正则表达式.DOC
正则表达式公式大全

正则表达式公式大全正则表达式是一种处理字符串的强大工具,它可以帮助我们快速、高效地匹配、替换、删除、提取字符串。
很多编程语言,包括Python、Java、JavaScript等都支持正则表达式,所以掌握正则表达式是非常重要的。
下面是一些常用的正则表达式公式:1. 匹配单个字符:(1).点号(.)表示匹配任何单个字符,除了换行符。
(2)\d表示数字,等价于[0-9]。
(3)\D表示非数字,等价于[^0-9]。
(4)\w表示字符,包括数字、字母和下划线,等价于[a-zA-Z0-9_]。
(5)\W表示非字符,等价于[^a-zA-Z0-9_]。
(6)\s表示空白字符,包括空格、制表符、换行符等。
(7)\S表示非空白字符。
2. 匹配重复字符:(1)*表示重复0次或更多次。
(2)+表示重复1次或更多次。
(3)?表示重复0次或1次。
(4){n}表示重复n次。
(5){n,}表示重复n次或更多次。
(6){n,m}表示重复n到m次。
3. 匹配位置:(1)^表示匹配开头位置。
(2)$表示匹配结尾位置。
(3)\b表示匹配单词边界。
(4)\B表示匹配非单词边界。
4. 匹配分组:(1)( )表示一个分组。
(2)\1、\2、\3等表示对之前的分组的引用。
(3)(?: )表示一个非捕获分组。
5. 匹配字符集:(1)[ ]表示一个字符集,例如[abc]表示匹配a、b、c中的任意一个字符。
(2)[^ ]表示一个否定字符集,例如[^abc]表示匹配除了a、b、c以外的任意一个字符。
(3)[a-z]表示一个范围,表示匹配a至z中的任意一个字母。
6. 匹配转义字符:(1)\表示转义字符,例如\\.表示匹配点号。
(2)\n表示匹配换行符。
(3)\r表示匹配回车符。
(4)\t表示匹配制表符。
(5)\xx表示匹配十六进制字符。
以上是一些常用的正则表达式公式,如果我们能够熟练掌握这些公式,就可以很好地应用正则表达式来处理字符串。
当然,对于不同编程语言来说,对于正则表达式的支持也会有所不同,所以需要我们在实际应用中注意区别。
正则表达式,匹配中文语句

正则表达式是一种用于匹配和操作文本模式的工具。
它使用特定的语法规则来定义搜索模式,以便在文本中查找符合这些规则的文本片段。
以下是一些常见的正则表达式语法和示例:
匹配单个字符:
匹配任意单个字符:.
匹配特定字符:例如,[abc] 将匹配字符a、b 或c。
匹配数字和字母:
匹配任意数字:\d
匹配任意字母或数字:\w
匹配任意字母:\p{L}
匹配重复字符或数字:
重复一次或多次:+
重复零次或多次:*
重复特定次数:例如,{3} 表示重复三次。
匹配特定模式:
匹配以特定字符开头的字符串:^abc 表示匹配以"abc" 开头的字符串。
匹配以特定字符结尾的字符串:abc$ 表示匹配以"abc" 结尾的字符串。
匹配包含特定字符的字符串:例如,[a-z]+ 表示匹配包含一个或多个小写字母的字符串。
转义特殊字符:
使用反斜杠() 来转义特殊字符,例如,\d 表示匹配实际的反斜杠字符而不是特殊含义。
下面是一些示例,演示如何使用正则表达式来匹配中文字符:
匹配单个中文字符:[\u4e00-\u9fa5]
匹配多个中文字符:[\u4e00-\u9fa5]+
匹配以中文字符开头的字符串:^[\u4e00-\u9fa5]
匹配以中文字符结尾的字符串:[\u4e00-\u9fa5]$
请注意,正则表达式的语法可能因语言和工具而异,上述示例适用于大多数常见的情况。
在使用正则表达式时,请务必参考相关文档或工具的语法规范以确保正确使用。
匹配符号正则表达式

匹配符号正则表达式
在正则表达式中,你可以使用以下特殊字符来匹配各种符号:
`.`:匹配除了换行符以外的任何字符。
`\d`:匹配任何数字,等价于 `[0-9]`。
`\D`:匹配任何非数字字符,等价于 `[^0-9]`。
`\w`:匹配任何字母、数字或下划线字符,等价于 `[a-zA-Z0-9_]`。
`\W`:匹配任何非字母、数字或下划线字符,等价于 `[^a-zA-Z0-9_]`。
`\s`:匹配任何空白字符,包括空格、制表符、换页符等等。
`\S`:匹配任何非空白字符。
如果你想匹配特定的符号,你可以直接在正则表达式中输入该符号。
例如,如果你想匹配感叹号,你可以使用正则表达式 `!`。
如果你想匹配美元符号,你可以使用正则表达式 `$`。
如果你想匹配特殊符号的转义版本,你可以在符号前面加上反斜杠 `\`。
例如,如果你想匹配反斜杠本身,你可以使用正则表达式 `\\`。
如果你想匹配星号,你可以使用正则表达式 `\`。
以下是一些示例:
匹配任何字母和数字的字符串:`[a-zA-Z0-9]+` 匹配以数字开头的字符串:`^[\d]+`
匹配以字母开头的字符串:`^[A-Za-z]+`
匹配包含空格的字符串:`.`
匹配以感叹号结尾的字符串:`^.!$`。
正则表达式

正则表达式(I)正则表达式是由英文词语regular expression翻译过来的,就是符合某种规则的表达式。
正则表达式在软件开发中应用非常广泛,例如,找出网页中的超链接,找出网页中的email 地址,找出网页中的手机号码,判断输入的内容是否全部是数字,是否满足某种日期格式等等。
可以将正则表达式理解为一种对文字进行模糊匹配的语言,它用一些特殊的符号(称为元字符)来代表具有某种特征的一组字符以及该组字符重复出现的次数。
例如,对于正则表达式“\d{5}(-\d{4})?”,\d就是一个元字符,它表示一个数字字,{5}表示紧靠它前面的元素项连续重复5次,\d和{5}的组合\d{5}就表示匹配任意连续的5个数字字符;-\d{4}匹配的是一个连字号(-)后加上4个任意的数字,(-\d{4})?表示连字号(-)和后面的4个数字可有可无。
对于整个正则表达式“\d{5}(-\d{4})?”,表示要么是5个连续的数字字符,要么是5个连续的数字后加上一个连字号(-)、再加上4个连续的数字组成的10个字符。
正则表达式中的圆括号除了能将多个元素组合成一个可统一操作的组合项外,它所括起来的表达式部分还成为了一个子匹配(也叫子表达式),也就是说,我们可以用圆括号在一个长的正则表达式中划分出子表达式。
这样,除了可以得到整个正则表达式的匹配结果外,还可以单独得到每个子表达式部分所匹配的结果。
要灵活运用正则表达式,必须了解其中各种元字符的功能。
元字符从功能上大致分为:限定符、选择匹配符、分组组合和反向引用符、特殊字符、字符匹配符、定位符。
限定符用于指定其前面的字符或组合项连续出现多少次,下面是各种限定符及其含义:●{n} 规定前面的元素或组合项的连续出现n 次●{n,} 规定前面的元素或组合项至少连续出现n 次●{n,m } 规定前面的元素或组合项至少连续出现n 次,至多连续出现m 次●+ 规定前面的元素或组合项必须出现一次或连续多次,等效于{1,}●* 规定前面的元素或组合项可以出现零次或连续多次,等效于{0,}●? 规定前面的元素或组合项出现零次或一次,等效于{0,1}默认情况下,正则表达式使用最长(也叫贪婪)匹配原则。
正则表达式讲解

正则表达式讲解正则表达式,又称规则表达式,(Regular Expression,在代码中常简写为regex、regexp或RE),是一种文本模式,包括普通字符(例如,a到z之间的字母)和特殊字符(称为“元字符”),是计算机科学的一个概念。
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
它通常被用来检索、替换那些符合某个模式(规则)的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。
例如,在Perl中就内建了一个功能强大的正则表达式引擎。
正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开来的,后来在广泛运用于Scala、PHP、C#、Java、C++、Objective-c、Perl、Swift、VBScript、Javascript、Ruby以及Python等等。
正则表达式由普通字符以及特殊字符组成。
例如,“^a”匹配以字母“a”开头的字符串,“a”匹配以字母“a”结尾的字符串,“a”则只匹配整个由字母“a”组成的字符串。
正则表达式中的特殊字符包括:^匹配字符串的开头$匹配字符串的结尾.匹配任意字符,除了换行符**转义特殊字符[...]定义字符集[^...]定义反向字符集(不在该字符集内的字符)[a-z]定义范围字符集[0-9]定义范围字符集,相当于\d\d匹配任意十进制数字,相当于[0-9]\D匹配任意非数字字符,相当于[^0-9]\s匹配任意空白字符,相当于[\f\n\r\t\v]\S匹配任意非空白字符,相当于[^f\n\r\t\v]\w匹配任意字母数字字符,相当于[a-zA-Z0-9_]\W匹配任意非字母数字字符,相当于[^a-zA-Z0-9_]***** 匹配前面的子表达式零次或多次+匹配前面的子表达式一次或多次匹配前面的子表达式零次或一次{n}匹配前面的子表达式n次{n,}匹配前面的子表达式n次或更多次{n,m}匹配前面的子表达式至少n次,但不超过m次此外,还有一些特殊的量词,可以用来表示重复次数,例如:{n,m}表示匹配前面的字符至少n次,最多m次。
Word中使用正则表达式进行查找和替换(高效进行文字处理)

Word中使用正则表达式进行查找和替换(高效进行文字处理)术语开始前,我们先定义一对术语:•通配符指的是您可以用来代表一个或多个字符的键盘字符。
例如,星号 (*) 通常代表一个或多个字符,问号 (?) 通常代表单个字符。
•对我们来说,正则表达式指的是您可以用来查找和替换文本模式的文本字符和通配符组合。
文本字符指的是必须存在于目标文本字符串中的文本。
通配符指的是目标字符串中可能各不相同的文本。
试一试!本节中的步骤介绍了如何使用正则表达式转置姓名。
请记住,始终使用“查找和替换”对话框来运行您的正则表达式。
同时请记住,如果表达式没有按预期工作,你始终可以按下 CTRL + Z 来撤销您的更改,然后尝试其他表达式。
转置姓名1.启动 Word,然后打开一个新的空白文档。
2.复制此表格,将它粘贴到该文档中。
Josh BarnhillDoris HartwigTamara JohnstonDaniel Shimshoni1.在“开始”选项卡上的“编辑”组中,单击“替换”以打开“查找和替换”对话框。
2.如果您没有看到“使用通配符”复选框,请单击“更多”,然后选中该复选框。
如果您没有选中该复选框,Word 会将通配符视作文本。
3.在“查找内容”框中键入以下字符。
请确保您在两组括号之间包含了空格:(<*>) (<*>)1.在“替换为”框中,键入以下字符。
请确保您在逗号和第二个斜杠之间包含了空格:\2, \11.选择该表格,然后单击“全部替换”。
Word 会转置这些姓名并使用逗号分隔它们,如下所示:Barnhill, JoshHartwig, DorisJohnston, TamaraShimshoni, Daniel正则表达式的工作原理从此处开始,请记住这条原则:文档内容决定了您绝大多数(并非全部)正则表达式的设计。
例如,在您之前使用的示例表格中,每个单元格都包含了两个单词。
如果单元格包含两个单词和一个中间名首写字母,您将使用不同的表达式。
正则表达式详解

正则表达式详解正则表达式1.什么是正则表达式简单的说,正则表达式是一种可以用于文字模式匹配和替换的强有力的工具。
是由一系列普通字符和特殊字符组成的能明确描述文本字符串的文字匹配模式。
正则表达式并非一门专用语言,但也可以看作是一种语言,它可以让用户通过使用一系列普通字符和特殊字符构建能明确描述文本字符串的匹配模式。
除了简单描述这些模式之外,正则表达式解释引擎通常可用于遍历匹配,并使用模式作为分隔符来将字符串解析为子字符串,或以智能方式替换文本或重新设置文本格式。
正则表达式为解决与文本处理有关的许多常见任务提供了有效而简捷的方式。
正则表达式具有两种标准:·基本的正则表达式(BRE –Basic Regular Expressions)·扩展的正则表达式(ERE – Extended Regular Expressions)。
ERE包括BRE功能和另外其它的概念。
正则表达式目前有两种解释引擎:·基于字符驱动(text-directed engine)·基于正则表达式驱动(regex-directed engine)Jeffery Friedl把它们称作DFA和NFA解释引擎。
约定:为了描述起来方便,在本文中做一些约定:1.本文所举例的所有表达时都是基于NFA解释引擎的。
2.正则表达式,也就是匹配模式,会简写为Regex。
3. Regex的匹配目标,也就是目标字符串,会简写为String。
4.匹配结果用会用黄色底色标识。
5.用1\+1=2 括起来的表示这是一个regex。
6.举例会用以下格式:testThis is a test会匹配test,testcase等2.正则表达式的起源正则表达式的”祖先”可以一直上溯至对人类神经系统如何工作的早期研究。
Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
(完整word版)正则表达式和字符串处理(全)

正则表达式和字符串处理(全)第一章正则表达式概述正则表达式(Regular Expression)起源于人类神经系统的研究。
正则表达式的定义有以下几种:●用某种模式去匹配一类字符串的公式,它主要是用来描述字符串匹配的工具。
●描述了一种字符串匹配的模式。
可以用来检查字符串是否含有某种子串、将匹配的子串做替换或者从中取出符合某个条件的子串等。
●由普通字符(a-z)以及特殊字符(元字符)组成的文字模式,正则表达式作为一个模版,将某个字符模式与所搜索的字符串进行匹配。
●用于描述某些规则的的工具。
这些规则经常用于处理字符串中的查找或替换字符串。
也就是说正则表达式就是记录文本规则的代码。
●用一个字符串来描述一个特征,然后去验证另一个字符串是否符合这个特征。
以上这些定义其实也就是正则表达式的作用。
第二章正则表达式基础理论这些理论将为编写正则表达式提供法则和规范,正则表达式主要包括以下基础理论:●元字符●字符串●字符转义●反义●限定符●替换●分组●反向引用●零宽度断言●匹配选项●注释●优先级顺序●递归匹配2.1 元字符在正则表达式中,元字符(Metacharacter)是一类非常特殊的字符,它能够匹配一个位置或字符集合中的一个字符,如:、 \w等。
根据功能,元字符可以分为两种类型:匹配位置的元字符和匹配字符的元字符。
2.1.1 匹配位置的元字符包括:^、$、和\b。
其中^(脱字符号)和$(美元符号)都匹配一个位置,分别匹配行的开始和结尾。
比如,^string匹配以string开头的行,string$匹配以string结尾的行。
^string$匹配以string开始和结尾的行。
单个$匹配一个空行。
单个^匹配任意行。
\b匹配单词的开始和结尾,如:\bstr匹配以str开始的单词,但\b不匹配空格、标点符号或换行符号,所以,\bstr可以匹配string、string fomat等单词。
\bstr正则表达式匹配的字符串必须以str开头,并且str以前是单词的分界处,但此正则表达式不能限定str之后的字符串形式。
括号的正则表达式

括号的正则表达式
在正则表达式中,如果你想匹配括号,你可以使用括号的字符本身或使用转义字符。
下面是一些基本的正则表达式示例,用于匹配不同类型的括号:
匹配圆括号:
匹配左圆括号:\(
匹配右圆括号:\)
示例:\(\d+\)可以匹配一个或多个数字被圆括号包围的情况。
匹配方括号:
匹配左方括号:\[
匹配右方括号:\]
示例:\[[a-zA-Z]+\]可以匹配一个由字母组成的方括号括起来的
字符串。
匹配花括号:
匹配左花括号:\{
匹配右花括号:\}
示例:\{[0-9]+\}可以匹配一个由数字组成的花括号括起来的内容。
匹配任意类型的括号:
匹配任意左括号:[({]
匹配任意右括号:[)}]
示例:[({].*?[)}]可以匹配任意类型括号中的任意字符。
请注意,在正则表达式中,一些字符具有特殊含义,因此在匹配它们时需要使用反斜杠进行转义。
不同的编程语言和正则表达式引擎可能会有一些细微的差异,因此在实际使用时,建议查看相关文档以确保正确的转义和匹配。
正则表达式

"^\d+$" //非负整数(正整数 + 0)"^[0-9]*[1-9][0-9]*$" //正整数"^((-\d+)|(0+))$" //非正整数(负整数 + 0)"^-[0-9]*[1-9][0-9]*$" //负整数"^-?\d+$" //整数"^\d+(\.\d+)?$" //非负浮点数(正浮点数 + 0)"^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数"^((-\d+(\.\d+)?)|(0+(\.0+)?))$" //非正浮点数(负浮点数 + 0)"^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[ 1-9][0-9]*)))$" //负浮点数"^(-?\d+)(\.\d+)?$" //浮点数"^[A-Za-z]+$" //由26个英文字母组成的字符串"^[A-Z]+$" //由26个英文字母的大写组成的字符串"^[a-z]+$" //由26个英文字母的小写组成的字符串"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串"^\w+$" //由数字、26个英文字母或者下划线组成的字符串"^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$" //email地址"^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$" //url/^(d{2}|d{4})-((0([1-9]{1}))|(1[1|2]))-(([0-2]([1-9]{1}))|(3[0|1]))$/ // 年-月-日/^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年"^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z ]{2,4}|[0-9]{1,3})(]?)$" //Emil/^((\+?[0-9]{2,4}\-[0-9]{3,4}\-)|([0-9]{3,4}\-))?([0-9]{7,8})(\-[0-9] +)?$/ //电话号码"^(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5]).(d{1,2}|1 dd|2[0-4]d|25[0-5]).(d{1,2}|1dd|2[0-4]d|25[0-5])$" //IP地址匹配中文字符的正则表达式: [\u4e00-\u9fa5]匹配双字节字符(包括汉字在内):[^\x00-\xff]匹配空行的正则表达式:\n[\s| ]*\r匹配HTML标记的正则表达式:/<(.*)>.*<\/\1>|<(.*) \/>/匹配首尾空格的正则表达式:(^\s*)|(\s*$)匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*匹配网址URL的正则表达式:^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$匹配国内电话号码:(\d{3}-|\d{4}-)?(\d{8}|\d{7})?匹配腾讯QQ号:^[1-9]*[1-9][0-9]*$元字符及其在正则表达式上下文中的行为:\ 将下一个字符标记为一个特殊字符、或一个原义字符、或一个后向引用、或一个八进制转义符。
c正则表达式

c正则表达式【最新版】目录1.正则表达式的概念与作用2.正则表达式的基本语法3.正则表达式的应用场景4.正则表达式的优缺点正文正则表达式(Regular Expression,简称 regex)是一种强大的文本处理工具,它可以用来检查文本是否符合某种模式,也可以用来在文本中查找、替换或分割符合某种模式的文本。
正则表达式广泛应用于计算机科学和编程领域,例如文本编辑器、搜索引擎、数据验证等。
正则表达式的基本语法包括以下几种元素:1.字面字符:例如 abc、123 等,它们表示自身。
2.元字符:例如.(匹配任意字符)、*(匹配 0 个或多个前面的字符)、+(匹配 1 个或多个前面的字符)等,它们表示特定的匹配规则。
3.字符类:例如 [a-z](匹配小写字母)、[0-9](匹配数字)等,它们用来匹配某一类字符。
4.量词:例如{m,n}(匹配 m 到 n 个前面的字符)、{n}(匹配 n 个前面的字符)等,用来指定匹配的字符数量。
5.分组和捕获:使用圆括号表示,可以对正则表达式的一部分进行分组,以供后续引用或操作。
6.选择和否定:使用 | 表示选择,使用!表示否定。
正则表达式的应用场景包括但不限于:1.验证输入数据格式,如邮箱地址、电话号码等。
2.从文本中提取特定信息,如链接、文件名等。
3.对文本进行查找和替换操作,如同时替换文档中的所有链接。
4.对文本进行分割,如将一段文本按空格分割成多个部分。
正则表达式的优点在于它可以简洁、高效地处理文本,节省编程人员的时间和精力。
然而,正则表达式也存在一定的缺点,如语法较为复杂,不易理解和掌握。
此外,正则表达式在某些场景下可能会产生性能问题,因为它需要大量的计算资源来处理复杂的文本。
总之,正则表达式是一种重要的文本处理工具,掌握它对于编程人员来说是很有必要的。
正则表达式逗号结束 -回复

正则表达式逗号结束-回复中括号内的主题是正则表达式。
正则表达式(Regular Expression)是一种具有很强表达能力的文本匹配模式。
它通过使用各种特殊字符和操作符来定义搜索模式,然后用这个模式来匹配文本中的字符串。
使用正则表达式能够有效地进行字符串匹配、查找、替换等操作,对于文本处理来说非常有用。
在正则表达式中,逗号用来分隔不同的匹配条件。
通常情况下,逗号它表示多个条件之间的或关系。
例如,正则表达式[a,b,c]可以匹配字符"a"、"b"或者"c"中的任意一个。
类似地,[0-9,a-z,A-Z]可以匹配任意一个数字或字母。
正则表达式不仅仅局限于逗号的使用,它还包括了许多其他特殊字符和操作符。
下面将一步一步回答关于正则表达式的主题,并介绍其基本语法和用法。
首先,正则表达式的基本单位是字符。
可以直接使用普通字符来匹配文本中的对应字符。
例如,正则表达式"abc"可以精确匹配文本中连续出现的"abc"字符串。
其次,正则表达式中的点号(.)表示匹配任意字符。
例如,正则表达式"a.b"可以匹配类似"axb"、"ayb"的字符串。
第三,正则表达式中的星号(*)表示匹配前面的字符出现0次或多次。
例如,正则表达式"ab*c"可以匹配"ac"、"abc"、"abbc"等字符串。
接着,正则表达式中的加号(+)表示匹配前面的字符出现1次或多次。
例如,正则表达式"ab+c"可以匹配"abc"、"abbc"等字符串,但不能匹配"ac"。
然后,正则表达式中的问号(?)表示匹配前面的字符出现0次或1次。
例如,正则表达式"ab?c"可以匹配"ac"、"abc"等字符串。
检验汉字的正则表达式

检验汉字的正则表达式正则表达式呢,就像是一把超级神奇的小钥匙,能帮我们在字符的大海洋里精准地找到我们想要的汉字。
那对于检验汉字来说,它可有着自己独特的构造哦。
比如说在Java里吧,我们可以这样写一个简单的正则表达式来检验汉字。
咱们可以用“[\u4e00 - \u9fff]”。
这个看起来有点像密码一样的东西呢,其实就是在告诉程序,去看看输入的字符是不是在这个汉字的编码范围之内。
如果是,那就很有可能是汉字啦。
这就好比我们在一个装满了各种东西的大盒子里,我们告诉一个小机器人,你就去找那些在某个特定编号区间的小物件,这个小物件就是我们的汉字。
再说说Python里的情况哦。
Python里也能很方便地用正则表达式来检验汉字呢。
我们同样可以用类似的编码范围规则。
当我们要处理一些文本,比如说从一大段包含了字母、数字、标点符号还有汉字的文字里把汉字都找出来的时候,这个正则表达式就超级有用啦。
就像我们在一堆混在一起的珠子里,要把红色的珠子(汉字)都挑出来,这个正则表达式就是我们的挑珠小能手。
不过呢,这里面也有一些小坑坑哦。
有时候我们可能会遇到一些特殊的汉字,比如说一些生僻字或者是一些在不同编码标准下有点小差异的汉字。
这时候我们的正则表达式可能就需要再调整调整啦。
就像我们本来以为一个小网子(正则表达式)能把所有的小鱼(汉字)都捞起来,结果发现有几条特别小或者特别奇怪的小鱼漏网了,那我们就得把网子的孔再调整调整咯。
而且呢,正则表达式在不同的语言里虽然大体上的原理是一样的,但是在一些小细节上可能会有不同的写法或者用法。
这就需要我们根据自己使用的具体语言去好好研究研究啦。
就像每个地方做蛋糕(使用正则表达式处理汉字)都有自己的一点小特色,我们要根据当地的食材(编程语言的特性)和口味(具体需求)来做出最完美的蛋糕。
中文数字正则表达式

中文数字正则表达式
中文数字正则表达式是用于匹配中文数字的一种技术。
在中文文本处理中,数字一般由中文汉字表示,如“一”、“二”、“三”等。
使用正则表达式可以在文本中快速匹配和替换中文数字。
下面是一些常用的中文数字正则表达式:
1. 匹配单个中文数字:[u4e00-u9fa5]
2. 匹配多个连续的中文数字:[u4e00-u9fa5]+
3. 匹配指定数量的中文数字:[u4e00-u9fa5]{n},其中n为数字,表示要匹配的数量。
4. 匹配中文数字和阿拉伯数字混合的情况:[u4e00-u9fa50-9]+
5. 匹配中文数字和阿拉伯数字混合,且中文数字为整数的情况:[u4e00-u9fa5]*(零|一|二|三|四|五|六|七|八|九)+[0-9]*
6. 匹配中文数字和阿拉伯数字混合,且中文数字为小数的情况:[u4e00-u9fa5]*(零|一|二|三|四|五|六|七|八|九)+[0-9]*(点|.)[0-9]+
以上是一些常用的中文数字正则表达式,可以根据具体的需求进行修改和扩展。
在使用中文数字正则表达式时,需要注意编码问题,确保文本和正则表达式的编码一致。
- 1 -。
正则表达式-用于页面校验
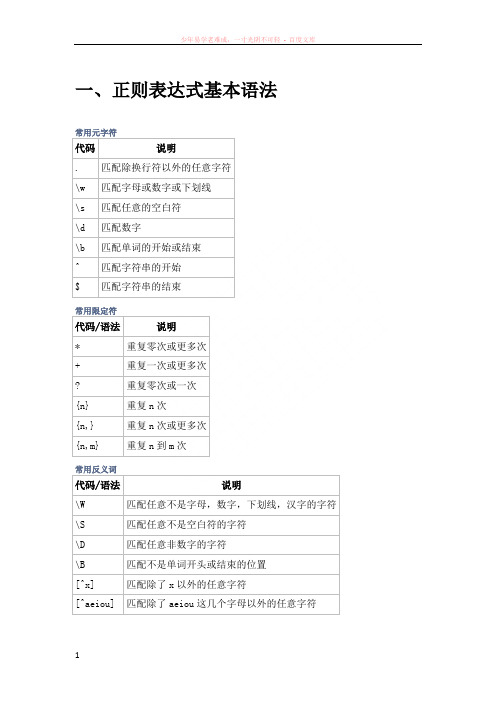
一、正则表达式基本语法常用元字符代码说明. 匹配除换行符以外的任意字符\w 匹配字母或数字或下划线\s 匹配任意的空白符\d 匹配数字\b 匹配单词的开始或结束^ 匹配字符串的开始$ 匹配字符串的结束常用限定符代码/语法说明* 重复零次或更多次+ 重复一次或更多次? 重复零次或一次{n} 重复n次{n,} 重复n次或更多次{n,m} 重复n到m次常用反义词代码/语法说明\W 匹配任意不是字母,数字,下划线,汉字的字符\S 匹配任意不是空白符的字符\D 匹配任意非数字的字符\B 匹配不是单词开头或结束的位置[^x] 匹配除了x以外的任意字符[^aeiou] 匹配除了aeiou这几个字母以外的任意字符二、常见的几种正则表达校验表达式中文字符:[\u4e00-\u9fa5]双字节字符:[^\x00-\xff]空白行:\sEmail地址:\w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14}网址URL:^((https|http|ftp|rtsp|mms)?:\/\/)[^\s]+手机(国内):0?(13|14|15|18)[0-9]{9}或者/^1[3|4|5|8] \d{9}$/--------------------------------------电话号码(国内):[0-9-()()]{7,18}负浮点数:-([1-9]\d*.\d*|0.\d*[1-9]\d*)匹配整数:-?[1-9]\d*正浮点数:[1-9]\d*.\d*|0.\d*[1-9]\d*腾讯QQ号:[1-9]([0-9]{5,11})邮政编码:\d{6}车牌号: var re=/^[\u4e00-\u9fa5]{1}[A-Z]{1}[A-Z_0-9]{5}$/;//普通车牌@"^[(\u4e00-\u9fa5)|(a-zA-Z)]{1}[a-zA-Z]{1}[a-zA-Z_0-9]{4,6}[a-zA-Z_0-9_\u4e00-\u9fa5] $"//带WJ等特殊车牌^[\u4e00-\u9fa5]{1}代表以汉字开头并且只有一个,这个汉字是车辆所在省的简称[A-Z]{1}代表A-Z的大写英文字母且只有一个,代表该车所在地的地市一级代码[A-Z_0-9]{5}代表后面五个数字是字母和数字的组合。
中文标点符号的正则表达式

匹配中文标点符号的正则表达式
```css
[\.\,\;\:\?]
```
这个正则表达式可以匹配中文的句号、逗号、顿号、分号、冒号、点号和问号。
具体来说:
* `\.` 匹配中文句号。
* `\,` 匹配中文逗号。
* `\;` 匹配中文分号。
* `\:` 匹配中文冒号。
* `\?` 匹配中文问号。
请注意,这个正则表达式不会匹配英文的句号、逗号、分号、冒号和问号。
如果您需要同时匹配英文和中文的标点符号,您可以使用以下的正则表达式:
```css
[\.\,\;\:\?|\。
\,\;\:\?]
```
这个正则表达式在原有的基础上,增加了英文的句号、逗号、分号、冒号和问号的匹配。
具体来说,`|` 符号表示或者,也就是说这个正则表达式可以匹配英文的句号(`.`)、逗号(`,`)、分号(`;`)、冒号(`:`)和问号(`?`),或者中文的句号(`.`)、逗号(`,`)、分号(`;`)、冒号(`:`)和问号(`?`)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
正则表达式第一部分:-----------------正则表达式(REs)通常被错误地认为是只有少数人理解的一种神秘语言。
在表面上它们确实看起来杂乱无章,如果你不知道它的语法,那么它的代码在你眼里只是一堆文字垃圾而已。
实际上,正则表达式是非常简单并且可以被理解。
读完这篇文章后,你将会通晓正则表达式的通用语法。
支持多种平台正则表达式最早是由数学家Stephen Kleene于1956年提出,他是在对自然语言的递增研究成果的基础上提出来的。
具有完整语法的正则表达式使用在字符的格式匹配方面上,后来被应用到熔融信息技术领域。
自从那时起,正则表达式经过几个时期的发展,现在的标准已经被ISO(国际标准组织)批准和被Open Group 组织认定。
正则表达式并非一门专用语言,但它可用于在一个文件或字符里查找和替代文本的一种标准。
它具有两种标准:基本的正则表达式(BRE),扩展的正则表达式(ERE)。
ERE包括BRE功能和另外其它的概念。
许多程序中都使用了正则表达式,包括xsh,egrep,sed,vi以及在UNIX平台下的程序。
它们可以被很多语言采纳,如HTML和XML,这些采纳通常只是整个标准的一个子集。
比你想象的还要普通随着正则表达式移植到交叉平台的程序语言的发展,这的功能也日益完整,使用也逐渐广泛。
网络上的搜索引擎使用它,e-mail程序也使用它,即使你不是一个UNIX程序员,你也可以使用规则语言来简化你的程序而缩短你的开发时间。
正则表达式101很多正则表达式的语法看起来很相似,这是因为你以前你没有研究过它们。
通配符是RE的一个结构类型,即重复操作。
让我们先看一看ERE标准的最通用的基本语法类型。
为了能够提供具有特定用途的范例,我将使用几个不同的程序。
第二部分:----------------------字符匹配正则表达式的关键之处在于确定你要搜索匹配的东西,如果没有这一概念,Res将毫无用处。
每一个表达式都包含需要查找的指令,如表A所示。
Table A:Character-matching regular expressions格式说明:---------------操作:解释:例子:结果:----------------.Match any one charactergrep.ord sample.txtWill match“ford”,“lord”,“2ord”,etc.in the file sample.txt.-----------------[]Match any one character listed between the bracketsgrep[cng]ord sample.txtWill match only“cord”,“nord”,and“gord”---------------------[^]Match any one character not listed between the bracketsgrep[^cn]ord sample.txtWill match“lord”,“2ord”,etc.but not“cord”or“nord”grep[a-zA-Z]ord sample.txtWill match“aord”,“bord”,“Aord”,“Bord”,etc.grep[^0-9]ord sample.txtWill match“Aord”,“aord”,etc.but not“2ord”,etc.重复操作符重复操作符,或数量词,都描述了查找一个特定字符的次数。
它们常被用于字符匹配语法以查找多行的字符,可参见表B。
Table B:Regular expression repetition operators格式说明:---------------操作:解释:例子:结果:----------------?Match any character one time,if it existsegrep“?erd”sample.txtWill match“berd”,“herd”,etc.and“erd”------------------*Match declared element multiple times,if it existsegrep“n.*rd”sample.txtWill match“nerd”,“nrd”,“neard”,etc.-------------------+Match declared element one or more timesegrep“[n]+erd”sample.txtWill match“nerd”,“nnerd”,etc.,but not“erd”--------------------{n}Match declared element exactly n timesegrep“[a-z]{2}erd”sample.txtWill match“cherd”,“blerd”,etc.but not“nerd”,“erd”,“buzzerd”,etc. ------------------------{n,}Match declared element at least n timesegrep“.{2,}erd”sample.txtWill match“cherd”and“buzzerd”,but not“nerd”------------------------{n,N}Match declared element at least n times,but not more than N times egrep“n[e]{1,2}rd”sample.txtWill match“nerd”and“neerd”----------------锚锚是指它所要匹配的格式,如图表C所示。
使用它能方便你查找通用字符的合并。
例如,我用vi行编辑器命令:s来代表substitute,这一命令的基本语法是:s/pattern_to_match/pattern_to_substitute/Table C:Regular expression anchors-------------操作解释例子结果---------------^Match at the beginning of a lines/^/blah/Inserts“blah“at the beginning of the line---------------$Match at the end of a lines/$/blah/Inserts“blah”at the end of the line---------------\<Match at the beginning of a words/\</blah/Inserts“blah”at the beginning of the wordegrep“\<blah”sample.txtMatches“blahfield”,etc.\>Match at the end of a words/\>/blah/Inserts“blah”at the end of the wordegrep“\>blah”sample.txtMatches“soupblah”,etc.---------------\bMatch at the beginning or end of a wordegrep“\bblah”sample.txtMatches“blahcake”and“countblah”-----------------\BMatch in the middle of a wordegrep“\Bblah”sample.txtMatches“sublahper”,etc.间隔Res中的另一可便之处是间隔(或插入)符号。
实际上,这一符号相当于一个OR语句并代表|符号。
下面的语句返回文件sample.txt中的“nerd”和“merd”的句柄:egrep“(n|m)erd”sample.txt间隔功能非常强大,特别是当你寻找文件不同拼写的时候,但你可以在下面的例子得到相同的结果:egrep“[nm]erd”sample.txt当你使用间隔功能与Res的高级特性连接在一起时,它的真正用处更能体现出来。
----------------一些保留字符Res的最后一个最重要特性是保留字符(也称特定字符)。
例如,如果你想要查找“ne*rd”和“ni*rd”的字符,格式匹配语句“n[ei]*rd”与“neeeeerd”和“nieieierd”相符合,但并不是你要查找的字符。
因为‘*’(星号)是个保留字符,你必须用一个反斜线符号来替代它,即:“n[ei]\*rd”。
其它的保留字符包括:^(carat).(period)[(left bracket}$(dollar sign)((left parenthesis))(right parenthesis)|(pipe)*(asterisk)+(plus symbol)?(question mark){(left curly bracket,or left brace)\backslash一旦你把以上这些字符包括在你的字符搜索中,毫无疑问Res变得非常的难读。
比如说以下的PHP中的eregi搜索引擎代码就很难读了。
eregi("^[_a-z0-9-]+(\.[_a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*$",$sendto)你可以看到,程序的意图很难把握。
但如果你抛开保留字符,你常常会错误地理解代码的意思。
总结在本文中,我们揭开了正则表达式的神秘面纱,并列出了ERE标准的通用语法。
如果你想阅览Open Group 组织的规则的完整描述,你可以参见:Regular Expressions,欢迎你在其中的讨论区发表你的问题或观点。
正则表达式和Java编程语言-----------------------------------------类和方法下面的类根据正则表达式指定的模式,与字符序列进行匹配。
Pattern类Pattern类的实例表示以字符串形式指定的正则表达式,其语法类似于Perl所用的语法。
用字符串形式指定的正则表达式,必须先编译成Pattern类的实例。
生成的模式用于创建Matcher对象,它根据正则表达式与任意字符序列进行匹配。
多个匹配器可以共享一个模式,因为它是非专属的。
用compile方法把给定的正则表达式编译成模式,然后用matcher方法创建一个匹配器,这个匹配器将根据此模式对给定输入进行匹配。