hadoop平台搭建
Hadoop环境搭建及wordcount实例运行
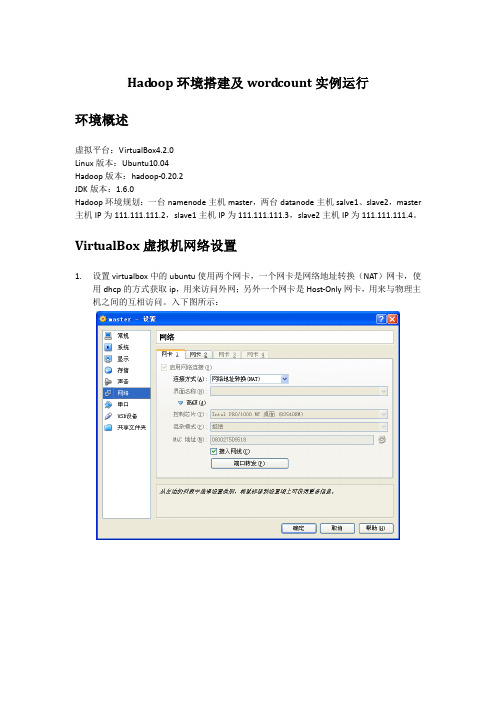
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop平台搭建简介

点击Arguments进行输入输出路径的设臵,如上图: 其中hdfs://node3/user/fengling/400为输入路径 hdfs://node3/user/fengling/out400为输出路径
JobTracker
应用程序提交到集群后由它决定哪个文件被处理,为不同的 task分配节点。每个集群只有一个JobTracker,一般运行在集群 的Master节点上。
DataNode
集群每个服务器都运行一个DataNode后台程序,这个后台
程序负责把HDFS数据块读写到本地的文件系统。
TaskTracker
指令sudo vi hdfs-site.xml
指令sudo vi mapred-site.xml
至此,Master节点的配臵已经基本完成,重启系统后执行 Hadoop,成果结果如下图所示
安装Slaves节点 将配臵好的Master(node3)复制为node4,node5,node6虚拟机。 复制前关闭Master,复制过程如下:
在hadoop installation directory后面填写保存的路径。设臵完 即可点击确定。
在如下图所示的Map/Reduce Location下空白地方点击,选 择New Hadoop location
Location nam可以随意填写,左边Host内填写的是jobtrack er所在集群机器,这里写node3。左边的port为node3的port, 为8021,右边的port为namenode的port,为8020。User na me为用户名。
以程序wordcount为例用指令hadoopdfscatout400进行查看即可看到输出文件out400自己设定中的部分内容程序分析程序分析wordcount是一个词频统计程序用来输入文件内的每个单词出现的次数统计出来如下
大数据--Hadoop集群环境搭建

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Hadoop大数据平台安装实验(详细步骤)(虚拟机linux)

大数据技术实验报告大数据技术实验一Hadoop大数据平台安装实验1实验目的在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建Hadoop(HDFS、MapReduce、HBase、Hive)、Spark、Scala、Storm、Kafka、JDK、MySQL、ZooKeeper等的大数据采集、处理分析技术环境。
2实验环境个人笔记本电脑Win10、Oracle VM VirtualBox 5.2.44、CentOS-7-x86_64-Minimal-1511.iso3实验步骤首先安装虚拟机管理程序,然后创建三台虚拟服务器,最后在虚拟服务器上搭建以Hadoop 集群为核心的大数据平台。
3.1快速热身,熟悉并操作下列Linux命令·创建一个初始文件夹,以自己的姓名(英文)命名;进入该文件夹,在这个文件夹下创建一个文件,命名为Hadoop.txt。
·查看这个文件夹下的文件列表。
·在Hadoop.txt中写入“Hello Hadoop!”,并保存·在该文件夹中创建子文件夹”Sub”,随后将Hadoop.txt文件移动到子文件夹中。
·递归的删除整个初始文件夹。
3.2安装虚拟机并做一些准备工作3.2.1安装虚拟机下载系统镜像,CentOS-7-x86_64-Minimal-1511.iso。
虚拟机软件使用Oracle VM VirtualBox 5.2.44。
3.2.2准备工作关闭防火墙和Selinux,其次要安装perl 、libaio、ntpdate 和screen。
然后检查网卡是否开机自启,之后修改hosts,检查网络是否正常如图:然后要创建hadoop用户,之后多次用,并且生成ssh 密钥并分发。
最后安装NTP 服务。
3.3安装MYSQL 3.3.1安装3.3.2测试3.4安装ZooKeeper。
Hadoop环境搭建

Hadoop环境搭建啥是⼤数据?问啥要学⼤数据?在我看来⼤数据就很多的数据,超级多,咱们⽇常⽣活中的数据会和历史⼀样,越来越多⼤数据有四个特点(4V):⼤多样快价值学完⼤数据我们可以做很多事,⽐如可以对许多单词进⾏次数查询(本节最后的实验),可以对股市进⾏分析,所有的学习都是为了赚⼤钱!(因为是在Linux下操作,所以⽤到的全是Linux命令,不懂可以百度,这篇⽂章有⼀些简单命令。
常⽤)第⼀步安装虚拟机配置环境1.下载虚拟机,可以⽤⾃⼰的,没有的可以下载这个 passowrd:u8lt2.导⼊镜像,可以⽤这个 password:iqww (不会创建虚拟机的可以看看,不过没有这个复杂,因为导⼊就能⽤)3.更换主机名,vi /etc/sysconfig/network 改HOSTNAME=hadoop01 (你这想改啥改啥,主要是为了清晰,否则后⾯容易懵)注:在这⾥打开终端4.查看⽹段,从编辑-虚拟⽹络编辑器查看,改虚拟机⽹段,我的是192.168.189.128-254(这个你根据⾃⼰的虚拟机配置就⾏,不⽤和我⼀样,只要记住189.128这个段就⾏)5.添加映射关系,输⼊:vim /etc/hosts打开⽂件后下⾯添加 192.168.189.128 hadoop01(红⾊部分就是你们上⾯知道的IP)(这⾥必须是hadoop01,为了⽅便后⾯直接映射不⽤敲IP)6.在配置⽂件中将IP配置成静态IP 输⼊: vim /etc/sysconfig/network-scripts/ifcfg-eth0 (物理地址也要⼀样哦!不知道IP的可以输⼊:ifconfig 查看⼀下)7.重启虚拟机输⼊:reboot (重启后输⼊ ping 能通就说明没问题)第⼆步克隆第⼀台虚拟机,完成第⼆第三虚拟机的配置1.⾸先把第⼀台虚拟机关闭,在右击虚拟机选项卡,管理-克隆即可(克隆两台⼀台hadoop02 ⼀台hadoop03)2.克隆完事后,操作和第⼀部基本相同唯⼀不同的地⽅是克隆完的虚拟机有两块⽹卡,我们把其中⼀个⽹卡注释就好(⼀定牢记!通过这⾥的物理地址⼀定要和配置⽂件中的物理地址相同)输⼊:vi /etc/udev/rules.d/70-persistent-net.rules 在第⼀块⽹卡前加# 将第⼆块⽹卡改为eth03.当三台机器全部配置完之后,再次在hosts⽂件中加⼊映射达到能够通过名称互相访问的⽬的输⼊:vim /etc/hosts (三台都要如此设置)(改完之后记得reboot重启)第三步使三台虚拟机能够通过SHELL免密登录1.查看SSH是否安装 rmp -qa | grep ssh (如果没有安装,输⼊sudo apt-get install openssh-server)2.查看SSH是否启动 ps -e | grep sshd (如果没有启动,输⼊sudo /etc/init.d/ssh start)3.该虚拟机⽣成密钥 ssh-keygen -t rsa(连续按下四次回车就可以了)4.将密钥复制到另外⼀台虚拟机⽂件夹中并完成免密登录输⼊:ssh-copy-id -i ~/.ssh/id_rsa.pub 2 (同样把秘钥给hadoop03和⾃⼰)(输⼊完后直接下⼀步,如果下⼀步失败再来试试改这个修改/etc/ssh/ssh_config中的StrictHostKeyCheck ask )5.之后输⼊ ssh hadoop02就可以正常访问第⼆台虚拟机啦注:可能你不太理解这是怎么回事,我这样解释⼀下,免密登录是为了后⾯进⾏集群操作时⽅便,⽣成秘钥就像是⽣成⼀个钥匙,这个钥匙是公钥,公钥可以打开所有门,之后把这个钥匙配两把,⼀把放在hadoop02的那⾥,⼀把放在hadoop03的那⾥,这样hadoop01可以对hadoop02和hadoop03进⾏访问。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)

Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
虚拟化与云计算课程实验报告——Hadoop平台搭建

虚拟化与云计算实验报告目录一、实验目标 (1)二、实验内容 (1)三、实验步骤 (1)四、实验遇到的问题及其解决方法 (24)五、实验结论 (25)一、实验目的1.实验题目:配置和使用SAN存储掌握在Linux上配置iSCSI target服务的方法。
2.实验题目:Hadoop&MapReduce安装、部署、使用Hadoop-HDFS配置运行MapReduce程序,使用MapReduce编程二、实验内容1.实验题目:配置和使用SAN存储配置在Linux上iSCSI实现两台机器间的共享存储。
2.实验题目:Hadoop&MapReduce1.掌握在集群上(使用虚拟机模拟)安装部署Hadoop-HDFS的方法。
2.掌握在HDFS运行MapReduce任务的方法。
3.理解MapReduce编程模型的原理,初步使用MapReduce模型编程。
三、实验步骤及实验结果1.实验题目:配置和使用SAN存储在实验1中我作为主机提供共享存储空间,实验地点是在机房,但是由于我当时没有截图所以回寝室在自己的电脑上重做,以下为主机步骤:1.1 确定以root身份执行以下步骤sudo su –1.2 安装iSCSI Target软件1.3 修改/etc/default/iscsitargetISCSITARGET_ENABLE=true1.4 创建共享存储共享存储可以是logical volumes, image files, hard drives , hard drive partitions or RAID devices例如使用image file的方法,创建一个10G大小的LUN:dd if=/dev/zero of=/storage/lun1.img bs=1024k count=102401.5修改/etc/iet/ietd.conf添加:Target .example:storage.lun1IncomingUser [username] [password]OutgoingUserLun 0 Path=/storage/lun1.img,Type=fileioAlias LUN1#MaxConnections 61.6 修改/etc/iet/initiators.allow如果只允许特定IP的initiator访问LUN,则如下设置.example:storage.lun1 192.168.0.100如果任意initiator均可以访问,则:ALL ALL1.6 启动/重启动iSCSI target/etc/init.d/iscsitarget start/etc/init.d/iscsitarget restart2.实验题目:Hadoop&MapReduce1.安装JDK——在实验中安装为OpenJDK 6 Runtime2.安装openssh-server,命令为:sudo apt-get install openssh-server,并检查ssh server是否已经启动:ps -e | grep ssh,如果只有ssh-agent 那ssh-server还没有启动,需要/etc/init.d/ssh start,如果看到sshd 那说明ssh-server已经启动了。
Hadoop开发环境搭建(Win8 + Eclipse + Linux)

Hadoop开发环境搭建(Win8+Linux)常见的Hadoop开发环境架构有以下三种:1、Eclipse与Hadoop集群在同一台Windows机器上。
2、Eclipse与Hadoop集群在同一台Linux机器上。
3、Eclipse在Windows上,Hadoop集群在远程Linux机器上。
点评:第一种架构:必须安装cygwin,Hadoop对Windows的支持有限,在Windows 上部署hadoop会出现相当多诡异的问题。
第二种架构:Hadoop机器运行在Linux上完全没有问题,但是有大部分的开发者不习惯在Linux上做开发。
这种架构适合习惯使用Linux的开发者。
第三种架构:Hadoop集群部署在Linux上,保证了稳定性,Eclipse在Windows 上,符合大部分开发者的习惯。
本文主要介绍第三种Hadoop开发环境架构的搭建方法。
Hadoop开发环境的搭建分为两大块:Hadoop集群搭建、Eclipse环境搭建。
其中Hadoop集群搭建可参考官方文档,本文主要讲解Eclipse环境搭建(如何在Eclipse 中查看和操作HDFS、如何在Eclipse中执行MapReduce作业)。
搭建步骤:1、搭建Hadoop集群(Linux、JDK6、Hadoop-1.1.2)2、在Windows上安装JDK6+3、在Windows上安装Eclipse3.3+4、在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件(如果没有,则需自行编译源码)5、在Eclipse上配置Map/Reduce Location搭建Hadoop集群此步骤可参考Hadoop官方文档在Windows上安装JDK此步骤可参考官方文档在Window上安装Eclipse此步骤可参考官方文档在Eclipse上安装hadoop-eclipse-plugin-1.1.2.jar插件Hadoop-1.1.2的发布包里面没有hadoop-eclipse-plugin-1.1.2.jar,开发者必须根据所在的环境自行编译hadoop-eclipse-plugin-1.1.2.jar插件。
hadoop完全分布式搭建步骤

Hadoop是一个开源的分布式计算框架,它能够处理大规模数据的存储和处理。
本文将介绍如何搭建Hadoop完全分布式集群。
一、准备工作1. 安装Java环境:Hadoop需要Java环境的支持,因此需要先安装Java环境。
2. 下载Hadoop:从官网下载Hadoop的最新版本。
3. 配置SSH:Hadoop需要通过SSH进行节点之间的通信,因此需要配置SSH。
二、安装Hadoop1. 解压Hadoop:将下载好的Hadoop压缩包解压到指定目录下。
2. 配置Hadoop环境变量:将Hadoop的bin目录添加到系统的PATH环境变量中。
3. 修改Hadoop配置文件:进入Hadoop的conf目录,修改hadoop-env.sh文件和core-site.xml 文件。
4. 配置HDFS:修改hdfs-site.xml文件,设置NameNode和DataNode的存储路径。
5. 配置YARN:修改yarn-site.xml文件,设置ResourceManager和NodeManager的地址和端口号。
6. 配置MapReduce:修改mapred-site.xml文件,设置JobTracker和TaskTracker的地址和端口号。
7. 格式化HDFS:在NameNode所在的节点上执行格式化命令:hadoop namenode -format。
8. 启动Hadoop:在NameNode所在的节点上执行启动命令:start-all.sh。
三、验证Hadoop集群1. 查看Hadoop进程:在NameNode所在的节点上执行jps命令,查看Hadoop进程是否启动成功。
2. 查看Hadoop日志:在NameNode所在的节点上查看Hadoop的日志文件,确认是否有错误信息。
3. 访问Hadoop Web界面:在浏览器中输入NameNode的地址和端口号,访问HadoopWeb界面,确认Hadoop集群是否正常运行。
Hadoop平台搭建方案

Hadoop平台搭建方案一、Hadoop简介Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。
以Hadoop 分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。
一个HDFS 集群是由一个NameNode和若干个DataNode组成的。
其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。
MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。
主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。
当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。
HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。
HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
二、系统安装及日常维护须知服务器型号:IBM X3850 X51.平时操作注意事项:机器上安装的有CentOS_6.4_64位操作系统和Windows server 2000操作系统。
大数据Hadoop学习之搭建Hadoop平台(2.1)

⼤数据Hadoop学习之搭建Hadoop平台(2.1) 关于⼤数据,⼀看就懂,⼀懂就懵。
⼀、简介 Hadoop的平台搭建,设置为三种搭建⽅式,第⼀种是“单节点安装”,这种安装⽅式最为简单,但是并没有展⽰出Hadoop的技术优势,适合初学者快速搭建;第⼆种是“伪分布式安装”,这种安装⽅式安装了Hadoop的核⼼组件,但是并没有真正展⽰出Hadoop的技术优势,不适⽤于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装⽅式安装了Hadoop的所有功能,适⽤于开发,提供了Hadoop的所有功能。
⼆、介绍Apache Hadoop 2.7.3 该系列⽂章使⽤Hadoop 2.7.3搭建的⼤数据平台,所以先简单介绍⼀下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是⼀个2.x.y发⾏版本中的⼀个次要版本,是基于2.7.2稳定版的⼀个维护版本,开发中不建议使⽤该版本,可以使⽤稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下: 1、common: ①、使⽤HTTP代理服务器时的⾝份验证改进。
当使⽤代理服务器访问WebHDFS时,能发挥很好的作⽤。
②、⼀个新的Hadoop指标接收器,允许直接写⼊Graphite。
③、与Hadoop兼容⽂件系统(HCFS)相关的规范⼯作。
2、HDFS: ①、⽀持POSIX风格的⽂件系统扩展属性。
②、使⽤OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS⽹关接收到⼀些可⽀持性改进和错误修复。
Hadoop端⼝映射程序不再需要运⾏⽹关,⽹关现在可以拒绝来⾃⾮特权端⼝的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进⾏了现代化改造。
3、yarn: ①、YARN的REST API现在⽀持写/修改操作。
Hadoop集群搭建详细简明教程

Linux 操作系统安装
利用 vmware 安装 Linux 虚拟机,选择 CentOS 操作系统
搭建机器配置说明
本人机器是 thinkpadt410,i7 处理器,8G 内存,虚拟机配置为 2G 内存,大家可以 按照自己的机器做相应调整,但虚拟机内存至少要求 1G。
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图: 选择“软驱”,点击“remove”移除软驱:
选择光驱,选择 CentOS ISO 镜像,如下图: 最后点击“Close”,回到“硬件配置页面”,点击“Finsh”即可,如下图: 下图为创建all or upgrade an existing system”
执行 java –version 命令 会出现上图的现象。 从网站上下载 jdk1.6 包( jdk-6u21-linux-x64-rpm.bin )上传到虚拟机上 修改权限:chmod u+x jdk-6u21-linux-x64-rpm.bin 解压并安装: ./jdk-6u21-linux-x64-rpm.bin (默认安装在/usr/java 中) 配置环境变量:vi /etc/profile 在该 profile 文件中最后添加:
选择“Skip”跳过,如下图:
选择“English”,next,如下图: 键盘选择默认,next,如下图:
选择默认,next,如下图:
输入主机名称,选择“CongfigureNetwork” 网络配置,如下图:
选中 system eth0 网卡,点击 edit,如下图:
选择网卡开机自动连接,其他不用配置(默认采用 DHCP 的方式获取 IP 地址), 点击“Apply”,如下图:
Hadoop大数据开发基础教案Hadoop集群的搭建及配置教案

Hadoop大数据开发基础教案-Hadoop集群的搭建及配置教案教案章节一:Hadoop简介1.1 课程目标:了解Hadoop的发展历程及其在大数据领域的应用理解Hadoop的核心组件及其工作原理1.2 教学内容:Hadoop的发展历程Hadoop的核心组件(HDFS、MapReduce、YARN)Hadoop的应用场景1.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节二:Hadoop环境搭建2.1 课程目标:学会使用VMware搭建Hadoop虚拟集群掌握Hadoop各节点的配置方法2.2 教学内容:VMware的安装与使用Hadoop节点的规划与创建Hadoop配置文件(hdfs-site.xml、core-site.xml、yarn-site.xml)的编写与配置2.3 教学方法:演示与实践相结合手把手教学,确保学生掌握每个步骤教案章节三:HDFS文件系统3.1 课程目标:理解HDFS的设计理念及其优势掌握HDFS的搭建与配置方法3.2 教学内容:HDFS的设计理念及其优势HDFS的架构与工作原理HDFS的搭建与配置方法3.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节四:MapReduce编程模型4.1 课程目标:理解MapReduce的设计理念及其优势学会使用MapReduce解决大数据问题4.2 教学内容:MapReduce的设计理念及其优势MapReduce的编程模型(Map、Shuffle、Reduce)MapReduce的实例分析4.3 教学方法:互动提问,巩固知识点教案章节五:YARN资源管理器5.1 课程目标:理解YARN的设计理念及其优势掌握YARN的搭建与配置方法5.2 教学内容:YARN的设计理念及其优势YARN的架构与工作原理YARN的搭建与配置方法5.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节六:Hadoop生态系统组件6.1 课程目标:理解Hadoop生态系统的概念及其重要性熟悉Hadoop生态系统中的常用组件6.2 教学内容:Hadoop生态系统的概念及其重要性Hadoop生态系统中的常用组件(如Hive, HBase, ZooKeeper等)各组件的作用及相互之间的关系6.3 教学方法:互动提问,巩固知识点教案章节七:Hadoop集群的调优与优化7.1 课程目标:学会对Hadoop集群进行调优与优化掌握Hadoop集群性能监控的方法7.2 教学内容:Hadoop集群调优与优化原则参数调整与优化方法(如内存、CPU、磁盘I/O等)Hadoop集群性能监控工具(如JMX、Nagios等)7.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节八:Hadoop安全与权限管理8.1 课程目标:理解Hadoop安全的重要性学会对Hadoop集群进行安全配置与权限管理8.2 教学内容:Hadoop安全概述Hadoop的认证与授权机制Hadoop安全配置与权限管理方法8.3 教学方法:互动提问,巩固知识点教案章节九:Hadoop实战项目案例分析9.1 课程目标:学会运用Hadoop解决实际问题掌握Hadoop项目开发流程与技巧9.2 教学内容:真实Hadoop项目案例介绍与分析Hadoop项目开发流程(需求分析、设计、开发、测试、部署等)Hadoop项目开发技巧与最佳实践9.3 教学方法:案例分析与讨论团队协作,完成项目任务教案章节十:Hadoop的未来与发展趋势10.1 课程目标:了解Hadoop的发展现状及其在行业中的应用掌握Hadoop的未来发展趋势10.2 教学内容:Hadoop的发展现状及其在行业中的应用Hadoop的未来发展趋势(如Big Data生态系统的演进、与大数据的结合等)10.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点重点和难点解析:一、Hadoop生态系统的概念及其重要性重点:理解Hadoop生态系统的概念,掌握生态系统的组成及相互之间的关系。
Hadoop平台搭建与应用课程标准

《Hadoop平台搭建与应用》课程标准1. 概述1.1课程的性质本课程是大数据技术与应用专业、云计算技术与应用专业、软件技术专业的专业基础课程,是校企融合系列化课程,该课程基于Hadoop生态系统进行大数据平台的构建。
1.2课程设计理念本课程遵循应用型本科和高等职业教育规律,以大数据技术与应用实际工作岗位需求为导向选取课程内容,课程目标是培养学生具备“大数据分析”应用项目所需系统环境的搭建与测试综合职业能力;坚持开放性设计原则,吸收企业专家参与,建立基于Hadoop的生态环境,以“工作任务”为载体的“项目化”课程结构;课程教学实施教、学、做一体,坚持理论为实践服务的教学原则,通过模拟企业“大数据分析”环境进行组织,锻炼学生的实践操作能力。
1.3课程开发思路通过岗位技能的项目化以及系统搭建与应用任务的序列化,对内容体系结构进行了适当调整与重构,以适应教学课程安排。
以项目案例及其任务实现为驱动,凭借翔实的操作步骤和准确的说明,帮助学生迅速掌握Hadoop生态系统环境构建与应用,并且充分考虑学习操作时可能发生的问题,并提供了详细的解决方案,突出岗位技能训练。
2.课程目标本课程的培养目标是使学生以大数据系统运维岗位需求为依托,以实际工作任务为导向,理清Hadoop生态系统中各个组件的作用及应用,培养学生大数据分析平台构建的实际动手能力。
2.1知识目标基于Hadoop2.X生态系统,要求学生全面掌握Hive环境搭建与基本操作、Zookeeper环境搭建与应用、HBase环境搭建与基本操作、 pig系统搭建与应用、Sqoop系统搭建与应用、Flume系统搭建与应用以及使用Apache Ambari实现Hadoop集群搭建及管理等的相关知识以及操作技能。
2.2素质目标(1)培养学生动手能力、自主学习新知识的能力(2)培养学生团队协作精神2.3能力目标通过该课程的学习,学生能利用所学的相关技术,能搭建适用于各种大数据分析应用业务需求的系统,能处理常见的系统运行问题。
Hadoop大数据平台构建与应用课件项目1 认识大数据,实现学情分析系统设计与环境搭建

项目1 认识大数据,实现学情分 析系统设计与环境搭建
A
B
项目描述
。
项目描述
大数据正在实现人类工作、生活与思维的大变革,其“威力”也强烈地冲击着整个教育系统,正在成为推动教育系 统创新与变革的颠覆性力量。
目前大数据在教育领域的应用还存在诸多挑战,诸多因素制约了大数据在教育领域的应用,通过收集学生就业趋向、 学习兴趣、专业技能、岗位需求的数据,结合“因材施教”教育理论,帮助学生认识自己,结合学生实际,为其推 荐学习资源、就业信息等,如图1-1所示。
3.安装JRE。 在安装完JDK后,会弹出安装JRE 窗口的界面(在这里要注意修改 安装路径必须和JDK在同一目录下 ,而不是安装在JDK目录下),如 图1-15所示。
图1-15安装JRE
4.验证安装是否成功。 安装完成后需要验证Java环境 是否安装成功。验证方式有多 种,可以编写一个最简单的 Java程序文件后编译执行它, 也可以通过显示Java版本的命 令方式进行验证。本书采用通 过输入java –version命令,验证 安装是否成功。读者也可以通 过这个命令检查本机所安装的 Java环境的版本。具体命令如 图1-16所示。
B
01
A
C
05
02
03
实现 思路
D 06
04
G F
07
E
3. 系统整体架构
学情分析系统架构图如图1-12所示.
图1-12 学情分析系统架构图
任务1.2
构建学情分析系统开发环境
任务描述 1. 学习JDK、JRE等相关API,了解二者的差别。 2. 学习Java开发工具Eclipse集成开发工具的使用,以及相关配置。 3. 学习JAVA WEB服务器Tomcat的安装和配置。 4. 学习MySQL服务器以及客户端的安装及配置。 5. 完成Hadoop大数据开发环境的配置。 任务目标 1. 学会Java EE开发工具的配置与使用。 2. 学会MySQL数据库和Tomcat的安装与配置 3. 学会Hadoop大数据开发环境的配置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一hadoop安装过程提示:文中标注红色字体,修改配置文件时需与实际环境结合注意更改主机名,ip,文件路径。
1.配置IP地址vi /etc/sysconfig/network-scripts/ifcfg-eth0修改:BOOTPROTO=none添加:NETMASK=255.255.255.0IPADDR=IP地址2.修改主机名vi /etc/sysconfig/network修改:HOSTNAME=主机名3.vi /etc/hosts (3节点都修改)添加:192.168.18.201 h201192.168.18.202 h202192.168.18.203 h203IP地址主机名#有几个节点添加几个#4.每台机器创建hadoop 用户hadoop 密码:password 命令如下useradd hadooppasswd hadoop#如果直接安装在root用户下则不用创建hadoop用户由于安全问题建议安装在hadoop用户下#5.安装jdk(每台都安装)#本次安装目录在/usr,安装目录随意但注意声明环境变量时注意修改jdk位置#解压jdk -C 指定安装目录[root@master usr]# tar -zxvf jdk-7u25-linux-i586.tar.gz -C /usr/修改环境变量[root@master~]# vi /etc/profileexport JA VA_HOME=/usr/jdk1.7.0_25export JA VA_BIN=/usr/jdk1.7.0_25/binexport PATH=$PATH:$JA V A_HOME/binexport CLASSPA TH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jarexport JA VA_HOME JA V A_BIN PATH CLASSPA TH重启机器使换进变量生效[root@master~]# reboot6.切换hadoop用户su - hadoop安装ssh 证书生成公钥#每个节点执行如下命令(本次安装三个节点)#[hadoop@master ~]$ ssh-keygen -t rsa[hadoop@slave1~]$ ssh-keygen -t rsa[hadoop@slave2~]$ ssh-keygen -t rsa输入命令后按四次Enter键不要输入任何命令显示如下内容表示创建成功Generating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa):/root/.ssh/id_rsa already exists.Overwrite (y/n)? yEnter passphrase (empty for no passphrase):Enter same passphrase again:Your identification has been saved in /root/.ssh/id_rsa.Your public key has been saved in /root/.ssh/id_rsa.pub.The key fingerprint is:49:3a:5c:3c:50:d8:b3:a4:13:f4:6c:a9:b0:96:53:cb root@The key's randomart image is:+--[ RSA 2048]----+| .o+. || o=+. || . .+Xo || BoB.o || = E.S || . . . || || |+-----------------+将生成的公钥拷贝到远程服务器上ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub 主机名#每个节点都要执行#[hadoop@master ~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub master [hadoop@slave1~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub slave1 [hadoop@slave2~]$ ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub slave2 按提示输入内容检验是否配置成功远程连接其他节点ssh 其他节点主机名免密码直接登录则成功注意:如果连接不成功将/home/hadoop/.ssh 文件中的内容删掉重新直接以上命令或拷贝/home/hadoop/.ssh/id_rsa.pub 内容到所要连接节点的/home/hadoop/.ssh/authorized_keys目录下。
7.拷贝hadoop安装包到/home/hadoop 解压缩[hadoop@master hadoop]$ cp hadoop-2.6.0.tar.gz /home/hadoop[hadoop@master~]$ tar -zxvf hadoop-2.6.0.tar.gz修改环境变量[hadoop@master ~]$ vi .bash_profile声明hadoop和java的home,bin,conf目录添加以下内容:export JA VA_HOME=/usr/jdk1.7.0_25export JA VA_BIN=/usr/jdk1.7.0_25/binexport PATH=$PATH:$JA V A_HOME/binexport CLASSPA TH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jarexport JA VA_HOME JA V A_BIN PATH CLASSPA THHADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.5.2HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopPATH=$HADOOP_HOME/bin:$PA THexport HADOOP_HOME HADOOP_CONF_DIR PATH执行以下命令使其生效[hadoop@master ~]$ source .bash_profile8.切换到hadoop-2.6.0-cdh5.5.2/etc/hadoop/目录下修改配置文件(现在主节点修改,修改完之后直接拷贝到其他节点)[hadoop@master ~]$ cd hadoop-2.6.0-cdh5.5.2/etc/hadoop/[hadoop@master hadoop]$ vi core-site.xml添加以下内容:<configuration><property><name>fs.defaultFS</name><value>hdfs://主机名:9000</value><description>NameNode URI.</description></property><property><name>io.file.buffer.size</name><value>131072</value><description>Size of read/write buffer used inSequenceFiles.</description></property></configuration>9.编辑hdfs-site.xml(管理hdfs的文件)首先创建三个目录用于保存nn ,snn,dn三个进程的信息[hadoop@master hadoop-2.6.0]$ mkdir -p /home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/name [hadoop@master hadoop-2.6.0]$ mkdir -p /home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/data [hadoop@masterhadoop-2.6.0]$mkdir -p/home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/namesecondary[hadoop@masterhadoop]$ vi hdfs-site.xml添加以下内容<property><name>node.secondary.http-address</name><value>主机名:50090</value><description>The secondary namenode http server address andport.</description></property><property><name>.dir</name><value>file:///home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/name</value><description>Path on the local filesystem where the NameNodestores the namespace and transactions logs persistently.</description></property><property><name>dfs.datanode.data.dir</name><value>file:///home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/data</value><description>Comma separated list of paths on the local filesystemof a DataNode where it should store its blocks.</description></property><property><name>node.checkpoint.dir</name><value>file:///home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/namesecondary</value><description>Determines where on the local filesystem the DFSsecondary name node should store the temporary images to merge. If this is acomma-delimited list of directories then the image is replicated in all of thedirectories for redundancy.</description></property><property><name>dfs.replication</name><value>2</value></property>#从节点有几个就填几,本次安装两个从节点填2 #10.编辑mapred-site.xml(执行mapreduce的文件)[hadoop@master hadoop]$ cp mapred-site.xml.template mapred-site.xml<property><name></name><value>yarn</value><description>Theruntime framework for executing MapReduce jobs. Can be one of local, classic oryarn.</description></property><property><name>mapreduce.jobhistory.address</name><value>主机名:10020</value><description>MapReduce JobHistoryServer IPC host:port</description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>主机名:19888</value><description>MapReduce JobHistoryServer Web UI host:port</description></property>*****属性”“表示执行mapreduce任务所使用的运行框架,默认为local,需要将其改为”yarn”*****11.编辑yarn-site.xml(管理yarn)[hadoop@master hadoop]$ vi yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>主机名</value><description>The hostname of theRM.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>Shuffle service that needs to be set for Map Reduceapplications.</description> </property>12.[hadoop@master hadoop]$ vi hadoop-env.shexport JA VA_HOME=/usr/jdk1.7.0_2513.[hadoop@master hadoop]$ vi slavesslave1slave2#天剑从节点主机名,有几个从节点几个#14.拷贝hadoop文件到其他从节点[hadoop@master ~]$ scp -r ./hadoop-2.6.0/ hadoop@slave1:/home/hadoop/[hadoop@master~]$ scp -r ./hadoop-2.6.0/ hadoop@slave2:/home/hadoop/15.格式化namenode[hadoop@master hadoop-2.6.0]$ bin/hdfs namenode -format开启hadoop所有进程[hadoop@master hadoop-2.6.0]$ sbin/start-all.sh查看进程主[hadoop@master hadoop-2.6.0]$ jps7054 SecondaryNameNode7844 Jps7318 NameNode7598 ResourceManager从[hadoop@slave1 hadoop-2.6.0-cdh5.5.2]$ jps3869 DataNode7087 Jps4854 NodeManager试用[hadoop@master hadoop-2.6.0]$ bin/hadoop fs -ls /[hadoop@masterhadoop-2.6.0]$ bin/hadoop fs -mkdir /aaa注意:1.WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable如果报上面的警告:[hadoop@h201 ~]$ tar -xvf hadoop-native-64-2.6.0.tar -C hadoop-2.6.0/lib/native/[root@h201 ~]# vi /etc/yum.conf[Server]name=rhel_yumbaseurl=file:///mnt/Serverenabled=1gpgcheck=1gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release[root@master]# yum -y install gcc*系统中的glibc的版本和libhadoop.so需要的版本不一致导致[hadoop@master ~]$ ls -l /lib/libc.so.6lrwxrwxrwx 1 root root 11 2015-07-04 /lib/libc.so.6 -> libc-2.5.so[hadoop@master~]$ tar -jxvf glibc-2.9.tar.bz2[hadoop@master~]$ cd glibc-2.9注意:glibc-linuxthreads解压到glibc目录下[hadoop@masterglibc-2.9]$ cp /ff/hadoopCDH5/glibc-linuxthreads-2.5.tar.bz2 .[hadoop@masterglibc-2.9]$ tar -jxvf glibc-linuxthreads-2.5.tar.bz2[hadoop@master~]$ export CFLAGS="-g -O2"(加上优化开关)[hadoop@master ~]$ ./glibc-2.9/configure --prefix=/usr --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin[hadoop@master~]$ make[hadoop@master~]$ make install[hadoop@master~]$ ls -l /lib/libc.so.6重新启动2.如果格式化namnode报错检查hdfs-site.xml文件是否配置正确,修改后删除/home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/name ,data,namesecondary 三个文件中的内容重新执行bin/hdfs namenode -format3.如开启hadoop进程后jps不全根据缺失进程检查日志/home/hadoop/hadoop-2.6.0-cdh5.5.2/logs/hadoop-hadoop-datanode-slave1.log根据日志错误查找原因可能原因:主/home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/name/current/VERSION 与从/home/hadoop/hadoop-2.6.0-cdh5.5.2/dfs/data/current/VERSION版本号不一致改为一致即可。