NvidiaGPU性能对比
NVIDIA显卡强化计算性能

NVIDIA显卡强化计算性能随着科技的不断发展,电脑的计算需求也越来越高。
在众多的计算设备中,NVIDIA显卡以其强大的计算性能和较低的功耗成为了计算领域的热门选择。
本文将对NVIDIA显卡的强化计算性能进行详细探讨,以帮助读者更好地了解和利用这一先进技术。
一、NVIDIA显卡的计算能力NVIDIA显卡作为一种图形处理器,其强大的计算能力源于其并行计算架构。
与传统的中央处理器(CPU)相比,NVIDIA显卡具有更多的处理单元和更高的并行度,这使得它能够同时处理多个计算任务,从而大大提高了计算效率。
二、NVIDIA显卡的硬件优势NVIDIA显卡在硬件方面采用了一系列先进的技术,以进一步强化其计算性能。
其中包括以下几个方面:1. CUDA架构:CUDA是NVIDIA开发的并行计算平台和编程模型,通过将计算任务分配给显卡上的多个处理单元,CUDA能够充分发挥显卡的计算能力,提高计算效率。
2. Tensor Cores:Tensor Cores是NVIDIA最新推出的硬件加速技术,专门用于深度学习和人工智能计算。
这些特殊的计算单元能够高效地执行矩阵运算,加速神经网络的训练和推理过程。
3. RT Cores:RT Cores是NVIDIA显卡中用于光线追踪的硬件引擎,通过光线追踪技术可以更真实地模拟光照效果,提高视觉效果的逼真程度。
三、NVIDIA显卡在计算领域的应用由于其强大的计算能力和硬件优势,NVIDIA显卡在计算领域有着广泛的应用。
以下是几个典型的应用场景:1. 科学计算:NVIDIA显卡能够加速各种科学计算,如气象模拟、物理仿真、计算流体力学等。
通过利用显卡的并行计算能力,科学家能够在更短的时间内完成复杂的计算任务。
2. 人工智能:深度学习是目前人工智能领域最热门的技术之一,而NVIDIA显卡在深度学习的训练和推理过程中能够发挥重要的作用。
通过Tensor Cores的加速和CUDA的并行计算能力,科研人员能够更快地训练出准确的神经网络模型。
显卡品牌大比拼NVIDIAvsAMD

显卡品牌大比拼NVIDIAvsAMD 显卡品牌大比拼 NVIDIA vs AMD显卡是计算机硬件中的关键部件,对于电脑性能的提升有着重要的作用。
在这个高度数字化的时代,人们对于图形处理的需求越来越高,所以选择一款优秀的显卡品牌也变得尤为重要。
NVIDIA和AMD作为当今市场上两大知名显卡品牌,一直以来都备受关注。
本文将对NVIDIA和AMD这两个品牌进行详细比较,以助您在购买显卡时做出明智的选择。
一、性能对比1. NVIDIA:NVIDIA是全球领先的图像处理单元(GPU)制造商,以其卓越的性能而闻名。
NVIDIA的显卡采用了最新的架构设计和高性能的处理器,能够提供出色的图形处理性能和流畅的游戏体验。
无论是在游戏还是工作中,NVIDIA显卡都能够轻松处理复杂的图形渲染任务,带来更加真实逼真的视觉效果。
2. AMD:AMD是另一个备受瞩目的显卡品牌,其显卡产品性能同样出色。
与NVIDIA不同,AMD显卡注重性价比和多功能性。
AMD显卡强调的是能够提供高性能的同时,还能满足用户对多媒体和创作工具的需求。
因此,如果您是一位对图形处理和娱乐需求较为平衡的用户,AMD显卡可能会更适合您。
二、技术对比1. NVIDIA:NVIDIA在技术方面一直走在行业的前沿。
该公司研发的DLSS(深度学习超级采样)技术可以通过人工智能的方式提高游戏的分辨率和画质,并减少资源的占用。
此外,NVIDIA还推出了实时光线追踪技术,使得游戏画面的光照效果更加逼真。
NVIDIA一直不断推陈出新,不断引领着显卡技术的发展潮流。
2. AMD:虽然相较于NVIDIA,AMD的技术研发力度稍逊一筹,但该公司同样引入了一些独特的技术。
AMD最新的RDNA2架构采用了高性能和高效能的设计,提供了令人惊艳的游戏性能。
此外,AMD的FreeSync技术可以在与支持的显示器配合使用时消除游戏画面的撕裂和卡顿现象,提升游戏体验。
三、兼容性对比1. NVIDIA:NVIDIA的显卡对于各种操作系统和游戏平台都具有较好的兼容性。
显卡和深度学习为深度学习爱好者推荐的显卡选择

显卡和深度学习为深度学习爱好者推荐的显卡选择深度学习是一种在人工智能领域中发展迅猛的技术,它需要强大的计算能力来处理大量的数据和复杂的计算任务。
而显卡作为计算机硬件的重要组成部分之一,对于深度学习的性能和效果有着重要的影响。
本文将为深度学习爱好者推荐一些适用于深度学习的显卡选择,并介绍它们的特点和性能。
一、NVIDIA GeForce系列显卡1. NVIDIA GeForce GTX 1080 TiNVIDIA GeForce GTX 1080 Ti是一款性能强大的显卡,拥有3584个CUDA核心和11GB的显存。
它的高性能和大显存容量使其在深度学习任务中表现优秀。
其强大的浮点运算能力和高速的内存带宽,能够快速处理大规模的神经网络模型,加速深度学习的训练和推断过程。
2. NVIDIA GeForce RTX 2080 TiNVIDIA GeForce RTX 2080 Ti是NVIDIA最新推出的一款显卡,它采用了基于Turing架构的GPU,拥有4352个CUDA核心和11GB的GDDR6显存。
相比于前一代显卡,RTX 2080 Ti在深度学习任务中能够提供更高的计算性能和更快的内存带宽。
同时,它还支持硬件加速的光线追踪技术,为深度学习和计算机图形学提供了更高的表现力。
二、AMD Radeon系列显卡1. AMD Radeon RX 5700 XTAMD Radeon RX 5700 XT是AMD最新推出的一款显卡,它采用了基于RDNA架构的GPU,拥有2560个流处理器和8GB的GDDR6显存。
它在深度学习任务中表现出色,能够处理大规模的神经网络模型,并为深度学习的训练和推断提供强大的计算性能。
2. AMD Radeon VIIAMD Radeon VII是一款高性能的显卡,拥有3840个流处理器和16GB的HBM2显存。
它采用了先进的制程工艺和高带宽内存技术,为深度学习任务提供出色的性能和内存带宽。
显卡品牌对比NVIDIA和AMD的优劣势分析

显卡品牌对比NVIDIA和AMD的优劣势分析显卡品牌对比 NVIDIA 和 AMD 的优劣势分析在计算机硬件领域,显卡(Graphics Processing Unit,GPU)是承担图像处理和渲染任务的重要组件之一。
在目前市场上的显卡品牌中,NVIDIA 和 AMD 是两个备受关注的竞争对手。
本文将对这两个品牌进行优劣势的分析,以帮助读者在购买显卡时做出明智的选择。
一、性能比较性能是选择显卡时最为重要的考虑因素之一。
在这方面,NVIDIA显卡以其卓越的性能而著称。
NVIDIA GPU 采用了先进的架构和技术,例如CUDA(Compute Unified Device Architecture),这使得其在游戏和专业图形应用中表现出色。
NVIDIA 的高端显卡还配备了较大的显存和更多的CUDA 核心,从而提供更快的计算速度和更流畅的游戏画面。
然而,AMD 也有其独到之处。
AMD 显卡采用了强大的图形处理能力和良好的价格性能比。
特别是在低端和中端市场,AMD 提供了多个性价比较高的选择。
此外,AMD 显卡对于开源社区的支持更为广泛,这使得其在 Linux 系统上的兼容性更好。
二、功耗与散热显卡的功耗和散热问题也是购买时需要考虑的重要因素之一。
在这方面,NVIDIA 在过去几年中取得了显著的进步。
NVIDIA 的显卡架构相对更为高效,能够在确保良好性能的同时保持较低的功耗。
此外,NVIDIA 的显卡通常采用了先进的散热技术,如风扇散热或液冷散热,以保持显卡的温度在合理范围内。
尽管如此,AMD 也在功耗和散热方面取得了一定的进展。
AMD 显卡在功耗管理上比以往更加出色,采用了更有效的电源管理策略。
此外,AMD 的一些显卡产品还支持自家的散热系统技术,提供了良好的散热性能。
三、驱动程序和软件支持驱动程序和软件支持是显卡的关键组成部分,对于用户体验和系统稳定性至关重要。
在这方面,NVIDIA 是业界的领导者之一。
了解电脑图形处理器的不同型号

了解电脑图形处理器的不同型号电脑图形处理器,即Graphics Processing Unit(GPU),是一种用于处理计算机图形和图像的重要组件。
它能够加速图像和视频的处理、呈现复杂的三维图形以及进行高性能计算。
随着科技的发展,市场上出现了各种不同型号的GPU,本文将介绍几种常见的电脑图形处理器型号,帮助读者更好地了解和选择。
一、NVIDIA GeForce系列NVIDIA GeForce系列是目前市场上最为知名和广泛应用的图形处理器之一。
它以出色的性能和可靠性而闻名,适用于各种应用场景,包括游戏、设计和科学计算等。
GeForce系列根据性能和功能的不同,分为不同的型号和系列,如GeForce RTX、GeForce GTX和GeForce MX。
1. GeForce RTX系列GeForce RTX系列是NVIDIA的旗舰级图形处理器,具备强大的实时光线追踪和人工智能计算能力。
它采用了图灵架构和光线追踪技术,能够提供逼真的图形效果和更高的渲染性能。
适用于对图形要求较高的游戏爱好者和专业设计人员。
2. GeForce GTX系列GeForce GTX系列是中高端游戏显卡的代表,性能稳定可靠,适用于大部分游戏和设计应用。
GTX系列拥有出色的处理能力和帧率表现,为玩家提供流畅的游戏体验。
同时,GTX系列还支持VR虚拟现实技术,使用户能够沉浸于虚拟的游戏世界中。
3. GeForce MX系列GeForce MX系列是为轻薄笔记本电脑设计的入门级图形处理器。
它拥有低功耗和高效能的特点,能够提供基本的图形处理能力和满足日常使用需求。
MX系列适合日常办公、浏览网页和轻度图形应用,是性价比较高的选择。
二、AMD Radeon系列AMD Radeon系列是另一家知名的图形处理器制造商。
与NVIDIA GeForce竞争激烈,广受消费者欢迎。
Radeon系列同样提供了丰富的型号和系列,适用于不同的应用场景。
1. Radeon RX系列Radeon RX系列是AMD的高性能图形处理器,主要面向游戏和虚拟现实等应用。
NVIDIA Kepler GPU 性能预测与分析

最早 使 用 到2 m r 8l K p r 产品之『 el 的 e ^
进 行 了严 格 的 保密 工 作 。 不过 世
界 上 没 有 不 透 风 的 墙 , 通 过 本 刊 的 努 力 ,我 们 还 是 搜 集 到 了 不 少 未 经 证 实 、 有 关 Ke l r 最 新 信 p e的
家带来 怎样 的惊 喜 。
假 如 此 消 息 属 实 ,那 么 我 们 可 后 期 生 产 “ 芯 片 ” 打 下 基 础 。 大
以大 胆 推 测 ,NVI A之 所 以一 改 DI
此 外 ,从 时 间上 来 看 ,
NVI A的2 n DI 8 m产 品 既 然 早 在 近
全面导入2 n 8 艺 小核 心 故 辙 主 要 有 两 方 面 原 因 : m工
既 不 是 顶 级 的 GK1 0,也 不 是 消 , 因此 NVI A p e 只 能 直 NV I A之 前 并 没 有 为 双 芯 显 卡 0 DI Ke lr DI
较 强 的 G K 1 4, 而 是 主 流 级 的 接 向 更 加 先 进 的 2 n 工 艺 “ 命 名 过 研 发 代 号 ,这 样 的 消 息 还 0 8 m 进 GK1 7 0 。我 们 知 道 ,NVI A在 化 ” 。  ̄ Ke e 全 线 产 品 都 使 用 值 得商榷 。 DI 1 pl r ] 以 往 总 是 先 生 产 、 发 布 定 位 最 高 2 n ,那 么 则 意 味 着 它 将 具 备 更 8m 端 、 规 模 最 庞 大 、 性 能 最 强 悍 的 大 的 集 成 规 模 、 更 低 的 功 耗 。 但 旗 舰 级 GP U芯 片 , 然 后 再 逐 渐 向
具 体 规 格 依 旧 是 迷 性 能 或
显卡性能对比不同显卡型号的性能表现比较

显卡性能对比不同显卡型号的性能表现比较显卡性能对比:不同显卡型号的性能表现比较在现代计算机领域,显卡作为一种重要的硬件设备,扮演着至关重要的角色。
它不仅决定了图像的质量和流畅度,还影响着计算机游戏、图形设计、数据处理等领域的性能。
随着科技的不断发展,显卡市场也涌现出众多不同型号的产品。
本文将就不同显卡型号的性能表现进行比较和评估。
一、显卡的性能参数首先,我们需要了解显卡的一些基本性能参数,以更好地进行比较。
以下是一些常见的显卡性能参数:1. 图形处理器(GPU):GPU是显卡的核心组件,它决定了显卡的计算能力和图像生成能力。
一般来说,GPU的核心数量越多、频率越高,显卡的性能越强。
2. 显存容量:显存是显卡用来存储图像数据的空间,直接影响显卡的图像处理速度和效果。
较大的显存容量意味着显卡可以处理更大规模的图像数据,对于高分辨率游戏和图形设计等任务来说尤为重要。
3. 显存带宽:显存带宽指的是显存与GPU之间的数据传输速度,通常以GB/s为单位。
较高的显存带宽可以提高数据传输效率,加快图像渲染速度。
4. CUDA核心数:对于支持CUDA加速技术的显卡来说,CUDA 核心数是一个重要的参数。
CUDA是NVIDIA公司开发的一种并行计算架构,可以提高显卡在科学计算、人工智能等领域的性能。
以上仅是显卡性能参数的一部分,不同厂商和型号的显卡还有许多其他参数,如功耗、显卡尺寸、接口类型等。
在选择显卡时,我们可以根据自身需求和预算来权衡这些参数。
二、不同显卡型号的性能对比接下来,我们将对几个不同型号的显卡进行性能对比,并分析它们在不同应用场景下的优势和劣势。
1. NVIDIA GeForce RTX 3080作为NVIDIA的旗舰级显卡,GeForce RTX 3080拥有强大的计算能力和图像处理能力。
它搭载了NVIDIA的Ampere架构和流处理器,具有8704个CUDA核心和10GB的GDDR6X显存。
这款显卡在游戏和图形设计方面表现出色,能够提供超高的帧率和逼真的图像效果。
英伟达GPUA100与3090性能测试及结果数据报告

A100算力测试
一、测试目的
测试A100与3090的性能差距;
二、测试环境
环境为cuda11.1,显卡驱动11.4,pytorch1.9;
GPU利用率均为100%;
使用的网络主要包括以下几种:
(1)、facebookresearch/detectron2框架下的目标检测、实例分割、关键点检测,主干网络为fasterrcnn;
(2)、ultralytics/yolov3;
(3)、lufficc/SSD;
三、测试方法
采用相同的数据集,不改变任何参数,查看训练完指定epochs后的时常;
四、测试结果
五、测试结论
在像facebook这样的团队写的detectron2框架下,A100速度明显快于3090。
但像是个人写的SSD或者小团队写的yolov3上,A100速度慢于SSD。
出现此问题的原因可能是相关代码里面有用到的gpu优化相关的技术,可能在相关gpu优化下,A100才能发挥出应有的性能。
例如detectron2里面就用到了apex库,apex是由Nvidia维护的一个支持混合精度分布式训练的第三方pytorch扩展库。
可以用短短三行代码就能实现不同程度的混合精度加速,使训练时间和显存占用直接缩小一半。
不过实际训练的时候显存差异并不大,A100速度确实是快了很多。
不过Nvidia官方给出的A100的cuda算力是不如3090的。
理论上A100速
度应该是慢于3090的。
显卡天梯图,2022年最新显卡GPU性能排行榜【2022.11桌面端NVIDIAAMD】中正测评

显卡天梯图,2022年最新显卡GPU性能排行榜【2022.11桌面端NVIDIAAMD】中正测评显卡定义显卡又称显示卡( Video card),是计算机中一个重要的组成部分,承担输出显示图形的任务,对喜欢玩游戏和从事专业图形设计的人来说,显卡非常重要。
主流显卡的显示芯片主要由NVIDIA(英伟达)和AMD(超威半导体)两大厂商制造,通常将采用NVIDIA显示芯片的显卡称为N卡,而将采用AMD显示芯片的显卡称为A卡。
而今年,Intel也开始来搅局,将面临三方争霸。
配置较高的计算机,都包含显卡计算核心。
在科学计算中,显卡被称为显示加速卡。
(数据引用:百度百科)显卡功能作用显示芯片( Video chipset)是显卡的主要处理单元,因此又称为图形处理器(GPU),在处理3D图形时,GPU使显卡减少了对CPU的依赖,并完成部分原本属于CPU的工作。
GPU所采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。
显卡所支持的各种3D特效由显示芯片的性能决定。
衡量一个显卡好坏的方法有很多,除了使用测试软件测试比较外,还有很多指标可供用户比较显卡的性能,影响显卡性能的高低主要有显卡频率、显示存储器等性能指标。
显卡性能指标•显卡频率(GPU Clock/显存频率Memory)显卡频率主要指显卡的核心频率和显存频率,均以MHz(兆赫兹)为单位。
一般来说,在同样级别的芯片中,显卡频率高的则性能要强一些。
主流显示芯片只有AMD和NVIDIA两家,两家都提供显示核心给第三方的厂商,在同样的显示核心下,部分厂商会适当提高其产品的显示核心频率,使其工作在高于显示核心固定的频率上以达到更高的性能。
•显示存储器(显存Memory Size)显示存储器也称为帧缓存,其主要功能就是暂时储存显示芯片处理过或即将提取的渲染数据,类似于主板的内存,是衡量显卡的主要性能指标之一。
NVIDIA更新Ampere架构,全面提升GPU应用性能

******************.cn ****************- 30 -采访 Interview文|齐健NVIDIA 更新Ampere 架构,全面提升GPU 应用性能随着数字技术的飞速发展,越来越多的行业对于专业可视化应用的需求加速上涨。
例如,在制造业应用中,CAD 设计阶段对产品的整机建模,零部件复杂的大型装配体设计等,CAE 仿真过程中对材料的模拟、拓扑优化以及多物理场仿真实验等,再到后期销售和推广阶段的效果展示,都对图形渲染效率和GPU 运算能力提出了严苛的要求。
在过去的20年中,专业图形显示技术的更新迭代日趋加快。
NVIDIA 在图形显卡领域,针对不同行业的用户推出了众多专业GPU 产品与应用解决方案,领域覆盖了电视、娱乐、传媒、现场直播、汽车制造、设计、大数据运算、科学运算、专业电影制作以及AI 等。
近年来,NVIDIA 推出的GPU 架构,从Kepler 到Maxwel 、Pascal 、Turing ,再到最近发布的Ampere 架构,NVIDIA 最近发布的五代GPU 架构都在AEC 、BIM 、CAD\CAM 以及仿真等领域推出了大量重要更新,以期提升NVIDIA GPU 在更多专业应用领域的性能表现。
Ampere 架构全面提升GPU 应用性能2020年秋季推出的基于全新Ampere 架构的NVIDIA RTX A6000和NVIDIA A40,采用了全新的RT Core 、Tensor Core 和CUDA Core 加速图形、渲染、计算和AI 。
NVIDIA RTX A6000和NVIDIA A40通过突破性的技术向用户提供更强大的性能,其中最重要的更新就是RTXGPU 的升级,作为第二代RTX GPU ,Ampere 架构与前代RTX GPU 的Turing 架构相比,主要有三方面优势:首先,新一代的SM (新一代流式多处理器)架构最高可以提供39TFLOPS 的FP32算力。
深度学习GPU显卡选型攻略

深度学习GPU显卡选型攻略一、选择算力在5.0以上的根据官方说明,在GPU算力高于5.0时,可以用来跑神经网络。
算力越高,计算能力越强,建议小伙伴们在资金充足的情况下,尽量买算力高一些的。
英伟达GeForce 与 TITAN 显卡算力对比:英伟达 Tesla 显卡算力对比:二、尽量选择大显存显存越高,意味着性能越强悍。
特别是对于CV领域的朋友们,建议至少有一个8GB显存的显卡。
下面是英伟达的部分中高端显卡的一些性能参数。
GeForce 与 TITAN 显卡参数:Tesla 显卡参数:三、GPU几个重要的参数•GPU架构:•不同款的GPU可能采用不同设计架构,比如GeForce 10系列的GTX 1080/1080Ti采用的是Pascal架构,而GeForce 20系列的RTX 2080/2080Ti采用的是Turing架构。
不同架构的GPU,即使其他参数差不多,性能差别可能非常大。
•显存带宽:•代表GPU芯片每秒与显存交换的数据大小,这个值等于显存位宽*工作频率,单位为GB/秒,该值越大,代表GPU性能越好。
Geforce GTX 1080的显存带宽为320GB/秒,而它的升级版Geforce RTX 2080的带宽为448GB/秒。
•显存位宽:•代表GPU芯片每个时钟周期内能从GPU显存中读取的数据大小,这个值越大代表GPU芯片和显存之间数据交换的速度越快,性能越好。
Geforce GTX 1080的显存位宽为256bit,Geforce RTX 2080Ti显存位宽为352bit。
•GPU工作频率:•代表GPU每秒钟工作次数,单位为MHz,跟CPU的频率类似。
该值越大代表性能越好。
•CUDA核心数量:•CUDA核心数量越大越好,Geforce GTX 1080的CUDA核心数量是2560个。
而Geforce RTX 2080Ti的CUDA核心数高达4352个。
•功耗:•GPU能耗,像Geforce这种消费级的显卡一般功耗非常高,Geforce GTX 1080的最大功耗为175W,Tesla P4的最大功耗为75W。
显卡算力排行

显卡算力排行在计算机硬件领域,显卡(Graphics Processing Unit,简称GPU)是一种用于图形处理的专用处理器。
除了在游戏领域发挥重要作用外,显卡的高性能算力也被广泛应用于机器学习、科学计算等领域。
显卡的算力是衡量其处理能力和性能的重要指标之一。
下面将介绍几款具有较高算力的显卡。
1. NVIDIA A100:NVIDIA A100是NVIDIA公司推出的一款基于Ampere架构的顶级数据中心显卡。
它采用了全新的Tensor Core架构,具备巨大的浮点计算能力和深度学习推理性能。
使用南半球剧场32GB HBM2高带宽内存,其单精度浮点性能可达9.7 TFLOPS,双精度浮点性能可达19.5 TFLOPS。
2. AMD Radeon VII:AMD Radeon VII是一款基于7nm工艺制程的顶级显卡。
它采用了Vega架构,并配备了16GB HBM2高带宽内存。
单精度浮点性能可达13.8 TFLOPS,双精度浮点性能可达6.9 TFLOPS。
AMD Radeon VII适用于机器学习、深度学习等需要大规模并行计算的领域。
3. NVIDIA RTX 3090:NVIDIA RTX 3090是NVIDIA公司推出的一款游戏和数据中心两用显卡。
它采用了Ampere架构,具备强大的浮点计算能力。
单精度浮点性能可达35.6 TFLOPS,双精度浮点性能可达11.2 TFLOPS。
NVIDIA RTX 3090适用于高分辨率游戏、深度学习等领域。
4. AMD Radeon RX 6900 XT:AMD Radeon RX 6900 XT是一款基于7nm工艺制程的顶级显卡。
它采用了RDNA 2.0架构,并配备了16GB GDDR6内存。
单精度浮点性能可达16.2 TFLOPS,双精度浮点性能可达5.1 TFLOPS。
AMD RadeonRX 6900 XT适用于游戏、科学计算等领域。
5. NVIDIA RTX 3080:NVIDIA RTX 3080是一款游戏和数据中心两用显卡。
AMD和NVIDIA的GPU特点及优势

AMD和NVIDIA的GPU特点及优势
AMD和NVIDIA是目前两家最大的GPU制造商,在全球各大游戏主机、台式电脑、笔记本电脑及数据中心计算机市场中拥有巨大的市场份额。
两
家公司的GPU分别拥有不同的特点及优势。
下面我们将介绍一下AMD和NVIDIA在GPU市场中的特点及优势。
AMD的GPU具有低成本、高工作能力和更好的性能/价格比的特点。
AMD的GPU能够以相对较低的价格处理高性能的游戏,尤其是数据中心应
用中,可以大大降低显示性能和使用成本。
此外,AMD拥有业界最先进的
技术,如FreeSync技术,可以消除画面卡顿、撕裂、拖拽等现象,改善
游戏的画质。
NVIDIA的GPU具有高性能、高显示质量和高能效的特点。
NVIDIA的GPU具有最先进的显卡技术,如NVIDIARTX光线跟踪技术,能够提供令人
惊叹的画质效果。
此外,其显卡也能够支持多屏幕显示,可以实现更好的
游戏体验。
此外,NVIDIAGPU还具有高能效的特点,可以通过节能技术减
少功耗,降低运行温度,延长耐用性。
总之,AMD和NVIDIA的GPU拥有不同的特点及优势,以不同的方式
满足消费者的个性化需求。
显卡详细参数对比和分析

显卡详细参数对比和分析显卡是计算机中的一个重要组成部分,它负责处理图形和影像相关的计算任务。
显卡的性能对计算机的图形处理能力和游戏性能有着很大的影响。
在市场上有各种不同的显卡型号,它们具有不同的参数和技术特点。
下面将对显卡的详细参数进行对比和分析。
1.显存容量:显存是显卡用于存储图像和视频数据的内存。
较大的显存容量有助于处理更复杂的图像和视频数据,并提供更好的游戏性能。
目前显存容量在2GB到16GB之间,通常来说高端显卡具有更大的显存容量。
2.核心频率:显卡的核心频率指的是其核心处理单元(GPU)的工作频率。
较高的核心频率意味着更快的计算速度和更出色的性能。
显卡的核心频率通常在1GHz到2GHz之间,不同的显卡在核心频率上可能有所不同。
3.流处理器数量:流处理器是显卡中执行并行计算的核心部分。
较多的流处理器数量可以提供更好的并行计算性能,对于计算密集型任务和游戏来说非常重要。
目前流处理器数量从几百个到几千个不等,高端显卡通常具有更多的流处理器数量。
4.纹理单元数量:纹理单元是显卡中用于处理纹理贴图的部分。
较多的纹理单元数量可以提供更高的纹理处理能力,对于游戏来说尤为重要。
目前纹理单元数量从几十个到几百个不等。
5.输出接口:显卡上的输出接口决定了它所能连接的显示器种类和数量。
目前常见的输出接口有HDMI、DisplayPort和DVI等。
不同的显卡在输出接口上可能有所不同,选择适合自己需求的输出接口是很重要的。
6.功耗:显卡的功耗决定了它在运行时所需要的能量,较高的功耗意味着显卡在工作时会产生较多的热量。
功耗较高的显卡通常需要更好的散热系统来保持稳定的工作状态。
7.架构:显卡的架构指的是其内部设计的方式和结构。
常见的显卡架构有NVIDIA的Pascal和Turing架构,以及AMD的GCN架构。
不同的架构会在性能和功耗上有所差异,选择适合自己需求的显卡架构很重要。
通过对显卡的详细参数进行对比和分析,我们可以选择适合自己需求的显卡。
AMD和NVIDIA的GPU特点及优势

AMD和NVIDIA的GPU特点及优势
1、低成本:AMDGPU的价格更加实惠,用户可以更轻松地拥有一台高性能多元处理器,从而满足自己的需求。
2、高性能:AMD的图形处理器是具有强大的图形处理单元(GPU),具有显着的计算能力,可以完成复杂的计算任务。
3、更低功耗:AMD的GPU确保更低的功耗,提供高性能的同时,降
低了系统的功耗,从而确保用户的更长的计算时间。
4、高帧率:AMD的GPU拥有更高的帧率,可以实现更流畅的游戏体
验和流媒体视频播放。
5、支持多种技术:AMD的GPU支持多种创新的技术,包括DirectX 12、OpenCL 2.0和AMD FreeSync,使开发商可以使用更多的创新技术。
1、高性能:NVIDIA的GPU是具有强大的图形处理单元(GPU),并
具有强大的计算能力,可以完成复杂的计算任务。
2、高频率:NVIDIA的GPU拥有更高的频率,可以提升多媒体游戏等游戏的性能,从而获得更流畅的画面。
3、图形技术支持:NVIDIA的GPU支持最新的图形技术,包括NVIDIA CUDA,NVIDIA PhysX,NVIDIA SLI,NVIDIA 3D Vision,NVIDIA G-Sync 等,可以为用户提供更加完善的图形体验。
4、集群系统支持:NVIDIA的GPU可以支持跨设备的集群系统,从而提供灵活的并行计算能力。
5、低功耗:NVIDIA的GPU可以降低系统的功耗,从而提升用户的使用体验。
显卡性能排行榜

显卡性能排行榜显卡性能排行榜是对市场上各种显卡性能进行评估和排名的榜单。
随着电子游戏的飞速发展,玩家对于显卡性能的需求也越来越高。
在这篇文章中,我们将为大家介绍一份700字的显卡性能排行榜。
首先,我们来介绍一些目前市场上最受欢迎的显卡品牌:1. NVIDIA:NVIDIA是目前市场上最大的显卡制造商之一,推出了一系列高性能显卡,如RTX 3080、RTX 3070等。
2. AMD:AMD的显卡在性价比方面表现出色,其RX 6000系列显卡是目前市场上最受关注的产品之一。
接下来,我们将列举一些当前市场上性能较为出色的显卡:1. NVIDIA GeForce RTX 3080:这款显卡是NVIDIA推出的一款顶级游戏显卡,采用了7nm制程工艺和Ampere架构,具备令人瞩目的性能表现和功耗。
它是目前市场上最强大的显卡之一,适用于高端游戏和专业应用。
2. AMD Radeon RX 6800 XT:这款显卡是AMD最新推出的顶级显卡之一,采用了7nm制程工艺和RDNA 2架构,拥有强大的游戏性能和高效的能源利用率。
它是当前市场上最具竞争力的显卡之一,适合高端游戏和创意应用。
3. NVIDIA GeForce RTX 3070:这款显卡是NVIDIA推出的中高端游戏显卡,采用了7nm制程工艺和Ampere架构,性能优秀,功耗较低。
它是当前市场上性价比最高的显卡之一,适合追求高品质游戏体验的玩家。
4. AMD Radeon RX 6700 XT:这款显卡是AMD最新推出的中高端显卡之一,采用了7nm制程工艺和RDNA 2架构,具有卓越的性能和优秀的性价比。
它适合中高端游戏和创意应用。
5. NVIDIA GeForce RTX 3060:这款显卡是NVIDIA推出的中端游戏显卡,采用了7nm制程工艺和Ampere架构,具备出色的游戏性能和能效。
它是当前市场上性价比较高的显卡之一,适合追求平衡性能和价格的玩家。
英伟达Tegra 2完胜高通8260
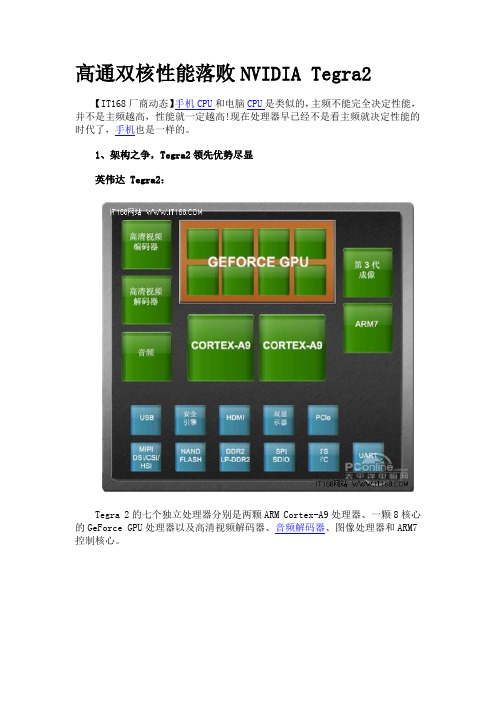
高通双核性能落败NVIDIA Tegra2【IT168厂商动态】手机CPU和电脑CPU是类似的,主频不能完全决定性能,并不是主频越高,性能就一定越高!现在处理器早已经不是看主频就决定性能的时代了,手机也是一样的。
1、架构之争,Tegra2领先优势尽显英伟达 Tegra2:Tegra 2的七个独立处理器分别是两颗ARM Cortex-A9处理器、一颗8核心的GeForce GPU处理器以及高清视频解码器、音频解码器、图像处理器和ARM7控制核心。
七个处理器独立处理任务七颗独立的处理器让Tegra 2无论在上网、音视频播放、图像处理器以及3D游戏的Flash加速方面都能得心应手。
高通MSM8260和NVIDA Tegra2相比,前者为A8双核-总线结构链接双核,以及每颗单独的256K二级缓存(双核A9统一是共享1M的),严重拖慢了adreno220(GPU)的表现,俗称胶水双核,而Tegra2是双核的A9。
从架构上高通8260就显落败之势。
2、使用体验比较:Tegra2全面取胜在使用体验尤其是游戏体验上,凭借规格强大的硬件支持下,Tegra2在和对手高通MSM8260的较量中,优势更是十分明显。
作为老牌显卡厂商,在显示方面的出色表现可谓是NVIDIA的拿手好戏。
没错,NVIDIA却是做到了这一点,基于Tegra2核心的手机可以享受到于其他手机完全不同的视觉冲击,而这就是NVIDIA一直推崇的专属游戏,这在PC市场早有历史,但是在手机市场却非常创新。
NVIDIA在图形计算领域的地位毋庸置疑,在移动平台方面,从一代开始,内建GeForce GPU的Tegra家族就展现出3D图形运算和高清编解码方面的实力,三年的发展让Tegra处理器成为智能手机和平板电脑上高娱乐性的代表。
目前NVIDIA专门针对双核手机推出了Tegra Zone平台,在这里面可以下载到专属的Tegra游戏,在整个游戏体验当中让我们可以更加了解双核心的澎湃性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Nvidia GPU性能对比
目前Nvidia推出支持CUDA架构用GPU运算的图形处理器分别:GeForce系列、Quadro 系列、及专业GPU Tesle系列。
从价格上来排序为GeForce最便宜为Tesla的1/2不到。
Quadro 价格比Tesla更高暂不评测。
从Nvidia推出GPU运算以来,很多专业人士就不断尝试用GeForce显卡来做GPU运算,核心数量一样,价格有很大优势,从表面上看就是内存好像比Tesla少了些。
究竟性能如何来看一下,下面测试GeForce GTX470性能测试。
GeForce GTX470参数:
下面用GPU基准测试软件对GTX470各个方面进行了测试,Nvidia GTX470单精度浮点运算性能为1049Gflops,而Tesla C2050的单精度浮点运算为1.03Tflops,说明在单精度浮点运算方面GTX470与C2050性能相当。
下面再在对比一下双精度浮点运算。
由下图可能看出GTX470的双精度浮点运算为134Gflops,是单精度浮点运算的1/8,我们再来看一下C2050的双精度浮点运算为515Gflops.由此可见Nvidia采用Fermi架构后双精度浮点运算能力C2050要远远大于GTX470。
下面再来看一下GTX470其它方面的性能
Tesla C2O50参数
由上图对比可以看出GTX470与C2050 除内存不同、与内存带宽不同其它几乎相同。
而Nvidia为什么推出专业的GPU运算处理器Tesla系列,而不采用GeForce显卡来做并行运算呢?而Tesla C2050系列处理器将近GeForce GTX470价格的三倍,到底不何不同呢?
根据测试及Nvidia官方资料做出了以下总结:
首先,Tesla系列比GeForce系列内存要高出一倍,而通过CUDA开发的程序要做一个并行运算,首先要把数据调入显存,显存与GPU的每个核心交换数据,这样显卡的内存越大对大规模的并行运算程序越好。
运行小程序中表现不出来。
通过以上测试GeForce显卡双精度浮点运算约为单精度浮点运算的1/8,而Tesla Fermi 系列双精度约为单精度的1/2.这是因为Nvidia设计不同,GeForce采用了openGL图形加速度技术。
而降低的双精度浮点运算的性能。
Tesla不支持openGL加速度技术,而增强的双精度浮点运算性能。
Geforce显卡还支持3D立体幻影、NVIDIA PureVideo等。
Tesla支持异步传输、并行datacache技术等,由此可见GeForce专为图形处理而设计,Tesla专为并行运算而设计。
.
建议用户在选择购买GPU时根据需求来选择是用Tesla还是GeForce。
如果你是企业用户主要工作处理大规模地震资料,石油及天燃汽应用最好选择Tesla系统,因为这些程序所处理的数据一般为TB甚至PB的海量数据,需要大容量内存支持。
如果你所应用程序为分子动力学等软件,可选择采用GeForce 系列。
选择Geforce时为能达到高的稳定性最好选择降频使用。