遥感上机监督分类与非监督分类
实习监督分类与非监督分类
1. 选取研究区数据(512×512),通过目视解译建立分类系统及其编码体系根据实习要求,在遥感影像上确定并提取出了12种地物,分别是居民点、砾石、道路、河流、水稻田、水浇地、水库、裸地、工业区、滩地、林地。
同时确定土地的覆盖类型、编码以及色调。
居民点Town 砾石gravel desert道路Road 水稻田paddy land水浇地irrigated land 水库reservoir裸地barren land 工业区industrial area滩地shoaly land 林地forest草地grassland 河流stream2. 按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
加载512*512影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
3. 计算各个样本之间的可分离性。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择中卫影像,点击确定,选择所有训练区,统计J—M距离和分散度。
4. 监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色5. 分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,并对结果进行解释。
实验四遥感图像的监督分类和非监督分类

实验四遥感图像的监督分类和⾮监督分类实验四遥感图像的⾮监督分类与监督分类⼀、实验⽬的1.⾮监督分类是对数据集中的像元依据统计数字,光谱类似度和光谱距离进⾏分类,在没有⽤户定义的条件下练习使⽤,在ENVI环境下的⾮监督分类技术有两种:迭代⾃组织数据分析技术(ISodata)和K均值算法(K-Means);2.分类过程中应注意:1)怎样确定⼀个最优的波段组合,从⽽达到最佳的分类精度,基于OIF和相关系数,协⽅差矩阵以及经验的使⽤来完成对最适合的组合的选取,分类效果的关键即在于此;2)K-Means的基本原理;3)Isodata的基本原理;4)分类结束后,被分类后的图像是⼀个新的图像,被分类类码秘填充,从⽽可以获得数据提取信息,统计不同类码数量,转化为实际⾯积,在得到后的图像上,可对不同⽬标的形态指标进⾏分析。
3.对训练区中的像元进⾏分类;4.⽤训练数据集估计查看监督分类后的统计参数;5.⽤不同⽅法进⾏监督分类,如最⼩距离法、马⽒距离法和最⼤似然法。
⼆、实验设备与材料1、软件ENVI 4.7软件2、所需材料TM数据三、实验步骤1.选择最优的波段组合ENVI主⼯具栏中File →Open image file →选择hbtmref.img打开→在Basic Tools中选择Statistics →Compute statistics选定原图,在Spectral subset中可选项全部选定→OK →OK →全选→保存→OK,则各类统计数字均可查;OIF计算,选择分类波段:1,2;2,3;1,3波段标准差分别为2.665727;3.473308;4.574609,和为10.713644。
Correlation Matrix 中1和2波段的相关系数0.964308,加上2和3波段的相关系数0.980166,再加上1和3波段的相关系数0.945880,最终等于2.890354。
⽤标准差相加的结果10.713644⽐上相关系数之和2.890354等于3.70668922。
遥感图像几种分类方法的比较

摘要遥感图像分类一直是遥感研究领域的重要内容,如何解决多类别的图像的分类识别并满足一定的精度,是遥感图像研究中的一个关键问题,具有十分重要的意义。
遥感图像的计算机分类是通过计算机对遥感图像像素进行数值处理,达到自动分类识别地物的目的。
遥感图像分类主要有两类分类方法:一种是非监督分类方法,另一种是监督分类方法。
非监督分类方法是一个聚类过程,而监督分类则是一个学习和训练的过程,需要一定的先验知识。
非监督分类由十不能确定类别属性,因此直接利用的价值很小,研究应用也越来越少。
而且监督分类随着新技术新方法的不断发展,分类方法也是层出不穷。
从传统的基十贝叶斯的最大似然分类方法到现在普遍研究使用的决策树分类和人工神经网络分类方法,虽然这些方法很大程度改善了分类效果,提高了分类精度,增加了遥感的应用能力。
但是不同的方法有其不同优缺点,分类效果也受很多因素的影响。
本文在对国内外遥感图像分类方法研究的进展进行充分分析的基础上,应用最大似然分类法、决策树分类法对TM影像遥感图像进行了分类处理。
在对分类实现中,首先对分类过程中必不可少的并影响分类效果的步骤也进行了详细地研究,分别是分类样本和分类特征;然后详细介绍两种方法的分类实验;最后分别分析分类结果图,采用混淆矩阵和kappa系数对两种方法的分类结果进行精度评价。
关键词:TM遥感影像,图像分类,最大似然法,决策树题目:遥感图像几种分类方法的比较........................................ 错误!未定义书签。
摘要.. (1)第一章绪论 (3)1.1遥感图像分类的实际应用及其意义 (4)1.2我国遥感图像分类技术现状 (5)1.3遥感图像应用于测量中的优势及存在的问题 (6)1.3.1遥感影像在信息更新方面的优越性 (6)1.3.2遥感影像在提取信息精度方面存在的问题 (6)1.4研究内容及研究方法 (8)1.4.1研究内容 (8)1.4.2 研究方法 (8)1.5 论文结构 (9)第二章遥感图像的分类 (9)2.1 监督分类 (9)2.1.1 监督分类的步骤 (9)2.1.2 最大似然法 (11)2.1.3 平行多面体分类方法 (12)2.1.4 最小距离分类方法 (13)2.1.5监督分类的特点 (13)2.2 非监督分类 (14)2.2.1 K-means算法 (14)K-均值分类法也称为 (14)2.2.2 ISODATA分类方法 (15)2.2.3非监督分类的特点 (17)2.4遥感图像分类新方法 (17)2.4.1基于决策树的分类方法 (17)2.4.2 人工神经网络方法 (19)2.4.3 支撑向量机 (20)2.4.4 专家系统知识 (21)2.5 精度评估 (22)第三章研究区典型地物类型样本的确定 (24)3.1 样本确定的原则和方法 (24)3.2 研究区地物类型的确定 (24)3.3样本区提取方案 (25)3.4 各个地物类型的样本的选取方法 (25)3.4.1 建立目视解译标志 (25)3.4.2 地面实地调查采集 (26)3.4.3 利用ENVI遥感图像处理软件选取样本点 (26)第四章遥感图像分类实验研究 (26)4.1遥感影像适用性的判定 (26)4.2分类前的预处理 (28)4.2.1空间滤波的处理 (28)4.2.2 频域滤波处理 (28)4.3利用ENVI软件对影像按照不同的分类方法进行监督分类 (30)4.3.1监督分类 (30)4.3.2 决策树 (33)4.4分类后的处理 (35)4.5 精度的比较 (36)第五章结论和展望 (37)参考文献 (37)致谢 (39)第一章绪论土地利用研究是全球环境变化研究的重要组成部分,土地利用变化驱动因子的研究也是目前研究的热点之一。
监督分类和非监督分类
影像的分类可分为监督与非监督分类。
监督分类器根据其原理有基于传统统计分析的、基于神经网络的、基于模式识别的等。
本专题以ENVI的监督与非监督分类的实际操作为例,介绍这两种分类方法。
有以下内容组成:∙ ∙ ●非监督分类∙ ∙ ●监督分类∙ ∙ ●分类后处理非监督分类非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
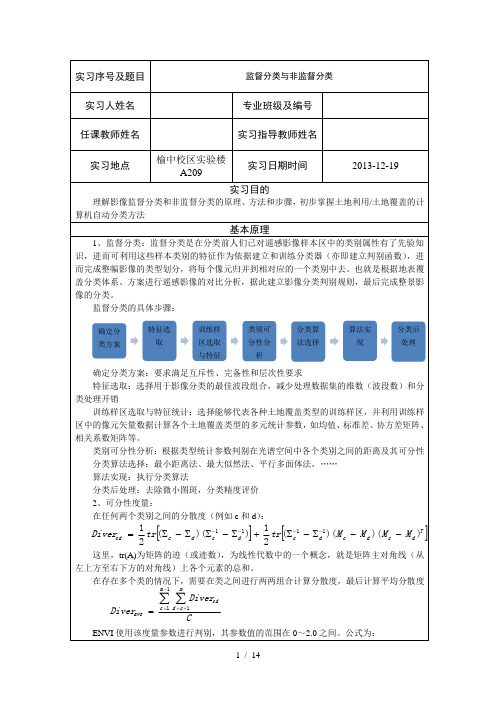
遥感影像的非监督分类一般包括以下6个步骤:图1 非监督分类操作流程1、影像分析大体上判断主要地物的类别数量。
一般监督分类设置分类数目比最终分类数量要多2-3倍为宜,这样有助于提高分类精度。
本案例的数据源为ENVI自带的Landsat tm5数据Can_tmr.img,类别分为:林地、草地/灌木、耕地、裸地、沙地、其他六类。
确定在非监督分类中的类别数为15。
2、分类器选择目前非监督分类器比较常用的是ISODATA、K-Mean和链状方法。
ENVI包括了ISODATA和K-Mean方法。
ISODATA(Iterative Self-Orgnizing Data Analysize Technique)重复自组织数据分析技术,计算数据空间中均匀分布的类均值,然后用最小距离技术将剩余像元进行迭代聚合,每次迭代都重新计算均值,且根据所得的新均值,对像元进行再分类。
K-Means使用了聚类分析方法,随机地查找聚类簇的聚类相似度相近,即中心位置,是利用各聚类中对象的均值所获得一个“中心对象”(引力中心)来进行计算的,然后迭代地重新配置他们,完成分类过程。
3、影像分类打开ENVI,选择主菜单->Classification->Unsupervised->IsoData或者K-Means。
envi遥感图像监督分类与非监督分类

envi遥感图像监督分类监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。
它就是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
使每个像元和训练样本作比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。
遥感影像的监督分类一般包括以下6个步骤,如下图所示:详细操作步骤第一步:类别定义/特征判别根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。
这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
启动ENVI5.1,打开待分类数据:can_tmr.img。
以R:TM Band 5,G: TM Band 4,B:TM Band 3波段组合显示。
通过目视可分辨六类地物:林地、草地/灌木、耕地、裸地、沙地、其他六类。
第二步:样本选择(1)在图层管理器Layer Manager中,can_tmr.img图层上右键,选择"New Region Of Interest",打开Region of Interest (ROI) Tool面板,下面学习利用选择样本。
1)在Region of Interest (ROI) Tool面板上,设置以下参数:ROI Name:林地ROI Color:2)默认ROIs绘制类型为多边形,在影像上辨别林地区域并单击鼠标左键开始绘制多边形样本,一个多边形绘制结束后,双击鼠标左键或者点击鼠标右键,选择Complete and Accept Polygon,完成一个多边形样本的选择;3)同样方法,在图像别的区域绘制其他样本,样本尽量均匀分布在整个图像上;4)这样就为林地选好了训练样本。
遥感影像监督分类与非监督分类的比较

第34 卷第3 期2004 年9 月河南大学学报(自然科学版)Journal of Henan U n iversity ( N at u ral Science)Vol . 34 No . 3Sep . 2004 遥感影像监督分类与非监督分类的比较赵春霞,钱乐祥3(河南大学环境与规划学院,河南开封475001)摘要: 遥感影像的分类方法按照是否有先验类别可以分为监督分类和非监督分类,这两种分类法有着本质的区别但也存在一定的联系. 从分类原理、分类过程、分类方法等不同角度分析了这两种方法的区别与联系,并展望了遥感影像分类的发展趋势与发展前景.关键词: 影像分类;监督分类;非监督分类中图分类号: P237 文献标识码: A 文章编号: 1003 - 4978 (2004) 03 - 0090 - 04Comparative Study of Supervised and U nsupervised C la s sif icationin R emote Sensing Im ageZHAO Chun2xia , Q IAN L e2xiang( Col l ege of En v i ron ment an d Pl a n n i ng , Hen a n U ni v ersi t y , Hen a n Kai f eng 475001 , Chi n a) Abstract : The classificatio n of Remote Sensing image can be divided into t he su pervised classificatio n and t he unsu pervisedto whet her t here is t he extant category. The t wo met hods have difference in essence , but t he y are co nnected wit h each ot her . The article has analyzed t he difference and relatio n of t he t wo met hods f ro m different as pect s such as t he p rinciple , t he course and ways of classificatio n , and forecasted t he tendency and p rospect of t he image classificatio n.K ey w ords : image classificatio n ; supervised classificatio n ; unsu pervised classificatio n遥感影像分类是影像分析的一个重要内容,它是利用计算机通过对影像中不同地物的空间信息和光信息进行分析,选择特征,并将特征空间划分为互不重叠的子空间,然后将影像中各个像元划归到子空间去目前国内国际上对影像分类的研究主要集中在应用具体的物理的、数学的方法等对影像进行的分类研究面1 - 8,对于影像分类方法的研究,从不同的方面可以划分为不同的类型. 按照利用图像要素的不同,影分类大体可以分为三种:一是基于图像灰度值的分类,二是基于图像纹理的分类,三是基于多源信息融合分类9 . 用计算机对影像进行分类应用的主要是模式识别技术,根据具体应用的数学方法不同又可分为:计法(决策分类法) 、语言结构法(句法方法) 、模糊法以及神经网络法. 在影像分类过程中,根据是否已知训样本的分类数据,影像分类方法又可以分为监督分类和非监督分类. 本文主要从分类原理、分类过程、分类法等方面来探讨这两种分类方法的区别与联系.1 监督分类的主要方法最大似然判别法. 也称为贝叶斯(Bayes) 分类,是基于图像统计的监督分类法,也是典型的和应用最广监督分类方法.它建立在Bayes 准则的基础上,偏重于集群分布的统计特性,分类原理是假定训练样本数在光谱空间的分布是服从高斯正态分布规律的,做出样本的概率密度等值线,确定分类,然后通过计算标收稿日期: 2004202209基金项目: 河南省高等学校创新人才培养对象基金项目;河南省杰出青年科学基金项目( 99200003) ; 河南省自然科学基项目(004070700)作者简介: 赵春霞(1980 - ) ,女,河南大学硕士研究生13 通信联系人1(像元) 属于各组(类) 的概率,将标本归属于概率最大的一组. 用最大似然法分类,具体分为三步:首先确定各类的训练样本,再根据训练样本计算各类的统计特征值,建立分类判别函数,最后逐点扫描影像各像元,将像元特征向量代入判别函数,求出其属于各类的概率,将待判断像元归属于最大判别函数值的一组. Bayes 判别分类是建立在Bayes 决策规则基础上的模式识别,它的分类错误最小精度最高,是一种最好的分类方法. 但是传统的人工采样方法由于工作量大,效率低,加上人为误差的干扰,使得分类结果的精度较差. 利用GIS 数据来辅助Bayes 分类,可以提高分类精度,再通过建立知识库,以知识来指导分类的进行,可以减少分类错误的发生1 ,这正是Bayes 分类的发展趋势和提高其分类精度的有效途径.神经元网络分类法. 是最近发展起来的一种具有人工智能的分类方法,包括B P 神经网络、K o ho nen 神经网络、径向基神经网络、模糊神经网络、小波神经网络等各种神经网络分类法. B P神经网络模型(前馈网络模型) 是神经网络的重要模型之一,也是目前应用最广的神经网络模型,它由输入层、隐含层、输出层三部分组成,所采取的学习过程由正向传播过程和反向传播过程组成. 传统的B P网络模型把一组样本的输入/ 输出问题作为一个非线性优化问题,它虽然比一般统计方法要好,但是却存在学习速度慢,不易收敛,效率不高等缺点. 采用动量法和学习率自适应调整的策略,可以提高学习效率并增加算法的可靠性3 .模糊分类法. 由于现实世界中众多的自然或半自然现象很难明确划分种类,反映在遥感影像上,也存在一些混合像素问题,并有大量的同谱异物或者同物异谱现象发生,使得像元的类别难以明确确定. 模糊分类方法忽略了监督分类的训练过程所存在的模糊性,沿用传统的方法,假定训练样本由一组可明确定义、归类, 并且具有代表性的目标(像素) 构成. 监督分类中的模糊分类可以利用神经元网络所具有的良好学习归纳机制、抗差能力和易于扩展成为动态系统等特点,设计一个基于神经元网络技术的模糊分类法来实现. 模糊神经网络模型由A R T 发展到A R TMA P 再到FasA R T 、简化的FasA R T 模型4 ,使得模糊神经网络的监督分类功能不断完善、分类精确度不断增加.最小距离分类法和Fisher 判别分类法. 它们都是基于图像统计的常用的监督分类法,偏重于几何位置.最小距离分类法的原则是各像元点划归到距离它最近距离的类别中心所在的类, Fisher 判别分类采用Fisher 准则即“组间最大距离”的原则,要求组间距离最大而组内的离散性最小,也就是组间均值差异最大而组内离差平方和最小. 用这两种分类法进行分类,其分类精度取决于对已知地物类别的了解和训练统计的精度,也与训练样本数量有关. 针对最小距离分类法受模式散布影响、分类精度不高的缺点,人们提出了一种自适应的最小距离分类法,在训练过程中,将各类样本集合自适应地分解为子集树,定义待分类点到子集树的距离作为分类依据2 ,这种方法有效地提高了最小距离法的分类正确率和分类速度,效率较高. Fisher 判别分类也可以通过增加样本数量进行严密的统计分类来增加分类精度.2 非监督分类的主要方法动态聚类. 它是按某些原则选择一些代表点作为聚类的核心,然后将其余待分点按某种方法(判据准则)分到各类中去,完成初始分类,之后再重新计算各聚类中心,把各点按初始分类判据重新分到各类,完成第一次迭代. 然后修改聚类中心进行下一次迭代,对上次分类结果进行修改,如此反复直到满意为止. 动态聚类的方法是目前非监督分类中比较先进、也较为常用的方法.典型的聚类过程包括以下几步:选定初始集群中心; 用一判据准则进行分类;循环式的检查和修改;输出分类结果.聚类的方法主要有基于最邻近规则的试探法、K - means 均值算法、迭代自组织的数据分析法( ISODA TA) 等.其中比较成熟的是K - means 和ISODA TA 算法,它们较之其他分类方法的优点是把分析判别的统计聚类算法和简单多光谱分类融合在一起,使聚类更准确、客观. 但这些传统的建立在统计方法之上的分类法存在着一定的缺点:很难确定初始化条件;很难确定全局最优分类中心和类别个数;很难融合地学专家知识. 基于尺度空间的分层聚类方法( SSHC) 是一种以热力学非线性动力机制为理论基础的新型聚类算法10 ,它与传统聚类算法相比最大的优点是其样本空间可服从自由分布,可获取最优聚类中心点及类别,可在聚类过程中融合后验知识,有更多的灵活性和实用性.模糊聚类法. 模糊分类根据是否需要先验知识也可以分为监督分类和非监督分类. 事实上,由于遥感影92 河南大学学报(自然科学版) ,2004 年,第34 卷第3 期关系的模糊聚类分析法、基于最大模糊支撑树的模糊聚类分析法等11 ,最典型的模糊聚类法是模糊迭代组织的数据分析法———Fussy - ISODA TA . 但纯粹的非监督分类对影像一无所知的情况下进行所得到的果往往与实际特征存在一定的差异,因此聚类结果的精度并不一定能够满足实际应用的要求,还需要地学识的辅助,也就是部分监督的Fussy - ISODA TA 聚类.系统聚类. 这种方法是将影像中每个像元各自看作一类,计算各类间均值的相关系数矩阵,从中选择相关的两类进行合并形成新类,并重新计算各新类间的相关系数矩阵,再将最相关的两类合并,这样继续去,按照逐步结合的方法进行类与类之间的合并. 直到各个新类间的相关系数小于某个给定的阈值为止.分裂法. 又称等混合距离分类法,它与系统聚类的方法相反,在开始时将所有像元看成一类,求出各变的均值和均方差,按照一定公式计算分裂后两类的中心,再算出各像元到这两类中心的聚类,将像元归并距离最近的那一类去,形成两个新类. 然后再对各个新类进行分类,只要有一个波段的均方差大于规定的值,新类就要分裂.两种分类方法原理及过程的比较遥感影像的监督分类是在已知类别的训练场地上提取各类别训练样本,通过选择特征变量、确定判别数或判别式把影像中的各个像元点划归到各个给定类的分类. 它的基本思想是:首先根据类别的先验知识定判别函数和相应的判别准则,利用一定数量的已知类别样本的观测值确定判别函数中的待定参数,然后未知类别的样本的观测值代入判别函数,再根据判别准则对该样本的所属类别做出判定. 遥感影像的非监分类也称为聚类,它是事先无法知道类别的先验知识,在没有类别先验知识的情况下将所有样本划分为若类别的方法. 它的基本思想是事先不知道类别的先验知识,仅根据地物的光谱特征的相关性或相似性来进分类,再根据实地调查数据比较后确定其类别属性. 二者分类流程如图1 所示.3图1 影像监督分类与非监督分类流程图影像监督分类法与非监督分类法是针对影像具体分类时是否有先验知识而产生的两种方法,二者的用范围、使用条件不同,因而在具体分类时各有一定的优缺点,监督分类与非监督分类的比较如表1 所示.表1 影像不同分类方法的适用范围及优缺点优点缺点适用范围精确度高,准确性好,与实际类别吻合较好监督分类工作量大有先验知识时使用该方法分类结果与实际类别相差较大,准确性差在没有类别先验知识时使用该方法非监督分类工作量小,易于实现影像分类方法的发展前景遥感影像的监督分类和非监督分类方法,是影像分类的最基本、最概括的两种方法. 传统的监督分类非监督分类方法虽然各有优势,但是也都存在一定的不足. 新方法、新理论、新技术的引入,为遥感影像分提供了广阔的前景,监督分类与非监督分类的混合使用更是大大的提高了分类的精度.计算机技术对影像分类的促进与发展. 计算机技术的引进,解决了影像分类中海量数据的计算与管理题;计算机技术支持下的GIS 用来辅助影像分类,主要通过四种模式进行12 : GIS 数据作为影像分析的训样本和先验信息;利用GIS 技术对研究区域场景和影像分层分析; GIS 建立面向对象的影像分类; 提取和掘GIS 中的知识进行专家分析. 这些模式促进了GIS 与遥感的结合,提高了影像分类精确性和准确性,使影像分类迈入了新的天地.数学方法的引入和模型研究的进展为影像分类注入了新的活力. 不同的数学方法被引用到模型研究来,为模型研究的发展提供了广阔的天地,相应地,在遥感影像分类中也产生了大量不同形式的分类模型. 径向基函数( RB F) 与粗糙理论结合的基于粗糙理论的RB F网络模型应用于遥感分类5 ,对于提供分类4度 、增加收敛性都有很好的作用 ;而基于 RB F 映射理论的神经网络模型更是融合了参数化统计分布模型和 非参数化线性感知器映射模型的优点 ,不仅学习速度快 ,而且有高度复杂的映射能力6 . 又如模糊数学理论 应用于影像分类产生模糊聚类 ,对影像中混合像元的分类有很好的效果 ;模糊理论与各种模型结合 ,更使得 影像分类方法的不断完善 ,分类精度不断提高. 人工智能技术对影像分类的促进. 专家分类系统被用于影像分类中 ,利用地学知识和专家系统来辅助遥 感影像分类12 ,大大提高了影像分类和信息提取的精度. 人工神经网络由大量神经元相互连接构成网络结 构 ,通过模拟人脑神经系统的结构和功能应用于影像分类 ,具有一定的智能推理能力 . 同时 ,它还引入了动量 法和学习自适率调整的策略 ,并与地学知识集成 ,很好的解决了专一的 B P 神经网络法分类的缺点和不足 , 提高了分类效率和分类精度.监督分类与非监督分类的结合. 由于遥感数据的数据量大 、类别多以及同物异谱和同谱异物现象的存 在 ,用单一的分类方法对影像进行分类其精确度往往不能满足应用目的要求 . 用监督分类与非监督分类相结 合的方法来对影像进行分类 ,却常常可以到达需要的目的. 利用这种方法分类时首先用监督分类法如多层神 经网络的 B P 算法将遥感图像概略地划分为几个大类 ,再用非监督分类法如 K - Means 聚类和 ISODA TA 聚 类对第一步已分出的各个大类进行细分 ,直到满足要求为止13 . 监督分类与非监督分类的结合的复合分类 方法 ,改变了传统的单一的分类方法对影像进行分类的弊端 ,弥补了其不足 ,为影像分类开辟了广阔的前景. 结论遥感影像的监督分类与非监督分类从内涵 、过程以及具体的分类方法上都不相同 ,它们在分类思路上有 着本质的差别 . 但是 ,作为影像分类的方法 ,它们都有着相同的目的和功效. 因此 ,在影像分类中 ,这两种方法 并不能够完全割裂开来 ,而应该根据实际分类的需要 ,合理科学灵活的运用这两种方法 ,甚至混合使用监督 5 分类与非监督分类 ,以使影像分类达到预期的目的要求. 监督分类与非监督分类方法灵活的使用 ,新的理论 、新的模型 、新技术的运用 ,使得遥感影像分类技术得到长足发展 ,影像分类结果的准确度 、精确度都不断提 高 ,从而更好的为应用服务.参考文献 :游代安 ,蒋定华 ,余旭初 . GIS 辅助下的 Bayes 法遥感影像分类 J . 测绘学院学报 ,2001 ,18 (2) :113 - 117 . 朱建华 ,刘政凯 ,俞能海 . 一种多光谱遥感图象的自适应最小距离分类方法 J . 中国图象图形学报 ,2000 ,5 (1) :22 - 24 . 贾永红 ,张春森 ,王爱平 . 基于 B P 神经网络的多源遥感影像分类 J . 西安科技学院学报 ,2001 ,21 (1) :58 - 60 . 林剑 ,鲍光淑 ,敬荣中 ,等 . FasAR T 模糊神经网络用于遥感图象监督分类的研究 J . 中国图象图形学报 , 2002 , 7 ( 12) : 1263 - 1268 . 巫兆聪 . 基于粗糙理论的 RB F 网络及其遥感影像分类应用 J . 测绘学报 ,2003 ,32 (1) :53 - 57 . 骆剑承 ,周成虎 ,杨艳. 基于径向基函 ( RB F ) 映射理论的遥感影像分类模型研究 J . 中国图象图形学报 ,2000 ,5 ( 2) : 94 - 99 .123456 7 Olivier Debeir , Pat r ice L a tinne , Isabelle Vanden Steen. Remote Sensin g Classificatio n Of S pect r al , spatial And Co n text u al DataU s ing Multiple Classifier System J . Ima ge Anal Stereol , 2001 ,20 ( S uppl 1) : 584 - 589 .8 L a kshmanan V , DeBrunner V , Rabin R. An U n su pervised , Agglo m erative , S patially Aware Text u re Segmentatio n TechniqueE . ht t p :/ / www . cimms. ou. edu/ ~lakshman/ Papers/ diss - t r ansip . p d f曾生根 ,王小敏 ,范瑞彬 ,等 . 基于独立量分析的遥感图像分类技术 J . 遥感学报 ,2004 ,8 (2) :150 - 157 .骆剑承 ,梁怡 ,周成虎. 基于尺度空间的分层聚类方法及其在遥感影像分类中的应用 J . 测绘学报 , 1999 , 28 ( 4) : 319 - 324 .徐建华 . 现代地理学中的数学方法 M . 北京 :高等教育出版社 ,2002 . 王莹 ,刘敏莺 ,黄文骞 . GIS 对遥感影像分类判读的辅助作用 J . 海洋测绘 ,2002 ,22 (3) :12 - 15 . 杨存建 ,周成虎 . 基于知识的遥感图像分类方法的探讨 J . 地理学与国土研究 ,2001 ,17 (1) :72 - 77 . 靳文戟 ,刘政凯 . 多类别遥感图像的复合分类方法 J . 环境遥感 ,1995 ,10 (4) :298 - 302 . 9 10 11121213。
监督分类与非监督分类遥感实习
B、在Overlay下选择Classification,选择之前的非监督分类影像,对照原影像将10种类型进行编号并改名字,改变颜色;进行相同类别的合并:选择Classification中的分类后处理post classification,选择合并同类别Combine Classes,选择之前的非监督分类影像,在输入的文件中依次选择要合并的类,在输出的文件中选择相同的类别,点击Add Combination,所有的类别合并完后点击确定即可。
3.注意:此次实习内容的操作环境为ENVI Classic经典版,上机课上将演示新版本操作。同时此次实习内容为大作业中视频教程中省略的部分。
基本原理
1、监督分类:监督分类是在分类前人们已对遥感影像样本区中的类别属性有了先验知识,进而可利用这些样本类别的特征作为依据建立和训练分类器(亦即建立判别函数),进而完成整幅影像的类型划分,将每个像元归并到相对应的一个类别中去。也就是根据地表覆盖分类体系、方案进行遥感影像的对比分析,据此建立影像分类判别规则,最后完成整景影像的分类。监督分类的具体步骤:
3、最大似然分类法是基于概率论中每个像元存在属于所有类别的概率,假设各个类别训练数据都呈现关于类均值矢量和方差参数的n维高斯正态分布,根据像元矢量和上述假设可利用n维正态分布函数计算像元矢量属于各个类别的概率,比较各个类别的概率值,并将像元划归到概率最大的那个类别当中去。
4、分类混淆矩阵(误差矩阵)是指采用随机采样的方法获取一批地面参考验证点的信息作为真值,与遥感分类图进行逐像元比较。然后将结果归纳到混淆矩阵,进而完成混淆矩阵分析。其中结果分为类别精度与总精度,其中类别精度被正确分类的类别像元数占该类别训练样本像元数的百分比,包括生产者精度(制图精度)和用户精度,总精度是指被正确分类的总像元数占评价样本像元总数的百分比。
实习三 遥感图像的监督分类与非监督分类

实验三遥感图像的监督分类与非监督分类[实验目的]1.理解遥感图像的监督分的含义;2.会使用ENVI软件对遥感图像进行监督分类。
[实验原理]在遥感图像分类中,按照是否有已知训练样本的分类依据,分类方法又分为两大类:监督分类与非监督分类。
遥感图像的监督分类是在已知类别的训练场地上提取各类别训练样本,通过选择特征变量、确定判别函数或判别式(判别规则),进而把图像中的各个像元点划归到各个给定类的分类。
遥感图像的非监督分类是在没有先验知识(训练场地)的情况下,根据图像本身的统计特征及自然点群的分布情况来划分地物类别的分类处理,事后再对已分出的各类的地物属性进行确认,也称作“边学习边分类法”。
两者的最大区别在于,监督分类首先给定类别,而非监督分类则由图像数据本身的统计特征来决定。
[实验步骤]一监督分类(数据采用njtmcorrected)监督分类技术需要在执行以前事先定义训练分类器(training classes), 训练分类器也可以用ENVI 感兴趣区(ROI)函数限定。
ENVI的监督分类技术包括平行六面体(平行管道)、最小距离、马氏距离、最大似然、波谱角度制图仪以及二进制编码方法1. “开始”->“程序”->RSI ENVI4.0->ENVI,打开ENVI4.0界面;2. 选择File > Open Image File.3. 当出现Enter Data Filename 对话框,选择要打开的文件名,再点击“OK”,在Available Bands List框里点击Load Band ,图像显示在图像显示窗口。
4. 选择“基本工具”->感兴趣区->ROI工具,弹出ROI Tool对话框。
5. 在ROI_Type菜单里选择建立感兴趣区的类型,可以选择Polygon、Polyline、point、Rectangle、Ellipse等类型。
6. 在Window栏里选择要建立感兴趣区的窗口,可以选择Image、Scroll、Zoom窗口。
遥感实习遥感图像监督分类

实验五:监督分类与非监督分类一、实验目的采用监督分类对多光谱遥感图像进行分类,并对分类后的数据进行处理,处理方法包括:聚合(clump)处理、筛选(sieve)处理、并类(combine)处理,以及精度评估。
监督法分类需要用户选择作为分类基础的训练样区。
分析下面处理的分类结果,或者采用每个分类法默认的分类参数,生成自己的类,然后对分类结果进行比较。
我们将使用各种监督分类法,并对它们进行比较,确定单个具体像素是否有资格作为某类的一部分。
二、实验数据与原理美国科罗拉多州(Colorado)Canon市的Landsat TM 影像数据,其中包括can_tmr.img、can_tmr.hdr、can_km.img、can_km.hdr、can_iso.img、can_iso.hdr、classes.roi、can_pcls.img、can_pcls.hdr 、can_bin.img、can_bin.hdr 、can_sam.img、can_sam.hdr 、can_rul.img 、can_rul.hdr、can_sv.img、can_sv.hdr、can_clmp.img、can_clmp.hdr。
ENVI 提供了多种不同的监督分类法,其中包括了平行六面体(Parallelepiped)、最小距离法(Minimum Distance)、马氏距离法(Mahalanobis Distance)、最大似然法(Maximum Likelihood)、波谱角法(Spectral Angle Mapper)、二值编码法(Binary Encoding)以及神经网络法(Neural Net)。
三、实验过程:1、打开TM图像,File →Open Image File,选择ljs-can_tmr.img文件,在可用波段列表中,选择RGB Color 单选按钮,然后使用鼠标左键,顺次点击波段4、波段3 和波段2。
点击Load RGB 按钮,把该影像加载到一个新的显示窗口中。
监督分类与非监督分类遥感实习
4、分类混淆矩阵(误差矩阵)是指采用随机采样的方法获取一批地面参考验证点的信息作为真值,与遥感分类图进行逐像元比较。然后将结果归纳到混淆矩阵,进而完成混淆矩阵分析。其中结果分为类别精度与总精度,其中类别精度被正确分类的类别像元数占该类别训练样本像元数的百分比,包括生产者精度(制图精度)和用户精度,总精度是指被正确分类的总像元数占评价样本像元总数的百分比。
Clump对话框Sieve对话框Majority对话框
【结果与分析3】:(clump—sieve—majority)请替换如下对比图并分析发生的变化
分类后影像clump后影像
【分析】:聚类处理将邻近的类似分类单元进行聚类合并,可以看到影像中比较小的地物被合并,但是也将一些比较孤立的地物被错分。
分类后影像sieve后影像
实验结果
1、监督分类:(请将前后对比图截图至此)
原始影像监督分类后影像
【分析】:
2.运用ISODATA方法进行非监督分类结果对比图:
监督分类影像非监督分类影像非监督分类合并后处理影像
【分析】:
存在问题与解决办法
1、在监督导致地物选取有很大的误差,城镇居民区、工业区选区不能有效地区分,裸地与砾石也比较难以辨别。
距离和变换分散度都是一种特征空间距离度量方法是指影像特征矢量与各个类中心的距离变换分散度是tdivercd1expdivercd8jm距离j21e3最大似然分类法是基于概率论中每个像元存在属于所有类别的概率假设各个类别训练数据都呈现关于类均值矢量和方差参数的n维高斯正态分布根据像元矢量和上述假设可利用n维正态分布函数计算像元矢量属于各个类别的概率比较各个类别的概率值并将像元划归到概率最大的那个类别当中去
遥感图像分类方法与分类精度评估技巧

遥感图像分类方法与分类精度评估技巧遥感图像分类是遥感技术的重要应用之一,通过对遥感图像中不同地物进行分类,可以有效提取地物信息,为各类地理研究和应用提供了重要数据支持。
而遥感图像分类方法和分类精度评估技巧则是遥感图像分类工作中的关键环节。
一、遥感图像分类方法遥感图像分类方法主要分为监督分类和非监督分类两种。
监督分类是根据人工定义的训练样本来进行分类,通过计算遥感图像像元的特征值与训练样本的特征值之间的距离或相似度来确定像元的地物类别。
监督分类方法具有分类精度高的优势,但需要大量准确的训练样本,并且需要人工干预进行样本分类。
非监督分类是根据图像像元自身的特征值进行分类,算法会自动对图像中的像元进行聚类,根据像元的特征相似性来确定地物类别。
非监督分类方法可以大幅降低人工干预量,但分类精度相对较低,对遥感图像的解译要求较高。
同时,还有基于物理模型的分类方法,该方法通过对地物的物理性质进行建模,从而实现对遥感图像地物的分类。
基于物理模型的分类方法可以较好地解决遥感图像的反射率与地物属性之间的关系,但对数据质量和物理模型的准确性要求较高。
二、分类精度评估技巧对于遥感图像分类的结果,需要进行分类精度评估来判断分类结果的准确性。
常用的分类精度评估技巧主要包括混淆矩阵、Kappa系数和面积误差指标等。
混淆矩阵是一种常用的分类精度评估方法,通过对分类结果与实际样本之间的差异进行矩阵统计,来获得分类的准确性。
混淆矩阵包括真阳性(TP)、假阴性(FN)、假阳性(FP)和真阴性(TN)四个参数,通过计算这些参数的比例可以得到分类的准确性。
Kappa系数是一种综合评估分类精度的方法,根据分类结果与实际样本的一致性程度来判断分类的准确性。
Kappa系数的取值范围为[-1,1],取值越接近1表示分类结果越准确。
面积误差指标是一种用来评估分类结果准确性的指标,通过计算分类结果与实际样本之间的面积差异来评估分类的准确性。
面积误差指标越小表示分类结果越准确。
监督分类和非监督分类的异同

监督分类和非监督分类的异同监督分类是纪检监察机关的一项重要职责,是对监督对象开展监督的依据。
实践中经常会遇到两类监督分类的概念表述问题,如何准确把握这两类监督分类界定?如果两者不能区分清楚,容易出现问题。
本文将从二者的关系入手进行阐述。
•一、界定对监督分类,《中华人民共和国监察法》第四十三条第一款明确规定,监督是指国家行政机关、检察机关及其工作人员在行使权力、履行职责过程中,对公职人员行使职权情况进行监督,发现公职人员违纪违法问题线索,及时向有关部门移送或者采取其他必要措施以加强对公职人员监督。
监察机关应当在监察调查终结后五个工作日内将审查调查结论、处分决定等文书送达被调查人,并抄送被调查人所在单位党组织。
对监察对象实施监督的同时,监察机关应当会同有关部门建立健全协调机制,加强信息共享,实现监督资源共享与共用。
根据监督分类规则,《中国共产党纪律检查机关监督执纪工作规则》第二十一条规定“监督对象可以通过谈话、函询、要求说明材料等方式被监督对象如实向纪检监察机关反映问题,或者被监督对象因特殊情况不能如实说明问题而进行询问、质询、检查、问责等方式进行询问、质询或者进行检查;对涉及党和国家工作人员利益的其他方式进行监督的”以及《中华人民共和国监察法》第三十一条规定“监察机关应当依照法定权限和程序对监察对象进行工作评议后认为存在不应当被监督问题的”等情形下组织开展监督或者开展其他监督时可以采取相应措施实现监督目的或目标,属于监督分类规定的情形之一。
”由此可见,监督分类并非仅限于对纪检监察机关工作人员进行监督或者进行其他形式监督那么简单。
•二、特征这两类监督分类的特征表现在:一是“监督”是纪委监委履行监督责任中,运用监督执纪“四种形态”的重要内容,体现了对腐败行为的有效遏制,体现了“四种形态”协同作用;二是“监督”是纪检监察机关履行监督职责的主要方式之一,是纪检监察机关工作规范化、科学化的重要内容。
“监督”的主要区别在于:“监督”重在“发现问题”,是纪检监察机关开展监督的基本方式之一;“监督”重在“督促整改”,是纪检监察机关开展监督的主要方式之一。
遥感影像监督分类与非监督分类及相关代码实现

遥感影像监督分类与非监督分类摘要:遥感影像的分类方法按照是否有先验类别可分为监督分类和非监督分类,这两种分类方法有着本质的区别但也有存在一定的联系。
本文从分类原理和分类方法等不同角度分别介绍了监督分类和非监督分类方法,并对两种方法的分类结果进行了对比和分析。
关键词:遥感;监督分类;非监督分类;ISODATA算法;贝叶斯分类算法。
1.数据来源本文使用的数据是华盛顿广场上空由卫星拍摄的高光谱遥感影像。
该幅影像使用的传感器系统覆盖0.4到2.4m的可见光到近红外的210个波段。
由于0.9-1.4米光谱对应的区域上空大气透光性很差,因此将这个区域内的波段从影像中删除,最后得到191个波段。
该数据集有1208个扫描行,每行307个像元,容量近似150MB。
为了清晰地反映影像中地物的特征,本文从191个波段中选择了3个波段,分别是120、140和160。
下面两幅图分别是全波段影像和三波段影像:图1全波段影像图2 三波段影像2.遥感影像的监督分类2.1监督分类的原理监督分类(supervised classification)又称训练场地法,是以建立统计识别函数为理论基础,依据典型样本训练方法进行分类的技术。
即根据已知训练区提供的样本,通过选择特征参数,求出特征参数作为决策规则,建立判别函数以对各待分类影像进行的图像分类,是模式识别的一种方法。
要求训练区域具有典型性和代表性。
判别准则若满足分类精度要求,则此准则成立;反之,需重新建立分类的决策规则,直至满足分类精度要求为止。
常用算法有:最大释然分类法、最小距离分类法、马氏距离分类法、平行六面体分类法、K-NN分类法。
本文选用最大释然分类法对遥感影像进行监督分类。
最大似然判别法. 也称为贝叶斯(Bayes) 分类,是基于图像统计的监督分类法,也是典型的和应用最广的监督分类方法. 它建立在Bayes 准则的基础上,偏重于集群分布的统计特性,分类原理是假定训练样本数据在光谱空间的分布是服从高斯正态分布规律的,做出样本的概率密度等值线,确定分类,然后通过计算标本(像元) 属于各组(类) 的概率,将标本归属于概率最大的一组. 用最大似然法分类,具体分为三步:首先确定各类的训练样本,再根据训练样本计算各类的统计特征值,建立分类判别函数,最后逐点扫描影像各像元,将像元特征向量代入判别函数,求出其属于各类的概率,将待判断像元归属于最大判别函数值的一组。
监督分类、非监督分类操作手册

ERDAS IMAGINE Professional 操作手册—监督分类和非监督分类图像分类简介:图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。
常规图像分类主要有两种方法:非监督分类与监督分类,专家分类方法是近年来发展起来的新兴遥感图像分类方法,下面介绍这三种分类方法。
非监督分类运用1SODATA(Iterative Self-Organizing Data Analysis Technique )算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。
使用该方法时。
原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。
由于人为干预较少,非监督分类过程的自动化程度较高。
非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。
监督分类比非监督分类更多地要求用户来控制,常用于对研究区域比较了解的情况。
在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。
对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。
监督分类一般要经过以下几个步骤:建立模板(训练样本)、评价模板、确定初步分类图、检验分类结果、分类后处理、分类特征统计、栅格矢量转换。
专家分类首先需要建立知识库,根据分类目标提出假设,井依据所拥有的数据资料定义支持假设的规则、条件和变量,然后应用知识库自动进行分类,ERDAS IMAG1NE图像处理系统率先推出专家分类器模块,包括知识工程师和知识分类器两部分,分别应用于不同的情况。
由于基本的非监督分类属于IMAGINE Essentia1s级产品功能、但在1MAGINE Professional级产品中有一定的功能扩展,而监督分类和专家分类只属于IMAGINE ProfeSsiona1级产品,所以,非监督分类命令分别出现在Data Preparation菜单和classification 菜单中,而监督分类和专家分类命令仅出现在Classification菜单中。
遥感图像处理实例分析03(监督分类、非监督分类)

遥感图像处理实例分析监督分类(supervised classification )一、方法原理监督分类方法是多光谱图像专题信息分类的两种方法之一(另一种方法是非监督分类).该方法是假设已经收集到多区域的地理图像,如Landsat TM 或 SPOT XS 卫星多谱图像(分类对其它类型的图像也有效),具有实地野外属性分类或覆盖类型(如城区、水域、沼泽地等)的位置和特性数据(也可以通过航片分析得到),对该已知分类区域的光谱特性,通过分类程序,进行训练,将图像中每类区域的像素进行已知类的分配,对每一类计算多变量统计参数,如均值、标准差、相关距阵等,根据分类方法,最后将图像中每一个像素以最大然似性分配到某一类中。
即通过自定义的已知分类区域的训练,对多波段图像进行专题信息分类.方法流程如下:二、实例演示及分析以1985年美国加利福利亚州圣地亚哥地区的TM —MSS(0.55,0。
65,0。
75,0.95um4波段)图像为例,进行土地覆盖类型分类,分为海洋、城区、居民区、草坪和秃地等类型。
监督分类主要步骤如下:1.由原始遥感图像文件Landsat_Mass_Notwarped 。
ers 复制出用于分类的图像数据文件Landsat_practice.ers.① 通过主菜单算法图标或主菜单View 中Algorithm 项,打开算法窗口,装载数据集,文件名为:\examples\shared_data\Landsat_Mass_Notwarped.ers 。
选择训练区计算训练区统计量 评价训练区统计量 进行图像分类 显示分类图像和精度计②复制3个假彩色层(现共有4个假彩色层),分别命名为B1、B2、B3、B4,并与装载数据集文件的4个波段相对应。
③选择主菜单File中的Save As项,以Er Mapper Raster Dataset格式保存文件,文件名为:\examples\miscellaneous\tutorial\Landsatt_practice.ers。
遥感图像分类

遥感图像分类遥感图像的分类就是通过对遥感图像中地物的光谱信息和空间信息进行分析,选择特征,将图像中每个象元按照某种规则或算法划分为不同的类别,然后获得遥感图像与实际地物的对应信息,从而实现遥感图像的分类。
一般的分类方法可分为两类:监督分类和非监督分类。
将多源数据应用于图像分类中,发展成基于专家知识的决策树分类。
一、监督分类监督分类(supervised),又称训练分类法,即用被确认的样本象元去识别其他未知象元的过程。
已经被确认类别的样本象元是指那些位于训练区的象元。
在这种分类中,分析者在图像上对每一种类别选取一定数量的训练区,计算机计算每种训练样区的统计或其他信息,每个象元和训练样本作比较,按照不同规则将其划分到其最相似的样本类。
监督分类的算法主要有:平行算法、最小距离法、最大似然法等。
这里采用最大似然法作为监督分类的算法。
原理:最大似然法假设遥感图像的每个波段数据都是正态分布。
其基本思想是:地物类数据在空间中构成特定的点群;每一类的每一维数据都在自己的数轴上成正态分布,该类的多维数据就构成了一个多维正态分布;各类多维正态分布模型各有其分布特征。
根据各类已有的数据,可以构造出各类的多维正态分布模型,在此基础上,对于任何一个像素,可反过来求出它属于各类的概率,取最大概率对应的类为分类结果。
步奏:第一步:分析图像①打开图像,将图像以5、4、3波段合成RGB显示在#1中。
②通过目视分析,可以定义6类样本:水体、建筑、耕地、草地、荒地、其他。
第二步:选择训练样本①在主图像窗口选择Overlay-----Region of Interest,打开ROI Tool对话框。
②在ROI Tool对话框中设置相关样本的名称、颜色等。
③选择ROI_Type—Polygon,在window中选择image,在图像上绘制训练区。
④重复②、③步奏,最终完成以下结果:第三步:评价训练样本①在ROI Tool对话框中,选择Options——Compute ROI Separability,打开目标图像。
监督分类与非监督分类

监督分类与非监督分类(1) 非监督分类监督分类的原理是利用计算机自动判别,erdas中我们主要采用isodata算法,在算法的设计上我们要做一个预算次数的限定,否则有些图像会出现死循环,没法继续。
在主菜单模块中点击CLASSIFIER,在打开的对话框中点击unsupervised classification项,打开如图二的对话框,在input raster file输入germtm.img 影像,填写输出文件名称,去掉右边的勾选项,在output colorScheme options 选项框打开,点选approximate true color 选项,close,number of classe改为12类,最大迭代次数改为24次,点击ok执行非监督分类。
其结果如下图三所示,图四为其属性值(2) 监督分类监督分类主要确定训训练样区,有很多种方法可以判定训练样区,当然也可以拿非监督分类的记过做实验样区。
本实验的训练样区是采用人工目视判别,首先制作训练样区的分类下图所示是确定好的类中分类,然后在训练样区的基础上对图像进行分类。
打开classifier 模块,在弹出对话框点选第一项signature editor 项,弹出对话框如图五所示。
在view1中选择一些典型特征区域,分别为耕地,城市,水域,森林四类,如图五所示。
选择signature editor菜单中classify中的supervised项,弹出如图六所示对话框,填写输入输出文件名及地址,然后选择overlap rule 为parametric 项,unclassified选择parametric,parametric rule选择parametric ,点击ok执行监督分类。
执行效果如图七所示。
监督分类与非监督分类

实习目的和内容1 .选取研究区数据(512X512或者1024X1024),通过目视解译建立分类系统及其编码体 系2 .按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用ROI工具建立训练区,给出各个类别的特征统计表。
3 .计算各个分类类别之间的可分离性,整理成表格。
说明哪些地物类型之间较易区分,哪些类型之间难以区分。
4 .监督分类:利用最大似然法完成分类。
5 .分类精度评价,从随机采集100〜200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa 系数,并对结果进行解释。
6 . 分类后处理(clump —sieve —majority)。
运用ISODATA 方法进行非监督分类:预先假定地表覆盖类型为30类,迭代次数选为15,由 系统完成非监督分类;然后进行类别定义与合并子类,最后进行结果的精度评价。
原理和方法1、监督分类:监督分类是在分类前人们已对遥感影像样本区中的类别属性有了先验知识, 进而可利用这些样本类别的特征作为依据建立和训练分类器(亦即建立判别函数),进而完 成整幅影像的类型划分,将每个像元归并到相对应的一个类别中去。
换句话说,监督分类就 是根据地表覆盖分类体系、方案进行遥感影像的对比分析,据此建立影像分类判别规则,最 后完成整景影像的分类;2、可分性度量:本次实习主要涉及J —M 距离和变换分散度,都是一种特征空间距离度量方 法,是指影像特征矢量与各个类中心的距离,变换分散度是 TDivercd=[1-exp(-Divercd/8)],J —M 距离 J=2*(1-e-B);3、最大似然分类法:在两类或多类判决中,假定各类分布函数为正态分布,并选择训练区, 用统计方法根据最大似然比贝叶斯判决准则法建立非线性判别函数集,计算各待分类样区的 归属概率,而进行分类的一种图像分类方法。
4、混淆矩阵:从随机点位上获取地面参考验证信息,并与遥感分类图进行逐像元比较,然 后将结果归纳到混淆矩阵,进而完成混淆矩阵分析。
遥感图像的分类实验报告
一、实验名称遥感图像的监督分类与非监督分类二、实验目的理解遥感图像监督分类及非监督分类的原理;掌握用ENVI对影像进行监督分类和非监督分类的方法,初步掌握图像分类后的相关操作;了解整个实验的过程以及实验过程中要注意的事项。
三、实验原理监督分类:又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。
它是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
非监督分类:也称为聚类分析或点群分类。
在多光谱图像中搜寻、定义其自然相似光谱集群的过程。
它不必对影像地物获取先验知识,仅依靠影像上不同类地物光谱(或纹理) 信息进行特征提取,再统计特征的差别来达到分类的目的,最后对已分出的各个类别的实际属性进行确认。
目前比较常见也较为成熟的是ISODATA、K-Mean和链状方法等。
四、数据来源本次实验所用数据来自于国际数据服务平台;landsat4-5波段30米分辨率TM 第三波段影像,投影为WGS-84,影像主要为山西省大同市恒山地区,中心纬度:38.90407 中心经度:113.11840。
鉴于实验内容及图像大小等问题,故从一景TM影像中裁取一个含有较丰富地物信息区域作为待分类影像。
五、实验过程1.监督分类1.1打开并显示影像文件,选择合适的波段组合加载影像打开并显示TM影像文件,从ENVI 主菜单中,选择File →Open Image File选择影像,为了更好地区分不同地物以及方便训练样本的选取,选择5、4、3波段进行相关操作,点击Load Band 在主窗口加载影像。
1.2使用感兴趣区(ROI)工具来选择训练样区1)主影像窗口菜单栏中,选择 Overlay >Region of Interest。
envi遥感图像监督分类与非监督分类

envi遥感图像监督分类监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程.它就是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。
使每个像元和训练样本作比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。
遥感影像的监督分类一般包括以下6个步骤,如下图所示:详细操作步骤第一步:类别定义/特征判别根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理.这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
启动ENVI5。
1,打开待分类数据:can_tmr。
img。
以R:TM Band 5,G: TM Band 4,B:TM Band 3波段组合显示。
通过目视可分辨六类地物:林地、草地/灌木、耕地、裸地、沙地、其他六类。
第二步:样本选择(1)在图层管理器Layer Manager中,can_tmr.img图层上右键,选择"New Region Of Interest",打开Region of Interest (ROI) Tool面板,下面学习利用选择样本。
1)在Region of Interest (ROI) Tool面板上,设置以下参数:ROI Name:林地ROI Color:2)默认ROIs绘制类型为多边形,在影像上辨别林地区域并单击鼠标左键开始绘制多边形样本,一个多边形绘制结束后,双击鼠标左键或者点击鼠标右键,选择Complete and Accept Polygon,完成一个多边形样本的选择;3)同样方法,在图像别的区域绘制其他样本,样本尽量均匀分布在整个图像上;4)这样就为林地选好了训练样本.注:1、如果要对某个样本进行编辑,可将鼠标移到样本上点击右键,选择Edit record是修改样本,点击Delete record是删除样本。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实习报告三
监督分类与非监督分类 实习人姓名
韦昭华 专业班级及编号 水文一班2014301580040 任课教师姓名
陈华 实习指导教师姓名 陈华 王佳伶 实习地点 八教二楼机房 实习日期时间 2016-12-09
实习目的与要求
1.目的:理解影像监督分类和非监督分类的原理、方法和步骤,初步掌握土地利用/土地覆盖的计算机自动分类方法
2.要求:将主要操作步骤截图替换教程中的图像,并按要求分析结果,下周四前交。
3.注意:此次实习内容的操作环境为ENVI Classic 经典版,上机课上将演示新版本操作。
同时此次实习内容为大作业中视频教程中省略的部分。
基本原理
1、监督分类:监督分类是在分类前人们已对遥感影像样本区中的类别属性有了先验知识,进而可利用这些样本类别的特征作为依据建立和训练分类器(亦即建立判别函数),进而完成整幅影像的类型划分,将每个像元归并到相对应的一个类别中去。
也就是根据地表覆盖分类体系、方案进行遥感影像的对比分析,据此建立影像分类判别规则,最后完成整景影像的分类。
监督分类的具体步骤:
确定分类方案:要求满足互斥性、完备性和层次性要求
特征选取:选择用于影像分类的最佳波段组合,减少处理数据集的维数(波段数)和分
确定分
类方案 特征选取 训练样区选取
与特征 类别可分性分析 分类算法选择 算法实现 分类后处理
操作方法及过程
1. 选择你熟悉的研究区数据,加载到ENVI,可以是裁剪前的图像,也可以是裁剪后的图像。
根据实习要求,通过目视解译预想好将要建立的地物种类,并基于此提取出各类地物(要求不少于5种),如可分为居民点、道路、河流、湖泊、在植耕地、水田……几类(或参考下表)。
根据以下操作步骤确定土地的覆盖类型、编码以及色调。
居民点Town砾石gravel desert
道路Road水稻田paddy land
水浇地irrigated land水库reservoir
裸地barren land工业区industrial area
滩地shoaly land林地forest
草地grassland河流stream
2.按照监督分类的步骤,在影像上找出对应各个土地利用/覆盖类型的参考图斑,利用(感兴趣的区域)ROI工具建立训练区,给出各个类别的特征统计表。
加载研究区影像,右击Image窗体,选择ROI Tool,进行ROI采集,在Zoom中选择样本区,根据地物的情况选择point、polyline、polygon方式建立训练区。
请根据实际图像选择分类类型和构建ROI,并截图至此(以下以两种地物选取ROI为例,请自行补全其他):
ROI选择河流样本
选择在植耕地样本
3.计算各样本之间的可分离性。
说明哪些地物类型之间易区分,哪些类型之间难以区分。
ROI Tool中选Options的统计训练区可分性Compute ROI Separability,选择影像点击确定,选择所有训练区,统计J—M距离和分散度(将结果截图如下)。
根据Jeffries-Matusita,Transformed Divergence,并分析各个样本之间的可分离性。
根据J—M距离的定义,其值大于1.9则两种地物具有很好的可分性,若介于1.5到1.8之间,则需要重采样来重新计算其值,而如果小于1就可将两种地物合并为同一种地物。
由导出的结果说明哪些地物类型之间较易区分,哪些类型之间难以区分。
【结果与分析1】:河流、湖泊、在植耕地具有很好的可分性,而街道和居民区可分性则较低。
4.监督分类:利用最大似然法完成分类。
①具体步骤:Classification |Supervised| Maximum Likelihood,在Set Input File对话框中导入影像。
在打开的对话框中选Select All Items,其中Set Probability Threshold设为NO,Output Rule Image设为No,选择保存路径。
②根据分类的情况修改监督分类后的地物的颜色等信息。
具体操作:在监督分类影像中的Image上选择Overlay |Classification,点击“Supervised”,选择Option |Edit class colors/name 等来修改地物的名称和颜色
5.分类精度评价,从随机采集100~200个样本点,并确保每一类别不少于10个样本;进行分类精度评价,得到分类混淆矩阵,计算Kappa系数,操作步骤:
选择Classification中的分类后处理post classification,选择混淆矩阵Confusion Matrix的Using Ground Truth ROIs,选择之前保存的最大似然法的影像,将所有的编好号的地物一一对应加载进来,点击确定,即可生成混淆矩阵
【结果与分析2】:分类精度评价结果截图替换上图,并分析结果:
Overall Accuracy = (6345/6569) 96.59%
Kappa Coefficient =0.9552
分析漏分和错分现象:错分指用户感兴趣的类,而实际属于另一类的像元,它混淆在混淆矩阵中,如上图中湖泊有1434个真实参考像元,正确分类1424个,有4个被错分为林地,错分率为4/1434=0.28%.漏分指本身属于地表真实分类,当没有被分类器分到相应类别中的像元数,如上图中的湖泊,有真实参考像元1434个,正确分类为1424个,其余10个被漏分为其余类,漏分误差为10/1434=0.70%。
6.分类后处理(clump—sieve—majority)。
类别集群:选择Classification |Post Classification,Clump Classes,在Select Input File对话框中选择Supervised。
最后设定数据输出路径。
类别筛选:选择Classification |Post Classification |Sieve classes,在Select Input File中选择Supervised,Group Min Threshold设为2, Number of Neighbors为8,进行保存。
主/次要分析:Classification |Post Classification |Majority/Minority Analysis,在Select Input File对话框中选择Supervised |Select All Items,Analysis Method设定为Majority,最后选择保存路径。
Clump对话框Sieve对话框Majority对话框
【结果与分析3】:(clump—sieve—majority)请替换如下对比图并分析发生的变化
分类后影像clump后影像
【分析】:聚类处理将邻近的类似分类单元进行聚类合并,可以看到影像中比较小的地物被合并,但是也将一些比较孤立的地物被错分。
分类后影像sieve后影像
【分析】:过滤处理解决分类影像中出现的孤岛问题。
过滤处理使用斑点分组方法来消除这些被隔离的分类像元。
但是使得影像更为破碎,出现了更多的黑点(在影像北方的裸地与砾石更加明显),椒盐现象更明显。
分类后影像Majority后影像
【分析】:主要分析后的影像效果较好,椒盐现象得到一定程度的避免,并且将一些影像里小的地块进行合并,使影像更加光滑。
7.非监督分类:预先假定地表覆盖类型为10类,迭代次数选为10,由系统完成非监督分类;然后进行类别定义与合并子类,最后进行结果评价。
A、选择Classification的非监督分类Unsupervised,选择者IsoData,选择512*512子区,设置参数。
B、在Overlay下选择Classification,选择之前的非监督分类影像,对照原影像将10种类型进行编号并改名字,改变颜色;进行相同类别的合并:选择Classification中的分类后处理post classification,选择合并同类别Combine Classes,选择之前的非监督分类影像,在输入的文件中依次选择要合并的类,在输出的文件中选择相同的类别,点击Add Combination,所有的类别合并完后点击确定即可。
实验结果
原始影像监督分类后影像
【分析】:
经过最大似然法的监督分类后,主要地物可以被分类出来,可以看出大概的分类结果和各种主要地物的分布情况,但由于算法本身存在问题和在选取训练区时的人为因素造成一些区域比较破碎并且由于人为因素使得居民点划分有很大误差。
2.运用ISODA TA方法进行非监督分类结果对比图:
监督分类影像非监督分类影像非监督分类合并后处理影像【分析】:
非监督分类影像中共多种根据遥感光谱划分的地物,明显可以感觉到地物分离太过破碎,并且由于“同物异谱”、“异物同谱”等原因使得同一地物被划分成不同类别或者不同地物被划分为同一地物;非监督分类处理影像将多类进行处理与合并,将名称与颜色进行重处理,然后得到影像,但是由于一些地物等分布较少、破碎,所以被漏分,并且由于非监督分类后,多种地物有的颜色一致,在后期处理里存在很大的问题,使得同一个地物不知道是何种。