手写藏文字符识别研究(黄鹤鸣, 马龙龙, 赵维纳)思维导图
藏文不自由虚词的自动识别研究

2 ) “ ” 栩 5 ” 是拉格助词
,
在虚词识别过程 中出现 以下规则 可
跳过。
≈
s 3 譬
(
)等・ 例如: 酶鬟 霉 s
( 能濠聃动词) 礴 等。 例如 :
3 ) “ ”葺 Q “ ”建离食诵 , 在盎调{ } l j 5 I l 进程串出现以下规则也霹瑞过 ・ ・
藏 文 不 自 由虚 词 的 自动 识 别 研 究
卓玛吉 安见 才让
摘 要 :本 文将通过传统藏文文法的语法规则 ,主要研 究藏文文本 中大量藏文不 自由虚 词的识别算 法,同时建立 了藏文 不 自由虚词 的 消岐规 则库 。使计算机快速地识别并消除藏文句子 中不 自由虚词的歧 义问题 。提 高藏 文 自动分词的准确 率。使 句子的 生产 、句法分析 、八 格 识 别 和机 器 翻译 等研 究 的基 础 更 扎 实 。 关 键 词 : 藏 文 不 自由虚 词 ; 自动 识 别 ;歧 艾 ;规 则 库
钢
等 四个虚词 外 ,其余 的 5 8 个
不 自由虚词在分词过程中都以单字词的形式 出现。 建立藏文虚词库 X C ;在 X C 库 中分别建立 b z y x c 和b z y x c 2 两 个表。在
表b z y x c 是不 自由虚词 中 “ 单 字词 ”类 虚词表 ( 如:
虚词表。
想:
c I 擎
等
倒如 : 争弹 l 峄 s 鞠
伪如: 争∞每
n
钠
倒如 : ㈣
’
1 )本课题 的研究根据传 统藏文文 法 ,结合最 大匹配 藏文分 词法 和 藏文树型分词法 ,在藏文 自动 分词过程 中与 自动 分词 同时 进行虚 词识
藏语文语转换系统关键技术的研究

2 藏 语 文 本 预 处 理
2 . 1 藏 文分词
藏 文分词 是 藏文信 息处 理 的一项基 础性 工作 。它
换系统 就显 得尤 为 重 要 。 同时 , 藏 语 文语 转 换 的实 现 将 会大 大 丰富藏 族地 区人 民 的生活 , 拓宽 信息 获取 、 发
布 和交 流 的渠道 , 对 藏 族 地 区 的社 会 稳 定 、 民族 团结 、 和谐进 步 有着重 要 意义 。
1 . 2 语音 合成历 史及 现状 回顾
是将 连 续 的藏 文文 本按 照一定 的算 法根 据藏 语语 法规 则切 分成 词 的过 程 。藏文 分 词 作 为语 音合 成 、 机 器 翻 译、 语 音识别 等研 究工作 的必 要前 提 , 在藏 文信 息处 理 领 域 很 是 重 要 。 下 面 本 文 就 藏 文 分 词 来 加 以 探 讨
行 了相关 文献 的研 究 和实 验 , 但 对 藏 语 语 音研 究 还 不
够深 入 , 国外对 藏语 语音 合成 方面 也未 曾有 相关报 告 。
答系统 , 电子邮件 的语音服务 以及残疾人语音辅助等
领 域 。藏语 文语转 换 系统 的研究 及应 用具 有很 重要 的 意义 , 尤其 是对 于藏 族地 区 的幼儿 和老人 , 藏语 文语 转
藏文分词方法跟其他语言分词方法类似, 都可以
用 基于 规则 的或 基于统 计 的方法 , 目前 , 作 者 阅读 过 的
诸 多文 献 中 , 处 理藏 文分 词 大 多 是用 基 于规 则 的正 向 最大 匹配上 加格 助词 的正 向最 大 匹配 , 另 外 有 逆 向的
在 2 0 世纪末 , 可训练 的语 音合 成 方法 诞 生 。而后 又
BP神经网络在脱机手写吾美藏文识别系统中的应用

1 引 言
目前 在我 国大 约有 50多万藏族 同胞 是使 用 藏 0 文的, 在他 们 的 日常 生活 中 , 大部 分还 是使 用传 统 绝
2 识 别 系统 设 计 方 案
2. 预 处 理 1
印刷体 文字 图像经 过 扫描 仪扫 描之 后得 到 了待
识别 图像 , 由于 在扫 描 的过 程 当中会 出现多 种 干扰 ,
第二步 , 为了使特 征数 变 少 , 需要 进 行特 征选 择 。本 文采用 降维 映射 法进行 特 征选 择 , 2 用模 板法 将 5个
初 步提取出的特 征值 进行 水平 投影 之后形 成 5个 特
对 于手写文字提取 了 5X 2 特征 , 过水 平投 5个 5= 经 影之后 只有 5个 特征 值 , 作为 神经 网络 的输 入 , 此 因 输入 节点为 5个 , 根据隐含层个数 大约为输 入节点 两 倍关系 , 隐含层取 1 O个节点 , 出层取 4个 节点 . 4 输 这 个输 出为 四位二进 制数 , 表神经 网络输 出 的数字 类 代
Ab t a t sr c : T e p p rman y d s u s d t e r c g i o e h i u s o f l e h n w t n Wu i o tsye h a e i l i s e e o n t n t c n q e fof i a d r t me n tl .A t r c h i -n i e f f e
sm lnm) a peu 函数 , 计算 步骤 如下 : 1 )正 向传播 输 出
2期
赵冬香 :P神经 网络 在脱 机手 写吾美 藏 文识别 系统 中的应用 B
5 1
2 )反 向传播 修正 权 值
藏文(含梵文)字丁自动识别方法研究

藏文(含梵文)字丁自动识别方法研究作者:完么才让来源:《卷宗》2015年第08期摘要:本文以《ISO/IEC 10646藏文编码字符集基本集》为参考,把其中除标点符号外的字符归类到字母集、主字集和元音集三个集合,再将测试文本中的藏文字符与三个集合逐一匹配的方法,准确识别(本文所讲识别,非OCR图形识别)出藏文字丁。
关键词:ISO/IEC 10646;音节;字丁;识别藏文字丁的准确识别是字丁频率、信息熵计算的前提,也是音节分类的基础,更是藏文识别必不可少的环节。
收录至中国知网的关于藏文字丁的几篇论文都未谈及藏文字丁的自动识别方法,本文从一下三个方面详细讲解藏文(含梵文)字丁的自动识别方法。
1 字母集、主字集和元音集把藏文unicode字符集中除标点符号等特殊字符外的其他字符分成字母集、主字集和元音集三个集合,分别用英文标记letter_set、main_char_set和vowels_set表示,则letter_set集合中的字符都无上加字,即字符上下均无main_char_set和vowels_set集合所示的空心圆圈,这类字符在实际文本中多作为字母出现,故将这类字符收录到字母集中。
相应地,main_char_set集合所含字符大都上有空心圈,结合时,附着在前一个字符的下面,把具有这个特征的字符收集到主字集中。
vowels_set集合中的字符都下附空心圆圈,表名这类字符在具体文本中充当元音,应收集到元音集中。
这三个集合是字丁识别的前提,以下内容中用L、M和V分别代表letter_set、main_char_set和vowels_set,Li、Mi和Vi表示对应集合中的任意元素。
2 藏文字丁的基本分类藏文字丁可分为六大类型,分别为:所有藏文字丁可归类到以上六种类型。
3 识别方法在有了集合的划分和字丁的基本分类后,即可依据如下所描述的方法识别出藏文字丁。
假设字符串变量Ttext存放待测试的藏文文本,字符串变量WR表示字丁。
藏文句子语义块识别方法

Qinghai Normal University, Xining, Qinghai 810008, China)
Abstract: Semantic understanding is an essential task in natural language understanding. Conventionally. grammar rule-based approaches including lexical and sentence analysis are leveraged to parse the semantic meaning of given text. In this work* we present a new method to address Tibetan sentence semantic parsing via semantic chunking. The semantic chunking is modeled by Bi-LSTM and ID-CNN neural network , respectively. In experiments, the proposed model shows a remarkable performance, achieving the average F)of 89% and 92%, respectively. Keywords: Tibetan; semantic chunk; semantic segmentation; semantic analysis
藏文联机手写识别的研究与实现

i mpl e me n t s i t . Fi r s t ,e a c h Ti b e t a n t e x t i s d e c o mp os e d i n t o v a r i o u s s u b p a t t e r ns ,a n d t h e n t h e s u b p a t t e n i r s f u r t h e r d i vi d e d i nt o
s t r o k e s .Th r o ug h t he i d e n t i i f c a t i o n of s t r o ke s a n d t h e c o r r e s p o n d i ng r u l e s o f e a c h Ti b e t a n c h a r a c t e r ,t he u s e r ’ s h a n d wr i t i n g c h a r a c t e r
ma r k i t ,a n d t h e n t h e s t r o k e i s d e t e r mi n e d. Be f o r e t h e i d e n t i ic f a t i o n,t h e s i mi l a r s t r o k e s a r e c l a s s i ie f d a n d me r g e d t o s o l ve t h e
藏文人名自动识别研究

藏文人名自动识别研究作者:娘本先安见才让来源:《电子技术与软件工程》2015年第19期摘要目前的藏文人名识别研究大多通过英语、汉语等语种的方法来研究藏文人名的识别,虽然有着较好的识别效果,但对人名的用词、构词特点及应用藏文文法规则对人名上下文信息特征的分析较浅。
本文提出了通过建立藏文人名构成词的成分属性词典,动态生成人名库,利用传统文法中人名上下文信息特征的文法规则建立藏文人名上下文指示词库对人名自动识别的方法。
【关键词】藏文人名自动识别动态人名库指示词在进行藏文自然语言处理时,分词与标注是藏语语言信息处理的基础内容,也是藏语词法分析的核心。
藏文人名识别作为藏文分词与标注系统的重要处理内容,目前的藏文分词与标注系统在处理含有藏文人名等未登录词时,其效果一般难以满足实际的需求。
而藏文人名在未登录词中占有较大的比重,也是未登录词识别的主要难点。
因此,藏文人名的自动识别对于藏文未登录词识别以及藏文自动分词与标注具有重要的意义。
1 藏文人名识别的研究现状及难点1.1 藏文人名识别的研究现状目前国内外针对人名的自动识别主要有三种:基于规则方法、统计方法以及规则与统计相结合的方法。
藏文人名自动识别研究也以上述三种方法为主要研究方法,加上藏文人名的上下文信息特征来识别藏文人名为主。
1.2 藏文人名识别的难点人名等命名实体识别发展至今在英文和中文领域已经取得了很大的成果,但是由于藏文人名自身的特殊性,使得藏文人名识别研究进展缓慢,藏文人名识别中的难点包括:(1)音节长度不固定。
按照藏族的传统命名方式藏文人名在起名时大多以3-4个音节结构较为普遍,但是由于在现实生活中对称呼的变化,藏文的音节长度最短的2个音节,最长可达26个音节。
(2)藏文人名本身并无明显的特征。
藏文人名不同于英文和汉文人名,如英文人名在文本中出现时首字母为大写,汉文人名一般采用“姓氏+名字”的命名方式。
藏文人名不存在大小写等形式上的特征,也没有严格意义上的姓氏。
基于深度学习的藏文手写字符识别研究

基于深度学习的藏文手写字符识别研究
师跃普 西热旦增 陈瑶 强巴旦增 西藏大学
摘要:深度学习经常被用来帮助计算机理解大量的图像、文本和声音等形式的信息。由于其包含多层类似人脑的感知器,它可以通过大量的数据 信息来学习,当在遇到类似情况的时候能够做出与之相适应的反应。本文主要通过构建和运用深度学习中的卷积神经网络来学习和认识藏文手写字符。
activations = tf.nn.relu(preactive,
name="activation")
池化层代码如下:
tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1],
padding='SAME')
全连接层代码如下:
with _scope(name):
表 1 训练 20 次数据表
次数 准确率
次数 准确率
1 0.58
11 0.95
2 0.67
12 0.938
3 0.72
13 0.91
4 0.83
14 0.9201
5 0.80
15 0.92
6 0.85
16 0.91
7 0.89
17 0.911
8
9
10
0.94 0.93 0.902
பைடு நூலகம்
18 19 20
0.902 0.8984 0.93
with _scope("weights"): W = init_weights(shape)
with _scope("biases"): b = init_bias([shape[3]])
藏文自动分词系统中紧缩词的识别

文分词是藏文语料库建设的基础, 已分词、标注的成 熟语料库是藏文文语转换、藏文与其他语言文字间 的机器翻译、藏文文本校对、藏文拼写检查、文本检 索等方面研究的重要资源[ 2] 。
2 藏文自动分词过程
分词技术属于自然语言处理技术范畴。众所周 知, 人通过自己的知识先把句子切分成词, 然后根据 词之间的关系来理解句子, 计算机理解句子也要先 把句子切分成词。
( 重要的 新闻我 听也听 了, 内容也 领
会了。) 字串
中有紧缩词
, 去掉紧缩词后的字
串为 , 在词库中存在, 分词结果为 和
具格助词 , 此时的 不是后置字, 从 而识别
了紧缩词 ; 字串
中有紧缩词 , 去掉
紧缩词后的字串为
,
在词库中存在,
分词结果为
和属格词 , 识别了紧缩词
; 字串
中有紧缩词 , 去掉紧缩词后
和属格助词 , 识别了
经测试用还原法 不能识别两种情况下的紧缩 词。其一, 去除紧缩词后的词仍不在词库中, 即 未 登录词+ 紧缩词 的形式, 这种情况一般可用扩大词 库的方法解决; 其二, 使用还原法时在第一步( 去除) 后就识别了紧缩词, 正确结果应该是第二步( 添加)
后识别紧缩词。例如, 词过程中去除紧缩词
成词。
常用规模式匹配的方式进行分词对分词速度的
影响非常大, 为提高分词速度可把藏文文本以几个
特殊的藏文格助词
( 以下把这
几个格助词简称 为特殊格助词 ) 为临 界符进行 分 块, 具体过程如下:
1) 对句子从前向后开始扫描, 直至遇到特殊格 助词;
2) 以特殊格助词为基准, 分别正向和逆向取字 合并, 并判断是否在临界库中存在。若不存在, 则将 该特殊格助词前的文本作为一个块, 继续执行 1) ; 否则切分出临界词, 将临界词前的文本作为一个块, 继续执行 1) 。
藏文古籍文本检测研究现状
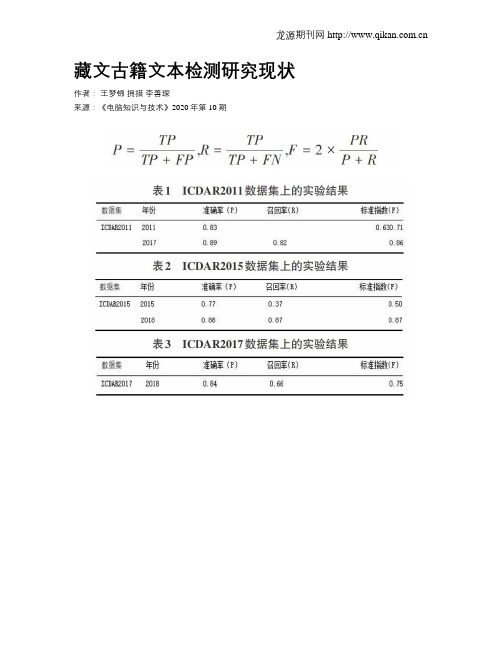
藏文古籍文本检测研究现状作者:王梦锦拥措李善琛来源:《电脑知识与技术》2020年第10期摘要:该文主要介绍了在过去十几年内自然场景文本检测最常用的算法以及其研究趋势,仔细阐述了藏文在文本检测与识别上的发展历程,讲述了众多研究学者根据藏文文字的结构特征,音节符特征等方面进行研究,为后期的藏文古籍文献检测试验打下基础。
关键词:藏文古籍文该文献;文本检测;深度学习;OCR中图分类号:TP399 文献标识码:A文章编号:1009-3044(2020)10-0204-04随着电子科技和移动互联网的快速发展,移动电话,相机和其他的移动端的普及,基于传统的文本搜索已经不能满足人们的日常需求,人们意识到识别复杂场景下图片上的文字的必要性。
顺应时代与信息科技发展的需求,藏文古籍文献数字化也变得必不可少。
藏文古籍文献的数字化,有助于藏文古籍文献的保存与文化传承,有效促进西藏文化的发展。
但藏文古籍文献的文本环境特殊,可用数据集较少,再加上扫描或者用相机进行拍照录入时,会导致其分辨率降低。
而藏文古籍文献本身就存在众多问题,随着时代的变迁,介于藏文古籍文献的保存完好程度来看,不同的文献会出现不一样的清晰度,字体的大小,颜色,尺寸也大不相同,有些文献会出现字迹模糊,文字扭曲等现象,还有一些非文字区域出现类似于文字的纹理,其干扰检测的准确率。
针对以上困难,国内外专家对其进行多次的研究,最常见的算法来源于国外,如文献等;但我国国内对这些经典算法改进迅速,如文献等。
文本检测传统方法有:SWT、MSER等;深度学习的方法有:R-CNN、Fast R-CNN、Faster R-CNN、CTPN等。
本文将自然场景文本检测的算法进行总结,阐述了藏文在文字检测、识别上发展历程。
1文本检测研究现状1.1自然场景文本检测研究现状传统文档分析与现代文档分析区别在于数据集外观上的不同,传统的文档分析所用的是光学字符识别(Optical Charac-ter Recognition,OCR),OCR技术这一概念是早在20世纪20年代由德国的一位科学家提出,后来由美国的一位科学家将其运用到文字识别上。
藏文信息处理

University
of
Science
and
Technology
of
China
北大方正藏文书版系统7.21和方正飞腾4.1(藏文版)、 班智达藏文字处理系统的键盘布局:
它遵循了部分藏文的规律,把一些上加字或下加字与辅 音中的该字组合放在一个键上,三十个辅音和元音等只占了三十 二个下档键键位。但其中有十七个键位上有两个以上的字符,为 了能够正确的识别该字符,输入时需要多次击有该字符的键。虽 不需用上档键,较方便,但一字需要多次击键而影响了文字的录 入速度。
University
of
Science
and
Technology
of
China
University
of
Science
and
Technology
of
China
University
of
Science
and
Technology
of
China
2)输入简单,速度较快。以上六种藏文字处理系统的键盘 输入法的输入顺序都是藏文的书写顺序,只要懂藏文的人一看 藏文的键盘布局就会输入;输入直观,有什么字输什么字,一 清二楚,一目了然;一字一键或一字两键的字占80%以上,速 度较快。其实,这些也是藏文本身的特点决定的。 3)识别能力强。键盘输入时,每个字的输入编码与唯一的 该字对应,所以,字的识别能力很强,也没有重码。 4)功能增强。纵观六种软件的发展,可以看出藏文字处理 系统也正在逐步提高、改进、完善。例如:北大方正藏文书版 系统和方正飞腾4.1(藏文版)、班智达藏文字处理系统在原 来的基础上增加了藏文词组的输入,提高了藏文的录入;同时, 对现代藏文的输入完全不用上档键,也方便了藏文的录入,得 到了使用人员的好评。华光藏文字处理系统可以简单的处理部 分的字体的变化,比原来单一的藏文正楷字在文字修饰上好很 多。 目前,藏文字处理系统虽然有以上几种优点,但仍然有很多不 足,需要改进的地方。
基于Tesseract_OCR的藏文手写乌金体研究

81221)"(#1Q<5 !'=>?@),-
!!!!ÙW!ÚÒ!Úeî!ÈÃÖ!ú;@
!!!¡n1267¯2³É2:!¡n ®¯ &$%%%%
B>#C/*%&8$31#"&X"&/D)$##1&NP$&#$6"21/%&81221)"(#1Q<5
qßà(PzI¾5=ßཾ I8,,8:=A>1"E5(uïó)D8Ô#{ts !®;½ó)Dïq(v#¿;Ðuï)Dï([8=ßà+',*'ýÌ M "E5^_IOvår`a(>?<=sâ<#qßàĵïxy=G_ßà`a ²m<(xy+),*
)> I3883S.PR+?C¼½)*
&'()*!IJ)$$ +,-./!K +01*!'%./0.1(.%'%'2&%)0%$220%2
2345%'%')0%.0'% 6789%12 S h $ h § ´ ± ² - y I8,,8:=A>3"E5 Mn(¸°±°g8 9 M µ § 5 à .#± ² x y% '%')$%/.2%)($ :;<=%ÙW#'%%'O$!¸!I-+¡ ¹!2¯ße!@Ao½%¤689' op:;%ÚÒ#$..'O$!Ã!/;³0 ¹!2¯#Â$!@Ao½%67XY'
藏文字符的分类与功能描述

【专题名称】语言文字学【专题号】H1【复印期号】2011年03期【原文出处】《西藏研究》(拉萨)2010年5期第75~85页【英文标题】A Classification and Description for Tibetan Characters【作者简介】江荻(1954- ),博士、研究员,中国社会科学院民族学与人类学研究所,博士生导师,主要从事藏语计算语言学、汉藏语言学研究(北京100081);燕海雄(1980- ),博士、助理研究员,中国社会科学院民族学与人类学研究所,主要从事藏语计算语言学、汉藏语言学研究(北京100081)。
【内容提要】藏文字符除了字母类符号,尚有大量其他文本符号,这些符号的名称、性质与功能历来未作勘定,积疑甚多。
藏文文本符号总体上可以分为三大类:藏文(本体)字符、梵源藏文字符、其他文本图形符号。
藏文字符专指藏文创制时期以及藏文历史应用中依据语言变化所创制的符号,通常所说的30个辅音字母和4个元音符号以及相应变体都在此列。
除此外,藏文数字符和标点符号也可归入此类。
梵源藏文字符是通过新创藏文字形表示藏语中没有的梵文读音形式和文字形式的字符,形成了所谓的藏(文)化梵文字符。
其他文本图形符号包括藏族自身创造的图形以及来源于梵文文本的图形,其基本特点是不表达语言声音,仅表示某种文本形式意义,或者以图形方式指示事物的意义。
这类符号有吟诵示意符、吟诵会意符、占星符、装饰符,等等。
以上藏文字符大多已收入ISO/IEC国际标准藏文字符基本集,对字符的分类有助于进一步展开藏文计算机处理研究。
There exist so many scripts and symbols in Tibetan characters, yet their names, graphic forms, origins,functions and applied domains are still not clear and always with some confusions so far. Tibetancharacters may be divided into three parts: Tibetan original characters, Tibetan transliteratedcharacters from Sanskrit and other picture symbols. Each of the scripts or symbols is given a name andother features according to its traditional ideas and functions, and with explanations to itsclassification. Classifing Tibetan characters is important to the research of computer processing ofTibetan characters.一、引言藏文文本中除了表达语言声音的字符之外,还存在大量其他类型的符号,这些符号有些具有表达语言功能的作用,有些则只是文本的装饰性图案。
藏文联想输入法设计

藏文联想输入法设计藏文输入法是藏文信息处理技术的一项基础工作,藏文输入法包括藏文单字输入法和词语联想输入法。
文章在讨论藏文输入法实现方法的基础上,设计了藏文联想输入法中的生成树模块、检索模块和联想模块。
标签:藏文信息处理联想输入法生成树一、引言藏文是属于拼写文字,具有纵向和横向组合的特点,一个完整的藏文字由七个部件组成,按书写顺序依次是前加字、上加字、基字、下加字、元音、后加字、又后加字。
藏文输入法就是根据用户的输入查找出相应的藏文字供用户选择,它分为两部分,一是运用分析、综合的方法将藏文字排序,也就是字库和码表的生成;二是运用一定的方法将需要的藏文字从字库中取出来,也就是检索,其难点在于检索算法的构造。
目前已经开发出来的藏文输入法有方正、华光、桑布扎、班智达等,这些输入法不具有联想功能,从而影响了藏文字输入的速度。
本文在讨论藏文输入法实现方法的基础上,设计了藏文联想输入法中的生成树模块、检索模块和联想模块。
二、藏文输入法的实现方法构造藏文外码到内码的转换通常有两种方法,一是采用数组,二是采用有序树。
1.数组方法藏文有30个辅音,将第一个字母相同的藏文字定义为一个数组,共有30个数组,分别用unsigned char zw-a[]、unsigned char zw-b[]、……、unsigned char zw-z[]表示。
根据用户输入的藏文字在相关的数组中查询,得出相应的藏文字供用户选择。
采用数组的方法虽然实现简单,但该方法不易实现藏文的联想功能。
2.有序树方法静态数组不能动态释放内存,由数据结构算法可知,其检索效率不高,因此有必要将藏文单字构成一棵有序树,动态生成与释放,并且在树中的结点域中不包含藏文字,节省资源。
键树是一种特殊的查找树,其树中每个结点不是通常意义的关键字,而是组成关键字中的一个字符,从根到叶子结点的一条“路径”才对应一个关键字。
设字符集{AE,AF,AG,AH,AI,AL,AN,AO,AR,AU,BA,BD,BG,BK,BN,BR,BS},按首字母将其分解得{AE,AES,AEH,AF,AFA,AFD,AFG,AG,AH,AI,AK,AKA,AKD,AKF,AL,AN,AO,AR,AU}和{BA,BD,BG,BGS,BK,BKS,BN,BR,BS}对于关键字个数大于1的集合再按第二个字母进行分解为{{ AF,AFA,AFD,AFG},{ AK,AKA,AKD,AKF }},其它的集合也按类似的方法分解。