VC++基于微软语音引擎开发语音识别总结
java实现微软文本转语音(TTS)经验总结

java实现微软⽂本转语⾳(TTS)经验总结⼀、使⽤背景公司项⽬之前⼀直是采⽤⼈⼯录⾳,然⽽上线⼀段时间之后发现,⼈⼯录⾳成本太⾼,⽽且每周上线的⾳频不多,⽼板发现问题后,甚⾄把⾳频功能裸停了⼀段时间。
直到最近项⽬要向海外扩展,需要内容做国际化,就想到了⽤机器翻译。
⽬前机翻已经相对成熟,做的好的国内有科⼤讯飞,国外有微软。
既然项⽬主要⾯对海外⽤户,就决定采⽤微软的TTS。
(PS:这⾥不是打⼴告,微软的TTS是真的不错,⾃⼰可以去官⽹试听下,虽然⽆法像⼈⼀样很有感情的朗读诗歌什么的,但是朗读新闻咨询类⽂章还是抑扬顿挫的。
)⼆、上代码使⽤背景已经啰嗦了⼀⼤堆,我觉得读者还是会关注的,但是我想作为资深CV码农,我想你们更关注还是如何应⽤,所以还是⽼规矩,简简单单的上代码。
(申请账号这些就不介绍了)1.依赖<dependency><groupId>com.microsoft.cognitiveservices.speech</groupId><artifactId>client-sdk</artifactId><version>1.12.1</version></dependency>2.配置常量public class TtsConst {/*** ⾳频合成类型(亲测这种效果最佳,其他的你⾃⼰去试试)*/public static final String AUDIO_24KHZ_48KBITRATE_MONO_MP3 = "audio-24khz-48kbitrate-mono-mp3";/*** 授权url*/public static final String ACCESS_TOKEN_URI = "https:///sts/v1.0/issuetoken";/*** api key*/public static final String API_KEY = "你⾃⼰的 api key";/*** 设置accessToken的过期时间为9分钟*/public static final Integer ACCESS_TOKEN_EXPIRE_TIME = 9 * 60;/*** 性别*/public static final String MALE = "Male";/*** tts服务url*/public static final String TTS_SERVICE_URI = "https:///cognitiveservices/v1";}3.https连接public class HttpsConnection {public static HttpsURLConnection getHttpsConnection(String connectingUrl) throws Exception {URL url = new URL(connectingUrl);return (HttpsURLConnection) url.openConnection();}}3.授权@Component@Slf4jpublic class Authentication {@Resourceprivate RedisCache redisCache;public String genAccessToken() {InputStream inSt;HttpsURLConnection webRequest;try {String accessToken = redisCache.get(RedisKey.KEY_TTS_ACCESS_TOKEN);if (StringUtils.isEmpty(accessToken)) {webRequest = HttpsConnection.getHttpsConnection(TtsConst.ACCESS_TOKEN_URI);webRequest.setDoInput(true);webRequest.setDoOutput(true);webRequest.setConnectTimeout(5000);webRequest.setReadTimeout(5000);webRequest.setRequestMethod("POST");byte[] bytes = new byte[0];webRequest.setRequestProperty("content-length", String.valueOf(bytes.length));webRequest.setRequestProperty("Ocp-Apim-Subscription-Key", TtsConst.API_KEY);webRequest.connect();DataOutputStream dop = new DataOutputStream(webRequest.getOutputStream());dop.write(bytes);dop.flush();dop.close();inSt = webRequest.getInputStream();InputStreamReader in = new InputStreamReader(inSt);BufferedReader bufferedReader = new BufferedReader(in);StringBuilder strBuffer = new StringBuilder();String line = null;while ((line = bufferedReader.readLine()) != null) {strBuffer.append(line);}bufferedReader.close();in.close();inSt.close();webRequest.disconnect();accessToken = strBuffer.toString();//设置accessToken的过期时间为9分钟redisCache.set(RedisKey.KEY_TTS_ACCESS_TOKEN, accessToken, TtsConst.ACCESS_TOKEN_EXPIRE_TIME); ("New tts access token {}", accessToken);}return accessToken;} catch (Exception e) {log.error("Generate tts access token failed {}", e.getMessage());}return null;}}4.字节数组处理public class ByteArray {private byte[] data;private int length;public ByteArray(){length = 0;data = new byte[length];}public ByteArray(byte[] ba){data = ba;length = ba.length;}/**合并数组*/public void cat(byte[] second, int offset, int length){if(this.length + length > data.length) {int allocatedLength = Math.max(data.length, length);byte[] allocated = new byte[allocatedLength << 1];System.arraycopy(data, 0, allocated, 0, this.length);System.arraycopy(second, offset, allocated, this.length, length);data = allocated;}else {System.arraycopy(second, offset, data, this.length, length);}this.length += length;}public void cat(byte[] second){cat(second, 0, second.length);}public byte[] getArray(){if(length == data.length){return data;}byte[] ba = new byte[length];System.arraycopy(data, 0, ba, 0, this.length);data = ba;return ba;}public int getLength(){return length;}}5.创建SSML⽂件@Slf4jpublic class XmlDom {public static String createDom(String locale, String genderName, String voiceName, String textToSynthesize){ Document doc = null;Element speak, voice;try {DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();DocumentBuilder builder = dbf.newDocumentBuilder();doc = builder.newDocument();if (doc != null){speak = doc.createElement("speak");speak.setAttribute("version", "1.0");speak.setAttribute("xml:lang", "en-us");voice = doc.createElement("voice");voice.setAttribute("xml:lang", locale);voice.setAttribute("xml:gender", genderName);voice.setAttribute("name", voiceName);voice.appendChild(doc.createTextNode(textToSynthesize));speak.appendChild(voice);doc.appendChild(speak);}} catch (ParserConfigurationException e) {log.error("Create ssml document failed: {}",e.getMessage());return null;}return transformDom(doc);}private static String transformDom(Document doc){StringWriter writer = new StringWriter();try {TransformerFactory tf = TransformerFactory.newInstance();Transformer transformer;transformer = tf.newTransformer();transformer.setOutputProperty(OutputKeys.OMIT_XML_DECLARATION, "yes");transformer.transform(new DOMSource(doc), new StreamResult(writer));} catch (TransformerException e) {log.error("Transform ssml document failed: {}",e.getMessage());return null;}return writer.getBuffer().toString().replaceAll("\n|\r", "");}}6.正主来了!TTS服务@Slf4j@Componentpublic class TtsService {@Resourceprivate Authentication authentication;/*** 合成⾳频*/public byte[] genAudioBytes(String textToSynthesize, String locale, String gender, String voiceName) {String accessToken = authentication.genAccessToken();if (StringUtils.isEmpty(accessToken)) {return new byte[0];}try {HttpsURLConnection webRequest = HttpsConnection.getHttpsConnection(TtsConst.TTS_SERVICE_URI);webRequest.setDoInput(true);webRequest.setDoOutput(true);webRequest.setConnectTimeout(5000);webRequest.setReadTimeout(300000);webRequest.setRequestMethod("POST");webRequest.setRequestProperty("Content-Type", "application/ssml+xml");webRequest.setRequestProperty("X-Microsoft-OutputFormat", TtsConst.AUDIO_24KHZ_48KBITRATE_MONO_MP3);webRequest.setRequestProperty("Authorization", "Bearer " + accessToken);webRequest.setRequestProperty("X-Search-AppId", "07D3234E49CE426DAA29772419F436CC");webRequest.setRequestProperty("X-Search-ClientID", "1ECFAE91408841A480F00935DC390962");webRequest.setRequestProperty("User-Agent", "TTSAndroid");webRequest.setRequestProperty("Accept", "*/*");String body = XmlDom.createDom(locale, gender, voiceName, textToSynthesize);if (StringUtils.isEmpty(body)) {return new byte[0];}byte[] bytes = body.getBytes();webRequest.setRequestProperty("content-length", String.valueOf(bytes.length));webRequest.connect();DataOutputStream dop = new DataOutputStream(webRequest.getOutputStream());dop.write(bytes);dop.flush();dop.close();InputStream inSt = webRequest.getInputStream();ByteArray ba = new ByteArray();int rn2 = 0;int bufferLength = 4096;byte[] buf2 = new byte[bufferLength];while ((rn2 = inSt.read(buf2, 0, bufferLength)) > 0) {ba.cat(buf2, 0, rn2);}inSt.close();webRequest.disconnect();return ba.getArray();} catch (Exception e) {log.error("Synthesis tts speech failed {}", e.getMessage());}return null;}}由于项⽬中需要将⾳频上传到OSS,所以这⾥⽣成的是字节码⽂件,你也可以选择下载或保存⾳频⽂件。
基于MicrosoftSpeechSDK的语音关键词检出系统的设计和实现

心智与计算433心智与计算, Vol.1,No.4 (2007), 433-441文章编号:MC - 2007-044收稿日期:2007-08-19出版日期:2007-12-30© 2007 MC– 厦门大学信息与技术学院基于Microsoft Speech SDK的语音关键词检出系统的设计和实现∗林 茜, 欧建林, 蔡 骏(厦门大学智能科学与技术系, 福建厦门 361005)mikecai@摘要:介绍了一个基于连续语音识别技术的语音关键词检出系统的实现.该系统使用微软语音开发平台Microsoft Speech SDK(SAPI)实现了从离线语音库中批量地检出含有指定关键词的语音文件,并提取含有关键词的句子,标注出其中所有的关键词.通过设计关键词检出语法限制了语音识别的语言模型,从而达到检出关键词的目的.同时针对实际应用中需要经常更新关键词、语言模型不固定的问题,采用了动态更新检出语法的方法,使得系统具有实用性.系统还设计了语音命令控制语法以实现语音交互.关键词: 关键词检出; Microsoft Speech SDK;语音识别中图分类号:TP391.42文献标识码: AThe Design and Implementation of a SpeechKeywords Retrieving Application Based onMicrosoft Speech SDKLIN Qian, OU Jian-Lin, CAI Jun(Department of Cognitive Science, Xiamen University, Xiamen 361005, China)mikecai@Abstract: T he design and implementation of a speech keywords retrieving system which is based on continuous speech recognition techniques is reported. The application system is developed with Microsoft Speech SDK (SAPI). It can retrieve audio files containing a predefined set of keywords from the corpus in batch processing and can properly mark all recognized keywords, therefore, the sentences containing the∗基金项目:福建省自然科学基金项目2006J0043;the ‘985 Innovation Project’ on Information Technology of Xiamen University (2004-2007) under Grant No. 0000-X07204 (厦门大学“985工程”二期信息创新平台项目)keywords can be located in the speech sentences. The recognition language model is confined by the keywords retrieving grammar, which can be modified by generating dynamic grammar. The change of keywords in the application can be easily performed by updating the keywords retrieving grammar correspondingly. Furthermore, the speech command and control grammar is designed to facilitate the speech-command manipulation of the system.Key words: keywords retrieving; Microsoft Speech SDK; speech recognition1 引言语音侦听作为情报获取、追踪的基本途径之一,在军事安全和公共安全领域都有着重要的应用.其基本功能之一是根据需要为系统设定若干关键词,当通讯语音中出现了所设定的关键词的语音,系统就将对应的语音段保存在存储设备中,以便进行详细的人工审听.不包含关键词内容的语音段则作删除或备份存档处理.语音关键词识别(speech keyword spotting或speech word spotting)[1-3]是实现此项功能的技术核心.作为语音识别领域的一个重要研究方向,语音关键词识别技术旨在从说话人的内容不受限的连续语音中辨认和确定一组预先定义好的特定词和特定短语.它无需像连续语音识别(continuous speech recognition, CSR)那样对连续语音的整体进行识别,而只需提取出语音段中的敏感信息.目前,国内外的语音关键词识别系统通常采用连续概率密度的HMM模型或半连续的HMM模型[1,2,4].随着研究的逐渐深入和完善,语音关键词识别越来越趋向于借鉴大词汇量连续语音识别(LVCSR)的技术,诸多研究表明,实现语音关键词识别的最好手段就是连续语音识别技术[2,5].通常可以通过改造已有的连续语音识别系统来实现关键词识别系统,在这样的系统构造过程中要解决的两个关键问题是:(1)对非关键词语音进行建模;(2)构造关键词识别的语言模型.本文介绍了一个用微软提供的语音开发平台Microsoft Speech SDK(SAPI)开发的语音关键词识别/检出系统的设计与实现,该系统利用Microsoft Speech SDK的命令控制模式实现语音识别功能,能以批量处理的方式从离线语音库中检出含有指定关键词的语音文件.文中介绍了这个语音关键词检出系统的设计思路,具体描述了各模块的实现方法,重点介绍了命令控制模式下关键词检出语法的构建.实验测试表明,这个采用Microsoft Speech SDK连续语音识别技术开发的系统有良好的语音关键词识别和检出性能,能满足实际应用的要求.2 系统原理和结构该语音关键词检出系统设计的核心和关键在于利用SAPI的连续语音识别技术实现关键词的检出.在语音识别方面,SAPI提供两种识别模式,即听写模式和命令控制模式.听写模式不对输入的语音进行限制,而在命令控制模式下,输入语音必须在语法限定的范围内才能被识别.由于关键词识别和语音命令的识别类似,因此可以利用SAPI的命令控制模式并设置适当的语法来实现语音关键词的检出.在SAPI的语法标志中, "*+"表示多个任意词,当一个语音句子中包含关键词和非关键词时,这个句子实际上可以用规则"*+关键词*+"来描述,即在关键词之前和之后可以有任意的非关键词语音.关键词检出的状态转换如图1所示.S: startA: accept图1 关键词检出状态转换图Fig.1 State transferring of retrieving keywords语音关键词检出系统按功能分为关键词生成模块、关键词检出模块、审听校验模块和语音控制模块.系统的结构图如图2所示.图2 语音关键词检出系统结构图Fig.2 Structure of speech keywords retrieving application系统各个模块的功能如下:关键词生成模块用于生成目标关键词.关键词检出模块根据关键词生成模块生成的关键词在语音库中进行搜索,批量地检出含有关键词的语音文件并生成检出结果,检出结果包括含关键词语音文件的文件名、关键词所在句子的开始时间及该句子.审听模块主要用于对检出的结果进行校验和修正.通过审听语音文件,用户可对误识和漏识的结果进行相应的手动修改.语音控制模块设计了语音命令控制语法,供用户与系统进行语音交互.3 Microsoft Speech SDK 5.1简介Microsoft Speech SDK 5.1是微软公司为开发Windows平台上的语音应用程序和语音引擎而提供的软件开发包,它主要包括兼容Win32的语音应用程序编程接口(Speech Application Programming Interface, SAPI)、微软连续语音识别引擎(CSR引擎)和微软语音合成引擎(TTS引擎),还包括了编译和调试语音应用程序的工具以及示例和帮助文档[6].此软件开发包结构如图3所示[7].图3 Microsoft Speech SDK结构图Fig.3 Structure of Microsoft Speech SDK语音应用程序编程接口SAPI是介于语音应用程序和语音引擎之间的中间层,这一层中包括对于底层控制和高度适应性的直接语音管理、训练向导、事件、语法编译、资源、语音识别管理以及文语转换管理等.Microsoft Speech SDK以COM接口调用的形式提供了两个接口:应用程序编程接口(API)和设备驱动接口(DDI).应用程序通过API层与SAPI通信,语音引擎则通过DDI层和SAPI进行交互,用户可以快速开发语音识别或语音合成的应用程序[8].SAPI提供的编程接口主要有两类,一类用于语音识别,另一类用于语音合成.这里只介绍语音识别的主要接口.3.1 ISpRecognizer语音识别引擎接口ISpRecognizer用于创建语音识别引擎的实例,每个ISpRecognizer接口代表CSR 引擎. CSR引擎又有共享语音识别引擎(Shared-recognizer)和进程内语音识别引擎(InProc-recognizer)两种实现方式.进程内语音识别引擎被创建在与应用程序同一个进程里,因此只能被这个应用程序使用,而共享的引擎可以供多个应用程序共同使用.3.2 ISpRecoContext语音识别上下文接口ISpRecoContext能关注不同的语音识别事件,装载或卸载识别时使用的语法文件.3.3 ISpRecoGrammar语音识别语法接口ISpRecoGrammar用于载入、激活、钝化识别语法.语法中定义了用户期望引擎识别的单词、短语和句子.语音识别引擎的工作模式分为听写模式和命令控制模式,语音识别语法对应地分为听写语法和命令控制语法.听写语法工作于听写模式,用于连续语音识别,用户一般无需对听写语法进行额外的修改;命令控制语法工作于命令控制模式,用于识别用户在语法文件中定义的短语或句子,以XML 文件的形式保存.3.4 ISpRecoResult识别结果接口ISpRecoResult用于获取有关识别引擎对输入语音的推测和识别,以及错误识别的有关信息,从而提取出相关的结果.4 系统的设计和实现4.1 语音控制模块的设计和实现和大多数SAPI语音控制应用程序一样,实现此模块需要使语音识别引擎工作于命令控制模式下,再装载一个包含所有控制命令的控制语法,具体实现步骤如下:(1) 初始化COM,并生成ISpRecognizer、ISpRecoContext和ISpRecoGrammar的实例,为识别消息设置通知.(2) 创建、装载及激活控制语法.控制语法中包含所有设定的控制命令,每个命令对应于一个应用功能,如选择语音库、开始检出、保存检出结果等.控制语法保存于一个XML文件中,将此XML文件编译出的cfg文件装载入系统并加以激活,即可启动语音控制功能.4.2 关键词生成模块的设计和实现在本系统中,关键词的生成可以通过手动输入和语音输入两种方式实现.手动输入关键词即通过键盘键入文字,输入的文字被保存在一个字符串数组中,这种方式的实现十分简单,在此不详细阐述.关键词的语音输入采用了SAPI的命令控制模式.由于在命令控制模式下输入的语音必须在语法限定的范围内才能被识别,因此为了准确识别出关键词就必须在关键词生成语法中装载一个预设的词汇库,以便用户从中选择目标关键词进行语音输入.当用户输入的语音段符合关键词生成语法,即用户语音输入的关键词在预设词汇库中,则该词被成功识别,成为关键词.关键词生成语法如下:<RULE ID="VID_KeyCmdType" TOPLEVEL="ACTIVE"><L PROPID="VID_KeyCmdType"><P VAL="VID_KeyWord"><P>关键词</P><RULEREF REFID="DYN_DataRule"/></P>……</L></RULE><RULE ID="DYN_DataRule" DYNAMIC="TRUE"><P>placeholder</P></RULE>规则VID_KeyWord是关键词生成的总规则;规则DYN_DataRule用于装载预设词汇库中的所有词汇,被规则VID_KeyWord引用.DYN_DataRule的属性DYNAMIC的值为TRUE,表示它是一个动态规则.该规则中的placeholder并不是目标词汇,只是一个占位符,之后placeholder将被清除,替换它的是预设词汇库中的所有词汇.以下过程用于动态设置规则DYN_DataRule:cpRecoGrammar->GetRule(NULL, DYN_DataRule, SPRAF_TopLevel | SPRAF_Active | SPRAF_Dynamic,TRUE, &hDynamicRuleHandle);cpRecoGrammar->ClearRule(hDynamicRuleHandle);cpRecoGrammar->Commit(0);这里,首先用GetRule函数获取DYN_DataRule的初始状态hDynamicRuleHandle,再用ClearRule函数清除该状态的所有信息,由此清除了placeholder占位符,最后用Commit(0)提交这种修改.以下过程实现了为规则DYN_DataRule装载预设词汇库中的所有词汇:CSpDynamicString ds(buffer);SPPROPERTYINFO prop;prop.pszName = L"Id";prop.pszValue = L"Property";prop.vValue.vt = VT_I4;prop.vValue.ulVal = i;cpRecoGrammar->AddWordTransition(hDynamicRuleHandle, NULL, ds, L" ",SPWT_LEXICAL, 1.0, &prop);cpRecoGrammar->Commit(0);首先ds获取buffer中存储的词汇,接着设置从状态hDynamicRuleHandle到NULL的状态转移边的属性.prop存储该边的语义属性,类型为VT_I4.其中属性名(pszName)为"Id",属性值字符串(pszValue)为"Property",属性值(vValue.ulVal)为i,i定义为当前词汇库中词汇的序号.通过AddWordTransition函数将ds 添加进从状态hDynamicRuleHandle到NULL的状态转移的边上,使ds中的词汇成为规则DYN_DataRule 的一个元素.反复执行上述操作直到所有词汇均添加完毕,用Commit(0)语句提交所做的修改.这样预设词汇库中的所有词汇全部被添加进规则DYN_DataRule中.在关键词生成过程中,当用户输入的语音在预设的词汇库中,则该语音被正确识别为关键词,否则不能被识别为关键词,需要修改预设的词汇库.关键词生成过程对应的状态转移图如图4所示.h:图4 关键词生成过程状态转换图Fig.4 Status transferring of creating keywords4.3 关键词检出模块的设计和实现关键词检出模块是语音关键词检出系统的主要功能模块,完成从语音库中检出含有关键词的语音文件,并提取出含有该关键词的语音句子、将语音句子识别为文字的功能,是本系统的核心模块.4.4 关键词检出语法的设置由于需要从被识别文件读入语音流进行识别,所以本模块中需要创建一个进程内语音识别引擎且工作在命令控制模式下,同时还需设置一个关键词检出语法用于限制检出.SAPI的语音识别语法一般预先设置在一个XML文件中,例如4.1节的控制语法文件中预先设置了语音控制模块的所有控制命令;也可以根据给定的命令集(闭集)动态生成控制语法,例如4.2节的关键词生成模块根据预设词汇库动态地生成语法.为了采用命令控制模式来实现关键词检出,检出语法除了包含关键词外,还需要包含非关键词.因此利用规则"*+关键词*+"可使检出语法包含关键词(闭集)和非关键词(开集),从而使语音识别引擎能够识别由关键词和非关键词组成的句子,实现关键词检出.这是本模块主要解决的问题,也是整个系统设计的关键.关键词检出语法定义如下:<RULE ID="VID_KeyGrammar" TOPLEVEL="ACTIVE"><P><O>*+</O><RULEREF REFID="DYN_KeyWordRule"/><O>*+</O></P></RULE><RULE ID="DYN_KeyWordRule" DYNAMIC="TRUE"><P>placeholder</P></RULE>规则VID_KeyGrammar是关键词检出的总规则;规则DYN_KeyWordRule用于装载关键词生成模块生成的关键词,被规则VID_KeyGrammar引用.设置动态规则DYN_KeyWordRule时采用和设置关键词生成语法中的规则DYN_DataRule相同的方法,先清除placeholder占位符,再将关键词生成模块生成的关键词添加进规则DYN_KeyWordRule中.由于实际应用中需要经常更新关键词,因而在改变目标关键词后,需要重新执行一次检出语法生成过程实现检出语法的实时更新,以生成新的连续语音识别时采用的语言模型.4.5 在语音库中检出含关键词的语音文件在SAPI的语音识别引擎处理语音文件之前需要设置语音输入流的格式.SAPI支持采样率为8、11、12、16、22、24、32、44或48kHz,字长为8或16Bit,声道数为单或双的输入流.经比较后,本系统将输入流格式设置为SPSF_8kHz16BitStereo,即采样率为8kHz,字长为16Bit,双声道.在关键词检出语法被激活后,语音识别引擎便可以自动识别语音输入流.在识别一个语音句子后,若该句子符合检出规则,即包含关键词,则语音识别引擎发出识别消息SPEI_RECOGNITION;否则发出错误识别消息SPEI_FALSE_RECOGNITION.当系统接收到消息SPEI_RECOGNITION后即可通过ISpRecoResult接口取出识别时间点和对应的文字识别结果.当一个语音文件识别结束后,识别引擎向系统发出SPEI_END_SR_STREAM消息,此时可继续下一个文件的识别,从而达到对语音库中的文件进行批量处理的目的.4.6 关键词定位当系统接收到识别消息,将检出结果显示之前需要对识别出的句子中的关键词进行定位,即标示出句子中的所有关键词,以便对检出结果有更加清晰和直观的了解.定位过程实际上是在一个字符串中查找指定的各个子串的位置,可以简单地使用C语言中的查找函数来实现.但是当关键词数目比较多时,需要重复使用查找函数,具体来说,若用户设定N个关键词,则对每一句识别出的句子,都要进行N遍关键词查找,这使系统耗时很大.由于系统的主要目的是检出含有关键词的句子,希望尽可能节约查找的时间,因此本系统采用了高效的单字符串匹配算法--BMHS算法[9]和多字符串匹配算法--Wu Manber算法[10]来实现字符串查找.这两种算法产生于英文环境,但都适用于中文环境,因为汉字在计算机中用两个字符表示,因此可以把汉字的匹配当成两个单字符的匹配,原理与单字符匹配相同,算法性能也相同.具体的算法原理在此不赘述.4.7 审听校验模块的设计和实现由于SAPI的识别不可避免地会出现错误,所以为了增强系统的可用性,系统中设置了审听校验模块,用于审听可能被误识的语音文件或文件中的个别句子,并为人工修改机器识别的结果提供操作环境.审听功能主要使用了MCI(Media Control Interface)媒体控制接口来完成语音文件的播放.MCI是Microsoft提供的一组多媒体设备和文件的标准接口,可以方便地控制绝大多数多媒体设备,包括音频、视频、影碟、录像等,因此可以轻松地应用MCI实现审听功能.用户通过此模块,即可以在审听语音文件后对识别错误的结果进行手工修改、更新.5 总结本文利用Microsoft Speech SDK的连续语音识别技术实现了语音关键词检出系统,该系统可以自动检出包含用户关心的关键词的语音,因此不需人为地监听所有语音,大大提高了语音信息过滤的工作效率.通常在Microsoft Speech SDK的命令控制模式下,用户只能按语法文件中的规则进行语音控制,而这些规则通常都是给定的文本,因此用户的命令属于一个闭集合.而本文中关键词检出语法虽然也是基于规则的,但是它将关键词(闭集)和非关键词(开集)结合,使既包含关键词、又包含非关键词的输入语音同样能被识别.由此设置的检出语法限制了连续语音识别时采用的语言模型,达到检出关键词的目的.同时这些关键词并不是在一开始就加入检出语法的,而是在动态设置关键词的过程中动态地生成,因此具有一定的灵活性,可针对不同的关键词识别需要进行检出.在测试本系统时,用离线语音库中的语音文件对SAPI进行训练后再进行关键词检出,检出结果显示关键词的检出率在95%以上.虽然检出结果中存在对某些非关键词的误识,但不影响系统对语音库的过滤功能,因此系统具有一定实用性.参考文献:[1] Wilpon J G, Rabiner L R, Lee C H, et al. Automatic recognition of keywords in unconstrained speech using hidden Markovmodels[J]. IEEE Transactions on Acoustics, Speech, and Signal Processing,1990, 38(11): 1870-1878.[2] Ling Y. Keyword Spotting in Continuous Speech Utterances[D]. School of Computer Science, McGill University, Canada,1999.[3] Amir A, Efrat A, Srinivasan S. Advances in phonetic word spotting[C]//Proc. of the 10th International Conference onInformation and Knowledge Management. New York: ACM Press, 2001:580-582.[4] Yan B F, Guo R, Zhu X Y, et al. An approach of keyword spotting based on HMM[C]//Proc. of the 3rd World Congress onIntelligent Control and Automation. Hefei: Press of University of Science and Technology of China, 2000: 2757-2759.[5] Huang X D, Acero A, Hon H W. Spoken language processing: a guide to theory, algorithm, and system development[M].Upper Saddle River: Prentice Hall PTR, 2001.[6] Microsoft Speech SDK(SAPI) 5.1 Help. Microsoft Corporation, 2001.[7] Chen B F. Development of Chinese speech application under Net platform.[8] /china/community/program/originalarticles/techdoc/Cnspeech.mspx.[9] Yang X J, Chi HS. Digital processing of speech signals[M]. Beijing: Publishing House of Electronics Industry, 1995.[10] S unday D M. A very fast substring search algorithm[J]. Communications of the ACM, 1990, 33(8): 132-142.[11] W u S, Manber U. A fast algorithm for multi-pattern searching. puter Science Department, University ofArizona, 1994.作者简介:林茜(1985-),女,硕士研究生,主要研究领域为人工智能,自然语言处理。
C语言音频识别音频特征提取和语音识别的方法

C语言音频识别音频特征提取和语音识别的方法C语言是一种广泛应用于计算机编程的程序设计语言,其功能强大且灵活。
在音频处理领域,C语言也被广泛用于音频特征提取和语音识别。
本文将介绍C语言中实现音频识别的方法,包括音频特征提取和语音识别。
一、音频特征提取音频特征提取是音频识别的重要一步,它将原始音频数据转换为数值特征,以供后续的语音识别算法使用。
以下是几种常用的音频特征提取方法:1. 傅里叶变换(Fourier Transform):傅里叶变换可以将时域信号转换为频域信号,通过分析不同频率的分量来提取音频特征。
在C语言中,可以使用FFT算法实现傅里叶变换。
2. 短时傅里叶变换(Short-Time Fourier Transform,STFT):STFT 是一种将音频信号分割为小片段来进行频谱分析的方法。
通过对每个时间段应用傅里叶变换,可以得到时频谱图。
C语言中可以使用窗函数来实现STFT算法。
3. Mel频率倒谱系数(Mel Frequency Cepstral Coefficients,MFCC):MFCC是一种用于音频和语音识别的特征表示方法。
它首先将音频信号应用STFT,然后对每个频率带的能量进行取对数并进行离散余弦变换,最后选择得分最高的几个系数作为特征向量。
二、语音识别在得到音频数据的特征向量后,可以使用各种机器学习算法来进行语音识别。
以下是几种常用的语音识别方法:1. 隐马尔可夫模型(Hidden Markov Model,HMM):HMM是一种常用的语音识别算法,它将语音信号视为一系列状态的序列,并通过观察发射概率和状态转移概率来计算最可能的状态序列。
在C语言中,可以使用HMM库来实现HMM算法。
2. 高斯混合模型(Gaussian Mixture Model,GMM):GMM是另一种用于语音识别的统计建模方法,它假设每个状态的概率密度函数由多个高斯分布组成。
通过最大似然估计,可以得到每个状态的高斯参数。
语音识别 实验报告

语音识别实验报告语音识别实验报告一、引言语音识别是一项基于人工智能的技术,旨在将人类的声音转化为可识别的文字信息。
它在日常生活中有着广泛的应用,例如语音助手、智能家居和电话客服等。
本实验旨在探究语音识别的原理和应用,并评估其准确性和可靠性。
二、实验方法1. 数据收集我们使用了一组包含不同口音、语速和语调的语音样本。
这些样本覆盖了各种语言和方言,并涵盖了不同的背景噪音。
我们通过现场录音和网络资源收集到了大量的语音数据。
2. 数据预处理为了提高语音识别的准确性,我们对收集到的语音数据进行了预处理。
首先,我们对语音进行了降噪处理,去除了背景噪音的干扰。
然后,我们对语音进行了分段和对齐,以便与相应的文字进行匹配。
3. 特征提取在语音识别中,特征提取是非常重要的一步。
我们使用了Mel频率倒谱系数(MFCC)作为特征提取的方法。
MFCC可以提取语音信号的频谱特征,并且对人类听觉系统更加符合。
4. 模型训练我们采用了深度学习的方法进行语音识别模型的训练。
具体来说,我们使用了长短时记忆网络(LSTM)作为主要的模型结构。
LSTM具有较好的时序建模能力,适用于处理语音信号这种时序数据。
5. 模型评估为了评估我们的语音识别模型的准确性和可靠性,我们使用了一组测试数据集进行了模型评估。
测试数据集包含了不同的语音样本,并且与相应的文字进行了标注。
我们通过计算识别准确率和错误率来评估模型的性能。
三、实验结果经过多次实验和调优,我们的语音识别模型在测试数据集上取得了较好的结果。
识别准确率达到了90%以上,错误率控制在10%以内。
这表明我们的模型在不同语音样本上具有较好的泛化能力,并且能够有效地将语音转化为文字。
四、讨论与分析尽管我们的语音识别模型取得了较好的结果,但仍存在一些挑战和改进空间。
首先,对于口音较重或语速较快的语音样本,模型的准确性会有所下降。
其次,对于噪音较大的语音样本,模型的鲁棒性也有待提高。
此外,模型的训练时间较长,需要更多的计算资源。
基于VisualC 2010开发基于Windows7的语音识别与语音合成-程序员投稿课案
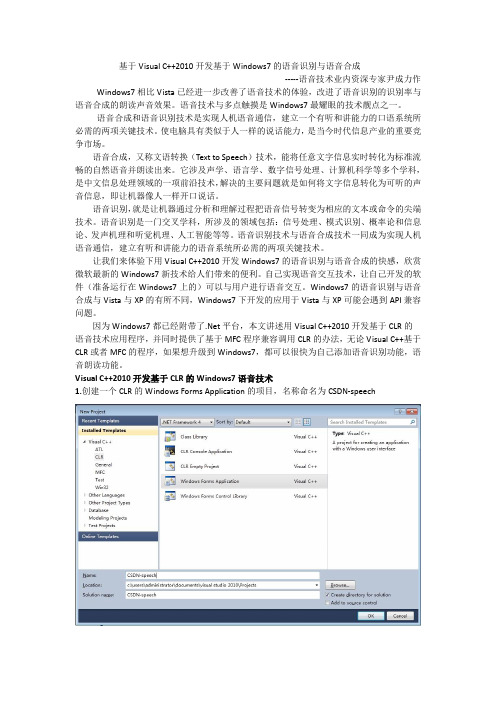
基于Visual C++2010开发基于Windows7的语音识别与语音合成-----语音技术业内资深专家尹成力作Windows7相比Vista已经进一步改善了语音技术的体验,改进了语音识别的识别率与语音合成的朗读声音效果。
语音技术与多点触摸是Windows7最耀眼的技术靓点之一。
语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。
使电脑具有类似于人一样的说话能力,是当今时代信息产业的重要竞争市场。
语音合成,又称文语转换(Text to Speech)技术,能将任意文字信息实时转化为标准流畅的自然语音并朗读出来。
它涉及声学、语言学、数字信号处理、计算机科学等多个学科,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何将文字信息转化为可听的声音信息,即让机器像人一样开口说话。
语音识别,就是让机器通过分析和理解过程把语音信号转变为相应的文本或命令的尖端技术。
语音识别是一门交叉学科,所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
语音识别技术与语音合成技术一同成为实现人机语音通信,建立有听和讲能力的语音系统所必需的两项关键技术。
让我们来体验下用Visual C++2010开发Windows7的语音识别与语音合成的快感,欣赏微软最新的Windows7新技术给人们带来的便利。
自己实现语音交互技术,让自己开发的软件(准备运行在Windows7上的)可以与用户进行语音交互。
Windows7的语音识别与语音合成与Vista与XP的有所不同,Windows7下开发的应用于Vista与XP可能会遇到API兼容问题。
因为Windows7都已经附带了.Net平台,本文讲述用Visual C++2010开发基于CLR的语音技术应用程序,并同时提供了基于MFC程序兼容调用CLR的办法,无论Visual C++基于CLR或者MFC的程序,如果想升级到Windows7,都可以很快为自己添加语音识别功能,语音朗读功能。
基于VC的语音传输系统的设计与开发论文

基于VC的语音传输系统的设计与开发摘要随着计算机应用技术的快速发展和日益普及,网络也遍及到我们生活的每个角落,为我们的学习和工作带来极大的方便。
很多人都使用过传统的文字输入聊天方式,与之不同的另外一种聊天方式就是语音聊天。
主要对那些不会使用键盘的老年用户和追求时尚的年轻人,语音聊天是一种非常好的聊天方式,它能增加聊天双方的亲切感和真实感,语音聊天就涉及到语音的传输。
本系统主要讨论了Windows系统下网络语音的传输,尤其是对网络编程做了较深入的学习和应用,并以语音聊天为例给出了应用实例。
本系统主要利用Windows系统下的API函数和SOCKET函数以及VC开发平台的强大功能来实现。
经过半年多的努力,终于完成了语音传输系统的需求分析、模块功能划分、多媒体编程、服务器-客户端模型等。
本系统可以实现网络间文字、语音信息的传输。
关键词信息传输;网络编程;语音传输;多媒体The design and development of voice transmission based onVCAbstractThe Internet is more and more popular in our lives because of the development of computer technology. Internet helps us in study and work. Many people use the traditional input method to chat, but there is a new method that we can speak to our friends in real-time. Voice chatting is developed for ones who do not know how to type, or the young people, it can increase the realistic and friendliness.This paper discusses the transmission of voice by network in windows operation system, such as voice chats. The system is programmed with API functions and Socket functions of the windows. After six months of effort, the voice chatting system was completed. This system includes requirements analysis, and functional modules, multimedia programming, server-client model. In network, the text and voice can be transported through this system .Key words: Information transmission; Network programming; V oice transmission; Multimedia目录论文总页数:19页1 引言 (1)2 语音传输系统需求分析 (1)3 开发工具与环境介绍 (2)3.1Visual C++概述 (2)3.1.1Visual C++简介 (2)3.1.2Visual C++的发展过程 (2)3.1.3Visual C++的特点 (3)3.2Visual C++的集成开发环境 (3)3.3Windows程序设计基础 (4)3.3.1概述 (4)3.3.2消息处理函数 (4)3.3.3窗口的建立 (5)3.3.4消息循环 (6)4 Windows网络编程 (8)4.1网络和协议 (8)4.2Winsock 接口 (9)4.3服务器程序和客户程序创建过程 (11)5 语音传输系统功能实现 (12)5.1语音模块实现 (13)5.2服务器和客户端功能的实现 (14)6 系统功能的测试与分析 (15)6.1语音聊天程序使用介绍 (15)6.2测试与分析 (16)结论 (16)参考文献 (17)致谢 (18)声明 (19)1引言20世纪是计算机的世纪,计算机及相关技术的快速发展令人目不暇接。
VC实现TTS文字语音朗读MicrosoftSpeechSDK

VC实现TTS文字语音朗读MicrosoftSpeechSDK一. TTS概述随着语音技术的发展,微软也推出了相应的语音开发工具,即Microsoft Speech SDK,这个SDK中包含了语音应用设计接口(SAPI)、微软的连续语音识别引擎(MCSR)以及微软的语音合成(TTS)引擎等等。
它其中的 TTS(text-to-speech)引擎可以用于实现语音合成,我们通过TTS引擎可以分析文本内容并且将其朗读出。
实现TTS技术的方法有很多种,现在主要采用三种:连词技术、语音合成技术、子字连接技术。
目前的5.1版本的SDK一共可以支持3种语言的识别 (英语,汉语和日语)以及2种语言的合成(英语和汉语)。
其中还包括对于低层控制和高度适应性的直接语音管理、训练向导、事件、语法编译、资源、语音识别(SR)管理以及TTS管理等强大的设计接口。
二. 实现原理以下是SpeechAPI的总体结构:从图中我们可以看出语音引擎则通过DDI层(设备驱动接口)和SAPI(SpeechAPI)进行交互,应用程序通过API层和SAPI通信。
通过使用这些API,用户可以快速开发在语音识别或语音合成方面应用程序。
应用程序使用ISpVoice接口来控制TTS,通过调用其中的Speak 方法可以朗读出文本内容,通过调用SetVoice / GetVoice方法(在.NET中已经转变成Voice属性)来获取或设置朗读的语音,而通过调用GetVolume / SetVolume、GetRate / SetRate等方法(在.NET中已经转变成Volume和Rate属性)来获取或设置朗读的音量和语速。
功能强大之处在于TTS能识别XML标记,通过给文本加上XML 标记,我们让TTS朗读出更加符合语言阅读习惯的句子。
例如:l 用于设置文本朗读的音量;l 、分别用于设置文本朗读的绝对速度和相对速度;l 、分别用于设置文本朗读的绝对语调和相对语调;l 在他们之间的句子被视为强调;l 可以将单词逐个字母的拼写出来;l 表示停止发声,并保持500微秒;l 02/03/07 可以按要求朗读出日期l 用于设置朗读所用的语言,其中409表示使用英语,804表示使用汉语,而411表示日语。
集成微软语音识别与语音合成代码的类代码

基于Microsoft Speech SDK 5.1的集成微软语音识别与语音合成代码的类代码(1)2009-02-24 13:37/////////////////////////////////////////////////////////1,生成动态连接库时,要#define USE_SPEECH_DLL,// 并且#define LANE_SPEECH_EXPORTS//2,使用动态连接库时,要#define USE_SPEECH_DLL//3,声称和使用静态连接库时,什么都不需要//4,另外主程序中静态连接库要调用的方式里要调用CoInitialize( NULL )和CoUninitialize(),// 动态连接库就不用调用了。
////////////////////////////////////////////////////////#ifndef LANE_SPEECH_H#define LANE_SPEECH_H#include <windows.h>#define _ATL_APARTMENT_THREADED#include <atlbase.h>extern CComModule _Module; //You may derive a class from CComModule and use it. if you want to override something,but do not change the name of _Module#include <atlcom.h>#include <sphelper.h> //sapi需要的头文件//-----生成动态连接库和静态库的处理----------------#ifdef USE_SPEECH_DLL //定义了USE_SPEECH_DLL,就按生成DLL,声明导出导入类#ifdef LANE_SPEECH_EXPORTS#define LANE_SPEECH_DLL __declspec(dllexport)#else#define LANE_SPEECH_DLL __declspec(dllimport)#endif//这个警告我现在还没闹清楚是怎么回事了,估计是DLL和com或atl有关//暂时只能屏蔽掉它,在静态库里就不会出现这个警告。
用Microsoft Speech SDK实现语音识别和语音合成

接库 , 释放资源 .
P re u >Deci t( ; ct n t at ae ) v L V md ik "p C S ) n ipV m ) f C C d ( i p Me u f C n) <
( Unnt l e ) iiai ( ; iz
d l e V nd ik e tp C t n ; e S d l ep V rd ee c C a ; t d l ep . n ; e t CMe u e
pCVT xt n w e CVo c Te t ie x :
h s F Re = CVCmd
> l i( VC Sn ) nt p md ik :
i( Re) r i 1 n h f eul L r ; h s p Re = CVCmd > En b e( a h tTRU ) S ; i h . f Re ) ( s tlF l eUH :
C eN t y i ts oi Sn f k类 在 响应 语 音 消息 时 不 同命 令 的 标 志 为 &) mma d e0 nz n R cg i e函数 的第一个 参数 .
2 3 结 束 时 的 处 理 .
பைடு நூலகம்
用 中可根据 具体 情 况进行 定义 .
2 2 语 音 识 别 程 序 的 初 始 化 . 典型 的语 音识 别程 序仞 始化段 如 下所 示 :
维普资讯
( 厂
一
I 一
6
箍 ' j
.
M _! ,
用 M i ootS e c DK 实 现 c s f p eh S r 语 音 识 别 和 语 音 合 成
乙 / . 一
语音识别心得(精选5篇)

语音识别心得(精选5篇)语音识别心得(精选5篇)语音识别心得要怎么写,才更标准规范?根据多年的文秘写作经验,参考优秀的语音识别心得样本能让你事半功倍,下面分享相关方法经验,供你参考借鉴。
语音识别心得篇1近期我们团队在进行语音识别技术的开发与应用,我想分享一些心得和体会。
首先,语音识别是一项极具挑战性的任务,需要深度学习、信号处理等多领域的综合知识。
在开发过程中,我们采用了最新的深度学习模型,成功地实现了高精度的语音识别。
同时,我们还发现,语音识别不仅仅是对语音信号的简单转化,还需要考虑到语音的情感、语气等因素,因此,我们需要对语音信号进行更深入的理解和建模。
其次,语音识别技术的应用非常广泛,不仅可以用于智能语音助手、智能客服等领域,还可以用于医疗、教育等更广阔的领域。
在医疗领域,我们可以通过语音识别技术,帮助医生快速准确地记录病患的病情,提高诊疗效率。
在教育领域,我们可以通过语音识别技术,实现智能化的在线教育,让学习变得更加轻松有趣。
最后,我认为语音识别技术还有很大的发展空间。
未来,我们可以通过更多的数据训练和模型优化,实现更加精准、自然的语音识别。
同时,我们还可以结合更多的应用场景,开发出更加智能、实用的语音识别产品。
总之,语音识别技术是一项具有深远意义的技术,它可以为人类带来更智能、更便捷的生活方式。
我们团队将继续努力,为实现这一目标而奋斗。
语音识别心得篇2语音识别是人工智能领域的一项重要技术,它让机器能够理解人类的语音并将其转化为文字。
以下是我在学习语音识别技术过程中的一些心得体会。
首先,语音识别是一项需要长期学习和实践的技术。
我在学习语音识别技术时,首先了解了语音识别的基本原理和常见的算法,如基于规则的方法和基于统计的方法。
然后,我开始学习Python编程语言,并使用语音识别库,如CMUSphinx 和GoogleCloudSpeech-to-Text等,进行实践操作。
在这个过程中,我不仅掌握了语音识别的基本技能,还学会了如何使用语音识别库进行文本转换和语音合成。
softvc vits singing voice conversion 推理

softvc vits singing voice conversion 推理1. 引言1.1 概述本文旨在介绍软件VC(Voice Conversion)和VITS(Voice Identity Transfer by Speech-to-speech synthesis)技术在声音转换领域中的应用。
声音转换是一种将说话人的语音样本转换为另一个说话人语音样本的技术,它在语音合成、语音转录、影视制作等领域具有广泛的应用前景。
本文主要聚焦于介绍SoftVC 和VITS这两种声音转换技术,并探讨它们在实际应用中的优势与不足。
1.2 文章结构本文分为引言、正文、推理过程分析、进一步研究与应用展望以及结论五个部分。
在引言部分,将简要概述文章目的并明确阐述软件VC和VITS的背景和意义。
接着,在正文部分详细介绍软件VC和VITS的原理、方法和应用情况。
随后,进行推理过程分析,重点探讨推理算法概述、数据准备与预处理以及实验结果与讨论。
之后,展望未来研究方向,包括声音转换技术研究方向以及SoftVC 和VITS在其他领域应用的前景分析。
最后,在结论部分回顾研究过程,总结发现,并对未来的发展趋势与挑战进行讨论。
1.3 目的本文旨在全面介绍软件VC和VITS技术在声音转换领域中的应用情况和进展,为读者提供对这两种技术有深入了解的基础。
同时,通过推理过程分析和展望未来研究方向,希望引导和启发更多学者从事相关研究,并探索SoftVC和VITS 在其他领域的应用潜力。
通过本文的撰写,旨在促进声音转换技术的发展与创新,并为相关领域的学术界和工业界人士提供有益参考和启示。
2. 正文:2.1 软件VC和VITS简介:软件VC(Voice Conversion)是一种音频处理技术,旨在改变说话者的声音特征,使其听起来像另一个人在说话。
VIPER Voice Conversion软件是一种常见的软件VC工具,它通过学习源说话者和目标说话者之间的语音差异,并将这些差异应用于输入语音信号,实现声音转换。
基于VC和Matlab的实时语音识别系统研究

N n hn 7 e 礼 f Tcn l y eig 1 0 4 hn ) o h C ia U H yo eh oo ,B n 0 1 4 C ia g
Ab t a t A A r a—i s e h e o nto s se sr c : e l me pe c r c g iin y tm b sd n y rd r ga t a e o h b i p o rmm ig o VC a d n f n M alb i ito u e t s nr d c d. I VC a n e vio n rnme t b usn W id ws M utme i API sg a a q iiin n e l i e s e lz d a d y he o rul c m p t g n, y ig no li da , in l c usto i ra t i r aie , n b t p wef o ui m n
DsTR => ,D[( ,( ( ) i [,】 Tn Rw n 】 t ‘ ) )
由于 D W不 断地计算两矢 量的距离 以寻找最优 的匹配路 T
z r=s m (i n . d fs 2 ; c u sg if, ) %每帧过零率 s
32 特 征 函 数 的 提 取 -
径 , 以得 到的 两矢 量的 匹配距 离是 累计 距离 最小 的规 整函 所
AI P 实现对信号的 实时采集 , 并且通过 Ma a tb强大的计算功 能 , l 实现对语音信 号的端点检测 、 特征值提取 和模板 匹配 , 从
而 实现 实 时的 语 音 识 别 。
关 键 词 :VC;Mal ;实 时语 音识 别 ;MF C;DT ;非 特 定 人 ;ME tb a C W X
用C_开发基于MicrosoftSpeechSDK的语音应用程序

用C_开发基于MicrosoftSpeechSDK的语音应用程序ComputerEraNo.220070引言一直以来,让计算机听懂人们说的话,从而让人与计算机用自然语言方便地进行交流,是语音识别技术追求的目标。
本文在分析MicrosoftSpeechSDK应用程序开发接口的基础上,阐述应用C#如何开发语音应用程序。
1MicrosoftSpeechSDKMicrosoftSpeechSDK5.1是微软提供的软件开发包,其中包含了语音识别和合成引擎相关组件、帮助文档和例程,它是一个语音识别和合成的二次开发平台。
我们可以利用这个平台,在自己开发的软件里嵌入语音识别和合成功能,从而使用户可以用声音来代替鼠标和键盘完成部分操作,例如:文字输入、菜单控制等,实现真正的“人机对话”。
2.NET与COM组件SDK中提供的组件采用COM(ComponentObjectModel)标准开发,底层协议都以COM组件的形式完全独立于应用程序层,为应用程序设计人员屏蔽掉复杂的语音技术,语音相关的一系列工作由COM组件完成,程序员只需专注于自己的应用,调用相关的语音应用程序接口(SAPI)就可实现语音功能。
COM组件为在Windows平台上开发跨语言程序提供了可能,但传统COM编程的一系列技术较为复杂,对程序员水平的要求较高。
Microsoft提供的.NET平台对此作了很大改进,最终大大简化了.NET-COM的互操作过程。
例如,利用VisualStudio.NET开发平台引用SDK提供的COM组件非常简单,在菜单选择中工程|添加引用,然后点击COM标签,选择MicrosoftSpeechObjectLibrary,即可完成对该组件的引用。
实际上,这一做法,意味着项目引用了下面路径中的程序集:C:\ProgramFiles\CommonFiles\MicrosoftShared\Speech\sapi.dll(具体路径与操作系统相关)。
人工智能语音助手的开发技巧与语音识别优化

人工智能语音助手的开发技巧与语音识别优化人工智能的快速发展,使得语音助手成为现代生活中不可或缺的一部分。
人们通过语音助手与设备进行交互,完成各种任务,提高了效率。
为了开发出更加智能、可靠的语音助手,开发者需要掌握一些关键的技巧和优化方法。
第一,合理设计语音助手的语音识别模型。
语音识别是语音助手的核心功能,所以设计一个准确、高效的语音识别模型非常重要。
首先,开发者需要收集大量的训练数据,包括各种语速、音量、口音等不同的语音样本。
然后,利用这些数据训练出一个强大的语音识别模型,能够准确地识别用户的语音输入。
第二,优化语音信号的预处理。
语音信号往往含有大量的噪音和杂音,这会对语音识别的准确性造成负面影响。
为了降低噪音的干扰,开发者可以采用预处理技术来处理语音信号,例如降噪、降采样和滤波等。
这些技术可以提高语音信号的质量,进而提高语音识别的准确率。
第三,引入上下文信息以提高语音助手的理解能力。
语音助手不仅需要准确识别用户的语音输入,还需要理解用户的意图。
为了更好地理解用户的意图,开发者可以利用上下文信息来提供更准确的回答。
例如,根据用户的问答历史和当前语境,语音助手可以更好地理解用户的需求,并给出针对性的回答。
这样可以提高语音助手的智能化水平,增强用户的体验。
第四,优化语音合成技术以提高语音助手的自然度。
语音合成是语音助手输出语音的过程,自然度的高低直接影响用户的体验。
为了提高语音合成的自然度,开发者可以采用深度学习技术来生成更加自然的语音。
此外,鉴于用户对语音合成速度的要求,开发者还可以使用流式语音合成技术,以降低延迟并提高实时性。
第五,利用机器学习算法优化语音识别的准确率。
语音识别是一个复杂的模式识别问题,因此机器学习算法在语音识别中扮演着重要的角色。
开发者可以利用深度学习算法,如卷积神经网络和循环神经网络,来提高语音识别的准确率。
此外,还可以运用特征提取和特征降维算法,对语音信号进行分析和处理,以提取出最有用的信息,从而提高语音识别的性能。
语音识别开源模型c语言

语音识别开源模型c语言全文共四篇示例,供读者参考第一篇示例:语音识别是人工智能领域中的一个热门研究方向,它的应用领域涵盖了语音助手、智能家居、车载导航等方方面面。
而语音识别的关键技术之一就是语音识别模型,它可以帮助计算机理解和识别人类的语音输入。
本文将介绍一种基于C语言的开源语音识别模型,并对其进行深入分析。
一、语音识别模型概述语音识别模型是根据语音信号的特征来实现对语音输入内容的识别。
目前比较流行的语音识别模型有基于深度学习的模型,如循环神经网络(RNN)、长短时记忆网络(LSTM)、端到端的深度学习模型等。
这些模型在语音识别领域取得了很好的效果。
本文选取的开源语音识别模型是一个基于C语言实现的模型,它采用了卷积神经网络(CNN)和长短时记忆网络(LSTM)相结合的架构。
该模型的特点是速度快、准确度高,且能够适应复杂的语音输入。
二、模型实现1. 数据预处理在语音识别模型中,数据的预处理是非常重要的一步。
需要将原始的语音信号转换成频谱图,然后进行特征提取和归一化处理。
在这一步中,应当注意去除噪声和无意义的信息,以提高模型的准确度。
2. 构建模型构建模型是语音识别模型的核心部分。
在选取的这个模型中,首先采用了卷积神经网络(CNN)来提取语音信号的局部特征,然后将特征序列输入到长短时记忆网络(LSTM)中进行时间序列建模。
这种结合了CNN和LSTM的架构可以更好地处理语音信号中的时序信息。
3. 损失函数和优化方法在训练模型过程中,损失函数和优化方法是至关重要的。
通常使用交叉熵损失函数来度量模型输出和真实标签之间的差距,然后采用随机梯度下降(SGD)等优化算法来更新模型参数,以最小化损失函数。
三、模型训练与部署1. 训练过程在训练模型时,需要将已经准备好的训练数据输入到模型中进行训练。
通常采用小批量梯度下降的方法来提高训练速度和减少计算量。
可以通过监控模型在验证集上的表现来避免模型过拟合。
2. 部署过程模型训练完成后,可以将其部署到实际应用中。
客户端开发教程:学会使用常见的语音识别技术(六)

客户端开发教程:学会使用常见的语音识别技术随着科技的进步,语音识别技术在客户端开发中越来越常见。
它使得用户可以通过语音与应用程序进行交互,提供了更加自然和便捷的用户体验。
无论是语音搜索、语音助手还是语音输入,语音识别技术的应用广泛而且前景广阔。
本文将为你介绍使用常见的语音识别技术开发客户端的基本步骤和注意事项。
一、了解语音识别技术的原理在开始开发之前,你需要了解语音识别技术的基本原理。
语音识别技术是通过将语音信号转换为文本来实现的。
在这个过程中,首先需要对语音信号进行录音,并将其转换为数字信号。
接下来,利用信号处理和模式识别的技术,将数字信号转换为文本。
最后,对文本进行语义分析,以理解用户的意图。
二、选择合适的语音识别技术在开发客户端时,你可以选择使用现有的语音识别技术库,也可以根据需求开发自己的语音识别模块。
常见的语音识别技术库包括Google的Speech API、微软的Azure 语音服务和百度的语音识别API等。
这些技术库提供了丰富的功能和易于使用的接口,可以帮助你快速实现语音识别功能。
如果你有特殊的需求,例如对某种语音的特定识别准确度要求较高,或者需要处理实时语音流等,那么你可以根据自己的情况选择开发自己的语音识别模块。
这将需要一些专业的知识和经验,但也能够提供更加个性化和灵活的功能。
三、设计用户界面和交互流程在开始开发客户端之前,你需要设计用户界面和交互流程。
语音识别技术可以为用户提供不同的交互方式,例如语音搜索、语音指令和语音输入等。
你可以根据具体的应用场景和用户需求,选择最合适的交互方式。
例如,如果你正在开发一个语音助手应用,你可以设计一个能够识别用户指令并执行相应操作的交互流程。
如果你正在开发一个语音输入应用,你可以设计一个能够将用户的语音转换为文本的交互界面。
同时,你需要考虑用户界面的友好性和易用性。
语音识别技术虽然便捷,但也有一定的限制。
在设计用户界面时,要注意提供适当的反馈和引导,以帮助用户正确使用语音识别功能。
VC基于微软语音引擎开发语音识别总结

关于SAPI的简介API 概述SAPI API在一个应用程序和语音引擎之间提供一个高级别的接口。
SAPI 实现了所有必需的对各类语音引擎的实时的操纵和治理等低级别的细节。
SAPI引擎的两个大体类型是文本语音转换系统(TTS)和语音识别系统。
TTS系统利用合成语音合成文本字符串和文件到声音音频流。
语音识别技术转换人类的声音语音流到可读的文本字符串或文件。
文本语音转换API应用程序能通过IspVoice的对象组建模型(COM)接口操纵文本语音转换。
一旦一个应用程序有一个已成立的IspVoice对象(见Text-to-Speech指南),那个应用程序就只需要挪用ISpVoice::Speak 就能够够从文本数据取得发音。
另外,ISpVoice接口也提供一些方式来改变声音和合成属性,如语速ISpVoice::SetRate,输出音量ISpVoice::SetVolume,改变当前发言的声音ISpVoice::SetVoice 等。
特定的SAPI操纵器也能够嵌入输入文本利用来实时的改变语音合成器的属性,如声音,音调,强调字,语速和音量。
这些合成标记在中,利用标准的XML格式,这是一个简单但很壮大定制TTS语音的方式,不依托于特定的引擎和当前利用的声音。
ISpVoice::Speak方式能够用于同步的(当完全的完成朗诵后才返回)或异步的(当即返回,朗诵在后台处置)操作。
当同步朗诵(SPF_ASYNC)时,实时的状态信息如朗诵状态和当前文本位置能够通过ISpVoice::GetStatus取得。
当异步朗诵时,能够打断当前的朗诵输出以朗诵一个新文本或把新文本自动附加在当前朗诵输出的文本的末尾。
除ISpVoice接口之外SAPI也为高级TTS应用程序提供许多有效的COM接口。
事件SAPI用标准的回调机制(Window消息, 回调函数 or Win32 事件)来发送事件来和应用程序通信。
关于TTS,事件大多用于同步地输出语音。
微软TTS语音引擎(speech api sapi)深度开发入门

Windows TTS开发介绍开篇介绍:我们都使用过一些某某词霸的英语学习工具软件,它们大多都有朗读的功能,其实这就是利用的Windows的TTS(Text To Speech)语音引擎。
它包含在Windows Speech SDK开发包中。
我们也可以使用此开发包根据自己的需要开发程序。
鸡啄米下面对TTS功能的软件开发过程进行详细介绍。
一.SAPI SDK的介绍SAPI,全称是The Microsoft Speech API。
就是微软的语音API。
由Windows Speech SDK提供。
Windows Speech SDK包含语音识别SR引擎和语音合成SS引擎两种语音引擎。
语音识别引擎用于识别语音命令,调用接口完成某个功能,实现语音控制。
语音合成引擎用于将文字转换成语音输出。
SAPI包括以下几类接口:Voice Commands API、Voice Dictation API、Voice Text API、Voice Telephone API和Audio Objects API。
我们要实现语音合成需要的是Voice Text API。
目前最常用的Windows Speech SDK版本有三种:5.1、5.3和5.4。
Windows Speech SDK 5.1版本支持xp系统和server 2003系统,需要下载安装。
XP系统默认只带了个Microsoft Sam英文男声语音库,想要中文引擎就需要安装Windows Speech SDK 5.1。
Windows Speech SDK 5.3版本支持Vista系统和Server 2008系统,已经集成到系统里。
Vista和Server 2003默认带Microsoft lili中文女声语音库和Microsoft Anna英文女声语音库。
Windows Speech SDK 5.4版本支持Windows7系统,也已经集成到系统里,不需要下载安装。
用C_实现文本朗读和语音识别功能

{ private SpeechRecognizer SRE; public event EventHandler<RecognizeEventArgs>
RecognitionEvent;// 声 明 事 件 成 员 // <summary> // 识别 // </summary> // <param name="text">识别的文字</param> // <param name="action">识别成功后的行为</
和 Recognition。 其中 Synthesizer 命名空间提供的 SpeechSynthesizer 类 , 可 以 轻 松 实 现 文 本 朗 读 功 能 ; Recognition 空 间 提 供 了语言识别类 SpeechRecognizer。 2.3 添加引用
要使用 SpeechSynthesizerhe、 SpeechRecognizer 这两个类 需 添加引用。 新建一个 Windows 窗体应用程序, 点击 “项目” 菜 单 下 的 “添 加 引 用 ” 子 菜 单 , 在 “.Net 选 项 ” 中 选 择 System. Speech 组件名称, 点击确定按钮, 如图 1 所示。
SpeechRecognizedEventArgs>(g_SpeechRecognized); //注 册 识 别 事 件
SRE.LoadGrammar(g);// 将 语 法 装 入 识 别 器 中 。 //SRE 是 SpeechRecognizerde 的实例
} // <summary>
// 函数作用:识别到文字后,通知 frmmain 窗体上的 //axAgent1 控件对象,执行动作
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
关于SAPI的简介API 概述SAPI API在一个应用程序和语音引擎之间提供一个高级别的接口。
SAPI 实现了所有必需的对各种语音引擎的实时的控制和管理等低级别的细节。
SAPI引擎的两个基本类型是文本语音转换系统(TTS)和语音识别系统。
TTS系统使用合成语音合成文本字符串和文件到声音音频流。
语音识别技术转换人类的声音语音流到可读的文本字符串或者文件。
文本语音转换API应用程序能通过IspVoice的对象组建模型(COM)接口控制文本语音转换。
一旦一个应用程序有一个已建立的IspVoice对象(见Text-to-Speech指南),这个应用程序就只需要调用ISpVoice::Speak 就可以从文本数据得到发音。
另外,ISpVoice接口也提供一些方法来改变声音和合成属性,如语速ISpVoice::SetRate,输出音量ISpVoice::SetVolume,改变当前讲话的声音ISpVoice::SetVoice 等。
特定的SAPI控制器也可以嵌入输入文本使用来实时的改变语音合成器的属性,如声音,音调,强调字,语速和音量。
这些合成标记在sapi.xsd中,使用标准的XML格式,这是一个简单但很强大定制TTS语音的方法,不依赖于特定的引擎和当前使用的声音。
ISpVoice::Speak方法能够用于同步的(当完全的完成朗读后才返回)或异步的(立即返回,朗读在后台处理)操作。
当同步朗读(SPF_ASYNC)时,实时的状态信息如朗读状态和当前文本位置可以通过ISpVoice::GetStatus得到。
当异步朗读时,可以打断当前的朗读输出以朗读一个新文本或者把新文本自动附加在当前朗读输出的文本的末尾。
除了ISpVoice接口之外SAPI也为高级TTS应用程序提供许多有用的COM接口。
事件SAPI用标准的回调机制(Window消息, 回调函数or Win32 事件)来发送事件来和应用程序通信。
对于TTS,事件大多用于同步地输出语音。
应用程序能够与它们发生的实时行为例如单词边界,音素,口型或者应用程序定制的书签等同步。
应用程序能够用ISpNotifySource, ISpNotifySink, ISpNotifyTranslator, ISpEventSink, ISpEventSource, 和ISpNotifyCallback初始化和处理这些实时事件。
字典应用程序通过使用ISpContainerLexicon, ISpLexicon 和IspPhoneConverter提供的方法能为语音合成引擎提供定制的单词发音。
资源查找和选择SAPI语音数据如声音文件及发音字典可以被下列COM接口控制:ISpDataKey, ISpRegDataKey, ISpObjectTokenInit, ISpObjectTokenCategory, ISpObjectToken, IEnumSpObjectTokens, ISpObjectWithToken, ISpResourceManager 和IspTask。
音频最后,有一个接口能把声音输出到一些指定目标如电话和自定硬件(ISpAudio, ISpMMSysAudio, ISpStream, ISpStreamFormat, ISpStreamFormatConverter)。
语音识别API就像ISpVoice是语音合成的主接口,IspRecoContext是语音识别的主接口。
像ISpVoice一样,它是一个IspEventSource接口,这意味着它是语音程序接收被请求的语音识别事件通知的媒介。
一个应用程序必须从两个不同类型的语音识别引擎(ISpRecognizer)中选择一种。
一种是可以与其它语音识别程序共享识别器的语音识别引擎,这在大多数识别程序中被推荐使用。
为了为IspRecognizer建立一个共享的ISpRecoContext接口,一个应用程序只需要用CLSID_SpSharedRecoContext调用COM的CoCreateInstance方法。
这种方案中,SAPI将建立一个音频输入流,把它设置为SAPI默认的音频输入流。
对于大型服务器程序,它可能在单独在一个系统上运行,性能是关键,一个InProc语音识别引擎更适合。
为了为InProc ISpRecognizer建立一个IspRecoContext,程序必须首先用CLSID_SpInprocRecoInstance调用CoCreateInstance 来建立属于它自己的InProc IspRecognizer。
然后程序必须调用ISpRecognizer::SetInput(见also ISpObjectToken)来建立一个音频输入流。
最后程序可以调用ISpRecognizer::CreateRecoContext来得到一个IspRecoContext。
下一步是建立程序感兴趣的事件通知,因为IspRecognizer也是一个IspEventSource,IspEventSource实际上是IspNotifySource,程序从它的ISpRecoContext可以调用IspNotifySource的一个方法来指出IspRecoContext的哪里的事件应该被报告。
然后它应该调用ISpEventSource::SetInterest来指出哪些事件应该通报。
最重要的事件是SPEI_RECOGNITION,指出和IspRecoContext相关的IspRecognizer已经识别了一些语音。
其他可用到的语音识别事件的详细资料参见SPEVENTENUM。
最后,一个语音程序必须建立,加载,并且激活一个IspRecoGrammar,本质上就是指出哪些类型的发言被识别,例如口述或一个命令和控制文法。
首先,程序用ISpRecoContext::CreateGrammar建立一个IspRecoGrammar,然后程序加载适合的文法,下面两个方法中调用其中一个:口述模式的调用方法ISpRecoGrammar::LoadDictation,命令和控制模式的则调用方法ISpRecoGrammar::LoadCmdxxx。
最后为了激活这些文法以开始进行识别,程序为口述模式调用ISpRecoGrammar::SetDictationState 或者为命令和控制模式调用调用ISpRecoGrammar::SetRuleState或者ISpRecoGrammar::SetRuleIdState。
当识别依靠通知机制返回到程序,SPEVENT结构的成员lParam将是一个IspRecoResult,程序可以确定什么被识别和使用了IspRecoContext的哪个IspRecoGrammar。
一个IspRecognizer,无论是否是共享的还是InProc的,都可以有多个IspRecoContexts和它关联,并且每个都可以通过它自己的事件通知方法通知IspRecognizer。
从一个IspRecoContext可以建立多个IspRecoGrammars,以便于识别不同类型的发言。
利用微软Speech SDK 5.1在MFC中进行语音识别开发时的主要步骤,以Speech API 5.1+VC6为例:1、初始化COM端口一般在CWinApp的子类中,调用CoInitializeEx函数进行COM初始化,代码如下:::CoInitializeEx(NULL,COINIT_APARTMENTTHREADED); // 初始化COM注意:调用这个函数时,要在工程设置(project settings)->C/C++标签,Category中选Preprocessor,在Preprocessor definitions:下的文本框中加上“,_WIN32_DCOM”。
否则编译不能通过。
2、创建识别引擎微软Speech SDK 5.1 支持两种模式的:共享(Share)和独享(InProc)。
一般情况下可以使用共享型,大的服务型程序使用InProc。
如下:hr = m_cpRecognizer.CoCreateInstance(CLSID_SpSharedRecognizer);//Sharehr = m_cpRecognizer.CoCreateInstance(CLSID_SpInprocRecognizer);//InProc如果是Share型,可直接进到步骤3;如果是InProc型,必须使用ISpRecognizer::SetInput 设置语音输入。
如下:CComPtr<ISpObjectToken> cpAudioToken; //定义一个tokenhr = SpGetDefaultTokenFromCategoryId(SPCAT_AUDIOIN, &cpAudioToken); //建立默认的音频输入对象if (SUCCEEDED(hr)) { hr = m_cpRecognizer->SetInput(cpAudioToken, TRUE);}或者:CComPtr<ISpAudio> cpAudio; //定义一个音频对象hr = SpCreateDefaultObjectFromCategoryId(SPCAT_AUDIOIN, &cpAudio);//建立默认的音频输入对象hr = m_cpRecoEngine->SetInput(cpAudio, TRUE);//设置识别引擎输入源3、创建识别上下文接口调用ISpRecognizer::CreateRecoContext 创建识别上下文接口(ISpRecoContext),如下:hr = m_cpRecoEngine->CreateRecoContext( &m_cpRecoCtxt );4、设置识别消息调用SetNotifyWindowMessage 告诉Windows哪个是我们的识别消息,需要进行处理。
如下:hr = m_cpRecoCtxt->SetNotifyWindowMessage(m_hWnd, WM_RECOEVENT, 0, 0); SetNotifyWindowMessage 定义在ISpNotifySource 中。
5、设置我们感兴趣的事件其中最重要的事件是”SPEI_RECOGNITION“。
参照SPEVENTENUM。
代码如下:const ULONGLONG ullInterest = SPFEI(SPEI_SOUND_START) | SPFEI(SPEI_SOUND_END) | SPFEI(SPEI_RECOGNITION) ;hr = m_cpRecoCtxt->SetInterest(ullInterest, ullInterest);6、创建语法规则语法规则是识别的灵魂,必须要设置。