编译原理与技术
编译原理 编译的过程

编译原理编译的过程编译原理是计算机科学与技术领域的一个重要学科,它研究的是将高级程序语言转化为机器语言的过程,以实现程序的运行。
编译的过程可以分为以下几个步骤。
1. 词法分析(Lexical Analysis):将输入的源代码序列划分为一个个的词素(Token),并对每个词素进行分类。
2. 语法分析(Syntactic Analysis):根据语法规则,利用词法分析得到的词法单元序列,生成抽象语法树(Abstract Syntax Tree),以表达程序的结构。
3. 语义分析(Semantic Analysis):对生成的抽象语法树进行语义的验证,包括类型检查、作用域检查等。
同时,将高级语言的语句转化为中间代码表示。
4. 优化(Optimization):对生成的中间代码进行优化,以提高程序的执行效率。
包括常量折叠、公共子表达式消除、循环优化等。
5. 中间代码生成(Intermediate Code Generation):将优化后的中间代码转化为目标机器独立的中间代码表示,如三地址码、虚拟机指令等。
6. 目标代码生成(Code Generation):根据目标机器的特点,将中间代码转化为目标机器代码,如汇编语言代码或机器指令。
7. 目标代码优化(Code Optimization):对生成的目标代码进行优化,以进一步提高程序的执行效率。
8. 目标代码的链接与装载(Linking and Loading):将编译得到的目标代码与库进行链接,生成可执行程序,并将其加载到内存中执行。
编译过程中的每个阶段都具有特定的功能和任务,它们相互协作,最终将高级语言的源代码转化为目标机器可执行的代码。
这个过程可以分为前端和后端两个部分,前端主要负责语法和语义分析等,后端主要负责中间代码的生成、目标代码生成和优化等。
编译过程需要充分考虑程序的正确性、效率和可维护性等方面的要求。
编译原理与技术

编译原理与技术编译原理与技术是计算机科学与技术中的一门重要课程,旨在教授学生如何设计、实现和优化编译器以及相关的编程工具和技术。
本文将介绍编译原理与技术的基本概念、主要任务以及在实际应用中的作用和挑战,并探讨编译原理与技术在不同编程语言和开发环境中的应用。
一、编译原理与技术的基本概念编译原理与技术研究的对象是编译器,而编译器是一种从一种语言(源语言)到另一种语言(目标语言)的程序转换工具。
编译器的主要任务是将源程序转换为等价的目标程序,以便计算机能够执行。
编译原理与技术的基本概念包括词法分析、语法分析、语义分析、中间代码生成、代码优化和代码生成等。
1. 词法分析词法分析是编译器的第一个阶段,它将源程序的字符流转换为有意义的词法单元序列。
词法单元是编程语言中具有独立含义的最小单元,例如关键字、标识符、运算符和常量等。
词法分析器通常通过有限自动机或正则表达式来实现。
2. 语法分析语法分析是编译器的第二个阶段,它通过对词法单元序列的分析来构造语法树。
语法树反映了源程序的语法结构,其中每个节点代表一个语法单元,每个子节点代表一个子表达式。
语法分析器通常使用上下文无关文法和分析方法(如递归下降分析和LR分析)来实现。
3. 语义分析语义分析是编译器的第三个阶段,它对语法树进行静态检查以确定源程序是否符合语义规则。
语义分析器通常处理类型检查、作用域分析和语义动作等任务,以确保生成的中间代码具有准确的语义含义。
4. 中间代码生成中间代码生成是编译器的第四个阶段,它将语法树转换为一种中间表示形式,以便后续的优化和目标代码生成。
中间代码通常是一种抽象的、与机器无关的形式,例如三地址码、虚拟机代码或中间表示IR。
5. 代码优化代码优化是编译器的第五个阶段,它利用各种优化技术来改进中间代码的性能和效率。
常见的代码优化技术包括常量传播、公共子表达式消除、循环优化和内联展开等。
6. 代码生成代码生成是编译器的最后一个阶段,它将优化后的中间代码转换为目标代码。
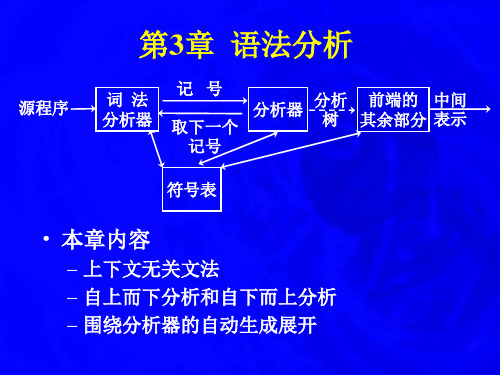
916073-编译原理原理与技术-第3章 语法分析
id
id
E E+E E E +E id E + E id id + E id id + id E
E +E
E
*
E id
id
id
3.2 语言和文法
• 文法的优点
–文法为语言给出了精确的、易于理解的语法规范 –自动产生高效的分析器 –可以给语言定义出层次结构 –以文法为基础的语言的实现便于语言的修改
FIRST(E) = FIRST(T) = FIRST(F) = { ( , id } FIRST(E ) = {+, } FRIST(T ) = {, } FOLLOW(E) = FOLLOW(E ) = { ), $} FOLLOW(T) = FOLLOW (T ) = {+, ), $} FOLLOW(F) = {+, , ), $}
id
+ term
term * factor
factor
id
id id + id id 分析树
3.2 语言和文法
3.2.5 消除二义性 stmt if expr then stmt
| if expr then stmt else stmt | other • 句型:if expr then if expr then stmt else stmt • 两个最左推导: stmt if expr then stmt if expr then if expr then stmt else stmt stmt if expr then stmt else stmt if expr then if expr then stmt else stmt
3.3 自上而下分析
编译原理与技术1

编译原理与技术模拟试题一一、填空题(20分,每空2分)1.1编译程序的工作过程可划分为词法分析、语法分析、、中间代码生成、代码优化、等阶段,一般在阶段对表达式中运算对象的类型进行检查。
答案:语义分析、目标代码生成、语义分析解释:要求掌握编译器的工作原理和特点。
编译和解释方式是翻译高级程序设计语言的两种基本方式。
解释程序也称为解释器,它或者直接解释执行源程序,或者将源程序翻译成某种中间表示形式后再加以执行;而编译程序(编译器)则首先将源程序翻译成目标语言程序,然后在计算机上运行目标程序。
编译过程包含词法分析、语法分析、语义分析、中间代码生成、代码优化、目标代码生成,以及符号表管理和出错处理。
表达式的类型信息属于语义信息,所以在语义分析阶段进行类型检查。
1.2 和预测分析法是自上而下的语法分析方法。
答案:递归下降法解释:语法分析的任务是根据语言的语法规则,分析单词串是否构成短语和句子,即表达式、语句和程序等基本语言结构,同时检查和处理程序中的语法错误。
根据语法树(或分析树)的建立方式,语法分析可分为自上而下分析和自下而上分析两类,递归下降分析和预测分析属于自上而下的语法分析方法。
1.3常用的存储分配策略有存储分配和动态存储分配,其中,动态存储分配策略包括分配和分配。
答案:静态、栈、堆解释:编译器怎样对存储空间进行组织和采用什么样的存储分配策略,很大程度上取决于程序设计语言中所采用的机制。
编译器具体实现时,根据语言机制的特性,采用静态分配策略、栈分配策略和堆分配策略三种方式的其中若干种。
静态分配策略是指编译时安排所有数据对象的存储,即绑定是静态确定的;栈分配策略是指按栈的方式管理运行时的存储;堆分配策略是指在运行时根据要求从堆数据区动态地分配和释放存储。
1.4移进、归约是分析中的典型操作。
答案:自下而上或LR解释:自下而上分析的一般思路是从句子ω开始,从左到右扫描ω,反复用产生式的左部替换产生式的右部、谋求对ω的匹配,最终得到文法的开始符号,或者发现一个错误。
编译原理与中间代码生成技术

编译原理与中间代码生成技术编译原理是计算机科学中的重要理论基础,它研究的是将高级语言翻译成机器语言的转换过程。
而中间代码生成技术则是编译原理中的一个关键环节,它负责将源代码转换为中间表示形式,为后续的优化和目标代码生成做准备。
本文将介绍编译原理的基本概念和中间代码生成技术的原理与应用。
一、编译原理基础编译原理是计算机科学中的一个重要分支,它研究的是高级语言程序如何转换为机器语言的过程。
编译原理包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等多个阶段。
其中,中间代码生成是编译原理的一个关键环节,它将源代码转换为中间表示形式,以便后续的优化和目标代码生成。
二、中间代码生成技术的原理中间代码是源代码与目标代码之间的一种中间表示形式。
它既比源代码更容易理解,又比目标代码更容易生成和优化。
中间代码生成技术的目的是将源代码转换为中间代码,为后续的优化和目标代码生成做准备。
中间代码生成技术的原理可以用以下步骤来描述:1. 词法分析:将源代码分割成一个个语法单元,比如标识符、关键字、操作符等。
词法分析器会根据事先定义好的词法规则,将源代码转换为词法单元序列。
2. 语法分析:将词法单元序列转换为抽象语法树(AST)。
语法分析器会根据事先定义好的语法规则,分析词法单元序列所组成的语法结构,并构建出相应的抽象语法树。
3. 语义分析:对抽象语法树进行语义检查和类型推断。
语义分析器会检查语法结构中是否存在语义错误,并为表达式推导出对应的类型信息。
4. 中间代码生成:将语法树转换为中间代码表示形式。
中间代码生成器会根据语义信息和事先定义好的转换规则,将语法树转换为中间代码表示形式。
三、中间代码生成技术的应用中间代码生成技术广泛应用于编译器、解释器和虚拟机等领域。
以下是中间代码生成技术在这些领域的具体应用场景:1. 编译器:编译器是将高级语言程序转换为机器语言的工具。
中间代码生成技术在编译器中起到了至关重要的作用,它能够将源代码转换为中间代码表示形式,为后续的代码优化和目标代码生成做准备。
编译原理陈火旺

编译原理陈火旺编译原理是计算机科学与技术中的重要学科,它涉及到程序设计语言、编译器、解释器等方面的知识。
在计算机软件开发中,编译原理扮演着至关重要的角色,它是软件开发的基础和核心。
本文将围绕编译原理展开讨论,介绍编译原理的基本概念、原理和应用。
首先,我们来了解一下编译原理的基本概念。
编译原理是指将高级语言程序翻译成机器语言程序的一门学科。
它包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等过程。
编译原理的主要任务是设计和实现编译器,将高级语言程序转换成目标代码,以便计算机能够执行。
其次,我们需要了解编译原理的基本原理。
编译原理的基本原理包括语言的文法、词法分析、语法分析和语义分析等内容。
语言的文法是描述语言结构的形式化规则,词法分析是将源程序转换成单词序列的过程,语法分析是将单词序列转换成语法树的过程,语义分析是对语法树进行语义检查和语义动作的过程。
这些原理是编译原理的基础,对于理解编译原理和设计编译器非常重要。
接下来,我们将介绍编译原理的应用。
编译原理在软件开发中有着广泛的应用,它是编程语言和编译器设计的基础。
通过学习编译原理,可以更好地理解编程语言的设计和实现原理,提高程序设计和编码的能力。
此外,编译原理还在软件工程、人工智能、计算机图形学等领域有着重要的应用,可以帮助开发者更好地理解和利用计算机系统的底层原理。
总的来说,编译原理是计算机科学与技术中的重要学科,它涉及到程序设计语言、编译器、解释器等方面的知识。
通过学习编译原理,可以更好地理解和应用计算机系统的底层原理,提高软件开发的能力。
希望本文能够帮助读者更好地理解编译原理的基本概念、原理和应用,为进一步深入学习和研究编译原理打下坚实的基础。
《编译原理》教学大纲

《编译原理》教学大纲一、课程概述编译原理是计算机科学与技术专业的一门重要课程,也是软件工程领域的基础课程之一、本课程通过对编译器的原理和实现技术的学习,使学生掌握编译器的设计和实现方法,培养学生独立解决实际问题的能力。
二、教学目标1.理解编译器的基本原理和工作流程;2.掌握常见编译器的构建方法和技术;3.能够设计和实现简单的编译器;4.培养分析和解决实际问题的能力。
三、教学内容和教学进度1.第一章:引论1.1编译器的定义和分类1.2编译器的基本工作流程2.第二章:词法分析2.1编译器的基本结构2.2词法单元的定义和识别方法2.3正则表达式和有限自动机3.第三章:语法分析3.1语法分析的基本概念3.2语法规则的定义和表示方法3.3自顶向下的语法分析方法3.4自底向上的语法分析方法4.第四章:语义分析4.1语义分析的基本概念4.2属性文法和语法制导翻译4.3语义动作和符号表管理5.第五章:中间代码生成5.1中间代码的定义和表示方法5.2基本块和控制流图5.3三地址码的生成方法6.第六章:优化6.1优化的基本概念和原则6.2常见的优化技术和方法6.3编译器的优化策略7.第七章:目标代码生成7.1目标代码生成的基本原理7.2目标代码的表示方法和存储管理7.3基本块的划分和目标代码生成算法8.第八章:附加主题8.1解释器和编译器的比较8.2面向对象语言的编译8.3并行编译和动态编译四、教学方法1.理论教学与实践相结合,注重教学案例的分析和实践;2.引导学生主动探索,注重培养学生的自主学习能力;3.激发学生的兴趣,鼓励学生提问和讨论。
五、考核方式1.平时成绩:包括课堂测验、作业和实验报告等;2.期末考试:闭卷笔试,主要考查学生对编译原理的理论知识和实践能力的掌握程度。
六、参考教材1.《编译原理与技术》(第2版),龙书,机械工业出版社,2024年2.《现代编译原理-C语言描述》(第2版),谢路云,电子工业出版社,2024年七、参考资源1. 实验环境:Dev-C++、gcc、llvm等2.相关网站:编译原理教学网站、编译器开源项目等八、教学团队本课程由计算机科学与技术学院的相关教师负责教学,具体安排详见教务处发布的教学计划。
编译原理与技术 - 习题集(含答案)

编译原理与技术 - 习题集(含答案)《编译原理与技术》课程习题集西南科技大学成人、网络教育学院版权所有习题【说明】:本课程《编译原理与技术》(编号为03002)共有简答题,计算题1,计算题2,问答与作图题,计算题3,计算题4,计算题5等多种试题类型,其中,本习题集中有[简答题]等试题类型未进入。
一、计算题1 1. 已知NFA M1、将NFA M确定化为DFA M;2、求DFA M的正规式; 2. 已知正规式:a+b(b|ab)*1、求等价的NFA;2、求等价的DFA; 3. 已知正规式((ε|a)b*)*1、求等价的NFA;2、将NFA确定化3、若所求DFA可最小化,则求其最小化DFA;若无,说明原因。
4. 写出字母表? = {a, b}上语言L = {w | w中a的个数是偶数}的正规式,并画出接受该语言的最简DFA。
5. 有文法 G[S] :第 1 页共 26 页S → aC | aA A → aC C → bC |b1、求等价的NFA;2、求等价的DFA;二、计算题2 6. 将文法G[S]:S→aA A→AS|Bc B→Bi|i1、消除左递归;2、证明该文法消除左递归后是LL(1)文法?3、给出相应的LL(1)分析表。
7. 已知文法G(S):E→aTb|iE|i T→TE|E1、提公因子和消除左递归;2、计算每个非终结符的FIRST和FOLLOW;3、证明该文法是否为LL(1)文法?8. 已知文法G(S)为:E → E or T | T T → T andF | FF → not F | ( E ) | true | false 1、对文法消除左递归;第 2 页共 26 页2、计算消除左递归后的文法的每个非终结符的FIRST和FOLLOW;3、判断消除左递归后的文法是否是LL(1) 文法。
9. 已知文法G(D)为:D→int L| real L L→L,id | id1、提公因子和消除左递归;2、计算每个非终结符的FIRST和FOLLOW;3、证明该文法是否为LL(1)文法?10. 已给文法 G[S]:S → SaP | Sf | P P → qbP | q1、对文法提公因子和消除左递归,得到其LL(1)文法;2、对LL(1)文法计算每个非终结符的FIRST和FOLLOW; 3、给出LL(1)文法的 LL(1)分析表。
编译原理的研究和优化

编译原理的研究和优化一、编译原理概述编译原理指的是将高级程序语言翻译成计算机能够理解的机器语言的过程。
编译器由词法分析器、语法分析器、语义分析器、优化器和代码生成器等模块组成。
在编译过程中,首先需要使用词法分析器将程序中的字符流分成多个词法单元,然后根据语法规则构建语法树,接着进行语义分析和中间代码生成,最后通过代码优化生成目标代码。
二、编译器的优化技术在编译器的代码生成阶段,优化器是一个非常重要的模块。
优化器的主要目标是在保持程序语义正确的前提下,尽可能地提高程序的执行效率和减少程序的空间占用。
常用的编译器优化技术包括以下几种:1.数据流分析数据流分析是一种静态分析技术,在程序执行前对程序的数据流进行分析,以便确定数据的流向和使用情况。
通过数据流分析,编译器可以确定哪些变量在程序的哪个地方被使用,以及它们的取值范围等信息,从而在生成目标代码时做出更优化的决策。
2.代码重排在编译器生成目标代码时,代码重排技术可以将一些计算结果存入临时变量中,以便后续使用。
此外,代码重排还可以将一些循环中的计算操作提前到循环开始之前,从而减少重复计算的次数,提高程序的运行速度。
3.寄存器分配寄存器分配是指将变量存储到寄存器中,以便更快速地访问它们。
编译器可以根据变量的使用情况和寄存器的可用性,对变量进行不同的分配策略。
4.指令选择和调度指令选择是指根据机器指令的特性和程序的需求,选择合适的机器指令替代高级语言中的语句。
指令调度是指通过重新排列指令的执行顺序,让程序的执行效率更高。
指令选择和调度技术可以将程序的执行时间缩短,提高程序的运行速度。
三、编译器的优化实践编译器的优化技术在实践中有广泛应用。
例如,GCC编译器就提供了一系列的优化选项,开发者可以根据自己的需求选择不同的优化级别。
在Google公司的V8引擎中,利用数据流分析、JIT (Just-In-Time)编译技术和代码缓存机制等多种优化技术,使得JavaScript代码在运行效率上有了显著的提升。
编译原理概述

编译原理概述
编译原理是计算机科学中的重要概念,是指设计和构建编译器的理论和技术。
编译器是一种将高级语言代码翻译成底层机器语言代码的程序,它起着将源代码翻译成目标代码的作用。
编译原理的主要研究对象是编译器的构造和实现方法,以及编译过程中涉及的各种理论和技术问题。
编译原理的基本概念包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等几个方面。
其中,词法分析是将源代码分解成一个个单词或记号的过程,语法分析是对单词或记号进行语法规则分析的过程,语义分析是确定代码真正含义的过程,中间代码生成是生成与源代码等价的目标代码的过程,代码优化是提高目标代码质量和性能的过程,目标代码生成是将中间代码翻译成机器代码的过程。
在编译原理中,最核心的部分是语法分析,它决定了编译器对源代码的理解和转换能力。
语法分析可以分为自上而下的分析方法和自下而上的分析方法。
自上而下的分析方法是从最抽象的语法规则开始逐步向下分解源代码,直到分解到最细粒度;自下而上的分析方法则是从最细粒度的语法规则开始逐步向上合成源代码,直到合成到最抽象的语法规则。
在编译原理的研究中,还涉及到一些高级主题,如编译器前端和后端的设计、编译器生成器的设计、抽象语法树和符号表的表示、代码生成技术、及时编译技术等。
总的来说,编译原理是计算机科学中非常重要的一个领域,它的研究成果直接影响着编程语言的设计和实现方式,也是软件工程师必须掌握的基础知识之一。
通过学习编译原理,可以更好地理解计算机语言的工作原理,提高编程能力和代码质量,为软件开发提供更好的支持和保障。
编译原理-计算机科学技术系

3 语义分析
检查代码意义并发现和纠正语义错误。
2 语法分析
将标记组成语法树以检查语法正确性。
4 代码生成
生成目标语言的代码。
词法分析
流程
源代码 => 单词流
实现
正则表达式 => 自动机
应用
编译器中的第一步,用于通 过扫描源码确定单词。
语法分析
1
Top-down分析
由上往下,层层分解源程序。
Bottom-up分析
2
由下往上,将单词组合成分析树。
3
LL分析
从左端向右端进行分析,是常用的一
LR分析
4
种自上而下语法分析方法。
从右端向左端进行分析,比LL更加通 用。
语义分析
变量声明与检查
检查变量声明和使用是否符合语法和类型。
类型检查
检查类型匹配情况和错误类型转换。
处理语言之间的差异、解决 类型检查等问题、优化代码 的性能。
编译原理-计算机科学技 术系
编译原理是计算机科学技术系的关键课程之一,是研究如何将高级语言翻译 为机器可执行代码的理论和技术。
编译过程
源代码输入
通过编辑器或IDE输入源代码。
编译器设计
确定编译器的结构和编译过程 的流程。
程序优化
对代码进行优化以提高代码质 量和性能。
生成可执行代码
将编译后的代码生成可执行文 件。
控制流分析
分析程序的控制流程以确定正确的行为和错误情况。
代码生成
汇编代码生成
将源代码转换为汇编代码的过 程。
输出文件类型
生成的可执行文件的类型取决 于操作系统和编译器。
优化技术
使用优化技术提高代码质量和 性能。
编译原理书籍

编译原理书籍
编译原理是计算机科学领域的重要课题之一。
它研究的是如何将高级程序语言代码转换为可执行的机器语言代码的过程。
编译原理的研究对于优化程序性能、提高程序可靠性以及实现新的语言特性都具有重要意义。
在编译原理的学习过程中,一本好的教材是必不可少的辅助工具。
以下是一些值得推荐的编译原理教材:
1. "编译原理与技术",作者:王生原
2. "编译原理",作者:周伯华
3. "现代编译原理",作者:Andrew W. Appel
4. "编译原理与实践",作者:龙书
5. "高级编译器设计与实现",作者:Steven Muchnick
这些教材涵盖了编译原理的基本概念、各个阶段的具体实现、相应的算法和数据结构等内容。
通过系统地学习这些教材,读者可以掌握编译原理的核心知识,并且能够应用于实际的编译工作中。
除了教材之外,还可以参考相关的学术论文、技术博客和开源项目,以获取更深入的理解和实战经验。
编译原理是一个广阔而有挑战性的领域,需要不断学习和实践才能掌握其中的精髓。
愿你在学习编译原理的过程中能够获得丰富的知识和宝贵的经验!。
编译原理与技术答案

编译原理与技术答案一、单选题1.1D 1.2C 1.3B 1.4B 1.5B二、填空题2.1词法分析语法分析目标代码生成词法分析语法分析2.2 语法语义2.3从左向右读取要判断的字符最左推导每次读取的字符数为1三、简答题3.1编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;解释器则是只在执行程序时,才一条条地解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的。
3.2DFA与NFA的主要差异在于:(1)DFA没有输入空串之上的转换动作。
(2)对于DFA,一个特定的符号输入,有且只能得到一个状态,而NFA就有可能得到一个状态集。
3.3 (a)参数a采用传值方式,参数b和c采用传引用方式(b)1:620 2:4001803.4 好处:能够把前端和后端分开,提高编译器的可移植性(因为结构清晰,对于编译器研究者来说也提高了可读性)和易优化性(对中间代码的优化可以独立于机器)。
特点:1、中间代码是源程序的一种内部表示,或称中间语言。
2、中间代码的作用是可使编译程序的结构在逻辑上更为简单明确,特别是可使目标代码的优化比较容易实现中间代码,即为中间语言程序,中间语言的复杂性介于源程序语言和机器语言之间。
3、中间语言有多种形式,常见的有逆波兰记号、四元式、三元式和树。
四、综合题4.1 (a)确定化:{1} 记为A,初态smove(A, a) = {2} 记为Bsmove(B, a) = {3,4} 记为C,终态smove(B, b) = {2}smove(C, a) = {2}如下图所示:它已经是最小DFA。
(b)r=a(b|aa)*a,它所描述的语言是由a开始和结尾的、偶数个a组成的a、b串。
4.2(a)EE*T T-FTF a bFc(b)拓广文法,增加产生式:S→E,识别活前缀的DFA如下图所示:存在移进-归约冲突。
编译原理与技术

编译原理与技术
编译原理与技术是一门关于编译器设计和实现的学科,它涉及到计算机科学的许多领域,包括计算机语言、算法、数据结构和计算机硬件等。
编译器是一种将高级语言代码转换为机器代码的自动化程序。
编译原理与技术的目的是让计算机能够理解人类语言,并将其转换为计算机可执行的指令,以实现现代计算机的各种应用。
编译原理与技术包括两个主要阶段:前端和后端。
前端是指将源代码转换为中间代码的过程,它包括词法分析、语法分析、语义分析和中间代码生成等步骤。
后端是指将中间代码转换为可执行代码的过程,它包括优化、代码生成和目标代码生成等步骤。
编译器的设计和实现需要使用多种数据结构和算法,例如有限自动机、语法树、中间代码、汇编代码等。
此外,编译原理与技术还涉及到计算机硬件方面的知识,例如指令集架构和计算机内存管理等。
编译原理与技术的应用非常广泛,例如编译器、解释器、代码优化器、虚拟机等。
它对于计算机科学的研究和发展具有重要的意义,可以帮助人们更好地理解计算机语言和编程的本质,提高计算机程序的性能和可维护性。
编译原理与技术第4版张强主编课后答案

编译原理与技术第4版张强主编课后答案这份文档旨在提供《编译原理与技术第4版》张强主编书中的课后答案。
以下是一些问题的详细解答:1. 什么是编译器?编译器的主要功能是什么?- 编译器是一种将源代码转化为目标代码的软件工具。
它的主要功能是将高级语言代码转换成机器语言或可执行代码。
2. 编译器的主要组成部分有哪些?- 编译器主要由以下几个组成部分构成:- 词法分析器(Lexical Analyzer):将源代码分解成词素或标记。
- 语法分析器(Syntax Analyzer):对词法分析得到的标记进行语法分析,构建语法树。
- 语义分析器(Semantic Analyzer):对语法树进行语义分析,检查类型错误等。
- 优化器(Optimizer):对中间代码进行优化,提高程序的性能。
- 代码生成器(Code Generator):将优化后的中间代码转换成目标机器代码。
3. 解释一下编译过程中的词法分析和语法分析。
- 词法分析(Lexical Analysis)是将源代码分解成词素或标记的过程。
它通过识别关键字、标识符、操作符等将代码分解成最小的可被理解的单元。
- 语法分析(Syntax Analysis)是对词法分析得到的标记进行语法分析,构建语法树的过程。
语法分析器通过检查标记之间的关系和顺序来确定源代码是否符合语法规则。
4. 请简要描述编译器的优化过程。
- 编译器的优化过程是对中间代码进行优化,以提高程序的性能。
优化器通过重新组织代码、减少不必要的计算、利用硬件特性等方式来减少程序的执行时间和内存占用。
以上是对《编译原理与技术第4版》张强主编书中的课后答案的简要解答。
详细的答案请参考该教材。
bit编译原理

bit编译原理编译原理是计算机科学与技术中的一门关键课程,主要研究编程语言的编译过程。
编译器将高级编程语言代码转化为机器语言,使计算机能够执行代码。
在本文中,我们将讨论编译原理的基本概念、过程和相关技术。
首先,我们将介绍编译原理的基本概念。
编译器是一种将高级编程语言转化为低级机器语言的程序。
编译器的主要任务包括词法分析、语法分析、语义分析、优化和代码生成等。
词法分析器将源代码分解成标记(tokens)的序列,语法分析器将标记组织成语法树,而语义分析器在语法树上执行类型检查等操作。
优化器通过改进代码结构来提高性能,代码生成器将优化后的代码转化为目标机器代码。
接下来,我们将讨论编译原理的过程。
编译器的主要过程分为两个阶段:分析(Analysis)和综合(Synthesis)。
分析阶段将源码转化为中间表示形式(IR,Intermediate Representation),并对其进行语法和语义分析。
综合阶段将IR转化为目标代码,并进行优化处理。
在分析阶段,词法分析器将源码分解为标记流,语法分析器将标记流组成语法树。
在综合阶段,代码生成器将语法树转化为中间表示形式,优化器对中间表示进行优化,最后生成目标代码。
编译原理涉及的相关技术有很多。
词法分析中常用的技术有有限自动机(DFA)和正则表达式。
语法分析中常用的技术有上下文无关文法(CFG)和递归下降分析。
语义分析中常用的技术有类型检查和语义动作。
优化器中常用的技术有数据流分析和代码重排。
代码生成中常用的技术有寄存器分配和指令选择。
编译原理在计算机科学与技术中有着广泛的应用。
编译器是现代软件开发的核心工具之一,几乎所有的程序语言都需要经过编译过程才能运行。
编译原理的研究对于提高软件性能、减少资源消耗和提高开发效率都有着重要的作用。
总结起来,编译原理是计算机科学与技术中一门重要的课程,主要研究编程语言的编译过程。
通过词法分析、语法分析、语义分析、优化和代码生成等过程,编译器将高级编程语言转化为机器语言。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3)A将返回地址放入B的活动记录并跳转到过程B 的代码入口,开始B的执行;(一般通过A中的 代码指令-“call B” 来完成这一步)
4)
2019/11/8
《编译原理与技术》-运行环境
14
栈式分配下的过程调用与返回 -过程A 调用 过程B 的过程调用序列: B的入口代码:4)~ 6) 4)在B自己的AR中保存A的活动记录的基址
mov bp,sp spbp
pop bp
//恢复调用者A的bp
ret
// B执行结束并返回
注:X86-Linux中的leave 和ret组合亦能达到目的。
至此,B的AR中除了参数/返回值区域,其余区域全部 回收(撤销)了。
2019/11/8
《编译原理与技术》-运行环境
16
栈式分配下的过程调用与返回 -过程A 调用 过程B 的过程返回序列: A的“调用”善后代码:3)~ 4) 3)A取回返回值以及引用型参数(有的话) 4)A调整栈顶sp(主要根据参数个数以及可 能有的访问链和可能有的返回值)。对应操 作: add para_size, sp 即spsp + para_size
“最接近嵌套” 序)
vs. 现行单元活动(调用次
分程序
- 含有声明和语句;如C的{…}
- 分程序具有以下特征:
-- 可以嵌套;
-- 没有参数;
-- 控制流沿静态文本进入、流出
-- 采用“最接近嵌套”的规则
2019/11/8
《编译原理与技术》-运行环境
24
非局部变量访问
e.g.6 分程序 main() { int a = 0 ; int b =0; //local VAR of main
(即当前bp,对应操作 push bp)并且将这 个位置作为B自己AR的基址(对应操作)
mov sp,bp 即 bpsp) 5)保存可选的机器状态(寄存器) 6)为局部数据分配空间,(对应操作) sub local_size,sp,即sp sp – local_size 7)“开始”B的执行。(至此,B的AR建好)
2019/11/8
《编译原理与技术》-运行环境
15
栈式分配下的过程调用与返回
- 过程返回:回收分配的被调过程的AR,并将程 序控制转移回调用过程继续执行;
-过程A 调用 过程B 的过程返回序列:
B的出口代码:1)~ 2)
1)B回收局部数据空间;恢复原先保存的机器状态 2)B恢复A的AR基址;取出返回地址将程序控制交 回到A。对应操作:
AR中的内容 - 临时区域。用以保存临时计算结果
- 局部数据区。源程序中程序单元声明的局 部变量对应在此区域。
- 机器状态保存区。存有机器的寄存器,程 序指令计数器 ip(返回地址)等。
2019/11/8
《编译原理与技术》-运行环境
5
活动记录
AR中的内容 - 访问链(静态链)。当前程序单元可以访 问的(静态程序中)外围程序单元的活动记 录链。 - 控制链(动态链)。程序单元的活动记录 按它们的生成(或调用)次序串成链。 - 实在参数 - 返回值
2019/11/8
《编译原理与技术》-运行环境
22
e.g.5 悬空引用
有C程序如下: main() {
int * p = dangle(); … }
int * dangle() {
int i; return &i; }
2019/11/8
《编译原理与技术》-运行环境
23
非局部变量访问
静态作用域规则 vs. 动态作用域规则
2019/11/8
《编译原理与技术》-运行环境
12
动态存储分配
栈式分配下的AR内容布局
高地址
返回值 实在参数
可选的访问链
参数/返回值区域放在AR 高端-靠近调用者过程的 活动记录,既便于双方存 取,又适应参数可变情况
返回地址
bp
调用者 bp
长度固定的区 域放在AR中间
可选机器状态
低地址
局部数据
至此,B的AR区域全部回收(撤销)了。
2019/11/8
《编译原理与技术》-运行环境
17
e.g.2 栈式存储分配
有C程序如下: void g() { int a ; a = 10 ; } void h() { int a ; a = 100; g(); } main() { int a = 1000; h(); }
主程序 : 0
嵌套深度:1
A:1
var j : integer; procedure C ;
嵌套深度:2
i: 2
begin
B;
C
B:2
end; begin
j := i;
BA 主程序
嵌套深度:3
j: 3
C;
C:3
end;
begin
B;
2019/11/8
《编译原理与技术》-运行环境
18
e.g.2 栈式存储分配
过程g被调用时,活动记录栈的(大致)内容
2019/11/8
返回地址
old bp
a : 1000 返回地址
old bp
a : 100
返回地址
bp
old bp
a : 10 sp
main程序的AR 函数h的AR 函数g的AR
《编译原理与技术》-运行环境
a0 = 0 b0 = 0 b1 = 1
a0 = 0 b0 = 0
a)进入block 1, b)进入block 2, c)退出block 2, d)退出block 3, e)退出block 1,
未进入block 2 未进入block 3 进入block 3
进入block 1
进入main
2019/11/8
19
e.g.3 有参函数的活动记录
参数 b 参数 a 返回地址 老bp 局部变量c 局部变量d
bp+12 bp+8
bp bp-4 bp-8
.file "ar.c"
void func( int a , int b )
.text
{
.globl func
int c , d;
.type func,@function
2019/11/8
《编译原理与技术》-运行环境
6
活动记录的内容
返回值(return value) 实在参数(actual parameter) 控制链(control link)
可选的访问链(optional access/static link)
机器状态(saved machine status) 局部数据(local data) 临时区(temporaries)
编译原理与技术
运行环境
2019/11/8
《编译原理与技术》-运行环境
1
运行环境
存储组织与分配
程序单元、运行时内存划分与活动记录 静态/动态存储分配 动态栈式的过程调用/返回 非局部名字的访问
参数传递
参数传递的方式及其实现
2019/11/8
《编译原理与技术》-运行环境
2
存储组织与分配
2019/11/8
《编译原理与技术》-运行环境
7
活动记录内容的存取
AR的基地址bp
返回值 实在参数 控制链 (old bp)
可选的访问链
机器状态 局部数据 临时区
2019/11/8
《编译原理与技术》-运行环境
8
活动记录内容的存取
返回值
地址:Βιβλιοθήκη 实在参数bp+d1
偏 移
控制链(old bp)
d1
可选的访问链
c = a;
func:
d = b;
pushl %ebp
}
movl %esp, %ebp
subl $8, %esp
movl 8(%ebp), %eax
movl %eax, -4(%ebp)
movl 12(%ebp), %eax
movl %eax, -8(%ebp)
leave
ret
2019/11/8
《编译原理与技术》-运行环境
栈顶sp 临时区
长度可变的区 域放在AR低端
2019/11/8
《编译原理与技术》-运行环境
13
栈式分配下的过程调用与返回
- 过程调用:分配被调过程的AR并填入相关信息, 然后程序控制转移到被调过程入口;
-过程A 调用 过程B 的过程调用序列:
A的“调用”准备操作:1)~ 3)
1)A 计算实在参数并放入(对应栈操作-push) B的活动记录中;(亦可考虑返回值存放空间)
《编译原理与技术》-运行环境
21
e.g.4. scanf的可变参数
&f &i 格式串1指针 返回地址 老bp … …
bp+8 bp
&j 格式串2指针
返回地址 老bp … …
scanf的第一次调用时AR scanf的第二次调用时AR
由于C语言采用 逆序传递参数, 格式串参数将被 放在AR中的“固 定”位置,即 bp+8。而由此参 数即可确定待输 入值的参数(变 量)的个数。从 而适应参数个数 变化的情况。
d1、d2谁正谁负?
bp
机器状态
偏移d2 局部数据
临时区
地址: bp+d2
2019/11/8
《编译原理与技术》-运行环境
9
静态存储分配
- 全局变量的存储绑定、AR均在编译时确定 且在整个程序执行中保持。