自然语言处理_NLP Dataset for Training and Testing Models(NLP训练和测试模型数据集)
pipe提取三元组的方法

pipe提取三元组的方法Extracting triplets from text using natural language processing (NLP) techniques can be a challenging task, especially when dealing with unstructured data. However, one effective method for extracting triplets from text is through the use of pipelining, which involves breaking down the extraction process into a series of smaller, more manageable steps. This approach allows for greater flexibility and control over the extraction process, making it easier to handle complex and diverse datasets.使用自然语言处理(NLP)技术从文本中提取三元组可能是一项具有挑战性的任务,尤其是在处理非结构化数据时。
然而,从文本中提取三元组的一个有效方法是通过使用管道技术,这涉及将提取过程分解成一系列更小、更易管理的步骤。
这种方法可以更灵活地控制提取过程,使处理复杂和多样化的数据集变得更容易。
One of the key advantages of using pipelining for triplet extraction is the ability to tailor each step of the process to the specific characteristics of the dataset being analyzed. For example, in the case of extracting triplets from news articles, the first step in thepipeline might involve tokenizing the text to break it down into individual words or phrases. This can be followed by part-of-speech tagging to identify the role of each word in the sentence, and then dependency parsing to capture the relationships between words. By customizing each step of the pipeline, it is possible to optimize the extraction process for the unique features of the input data.使用管道技术进行三元组提取的一个关键优势是能够针对特定数据集的特征定制每个步骤。
人工智能导论-第四课自然语言处理
研究表示,在大脑皮层中局部回路的基本连接 可以通过一系列的互联规则所捕获,而且这些 规则在大脑皮层中处于不断循环之中。
模拟人脑利用历史信息来做决策
两种不同神经网络的缩写。
时间递归神经网络(recurrent neural network) 结构递归神经网络(recursive neural network)
无法对词向量做比较,任意两个词之间都是孤立的
34
自然语言处理
词向量
使用上下文来表示单词
使用共现矩阵(Cooccurrence matrix) 一个基于窗口的共现矩阵例子
窗口长度是1(一般是5-10) 语料样例
▪ I like deep learning. ▪ I like NLP. ▪ I enjoy flying
7
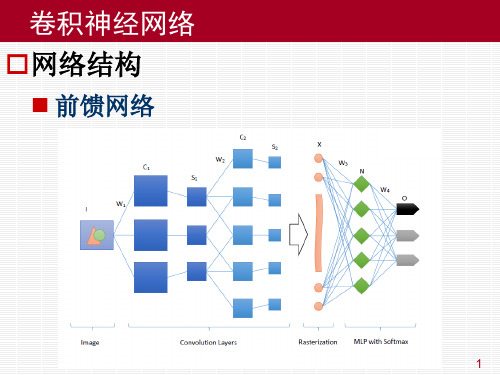
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
光栅化层 ▪ 从上一层传过来的残差为
▪ 重新整理成为一系列矩阵即可,若上一层 Q 有 q 个 池化核,则传播到池化层的残差为
8
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
池化层 ▪ 应池化过程中常用的两种池化方案,反传残差的时 候也有两种上采样方案 ▪ 最大池化:将1个点的残差直接拷贝到4个点。 ▪ 均值池化:将1个点的残差平均到4个点。 ▪ 传播到卷积层的残差为
9
卷积神经网络 卷积网络训练过程
反向传播过程
从高层到底层,逐层进行分析
卷积层 ▪ 卷积层有参数,所以卷积层的反传过程需要更新权 值,并反传残差。 ▪ 先考虑权值更新,考虑卷积层某个“神经中枢”中 的第一个神经元 ▪ 多层感知器的梯度公式
transformer模型用法

transformer模型用法英文回答:Transformers are a type of neural network that has become increasingly popular in natural language processing (NLP) tasks. They are particularly well-suited for tasksthat involve understanding the meaning of text, such as machine translation, text summarization, and question answering.Transformers work by attending to different parts ofthe input sequence. This allows them to capture long-range dependencies between words and phrases, which is essential for understanding the meaning of text. Transformers alsouse self-attention, which allows them to learnrelationships between different parts of the input sequence.There are many different types of transformers, eachwith its own strengths and weaknesses. Some of the most popular transformer models include:BERT: BERT (Bidirectional Encoder Representations from Transformers) is a transformer model that was developed by Google. BERT is a large transformer model that has been trained on a massive dataset of text. BERT has achieved state-of-the-art results on a wide range of NLP tasks.GPT-3: GPT-3 (Generative Pre-trained Transformer 3) is a transformer model that was developed by OpenAI. GPT-3 is a very large transformer model that has been trained on a massive dataset of text and code. GPT-3 can generate text, translate languages, and answer questions.T5: T5 (Text-To-Text Transfer Transformer) is a transformer model that was developed by Google. T5 is a general-purpose transformer model that can be used for a wide range of NLP tasks. T5 has achieved state-of-the-art results on a variety of NLP tasks, including machine translation, text summarization, and question answering.Transformers are a powerful tool for NLP tasks. They have achieved state-of-the-art results on a wide range oftasks, and they are likely to continue to play an important role in NLP research and development in the years to come.中文回答:Transformer模型是一种神经网络,在自然语言处理(NLP)任务中变得越来越流行。
机器学习与人工智能领域中常用的英语词汇

机器学习与人工智能领域中常用的英语词汇1.General Concepts (基础概念)•Artificial Intelligence (AI) - 人工智能1)Artificial Intelligence (AI) - 人工智能2)Machine Learning (ML) - 机器学习3)Deep Learning (DL) - 深度学习4)Neural Network - 神经网络5)Natural Language Processing (NLP) - 自然语言处理6)Computer Vision - 计算机视觉7)Robotics - 机器人技术8)Speech Recognition - 语音识别9)Expert Systems - 专家系统10)Knowledge Representation - 知识表示11)Pattern Recognition - 模式识别12)Cognitive Computing - 认知计算13)Autonomous Systems - 自主系统14)Human-Machine Interaction - 人机交互15)Intelligent Agents - 智能代理16)Machine Translation - 机器翻译17)Swarm Intelligence - 群体智能18)Genetic Algorithms - 遗传算法19)Fuzzy Logic - 模糊逻辑20)Reinforcement Learning - 强化学习•Machine Learning (ML) - 机器学习1)Machine Learning (ML) - 机器学习2)Artificial Neural Network - 人工神经网络3)Deep Learning - 深度学习4)Supervised Learning - 有监督学习5)Unsupervised Learning - 无监督学习6)Reinforcement Learning - 强化学习7)Semi-Supervised Learning - 半监督学习8)Training Data - 训练数据9)Test Data - 测试数据10)Validation Data - 验证数据11)Feature - 特征12)Label - 标签13)Model - 模型14)Algorithm - 算法15)Regression - 回归16)Classification - 分类17)Clustering - 聚类18)Dimensionality Reduction - 降维19)Overfitting - 过拟合20)Underfitting - 欠拟合•Deep Learning (DL) - 深度学习1)Deep Learning - 深度学习2)Neural Network - 神经网络3)Artificial Neural Network (ANN) - 人工神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Autoencoder - 自编码器9)Generative Adversarial Network (GAN) - 生成对抗网络10)Transfer Learning - 迁移学习11)Pre-trained Model - 预训练模型12)Fine-tuning - 微调13)Feature Extraction - 特征提取14)Activation Function - 激活函数15)Loss Function - 损失函数16)Gradient Descent - 梯度下降17)Backpropagation - 反向传播18)Epoch - 训练周期19)Batch Size - 批量大小20)Dropout - 丢弃法•Neural Network - 神经网络1)Neural Network - 神经网络2)Artificial Neural Network (ANN) - 人工神经网络3)Deep Neural Network (DNN) - 深度神经网络4)Convolutional Neural Network (CNN) - 卷积神经网络5)Recurrent Neural Network (RNN) - 循环神经网络6)Long Short-Term Memory (LSTM) - 长短期记忆网络7)Gated Recurrent Unit (GRU) - 门控循环单元8)Feedforward Neural Network - 前馈神经网络9)Multi-layer Perceptron (MLP) - 多层感知器10)Radial Basis Function Network (RBFN) - 径向基函数网络11)Hopfield Network - 霍普菲尔德网络12)Boltzmann Machine - 玻尔兹曼机13)Autoencoder - 自编码器14)Spiking Neural Network (SNN) - 脉冲神经网络15)Self-organizing Map (SOM) - 自组织映射16)Restricted Boltzmann Machine (RBM) - 受限玻尔兹曼机17)Hebbian Learning - 海比安学习18)Competitive Learning - 竞争学习19)Neuroevolutionary - 神经进化20)Neuron - 神经元•Algorithm - 算法1)Algorithm - 算法2)Supervised Learning Algorithm - 有监督学习算法3)Unsupervised Learning Algorithm - 无监督学习算法4)Reinforcement Learning Algorithm - 强化学习算法5)Classification Algorithm - 分类算法6)Regression Algorithm - 回归算法7)Clustering Algorithm - 聚类算法8)Dimensionality Reduction Algorithm - 降维算法9)Decision Tree Algorithm - 决策树算法10)Random Forest Algorithm - 随机森林算法11)Support Vector Machine (SVM) Algorithm - 支持向量机算法12)K-Nearest Neighbors (KNN) Algorithm - K近邻算法13)Naive Bayes Algorithm - 朴素贝叶斯算法14)Gradient Descent Algorithm - 梯度下降算法15)Genetic Algorithm - 遗传算法16)Neural Network Algorithm - 神经网络算法17)Deep Learning Algorithm - 深度学习算法18)Ensemble Learning Algorithm - 集成学习算法19)Reinforcement Learning Algorithm - 强化学习算法20)Metaheuristic Algorithm - 元启发式算法•Model - 模型1)Model - 模型2)Machine Learning Model - 机器学习模型3)Artificial Intelligence Model - 人工智能模型4)Predictive Model - 预测模型5)Classification Model - 分类模型6)Regression Model - 回归模型7)Generative Model - 生成模型8)Discriminative Model - 判别模型9)Probabilistic Model - 概率模型10)Statistical Model - 统计模型11)Neural Network Model - 神经网络模型12)Deep Learning Model - 深度学习模型13)Ensemble Model - 集成模型14)Reinforcement Learning Model - 强化学习模型15)Support Vector Machine (SVM) Model - 支持向量机模型16)Decision Tree Model - 决策树模型17)Random Forest Model - 随机森林模型18)Naive Bayes Model - 朴素贝叶斯模型19)Autoencoder Model - 自编码器模型20)Convolutional Neural Network (CNN) Model - 卷积神经网络模型•Dataset - 数据集1)Dataset - 数据集2)Training Dataset - 训练数据集3)Test Dataset - 测试数据集4)Validation Dataset - 验证数据集5)Balanced Dataset - 平衡数据集6)Imbalanced Dataset - 不平衡数据集7)Synthetic Dataset - 合成数据集8)Benchmark Dataset - 基准数据集9)Open Dataset - 开放数据集10)Labeled Dataset - 标记数据集11)Unlabeled Dataset - 未标记数据集12)Semi-Supervised Dataset - 半监督数据集13)Multiclass Dataset - 多分类数据集14)Feature Set - 特征集15)Data Augmentation - 数据增强16)Data Preprocessing - 数据预处理17)Missing Data - 缺失数据18)Outlier Detection - 异常值检测19)Data Imputation - 数据插补20)Metadata - 元数据•Training - 训练1)Training - 训练2)Training Data - 训练数据3)Training Phase - 训练阶段4)Training Set - 训练集5)Training Examples - 训练样本6)Training Instance - 训练实例7)Training Algorithm - 训练算法8)Training Model - 训练模型9)Training Process - 训练过程10)Training Loss - 训练损失11)Training Epoch - 训练周期12)Training Batch - 训练批次13)Online Training - 在线训练14)Offline Training - 离线训练15)Continuous Training - 连续训练16)Transfer Learning - 迁移学习17)Fine-Tuning - 微调18)Curriculum Learning - 课程学习19)Self-Supervised Learning - 自监督学习20)Active Learning - 主动学习•Testing - 测试1)Testing - 测试2)Test Data - 测试数据3)Test Set - 测试集4)Test Examples - 测试样本5)Test Instance - 测试实例6)Test Phase - 测试阶段7)Test Accuracy - 测试准确率8)Test Loss - 测试损失9)Test Error - 测试错误10)Test Metrics - 测试指标11)Test Suite - 测试套件12)Test Case - 测试用例13)Test Coverage - 测试覆盖率14)Cross-Validation - 交叉验证15)Holdout Validation - 留出验证16)K-Fold Cross-Validation - K折交叉验证17)Stratified Cross-Validation - 分层交叉验证18)Test Driven Development (TDD) - 测试驱动开发19)A/B Testing - A/B 测试20)Model Evaluation - 模型评估•Validation - 验证1)Validation - 验证2)Validation Data - 验证数据3)Validation Set - 验证集4)Validation Examples - 验证样本5)Validation Instance - 验证实例6)Validation Phase - 验证阶段7)Validation Accuracy - 验证准确率8)Validation Loss - 验证损失9)Validation Error - 验证错误10)Validation Metrics - 验证指标11)Cross-Validation - 交叉验证12)Holdout Validation - 留出验证13)K-Fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation - 留一法交叉验证16)Validation Curve - 验证曲线17)Hyperparameter Validation - 超参数验证18)Model Validation - 模型验证19)Early Stopping - 提前停止20)Validation Strategy - 验证策略•Supervised Learning - 有监督学习1)Supervised Learning - 有监督学习2)Label - 标签3)Feature - 特征4)Target - 目标5)Training Labels - 训练标签6)Training Features - 训练特征7)Training Targets - 训练目标8)Training Examples - 训练样本9)Training Instance - 训练实例10)Regression - 回归11)Classification - 分类12)Predictor - 预测器13)Regression Model - 回归模型14)Classifier - 分类器15)Decision Tree - 决策树16)Support Vector Machine (SVM) - 支持向量机17)Neural Network - 神经网络18)Feature Engineering - 特征工程19)Model Evaluation - 模型评估20)Overfitting - 过拟合21)Underfitting - 欠拟合22)Bias-Variance Tradeoff - 偏差-方差权衡•Unsupervised Learning - 无监督学习1)Unsupervised Learning - 无监督学习2)Clustering - 聚类3)Dimensionality Reduction - 降维4)Anomaly Detection - 异常检测5)Association Rule Learning - 关联规则学习6)Feature Extraction - 特征提取7)Feature Selection - 特征选择8)K-Means - K均值9)Hierarchical Clustering - 层次聚类10)Density-Based Clustering - 基于密度的聚类11)Principal Component Analysis (PCA) - 主成分分析12)Independent Component Analysis (ICA) - 独立成分分析13)T-distributed Stochastic Neighbor Embedding (t-SNE) - t分布随机邻居嵌入14)Gaussian Mixture Model (GMM) - 高斯混合模型15)Self-Organizing Maps (SOM) - 自组织映射16)Autoencoder - 自动编码器17)Latent Variable - 潜变量18)Data Preprocessing - 数据预处理19)Outlier Detection - 异常值检测20)Clustering Algorithm - 聚类算法•Reinforcement Learning - 强化学习1)Reinforcement Learning - 强化学习2)Agent - 代理3)Environment - 环境4)State - 状态5)Action - 动作6)Reward - 奖励7)Policy - 策略8)Value Function - 值函数9)Q-Learning - Q学习10)Deep Q-Network (DQN) - 深度Q网络11)Policy Gradient - 策略梯度12)Actor-Critic - 演员-评论家13)Exploration - 探索14)Exploitation - 开发15)Temporal Difference (TD) - 时间差分16)Markov Decision Process (MDP) - 马尔可夫决策过程17)State-Action-Reward-State-Action (SARSA) - 状态-动作-奖励-状态-动作18)Policy Iteration - 策略迭代19)Value Iteration - 值迭代20)Monte Carlo Methods - 蒙特卡洛方法•Semi-Supervised Learning - 半监督学习1)Semi-Supervised Learning - 半监督学习2)Labeled Data - 有标签数据3)Unlabeled Data - 无标签数据4)Label Propagation - 标签传播5)Self-Training - 自训练6)Co-Training - 协同训练7)Transudative Learning - 传导学习8)Inductive Learning - 归纳学习9)Manifold Regularization - 流形正则化10)Graph-based Methods - 基于图的方法11)Cluster Assumption - 聚类假设12)Low-Density Separation - 低密度分离13)Semi-Supervised Support Vector Machines (S3VM) - 半监督支持向量机14)Expectation-Maximization (EM) - 期望最大化15)Co-EM - 协同期望最大化16)Entropy-Regularized EM - 熵正则化EM17)Mean Teacher - 平均教师18)Virtual Adversarial Training - 虚拟对抗训练19)Tri-training - 三重训练20)Mix Match - 混合匹配•Feature - 特征1)Feature - 特征2)Feature Engineering - 特征工程3)Feature Extraction - 特征提取4)Feature Selection - 特征选择5)Input Features - 输入特征6)Output Features - 输出特征7)Feature Vector - 特征向量8)Feature Space - 特征空间9)Feature Representation - 特征表示10)Feature Transformation - 特征转换11)Feature Importance - 特征重要性12)Feature Scaling - 特征缩放13)Feature Normalization - 特征归一化14)Feature Encoding - 特征编码15)Feature Fusion - 特征融合16)Feature Dimensionality Reduction - 特征维度减少17)Continuous Feature - 连续特征18)Categorical Feature - 分类特征19)Nominal Feature - 名义特征20)Ordinal Feature - 有序特征•Label - 标签1)Label - 标签2)Labeling - 标注3)Ground Truth - 地面真值4)Class Label - 类别标签5)Target Variable - 目标变量6)Labeling Scheme - 标注方案7)Multi-class Labeling - 多类别标注8)Binary Labeling - 二分类标注9)Label Noise - 标签噪声10)Labeling Error - 标注错误11)Label Propagation - 标签传播12)Unlabeled Data - 无标签数据13)Labeled Data - 有标签数据14)Semi-supervised Learning - 半监督学习15)Active Learning - 主动学习16)Weakly Supervised Learning - 弱监督学习17)Noisy Label Learning - 噪声标签学习18)Self-training - 自训练19)Crowdsourcing Labeling - 众包标注20)Label Smoothing - 标签平滑化•Prediction - 预测1)Prediction - 预测2)Forecasting - 预测3)Regression - 回归4)Classification - 分类5)Time Series Prediction - 时间序列预测6)Forecast Accuracy - 预测准确性7)Predictive Modeling - 预测建模8)Predictive Analytics - 预测分析9)Forecasting Method - 预测方法10)Predictive Performance - 预测性能11)Predictive Power - 预测能力12)Prediction Error - 预测误差13)Prediction Interval - 预测区间14)Prediction Model - 预测模型15)Predictive Uncertainty - 预测不确定性16)Forecast Horizon - 预测时间跨度17)Predictive Maintenance - 预测性维护18)Predictive Policing - 预测式警务19)Predictive Healthcare - 预测性医疗20)Predictive Maintenance - 预测性维护•Classification - 分类1)Classification - 分类2)Classifier - 分类器3)Class - 类别4)Classify - 对数据进行分类5)Class Label - 类别标签6)Binary Classification - 二元分类7)Multiclass Classification - 多类分类8)Class Probability - 类别概率9)Decision Boundary - 决策边界10)Decision Tree - 决策树11)Support Vector Machine (SVM) - 支持向量机12)K-Nearest Neighbors (KNN) - K最近邻算法13)Naive Bayes - 朴素贝叶斯14)Logistic Regression - 逻辑回归15)Random Forest - 随机森林16)Neural Network - 神经网络17)SoftMax Function - SoftMax函数18)One-vs-All (One-vs-Rest) - 一对多(一对剩余)19)Ensemble Learning - 集成学习20)Confusion Matrix - 混淆矩阵•Regression - 回归1)Regression Analysis - 回归分析2)Linear Regression - 线性回归3)Multiple Regression - 多元回归4)Polynomial Regression - 多项式回归5)Logistic Regression - 逻辑回归6)Ridge Regression - 岭回归7)Lasso Regression - Lasso回归8)Elastic Net Regression - 弹性网络回归9)Regression Coefficients - 回归系数10)Residuals - 残差11)Ordinary Least Squares (OLS) - 普通最小二乘法12)Ridge Regression Coefficient - 岭回归系数13)Lasso Regression Coefficient - Lasso回归系数14)Elastic Net Regression Coefficient - 弹性网络回归系数15)Regression Line - 回归线16)Prediction Error - 预测误差17)Regression Model - 回归模型18)Nonlinear Regression - 非线性回归19)Generalized Linear Models (GLM) - 广义线性模型20)Coefficient of Determination (R-squared) - 决定系数21)F-test - F检验22)Homoscedasticity - 同方差性23)Heteroscedasticity - 异方差性24)Autocorrelation - 自相关25)Multicollinearity - 多重共线性26)Outliers - 异常值27)Cross-validation - 交叉验证28)Feature Selection - 特征选择29)Feature Engineering - 特征工程30)Regularization - 正则化2.Neural Networks and Deep Learning (神经网络与深度学习)•Convolutional Neural Network (CNN) - 卷积神经网络1)Convolutional Neural Network (CNN) - 卷积神经网络2)Convolution Layer - 卷积层3)Feature Map - 特征图4)Convolution Operation - 卷积操作5)Stride - 步幅6)Padding - 填充7)Pooling Layer - 池化层8)Max Pooling - 最大池化9)Average Pooling - 平均池化10)Fully Connected Layer - 全连接层11)Activation Function - 激活函数12)Rectified Linear Unit (ReLU) - 线性修正单元13)Dropout - 随机失活14)Batch Normalization - 批量归一化15)Transfer Learning - 迁移学习16)Fine-Tuning - 微调17)Image Classification - 图像分类18)Object Detection - 物体检测19)Semantic Segmentation - 语义分割20)Instance Segmentation - 实例分割21)Generative Adversarial Network (GAN) - 生成对抗网络22)Image Generation - 图像生成23)Style Transfer - 风格迁移24)Convolutional Autoencoder - 卷积自编码器25)Recurrent Neural Network (RNN) - 循环神经网络•Recurrent Neural Network (RNN) - 循环神经网络1)Recurrent Neural Network (RNN) - 循环神经网络2)Long Short-Term Memory (LSTM) - 长短期记忆网络3)Gated Recurrent Unit (GRU) - 门控循环单元4)Sequence Modeling - 序列建模5)Time Series Prediction - 时间序列预测6)Natural Language Processing (NLP) - 自然语言处理7)Text Generation - 文本生成8)Sentiment Analysis - 情感分析9)Named Entity Recognition (NER) - 命名实体识别10)Part-of-Speech Tagging (POS Tagging) - 词性标注11)Sequence-to-Sequence (Seq2Seq) - 序列到序列12)Attention Mechanism - 注意力机制13)Encoder-Decoder Architecture - 编码器-解码器架构14)Bidirectional RNN - 双向循环神经网络15)Teacher Forcing - 强制教师法16)Backpropagation Through Time (BPTT) - 通过时间的反向传播17)Vanishing Gradient Problem - 梯度消失问题18)Exploding Gradient Problem - 梯度爆炸问题19)Language Modeling - 语言建模20)Speech Recognition - 语音识别•Long Short-Term Memory (LSTM) - 长短期记忆网络1)Long Short-Term Memory (LSTM) - 长短期记忆网络2)Cell State - 细胞状态3)Hidden State - 隐藏状态4)Forget Gate - 遗忘门5)Input Gate - 输入门6)Output Gate - 输出门7)Peephole Connections - 窥视孔连接8)Gated Recurrent Unit (GRU) - 门控循环单元9)Vanishing Gradient Problem - 梯度消失问题10)Exploding Gradient Problem - 梯度爆炸问题11)Sequence Modeling - 序列建模12)Time Series Prediction - 时间序列预测13)Natural Language Processing (NLP) - 自然语言处理14)Text Generation - 文本生成15)Sentiment Analysis - 情感分析16)Named Entity Recognition (NER) - 命名实体识别17)Part-of-Speech Tagging (POS Tagging) - 词性标注18)Attention Mechanism - 注意力机制19)Encoder-Decoder Architecture - 编码器-解码器架构20)Bidirectional LSTM - 双向长短期记忆网络•Attention Mechanism - 注意力机制1)Attention Mechanism - 注意力机制2)Self-Attention - 自注意力3)Multi-Head Attention - 多头注意力4)Transformer - 变换器5)Query - 查询6)Key - 键7)Value - 值8)Query-Value Attention - 查询-值注意力9)Dot-Product Attention - 点积注意力10)Scaled Dot-Product Attention - 缩放点积注意力11)Additive Attention - 加性注意力12)Context Vector - 上下文向量13)Attention Score - 注意力分数14)SoftMax Function - SoftMax函数15)Attention Weight - 注意力权重16)Global Attention - 全局注意力17)Local Attention - 局部注意力18)Positional Encoding - 位置编码19)Encoder-Decoder Attention - 编码器-解码器注意力20)Cross-Modal Attention - 跨模态注意力•Generative Adversarial Network (GAN) - 生成对抗网络1)Generative Adversarial Network (GAN) - 生成对抗网络2)Generator - 生成器3)Discriminator - 判别器4)Adversarial Training - 对抗训练5)Minimax Game - 极小极大博弈6)Nash Equilibrium - 纳什均衡7)Mode Collapse - 模式崩溃8)Training Stability - 训练稳定性9)Loss Function - 损失函数10)Discriminative Loss - 判别损失11)Generative Loss - 生成损失12)Wasserstein GAN (WGAN) - Wasserstein GAN(WGAN)13)Deep Convolutional GAN (DCGAN) - 深度卷积生成对抗网络(DCGAN)14)Conditional GAN (c GAN) - 条件生成对抗网络(c GAN)15)Style GAN - 风格生成对抗网络16)Cycle GAN - 循环生成对抗网络17)Progressive Growing GAN (PGGAN) - 渐进式增长生成对抗网络(PGGAN)18)Self-Attention GAN (SAGAN) - 自注意力生成对抗网络(SAGAN)19)Big GAN - 大规模生成对抗网络20)Adversarial Examples - 对抗样本•Encoder-Decoder - 编码器-解码器1)Encoder-Decoder Architecture - 编码器-解码器架构2)Encoder - 编码器3)Decoder - 解码器4)Sequence-to-Sequence Model (Seq2Seq) - 序列到序列模型5)State Vector - 状态向量6)Context Vector - 上下文向量7)Hidden State - 隐藏状态8)Attention Mechanism - 注意力机制9)Teacher Forcing - 强制教师法10)Beam Search - 束搜索11)Recurrent Neural Network (RNN) - 循环神经网络12)Long Short-Term Memory (LSTM) - 长短期记忆网络13)Gated Recurrent Unit (GRU) - 门控循环单元14)Bidirectional Encoder - 双向编码器15)Greedy Decoding - 贪婪解码16)Masking - 遮盖17)Dropout - 随机失活18)Embedding Layer - 嵌入层19)Cross-Entropy Loss - 交叉熵损失20)Tokenization - 令牌化•Transfer Learning - 迁移学习1)Transfer Learning - 迁移学习2)Source Domain - 源领域3)Target Domain - 目标领域4)Fine-Tuning - 微调5)Domain Adaptation - 领域自适应6)Pre-Trained Model - 预训练模型7)Feature Extraction - 特征提取8)Knowledge Transfer - 知识迁移9)Unsupervised Domain Adaptation - 无监督领域自适应10)Semi-Supervised Domain Adaptation - 半监督领域自适应11)Multi-Task Learning - 多任务学习12)Data Augmentation - 数据增强13)Task Transfer - 任务迁移14)Model Agnostic Meta-Learning (MAML) - 与模型无关的元学习(MAML)15)One-Shot Learning - 单样本学习16)Zero-Shot Learning - 零样本学习17)Few-Shot Learning - 少样本学习18)Knowledge Distillation - 知识蒸馏19)Representation Learning - 表征学习20)Adversarial Transfer Learning - 对抗迁移学习•Pre-trained Models - 预训练模型1)Pre-trained Model - 预训练模型2)Transfer Learning - 迁移学习3)Fine-Tuning - 微调4)Knowledge Transfer - 知识迁移5)Domain Adaptation - 领域自适应6)Feature Extraction - 特征提取7)Representation Learning - 表征学习8)Language Model - 语言模型9)Bidirectional Encoder Representations from Transformers (BERT) - 双向编码器结构转换器10)Generative Pre-trained Transformer (GPT) - 生成式预训练转换器11)Transformer-based Models - 基于转换器的模型12)Masked Language Model (MLM) - 掩蔽语言模型13)Cloze Task - 填空任务14)Tokenization - 令牌化15)Word Embeddings - 词嵌入16)Sentence Embeddings - 句子嵌入17)Contextual Embeddings - 上下文嵌入18)Self-Supervised Learning - 自监督学习19)Large-Scale Pre-trained Models - 大规模预训练模型•Loss Function - 损失函数1)Loss Function - 损失函数2)Mean Squared Error (MSE) - 均方误差3)Mean Absolute Error (MAE) - 平均绝对误差4)Cross-Entropy Loss - 交叉熵损失5)Binary Cross-Entropy Loss - 二元交叉熵损失6)Categorical Cross-Entropy Loss - 分类交叉熵损失7)Hinge Loss - 合页损失8)Huber Loss - Huber损失9)Wasserstein Distance - Wasserstein距离10)Triplet Loss - 三元组损失11)Contrastive Loss - 对比损失12)Dice Loss - Dice损失13)Focal Loss - 焦点损失14)GAN Loss - GAN损失15)Adversarial Loss - 对抗损失16)L1 Loss - L1损失17)L2 Loss - L2损失18)Huber Loss - Huber损失19)Quantile Loss - 分位数损失•Activation Function - 激活函数1)Activation Function - 激活函数2)Sigmoid Function - Sigmoid函数3)Hyperbolic Tangent Function (Tanh) - 双曲正切函数4)Rectified Linear Unit (Re LU) - 矩形线性单元5)Parametric Re LU (P Re LU) - 参数化Re LU6)Exponential Linear Unit (ELU) - 指数线性单元7)Swish Function - Swish函数8)Softplus Function - Soft plus函数9)Softmax Function - SoftMax函数10)Hard Tanh Function - 硬双曲正切函数11)Softsign Function - Softsign函数12)GELU (Gaussian Error Linear Unit) - GELU(高斯误差线性单元)13)Mish Function - Mish函数14)CELU (Continuous Exponential Linear Unit) - CELU(连续指数线性单元)15)Bent Identity Function - 弯曲恒等函数16)Gaussian Error Linear Units (GELUs) - 高斯误差线性单元17)Adaptive Piecewise Linear (APL) - 自适应分段线性函数18)Radial Basis Function (RBF) - 径向基函数•Backpropagation - 反向传播1)Backpropagation - 反向传播2)Gradient Descent - 梯度下降3)Partial Derivative - 偏导数4)Chain Rule - 链式法则5)Forward Pass - 前向传播6)Backward Pass - 反向传播7)Computational Graph - 计算图8)Neural Network - 神经网络9)Loss Function - 损失函数10)Gradient Calculation - 梯度计算11)Weight Update - 权重更新12)Activation Function - 激活函数13)Optimizer - 优化器14)Learning Rate - 学习率15)Mini-Batch Gradient Descent - 小批量梯度下降16)Stochastic Gradient Descent (SGD) - 随机梯度下降17)Batch Gradient Descent - 批量梯度下降18)Momentum - 动量19)Adam Optimizer - Adam优化器20)Learning Rate Decay - 学习率衰减•Gradient Descent - 梯度下降1)Gradient Descent - 梯度下降2)Stochastic Gradient Descent (SGD) - 随机梯度下降3)Mini-Batch Gradient Descent - 小批量梯度下降4)Batch Gradient Descent - 批量梯度下降5)Learning Rate - 学习率6)Momentum - 动量7)Adaptive Moment Estimation (Adam) - 自适应矩估计8)RMSprop - 均方根传播9)Learning Rate Schedule - 学习率调度10)Convergence - 收敛11)Divergence - 发散12)Adagrad - 自适应学习速率方法13)Adadelta - 自适应增量学习率方法14)Adamax - 自适应矩估计的扩展版本15)Nadam - Nesterov Accelerated Adaptive Moment Estimation16)Learning Rate Decay - 学习率衰减17)Step Size - 步长18)Conjugate Gradient Descent - 共轭梯度下降19)Line Search - 线搜索20)Newton's Method - 牛顿法•Learning Rate - 学习率1)Learning Rate - 学习率2)Adaptive Learning Rate - 自适应学习率3)Learning Rate Decay - 学习率衰减4)Initial Learning Rate - 初始学习率5)Step Size - 步长6)Momentum - 动量7)Exponential Decay - 指数衰减8)Annealing - 退火9)Cyclical Learning Rate - 循环学习率10)Learning Rate Schedule - 学习率调度11)Warm-up - 预热12)Learning Rate Policy - 学习率策略13)Learning Rate Annealing - 学习率退火14)Cosine Annealing - 余弦退火15)Gradient Clipping - 梯度裁剪16)Adapting Learning Rate - 适应学习率17)Learning Rate Multiplier - 学习率倍增器18)Learning Rate Reduction - 学习率降低19)Learning Rate Update - 学习率更新20)Scheduled Learning Rate - 定期学习率•Batch Size - 批量大小1)Batch Size - 批量大小2)Mini-Batch - 小批量3)Batch Gradient Descent - 批量梯度下降4)Stochastic Gradient Descent (SGD) - 随机梯度下降5)Mini-Batch Gradient Descent - 小批量梯度下降6)Online Learning - 在线学习7)Full-Batch - 全批量8)Data Batch - 数据批次9)Training Batch - 训练批次10)Batch Normalization - 批量归一化11)Batch-wise Optimization - 批量优化12)Batch Processing - 批量处理13)Batch Sampling - 批量采样14)Adaptive Batch Size - 自适应批量大小15)Batch Splitting - 批量分割16)Dynamic Batch Size - 动态批量大小17)Fixed Batch Size - 固定批量大小18)Batch-wise Inference - 批量推理19)Batch-wise Training - 批量训练20)Batch Shuffling - 批量洗牌•Epoch - 训练周期1)Training Epoch - 训练周期2)Epoch Size - 周期大小3)Early Stopping - 提前停止4)Validation Set - 验证集5)Training Set - 训练集6)Test Set - 测试集7)Overfitting - 过拟合8)Underfitting - 欠拟合9)Model Evaluation - 模型评估10)Model Selection - 模型选择11)Hyperparameter Tuning - 超参数调优12)Cross-Validation - 交叉验证13)K-fold Cross-Validation - K折交叉验证14)Stratified Cross-Validation - 分层交叉验证15)Leave-One-Out Cross-Validation (LOOCV) - 留一法交叉验证16)Grid Search - 网格搜索17)Random Search - 随机搜索18)Model Complexity - 模型复杂度19)Learning Curve - 学习曲线20)Convergence - 收敛3.Machine Learning Techniques and Algorithms (机器学习技术与算法)•Decision Tree - 决策树1)Decision Tree - 决策树2)Node - 节点3)Root Node - 根节点4)Leaf Node - 叶节点5)Internal Node - 内部节点6)Splitting Criterion - 分裂准则7)Gini Impurity - 基尼不纯度8)Entropy - 熵9)Information Gain - 信息增益10)Gain Ratio - 增益率11)Pruning - 剪枝12)Recursive Partitioning - 递归分割13)CART (Classification and Regression Trees) - 分类回归树14)ID3 (Iterative Dichotomiser 3) - 迭代二叉树315)C4.5 (successor of ID3) - C4.5(ID3的后继者)16)C5.0 (successor of C4.5) - C5.0(C4.5的后继者)17)Split Point - 分裂点18)Decision Boundary - 决策边界19)Pruned Tree - 剪枝后的树20)Decision Tree Ensemble - 决策树集成•Random Forest - 随机森林1)Random Forest - 随机森林2)Ensemble Learning - 集成学习3)Bootstrap Sampling - 自助采样4)Bagging (Bootstrap Aggregating) - 装袋法5)Out-of-Bag (OOB) Error - 袋外误差6)Feature Subset - 特征子集7)Decision Tree - 决策树8)Base Estimator - 基础估计器9)Tree Depth - 树深度10)Randomization - 随机化11)Majority Voting - 多数投票12)Feature Importance - 特征重要性13)OOB Score - 袋外得分14)Forest Size - 森林大小15)Max Features - 最大特征数16)Min Samples Split - 最小分裂样本数17)Min Samples Leaf - 最小叶节点样本数18)Gini Impurity - 基尼不纯度19)Entropy - 熵20)Variable Importance - 变量重要性•Support Vector Machine (SVM) - 支持向量机1)Support Vector Machine (SVM) - 支持向量机2)Hyperplane - 超平面3)Kernel Trick - 核技巧4)Kernel Function - 核函数5)Margin - 间隔6)Support Vectors - 支持向量7)Decision Boundary - 决策边界8)Maximum Margin Classifier - 最大间隔分类器9)Soft Margin Classifier - 软间隔分类器10) C Parameter - C参数11)Radial Basis Function (RBF) Kernel - 径向基函数核12)Polynomial Kernel - 多项式核13)Linear Kernel - 线性核14)Quadratic Kernel - 二次核15)Gaussian Kernel - 高斯核16)Regularization - 正则化17)Dual Problem - 对偶问题18)Primal Problem - 原始问题19)Kernelized SVM - 核化支持向量机20)Multiclass SVM - 多类支持向量机•K-Nearest Neighbors (KNN) - K-最近邻1)K-Nearest Neighbors (KNN) - K-最近邻2)Nearest Neighbor - 最近邻3)Distance Metric - 距离度量4)Euclidean Distance - 欧氏距离5)Manhattan Distance - 曼哈顿距离6)Minkowski Distance - 闵可夫斯基距离7)Cosine Similarity - 余弦相似度8)K Value - K值9)Majority Voting - 多数投票10)Weighted KNN - 加权KNN11)Radius Neighbors - 半径邻居12)Ball Tree - 球树13)KD Tree - KD树14)Locality-Sensitive Hashing (LSH) - 局部敏感哈希15)Curse of Dimensionality - 维度灾难16)Class Label - 类标签17)Training Set - 训练集18)Test Set - 测试集19)Validation Set - 验证集20)Cross-Validation - 交叉验证•Naive Bayes - 朴素贝叶斯1)Naive Bayes - 朴素贝叶斯2)Bayes' Theorem - 贝叶斯定理3)Prior Probability - 先验概率4)Posterior Probability - 后验概率5)Likelihood - 似然6)Class Conditional Probability - 类条件概率7)Feature Independence Assumption - 特征独立假设8)Multinomial Naive Bayes - 多项式朴素贝叶斯9)Gaussian Naive Bayes - 高斯朴素贝叶斯10)Bernoulli Naive Bayes - 伯努利朴素贝叶斯11)Laplace Smoothing - 拉普拉斯平滑12)Add-One Smoothing - 加一平滑13)Maximum A Posteriori (MAP) - 最大后验概率14)Maximum Likelihood Estimation (MLE) - 最大似然估计15)Classification - 分类16)Feature Vectors - 特征向量17)Training Set - 训练集18)Test Set - 测试集19)Class Label - 类标签20)Confusion Matrix - 混淆矩阵•Clustering - 聚类1)Clustering - 聚类2)Centroid - 质心3)Cluster Analysis - 聚类分析4)Partitioning Clustering - 划分式聚类5)Hierarchical Clustering - 层次聚类6)Density-Based Clustering - 基于密度的聚类7)K-Means Clustering - K均值聚类8)K-Medoids Clustering - K中心点聚类9)DBSCAN (Density-Based Spatial Clustering of Applications with Noise) - 基于密度的空间聚类算法10)Agglomerative Clustering - 聚合式聚类11)Dendrogram - 系统树图12)Silhouette Score - 轮廓系数13)Elbow Method - 肘部法则14)Clustering Validation - 聚类验证15)Intra-cluster Distance - 类内距离16)Inter-cluster Distance - 类间距离17)Cluster Cohesion - 类内连贯性18)Cluster Separation - 类间分离度19)Cluster Assignment - 聚类分配20)Cluster Label - 聚类标签•K-Means - K-均值1)K-Means - K-均值2)Centroid - 质心3)Cluster - 聚类4)Cluster Center - 聚类中心5)Cluster Assignment - 聚类分配6)Cluster Analysis - 聚类分析7)K Value - K值8)Elbow Method - 肘部法则9)Inertia - 惯性10)Silhouette Score - 轮廓系数11)Convergence - 收敛12)Initialization - 初始化13)Euclidean Distance - 欧氏距离14)Manhattan Distance - 曼哈顿距离15)Distance Metric - 距离度量16)Cluster Radius - 聚类半径17)Within-Cluster Variation - 类内变异18)Cluster Quality - 聚类质量19)Clustering Algorithm - 聚类算法20)Clustering Validation - 聚类验证•Dimensionality Reduction - 降维1)Dimensionality Reduction - 降维2)Feature Extraction - 特征提取3)Feature Selection - 特征选择4)Principal Component Analysis (PCA) - 主成分分析5)Singular Value Decomposition (SVD) - 奇异值分解6)Linear Discriminant Analysis (LDA) - 线性判别分析7)t-Distributed Stochastic Neighbor Embedding (t-SNE) - t-分布随机邻域嵌入8)Autoencoder - 自编码器9)Manifold Learning - 流形学习10)Locally Linear Embedding (LLE) - 局部线性嵌入11)Isomap - 等度量映射12)Uniform Manifold Approximation and Projection (UMAP) - 均匀流形逼近与投影13)Kernel PCA - 核主成分分析14)Non-negative Matrix Factorization (NMF) - 非负矩阵分解15)Independent Component Analysis (ICA) - 独立成分分析16)Variational Autoencoder (VAE) - 变分自编码器17)Sparse Coding - 稀疏编码18)Random Projection - 随机投影19)Neighborhood Preserving Embedding (NPE) - 保持邻域结构的嵌入20)Curvilinear Component Analysis (CCA) - 曲线成分分析•Principal Component Analysis (PCA) - 主成分分析1)Principal Component Analysis (PCA) - 主成分分析2)Eigenvector - 特征向量3)Eigenvalue - 特征值4)Covariance Matrix - 协方差矩阵。
自然语言处理的顶会文章 精读

自然语言处理的顶会文章精读自然语言处理(Natural Language Processing,NLP)是人工智能领域中与人类语言相对应的技术。
近年来,NLP在学术界和工业界都取得了巨大的进展。
本文将精读几篇顶会文章,探讨其中的创新思路和研究成果。
1. 文章标题:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding这篇文章介绍了一种名为BERT的模型,通过预训练深度双向Transformer模型,实现了在多个自然语言处理任务上的卓越表现。
BERT不仅仅是一个语言模型,还能够进行各种下游任务的微调,如文本分类、命名实体识别等。
该模型采用了Masked Language Model和Next Sentence Prediction两种预训练任务,通过大规模语料库的预训练,实现了对上下文的理解。
2. 文章标题:Attention Is All You Need这篇文章提出了一种新颖的神经网络架构 Transformer,完全摒弃了传统的序列模型,并通过自注意力机制实现了对上下文的建模。
Transformer网络在机器翻译任务上表现出色,且在处理长序列时具有更好的效果。
该模型的创新点在于将序列转化为一种全局表示,避免了传统循环神经网络中的局限性。
3. 文章标题:GloVe: Global Vectors for Word Representation这篇文章介绍了一种新的词向量表示方法 GloVe。
与传统的词向量模型不同,GloVe利用全局词共现矩阵来学习词向量,将词之间的关系建模成概率分布。
通过这种方式,GloVe能够更好地捕捉词语之间的语义关联,提高了词向量的质量。
该方法在多个自然语言处理任务中取得了优秀的表现。
4. 文章标题:ELMo: Deep contextualized word representations这篇文章提出了一种基于深度双向LSTM的词向量表示模型ELMo。
利用Tensorflow进行自然语言处理(NLP)系列之二高级Word2Vec

利⽤Tensorflow进⾏⾃然语⾔处理(NLP)系列之⼆⾼级Word2Vec本篇也同步笔者另⼀博客上(https:///qq_37608890/article/details/81530542)⼀、概述在上⼀篇中,我们介绍了Word2Vec即词向量,对于Word Embeddings即词嵌⼊有了些基础,同时也阐述了Word2Vec算法的两个常见模型:Skip-Gram模型和CBOW模型,本篇会对两种算法做出⽐较分析并给出其扩展模型-GloVe模型。
⾸先,我们将⽐较下原Skip-gram算法和优化后的新Skip-gram算法情况。
对⽐下Skip-gram与CBOW之间的差异以及两者随迭代次数变化⽽表现出的不同,利⽤现有资料,分析⼀下哪种⽅法更有利于⼯作的开展。
其次,讨论⼀些有助于提⾼⼯作效率的Word2Vec的扩展⽅法。
在学习的过程中,Word2Vec扩展⽅法涉及负例采样、忽略⽆效信息等等。
当然,还会涉及到⼀种新的词嵌⼊技术---Global Vectors(GloVe)及GloVe与Skip-gram和CBOW的⽐较。
最后,将学习如何使⽤Word2VEC来解决现实世界的问题:⽂档分类。
⼆、原始Skip-gram模型优化前后⽐较1、理论说明原始Skip-gram模型实际是因为没有中间隐含层(Hidden Layers),⽽是使⽤两个不同的embedding 层(嵌⼊层)或projection层(投影层),且定义了由嵌⼊层本⾝派⽣的代价函数。
这⾥可以对原始Skip-gram和改进后的Skip-gram模型图做个对⽐。
图2-1 是原始Skip-gram模型图,图2-2是改进后的Skip-gram模型图(在上⼀篇系列⼀中也有出现)。
图2-1 不含隐藏层的原始Skip-gram模型图图2-2 含有隐含层的改进型Skip-gram模型图2、Tensorflow实施对⽐由于原始Skip-gram模型不含有隐藏层,所以我们⽆法像上⼀篇实现的版本那样简单,因为这⾥的损失函数需要利⽤TensorFlow⼿⼯编制,不像改进版的那样可以直接使⽤内置函数。
自然语言处理应用与实践综合项目课程大纲

自然语言处理应用与实践综合项目课程大纲课程简介:自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的重要分支,旨在使计算机能够理解、分析和生成人类语言。
本课程将结合理论与实践,探讨自然语言处理在实际应用中的相关技术和方法,并引导学生进行综合项目实践,提升其在NLP领域的应用能力。
课程目标:1.熟悉自然语言处理技术的理论基础和关键概念;2.了解自然语言处理在不同领域的实际应用场景;3.掌握自然语言处理常用工具与框架的使用方法;4.培养学生解决实际问题的能力,提升其在自然语言处理领域的实践能力。
教学内容:第一部分:自然语言处理基础(40学时)1. 自然语言处理概述1.1 自然语言处理的定义和历史发展1.2 自然语言处理的重要性和应用前景2. 文本处理与分析2.1 文本预处理:分词、停用词过滤、词性标注 2.2 文本特征表示:词袋模型、TF-IDF模型2.3 文本分类与情感分析3. 语言模型与机器翻译3.1 n-gram语言模型3.2 统计机器翻译与神经网络机器翻译3.3 翻译中的问题与挑战4. 信息抽取与实体识别4.1 实体识别的基本概念与方法4.2 命名实体识别与关系抽取4.3 信息抽取的应用场景与案例分析第二部分:自然语言处理实践(60学时)1. 文本分类与情感分析实践1.1 搭建文本分类与情感分析的实验环境1.2 数据预处理与特征工程1.3 构建文本分类与情感分析模型1.4 模型评估与调优2. 机器翻译实践2.1 构建机器翻译系统的实验环境2.2 数据预处理与特征选择2.3 神经网络机器翻译模型的训练与调优2.4 模型评估与性能优化3. 实体识别与关系抽取实践3.1 搭建实体识别与关系抽取的实验环境3.2 数据预处理与特征选择3.3 构建实体识别与关系抽取模型3.4 模型评估与优化综合项目实践(40学时)学生将根据自己的兴趣与实际需求,选择一个自然语言处理的应用场景进行综合项目实践。
自然语言处理技术的开发与应用教程

自然语言处理技术的开发与应用教程自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的重要分支,旨在使计算机能够理解、识别和处理人类语言。
随着人工智能技术的不断发展,NLP在各个领域展现出巨大的潜力和应用前景。
本文将介绍自然语言处理技术的开发与应用,并探讨其在实践中的价值和挑战。
自然语言处理技术的开发是一个复杂且多学科交叉的过程,主要涉及语言学、计算机科学和数学等领域的知识。
在NLP的开发过程中,常见的任务包括文本分类、信息抽取、命名实体识别、情感分析、机器翻译以及问答系统等。
这些任务都是基于大规模语料库进行训练,并使用机器学习、深度学习和统计方法等来构建模型和算法。
在应用方面,自然语言处理技术有着广泛的应用场景。
其中,机器翻译是NLP的重要应用之一。
通过将一种语言的文本翻译为另一种语言,机器翻译可以在跨语言交流和文化交流方面发挥重要作用。
例如,谷歌翻译等在线翻译工具就是通过NLP技术实现的。
此外,情感分析也是NLP的另一个重要应用领域。
通过分析用户在社交媒体上发布的文本,情感分析可以判断用户的情绪状态,对市场调查和舆情监控等领域具有重要意义。
NLP的发展和应用也面临着一些挑战。
首先,自然语言的复杂性是NLP领域的一大难题。
词义的多义性、句子的歧义性以及语法结构的多样性给NLP的任务带来了极大的困难。
为了解决这些问题,研究人员不断探索新的模型和算法,以提高NLP系统的准确性和鲁棒性。
其次,数据的标注和收集也是NLP中的一大挑战。
由于NLP任务需要大量标记好的数据来进行训练,因此数据的标注成本往往很高。
另外,因为人类语言的多样性,不同领域和不同领域之间的数据差异也会对NLP系统的性能产生影响。
为了顺利开发和应用自然语言处理技术,我们可以采用一系列的步骤和方法。
首先,我们需要明确NLP系统所需实现的任务,并选取适当的算法和模型来解决问题。
机器学习和深度学习方法常常被应用于NLP任务中,如支持向量机、循环神经网络和卷积神经网络等。
用Python轻松实现NLP自然语言处理

用Python轻松实现NLP自然语言处理Python作为一种流行的编程语言,能够运用在许多领域,其中包括NLP (Natural Language Processing,自然语言处理)。
NLP是人工智能领域的重要分支,通过使用Python,可以轻松实现各种NLP任务,如自然语言理解、文本挖掘、实体识别、情感分析等。
在Python中支持NLP的主要库有nltk、spaCy、gensim等。
这些库提供了对不同NLP任务的解决方案和算法,可以帮助开发者快速处理和分析文本数据。
下面我们将介绍如何使用Python和这些库来完成一些基本的NLP 任务。
首先,我们可以使用nltk库来进行自然语言处理。
nltk是Python中NLP 最流行的库之一,它提供了丰富的语料库,可以用于文本预处理、词性标注、分块、语法分析等任务。
例如,在nltk库中,我们可以使用“punkt”分词器进行分词,使用“averaged_percep ron_tagger”标注工具进行词性标注。
以下是一个简单的例子:```\nimport nltk \nfrom nltk.tokenize import word_tokenize \nfrom nltk import pos_tagtext = \This is a sample text for NLP.\tokens = word_tokenize(text)\nprint(tokens)tags = pos_tag(tokens) \nprint(tags)\n```上面的代码将文本分成了单词并打印出来,然后对每个单词进行词性标注并打印出来。
这是NLP中常用的两个任务,nltk库让我们可以轻松地实现。
除了nltk,spaCy也是一个流行的NLP库。
spaCy提供了快速的语言处理能力,可以让你在处理大量文本时更快地实现NLP任务。
由于它使用了Cython进行加速,因此可以处理大量的文本数据。
自然语言处理技术实验报告

自然语言处理技术实验报告自然语言处理(Natural Language Processing, NLP)是一门涉及语言、计算机科学和人工智能的交叉领域,致力于使计算机能够理解、分析、操作人类语言。
在本实验报告中,我们将重点关注自然语言处理技术在实际应用中的表现和效果。
通过对实验结果的详细分析,我们希望能够深入了解自然语言处理技术的优势和局限性。
一、实验背景自然语言处理技术近年来取得了长足的发展,在语音识别、机器翻译、文本分类等方面有着广泛的应用。
本次实验将利用一些经典的自然语言处理技术模型和算法,通过对大规模文本数据的处理和分析,来评估这些技术在真实场景中的效果和性能。
二、实验数据在实验中,我们使用了包括中文新闻文本、英文文本和多语种文本在内的大规模数据集,用于测试和验证自然语言处理技术在不同语言和领域中的适用性。
数据集经过预处理和清洗,确保数据的质量和准确性,以提高实验结果的可信度和可靠性。
三、实验方法我们采用了一系列经典的自然语言处理技术和算法,包括但不限于以下几种:1. 词袋模型(Bag of Words):将文本数据转换为向量表示,忽略词语的顺序和语法结构,用于文本分类和情感分析等任务。
2. 递归神经网络(Recurrent Neural Network, RNN):通过记忆和迭代的方式来处理序列数据,适用于语言模型和机器翻译等任务。
3. 卷积神经网络(Convolutional Neural Network, CNN):利用卷积操作来提取文本中的局部特征,用于文本分类和情感分析等任务。
4. 词嵌入技术(Word Embedding):将词语映射到连续向量空间,有效捕捉词语之间的语义信息,提高模型的表达能力和泛化能力。
四、实验结果基于以上方法和技术,我们对实验数据进行了处理和分析,得出了以下结论:1. 词袋模型在文本分类和情感分析等任务中表现出了不错的效果,但在处理语义和语法信息方面存在一定局限性。
gpt4.0写作术语

GPT-4.0 是OpenAI 公司开发的一种大型语言模型,它使用了自然语言处理技术,可以生成自然语言文本。
以下是一些GPT-4.0 写作中可能会用到的术语:1.自然语言处理(Natural Language Processing, NLP):是计算机科学领域与人工智能领域中的一个重要方向,它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
2.语言模型(Language Model, LM):是一种用于预测下一个单词或字符的统计模型,它基于已知的语言数据进行训练。
3.生成式对抗网络(Generative Adversarial Network, GAN):是一种深度学习模型,由生成器和判别器组成,用于生成新的样本。
4.预训练(Pre-training):是指在训练语言模型之前,先使用大量的文本数据进行训练,以提高模型的泛化能力。
微调(Fine-tuning):是指在预训练的语言模型基础上,使用特定领域的数据进行微调,以提高模型在该领域的性能。
6.词向量(Word Embedding):是一种将单词表示为向量的技术,它将单词映射到低维空间中,以便进行机器学习任务。
7.注意力机制(Attention Mechanism):是一种用于处理长序列数据的机制,它可以动态地分配权重给不同的输入,以提高模型的性能。
8.多头注意力机制(Multi-Head Attention Mechanism):是一种改进的注意力机制,它使用多个头来关注不同的位置,以提高模型的性能。
9.编码器-解码器架构(Encoder-Decoder Architecture):是一种常用的自然语言处理架构,它由编码器和解码器组成,用于将一种语言转换为另一种语言。
生成对抗网络(Generative Adversarial Network, GAN):是一种深度学习模型,由生成器和判别器组成,用于生成新的样本。
以上是一些GPT-4.0 写作中可能会用到的术语,这些术语可以帮助您更好地理解和使用GPT-4.0 进行自然语言处理任务。
cog一级功能和二级功能分类

cog一级功能和二级功能分类Cog一级功能和二级功能分类一、Cog一级功能分类1. 自然语言处理(Natural Language Processing, NLP)- 文本识别与解析(Text Recognition and Parsing):能够识别和解析输入的文本,提取其中的关键信息。
- 文本生成与合成(Text Generation and Synthesis):能够根据输入的要求和条件生成符合语法规则且意义明确的文本。
- 语义理解与推理(Semantic Understanding and Reasoning):能够理解文本的语义,并进行推理和逻辑分析。
2. 计算机视觉(Computer Vision)- 图像识别与分类(Image Recognition and Classification):能够识别和分类输入的图像,识别其中的对象、场景或特征。
- 目标检测与跟踪(Object Detection and Tracking):能够检测和跟踪图像或视频中的目标,并标注其位置和轨迹。
- 图像生成与合成(Image Generation and Synthesis):能够根据输入的条件和要求生成新的图像,具有一定的创造性。
3. 机器学习与深度学习(Machine Learning and Deep Learning) - 模型训练与调优(Model Training and Tuning):能够根据给定的数据集训练模型,并通过调优提高模型的性能。
- 特征提取与降维(Feature Extraction and Dimensionality Reduction):能够从原始数据中提取有用的特征,并降低数据的维度。
- 模型评估与预测(Model Evaluation and Prediction):能够评估模型的性能,对新的数据进行预测并给出相应的概率或置信度。
4. 自动化与控制(Automation and Control)- 过程监测与控制(Process Monitoring and Control):能够监测和控制系统或过程的状态和行为,实现自动化的控制和优化。
第二届CCF自然语言处理与中文计算会议(NLPAMPCC2013)TUTORIALS及...

中国计算机学会《学科前沿讲习班》第四十六期面向大数据的自然语言处理与机器学习2013年11月15日-17日重庆简介自然语言处理(Natural Language Processing, NLP)与机器学习(Machine Learning,ML)一直是计算机科学,尤其是人工智能研究方向的两个核心问题。
近几年来,互联网、社交媒体与移动平台的迅猛发展为传统自然语言处理与机器学习技术带来前所未有的挑战和机遇,使其成为学术界和工业界的研究热点。
一方面,传统的自然语言处理与机器学习在基础研究方面取得了长足进展,为工业应用提供了有效的技术支持;另一方面,不断涌现的真实问题和大规模数据又呼唤更加有效的自然语言处理与机器学习技术。
本期CCF学科前沿讲习班《面向大数据的自然语言处理与机器学习》将邀请学术界和工业界的著名专家、学者对自然语言处理基础理论、方法和应用,面向自然语言的机器学习技术,以及当前面向大数据时代的热点问题进行深入浅出的讲解。
目的是为青年学者和学生提供一个三天的学习、交流机会,快速了解本领域的基本概念、研究内容、方法和发展趋势。
本讲习班同时作为第二届CCF自然语言处理与中文计算会议(NLP&CC 2013)的Tutorials,将围绕大会主题——“数据智能、知识智能与社会智能”,重点讲解自然语言处理基础、社会媒体和语言计算、NLP工业应用和典型案例、面向NLP的机器学习、Deep Learning以及深层神经网络计算等内容。
学术主任张民,苏州大学教授李沐,微软亚洲研究院研究员协办单位重庆大学苏州大学微软亚洲研究院日程安排================2013年11月15日:自然语言处理和机器翻译8:30-9:00 开班仪式、合影第一讲自然语言处理:基础技术与互联网创新万小军北京大学副教授第一课 09:00-10:20 自然语言处理基础第二课 10:40-11:40 语义计算和篇章分析第三课 11:40-12:00 互动问答第二讲大数据时代的机器翻译刘洋清华大学副教授第一课 13:30-15:30 机器翻译概况、基于词和短语的方法第二课 16:00-17:30 基于句法的方法和未来发展趋势第三课 17:30-17:50 互动问答==============2013年11月16日:社会计算与自然语言处理应用第三讲社会网络计算及社会影响力分析唐杰清华大学副教授第一课 09:00-10:20 社会网络计算基础第二课 10:40-11:40 社会网络计算之社会影响力分析第三课 11:40-12:00 互动问答第四讲自然语言处理工业应用/开发实践第一课 13:20-15:20 大数据时代的智能问答和搜索张阔搜狗研究员第二课 15:40-16:40 大数据时代的搜索广告查询分析胡云华阿里研究员第三课 16:40-17:40 大数据下的广告排序技术及实践蒋龙阿里研究员第四课 17:40-18:00 互动问答==============2013年11月17日:机器学习第五讲 Statistical Machine Learning for NLP (统计机器学习与自然语言处理)朱小槿 University of Wisconsin-Madison 副教授第一课 09:00-10:00 Basics of Statistical Learning (统计机器学习基础)第二课 10:20-11:10 Graphical Models (图模型)第三课 11:10-12:00 Bayesian Non-Parametric Models (贝叶斯非参数方法)第四课 12:00-12:20 互动问答第六讲 Deep Learning - What, Why, and How 俞栋 MSR 研究员第一课 13:40-14:40 Deep Learning: Premise, Philosophy, and ItsRelation to Other Techniques 第二课 14:40-15:40 Basic Deep Learning Models第三课 16:00-17:15 Deep Neural Network and Its Applicationin Speech Recognition 第四课 17:15-17:35 互动问答17:35-18:00 结业式讲者介绍========================万小军北京大学副教授报告题目:自然语言处理:基础技术与互联网创新摘要:随着互联网上文本数据的爆炸性增长,如何对这些数据进行智能分析、语义挖掘与深度利用是学术界和工业界所共同面临的重大挑战。
自然语言处理实验报告

自然语言处理实验报告一、实验背景自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和生成人类语言。
在本次实验中,我们将探讨NLP在文本分类任务上的应用。
二、实验数据我们选取了一个包含新闻文本的数据集作为实验数据,共包括数千条新闻文本样本,每个样本均有对应的类别标签,如政治、经济、体育等。
三、实验步骤1. 数据预处理:首先对文本数据进行清洗,如去除标点符号、停用词和数字等干扰项,然后对文本进行分词处理。
2. 特征提取:选取TF-IDF(Term Frequency-Inverse Document Frequency)作为特征提取方法,将文本表示为向量形式。
3. 模型选择:本次实验中我们选择了朴素贝叶斯分类器作为文本分类的基本模型。
4. 模型训练:将数据集按照8:2的比例划分为训练集和测试集,用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算准确率、召回率和F1值等指标。
四、实验结果经过多次实验和调优,我们最终得到了一个在文本分类任务上表现良好的模型。
在测试集上,我们的模型达到了90%以上的准确率,表现优异。
五、实验总结通过本次实验,我们深入了解了自然语言处理在文本分类任务上的应用。
同时,我们也发现了一些问题和改进空间,如模型泛化能力不足、特征选择不合适等,这些将是我们未来研究的重点方向。
六、展望未来在未来的研究中,我们将进一步探索不同的特征提取方法和模型结构,以提升文本分类的准确率和效率。
同时,我们还将探索深度学习等新领域的应用,以更好地解决自然语言处理中的挑战和问题。
七、参考文献1. Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing (3rd ed.). Pearson.2. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press.以上为自然语言处理实验报告的内容,希望对您有所帮助。
自然语言处理实验—文本分类

自然语言处理实验—文本分类
实验目的:
文本分类是自然语言处理中的重要任务之一,旨在将文本按照预定义的类别进行分类。
本实验旨在使用自然语言处理技术,对给定的文本数据集进行分类。
实验步骤:
1. 数据集准备:选择合适的文本数据集作为实验数据,确保数据集包含已经标注好的类别信息。
2. 数据预处理:对文本数据进行预处理,包括去除特殊字符、分词、停用词处理、词形还原等步骤。
3. 特征提取:选择合适的特征提取方法,将文本转化为向量表示。
常用的特征提取方法包括词袋模型、TF-IDF等。
4. 模型选择:选择合适的分类模型,如朴素贝叶斯、支持向量机、深度学习模型等。
5. 模型训练:使用训练集对选择的分类模型进行训练。
6. 模型评估:使用测试集对训练好的分类模型进行评估,计算分类准确率、精确率、召回率等指标。
7. 结果分析:分析实验结果,对分类结果进行调整和改进。
注意事项:
1. 数据集的选择应该符合实验目的,且包含足够的样本和类别信息。
2. 在预处理和特征提取过程中,需要根据实验需求进行适当的调整
和优化。
3. 模型选择应根据实验数据的特点和要求进行选择,可以尝试多种模型进行比较。
4. 在模型训练和评估过程中,需要注意模型的调参和过拟合问题,并及时进行调整。
5. 结果分析过程可以包括对错分类样本的分析,以及对模型的改进和优化思路的探讨。
实验结果:
实验结果包括模型的分类准确率、精确率、召回率等指标,以及对实验结果的分析和改进思路。
根据实验结果,可以对文本分类问题进行更深入的研究和探讨。
自然语言处理参考文献

自然语言处理参考文献自然语言处理(Natural Language Processing, NLP)是人工智能领域中研究和应用最为广泛的分支之一。
它涉及对人类语言进行理解、生成和处理的技术与方法。
随着深度学习和大数据技术的快速发展,NLP在机器翻译、情感分析、问答系统、文本分类等领域取得了突破性的进展。
以下是一些经典的NLP领域相关的参考文献。
1. Jurafsky, D., & Martin, J. H. (2019). Speech and Language Processing (3rd ed.). Prentice-Hall. 这本教材是NLP领域的经典教材之一,涵盖了从基础知识到最新技术的广泛内容,包括分词、词性标注、句法分析、语义角色标注、情感分析等。
2. Manning, C. D., & Schütze, H. (1999). Foundations of Statistical Natural Language Processing. MIT Press. 这本书介绍了NLP中统计方法的基础理论和应用技术,包括统计语言模型、文本分类、机器翻译、信息抽取等。
3. Goldberg, Y. (2017). Neural Network Methods for Natural Language Processing. Morgan & Claypool Publishers. 这本书介绍了NLP中基于神经网络的方法和技术,包括词向量表示、循环神经网络、注意力机制、生成模型等。
4. Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge University Press. 这本书主要介绍了信息检索领域的基本理论和技术,包括倒排索引、查询扩展、评估指标等,对NLP中的文本搜索和知识图谱构建有重要参考价值。
使用TensorFlow进行自然语言处理(NLP)

使用TensorFlow进行自然语言处理(NLP)自然语言处理(NLP)是人工智能中的一个重要领域,旨在使计算机能够理解和处理人类语言。
TensorFlow是一个开源的机器学习框架,具有强大的计算能力和丰富的工具库,被广泛用于NLP任务的处理和分析。
本文将介绍如何使用TensorFlow进行自然语言处理。
1. 导入TensorFlow库首先,我们需要导入TensorFlow库。
在Python中,可以使用以下语句导入TensorFlow:```import tensorflow as tf```2. 文本预处理在进行自然语言处理之前,通常需要对文本进行预处理。
预处理包括文本分词、去除停用词、词性还原等。
TensorFlow提供了一些工具,如Tokenizer和tf.data.Dataset等,可以帮助我们进行文本预处理。
下面是一个简单的示例:```# 创建Tokenizer对象tokenizer = tf.keras.preprocessing.text.Tokenizer()# 根据文本进行分词tokenizer.fit_on_texts(texts)# 将分词后的文本转换成序列sequences = tokenizer.texts_to_sequences(texts)# 将序列填充为固定长度padded_sequences =tf.keras.preprocessing.sequence.pad_sequences(sequences,maxlen=max_length)```3. 构建词嵌入模型词嵌入是NLP中常用的技术,用于将词汇表示为向量。
TensorFlow 提供了许多预训练的词嵌入模型,如Word2Vec、GloVe等。
可以使用这些模型将词汇表达为向量,并在NLP任务中应用这些向量。
以下是一个简单的示例:```# 导入预训练词嵌入模型embedding_model = tf.keras.models.load_model('embedding_model.h5') # 对文本进行词嵌入embedded_sequences = embedding_model.predict(padded_sequences) ```4. 构建神经网络模型使用TensorFlow可以构建各种神经网络模型来进行NLP任务。
与人工智能相关的英语单词

与人工智能相关的英语单词1. Artificial Intelligence (AI): 人工智能,它是计算机科学的分支,旨在模拟人类的智能和思维。
AI包括机器学习、自然语言处理、计算机视觉等技术,这些技术可以用于创建智能机器人、智能助理、自动驾驶汽车等。
举例:Google's AI language model can answer complex questions and translate text between languages.2. Machine Learning (ML): 机器学习是AI的一个分支,它是指通过计算机程序从数据中学习并做出决策。
ML使用算法来分析大量数据并自动识别模式和趋势,从而进行预测和分类。
举例:Amazon's ML algorithm can predict which products a customer might be interested in based on their previous purchases and browsing history.3. Natural Language Processing (NLP): 自然语言处理是AI的一个分支,它是指将人类语言转化为计算机可理解的形式。
NLP包括文本分析、情感分析、语音识别等技术,这些技术可以用于创建聊天机器人、语音助手、自动翻译等。
举例:Apple's Siri can understand and respond to human speech through NLP technology.4. Computer Vision (CV): 计算机视觉是AI的一个分支,它是指将图像转化为计算机可理解的形式。
CV包括图像识别、目标检测、人脸识别等技术,这些技术可以用于创建智能监控系统、自动驾驶汽车、智能家居等。
举例:Facebook's CV technology can identify and tag friends in photos posted on the social network.5. Deep Learning (DL): 深度学习是机器学习的一个分支,它是指使用深度神经网络进行学习。
supervised fine-tuning训练方式

supervised fine-tuning训练方式Supervised fine-tuning is a training technique used in machine learning, particularly in the field of natural language processing (NLP). It involves taking a pre-trained model and further training it on a specific task with labeled data. This technique is used to adapt a pre-trained model to perform better on a specific task or domain.The process of supervised fine-tuning involves several steps. First, a large-scale pre-training is performed on a general task using a vast amount of unlabeled data. This pre-training phase helps the model learn general language representations and capture common patterns and structures. Pre-training is usually done using techniques like masked language modeling and next sentence prediction.Once the pre-training is complete, the model is fine-tuned on a specific task using labeled data. This task could be anything from sentiment analysis to named entity recognition or machine translation. Fine-tuning involves training the model on a smaller dataset that is annotated with labels or targets for the task at hand.Supervised fine-tuning is a powerful technique because it leverages the knowledge learned by the pre-trained model on a large amount ofunlabeled data. This knowledge can then be transferred to the specific task, making the model perform better with less labeled data.There are several advantages to using supervised fine-tuning. Firstly, it reduces the need for large amounts of labeled data. Pre-training on unlabeled data helps the model learn general language representations, which can be fine-tuned on a smaller, labeled dataset. This reduces the cost and effort required to collect and annotate large amounts of labeled data.Secondly, supervised fine-tuning allows for quicker training times. Since the initial model has already learned basic language representations during pre-training, the fine-tuning process requires fewer training iterations. This results in faster convergence and quicker deployment of the model.Another advantage of supervised fine-tuning is its ability to adapt to specific task requirements. By fine-tuning the pre-trained model on a labeled dataset, we can tailor the model to perform better on a specialized task or a specific domain. This is especially useful inreal-world applications where the data distribution or the characteristics of the task may differ from the pre-training data.However, there are also some challenges and considerations when using supervised fine-tuning. One challenge is the choice of hyperparameters during fine-tuning. Hyperparameters control the learning rate, batch size, number of training steps, and other aspects of the training process. Fine-tuning requires careful tuning of hyperparameters to ensure optimal performance on the specific task.Another consideration is the issue of catastrophic forgetting. Fine-tuning a pre-trained model on a specific task could cause it to forget some of the general language representations learned during pre-training. This becomes a trade-off between task-specific knowledge and general language understanding. Techniques like gradual unfreezing and learning rate scheduling can be used to mitigate catastrophic forgetting.Furthermore, the availability and quality of labeled data are crucial for supervised fine-tuning. If the labeled dataset is small or of low quality, the fine-tuned model may not generalize well or may overfit to the limited training examples. Additionally, biases present in the labeled data can be inadvertently learned by the model, leading to biased predictions.In conclusion, supervised fine-tuning is a powerful technique in machinelearning for adapting pre-trained models to specific tasks. It leverages the knowledge learned during pre-training and allows for quicker training and adaptation to specialized tasks. However, careful consideration of hyperparameters, potential catastrophic forgetting, and the availability and quality of labeled data are essential for successful fine-tuning.。
transformer dataset用法(一)

transformer dataset用法(一)Transformer Dataset的用途和应用Transformer Dataset,即Transformer数据集,是用于训练和评估基于Transformer模型的各种自然语言处理(NLP)任务的标准数据集。
它由一系列的输入-输出样本组成,其中输入是一个文本序列,输出是该序列的标签或相应的预测结果。
以下是一些Transformer Dataset的常见用法及详细讲解:1. 机器翻译描述:在机器翻译任务中,Transformer Dataset被用作训练和评估模型的数据源。
输入样本是一种语言的句子,输出样本是该句子的翻译结果,通常是另一种语言的句子。
用法:•将Transformer Dataset应用于机器翻译任务有助于训练机器翻译模型,使其能够将一个句子从一种语言翻译成另一种语言。
•根据Transformer Dataset的样本,机器翻译模型能够学习语言之间的对应关系和翻译规则,提高翻译的准确性和流畅性。
2. 文本分类描述:文本分类任务旨在将输入的文本序列分类到预定义的类别中。
Transformer Dataset中的输入是一个文本序列,输出是序列所属的类别标签。
用法:•利用Transformer Dataset可以训练文本分类模型,使其能够基于输入文本的语义和特征将其分类到正确的类别中。
•Transformer模型通过学习Transformer Dataset中文本序列与类别之间的关系,可以实现高效准确的文本分类。
3. 命名实体识别描述:命名实体识别(NER)任务是识别自然语言文本中特定类别的命名实体,如人名、地名、组织机构等。
Transformer Dataset中的输入是一段文本,输出是文本中识别到的命名实体的标签或边界。
用法:•使用Transformer Dataset训练NER模型,可以使模型具备识别文本中命名实体的能力。
•基于Transformer的模型,可以通过从Transformer Dataset中学习到的知识和规律,提高NER任务的准确性和泛化能力。