使用HP crashinfo 和oradebug close
“Outlook 已停止工作 windows正在检查该问题的解决方案

出错停止工作c0000374| no.msacm.voxacm160,Outlook2007的自动提醒功能引起Outlook自动关闭的解决办法问题描述我的同事又再向我抱怨Outlook 2007了,她在打开Outlook2007后,没过多久Outlook就失去了响应,系统提示“Outlook 已停止工作windows正在检查该问题的解决方案",然后自动关闭了。
我马上想到了用sysinternals 随后我想到了日志,在eventvwr。
msc中没有看到相关的日志,倒是打开“问题报告和解决方案”的时候,点击“查看问题历史记录”,看到了错误报告。
gnaw0725注:这个错误报告是由控制面板,要打开它有个简单的办法,您可以直接在开始搜索栏,输入“问题",然后就可以搜索到它了。
另外您也可以执行如下命令,打开它.%systemroot%\system32\control.exe /nameMicrosoft.ProblemReportsAndSolutions奥,这么长的命令怎么记得住?不用怕,用start ++吧,请参考http://gnaw0725。
/logs/4888446.html该报错内容如下:产品Microsoft Office Outlook问题已停止工作日期2007/8/20 13:52状态未报告问题签名问题事件名称: APPCRASH应用程序名: OUTLOOK。
EXE应用程序版本: 12。
0。
6023。
5000应用程序时间戳: 46574050故障模块名称: StackHash_757e故障模块版本: 6.0.6000.16386故障模块时间戳: 4549bdc9异常代码: c0000374异常偏移量: 000af1c9OS 版本: 6.0.6000。
2.0。
0。
256。
1区域设置ID: 2052其他信息1: 757e其他信息2: 5da28544f92a22e5d56c0b91b01a18b0其他信息3: 09b3其他信息4: 256f34f9755b7e6e969ea15c59857d57处理过程先按下ctrl+shift+esc 打开任务管理器,尽量关闭应用程序和服务,特别是防病毒软件,(前面我们见过一个防病毒软件干扰word2007启动的例子:word2007对话框打开时命令无法执行)启动sysinternals processmonitor ,然后按下ctrl+e,停止事件日志获取,然后按ctrl+x 清除掉processmonitor启动过程中获取的日志。
HPUX_高级排错._启动文件丢失或损坏

系统启动: 两进制启动文件丢失或损坏
系统启动:两进制启动文件
这些启动文件丢失或 损坏了系统会发生?
lvol3 (/)
/sbin/init /sbin/reboot /sbin/ioinit /sbin/lvinboot /sbin/insf /sbin/vgchange /sbin/mount /sbin/newfs /sbin/vgcfgrestore
Welcome to the HP-UX installation/recovery process!
Use the tab and /or arrow keys to navigate through the following e the return key to select an item.If the menu items are not clear,select the Help item for more information.
HP -UX CORE MEDIA SYSTEM RECOVERY MAIN MENU
[ [ [ [
Install HP-UX Run a Recovery Shell Cancel and Reboot Advanced Options [ Help ]
] ] ] ]
s. ቤተ መጻሕፍቲ ባይዱ. l. r. x. c.
sbin . . .
. . . . . . etc stand
Main Memory (RAM)
正常启动盘
系统启动:实例(意外删除了VMUNIX)
ISL booting hpux Exec failed:cannot find /stand/vmunix or /vmunix ISL> hpux 11 (searching backup file of vmunix) LS : isc(52.6.0;0)/. dr-xr-xr-x 5 -rw-r--r-dr-xr-xr-x drwxr-xr-x 1 5 5
HP诊断日志收集指南—Linuxv1.0

HP诊断日志收集指南—Linuxv1.0HP诊断日志收集指南—LinuxLinux操作系统下判断服务器硬件故障,需要收集以下日志文件:1.Sosreport2.IML log3.HP Insight Diagnostics Survey4.ILO log或者5.特定情况下可收集cfg2html Report以下是收集方法:1.SosreportSosreport (需要RHEL4 Upgrade6及以后版本):1)对于Redhat用户(大致5分钟以内收集完成)使用root用户执行sosreport,会在/tmp下产生新的.tar.gz的日志文件2)对于Suse redhat(大致5分钟以内收集完成)使用脚本supportconfig -A收集日志,日志路径会存在/var/log 下。
2.IMLLog用户可以用在线或者离线两种方式收集IML日志。
首先确认系统中是否有安装PSP。
如果未安装PSP,请先参考以下文档进行安装:Linux系统安装PSP指南.doc安装完成后,请进行下一步操作。
1)如果服务器上已经安装PSP,请在命令行中输入:hplog –v > “filename”2)如果用户系统无法安装PSP,请采取离线方式收集IML日志,请参考以下指南《离线方式收集IML日志》离线方式收集IML日志.docx3.HP Insight Diagnostics Survey用户可以用在线或者离线两种方式收集HP Insight Diagnostics Survey报告。
使用在线方式收集,首先确认系统中是否有安装PSP。
如果未安装PSP,请先参考以下文档进行安装:Linux系统安装PSP指南.doc安装完成后,请进行下一步操作。
1)安装完成HP Insight Diagnostics后,可以通过图形界面和命令行两种方式获得HP InsightDiagnostics Survey。
A.图形界面方式:a)访问https://:2381来打开System Management Homepage.b)点击webapps,c)点击HP Insight Diagnostics in Other Agents.d)Survey页面会显示HP Insight Diagnostics Survey。
如何进入惠普服务器系统日志察看工具
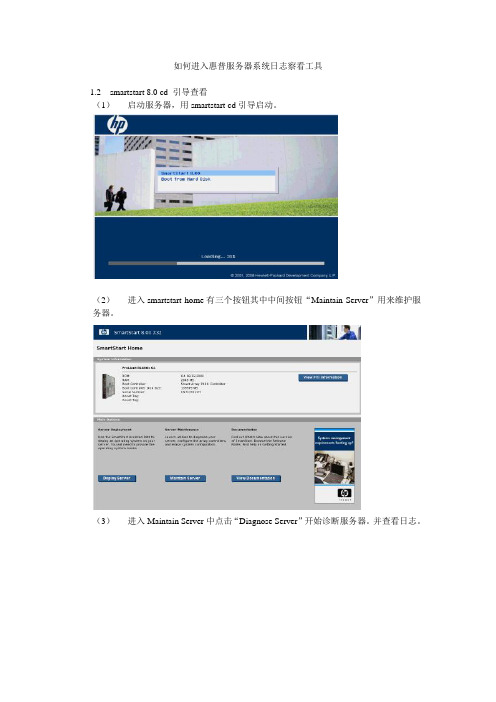
如何进入惠普服务器系统日志察看工具
1.2 smartstart 8.0 cd 引导查看
(1)启动服务器,用smartstart cd引导启动。
(2)进入smartstart home有三个按钮其中中间按钮“Maintain Server”用来维护服务器。
(3)进入Maintain Server中点击“Diagnose Server”开始诊断服务器。
并查看日志。
(4)进入诊断选项前的服务器检测。
(5)进入诊断模式,首页为“Survey”选项,右下角有“save”按钮,可以保存出来,该日志记录了服务器硬件配置和硬件信息等。
又称“survey 报告”。
另外“test”选项中用户可以自定义对服务器进行检测和测试。
“status”中可以查看到检测硬件的状态。
“log”选项中记录了检测日志,错误日志和iml日志。
(1)Test log
(7)Error log
(8)iml log,可以点击右下角“save”来保存iml日志。
【Crash】C++程序崩溃排查方法

【Crash】C++程序崩溃排查⽅法windows下C++程序release版本崩溃错误排查⽅法。
⼀个你精⼼设计的24⼩时不间断运⾏,多线程的程序,突然运⾏了⼏个⽉后崩了,此问题是⾮常难以排查的,也是很头疼的问题。
现利⽤Google开源⼯具crashrpt与Microsoft windbg⼯具,解决这个问题,并分享给⼤家。
使⽤⼯具Crashrpt、Windbg.因为windbg这个⼯具很常见,暂不介绍。
其中重点介绍⼀下crashrpt。
⼀、crashrpt 简介 crashrpt是⼀个包含能够在程序出现各种类型未处理异常时⽣成程序错误报告,然后将该报告按照指定的⽅式(例如HTTP或者SMTP)发送给开发者,最后分析这些信息的⼯具。
crashrpt由3个部分组成: (1)错误报告⽣成库CrashRpt 我们需要在⾃⼰的程序中使⽤该库捕获我们的程序没有处理的异常,在该库捕获到这些未处理的异常后,CrashRpt会⽣成MiniDump⽂件, 并将和你使⽤该库指定的信息(例如⽇志⽂件和屏幕截图等)⼀起打包成错误报告。
CrashRpt库⽀持处理我所知道的所有Windows C/C++程序抛出的各类异常,还能捕获C++异常、信号和调⽤各类CRT库中的函数出现的错误。
(2)异常信息发送⼯具CrashSender 该⼯具能够按照我们使⽤CrashRpt设置的⽅式,将⽣成的错误报告按照我们指定的⽅式(HTTP、SMTP或者MAPI)发送给我们。
(3)⾃动异常信息处理⼯具crprober 该⼯具能够在后台接收CrashSender发送给我们的错误报告,通过分析错误报告后以⽂本的形式输出程序的异常信息。
⼆、下载安装 crashrpt (1)下载crashrpt crashrpt下载地址:https:///p/crashrpt 关于crashrpt更详细的介绍,可以参考⾯https:///p/crashrpt/ (⼤陆可能很难访问到)以及/docs/html/getting_started.html (⼤陆可能很难访问到) 下载解压后的⽬录如下图所⽰:其中bin⽬录中包含使⽤vc10编译出来的所有crashrpt相关库和程序,include和lib⽬录中包含了开发所需要的头⽂件以及lib⽂件。
oradebug使用详解

oradebug使用详解ToolsORADEBUGORADEBUG is an undocumented debugging utility supplied with Oracle For more general information see ORADEBUG introductionIn Oracle 9.2 commands includeHELPSETMYPIDSETORAPIDSETOSPIDTRACEFILE_NAMEUNLIMITFLUSHCLOSE_TRACESUSPENDRESUMEWAKEUPDUMPLISTDUMPEVENTSESSION_EVENTDUMPSGADUMPVARPEEKPOKEIPCDumping the SGAHELP commandThe ORADEBUG HELP command lists the commands available within ORADEBUGThese vary by release and platform. Commands appearing in this help do not necessarily work for the release/platform on which the database is runningFor example in Oracle 9.2.0.1 (Windows 2000) the commandORADEBUG HELPreturns the followingSETMYPID commandBefore using ORADEBUG commands, a process must be selected. Depending on the commands to be issued, this can either be the current process or another processOnce a process has been selected, this will be used as the ORADEBUG process until another process is selectedThe SETMYPID command selects the current process as the ORADEBUG processFor exampleORADEBUG SETMYPIDORADEBUG SETMYPID can be used to select the current process to run systemwide commands such as dumpsDo not use ORADEBUG SETMYPID if you intend to use the ORADEBUG SUSPEND command SETORAPID commandBefore using ORADEBUG commands, a process must be selected. Depending on the commands to be issued, this can either be the current process or another processOnce a process has been selected, this will be used as the ORADEBUG process until another process is selectedThe SETORAPID command selects another process using the Oracle PID as the ORADEBUG processThe syntax isORADEBUG SETORAPID pidwhere pid is the Oracle process ID of the target process For exampleORADEBUG SETORAPID 9The Oracle process id for a process can be found in V$PROCESS.PIDTo obtain the Oracle process ID for a foreground process useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$sessionWHERE sid = DBMS_SUPPORT.MYSID);Alternatively, if the DBMS_SUPPORT package is not available useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$sessionWHERE sid =(SELECT sid FROM v$mystat WHERE ROWNUM = 1));To obtain the process ID for a background process e.g. SMON useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$bgprocessWHERE name = 'SMON');To obtain the process ID for a dispatcher process e.g. D000 useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$dispatcherWHERE name = 'D000');To obtain the process ID for a shared server process e.g. S000 useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$shared_serverWHERE name = 'S000');To obtain the process ID for a job queue process e.g. job 21 useSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$sessionWHERE sid =(SELECT sid FROM dba_jobs_running WHERE job = 21));To obtain the process ID for a parallel execution slave e.g. P000 useSELECT pid FROM v$px_processWHERE server_name = 'P000';SETOSPID commandBefore using ORADEBUG commands, a process must be selected. Depending on the commands to be issued, this can either be the current process or another processOnce a process has been selected, this will be used as the ORADEBUG process until another process is selectedThe SETOSPID command selects the another process using the operating system PID as the ORADEBUG processThe syntax isORADEBUG SETOSPID pidwhere pid is the operating system process ID of the target process For example ORADEBUG SETOSPID 34345The operating system process ID is the PID on Unix systems and the thread number on Windows NT/2000 systemsOn Unix the PID of interest may have been identified using a top or ps command TRACEFILE_NAME commandThis command prints the name of the current trace file e.g.ORADEBUG TRACEFILE_NAMEFor example/export/home/admin/SS92003/udump/ss92003_ora_14917.trcThis command does not work on Windows 2000 (Oracle 9.2)UNLIMIT commandIn Oracle 8.1.5 and below the maximum size of the trace file is restricted by default. This means that large dumps (LIBRARY_CACHE, BUFFERS) may fail.To remove the limitation on the size of the trace file useORADEBUG UNLIMITIn Oracle 8.1.6 and above the maximum size of the trace file defaults to UNLIMITEDFLUSH commandTo flush the current contents of the trace buffer to the trace file useORADEBUG FLUSHCLOSE_TRACE commandTo close the current trace file useORADEBUG CLOSE_TRACESUSPEND commandThis command suspends the current processFirst select a process using SETORAPID or SETOSPIDDo not use SETMYPID as the current ORADEBUG process will hang and cannot be resumed even from another ORADEBUG processFor example the commandORADEBUG SUSPENDsuspends the current processThe commandORADEBUG RESUMEresumes the current processWhile the process is suspended ORADEBUG can be used to take dumps of the current process state e.g. global area, heap, subheaps etc.This example demonstrates how to take a heap dump during a large (sorting) queryThis example requires two sessions, session 1 logged on SYS AS SYSDBA and session 2 which executes the query. In session 2 identify the PID usingSELECT pid FROM v$processWHERE addr IN(SELECT paddr FROM v$sessionWHERE sid = dbms_support.mysid);In this example the PID was 12In session 1 set the Oracle PID usingORADEBUG SETORAPID 12In session 2 start the querySELECT ... FROM t1 ORDER BY ....In session 1 suspend session 2ORADEBUG SUSPENDThe query in session 2 will be suspendedIn session 1 run the heap dumpORADEBUG DUMP HEAPDUMP 1The heapdump will show the memory structures allocated for the sort. At this point further dumps e.g. subheap dumps can be taken.In session 1 resume session 2The query in session 2 will resume executionRESUME commandThis command resumes the current processFirst select a process using SETORAPID or SETOSPIDDo not use SETMYPID as the current ORADEBUG process will hang and cannot be resumed even from another ORADEBUG processFor example the commandORADEBUG SUSPENDsuspends the current processThe commandORADEBUG RESUMEresumes the current processWhile the process is suspended ORADEBUG can be used to take dumps of the current process state e.g. global area, heap, subheaps etc.See SUSPEND for an example of use of the SUSPEND and RESUME commands WAKEUP commandTo wake up a process useORADEBUG WAKEUP pidFor example to wake up SMON, first obtain the PID usingSELECT pid FROM v$processWHERE addr =(SELECT paddr FROM v$bgprocessWHERE name = 'SMON');If the PID is 6 then send a wakeup call usingDUMPLIST commandTo list the dumps available in ORADEBUG useORADEBUG DUMPLIST pidFor example in Oracle 9.2 (Windows 2000) this command returns the followingDUMP commandTo perform a dump useORADEBUG DUMP dumpname levelFor example for a level 4 dump of the library cache useORADEBUG SETMYPIDORADEBUG DUMP LIBRARY_CACHE 4EVENT commandTo set an event in a process useORADEBUG EVENT event TRACE NAME CONTEXT FOREVER, LEVEL levelFor example to set event 10046, level 12 in Oracle process 8 useORADEBUG SETORAPID 8ORADEBUG EVENT 10046 TRACE NAME CONTEXT FOREVER, LEVEL 12SESSION_EVENT commandTo set an event in a session useORADEBUG SESSION_EVENT event TRACE NAME CONTEXT FOREVER, LEVEL levelFor exampleORADEBUG SESSION_EVENT 10046 TRACE NAME CONTEXT FOREVER, LEVEL 12DUMPSGATo dump the fixed SGA useORADEBUG DUMPSGADUMPVARTo dump an SGA variable useORADEBUG DUMPVAR SGA variable_namee.g.ORADEBUG DUMPVAR SGA kcbnhbwhich returns the number of hash buckets in the buffer cacheThe names of SGA variables can be found in X$KSMFSV.KSMFSNAM. Variables in this view are suffixed with an underscore e.g.kcbnhb_PEEKTo peek memory locations useORADEBUG PEEK address lengthwhere address can be decimal or hexadecimal and length is in bytesFor exampleORADEBUG PEEK 0x20005F0C 12returns 12 bytes starting at location 0x20005f0cPOKETo poke memory locations useORADEBUG POKE address length valuewhere address and value can be decimal or hexadecimal and length is in bytesFor ExampleORADEBUG POKE 0x20005F0C 4 0x46495845ORADEBUG POKE 0x20005F10 4 0x44205349ORADEBUG POKE 0x20005F14 2 0x5A45WARNING Do not use the POKE command on a production systemIPCTo dump information about operating system shared memory and semaphores configuration use the commandORADEBUG IPCThis command does not work on Windows NT or Windows 2000 (Oracle 9.2)On Solaris, similar information can be obtained using the operating system commandipcs -bDumping the SGAIn some versions it is possible to dump the entire SGA to a fileFreeze the instance usingORADEBUG FFBEGINDump the SGA to a file usingORADEBUG SGATOFILE directoryUnfreeze the instance usingORADEBUG FFRESUMEINSTThis works in Oracle 9.0.1 and 9.2.0 on Solaris, but fails in both versions in Windows 2000。
排查程序错误和崩溃的常见方法

排查程序错误和崩溃的常见方法在软件开发过程中,程序错误和崩溃是非常常见的问题。
这些问题不仅会影响用户的体验,还可能导致数据丢失和系统不稳定。
因此,及时排查和解决这些问题是非常重要的。
本文将介绍一些常见的方法来排查程序错误和崩溃。
1. 调试工具的使用调试工具是排查程序错误的利器。
其中,最常用的工具是调试器。
调试器可以让开发人员逐步执行程序,并观察程序的运行状态。
当程序出现错误或崩溃时,调试器可以提供相关的错误信息和堆栈跟踪,帮助开发人员定位问题所在。
常见的调试器有GDB、Xcode和Visual Studio等。
除了调试器,还有一些其他的调试工具可以帮助排查程序错误。
例如,内存检测工具可以检测内存泄漏和越界访问等问题;性能分析工具可以帮助发现程序的性能瓶颈等。
根据具体的问题,选择合适的调试工具可以提高排查效率。
2. 日志记录和错误报告日志记录是排查程序错误的重要手段之一。
通过在程序中添加日志输出语句,可以记录程序的运行过程和关键信息。
当程序出现错误或崩溃时,可以通过查看日志来获取相关的调试信息。
可以记录程序的输入、输出、运行时状态等信息,以便更好地定位问题。
除了日志记录,错误报告也是一种重要的排查程序错误的方法。
当程序出现错误或崩溃时,可以向开发团队发送错误报告,包括错误信息、堆栈跟踪和运行环境等。
开发团队可以通过错误报告来分析和解决问题。
为了保护用户隐私,错误报告中不应包含敏感信息。
3. 单元测试和集成测试单元测试和集成测试是预防程序错误的重要手段。
单元测试是对程序中最小的可测试单元进行测试,例如函数或方法。
通过编写单元测试用例,可以验证程序的各个功能是否正常工作。
集成测试是对程序的不同模块进行测试,验证它们之间的交互是否正确。
通过进行单元测试和集成测试,可以及早发现和修复程序中的错误。
测试用例应该覆盖各种可能的输入和边界情况,以确保程序的正确性和稳定性。
自动化测试工具可以帮助开发人员更方便地编写和运行测试用例。
hp小型机常用操作

[1]启动(1)启动次序MP stand/vmunix /sbin/init(调用/etc/inittab) /sbin/rc(调用/sbin/rc[run-level].d) 用户登入脚本等(2)pre_init_rc用来检查启动文件的正确性(3)M P 界面MP确省用户:Admin 密码:Admin进入MP ctrl+B退出MP先执行ma (即main)再执行co (即console)(4)如何查看Primary,Alternate Boot Path?重新启动主机,在十秒钟中断时按任意键进入BootAdmin 菜单,此时在BootAdmin 的提示符下键入pa 命令如下:main menu> pa就会列出Primary,Alternate Path。
或在操作系统下执行#setboot 命令。
(5)/sbin/initinit使用的参数如下:0 关闭机器,处于halt状态1 机器进入系统管理模式,与单用户模式相似,但所有文件系统都可使用,只有超级用户的控制台才可访问系统2 多用户模式,允许所有用户进入系统3 多用户模式,能够共享远程文件等(如NFS)4 多用户模式,VUE(visual user environment),是一个图形环境并有一组X Windows程序被激活5-6 HPUX没有定义,作为用户自定义模式a,b,c 不改变当前运行级别,而是运行一组给定程序s 单用户模式,S 与s模式相似。
在s模式之用物理的系统控制台才可进入系统,而在S模式虚拟的系统控制台可以进入系统Q/q 不改变运行模式,使用当前级别重新读取inittab文件。
不用重启系统就使inittab的文件改变生效。
(6)/etc/inittab启动后,init进程根据/etc/inittab的内容创建任务1.inittab文件内容举例### change the default run level herei nit:3:initdefault:### pre-configured lines required for boot - don‘t change!ioin::sysinit:/sbin/ioinitrc >/dev/console 2>&1tape::sysinit:/sbin/mtinit > /dev/console 2>&1stty::sysinit:/sbin/stty 9600 clocal icanon echo opost onlcr ixon icrnl ignpar </dev/systtysqnc::wait:/sbin/rc </dev/console >/dev/console 2>&1 # system init### these lines display login promptscons:123456:respawn:/usr/sbin/getty console console # system console#ttp1:234:respawn:/usr/sbin/getty -h tty0p1 9600krsd:123456:respawn:/sbin/krsd -I2.inittab文件格式说明Label:Run-level:Action-keyword:ProcessLabel 4个字符长的唯一标示符Run-level 1个或多个init参数,表运行级别。
HP服务器的一些启动报错的原因和解决办法(中英双语)

304-Keyboard or System Unit Erroraudible beeps: nonepossible cause: keyboard, keyboard cable, mouse controller, or system board failure.action:1. be sure the keyboard and mouse are connected.only authorized technicians trained by hp should attempt to remove the system board. if you believe the system board requires replacement, contact hp technical support before proceeding.2. run insight diagnostics ("hp insight diagnostics" on page 101) and replace failed components as indicated.400 serieslist of messages:40x-parallel port x address assignment conflict404-parallel port address conflict detected40x-parallel port x address assignment conflictaudible beeps: 2 shortpossible cause: both external and internal ports are assigned to parallel port x.action: run the server setup utility and correct the configuration.404-parallel port address conflict detected......a hardware conflict in your system is keeping some system components from working correctly. if you have recently added new hardware remove it to see if it is the cause of the conflict. alternatively, use computer setup or your operating system to insure that no conflicts exist.audible beeps: 2 shortpossible cause: a hardware conflict in the system is preventing the parallel port from working correctly.action:1. if you have recently added new hardware, remove it to see if the hardware is the cause of the conflict.2.run the server setup utility to reassign resources for the parallel port and manually resolve the resource conflict.3. run insight diagnostics ("hp insight diagnostics" on page 101) and replace failed componentsas indicated.600 serieslist of messages:601-diskette controller error602-diskette boot record error605-diskette drive type error611-primary floppy port address assignment conflict612-secondary floppy port address assignment conflict601-diskette controller erroraudible beeps: nonepossible cause: diskette controller circuitry failure occurred.action:1. be sure the diskette drive cables are connected.2. replace the diskette drive, the cable, or both.3. run insight diagnostics ("hp insight diagnostics" on page 101) and replace failed components as indicated.602-diskette boot record erroraudible beeps: nonepossible cause: the boot sector on the boot disk is corrupt.action:1. remove the diskette from the diskette drive.2. replace the diskette in the drive.3. reformat the diskette.605-diskette drive type error.audible beeps: 2 shortpossible cause: mismatch in drive type occurred.action: run the server setup utility to set the diskette drive type correctly.611-primary floppy port address assignment conflictaudible beeps: 2 shortpossible cause: a hardware conflict in the system is preventing the diskette drive fromoperating properly.action:1. run the server setup utility to configure the diskette drive port address and manually resolve the conflict.2. run insight diagnostics ("hp insight diagnostics" on page 101) and replace failed components as indicated.612-secondary floppy port address assignment conflictaudible beeps: 2 shortpossible cause: a hardware conflict in the system is preventing the diskette drive from operating properly.action:1. run the server setup utility to configure the diskette drive port address and manually resolve the conflict.2. run insight diagnostics ("hp insight diagnostics" on page 101) and replace failed components as indicated.1100 serieslist of messages:1151-com port 1 address assignment conflict1151-com port 1 address assignment conflictaudible beeps: 2 shortpossible cause: both external and internal serial ports are assigned to com x.action: run the server setup utility and correct the configuration.1600 serieslist of messages:1609 - the server may have a failed system battery. some1610-temperature violation detected. - waiting 5 minutes for system to cool1611-cpu zone fan assembly failure detected. either1611-cpu zone fan assembly failure detected. single fan1611-fan failure detected1611-fan x failure detected (fan zone cpu)1611-fan x failure detected (fan zone i/o)1611-fan x not present (fan zonecpu)1611-fan x not present (fan zone i/o)1611- power supply zone fan assembly failure detected. either1611-power supply zone fan assembly failure detected. single fan1611-primary fan failure (fan zone system)1611-redundant fan failure (fan zone system)1612-primary power supply failure1615-power supply configuration error1615-power supply configuration error1615-power supply failure, power supply unplugged, or power supply fan failure in bay x 1616-power supply configuration failure1609 - the server may have a failed system battery. some......configuration settings may have been lost and restored to defaults. refer to server documentation for more information. if you have just replaced the system battery, disregard this message.audible beeps: nonepossible cause: real-time clock system battery has lost power. the system will lose its configuration every time ac power is removed (when the system is unplugged from ac power source) and this message displays again if a battery failure has occurred. however, the system will function and retain configuration settings if the system is connected to the ac power source.action: replace battery (or add external battery).1610-temperature violation detected. - waiting 5 minutes for system to coolaudible beeps: nonepossible cause: the ambient system temperature exceeded acceptable levels.action: lower the room temperature.1611-cpu zone fan assembly failure detected. either......the assembly is not installed or multiple fans have failed in the cpu zone.audible beeps: nonepossible cause: required fans are missing or not spinning.action:1. check the fans to be sure they are installed and working.2. be sure the assembly is properly connected and each fan is properly seated.3. if the problem persists, replace the failed fans.4. if a known working replacement fan is not spinning, replace the assembly.1611-cpu zone fan assembly failure detected. single fan......failure. assembly will provide adequate cooling.audible beeps: nonepossible cause: required fan not spinning.action: replace the failed fan to provide redundancy, if applicable.1611-fan failure detectedaudible beeps: 2 shortpossible cause: required fan not installed or spinning.action:1. check the fans to be sure they are working.2. be sure each fan cable is properly connected and each fan is properly seated.3. if the problem persists, replace the failed fans.1611-fan x failure detected (fan zone cpu)audible beeps: 2 shortpossible cause: required fan not installed or spinning.action:1. check the fans to be sure they are working.2. be sure each fan cable is properly connected, if applicable, and each fan is properly seated.3. if the problem persists, replace the failed fans.1611-fan x failure detected (fan zone i/o)audible beeps: 2 shortpossible cause: required fan not installed or spinning.action:1. check the fans to be sure they are working.2. be sure each fan cable is properly connected, if applicable, and each fan is properly seated.3. if the problem persists, replace the failed fans.1611-fan x not present (fan zonecpu)audible beeps: 2 shortpossible cause: required fan not installed or spinning.action:1. check the fans to be sure they are working.2. be sure each fan cable is properly connected, if applicable, and each fan is properly seated.3. if the problem persists, replace the failed fans.1611-fan x not present (fan zone i/o)audible beeps: 2 shortpossible cause: required fan not installed or spinning.action:1. check the fans to be sure they are working.2. be sure each fan cable is properly connected, if applicable, and each fan is properly seated.3. if the problem persists, replace the failed fans.1611- power supply zone fan assembly failure detected. either......the assembly is not installed or multiple fans have failed.audible beeps: nonepossible cause: required fans are missing or not spinning.action:1. check the fans to be sure they are installed and working.2. be sure the assembly is properly connected and each fan is properly seated.3. if the problem persists, replace the failed fans.4. if a known working replacement fan is not spinning, replace the assembly.1611-power supply zone fan assembly failure detected. single fan......failure. assembly will provide adequate cooling.audible beeps: nonepossible cause: required fan not spinning.action: replace the failed fan to provide redundancy, if applicable.1611-primary fan failure (fan zone system)audible beeps: nonepossible cause: a required fan is not spinning.action: replace the failed fan.1611-redundant fan failure (fan zone system)audible beeps: nonepossible cause: a redundant fan is not spinning.action: replace the failed fan.1612-primary power supply failureaudible beeps: 2 shortpossible cause: primary power supply has failed.action: replace power supply.1615-power supply configuration erroraudible beeps: nonepossible cause: the server configuration requires an additional power supply. a moving bar is displayed, indicating that the system is waiting for another power supply to be installed.action: install the additional power supply.1615-power supply configuration error- a working power supply must be installed in bay 1 for proper cooling.- system halted!audible beeps: nonepossible cause: the server configuration requires an additional power supply. a moving bar is displayed, indicating that the system is waiting for another power supply to be installed.action: install the additional power supply.1615-power supply failure, power supply unplugged, or power supply fan failure in bay x audible beeps: nonepossible cause: the power supply has failed, or it is installed but not connected to the system board or ac power source.action: reseat the power supply firmly and check the power cable or replace power supply.1616-power supply configuration failure-a working power supply must be installed in bay 1 for proper cooling.-system halted!audible beeps: nonepossible cause: power supply is improperly configured.action: run the server setup utility and correct the configuration.304键盘或系统组合误差听见蜂鸣声:无可能的原因:键盘,键盘线,鼠标控制器或系统板故障。
惠普电脑经常蓝屏怎么解决

惠普电脑经常蓝屏怎么解决惠普电脑经常蓝屏的解决方法一:一、启动时加载程序过多不要在启动时加载过多的应用程序尤其是你的内存小于64MB,以免使系统资源消耗殆尽。
正常情况下,Win9X启动后系统资源应不低于90%。
最好维持在90%以上,若启动后未运行任何程序就低于70%,就需要卸掉一部分应用程序,否则就可能出现“蓝屏”。
二、应用程序存在着BUG有些应用程序设计上存在着缺陷或错误,运行时有可能与Win9X发生冲突或争夺资源,造成Win9X无法为其分配内存地址或遇到其保护性错误。
这种BUG可能是无法预知的,免费软件最为常见。
另外,由于一些用户还在使用盗版软件包括盗版Win9X,这些盗版软件在解密过程中会破坏和丢失部分源代码,使软件十分不稳定,不可靠,也常常导致“蓝屏”。
三、遭到不明的程序或病毒攻击所至这个现象只要是平时我们在上网的时候遇到的,当我们在冲浪的时候,特别是进到一些BBS站时,可能暴露了自己的IP,被"黑客"用一些软件攻击所至。
对互这种情况最好就是在自己的计算机上安装一些防御软件。
再有就是登录BBS要进行安全设置,隐藏自己IP。
四、版本冲突有些应用程序需调用特定版本的动态链接库DLL,如果在安装软件时,旧版本的DLL覆盖了新版本的DLL,或者删除应用程序时,误删了有用的DLL文件,就可能使上述调用失败,从而出现“蓝屏”。
不妨重新安装试一试。
五、注册表中存在错误或损坏很多情况下这是出现“蓝屏”的主要原因。
注册表保存着Win9X的硬件配置、应用程序设置和用户资料等重要数据,如果注册表出现错误或被损坏,就很可能出现“蓝屏”。
如果你的电脑经常出现“蓝屏”,你首先就应考虑是注册表出现了问题,应及时对其检测、修复,避免更大的损失。
六、软硬件不兼容新技术、新硬件的发展很快,如果安装了新的硬件常常出现“蓝屏”,那多半与主板的BIOS或驱动程序太旧有关,以致不能很好支持硬件。
如果你的主板支持BIOS升级,应尽快升级到最新版本或安装最新的设备驱动程序。
HP-UX系统诊断日志

Troubleshooting和Error_Logs:
1. system error logs :一般有SEL,FPL,在MP卡下SL命令可以收集SEL和FPL.
2. Init日志在EFI shell下输入errdump init命令可以收集,MCA日志在EFI shell下输入errdump mca命令可以收集。
在MP卡用fw命令刷新固件,在笔记本上配置FTP服务器,在输入fw命令后选择从ftp上传固件版本,进行更新固件。
日志文件的查询
/var/adm/syslog/syslog.log (系统常用信息,如配置、修改、启动、关闭等信息)
/var/adm/syslog/mail.log (电子邮件信息)
/var/adm/syslog/swinstall.log (软件安装产生的信息)
/var/adm/syslog/swremove.log (软件卸载产生的信息)
/var/adm/sulog (执行su的情况)
/var/adm/btmp (所有注册失败信息)
/var/adm/vtmp (所有注册信息)
查看日志主要是查看关键字panic、warning、err等信息,如:
cat /var/adm/syslog/syslog.log |grep panic
cat /var/adm/syslog/syslog.log |grep warning
cat /var/adm/syslog/syslog.log |grep err。
hpsocket用法

hpsocket用法
hpsocket是一个基于IOCP的高性能网络库,用于快速开发可
靠的高性能TCP/UDP/HTTP/WebSocket服务器和客户端。
它提供了一
套简单易用的接口,可以帮助开发者快速构建网络应用程序。
首先,你需要下载hpsocket库的最新版本,并将其集成到你的
项目中。
你可以从官方网站或者GitHub上找到hpsocket的最新版本,并按照官方文档中的说明进行安装和集成。
一旦集成完成,你可以开始使用hpsocket库来开发网络应用程序。
首先,你需要创建一个Server或Client对象,然后通过设置
一些回调函数来处理网络事件,比如连接建立、数据到达、连接断
开等。
在回调函数中,你可以编写具体的业务逻辑来处理这些事件。
除了基本的网络事件处理,hpsocket还提供了丰富的功能和工具,比如SSL支持、自定义协议支持、性能优化工具等。
你可以根
据自己的需求选择合适的功能和工具来完善你的网络应用程序。
在使用hpsocket的过程中,你可能会遇到一些常见的问题,比
如内存泄漏、性能瓶颈等。
在这种情况下,你可以查阅官方文档或
者在官方论坛上寻求帮助,也可以查看一些开源项目或者案例来学习其他开发者是如何使用hpsocket来解决类似的问题的。
总的来说,hpsocket是一个功能强大、易用性高的网络库,可以帮助开发者快速构建可靠的高性能网络应用程序。
通过学习官方文档和案例,以及参与开发者社区的讨论,你可以更好地掌握hpsocket的用法并发挥其最大的潜力。
c++崩溃问题定位方法

c++崩溃问题定位方法C++程序的崩溃问题是开发过程中常见的挑战之一。
由于C++是一种底层语言,程序员需要对内存管理和指针操作等细节非常小心。
当一个C++程序崩溃时,问题的定位可能会非常困难。
然而,以下是一些常用的方法,可以帮助你定位C++程序崩溃问题。
1. 调试器(Debugger)的使用:调试器是定位和修复C++程序问题的首选工具。
它允许你逐行执行代码,并在执行过程中检查变量的值。
当程序崩溃时,调试器可以提供有关崩溃点的信息,例如崩溃发生的代码行号和堆栈跟踪信息。
你可以使用常见的调试器,如GDB(GNU调试器)或LLDB(Low-Level 调试器),根据你的开发环境选择。
2. 核心转储(Core Dump)的分析:当C++程序崩溃时,操作系统可以生成一个核心转储文件(core dump),它记录了程序崩溃时的内存状态。
你可以使用调试器加载核心转储文件,并查看堆栈跟踪信息、变量值等。
这些信息可以帮助你确定崩溃发生的位置和可能的原因。
使用调试器加载核心转储文件的方法与调试正在运行的程序相似。
3. 日志记录(Logging):在程序中添加日志记录是一种常用的调试方法。
你可以在关键代码路径中插入日志语句,并在程序崩溃时检查日志以确定问题的根源。
使用日志记录库,如Log4cpp或Boost.Log,可以方便地在程序中添加日志功能。
记得在发布版本中关闭或移除日志记录代码,以避免性能损失。
4. 编译器警告和错误信息的检查:编译器在编译C++代码时会生成警告和错误信息。
仔细检查这些信息,特别是错误信息,可以帮助你找到代码中的问题。
修复这些问题可能会消除潜在的崩溃点。
5. 代码审查(Code Review):请同事或其他开发人员对你的代码进行审查。
他们可能会提供不同的观点和发现你忽略的问题。
代码审查是一种有助于发现潜在问题的有效方法。
6. 内存错误检测工具:使用内存错误检测工具,如Valgrind或AddressSanitizer,可以帮助你发现内存泄漏、越界访问和非法指针等问题。
Oracle数据库教程 ——oradebug命令详解

Oracle数据库教程——orad ebug命令详解oradebug它可以启动跟踪任何会话,dump SGA和其它内存结构,唤醒ORACLE进程,如SMON、PMON进程,也可以通过进程号使进程挂起和恢复等,还有很多功能,实际上这些功能都不常用,但是我们在看别人做问题诊断时,常看到别人在使用oradebug命令,其实我感觉最好用的就是他可以直接通过命令输出生成trace文件的名称(带路径的哦),省去不少麻烦,系统HANG住用它做分析也比较好用,和大家分享一下它最常用的方法!以sysdba登陆后SQL> oradebug helpHELP [command] Describe one or all commandsSETMYPID Debug current processSETOSPID <ospid> Set OS pid of process to debugSETORAPID <orapid> ['force'] Set Oracle pid of process to debug SETORAPNAME <orapname> Set Oracle process name to debugSHORT_STACK Get abridged OS stack--查找系统内存堆栈CURRENT_SQL Get current SQLDUMP <dump_name> <lvl> [addr] Invoke named dumpDUMPSGA [bytes] Dump fixed SGADUMPLIST Print a list of available dumpsEVENT <text> Set trace event in processSESSION_EVENT <text> Set trace event in sessionDUMPVAR <p|s|uga> <name> [level] Print/dump a fixed PGA/SGA/UGA variable DUMPTYPE <address> <type> <count> Print/dump an address with type infoSETVAR <p|s|uga> <name> <value> Modify a fixed PGA/SGA/UGA variablePEEK <addr> <len> [level] Print/Dump memoryPOKE <addr> <len> <value> Modify memoryWAKEUP <orapid> Wake up Oracle processSUSPEND Suspend executionRESUME Resume executionFLUSH Flush pending writes to trace fileCLOSE_TRACE Close trace fileTRACEFILE_NAME Get name of trace fileLKDEBUG Invoke global enqueue service debuggerNSDBX Invoke CGS name-service debugger-G <Inst-List | def | all> Parallel oradebug command prefix-R <Inst-List | def | all> Parallel oradebug prefix (return outputSETINST <instance# .. | all> Set instance list in double quotesSGATOFILE <SGA dump dir> Dump SGA to file; dirname in double quotes DMPCOWSGA <SGA dump dir> Dump & map SGA as COW; dirname in double quotes MAPCOWSGA <SGA dump dir> Map SGA as COW; dirname in double quotes HANGANALYZE [level] [syslevel] Analyze system hangFFBEGIN Flash Freeze the InstanceFFDEREGISTER FF deregister instance from clusterFFTERMINST Call exit and terminate instanceFFRESUMEINST Resume the flash frozen instanceFFSTATUS Flash freeze status of instanceSKDSTTPCS <ifname> <ofname> Helps translate PCs to namesWATCH <address> <len> <self|exist|all|target> Watch a region of memoryDELETE <local|global|target> watchpoint <id> Delete a watchpointSHOW <local|global|target> watchpoints Show watchpointsDIRECT_ACCESS <set/enable/disable command | select query> Fixed table accessCORE Dump core without crashing processIPC Dump ipc informationUNLIMIT Unlimit the size of the trace filePROCSTAT Dump process statisticsCALL [-t count] <func> [arg1]...[argn] Invoke function with arguments上面试oradebug的命令参数,可以实现我们不同的跟踪方式,功能还是比较强大的,我们先测试一个用oradebug做oracle process级10046SQL> select distinct sid from v$mystat;SID----------96SQL> select spid,pid from v$Process where addr=(select paddr from v$session where sid=96);SPID PID------------------------ ----------2556166 19SQL> !ps -ef | grep LOCALoracle 3670242 10485930 0 11:25:50 - 0:00 oraclexupeng11g(DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))oracle 2556166 2031934 0 11:13:54 - 0:00 oraclexupeng11g(DESCRIPTION=(LOCAL=YES)(ADDRESS=(PROTOCOL=beq)))oracle 10617238 2031934 0 11:34:30 pts/0 0:00 grep LOCAL对SPID系统进程进行追踪SQL> oradebug setorapid 19Oracle pid: 19, Unix process pid: 2556166, image: oracle@cecgt (TNS V1-V3)SQL> oradebug event 10046 trace name context forever,level 28;Statement processed.SQL> oradebug tracefile_name/u01/app/oracle/diag/rdbms/xupeng11g/xupeng11g/trace/xupeng11g_ora_2556166.trcSQL> !more /u01/app/oracle/diag/rdbms/xupeng11g/xupeng11g/trace/xupeng11g_ora_2556166.trc 我们这里查看完整的一段就行了,看用oradebug trace 10046事件的内容。
debugging tools for windows用法

使用Debugging Tools for Windows进行调试的步骤如下:
1.下载并安装Debugging Tools for Windows。
2.打开Debugging Tools for Windows,在开始菜单下找到【Debugging Tools for Windows
(x86)】文件夹,点击进入。
3.在打开的窗口中,选择WinDbg,点击【File】-【Open Crash Dump】选择.DMP文件打开。
4.在打开文件的时候会提示会打开一个工作区域是否在开启,点击【Yes】。
5.打开.DMP文件后,可以使用WinDbg的命令进行调试,例如常用的命令是"!analyze -v",用
于显示崩溃堆栈。
注意,在解析dump文件时,一定要根据发生crash的机型来选择对应的分析平台和WinDbg类型。
以上步骤仅供参考,建议咨询专业人士获取准确信息。
如何使用Debugging Tools for Windows (windebug)简单的使用心得

Debugging Tools for Windows是微软的一个蓝屏故障调试工具,可以方便地解决蓝屏问题。
一般地,电脑上已经设置过保存故障转储文件,但是,某些GHOST版的操作系统关掉了这个功能,我们必须打开它。
在“我的电脑”上按鼠标右键,属性找到“高级”选项卡,在“启动和故障恢复”处点击设置在这里设置为小内存转储(64K),节省磁盘空间当系统蓝屏以后,我们就可以在C:\WINDOWS\Minidump中发现dmp文件(蓝屏后的内存转储文件)。
启动Debugging Tools,依次点击“File”-“Open Crash Dump”选择蓝屏时产生的那个dmp文件打开之后,前面那些字符不用理会,注意最后一行1.安装debug工具下载页面地址:/whdc/devtools/debugging/installx86.mspx选择合适的版本安装2.安装Symbols(特征库)建议可以多安装以免出现分析不出来的情况下载地址:/whdc/devtools/debugging/symbolpkg.mspx 推荐使用VISTA的symbol packages,解析的更详细3.添加Symbols把Symbols的安装路径添加进去4.运行解析找到dump文件添加进去5.以下是一个例子当时的蓝屏代码是0X0000000A,操作系统是XP SP2,是一个QQ引起蓝屏的问题Loading Dump File [e:\!minidump\Mini032707-01.dmp]Mini Kernel Dump File: Only registers and stack trace are availableSymbol search path is: F:\WINDOWS\SymbolsExecutable search path is:Unable to load image ntoskrnl.exe, Win32 error 2*** WARNING: Unable to verify timestamp for ntoskrnl.exeWindows XP Kernel Version 2600 (Service Pack 2) UP Free x86 compatibleProduct: WinNt, suite: TerminalServer SingleUserTSKernel base = 0x804d8000 PsLoadedModuleList = 0x805543a0Debug session time: Tue Mar 27 08:12:47.390 2007 (GMT+8)System Uptime: 0 days 0:18:24.941Unable to load image ntoskrnl.exe, Win32 error 2*** WARNING: Unable to verify timestamp for ntoskrnl.exeLoading Kernel Symbols ............................................................................................................................. Loading User SymbolsLoading unloaded module list.............******************************************************************************** ** Bugcheck Analysis ** ********************************************************************************Use !analyze -v to get detailed debugging information.BugCheck 1000000A, {e1821a40, 2, 0, 805cf120}Unable to load image npkcusb.sys, Win32 error 2*** WARNING: Unable to verify timestamp for npkcusb.sys*** ERROR: Module load completed but symbols could not be loaded for npkcusb.sys Unable to load image hidusb.sys, Win32 error 2*** WARNING: Unable to verify timestamp for hidusb.sys*** WARNING: Unable to verify timestamp for HIDCLASS.SYSUnable to load image USBPORT.SYS, Win32 error 2*** WARNING: Unable to verify timestamp for USBPORT.SYSProbably caused by : npkcusb.sys ( npkcusb+384 )Followup: MachineOwner---------由于npkcusb.sys不是系统文件可以选择删除他来解决6.也有分析不出来的情况这个时候就需要多个minidump分析了如果出现如下的情况,则为symbols文件不足以分析这个dump文件;需要重新添加,或是寻找新的updata 文件。
heap corruption detected after

heap corruption detected after
堆栈损坏是一种常见的程序错误。
它通常由于程序中的内存溢出或错误的内存访问引起。
在许多情况下,这种错误可能会导致程序崩溃或出现不可预测的行为。
当程序出现堆栈损坏时,通常会出现一条错误消息,提示用户堆栈已损坏。
此时,程序会停止执行,并且可能会导致数据丢失或其他问题。
为了解决这个问题,开发人员需要仔细检查他们的代码,找出可能导致堆栈损坏的原因。
他们可以使用调试工具来跟踪程序执行,并检测堆栈损坏的位置。
一旦发现问题,开发人员可以采取措施来修复它。
这可能包括重新设计程序逻辑,修改内存分配和释放策略,或者使用其他技术来避免堆栈损坏。
总之,堆栈损坏是一种常见且严重的程序错误,需要开发人员注意和及时处理。
通过仔细检查代码,使用调试工具和采取适当的措施,开发人员可以避免或修复这种错误,提高程序的可靠性和稳定性。
- 1 -。
HP ProLiant Gen9 故障排除指南

HP ProLiant Gen9 故障排除指南第一卷:故障排除指南摘要本文介绍了很多级别的 HP ProLiant Gen9 服务器故障排除的常见步骤和解决方法。
本文适合安装和管理服务器或服务器刀片以及对其进行故障排除的人员使用。
HP 假定您有资格维修计算机设备,并经过培训,可识别高压带电产品中的危险情况。
© Copyright 2014, 2015 Hewlett-Packard Development Company, L.P.本文档中包含的信息如有更改,恕不另行通知。
随 HP 产品和服务附带的明确保修声明中阐明了此类产品和服务的全部保修服务。
本文档中的任何内容均不应理解为构成任何额外保证。
HP 对本文档中出现的技术错误、编辑错误或遗漏之处概不负责。
AMD 是 Advanced Micro Devices, Inc. 的商标。
Microsoft® 和 Windows® 是 Microsoft 集团公司的商标。
Oracle 是 Oracle 和/或其分支机构的注册商标。
Linux® 是 Linus Torvalds 在美国和其它国家/地区的注册商标。
Red Hat® 是 Red Hat, Inc. 在美国和其它国家/地区的注册商标。
SD 和 microSD 是 SD-3C 在美国和/或其它国家/地区的商标或注册商标。
VMware 是 VMware, Inc. 在美国和/或其它司法辖区的注册商标或商标。
部件号:795674-AA32015 年 6 月版本:3目录1 使用本指南 (1)如何使用本指南 (1)新增内容(第三版) (2)795674-XX2(2014 年 12 月) (2)2 故障排除的准备工作 (4)预诊断步骤 (4)重要安全信息 (4)设备上的符号 (4)警告和注意 (5)静电释放 (6)防止静电释放 (6)防止静电释放的接地方法 (6)症状信息 (7)服务器诊断的准备工作 (8)执行故障排除流程中的处理器步骤 (9)将服务器降级到最低硬件配置 (9)3 常见问题的解决方法 (10)连接松动 (10)服务通知 (10)固件更新 (10)在启用了 HP Trusted Platform Module 和 BitLocker 的情况下更新服务器 (11)DIMM 操作准则 (11)DIMM 安装和配置准则 (11)组件 LED 指示灯定义 (11)SAS、SATA 和 SSD 驱动器准则 (12)热插拔驱动器 LED 定义 (12)系统电源 LED 指示灯定义 (13)运行状况 LED 条形指示灯定义(仅限刀片) (13)前面板 LED 指示灯和按钮 (13)前面板 LED 指示灯电源故障代码 (14)4 远程故障排除 (16)远程故障排除工具 (16)远程访问 Virtual Connect Manager (17)ZHCN iii使用 HP iLO 对服务器和服务器刀片进行远程故障排除 (17)使用 Onboard Administrator 对服务器刀片进行远程故障排除 (18)使用 OA CLI (18)5 诊断流程图 (20)故障排除流程图 (20)使用诊断流程图 (20)在开始之前收集重要信息 (21)故障排除流程图引用网站 (21)初始诊断流程图 (21)远程诊断流程图 (22)开机故障流程图 (23)服务器开机故障流程图(ML、DL 和 SL 系列) (23)服务器开机故障流程图(XL 系列) (24)服务器刀片开机故障流程图(BL 系列) (25)POST 故障流程图 (27)Intelligent Provisioning 故障流程图 (29)控制器问题 (29)缓存模块问题 (31)HP Smart Storage 电池问题 (32)物理驱动器问题 (33)逻辑驱动器问题 (34)操作系统引导故障流程图 (35)故障指示流程图 (36)服务器故障指示流程图(非刀片服务器) (37)服务器故障指示流程图(BL 系列) (38)电源配置文件问题 (38)网卡问题 (39)常规诊断流程图 (41)6 硬件问题 (43)用于所有 ProLiant 服务器的步骤 (43)电源问题 (43)电源问题 (43)电源问题 (43)无法打开服务器电源 (44)HP ProLiant 引导前运行状况摘要 (44)UPS 问题 (45)UPS 无法正常供电 (45)显示电池电量不足警告 (46)UPS 上的一个或多个 LED 指示灯呈红色 (46)iv ZHCN常规硬件问题 (46)新硬件的问题 (46)未知问题 (47)第三方设备的问题 (47)测试设备 (47)系统内部问题 (48)CD-ROM 和 DVD 驱动器问题 (48)系统无法从该驱动器引导 (48)从驱动器读取的数据不一致,或驱动器无法读取数据 (48)未检测到驱动器 (49)驱动器问题(硬盘驱动器和固态驱动器) (49)驱动器发生故障 (49)无法识别驱动器 (49)无法访问数据 (50)服务器响应时间比平时慢 (50)HP SmartDrive 图标或 LED 指示灯指示驱动器错误,或者在 POST、HP SSA 或 HP SSADUCLI 中显示错误消息 (51)存储问题 (51)在安装操作系统时,操作系统安装无法识别 HP Dynamic Smart Array B140iRAID 控制器驱动器 (51)具有 10 SFF 驱动器背板或 12 LFF 驱动器背板的服务器上的数据故障或磁盘错误 (51)具有 25 SFF 驱动器背板的服务器上的数据故障或磁盘错误 (51)SD 和 microSD 卡问题 (51)系统无法从该驱动器引导 (51)U 盘问题 (51)系统无法从该驱动器引导 (51)风扇问题 (52)出现一般的风扇问题 (52)出现热插拔风扇问题 (52)HP BladeSystem c 系列机箱中的所有风扇高速运行 (53)HP Trusted Platform Module 问题 (53)HP Trusted Platform Module 出现故障,或者未检测到 (53)内存问题 (53)出现一般的内存问题 (53)服务器内存不足 (54)出现内存计数错误 (54)服务器无法识别现有的内存 (54)服务器无法识别新的内存 (55)处理器问题 (55)磁带机问题 (56)ZHCN v磁带卡住问题 (56)读取/写入问题 (56)备份问题 (56)介质问题 (57)图形和视频适配器问题 (57)出现了常规图形和视频适配器问题 (57)外部设备问题 (58)视频问题 (58)启动服务器之后,屏幕持续 60 多秒钟没有显示 (58)如果使用节能功能,显示器无法正常工作 (58)显示颜色不对 (58)显示慢慢移动的水平线 (59)鼠标和键盘问题 (59)电缆问题 (59)在使用较旧的小型 SAS 电缆时,发生驱动器错误、重试、超时和无根据的驱动器故障 (59)无法识别 USB 设备,显示错误消息,或者设备在连接到 SUV 电缆时无法打开电源 (59)网络控制器或 FlexibleLOM 问题 (59)安装了网络控制器或 FlexibleLOM,但运行不正常 (59)网络控制器或 FlexibleLOM 已停止工作 (60)添加了扩展卡后,网络控制器或 FlexibleLOM 停止工作 (60)网络互联刀片出现问题 (61)控制器问题 (61)在禁用 RAID 模式时,找不到 HP Dynamic Smart Array B140i 驱动器 (61)在 RAID 模式中访问的驱动器上的数据不与从非 RAID 模式中访问的数据兼容 (61)在将驱动器移至新的服务器或 JBOD 后,Smart Array 控制器不显示逻辑驱动器 (61)驱动器漫游 (61)扩展卡问题 (61)系统在更换扩展卡期间要求使用恢复方法 (61)7 软件问题 (63)操作系统问题和解决方法 (63)操作系统问题 (63)操作系统锁定 (63)错误日志中显示错误 (63)安装 Service Pack 之后出现问题 (63)操作系统更新 (63)恢复为备份版本 (64)vi ZHCN何时重新配置或重新加载软件 (64)Linux 资源 (64)应用程序软件问题 (64)软件锁定 (64)更改软件设置后出错 (65)更改系统软件后出错 (65)安装了应用程序后出错 (65)ROM 问题 (65)远程 ROM 刷新问题 (65)命令行语法错误 (65)目标计算机上拒绝访问 (65)无效或不正确的命令行参数 (65)网络连接在进行远程通信时失败 (65)ROM 刷新期间发生故障 (65)不支持目标系统 (66)系统在固件更新期间要求使用恢复方法 (66)更新固件 (66)引导问题 (66)服务器无法引导 (66)UEFI 服务器的 PXE 引导准则 (68)8 软件工具和解决方案 (69)服务器模式 (69)产品规格说明简介 (69)HP iLO (69)Active Health System (70)用于 HP iLO 的 HP REST API 支持 (71)Integrated Management Log (71)HP Insight Remote Support (71)HP Insight Remote Support 集中连接 (72)HP Insight Online 直接连接 (72)HP Insight Online (72)Intelligent Provisioning (72)HP Insight Diagnostics (73)HP Insight Diagnostics 检测功能 (73)Erase Utility (73)适用于 Windows 和 Linux 的 Scripting Toolkit (73)HP Service Pack for ProLiant (74)HP Smart Update Manager (74)HP UEFI System Utilities (74)使用 HP UEFI System Utilities (74)ZHCN vii安全引导配置 (76)嵌入式 UEFI Shell (76)嵌入式诊断选件 (76)用于 UEFI 的 HP REST API 支持 (76)重新输入服务器序列号和产品 ID (76)实用程序和功能 (77)HP Smart Storage Administrator (77)Automatic Server Recovery(自动服务器恢复) (77)USB 支持 (78)外置 USB 功能 (78)支持冗余 ROM (78)安全性和安全优势 (78)使系统保持最新状态 (79)访问 HP 支持材料 (79)更新固件或系统 ROM (79)FWUPDATE 实用程序 (79)嵌入式 UEFI Shell 中的 FWUpdate 命令 (79)System Utilities 中的固件更新应用程序 (80)联机刷新组件 (80)驱动程序 (80)软件和固件 (81)支持的操作系统版本 (81)版本控制 (81)HP 对于 ProLiant 服务器支持的操作系统和虚拟化软件 (81)HP 技术服务组合 (81)更改控制和主动通知 (82)9 HP 故障排除资源 (83)在线资源 (83)HP 支持中心网站 (83)HP 企业信息库 (83)HP 指导的故障排除网站 (83)以前的 HP ProLiant 服务器型号的故障排除资源 (83)服务器刀片机箱故障排除资源 (84)错误消息资源 (84)服务器文档 (84)HP 产品规格说明简介 (84)白皮书 (84)服务通知、咨询和通告 (85)viii ZHCN产品信息资源 (85)其它产品信息 (85)注册服务器 (85)服务器功能概述和安装说明 (85)主要功能和选件部件号 (85)服务器和选件的规格、符号、安装警告和通告 (85)备件号 (86)拆卸步骤、部件号和规格 (86)拆卸或卸除和更换过程视频 (86)技术主题 (86)产品安装资源 (86)外部布线信息 (86)电源容量 (86)开关设置、LED 指示灯功能、驱动器、内存、扩展卡和处理器安装说明以及板卡布局 (86)产品配置资源 (87)设备驱动程序信息 (87)DDR4 内存配置 (87)支持的操作系统版本 (87)操作系统安装和配置信息(对于出厂时安装的操作系统) (87)服务器配置信息 (87)服务器设置软件的安装和配置信息 (87)服务器的软件安装和配置 (87)HP iLO 信息 (87)服务器管理 (87)服务器管理系统的安装和配置信息 (87)容错、安全保护、保养和维护、配置和设置 (88)10 支持和其它资源 (89)与 HP 技术支持部门或授权经销商联系 (89)客户自行维修 (89)所需的服务器信息 (89)所需的操作系统信息 (90)Microsoft 操作系统 (90)Linux 操作系统 (91)Oracle Solaris 操作系统 (92)报告和日志 (92)Active Health System 日志概述 (92)Active Health System 下载 CLI 实用程序 (93)HP iLO Web 界面 (93)ZHCN ixHP Intelligent Provisioning (93)下载 Active Health System 日志 (94)使用 HP iLO (94)使用 Intelligent Provisioning (95)使用用于 Windows 操作系统的 Active Health System 下载 CLI (96)使用用于 Linux 分发的 Active Health System 下载 CLI (96)使用 curl 命令行工具 (97)HP SSA 诊断任务 (97)HP Smart Storage Administrator Diagnostic Utility CLI 报告 (98)HPS 报告 (99)cfg2html 报告 (99)11 缩略语和缩写 (100)12 文档反馈 (103)索引 (104)x ZHCN1使用本指南如何使用本指南《HP ProLiant Gen9 故障排除指南,第一卷:故障排除》重点介绍了 HP ProLiant Gen9 ML、DL、BL、XL 和 SL 服务器的故障排除步骤。
「HP台式机硬盘160G用GHOST重做系统后无法正常启动解决办法」

HP不能GHOST GHOST后不能启动HP台式机ghost后无法启动的解决方法一个HP台式机2310其硬盘是串口的,160G,只分有C分区和一个备份用的加密小分区,且安装的系统是HOME版的,用GHOST重做系统后,无法正常启动出现以下提示:windows could notstart because of a computer dis khardware configuration problemcould notread from the selected boot disk check boot path and disk harwareplease check the windowsdocumentation abouthardware d isk configuationand your hardware refer once manuals for additional information大概意思:因计算机磁盘硬件的配置问题,无法启动。
不能读取所选的引导盘,请检查引导路径和磁盘硬件。
请参阅文档中有关磁盘配置的信息并参阅您的硬件参考手册,以获得进一步的信息。
A:以为不兼容SATA硬盘,但机器BIOS中并没有SATA兼容模式选项可以更改B:使用较新的支持SATA的GHOST系统也无济于事(使用全新安装的应该没有问题,不过没试过,但我还是准备用GHOST系统)C:重新分区,在PE下删除隐藏的分区也重启电脑,问题依旧解决办法:GOOGLE了一把,问题解决,方法如下:——————————————————————————————————————————————ﻫ开机进入bios设置(按F10),选择Power management Setup ;再选择WDRT Support 回车,按上下键把参数值修改为disableﻫ——————————————————————————————————ﻫ说明:wdrt support此项可激活或关闭watchdog timer。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用HP crashinfo 和oradebug close_trace清理oracle目录
在oracle数据库日常维护中,会出现进程仍然活动时,删除了其对应的trace文件而导致oracle目录空间不释放的情况。
以下根据山东电信生产环境案例,对该问题的处理进行总结。
问题描述:
销账数据库oracle目录持续报警,使用率达到95%。
通过清理listener.log和dump文件夹后,使用率仍然在90%以上。
对比bdf和du –k输出结果发现实际空间使用率与bdf显示使用率存在2.5G的差额。
Bdf
/dev/vg00/lvoracle 20480000 17214819 3073469 85% /oracle
Du –k
7722586 .
问题解决:
通过与HP原厂的case,由原厂提供HP专用crashinfo工具。
该工具能够将操作系统中已删除但仍占用空间的进程罗列出来。
操作步骤和输出如下:
解压,以2进制传到/tmp下
#/tmp/crashinfo –unlinked
输出结果如下:
crmdb1:/#/tmp/crashinfo -unlinked
crashinfo (4.57) - HP CONFIDENTIAL
Note: HP CONFIDENTIAL
libp4 (9.252): Opening /stand/current/vmunix /dev/kmem
Loading symbols from /stand/current/vmunix
Kernel TEXT pages not requested in crashconf
Will use an artificial mapping from a.out TEXT pages
Loading symbols from /stand/current/mod/rng
Loading symbols from /stand/current/mod/btlan
Loading symbols from /stand/current/mod/procsm
Loading symbols from /stand/current/mod/c8xx
Loading symbols from /stand/current/mod/cdfs
Loading symbols from /stand/current/mod/igssn
Loading symbols from /stand/current/mod/fcd
Loading symbols from /stand/current/mod/td
Loading symbols from /stand/current/mod/gelan
Loading symbols from /stand/current/mod/iether
Loading symbols from /stand/current/mod/igelan
Loading symbols from /stand/current/mod/lvmp
Loading symbols from /stand/current/mod/ciss
Loading symbols from /stand/current/mod/sasd
Loading symbols from /stand/current/mod/mpt
Loading symbols from /stand/current/mod/nadv
Command line: /tmp/crashinfo -unlinked
crashinfo (4.57) - HP CONFIDENTIAL
PID PPID COMMAND INODE DEVICE SIZE(bytes) 4923 4815 tldd 3388 /dev/vg00/lvol5 348 4989 4815 avrd 3388 /dev/vg00/lvol5 348 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5162 1 nbrmms 5425 /dev/vg00/nbu 52428649 5415 1 nbsl 9347 /dev/vg00/nbu 14711 5415 1 nbsl 9347 /dev/vg00/nbu 14711 5415 1 nbsl 9347 /dev/vg00/nbu 14711 5415 1 nbsl 9347 /dev/vg00/nbu 14711 5415 1 nbsl 9347 /dev/vg00/nbu 14711 5475 1 nbsvcmon 9348 /dev/vg00/nbu 7795 5475 1 nbsvcmon 9348 /dev/vg00/nbu 7795 5475 1 nbsvcmon 9348 /dev/vg00/nbu 7795 5475 1 nbsvcmon 9348 /dev/vg00/nbu 7795 5755 1 perfalarm 22193 /dev/vg00/lvol7 14 5856 5770 ovbbccb 22193 /dev/vg00/lvol7 14 6076 5770 coda 22193 /dev/vg00/lvol7 14 16545 1 oracle 66445 /dev/vg00/lvoracle 2157470667
可以看到,oracle进程16545占用了大量空间不释放
通过ps可以看到相对应的进程
crmdb1$[/oracle]$ps -ef|grep 16545
oracle 8236 21755 1 11:08:55 pts/tb 0:00 grep 16545
oracle 16545 1 0 Oct 8 ? 92:51 ora_smon_bizdb
如果进程是普通oracle进程,我们可以通过kill -9杀掉相关进程来释放空间,但这里看到,16545是SMON进程,杀掉后会导致数据库宕库。
另一种方法是如果情况允许下,可以通过重启数据库来解决问题。
最后,只有一种方法可以解决,即使用oradebug提供的close_trace命令,该命令使用如下:SQL> oradebug setospid 16545
Oracle pid: 114, Unix process pid: 16545, image: oracle@crmdb1 (SMON)
SQL> oradebug close_trace
Statement processed.
将该进程对应trace强行关闭后,查看bdf
/dev/vg00/lvoracle 20480000 15109028 5047647 75% /oracle
Oracle目录使用率下降到75%
该进程已释放空间。