使用taskset来进行多核系统调优
多核处理器系统的任务调度优化算法设计

多核处理器系统的任务调度优化算法设计1. 引言多核处理器系统在现代计算机体系结构中发挥着至关重要的作用。
通过利用多个核心同时执行任务,多核处理器可以提供更高的效率和性能。
然而,为了充分利用多核处理器的潜力,需要设计高效的任务调度算法,以平衡负载、避免资源竞争,并最大限度地发挥多核处理器的并行性能。
2. 现有的任务调度算法目前已经有很多任务调度算法被提出和应用于多核处理器系统。
其中,最常见和经典的算法包括负载均衡调度算法、静态分配算法、动态分配算法和基于进程优先级的调度算法等。
负载均衡调度算法:负载均衡调度算法旨在将任务均匀地分配给多个核心,以使每个核心的负载尽可能平衡。
这些算法通常基于任务的执行时间、优先级等因素进行任务分配,如轮转调度、最小作业优先法等。
静态分配算法:静态分配算法在任务启动之前将任务静态地分配给各个核心,以充分利用处理器资源。
这些算法适用于任务有固定的执行次序或依赖关系的情况。
动态分配算法:动态分配算法根据任务的执行情况和处理器的负载状况,动态地将任务分配给处理器核心。
这些算法通常包括任务窃取和任务迁移等策略,以实现负载均衡和充分利用处理器资源。
基于进程优先级的调度算法:基于进程优先级的调度算法通过给任务分配优先级来决定任务的执行次序。
这些算法可以根据任务的优先级和各个处理器核心的负载情况动态地调整任务的执行次序,以实现最优的任务调度。
3. 任务调度优化算法设计为了进一步提高多核处理器系统的性能和效率,可以设计一种综合考虑负载均衡、资源利用率和响应时间等因素的任务调度优化算法。
下面是一个基于进程优先级和动态负载均衡策略的任务调度优化算法设计。
步骤1:初始化任务队列和处理器核心队列。
将所有待执行的任务和多个处理器核心分别放入两个队列中。
步骤2:计算任务优先级。
根据任务的属性、执行时间和依赖关系等因素计算每个任务的优先级,并按照优先级进行排列。
步骤3:负载均衡策略。
从任务队列中选择一个任务,根据处理器核心的负载情况将该任务分配给合适的处理器核心。
多核处理器中的任务调度算法研究与优化

多核处理器中的任务调度算法研究与优化多核处理器是一种能够同时处理多个任务的计算机处理器,由于其高效的并行计算能力,越来越多的应用程序开始利用多核处理器来提高计算性能。
在多核处理器中,任务调度算法起着至关重要的作用,可以合理地分配和调度任务,最大程度地利用处理器资源,提高系统性能。
本文将重点研究和优化多核处理器中的任务调度算法,并探讨其应用和挑战。
首先,我们需要了解多核处理器中常用的任务调度算法。
目前,常见的多核处理器任务调度算法包括静态调度算法和动态调度算法。
静态调度算法在系统启动时就事先确定任务的调度顺序,这样的算法具有简单、高效的特点,适用于任务数固定、稳定的系统。
常见的静态调度算法有轮转调度算法、优先级调度算法和比例公平调度算法。
动态调度算法则根据任务的特征和系统的运行状态,动态地选择合适的任务调度顺序。
常见的动态调度算法有最短处理时间优先调度算法、最短剩余时间优先调度算法和多级反馈队列调度算法。
这些算法各有优劣,适用于不同的系统和任务负载。
然而,在实际应用中,使用预定义的调度算法可能无法满足多核处理器的需求,并且面临一些挑战。
首先,多核处理器的任务调度算法需要解决任务间的负载均衡问题。
负载均衡是指将任务合理地分配到各个处理器核心上,平衡地利用处理器资源。
如果分配不均衡,某些处理器核心可能会空闲,而其他核心则会超负荷工作,降低系统整体性能。
因此,任务调度算法需要能够动态地感知任务负载,选择适合的处理器核心进行调度。
其次,多核处理器的任务调度算法还需要解决任务间的通信和同步问题。
多个任务在多核处理器上进行并行计算时,可能会需要共享数据或进行通信、同步操作。
如果任务间的通信和同步不得当,会导致资源竞争和性能下降。
因此,任务调度算法需要考虑任务的依赖关系和通信开销,能够有效地管理任务之间的通信和同步操作。
针对以上挑战,研究者们提出了一些优化多核处理器任务调度算法的方法。
一种常见的优化方法是通过任务迁移来实现负载均衡。
【推荐下载】系统多核CPU速度提高设置的教程-精选word文档 (2页)

【推荐下载】系统多核CPU速度提高设置的教程-精选word文档本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==系统多核CPU速度提高设置的教程Windows7系统多核CPU速度提高设置现在的CPU都是双核CPU,而Windows 7对多核CPU有着良好的支持,如果没有进行适当的设置,在双核CPU启动过程中,就不能发挥多核CPU的性能,那么在Win7下应该怎么设置才能提升多核CPU的速度呢,下面来看看笔者怎么去提高多核CPU的速度。
1、点击开始菜单,在“搜索程序和文件”中输入“msconfig”,回车即打开“系统配置”对话框,请在此对话框中切换到“引导”标签,然后单击图中红圈处的“高级选项”按钮,弹出引导高级选项对话框。
2、在弹出的“引导高级选项”对话框中勾选处理器数,Windows 7系统默认情况下处理器个数为1,如果你是双核用户,在下拉菜单里选择处理器的数目,比如双核就选择“2”,并勾选最大内存选项。
3、修改完毕后,点击“确定”按钮,保存设置退出即可。
虽然现在Windows 7系统优化提速的软件,但是这些软件往往会“由于优化过头,导致部分系统功能丢失”,因此我们还是使用win7内在的设置来提升多核CPU的速度。
如何利用win7系统驱动程序解决电脑没有声音:windows 7系统中集成了海量的设备驱动程序,安装完成后,所有的设备驱动都已装上,主板中集成的Analog Devices公司生产的SoundMax AD1986A声卡被识别为"高清晰度音频设备",用Windows Media Player可以播放MP3,音量控制滑块可以拖动,音量指示器也在跳动,但是电脑就是没有声音。
几番摸索,终于从音量图标提示和音量控制对话框上看到了问题,它们提示的播放设备竟然是"耳机"。
Linux下进程绑定多CPU运行
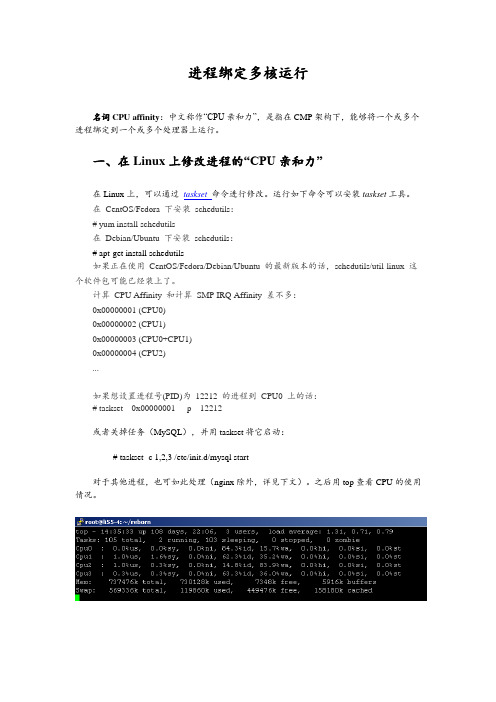
进程绑定多核运行名词CPU affinity:中文称作“CPU亲和力”,是指在CMP架构下,能够将一个或多个进程绑定到一个或多个处理器上运行。
一、在Linux上修改进程的“CPU亲和力”在Linux上,可以通过taskset命令进行修改。
运行如下命令可以安装taskset工具。
在CentOS/Fedora 下安装schedutils:# yum install schedutils在Debian/Ubuntu 下安装schedutils:# apt-get install schedutils如果正在使用CentOS/Fedora/Debian/Ubuntu 的最新版本的话,schedutils/util-linux 这个软件包可能已经装上了。
计算CPU Affinity 和计算SMP IRQ Affinity 差不多:0x00000001 (CPU0)0x00000002 (CPU1)0x00000003 (CPU0+CPU1)0x00000004 (CPU2)...如果想设置进程号(PID)为12212 的进程到CPU0 上的话:# taskset 0x00000001 -p 12212或者关掉任务(MySQL),并用taskset将它启动:# taskset -c 1,2,3 /etc/init.d/mysql start对于其他进程,也可如此处理(nginx除外,详见下文)。
之后用top查看CPU的使用情况。
二、配置nginx绑定CPU刚才说nginx除外,是因为nginx提供了更精确的控制。
在conf/nginx.conf中,有如下一行:worker_processes 1;这是用来配置nginx启动几个工作进程的,默认为1。
而nginx还支持一个名为worker_cpu_affinity的配置项,也就是说,nginx可以为每个工作进程绑定CPU。
我做了如下配置:worker_processes 3;worker_cpu_affinity 0010 0100 1000;这里0010 0100 1000是掩码,分别代表第2、3、4颗cpu核心。
多核处理器上的操作系统调度

多核处理器上的操作系统调度多核处理器上的操作系统调度随着科技的不断发展和计算机性能的不断提升,多核处理器成为了如今计算机体系结构的主流。
多核处理器能够同时执行多个任务,提高计算效率,但同时也提出了新的挑战,即如何合理高效地分配和调度任务,充分利用多核处理器的性能优势。
在多核处理器上,操作系统的调度策略是关键,直接影响到系统的性能和资源利用率。
一个好的调度策略能够充分利用多核处理器的并行计算能力,提高系统吞吐量和响应速度。
下面将介绍几种常见的多核处理器上的操作系统调度策略。
首先,常见的调度策略之一是静态调度。
静态调度是指在任务开始执行之前,由操作系统预先确定每个任务的执行顺序和时间片分配。
这种调度策略对于任务具有明确的执行顺序和时间要求的场景非常有效。
比如,对于实时系统,可以通过静态调度保证任务按照严格的时间要求完成。
然而,静态调度策略往往需要提前对任务进行合理的预估和分析,如果任务的特性发生变化,可能需要重新进行调度。
另一种常见的调度策略是动态调度,动态调度是指根据实时的系统状态和任务要求,实时地进行任务调度和资源分配。
动态调度能够根据系统负载和任务的紧急程度决定任务的执行顺序和时间片分配。
动态调度策略更加灵活,能够根据任务的特性和系统当前状态进行实时调整,提高系统的响应速度和资源利用率。
但相应地,动态调度策略需要更加复杂和高效的调度算法和机制,来快速准确地做出调度决策。
除了静态调度和动态调度,还有一种常见的调度策略是混合调度。
混合调度策略结合了静态调度和动态调度的特点,既能根据任务的要求分配一定的时间片给任务,又能在运行过程中动态地调整任务的执行顺序。
混合调度策略能够在保证任务执行顺序和时间要求的前提下,充分利用多核处理器的并行性能,提高系统的吞吐量和响应速度。
混合调度策略通常需要通过一些特殊的数据结构和算法来实现,以便快速准确地做出调度决策。
除了调度策略,操作系统调度还需要考虑任务的调度粒度。
多核处理器中的任务调度算法优化研究

多核处理器中的任务调度算法优化研究随着技术的发展,多核处理器已经成为了计算机系统中的重要组成部分。
多核处理器有着更高的运算能力和更强的并行处理能力,可以同时执行多个任务,提高系统的性能和效率。
然而,多核处理器中的任务调度算法却是一个具有挑战性的问题。
本文将探讨多核处理器中的任务调度算法优化研究。
首先,我们需要了解任务调度算法在多核处理器中的作用。
任务调度算法的主要功能是将各个任务分配给不同的处理器核心,使得多个任务能够在不同的核心上并行执行。
一个好的任务调度算法可以合理地分配任务,充分利用处理器核心的计算资源,提高系统的性能和效率。
目前,多核处理器中常用的任务调度算法主要有静态任务调度算法和动态任务调度算法两种。
静态任务调度算法在任务分配之前就已经确定好任务的执行顺序和分配方式,包括静态轮转法、静态优先级算法等。
这些算法的优点是简单高效,适用于一些对响应时间要求不高的应用场景。
然而,静态任务调度算法无法适应任务的动态变化,并且不能充分利用多核的并行能力。
相比之下,动态任务调度算法在任务分配时可以实时地根据任务的特性和系统的状态来调整任务的执行顺序和分配方式,如最短作业优先算法、最高优先级优先算法等。
这些算法可以根据任务的优先级来合理地对任务进行调度,提高系统的性能和效率。
然而,动态任务调度算法的复杂度较高,需要更多的计算和判断,可能会导致一定的延迟和开销。
为了解决多核处理器中任务调度算法的优化问题,研究者们提出了许多新的算法和方法。
例如,基于遗传算法的任务调度算法可以通过模拟生物进化的方式来优化任务的分配,提高系统的负载均衡和性能。
基于多目标优化的任务调度算法可以综合考虑任务的优先级、任务之间的依赖关系和系统的资源限制等因素,使得任务调度更加智能化和灵活化。
另外,一些研究者还从硬件的角度进行优化。
例如,通过设计具有较大缓存和更快的内存访问速度的处理器芯片,可以减小任务之间的竞争和延迟,提高任务的执行效率。
多核处理器任务并行调度算法设计与优化

多核处理器任务并行调度算法设计与优化随着计算机技术的快速发展,多核处理器成为了当前计算机系统的主要设计方向之一。
多核处理器拥有多个处理核心,可以同时处理多个任务,提高计算机的处理性能和并行计算能力。
然而,如何有效地调度和管理多核处理器上的任务,成为了一个重要的课题。
本文将介绍多核处理器任务并行调度算法的设计与优化。
首先,我们需要了解多核处理器任务并行调度算法的基本原理。
多核处理器上的任务调度是指将不同的任务分配到不同的处理核心上,以最大程度地提高处理器的利用率和性能。
而并行调度算法则侧重于如何将任务分配到不同的处理核心上,并保持任务之间的并行执行,以实现更高效的任务处理。
在多核处理器上,任务并行调度算法需要考虑以下几个关键因素。
首先是任务之间的依赖关系。
如果一个任务依赖于另一个任务的结果,那么在调度时需要确保被依赖的任务先于依赖任务调度执行。
其次是处理核心之间的负载均衡。
为了实现最佳的性能,需要确保每个处理核心上的任务负载平衡,避免出现某个处理核心负载过高而其他核心空闲的情况。
最后是通信开销。
在多核处理器上,任务之间的通信会引入额外的开销,调度算法需要尽量减少通信开销,提高整体的执行效率。
在设计多核处理器任务并行调度算法时,可以采用以下的一些经典算法。
首先是最短作业优先(SJF)调度算法。
该算法将任务按照执行时间进行排序,先执行执行时间最短的任务,从而减少任务的等待时间,提高整体的处理效率。
其次是先来先服务(FCFS)调度算法。
该算法按照任务到达的顺序进行调度,保证任务的公平性,但不能有效地利用处理器资源。
再次是最高响应比优先(HRRN)调度算法。
该算法通过计算任务等待时间和服务时间的比值,选择具有最高响应比的任务进行调度,以提高任务的响应速度和处理器利用率。
最后是多级反馈队列(MFQ)调度算法。
该算法将任务分为多个队列,根据任务的优先级进行调度,优先处理优先级高的任务,并逐渐降低任务的优先级,以实现负载均衡。
使用taskset来进行多核系统调优

使用taskset来进行多核系统调优查看pid和那个cpu亲和taskset -pc 3687返回pid 3687's current affinity list: 0,1,2,3表示3687和0,1两个cpu内核比较亲和taskset -pc 0-1 3687设置线程3678和0,1两个cpu内核亲和top -p 3687查看此线程具体执行情况************************************************ ************************************************ ******************************利用taskset可以充分利用多核cpu的好处,可以让某个程序或脚本,运行在某个具体的cpu上。
这个工具系统可能没有默认安装:,rpm包名util-linux#taskset --helptaskset (util-linux 2.13-pre7)usage: taskset [options] [mask | cpu-list] [pid | cmd [args...]]set or get the affinity of a process-p, –pid operate on existing given pid-c, –cpu-list display and specify cpus in list format-h, –help display this help-v, –version output version information1:让某个程序运行在特定cpu上面taskset -c 0 sh wade.sh2:切换某个进程到特定的cpu上。
taskset -pc 0 12345比如你有一个cpu是4 core你可以这样写你的脚本#!/bin/bashtaskset -c 0 sh a.sh &taskset -c 1 sh b.sh &taskset -c 2 sh c.sh &taskset -c 3 sh d.sh &应该可以充分利用你的cpu了。
多核处理器中的任务调度算法优化研究

多核处理器中的任务调度算法优化研究引言:随着计算机技术的不断发展,多核处理器已经成为了当前主流的计算机架构之一。
多核处理器通过在一个集成电路上组合多个处理器核心,可以并行处理多个任务,从而实现更高的计算性能。
然而,随着核心数量的增加,任务调度算法的性能优化变得越来越重要。
本文将探讨多核处理器中任务调度算法的优化研究。
一、多核处理器的任务调度算法介绍1.1 静态任务调度算法静态任务调度算法是在任务开始执行前就确定了任务的调度顺序。
常见的静态任务调度算法包括FIFO(先进先出)、RR(轮转调度)等。
这些算法简单易实现,但对于多核处理器的利用率不高,因为它们无法根据核心的负载情况进行动态调整。
1.2 动态任务调度算法动态任务调度算法是根据当前核心的负载情况,动态地选择合适的任务进行调度。
常见的动态任务调度算法包括最短作业优先(SJF)、最小可剩余时间(SRT)、最高响应比优先(HRRN)等。
这些算法可以根据任务的执行时间和优先级灵活选择最佳的任务调度方案,从而提高多核处理器的利用率。
二、多核处理器中任务调度算法的优化2.1 平衡负载算法在多核处理器中,任务调度的一个关键目标是平衡负载,即使各个核心的工作负载尽量均衡。
常见的平衡负载算法包括最少剩余时间(LSF)、最佳适应度算法(BFA)等。
这些算法通过动态地调整任务之间的切换和分配,使得各个核心的负载保持均衡,从而提高系统的整体性能。
2.2 优先级调度算法优先级调度算法是根据任务的优先级进行调度。
常见的优先级调度算法包括最高优先级(HPF)、最低优先级(LPF)等。
这些算法通过赋予不同任务不同的优先级,保证高优先级任务的及时响应,从而提高系统的实时性能。
2.3 预测性任务调度算法预测性任务调度算法是根据任务的历史执行情况进行调度。
常见的预测性任务调度算法包括最小错误率预测(MLP)、人工神经网络(ANN)等。
这些算法通过学习任务的历史执行情况,预测未来任务的执行情况,从而预先分配合适的任务给核心,提高多核处理器的利用率和执行效率。
操作系统在多核处理器中的优化方法

操作系统在多核处理器中的优化方法随着科技的不断发展和计算机硬件的进步,多核处理器成为了现代计算机的主流配置。
然而,要充分发挥多核处理器的潜力并提高系统性能,并不仅仅依靠硬件的升级,操作系统在多核处理器中的优化也起着至关重要的作用。
本文将探讨操作系统在多核处理器中的优化方法。
一、任务调度优化在多核处理器中,任务的调度是操作系统的一个关键功能。
传统单核处理器的任务调度算法不再适用于多核场景,因此需要针对多核处理器进行优化。
以下是几种常见的任务调度优化方法。
1. 对称多处理(SMP)对称多处理是一种常见的任务调度方法,也是传统单核处理器的延续。
该方法将所有处理核心视为对称的,任务可以在任何一个核心上运行,系统会动态地将任务在核心之间进行平衡,使得每个核心的负载尽可能均衡。
然而,SMP方法主要使用在对称多处理器上,并未充分利用多核处理器的潜力。
2. 异步多线程(ASMP)异步多线程是一种更高级的任务调度方法,可以更好地适应多核处理器。
该方法将一个进程拆分为多个线程,并在不同的核心上运行,实现并行计算。
每个线程可以独立执行,通过合理调度和资源管理来优化系统性能。
3. 任务粒度调整任务的粒度对于多核处理器的性能至关重要。
过小的任务粒度会导致频繁的上下文切换和负载不均衡,而过大的任务粒度会导致部分核心空闲。
因此,操作系统需要根据任务的特点和处理器的性能调整任务的粒度,以最大程度地发挥多核处理器的并行能力。
二、内存管理优化内存管理是操作系统的核心功能之一,而在多核处理器中,如何优化内存管理对于系统性能至关重要。
1. 缓存一致性多核处理器的一个重要特点是共享缓存。
当多个核心同时修改同一个缓存区域时,需要保证缓存的一致性,否则会导致数据错误。
操作系统可以通过合理的缓存一致性协议来保证数据的正确性和一致性。
2. NUMA架构优化在某些情况下,多核处理器会采用非一致性访问内存(NUMA)的架构。
这种架构下,每个核心访问本地内存的速度要快于访问远程内存。
多核处理器中的任务调度与优化策略

多核处理器中的任务调度与优化策略随着计算机技术的不断发展,多核处理器已经成为现代计算机系统的标配。
多核处理器内部的任务调度与优化策略对于提高系统性能和资源利用率起着至关重要的作用。
本文将重点探讨多核处理器中的任务调度与优化策略,并分析其实际应用和挑战。
首先,我们需要了解多核处理器的基本原理。
多核处理器是指在一个集成电路芯片上集成多个处理核心,每个处理核心都能够独立地执行程序指令。
多核处理器遵循并行计算的原则,通过同时运行多个任务来提高系统的处理能力。
因此,任务调度和优化的目标是尽可能地实现任务的并行计算,以提高系统的整体性能。
任务调度是指将多个任务分配给多核处理器上的处理核心,以便合理利用系统资源并优化性能。
在任务调度过程中,需要考虑以下几个关键因素:1. 负载均衡:负载均衡是指将任务合理地分配给处理核心,以避免某些核心过载而其他核心处于空闲状态。
负载均衡可以通过静态调度或动态调度来实现。
静态调度是指在程序运行前就确定任务的分配方式,而动态调度是指在运行时根据系统的负载情况进行任务分配。
2. 任务依赖关系:任务之间可能存在依赖关系,即某个任务的执行需要依赖其他任务的结果。
在任务调度中,需要考虑任务之间的依赖关系,确保依赖关系正确处理并合理利用。
一种常见的解决方案是使用依赖图来描述任务之间的关系,并根据依赖关系进行调度。
3. 数据共享与通信开销:在多核处理器中,任务之间可能需要共享数据或进行通信。
数据共享和通信操作会带来额外的开销,影响系统的性能。
因此,在任务调度过程中,需要考虑最小化数据共享和通信的开销,以提高系统的效率。
为了实现任务调度的优化,研究人员提出了多种策略和算法。
以下是一些常见的优化策略:1. 分治策略:分治策略是一种将大任务划分为多个小任务,然后分配给不同的处理核心并行执行的策略。
这种策略能够提高系统的并行度,加速任务的执行速度。
在任务划分过程中,需要考虑任务的负载均衡和依赖关系,确保任务可以有效地并行执行。
多核处理器的任务调度算法研究与优化

多核处理器的任务调度算法研究与优化多核处理器是当前高性能计算系统中的重要组成部分,可以提供更高的计算能力和吞吐量。
然而,在多核处理器中,如何合理地调度任务以充分利用处理器的计算资源,是一个重要的研究课题。
本文将对多核处理器的任务调度算法进行研究与优化,以提高系统的执行效率和性能。
一、任务调度算法的概念任务调度算法是指根据任务的特性和系统的资源情况,将任务分配给合适的处理器核心,使得系统可以以尽可能高的性能运行。
任务调度算法要考虑到任务之间的依赖关系、处理器的负载均衡、功耗以及系统响应时间等因素。
二、常用的任务调度算法1. 先来先服务(FCFS)调度算法:按任务提交的顺序进行调度,每个核心依次执行任务,没有考虑任务的优先级和执行时间。
2. 时间片轮转调度算法:每个核心被分配一个时间片,按照轮转的方式执行任务。
当一个时间片用完后,如果任务没有完成,则将其放入队列的末尾,继续执行下一个任务。
3. 最短作业优先(SJF)调度算法:根据任务的执行时间,优先调度执行时间最短的任务。
4. 最高响应比优先(HRRN)调度算法:根据任务等待时间和执行时间的比例,选择具有最高响应比的任务进行调度。
5. 多级反馈队列调度算法:根据任务的优先级和执行时间,将任务分配到不同的队列中,在每个队列中按照不同的调度策略进行任务调度。
三、任务调度算法的优化方法1. 负载均衡优化:在多核处理器中,各个核心的负载均衡是一个重要的问题。
通过监测各个核心的负载情况,实时调整任务的分配,使各个核心的负载保持均衡,以提高系统整体的性能。
2. 动态优先级调度:根据任务的特性和重要程度,动态调整任务的优先级。
例如,对于一些需要实时响应的任务,将其优先级提高,以确保其能够及时得到执行。
3. 预测任务执行时间:通过对任务的历史执行数据进行分析和建模,预测任务的执行时间,以便更准确地分配任务,避免任务因执行时间过长而导致系统性能下降。
4. 混合式调度算法:将不同的调度算法结合起来,根据任务的特性和系统的资源情况,选择最适合的调度算法。
多核处理器中的任务调度算法优化

多核处理器中的任务调度算法优化随着计算机技术的迅猛发展,多核处理器已经成为了现代计算机的主流。
多核处理器的出现使得计算机能够同时执行多个任务,提高了计算机的并行处理能力。
然而,在多核处理器中,任务调度算法的优化是一个至关重要的问题。
任务调度算法是指决定在多核处理器上如何分配任务的方法。
优秀的任务调度算法可以提高多核处理器的利用率,减少任务执行时间,提高系统的性能。
因此,如何优化多核处理器中的任务调度算法成为了一个热门的研究领域。
在多核处理器中,任务调度算法的优化可以从多个方面入手。
首先,可以考虑任务的负载均衡问题。
负载均衡是指将任务合理地分配到多个核心上,使得每个核心的负载尽可能均衡。
如果某个核心负载过重,而其他核心负载较轻,就会导致系统的性能下降。
因此,优化任务调度算法应该考虑如何实现负载均衡。
其次,可以考虑任务的优先级问题。
在多核处理器中,不同的任务可能具有不同的优先级。
一些任务可能需要更快地得到执行,而另一些任务则可以稍后执行。
优化任务调度算法应该考虑任务的优先级,合理地安排任务的执行顺序,以提高系统的性能。
另外,可以考虑任务的通信开销问题。
在多核处理器中,任务之间可能需要进行通信,以完成某些协作任务。
然而,任务之间的通信可能会引入额外的开销,降低系统的性能。
因此,优化任务调度算法应该尽量减少任务之间的通信开销,提高系统的性能。
此外,可以考虑任务的并行度问题。
在多核处理器中,任务之间可能存在一定的依赖关系。
一些任务必须按照一定的顺序执行,而另一些任务可以并行执行。
优化任务调度算法应该尽量提高任务的并行度,以提高系统的性能。
为了优化多核处理器中的任务调度算法,研究者们提出了许多优秀的方法。
例如,可以使用遗传算法来优化任务调度算法。
遗传算法是一种模拟生物进化过程的优化算法,通过不断地进化和选择,可以找到最优的任务调度算法。
另外,可以使用模拟退火算法来优化任务调度算法。
模拟退火算法是一种模拟金属退火过程的优化算法,通过不断地降低系统能量,可以找到最优的任务调度算法。
shell中taskset的使用方法

shell中taskset的使用方法(实用版4篇)目录(篇1)1.引言2.taskset 命令的介绍3.taskset 命令的用法4.taskset 命令的示例5.结论正文(篇1)一、引言在Linux系统中,taskset命令是一个常用的工具,用于控制和管理多线程或进程的执行。
taskset可以用来限制进程使用CPU的资源,以保证各个进程公平地共享CPU时间。
在本文中,我们将介绍taskset命令的使用方法。
二、taskset命令的介绍taskset是一个Linux系统自带的命令行工具,它能够控制一个进程所分配的CPU资源。
通过使用taskset,我们可以确保一个进程在运行时不会被其他进程占用太多的CPU资源,从而提高了系统的性能和稳定性。
三、taskset命令的用法taskset命令的基本语法如下:taskset [options] [mask] [program]其中,options是可选参数,mask是一个二进制掩码,program是要执行的程序。
mask和program可以缺省,其中mask是必需的。
mask是一个二进制掩码,用于指定要分配给程序的CPU资源。
可以使用CPU编号或0b11111111来指定CPU资源。
例如,使用1表示使用CPU 0和CPU 1,使用4表示使用CPU 2、CPU 3、CPU 4和CPU 5。
program是要执行的程序名或可执行文件的路径。
四、taskset命令的示例假设我们有两个CPU,编号为0和1。
我们想要让一个进程只使用CPU 0,另一个进程只使用CPU 1。
我们可以使用以下命令:taskset -c 0 program1 u0026taskset -c 1 program2 u0026这将分别运行program1和program2两个进程,并确保它们分别占用CPU 0和CPU 1。
五、结论taskset命令是一个非常有用的工具,可以帮助我们更好地控制和管理多线程或进程的执行。
taskset 命令参数

taskset 命令参数
taskset命令是Linux操作系统中的一个命令,它可以对进程进行CPU亲和性设置,即让进程在指定的CPU核心或者CPU核心集合上运行,这样可以更好地利用多核CPU的并行性能,提高系统的吞吐量和响应速度。
以下是taskset命令的参数:
`-p, --pid`:显示指定进程的CPU亲和性设置。
`-c, --cpu-list`:设置CPU核心的列表,多个核心之间用逗号隔开,例如“0,2,4”。
`-h, --help`:显示帮助信息。
`-V, --version`:显示版本信息。
`-a, --all-tasks`:操作所有的任务线程。
在使用taskset命令时,可以指定一个进程ID或一个要启动的新进程的命令和参数。
如果未指定进程ID,则taskset命令将操作当前进程。
请注意,对于超级用户权限下执行的进程,可以使用“1”表示当前CPU核心,或者使用“0”表示任意核心。
此外,使用taskset命令还可以根据CPU亲和性来调度任务。
例如,如果某个任务需要在指定的CPU核心上运行,则可以使用taskset命令来将该
任务绑定到该核心上。
这样可以使该任务获得更好的CPU资源利用率和执行效率。
以上信息仅供参考,建议咨询专业人士获取具体信息。
taskset机理

taskset机理taskset机制是一种用于管理进程CPU亲和性的机制。
CPU亲和性是指将进程绑定到特定的CPU核心上,以提高系统性能和资源利用率。
本文将介绍taskset机制的原理、使用方法以及相关注意事项。
一、taskset机制的原理在多核系统中,操作系统会将进程分配到不同的CPU核心上执行。
然而,进程的切换和迁移会带来一定的开销,影响系统性能。
为了最大程度地减少进程切换和迁移的开销,可以使用taskset机制将进程绑定到特定的CPU核心上,使其始终在该核心上执行。
taskset机制的原理是通过设置进程的CPU亲和性掩码来实现的。
CPU亲和性掩码是一个位图,每一位代表一个CPU核心,进程可以绑定到对应位为1的核心上执行。
通过设置不同的掩码,可以实现进程在多个核心之间的切换和迁移。
二、taskset机制的使用方法在Linux系统中,可以使用taskset命令来设置进程的CPU亲和性。
其基本的使用方法如下:taskset -c <cpu_list> <command>其中,<cpu_list>表示要绑定的CPU核心列表,可以使用逗号分隔不同的核心编号,也可以使用连字符表示一个范围。
例如,0,2,4-7表示绑定0号、2号以及4到7号核心。
而<command>则表示要执行除了使用taskset命令外,还可以通过在程序中调用sched_setaffinity函数来设置进程的CPU亲和性。
这个函数的使用方法类似于taskset命令。
三、taskset机制的注意事项在使用taskset机制时,需要注意以下几点:1. 确定绑定的CPU核心数目。
过多的核心绑定可能导致负载不均衡,影响系统整体性能;而过少的核心绑定可能无法充分利用系统资源。
2. 避免绑定关键进程。
某些关键进程,如系统进程或关键服务进程,最好不要进行CPU绑定,以免影响系统的稳定性和可用性。
3. 考虑NUMA架构。
cpu亲和力总结taskset和setcpu及其他相关

cpu亲和⼒总结taskset和setcpu及其他相关⼀:taskset -- 获取或指定进程运⾏的CPU.man taskset出现CPU affinity is a scheduler property that "bonds" a process to a given set of CPUs on the system. The Linux scheduler will honor the given CPU affinity and the process will not run on any other CPUs. Note that the Linux scheduler also supports natural CPU affinity:翻译:taskset设定cpu亲和⼒,cpu亲和⼒是指CPU调度程序属性关联性是“锁定”⼀个进程,使他只能在⼀个或⼏个cpu线程上运⾏。
对于⼀个给定的系统上设置的cpu。
给定CPU亲和⼒和进程不会运⾏在任何其他CPU。
注意,Linux调度器还⽀持⾃然CPU关联:(不能让这个cpu只为这⼀个进程服务)这⾥要注意的是我们可以把某个程序限定在某⼀些CPU上运⾏,但这并不意味着该程序可以独占这些CPU,其实其他程序还是可以利⽤这些CPU运⾏。
如果要精确控制CPU,taskset就略嫌不⾜,cpuset才是可以-a, --all-tasks 操作所有的任务线程-p, --pid 操作已存在的pid-c, --cpu-list 通过列表显⽰⽅式设置CPU(1)指定1和2号cpu运⾏25718线程的程序taskset -cp 1,2 25718(2),让某程序运⾏在指定的cpu上 taskset -c 1,2,4-7 tar jcf test.tar.gz test(3)指定在1号CPU上后台执⾏指定的perl程序taskset –c 1 nohup perl pi.pl &⼆:cpuset编码测试⼀个进程的CPU亲合⼒掩码决定了该进程将在哪个或哪⼏个CPU上运⾏.在⼀个多处理器系统中,设置CPU亲合⼒的掩码可能会获得更好的性能.⼀个CPU的亲合⼒掩码⽤⼀个cpu_set_t结构体来表⽰⼀个CPU集合,下⾯的⼏个宏分别对这个掩码集进⾏操作: ·CPU_ZERO() 清空⼀个集合·CPU_SET()与CPU_CLR()分别对将⼀个给定的CPU号加到⼀个集合或者从⼀个集合中去掉.·CPU_ISSET()检查⼀个CPU号是否在这个集合中.下⾯两个函数就是⽤来设置获取线程CPU亲和⼒状态: ·sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask) 该函数设置进程为pid的这个进程,让它运⾏在mask所设定的CPU上.如果pid的值为0,则表⽰指定的是当前进程,使当前进程运⾏在mask所设定的那些CPU上.第⼆个参数cpusetsize是mask所指定的数的长度.通常设定为sizeof(cpu_set_t).如果当前pid所指定的进程此时没有运⾏在mask所指定的任意⼀个CPU上,则该指定的进程会从其它CPU上迁移到mask的指定的⼀个CPU上运⾏.·sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask) 该函数获得pid所指⽰的进程的CPU位掩码,并将该掩码返回到mask所指向的结构中.即获得指定pid当前可以运⾏在哪些CPU上.同样,如果pid的值为0.也表⽰的是当前进程.[html] view plain copy1. cpu_set_t的定义2.3. # define __CPU_SETSIZE 10244. # define __NCPUBITS (8 * sizeof (__cpu_mask))5. typedef unsigned long int __cpu_mask;6. # define __CPUELT(cpu) ((cpu) / __NCPUBITS)7. # define __CPUMASK(cpu) ((__cpu_mask) 1 << ((cpu) % __NCPUBITS))8. typedef struct9. {10. __cpu_mask __bits[__CPU_SETSIZE / __NCPUBITS];11. } cpu_set_t;12.13. # define __CPU_ZERO(cpusetp) \14. do { \15. unsigned int __i; \16. cpu_set_t *__arr = (cpusetp); \17. for (__i = 0; __i < sizeof (cpu_set_t) / sizeof (__cpu_mask); ++__i) \18. __arr->__bits[__i] = 0; \19. } while (0)20. # define __CPU_SET(cpu, cpusetp) \21. ((cpusetp)->__bits[__CPUELT (cpu)] |= __CPUMASK (cpu))22. # define __CPU_CLR(cpu, cpusetp) \23. ((cpusetp)->__bits[__CPUELT (cpu)] &= ~__CPUMASK (cpu))24. # define __CPU_ISSET(cpu, cpusetp) \25. (((cpusetp)->__bits[__CPUELT (cpu)] & __CPUMASK (cpu)) != 0) 上⾯⼏个宏与函数的具体⽤法:[html] view plain copy1. cpu.c2.3. #include<stdlib.h>4. #include<stdio.h>5. #include<sys/types.h>6. #include<sys/sysinfo.h>7. #include<unistd.h>8.9. #define __USE_GNU10. #include<sched.h>11. #include<ctype.h>12. #include<string.h>13.14. int main(int argc, char* argv[])15. {16. int num = sysconf(_SC_NPROCESSORS_CONF);17. int created_thread = 0;18. int myid;19. int i;20. int j = 0;21.22. cpu_set_t mask;23. cpu_set_t get;24.25. if (argc != 2)26. {27. printf("usage : ./cpu num\n");28. exit(1);29. }30.31. myid = atoi(argv[1]);32.33. printf("system has %i processor(s). \n", num);34.35. CPU_ZERO(&mask);36. CPU_SET(myid, &mask);37.38. if (sched_setaffinity(0, sizeof(mask), &mask) == -1)39. {40. printf("warning: could not set CPU affinity, continuing...\n");41. }42. while (1)43. {44.45. CPU_ZERO(&get);46. if (sched_getaffinity(0, sizeof(get), &get) == -1)47. {48. printf("warning: cound not get cpu affinity, continuing...\n");49. }50. for (i = 0; i < num; i++)51. {52. if (CPU_ISSET(i, &get))53. {54. printf("this process %d is running processor : %d\n",getpid(), i);55. }56. }57. }58. return 0;59. }下⾯是在两个终端分别执⾏了./cpu 0 ./cpu 2 后得到的结果. 效果⽐较明显.QUOTE:Cpu0 : 5.3%us, 5.3%sy, 0.0%ni, 87.4%id, 0.0%wa, 0.0%hi, 2.0%si, 0.0%stCpu1 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu2 : 5.0%us, 12.2%sy, 0.0%ni, 82.8%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%stCpu3 : 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st在我的机器上sizeof(cpu_set_t)的⼤⼩为128,即⼀共有1024位.第⼀位代表⼀个CPU号.某⼀位为1则表⽰某进程可以运⾏在该位所代表的cpu上.例如CPU_SET(1, &mask);则mask所对应的第2位被设置为1.此时如果printf("%d\n", mask.__bits[0]);就打印出2.表⽰第2位被置为1了.具体我是参考man sched_setaffinity⽂档中的函数的.然后再参考了⼀下IBM的 developerWorks上的⼀个讲解.三:,使⽤nice和renice设置程序执⾏的优先级格式:nice [-n 数值] 命令nice 指令可以改变程序执⾏的优先权等级。
taskset 用法

taskset 用法
taskset 是一个Linux命令,用于将进程或任务绑定到特定的CPU核心或CPU集合上。
它提供了一种方式来控制进程运行
在哪个CPU上,以及限制进程的CPU使用。
下面是taskset的常见用法:
1. 将进程绑定到特定的CPU核心:可以使用taskset命令将一
个已经运行的进程绑定到特定的CPU核心。
例如,下面的命
令将PID为123的进程绑定到CPU核心2上:
```
taskset -p 2 123
```
2. 启动一个新进程并绑定到特定的CPU核心:可以在启动新
进程时使用taskset命令将其绑定到特定的CPU核心。
例如,
下面的命令将执行“./myprogram”并将其绑定到CPU核心3上:
```
taskset -c 3 ./myprogram
```
3. 查看进程当前的CPU绑定情况:可以使用taskset命令查看
进程当前绑定到哪个CPU核心。
例如,下面的命令将显示
PID为123的进程当前绑定的CPU核心:
```
taskset -p 123
```
4. 限制进程的CPU使用集合:可以使用taskset命令限制进程
的CPU使用集合。
例如,下面的命令将限制PID为123的进
程只能在CPU核心0和1上运行:
```
taskset -c 0,1 -p 123
```
这些只是taskset命令的一些常见用法,更详细的用法和选项
可以通过在终端中输入"man taskset" 来查看taskset的手册页。
taskset机理

taskset机理taskset是Linux操作系统中的一个命令,它可以设置进程的CPU 亲和性,即绑定进程到特定的CPU上运行。
通过taskset命令,我们可以控制进程在多个CPU核心中的调度方式,从而提高系统的性能和效率。
在Linux操作系统中,每个CPU核心都有一个唯一的标识号,从0开始递增。
taskset命令可以指定进程运行在哪个或哪些CPU核心上,以及运行的优先级。
使用taskset命令的基本语法如下:taskset [options] [mask] [pid | command [arg...]]其中,options表示选项,mask表示CPU核心的掩码(即二进制表示的整数),pid表示进程的ID,command表示要运行的命令,arg 表示命令的参数。
taskset命令的常用选项包括:- -c, --cpu-list:指定CPU核心列表,用逗号分隔。
- -p, --pid:指定进程的ID。
- -a, --all-tasks:对所有进程设置CPU亲和性。
在实际使用taskset命令时,我们需要先了解系统中的CPU核心数量和标识号。
可以通过查看/proc/cpuinfo文件或使用lscpu命令来获取这些信息。
然后,根据需要设置进程的CPU亲和性,可以使用taskset命令的不同选项和参数来实现。
例如,假设我们要将进程的ID为1234的进程绑定到CPU核心0和1上运行,可以使用以下命令:taskset -c 0,1 -p 1234这样,进程1234将只在CPU核心0和1上运行,不会被调度到其他CPU核心上。
这种方式可以有效地避免进程在不同CPU核心之间的切换,提高系统的性能和效率。
除了绑定进程到特定的CPU核心上,taskset命令还可以设置进程的运行优先级。
通过使用nice命令结合taskset命令,我们可以在绑定CPU核心的同时,调整进程的优先级。
nice命令用于修改进程的调度优先级,数值越低表示优先级越高。
Win7系统下设置提高多核CPU性能(提高win7处理器速度设置)

Win7系统下设置提高多核CPU的方案
随着科技的进步,各类电脑CPU处理器的核心数也逐渐增多,如何才能更好地优化设置以提高电脑的整体运行性能呢?对于目前逐渐广泛使用的win7系统,对多核CPU有着良好的支持,可以通过适当的设置来更好的提升电脑的处理速度和CPU性能。
具体操作步骤如下:1、使用键盘上的快捷键Win+R,打开运行对话框,并在对话框中输入“msconfig”命令
2、回车即可打开系统配置的对话框
3、点击选择“引导”选项卡
4、点击上图中中间左侧区域的“高级选项”按钮,弹出如下窗口
5、根据电脑处理器数,勾选“处理器数和最大内存”,并在下拉列表中选择处理器的个数,点击确定,然后应用,再确定后弹出下面对话框
6、可以选择重新启动,亦可选择“退出而不重新启动”,这样便保存退出了,也就完成了使用win7自带的设置提升了多核CPU的处理性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
查看pid和那个cpu亲和taskset -pc 3687返回pid 3687's current affinity list: 0,1,2,3表示3687和0,1两个cpu内核比较亲和taskset -pc 0-1 3687设置线程3678和0,1两个cpu内核亲和top -p 3687查看此线程具体执行情况******************************************************** ******************************************************** **************利用taskset可以充分利用多核cpu的好处,可以让某个程序或脚本,运行在某个具体的cpu上。
这个工具系统可能没有默认安装:,rpm包名util-linux#taskset --helptaskset (util-linux 2.13-pre7)usage: taskset [options] [mask | cpu-list] [pid | cmd [args...]]set or get the affinity of a process-p, –pid operate on existing given pid-c, –cpu-list display and specify cpus in list format-h, –help display this help-v, –version output version information1:让某个程序运行在特定cpu上面taskset -c 0 sh wade.sh2:切换某个进程到特定的cpu上。
taskset -pc 0 12345比如你有一个cpu是4 core你可以这样写你的脚本#!/bin/bashtaskset -c 0 sh a.sh &taskset -c 1 sh b.sh &taskset -c 2 sh c.sh &taskset -c 3 sh d.sh &应该可以充分利用你的cpu了。
**************************************************************************************************************** **************我的Linode十分繁忙,在跑一些密集操作数据库的Rake任务时尤其如此。
但我观察发现,Linode服务器的4核CPU,只有第1个核心(CPU#0)非常忙,其他都处于idle状态。
不了解Linux是如何调度的,但目前显然有优化的余地。
除了处理正常任务,CPU#0还需要处理每秒网卡中断。
因此,若能将CPU#0分担的任务摊派到其他CPU 核心上,可以预见,系统的处理能力将有更大的提升。
两个名词SMP (Symmetrical Multi-Processing):指在一个计算机上汇集了一组处理器(多CPU),各CPU之间共享内存子系统以及总线结构。
[更多...]CPU affinity:中文唤作“CPU亲和力”,是指在CMP架构下,能够将一个或多个进程绑定到一个或多个处理器上运行。
[更多...]一、在Linux上修改进程的“CPU亲和力”在Linux上,可以通过taskset命令进行修改。
以Ubuntu为例,运行如下命令可以安装taskset工具。
# apt-get install schedutils对运行中的进程,文档上说可以用下面的命令,把CPU#1 #2 #3分配给PID为2345的进程:# taskset -cp 1,2,3 2345但我尝试没奏效,于是我关掉了MySQL,并用taskset将它启动:# taskset -c 1,2,3 /etc/init.d/mysql start对于其他进程,也可如此处理(nginx除外,详见下文)。
之后用top查看CPU 的使用情况,原来空闲的#1 #2 #3,已经在辛勤工作了。
二、配置nginx绑定CPU刚才说nginx除外,是因为nginx提供了更精确的控制。
在conf/nginx.conf中,有如下一行:worker_processes 1;这是用来配置nginx启动几个工作进程的,默认为1。
而nginx还支持一个名为worker_cpu_affinity的配置项,也就是说,nginx可以为每个工作进程绑定CPU。
我做了如下配置:worker_processes 3;worker_cpu_affinity 0010 0100 1000;这里0010 0100 1000是掩码,分别代表第2、3、4颗cpu核心。
重启nginx后,3个工作进程就可以各自用各自的CPU了。
三、刨根问底1.如果自己写代码,要把进程绑定到CPU,该怎么做?可以用sched_setaffinity函数。
在Linux上,这会触发一次系统调用。
2.如果父进程设置了affinity,之后其创建的子进程是否会有同样的属性?我发现子进程确实继承了父进程的affinity属性。
四、Windows?在Windows上修改“CPU亲和力”,可以通过任务管理器搞定。
* 个人感觉,Windows系统中翻译的“处理器关系”比“CPU亲和力”容易理解点儿—————–进行了这样的修改后,即使系统负载达到3以上,不带缓存打开 首页(有40多次查询)依然顺畅;以前一旦负载超过了1.5,响应就很慢了。
效果很明显。
linux taskset命令详解SYNOPSIStaskset [options] [mask | list ] [pid | command [arg]...] OPTIONS-p, --pidoperate on an existing PID and not launch a new task -c, --cpu-listspecifiy a numerical list of processors instead of a bitmask.The list may contain multipleitems, separated by comma, andranges. For example, 0,5,7,9-11.-h, --helpdisplay usage information and exit-V, --versionoutput version information and exit********************************************************************* *********************************************************现在多核的CPU已经相当普遍了,那么这种多核的服务器如何让CPU得到充分利用,可以靠应用自己来定义,或者依赖操作系统来调度。
根据红帽的说法RHEL5有一个很强壮的CPU调度机制,RHEL6就更强壮了,所以看起来跑在LINUX 下面的应用应该都不用去管该用哪个CPU。
首先我们来看看CPU中断请求的统计:CentOS release 5.2 (Final)从图上看,CPU的使用基本上还是均匀的。
不过CPU0负载还是最大的。
所有在某种情况下可能会需要手工来设置进程使用CPU核的优先级。
下面是一个操作的例子:postgres 6457 1 0 May05 ? 00:00:00/app/pgsql/bin/postgres -D /database/pgdata -p 1921[root@develop1 ~]# taskset -pc 6457pid 6457’s current affinity list: 0-3这个进程目前是默认与0-3 这4个核心亲和的。
也就是说会在0-3这几个核心调度。
[root@develop1 ~]# taskset -pc 0-1 6457pid 6457’s current affinity list: 0-3pid 6457’s new affinity list: 0,1修改之后我们看到,已经修改为0,1的范围了。
可以通过top -p 6457 [f -> j]查看P列可以看到当前运行的核心号。
如果该成在单个CORE上跑的话,马上就能看到CORE的变化。
下面是taskset的MAN PAGE:从描述上来看的话,只要taskset返回结果了,那LINUX肯定是确保得到了你想要的结果。
DESCRIPTIONtaskset is used to set or retrieve the CPU affinity of a running process given its PID or to launch a new COM-MAND with a given CPU affinity. CPU affinity is a scheduler property that “bonds” a process to a given set ofCPUs on the system. The Linux scheduler will honor the given CPU affinity and the process will not run on anyother CPUs. Note that the Linux scheduler also supports natural CPU affinity: the scheduler attempts to keepprocesses on the same CPU as long as practical for performance reasons. Therefore, forcing a specific CPUaffinity is useful only in certain applications.The CPU affinity is represented as a bitmask, with the lowest order bit corresponding to the first logical CPUand the highest order bit corresponding to the last logical CPU. Not all CPUs may exist on a given system buta mask may specify more CPUs than are present. A retrieved mask will reflect only the bits that correspond toCPUs physically on the system. If an invalid mask is given (i.e., one that corresponds to no valid CPUs on thecurrent system) an error is returned. The masks are typically given in hexadecimal. For example,0×00000001is processor #00×00000003is processors #0 and #10xFFFFFFFFis all processors (#0 through #31)When taskset returns, it is guaranteed that the given program has been scheduled to a legal CPU.。