杜立 - 从JStorm到Flink:腾讯实时流计算平台的建设与实践
中国算力大会优秀案例集

中国算力大会优秀案例集
1. 阿里巴巴云计算平台:阿里云计算平台是中国最大的云计算服务提供商之一。
它提供了强大的计算和存储资源,帮助企业轻松部署和管理自己的应用程序,并根据实际需求弹性扩缩容。
2. 腾讯人工智能:腾讯人工智能是中国最大的人工智能技术研究与应用平台之一。
腾讯利用算力优势和大数据技术,开发了多种人工智能应用,包括语音识别、图像识别和智能推荐等。
3. 华为云:华为云是华为推出的云计算服务平台。
它提供了高效、安全、可靠的云计算资源,帮助企业实现数字化转型。
华为云还积极推动人工智能的发展,并与各行业合作伙伴共同探索人工智能的应用场景。
4. 百度大脑:百度大脑是百度推出的人工智能开放平台。
它整合了百度在语音、图像、自然语言处理等领域的算法和技术,为开发者提供了一整套人工智能解决方案。
百度大脑已经应用到多个领域,包括智能车载、智能家居和智能商店等。
5. 英特尔中国AI创新中心:英特尔中国AI创新中心致力于
推动人工智能技术在中国的发展。
它与中国的高校和企业合作,共同研究人工智能算法和应用,培养人工智能人才,推动人工智能技术的商业化。
这些优秀案例展示了中国在算力方面的强大实力和创新能力,并为各行业提供了丰富的云计算和人工智能解决方案。
它们的
出现有力地推动了中国数字经济的发展,为中国经济转型升级提供了重要支撑。
JStorm—实时流式计算框架入门介绍
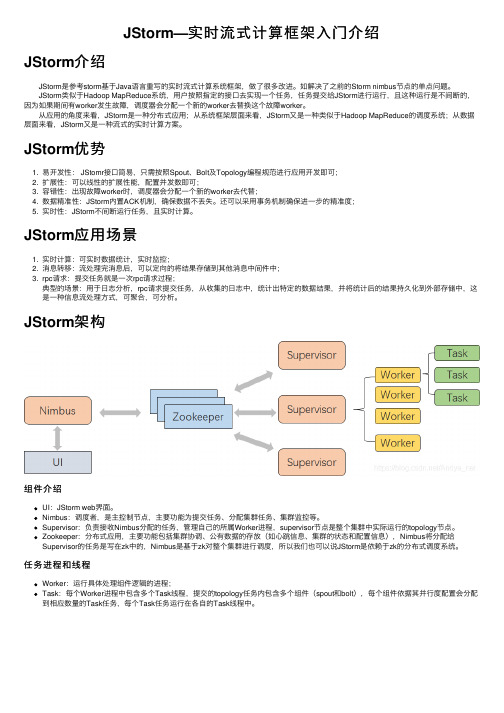
JStorm—实时流式计算框架⼊门介绍JStorm介绍 JStorm是参考storm基于Java语⾔重写的实时流式计算系统框架,做了很多改进。
如解决了之前的Storm nimbus节点的单点问题。
JStorm类似于Hadoop MapReduce系统,⽤户按照指定的接⼝去实现⼀个任务,任务提交给JStorm进⾏运⾏,且这种运⾏是不间断的,因为如果期间有worker发⽣故障,调度器会分配⼀个新的worker去替换这个故障worker。
从应⽤的⾓度来看,JStorm是⼀种分布式应⽤;从系统框架层⾯来看,JStorm⼜是⼀种类似于Hadoop MapReduce的调度系统;从数据层⾯来看,JStorm⼜是⼀种流式的实时计算⽅案。
JStorm优势1. 易开发性: JStomr接⼝简易,只需按照Spout、Bolt及Topology编程规范进⾏应⽤开发即可;2. 扩展性:可以线性的扩展性能,配置并发数即可;3. 容错性:出现故障worker时,调度器会分配⼀个新的worker去代替;4. 数据精准性:JStorm内置ACK机制,确保数据不丢失。
还可以采⽤事务机制确保进⼀步的精准度;5. 实时性:JStorm不间断运⾏任务,且实时计算。
JStorm应⽤场景1. 实时计算:可实时数据统计,实时监控;2. 消息转移:流处理完消息后,可以定向的将结果存储到其他消息中间件中;3. rpc请求:提交任务就是⼀次rpc请求过程;典型的场景:⽤于⽇志分析,rpc请求提交任务,从收集的⽇志中,统计出特定的数据结果,并将统计后的结果持久化到外部存储中,这是⼀种信息流处理⽅式,可聚合,可分析。
JStorm架构组件介绍UI:JStorm web界⾯。
Nimbus:调度者,是主控制节点,主要功能为提交任务、分配集群任务、集群监控等。
Supervisor:负责接收Nimbus分配的任务,管理⾃⼰的所属Worker进程,supervisor节点是整个集群中实际运⾏的topology节点。
Tencent大数据技术架构

SetA
网关 主 MySQL + Agent 备1 MySQL + Agent
…
应用 MySQL API
备2n MySQL + Agent
网关
SetB
网关 主 MySQL + Agent 备1 MySQL + Agent
…
备2n MySQL + Agent
1、识别DDL类sql,并以任务形式保存至scheduler; 2、解析DML类sql,并转发至对应Set; 3、收集Set返回的结果,组合后返回请求端; 4、watch并获取表的访问路由; …
容量:自动分表
GW(逻辑表) Mysql(物理表) GW(逻辑表) Mysql(物理表)
T 0 T 1
T
T
当SET资源不够或表 记录超标时,触发 扩容,物理表分裂
T 2 T T 3
该过程自动完成
初始态:逻辑表=物理表
T n
扩容后:逻辑表=N个物理表
容量:自动伸缩
伸缩方式
整表迁移 子表分裂
T1 T2 T3
原则:避免表分裂,及时表合并 表分裂的问题
在一个集群中,每次表分裂,会导致集群 表数量的增加;集群中表的数量就是路由 的条数,表数量越多,路由的效率就会越 低
•
• •
采用hardlimit+softlimit结合的方式
Hardlimit保证安全,不超机器总容量 Softlimit保证充分利用整机资源
14
Gaia 技术特点
强扩展性:支持单cluster万台规模
(即将达到
8800节点,20w+核,1500个pool)
微软Dryad分布式并行计算平台

一
个有 向无环图。图中的每个节点表示
个要执行的程序 ,节 点之 间的边表示
一
数据通道 中数据的传输方式,其可能是 文件 、T PPp 、共享 内存等 ,为 了支 C ie
持数据类型需要针对每个类型有序列化
如 图2 示 , 当 用 户 使 用 Dr a 平 所 yd
算法 以充分利用细颗粒度并行的优势 ,
编 写 的程 序 可 以轻 易 运 行 在 分 布 式 并行
 ̄ 雌 哺 嚷
l ain | t s c o O t aa
辐 播
M a hn c ie
| 哪
哟
嚣 精 _ ¨ : 二麓 C
嘲 , e
i mi G a r  ̄ 穗种 ¥ n ̄ 譬m|t
孽 o ¥ r u 糖 £ iti 雹 0毽 S r c u e 、 b I  ̄u t r s
集群计算平 台,无论是单台多核 计算机 务在各 个节点上 的运 行。在D y d r a 平台 还是由多台计算机组成的集群 ,甚至拥 上 ,每个工作或并行计 算过程被表示为
计算编程框架 ,支持常用 的协 同任务调 度和硬件 资源管理 ,通过Woks aig r el t n
有数千 台计算机 的数据中心,都 可以从 任务队列 中创建的策略建 模来 实现分布 式并行计算 的编程框架。
传递 组成 。任务 管理 器 获取 无环 图之 有 向无 环 图 。这些 操作 包 括建 立新 节 候 ,会 先 查 看 用 户 属 于 哪 一 类 ,然 后 后 ,便 会在 程序 的 输入 通道 准备 ,当 点 ,在 节点 问 加入 边 ,合 并两 个 图 以 直 接 访 问存 储 那 类 用 户 数 据 的数 据 有 可用机 器 的时 候便 对 它进 行调 度 。 随后J M从命名 服务 器那 里获得 一个 可
研制任务书

产品处理系统(PGS)数据支撑分系统
研制任务书
编写 校对 审核 会签 批准
国家卫星气象中心 2017 年 8 月
版本号
日期
0.1 2015.03.01
1.0 2015.11.04
2.0 2015.11.15
文档修改记录
所修改章节 所有
所修改页
注记
初稿
所有 所有
终稿
5 设计约束与要求 .................................................. 21
5.1 质量要求 ..................................................... 21 5.1.1 正确性与准确性........................................... 21 5.1.2 稳定性与可靠性........................................... 21 5.1.3 安全性................................................... 22 5.1.4 可扩展性和易维护性....................................... 22 5.1.5 易用性................................................... 22 5.1.6 时效性................................................... 22
4.1.1 概述..................................................... 16 4.1.2 功能要求................................................. 16 4.1.3 非功能要求............................................... 18 4.2 系统及平台子系统 ............................................. 19 4.2.1 概述..................................................... 19 4.2.2 功能要求................................................. 19 4.2.3 非功能要求............................................... 21
BJ-ATMTB-易卓方登

700,000
600,000 500,000 400,000 300,000 200,000 100,000 0 2012/10 2013/09 2014/08
DAU
web+wap
app
SPO
15
用户众包产生海量丰富的UGC内容
类型与数量丰富的游戏覆盖
攻略端数量 着迷网 任玩堂 口袋巴士 游戏多 不凡游戏网 17173手游网 49 9 1 1 10 14 精品wiki+专区数量 206 71 13 52 31 10
娱乐粉丝
数据库
爱车一族
垂直领域的核心品牌
时尚女性
+
价值极高的用户池
视觉瀑布流
+ 微博客
沉淀的优质内容资产
投资人士
形成互动性强的聚合平台
医学人士
BBS
图文攻略
旅游爱好者
7
发力游戏行业的上游流量入口
数字娱乐领域飞速增长,规模达 千亿级别,强势IP不断涌现
游
戏
动
漫
移动游戏市场规模:2013年 148.5亿,同比增长69.3%, 2014年预计236.4亿 用户规模:2013年1.9亿, 2014年预计超3亿 2013年月流水过千万国产手 游超60款,比2012年的10款 迅猛增长 2013年,首款月流水过亿产 品《时空猎人》诞生
12
03
着迷在游戏领域的斐然成绩
预先在游戏领域成功试水
月活跃用户达到 移动端流量占比
1,000万 60% 227,领先所有游
用户 和流量 覆盖 和生成的 内容量
累计
30万UGC攻略页面,超过其他
手游媒体总和 覆盖游戏
在网计算推动算网融合落地

在网计算概述
典型应用场景
场景 1:高性能计算
在网计算是一种将计算任务和数据处理能力从传统的中
正逐渐成为推动数字经济转型升级的重要力量,其广泛应用 算资源突破落地。
推动了算网融合从概念走向实践。单一的在网计算技术难以
满足日益复杂的业务需求和多元化的应用场景,通过将计算、
通信、存储及应用服务下沉至网络边缘,集成云计算的强大
作者单位:中国移动广东公司
80
中国电信业 CHINA TELECOMMUNICATIONS TRADE
段为概念萌芽阶段,主要是面向传统集合通信操作造成的资 性需求,以及减轻中央数据中心的负担。
源堵塞、计算资源浪费等问题,在本世纪初高性能计算领域 传统式高性能计算依赖于中央集中式的
提出硬件卸载的方式,即相对于传统的基于软件的集合操作, 超级计算机或数据中心。在网计算为高
将集合操作由网卡、交换机等硬件执行,有效加快了集合通 性能计算带来了新的维度,在网计算功
行性、张量并行性等不同维度并行技术,
在网计算技术架构包括设备、功能、平台、应用多个层
对计算任务、训练数据和模型进行划分, 次,涉及网络协议卸载、数据处理、异构网元、高性能互联、
实现分布式存储和分布式训练,大幅提 分布式应用等多方面的技术能力。
升训练效率。
网络协议卸载
场景 3:车联网
在进行数据发送和接送操作时,TCP/IP 协议栈一般通过
例如,英伟达在业界率先实现公有云业
大模型时代的基础架构读书笔记

《大模型时代的基础架构》读书笔记目录一、内容描述 (2)二、大模型时代的挑战与机遇 (3)2.1 大模型带来的挑战 (5)2.1.1 计算资源的限制 (6)2.1.2 数据隐私与安全问题 (7)2.1.3 模型可解释性与透明度 (9)2.2 大模型带来的机遇 (10)2.2.1 新算法与新架构的出现 (11)2.2.2 跨领域合作与创新 (12)三、大模型时代的基础架构 (14)3.1 硬件架构 (15)3.1.1 GPU与TPU的发展与应用 (16)3.1.2 其他硬件技术的发展 (18)3.2 软件架构 (19)3.2.1 深度学习框架的功能与特点 (21)3.2.2 软件架构的可扩展性与灵活性 (22)3.3 优化与加速 (23)3.3.1 模型压缩技术 (24)3.3.2 知识蒸馏技术 (26)四、大模型时代的基础架构发展趋势 (27)4.1 技术融合与创新 (28)4.1.1 硬件与软件的融合 (29)4.1.2 多种技术的综合应用 (31)4.2 用户需求与市场导向 (32)4.2.1 用户需求的变化 (34)4.2.2 市场导向的影响 (35)五、结论 (37)一、内容描述《大模型时代的基础架构》是一本关于人工智能和深度学习领域的重要著作,作者通过对当前最先进的技术和方法的深入剖析,为我们揭示了大模型时代下的基础架构设计原则和实践经验。
本书共分为四个部分,分别从基础架构的概念、技术选型、部署和管理以及未来发展趋势等方面进行了全面阐述。
在第一部分中,作者首先介绍了基础架构的概念,包括什么是基础架构、为什么需要基础架构以及基础架构的主要组成部分等。
作者对当前主流的基础架构技术进行了简要梳理,包括云计算、分布式计算、容器化、微服务等。
通过对比分析各种技术的优缺点,作者为读者提供了一个清晰的技术选型参考。
第二部分主要围绕技术选型展开,作者详细介绍了如何根据项目需求和业务场景选择合适的基础架构技术。
Flink及Storm、Spark主流流框架比较

Flink及Storm、Spark主流流框架⽐较引⾔随着⼤数据时代的来临,⼤数据产品层出不穷。
我们最近也对⼀款业内⾮常⽕的⼤数据产品 - Apache Flink做了调研,今天与⼤家分享⼀下。
Apache Flink(以下简称flink) 是⼀个旨在提供‘⼀站式’ 的分布式开源数据处理框架。
是不是听起来很像spark?没错,两者都希望提供⼀个统⼀功能的计算平台给⽤户。
虽然⽬标⾮常类似,但是flink在实现上和spark存在着很⼤的区别,flink是⼀个⾯向流的处理框架,输⼊在flink中是⽆界的,流数据是flink中的头等公民。
说到这⾥,⼤家⼀定觉得flink和storm有⼏分相似,确实是这样。
那么有spark和storm这样成熟的计算框架存在,为什么flink还能占有⼀席之地呢?今天我们就从流处理的⾓度将flink和这两个框架进⾏⼀些分析和⽐较。
1 本⽂的流框架基于的实现⽅式本⽂涉及的流框架基于的实现⽅式分为两⼤类。
第⼀类是Native Streaming,这类引擎中所有的data在到来的时候就会被⽴即处理,⼀条接着⼀条(HINT:狭隘的来说是⼀条接着⼀条,但流引擎有时会为提⾼性能缓存⼀⼩部分data然后⼀次性处理),其中的代表就是storm和flink。
第⼆种则是基于Micro-batch,数据流被切分为⼀个⼀个⼩的批次,然后再逐个被引擎处理。
这些batch⼀般是以时间为单位进⾏切分,单位⼀般是‘秒‘,其中的典型代表则是spark了,不论是⽼的spark DStream还是2.0以后推出的spark structured streaming都是这样的处理机制;另外⼀个基于Micro-batch实现的就是storm trident,它是对storm的更⾼层的抽象,因为以batch为单位,所以storm trident的⼀些处理变的简单且⾼效。
2 流框架⽐较的关键指标从流处理的⾓度将flink与spark和storm这两个框架进⾏⽐较,会主要关注以下⼏点,后续的对⽐也主要基于这⼏点展开:• 功能性(Functionality)- 是否能很好解决流处理功能上的痛点 , ⽐如event time和out of order data。
一种面向企业广域网的新型算力连接和路由技术试点方案

doi:10.3969/j.issn.1003-3106.2023.10.025引用格式:庆祖良,史庭祥,徐法禄,等.一种面向企业广域网的新型算力连接和路由技术试点方案[J].无线电工程,2023,53(10):2416-2423.[QINGZuliang,SHITingxiang,XUFalu,etal.APilotSolutionforaNewComputingPowerConnectionandRoutingTechnologyforEnterpriseWideAreaNetworks[J].RadioEngineering,2023,53(10):2416-2423.]一种面向企业广域网的新型算力连接和路由技术试点方案庆祖良1,史庭祥2,3,徐法禄3,张 健3,徐 方3(1.中国移动通信集团江苏有限公司,江苏南京210012;2.移动网络和移动多媒体技术国家重点实验室,广东深圳518055;3.中兴通讯股份有限公司,江苏南京210012)摘 要:企业数字化转型中,应用上云只是手段,如何在满足用户体验情况下,面向不同应用提升算网基础设施的资源效率和运营效率才是目标。
随着2C流量见顶,高效算力服务成为基础网络发展的另一个目标。
为此,IP网络对业务质量的作用将从保障型向“有效型”转变,从IP路由向“算力路由”转变。
围绕企业广域网(WideAreaNetwork,WAN)场景和多种典型应用,研究新型算力连接和路由技术,提出基于业务优先级调度、接入和服务一体化调度的企业广域网算力连接试点方案。
该方案通过控制与转发部分的创新,探索算力连接的服务化和差异化,技术赋能“算力网络化”,并在运营商和企业合作项目开展试点验证,验证结果表明,从改善企业应用体验和算力资源效率的角度,显著提升了IP网络的传输有效性。
关键词:算力路由;算力连接;企业广域网;业务优先级调度;业务服务质量中图分类号:TP939.1文献标志码:A开放科学(资源服务)标识码(OSID):文章编号:1003-3106(2023)10-2416-08APilotSolutionforaNewComputingPowerConnectionandRoutingTechnologyforEnterpriseWideAreaNetworksQINGZuliang1,SHITingxiang2,3,XUFalu3,ZHANGJian3,XUFang3(1.ChinaMobileJiangsuCo.,Ltd.,Nanjing210012,China;2.StateKeyLaboratoryofMobileNetworkandMobileMultimediaTechnology,Shenzhen518055,China;3.ZTECorporation,Nanjing210012,China)Abstract:Inthedigitaltransformationofenterprises,cloud enabledapplicationsisnotallbutameansandastart up.Howtoimprovetheresourceefficiencyandoperationalefficiencyofcomputingnetworkinfrastructurefordifferentapplicationsundertheconditionofsatisfyinguserexperienceistheessentialtarget.Withthepeakof2Ctraffic,efficientcomputingserviceshavebecomeanothertargetoffundamentalnetworkdevelopment.Therefore,theroleofIPnetworkonservicequalitywillchangefromguaranteeto“effective”,andfromIProutingto“computing powerrouting”.FocusingontheenterpriseWideAreaNetwork(WAN)scenarioandvarioustypicalapplications,newcomputing powerconnectionandroutingtechnologiesarestudied,andapilotsolutionforcomputing powerconnectioninenterpriseWANbasedonservicepriorityscheduling,integratedaccessandserviceschedulingisproposed.Throughtheinnovationofthecontrolandforwardingpart,thesolutionexplorestheserviceabilityanddifferentiationofcomputing powerconnection,andthetechnologyenables“computing powernetworking”.Andpilotverificationinthecooperationprojectbetweenoperatorsandenterprisesiscarriedout.TheresultsshowthattheeffectivenessofIPnetworkcanbesignificantlyimprovedfromtheperspectiveofimprovingenterpriseapplicationexperienceandcomputingresourceefficiency.Keywords:computing powerrouting;computing powerconnection;enterpriseWAN;servicepriorityscheduling;QoS收稿日期:2023-06-11基金项目:国家重点研发计划(2021YFB2900200)FoundationItem:NationalKeyR&DProgramofChina(2021YFB2900200)0 引言伴随千行百业的应用上云和5G网络大规模建设接近尾声,流量“增量不增收”已使运营商依赖的流量经营模式难以支撑收入持续、大幅增长。
07-TBDS-4.0.5.0-实时计算开发指导

CONTENTS
章 节
第三开发流程
章
云 计
3.2 准备阶段
算
发 展
3.3 开发阶段
历
史 3.4 运行阶段
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
1.1Oceanus架构图
kafka
Oracl e
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
CONTENTS
章 节
第二章 实时计算应用场景举例
第 一
2.1 实时计算应用场景举例
章
云
计
算
发
展
历
史
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
TBDS-4.0.5.0-实时计算开发指导
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
课程目标
通过本课程的学习,您将可以
能够理解实时计算的开发过程 能够理解实时计算的基本原理 能够顺利完成最基本的实时计算应用开发
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
3.3开发阶段(续)
建立表映射-数据库
建立数据库的意义是对表进行“逻辑”管理,库名随意,建议能够表达一定的意义
版权归© 2019 Tencent, Inc.或其附属公司所有 保留所有权利
3.3开发阶段(续)
建立表映射-kafka映射表
2018-09-11 00:09:01,1,login 2018-09-11 00:09:01,3,login 2018-09-11 00:09:01,12,logout 2018-09-11 00:09:02,11,login 2018-09-11 00:09:02,10,login 2018-09-11 00:09:02,10,logout
《快速部署大模型:LLM策略与实践》笔记

《快速部署大模型:LLM策略与实践》阅读札记目录一、内容简述 (2)1.1 背景介绍 (3)1.2 研究目的与意义 (3)二、大型语言模型概述 (4)2.1 LLM的定义与发展历程 (4)2.2 LLM的技术原理与架构 (5)2.3 LLM的应用场景与挑战 (6)三、快速部署大模型的策略与方法 (8)3.1 模型压缩与优化技术 (9)3.1.1 知识蒸馏 (10)3.1.2 量化训练 (12)3.1.3 模型剪枝与参数共享 (13)3.2 模型加速技术 (15)3.2.1 硬件加速器 (15)3.2.2 低秩分解 (16)3.2.3 分布式训练与计算资源调度 (17)3.3 模型部署与运行时管理 (19)3.3.1 模型版本控制与管理 (21)3.3.2 自动化部署与持续集成 (22)3.3.3 监控与调优 (24)四、LLM在具体应用场景中的实践案例 (25)4.1 自然语言处理 (26)4.1.1 机器翻译 (27)4.1.2 文本摘要 (28)4.1.3 情感分析与观点抽取 (29)4.2 问答系统 (30)4.2.1 实时问答 (32)4.2.2 个性化推荐与智能客服 (32)4.3 推荐系统 (33)4.3.1 协同过滤与内容推荐 (34)4.3.2 图像与视频推荐 (34)五、结论与展望 (36)5.1 研究成果总结 (37)5.2 存在的问题与挑战 (37)5.3 未来发展趋势与展望 (39)一、内容简述本书介绍了LLM的基本概念、发展历程及其在各个领域的应用价值。
通过深入浅出的方式,让读者对LLM有一个初步的了解和认识。
重点阐述了在快速部署大模型的过程中所需的关键技术和工具,包括模型训练、优化、压缩、推理等方面的技术细节。
本书详细解析了在实际部署过程中可能遇到的挑战和问题,如模型性能瓶颈、资源限制、安全性考虑等。
针对这些问题,书中给出了具体的解决方案和实践经验,为读者在实际操作中提供了有力的指导。
腾讯TBase运维平台架构详解

N个数据库服务
N个数据库服务
架构解说
Center
OSS大脑处理前端请求管理和下发任务
Confdb元数据存储访问
Etcd底座支撑关键数据存储
Agent任务执行者状态数据采集指标数据采集
Etcd
12
Center
3
Confdb
4
Agent
5
设计参考
目录CONTENTS
Etcd功能概述
运营平台底座, 存储关键数据
故障管理crontab定时脚本监控拉起,告警
部署要求2个以上,对于生产系统建议3节点,与etcd共用机器部署
扩展性可扩容,也可以缩容
承担功能运营平台大脑,接收运维指令,派发 任务给Agent,调度任务
Confdb功能概述
故障管理 C e n t e r 监控拉起, 故障告警
承担功能 运营支撑平台元数据存储及管理
同城备中心 机器3 : Conf db S l a ve + E t c d N o de + C e nt er S l a ve机器4 : Conf db S l a ve + E t c d N o de + C e nt er S l a ve
异地双活二中心部署规范
南生产中心 机器1 : C o n f d b M a s t e r + E t c d N o d e + C e n t e r S l a v e 机器2 : C o n f d b S l a v e + E t c d L e a d e r + C e n t e r S l a v e 机器3 : C o n f d b S l a v e + E t c d N o d e + C e n t e r M a s t e r
2023 腾讯基础平台技术犀牛鸟专项研究计划

2023腾讯基础平台技术犀牛鸟专项研究计划研究课题目录1. 基于大模型的代码智能化技术研究 (2)2. 面向AI大模型的高性能网络技术研究 (3)3. 基于操作系统通用QoS指标特征反映业务状况的研究 (4)4. 3D视频编码技术 (6)5. 云游戏的视频超分辨率研究 (7)6. 数据中心配电系统动态可靠性模型 (8)7. 数据中心智能传感网络 (9)1.基于大模型的代码智能化技术研究研究概要描述:当前基于大模型的代码推荐与生成开始走出实验室,并逐步应用到工业界中。
我们期望研究Copilot、ChatGPT工具相关的大模型、RLHF等技术在代码领域中的应用,并依托工蜂代码托管平台,打造下一代代码智能化工具,提升公司研效。
可围绕如下三个大方向任选2~3个技术点开展研究合作。
1)高质量软工数据集的构建、精标与评估。
研究高质量代码数据清洗方法;代码漏洞、缺陷、坏味道检测,修复建议,及其修复前后的数据对构造方法;函数的测试用例,运行结果,编译调试信息等数据对的构造方法,以及这些软工任务的数据精标方法和评估方法,确保构造数据集的精准性。
期望覆盖社交、游戏领域,C、C++、Go语言优先;2)研究SFT、RLHF技术在软工任务中的应用,提升大模型在相关软工任务上的精准度;3)大模型的优化技术研究。
研究GPT式大模型推理加速技术,提升模型的推理速度,达到工业级用户可接收的标准;以及GPT式大模型的压缩技术研究和算法实现。
技术目标:研究成果需在企业内(腾讯工蜂)实现工程落地,鼓励并支持发表相关领域的CCF A类学术论文。
可提供实验资源:计算资源、专家指引和落地场景。
2.面向AI大模型的高性能网络技术研究研究概要描述:为了充分利用GPU集群的分布式计算资源,需要设计一种软硬结合、全栈优化的网络系统,可围绕如下三个大方向任选1~3个方向开展研究合作:1)高性能网络协议研究a. QoS相关:流调度时,如果流量在不同队列切换,会使拥塞控制误判,导致尾时延恶化;此外,分析大规模组网时,评估WRR的流调度方式产生的乱序程度、对当前CX6可靠传输机制的影响,及解决方案;b. 现网数据采集、分析:评估数据中心流量负载、微突发、incast/outcast程度;支撑去年设计的tita协议的motivation;c. Tita协议硬件版本,相关技术问题(例如:在pkg-RR的网络,如何在NIC上实现高效的可靠传输机制)。
地震与台风信息采集WEB应用方传极

地震信息采集模块在应用中的作用至关重要,它不仅可以帮助用户了解地震情况,还可以提供地震预警服务,为用户提供更好的防灾保护措施。在未来的发展中,我们将继续优化地震信息采集模块的功能,提升数据采集的效率和准确性,为用户提供更好的地震信息服务。
3.2 总结
地震与台风信息采集WEB应用方传极的总结如下:
通过对地震和台风信息采集模块的设计与实现,我们成功地构建了一个能够实时获取并展示地震和台风信息的WEB应用。地震信息采集模块可以及时获取地震事件的发生时间、震级和震源位置等关键信息,并将其展示在用户界面上,为用户提供了快速、准确的地震信息查询功能。台风信息采集模块则可以实时获取台风的路径、强度和预测信息,帮助用户及时做好防范措施。在WEB应用功能设计方面,我们充分考虑了用户需求,提供了地震和台风信息的实时更新、推送功能,为用户提供了更加便捷的信息获取体验。数据采集与存储方面,我们建立了完善的数据采集和存储系统,确保了数据的准确性和完整性。通过精心设计的用户界面,我们成功地将复杂的地震和台风信息呈现给用户,提高了用户对地震和台风信息的认识和理解。未来,我们将继续完善地震与台风信息采集WEB应用,提高数据的准确性和及时性,为用户提供更加全面的地震和台风信息服务。地震与台风信息采集WEB应用将为用户提供更加方便、快捷的信息查询和预警服务,有助于提升社会对地震和台风灾害的应对能力。
在用户界面设计中,交互设计也是非常关键的一点。要确保用户可以方便地进行各种操作,比如输入查询条件、查看信息、下载数据等。按钮的设计要清晰明了,用户一目了然地知道如何进行下一步操作。要考虑到各种用户的需求,设计出适合不同用户群体的用户界面。
geo-hms分布式水文建模流程

英文回答:Water basins are divided into sub—water catchments based on information on topography,land use,rainfall,evaporation,soil type, and hydrological processes are modelled and analysed for each sub—water catchment for the purpose of distributive hydrological modelling。
The process includes four main steps: data preparation, model construction, model operation and results analysis。
Data collection and pre—processing of such data as watershed topography, land use and soil type are required during the data preparation phase。
During the model construction phase, including input of parameters and configuration of models。
The model is thenrun and the simulation results analysed and evaluated。
The whole process requires data interaction and model integrationin conjunction with GIS and HMS systems。
Such a distributed hydrologic modelling process can contribute to an improved understanding and prediction of the hydrological processes in the basin and provide an important technical support for scientifically sound water resource management and protection。
分布式实时(流)计算框架

信息,结合本次点击及从数据库中获取的信息,生成一条推荐数据,推荐给该用户。并且该次点
击记录将会更新其数据库中的参考信息,这样就是实现了简单的智能推荐。
9
Storm实时计算具体业务需求
(5) 分布式RPC
Storm有对RPC进行专门的设计,分布式RPC用于对Storm上大量的函数调用进行并行 计算,最后将结果返回给客户端。(这部分我也不是很懂) (6) 批处理 所谓批处理就是数据攒积到一定触发条件,就批量输出,所谓的触发条件类似时间 窗口到了,统计数量够了及检测到某种数据传入等等。 (7) 热度统计 热度统计实现依赖于TimeCacheMap数据结构,该结构能够在内存中保存近期活跃的 对象。我们可以使用它来实现例如论坛中的热帖排行计算等。
每秒处理 的数据量
24
MZ案例介04—GPRS数据处理
GPRS和IMEI数据关 联汇总处理流程
8,000 7,000 6,000 5,000
每秒处理 的数据量
4,000 3,000 2,000 1,000 -
3个并发流程
6个并发流程
9个并发流程
25
MZ案例介04—GPRS数据处理
MediationZone 處理解析
• 使用4核CPU,每个CPU的负荷量大致平均 • 3个Java处理进程 + 1个Java核心进程共耗内存13GB (虚拟机Vmware内存为16GB) • GPRS文档解析处理的主要负荷在CPU • GPRS和IMEI数据关联,汇总处理主要负荷在内存
Storm 只是实时计算的解决方案之一,后面我们介绍一款与实时
计算相关的产品,并且NotOnly实时计算,那就是MediationZone。
10
MediationZone系统架构
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
演讲人:杜立
2019
中国数据智能管理峰会
目录
01 02 03
腾讯实时计算概况 Oceanus平台介绍 开源特性增强
04
流计算业务实践
2019
中国数据智能管理峰会
实时计算业务赋能
2019
中国数据智能管理峰会
腾讯实时计算规模
2.1亿/秒
峰值消息处理
2018.01
Flink产品化
开始建设基于Flink的一站式流计算 平台Oceanus,并针对性优化社区 Flink On Yarn模式的部分功能。
2019.03
Oceanus场景化建设
打造内部Oceanus生态,完善场 景化服务,上线在线ML,开始 建设秒级监控等平台。
2017.09
Flink开源版本增强,业务迁移
……..
2019
24h Purge R(n+m)
5min R(n+m) = R(n+m-1) + delta
Sink R(n+m)
中国数据智能管理峰会
Enhanced Window
t tt t Event
t tt t Event
2019
Window
Current watermark 大于
小于(丢弃)
中国数据智能管理峰会
(Local)KeyBy对比
2019
中国数据智能管理峰会
Flink指标及UI重构
2019
中国数据智能管理峰会
目录
01 02 03
腾讯实时计算概况 Oceanus平台介绍 开源特性增强
04
流计算业务实践
2019
中国数据智能管理峰会
实时ETL
2019
中国数据智能管理峰会
实时统计分析
04
流计算业务实践
2019
中国数据智能管理峰会
可靠性提升
2019
中国数据智能管理峰会
Increment Window
Event
e ee ee ee e
……..
e ee e
5min R(n) = R(n-1) + delta
5min R(n+1) = R(n) + delta
Sink R(n)
Sink R(n+1)
2019
中国数据智能管理峰会
监控告警
2019
中国数据智能管理峰会
机器学习-在线训练
2019
中国数据智能管理峰会
机器学习-在线推理
2019
中国数据智能管理峰会
THANK YOU!
2019
中国数据智能管理峰会
20万亿
日均消息总条数
3PB
日均消息总大小
2019
中国数据智能管理峰会
JStorm到Flink的演进历程
2017.03
Flink框架预研,JStorm上K8S
新框架调研,评估Flink替代JStorm 的可行性,包括:功能、性能等的 对比。此时所有的流计算任务全部 由JStorm承载,且继续演进新版本。
Window
Current watermark 大于
小于
中国数据智能管理峰会
LocalKeyBy
2019
4 5 5
Source -> KeyBy -> Window -> Sum -> Sink
4
5
4
3
2
2
1
3
3
3
1
4
2
3
5
3
2
5
4
5
4
Source -> LocalKeyBy -> Sum -> Window -> KeyBy -> Sum -> Sink
Oceanus-在线调试
2019
中国数据智能管理峰会
Oceanus-指标统计
2019
中国数据智能管理峰会
Oceanus-并行度调整
2019
中国数据智能管理峰会
Oceanus-自助诊断
2019
中国数据智能管理峰会
Oceanus-告警配置
2019
中国数据智能管理峰会
目录
01 02 03
腾讯实时计算概况 Oceanus平台介绍 开源特性增强
针对内部场景,部分改造优化开源 版本,开始迁移部分JStorm上的任 务,以standalone模式运行
2019
2018.09
Oceanus平台上线
实时流计算平台规模化接入腾讯内部业务(覆 盖所有BG)、TBDS客户,上线公有云。开始 批量迁移存量JStorm的任务到Oceanus。内 部宣布JStorm版本不再演进。
不仅通过平台Web页面可轻松查看指标、打点日志等数据,同时对调 试结果,应用输出等,都提供了可视化的方式。
持续增强
结合业务实践,持续优化既有能力,并且迭代新功能;在满足自身客 户需求的同时,适时回馈社区。
2019
中国数据智能管理峰会
Oceanus-提交计算任务
配置元数据
2019
创建DAG
编译提交
中国数据智能管理峰会
中国数据智能管理峰会
目录
01 02 03
腾讯实时计算概况 Oceanus平台介绍 开源特性增强
04
流计算业务实践
2019
中国数据智能管理峰会
Oceanus实时计算平台
2019
中国数据智能管理峰会
平台建设重点
一站式
提供完善的上下游数据生态,形成从接入、处理,到应用的数据闭环。
自助化 可视化
借助平台的应用调试、丰富的实时指标数据、配置化告警等功能,实 现监控、运维自助化。