20100226_1字符集
字符集及消对规则的定义

字符集及消对规则的定义简要说明;字符集和校对规则字符集是一套符号和编码。
校对规则是在字符集内用于比较字符的一套规则。
MySql在collation提供较强的支持,oracel在这方面没查到相应的资料。
不同字符集有不同的校对规则,命名约定:以其相关的字符集名开始,通常包括一个语言名,并且以_ci(大小写不敏感)、_cs(大小写敏感)或_bin(二元)结束校对规则一般分为两类:binary collation,二元法,直接比较字符的编码,可以认为是区分大小写的,因为字符集中'A'和'a'的编码显然不同。
字符集_语言名,utf8默认校对规则是utf8_general_cimysql字符集和校对规则有4个级别的默认设置:服务器级、数据库级、表级和连接级。
具体来说,我们系统使用的是utf8字符集,如果使用utf8_bin 校对规则执行sql查询时区分大小写,使用utf8_general_ci 不区分大小写。
不要使用utf8_unicode_ci。
如create database demo CHARACTER SET utf8; 默认校对规则是utf8_general_ci 。
Unicode与UTF8Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储.UTF8字符集是存储Unicode数据的一种可选方法。
mysql同时支持另一种实现ucs2。
详细说明:字符集(charset):是一套符号和编码。
校对规则(collation):是在字符集内用于比较字符的一套规则,比如定义'A'<'B'这样的关系的规则。
不同collation可以实现不同的比较规则,如'A'='a'在有的规则中成立,而有的不成立;进而说,就是有的规则区分大小写,而有的无视。
每个字符集有一个或多个校对规则,并且每个校对规则只能属于一个字符集。
汉字字符集表

英
樱
婴
鹰
应
缨
莹
萤
营
荧
蝇
迎
赢
盈
影
颖
硬
映
哟
拥
佣
臃
痈
庸
54
52 (34H)
浴
寓
裕
预
豫
驭
鸳
渊
冤
元
垣
袁
原
援
辕
园
员
圆
猿
源
缘
远
苑
愿
怨
55
53 (35H)
铡
闸
眨
栅
榨
咋
乍
炸
诈
摘
斋
宅
窄
债
寨
瞻
毡
詹
粘
沾
盏
斩
辗
崭
展
56
54 (36H)
帧
症
郑
证
芝
枝
支
吱
蜘
知
肢
脂
汁
之
组
职
直
植
殖
执
值
侄
址
指
止
57
55 (37H)
住
注
祝
驻
抓
爪
拽
专
砖
转
76
77
78
79
7A
7B
7C
7D
7E
国标
区位
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
计算机系统字符集和程序设计语言字符集

计算机系统字符集和程序设计语言字符集计算机系统字符集是指计算机系统中能够使用的字符的集合。
字符是组成文本的基本单位,包括字母、数字、标点符号、特殊符号等。
计算机系统字符集的选择和设计对于计算机系统的功能和性能都有重要影响。
在计算机系统中,常用的字符集包括ASCII码、Unicode和UTF-8等。
ASCII码是美国标准信息交换码,使用7位二进制数表示128个字符,包括英文字母、数字和一些特殊符号。
ASCII码是最早的字符集,被广泛应用于计算机系统中。
然而,ASCII码只能表示有限的字符集,无法满足其他国家和地区的字符需求。
为了解决这个问题,Unicode字符集应运而生。
Unicode字符集包含了世界上几乎所有的字符,每个字符都有唯一的编码。
Unicode字符集的编码长度不固定,最常见的是16位编码,即Unicode编码。
Unicode字符集的应用使得计算机系统能够处理各种语言的文字,方便了全球信息交流。
然而,Unicode字符集的编码长度较长,对于存储和传输效率有一定的影响。
为了解决这个问题,UTF-8字符集应运而生。
UTF-8字符集是一种可变长度的Unicode编码,根据字符的不同,使用1至4个字节进行编码。
UTF-8字符集兼容ASCII码,对于英文字符只使用1个字节进行编码,对于常用的汉字也只使用3个字节进行编码,极大地提高了存储和传输效率。
除了计算机系统字符集,程序设计语言字符集也是程序员必须了解的内容。
程序设计语言字符集是指程序设计语言中可以使用的字符的集合。
不同的程序设计语言字符集可能有所不同,但一般都包含了ASCII码字符集。
在程序设计语言中,字符集的选择和使用对于程序的编写和执行都有重要影响。
一方面,字符集的选择会影响程序的可读性和可维护性。
如果使用的字符集较少,可能会导致代码可读性较差,难以理解和修改。
另一方面,字符集的使用还会影响程序的执行效率。
一些字符集的操作可能比较耗时,会导致程序执行速度较慢。
计算机中文编码表

计算机中常用的中文编码表有:
1.GB2312:是中国国家强制标准,包含了超过6000多个常用汉字和非汉字字符,主要支持简体中文,也包括部分繁体中文字符。
2.GBK:是GB2312的扩展,支持更多的汉字字符,包括繁体中文和简体中文,以及部分其他语言字符。
3.GB18030:中文信息技术领域最重要的基础性标准,对汉字和中国多种少数民族文字进行了统一编码,需要进行中文处理的信息系统均需应用
此类编码标准,覆盖中国绝大部分人名、地名用生僻字以及文献、科技等专业领域的用字,能够满足各类使用需求。
4.Big5:使用繁体中文(正体中文)社区中最常用的电脑汉字字符集标准,共收录13,060个汉字。
以上是计算机中常用的中文编码表,不同的编码表支持不同的字符集和语言,根据实际需要选择合适的编码表。
计算机字符集

55
7
56
8
57
9
58
:
59
;
60
<
61
=
62
>
63
?
64
@
65
A
66
B
67
C
68
D
69
E
70
F
71
G
72
H
73
I
74
J
75
K
76
L
77
M
78
N
79
O
80
P
81
Q
82
R
83
S
84
T
85
U
86
V
87
W
88
X
89
Y
90
Z
91
[
92
\
93
]
94
^
95
_
96
`
97
a
98
b
99
c
100
d
101
e
102
f
103
GB2312的编码范围是0xA1A1-0x7E7E,去掉未定义的区域之后可以理解为实际编码范围是0xA1A1-0xF7FE。
上面这句有误,应该说GB2312的每一个汉字由两个字节构成,其中每一个字节的范围都在0xA1~0xFE,正好每一个字节都有94个编码范围,与区位码个数完全对应。
EUC-CN可以理解为GB2312的别名,和GB2312完全相同。
GBK的整体编码范围是为:高字节范围是0×81-0xFE,低字节范围是0x40-7E和0x80-0xFE,不包括低字节是0×7F的组合。
数据库字符集编码和表字符集编码

数据库字符集编码和表字符集编码数据库字符集编码和表字符集编码是数据库中非常重要的概念,它们决定了数据库中存储的数据的字符编码方式。
正确设置字符集编码可以确保数据的正确存储和显示,避免出现乱码等问题。
数据库字符集编码是指数据库服务器使用的字符编码方式,它决定了数据库中所有表的默认字符集编码。
常见的数据库字符集编码有UTF-8、GBK、GB2312等。
UTF-8是一种通用的字符编码方式,支持全球范围内的字符,是目前最常用的字符集编码方式。
GBK和GB2312是中文字符集编码方式,适用于中文环境。
表字符集编码是指每个表在数据库中的字符编码方式,它可以与数据库字符集编码不同。
在创建表时,可以指定表的字符集编码,也可以使用数据库的默认字符集编码。
如果表的字符集编码与数据库的字符集编码不一致,那么在存储和显示数据时就需要进行字符集转换,这可能会导致性能下降和数据损坏。
正确设置数据库字符集编码和表字符集编码非常重要。
首先,它可以确保数据的正确存储和显示。
如果数据库字符集编码和表字符集编码不一致,那么在存储和显示数据时就可能出现乱码等问题,影响用户体验。
其次,它可以提高数据库的性能。
如果数据库字符集编码和表字符集编码一致,那么在存储和显示数据时就不需要进行字符集转换,可以提高数据库的性能。
在设置数据库字符集编码和表字符集编码时,需要考虑以下几个因素。
首先,需要考虑数据库的使用环境。
如果数据库主要用于存储中文数据,那么可以选择中文字符集编码,如GBK或GB2312。
如果数据库需要支持全球范围内的字符,那么可以选择UTF-8字符集编码。
其次,需要考虑数据库的性能和存储空间。
不同的字符集编码对存储空间的占用和性能有不同的影响。
一般来说,UTF-8字符集编码占用的存储空间较大,但支持更多的字符,而GBK和GB2312字符集编码占用的存储空间较小,但只支持中文字符。
最后,需要考虑与其他系统的兼容性。
如果数据库需要与其他系统进行数据交换,那么需要确保数据库字符集编码和表字符集编码与其他系统兼容。
编码规则和字符集

编码规则和字符集是计算机中用于表示和处理文本数据的重要概念。
编码规则(Encoding)定义了如何将字符映射为计算机内部的二进制数据表示形式。
不同的编码规则采用不同的映射方式,可以表示不同范围的字符集。
字符集(Character Set)是一组字符的集合,它定义了一个编码规则所能表示的字符的范围。
常见的字符集包括ASCII、Unicode等。
下面是一些常见的编码规则和字符集:1. ASCII(American Standard Code for Information Interchange):ASCII是最早的字符集和编码规则之一,包含128个字符,用7位二进制数表示,包括英文字母、数字、标点符号等常见字符。
2. Unicode:Unicode是一种字符集,包含了全球范围内几乎所有的字符。
它用于表示各种语言文字、符号、表情符号等。
Unicode使用不同的编码规则,最常见的是UTF-8、UTF-16、UTF-32。
其中,UTF-8是较为常用的编码规则,使用1至4个字节表示一个字符,兼容ASCII 字符集。
3. UTF-8(Unicode Transformation Format-8):UTF-8是一种可变长度的Unicode编码规则。
它使用8位字节表示一个字符,能够表示Unicode字符集中的所有字符。
4. UTF-16(Unicode Transformation Format-16):UTF-16使用16位字节表示一个字符,能够表示Unicode字符集中所有的字符,包括较为罕见的字符。
除了上述编码规则和字符集,还有一些其它编码规则如GB2312、GBK、Big5等,它们主要用于表示中文字符集。
在处理文本数据时,需要明确所使用的编码规则和字符集,以确保正确地解码和显示文本内容。
如果编码规则和字符集不匹配,就可能导致乱码或无法正确显示文本。
因此,在处理文本数据时,应注意确认输入输出所使用的编码规则,并进行适当的编码和解码操作。
数据库字符集类型

数据库中常用的字符集类型有以下几种:
ASCII:ASCII(American Standard Code for Information Interchange)是美国标准信息交换码,用于表示英语字符的编码标准。
ASCII 字符集包含128 个字符,包括字母、数字、标点符号等。
UTF-8:UTF-8(Unicode Transformation Format-8)是一种针对Unicode 字符集的可变长度字符编码方案。
UTF-8 支持包括中文、日文、韩文等各种字符,是目前最常用的字符集之一。
UTF-8 中的字符可以使用1 到4 个字节表示,英文字符占用一个字节,中文字符占用三个字节。
UTF-16:UTF-16 是Unicode 字符集的一种编码方案,采用16 位编码表示字符。
UTF-16 中的字符可以使用2 个或 4 个字节表示,英文字符占用 2 个字节,中文字符占用 4 个字节。
GBK:GBK(GuoBiao Kuozhan)是国家标准扩展码的简称,是对汉字进行编码的字符集标准。
GBK 包含了GB2312 字符集的全部字符,并增加了许多繁体字和生僻字。
Big5:Big5 是繁体中文的字符集标准,广泛应用于台湾、香港等地区。
Big5 字符集可以表示繁体中文字符,不包含简体中文字符。
ISO-8859-1:ISO-8859-1(又称Latin-1)是国际标准化组织制定的字符集标准,包含了西欧各国所需的字符。
代码页字符集对照表
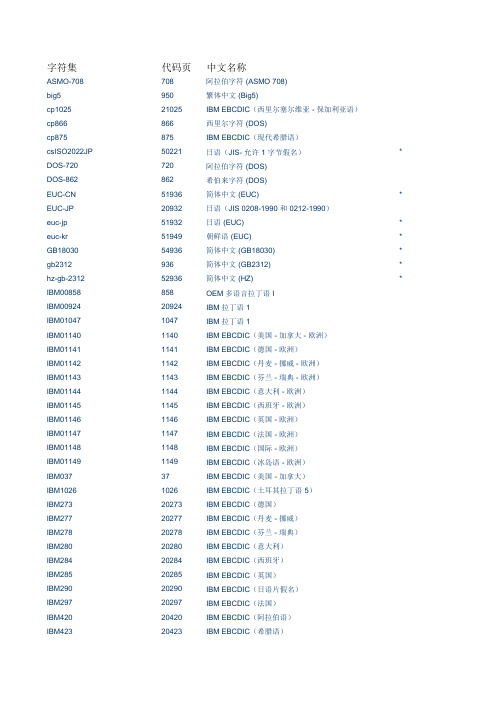
字符集代码页中文名称ASMO-708708阿拉伯字符 (ASMO 708)big5950繁体中文 (Big5)cp102521025IBM EBCDIC(西里尔塞尔维亚 - 保加利亚语)cp866866西里尔字符 (DOS)cp875875IBM EBCDIC(现代希腊语)csISO2022JP50221日语(JIS- 允许 1 字节假名)* DOS-720720阿拉伯字符 (DOS)DOS-862862希伯来字符 (DOS)EUC-CN51936简体中文 (EUC)* EUC-JP20932日语(JIS 0208-1990 和 0212-1990)euc-jp51932日语 (EUC)* euc-kr51949朝鲜语 (EUC)* GB1803054936简体中文 (GB18030)* gb2312936简体中文 (GB2312)* hz-gb-231252936简体中文 (HZ)* IBM00858858OEM 多语言拉丁语 IIBM0092420924IBM 拉丁语 1IBM010471047IBM 拉丁语 1IBM011401140IBM EBCDIC(美国 - 加拿大 - 欧洲)IBM011411141IBM EBCDIC(德国 - 欧洲)IBM011421142IBM EBCDIC(丹麦 - 挪威 - 欧洲)IBM011431143IBM EBCDIC(芬兰 - 瑞典 - 欧洲)IBM011441144IBM EBCDIC(意大利 - 欧洲)IBM011451145IBM EBCDIC(西班牙 - 欧洲)IBM011461146IBM EBCDIC(英国 - 欧洲)IBM011471147IBM EBCDIC(法国 - 欧洲)IBM011481148IBM EBCDIC(国际 - 欧洲)IBM011491149IBM EBCDIC(冰岛语 - 欧洲)IBM03737IBM EBCDIC(美国 - 加拿大)IBM10261026IBM EBCDIC(土耳其拉丁语 5)IBM27320273IBM EBCDIC(德国)IBM27720277IBM EBCDIC(丹麦 - 挪威)IBM27820278IBM EBCDIC(芬兰 - 瑞典)IBM28020280IBM EBCDIC(意大利)IBM28420284IBM EBCDIC(西班牙)IBM28520285IBM EBCDIC(英国)IBM29020290IBM EBCDIC(日语片假名)IBM29720297IBM EBCDIC(法国)IBM42020420IBM EBCDIC(阿拉伯语)IBM42320423IBM EBCDIC(希腊语)IBM42420424IBM EBCDIC(希伯来语)IBM437437OEM 美国IBM500500IBM EBCDIC(国际)ibm737737希腊字符 (DOS)ibm775775波罗的海字符 (DOS)ibm850850西欧字符 (DOS)ibm852852中欧字符 (DOS)IBM855855OEM 西里尔语ibm857857土耳其字符 (DOS)IBM860860葡萄牙语 (DOS)ibm861861冰岛语 (DOS)IBM863863加拿大法语 (DOS)IBM864864阿拉伯字符 (864)IBM865865北欧字符 (DOS)ibm869869现代希腊字符 (DOS)IBM870870IBM EBCDIC(多语言拉丁语 2)IBM87120871IBM EBCDIC(冰岛语)IBM88020880IBM EBCDIC(西里尔俄语)IBM90520905IBM EBCDIC(土耳其语)IBM-Thai20838IBM EBCDIC(泰语)iso-2022-jp50220日语 (JIS)* iso-2022-jp50222日语(JIS- 允许 1 字节假名 - SO/SI)* iso-2022-kr50225朝鲜语 (ISO)* iso-8859-128591西欧字符 (ISO)* iso-8859-1328603爱沙尼亚语 (ISO)iso-8859-1528605拉丁语 9 (ISO)iso-8859-228592中欧字符 (ISO)iso-8859-328593拉丁语 3 (ISO)iso-8859-428594波罗的海字符 (ISO)iso-8859-528595西里尔字符 (ISO)iso-8859-628596阿拉伯字符 (ISO)iso-8859-728597希腊字符 (ISO)iso-8859-828598希伯来字符 (ISO-Visual)* iso-8859-8-i38598希伯来字符 (ISO-Logical)* iso-8859-928599土耳其字符 (ISO)Johab1361朝鲜语 (Johab)koi8-r20866西里尔字符 (KOI8-R)koi8-u21866西里尔字符 (KOI8-U)ks_c_5601-1987949朝鲜语macintosh10000西欧字符 (Mac)shift_jis932日语 (Shift-JIS)UnicodeFFFE1201Unicode (Big-Endian)* us-ascii20127US-ASCII* utf-161200Unicode* utf-3265005Unicode (UTF-32)* utf-32BE65006Unicode (UTF-32 Big-Endian)* utf-765000Unicode (UTF-7)* utf-865001Unicode (UTF-8)* windows-12501250中欧字符 (Windows)windows-12511251西里尔字符 (Windows)Windows-12521252西欧字符 (Windows)* windows-12531253希腊字符 (Windows)windows-12541254土耳其字符 (Windows)windows-12551255希伯来字符 (Windows)windows-12561256阿拉伯字符 (Windows)windows-12571257波罗的海字符 (Windows)windows-12581258越南字符 (Windows)windows-874874泰语 (Windows)x-Chinese-CNS20000繁体中文 (CNS)x-Chinese-Eten20002繁体中文 (Eten)x-cp2000120001TCA 台湾x-cp2000320003IBM5550 台湾x-cp2000420004TeleText 台湾x-cp2000520005Wang 台湾x-cp2026120261T.61x-cp2026920269ISO-6937x-cp2093620936简体中文 (GB2312-80)* x-cp2094920949朝鲜语 Wansung* x-cp5022750227简体中文 (ISO-2022)* x-EBCDIC-KoreanExtended20833IBM EBCDIC(朝鲜语扩展)x-Europa29001欧罗巴x-IA520105西欧字符 (IA5)x-IA5-German20106德语 (IA5)x-IA5-Norwegian20108挪威语 (IA5)x-IA5-Swedish20107瑞典语 (IA5)x-iscii-as57006ISCII 阿萨姆语* x-iscii-be57003ISCII 孟加拉语* x-iscii-de57002ISCII 梵文* x-iscii-gu57010ISCII 古吉拉特语* x-iscii-ka57008ISCII 卡纳达语* x-iscii-ma57009ISCII 马拉雅拉姆语* x-iscii-or57007ISCII 奥里雅语*x-iscii-pa57011ISCII 旁遮普语* x-iscii-ta57004ISCII 泰米尔语* x-iscii-te57005ISCII 泰卢固语* x-mac-arabic10004阿拉伯字符 (Mac)x-mac-ce10029中欧字符 (Mac)x-mac-chinesesimp10008简体中文 (Mac)* x-mac-chinesetrad10002繁体中文 (Mac)x-mac-croatian10082克罗地亚语 (Mac)x-mac-cyrillic10007西里尔字符 (Mac)x-mac-greek10006希腊字符 (Mac)x-mac-hebrew10005希伯来字符 (Mac)x-mac-icelandic10079冰岛语 (Mac)x-mac-japanese10001日语 (Mac)x-mac-korean10003朝鲜语 (Mac)* x-mac-romanian10010罗马尼亚语 (Mac)x-mac-thai10021泰语 (Mac)x-mac-turkish10081土耳其字符 (Mac)x-mac-ukrainian10017乌克兰语 (Mac)。
汉字编码常用字符集 -回复

汉字编码常用字符集-回复汉字编码常用字符集,是指用来表示汉字和其他汉字相关字符的一系列编码规范,其中最为常用的是Unicode(统一码)。
Unicode是一种国际标准,涵盖了世界上几乎所有的文字字符,因此也包含了汉字。
Unicode编码通过为每个字符分配一个唯一的代码点来表示字符。
这些代码点可以是十进制、十六进制或者八进制表示。
在Unicode字符集中,汉字的编码范围为4E00(十六进制)至9FFF(十六进制)。
不同的编码标准采用了不同的转换方案,将Unicode编码转化为实际的二进制数据。
汉字主要有UTF-8、UTF-16和UTF-32这三种常用的编码方式。
UTF-8是一种可变长度的编码方式,它使用1到4个字节来表示一个字符。
对于ASCII字符,UTF-8使用一个字节表示;对于汉字,UTF-8使用三个字节表示。
这种编码方式经济紧凑,适用于在存储和传输上限制空间的应用场景。
UTF-16是一种固定长度的编码方式,它使用两个字节表示一个字符。
对于Unicode代码点小于U+10000的字符,UTF-16中使用一个字节表示;对于Unicode代码点大于U+10000的字符,UTF-16中使用两个字节表示。
UTF-16编码方式用于Java和Windows平台。
UTF-32是一种固定长度的编码方式,它使用四个字节表示一个字符。
UTF-32将每个字符编码为固定长度的32位二进制数。
UTF-32编码方式适用于需要随机访问字符的应用,但由于其空间占用较大,一般不被广泛采用。
除了这些常用的编码方式,还有一些其他的汉字编码标准。
比如GB2312编码,是由中国国家标准局发布的,它包含了7445个简化汉字和拉丁字母、标点符号等字符。
GB2312是一种双字节编码方式,对于一个汉字使用两个字节表示。
随着计算机技术的发展,Unicode编码已经成为最主要的汉字编码标准。
Unicode解决了不同国家、不同编码标准下字符不一致的问题,实现了全球范围内的字符互通。
汉字编码常用的字符集

汉字编码常用的字符集
1. GB2312,GB2312是中国国家标准简化汉字字符集,于1980年发布。
它包含了6763个常用汉字和682个非汉字字符,使用双字节编码,其中包括了简体中文的基本字符。
2. GBK,GBK是GB2312的扩展字符集,于1995年发布。
它兼容GB2312,并增加了近两万个汉字和符号。
GBK使用双字节编码,其中包括了简体中文的扩展字符。
3. GB18030,GB18030是中国国家标准的多字节字符集,于2000年发布。
它兼容GB2312和GBK,并增加了更多的汉字和字符,包括繁体中文和一些少数民族文字。
GB18030使用单字节、双字节和四字节编码。
4. Unicode,Unicode是国际标准字符集,旨在涵盖地球上所有的字符。
Unicode采用统一的编码方式,为每个字符分配唯一的编码值。
其中,汉字统一采用了CJK统一汉字扩展A(CJK Unified Ideographs Extension A)和CJK统一汉字扩展B(CJK Unified Ideographs Extension B)等多个扩展区。
5. UTF-8,UTF-8是一种可变长度的Unicode编码方式,它可以表示任意Unicode字符。
UTF-8使用1到4个字节来表示不同的字符,其中包括了汉字。
这些字符集在不同的环境下使用,常见的应用包括操作系统、编程语言、文本编辑器、网页浏览器等。
使用不同的字符集可以满足不同的需求,如支持不同语言的文字显示和输入。
字符集(Characterset)

字符集(Characterset)字符编码:是指将计算机的⼆进制编码与某个抽象字符集合⼀⼀对应的规则.常见字符集名称:ASCII字符集(7bit)、GB2312字符集(2B)、BIG5字符集(2B)、GB18030字符集(4B)、Unicode字符集等。
计算机要准确的处理各种字符集⽂字,需要进⾏字符编码,以便计算机能够识别和存储各种⽂字。
[GB2312 字符集]内容: GB2312收录简化汉字及⼀般符号、序号、数字、拉丁字母、⽇⽂假名、希腊字母、俄⽂字母、汉语拼⾳符号、汉语注⾳字母,共7445 个图形字符。
其中包括6763个汉字,其中⼀级汉字3755个,⼆级汉字3008个;包括拉丁字母、希腊字母、⽇⽂平假名及⽚假名字母、俄语西⾥尔字母在内的682个全⾓字符。
特点:因为未收录繁体中⽂字,只在中国⼤陆和新加坡获⼴泛使⽤,[BIG5 字符集]由台湾财团法⼈信息⼯业策进会和五间软件公司创⽴,故称⼤五码。
Big5字符集共收录13,053个中⽂字,该字符集在中国台湾使⽤。
尽管Big5码内包含⼀万多个字符,但是没有考虑社会上流通的⼈名、地名⽤字、⽅⾔⽤字、化学及⽣物科等⽤字,没有包含⽇⽂平假名及⽚假名字母。
[GB18030 字符集]内容:GB 18030字符集标准解决汉字、⽇⽂假名、朝鲜语和中国少数民族⽂字组成的⼤字符集计算机编码问题。
该标准的字符总编码空间超过150万个编码位,收录了27484个汉字,覆盖中⽂、⽇⽂、朝鲜语和中国少数民族⽂字。
满⾜中国⼤陆、⾹港、台湾、⽇本和韩国等东亚地区信息交换多⽂种、⼤字量、多⽤途、统⼀编码格式的要求。
并且与Unicode 3.0版本兼容,填补Unicode扩展字符字汇“统⼀汉字扩展A”的内容。
并且与以前的国家字符编码标准(GB2312,GB13000.1)兼容。
[Unicode字符集(统⼀码、万国码)]跨语⾔、跨平台UTF-32:4B,UTF-16:2B,UTF-8:1B-4B 可变长度(前缀码)[UTF-8(前缀码)设计原理]# 字节字符的最⾼有效⽐特永远为0。
Windows程序员必须知道的字符编码和字符集

Windows程序员必须知道的字符编码和字符集1. 字符编码 (Character encoding)在存储和传递⽂本过程中,为了使得所有电脑都能够正确的识别出⽂本内容,需要有⼀个统⼀的规则。
2. 字符集 (Character Set) )⼀般情况,⼀种编码⽅式对应⼀种字符集。
如 ASCII,对应 ASCII 字符集。
GBK 编码⽅式对应 GBK 字符集。
但是也有⼀种编码⽅式,多种字符集的,Unicode 字符集有多种编码⽅式,如 utf-8,utf-16 等。
3. ASCIIASCII(American Standard Code for Information Interchange,美国信息交换标准代码):使⽤ 7 个 Bit 表⽰,共 128 个字符,刚好占⽤了⼀个字节中的后 7 位,共包括33 个控制字符和 95 个可显⽰字符。
. 4. ANSIANSI (⼀种字符编码,此处不是表⽰美国国家标准学会的意思):ANSI 是为了让计算机⽀持更多的语⾔,⽽在 ASCII 的*础上的⼀种扩展字符编码。
在不同语⾔操作上,ANSI 都表⽰当前计算机默认的编码⽅式。
如在简体 Windows 操作下,ANSI 编码代表 GBK 编码;在繁体中⽂操作下,ANSI 编码代表 Big5 编码;在⽇⽂ Windows 操作系统中,ANSI 编码代表 Shift_JIS 编码;在英⽂操作系统下,ANSI 就是ASCII 编码。
. 5. MBCSMBCS(Multi-Byte Character Set),早在 1980 年,中国就提出了使⽤ GB2312 编码⽅式来描述汉字。
后来其他东亚国家也利⽤这种⽅式扩展 ASCII 编码字符集。
台湾地区 5 ⼤企业推出的繁体 Big5 码,⾹港新加坡等后来也利⽤。
⽇本韩国也相应推出了⾃⼰的编码⽅式。
其实在这⾥,BIG5 既是编码⽅式,也是字符集。
. 6. GB2312(Guo Biao 2312) )⽤双字节表⽰汉字,但是为了完全兼容 ASCII。
中文字符集、编码

前言由于工作的需要,参考了好多资料整理出来一份计算机汉字处理报告,不敢独享,希 望与大家共享。
Ziggler 现代计算机技术虽然先进, 但大多数人只知录入 GB-2313 字符集内的 6763 个简体汉字, 对包含 21003 个简繁体汉字的 GBK 字符集的文字录入、字体 显示就已不甚了解(市面上 绝大多数所谓的繁体字体,其实采用的是 GB2313 字符集简体字的编码,用字体显示为繁体 字,而不是直接用 GBK 字符集中繁体字 的编码,错误百出) 。
而汉字总数至少有近 10 万 个,目前计算机能处理的,也有 70244 个,已非一般人所能知能用了。
由于汉字总数非常庞大。
汉字总共有多少字?到目前为止, 恐怕没人能够答得上来精确 的数字。
据估计,汉字数量达到 11 万左右。
这里所说的七万多汉字, 是指 UNICODE 超大字集全部七万多中日韩汉字。
(注: Unicode 是指用两个字节表示每个字符的字符编码方案。
) 那一般计算机能够显示多少个汉字呢?比如大陆这边普遍安装简体 Windows 系统,而 简体 windows 以宋体为系统字型,宋体支持 GBK 编码,所以能显示 20902 个汉字。
要显示 71564 个汉字, 可以采取多种方案, 如: 宋体-方正超大字符集+新细明体 EXTB、 宋体-方正超大字符集+中易宋体 EXTB、宋体 GB18030+新细明体 ExtB、宋体 18030+宋体 ExtB 等等。
中文字符集、编码字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符 集是多个字符的集合,字符集 种类较多,每个字符集包含的字符个数不同。
计算机要准确的处理各种字符集文字, 需要进行字符编码, 以便计算机能够识别和存储 各种文字。
中文文字数目大, 而且还分为简体中文和繁体中文两种不同书写规则的文字, 而计算机 最初是按英语单字节字符设计的, 因此, 对中文字符进行编码, 是中文信息交流的技术基础。
常用字符集

常用字符集字符集经常使用于计算机编程中,其本质是一系列标准映射规则,它们由定义了相应字符编码的编码字符集和描述性指令集组成。
这些字符集用来将汉字或者其他字符转换成一系列的二进制字节(又称计算机可识别的字符)。
这些字符集通常被用来表示文本文件,文件可以被转换成可以在计算机上读取的内容,并且能够正确的显示方框字符、符号、图形和汉字等等。
目前,计算机和软件使用的最常用的字符集可以分为两大类:Unicode字符集和 ASCII符集。
一、Unicode字符集Unicode是全世界最广泛使用的字符编码方案,它定义了统一的码位空间,用来表示所有的文字。
Unicode的码位空间范围是0-10FFFF”,Unicode字符集使用两个字节表示每一个字符,因此总共可以表示 1,114,112个字符,Unicode可以表示几乎所有的字符,包括拉丁文、希腊文、中文、日文等等。
二、ASCII字符集ASCII (American Standard Code for Information Interchange)是一种最早定义的字符编码标准,它是1960年由美国国家标准技术研究所(NIST)提出的。
ASCII字符集定义了128个字符,其中包括26个大写和小写英文字母、数字(0-9)、标点符号、控制字符等。
用户可以在不同的软件中使用ASCII字符集,交换、查看和处理文件等,以便满足不同的文件格式要求。
每一种字符集都有它自己的特点和用途,但Unicode字符集更加通用,其能够满足大多数对中文、拉丁字母、希腊字母、日文等字符的要求,因此,它是应用最为广泛的字符集。
尽管Unicode是当前计算机领域最常用的字符集,但它也有一些问题,比如字符编码的字节数相较于其他字符集较大,并且在兼容处理上存在一定的困难。
此外,在处理多语言文本时也必须谨慎,因为不同语言的字符集可能存在不兼容的问题。
比如,中文和英文之间的字符、汉字和日文的符号等等,如果使用错误的字符集,可能会导致有关文件的正确显示受到影响,从而造成误解。
字符集编码详解

字符集编码详解字符集编码是计算机科学中的一个重要概念,主要用于将字符集中的字符转换为计算机可以理解和处理的数字形式。
以下是一些常见的字符集编码及其详解:ASCII码:ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是最基础的字符集编码,它使用7位或8位二进制数来表示字符。
ASCII码包括了128个或256个字符,包括英文字母、数字、标点符号等。
其中,0x00-0x20和0x7F是控制字符,如换行、回车等。
GB2312:GB2312是中国国家标准的简体中文字符集编码,收录了简化汉字及符号、字母、日文假名等共7445个图形字符,其中汉字占6763个。
在GB2312编码中,一个汉字通常由两个字节表示,每个字节均采用七位编码表示。
这种表示方式也称为区位码,其中前字节表示区号,后字节表示位号。
UTF-8:UTF-8是一种针对Unicode的可变长度字符编码,也是一种广泛使用的编码方式。
在UTF-8编码中,一个字符可以占用1到4个字节,其中英文字符通常占用1个字节,而中文字符则占用3个字节。
UTF-8编码具有良好的兼容性和扩展性,可以表示全世界绝大多数语言的字符。
UTF-7:UTF-7是一种使用7位ASCII码对Unicode码进行转换的编码方式。
它的设计目的是为了在只能传递7位编码的邮件网关中传递信息。
UTF-7对英语字母、数字和常见符号直接显示,而对其他符号用修正的Base64编码。
UTF-7编码通常用于电子邮件等需要传输多种语言字符的场景。
除了以上几种常见的字符集编码外,还有许多其他的编码方式,如UTF-16、UTF-32、ISO-8859-1等。
不同的编码方式具有不同的特点和适用范围,需要根据具体的应用场景选择合适的编码方式。
需要注意的是,不同的字符集编码之间可能存在不兼容的情况,因此在进行字符编码转换时需要谨慎处理,以避免出现乱码等问题。
字符集(乱码)

国标GBGB2312GB2312 是对ASCII 的中文扩展,在保留原ASCII前127个字符的基础上用两个字节(16位)表示一个汉字,分别叫高字节(0xA1~0xF7)和低字节(0xA1~0xFE)。
而且又把原ASCII的127个字符用双字节重新编码了一次,即我们所说的全角字符。
如:“测”的编码是B2E2“测试”的编码是B2E2 CAD4如:(半角)“A”的编码是0X41(十进制:65),和ASCII中的编码一致,占一个字节;(全角)“A”的编码是0XA3C1(二进制:10100011 11000001),占两个字节;“联通”乱码当你在windows 的记事本里新建一个文件,输入"联通"两个字之后,保存,关闭,然后再次打开,你会发现这两个字已经消失了,代之的是几个乱码,有人说这就是联通之所以拼不过移动的原因。
其实这是因为GB2312编码与UTF8编码产生了编码冲撞的原因。
从UNICODE到UTF8的转换规则:Unicode UTF-80000 - 007F 0xxxxxxx0080 - 07FF 110xxxxx 10xxxxxx0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx例如"汉"字的Unicode编码是6C49。
6C49在0800-FFFF之间,所以要用3字节模板:1110xxxx 10xxxxxx 10xxxxxx。
将6C49写成二进制是:0110 1100 0100 1001,将这个比特流按三字节模板的分段方法分为0110 110001 001001,依次代替模板中的x,得到:1110-0110 10-110001 10-001001,即E6 B1 89,这就是其UTF8的编码。
汉:0110110001001001套用:1110XXXX10XXXXXX10XXXXXX0110110001001001UTF8:111001101011000110001001而当你新建一个文本文件时,记事本的编码默认是ANSI, 如果你在ANSI的编码输入汉字,那么他实际就是GB系列的编码方式,在这种编码下,"联通"的内码是:c1 11000001aa 10101010cd 11001101a8 10101000UTF8:110XXXXX10XXXXXX注意到了吗?第一二个字节、第三四个字节的起始部分的都是"110"和"10",正好与UTF8规则里的两字节模板是一致的,于是再次打开记事本时,记事本就误认为这是一个UTF8编码的文件,让我们把第一个字节的110和第二个字节的10去掉,我们就得到了"00001 101010",再把各位对齐,补上前导的0,就得到了"0000 0000 0110 1010",不好意思,这是UNICODE的006A,也就是小写的字母"j",而之后的两字节用UTF8解码之后是0368,这个字符什么也不是。
汉字编码常用字符集 -回复

汉字编码常用字符集-回复汉字编码常用字符集是指根据汉字的特点和使用频率,将每个汉字都映射为一个特定的数字或编码,以方便计算机处理和存储。
在常用的字符集中,最著名的就是Unicode字符集。
Unicode字符集是一套完备的全球字符编码方案,它包含了各种语言中使用的所有字符,包括中文、英文、拉丁文、数学符号、标点符号等。
它将每个字符都分配了一个唯一的Unicode编码,这个编码是由一串十六进制数字表示的。
Unicode字符集的编码方式主要分为UTF-8、UTF-16和UTF-32三种。
UTF-8编码是Unicode字符集的一种变长编码方式,它可以表示任意Unicode字符,并且对于英文字母和数字等ASCII字符,使用一个字节来表示,节省了存储空间。
UTF-8编码的基本单位是字节,但是由于Unicode 字符的编码长度不定,所以UTF-8编码中一个字符的长度可以是1至4个字节。
对于汉字来说,UTF-8编码通常会使用3个字节来表示。
UTF-16编码也是Unicode字符集的变长编码方式,但它的基本单位是16位,即两个字节。
UTF-16编码可以表示Unicode字符集中的所有字符,对于非ASCII字符,UTF-16编码使用两个字节或四个字节来表示。
对于汉字来说,UTF-16编码通常会使用两个字节来表示。
UTF-32编码是Unicode字符集的定长编码方式,它将每个字符都使用四个字节来表示,不论字符的实际长度。
UTF-32编码对于处理和存储来说较为简单,但占用的存储空间较大,因此在实际应用中较少使用。
在使用汉字编码时,我们通常使用的是UTF-8编码,因为它兼容性强,可以表示任意Unicode字符,同时在存储空间占用上也比较高效。
在实际应用中,我们常常需要将汉字编码转换为其他字符集,或者将其他字符集中的编码转换为汉字编码。
这就需要使用字符集转换工具或编程语言提供的相关函数。
Java语言中,可以使用String类的getBytes()方法将字符串转换为字节数组,传入指定的编码方式参数,即可将汉字转换为对应的编码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
sqlplus scott/tiger
sql>seleຫໍສະໝຸດ t * from test 张飞
显示中文OK
插入中文不行
很多人都碰到过因为字符集不同而使数据导入失败的情况。
这涉及三方面的字符集,
一是Oracel server端的字符集,
SQL> select * from hh;
ERROR at line 1:
ORA-00942: table or view does not exist
C:\>set NLS_LANG=simplified chinese_china.zhs16gbk
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
select * from props$
SELECT parameter, value
FROM nls_database_parameters
比如:set nls_lang=SIMPLIFIED CHINESE_CHINA.ZHS16GBK
在Unix平台下 $echo $NLS_LANG
4.exp imp 时的字符集转换
linux:
oracle
export NLS_LANG='SIMPLIFIED CHINESE_CHINA.ZHS16GBK'
export LANG=zh_CN.GB18030
终端 工具 settings -> set Encoding: gb18030
sqlplus scott/tiger
sql>select * from test
张飞
显示中文OK
插入中文OK
putty:
export NLS_LANG='simplified chinese_'
Language指定Oracle消息的语言,(对应NLS_LANGUAGE)
territory指定货币,日期和数字的格式,
(对应 NLS_TERRITORY)
charset指定客户端应用程序的字符集
如:AMERICAN_AMERICA.ZHS16GBK
AMERICAN_CHINA.ZHS16GBK
NLS_LANG='SIMPLIFIED CHINESE_CHINA.ZHS16GBK'
NLS_LANG=AMERICAN_AMERICA.AL32UTF8
SIMPLIFIED CHINESE_CHINA.al32utf8
ORA-00942: table or view does not exist
NLS_LANG=simplified chinese_china.zhs16gbk
linux 服务器
oracle
export NLS_LANG='simplified chinese_'
但Oracle8之后,至少有三张系统表记录了数据库字符集的信息,只改props$表并不完全,
可能引起严重的后果。
正确的修改方法如下:
SQL>STARTUP MOUNT;
SQL>ALTER SYSTEM ENABLE RESTRICTED SESSION;
字符文件位置
9i: $ORACLE_HOME/ocommon/nls/admin/data
10g: $ORACLE_HOME/nls/data
环境变量(客户端)
NLS_LANG = language_territory.charset
它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。其中:
ZHS16GBK
如果dmp文件很大,比如有2G以上(这也是最常见的情况),
用文本编辑器打开很慢或者完全打不开,可以用以下命令(在unix主机上):
cat exp.dmp |od -x|head -1|awk '{print $2 $3}'|cut -c 3-6
查询dmp文件的字符集:用Oracle的exp工具导出的dmp文件也包含了字符集信息,
dmp文件的第2和第3个字节记录了dmp文件的字符集。
如果dmp文件不大,比如只有几M或几十M,可以用UltraEdit打开(16进制方式),
子集和超集关系的情况下也可以修改,我们常用的一些字符集,如US7ASCII,WE8ISO8859P1,
ZHS16CGB231280,ZHS16GBK基本都可以改。因为改的只是dmp文件,所以影响不大。
具体的修改方法比较多,最简单的就是直接用UltraEdit修改dmp文件的第2和第3个字节。
SIMPLIFIED CHINESE_CHINA.WE8ISO8859P1
从NLS_LANG的组成我们可以看出,真正影响数据字符集的其实是第三部分。
所以两个数据(数据库和客户端)之间的字符集只要第三部分一样就可以相互导入导出数据,
前面影响的只是提示信息是中文还是英文。
SQL> select userenv('language') from dual;
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
create table test(id number,name varchar2(30)) tablespace users;
Using Globalization Support
1.create database
character set
2.some concepts
OS:LANG (/etc/profile,/etc/sysconfig/i18n)
NLS_LANG
DB:NLS_LANGUAGE
ZHS16CGB231280(字符少,旧,1981年5月)
之间不存在子集和超集关系,
因此理论上讲这两种字符集之间的相互转换不受支持。
修改Server端字符集(不建议使用):
在Oracle 8之前,可以用直接修改数据字典表props$来改变数据库的字符集。
SQL> select * from test;
1 hello
2 张飞
sql>select * from hh;
第 1 行出现错误:
ORA-00942: table or view does not exist
二是oracle client端的字符集,
三是dmp文件的字符集。在做数据导入的时候,需要这三个字符集都一致才能正确导入。
3.Oracle Server端和Client端的字符集
查询Oracle Server端的字符集
SQL>select userenv('language') from dual;
SQL>ALTER SYSTEM SET JOB_QUEUE_PROCESSES=0;
SQL>ALTER SYSTEM SET AQ_TM_PROCESSES=0;
SQL>ALTER DATABASE OPEN;
SQL>ALTER DATABASE CHARACTER SET ZHS16GBK;
WHERE parameter LIKE '%CHARACTERSET%';
查询Oracle client端的字符集:
在Windows平台下,就是注册表里面相应OracleHome的NLS_LANG.
还可以在Dos窗口里面自己设置,
看第2第3个字节的内容,如0354,然后用以下SQL查出它对应的字符集:
scott:
SQL> select nls_charset_name(to_number('0354','xxxx')) from dual;
然后用上述SQL也可以得到它对应的字符集。
5.不建议修改oracle数据库server端的字符集
特别说明,我们最常用的两种字符集
ZHS16GBK(new,1995年12月,20902字)和
regedit
HKEY_LOCAL_MACHINE\SOFTWARE\ORACLE\KEY_
win:
C:\>set NLS_LANG=
C:\>echo %NLS_LANG%
%NLS_LANG%
C:\>sqlplus sys/oracle@hh as sysdba
ALTER DATABASE CHARACTER SET internal_convert ZHS16GBK;
SQL>ALTER DATABASE national CHARACTER SET ZHS16GBK;
SQL>SHUTDOWN IMMEDIATE;
exp scott/tiger owner=scott file=scott.dmp
没有发生字符集转换
C:\>set NLS_LANG=simplified chinese_china.zhs16gbk
C:\>exp scott/tiger@lh owner=scott file=scott.dmp
SQL>STARTUP
修改dmp文件字符集:
dmp文件的第2第3字节记录了字符集信息,因此直接修改dmp文件的第2第3字节的内容就可以
‘骗’过oracle的检查。这样做理论上也仅是从子集到超集可以修改,但很多情况下在没有
sql>quit
C:\>set NLS_LANG=AMERICAN_AMERICA.ZHS16GBK