网页信息预处理
数据采集与预处理技术

数据采集与预处理技术随着大数据时代的到来,数据采集和预处理技术的重要性也日益凸显。
数据采集是指从各种数据源中获取数据的过程,包括网络爬虫、传感器获取、实时监测等;而数据预处理则是对采集到的数据进行处理和清洗,以便后续分析和挖掘。
一、数据采集技术1.网络爬虫网络爬虫是一种自动化获取互联网数据的技术,通过访问网页的URL 来获取网页内容,然后进行解析和提取有用的信息。
常见的网络爬虫有Google爬虫、百度蜘蛛、爬虫之家等。
2.传感器获取传感器获取技术主要用于获取物理、化学、生物等领域中的各种实时数据,包括温度、湿度、压力、光强、声音等。
传感器将实时数据通过数字化方式传送到中心服务器。
3.实时监测实时监测是指对于一些涉及物理、化学、生物等领域的数据进行实时收集和监测。
它可以帮助企业在生产过程中发现问题,及时做出调整和处理。
比如工厂的生产线监测,医院的病人监测等。
二、数据预处理技术1.数据清洗数据清洗是指对数据进行去除重复,归一化,补全缺失值,处理异常值等的过程。
这个过程对于后续的分析和挖掘具有重要的意义。
因为如果数据的质量不好,后续的分析结果也会受到影响。
2.数据转换数据转换是指对数据进行转换和重构,以便于后续分析处理。
常见的数据转换操作包括数据格式转换、数据集成、数据聚集、数据抽样等。
3.数据规约数据规约是指对数据进行压缩,以便于后续处理。
常见的数据规约方法有随机采样、聚类、PCA等。
三、数据采集与预处理技术的应用数据采集与预处理技术广泛应用于各个领域,包括工业自动化、生物医学、金融、能源等。
例如,工业自动化系统需要采集大量的数据来监测生产线上的工艺参数,并对数据进行处理和分析,判断生产过程是否正常运行,是否需要进行调整。
生物医学领域需要对患者的健康状况进行实时监测,并及时预测病情的变化。
为此,需要采用各种生理参数传感器对患者的身体数据进行采集,然后通过数据预处理技术进行清洗和筛选,最后进行挖掘分析。
网络舆情中的信息预处理与自动摘要算法

Absr c : i a e isl n r d e n a p o c ft e d t r p o e sng a d f r ti r m h ta t Th sp p rfrty i t o uc d a p r a h o h a a p e r c si n o ma tng fo t e
第3 4卷 第 5期
21 0 0年 1 0月
北
京
交
通
大
学
学
报
Vo . 4 NO 5 13 .
0c .2 0 t 01
J 0URNAL OF BE J NG I II J AOTONG UNI RS TY VE I
文章 编号 :6 30 9 (0 00 —0 40 1 7—2 12 1 )50 9 .6
L AN i I Je l Y n L U u
(col f l t ncadIfr t nE gne n , ei i tn ie i , eig1 04 ,hn ) Sh o o e r i n noma o nier g B in J oo gUnvr t Bin 0 0 4 C ia E co i i jg a sy j
b s d o e r si s d t n u e p o l o fn h s a e n o ma in.Fi al a e n k y wo d s u e o e s r e p e t d t e mo tc r d i f r to i n ly,t e e p r— h x e i
o nin i r s ntd.Durn h r c s f t e a o tc a ta to e a i n, we u e t e tc niu f pi o sp e e e i g t e p o e s o h ut ma i bsr c p r to s h e h q e o
大数据基础-数据采集与预处理

大数据基础-数据采集与预处理大数据基础数据采集与预处理在当今数字化的时代,数据已成为企业和组织决策的重要依据。
大数据的价值日益凸显,而数据采集与预处理作为大数据处理的基础环节,其重要性不言而喻。
本文将详细探讨数据采集与预处理的相关知识,帮助您更好地理解这一关键领域。
一、数据采集数据采集是获取原始数据的过程,它就像是为大数据这座大厦收集原材料。
常见的数据采集方法包括以下几种:(一)系统日志采集许多系统和应用程序会自动生成日志,记录其运行过程中的各种信息,如用户操作、错误信息等。
通过对这些日志的收集和分析,可以了解系统的运行状况和用户行为。
(二)网络爬虫当我们需要从互联网上获取大量数据时,网络爬虫是一个常用的工具。
它可以按照一定的规则自动访问网页,并提取所需的信息。
(三)传感器数据采集随着物联网的发展,各种传感器被广泛应用于收集物理世界的数据,如温度、湿度、位置等。
(四)数据库导入企业内部通常会有各种数据库存储业务数据,通过特定的接口和工具,可以将这些数据导入到大数据处理系统中。
在进行数据采集时,需要考虑数据的来源、质量和合法性。
数据来源的多样性可以保证数据的丰富性,但也可能带来数据格式不一致、数据重复等问题。
同时,要确保采集的数据合法合规,遵循相关的法律法规和隐私政策。
二、数据预处理采集到的原始数据往往存在各种问题,如缺失值、噪声、异常值等,这就需要进行数据预处理,将数据“清洗”和“整理”,为后续的分析和处理做好准备。
(一)数据清洗1、处理缺失值缺失值是数据中常见的问题。
可以通过删除包含缺失值的记录、填充缺失值(如使用平均值、中位数或其他合理的方法)等方式来处理。
2、去除噪声噪声数据会干扰分析结果,需要通过平滑技术或聚类等方法来去除。
3、识别和处理异常值异常值可能是由于数据录入错误或真实的异常情况导致的。
需要通过统计方法或业务知识来判断并处理。
(二)数据集成当数据来自多个数据源时,需要进行数据集成。
.net 预处理详解

.net 预处理详解在使用.net框架进行软件开发时,我们经常会遇到需要在编译阶段对代码进行预处理的情况。
预处理是指在编译代码之前,通过指定一些预处理指令来控制代码的编译过程。
预处理指令在代码中以`#`符号开头,告诉编译器应该如何处理代码。
在本文中,我们将详细介绍.net 框架中常用的预处理指令及其用法。
1. 条件编译条件编译是预处理中最常用的功能之一,它可以根据一些条件来决定是否编译一段特定的代码。
通过使用`#if`和`#endif`指令,我们可以在代码中嵌入任意条件来控制编译过程。
例如,我们可以使用条件编译来根据不同的操作系统平台编译不同的代码片段:```csharp#if WINDOWSConsole.WriteLine("This is a Windows platform.");#elif LINUXConsole.WriteLine("This is a Linux platform.");#endif```上述代码中,`#if`指令用于判断是否为Windows平台,如果是则输出相应的信息;`#elif`指令用于判断是否为Linux平台,如果是则输出相应的信息。
通过条件编译,我们可以根据具体情况选择性地编译代码,以实现更好的跨平台兼容性。
2. 定义常量预处理指令还可以用于定义常量,在编译过程中将其替换为指定的值。
通过`#define`指令可以定义一个常量,并在代码中使用该常量。
例如:```csharp#define MAX_VALUE 100int value = MAX_VALUE;```上述代码中,我们使用`#define`指令定义了一个名为`MAX_VALUE`的常量,并将其设置为100。
之后,在代码中使用该常量时,编译器会将其替换为实际的值。
这样可以提高代码的可读性和维护性。
3. 跳过代码有时候,在调试或者测试代码时,我们需要暂时跳过一些代码片段而不编译它们。
搜索引擎工作原理三个阶段简介

SEO实战密码:搜索引擎工作原理三个阶段简介搜索引擎工作过程非常复杂,接下来的几节我们简单介绍搜索引擎是怎样实现网页排名的。
这里介绍的内容相对于真正的搜索引擎技术来说只是皮毛,不过对SEO人员已经足够用了。
搜索引擎的工作过程大体上可以分成三个阶段。
(1)爬行和抓取:搜索引擎蜘蛛通过跟踪链接访问网页,获得页面HTML代码存入数据库。
(2)预处理:索引程序对抓取来的页面数据进行文字提取、中文分词、索引等处理,以备排名程序调用。
(3)排名:用户输入关键词后,排名程序调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬行和抓取爬行和抓取是搜索引擎工作的第一步,完成数据收集的任务。
1.蜘蛛搜索引擎用来爬行和访问页面的程序被称为蜘蛛(spider),也称为机器人(bot)。
搜索引擎蜘蛛访问网站页面时类似于普通用户使用的浏览器。
蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序把收到的代码存入原始页面数据库。
搜索引擎为了提高爬行和抓取速度,都使用多个蜘蛛并发分布爬行。
蜘蛛访问任何一个网站时,都会先访问网站根目录下的robots.txt文件。
如果robots.txt文件禁止搜索引擎抓取某些文件或目录,蜘蛛将遵守协议,不抓取被禁止的网址。
和浏览器一样,搜索引擎蜘蛛也有标明自己身份的代理名称,站长可以在日志文件中看到搜索引擎的特定代理名称,从而辨识搜索引擎蜘蛛。
下面列出常见的搜索引擎蜘蛛名称:· Baiduspider+(+/search/spider.htm)百度蜘蛛· Mozilla/5.0 (compatible; Yahoo! Slurp China;/help.html)雅虎中国蜘蛛· Mozilla/5.0 (compatible; Yahoo! Slurp/3.0;/help/us/ysearch/slurp)英文雅虎蜘蛛· Mozilla/5.0 (compatible; Googlebot/2.1; +/bot.html)Google蜘蛛· msnbot/1.1 (+/msnbot.htm)微软 Bing蜘蛛· Sogou+web+robot+(+/docs/help/webmasters.htm#07)搜狗蜘蛛· Sosospider+(+/webspider.htm)搜搜蜘蛛· Mozilla/5.0 (compatible; YodaoBot/1.0;/help/webmaster/spider/; )有道蜘蛛2.跟踪链接为了抓取网上尽量多的页面,搜索引擎蜘蛛会跟踪页面上的链接,从一个页面爬到下一个页面,就好像蜘蛛在蜘蛛网上爬行那样,这也就是搜索引擎蜘蛛这个名称的由来。
数据采集和预处理

数据采集和预处理在当今社会,数据已经成为了企业竞争的利器,越来越多的企业开始重视数据的价值,积极采集和分析数据。
数据采集和预处理是数据分析的前置工作,对于数据质量和分析效果具有至关重要的作用。
本文将从数据采集的方式、数据预处理的步骤和常用方法等方面进行探讨。
一、数据采集的方式1. 网页抓取网页抓取是一种常用的数据采集方式,同时也是最为简单的一种方式。
它通过程序模拟用户的行为,访问网页并抓取所需的数据信息。
网页抓取可以采用一些工具库实现,比如requests、beautifulsoup4等。
2. API调用API(Application Programming Interface)是一种常用的服务接口,它提供了一系列的接口方法,方便开发人员访问和获取服务端的数据。
API调用的方式通常是通过向服务端发送请求并接收响应实现。
API调用的优势是数据结构简单、数据质量高、查询效率高等。
3. 数据库读取在一些需要处理大量数据的场景下,数据库读取是一种更加高效的数据采集方式。
这种方式不需要通过网络传输,将数据直接读取到内存中并且进行处理,降低了数据采集的时间成本。
4. 传感器采集在一些实时监控场景下,传感器采集可以实时获取到物理环境状态、温度、气压等实时数据。
基于传感器采集的数据可以有效地进行分析和预测。
二、数据预处理的步骤1. 数据清洗数据清洗是数据预处理的第一步,它主要针对数据质量问题进行处理。
数据清洗的处理内容包括去除无效数据、数据格式转换、填充缺失值等。
2. 数据集成数据集成是将不同数据源中的数据整合在一起的过程。
数据集成的过程需要保持数据的一致性以及正确性。
3. 数据转换数据转换是指将原始数据转换为适合数据挖掘算法处理的数据结构。
数据转换的过程需要注意数据类别的转换,比如将数据离散化、归一化等。
4. 数据规约数据规约是指将数据集中的某些维度进行合并,从而减少数据维度,提高数据处理效率。
三、常用方法1. 特征选择特征选择是指通过评估不同维度或特征的重要性,选择对结果影响较大的特征。
数据采集与预处理技术

数据采集与预处理技术数据采集和预处理是数据分析的重要环节,它们对于获取准确、完整的数据以及保证数据质量至关重要。
本文将介绍数据采集与预处理技术的基本概念、常用方法和应用场景。
一、数据采集技术数据采集是指从各种来源获取数据的过程。
随着互联网和物联网的发展,数据采集的方式越来越多样化。
常见的数据采集方式包括传感器采集、网络爬虫、API接口等。
1. 传感器采集:传感器是一种能够感知和测量环境中各种参数的装置,如温度、湿度、压力等。
通过传感器采集的数据可以用于环境监测、物流追踪等领域。
2. 网络爬虫:网络爬虫是一种自动化程序,可以通过模拟浏览器的方式访问网页,并提取网页中的数据。
网络爬虫广泛应用于搜索引擎、舆情监测、电商价格监控等领域。
3. API接口:API(Application Programming Interface)是一组定义了软件组件之间交互规范的接口。
通过调用API接口,可以获取到特定网站或应用程序中的数据。
API接口常用于社交媒体数据分析、金融数据分析等领域。
二、数据预处理技术数据预处理是指对原始数据进行清洗、转换和集成等操作,以便后续分析使用。
数据预处理的目标是提高数据的质量、准确性和适用性。
1. 数据清洗:数据清洗是指对数据中的噪声、异常值、缺失值等进行处理,以提高数据的质量。
常用的数据清洗方法包括删除重复数据、处理异常值、填补缺失值等。
2. 数据转换:数据转换是指将数据从一种形式转换为另一种形式,以适应分析的需求。
常用的数据转换方法包括数据规范化、数据离散化、数据编码等。
3. 数据集成:数据集成是指将来自不同来源、不同格式的数据进行整合,以便后续分析使用。
常用的数据集成方法包括数据合并、数据连接、数据关联等。
数据采集和预处理技术在各个领域都有广泛的应用。
以金融领域为例,金融机构需要从不同的数据源采集相关数据,如股票交易数据、经济指标数据等。
然后对采集到的数据进行清洗、转换和集成,以便进行风险评估、投资决策等分析。
搜索引擎对网页去重技术算法-用来解析伪原创与网页相似度

搜索引擎对⽹页去重技术算法-⽤来解析伪原创与⽹页相似度⾸先,搜索引擎对所索引的所有⽹页进⾏页⾯净化和内部消重。
任何⼀家搜索引擎在尚未进⾏复制⽹页判断这⼀操作之前都定然会有个⽹页净化和内部消重的过程。
搜索引擎⾸先要清除噪⾳内容,对⽹页内部的⼴告、版权信息、共同的页眉页脚部分等进⾏净化,然后提取出该页⾯的主题以及和主题相关的内容,⽤以排名⼯作,噪⾳内容是不计⼊排名权重之中的。
消重也差不多是这个意思,搜索引擎对其所收集的⽹页集⾥⾯主题相同或极端相似的,⽐如同⼀模板之中多次出现的共同代码,将其作为冗余内容,进⾏消除。
我们可以这样理解,最理想的状态之下,⼀篇原创⽂章,搜索引擎仅将标题和内容计⼊排名之中,其他全部都消除。
DocView模型就是⼀个⾃动分类和消重的模型,当然,不是⾮常准确。
⼤家可以简单了解⼀下,DocView模型包括⽹页表识、⽹页类型、内容类别、标题、关键词、摘要、正⽂、相关链接等要素,它通过提取DocView模型要素的⽅法应⽤在⽹页⾃动分类和⽹页消重之中。
通过了解以上内容,我们就能⼤致明⽩,同⼀篇⽂章,为什么放到两个完全不同模板的站点之上,搜索引擎仍然能够正确识别出这是⼀个复制页⾯的原因了吧。
其次,搜索引擎对净化的页⾯进⾏重复内容的判断。
那么搜索引擎具体是如何判断复制页⾯的呢?以下内容是北⼤天⽹搜索引擎的去重算法,⼤部分来⾃对《搜索引擎——原理、技术与系统》相关知识的整理,⼤家可以⾃⾏参考相关⽂档。
现有⽅法⼤致可以分为以下三类:1、利⽤内容计算相似2、结合内容和链接关系计算相似3、结合内容,链接关系以及url⽂字进⾏相似计算现有绝⼤部分⽅法还是利⽤⽂本内容进⾏相似识别,其它两种利⽤链接关系以及URL⽂字的⽅法还不是很成熟,⽽且从效果看引⼊其它特征收效并不明显,所以从实际出发还是选择利⽤内容进⾏相似计算的算法。
搜索引擎判断复制⽹页⼀般都基于这么⼀个思想:为每个⽹页计算出⼀组信息指纹(信息指纹,英⽂是Fingerprint,就是把⽹页⾥⾯正⽂信息,提取⼀定的信息,可以是关键字、词、句⼦或者段落及其在⽹页⾥⾯的权重等,对它进⾏加密,如MD5加密,从⽽形成的⼀个字符串。
C语言对源程序处理的四个步骤:预处理、编译、汇编、链接——预处理篇

C语⾔对源程序处理的四个步骤:预处理、编译、汇编、链接——预处理篇预处理1)预处理的基本概念C语⾔对源程序处理的四个步骤:预处理、编译、汇编、链接。
预处理是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进⾏的处理。
这个过程并不对程序的源代码语法进⾏解析,但它会把源代码分割或处理成为特定的符号为下⼀步的编译做准备⼯作。
2)预编译命令C编译器提供的预处理功能主要有以下四种:1)⽂件包含 #include2)宏定义 #define3)条件编译 #if #endif ..4)⼀些特殊作⽤的预定义宏a、⽂件包含处理1)⽂件包含处理⽂件包含处理”是指⼀个源⽂件可以将另外⼀个⽂件的全部内容包含进来。
C语⾔提供了#include命令⽤来实现“⽂件包含”的操作。
2)#include< > 与 #include ""的区别" "表⽰系统先在file1.c所在的当前⽬录找file1.h,如果找不到,再按系统指定的⽬录检索。
< >表⽰系统直接按系统指定的⽬录检索。
注意:1. #include <>常⽤于包含库函数的头⽂件2. #include " "常⽤于包含⾃定义的头⽂件 (⾃定义的头⽂件常⽤“ ”,因为使⽤< >时需要在系统⽬录检索中加⼊⾃定义头⽂件的绝对地址/相对地址否则⽆法检索到该⾃定义的头⽂件,编译时会报错)3. 理论上#include可以包含任意格式的⽂件(.c .h等) ,但我们⼀般⽤于头⽂件的包含。
b、宏定义1)基本概念在源程序中,允许⼀个标识符(宏名)来表⽰⼀个语⾔符号字符串⽤指定的符号代替指定的信息。
在C语⾔中,“宏”分为:⽆参数的宏和有参数的宏。
2)⽆参数的宏定义#define 宏名 字符串例: #define PI 3.141926在编译预处理时,将程序中在该语句以后出现的所有的PI都⽤3.1415926代替。
如何进行数据采集和预处理

如何进行数据采集和预处理数据采集和预处理是数据分析的前提,它们对于数据科学家和研究人员来说至关重要。
正确的数据采集和预处理方法可以确保数据的准确性和可靠性,从而为后续的数据分析和建模提供可靠的基础。
本文将介绍几种常见的数据采集和预处理方法,并探讨它们的优缺点。
一、数据采集数据采集是指从各种来源中收集和获取数据的过程。
数据采集的方法多种多样,可以根据数据的类型和来源选择合适的方法。
以下是几种常见的数据采集方法:1. 网络爬虫:网络爬虫是一种自动化的数据采集工具,可以从互联网上抓取数据。
它可以通过模拟浏览器行为访问网页,并提取所需的数据。
网络爬虫可以用于采集各种类型的数据,如文本、图片、视频等。
但是,网络爬虫也面临着一些挑战,如反爬虫机制和网站的访问限制。
2. 传感器数据采集:传感器是一种可以感知和测量环境变化的设备。
传感器可以用于采集各种类型的数据,如温度、湿度、压力等。
传感器数据采集通常需要专门的硬件设备和软件支持,可以应用于各种领域,如气象学、环境监测等。
3. 调查问卷:调查问卷是一种常见的数据采集方法,可以用于收集人们的意见、偏好和行为等信息。
调查问卷可以通过面对面、电话、邮件或在线方式进行。
调查问卷可以采集大量的数据,但是需要考虑样本的代表性和回答者的主观性。
二、数据预处理数据预处理是指对采集到的原始数据进行清洗、转换和集成等操作,以便后续的数据分析和建模。
数据预处理的目标是提高数据的质量和可用性,减少错误和噪声的影响。
以下是几种常见的数据预处理方法:1. 数据清洗:数据清洗是指对数据中的错误、缺失和异常值进行处理。
数据清洗可以通过删除、替换或插补等方式进行。
数据清洗可以提高数据的准确性和一致性,但是需要谨慎处理,以免丢失重要信息。
2. 数据转换:数据转换是指对数据进行格式、单位或尺度的转换。
数据转换可以使数据更易于分析和理解。
常见的数据转换方法包括标准化、归一化和对数转换等。
数据转换可以提高数据的可比性和可解释性。
基于协作过滤的Web日志数据预处理研究

址 。第 2项用 于 记 录 浏览 者 的标 识 和 登 录 名 , 当用 户 匿 名登 录 时 , 处 为空 白, “ 一” 此 用 一 占位 符 替 代 。 第 3项是 请 求 的 日期 和 时 间 , +0 0 ” 示 服 务 器 “ 00表 所 处 的 时 区位 于 国 际标 准 时 区 ( UTC) 。第 4项 记 录 了请求 的 方法 、 问的 资 源 和所 采 用 的协 议 及 版 访 本 号 。第 5项是 服 务 器 状态 码 , 它标 识访 问是 否 成 功 。一般 而 言 , 态码 以 2开 头 表示 请 求 成 功 , 3 状 以 开头 表示 用 户请 求 被重 定 向到 其 他 位 置 , 4开 头 以 表 示 客户 端存 在 错误 , 5开 头表 示 服务 器 端 存 在 以
出 了基 于 协 作 过 滤 的 we 日志数 据 预 处 理 过 程 结 构 图 和 一 种 可 行 的 数 据 预 处 理 方 法 , 方 法 不仅 可 以 提 供 更 加 b 该 干 净 、 则的 数 据 源 , 且 在 用 户 兴 趣 度 量 方 面 , 补 了 以 往 诸 多兴 趣 度 量 方 法 的 不 足 , 协 作 过 滤 算 法 提 供 了 更 规 而 弥 为
V 11 N . o.8 o5
O t2 0 c. 0 6
文 章 编 号 :0 45 9 (0 6 0 —6 60 10 —6 4 20 ) 50 4 —4
基 于协 作 过 滤 的 We b日志数 据 预 处 理 研 究 -
纪 良浩 , 国胤 , 勇 王 杨
( 庆邮 电大 学 计 算机 科学 与技 术研 究所 , 庆 4 0 6 ) 重 重 0 0 5
CSS中的预处理器有哪些各自的特点是什么

CSS中的预处理器有哪些各自的特点是什么在当今的网页开发领域,CSS(层叠样式表)是构建网页样式的重要基石。
然而,为了更高效地编写和管理 CSS 代码,预处理器应运而生。
它们为开发者提供了更强大的功能和更便捷的语法,大大提升了开发效率和代码的可维护性。
接下来,让我们一起探讨几种常见的CSS 预处理器及其各自的特点。
Sass(Syntactically Awesome Style Sheets)Sass 是一种非常流行的 CSS 预处理器,它具有许多强大的功能和特点。
首先,Sass 支持变量。
通过使用变量,我们可以将一些常用的值,如颜色、字体大小、边距等,定义为变量,然后在整个样式表中重复使用。
这不仅减少了代码的重复,还使得修改这些值变得极为方便。
例如,我们可以定义一个主色调变量`$primarycolor: 007bff;`,然后在需要使用该颜色的地方直接引用`$primarycolor` 。
其次,Sass 支持嵌套规则。
这意味着我们可以将相关的选择器嵌套在一起,使得代码的结构更加清晰和直观。
比如,对于一个导航栏的样式,我们可以将`nav` 下的`navitem` 嵌套在`nav` 里面进行样式设置。
再者,Sass 还支持混合(Mixin)。
混合是一种可重用的代码块,可以接受参数。
这对于定义一些常用的样式组合非常有用,比如定义一个带有阴影效果的混合,然后在需要的地方调用。
另外,Sass 具有函数功能,允许我们创建自定义的函数来处理和生成样式值。
Sass 分为两种语法:Sass 和 SCSS。
SCSS 语法类似于 CSS,具有更友好的可读性,而 Sass 语法则更加简洁,但相对来说可能对新手不太友好。
Less(Leaner Style Sheets)Less 也是一种广泛使用的 CSS 预处理器,它与 Sass 有一些相似之处,但也有其独特的特点。
和 Sass 一样,Less 支持变量。
通过定义变量来统一管理样式值,使得修改样式变得轻松高效。
【国家自然科学基金】_网页预处理_基金支持热词逐年推荐_【万方软件创新助手】_20140803
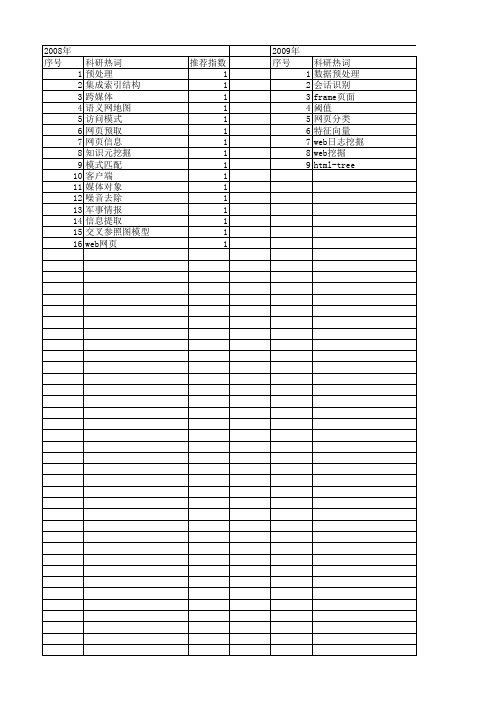
推荐指数 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2014年 序号 1 2 3 4 5 6 7 8 9 10
2014年 科研热词 领域本体 路径补全 站点结构 用户浏览时间 模板 数据预处理 决策树 信息抽取 web使用挖掘 deep web 推荐指数 1 1 1 1 1 1 1 1 1 1
推荐指数 2 1 1 1 1 1 1 1 1 1 1
2011年 序号 1 2 3
2011年 科研热词 网页预处理 网页分类 维文网页 推荐指数 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9
科研热词 词共现图 聚类 用户会话 新闻话题识别 新闻话题 微博 主题词 web日志 web使用挖掘
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
科研热词 预处理 集成索引结构 跨媒体 语义网地图 访问模式 网页预取 网页信息 知识元挖掘 模式匹配 客户端 媒体对象 噪音去除 军事情报 信息提取 交叉参照图模型 web网页
推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2009年 序号 1 2 3 4 5 6 7 8 9
科研热词 数据预处理 会话识别 frame页面 阈值 网页分类 特征向量 web日志挖掘 web挖掘 html-tree
推荐指数 2 2 2 1 1 1 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9 10 11
科研热词 信息抽取 自动摘要 网页预处理 网络舆情 文本过滤 抽取窗口 分层过滤 倒排索引 二元词串 htmlparser bt种子信息
推荐指数 1 1 1 1 1 1 1 1 1
网站优化

网站优化一、搜索引擎的分析1搜索引擎的定义及构成:搜索引擎就是一个计算机的应用软件系统,或者说就是一个网络应用软件系统,它会根据用户提交的类自然语言查询词或短语,返回一系列很可能与该查询相关的网页信息,供用户进一步判断和选取。
为了有效的做到这一点,大致分为三个功能模块,或者三个子系统:网页搜集、预处理和查询服务。
2、网页的搜集:面对大量的用户查询,不可能想象每来一个查询,系统就到网上“搜索”一次,因此我们看到,大规模引擎服务的基础就该是一批预先搜集好的网页。
a) 定期搜索:每搜集一替换上一次的内容,我们称之为“批量搜集”。
由于每改新一次对大型搜索引擎开销大,同时也带来额外流量消耗,所以改新时间大概是20~30天。
b) 增量搜索:开始搜索一批,往后只是✧ 搜集新出现的的网页✧ 搜集那些上次搜集后有过改变的网页✧ 发现自上次搜集后不存在的页面,从库中删除。
这种周期大概30~50天。
3、预处理:a)关键词的提取:随便查看一个网页,查看一下源文件,我们可以看到其内容纷乱繁杂,它有大量的html标记。
网站公司的优化很多都采取这方面的优化,大<title>……</title>在放入关键词,在link、intext、url等后放置关键词。
b)链接分析:html标记繁杂,便同时也能带来机遇,比如从代码分析在、<h1>……</h1>与<h4>……</h4>,系统会认为h1内的内容要比h4当中的重要。
c)网页重要程度的计算:用户观看网站对网站的满意程度(网站打的速度及用户打开页面后在网页上停留的时间长短),网站对于搜索引擎是否投其所好,被引用多的就是重要的。
“引用”概念恰好可以通过html超链接之间体现的得非常好。
注意:在网站中关键词出现的的字数比例很重要(关键词占文章总篇幅的2%~8%为最佳,超过11%之后,很有可能会被搜索引擎认为垃圾网页,会被屏闭,虽然说它短时间能达到预期效果,但这种方法不可取)。
面向主题的WWW信息的分类系统的设计与实现

 ̄ j t h柏 pp ,a 啪 e . c ae r
—0 l dW b¨ r t e he 佣
C sictnSse ( I )i p sne, b h h l si i ytm WG s r etd y wi a , ̄ o f S e c
we a e a b e tc n l Oi t d a d z s l b p g s c n e f i t C l c e n d si d i e y e f e
本系统跨越 了多个类别。对 网页正文 文本信息的分析属于文本挖掘部分 ,对一 个网页上的超链接的分析属于 We 结构挖 b
掘 的超 链接挖 掘部 分 。在用户子 系统中 , 对用 户的访问进行跟踪又属于 we b日志挖 掘 的用户 访问模式 分析 。
b c m n nra g if u . r u es t o e t a d e o ig i e ̄n l d'i l f g P o c l c n c y fct o ' l a lz e P g s t a ae r l a t t at ua  ̄ yew b a e h t r e v n o a D ri Ir e c
不 。
随 着互联 网技 术的不 断发展 , 用户收集和 分
析 与特 定主题 相 关的 网页显得 越 来越 困难 。
上高效地获取有用的信息。 网络搜索引擎 的出现 ,使 人们 检索 信 息的效 率 大大提 高 。但是 由于 各网站 相互 转载 、引 用信 息 ,We b上存在许 多内容相同或者相似的 网页 ,网上信息冗余严重 。这也就使得搜 索有用信 息的效率降低 了。为 了提高检索 的 效 率 ,面 向 主题 www 信 息的 分 类 系统
网页信 息资源进行分析 ,采用分词技术和 词频分 析技 术, 自动提取关键 词,并通过
SEM SEO专业名词术语解释大全(新手必看)

SEM/SEO专业名词解释(新手必看)SEO专业术语解释:1、网页蜘蛛(Spider)网页蜘蛛(又被称为网络爬虫,网络机器人,搜索引擎蜘蛛),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
2、蜘蛛陷阱(Spider trap)“蜘蛛陷阱”是阻止蜘蛛程序爬行网站的障碍物,通常是那些显示网页的技术方法,目前很多浏览器在设计的时候考虑过这些因素,所以可能网页界面看起来非常正常,但这些蜘蛛陷阱会对蜘蛛程序造成障碍,如果消除这些蜘蛛陷阱,可以使蜘蛛程序收录更多的网页。
3、抓取频次抓取频次是搜索引擎在单位时间内(天级)对网站服务器抓取的总次数,如果搜索引擎对站点的抓取频次过高,很有可能造成服务器不稳定,Baiduspider 会根据网站内容更新频率和服务器压力等因素自动调整抓取频次。
4、索引(Index)俗称“预处理”。
蜘蛛抓取的页面文件分解、分析,并以巨大表格的形式存入数据库,这个过程即是索引。
在索引数据库中,网页文字内容,关键词出现的位置、字体、颜色、加粗、斜体等相关信息都有相应记录。
5、站点索引量站点中有多少页面可以作为搜索候选结果,就是一个网站的索引量。
站点内容页面需要经过搜索引擎的抓取和层层筛选后,方可在搜索结果中展现给用户。
6、网页快照搜索引擎在收录网页时,对网页进行备份,存在自己的服务器缓存里,当用户在搜索引擎中点击“网页快照”链接时,搜索引擎将Spider 系统当时所抓取并保存的网页内容展现出来,称为“网页快照”。
7、网站权重(Page Strength)网站权重是指搜索引擎给网站(包括网页)赋予一定的权威值,对网站(含网页)权威的评估评价。
一个网站权重越高,在搜索引擎所占的份量越大,在搜索引擎排名就越好。
其中有几点需要注意:A、权重不等于排名B、权重对排名有着非常大的影响C、整站权重的提高有利于内页的排名。
8、网站降权(Rightdown)利用搜索引擎策略缺陷,以恶意手段获取与网页质量不符排名,而引发搜索结果和用户体验下降的行为都会被搜索引擎视为作弊行为,处罚原则:对用户体验及搜索结果质量影响不大的,去除作弊部分所获权值,对用户体验及搜索结果质量影响严重的,去除作弊部分所获权值并降低网站权重,直至彻底清理出搜索结果。
自然语言处理中的数据预处理方法

自然语言处理中的数据预处理方法自然语言处理(Natural Language Processing,简称NLP)是人工智能领域中的一个重要分支,旨在使计算机能够理解和处理人类语言。
在NLP中,数据预处理是一个至关重要的步骤,它对于后续的文本分析、语义理解等任务起着决定性的作用。
本文将介绍几种常见的数据预处理方法,以帮助读者更好地理解和应用自然语言处理技术。
一、文本清洗文本清洗是数据预处理的第一步,它主要包括去除噪声、特殊字符、标点符号等。
常见的文本清洗操作包括去除HTML标签、去除停用词、转换为小写等。
例如,在处理网页数据时,我们需要去除HTML标签,只保留其中的文本内容;在处理英文文本时,我们需要将大写字母转换为小写字母,以便统一处理。
二、分词分词是将连续的文本划分为独立的词语的过程。
在中文中,由于没有明显的词语间的分隔符,因此分词是一项具有挑战性的任务。
常见的中文分词方法包括基于规则的分词、基于统计的分词和基于机器学习的分词。
而对于英文文本,分词相对简单,可以通过空格或标点符号进行分割。
三、词性标注词性标注是为文本中的每个词语标注其词性的过程。
词性标注对于后续的句法分析、语义分析等任务非常重要。
常见的词性标注方法包括基于规则的标注和基于统计的标注。
基于规则的标注方法依赖于事先定义的规则集,而基于统计的标注方法则通过学习大量已标注的语料库来预测词语的词性。
四、去除停用词停用词是指在文本中频繁出现但对文本分析任务没有帮助的词语,如“的”、“是”、“在”等。
去除停用词可以减少文本的维度,提高后续任务的效率。
常见的停用词表可以从自然语言处理工具包中获取,也可以根据具体任务进行定制。
五、词干提取和词形还原词干提取和词形还原是将词语还原为其原始形式的过程。
例如,将“running”还原为“run”或将“mice”还原为“mouse”。
词干提取和词形还原可以减少词语的变体,提高文本的一致性和可比性。
常见的词干提取和词形还原方法包括基于规则的方法和基于统计的方法。
基于规则的网页分割预处理算法研究

计
算
机科学 源自Vo 1 . 4 0 No . 1 1 A
No v 2 01 3
Co mp u t e r S c i e n c e
基 于 规 则 的 网 页分 割预 处 理 算 法研 究
彭红 超 童 名文 邹 军华。 郝 秋红
页分割预 处理算法 , 建 立了网页标 签和样 式信 息的关联 。算 法包括 3个步骤 : 第一 , 获取样 式信 息 ; 第二 , 关联样 式信 息和标 签; 第三 , 输 出 HT ML和 P e r f e c t No d e 关联类列表 。随机选取 了 1 0 0个 国家精品课程 网站的 网页运行预处理算
P ENG Ho n g - c ha o TONG Mi n g I 、 v e Z OU j u n - h u a 2 H AO Qi u - h o n g 1
( C o l l e g e o f I n f o r ma t i o n Te c h n o l o g y , J o u r n a l i s m a n d o m C mu n i c a t i o n s , C e n t r a l C h i n a No r ma l Un i v e r s i t y , Wu h a n 4 3 0 0 7 9 , ( 、 h i n a )
( Fa c ul t y o f Edu c a t i o n, Hu be i Un i v e r s i t y, Wu ha n 4 3 0 0 7 0, Ch i n a ) 。
Ab s t r a c t S i n c e t h e i n d e p e n d e n t d e s i g n b e t we e n we b c o n t e n t s a n d s t y l e s o f Na t i o n a l Le v e l Ex c e l l e n t C o u r s e s , we b p a g e s e g me n t a t i o n a l g o r i t h m c a n h a r d l y r u n . We p r e s e n t a r u l e - b a s e d p r e p r o c e s s i n g a l g o r i t h m o f we b p a g e s e g me n t a t i o n t o c r e a t e c o r r e l a t i o n b e t we e n t a g s a n d s t y l e i n f o r ma t i o n . Th e a l g o it r h m c o n s i s t s o f t h r e e s t e p s : f i r s t , g e t t h e s t y l e i n f o r ma — t i o n; s e c o n d , a s s o c i a t e s t y l e s wi t h t a g s ; t h i r d , o u t p u t HTML a n d Pe r f e c t No d e wh i c h i s a s s o c i a t e d c l a s s l i s t . We s e l e c t e d 1 0 0 p a g e s f r o m t h e Na t i o n a l Le v e l Ex c e l l e n t o u C r s e s r a n d o ml y t o r u n t h e p r e p r o c e s s i n g a l g o r i t h m. Ex p e r i me n t a l r e s u l t s s h o w t h a t t h e a l g o r i t h m c a n a s s o c i a t e t a g s wi t h s t y l e s e f f i c i e n t l y , wh i c h c a n s o l v e t h e p r o b l e ms t h a t we b p a g e s e g me n t a — t i o n a l g o r i t h m c a n n o t r u r L Ke y wo r d s We b p a g e s e m e g n t a t i o n, Pr e p r o c e s s i n g a l g o r i t m , h Ca s c a d i n g s t y l e s h e e t s , S t y l e i n f o r ma t i o n
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<tr> <td>搜索引擎基础教程:第1章</td> </tr> <tr> <td>搜索引擎基础教程:第2章</td> </tr> <tr> <td>搜索引擎基础教程:第3章</td> </tr> </table> </body> </html>
Scrapy: 基于Python的爬虫框架库
Windows下的Scrapy安装和环境搭建
检查Platform specific installation notes
Python 2.7 pip and setuptools Python packages. Nowadays pip requires and
Selectors类:从网页中提取数据
Scrapy基于Xpath(XML Path Language)和CSS
/html/head/title /html/head/title/text() //td //div[@class=“mine”] 选择包含在<head>中的 <title> 信息 选择文本信息 选择所有的 <td> 选择所有clase=“mine”的div
在命令行下,添加环境变量:
c:\python27\python.exe c:\python27\tools\scripts\win_add2path.py
测试python 版本
python --version
安装pywin32: /projects/pywin32/
深圳大学未来媒体技术与计算研究所
2
Scrapy: 基于Python的爬虫框架
Scrapy是使用Python开发的一个速度快、效率高的web和屏幕数据抓取的框架,多用
于抓取web站点并从结构复杂的Web页面中提取出结构化的数据。Scrapy的用途非 常广泛,可以用于自动化测试、监测、数据挖掘等任务。Scrapy 的底层是基于 Twisted网络引擎,
23
网页结构化的目标
网页结构化的目标是根据搜索的需要,将半结构化的
HTML网页中的数据按照约定的基本属性组合成一个网页 的对象。一个网页对象至少有5个属性:
(1)锚文本(anchor text)
(2)标题(title) (3)正文标题(content title) (4)正文(content) (5)正向链接(link)
An interactive shell console (IPython aware) for trying out the CSS and XPath expressions to scrape data, very useful when writing or debugging your spiders. Built-in support for generating feed exports in multiple formats (JSON, CSV, XML) and storing them in multiple backends (FTP, S3, local filesystem) Robust encoding support and auto-detection, for dealing with foreign, non-standard and broken encoding declarations. Strong extensibility support, allowing you to plug in your own functionality using signals and a welldefined API (middlewares, extensions, and pipelines). Wide range of built-in extensions and middlewares for handling:
– cookies and session handling – HTTP features like compression, authentication, caching – user-agent spoofing – robots.txt – crawl depth restriction
安装pip: https://pip.pypa.io/en/latest/installing.html
pip –version
安装IPython 安装scrapy
pip install Scrapy
Scrapy使用:基本教程
新建一个新的scrapy工程
建议需要提取的item对象
Scrapy基本教程:提取网页中 的数据
在命令行中键入下列命令
scrapy shell /Computers/Programming/Languages/Python/Books/
可以查看的对象
Scrapy基本教程:提取网页中 的数据
查看数据,例子
截止日期:2015.10.25 相似度要求:50%以上相似,不合格; 增加两点以上的功能,功能越多,分数越高 实验报告+源程序 基础分15分(报告完整,代码可执行),总分:20分
作业一
(选择二)实践作业:基于搜索引擎和个人兴趣, 调研社交搜索或者垂直搜索,完成一份行业调研和 综述报告。
页的源代码整理成一个可以有层次的、利于分析的、包含 原始网页中的各种属性的网页对象,即DOM树;二是从整 理出来的网页对象中提取文本内容,将这些文本内容切分 成以词为单位的集合。
深圳大学未来媒体技术与计算研究所
22
网页信息结构化
结构化数据是指被标签定义了其内容、意义和用法的数据
。结构化数据除了包含数据本身之外,一般还包含对数据 的描述信息,而且其中的数据与描述信息都按照严格的规 则进行组织。语法上不具有层次特点的数据称为非结构化 数据。介于结构化数据和非结构化数据之间的数据称为半 结构化数据。
OpenSSL. This comes preinstalled in all operating systems, except
Windows where the Python installer ships it bundled.
具体步骤
安装 Python 2.7: https:///downloads/
主讲教师:王旭 博士 深圳大学计算机与软件学院 未来媒体技术与计算研究所
Email: wangxu@
1
模块一:商用搜索引擎架构与原理
搜索引擎基础
网页抓取技术
网页信息预处理技术
信息索引技术 信息查询与评价技术
参考书籍:
袁津生,李群编著,《搜索引擎基础教程》,清华大学出版社 其他文献/互联网资料
结构化的数据模型可以用二维表(关系型)来表示,半结
构化数据模型可以用树和图来表示,非结构化数据没有数 据模型。结构化数据的特点是先有结构、再有数据,半结 构化数据的特点是先有数据,再有结构。典型的结构化数 据的格式有:XML、XHTML、INI等,半结构化数据的格 式有:HTML。
深圳大学未来媒体技术与计算研究所
页中提取有价值的,能够代表网页的属性(如网页的URL 、编码类型、标题、正文、关键词等),并将这些属性组 成一个网页的对象。然后根据一定的相关度算法进行大量 复杂的计算,得到每一个网页针对页面内容及链接每一个 关键词的相关度,并用这些信息建立索引数据库。
从网页中提取关键词,至少要作两部分的工作:一是将网
截止日期:2015.10.25
1、字数:3000字
2、相似度要求:大于30%以上不合格;
3、基础分15分,总分20分
4、Oral Presentation加5分
模块一:商用搜索引擎架构与原理
搜索引擎基础
网页抓取技术
网页信息预处理技术
信息索引技术 信息查询与评价技术
参考书籍:
袁津生,李群编著,《搜索引擎基础教程》,清华大学出版社 其他文献/互联网资料
深圳大学未来媒体技术与计算研究所
20
网页信息预处理
4.1 网页信息结构化
4.2 文本处理 4.3 PageRank算法
深圳大学未来媒体技术与计算研究所
21
网页信息预处理技术
对于信息预处理系统来说,最主要的工作就是从抓取的网
installs setuptools if not installed.
lxml. Most Linux distributions ships prepackaged versions of lxml.
Otherwise refer tohttp://lxml.de/installation.html
Scrapy基本教程:新建spider
在“spiders”文件夹下新建一个文件: tutorial.py
Scrapy基本教程:新建spider
进入到当前文件夹
cd <path>
在命令行下键入以下命令
scrapy crawl tutorial 结果在文件中查看
Scrapy基本教程:提取网页中 的数据
Scrapy: 基于Python的爬虫框架
Built-in support for selecting and extracting data from HTML/XML sources using extended CSS selectors and XPath expressions, with helper methods to extract using regular expressions.