python+xpath笔记
xpath 常用语法

xpath 常用语法一、XPath简介XPath是一种用于在XML文档中定位节点的语言。
它是一种基于路径表达式的查询语言,可以通过节点名称、属性、位置等信息来查找XML文档中的节点。
二、XPath语法1. 节点选择器- 通配符:使用星号(*)表示选择所有节点。
- 元素节点:使用元素名称选择节点。
- 属性节点:使用[@属性名]选择节点。
- 文本节点:使用text()选择节点。
2. 路径表达式- 相对路径:使用斜杠(/)表示从根节点开始的路径。
- 绝对路径:使用双斜杠(//)表示不考虑节点位置的路径。
- 父节点:使用双点(..)表示选取当前节点的父节点。
- 子节点:使用斜杠(/)表示选取当前节点的子节点。
- 兄弟节点:使用斜杠加节点名称(/节点名称)表示选取当前节点的同级节点。
3. 谓语- 谓语是用来过滤节点的条件表达式,可以在节点选择器后面使用方括号([])来添加谓语。
- 谓语可以使用比较运算符(=、!=、<、>等)和逻辑运算符(and、or)进行条件判断。
4. 逻辑运算符- and:逻辑与运算符,表示同时满足两个条件。
- or:逻辑或运算符,表示满足其中一个条件。
- not:逻辑非运算符,表示不满足条件。
5. 数字函数- count():返回指定节点集合的节点数量。
- sum():计算指定节点集合的数值之和。
- avg():计算指定节点集合的数值平均值。
- min():返回指定节点集合的最小值。
- max():返回指定节点集合的最大值。
6. 字符串函数- concat():连接两个字符串。
- contains():判断一个字符串是否包含另一个字符串。
- starts-with():判断一个字符串是否以另一个字符串开头。
- ends-with():判断一个字符串是否以另一个字符串结尾。
- substring():截取字符串的一部分。
- string-length():返回字符串的长度。
XPath语法参考

XPath语法参考XPath语法参考收藏之所以要引入XPath的概念,目的就是为了在匹配XML文档结构树时能够准确地找到某一个节点元素。
可以把XPath比作文件管理路径:通过文件管理路径,可以按照一定的规则查找到所需要的文件;同样,依据XPath所制定的规则,也可以很方便地找到XML结构文档树中的任何一个节点.不过,由于XPath可应用于不止一个的标准,因此W3C将其独立出来作为XSLT的配套标准颁布,它是XSLT以及我们后面要讲到的XPointer的重要组成部分。
在介绍XPath的匹配规则之前,我们先来看一些有关XPath的基本概念。
首先要说的是XPath数据类型。
XPath可分为四种数据类型:节点集(node-set)节点集是通过路径匹配返回的符合条件的一组节点的集合。
其它类型的数据不能转换为节点集。
布尔值(boolean)由函数或布尔表达式返回的条件匹配值,与一般语言中的布尔值相同,有true和false两个值。
布尔值可以和数值类型、字符串类型相互转换。
字符串(string)字符串即包含一系列字符的集合,XPath中提供了一系列的字符串函数。
字符串可与数值类型、布尔值类型的数据相互转换。
数值(number)在XPath中数值为浮点数,可以是双精度64位浮点数。
另外包括一些数值的特殊描述,如非数值NaN(Not-a-Number)、正无穷大infinity、负无穷大-infinity、正负0等等。
number的整数值可以通过函数取得,另外,数值也可以和布尔类型、字符串类型相互转换。
其中后三种数据类型与其它编程语言中相应的数据类型差不多,只是第一种数据类型是XML文档树的特有产物。
另外,由于XPath包含的是对文档结构树的一系列操作,因此搞清楚XPath节点类型也是很必要的。
回忆一下第二章中讲到的XML文档的逻辑结构,一个XML文件可以包含元素、CDATA、注释、处理指令等逻辑要素,其中元素还可以包含属性,并可以利用属性来定义命名空间。
Python爬虫学习总结-爬取某素材网图片
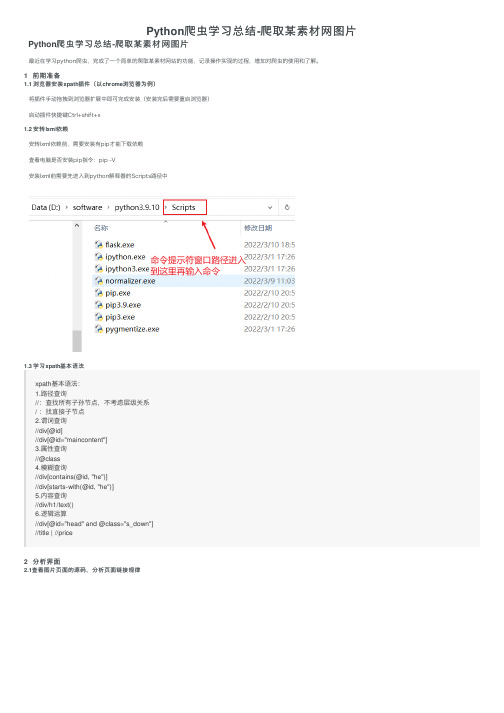
Python爬⾍学习总结-爬取某素材⽹图⽚ Python爬⾍学习总结-爬取某素材⽹图⽚最近在学习python爬⾍,完成了⼀个简单的爬取某素材⽹站的功能,记录操作实现的过程,增加对爬⾍的使⽤和了解。
1 前期准备1.1 浏览器安装xpath插件(以chrome浏览器为例)将插件⼿动拖拽到浏览器扩展中即可完成安装(安装完后需要重启浏览器)启动插件快捷键Ctrl+shift+x1.2 安转lxml依赖安转lxml依赖前,需要安装有pip才能下载依赖查看电脑是否安装pip指令:pip -V安装lxml前需要先进⼊到python解释器的Scripts路径中1.3 学习xpath基本语法xpath基本语法:1.路径查询//:查找所有⼦孙节点,不考虑层级关系/ :找直接⼦节点2.谓词查询//div[@id]//div[@id="maincontent"]3.属性查询//@class4.模糊查询//div[contains(@id, "he")]//div[starts‐with(@id, "he")]5.内容查询//div/h1/text()6.逻辑运算//div[@id="head" and @class="s_down"]//title | //price2 分析界⾯2.1查看图⽚页⾯的源码,分析页⾯链接规律打开有侧边栏的风景图⽚(以风景图⽚为例,分析⽹页源码)通过分析⽹址可以得到每页⽹址的规律,接下来分析图⽚地址如何获取到2.2 分析如何获取图⽚下载地址⾸先在第⼀页通过F12打开开发者⼯具,找到图⽚在源代码中位置: 通过分析源码可以看到图⽚的下载地址和图⽚的名字,接下来通过xpath解析,获取到图⽚名字和图⽚地址2.3 xpath解析获取图⽚地址和名字调⽤xpath插件得到图⽚名字://div[@id="container"]//img/@alt图⽚下载地址://div[@id="container"]//img/@src2注意:由于该界⾯图⽚的加载⽅式是懒加载,⼀开始获取到的图⽚下载地址才是真正的下载地址也就是src2标签前⾯的⼯作准备好了,接下来就是书写代码3 代码实现3.1 导⼊对应库import urllib.requestfrom lxml import etree3.2 函数书写请求对象的定制def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'# 请求伪装headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }# 请求对象的定制request = urllib.request.Request(url = url_end,headers=headers)# 返回伪装后的请求头return request获取⽹页源码def get_content(request):# 发送请求获取响应数据response = urllib.request.urlopen(request)# 将响应数据保存到contentcontent = response.read().decode('utf8')# 返回响应数据return content下载图⽚到本地def down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')# 解析⽹页tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')# 循环下载图⽚for i in range(len(img_name)):# 挨个获取下载的图⽚名字和地址name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地下载图⽚到当前代码同⼀⽂件夹的imgs⽂件夹中需要先在该代码⽂件夹下创建imgs⽂件夹urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')主函数if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)完整代码# 1.请求对象的定制# 2.获取⽹页源码# 3.下载# 需求:下载前⼗页的图⽚# 第⼀页:https:///tupian/touxiangtupian.html# 第⼆页:https:///tupian/touxiangtupian_2.html# 第三页:https:///tupian/touxiangtupian_3.html# 第n页:https:///tupian/touxiangtupian_page.htmlimport urllib.requestfrom lxml import etree# 站长素材图⽚爬取下载器def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }request = urllib.request.Request(url = url_end,headers=headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf8')return contentdef down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(img_name)):name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)4 运⾏结果总结此次案例是基于尚硅⾕的python视频学习后的总结,感兴趣的可以去看全套视频,⼈们总说兴趣是最好的⽼师,⾃从接触爬⾍后我觉得python⼗分有趣,这也是我学习的动⼒,通过对⼀次案例的简单总结,回顾已经学习的知识,并不断学习新知识,是记录也是分享。
python xpath写法

Python xpath写法一、概述XPath(XML Path Language)是一门在 XML 文档中查找信息的语言,可以用来在 XML 文档中对元素和属性进行定位。
在 Python 中,使用 XPath 可以很方便地对 XML 或 HTML 文档进行解析和提取信息。
本文将介绍 Python 中使用 XPath 的写法,帮助读者更好地理解和应用这一技术。
二、导入相关库在使用 Python 进行 XPath 解析之前,需要导入相关的库。
通常情况下,我们会使用lxml 库进行XPath 解析。
在代码中需要先导入该库。
``` pythonfrom lxml import etree```三、XPath 基本写法在使用 Python 进行 XPath 解析时,需要掌握一些基本的写法规则。
下面将介绍几种常用的 XPath 写法。
1. 选取节点要选取节点,可以使用路径表达式。
路径表达式(Path Expression)用于选取 XML 文档中的节点或者节点集。
要选取 XML 文档中的所有<book> 节点,可以使用以下写法:``` pythonxpath = '//book'```2. 选取子节点如果要选取某个节点的子节点,可以使用斜杠(/)。
要选取 XML 文档中 <book> 节点的所有 <title> 子节点,可以使用以下写法:``` pythonxpath = '//book/title'```3. 选取父节点要选取某个节点的父节点,可以使用两个点(..)。
要选取 <title> 节点的父节点 <book>,可以使用以下写法:``` pythonxpath = '//title/..'```4. 选取指定属性的节点如果要选取具有指定属性的节点,可以使用方括号。
要选取所有带有category 属性的 <book> 节点,可以使用以下写法:``` pythonxpath = '//book[category]'```5. 选取指定条件的节点XPath 还支持使用谓语(Predicates)来选取满足指定条件的节点。
python xpath matches使用方法

python xpath matches使用方法在Python中,可以使用lxml库来解析和操作XML文档,并使用XPath语法进行节点定位和匹配。
下面是使用Python中的lxml库的XPath的基本用法:```pythonfrom lxml import etree# 创建XML文档树xml = '<root><foo>hello</foo><bar>world</bar></root>'tree = etree.XML(xml)# 使用XPath选择节点result = tree.xpath('//foo') # 选择所有名称为"foo"的节点print(result) # 输出: [<Element foo at 0x7f4179f63cc8>]# 获取节点的文本内容text = result[0].textprint(text) # 输出: hello# 使用XPath选择多个节点result = tree.xpath('//foo | //bar') # 选择名称为"foo"的节点和名称为"bar"的节点print(result) # 输出: [<Element foo at 0x7f4179f63cc8>,<Element bar at 0x7f417b9e7b08>]# 使用属性进行节点选择result = tree.xpath('//foo[@attr="value"]') # 选择名称为"foo"且具有attr属性值为"value"的节点print(result) # 输出: []# 使用通配符选择节点result = tree.xpath('//*[@attr="value"]') # 选择具有attr属性值为"value"的任意节点print(result) # 输出: []# 获取节点的父节点parent = result[0].getparent()print(parent.tag) # 输出: root```这只是XPath在Python中的基本使用方法,可以根据具体的需求来进行更复杂和灵活的节点选择和操作。
python笔记知识点总结

python笔记知识点总结一、Python基础知识1. Python语法Python的语法非常简洁和易读,它的代码块通过缩进来表示,通常使用四个空格缩进,而不是制表符。
此外,Python没有分号来表示语句的结束,而是通过换行来分隔不同的语句。
这种简洁的语法使得Python代码更具可读性和易维护性。
2. 变量和数据类型Python中的变量不需要声明,可以直接赋值使用。
Python有多种内置的数据类型,包括整数、浮点数、字符串、列表、元组、字典等。
另外,Python还支持动态类型,即变量的数据类型可以随时改变。
3. 控制流Python支持条件语句(if-else)、循环语句(for和while)、跳出语句(break和continue)等控制流结构。
这些结构可以帮助你更好地控制程序的执行流程。
4. 函数和模块函数是一种封装了一些代码块的可重用的结构,Python中使用def关键字来定义函数,可以有参数和返回值。
另外,Python中还有很多内置的模块,可以直接使用或者通过import语句引入。
5. 异常处理Python中的异常处理机制可以帮助你更好地处理程序中的错误。
使用try-except语句可以捕获并处理异常,保证程序的稳定性和可靠性。
二、Python高级知识1. 面向对象编程Python是一种面向对象的编程语言,它提供了类、对象、继承、多态等面向对象的特性。
通过使用类和对象,你可以更好地组织和管理程序的代码。
2. 文件操作Python中有丰富的文件操作函数和模块,可以帮助你读写文件和目录、处理文件路径等操作。
3. 正则表达式正则表达式是一种强大的文本匹配工具,Python中的re模块提供了对正则表达式的支持,可以帮助你更好地处理字符串。
4. 网络编程Python有丰富的网络编程库,可以用来构建服务器、客户端、处理HTTP请求等网络应用程序。
5. 数据库操作Python可以连接各种数据库,包括MySQL、PostgreSQL、SQLite等,用于数据存储和管理。
(word完整版)xpath详解总结,很全面

经常在工作中会使用到XPath的相关知识,但每次总会在一些关键的地方不记得或不太清楚,所以免不了每次总要查一些零碎的知识,感觉即很烦又浪费时间,所以对XPath归纳及总结一下。
在这篇文章中你将能学习到:•XPath简介•XPath 路径表达式详解•XPath在DOM,XSLT及XQuery中的应用XPath简介XPath是W3C的一个标准。
它最主要的目的是为了在XML1.0或X ML1.1文档节点树中定位节点所设计。
目前有XPath1.0和XPath2. 0两个版本。
其中Xpath1.0是1999年成为W3C标准,而XPath 2.0标准的确立是在2007年。
W3C关于XPath的英文详细文档请见:/TR/xpath20/。
XPath是一种表达式语言,它的返回值可能是节点,节点集合,原子值,以及节点和原子值的混合等。
XPath2.0是XPath1.0的超集。
它是对XPath1.0的扩展,它可以支持更加丰富的数据类型,并且X Path2.0保持了对XPath1.0的相对很好的向后兼容性,几乎所有的XPath2.0的返回结果都可以和XPath1.0保持一样。
另外XPath2. 0也是XSLT2.0和XQuery1.0的用于查询定位节点的主表达式语言。
XQuery1.0是对XPath2.0的扩展。
关于在XSLT和XQuery中使用XPath表达式定位节点的知识在后面的实例中会有所介绍。
在学习XPath之前你应该对XML的节点,元素,属性,原子值(文本),处理指令,注释,根节点(文档节点),命名空间以及对节点间的关系如:父(Parent),子(Children),兄弟(Sibling),先辈(Ancestor),后代(Descendant)等概念有所了解。
这里不在说明。
XPath路径表达式在本小节下面的内容中你将可以学习到:•路径表达式语法•相对/绝对路径•表达式上下文•谓词(筛选表达式)及轴的概念•运算符及特殊字符•常用表达式实例•函数及说明这里给出一个实例Xml文件。
xpath使用方法

xpath使⽤⽅法⼀、选取节点常⽤的路劲表达式:表达式描述实例nodename选取nodename节点的所有⼦节点xpath(‘//div’)选取了div节点的所有⼦节点/从根节点选取xpath(‘/div’)从根节点上选取div节点//选取所有的当前节点,不考虑他们的位置xpath(‘//div’)选取所有的div节点.选取当前节点xpath(‘./div’)选取当前节点下的div节点..选取当前节点的⽗节点xpath(‘..’)回到上⼀个节点@选取属性xpath(’//@calss’)选取所有的class属性⼆、谓语谓语被嵌在⽅括号内,⽤来查找某个特定的节点或包含某个制定的值的节点实例:表达式结果xpath(‘/body/div[1]’)选取body下的第⼀个div节点xpath(‘/body/div[last()]’)选取body下最后⼀个div节点xpath(‘/body/div[last()-1]’)选取body下倒数第⼆个div节点xpath(‘/body/div[positon()<3]’)选取body下前两个div节点xpath(‘/body/div[@class]’)选取body下带有class属性的div节点xpath(‘/body/div[@class=”main”]’)选取body下class属性为main的div节点xpath(‘/body/div[price>35.00]’)选取body下price元素值⼤于35的div节点三、通配符Xpath通过通配符来选取未知的XML元素表达式结果xpath(’/div/*’)选取div下的所有⼦节点xpath(‘/div[@*]’)选取所有带属性的div节点四、取多个路径使⽤“|”运算符可以选取多个路径表达式结果xpath(‘//div|//table’)选取所有的div和table节点五、Xpath轴轴可以定义相对于当前节点的节点集轴名称表达式描述ancestor xpath(‘./ancestor::*’)选取当前节点的所有先辈节点(⽗、祖⽗)ancestor-or-self xpath(‘./ancestor-or-self::*’)选取当前节点的所有先辈节点以及节点本⾝attribute xpath(‘./attribute::*’)选取当前节点的所有属性child xpath(‘./child::*’)返回当前节点的所有⼦节点descendant xpath(‘./descendant::*’)返回当前节点的所有后代节点(⼦节点、孙节点)following xpath(‘./following::*’)选取⽂档中当前节点结束标签后的所有节点following-sibing xpath(‘./following-sibing::*’)选取当前节点之后的兄弟节点parent xpath(‘./parent::*’)选取当前节点的⽗节点preceding xpath(‘./preceding::*’)选取⽂档中当前节点开始标签前的所有节点preceding-sibling xpath(‘./preceding-sibling::*’)选取当前节点之前的兄弟节点self xpath(‘./self::*’)选取当前节点self xpath(‘./self::*’)选取当前节点六、功能函数使⽤功能函数能够更好的进⾏模糊搜索函数⽤法解释starts-with xpath(‘//div[starts-with(@id,”ma”)]‘)选取id值以ma开头的div节点contains xpath(‘//div[contains(@id,”ma”)]‘)选取id值包含ma的div节点and xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘)选取id值包含ma和in的div节点text()xpath(‘//div[contains(text(),”ma”)]‘)选取节点⽂本包含ma的div节点。
Python3xml.etree.ElementTree支持的XPath语法详解

Python3xml.etree.ElementTree⽀持的XPath语法详解xml.etree.ElementTree可以通过⽀持的有限的XPath表达式来定位元素。
语法ElementTree⽀持的语法如下:语法说明tag查找所有具有指定名称tag的⼦元素。
例如:country表⽰所有名为country的元素,country/rank表⽰所有名为country的元素下名为rank的元素。
*查找所有元素。
如:*/rank表⽰所有名为rank的孙⼦元素。
.选择当前元素。
在xpath表达式开头使⽤,表⽰相对路径。
//选择当前元素下所有级别的所有⼦元素。
xpath不能以“//”开头。
..选择⽗元素。
如果视图达到起始元素的祖先,则返回None(或空列表)。
起始元素为调⽤find(或findall)的元素。
[@attrib]选择具有指定属性attrib的所有⼦元素。
[@attrib='value']选择指定属性attrib具有指定值value的元素,该值不能包含引号。
[tag]选择所有具有名为tag的⼦元素的元素。
[.='text']Python3.7+,选择元素(或其⼦元素)完整⽂本内容为指定的值text的元素。
[tag='text']选择元素(或其⼦元素)名为tag,完整⽂本内容为指定的值text的元素。
[position]选择位于给定位置的所有元素,position可以是以1为起始的整数、表达式last()或相对于最后⼀个位置的位置(如:last()-1)⽅括号表达式前⾯必须有标签名、星号或者其他⽅括号表达式。
position前必须有⼀个标签名。
简单⽰例#!/usr/bin/python# -*- coding:utf-8 -*-import osimport xml.etree.cElementTree as ETxml_string="""<?xml version="1.0"?><data><country name="Liechtenstein"><rank updated="yes">2</rank><year>2008</year><gdppc>141100</gdppc><neighbor name="Austria" direction="E"/><neighbor name="Switzerland" direction="W"/></country><country name="Singapore"><rank updated="yes">5</rank><year>2011</year><gdppc>59900</gdppc><neighbor name="Malaysia" direction="N"/></country><country name="Panama"><rank updated="yes">69</rank><year>2011</year><gdppc>2011</gdppc><neighbor name="Costa Rica" direction="W"/><neighbor name="Colombia" direction="E"/></country><country name="Washington"><rank updated="yes">55</rank><gdppc>13600</gdppc></country></data>"""root=ET.fromstring(xml_string)#查找data下所有名为country的元素for country in root.findall("country"):print("name:"+country.get("name"))#查找country下所有名为year的元素year=country.find("./year")if year:print("year:"+year.text)#查找名为neighbor的孙⼦元素for neighbor in root.findall("*/neighbor"):print("neighbor:"+neighbor.get("name"))#查找country下的所有⼦元素for ele in root.findall("country//"):print(ele.tag)#查找当前元素的⽗元素,结果为空print(root.findall(".."))#查找与名为rank的孙⼦元素同级的名为gdppc的元素for gdppc in root.findall("*/rank/../gdppc"):print("gdppc:"+gdppc.text)#查找data下所有具有name属性的⼦元素for country in root.findall("*[@name]"):print(country.get("name"))#查找neighbor下所有具有name属性的⼦元素for neighbor in root.findall("country/*[@name]"):print(neighbor.get("name"))#查找country下name属性值为Malaysia的⼦元素print("direction:"+root.find("country/*[@name='Malaysia']").get("direction"))#查找root下所有包含名为year的⼦元素的元素for country in root.findall("*[year]"):print("name:"+country.get("name"))#查找元素(或其⼦元素)⽂本内容为2011的元素(Python3.7+)#print(len(root.findall("*[.='2011']")))#查找元素(或其⼦元素)名为gdppc,⽂本内容为2011的元素for ele in root.findall("*[gdppc='2011']"):print(ele.get("name"))#查找第⼆个country元素print(root.find("country[2]").get("name"))补充知识:python lxml etree xpath定位etree全称:ElementTree 元素树⽤法:import requestsfrom lxml import etreeresponse = requests.get('html')res = etree.HTML(response.text) #利⽤ etree.HTML 初始化⽹页内容resp = res.xpath('//span[@class="green"]/text()')以上这篇Python3 xml.etree.ElementTree⽀持的XPath语法详解就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
python xpath基本语法

在深入探讨 Python XPath 基本语法之前,我们首先需要了解什么是XPath。
XPath(XML Path Language)是一种用来在 XML 文档中定位节点的语言,同时也适用于 HTML 和 XHTML 文档。
Python 中的 XPath 主要用于解析 XML 或 HTML 文件,获取特定节点或元素的信息。
接下来,我们将深入探讨 Python 中 XPath 的基本语法,以便更好地理解和应用它。
1. XPath 基本语法XPath 语法非常灵活,可以根据不同的需求来定位和选择节点。
在Python 中,我们可以使用 lxml 库来实现 XPath 的解析和定位。
下面是 Python 中 XPath 的基本语法:1) 选择节点要选择节点,可以使用节点名称,例如:```//book```这表示选取文档中的所有 `<book>` 节点。
2) 路径表达式路径表达式用于选取 XML 文档中的节点或者节点集。
可以通过 `/` 或`//` 来指定路径。
例如:```/catalog/book/title```这表示选取 `<catalog>` 下的所有 `<book>` 下的 `<title>` 节点。
3) 谓语谓语用于查找满足条件的节点。
选取第二个 `<book>` 节点:```/catalog/book[2]```或者选取价格大于 30 的 `<book>` 节点:```/catalog/book[price>30]```4) 通配符通配符 `*` 用于选取所有元素节点或者匹配所有节点。
例如:```//* 选取文档中的所有节点//@class 选取名为 class 的所有属性```2. Python 中的实践在 Python 中,我们可以使用 lxml 库来实现对 XML 或 HTML 文档的解析和 XPath 定位。
python的xpath方法

python的xpath方法Python的XPath方法XPath(XML Path Language)是一种在XML文档中定位节点的语言。
在Python中,我们可以使用XPath方法来解析XML文档,并通过指定XPath表达式来提取我们需要的数据。
在Python中,我们可以使用lxml库来实现XPath方法。
首先,我们需要安装lxml库,可以使用以下命令来安装:```pip install lxml```安装完成后,我们就可以开始使用XPath方法了。
1. 导入库我们需要导入lxml库和requests库(用于发送HTTP请求获取XML文档):```import requestsfrom lxml import etree```2. 发送HTTP请求获取XML文档使用requests库发送HTTP请求获取XML文档:```response = requests.get(url)xml_doc = response.content```3. 创建XPath解析对象使用lxml库的etree模块创建XPath解析对象:```xml_tree = etree.XML(xml_doc)xpath_parser = etree.XPathEvaluator(xml_tree)```4. 使用XPath表达式提取数据我们可以通过XPath表达式来提取我们需要的数据。
以下是一些常用的XPath表达式示例:- 提取所有的节点:```nodes = xpath_parser('//node')```- 提取指定节点的文本内容:```text = xpath_parser('//node/text()')```- 提取指定节点的属性值:```attribute = xpath_parser('//node/@attribute') ```- 提取符合条件的第一个节点:```node = xpath_parser('//node[condition][1]') ```- 提取符合条件的所有节点:```nodes = xpath_parser('//node[condition]')```- 提取符合条件的节点的文本内容:```text = xpath_parser('//node[condition]/text()')```- 提取符合条件的节点的属性值:```attribute = xpath_parser('//node[condition]/@attribute') ```5. 处理提取到的数据我们可以使用循环来处理提取到的数据,例如打印出文本内容:```for t in text:print(t)```或者保存到文件中:```with open('output.txt', 'w') as f:for t in text:f.write(t + '\n')```这样,我们就可以使用Python的XPath方法来解析XML文档并提取我们需要的数据了。
python读书笔记

python读书笔记最近迷上了 Python 这门编程语言,一头扎进书里,那感觉就像是在一个全新的世界里探险,充满了新奇和挑战。
我读的这本书,没有那种让人望而生畏的高深理论,而是用一种通俗易懂的方式,把 Python 的知识点像讲故事一样娓娓道来。
从最基础的变量、数据类型,到复杂一些的函数、模块,每一个概念都解释得清清楚楚。
就拿变量来说吧,以前我总觉得这是个很抽象的东西,可书里用了一个特别有趣的例子。
它说变量就像是一个盒子,你可以把任何东西放进去,数字、文字、甚至是其他更复杂的数据结构。
比如说,你可以创建一个叫“age”的变量,然后把自己的年龄放进去,就像是把年龄这个数字装进了一个叫“age”的小盒子里。
而且这个盒子里的东西还能随时更换,今天你 20 岁,把 20 放进去,明天过生日变成 21 岁了,就把 21 再放进去。
这一下就让我明白了变量的本质,原来就是用来存储和操作数据的容器呀。
还有数据类型,书里把整数、浮点数、字符串这些比作不同种类的宝贝。
整数就像是整整齐齐的积木块,一块一块清清楚楚;浮点数呢,则像是有点调皮的小水珠,总是带着小数点在那蹦跶;字符串则像是一串五颜六色的珠子,每个字符都是一颗独特的珠子,串在一起形成了有意义的话语。
这种比喻真的太形象了,让我一下子就记住了它们的特点。
说到函数,那可真是 Python 里的大功臣。
书里把函数比作是一个魔法盒子,你把需要处理的东西放进去,它就能按照特定的规则给你变出你想要的结果。
比如说,你写了一个计算两个数之和的函数,每次只要把两个数扔进去,它就能迅速给你算出结果,简直太方便了!而且函数还可以重复使用,就像这个魔法盒子永远不会失效,随时都能为你服务。
在学习模块的时候,我更是感受到了 Python 的强大。
模块就像是一个超级大的工具箱,里面装满了各种各样的工具,每个工具都有自己独特的功能。
你需要什么功能,就从这个工具箱里把对应的工具拿出来用就行。
python爬虫之xpath的基本使用详解

python爬⾍之xpath的基本使⽤详解⼀、简介XPath 是⼀门在 XML ⽂档中查找信息的语⾔。
XPath 可⽤来在 XML ⽂档中对元素和属性进⾏遍历。
XPath 是 W3C XSLT 标准的主要元素,并且XQuery 和 XPointer 都构建于 XPath 表达之上。
⼆、安装pip3 install lxml三、使⽤1、导⼊from lxml import etree2、基本使⽤from lxml import etreewb_data = """<div><ul><li class="item-0"><a href="link1.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >first item</a></li><li class="item-1"><a href="link2.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >second item</a></li> <li class="item-inactive"><a href="link3.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >third item</a></li><li class="item-1"><a href="link4.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >fourth item</a></li><li class="item-0"><a href="link5.html" rel="external nofollow" rel="external nofollow" rel="external nofollow" >fifth item</a></ul></div>"""html = etree.HTML(wb_data)print(html)result = etree.tostring(html)print(result.decode("utf-8"))从下⾯的结果来看,我们打印机html其实就是⼀个python对象,etree.tostring(html)则是不全⾥html的基本写法,补全了缺胳膊少腿的标签。
python中xpath的用法

python中xpath的用法在Python中,可以使用xpath来解析、定位和提取HTML或XML 文档中的数据。
XPath是一种用于根据元素的层级结构和属性来定位节点的查询语言。
以下是xpath的基本用法:1.导入相关库:```pythonfrom lxml import html```2.创建一个Element对象:```pythonelement = html.fromstring(html_content)```这里的`html_content`可以是HTML网页的内容或XML文档。
3.使用XPath表达式来定位节点:```pythonnodes = element.xpath(xpath_expression)````xpath_expression`是一个XPath表达式,用于定位所需的节点。
可以使用节点名称、节点属性、轴、谓语等来构建XPath表达式。
4.获取节点的文本或属性值:```pythonnode_text = node.xpath("string()")attribute_value = node.get("attribute_name")````string()`用于获取节点的文本值,`attribute_name`是节点的属性名称。
拓展:1.指定节点名称:```pythonnodes = element.xpath("//div")````//div`表示匹配文档中所有的`div`节点。
2.指定节点属性值:```pythonnodes = element.xpath("//div[@class='container']")````[@class='container']`表示匹配具有`class`属性值为`container`的`div`节点。
3.使用轴:```pythonnodes = element.xpath("//div/following-sibling::span") ````following-sibling::span`表示匹配`div`节点之后的所有同级的`span`节点。
python简单使用xpath查找网页元素

python简单使⽤xpath查找⽹页元素xPath⼀种HTML和XML的查询语⾔,他能在XML和HTML的树状结构中寻找节点安装pip install lxmlHTML超⽂本标记语⾔,是⼀种规范,⼀种标注,是构成⽹页⽂档的主要语⾔URL统⼀资源定位器,互联⽹上的每个⽂件都有⼀个唯⼀的URL,它包含的信息指出⽂件的位置以及浏览应该怎么处理它。
xPath的使⽤获取⽂本//标签1[@属性1="属性值1"]/标签2[@属性2="属性值"]/..../text()获取属性值//标签1[@属性1="属性值1"]/标签2[@属性2="属性值"]/..../@属性n所需要的html⽂档<!DOCTYPE html><html><head lang="en"><meta charset="UTF-8"><title>注册页⾯</title><style>table{border: 1px solid beige;}span{color: #66CCFF;}th{background-color: gainsboro;}tr{border: 1px solid beige;}td{border: 1px solid aliceblue;}.redText{color: red;}.redStar{color: red;}</style></head><body><p>开始</p><!-- 8列--><h3>标题,我是⼀个⼤帅哥</h3><ul><li>内容1</li><li>内容2</li><li class="important">内容3important</li><li>内容4</li><li>内容5</li></ul><p>中间</p><div id = "container">段落⽂字<a href="" title="超链接">跳转到百度⾸页</a></div><p>最后</p><form action=""><table align="center" cellspacing="0"><tr><th colspan="8" align="left">1.会员登录名和密码</th></tr><tr><td>⽤户名:</td><td colspan="2"><input type="text"/><span class="redStar">* </span></td><td colspan="5"><input type="button" value="检测⽤户名"/><span>5-15位,请使⽤英⽂(a-z、A-Z)、数字(0-9)</span></td></tr><tr><td>密 码:</td><td colspan="2"><input type="password"/><span class="redStar">* </span></td><td colspan="5"><span>5-15位,请使⽤英⽂(a-z)、数字(0-9)注意区分⼤⼩写;<br/>密码不能与登录名相同;易记;难猜;</span></td> </tr><tr><td>再次输⼊密码:</td><td colspan="2"><input type="password"/><span class="redStar">* </span></td><td colspan="5"><span>两次输⼊的密码必须⼀致</span></td></tr><tr><th colspan="8" align="left">2.姓名和联系⽅式</th></tr><tr><td>真实姓名:</td><td colspan="2"><input type="text"/><span class="redStar">* </span></td><td colspan="5"><input type="radio" checked="checked" name="Sex" value="male"/>先⽣<input type="radio" name="Sex" value="female"/>⼩姐</td></tr><tr><td>电⼦邮箱:</td><td colspan="2"><input type="text"/><span class="redStar">* </span></td><td colspan="5"><span class="redText">⾮常重要!</span><br/><span>这是客户与您联系的⾸选⽅式,请⼀定填写真实。
python xpath parent用法

Python XPath Parent 用法示例1. 概述XPath 是一种用于在 XML 文档中定位节点的语言,通过使用 XPath 可以方便地从 XML 文档中提取所需的数据。
在 Python 中,可以使用lxml 库来实现 XPath 定位和解析。
2. Python 中的 XPath 定位在 Python 中,可以使用 lxml 库来实现对 XML 文档的解析和 XPath 定位。
要使用 lxml 库,首先需要安装该库,可以通过 pip 命令进行安装。
```pip install lxml```3. 使用 lxml 库实现 XPath 定位下面是一个简单的 XML 文档示例:```<bookstore><book category="cooking"><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price></book><book category="children"><title lang="en">Harry Potter</title><author>J.K. Rowling</author><year>2005</year><price>29.99</price></book></bookstore>```接下来,我们可以使用 lxml 库来解析上面的 XML 文档,并使用XPath 定位来获取特定节点的数据。
pythonxpath用法

pythonxpath用法Python's xpath is a powerful library used for parsing XML and HTML documents, allowing users to extract specific data using XPath expressions. XPath is a query language for selecting nodes from an XML or HTML document.Here's how to use xpath in Python:1.Installation: Install the xpath library using pip:pip install xpath2.Import: Import the xpath module in your Python script:import xpath3.Parsing: Parse the XML or HTML document usingxpath.parse():doc = xpath.parse('example.xml')4.Querying: Use XPath expressions to query specificelements or attributes in the document:result = doc.find('//element[@attribute="value"]')5.Accessing Results: Access the results returned by thepythonCopy codefor element in result: print(element.text)6.Cleanup: Close the document parser when done:doc.close()Here's a simple example of using xpath to parse an XML document:# Parse the XML documentdoc = xpath.parse('example.xml')# Query specific elements using XPathresult = doc.find('//book[@category="programming"]')# Access and print resultsfor book in result:print("Title:", book.find('title').text)print("Author:", book.find('author').text)# Close the document parserdoc.close()Chinese Parsing: Python的xpath是一个强大的库,用于解析XML和HTML文档,允许用户使用XPath表达式提取特定数据。
python中用xpath匹配文本段落内容的技巧

python中⽤xpath匹配⽂本段落内容的技巧content = item.xpath('//div[@class="content"]/span')[0].xpath('string(.)')content = item.xpath('//div[@class="content"]/span//text()')两种匹配规则,都能匹配到图中的⽂本段落内容:第⼀种匹配到的结果是:"content":"\n\n\n⼩⼉⼦5岁天⽣戏精在⾼铁站,⼀对夫妻带⼀男孩也5岁左右,⼩男孩坐地上耍赖,⼩夫妻与⼩男孩全程英语交流,坐他们对⾯的⼩⼉⼦看的云⾥雾⾥,突然转过头跟我说,“妈妈,他们说的话我也会。
”正在我惊讶之际,这⼩⼦⼀⾸“ABCDEFG……”好吧~\n\n"第⼆种匹配到的结果是:"content":["\n\n\n⼩⼉⼦5岁天⽣戏精", "在⾼铁站,⼀对夫妻带⼀男孩也5岁左右,⼩男孩坐地上耍赖,⼩夫妻与⼩男孩全程英语交流,坐他们对⾯的⼩⼉⼦看的云⾥雾⾥,突然转过头跟我说,“妈妈,他们说的话我也会。
”", "正在我惊讶之际,这⼩⼦⼀⾸“ABCDEFG……”", "好吧~\n\n"]第⼀种匹配规则得到的content,内容中的<br/>⾃动忽略,得到包含全部字符内容的整串,但是原本⽤换⾏符断句处没有逗号,产⽣的内容阅读起来可能不连贯。
第⼆种匹配规则得到的content,也将忽略内容中的<br/>,同时会以<br/>为间隔,将⽂本内容⽤逗号切开,最终得到⼀个字符串列表。
在对⽂本内容要求⽐较精确的情况下,可以将第⼆种规则匹配后的结果,⽤ "\n".join() 来对字符串列表进⾏处理,不会出现不连贯情况。
xpath提取目录下所有标签内的内容,递归text()

xpath提取⽬录下所有标签内的内容,递归text()利⽤xpath来提取所有标签⾥⾯的内容,即使标签头不同1#-*-coding:utf8-*-2import re3import os4from lxml import etree5 html = '''6<!DOCTYPE html>7<html>8<head lang="en">9 <meta charset="UTF-8">10 <title>测试-常规⽤法</title>11</head>12<body>13<div id="content">14 <ul id="useful">15 <li>我</li>16 <ml>是</ml>17 <li>谁</li>18 </ul>19 <ul id="useless">20 <li>who </li>21 <li>am </li>22 <li>i!</li>23 </ul>24</div>25<div id="content">26 <ul id="useful"><li>你</li><ml>是</ml><li>谁!</li>27 </ul>28 <ul id="useless"><li>who </li><li>you </li><li>are!</li>29 </ul>30</div>3132</body>33</html>34'''35 selector = etree.HTML(html)36for k in range(1,3):37 chinese = selector.xpath('//div[@id="content"][%s]/ul[@id="useful"]//text()'%k)38 data = "".join([each for each in chinese])39 english = selector.xpath('//div[@id="content"][%s]/ul[@id="useless"]//text()'%k)40 Data = "".join([each for each in english])41print data42print Data结果:。
python使用xpath获取页面元素的使用

python使⽤xpath获取页⾯元素的使⽤关于python 使⽤xpath获取⽹页信息的⽅法?1、xpath的使⽤⽅法?XPath 使⽤路径表达式来选取 XML ⽂档中的节点或节点集。
节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
常⽤路径表达式含义表达式描述/从根节点选取(取⼦节点)//选择的当前节点选择⽂档中的节点.选取当前节点。
…选取当前节点的⽗节点。
@选取属性*表⽰任意内容(通配符)|运算符可以选取多个路径常⽤功能函数函数⽤法解释startswith()xpath(‘//div[starts-with(@id,”ma”)]‘)#选取id值以ma开头的div节点contains()xpath(‘//div[contains(@id,”ma”)]‘)#选取id值包含ma的div节点and()xpath(‘//div[contains(@id,”ma”) and contains(@id,”in”)]‘)#选取id值包含ma的div节点text()_.xpath('./div/div[4]/a/em/text()')#选取em标签下⽂本内容备注:1、html中当相同层次存在多个标签例如div,它们的顺序是从1开始,不是02、浏览器中使⽤开发者⼯具可以快速获取节点信息2、实例:#!/usr/bin/python3# -*- coding: utf-8 -*-# @Time : 2021/9/7 9:35# @Author : Sun# @Email : 8009@# @File : sun_test.py# @Software: PyCharmimport requestsfrom lxml import etreedef get_web_content():try:url = "htpps://***keyword=%E6%97%A0%E9%92%A2%E5%9C%88&wq=%E6%97%A0%E""9%92%A2%E5%9C%88&ev=1_68131%5E&pvid=afbf41410b164c1b91d""abdf18ae8ab5c&page=5&s=116&click=0 "header = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64)""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/75.0.3770.100 Safari/537.36 "}response = requests.request(method="Get", url=url, headers=header)result = response.textreturn resultexcept TimeoutError as e:return Nonedef parsing():result = get_web_content()if result is not None:html = etree.HTML(result)# 先获取⼀个⼤的节点,包含了想要获取的所有信息ii = html.xpath('//*[@id="J_goodsList"]/ul/li')for _ in ii:# 采⽤循环,依次从⼤节点中获取⼩的节点内容# ''.join() 将列表中的内容拼接成⼀个字符串infoResult = {# @href 表⽰:获取属性为href的内容'href': "https:" + _.xpath('./div/div[1]/a/@href')[0],'title': ''.join(_.xpath('./div/div[2]/div/ul/li/a/@title')),# text()表⽰获取节点i⾥⾯的⽂本信息'price': _.xpath('./div/div[3]/strong/i/text()')[0],'info': ''.join(_.xpath('./div/div[4]/a/em/text()')).strip(),'province': _.xpath('./div/div[9]/@data-province')[0]}print(infoResult)else:raise Exception("Failed to get page information, please check!")return Noneif __name__ == '__main__':parsing()结果图⽚:到此这篇关于python使⽤xpath获取页⾯元素的使⽤的⽂章就介绍到这了,更多相关python xpath获取页⾯元素内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
使用“|”运算符可以选取多个路径
表达式结果
xpath(…//div|//table‟)选取所有的div和table节点
五、Xpath轴
轴可以定义相对于当前节点的节点集
轴名称表达式描述
ancestor xpath(…./ancestor::*‟)选取当前节点的所有先辈节点(父、祖父)
ancestor-or-self xpath(…./ancestor-or-self::*‟)
选取当前节点的所有先辈节点以及节
点本身
attribute xpath(…./attribute::*‟)选取当前节点的所有属性child xpath(…./child::*‟)返回当前节点的所有子节点
descendant xpath(…./descendant::*‟)返回当前节点的所有后代节点(子节点、孙节点)
following xpath(…./following::*‟)选取文档中当前节点结束标签后的所有节点
following-
sibing
xpath(…./following-sibing::*‟)选取当前节点之后的兄弟节点parent xpath(…./parent::*‟)选取当前节点的父节点
preceding xpath(…./preceding::*‟)选取文档中当前节点开始标签前的所有节点
preceding-
sibling
xpath(…./preceding-sibling::*‟)选取当前节点之前的兄弟节点self xpath(…./self::*‟)选取当前节点
六、功能函数
使用功能函数能够更好的进行模糊搜索。