CUDA基本介绍
CUDA GPU 入门介绍

1. GPU高性能计算
GPU关键概念
SM: Stream Multiprocessor SP: Stream Processor
每个SM包含8个SP, 由SM取指, 解码, 发射到各个SP, GPU可看作是一组SM
SMEM: shared memory, GPU片内每个SM所占有的高速存储器
(3) 在.bash_profile中添加:
PATH=$PATH:<CUDA_INSTALL_PATH>/bin LD_LIBRARY_PATH=$LD_LIBRARY_PATH:<CUDA_INSTALL_PATH>/lib64 export PATH export LD_LIBRARY_PATH 其中: <CUDA_INSTALL_PATH>为实际安装路径
2. CUDA架构
CPU/GPU异构并行模型
由CPU端 (主机端) 传送参数及配置Kernel的执 行 (Block, Thread数量, 尺寸等) Kernel在GPU (设备端) 上执行
显存分配, 显存不PC主存间的交互通过API完成
2. CUDA架构
CUDA C扩展: 编译器nvcc
右键工程名 属性, 打开链接器, 在以下项做相应修改 ―启用增量链接‖ : 否(/INCREMENTAL:NO) ―附加库目录‖ :改为 ―$(CUDA_LIB_PATH)‖ ―链接器‖ 子项 ―输入‖: ―附加依赖项‖ 中输入cudart.lib
3. CUDA环境搭建
2. Linux (Fedora, Redhat, Ubuntu…)
使用线程结构的x维度, 8×8一共64个线程
还有多种其他开辟方式
显卡中CUDA是什么及作用介绍

显卡中CUDA是什么及作用介绍显卡中CUDA是什么及作用介绍自第一台计算机ENIAC发明以来,计算机系统的技术已经得到了很大的发展,但计算机硬件系统的基本结构没有发生变化,仍然属于冯·诺依曼体系计算机。
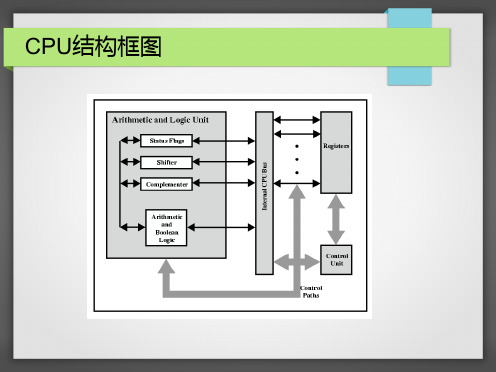
计算机硬件系统仍然由运算器,控制器,存储器,输入设备和输出设备5部分组成。
以下是小编整理的显卡中CUDA是什么及作用介绍,欢迎阅读。
CUDA(Compute Unified Device Architecture),显卡厂商NVidia推出的运算平台。
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
它包含了CUDA 指令集架构(ISA)以及GPU内部的并行计算引擎。
计算行业正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。
为打造这一全新的计算典范,NVIDIA(英伟达)发明了CUDA(Compute Unified Device Architecturem,统一计算设备架构)这一编程模型,是想在应用程序中充分利用CPU和GPU各自的优点。
现在,该架构现已应用于GeForce(精视)、ION(翼扬)、Quadro以及Tesla GPU(图形处理器)上,对应用程序开发人员来说,这是一个巨大的市场。
在消费级市场上,几乎每一款重要的`消费级视频应用程序都已经使用CUDA加速或很快将会利用CUDA来加速,其中不乏Elemental Technologies公司、MotionDSP公司以及LoiLo公司的产品。
在科研界,CUDA一直受到热捧。
例如,CUDA现已能够对AMBER进行加速。
AMBER是一款分子动力学模拟程序,全世界在学术界与制药企业中有超过60,000名研究人员使用该程序来加速新药的探索工作。
在金融市场,Numerix以及CompatibL针对一款全新的对手风险应用程序发布了CUDA支持并取得了18倍速度提升。
Numerix为近400家金融机构所广泛使用。
cuda constant memory上限-概述说明以及解释

cuda constant memory上限-概述说明以及解释1.引言1.1 概述部分:在计算机科学领域,CUDA技术已经成为一种广泛应用的并行计算框架。
CUDA技术通过利用GPU的强大并行计算能力,有效提高了计算性能,加快了各种科学和工程计算任务的执行速度。
在CUDA编程中,常量内存是一种特殊的内存区域,被设计用来存储在应用程序执行过程中不会发生改变的数据。
本文将重点讨论CUDA常量内存的使用限制,即常量内存的上限,并分析影响常量内存上限的因素。
通过深入探讨这些问题,可以帮助开发者更好地使用CUDA技术,优化并发计算任务的执行效率。
1.2 文章结构本文将分为三个主要部分,即引言、正文和结论。
在引言部分,将对整篇文章进行概述,并说明文章的结构和目的。
正文部分将包括三个小节。
首先,将简要介绍CUDA技术,包括其背景和基本概念。
其次,将详细介绍CUDA常量内存的概念、特点和用途。
最后,将对CUDA常量内存的上限进行分析,探讨其影响因素和解决方法。
在结论部分,将对文章所述内容进行总结,并指出影响CUDA常量内存上限的因素。
最后,将展望CUDA常量内存技术的未来发展趋势。
1.3 目的:本文旨在探讨CUDA常量内存的上限问题,通过对CUDA技术和常量内存的介绍,分析常量内存的使用限制以及影响因素,为开发者在使用CUDA常量内存时提供参考和指导。
同时,展望未来可能的解决方案和发展趋势,以期为CUDA编程的优化和性能提升提供帮助。
}}请编写文章1.3 目的部分的内容2.正文2.1 CUDA技术简介CUDA(Compute Unified Device Architecture)是由NVIDIA推出的一种用于通用计算的并行计算架构,它允许开发人员使用基于NVIDIA GPU的并行计算能力来加速应用程序的运行速度。
CUDA技术利用GPU的大量并行处理单元,可以在处理数据密集型任务时实现比传统CPU更高的性能和效率。
CUDA介绍

Block – 一组线程
一维,二维或三维 一个Grid里面的每个Block的线程数是一样的 block内部的每个线程可以: 同步 synchronize 访问共享存储器 shared memory
线程层次 Thread Hierarchies
Image from: /ece498/al/textbook/Chapter2-CudaProgrammingModel.pdf
通过调用kernel函数在设备端创建轻量级 线程 线程由硬件负责创建并调度
类似于OpenGL的 shader?
CUDA 核函数(Kernels)
在N个不同的CUDA线程上并行执行
Thread ID
Declaration Specifier
Execution Configuration
CUDA 程序的执行
CUDA 内存传输
Host
Device Global Memory
Code from: /ece498/al/textbook/Chapter2-CudaProgrammingModel.pdf
Matrix Multiply 矩阵相乘算法提示
Code from: /ece498/al/textbook/Chapter2-CudaProgrammingModel.pdf
CUDA 内存传输
cudaMemcpy()
内存传输 Host to host Host to device Device to host Device to device
Host
– 即主机端 通常指 CPU – 即设备端 通常指 GPU (数据可并
CUDA编程之快速入门

CUDA编程之快速⼊门CUDA(Compute Unified Device Architecture)的中⽂全称为计算统⼀设备架构。
做图像视觉领域的同学多多少少都会接触到CUDA,毕竟要做性能速度优化,CUDA是个很重要的⼯具,CUDA是做视觉的同学难以绕过的⼀个坑,必须踩⼀踩才踏实。
CUDA编程真的是⼊门容易精通难,具有计算机体系结构和C语⾔编程知识储备的同学上⼿CUDA编程应该难度不会很⼤。
本⽂章将通过以下五个⽅⾯帮助⼤家⽐较全⾯地了解CUDA编程最重要的知识点,做到快速⼊门:1. GPU架构特点2. CUDA线程模型3. CUDA内存模型4. CUDA编程模型5. CUDA应⽤⼩例⼦1. GPU架构特点⾸先我们先谈⼀谈串⾏计算和并⾏计算。
我们知道,⾼性能计算的关键利⽤多核处理器进⾏并⾏计算。
当我们求解⼀个计算机程序任务时,我们很⾃然的想法就是将该任务分解成⼀系列⼩任务,把这些⼩任务⼀⼀完成。
在串⾏计算时,我们的想法就是让我们的处理器每次处理⼀个计算任务,处理完⼀个计算任务后再计算下⼀个任务,直到所有⼩任务都完成了,那么这个⼤的程序任务也就完成了。
如下图所⽰,就是我们怎么⽤串⾏编程思想求解问题的步骤。
但是串⾏计算的缺点⾮常明显,如果我们拥有多核处理器,我们可以利⽤多核处理器同时处理多个任务时,⽽且这些⼩任务并没有关联关系(不需要相互依赖,⽐如我的计算任务不需要⽤到你的计算结果),那我们为什么还要使⽤串⾏编程呢?为了进⼀步加快⼤任务的计算速度,我们可以把⼀些独⽴的模块分配到不同的处理器上进⾏同时计算(这就是并⾏),最后再将这些结果进⾏整合,完成⼀次任务计算。
下图就是将⼀个⼤的计算任务分解为⼩任务,然后将独⽴的⼩任务分配到不同处理器进⾏并⾏计算,最后再通过串⾏程序把结果汇总完成这次的总的计算任务。
所以,⼀个程序可不可以进⾏并⾏计算,关键就在于我们要分析出该程序可以拆分出哪⼏个执⾏模块,这些执⾏模块哪些是独⽴的,哪些⼜是强依赖强耦合的,独⽴的模块我们可以试着设计并⾏计算,充分利⽤多核处理器的优势进⼀步加速我们的计算任务,强耦合模块我们就使⽤串⾏编程,利⽤串⾏+并⾏的编程思路完成⼀次⾼性能计算。
cuda中文手册

cuda中文手册
CUDA中文手册(CUDA中文手册【原创版】)包括以下内容:
1. CUDA 概述:CUDA 是 NVIDIA 推出的一种通用并行计算架构,旨在利用 NVIDIA GPU 进行高性能计算。
2. CUDA 安装与配置:介绍如何安装和配置 CUDA,以便在 NVIDIA GPU 上运行并行计算。
3. CUDA 编程模型:介绍 CUDA 的编程模型,包括线程块、线程和共享内存等概念。
4. CUDA 内存管理:介绍 CUDA 中的内存类型和内存管理机制。
5. CUDA 线程组织:介绍 CUDA 中的线程组织方式和线程同步机制。
6. CUDA 性能优化:介绍如何优化 CUDA 程序的性能,包括减少内存访问延迟、提高并行度等。
7. CUDA 应用实例:介绍一些 CUDA 的应用实例,包括科学计算、图像处理等领域。
总的来说,CUDA 中文手册是全面介绍 CUDA 的中文资料,可以帮助开发者更好地理解和使用 CUDA,提高程序的性能和效率。
GPU之CUDA C基础知识介绍
__shared__
• 位于线程块的共享存储器空间中; • 与块具有相同的生命周期; • 尽可通过块内的所有线程访问。
天津医科大学
内核调用函数
Kernel<<<Dg,Db>>>(param1, param1,…)
• Dg,指定网格的维度和大小 • Db,指定各块的维度和大小
基于C语言的扩展函数
对于大小为(DX,Dy)的二维
block,线程的threadID是
(threadIdx.x+threadIdx.y*Dx);
对于大小为(DX,Dy,Dz)的三维block ,线程的threadID是 (threadIdx.x+threadIdx.y*Dx +threadIdx.z*Dx*Dy)。
cudagraphicsglregisterbuffer 使用-概述说明以及解释

cudagraphicsglregisterbuffer 使用-概述说明以及解释1.引言1.1 概述CUDA(Compute Unified Device Architecture)是一种由英伟达(NVIDIA)推出的并行计算平台和编程模型,能够利用GPU的并行计算能力来加速计算密集型应用程序。
而OpenGL(Open Graphics Library)是一种用于渲染2D和3D矢量图形的跨平台图形库。
在现代计算机应用程序中,往往需要同时利用GPU加速计算和提供图形渲染功能。
为了实现这种融合,CUDA和OpenGL提供了一种互操作性机制,使得开发人员可以在CUDA核函数中直接操作OpenGL绑定的缓冲区对象。
其中,glRegisterBuffer函数就是CUDA Graphics中的一个重要函数,用于将OpenGL的缓冲区对象注册为CUDA图形资源,实现CUDA和OpenGL之间的数据共享和互操作。
本文将介绍CUDA Graphics中的glRegisterBuffer函数的使用方法和注意事项,结合示例和应用场景,帮助读者了解如何在CUDA和OpenGL之间实现高效的数据互操作,以及未来该技术的发展方向和应用前景。
1.2 文章结构本文将首先介绍CUDA Graphics Interoperability的基本概念和原理,以及其与OpenGL之间的关系。
然后,重点讨论如何使用CUDA Graphics中的glRegisterBuffer函数来实现CUDA与OpenGL之间的数据交互。
接下来,我们将通过具体的示例和实际应用来说明glRegisterBuffer函数的使用方法和效果。
最后,我们将对CUDA Graphics与OpenGL之间的互操作性进行总结,并分析glRegisterBuffer 函数的优势和适用场景。
最后,我们将展望未来CUDA与OpenGL之间更深入的合作和发展。
1.3 目的本文的目的是介绍如何使用CUDA Graphics中的glRegisterBuffer 函数实现CUDA与OpenGL之间的数据交互,以及探讨glRegisterBuffer 的优势和适用场景。
cuda常用的数学库

cuda常用的数学库CUDA(Compute Unified Device Architecture)是一种并行计算平台和编程模型,用于利用GPU(图形处理器)进行高性能计算。
在CUDA编程中,数学库是非常重要的工具,它提供了丰富的数学函数来支持各种数值计算任务。
本文将介绍CUDA常用的数学库及其功能。
1. CUDA Math Library(cuBLAS):cuBLAS是CUDA的基本线性代数库,提供了丰富的线性代数运算函数,如矩阵乘法、矩阵转置、矩阵求逆等。
它能够充分利用GPU的并行计算能力,加速线性代数运算任务。
2. CUDA Random Number Generation(cuRAND):cuRAND是CUDA的随机数生成库,提供了各种随机数生成函数,如均匀分布、正态分布、泊松分布等。
它能够高效地生成大量随机数,并利用GPU的并行计算能力进行加速。
3. CUDA Fast Fourier Transform(cuFFT):cuFFT是CUDA的快速傅里叶变换库,提供了各种快速傅里叶变换函数,如一维傅里叶变换、二维傅里叶变换、多维傅里叶变换等。
它能够高效地进行信号和图像处理任务,如滤波、频域分析等。
4. CUDA Sparse Linear Algebra Library(cuSPARSE):cuSPARSE 是CUDA的稀疏线性代数库,提供了各种稀疏矩阵运算函数,如稀疏矩阵乘法、稀疏矩阵转置等。
它能够高效地处理大规模稀疏矩阵,节省内存和计算资源。
5. CUDA Performance Primitives(NPP):NPP是CUDA的性能优化库,提供了各种图像和信号处理函数,如图像滤波、图像变换、信号采样等。
它能够高效地进行图像和信号处理任务,加速计算过程。
6. CUDA Math Library(cuBLAS):cuBLAS是CUDA的基本线性代数库,提供了丰富的线性代数运算函数,如矩阵乘法、矩阵转置、矩阵求逆等。
最全与最好的CUDA入门教程

图形图像处理应用
图像滤波与增强
CUDA可用于实现高效的图像滤波算法,如 高斯滤波、中值滤波等,以及图像增强技术 ,如直方图均衡化、锐化等。
图像压缩与编码
CUDA可加速图像压缩算法,如JPEG、PNG等格式 的编码和解码过程,提高图像处理的实时性。
最全与最好的CUDA 入门教程
目录
• CUDA概述与基础 • CUDA编程基础 • CUDA进阶技术 • CUDA高级特性 • CUDA实战案例解析 • 总结与展望
01 CUDA概述与基础
CUDA定义及发展历程
CUDA(Compute Unified Device Architecture)是 NVIDIA推出的并行计算平台和API模型,它允许开发者使用 NVIDIA GPU进行通用计算。
其他框架支持
CUDA还支持与其他深度学习框架(如Caffe、Keras等) 的集成,为各种深度学习应用提供统一的GPU加速方案。
性能评估与调优方法
性能分析工具
CUDA提供了一套完整的性能分析工具,如NVIDIA Visual Profiler、Nsight等,帮助开发者定位性能瓶颈并进行优化 。
优化策略
针对CUDA程序的性能问题,可以采用一系列优化策略,如 减少全局内存访问、优化内存访问模式、利用并行化减少 计算复杂度等。
最佳实践
在编写CUDA程序时,遵循一些最佳实践可以提高程序性能 ,如合理划分任务、减少线程同步、优化内核函数设计等 。
05 CUDA实战案例解析
矩阵乘法加速实现
01
利用CUDA进行矩阵乘法的并行化处理和优化,包括 分块处理、共享内存使用等策略。
cuda c++ 编译 cmakelist 概述及解释说明

cuda c++ 编译cmakelist 概述及解释说明1. 引言1.1 概述本文将介绍CUDA C++编译CMakeList的概述及解释说明。
随着计算机科学的快速发展,图形处理单元(GPU)已经成为并行计算领域的重要组成部分。
CUDA C++作为一种用于并行计算的编程语言,能够有效利用GPU的强大计算能力,从而提高程序的性能。
本文将重点讨论如何使用CMakeList来编译CUDA C++代码。
CMake是一个跨平台的自动化构建工具,它可以根据不同平台和编译器生成相应的构建脚本,并简化项目配置和管理过程。
通过使用CMakeList,我们可以轻松地管理项目中的源文件、头文件路径以及CUDA编译器选项和链接库依赖关系,从而方便地进行CUDA C++代码编译。
1.2 文章结构本文共分为四个部分:引言、CUDA C++ 编译CMakeList概述、CUDA C++ 编译CMakeList正文和结论。
在引言中,我们将对文章进行概述并介绍其结构。
接下来,在第二部分中,我们将详细探讨什么是CUDA C++编译以及CMakeList 简介,并对CUDA编译器选项进行解释说明。
然后,在第三部分中,我们将重点介绍如何设置项目和版本号信息、添加源文件和头文件路径以及配置CUDA 编译选项和链接库依赖关系。
最后,在结论部分,我们将总结主要要点,并对CUDA C++编译CMakeList进行展望和提出建议。
1.3 目的本文的目的是提供一个全面的指南,帮助读者了解和掌握使用CMakeList来编译CUDA C++代码的过程。
通过学习本文,读者将能够清晰地理解如何设置项目和版本号信息、添加源文件和头文件路径以及配置CUDA编译选项和链接库依赖关系。
此外,本文还将提供一些展望和建议,帮助读者进一步优化他们的CUDA C++编译CMakeList流程,并改善代码性能。
无论是初学者还是有一定经验的开发人员,都可以从本文中获得实用而宝贵的知识。
cuda标准库介绍

cuda标准库介绍
CUDA(Compute Unified Device Architecture)是由NVIDIA
推出的并行计算平台和编程模型,用于利用GPU进行通用目的的并
行计算。
CUDA标准库是CUDA平台提供的一组库函数,用于支持并
行计算和GPU编程。
下面我将从多个角度介绍CUDA标准库。
首先,CUDA标准库提供了一系列的数学函数,包括基本的数学
运算(如加减乘除、取模等)、三角函数、指数函数、对数函数、
双曲函数等。
这些函数可以直接在GPU上进行并行计算,加速数值
计算和科学计算应用。
其次,CUDA标准库还包括了一些图像处理相关的函数,如图像
滤波、图像转换、图像合成等。
这些函数可以帮助开发人员在GPU
上实现高效的图像处理算法,加速图像处理和计算机视觉应用。
此外,CUDA标准库还提供了一些并行算法和数据结构,如并行
排序、并行归约、并行扫描等。
这些算法和数据结构可以帮助开发
人员在GPU上实现高效的并行计算,充分发挥GPU的并行计算能力。
除此之外,CUDA标准库还包括了一些输入输出相关的函数,如
文件读写、内存拷贝等。
这些函数可以帮助开发人员在GPU和主机之间进行数据传输,实现高效的数据交换和通信。
总的来说,CUDA标准库为开发人员提供了丰富的函数库,可以帮助他们在GPU上实现高效的并行计算和并行算法,加速各种科学计算、图像处理和并行计算应用。
同时,开发人员也可以通过CUDA 标准库来充分发挥GPU的并行计算能力,实现更加复杂和高效的计算任务。
CUDA基本介绍

CUDA基本介绍CUDA的出现源于对传统CPU计算能力的限制。
在传统的串行计算模式下,CPU只能执行一个指令,一个时钟周期只能执行一个操作数。
随着计算需求的增加,CPU的计算性能逐渐达到瓶颈。
而GPU拥有大量的计算核心,可以并行执行大量的计算任务,提供了与CPU不同的计算模式。
CUDA利用GPU的并行计算能力,为开发人员提供了更高的计算性能和自由度。
CUDA的核心编程模型是将计算任务分解成多个线程,并交由GPU进行并行计算。
开发人员可以使用CUDA编程模型中的线程层次结构,将线程组织成线程块(block)和线程网格(grid),并根据应用的需求将任务分配给GPU执行。
每个线程都有自己的ID,可以执行独立的计算任务。
线程块是线程的集合,可以同步和共享数据。
线程网格则由多个线程块组成,可以分配和管理线程块的执行。
CUDA提供了一套丰富的编程接口和库,开发人员可以使用C、C++、Fortran等语言来编写CUDA程序。
CUDA的编程接口负责管理GPU资源、数据传输和计算任务的调度。
开发人员可以通过编写CUDA核函数,将需要大量计算的任务分配给GPU执行。
在CUDA核函数中,开发人员可以使用NVIDIA提供的GPU并行计算指令集(SIMD指令集)来执行计算任务。
此外,CUDA还提供了一些常用的数学和向量运算库,如cuBLAS、cuFFT和cuDNN,方便开发人员进行科学计算、信号处理和深度学习等应用。
CUDA的应用范围十分广泛。
首先,CUDA适用于各种科学计算和数字信号处理应用。
CUDA可以加速矩阵运算、信号滤波、图像处理等任务,提高计算速度和效率。
其次,CUDA也适用于机器学习和深度学习领域。
利用GPU的并行计算能力,CUDA可以加速神经网络的训练和推断过程,加快模型的收敛速度。
此外,CUDA还可以用于虚拟现实(VR)和游戏领域,高性能的图像处理能力可以提供更流畅和真实的视觉效果。
总之,CUDA是一种高效的并行计算平台和应用编程接口,为开发人员提供了利用GPU进行通用目的的并行计算的能力。
CUDA简介
__device__ __host__ 可以同时使用
GPU应用-基数排序
基数排序是一个具有固定迭代次数核一致执行流的算法。塔 通过从最低有效位到最高有效位一一进行比较,对数值排序 。对于一个32位的整型数 ,使用一个基数位,无论数据集 有多大,整个排序需要迭代32次。 整个算法过程描述如下:
1. SP (流处理器):最基本的处理单元,streaming processor 具体 的指令和任务都是在sp上处理的。GPU进行并行计算,也就是很 多个sp同时做处理。 2.SM(流处理器簇): 多个sp加上其他的一些资源组成一个sm, streaming multiprocessor. 其他资源也就是存储资源,共享内存 ,寄储器等。 3.warp:GPU执行程序时的调度单位,目前cuda的warp的大小为 32,同在一个warp的线程,以不同数据资源执行相同的指令。 4.grid、block、thread:在利用cuda进行编程时,一个grid分为 多个block,而一个block分为多个thread.
例如: cudaMalloc(),cudaMemcpy()
Cuda 函数声明
名称
1. __device__ 2. __global__ 3. __host__
调用位置
device host host
执行位置
device device host
__global__ 定义一个kernel函数,也可以叫做入口函数,在 CPU上调用,GPU上执行
GPU线程组织结构说明
1.一个kernel具有大量线程
2.线程被划分成若干个块(“block”)
一个线程块之间共享 共享内存; 可以同步 “__syncthreads()” 可以是一维(x),二维(x,y),三维(x,y,z)
CUDA基本介绍

CUDA
CUDA(Compute Unified Device Architecture, 计算统一设备架构),由显卡厂商Nvidia推出的 运算平台。 CUDA是一种通用并行计算架构,该架构使GPU 能够解决复杂的计算问题。开发人员可以使用C 语言来为CUDA架构编写程序。 CUDA的硬件架构 CUDA的软件架构
GPU的优势 的优势
强大的处理能力 GPU接近1Tflops/s 高带宽 140GB/s 低成本 Gflop/$和Gflops/w高于CPU 当前世界超级计算机五百强的入门门槛为 12Tflops/s 一个三节点,每节点4GPU的集群,总处理能力 就超过12Tflops/s,如果使用GTX280只需10万 元左右,使用专用的Tesla也只需20万左右
GT200架构 架构
TPC
•3 SM •Instruction and constant cache •Texture •Load/store
SM
ROP
•对DRAM 进行访问 •TEXTURE 机制 •对global的 atomic操作
CUDA 执行模型
将CPU作为主机(Host),而GPU作为协处理器 (Coprocessor) 或者设备(Device),从而让 GPU来运行一些能够被高度线程化的程序。 在这个模型中,CPU与GPU协同工作,CPU负 责进行逻辑性强的事务处理和串行计算,GPU 则专注于执行高度线程化的并行处理任务。 一个完整的CUDA程序是由一系列的设备端kernel 函数并行步骤和主机端的串行处理步骤共同组成 的。
设备端代码主要完成的功能
从显存读数据到GPU中 对数据处理 将处理后的数据写回显存
CUDA执行模型 执行模型
grid运行在SPA上 block运行在SM上 thread运行在SP上
cuda定义的数组最大值

CUDA定义的数组最大值一、背景介绍在计算机科学和并行计算领域,CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和编程模型。
它允许开发者使用C、C++、Fortran等编程语言在NVIDIA GPU上进行高性能计算。
CUDA广泛应用于科学计算、深度学习、图形处理等领域,在处理大规模数据集时具有显著的优势。
在CUDA中,数组是一种常见的数据结构,用于存储和处理大量的数据。
而寻找数组中的最大值是一个常见的问题,本文将介绍如何在CUDA中定义数组并找到其中的最大值。
二、CUDA数组定义在CUDA中,我们可以使用一维或多维数组来存储数据。
CUDA数组的定义和使用与普通的C/C++数组类似,但需要使用CUDA提供的特定语法和函数来管理和操作数组。
2.1 一维数组定义一维数组是最简单的一种数组形式,它由一个连续的内存块组成,每个元素在内存中的地址是连续的。
在CUDA中,我们可以使用以下方式定义一维数组:// 定义一维数组int array[N];上述代码中,N表示数组的大小,int表示数组元素的类型。
我们可以根据实际需要替换int为其他类型,如float、double等。
2.2 多维数组定义多维数组是由多个一维数组组成的,可以看作是一个矩阵。
在CUDA中,我们可以使用以下方式定义多维数组:// 定义二维数组int array[M][N];上述代码中,M和N分别表示数组的行数和列数,int表示数组元素的类型。
同样,我们可以根据实际需要替换int为其他类型。
三、寻找数组最大值在CUDA中,寻找数组中的最大值是一个常见的问题。
我们可以使用不同的算法和方法来实现这个目标。
3.1 串行算法串行算法是最直观和简单的方法,它通过遍历数组的所有元素来找到最大值。
以下是一个使用串行算法寻找一维数组最大值的示例代码:int findMax(int array[], int size) {int max = array[0];for (int i = 1; i < size; i++) {if (array[i] > max) {max = array[i];}}return max;}上述代码中,array表示输入的一维数组,size表示数组的大小。
CUDACC编程介绍培训

CUDACC并行计算实践
CUDACC编程基础
01
讲解CUDACC的编程基础,包括数据类型、内存管理、线程模
型等。
CUDACC并行算法设计
02
介绍如何使用CUDACC设计并行算法,包括矩阵运算、图像处
理、物理模拟等。
CUDACC并行计算案例
03
展示一些使用CUDACC实现的并行计算案例,如N体问题模拟、
图像变换
实现图像缩放、旋转、仿 射变换等操作,利用GPU 并行计算能力加速处理过 程。
图像分割与识别
应用CUDACC于图像分割 算法,如k-means聚类、 区域生长等,实现快速图 像分割与目标识别。
CUDACC在科学计算中的应用
线性代数运算 利用CUDACC加速矩阵运算,如矩 阵乘法、LU分解等,提高计算性能。
更强大的硬件支持
随着GPU硬件的不断发展,CUDA将能够利用更强大的计算能力来加速更广泛的应用领域。
REPORT
THANKS
感谢观看
CATALOG
DATE
ANALYSIS
SUMMAR Y
跨平台性
CUDA支持多种操作系统和硬件平台,具 有良好的跨平台性,方便开发者在不同环 境下进行开发和部署。
REPORT
CATALOG
DATE
ANALYSIS
SUMMAR Y
02
CUDACC编程基础
C/C基础知识
变量和数据类型
了解C/C中的基本数据类型,如int、float、double等,以及变量的 声明和初始化。
分享一些CUDACC并行计算的最佳实践,包括代码优化技巧、调试技巧
等。
REPORT
CATALOG
DATE
linux cuda cudnn 卸载

linux cuda cudnn 卸载【原创实用版】目录1.介绍 CUDA 和 cuDNN2.CUDA 和 cuDNN 的安装3.CUDA 和 cuDNN 的卸载4.总结正文一、介绍 CUDA 和 cuDNNCUDA(Compute Unified Device Architecture)是 NVIDIA 推出的一种通用并行计算架构,它允许开发人员利用 NVIDIA GPU 进行高性能计算。
而 cuDNN(CUDA Deep Neural Network library)是专为深度神经网络推理设计的 GPU 加速库,它提供了一套高效的算法,可以大大提高深度学习模型的推理速度。
二、CUDA 和 cuDNN 的安装在安装 CUDA 和 cuDNN 之前,确保系统满足安装要求,如操作系统、CUDA 版本等。
安装过程如下:1.下载 CUDA 工具包和 cuDNN 库。
2.解压 CUDA 工具包,并配置环境变量。
3.将 cuDNN 库文件复制到 CUDA 安装目录。
4.在编译器中添加 CUDA 和 cuDNN 路径。
5.测试安装是否成功。
三、CUDA 和 cuDNN 的卸载卸载 CUDA 和 cuDNN 的过程如下:1.依次运行如下命令:```cd /usr/local/cuda-11.5/bin./cuda-uninstaller```会出现要卸载的选择,直接按 Enter 键选择,下键到 Done 即可。
成功后,会出现如下的提示。
2.直接删除 Linux 里面解压文件即可。
四、总结本文介绍了 CUDA 和 cuDNN 的概念、安装和卸载方法。
CUDA 和cuDNN 为深度学习开发者提供了强大的硬件加速支持,但在使用过程中,可能会遇到各种问题,需要进行卸载。
cuda显存分配方式

CUDA显存分配方式1. 背景介绍CUDA(Compute Unified Device Architecture)是美国NVIDIA公司推出的一种并行计算架构,可以利用GPU(Graphics Processing Unit)的强大计算能力来加速各种计算任务。
在CUDA编程中,显存(Graphics Memory)是GPU上的一种特殊内存,用于存储计算中所使用的数据。
显存分配方式是指在CUDA程序运行中,如何有效地分配和利用显存空间。
显存的分配方式对程序的性能和效率有着重要的影响,因此合理分配显存是CUDA编程中不可忽视的一部分。
2. CUDA显存分配方式在CUDA编程中,通常有两种主要的显存分配方式:静态分配(Static Allocation)和动态分配(Dynamic Allocation)。
下面将对这两种分配方式进行详细介绍。
2.1 静态分配静态分配是指在程序运行之前就确定了每个变量所占用的显存空间。
在CUDA中,可以使用__device__关键字将变量声明为设备变量(Device Variable),并在程序的顶层定义。
静态分配的好处是内存访问速度快,因为所有显存的分配和释放都在编译时确定,无需在运行时再进行额外的内存操作。
使用静态分配时,可以通过以下方式指定显存分配的位置和大小:__device__ int d_staticVar; // 声明一个设备变量,占用一个整数的显存空间__device__ int d_staticArray[100]; // 声明一个设备数组,占用100个整数的显存空间__shared__ int sharedArray[256]; // 声明一个共享数组(Shared Memory),占用256个整数的显存空间静态分配的显存空间在程序的生命周期内都不会发生改变,因此需要提前估计和分配足够的空间。
如果程序中的变量或数组引用超过了静态分配的空间范围,就会发生溢出错误。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何选购硬件
目前(2008. 12)只有CUDA能够完全发挥新一 代GPU的全部计算能力。Nvidia的G80以上的 GPU能够支持CUDA。
GT200系列不仅性能更强,而且具有很多实用 的新特性
Tesla专用流处理器拥有更大的显存和更高的核 心频率,通过降低显存频率,屏蔽不需要的图形 单元和改善散热获得了更好的稳定性,适合服务 器或者集群使用
CUDA基本介绍
基于Nvidia GPU的通 用计算开发 张舒
电子科技大学 电子工程学院 06级硕士研究生 信号探测与获取技术专业 研究方向:合成孔径雷达成像与雷达目标像识别 信号处理与模式识别的算法与硬件实现研究
GPU的优势
强大的处理能力 GPU接近1Tflops/s
高带宽
140GB/s
不适合的应用
需要复杂数据结构的计算如树,相关矩阵,链表, 空间细分结构等,则不适用于使用GPU进行计 算。
串行和事务性处理较多的程序 并行规模很小的应用,如只有数个并行线程 需要ms量级实时性的程序
需要重新设计算法和数据结构或者打包处理
CUDA 执行模型
重点是将CPU做为终端(Host),而GPU做为服务 器(Server)或协处理器(Coprocessor),或者设备 (Device),从而让GPU来运行一些能够被高 度线程化的程序。
Kernel不是一个完整的程序,而只是其中的一个 关键并行计算步
Kernel以一个网格(Grid)的形式执行,每个网格 由若干个线程块(block)组成,每一个线程块 又由最多512个线程(thread)组成。
grid block thread
一个grid最多可以有65535 * 65535个block 一个block总共最多可以有512个thread,在三个
如果一个warp内需要执行N个分支,那么SM就需要把每一 个分支的指令发射到每一个SP上,再由SP根据线程的逻 辑决定需不需要执行。这是一个串行过程,此时SIMT完 成分支的时间是多个分支时间之和。
存储器模型
Register Local shared Global Constant Texture Host memory Pinned host memory
CUDA的硬件架构适合通用计算
G8x系 G9x系 GT200系列 标量机架构提高了处理效率,更加适合通用计算 增加了shared memory和同步机制,实现线程间
通信 以通用的处理器矩阵为主,辅以专用图形单元
GTX280性能
933 Gflops(MAD)单精度 116 Gflops双精度(MAD )
CUDA的基本思想是尽量得开发线程级并行 (Thread Level Parallel),这些线程能够在硬 件中被动态的调度和执行。
CUDA执行模型
调用核程序时CPU调用 API将显卡端程序的二进 制代码传到GPU
grid运行在SPA上 block运行在SM上 thread运行在SP上
grid block thread
而SIMT中的warp中的每个线程的寄存器都是私 有的,它们只能通过shared memory来进行通信。
分支性能
与现代的微处理器不同,Nvidia的SM没有预测执行机制 -没有分支预测单元(Branch Predicator)。
在需要分支时,只有当warp中所有的线程都计算出各自 的分支的地址,并且完成取指以后,warp才能继续往下 执行。
每个SM中有16K shared memory 一共可以声明64K的constant memory,但每个
SM的cache序列只有8K 可以声明很大的texture memory,但是实际上的
texture cache序列为每SM 6-8K
使用存储器时可能出现的问题
致命问题:无法产生正确结果 多个block访问global同一块,以及block内
constant memory, texture memory
利用GPU用于图形计算的专用单元发展而来的 高速只读缓存
速度与命中率有关,不命中时将进行对显存的访 问
常数存储器空间较小(只有64k),支持随机访问。 从host端只写,从device端只读
纹理存储器尺寸则大得多,并且支持二维寻址。 (一个数据的“上下左右”的数据都能被读入缓 存)适合实现图像处理算法和查找表
频率提高遇到了瓶颈 从p4时代至今主流处理器 频率一直在2GHz-3GHz左右
架构上已无潜力可挖。超线程 多流水线 复杂的 分支预测 大缓存等技术已经将性能发挥到了极 致,但是通用计算中的指令级并行仍然偏低
上述技术占用了芯片上的绝大多数晶体管和面积, 目的却只是让极少数的执行单元能够满负荷工作
寄存器与local memory
对每个线程来说,寄存器都是线程私有的--这与 CPU中一样。如果寄存器被消耗完,数据将被 存 储 在 本 地 存 储 器 ( local memory)。Local memory 对 每 个 线 程 也 是 私 有 的 , 但 是 local memory中的数据是被保存在显存中,而不是片 内的寄存器或者缓存中,速度很慢。线程的输入 和中间输出变量将被保存在寄存器或者本地存储 器中。
低成本
Gflop/$和Gflops/w高于CPU
当前世界超级计算机五百强的入门门槛为 12Tflops/s
一个三节点,每节点4GPU的集群,总处理能力 就超过12Tflops/s,如果使用GTX280只需10万 元左右,使用专用的Tesla也只需20万左右
GPU /CPU计算能力比较
GPU/CPU存储器带宽比较
CUDA:目前最佳选择
未来的发展趋势
GPU通用计算进一步发展:更高版本的CUDA, OpenCL
新产品涌现:Nvidia和AMD的下一代产品,Intel 的LarraBee
CPU+GPU产品:减少了CPU-GPU通信成本, 但存储器带宽和功耗面积等可能将制约集成度。 在较低端的应用中将有用武之地。
短
GPU
1.78 (FX9800GTX+)
较小 容易 无需修改代码 通过PCI-E,实际速度一 般为3G左右,通过API实 现,较简单 低 显存,容量较大,速度 高 短
FPGA
1.02 (互联网资料中单片FPGA最大
值)
大
难
需要修改代码
需要为FPGA编写额外的驱动 程序,实现通信协议需要额
外的硬件资源
SIMT编程模型
SIMT是对SIMD(Single Instruction, Multiple Data,单指令多数据)的一种变形。
两者的区别在于:SIMD的向量宽度是显式的, 固定的,数据必须打包成向量才能进行处理;而 SIMT中,执行宽度则完全由硬件自动处理了。 (每个block中的thread数量不一定是32)
适合的应用
GPU只有在计算高度数据并行任务时才能发挥 作用。在这类任务中,需要处理大量的数据,数 据的储存形式类似于规则的网格,而对这写数据 的进行的处理则基本相同。这类数据并行问题的 经典例子有:图像处理,物理模型模拟(如计算 流体力学),工程和金融模拟与分析,搜索,排 序。
在很多应用中取得了1-2个数量级的加速
硬件资源模块化,根据市场定位裁减 高度并行 存在TPC SM 两层 每个SM又有8SP SM内存在高速的shared memory和同步机制 原子操作有利于实现通用计算中的数据顺序一致
性 shared memory Texture cache constant
cache等高速片内存储器有助于提高数据访问速 度,节省带宽
GPU/CPU架构比较
延迟与吞吐量
CPU: 通过大的缓存保证线程访问内存的低延迟, 但内存带宽小,执行单元太少,数据吞吐量小 需要硬件机制保证缓存命中率和数据一致性
GPU: 高显存带宽和很强的处理能力提供了很大 的数据吞吐量 缓存不检查数据一致性 直接访问显存延时可达数百乃至上千时钟周期
单核CPU已经走到了尽头
GPU能够更好的利用摩尔定律提供的 晶体管
图形渲染过程高度并行,因此硬件也是高度并行 的
少量的控制单元,大量的执行单元 显存被固化在了PCB上,拥有更好的EMI性能,
因此运行频率高于内存 通过更大的位宽实现了 高带宽
当前的单核并行计算产品
IBM Cell 应用主要见于PS3 SUN Niarraga NPU NV/ATI GPU 大规模应用
Shared memory
用于线程间通信的共享存储器。共享存储器是一 块可以被同一block中的所有thread访问的可读 写存储器。
访问共享存储器几乎和访问寄存器一样快,是实 现线程间通信的延迟最小的方法。
共享存储器可以实现许多不同的功能,如用于保 存共用的计数器(例如计算循环次数)或者block的 公用结果(例如计算512个数的平均值,并用于以 后的计算)。
全局存储器
使用的是普通的显存,无缓存,可读写,速度慢 整个网格中的任意线程都能读写全局存储器的任
意 位 置 , 并 且 既 可 以 从 CPU 访 问 , 也 可 以 从 CPU访问。
各种存储器的延迟
register: 1 周期 shared memory: 1 周期( 无bank conflict ) - 16
周期( 发生16路 bank conflict) texture memory: 1 ( 命中) - 数百周期(不命中) constant memory: 1 ( 命中) - 数百周期( 不命中) global local memory: 数百周期
各存储器大小
每个SM中有64K(GT200)或者32K(G8x, G9x) 寄存器,寄存器的最小单位是32bit的register file
GPU最为常见,受市场牵引发展最快,性价比 最高
架构比较
CPU GPU FPGA实现比较