l e r a s y s t e m w i h t mu l t i p l e p ra a ll e l p r o ra g m
V0 I . 2 7 No . 1 Ma L 2 0 1 3
文章编号 : 1 6 7 3— 0 0 6 2 ( 2 0 1 3 ) 0 1— 0 0 6 4— 0 5
基于 O p e n MP的多核 系统并行程 序设计 方法研究
龚向 坚, 邹腊 梅 , 胡 义 香
( 南华大学 计算机科学与技术学 院, 湖南 衡 阳 4 2 1 0 0 1 )
基于OpenMP的并行求和算法的研究与分析

基于OpenMP的并行求和算法的研究与分析【摘要】目前几乎所有主流CPU厂商都致力于大力发展多核处理器,增加芯片支持的并行能力,从而提升计算机运算速度。
本文主要探讨近来流行的多核计算技术,介绍一种重要的工业标准OpenMP,以及通过一个基于OpenMP的并行求和的简单例子来分析和说明并行计算效率与传统串行计算效率比较的优势。
【关键词】多核处理;并行求和算法;多线程;OpenMP0.引言多核技术始终是近年来全球计算机技术发展的重要内容。
自从英特尔在2006年底发布了全球第一基于OpenMP的并行遗传算法探讨397款主流服务器四核处理器后,英特尔一直致力于推动多核应用生态系统的成熟与发展。
实际上,从2002年推出超线程技术开始,英特尔就开始了向多核技术转型的步伐。
最终,英特尔公司将四个计算“大脑”装入一枚处理器中,随着至强5300的诞生,计算机行业宣告正式进入了多核时代。
多核计算将成为一种广泛普及的计算模式,影响企业和消费者用户的使用模式。
如目前的服务器应用,要求高的吞吐率和在多处理器上的多线程应用;Internet的应用、P2P和普适计算的应用都促使了计算机性能的不断提升。
大型企业的ERP、CRM等复杂应用,科学计算、政府的大型数据库管理系统、数字医疗领域、电信、金融等都需要高性能计算,多核技术可以满足这些应用的需求。
本文主要探讨近来流行的多核计算技术,介绍一种重要的工业标准OpenMP,以及通过一个基于OpenMP的并行求和的简单例子来分析和说明并行计算效率与传统串行计算效率比较的优势。
1.OpenMPOpenMP是一种适用于多种硬件平台的共享存储编程的工业应用标准,提供了一个可用的编程模型,具有简单、可移植性和可扩展性,灵活支持多线程和负载平衡的潜在能力,目前支持Fortran语言,c和c++。
OpenMP规范中定义的制导指令、运行库和环境变量,能够在保证程序可移植性的前提下,按照标准将已有的串行程序逐步并行化。
多核微机基于OpenMP的并行计算

p tr. iti r ue pn Psad dwhc s p lai rga uesFr t cdO eM t a i ia api t npo rmmi tr c( P )o aal rga s no d n r h n co g nf n i e ae A I np l epormmi dl f hrd r l g n mo eo ae s
C i j , I n — iZ E eg AI a L gs , H NG F n J —a i Mi h
( eto o ue c n eXi nUnvrt , i n3 1 0 , h a D p.f mp tr i c, a i sy Xa 6 0 5 C i ) C Se me ei me n
多核 微 机基 于 Op n e MP的并行 计 算
蔡佳佳 , 李名世 , 郑 锋
( 门大 学 计 算机科 学 系, 厦 福建 厦 门 3 10 ) 60 5
摘 要 : 四核 微机走 向市场 和八 十核处 理器 在实 验室 研 制成 功 , 核 正 引领 软件 研 发发 生 基础 性 变 化。开 发 人员 需 随着 多
n pi ain t n lg . n l h u h h thg f r n ep l o u ig a do t zto eh oo y Fial to g tta ih p roma c a allcmp tn  ̄fwaec mp e tl rr s eap rete — mi c y, e r e tr o on n i ay mu tb fc x b e
中 图分 类号 : P 0 . T 3 16 文献 标识 码 : A 文章编 号 :6 3 2 X(【】 l 一【 8 — 5 1 7 —6 9 2 ( ) 0 ) 7 0 )7 0
多核微机基于OpenMP的并行计算

择[2]。#pragrna omp parallel for[子句…]是最频繁使 用的编译指导语句,可搭配使用的子句有firstpfivate,
if,lastprivate,private,reduction,schedule等。firstprivate 子句指定每个线程都有它自己的变量私有副本,并且
要在代码中添加线程来利用系统所提供的多个内核,从而提升Pc应用软件的功能和性能。文中探讨在多核微机上进行
并行计算的实现技术。介绍了共享存储系统并行编程接口OpenMP的模型、指令和库函数,以及IntelC++编译器9.1和
Microsoft Visual Studio 2005等对OpenMP的支持;着重探讨了二维离散快速傅里叶变换并行算法的设计、实现与优化技
·88·
计算机技术与发展
第17卷
序,尤其是在科学计算领域,经典算法均已收入库程 序。如果把程序库中所有程序用适合并行计算的方法 重写,那么用户在写应用程序时就可以直接调用这些 并行程序库,从而加速应用程序的运行。
目前可选择的多核多线程开发工具有Win32线 程库、pThread库以及OpenMP。Win32线程库运行于 WinNT和Win 9X平台,拥有完善而复杂的函数库, 目前比较成熟,但对编程人员有较高的要求;pThread 库是Linux下最常用的多线程支持库,具有方便移植 的特点,但使用难度比较大;OpenMP则针对共享地址 空间的并行计算机提供并行计算支持,具有使用简单 的特点。目前Intel极力推荐多线程开发工具Open— MP,在Imd C++编译器9.1、Microsoft Visual Studio
OpemMP是可移植多线程应用程序开发的行业标 准,在细粒度(循环级别)与粗粒度(函数级别)线程技 术上具有很高的效率。对于将串行应用程序转换成并 行应用程序,OpenMP指令是一种容易使用且作用强 大的工具,它具有使应用程序因为在对称多处理器或 多核系统上并行执行而获得大幅性能提升的潜力。 open伊自动将循环线程化,提高多处理器系统上的 应用程序性能。用户不必处理迭代划分、数据共享、线 程调度及同步等低级别的细节【2』。目前Intel C++编 译器9.1、Visual C++8.0和Microsoft Visual Studio 2005均支持opemvly2.5。文中主要介绍在Microsoft
嵌入式系统中的并行计算优化技术研究

嵌入式系统中的并行计算优化技术研究嵌入式系统是一种应用领域特殊的计算机系统,这种系统通常需要具备低功耗、小型化、高可靠性和高实时性等特点,而且通常嵌入在各种智能终端中,如智能手机、平板电脑、车载导航系统、智能家居设备等等。
在这些应用中,嵌入式系统需要完成各种各样的任务,如音视频处理、图像识别、智能控制等等,其中很多任务都需要并行计算来提高计算效率和实时性能。
并行计算是指多个计算单元同时进行计算的一种计算模式,其中每个计算单元都有自己的指令流和数据流,它们之间相互独立,但又可以相互协作,共同完成一个任务。
在嵌入式系统中,有许多任务可以采用并行计算的方式来优化,如图像处理、语音识别、运动控制等等,这些任务通常需要处理大量的数据,而且要求实时性能和计算精度都很高,因此采用并行计算可以显著提高系统的性能和可靠性。
在嵌入式系统中,采用并行计算需要解决许多技术问题,如任务分配、负载均衡、通信协议、数据传输等等。
其中最基础的问题是任务分配,即如何将一个任务分解成若干个子任务,并将这些子任务分配给不同的计算单元进行处理,以达到最大的计算效率和实时性能。
通常情况下,任务分配需要根据任务的特点和硬件的特点来进行优化,如任务的计算复杂度、数据依赖关系、计算单元的数量和类型等等。
对于许多计算密集型的任务,如图像处理和语音识别,通常需要采用并行计算的方式进行优化,其中最常见的方式是采用GPU并行计算技术。
GPU是指图形处理器,它是一种专门用于图像处理和并行计算的硬件设备,具备高并行性、高吞吐量和低功耗等特点,可以大幅提高计算效率和实时性能。
在嵌入式系统中,GPU通常是通过PCI-E接口或者SOC集成的方式来实现的,其中SOC集成方式更为常见,可以大幅降低系统的成本和功耗。
除了GPU并行计算之外,还有许多其他并行计算的优化技术,如SIMD、SMP、MPI等等。
其中SIMD是指单指令多数据流技术,它是一种向量化操作技术,通过一条指令同时操作多个数据,从而实现高效的并行计算。
面向多核CPU的并行计算技术研究

面向多核CPU的并行计算技术研究计算机的性能是影响当前科技发展水平的重要因素之一。
随着科技的发展,计算机CPU的频率和核心数量都在不断飞速增长。
然而,单核CPU的频率已经无法再提升,这就需要面向多核CPU的并行计算技术来利用多核CPU的性能。
这篇文章将探讨面向多核CPU的并行计算技术,从原理、技术、应用等方面进行探讨。
并行计算的原理并行计算是指让计算机多个处理器或核心同时执行一个计算任务的技术,让计算机提高计算速度的方法。
并行计算有以下两个基本原理:1.任务分割原理将大块的任务分成若干个小块,每个处理器或核心只负责其中的一小部分计算。
这样,每个处理器或核心只负责一小部分计算,每一小部分计算都可以获得充分利用。
2.任务协作原理处理器或核心之间相互通讯,协调彼此的计算任务。
这样,不同的处理器或核心能够共同实现一项计算任务,提高计算效率。
并行计算的技术并行计算的应用领域非常广泛。
著名的并行计算技术有:1.线程技术线程技术是很常用并行计算技术。
线程是一个相对于进程更小的计算单位,它负责将任务分为更小的部分。
线程有自己的栈、寄存器和局部变量,同时也可以与其它线程共享同一个地址空间。
2.OpenMP技术OpenMP是一种共享存储高级的多线程并行计算技术。
OpenMP让程序员能在单个系统或网络上利用多个处理器或核心执行计算。
OpenMP是由许多并行化语言和编译器都支持的,比较容易上手。
3. MPI技术MPI是一种高级、广泛使用的并行计算技术。
MPI是一种消息传递接口和应用程序编程接口。
MPI实现并行计算通信的主要手段,可以实现多个进程之间进行相互通讯。
MPI被视为最常用的发展并行化高性能计算技术之一。
并行计算的应用并行计算在不同领域得到了广泛的应用和推广,如:1.科学计算在科学计算领域,需要进行大量的计算,而多核CPU可以大大提高计算效率。
例如,求解介观热传导方程和流体动力学方程。
2.数据处理数据处理也是并行计算技术的应用领域之一。
面向多核处理器的并行编程模型与优化方法研究

面向多核处理器的并行编程模型与优化方法研究随着科技的不断进步,计算机处理器的性能也在不断提升。
多核处理器作为一种高性能计算机硬件架构,具有更好的并行计算能力。
而并行编程模型与优化方法的研究,能够充分发挥多核处理器的性能,提高计算效率。
一、多核处理器并行编程模型多核处理器并行编程模型是指在多核处理器上进行并行程序设计的模式和框架。
常见的多核处理器并行编程模型有OpenMP、CUDA和MPI等。
1. OpenMP:OpenMP(Open Multi-Processing)是一种针对共享内存系统的并行编程模型。
它可以通过将代码中的特定部分标记为并行执行,实现多线程并行运算。
OpenMP具有简单易用、高效灵活的特点,适用于许多多核处理器平台。
2. CUDA:CUDA(Compute Unified Device Architecture)是由NVIDIA推出的针对GPU的并行计算平台和API模型。
它利用GPU的并行计算能力,将任务分配给多个核心,实现高效的并行加速。
CUDA在科学计算、图像处理和机器学习等领域有广泛的应用。
3. MPI:MPI(Message Passing Interface)是一种针对分布式内存系统的并行编程模型。
它通过消息传递的方式实现多个进程之间的通信和协作。
MPI适用于集群系统和分布式计算环境,能够实现跨节点的并行计算。
二、多核处理器并行编程优化方法多核处理器并行编程的优化方法主要包括任务分配与负载平衡、数据局部性优化、并行算法设计和通信优化等。
1. 任务分配与负载平衡:合理的任务划分和负载平衡对于多核处理器的并行性能至关重要。
通过合适的任务调度算法和任务分配策略,确保每个处理核心的计算负载均衡,避免出现负载不均衡的情况。
2. 数据局部性优化:多核处理器的缓存系统对程序性能有着重要影响。
通过优化数据局部性,使得程序访问的数据尽量接近处理核心,减少缓存缺失,提高计算效率。
常用的优化方法包括数据重排、数据对齐和数据预取等。
云计算环境下基于多核的并行计算技术研究

云计算环境下基于多核的并行计算技术研究随着现代技术不断更新,云计算已经成为了生活和工作中必备的一部分。
在这个背景下,基于多核心的并行计算技术也越来越受到了人们的重视。
本文旨在探讨云计算环境下基于多核的并行计算技术的研究以及应用。
一、并行计算技术的发展历程计算机技术的发展始终是以提高计算效率为最终目标。
而并行计算技术就是解决这一问题的一个途径。
早在20世纪80年代,计算机科学领域就已经开始了关于并行计算的研究。
当时,人们主要关注的是并行机的制造和使用问题。
到了21世纪,人们的研究重心开始从并行机转向了软件并行计算技术。
作为多核心并行计算的代表,OpenMP和MPI等并行计算框架被开发出来。
这些技术奠定了多核心并行计算的基础,也促进了云计算的兴起。
二、云计算环境下多核心并行计算的实现云计算环境下的多核心并行计算技术可以分为两种方式:共享内存和分布式计算。
共享内存是指多核心处理器共享一块主存储器,通过加锁机制来实现多进程之间的数据共享。
这种方式的优点在于操作简单,但缺点也显而易见,由于多个进程访问同一块主存储器,会导致数据访问冲突,存在较大的并发问题。
分布式计算是指将数据分成多个子问题,然后在不同的处理器上并行执行。
分布式计算的好处是可以有效避免共享内存中出现的并发问题,缺点就在于需要较高的网络通讯带宽和低延迟。
三、多核心并行计算技术的应用多核心并行计算技术已经在多个领域得到了广泛应用。
例如,图像处理、机器学习、物流管理等领域都需要大量的计算资源来运行分析算法。
通过多核心并行计算技术,可以显著提高这些领域的计算速度,从而为人们提供更便捷的服务。
教育也是多核心并行计算技术的一个重要领域。
现在的教育活动中,常常需要通过运算和模拟来验证教学中的理论。
并行计算技术为这些需求提供了一种有效的解决方案。
四、多核心并行计算技术的未来展望随着云计算进行的日益发展,多核心并行计算技术也将更好地发挥作用。
未来,随着技术进步,我们可以期待更强大的计算能力,更快的数据处理速度,以及更为人性化的用户体验。
高性能计算中的多核多线程并行化方法研究

高性能计算中的多核多线程并行化方法研究近年来,随着计算机硬件性能的不断提升,在高性能计算领域,多核多线程并行化已经成为了一种不可避免的趋势。
在许多科学计算和数据处理任务中,利用多核多线程的优势可以极大地提高计算速度和效率。
因此,本文将分析高性能计算中的多核多线程并行化方法,并探讨其在实际运用中的一些问题和挑战。
一、多核多线程并行化的优势多核多线程并行化是一种利用计算机硬件的多个核心和线程资源进行计算的方法。
通常情况下,一个计算机处理器内部都会有多个核心和线程资源,而这些资源可以同时进行计算,从而提高计算效率和速度。
在高性能计算中,通过将一个计算任务划分为多个子任务,然后将每个子任务分配到不同的核心和线程上,可以极大地提高计算速度和效率。
具体来说,多核多线程并行化的优势包括:1. 提高计算速度:通过利用计算机硬件的多个核心和线程资源,可以同时进行多个计算任务,从而大大提高计算速度。
2. 提高计算效率:在多核多线程并行化过程中,每个核心和线程可以并行地进行计算,从而大大缩短单个计算任务的计算时间,提高计算效率。
3. 极大地扩展了计算能力:通过多核多线程并行化,可以将一个计算任务拆分成多个子任务,每个子任务分配到不同核心和线程上,从而极大地提高计算能力,增加处理大规模数据任务的吞吐量。
二、多核多线程并行化的方法在高性能计算中,多核多线程并行化有多种方法,下面将介绍其中几种比较常用的方法。
1. OpenMPOpenMP是一种共享内存多线程并行化编程模型。
它的基本原理是通过使用预编译指令来将应用程序分成多个线程,并利用每个线程的计算资源进行并行计算。
OpenMP最大的优点是编程简单,支持C/C++、Fortran等编程语言,并且具有良好的兼容性和可移植性。
2. MPIMPI是一种消息传递接口,用于在分布式系统中实现多进程间的通信。
MPI的基本原理是将一个任务分成多个子任务,这些子任务分配到不同的进程中运行,通过进程间的通信来完成整个任务。
OpenMP 在 Android 多核编程中的研究与运用

OpenMP 在 Android 多核编程中的研究与运用王冲;杨斌【摘要】As arisen technology in desktop system,OpenMP is very mature in PC platform,but most of Android developments use tradi-tional single-core mode.Google’s NDK R9 provides the support for OpenMP library.This paper describes the application of OpenMP in Android and corrects the existing problems.%作为在桌面系统上兴起的技术,OpenMP 在 PC 平台上已经非常成熟,但是在嵌入式领域,尤其是 Android 的开发大多还停留在传统的单核模式。
Google 推出的 NDK R9提供了对 OpenMP 函数库的支持,本文介绍了 OpenMp 在 An-droid 上的运用,并对存在的问题进行了修正。
【期刊名称】《单片机与嵌入式系统应用》【年(卷),期】2014(000)008【总页数】3页(P24-26)【关键词】Android;多核;NDK;OpenMP【作者】王冲;杨斌【作者单位】西南交通大学信息科学与技术学院,成都 610031;西南交通大学信息科学与技术学院,成都 610031【正文语种】中文【中图分类】TP311虽然多核平台具有很大的潜能,但由于多核软件开发工具和标准的缺乏减缓了它们的全面普及。
编程人员要想从这些系统中获得更大的好处,可能还需要编写底层代码、调度工作单元,并管理内核之间的同步。
作为在桌面系统上兴起的技术,OpenMP在PC平台上已经非常成熟,但是在嵌入式领域,尤其是Android平台的开发,大多还停留在传统的单核模式。
OpenMP论文:多核并行插值算法的研究

OpenMP论文:多核并行插值算法的研究【中文摘要】目前多核计算机已经普及,多核的意义在于其超高的多任务处理能力。
然而多核计算机仅仅提供了一个可以更高效工作的平台,如何实现更高效地运算的关键还是将程序并行化。
采用多核并行算法可以突破物理极限的约束,以较低的投入完成大计算量的任务,能够满足人们对更高性能的需求。
在并行程序设计领域,共享存储工业标准OpenMP因其简单易用,而且开发周期较短,并行效率较高等优点,在多核体系结构的并行编程中得到了广泛的应用。
插值法具有广泛的应用背景和实用价值,被应用于外形设计、图像重建、现代土木、天文学以及水利等许多与科学计算相关的领域。
关于插值的理论与应用方面的研究一直是极受关注的重要课题。
随着科技的发展,对插值问题的求解速度也提出了极高的要求,因此学者们开始研究各种加快插值问题求解速度的方法,多核计算机的出现为其提供了一个更加有效的途径。
本文研究了三次样条插值和双线性插值算法,针对三次样条插值过程中因需求解大量的三对角方程组而运算量大、运行速度慢的问题,提出了一种加速三次样条插值计算的方法。
解三对角方程组的并行算法有矩阵分解法、循环约化法、递推耦合法等,本文选择比较适合于多核环境的奇偶约化法进行并行化。
通过实验结果的加速比对比,证明本并行算法加快了求解三对角方程组的速度,从而减少了求解样条插值问题的时间。
其次针对目前一些特殊场合实时图像处理的需要,对常用的图像插值算法进行了比较分析,研究了双线性插值算法的计算过程及数据相关性,提出了基于OpenMP的双线性插值多核并行算法,并通过在图像放大处理中的应用,证明了此并行算法的有效性及可行性。
本文验证了并行程序设计理论与多核平台相结合提高插值问题速度的优越性,具有重要的现实意义和使用价值,达到了研究的。
【英文摘要】At present multi-core computers are widespread.The significance of multi-core lies in its high multi-tasking capability.However,multi-core only provides a platform for more efficient work, the key of how to achieve more efficient operation is to parallel the programs. Multi-core parallel algorithms can break the constraints of physical limit,complete large calculating tasks in lower investments and can meet the demand of higher performance.In parallel programming field,the industry standard of shared memory OpenMP is ease to use,its development cycle is shorter and parallel efficiency is higher.It is widely used inmulti-coreparallel programming. Interpolation has widely practical background and value,be used to shape design, image reconstruction,modern civil,astronomy,water calculation and many other science-related fields.The research about interpolation theory and application is an important subject always be great concerned.With the development oftechnology,requirements about resolving interpolation speed also be proposed,scholars began to study variety interpolation methods to accelerate resolve speed, the emergence ofmulti-core provides a more effective way.This paper studies cubic spline interpolation and bilinear interpolation algorithm. Because in cubic spline interpolation processing demands resolving tridiagonal equations,so has many operations and running slowly,proposes a method of resovling cubic spline interpolation acceleratly.The parallel algorithm of solving tridiagonal equations has matrix decomposition,cyclic reduction,recursive coupling,etc.This paper chooses odd-even reduction method to parallelization,because it is suitable for multi-core environment.Through compare with the speedup ratio,proves this parallel algorithm can resolve tridiagonal equations acceleratly,then reduce the time of resolving spline interpolation.Secondly,according to some special occasion’s demands of real-time image processing,contrasts common image interpolation algorithm,researches the calculating process and data dependency of bilinear interpolation algorithm.The paper raises the bilinear interpolation multi-core parallel algorithm based on OpenMP.Through apply in the image zooming processing,indicates that the algorithm is effective andfeasible.This paper verifies the advantage of combining parallel programming theory with multi-core platform to enhance the interpolation speed.It has realistic significance and the value of use,achieving the purpose of the research.【关键词】OpenMP 多核CPU 并行算法插值【英文关键词】OpenMP multi-core parallel algorithm interpolation【目录】多核并行插值算法的研究摘要3-4Abstract41 绪论7-111.1 研究背景和意义7-81.1.1 硬件平台的多核趋势71.1.2 多核并行编程的意义7-81.2 研究现状8-91.3 本文主要工作及组织结构9-112 多核并行计算11-192.1 并行机体系结构11-132.2 并行算法13-162.2.1 数据相关性13-142.2.2 并行算法设计方法142.2.3 并行算法性能度量14-162.3 并行编程环境16-172.3.1 共享存储编程环境162.3.2 分布存储编程环境16-172.4 多核技术17-192.4.1 多核处理器硬件结构17-182.4.2 多核并行设计模式182.4.3 多核编程面临的挑战18-193 插值的基本理论19-233.1 插值概念19-203.2 插值算法20-213.3 插值的应用21-234 OpenMP 多核程序设计23-304.1 OpenMP 并行编程基础23-254.1.1 OpenMP 编译指导语句23-244.1.2 OpenMP 任务调度24-254.1.3 OpenMP 常用库函数254.2 OpenMP 性能优化25-274.2.1 影响OpenMP 程序性能的因素25-264.2.2 提高OpenMP 程序性能的方法26-274.3 编译环境的设置27-304.3.1 Microsoft Visual Studio27-284.3.2 VC6.0+Intel编译器28-305 三次样条插值多核并行算法30-375.1 三次样条插值函数的定义305.2 三次样条插值函数的构造30-315.3 求解三对角方程组31-355.3.1 串行追赶算法32-335.3.2 奇偶约化并行算法33-355.4 实验结果分析35-365.5 小结36-376 双线性插值图像放大多核并行算法37-436.1 图像放大37-386.2 常用算法38-396.3 双线性插值原理396.4 并行算法设计与实现39-416.5 实验结果分析41-426.6 小结42-43结论43-44参考文献44-47攻读硕士学位期间发表学术论文情况47-48致谢48。
多核多线程技术OpenMP_实验报告2
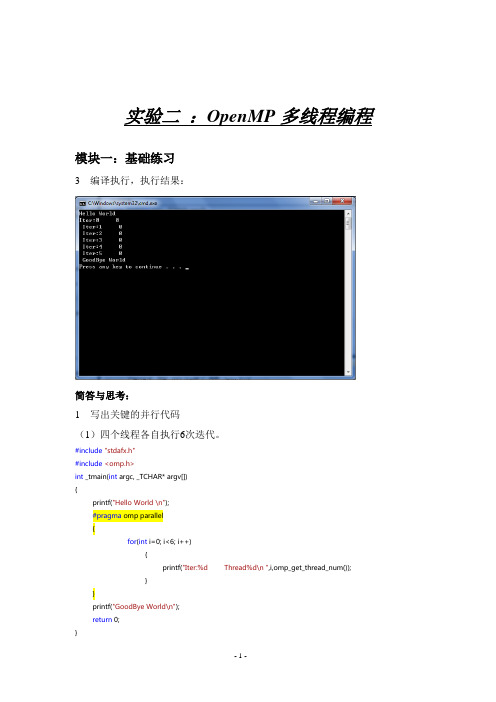
实验二:OpenMP多线程编程模块一:基础练习3 编译执行,执行结果:简答与思考:1 写出关键的并行代码(1)四个线程各自执行6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{for(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}(2)四个线程协同完成6次迭代。
#include"stdafx.h"#include<omp.h>int _tmain(int argc, _TCHAR* argv[]){printf("Hello World \n");#pragma omp parallel{#pragma omp forfor(int i=0; i<6; i++){printf("Iter:%d Thread%d\n ",i,omp_get_thread_num());}}printf("GoodBye World\n");return 0;}2 附加练习:(1)编译执行下面的代码,写出两种可能的执行结果。
int i=0,j = 0;#pragma omp parallel forfor ( i= 2; i < 7; i++ )for ( j= 3; j< 5; j++ )printf(“i = %d, j = %d\n”, i, j);可能的结果:1种2种i=2,j=3 i=2,j=3i=2,j=4 i=2,j=4i=3,j=3 i=3,j=3i=3,j=4 i=3,j=4i=6,j=3 i=5,j=3i=6,j=4 i=5,j=4i=4,j=3 i=5,j=3i=4,j=4 i=5,j=4i=5,j=3 i=6,j=3i=5,j=4 i=6,j=4(2)编译执行下面的代码,写出两种可能的执行结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第27卷 第1期2010年2月黑龙江大学自然科学学报J OURNAL OF NATURAL SC IE N CE O F HEILONG JI ANG UN I V ERS I TY V o l 27N o 1February ,2010基于嵌入式eCos 多核平台的OpenMP 并行算法的研究王 庆, 季振洲, 刘 涛(哈尔滨工业大学计算机科学与技术学院,哈尔滨150001)摘 要:当前嵌入式多核处理器的应用越来越普遍,如何提高嵌入式多核系统的并行计算效率已经成为嵌入式并行计算的核心问题。
讨论了基于嵌入式e C os 系统多核平台的Open M P 并行计算,设计实现了基于嵌入式平台的Open M P 运行库。
实验结果分析表明,在嵌入式eCos 系统多核平台上进行OpenMP 并行计算可以成倍提高应用程序在嵌入式的运行性能。
关键词:e Cos 操作系统;Open MP ;嵌入式并行计算中图分类号:TP303文献标志码:A 文章编号:1001-7011(2010)01-0069-04收稿日期:2009-06-30基金项目:国防科技工业技术基础项目作者简介:王 庆(1982-),男,博士研究生,主要研究方向:并行计算通讯作者:季振洲(1966-),男,教授,博士,博士生导师0 引 言随着集成电路物理极限的到来,仅仅通过提高处理器速度来提高计算能力已变得越来越困难。
所以多核处理器通过增加处理器个数来满足不断增长的计算能力需求。
多核处理器结构在处理器频率不变的情况下让处理器的整体性能获得明显的提升,这将是未来嵌入式系统的发展趋势。
为了充分利用嵌入式多核处理器,并行计算成为提高嵌入式系统的计算速度和可靠程度的有效手段。
嵌入式多核平台在硬件基础上通过多处理器等实现并行处理,在并行计算软件基础主要有操作系统和支持并行计算的软件程序。
目前主要的并行计算平台有基于消息传递的M PI 和P VM 、基于数据并行的H PF 和基于共享变量的Open M P 。
Open M P 是共享主存结构下基于编译指导命令的并行程序设计模式[1],其抽象程度高,可移植性好,支持并行的增量开发,开发效率高。
现在Open M P 已成为可移植多线程应用程序开发的行业标准,在细粒度(循环级别)于粗粒度(函数级别)线程技术上具有很高的效率。
因此本文提出基于嵌入式多核平台的Open M P 并行计算方法,提高嵌入式的性能。
本文在eCos 多核系统平台上引入OpenMP 并行计算,提出在嵌入式系统中实现并行计算的方法,设计基于嵌入式eCos 系统的Open M P 中间运行库,最后用实验结果来分析嵌入式多核平台的OpenMP 并行计算的加速比。
1 嵌入式eCos 多核并行计算嵌入式操作系统eCos(e mbedded Configurableoperati n g syste m )是一种嵌入式可配置实时操作系统[2],它适用于深度嵌入式应用、主要应用对象包括消费电子、电讯、车载设备、手持设备以及其它一些低成本和便携式应用设备。
1 1 Open M P 并行计算Open M P 是面向S MP (Sy mm etric M u lt-i Proces -sor)系统的并行编程语言[3]。
Open M P 采用了共享存储中标准的并行模式fork -jo i n ,当程序开始执行时只有主线程存在,主线程执行程序的串行部分,通过派生出其他的线程来执行其他的并行部分。
当重新执行程序的串行部分时,这些线程将终止。
如图1所示。
由于结构上的特点和设计上的精心考虑,Open M P 比其他程序模型要更适合于嵌入式多核S M P 系统。
首先,它有更小的额外开销[4-5]。
Open M P 基于多线程的运行模型,这从根本上减小了嵌入式系统开销,而且更有利于充分利用存储器。
其次,OpenMP 采用语句制导方式,更加便于手工并行化和编译器自动并行化,同时,也提供了较为充分的控制功能。
再次,OpenMP 主要面向循环的并行性开发,它可以很容易的实现增量性地并行化。
它还允许表达嵌套并行性,对某些应用,这种方式有相当好的效果。
因此在嵌入式eCos 对称多处理器(S MP)系统中,通过实现Open MP 程序的并行计算,可以成倍的提高嵌入式系统的运行性能。
1 2并行编译Open M P 在嵌入式下的编译系统由两部分组成:源到源转译器和本地编译器。
源到源转译器负责处理Open M P 指导命令,将包含Open MP 指导命令的并行程序转译为包含Open M P 运行库调用的程序。
此外,源到源转译器还要根据数据属性处理数据,例如将私有变量放入线程的栈空间,为共享变量在存储器的指定共享区域分配空间。
Open M P 程序编译的结构如图2所示。
Open M P 在e Cos 系统下的实现方法,首先在Open M P 编译程序时编译器先对Open M P 源程序进行预编译,展开源程序中的Open M P 预编译命令。
生成一个经过预处理的源程序,再用本地编译器来进行后段编译和连接,最后生成嵌入式e Cos 系统的执行程序。
2 Open M P 在嵌入式下的设计及实现2 1 运行库的功能与结构在通过OpenMP 源到源的转译器生成的OpenMP 程序中调用了OpenMP 的运行库中的函数或者变量,因此Open M P 运行库是整个Open MP 在e C os 多核系统平台下的基础,在Open M P 运行库中要实现以下功能:1.提供用户级函数调用接口,转译后的OpenMP 程序在其它后端交叉编译器编译过程中可以直接调用;2.处理Open M P 的环境变量;3.线程和线程组的管理,包括线程和线程组的生成,结束和调度;4.同步的管理,包括锁和临界区的管理。
Open M P 运行库是在e Cos 系统上的线程库(cyg -thread)上实现的,提供实现Open M P 语义所需要的基本函数。
它的基本结构可以用图2表示,整个OpenMP 运行库可以分为5层结构,线程的基本操作,任务的调度和管理以及同步管理都是有底层的eCos 操作系统的线程库来实现的,顶层的函数接口基本上对下面几层相关函数的一个高层封装。
2 2 同步模型设计由于多个线程需要访问共享的内部数据结构,运行库里需要一些必要的同步操作,同时,运行库必须对外提供实现Open M P 语义所需要的四种基本的同步原语:锁,嵌套锁,临界区和barrier 。
它们的组织构成了Open M P 运行时库的同步模型。
同步的等待采用条件变量(cond iti o n variable)的方法。
条件变量与允许多个线程访问共享数据的互斥量一起使用。
每个子线程在创建以后进入阻塞状态,等待指定的条件变量(cyg -cond -w a it),当条件变量被激发或者广播函数(cyg -cond -broadcast)唤醒等待条件变量的所有线程,该子线程再进行执行任务。
2 3 多核调度的实现在eCos 系统多核平台下,OpenMP 中间运行库能够启用e Cos 系统内核调度器,实现e Cos 系统对Open M P 并行计算的线程以及同步等进行调度。
e C os 系统的内核启动程序是在HAL 在所有硬件初始化后完成以后调用,在最后一步调用例程cyg -star,t 这是内核启动程序的开始。
内核启动程序包含在一个核心函数cyg -start 中,这个函数调用其他默认的启动函数来完成各种初始化任务。
Open M P 程序的入口调度如图3所示。
70 黑 龙 江 大 学 自 然 科 学 学 报 第27卷在函数cyg -user -start 中,首先创建一个线程来调用Open M P 的入口函数o m pc -m ain ,这个线程作为主线程来使用,该线程的生命周期就是整个程序的运行周期,在Open MP 的fork-jo i n 线程模式中:在碰到并行任务的时候,主线程进行fork 操作,产生一组线程进行,共同完成任务;任务完成时,各线程进行j o i n 操作,回到一个主线程线程执行的状态。
3 实验结果3 1 实验平台采用X I LI N X V I RTEX4XC4VLX160芯片的FPGA 平台,将配置有LEON3四核心的I P 写入ROM 中实现仿真。
其中每核心运行频率20MH z ,具备8kBy te 指令缓存与8kByte 数据缓存。
系统平台安装有4M Byte 片上SRAM 和128MBy te 外部SDRAM (可选)。
系统平台采用嵌入式e Cos 操作系统。
3 2 实验结果实验1 矩阵乘法并行算法的原理是通过将相乘的两个矩阵分为子块产生多个子矩阵乘法任务,可以将相应的子矩阵交给单个线程,计算乘积,而后将结果合并便得到了所求矩阵的相乘结果。
实验中将矩阵乘法算法中矩阵的阶数由50、100、200、300等变化,通过单核串行、双核并行和四核并行统计Open MP 程序计算时间,得到数据如表1所示。
表1 矩阵乘法算法的运行结果(单位:s)Tab l e 1 Th e re s u lts of Cannon al gor is mC ore Numb er5010020030040010 715 8347 10158 66381 0720 362 9823 9680 67193 6040 221 5112 2441 8898 78由表1可知在嵌入式e Cos 操作系统多核平台的Open M P 并行计算方法是有效的,并行程序的运行时间明显短于串行,并且随着核心数量的增加,并行与串行间的时间差距再增大。
根据Am dah l 法则计算相应双核及四核程序加速比,结果如图4。
可见在矩阵乘法算法中加速比随计算规模增加而提高,在100阶以上的矩阵乘法运算中加速比超过了3 7,400阶时4线程并行加速比为3 86。
实验2 快速傅立叶计算中将问题规模参数定义为2048、4096、8192等,每次计算10组数据,同样通过单核、双核和四核统计每次的计算总时间。
计算相应双核及四核程序加速比,如图5所示。
由图中的数据可知并行加速比随计算规模的增大而提高,在规模213时达到3,在215时达到3 4。
快速傅立叶计算中总时间是包含少量串行程序的时间统计,这部分代码是无法并行的,对加速比的计算有负面影响,此外还有部分代码的并行化效果受到并行区域规模的影响而加速比不高,当总计算规模较小时对加速比的影响很大。
71 第1期王 庆等:基于嵌入式eCos 多核平台的Open M P 并行算法的研究实验表明,通过实现在嵌入式e Cos 系统下的Open MP 并行计算方法,能够充分利用嵌入式多核平台资源,进而成倍提高应用程序在嵌入式多核平台上的运行性能。