怎样把数据转化成bibexcel识别的格式_构造共现矩阵
biblatex格式参考文献转换

biblatex 是一种用于排版参考文献的 LaTeX 套件,可以实现灵活的参考文献格式控制、文献分类及排序、文献著录格式修改等功能,是许多学术论文、期刊文章的参考文献管理常用工具。
然而在某些特定情况下,我们需要将 biblatex 格式的参考文献转换为其他格式,比如转换为 EndNote、Mendeley 或者普通的 BibTeX 格式。
下面将介绍如何进行 biblatex 格式参考文献的转换。
1. 转换为 BibTeX 格式BibTeX 格式是一种用于排版参考文献的标准格式,通常以 .bib 为扩展名。
要将 biblatex 格式的参考文献转换为 BibTeX 格式,可以使用biblatex2bibtex 工具。
需要安装该工具,并确保其在系统环境变量中。
然后在命令行中使用命令行工具进入 biblatex 格式的参考文献所在目录,并执行以下命令:```biblatex2bibtex <filename>.bib```其中 <filename>.bib 是 biblatex 格式的参考文献文件名。
执行该命令后,将会生成一个对应的 BibTeX 格式参考文献文件。
2. 转换为 EndNote 格式EndNote 是一款常用的参考文献管理工具,支持多种文献格式。
要将biblatex 格式的参考文献转换为 EndNote 格式,首先需要将biblatex 格式的参考文献导出为 .ris 格式(一种文献格式通用格式)。
然后打开 EndNote,选择文件 -> 导入 -> 文件,选择刚刚导出的 .ris 文件,点击“打开”按钮即可将 biblatex 格式的参考文献转换为EndNote 格式。
3. 转换为 Mendeley 格式Mendeley 是另一款常用的参考文献管理工具,同样支持多种文献格式。
要将 biblatex 格式的参考文献转换为 Mendeley 格式,也需要先将 biblatex 格式的参考文献导出为 .ris 格式。
Bibexcel软件使用说明

Bibexcel软件使用说明Bibexcel 是一款功能强大的文献计量分析软件,它在学术研究和文献管理方面发挥着重要作用。
本文将为您详细介绍 Bibexcel 的使用方法,帮助您快速上手并充分利用其功能。
一、软件安装首先,您需要从官方网站或可靠的软件下载平台获取 Bibexcel 的安装文件。
安装过程相对简单,按照安装向导的提示逐步进行操作即可。
二、软件界面打开Bibexcel 后,您会看到一个简洁直观的界面。
主要包括菜单栏、工具栏和工作区域。
菜单栏提供了各种功能选项,工具栏则包含了一些常用操作的快捷按钮。
三、数据导入Bibexcel 支持多种数据格式的导入,如 BibTeX、EndNote 等。
您可以通过以下步骤导入数据:1、点击菜单栏中的“File”(文件)选项。
2、选择“Import”(导入)。
3、在弹出的对话框中,选择您要导入的数据文件,并设置相应的参数。
四、数据预处理在进行分析之前,可能需要对导入的数据进行预处理,例如去除重复记录、筛选特定字段等。
五、生成共现矩阵共现矩阵是 Bibexcel 中常用的分析工具之一。
您可以通过以下步骤生成:1、选择要分析的字段,比如作者、关键词等。
2、点击菜单栏中的“Matrix”(矩阵)选项。
3、选择“Create”(创建),并根据提示设置相关参数。
六、分析矩阵生成共现矩阵后,可以对其进行进一步的分析,例如计算频次、中心度等指标。
七、数据导出分析完成后,您可以将结果导出为多种格式,如 Excel、CSV 等,以便在其他软件中进行进一步处理或展示。
八、常见问题及解决方法1、数据导入错误:检查数据格式是否正确,以及设置的导入参数是否合适。
2、分析结果不准确:可能是数据预处理不当或分析方法选择有误,重新检查并调整相关步骤。
九、应用案例为了让您更好地理解 Bibexcel 的应用,以下是一个简单的案例:假设我们研究某个领域的学术文献,通过导入相关数据,生成作者共现矩阵,分析出该领域的核心作者群体。
BIBEXCEL简单使用教程

File菜单-文件
复制文件 重命名 删除文件 新建目录 删除目录 某个文件合并到另一文件 将所有被选择的文件合并到另一文件 将列表保存到文件 退出
Edit doc file菜单-编辑doc文件
生成新记录 删除字段 识别重复记录 删除重复记录 删除指定文字 重命名字段标签 将换行符替换成回车符 从doc文件中选择文档号 从out文件中选择文档号
Add data classify菜单
给out文件添加分类一精确匹配 给out文件添加分类一子字符串匹配 给out文件添加分类一子字符串匹配 给词频对文件添加分类 利用Levenshtein距离添加分类 为词频—文档号-文档号添加标签 为文档号—文档号对添加标签 二进制查找 合并两个文件 比较相似字符串 将简写形式的期刊名与其全名进行匹配 将简写形式的单词与其全名进行匹配 在字符串中查找某个代码词 在字符串中查找某个字符串 在列表中查找某个单词
操作流程
数据转换 (.txt→.txt2→.doc)
字段抽取 (.doc→.out)
共现分析(作者、关键词) .coc→.ccc→.ma2
可视化图谱 Pajek、NetDraw
1 数据准备 wos
1 数据准备 cnki
• Notexpress等文献管理软件 • 导出NE:导出题录(RIS格式) • AU、DE等,不能分析参考咨询CD字段
界面左上部分显示了文件名称和路径,默认的路径是bibexcel.exe程序所在的目录。 选中某个文件,单击下方的View whole file按钮,就会在界面右下部分显示文件内容。
文件夹
文件
文件内容
划分方法栏
CSSCI数据导入Bibexcel实现共现矩阵的方法及实证研究

CSSCI数据导入Bibexcel实现共现矩阵的方法及实证研究CSSCI数据是指中国社会科学引文索引,它是中国社会科学文献的核心数据库之一,收录了大量高质量的社会科学文献。
Bibexcel是一个常用的数据分析工具,可以用于创建共现矩阵和进行共现分析。
本文将介绍如何使用Bibexcel将CSSCI数据导入,并通过实证研究来展示该方法的应用。
首先,我们需要从CSSCI数据库中获取需要的文献数据。
可以通过登录CSSCI数据库,选择相应的搜索词并进行检索,然后将检索到的文献导出为一个文本文件(如txt格式),确保每篇文献的信息被正确地导出。
接下来,我们需要安装Bibexcel软件。
可以在官方网站上下载该软件,并按照安装指南进行安装。
安装完成后,打开Bibexcel软件。
在Bibexcel软件主界面上,点击“File”选项,然后选择“Import”来导入文献数据。
在弹出的窗口中,选择之前导出的文本文件,并点击“打开”按钮。
软件会自动识别文件格式并导入数据。
导入数据后,Bibexcel会生成一个包含所有文献信息的表格。
在这个表格中,我们可以看到每篇文献的标题、作者、期刊名称等多个属性。
可以根据需要对表格进行排序、过滤等操作,以便于后续的共现分析。
接下来,我们需要创建共现矩阵。
在Bibexcel软件的主界面上,点击“Co-occurrence”选项,然后选择“Createco-occurrence matrix”来创建共现矩阵。
在弹出的窗口中,可以选择共现矩阵的内容,比如可以选择以作者为单位进行共现分析,也可以选择以关键词为单位进行共现分析。
在本文中,我们选择以关键词为单位进行共现分析。
在选择了关键词之后,点击“OK”按钮,Bibexcel会自动计算关键词之间的共现频次,并将结果呈现在新窗口中。
可以在新窗口中查看每个关键词之间的共现频次,并可以通过可视化方式展示共现网络。
通过上述步骤,我们成功地将CSSCI数据导入Bibexcel,并创建了共现矩阵。
BIBEXCEL简单使用教程PPT

Edit doc-files菜单
2020/3/9
转换大小写 创建多个out文件 [压缩out文件(每字段一行)] 转换以逗号分隔格式的地址 压缩out文件 压缩独立的空out文件 删除低频项 删除高频项 从引文中抽取出版年 给字符串编号 增加分号 保留0-9及A-Z的字符 保留作者首字母 保留前n个字符 Levenshtein距离计算 只列出out文件中的实词等
BIBEXCEL简介
福州大学情报学
2020/3/9
1
目录
2020/3/9
概述
工作界面
数据准备
4 Pajek可视化
2
2020/3/9
发展简史
Bibexcel是瑞典于默奥大学(Umea University) 信息研究小组(The Information Research Group,Inforsk)欧莱·皮尔逊教授设计开发的一 款软件。Bibexcel的设计宗旨是辅助用户分析 书目数据,或者格式相近的自然语言文本,最 终产生的数据可导出至Excel或其他采用【Tab 】键隔开数据的程序中。主要用于文献计量分 析,并可为Pajek、NetDraw软件提供绘图所用 数据
17
Add data classify菜单给out文件添加分类一精确匹配
给out文件添加分类一子字符串匹配
给out文件添加分类一子字符串匹配
给词频对文件添加分类
利用Levenshtein距离添加分类
为词频—文档号-文档号添加标签
为文档号—文档号对添加标签
二进制查找
合并两个文件
比较相似字符串
将简写形式的期刊名与其全名进行匹配
21
Help菜单
Help菜单可以调出Bibexcel的帮助文件 帮助文件只有在—Windows 7以下版本的机器上才能打开
bibexcel 操作步骤

学年论文题目基于共词分析的国内竞争情报领域研究现状分析学生姓名李雨洪学号***********院系经济管理学院专业信息管理与信息系统指导教师曹玲二OO八年十二月十四日基于共词分析的国内竞争情报领域研究现状分析李雨洪南京信息工程大学经济管理学院,南京 210044摘要: 本文以CNKI 数据库中1997 - 2007 年与竞争情报相关的期刊论文为基础, 借助文献计量软件Bibexcel,采用词频统计及共词分析法分析国内竞争情报的研究现状。
文中详细说明了使用Bibexcel进行词频统计和共词分析的具体步骤,并对我国竞争情报领域的研究进行了综述。
关键词:共词分析;词频统计;竞争情报;Bibexcel1引言竞争情报日益成为学者们关注的焦点,十余年里,国内竞争情报研究已经取得了丰硕的成果。
笔者尝试以CNKI 数据库中1997—2008年的相关期刊论文为基础,采用共词分析法分析国内竞争情报的研究现状。
2共词分析法“共词分析法”最早起源于20 世纪70 年代中后期,属于内容分析法的一种。
该方法主要统计一组词中两两之间同时出现于一篇文献的次数,以这种“共现”次数反映这些词之间的关联程度,然后借助聚类方法可分析学科的主题结构。
共词分析法的原理可描述为:两个词的“共词强度”(指两个词同时出现于一篇论文中的次数)越高,则这两个词之间的关联越紧密。
事实上,图书情报学领域的学者在运用共词分析法时,多将其中的“词”理解为论文中的关键词,因为一方面关键词具有概括性,是用于概括论文主题的词语;另一方面,关键词的数量一般在3 - 7 个,易于统计。
3数据获取与预处理在CNKI 中检索题名包括“竞争情报”的期刊论文, 检索结果显示共有1898篇相关论文,如果限定时间为“1997-2008”,检索结果显示共有1765篇相关论文。
排除无关键词项论文,下载题录后,建立1425条记录的关键词表。
笔者借助文献计量软件Bibexcel分析关键词词频,并进行共词分析,具体过程如下:(1)使用bibexcel打开数据文件(关键词.txt),特别注意的是,事先要将数据文件进行格式化,如图1所示:(2)在窗口“Frequency distribution”的下拉菜单中选中“Whole string”,并选中“Make new out-file”,以及“Old tag”中填写字段“DE”,单击按钮“Start”,将产生一个后缀名为.oux 的新文件。
Bibexcel在关键词共词矩阵构建中的应用
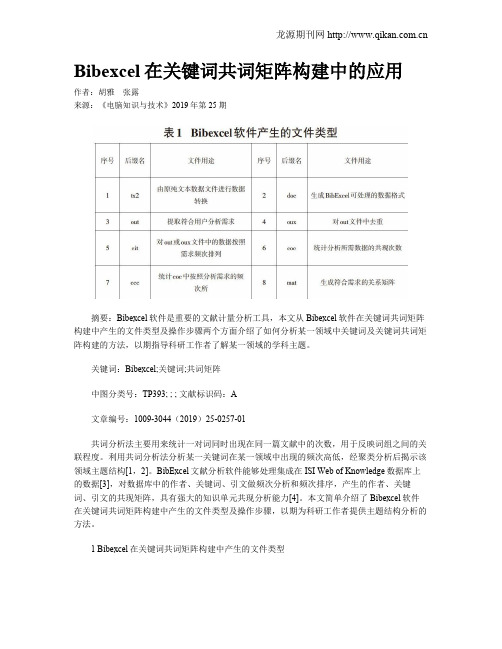
Bibexcel在关键词共词矩阵构建中的应用作者:胡雅张露来源:《电脑知识与技术》2019年第25期摘要:Bibexcel软件是重要的文献计量分析工具,本文从Bibexcel软件在关键词共词矩阵构建中产生的文件类型及操作步骤两个方面介绍了如何分析某一领域中关键词及关键词共词矩阵构建的方法,以期指导科研工作者了解某一领域的学科主题。
关键词:Bibexcel;关键词;共词矩阵中图分类号:TP393; ; ; 文献标识码:A文章编号:1009-3044(2019)25-0257-01共词分析法主要用来统计一对词同时出现在同一篇文献中的次数,用于反映词组之间的关联程度。
利用共词分析法分析某一关键词在某一领域中出现的频次高低,经聚类分析后揭示该领域主题结构[1,2]。
BibExcel文献分析软件能够处理集成在ISI Web of Knowledge数据库上的数据[3],对数据库中的作者、关键词、引文做频次分析和频次排序,产生的作者、关键词、引文的共现矩阵,具有强大的知识单元共现分析能力[4]。
本文简单介绍了Bibexcel软件在关键词共词矩阵构建中产生的文件类型及操作步骤,以期为科研工作者提供主题结构分析的方法。
1 Bibexcel在关键词共词矩阵构建中产生的文件类型利用Bibexcel文献信息统计分析软件进行关键词的抽取、共词矩阵构建以及相异矩阵的转换过程中文件类型如表1所示。
2 Bibexcel在关键词共词矩阵构建中需要的分析步骤2.1 题录导出通过Web of Science数据库的题录信息导出功能,对所有文献信息进行标记,将所有文献记录以Txt格式导出包括标题、作者、摘要、关键词的文献题录信息,每500条记录分成一批进行下载,保留首批数据开头符“FN Clarivate Analytics Web of ScienceVR 1.0”和结束符“EF”,删除其余批次开头符合结束符,将所有批次的txt整合至同一纯文本中。
bibexcel使用说明
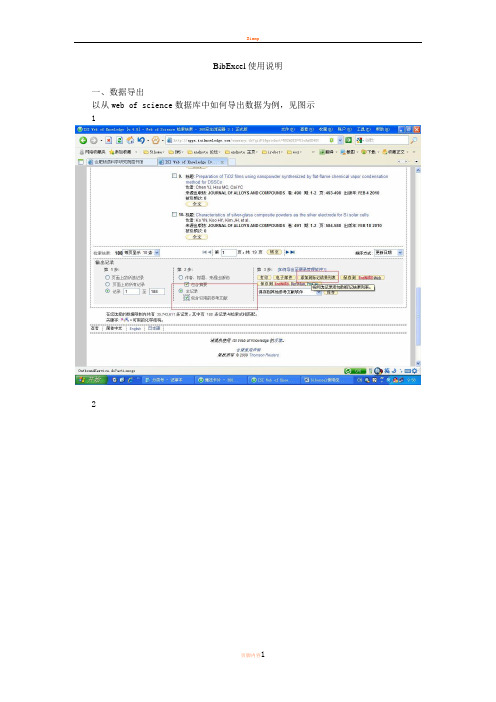
BibExcel使用说明一、数据导出以从web of science数据库中如何导出数据为例,见图示123、导出的纯文本文件一定要放到bibexcel运行程序所在的文件夹中,如下图所示二、准备数据把从Web of science中导出的数据转换成bibexcel需要的格式,步骤如下:1、利用bibexcel的转换功能Edit doc file Replace line feed with carriage returna、选择要转换的.txt文件,被选的文件会变成蓝色背景在这一步转换成了.tx2文件b、选择.tx2文件Misc->convert to dialog format->convert from web of science在这步生成了.doc文件。
这样数据就准备好了。
二、生成.out文件与分析在分析题录文献(bibliographic data)前,首先要生成一个.out文件,换句话说,在你对题录文献中的字段进行分析前,第1步就要生成.out文件。
对哪个字段分析,就生成哪个字段的.out文件。
2.1基本分析例如,如果要分析论文的标题词,可以当作寻找将不同论文联系到一起的关键词,最常用的单词是什么?这个时候,需要抽取出TI-字段的内容,通过选择.doc文件(如前面查看文件时候的步骤)开始,将(TI)标签放到old tag(旧标签)框内(左下角),从中间上部的PREP旁边的下拉菜单选择正确的数据格式(blank separated field to treat each word alone,字段由空格分隔使每一个单词独立计数),然后按下PREP按钮来执行操作。
生成的.out文件,见上图中的红框。
其中的第一列的数字表示来源文献。
通过选择.out文件,来查看在标题中关键词的频次。
用左边中间的窗口中使用“whole string, sort descending, start”生成一个.cit (citation)频次文件。
Bibexcel基础教程

写在前面的话,想学Bibexcel软件同学的福音来啦!本人写这篇文章,仅仅是想帮助那些为了完成课程论文或者毕业论文而需要去进行文献计量分析和引文分析的同学,里面所有内容均是本人一步步操作实验画面,俱是本人呕心沥血奋战几昼夜所做,如有雷同,纯属巧合。
当然,里面也有许多不完善的地方,请敬谅。
下载本文档后,不得用于其他犯罪行为,如若危害其他人利益,与本人无关。
友情提示:尽量不要在网购时打开Bibexcel软件。
——soonfyBibexcel基础教程Bibexcel界面简单介绍Bibexcel软件打开,如图1所示。
图1首先,要注意软件版本,因为不同的版本可能会有不同的界面和不同的功能。
我的版本是【2012-12-05】。
方框1(Select file here):文件位置栏。
选择要去操作的文件或者显示操作后产生的新文件的位置。
方框2(Select field to be analysed):划分方法栏。
后面利用划分方法截取某个字段的内容时会用到这个部分,展开如图2所示。
图2CR表示参考文献,Any表示按;(分号)划分整个字段,JN表示期刊,Blank表示按空格划分整个字段,Whole表示不进行具体的划分,整个字段是一个整体单元。
方框3(The Box):状态栏。
表示正在操作的状态或者最后操作的结果。
方框4(The List):列表框栏。
显示操作最后的执行结果。
方框5(Frequency distribution):频数分布栏。
后面进行某一字段的具体分析时会用到这个部分,其中复选框,Sort表示降序排列,Remove 表示去重,Make表示输出一个新的out文件,Fractionalize表示用频率表示,下拉菜单展开如图3所示。
图3里面具体划分为很多字段,如所有字段、被引文献字段、被引作者字段、被引年字段、被引期刊字段等等,这里不再一一说明。
方框6(Old Tag):标签栏。
后面产生具体某一字段的out文件时会用到这个部分,也可以在转换文件格式时产生的doc文件中查看所有的标签,如TI、AU、CD、DE、LA、DT、AF等等。
bibexcel使用步骤

检索词:人工智能(artificial intelligence)在web of science上面使用人工智能检索词,限定主题检索,时间范围从1950-2017年,得到了上万条结果,所以我以被引量降序排列为条件,选取了前450篇文献,下载在本地文件夹中。
1.导入savedrecs.txt文件2. 将.txt文件转成.tx2文件,点选.txt文件,使其变为蓝底,选择在“Edit doc file”栏下的“Replace line feed with carriage return”选项,选择“确定”选项、选择“是”选项、选择“是”选项。
得到如下图3. 将.tx2文件转成.doc文件,点选该.tx2文件,使其会变为蓝底,选择在“Misc”栏下的“Convent to Dialog format”选项卡下面的“Convent from Web of Science”选项,选择“确定”选项。
得到如下图选择作者(author)4. 选择作者(author)进行频次分析,在Old Tag中输入au(不区分大小写),在中选择Any;separated field 划分方式,点击Prep。
得到如下图5.重命名,为防止文件名相同的话被覆盖,在“Type new file name here”下面的文本框中输入“author”,选择“file”选项卡下面的“Renamefile”,选择“确定”选项,即可重命名。
如下图所示分析:得到的两列结果,第二列代表文献作者,第一列代表文献作者出现次数(升序排列),第一列中有相同数字的,如:2、6、9等,这代表这些作者出现在同一篇文献,比如出现两次2,说明有2个作者写了在“第2篇”文献。
6. 对含有作者(au)的out文件分析,先点选需要转换的out文件,使其out文件变为蓝底,再在中选择“Whole string”,然后再勾选“Sort descending”表示对结果进行降序排列,最后点击“Start”。
应用BICOMB2处理EXCEL数据软件生成共现矩阵案例

应用BICOMB2处理EXCEL数据软件生成共现矩阵案例东北农业大学翟洪江最近做了一个关于文件计量的研究。
由于本人没有任何基础,所以做起来比较难。
在网上收集了很多资料,发现崔雷老师的BICOMB2软件很适合我的研究。
第一,这个软件针对于中文数据制作,我的数据主要来自于cnki;第二,我已经将所以论文的数据导入到EXCEL之中,这个软件对格式的自定义功能可以让我处理这些数据,不必在从cnki 上重新下数据。
由于本人没有学习过文献计量学的软件,所有用起来比较难,尽管有崔雷老师的指导,但是仍然做了很多次试验才操作成功。
为了让如我这样笨的菜鸟少走弯路,我写下这个案例,供大家参考。
本案例只适合于没有任何文献计量学基础的人使用。
我的文件结构如下图(案例中文献是我在cnki中主题,输入“文献计量学”,被引前150的文章)。
我要做的是作者的共现分析。
由于BICOMB不支持EXCEL格式(好像所有的文献计量学软件都不支持),我们要把它转化成TXT文件,但直接另存为txt文件可不可以呢?答案是否定的。
在转化之前我们要制作节点。
要制作两个节点:一个是文章节点,它要使软件能区分哪些作者是一个文章出现的;一个是字段节点,抽取作者字段从哪里开始。
单独将作者这一列加入到新的表中,在前面加一列,写上抽取字段节点字符,似乎写什么字符都可以,我是按照cnki里面给的代表作者的字符写的。
下一步制作文章节点。
稍微有些复杂。
在c列输入2、4、6、8……等差数列,在d 列输入1、3、5、7……等差数列,在E列输入文章节点字符,我输入的字符就是“文章节点”。
(c、d、e列输入比较简单,只输入前两行,然后点住单元格右下角“黑方点”双机即可。
但也不排除有人不会用EXCEL)将d列和e列整体选中,剪切,将d列数字与c列数字相接。
然后以c列为主要关键字进行排序。
排列完如下图。
C列和d列换一下。
在e列插入函数=CONCATENATE(A1,B1,C1,),这个函数是将所选单元格中的字符串合并,可以学习一下这个函数的相关说明。
Bibexcel基础教程
写在前面的话,想学Bibexcel软件同学的福音来啦!本人写这篇文章,仅仅是想帮助那些为了完成课程论文或者毕业论文而需要去进行文献计量分析和引文分析的同学,里面所有内容均是本人一步步操作实验画面,俱是本人呕心沥血奋战几昼夜所做,如有雷同,纯属巧合。
当然,里面也有许多不完善的地方,请敬谅。
下载本文档后,不得用于其他犯罪行为,如若危害其他人利益,与本人无关。
友情提示:尽量不要在网购时打开Bibexcel软件。
——soonfyBibexcel基础教程Bibexcel界面简单介绍Bibexcel软件打开,如图1所示。
图1首先,要注意软件版本,因为不同的版本可能会有不同的界面和不同的功能。
我的版本是【2012-12-05】。
方框1(Select file here):文件位置栏。
选择要去操作的文件或者显示操作后产生的新文件的位置。
方框2(Select field to be analysed):划分方法栏。
后面利用划分方法截取某个字段的内容时会用到这个部分,展开如图2所示。
图2CR表示参考文献,Any表示按;(分号)划分整个字段,JN表示期刊,Blank表示按空格划分整个字段,Whole表示不进行具体的划分,整个字段是一个整体单元。
方框3(The Box):状态栏。
表示正在操作的状态或者最后操作的结果。
方框4(The List):列表框栏。
显示操作最后的执行结果。
方框5(Frequency distribution):频数分布栏。
后面进行某一字段的具体分析时会用到这个部分,其中复选框,Sort表示降序排列,Remove 表示去重,Make表示输出一个新的out文件,Fractionalize表示用频率表示,下拉菜单展开如图3所示。
图3里面具体划分为很多字段,如所有字段、被引文献字段、被引作者字段、被引年字段、被引期刊字段等等,这里不再一一说明。
方框6(Old Tag):标签栏。
后面产生具体某一字段的out文件时会用到这个部分,也可以在转换文件格式时产生的doc文件中查看所有的标签,如TI、AU、CD、DE、LA、DT、AF等等。
excel中数据转换矩阵

excel中数据转换矩阵
Excel中的数据转换矩阵指的是将数据表格中的行列转换,将原本的行变成列,将原本的列变成行,从而使数据更加清晰易读的一种操作。
这种转换可以通过Excel中的转置功能来实现,具体步骤如下:
1. 选中需要进行转换的数据区域。
2. 在“剪贴板”选项卡中,点击“转置”按钮。
3. 在弹出的“转置”对话框中,选择需要转换的数据的位置,即选择“将列转换为行”或“将行转换为列”。
4. 点击“确定”按钮,转换完成。
需要注意的是,在进行数据转换矩阵的操作时,需要保证数据的格式清晰、整齐,并且数据中不应该有合并的单元格或空白行列等情况,否则可能会导致数据转换后的结果不准确或出现错误。
- 1 -。
bibexcel软件详细使用说明

Bibexcel软件使用说明Bibexcel软件是Olle Persson开发的一款文献计量学工具。
在Bibexcel软件中,用户可以完成大多数文献计量学分析工作,并且Bibexcel软件可以很方便地与其他软件进行数据交换,如:Pajek,Excel和SPSS等。
本使用说明共分为四个部分:第一部分描述如何重构从Web of Science下载的数据;第二部分介绍OUT文献,Bibexcel软件需要生成几种类型的文件,每一个处理过程将产生一个文件,OUT文件是最先生成的,它是分析的开始点;第三部分描述Bibexcel软件的基本分析功能;最后介绍如何导出数据,以便利用Pajek软件进行可视化。
第一部分如何准备和导入数据重构Web of Science数据需要两个步骤:第一步在从Web of Science下载的纯文本文件中插入回车符。
在文件管理系统“Select file here”,然后从菜单条选择:Edit doc file-->Replace line feed with carriage return这个过程将生成*.tx2文件。
第二步将文件转换为Dialog格式。
从菜单条选择:Misc-->Convert to dialog format-->Convert from Web of Science这个过程将生成*.doc文件。
第二部分创建OUT文件和计算频率分布在完成上述格式转换后,我们就可以创建OUT文件了。
创建OUT文件是我们使用Bibexcel 软件进行文献计量学分析的第一步。
当我们创建OUT文件时,我们首先需要确定使用书目记录中的哪一个字段来创建OUT文件,也就是选择将要分析的字段(标识符)。
第一步在文件管理系统中选择DOC文件;第二步在“Old tag”文本框中键入字段标识符,如AU、DE等。
第三步在“Select field to be analysed”下拉框中,选择识别字段内容的操作,如“Any;separated field”等。
将excel数据转换为共现矩阵的方法

很高兴接到您的委托,让我来帮您撰写关于将excel数据转换为共现矩阵的方法的文章。
这是一个非常实用的技能,特别是在数据分析和统计领域中。
我将按照您的要求,从浅入深地探讨这个主题,希望能够帮助您更全面、深入地理解这一方法。
1. 什么是共现矩阵?共现矩阵是一种用来表示两个或多个变量之间共同出现的情况的数据结构。
在数据分析中,共现矩阵通常用来分析文本、标签、标签-用户关系等数据,以便进一步分析它们之间的关联性和联系度。
在统计学中,共现矩阵也被广泛应用于协同过滤、社交网络分析、关联规则挖掘等领域。
2. Excel中数据转换为共现矩阵的基本步骤在Excel中,将数据转换为共现矩阵通常需要以下基本步骤:步骤一:准备原始数据需要准备原始数据。
原始数据可以是文本数据、标签数据,或者其他可以展现关联性的数据。
这些数据可以是一份文档、一张表格或者一个数据库文件。
步骤二:数据清洗和整理接下来,需要对原始数据进行清洗和整理。
这包括去除重复数据、处理缺失值、进行格式规范化等操作。
在Excel中,可以通过筛选、排序、去重等功能来完成这些操作。
步骤三:构建共现矩阵一般来说,共现矩阵是一个二维的矩阵,行和列分别代表变量,每个元素表示对应变量之间的共现次数。
在Excel中,可以利用函数和透视表来实现共现矩阵的构建。
需要创建一个新的工作表或者区域用来存放共现矩阵。
使用COUNTIF等函数来计算变量之间的共现次数,并填入对应的位置。
步骤四:数据分析和可视化可以对共现矩阵进行数据分析和可视化。
可以使用Excel自带的图表功能,比如热力图、散点图等来展现变量之间的关系。
还可以利用Excel中的数据透视表、数据透视图等功能进行更深入的数据分析和挖掘。
3. 我对将excel数据转换为共现矩阵的个人理解将excel数据转换为共现矩阵是一项非常有用的技能。
通过共现矩阵,我们可以更直观地了解变量之间的关系,帮助我们更好地进行数据分析和挖掘。
在实际应用中,我发现在处理大量文本数据时,将其转换为共现矩阵可以帮助我更好地理解文本之间的关联性,进而进行更深入的文本分析和挖掘。
将国标参考文献转换成bib文件

将国标参考文献转换成bib文件如今,学术论文的撰写已经成为了学术研究的一项必须工作,而在这个过程中“文献综述”是不可或缺的一环。
而在文献综述中所引用的参考文献则是引用规范和标准的,因此我们需要将国家规定的参考文献格式转换成能够被Latex识别的Bib文件格式。
今天,我们就来为大家介绍一下如何将国标参考文献转换成bib文件。
第一步:获取转换工具虽然我们可以通过手动输入来将参考文献转换成bib文件,但这样的工作量非常大,耗费时间和精力。
因此,我们建议您使用专门的工具来完成这项工作。
这里,我们推荐JabRef和EndNote这两种工具,它们都提供了转换工具,可以让您将参考文献快速有效地转换成bib文件。
第二步:下载文献内容在进行格式转换之前,您需要先找到需要转换的参考文献。
学术文献可以通过学校的图书馆网站、Cnki、Web of Science等数据库进行搜索和下载,但这些文献的格式并不是bib格式。
在这里,我们选择到知网上面查找一篇文献为例进行说明。
第三步:将参考文献内容粘贴到转换工具中现在,您需要将下载的文献复制并粘贴到您选择的转换工具中。
以JabRef为例,打开JabRef,从编辑-》导入-》从剪贴板导入,即可将文献中的内容粘贴到JabRef中。
第四步:开始转换当文献被成功导入到转换器中后,您还需要对文献进行一些调整,以使其满足bib文件的格式要求。
因为各种工具的操作界面可能不太一样,这里我依然以JabRef这个工具为例进行说明。
通常我们需要注意以下几点:1. 检查文献的作者是否按照规范格式排序,并且每个作者之间用“and”分隔,而不是逗号分隔。
2. 检查文献中的顿号是否已经转换成了英文的逗号。
3. 检查文章题目是应该在引号内还是应该使用斜体。
4. 检查数字和符号的使用是否正确。
在所有的调整后,您只要点击导出bib文件,即可将文献成功转换成bib格式的文件。
您可以将此文件直接导入到您的Latex文档中,以便系统自动管理和引用参考文献。
CSSCI 数据导入Bibexcel 实现共现矩阵的方法及实证研究

CSSCI数据导入Bibexcel实现共现矩阵的方法及实证研究姜春林陈玉光(大连理工大学21世纪发展研究中心辽宁大连 116024)摘要:本文以针对Web of Knowledge开发的文献信息共现分析的应用软件——Bibexcel为研究对象,结合CSSCI数据库数据格式特点,解决了Bibexcel不能处理中文文献的瓶颈问题,实现了知识单元共现关系矩阵。
并以CSSCI数据库中1998—2008年“信息可视化”引文数据为例,数据经过预处理后,由Bibexcel 构建其知识单元共现矩阵,利用Ucinet、Netdraw软件,实现了作者共现、关键词共现、引文共现的可视化分析。
本研究扩展了Bibexcel的应用范围功能,为CSSCI数据的可视化研究提供了一种新的手段。
关键词:Bibexcel、CSSCI、共现矩阵、知识图谱、可视化Transform CSSCI Data to Bibexcel data to Actualize Co-occurrence Matrix and A Case StudyJIANG Chun-lin, CHEN Yu-guang(Center of the 21st Century Development and Research, Dalian University of Technology, Dalian 116024)Abstract:This paper researchs on Bibexcel that developed for the co-occurrence analysis of literature information that come from Web of Knowledge, and combined with the characteristics of data formats in the CSSCI database, to resolve the bottleneck of co-occurrence of Chinese literature information which Bibexcel can not handle by itself. We actualized the co-occurrence matrix of knowledge unit relations. CSSCI database in 1998-2008 "Information Visualization" Citation data as an example, after data preprocessing, the knowledge unit co-occurrence matrix built by Bibexcel,then we use Ucinet, Netdraw softwares,to actualizes the authors cooperative network analysis、keywords cooccurrence analysis and cocitation analysis. This study extends the scope of application of Bibexcel, and provides a new means of visualization for CSSCI data.Keywords:Bibexcel、CSSCI、Co-occurrence matrix、Knowledge map、visualization1.引言科技文献数据量的快速增长给我们的研究工作带来了极大便利,同时,文献数量的增长,也给文献的管理与分析利用带来了诸多的不便[1]。
如何使用大数据分析BI工具FineBI进行行列转换

如何使用大数据分析BI工具FineBI进行行列转换1. 描述FineBI中的行列转换特指将关系数据表中的行转换为列,简单来说就是将转化前数据表中某个字段的所有值取出来,配以某个指标字段,成为新表的列名。
很多时候用户也会从不规范的数据源中提取数据到CUBE中,比如将EXCEL文件导入。
而excel文件的字段和展示样式并不固定,往往会与规范化的数据库表数据不能很好的兼容合并,导入excel后就有可能用到行列转换,将很多行展示数据转化为规范的列字段进行分析。
2. 示例如下图所示的excel表格保存了学生成绩,每个学生都有3门课程的成绩,如果导入excel 存储到数据库后每人占据3条记录,但是正常的学生信息表的话,每个学生只有一条记录:那么如何使每位学生的成绩只占据一条记录呢,也就是说,将不同学科的值作为字段名,实现如下图效果:2.1 源数据表ETL转换表需要基于一个原始表,我们需要将此excel导入到BIDemo业务包中。
导入后可以打开该excel数据集进行查看。
如图所示就是打开的数据集:注:由于是新导入的excel数据集,需要生成cube之后,才能进行行列转化。
2.2 ETL行列转化被转化的表添加完成之后,点击右侧ETL处理中间的表名称按钮,进入行列转化配置界面,如下图:根据字段识别生成的指标所在列:是指数据表中根据需要转化的字段值重复的字段,如上示例,姓名就根据“需要被转化字段-科目”的值重复出现(即因为有多个科目的成绩导致每个人重复出现),那么该下拉框中的字段可以选择姓名,该选项可以选择最终显示时需要唯一值的字段栏次名:是指需要被转化的行字段名称,如上示例,是指科目字段;原始指标字段:是指原始数据表中包含的字段都会出现生成的指标字段:是指被转化字段所对应的值字段,如上示例,是指每个科目的成绩字段值,那么可以添加为科目种类-成绩的关系。
设置完成后,效果如下图:点击保存直到回到表设置页面。
注:如果要更改ETL转化表的结构设置,点击右侧ETL处理中的行列转化即可。
编程实现BIP、BSQ、BIL三种格式转换详解

编程实现BIP、BSQ、BIL三种格式转换一、实验目的理解遥感图像BIP、BIL、BSQ三种格式数据的组织方式,以及它们互相转换原理和方法。
二、实验原理ENVI栅格图像文件,是以字节数据为单位,再按照指定顺序组织、排列而成,具体有如下三种方式:1.BIP(像元波段交叉式):以一对像元为基本单位进行记录;2.BIL(波段按行交叉格式):按照扫描行为单位各波段同一扫描行数据依次记录,图像按顺序第一个像元所有的波段,接着是第二个像元的所有波段,然后是第三个像元的所有波段,等等,直到像元总数为止;3.BSQ(波段顺序格式):以波段为单位,每波段所有扫描行依次记录, 每行数据后面紧接着同一波谱波段的下一行数据。
所以实现三种格式的转换,实际上是对图像字节进行重新排序。
三、实验思路获取图像相关信息(可通过读取头文件)根据图像格式读取字节数据对获取的字节数据按照目标文件格式顺序写入、保存四、实验步骤1.新建项目文件:本实验选用的语言是C#,开发工具是VisualStudio2010,通过“文件—新建—项目—C#—Windows窗体应用程序”,命名“格式转换”即可;2.编写代码:通过实验思路的流程图,我们确定代码也应该分这三个功能来写,对应可以组织为三个大方法,再细分,调用即可。
(1).编写读取头文件代码:ENVI中栅格图像被分为两个文件存储,一个“.HDR”头文件和一个数据文件,头文件存储了图像描述信息,它是一个文本文件,我们可以用System.IO.SreamReader字符读取流按行读取,再用字符串匹配方法,以读取字段的方式获取图像的行数、列数、波段数、基本数据类型,即可,具体代码可见后文代码附录;(2).编写数据读取数据文件代码:图像数据组织方式有BIP、BIL、BSQ三种,那么对应的也应该有三个方法按照行、列、波段交叉顺序对图像字节数据进行读取,具体代码见后文;(3).编写字节数据重排列存储代码:在读取了图像数据文件后,可以通过FileStream类按照目标类型格式文件组织顺序,把字节数据写入到文件中保存即可,具体代码见后文。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
怎样把数据转化成bibexcel识别的格式
构造共现矩阵
Step1:把数据保存成txt格式,格式如下:
AU-卫郭敏|
AU-刘高岑|
AU-郭金明;杨起全|
AU-李怡娜;叶飞|
AU-王元地;刘凤朝;潘雄锋|
AU-陶长琪;齐亚伟|
AU-李瑶;刘婷;薛佳奇|
AU-张旭梅;陈伟|
AU-裴云龙;蔡虹;向希尧|
Step2:选中.txt文件,点击View file按钮,The list窗口就会显示这个文件的内容。
根据你要分析的知识单元,在Old Tag中填写相应的标签代号。
作者、关键词、机构、参考文献、被引期刊的标签依次为AU、DE、C1、CD、CD。
输入相应的标签后,在Select field to be analysed 下拉列表框中选择“Any;separated field”;如果要分析被引期刊,在输入CD标签后,在Select field to be analysed下拉列表框中选择“JN-Journal”,然后点Prep按钮,在弹出的对话框中,点击“确定”,生成后缀名为.out文件;
Step3:选中.out,在Frequency distribution下拉列表框中选择相应的分析对象,如果分析作者共现,选择“Author”;如果分析关键词共现,选择“whole string”;如果分析机构共现,选择“whole string”;如果分析参考文献共现,选中“Cited Reference”;如果分析被引期刊共现,选择“whole string”;选择相应的分析单元后,在下面的复选框中选择“Sorted descending”,点击Start按钮,在弹出的窗口中,点击“确定”,生成后缀名为.cit文件;
Step4:选中.out文件,在Frequency distribution下面的复选框中选择“remove duplicate”和“make new out-file”,点击Start按钮,在弹出的窗口中,点击“确定”,生成后缀名为.oux文件;
Step5:选中.cit文件,点击“view file”,在The List显示窗口中选择频次较高的前多少位分析对象,然后点击“Analyze----co-occurrence----select units via listbox”,然后选中.oux文件,点击“Analyze----co-occurrence----make pairs via listbox”,在弹出的窗口中,点击“否”,此时生成后缀名为.coc文件;
Step6:选中.cit文件,同样点击“view file”,在The List显示窗口中选择频次较高的前多少位分析对象,然后点击“Analyze----co-occurrence----select units via listbox”,然后选中.coc文
件,点击“Analyze----make a matrix for MDS etc”,在弹出的对话框中,按照提示,点“是”还是“否”,选择生成方阵还是下三角矩阵,生成的共现矩阵文件名为.ma2,将其打开,另存为后缀名为.xls文件。