编译原理_第4章_第2节_LL(1)分析法
编译原理实验报告材料LL(1)分析报告法84481

课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," "); cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论: ";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
LL(1)分析法

LL(1)分析法LL(1)分析法⼜叫预测分析法,是⼀种不带回溯的⾮递归⾃顶向下的分析法。
LL(1)是不带回溯的⾮递归的分析法是因为,它每次都只有⼀个可⽤的产⽣式,所以是不带回溯和⾮递归的,当⽆法处理输⼊符号时,即出错。
第⼀个L表⽰是从左到右扫描输⼊串,第⼆个L表⽰推导过程中使⽤最左推导,(1)表明只需要向右看⼀个符号,就可以决定如何推导的(即知道⽤哪个产⽣式进⾏推导)。
什么是LL(1)分析法LL(1)分析法的原理是这样的,它的基本思想是根据输⼊串的当前输⼊符号来唯⼀确定选⽤哪个产⽣式来进⾏推导。
⽐如当前的⽂法符号是A,⾯临输⼊串的⾸个符号是a,存在若⼲个产⽣式,A→X1|X2|...|X k,如果a∈FIRST(X i),那么肯定就是⽤A→X i这个产⽣式来进⾏推导。
⼜或者当前的⽂法符号是A,⾯临的输⼊串的⾸个符号是a,存在产⽣式A→X,若ϵ∈FIRST(X), 且a∈FOLLOW(A),那么肯定是⽤产⽣式A=>ϵ进⾏推导。
即当然⽂法符号是没⽤的。
所以LL(1)⽂法要满⾜下⾯的条件,若存在A→X1|X2(1)FIRST(X1)⋂FIRST(X2)=ϕ。
即如果对于⽂法符号A,有两个产⽣式的FIRST交集不为空,那么就是⼆义的,就不是LL(1)⽂法(2)若ϵ∈FIRST(X2),则有FIRST(X1)⋂FOLLOW(X2)=ϕ,同样的,这样也是⼆义的。
对LL(1)⽂法构造LL(1)分析表根据上⾯的思想,我们可以预处理出⼀张LL(1)分析表,对于任意的⽂法符号S,⾯临输⼊符号a,该⽤哪个产⽣式。
⾸先,然后根据3条规则来构造LL(1)分析表(这⾥默认该⽂法是LL(1)⽂法)。
①对⽂法G[S]的每个产⽣式A→α执⾏②,③两步②对每个终结符a∈FIRST(α),把A→α加⼊到表格中的[A,a] 这个格⼦。
即当⽂法符号A⾯临输⼊符号a时,应该使⽤产⽣式A→α③若ϵ∈FIRST(α),则对所有的终结符b∈FOLLOW(A),将A→ϵ加⼊到[A,b]这个格⼦。
【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集

【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。
编译原理 语法分析(2)_ LL(1)分析法1
自底向上分析法
LR分析法的概念 LR分析法的概念 LR(0)项目族的构造 LR(0)项目族的构造 SLR分析法 SLR分析法 LALR分析法 LALR分析法
概述
功能:根据文法规则 文法规则, 源程序单词符号串 单词符号串中 功能:根据文法规则,从源程序单词符号串中
识别出语法成分,并进行语法检查。 识别出语法成分,并进行语法检查。
9
【例】文法G[E] 文法G[E] E→ E +T | T 消除左递归 T→ T * F | F F→(E)|i 请用自顶向下的方法分析是否字 分析表 符串i+i*i∈L(G[E])。 符串i+i*i∈L(G[E])。
E→TE’ E’→+TE’|ε T →FT’ T’→*FT’|ε F→(E)|i
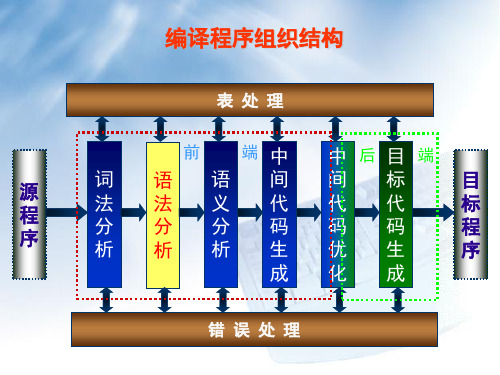
编译程序组织结构
表 处 理
前
端 中
源 程 序
词 法 分 析
语 法 分 析
语 义 分 析
间 代 码 生 成
中 后 目 端 间 标 代 代 码 码 优 生 化 成
目 标 程 序
错 误 处 理
第4章 语法分析
自顶向下分析法
递归子程序法(递归下降分析法) 递归子程序法(递归下降分析法) LL(1)分析法 LL(1)分析法
通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 通常把按LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器。 LL(1)方法完成语法分析任务的程序叫LL(1)分析程序或者LL(1)分析器
输入串
一、分析过程
#
此过程有三部分组成: 此过程有三部分组成: 分析表 总控程序) 执行程序 (总控程序) 分析栈) 符号栈 (分析栈)
编译原理实验报告LL(1)分析法

编译原理实验报告LL(1)分析法课程编译原理实验名称实验二 LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造方法;3.掌握LL(1)驱动程序的构造方法。
一.实验内容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length()) NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;iif(first.find(w[i])>first.length())first+=w[i];}void edge::newfollow(string w){int i;for(i=0;iif(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;iif(select.find(w[i])>select.length()&&w[i]!='@') select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j{if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro()){for(i=0;iif(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i{s=NODE.find(ni.getrg()[i]);if(s-1) //是非终结符if(ifor(j=0;jif(n[j].getlf().find(ni.getrg()[i])==0) {if(NODE.find(ni.getrg()[i+1]){for(k=0;kif(n[k].getlf().find(ni.getrg()[i+1])==0) {n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i{for(j=0;jif(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length()) return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;coutfor(i=0;i{cout}cout}//连续输出符号void outfu(int a,string c){int i;for(i=0;icout}//输出预测分析表void outgraph(edge *n,string (*yc)[50]) {int i,j,k;bool flag;for(i=0;i{if(ENODE[i]!='@'){outfu(10," ");cout}}outfu(10," ");coutint x;for(i=0;i{outfu(4," ");coutoutfu(5," ");for(k=0;k{flag=1;for(j=0;j{if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]); if(x-1){cout"yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x-1) {cout"yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b){char ch,a;int x,i,j,k; b++; cout9) outfu(8," "); else outfu(9," "); cout-1) { if(ch==a) { fenxi.erase(fenxi.length()-1,1); chuan.erase(0,1); coutfenxi.erase(fenxi.length()-1,1); if(pipei(chuan,fenxi,yc,b)) return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x-1) j=ENODE.length()-1; elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout"-1;k--) if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b)) return 1; elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cin>>SUM; coutNODE.length()&&ENODE.find(str[j])>ENODE.length())ENODE+=str[j]; } //计算first集合 for(i=0;in[j].getfirst().length()){ n[i].delfirst(); break; } } } } }for(k=0;koutfu(SUM," "); cout>chuan; fchuan=chuan; fenxi="#"; fenxi+=NODE[0]; i=0; coutoutfu(7," ");coutoutfu(10," ");coutoutfu(8," ");coutif(pipei(chuan,fenxi,yc,i))coutelsecout}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造方法。
编译原理第4章 语法分析——自上而下分析

17
例3.4.1 假定有文法G(S): (1) S→xAy (2) A→**|*
分析输入串x*y(记为)。
x*y
S
IP x A y **
18
例3.4.1 假定有文法G(S): (1) S→xAy (2) A→**|*
分析输入串x*y(记为)。
x*y
S
IP x A y **
19
例3.4.1 假定有文法G(S): (1) S→xAy (2) A→**|*
(4.3)
虽没有直接左递归,但S、Q、R都是左递归的
SQcRbcSabc
一个文法消除左递归的条件
丌含以为右部的产生式
丌含回路
PP
30
例 文法G(S): S→Qc|c Q→Rb|b R→Sa|a
(4.3)
虽没有直接左递归,但S、Q、R都是左递归的
SQcRbcSabc
Q
Q
ⅹ
S
R
S→Qc|c Q→Rb|b R→Sa|a
35
例 考虑文法G(S)
S→Qc|c Q→Rb|b R→Sa|a
消除S的直接左递归后: S→abcS | bcS | cS S→abcS | Q→Sab |ab | b R→Sa|a
关于Q和R的觃则已是多余的,化简为:
S→abcS | bcS | cS
S→abcS |
(4.4)
36
注意,由于对非终结符排序的丌同,最 后所得的文法在形式上可能丌一样。但 丌难证明,它们都是等价的。
分析输入串x*y(记为)。
x*y
S
IP
15
例3.4.1 假定有文法G(S): (1) S→xAy (2) A→**|*
分析输入串x*y(记为)。
编译原理完整课件_第4章 语法分析-自上而下分析

2022/3/20
中南大学软件学院 陈志刚
6
第四章 语法分析-自上而下分析
4.2 自上而下分析面临的问题
➢ 顾名思义,自上而下就是从文法的开始符号出 发,向下推导,推出句子。 • 带回溯的分析方法 • 不带回溯的递归子程序(递归下降)分析方 法
➢ 自上而下分析的主旨: 对任意输入串,试图用一切可能的办法,从文 法开始符号(根结)出发,自上而下地为输入 串建立一棵语法树。或者说,为输入串寻找一 个最左推导。
设 ,有P→Pα|β,若α≠>ε,β不以P开头 (否则不可能消除左递归)。
则改写为:
可消除左递归。
2022/3/20
中南大学软件学院 陈志刚
12
第四章 语法分析-自上而下分析
一般地,若 αi≠ε,βj不以P开头, 则可改写为:
从而消除直接左递归。 ■ 例:S→Sabc|Sab|ab ■ 消除直接左递归得:
2022/3/20
中南大学软件学院 陈志刚
13
2、完全消除左递归 分析
第四章 语法分析-自上而下分析
虽不含直接左递归,但
所以含有左递归。
■ 如果文法G不含回路( ),也不含ε产生式,
则下列算法可消除左递归(完全)
①把G的非终结符按任意顺序排列成P1,…,Pn
②for i:=1 to n do
begin for j:=1 to i-1 do
➢ 关键:对一个文法,当给你一串(终结)符号 时,怎样知道它是不是该文法的一个句子呢? 这就要判断,看是否能从文法的开始符号出发 推导出这个字符串。或者,从概念上讲,就是 要建立一棵与输入串相匹配的语法分析树。
2022/3/20
中南大学软件学院 陈志刚
编译原理语法4(自顶向下语法分析:LL分析法)

PART 01
引言
编译原理概述
01
编译原理是研究将高级语言程序转换为低级语言程序的过程、 方法和技术的学科。
02
编译过程包括词法分析、语法分析、语义分析、优化和代码生
成等多个阶段。
编译原理是计算机科学的重要分支,对于理解计算机如何执行
03
程序以及开发高效、可靠的软件具有重要意义。
语法分析在编译过程中的作用
递归下降分析法
递归下降分析法基本原理
基于文法规则
递归下降分析法是一种自顶向下 的语法分析方法,它基于文法规 则进行推导。
递归调用
对于每个非终结符,都编写一个 相应的子程序来进行识别和处理。 当遇到非终结符时,就调用相应 的子程序进行处理。
预测分析
在子程序中,根据当前输入符号 和文法规则,预测下一个可能的 输入符号,并据此选择正确的推 导路径。
WENKU DESIGN
2023-2026
END
THANKS
感谢观看
KEEP VIEW
WENKU DESIGN
WENKU DESIGN
WENKU
REPORTING
https://
01
深入学习编译原理中的其他分 析方法,如LR分析法、SLR分 析法等,以便更全面地掌握编 译原理的核心内容。
02
探索编译原理在实际应用中的 价值,如编译器设计、程序优 化等,将理论知识与实践相结 合。
03
关注编译原理领域的最新研究 动态和技术发展,不断拓宽自 己的视野和知识面。
WENKU DESIGN
递归下降分析法实现步骤
构造文法
首先,需要构造一个合适的文法,用于描述待分 析的语言。
调用子程序
编译原理语法分析——LL(1)分析表的实现

printf("Please input your chioc : ");
ch = getche();
printf("\n");
if(ch == 'I' || ch == 'i')
{
printf("Input a string end up with \'#\':");
gets(string);
i = strlen(string);
if(string[i-1] != '#')
{
string[i] = '#';
string[i+1] = '\0';
}
AnalysisProcess();
goto re2;
}
else if(ch == 'Q' || ch == 'q')
{
Quit();
return ;
int i;
int j;
count = 0;
ch = fgetc(f);
while(!feof(f))
{
if (ch == '-')
{
if ( (ch2=fgetc(f)) == '>' )
{
count++; //累计产生式的字符数条数
}
else
{
fseek(f,-1L, 1);
}
}//if
else if( ch == '|' )
fclose(f);
}//Input
编译原理LL(1)分析实验报告

青岛科技大学LL(1)分析编译原理实验报告学生班级__________________________学生学号__________________________学生姓名________________________________年 ___月 ___日一、实验目的LL(1)分析法的基本思想是:自项向下分析时从左向右扫描输入串,分析过程中将采用最左推导,并且只需向右看一个符号就可决定如何推导。
通过对给定的文法构造预测分析表和实现某个符号串的分析,掌握LL(1)分析法的基本思想和实现过程。
二、实验要求设计一个给定的LL(1)分析表,输入一个句子,能根据LL(1)分析表输出与句子相应的语法数。
能对语法数生成过程进行模拟。
三、实验内容(1)给定表达式文法为:G(E’): E’→#E# E→E+T | T T→T*F |F F→(E)|i(2)分析的句子为:(i+i)*i四、模块流程五、程序代码#include<iostream>#include<stdio.h>#include <string>#include <stack>using namespace std;char Vt[]={'i','+','*','(',')','#'}; /*终结符*/char Vn[]={'E','e','T','t','F'}; /*非终结符*/ int LENVt=sizeof(Vt);void showstack(stack <char> st) //从栈底开始显示栈中的内容{int i,j;char ch[100];j=st.size();for(i=0;i<j;i++){ch[i]=st.top();st.pop();}for(i=j-1;i>=0;i--){cout<<ch[i];st.push(ch[i]);}}int find(char c,char array[],int n) //查找函数,返回布尔值{int i;int flag=0;for(i=0;i<n;i++){if(c==array[i])flag=1;}return flag;}int location(char c,char array[]) //定位函数,指出字符所在位置,即将字母转换为数组下标值{int i;for(i=0;c!=array[i];i++);return i;}void error(){cout<<" 出错!"<<endl;}void analyse(char Vn[],char Vt[],string M[5][6],string str){int i,j,p,q,h,flag=1;char a,X;stack <char> st; //定义堆栈st.push('#');st.push(Vn[0]); //#与识别符号入栈j=0; //j指向输入串的指针h=1;a=str[j];cout<<"步骤"<<"分析栈"<<"剩余输入串"<<" 所用产生式"<<endl;while(flag==1){cout<<h<<" "; //显示步骤h++;showstack(st); //显示分析栈中内容cout<<" ";for(i=j;i<str.size();i++) cout<<str[i]; //显示剩余字符串X=st.top(); //取栈顶符号放入X if(find(X,Vt,LENVt)==1) //X是终结符if(X==a) //分析栈的栈顶元素和剩余输入串的第一个元素相比较if (X!='#'){cout<<" "<<X<<"匹配"<<endl;st.pop();a=str[++j]; //读入输入串的下一字符}else{ cout<<" "<<"acc!"<<endl<<endl; flag=0;}else{error();break;}else{p=location(X,Vn); //实现下标的转换(非终结符转换为行下标)q=location(a,Vt); //实现下标的转换(终结符转换为列下标)string S1("NULL"),S2("null");if(M[p][q]==S1 || M[p][q]==S2) //查找二维数组中的产生式{error();break;} //对应项为空,则出错else{string str0=M[p][q];cout<<" "<<X<<"-->"<<str0<<endl; //显示对应的产生式st.pop();if(str0!="$") //$代表"空"字符for(i=str0.size()-1;i>=0;i--) st.push(str0[i]);//产生式右端逆序进栈}}}}main(){string M[5][6]={"Te" ,"NULL","NULL","Te", "NULL","NULL","NULL","+Te" ,"NULL","NULL","$", "$","Ft", "NULL","NULL","Ft", "NULL","NULL","NULL","$", "*Ft", "NULL","$", "$","i", "NULL","NULL","(E)", "NULL","NULL"}; //预测分析表j string str;int errflag,i;cout<<"文法:E->E+T|T T->T*F|F F->(E)|i"<<endl;cout<<"请输入分析串(以#结束):"<<endl;do{ errflag=0;cin>>str;for(i=0;i<str.size();i++)if(!find(str[i],Vt,LENVt)){ cout<<"输入串中包含有非终结符"<<str[i]<<"(输入错误)!"<<endl;errflag=1;}} while(errflag==1); //判断输入串的合法性analyse(Vn, Vt, M,str);return 0;}六、实验结果七、实验总结。
编译原理第四章语法分析-自上而下分析

• 例 4.4
4.4 递归下降分析程序构造
• 递归下降分析器:
这个分析程序由一组递归过程组成的,每个过程对应 文法的一个非终结符。 E→TE’ E’→+TE’| T→FT’ T’→*FT’| F→(E)|i
PROCEDURE E BEGIN T ; E’ END PROCEDURE E’ IF SYM=‘+’THEN BEGIN ADVANCE ; T ; E’ END
4.2 自上而下分析面临的问题
• 例4.1 假定有文法
(1) SxAy (2)A**|*
对输入串x*y,构造语法树。 • 构造过程:
(1)把S作为根 (2)用S的产生式构造子树 (3)让输入串指示器IP指向输入串的第一个符号。
S x A y x
S
A y x
S
A y
*
*
*
(4)调整输入串指示器IP与叶结点进行匹配。 (5)如果为非终结符,用A的下一个产生式构建子树。 (6)如果匹配成功则结束;否则,回溯到步骤(4)。
• 一个反例:
– 文法:SQc|c;QRb|b;RSa|a虽然不是直接 左递归,但S、Q、R都是左递归。
• 消除左递归算法:
– 算法的思想是:
• • • • 首先构造直接左递归; 再利用一般转换规则,消除直接左递归 化简文法。 下面算法在不含PP,也不含在右部产生式时可以消除 左递归。
• 消除一个文法的左递归算法:
(1) 把文法 G 的所有非终结符按任一种顺利排列成 P1…Pn;按此顺序执行; (2) FOR i:=1 TO n DO
BEGIN FOR j:=1 TO i-1 DO 把形如Pj+1→Pj 的规则改写成 Pj+11|1|…k| 。其中 Pj1|1|…k 是关于 Pj 的 所有规则; 消除关于Pi规则的直接左递归性。 END 化简由(2)所得的文法。即去除那些从开始符号出发永 远无法到达的非终结符的产生规则。
编译技术原理及方法 课件 第四章 语法分析1

具体的说,语法分 析是在单词流的基础 上建立一个层次结构
标识符 a
——语法树
=
表达式
标识符 +
表达式
b
标识符 *ቤተ መጻሕፍቲ ባይዱ标识符
c
d
4-1语法分析概述
一、语法分析的主要任务
举例 a=b+c*d
语法分析 任务:将词法分析后所有单词组成句子,根据不同高级语言
不同语法规则来分析这些句子乃至程序是否正确。
如果写成 a=b+-c*d 会不会发现?
cad
S
i
ScAd c A d cabd a b
4-1语法分析概述 二、自顶向下语法分析概述
2、分析方法
若按自上而下语法分析程序的步骤进行分析判断,其过程如下:
P: S∷=cAd A∷=ab|a
(3)此时子树A最左端末结点a 与i所指的符号a匹配。于是 再调整i使其指向下一输入符 号d,并试图用A的最右末端 结点b与之匹配。但它们不 匹配,因此,子树A的匹配 失败,这意味着选用A的第 一个候选式对此时的情况不 适合,不能构造出输入串x 的语法树。
4-2自顶向下语法分析
4.2.1消除回溯和左递归
一、消除回溯
2、运气不好的情况——同一个非终结符的不同候选式的不以终 结符号开头 : 通过求FIRST集分析路标
不难总结出,构造FIRST集的方法步骤如下—— 对任一符号X(X∈VN∪VT),构造FIRST(X)时,只要连续使用下列规则,直至每个FIRST
ScAd c
A
d
4-1语法分析概述 二、自顶向下语法分析概述
2、分析方法
若按自上而下语法分析程序的步骤进行分析判断,其过程如下:
P: S∷=cAd A∷=ab|a
编译原理之LL(1)分析

LL(1)分析#include "LL(1)GFG.cpp"char M[MAX_NUM][MAX_NUM+1][STR_MAX];//构造并输出预测分析表void creatLLTable(){//构造预测分析表for(int i=0;i<P_CNT;i++){char vn=P[i].left;int sel_num=strlen(P[i].select);char a;for(int j=0;j<sel_num;j++){a=P[i].select[j];if(a!='#')strcpy(M[isVN(vn)][isVT(a)],P[i].right);elsestrcpy(M[isVN(vn)][VT_CNT],P[i].right);}}//输出预测分析表for(int l=0;l<VT_CNT;l++){printf("\t%c",VT[l]);fprintf(OUTF,"\t%c",VT[l]);}printf("\t#");fprintf(OUTF,"\t#");for(int m=0;m<VN_CNT;m++){printf("\n%c",VN[m]);fprintf(OUTF,"\n%c",VN[m]);for(int n=0;n<VT_CNT+1;n++){printf("\t%s",M[m][n]);fprintf(OUTF,"\t%s",M[m][n]);}}}char STACK[MAX_NUM];void push(char ch){for(int i=strlen(STACK);i>=0;i--)STACK[i+1]=STACK[i];STACK[0]=ch;}void pop(){for(int i=1;i<=strlen(STACK);i++)STACK[i-1]=STACK[i];}void ERROR(int eflag){if(eflag==1){printf("出错:终结符不匹配。
4-第四章_LL(1)补充讲解

例: G[A]: A → Ba |d
B → abc|ε first(d)={d} first(ε)={ε} FOLLOW(B)={a} M[A,a] 填入 A→Ba M[A,d] 填入 A→d M[B,a] 填入 B→abc
α的first集合: first(Ba)={a} first集合: 集合 first(abc)={a} FOLLOW集合 集合: VN的FOLLOW集合:FOLLOW(A)={#} 对A→Ba A→d B→abc B→ε ∴ A B ∵ first(Ba)={a} ∵ first(d)={d} ∵ first(abc)={a}
只需查看只需查看一个当前符号便可决定如何推导个当前符号便可决定如何推导即选择哪个产生式进行推导的语法分析法
LL(1)分析法 §4.2 LL(1)分析法
LL(1)分析法的含义: LL(1)分析法的含义: 分析法的含义 自上而下分析是从左向右扫描输入串; • LL(1) :自上而下分析是从左向右扫描输入串; 分析过程中将采用最左推导; • LL(1) :分析过程中将采用最左推导; • LL(1) :只需查看一个(当前)符号便可决定如何推导 只需查看一个(当前) (即选择哪个产生式进行推导)的语法分析法。 即选择哪个产生式进行推导)的语法分析法。 LL(1)文法:可采用LL(1)分析法进行分析的文法。 LL(1)文法:可采用LL(1)分析法进行分析的文法。 文法 LL(1)分析法进行分析的文法
ε∈First( First(ε ∵ ε∈First(ε), FOLLOW(B)={a} 填入B→ε M[B,a] 填入B→ε 不是LL(1) LL(1)文法 不是LL(1)文法 a b c d # A→Ba A→d B→abc B→ε
用预测分析法分析句子
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4.2.1 LL(1)文法
文法G=({S,A}, {x, y, z, *}, {SxAy|z, A*|ε}, S)
当前输入符号为a, Aα1|α2|…|αn ,aFIRST(αi),εFIRST(αj), 是否可以用ε匹配A?
xy x S
A
y
ε 只有a是跟在A后面的终结符时,才能运行A自动匹配,否则,a在这里的出现就 是一种语法错误。
4.2.7 非LL(1)文法的LL(1)分析
SiCtSS’|a S’eS|ε Cb First(S)={i, a} First(S’)={e, ε} First(C)={b} a S S’ C C b S a SS ’ ’ eS|ε eS b e i SiCtSS’ S’ε t # 对任意产生式Aα: (1) 若aFirst(α),则M[A, a]=Aα;
Sif B then S1S3 S3 else S2;|; 例:Sif B then S1 else S2 | if B then S1 Sif B then S1S3 S3 else S2|ε
4.2.1 LL(1)文法
构造不带回溯的自上而下分析的文法条件:
(1)文法不含左递归。 (2)对每个非终结符A,若Aα1|α2|…|αn,有FIRST(αi) ∩ FIRST(αj)=Φ (i≠j)。 (3)对每个非终结符A,若Aα1|α2|…|αn,εFIRST(αi) ,有FIRST(αi) ∩ FOLLOW(A)=Φ。
注意:
并非多有的文法都是LL(1)文法,只有是LL(1)文法时才 能采用LL(1)分析法 对某些非LL(1)文法,可以通过消除左递归或提取左公因 子的方法改写成为等价的LL(1)文法 LL(1)文法可采用确定的自顶向下语法分析方法
4.2.6 if_then_else 文法
stmtif expr then stmt else stmt | if expr then stmt | other 文法含有左公因子,因此必存在冲突: 当已推导或归约出if expr then stmt,遇到else时会出现冲突。
规定else与最接近的if配对,因此if expr then stmt else stmt优先。 推广:当一个候选式是另外一个候选式的前缀时,规定较长的候选式优先。
4.2.3 求FOLLOW(A)
文法G[S]中的产生式 S xAy S z A * A ε x y S
x
A ε
y
4.2.3 求FOLLOW(A)
(1) 置初值:对任一AVN,令FOLLOW(A)={},若A是开始符号,FOLLOW(A)={#}; (2) 若有AαBβ,BVN,置FOLLOW(B)= FOLLOW(B) ∪ ( FIRST(β)-{ε} ); (3) 若有AαB,置FOLLOW(B)= FOLLOW(B) ∪ FOLLOW(A); FOLLOW(B)∪ FOLLOW(A);
经过反复提取左因子,就能够把每个非终结符(包括新引进 者)的所有候选首符集变成为两两不相交。
PαA1 | αA2 | … | αAn | β1 | β2 | … |βm PαA | β1 | β2 | … | βm A A1 | A2 |… | An
例:Sif B then S1 else S2; | if B then S1;
如果文法G满足以上条件,则该文法称为LL(1)文法。
第一个L表示从左到右扫描输入串,第二个L表示最左推导,1表示分析 时每步只需向右查看一个符号。
构造无回溯文法算法的问题
如何构造FIRST(α)? 如何构造FOLLOW(A)? 如何根据当前输入符号a决定A的匹配式?
4.2.2 求FIRST(x)
T’*FT’|ε
F(E)|i
E
E’ T T’
ETE’
E’+TE’ TFT’
ETE’
F
Fi
F(E)
4.2.5 LL(1)分析法
设文法符号栈为STACK,初始值存放句子左界符#和开始符号。总控程序根 据STACK栈顶符号X和当前输入符号a查LL(1)分析表: (1) 若X=a=‘#’,分析成功,退出; (2) 若X=a≠‘#’,POP(X),并从输入串中读入下一个符号存入a; (3) 若XVT,且X≠a,ERROR() ,退出; (4) 若XVN, 若M[X, a]为一产生式,则POP(X),并将X右部反序进栈; 若候选式为ε,则ε不进栈; 若M[X, a]为空白,ERROR(),退出。
4.2.1
消除回溯、提左因子
为了消除回溯就必须保证:
对文法的任何非终结符,当要它去匹配输 入串时,能够根据它所面临的输入符号准确地 指派它的一个候选去执行任务,并且此候选的 工作结果应是确信无疑的。
A→ 1 |
2
| … |
n
a….
IP ...
S
A ...
4.2.1
消除回溯、提左因子
FOLLOW(E’) #, # ) FOLLOW(T) + #, +, # )
FOLLOW(T’) +, #, # ) FOLLOW(F) * +, #, *, # )
4.2.4 确定匹配产生式
A可以用候选式α匹配的条件: (1)aFIRST(α); (2)εFIRST(α),aFOLLOW(A)
1 2 k j i
* ε,则εFIRST(x)。 特别地,若Y1Y2…Yk
4.2.2 求FIRST(x)
(2)若x(VN∪VT)*,不妨设x=x1x2x3…xn
(a)FIRST(x1)-{ε}FIRST(x) ;
(b)对任何1≤j≤i-1,若εFIRST(xj),则FIRST(xi)-{ε}FIRST(x);
T
T’ F 符合栈
#E
#E’T #E’T’F #E’T’i
i*i+i#
i*i+i# i*i+i# i*i+i#
#E’
#E’T+ #E’T #E’T’F
+i#
+i# i# i#
T’ε
E’+TE’ TFT’
#E’T’
#E’T’F* #E’T’F #E’T’i
*i+i#
*i+i# i+i# i+i#
ห้องสมุดไป่ตู้
a A B C D E
b
c
d
e
f
4.2.4 确定匹配产生式
G={VN, VT, P, S},构造分析表:列为aVT,行为AVN,A与a对应的元素 记为M[A, a],对所有的产生式Aα: (1) 若aFIRST(α),则置M[A, a]=Aα; (2) 若εFIRST(α),且bFOLLOW(A), 则置M[A, b]=A ε ; (3) 若M[A, a]为空,则表示出错。 用上述方法构造的分析表称为LL(1)分析表。
(c)对任何1≤i≤n,若εFIRST(xi),则εFIRST(x);
4.2.2 求FIRST(x)
例:求FIRST(X): XY1Y2Y3Y4Y5 Y1a|ε Y2b|ε Y3c|ε Y4d|ε Y5e|ε
FIRST(Y1)={a,ε} FIRST(Y2)={b,ε}
FIRST(Y3)={c,ε} FIRST(Y4)={d,ε} FIRST(Y5)={e,ε} FIRST(X)={a, b, c, d, e,ε}
4.2.1 LL(1)文法
FIRST集合
非终结符号集合FIRST(x)定义: * a…, aV }, 特别地,若x * ε成立,则规定 FIRST(x) = {a|x
T
ε FIRST(α)
如 果 非 终 结 符 A 的 任 何 两 个 候 选 式 αi 和 αj( 不 考 虑 ε 的 情 况 ) , 有 FIRST(αi)∩FIRST(αj)=Φ,那么要求A匹配输入串时,A就能根据它所面临 的第一个输入符号a,准确的指派某个候选去执行匹配任务。
(2) 若εFirst(α),对任何bFollow(A),置M[A, b]=Aα
Follow(S)=Follow(S’)={#, e} Follow(C)={t}
4.2.8 如何判定是否为LL(1)文法
根据定义判断 直接构造给定文法的分析表,若分析表中无多重 定义,则文法是LL(1)文法,否则不是
4.2.1 LL(1)文法
FOLLOW集合
定义: * …Aa…, AV , aV , S是开始符号}, FOLLOW(A)={a|S N T * …A,则#FOLLOW(A)。 特别地,若S 当前输入符号为a, Aα1|α2|…|αn ,aFIRST(αi),εFIRST(αj), 是否可以用ε匹配A? (1)若a FOLLOW(A),则可以用ε匹配A (2)若a FOLLOW(A),则不可以用ε匹配A
(5) 转(1)。
例:LL(1)分析法:i*i+i
i E E’ ETE’ E’+TE’ TFT’ T’ε Fi 输入串 产生式 ETE’ TFT’ Fi T’*FT’ Fi T’*FT’ F(E) #E’T’ +i# TFT’ T’ε T’ε + * ( ETE’ E’ε E’ε ) #
4.2.2 求FIRST(x)
(1)若x(VN∪VT)
(a)若xVT,则FIRST(x)={x}; (b)若xVN,且有产生式xa…,aVT,则aFIRST(x);当产生式
为xε时,εFIRST(x);
(c)若xY…,YVN,则FIRST(Y)-{ε}FIRST(x); * ε,则FIRST(Y )-{ε} FIRST(x); 若xY Y …Y ,且对1≤j≤i-1,都有Y
文法G[S]中的产生式 S xAy S z A * A ε x * y S
x
A *
y